#nodes in the kubernetes cluster
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Video
youtube
Session 5 Kubernetes 3 Node Cluster and Dashboard Installation and Confi...
#youtube#In this exciting video tutorial we dive into the world of Kubernetes exploring how to set up a robust 3-node cluster and configure the Kuber
0 notes
Text
#kubernetes cluster setup#kubernetes etcd cluster setup#master node#kubernetes cluster#kubernetes#kubernetes architecture
0 notes
Text
CNAPP Explained: The Smartest Way to Secure Cloud-Native Apps with EDSPL

Introduction: The New Era of Cloud-Native Apps
Cloud-native applications are rewriting the rules of how we build, scale, and secure digital products. Designed for agility and rapid innovation, these apps demand security strategies that are just as fast and flexible. That’s where CNAPP—Cloud-Native Application Protection Platform—comes in.
But simply deploying CNAPP isn’t enough.
You need the right strategy, the right partner, and the right security intelligence. That’s where EDSPL shines.
What is CNAPP? (And Why Your Business Needs It)
CNAPP stands for Cloud-Native Application Protection Platform, a unified framework that protects cloud-native apps throughout their lifecycle—from development to production and beyond.
Instead of relying on fragmented tools, CNAPP combines multiple security services into a cohesive solution:
Cloud Security
Vulnerability management
Identity access control
Runtime protection
DevSecOps enablement
In short, it covers the full spectrum—from your code to your container, from your workload to your network security.
Why Traditional Security Isn’t Enough Anymore
The old way of securing applications with perimeter-based tools and manual checks doesn’t work for cloud-native environments. Here’s why:
Infrastructure is dynamic (containers, microservices, serverless)
Deployments are continuous
Apps run across multiple platforms
You need security that is cloud-aware, automated, and context-rich—all things that CNAPP and EDSPL’s services deliver together.
Core Components of CNAPP
Let’s break down the core capabilities of CNAPP and how EDSPL customizes them for your business:
1. Cloud Security Posture Management (CSPM)
Checks your cloud infrastructure for misconfigurations and compliance gaps.
See how EDSPL handles cloud security with automated policy enforcement and real-time visibility.
2. Cloud Workload Protection Platform (CWPP)
Protects virtual machines, containers, and functions from attacks.
This includes deep integration with application security layers to scan, detect, and fix risks before deployment.
3. CIEM: Identity and Access Management
Monitors access rights and roles across multi-cloud environments.
Your network, routing, and storage environments are covered with strict permission models.
4. DevSecOps Integration
CNAPP shifts security left—early into the DevOps cycle. EDSPL’s managed services ensure security tools are embedded directly into your CI/CD pipelines.
5. Kubernetes and Container Security
Containers need runtime defense. Our approach ensures zero-day protection within compute environments and dynamic clusters.
How EDSPL Tailors CNAPP for Real-World Environments
Every organization’s tech stack is unique. That’s why EDSPL never takes a one-size-fits-all approach. We customize CNAPP for your:
Cloud provider setup
Mobility strategy
Data center switching
Backup architecture
Storage preferences
This ensures your entire digital ecosystem is secure, streamlined, and scalable.
Case Study: CNAPP in Action with EDSPL
The Challenge
A fintech company using a hybrid cloud setup faced:
Misconfigured services
Shadow admin accounts
Poor visibility across Kubernetes
EDSPL’s Solution
Integrated CNAPP with CIEM + CSPM
Hardened their routing infrastructure
Applied real-time runtime policies at the node level
✅ The Results
75% drop in vulnerabilities
Improved time to resolution by 4x
Full compliance with ISO, SOC2, and GDPR
Why EDSPL’s CNAPP Stands Out
While most providers stop at integration, EDSPL goes beyond:
🔹 End-to-End Security: From app code to switching hardware, every layer is secured. 🔹 Proactive Threat Detection: Real-time alerts and behavior analytics. 🔹 Customizable Dashboards: Unified views tailored to your team. 🔹 24x7 SOC Support: With expert incident response. 🔹 Future-Proofing: Our background vision keeps you ready for what’s next.
EDSPL’s Broader Capabilities: CNAPP and Beyond
While CNAPP is essential, your digital ecosystem needs full-stack protection. EDSPL offers:
Network security
Application security
Switching and routing solutions
Storage and backup services
Mobility and remote access optimization
Managed and maintenance services for 24x7 support
Whether you’re building apps, protecting data, or scaling globally, we help you do it securely.
Let’s Talk CNAPP
You’ve read the what, why, and how of CNAPP — now it’s time to act.
📩 Reach us for a free CNAPP consultation. 📞 Or get in touch with our cloud security specialists now.
Secure your cloud-native future with EDSPL — because prevention is always smarter than cure.
0 notes
Text
Mastering OpenShift at Scale: Red Hat OpenShift Administration III (DO380)
In today’s cloud-native world, organizations are increasingly adopting Kubernetes and Red Hat OpenShift to power their modern applications. As these environments scale, so do the challenges of managing complex workloads, automating operations, and ensuring reliability. That’s where Red Hat OpenShift Administration III: Scaling Kubernetes Workloads (DO380) steps in.
What is DO380?
DO380 is an advanced-level training course offered by Red Hat that focuses on scaling, performance tuning, and managing containerized applications in production using Red Hat OpenShift Container Platform. It is designed for experienced OpenShift administrators and DevOps professionals who want to deepen their knowledge of Kubernetes-based platform operations.
Who Should Take DO380?
This course is ideal for:
✅ System Administrators managing large-scale containerized environments
✅ DevOps Engineers working with CI/CD pipelines and automation
✅ Platform Engineers responsible for OpenShift clusters
✅ RHCEs or OpenShift Certified Administrators (EX280 holders) aiming to level up
Key Skills You Will Learn
Here’s what you’ll master in DO380:
🔧 Advanced Cluster Management
Configure and manage OpenShift clusters for performance and scalability.
📈 Monitoring & Tuning
Use tools like Prometheus, Grafana, and the OpenShift Console to monitor system health, tune workloads, and troubleshoot performance issues.
📦 Autoscaling & Load Management
Configure Horizontal Pod Autoscaling (HPA), Cluster Autoscaler, and manage workloads efficiently with resource quotas and limits.
🔐 Security & Compliance
Implement security policies, use node taints/tolerations, and manage namespaces for better isolation and governance.
🧪 CI/CD Pipeline Integration
Automate application delivery using Tekton pipelines and manage GitOps workflows with ArgoCD.
Course Prerequisites
Before enrolling in DO380, you should be familiar with:
Red Hat OpenShift Administration I (DO180)
Red Hat OpenShift Administration II (DO280)
Kubernetes fundamentals (kubectl, deployments, pods, services)
Certification Path
DO380 also helps you prepare for the Red Hat Certified Specialist in OpenShift Scaling and Performance (EX380) exam, which counts towards the Red Hat Certified Architect (RHCA) credential.
Why DO380 Matters
With enterprise workloads becoming more dynamic and resource-intensive, scaling OpenShift effectively is not just a bonus — it’s a necessity. DO380 equips you with the skills to:
✅ Maximize infrastructure efficiency
✅ Ensure high availability
✅ Automate operations
✅ Improve DevOps productivity
Conclusion
Whether you're looking to enhance your career, improve your organization's cloud-native capabilities, or take the next step in your Red Hat certification journey — Red Hat OpenShift Administration III (DO380) is your gateway to mastering OpenShift at scale.
Ready to elevate your OpenShift expertise?
Explore DO380 training options with HawkStack Technologies and get hands-on with real-world OpenShift scaling scenarios.
For more details www.hawkstack.com
0 notes
Text

Comparison of Ubuntu, Debian, and Yocto for IIoT and Edge Computing
In industrial IoT (IIoT) and edge computing scenarios, Ubuntu, Debian, and Yocto Project each have unique advantages. Below is a detailed comparison and recommendations for these three systems:
1. Ubuntu (ARM)
Advantages
Ready-to-use: Provides official ARM images (e.g., Ubuntu Server 22.04 LTS) supporting hardware like Raspberry Pi and NVIDIA Jetson, requiring no complex configuration.
Cloud-native support: Built-in tools like MicroK8s, Docker, and Kubernetes, ideal for edge-cloud collaboration.
Long-term support (LTS): 5 years of security updates, meeting industrial stability requirements.
Rich software ecosystem: Access to AI/ML tools (e.g., TensorFlow Lite) and databases (e.g., PostgreSQL ARM-optimized) via APT and Snap Store.
Use Cases
Rapid prototyping: Quick deployment of Python/Node.js applications on edge gateways.
AI edge inference: Running computer vision models (e.g., ROS 2 + Ubuntu) on Jetson devices.
Lightweight K8s clusters: Edge nodes managed by MicroK8s.
Limitations
Higher resource usage (minimum ~512MB RAM), unsuitable for ultra-low-power devices.
2. Debian (ARM)
Advantages
Exceptional stability: Packages undergo rigorous testing, ideal for 24/7 industrial operation.
Lightweight: Minimal installation requires only 128MB RAM; GUI-free versions available.
Long-term support: Up to 10+ years of security updates via Debian LTS (with commercial support).
Hardware compatibility: Supports older or niche ARM chips (e.g., TI Sitara series).
Use Cases
Industrial controllers: PLCs, HMIs, and other devices requiring deterministic responses.
Network edge devices: Firewalls, protocol gateways (e.g., Modbus-to-MQTT).
Critical systems (medical/transport): Compliance with IEC 62304/DO-178C certifications.
Limitations
Older software versions (e.g., default GCC version); newer features require backports.
3. Yocto Project
Advantages
Full customization: Tailor everything from kernel to user space, generating minimal images (<50MB possible).
Real-time extensions: Supports Xenomai/Preempt-RT patches for μs-level latency.
Cross-platform portability: Single recipe set adapts to multiple hardware platforms (e.g., NXP i.MX6 → i.MX8).
Security design: Built-in industrial-grade features like SELinux and dm-verity.
Use Cases
Custom industrial devices: Requires specific kernel configurations or proprietary drivers (e.g., CAN-FD bus support).
High real-time systems: Robotic motion control, CNC machines.
Resource-constrained terminals: Sensor nodes running lightweight stacks (e.g., Zephyr+FreeRTOS hybrid deployment).
Limitations
Steep learning curve (BitBake syntax required); longer development cycles.
4. Comparison Summary
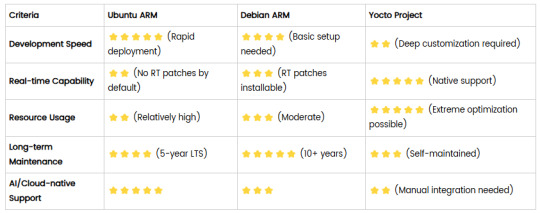
5. Selection Recommendations
Choose Ubuntu ARM: For rapid deployment of edge AI applications (e.g., vision detection on Jetson) or deep integration with public clouds (e.g., AWS IoT Greengrass).
Choose Debian ARM: For mission-critical industrial equipment (e.g., substation monitoring) where stability outweighs feature novelty.
Choose Yocto Project: For custom hardware development (e.g., proprietary industrial boards) or strict real-time/safety certification (e.g., ISO 13849) requirements.
6. Hybrid Architecture Example
Smart factory edge node:
Real-time control layer: RTOS built with Yocto (controlling robotic arms)
Data processing layer: Debian running OPC UA servers
Cloud connectivity layer: Ubuntu Server managing K8s edge clusters
Combining these systems based on specific needs can maximize the efficiency of IIoT edge computing.
0 notes
Text
Effective Kubernetes cluster monitoring simplifies containerized workload management by measuring uptime, resource use (such as memory, CPU, and storage), and interaction between cluster components. It also enables cluster managers to monitor the cluster and discover issues such as inadequate resources, errors, pods that fail to start, and nodes that cannot join the cluster. Essentially, Kubernetes monitoring enables you to discover issues and manage Kubernetes clusters more proactively. What Kubernetes Metrics Should You Measure? Monitoring Kubernetes metrics is critical for ensuring the reliability, performance, and efficiency of applications in a Kubernetes cluster. Because Kubernetes constantly expands and maintains containers, measuring critical metrics allows you to spot issues early on, optimize resource allocation, and preserve overall system integrity. Several factors are critical to watch with Kubernetes: Cluster monitoring - Monitors the health of the whole Kubernetes cluster. It helps you find out how many apps are running on a node, if it is performing efficiently and at the right capacity, and how much resource the cluster requires overall. Pod monitoring - Tracks issues impacting individual pods, including resource use, application metrics, and pod replication or auto scaling metrics. Ingress metrics - Monitoring ingress traffic can help in discovering and managing a variety of issues. Using controller-specific methods, ingress controllers can be set up to track network traffic information and workload health. Persistent storage - Monitoring volume health allows Kubernetes to implement CSI. You can also use the external health monitor controller to track node failures. Control plane metrics - With control plane metrics we can track and visualize cluster performance while troubleshooting by keeping an eye on schedulers, controllers, and API servers. Node metrics - Keeping an eye on each Kubernetes node's CPU and memory usage might help ensure that they never run out. A running node's status can be defined by a number of conditions, such as Ready, MemoryPressure, DiskPressure, OutOfDisk, and NetworkUnavailable. Monitoring and Troubleshooting Kubernetes Clusters Using the Kubernetes Dashboard The Kubernetes dashboard is a web-based user interface for Kubernetes. It allows you to deploy containerized apps to a Kubernetes cluster, see an overview of the applications operating on the cluster, and manage cluster resources. Additionally, it enables you to: Debug containerized applications by examining data on the health of your Kubernetes cluster's resources, as well as any anomalies that have occurred. Create and modify individual Kubernetes resources, including deployments, jobs, DaemonSets, and StatefulSets. Have direct control over your Kubernetes environment using the Kubernetes dashboard. The Kubernetes dashboard is built into Kubernetes by default and can be installed and viewed from the Kubernetes master node. Once deployed, you can visit the dashboard via a web browser to examine extensive information about your Kubernetes cluster and conduct different operations like scaling deployments, establishing new resources, and updating application configurations. Kubernetes Dashboard Essential Features Kubernetes Dashboard comes with some essential features that help manage and monitor your Kubernetes clusters efficiently: Cluster overview: The dashboard displays information about your Kubernetes cluster, including the number of nodes, pods, and services, as well as the current CPU and memory use. Resource management: The dashboard allows you to manage Kubernetes resources, including deployments, services, and pods. You can add, update, and delete resources while also seeing extensive information about them. Application monitoring: The dashboard allows you to monitor the status and performance of Kubernetes-based apps. You may see logs and stats, fix issues, and set alarms.
Customizable views: The dashboard allows you to create and preserve bespoke dashboards with the metrics and information that are most essential to you. Kubernetes Monitoring Best Practices Here are some recommended practices to help you properly monitor and debug Kubernetes installations: 1. Monitor Kubernetes Metrics Kubernetes microservices require understanding granular resource data like memory, CPU, and load. However, these metrics may be complex and challenging to leverage. API indicators such as request rate, call error, and latency are the most effective KPIs for identifying service faults. These metrics can immediately identify degradations in a microservices application's components. 2. Ensure Monitoring Systems Have Enough Data Retention Having scalable monitoring solutions helps you to efficiently monitor your Kubernetes cluster as it grows and evolves over time. As your Kubernetes cluster expands, so will the quantity of data it creates, and your monitoring systems must be capable of handling this rise. If your systems are not scalable, they may get overwhelmed by the volume of data and be unable to offer accurate or relevant results. 3. Integrate Monitoring Systems Into Your CI/CD Pipeline Source Integrating Kubernetes monitoring solutions with CI/CD pipelines enables you to monitor your apps and infrastructure as they are deployed, rather than afterward. By connecting your monitoring systems to your pipeline for continuous integration and delivery (CI/CD), you can automatically collect and process data from your infrastructure and applications as it is delivered. This enables you to identify potential issues early on and take action to stop them from getting worse. 4. Create Alerts You may identify the problems with your Kubernetes cluster early on and take action to fix them before they get worse by setting up the right alerts. For example, if you configure alerts for crucial metrics like CPU or memory use, you will be informed when those metrics hit specific thresholds, allowing you to take action before your cluster gets overwhelmed. Conclusion Kubernetes allows for the deployment of a large number of containerized applications within its clusters, each of which has nodes that manage the containers. Efficient observability across various machines and components is critical for successful Kubernetes container orchestration. Kubernetes has built-in monitoring facilities for its control plane, but they may not be sufficient for thorough analysis and granular insight into application workloads, event logging, and other microservice metrics within Kubernetes clusters.
0 notes
Text
EKS Dashboard: Kubernetes cluster Access over AWS Regions

Kubernetes cluster visibility may be centralised across AWS regions and accounts using EKS Dashboard.
EKS Dashboard
EKS Dashboard is a new AWS feature. A centralised display allows cluster administrators and cloud architects monitor their Kubernetes clusters organisationally. Its major goal is to give clients a single view of clusters across AWS Regions and accounts. This single view helps track cluster inventories, compliance, operational activity planning, and version updates.
The EKS Dashboard helps companies scale Kubernetes deployments. Multiple clusters are often run for data sovereignty, business continuity, or better availability. This distributed technique makes visibility and control difficult, especially in decentralised systems with several regions and accounts. Clients have traditionally used external products for centralised cluster visibility. Third-party solutions' identification and access setup, licensing costs, and ongoing maintenance added complexity.
The EKS Dashboard simplifies this procedure with native AWS Console dashboard features. It offers data about clusters, regulated node groups, and EKS add-ons. Dashboard insights include cluster health indicators, predicted extended support EKS control plane charges, support status, account, version, and cluster distribution by region. Automatic filtering lets users explore certain data points. This feature makes clusters easier to find and focus on.
A brief tour of the EKS Dashboard shows tabular, graphical, and map representations of Kubernetes clusters. Advanced search and filtering are offered. There are several widgets for cluster visualisation. You can visualise managed node groups by AMI versions, launch templates, and instance type distribution. You can also map your clusters worldwide. Data from the dashboard can be exported for study or custom reports.
Setting up EKS Dashboard
According to reports, EKS Dashboard setup is easy. AWS Organisation management and administrator accounts grant clients access to the EKS interface Dashboard. Turning on trusted access on the organization's Amazon EKS settings page is the only setup requirement. Dashboard settings allow trusted access. The management account can view the Dashboard with trusted access. The official AWS Documentation provides setup and configuration details.
Importantly, the EKS Dashboard is not limited to Amazon EKS clusters. It can also provide visibility into linked Kubernetes clusters on-site or on other cloud providers. Even while hybrid or multi-cloud clusters may have inferior data quality than native Amazon EKS clusters, this functionality provides uniform visibility for enterprises.
Availability
The EKS Dashboard is currently available in the US East (N. Virginia). Use it to integrate data from all commercial AWS Regions. No additional fees apply to the EKS Dashboard.
This new functionality emphasises AWS's commitment to simplifying Kubernetes operations. To let clients focus on app development and growth, infrastructure management is removed.
Finally, the native AWS EKS Dashboard provides a unified view of Kubernetes clusters across accounts and regions. It provides basic visibility for linked non-EKS clusters, comprehensive visualisations, extensive insights, and quick setup at no additional cost.
#EKSDashboard#Kubernetesclusters#AmazonEKS#AmazonEKSclusters#AmazonEKSDashboard#AWSRegions#technology#technews#technologynews#news#govindhtech
0 notes
Text
Kubernetes vs. Traditional Infrastructure: Why Clusters and Pods Win
In today’s fast-paced digital landscape, agility, scalability, and reliability are not just nice-to-haves—they’re necessities. Traditional infrastructure, once the backbone of enterprise computing, is increasingly being replaced by cloud-native solutions. At the forefront of this transformation is Kubernetes, an open-source container orchestration platform that has become the gold standard for managing containerized applications.
But what makes Kubernetes a superior choice compared to traditional infrastructure? In this article, we’ll dive deep into the core differences, and explain why clusters and pods are redefining modern application deployment and operations.
Understanding the Fundamentals
Before drawing comparisons, it’s important to clarify what we mean by each term:
Traditional Infrastructure
This refers to monolithic, VM-based environments typically managed through manual or semi-automated processes. Applications are deployed on fixed servers or VMs, often with tight coupling between hardware and software layers.
Kubernetes
Kubernetes abstracts away infrastructure by using clusters (groups of nodes) to run pods (the smallest deployable units of computing). It automates deployment, scaling, and operations of application containers across clusters of machines.
Key Comparisons: Kubernetes vs Traditional Infrastructure
Feature
Traditional Infrastructure
Kubernetes
Scalability
Manual scaling of VMs; slow and error-prone
Auto-scaling of pods and nodes based on load
Resource Utilization
Inefficient due to over-provisioning
Efficient bin-packing of containers
Deployment Speed
Slow and manual (e.g., SSH into servers)
Declarative deployments via YAML and CI/CD
Fault Tolerance
Rigid failover; high risk of downtime
Self-healing, with automatic pod restarts and rescheduling
Infrastructure Abstraction
Tightly coupled; app knows about the environment
Decoupled; Kubernetes abstracts compute, network, and storage
Operational Overhead
High; requires manual configuration, patching
Low; centralized, automated management
Portability
Limited; hard to migrate across environments
High; deploy to any Kubernetes cluster (cloud, on-prem, hybrid)
Why Clusters and Pods Win
1. Decoupled Architecture
Traditional infrastructure often binds application logic tightly to specific servers or environments. Kubernetes promotes microservices and containers, isolating app components into pods. These can run anywhere without knowing the underlying system details.
2. Dynamic Scaling and Scheduling
In a Kubernetes cluster, pods can scale automatically based on real-time demand. The Horizontal Pod Autoscaler (HPA) and Cluster Autoscaler help dynamically adjust resources—unthinkable in most traditional setups.
3. Resilience and Self-Healing
Kubernetes watches your workloads continuously. If a pod crashes or a node fails, the system automatically reschedules the workload on healthy nodes. This built-in self-healing drastically reduces operational overhead and downtime.
4. Faster, Safer Deployments
With declarative configurations and GitOps workflows, teams can deploy with speed and confidence. Rollbacks, canary deployments, and blue/green strategies are natively supported—streamlining what’s often a risky manual process in traditional environments.
5. Unified Management Across Environments
Whether you're deploying to AWS, Azure, GCP, or on-premises, Kubernetes provides a consistent API and toolchain. No more re-engineering apps for each environment—write once, run anywhere.
Addressing Common Concerns
“Kubernetes is too complex.”
Yes, Kubernetes has a learning curve. But its complexity replaces operational chaos with standardized automation. Tools like Helm, ArgoCD, and managed services (e.g., GKE, EKS, AKS) help simplify the onboarding process.
“Traditional infra is more secure.”
Security in traditional environments often depends on network perimeter controls. Kubernetes promotes zero trust principles, pod-level isolation, and RBAC, and integrates with service meshes like Istio for granular security policies.
Real-World Impact
Companies like Spotify, Shopify, and Airbnb have migrated from legacy infrastructure to Kubernetes to:
Reduce infrastructure costs through efficient resource utilization
Accelerate development cycles with DevOps and CI/CD
Enhance reliability through self-healing workloads
Enable multi-cloud strategies and avoid vendor lock-in
Final Thoughts
Kubernetes is more than a trend—it’s a foundational shift in how software is built, deployed, and operated. While traditional infrastructure served its purpose in a pre-cloud world, it can’t match the agility and scalability that Kubernetes offers today.
Clusters and pods don’t just win—they change the game.
0 notes
Text
Why GPU PaaS Is Incomplete Without Infrastructure Orchestration and Tenant Isolation
GPU Platform-as-a-Service (PaaS) is gaining popularity as a way to simplify AI workload execution — offering users a friendly interface to submit training, fine-tuning, and inferencing jobs. But under the hood, many GPU PaaS solutions lack deep integration with infrastructure orchestration, making them inadequate for secure, scalable multi-tenancy.
If you’re a Neocloud, sovereign GPU cloud, or an enterprise private GPU cloud with strict compliance requirements, you are probably looking at offering job scheduling of Model-as-a-Service to your tenants/users. An easy approach is to have a global Kubernetes cluster that is shared across multiple tenants. The problem with this approach is poor security as the underlying OS kernel, CPU, GPU, network, and storage resources are shared by all users without any isolation. Case-in-point, in September 2024, Wiz discovered a critical GPU container and Kubernetes vulnerability that affected over 35% of environments. Thus, doing just Kubernetes namespace or vCluster isolation is not safe.
You need to provision bare metal, configure network and fabric isolation, allocate high-performance storage, and enforce tenant-level security boundaries — all automated, dynamic, and policy-driven.
In short: PaaS is not enough. True GPUaaS begins with infrastructure orchestration.
The Pitfall of PaaS-Only GPU Platforms
Many AI platforms stop at providing:
A web UI for job submission
A catalog of AI/ML frameworks or models
Basic GPU scheduling on Kubernetes
What they don’t offer:
Control over how GPU nodes are provisioned (bare metal vs. VM)
Enforcement of north-south and east-west isolation per tenant
Configuration and Management of Infiniband, RoCE or Spectrum-X fabric
Lifecycle Management and Isolation of External Parallel Storage like DDN, VAST, or WEKA
Per-Tenant Quota, Observability, RBAC, and Policy Governance
Without these, your GPU PaaS is just a thin UI on top of a complex, insecure, and hard-to-scale backend.
What Full-Stack Orchestration Looks Like
To build a robust AI cloud platform — whether sovereign, Neocloud, or enterprise — the orchestration layer must go deeper.
How aarna.ml GPU CMS Solves This Problem
aarna.ml GPU CMS is built from the ground up to be infrastructure-aware and multi-tenant-native. It includes all the PaaS features you would expect, but goes beyond PaaS to offer:
BMaaS and VMaaS orchestration: Automated provisioning of GPU bare metal or VM pools for different tenants.
Tenant-level network isolation: Support for VXLAN, VRF, and fabric segmentation across Infiniband, Ethernet, and Spectrum-X.
Storage orchestration: Seamless integration with DDN, VAST, WEKA with mount point creation and tenant quota enforcement.
Full-stack observability: Usage stats, logs, and billing metrics per tenant, per GPU, per model.
All of this is wrapped with a PaaS layer that supports Ray, SLURM, KAI, Run:AI, and more, giving users flexibility while keeping cloud providers in control of their infrastructure and policies.
Why This Matters for AI Cloud Providers
If you're offering GPUaaS or PaaS without infrastructure orchestration:
You're exposing tenants to noisy neighbors or shared vulnerabilities
You're missing critical capabilities like multi-region scaling or LLM isolation
You’ll be unable to meet compliance, governance, and SemiAnalysis ClusterMax1 grade maturity
With aarna.ml GPU CMS, you deliver not just a PaaS, but a complete, secure, and sovereign-ready GPU cloud platform.
Conclusion
GPU PaaS needs to be a complete stack with IaaS — it’s not just a model serving interface!
To deliver scalable, secure, multi-tenant AI services, your GPU PaaS stack must be expanded to a full GPU cloud management software stack to include automated provisioning of compute, network, and storage, along with tenant-aware policy and observability controls.
Only then is your GPU PaaS truly production-grade.
Only then are you ready for sovereign, enterprise, and commercial AI cloud success.
To see a live demo or for a free trial, contact aarna.ml
This post orginally posted on https://www.aarna.ml/
0 notes
Text
Modern Tools Enhance Data Governance and PII Management Compliance

Modern data governance focuses on effectively managing Personally Identifiable Information (PII). Tools like IBM Cloud Pak for Data (CP4D), Red Hat OpenShift, and Kubernetes provide organizations with comprehensive solutions to navigate complex regulatory requirements, including GDPR (General Data Protection Regulation) and CCPA (California Consumer Privacy Act). These platforms offer secure data handling, lineage tracking, and governance automation, helping businesses stay compliant while deriving value from their data.
PII management involves identifying, protecting, and ensuring the lawful use of sensitive data. Key requirements such as transparency, consent, and safeguards are essential to mitigate risks like breaches or misuse. IBM Cloud Pak for Data integrates governance, lineage tracking, and AI-driven insights into a unified framework, simplifying metadata management and ensuring compliance. It also enables self-service access to data catalogs, making it easier for authorized users to access and manage sensitive data securely.
Advanced IBM Cloud Pak for Data features include automated policy reinforcement and role-based access that ensure that PII remains protected while supporting analytics and machine learning applications. This approach simplifies compliance, minimizing the manual workload typically associated with regulatory adherence.
The growing adoption of multi-cloud environments has necessitated the development of platforms such as Informatica and Collibra to offer complementary governance tools that enhance PII protection. These solutions use AI-supported insights, automated data lineage, and centralized policy management to help organizations seeking to improve their data governance frameworks.
Mr. Valihora has extensive experience with IBM InfoSphere Information Server “MicroServices” products (which are built upon Red Hat Enterprise Linux Technology – in conjunction with Docker\Kubernetes.) Tim Valihora - President of TVMG Consulting Inc. - has extensive experience with respect to:
IBM InfoSphere Information Server “Traditional” (IIS v11.7.x)
IBM Cloud PAK for Data (CP4D)
IBM “DataStage Anywhere”
Mr. Valihora is a US based (Vero Beach, FL) Data Governance specialist within the IBM InfoSphere Information Server (IIS) software suite and is also Cloud Certified on Collibra Data Governance Center.
Career Highlights Include: Technical Architecture, IIS installations, post-install-configuration, SDLC mentoring, ETL programming, performance-tuning, client-side training (including administrators, developers or business analysis) on all of the over 15 out-of-the-box IBM IIS products Over 180 Successful IBM IIS installs - Including the GRID Tool-Kit for DataStage (GTK), MPP, SMP, Multiple-Engines, Clustered Xmeta, Clustered WAS, Active-Passive Mirroring and Oracle Real Application Clustered “IADB” or “Xmeta” configurations. Tim Valihora has been credited with performance tuning the words fastest DataStage job which clocked in at 1.27 Billion rows of inserts\updates every 12 minutes (using the Dynamic Grid ToolKit (GTK) for DataStage (DS) with a configuration file that utilized 8 compute-nodes - each with 12 CPU cores and 64 GB of RAM.)
0 notes
Video
youtube
Session 5 Kubernetes 3 Node Cluster and Dashboard Installation and Confi...
#youtube#Kubernetes 3 Node Cluster and Dashboard Installation and Configuration with Podman 🚀 In this exciting video tutorial we dive into the worl
1 note
·
View note
Text
Kubernetes Objects Explained 💡 Pods, Services, Deployments & More for Admins & Devs
learn how Kubernetes keeps your apps running as expected using concepts like desired state, replication, config management, and persistent storage.
✔️ Pod – Basic unit that runs your containers ✔️ Service – Stable network access to Pods ✔️ Deployment – Rolling updates & scaling made easy ✔️ ReplicaSet – Maintains desired number of Pods ✔️ Job & CronJob – Run tasks once or on schedule ✔️ ConfigMap & Secret – Externalize configs & secure credentials ✔️ PV & PVC – Persistent storage management ✔️ Namespace – Cluster-level resource isolation ✔️ DaemonSet – Run a Pod on every node ✔️ StatefulSet – For stateful apps like databases ✔️ ReplicationController – The older way to manage Pods
youtube
0 notes
Text
Getting Started with Google Kubernetes Engine: Your Gateway to Cloud-Native Greatness
After spending over 8 years deep in the trenches of cloud engineering and DevOps, I can tell you one thing for sure: if you're serious about scalability, flexibility, and real cloud-native application deployment, Google Kubernetes Engine (GKE) is where the magic happens.
Whether you’re new to Kubernetes or just exploring managed container platforms, getting started with Google Kubernetes Engine is one of the smartest moves you can make in your cloud journey.
"Containers are cool. Orchestrated containers? Game-changing."
🚀 What is Google Kubernetes Engine (GKE)?
Google Kubernetes Engine is a fully managed Kubernetes platform that runs on top of Google Cloud. GKE simplifies deploying, managing, and scaling containerized apps using Kubernetes—without the overhead of maintaining the control plane.
Why is this a big deal?
Because Kubernetes is notoriously powerful and notoriously complex. With GKE, Google handles all the heavy lifting—from cluster provisioning to upgrades, logging, and security.
"GKE takes the complexity out of Kubernetes so you can focus on building, not babysitting clusters."
🧭 Why Start with GKE?
If you're a developer, DevOps engineer, or cloud architect looking to:
Deploy scalable apps across hybrid/multi-cloud
Automate CI/CD workflows
Optimize infrastructure with autoscaling & spot instances
Run stateless or stateful microservices seamlessly
Then GKE is your launchpad.
Here’s what makes GKE shine:
Auto-upgrades & auto-repair for your clusters
Built-in security with Shielded GKE Nodes and Binary Authorization
Deep integration with Google Cloud IAM, VPC, and Logging
Autopilot mode for hands-off resource management
Native support for Anthos, Istio, and service meshes
"With GKE, it's not about managing containers—it's about unlocking agility at scale."
🔧 Getting Started with Google Kubernetes Engine
Ready to dive in? Here's a simple flow to kick things off:
Set up your Google Cloud project
Enable Kubernetes Engine API
Install gcloud CLI and Kubernetes command-line tool (kubectl)
Create a GKE cluster via console or command line
Deploy your app using Kubernetes manifests or Helm
Monitor, scale, and manage using GKE dashboard, Cloud Monitoring, and Cloud Logging
If you're using GKE Autopilot, Google manages your node infrastructure automatically—so you only manage your apps.
“Don’t let infrastructure slow your growth. Let GKE scale as you scale.”
🔗 Must-Read Resources to Kickstart GKE
👉 GKE Quickstart Guide – Google Cloud
👉 Best Practices for GKE – Google Cloud
👉 Anthos and GKE Integration
👉 GKE Autopilot vs Standard Clusters
👉 Google Cloud Kubernetes Learning Path – NetCom Learning
🧠 Real-World GKE Success Stories
A FinTech startup used GKE Autopilot to run microservices with zero infrastructure overhead
A global media company scaled video streaming workloads across continents in hours
A university deployed its LMS using GKE and reduced downtime by 80% during peak exam seasons
"You don’t need a huge ops team to build a global app. You just need GKE."
🎯 Final Thoughts
Getting started with Google Kubernetes Engine is like unlocking a fast track to modern app delivery. Whether you're running 10 containers or 10,000, GKE gives you the tools, automation, and scale to do it right.
With Google Cloud’s ecosystem—from Cloud Build to Artifact Registry to operations suite—GKE is more than just Kubernetes. It’s your platform for innovation.
“Containers are the future. GKE is the now.”
So fire up your first cluster. Launch your app. And let GKE do the heavy lifting while you focus on what really matters—shipping great software.
Let me know if you’d like this formatted into a visual infographic or checklist to go along with the blog!
1 note
·
View note
Text
Mastering Enterprise-Grade Kubernetes with Red Hat OpenShift Administration III (DO380)
Introduction
In today's fast-paced digital landscape, enterprises require robust, scalable, and secure platforms to run their mission-critical applications. Red Hat OpenShift has emerged as a leading Kubernetes-based platform for modern application development and deployment. However, managing OpenShift at scale demands specialized knowledge and skills. This is where Red Hat OpenShift Administration III (DO380) becomes indispensable.
What is DO380? The Red Hat OpenShift Administration III (DO380) course is designed for experienced OpenShift administrators who are looking to advance their skills in managing large-scale OpenShift clusters. It goes beyond the basics, empowering professionals to scale, optimize, and automate OpenShift environments for enterprise-level operations.
Who Should Take DO380? This course is ideal for:
System Administrators and DevOps Engineers managing OpenShift environments
IT professionals aiming to optimize OpenShift for performance and security
Anyone preparing for the Red Hat Certified Specialist in OpenShift Automation and Integration exam
Key Skills You’ll Gain
Scaling OpenShift Clusters Learn strategies for managing growing workloads, including adding worker nodes and configuring high availability for production-ready clusters.
Cluster Performance Tuning Understand how to fine-tune OpenShift to meet performance benchmarks, including CPU/memory limits, QoS configurations, and persistent storage optimization.
Security Hardening Explore advanced techniques for securing your OpenShift environment using Role-Based Access Control (RBAC), NetworkPolicies, and integrated logging and auditing.
Automation and GitOps Harness the power of automation using Ansible and GitOps workflows to maintain consistent configurations and speed up deployments across environments.
Monitoring and Troubleshooting Dive into OpenShift’s built-in tools and third-party integrations to proactively monitor system health and quickly troubleshoot issues.
Why DO380 Matters With hybrid cloud adoption on the rise, enterprises are running applications across on-premises and public cloud platforms. DO380 equips administrators with the ability to:
Deliver consistent, secure, and scalable services across environments
Minimize downtime and improve application performance
Automate complex operational tasks for increased agility
Final Thoughts If you're looking to elevate your OpenShift administration skills to an expert level, Red Hat OpenShift Administration III (DO380) is the course for you. It’s not just a training—it's a career accelerator for those managing enterprise workloads in dynamic Kubernetes environments.
For more details www.hawkstack.com
0 notes
Text

Comparison of Ubuntu, Debian, and Yocto for IIoT and Edge Computing
In industrial IoT (IIoT) and edge computing scenarios, Ubuntu, Debian, and Yocto Project each have unique advantages. Below is a detailed comparison and recommendations for these three systems:
1. Ubuntu (ARM)
Advantages
Ready-to-use: Provides official ARM images (e.g., Ubuntu Server 22.04 LTS) supporting hardware like Raspberry Pi and NVIDIA Jetson, requiring no complex configuration.
Cloud-native support: Built-in tools like MicroK8s, Docker, and Kubernetes, ideal for edge-cloud collaboration.
Long-term support (LTS): 5 years of security updates, meeting industrial stability requirements.
Rich software ecosystem: Access to AI/ML tools (e.g., TensorFlow Lite) and databases (e.g., PostgreSQL ARM-optimized) via APT and Snap Store.
Use Cases
Rapid prototyping: Quick deployment of Python/Node.js applications on edge gateways.
AI edge inference: Running computer vision models (e.g., ROS 2 + Ubuntu) on Jetson devices.
Lightweight K8s clusters: Edge nodes managed by MicroK8s.
Limitations
Higher resource usage (minimum ~512MB RAM), unsuitable for ultra-low-power devices.
2. Debian (ARM)
Advantages
Exceptional stability: Packages undergo rigorous testing, ideal for 24/7 industrial operation.
Lightweight: Minimal installation requires only 128MB RAM; GUI-free versions available.
Long-term support: Up to 10+ years of security updates via Debian LTS (with commercial support).
Hardware compatibility: Supports older or niche ARM chips (e.g., TI Sitara series).
Use Cases
Industrial controllers: PLCs, HMIs, and other devices requiring deterministic responses.
Network edge devices: Firewalls, protocol gateways (e.g., Modbus-to-MQTT).
Critical systems (medical/transport): Compliance with IEC 62304/DO-178C certifications.
Limitations
Older software versions (e.g., default GCC version); newer features require backports.
3. Yocto Project
Advantages
Full customization: Tailor everything from kernel to user space, generating minimal images (<50MB possible).
Real-time extensions: Supports Xenomai/Preempt-RT patches for μs-level latency.
Cross-platform portability: Single recipe set adapts to multiple hardware platforms (e.g., NXP i.MX6 → i.MX8).
Security design: Built-in industrial-grade features like SELinux and dm-verity.
Use Cases
Custom industrial devices: Requires specific kernel configurations or proprietary drivers (e.g., CAN-FD bus support).
High real-time systems: Robotic motion control, CNC machines.
Resource-constrained terminals: Sensor nodes running lightweight stacks (e.g., Zephyr+FreeRTOS hybrid deployment).
Limitations
Steep learning curve (BitBake syntax required); longer development cycles.
4. Comparison Summary
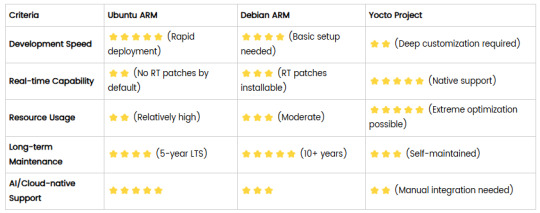
5. Selection Recommendations
Choose Ubuntu ARM: For rapid deployment of edge AI applications (e.g., vision detection on Jetson) or deep integration with public clouds (e.g., AWS IoT Greengrass).
Choose Debian ARM: For mission-critical industrial equipment (e.g., substation monitoring) where stability outweighs feature novelty.
Choose Yocto Project: For custom hardware development (e.g., proprietary industrial boards) or strict real-time/safety certification (e.g., ISO 13849) requirements.
6. Hybrid Architecture Example
Smart factory edge node:
Real-time control layer: RTOS built with Yocto (controlling robotic arms)
Data processing layer: Debian running OPC UA servers
Cloud connectivity layer: Ubuntu Server managing K8s edge clusters
Combining these systems based on specific needs can maximize the efficiency of IIoT edge computing.
0 notes
Text
EX280: Red Hat OpenShift Administration
Red Hat OpenShift Administration is a vital skill for IT professionals interested in managing containerized applications, simplifying Kubernetes, and leveraging enterprise cloud solutions. If you’re looking to excel in OpenShift technology, this guide covers everything from its core concepts and prerequisites to advanced certification and career benefits.
1. What is Red Hat OpenShift?
Red Hat OpenShift is a robust, enterprise-grade Kubernetes platform designed to help developers build, deploy, and scale applications across hybrid and multi-cloud environments. It offers a simplified, consistent approach to managing Kubernetes, with added security, automation, and developer tools, making it ideal for enterprise use.
Key Components of OpenShift:
OpenShift Platform: The foundation for scalable applications with simplified Kubernetes integration.
OpenShift Containers: Allows seamless container orchestration for optimized application deployment.
OpenShift Cluster: Manages workload distribution, ensuring application availability across multiple nodes.
OpenShift Networking: Provides efficient network configuration, allowing applications to communicate securely.
OpenShift Security: Integrates built-in security features to manage access, policies, and compliance seamlessly.
2. Why Choose Red Hat OpenShift?
OpenShift provides unparalleled advantages for organizations seeking a Kubernetes-based platform tailored to complex, cloud-native environments. Here’s why OpenShift stands out among container orchestration solutions:
Enterprise-Grade Security: OpenShift Security layers, such as role-based access control (RBAC) and automated security policies, secure every component of the OpenShift environment.
Enhanced Automation: OpenShift Automation enables efficient deployment, management, and scaling, allowing businesses to speed up their continuous integration and continuous delivery (CI/CD) pipelines.
Streamlined Deployment: OpenShift Deployment features enable quick, efficient, and predictable deployments that are ideal for enterprise environments.
Scalability & Flexibility: With OpenShift Scaling, administrators can adjust resources dynamically based on application requirements, maintaining optimal performance even under fluctuating loads.
Simplified Kubernetes with OpenShift: OpenShift builds upon Kubernetes, simplifying its management while adding comprehensive enterprise features for operational efficiency.
3. Who Should Pursue Red Hat OpenShift Administration?
A career in Red Hat OpenShift Administration is suitable for professionals in several IT roles. Here’s who can benefit:
System Administrators: Those managing infrastructure and seeking to expand their expertise in container orchestration and multi-cloud deployments.
DevOps Engineers: OpenShift’s integrated tools support automated workflows, CI/CD pipelines, and application scaling for DevOps operations.
Cloud Architects: OpenShift’s robust capabilities make it ideal for architects designing scalable, secure, and portable applications across cloud environments.
Software Engineers: Developers who want to build and manage containerized applications using tools optimized for development workflows.
4. Who May Not Benefit from OpenShift?
While OpenShift provides valuable enterprise features, it may not be necessary for everyone:
Small Businesses or Startups: OpenShift may be more advanced than required for smaller, less complex projects or organizations with a limited budget.
Beginner IT Professionals: For those new to IT or with minimal cloud experience, starting with foundational cloud or Linux skills may be a better path before moving to OpenShift.
5. Prerequisites for Success in OpenShift Administration
Before diving into Red Hat OpenShift Administration, ensure you have the following foundational knowledge:
Linux Proficiency: Linux forms the backbone of OpenShift, so understanding Linux commands and administration is essential.
Basic Kubernetes Knowledge: Familiarity with Kubernetes concepts helps as OpenShift is built on Kubernetes.
Networking Fundamentals: OpenShift Networking leverages container networks, so knowledge of basic networking is important.
Hands-On OpenShift Training: Comprehensive OpenShift training, such as the OpenShift Administration Training and Red Hat OpenShift Training, is crucial for hands-on learning.
Read About Ethical Hacking
6. Key Benefits of OpenShift Certification
The Red Hat OpenShift Certification validates skills in container and application management using OpenShift, enhancing career growth prospects significantly. Here are some advantages:
EX280 Certification: This prestigious certification verifies your expertise in OpenShift cluster management, automation, and security.
Job-Ready Skills: You’ll develop advanced skills in OpenShift deployment, storage, scaling, and troubleshooting, making you an asset to any IT team.
Career Mobility: Certified professionals are sought after for roles in OpenShift Administration, cloud architecture, DevOps, and systems engineering.
7. Important Features of OpenShift for Administrators
As an OpenShift administrator, mastering certain key features will enhance your ability to manage applications effectively and securely:
OpenShift Operator Framework: This framework simplifies application lifecycle management by allowing users to automate deployment and scaling.
OpenShift Storage: Offers reliable, persistent storage solutions critical for stateful applications and complex deployments.
OpenShift Automation: Automates manual tasks, making CI/CD pipelines and application scaling efficiently.
OpenShift Scaling: Allows administrators to manage resources dynamically, ensuring applications perform optimally under various load conditions.
Monitoring & Logging: Comprehensive tools that allow administrators to keep an eye on applications and container environments, ensuring system health and reliability.
8. Steps to Begin Your OpenShift Training and Certification
For those seeking to gain Red Hat OpenShift Certification and advance their expertise in OpenShift administration, here’s how to get started:
Enroll in OpenShift Administration Training: Structured OpenShift training programs provide foundational and advanced knowledge, essential for handling OpenShift environments.
Practice in Realistic Environments: Hands-on practice through lab simulators or practice clusters ensures real-world application of skills.
Prepare for the EX280 Exam: Comprehensive EX280 Exam Preparation through guided practice will help you acquire the knowledge and confidence to succeed.
9. What to Do After OpenShift DO280?
After completing the DO280 (Red Hat OpenShift Administration) certification, you can further enhance your expertise with advanced Red Hat training programs:
a) Red Hat OpenShift Virtualization Training (DO316)
Learn how to integrate and manage virtual machines (VMs) alongside containers in OpenShift.
Gain expertise in deploying, managing, and troubleshooting virtualized workloads in a Kubernetes-native environment.
b) Red Hat OpenShift AI Training (AI267)
Master the deployment and management of AI/ML workloads on OpenShift.
Learn how to use OpenShift Data Science and MLOps tools for scalable machine learning pipelines.
c) Red Hat Satellite Training (RH403)
Expand your skills in managing OpenShift and other Red Hat infrastructure on a scale.
Learn how to automate patch management, provisioning, and configuration using Red Hat Satellite.
These advanced courses will make you a well-rounded OpenShift expert, capable of handling complex enterprise deployments in virtualization, AI/ML, and infrastructure automation.
Conclusion: Is Red Hat OpenShift the Right Path for You?
Red Hat OpenShift Administration is a valuable career path for IT professionals dedicated to mastering enterprise Kubernetes and containerized application management. With skills in OpenShift Cluster management, OpenShift Automation, and secure OpenShift Networking, you will become an indispensable asset in modern, cloud-centric organizations.
KR Network Cloud is a trusted provider of comprehensive OpenShift training, preparing you with the skills required to achieve success in EX280 Certification and beyond.
Why Join KR Network Cloud?
With expert-led training, practical labs, and career-focused guidance, KR Network Cloud empowers you to excel in Red Hat OpenShift Administration and achieve your professional goals.
https://creativeceo.mn.co/posts/the-ultimate-guide-to-red-hat-openshift-administration
https://bogonetwork.mn.co/posts/the-ultimate-guide-to-red-hat-openshift-administration
#openshiftadmin#redhatopenshift#openshiftvirtualization#DO280#DO316#openshiftai#ai267#redhattraining#krnetworkcloud#redhatexam#redhatcertification#ittraining
0 notes