#openrouter
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Link
So, you can add your own key for Gemini to OpenRouter and it will use your (free for a number of tokens) Google AI Studio key instead of it's own. Costs 5% of a model usage, but worth it for the all-in-one facility. Gemini flash 2 is getting some love at the moment in the stats.
Add pre-existing keys to Profile -> Settings -> Integrations.
0 notes
Text
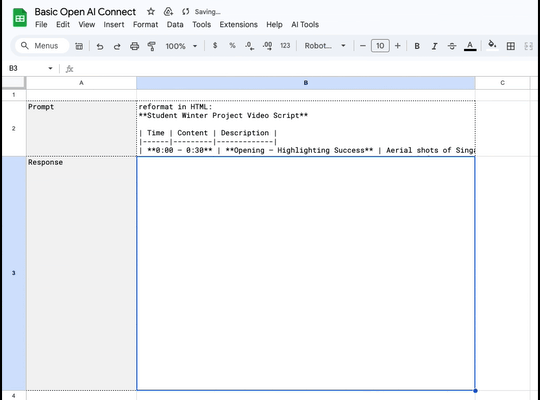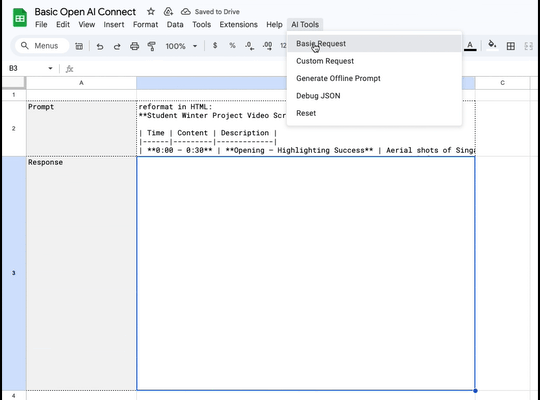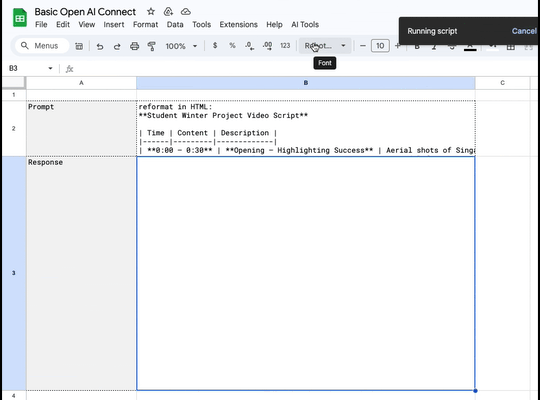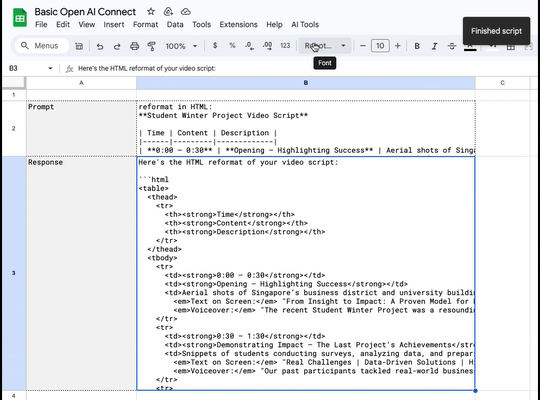
I'm writing code again.
Google Spreadsheets + AppScript + Openrouter + any one of it's excellent models = loads of fun.
And animated gifs now available out of Davinci Resolve's timelines.
0 notes
Text
“People are often curious about how much energy a ChatGPT query uses,” Sam Altman, the CEO of OpenAI, wrote in an aside in a long blog post last week. The average query, Altman wrote, uses 0.34 watt-hours of energy: “About what an oven would use in a little over one second, or a high-efficiency lightbulb would use in a couple of minutes.”
For a company with 800 million weekly active users (and growing), the question of how much energy all these searches are using is becoming an increasingly pressing one. But experts say Altman’s figure doesn’t mean much without much more public context from OpenAI about how it arrived at this calculation—including the definition of what an “average” query is, whether or not it includes image generation, and whether or not Altman is including additional energy use, like from training AI models and cooling OpenAI’s servers.
As a result, Sasha Luccioni, the climate lead at AI company Hugging Face, doesn’t put too much stock in Altman’s number. “He could have pulled that out of his ass,” she says. (OpenAI did not respond to a request for more information about how it arrived at this number.)
As AI takes over our lives, it’s also promising to transform our energy systems, supercharging carbon emissions right as we’re trying to fight climate change. Now, a new and growing body of research is attempting to put hard numbers on just how much carbon we’re actually emitting with all of our AI use.
This effort is complicated by the fact that major players like OpenAI disclose little environmental information. An analysis submitted for peer review this week by Luccioni and three other authors looks at the need for more environmental transparency in AI models. In Luccioni’s new analysis, she and her colleagues use data from OpenRouter, a leaderboard of large language model (LLM) traffic, to find that 84 percent of LLM use in May 2025 was for models with zero environmental disclosure. That means that consumers are overwhelmingly choosing models with completely unknown environmental impacts.
“It blows my mind that you can buy a car and know how many miles per gallon it consumes, yet we use all these AI tools every day and we have absolutely no efficiency metrics, emissions factors, nothing,” Luccioni says. “It’s not mandated, it’s not regulatory. Given where we are with the climate crisis, it should be top of the agenda for regulators everywhere.”
As a result of this lack of transparency, Luccioni says, the public is being exposed to estimates that make no sense but which are taken as gospel. You may have heard, for instance, that the average ChatGPT request takes 10 times as much energy as the average Google search. Luccioni and her colleagues track down this claim to a public remark that John Hennessy, the chairman of Alphabet, the parent company of Google, made in 2023.
A claim made by a board member from one company (Google) about the product of another company to which he has no relation (OpenAI) is tenuous at best—yet, Luccioni’s analysis finds, this figure has been repeated again and again in press and policy reports. (As I was writing this piece, I got a pitch with this exact statistic.)
“People have taken an off-the-cuff remark and turned it into an actual statistic that’s informing policy and the way people look at these things,” Luccioni says. “The real core issue is that we have no numbers. So even the back-of-the-napkin calculations that people can find, they tend to take them as the gold standard, but that’s not the case.”
One way to try and take a peek behind the curtain for more accurate information is to work with open source models. Some tech giants, including OpenAI and Anthropic, keep their models proprietary—meaning outside researchers can’t independently verify their energy use. But other companies make some parts of their models publicly available, allowing researchers to more accurately gauge their emissions.
A study published Thursday in the journal Frontiers of Communication evaluated 14 open-source large language models, including two Meta Llama models and three DeepSeek models, and found that some used as much as 50 percent more energy than other models in the dataset responding to prompts from the researchers. The 1,000 benchmark prompts submitted to the LLMs included questions on topics such as high school history and philosophy; half of the questions were formatted as multiple choice, with only one-word answers available, while half were submitted as open prompts, allowing for a freer format and longer answers. Reasoning models, the researchers found, generated far more thinking tokens—measures of internal reasoning generated in the model while producing its answer, which are a hallmark of more energy use—than more concise models. These models, perhaps unsurprisingly, were also more accurate with complex topics. (They also had trouble with brevity: During the multiple choice phase, for instance, the more complex models would often return answers with multiple tokens, despite explicit instructions to only answer from the range of options provided.)
Maximilian Dauner, a PhD student at the Munich University of Applied Sciences and the study’s lead author, says he hopes AI use will evolve to think about how to more efficiently use less-energy-intensive models for different queries. He envisions a process where smaller, simpler questions are automatically directed to less-energy-intensive models that will still provide accurate answers. “Even smaller models can achieve really good results on simpler tasks, and don't have that huge amount of CO2 emitted during the process,” he says.
Some tech companies already do this. Google and Microsoft have previously told WIRED that their search features use smaller models when possible, which can also mean faster responses for users. But generally, model providers have done little to nudge users toward using less energy. How quickly a model answers a question, for instance, has a big impact on its energy use—but that’s not explained when AI products are presented to users, says Noman Bashir, the Computing & Climate Impact Fellow at MIT’s Climate and Sustainability Consortium.
“The goal is to provide all of this inference the quickest way possible so that you don’t leave their platform,” he says. “If ChatGPT suddenly starts giving you a response after five minutes, you will go to some other tool that is giving you an immediate response.”
However, there’s a myriad of other considerations to take into account when calculating the energy use of complex AI queries, because it’s not just theoretical—the conditions under which queries are actually run out in the real world matter. Bashir points out that physical hardware makes a difference when calculating emissions. Dauner ran his experiments on an Nvidia A100 GPU, but Nvidia’s H100 GPU—which was specially designed for AI workloads, and which, according to the company, is becoming increasingly popular—is much more energy-intensive.
Physical infrastructure also makes a difference when talking about emissions. Large data centers need cooling systems, light, and networking equipment, which all add on more energy; they often run in diurnal cycles, taking a break at night when queries are lower. They are also hooked up to different types of grids—ones overwhelmingly powered by fossil fuels, versus those powered by renewables—depending on their locations.
Bashir compares studies that look at emissions from AI queries without factoring in data center needs to lifting up a car, hitting the gas, and counting revolutions of a wheel as a way of doing a fuel-efficiency test. “You’re not taking into account the fact that this wheel has to carry the car and the passenger,” he says.
Perhaps most crucially for our understanding of AI’s emissions, open source models like the ones Dauner used in his study represent a fraction of the AI models used by consumers today. Training a model and updating deployed models takes a massive amount of energy—figures that many big companies keep secret. It’s unclear, for example, whether the light bulb statistic about ChatGPT from OpenAI’s Altman takes into account all the energy used to train the models powering the chatbot. Without more disclosure, the public is simply missing much of the information needed to start understanding just how much this technology is impacting the planet.
“If I had a magic wand, I would make it mandatory for any company putting an AI system into production, anywhere, around the world, in any application, to disclose carbon numbers,” Luccioni says.
3 notes
·
View notes
Text
im naming my kids deepseek openrouter and sillytavern like this is crazy
4 notes
·
View notes
Text
🚀 Ilimitado OpenRouter & Replicate
Redatudo Ilimitado com OpenRouter & Replicate Tenha acesso total ao melhor da IA em produtividade, criação de conteúdos e automação — sem limites mensais, sem bloqueios por créditos. Utilize suas próprias APIs OpenRouter e Replicate no Redatudo e explore as ferramentas avançadas como e quanto quiser! Liberdade total: produtividade e criatividade ilimitadas usando suas chaves (API Key)…
0 notes
Text
Unlock the secrets of AI! Learn to create an OpenRouter Python chatbot from scratch with our easy tutorial. Start building your smart assistant today! #OpenRouter #Python #Chatbot #AI #Programming
0 notes
Text
🧠 5 Genius AI Hacks to Automate Your Life (And Make Money Doing It)
#AIAutomation #ProductivityHack #SideHustleTips #AIForCreators
Hey Tumblr fam 👋✨
If you’re still doing everything manually in 2025, you’re already falling behind. AI isn't just for techies anymore—it’s for YOU, especially if you’re into saving time, making cash, or building something scalable without burning out.
Here are 5 underrated AI tricks I personally use to automate my life (and biz):
💡1. Use AI to Write Your Emails, Blogs & Captions Tools like OpenRouter + ChatGPT can crank out entire newsletters, SEO blogs, and even spicy IG captions in minutes. You don’t need to be a writer—just prompt smartly and tweak the tone.
💡2. Auto-Reply to DMs with AI Bots I built a Telegram AI bot that replies in my voice 24/7. If you run a brand or a page, this saves HOURS. Zero ghosting. Full engagement.
💡3. Daily Auto-Posting on Socials with Trend-Powered Bots Using Python bots + Google Trends + Reddit, I post AI-generated content every single day on Twitter, Pinterest & more—without lifting a finger. Traffic flows while I sleep.
💡4. AI-Powered Visuals for Pinterest & TikTok No design skills? No problem. There are bots that create scroll-stopping images + auto-caption them to boost reach. It’s not just automation—it’s growth hacking.
💡5. Sell Your Own AI Tools Here’s the kicker: I’ve packaged my top bots (IG, TikTok, Telegram, AI Caller Bot) and I sell them as digital products. No physical inventory, pure profit.
🎯 Wanna try them out or resell them yourself? I’ve made everything plug-and-play: 👉 Shop AI Bots + Earn from Reselling (No code? No problem. Comes with guides.)
You can literally use these bots, make them your own, or flip them as your side hustle. Gen Z style: fast, passive, and scalable. 💸
🧠 Follow for more no-fluff AI tips 💬 Drop questions or DM if you want help setting things up 🔁 Reblog to help others automate smarter
#AIBusiness #PassiveIncomeTools #DigitalHustle #AIforEveryone #TumblrTechTips #GumroadGang
1 note
·
View note
Text
OpenRouter – One API Key to Rule Them All – CyberSEO Pro
OpenRouter – One API Key to Rule Them All – CyberSEO Pro
0 notes
Quote
コスト意識の高いチーム向け: Cursor と WindSurf は、機能面では Cline ほど包括的ではありませんが、優れた価値を提供します。コストは、OpenRouter、ローカル モデル、またはフォーク (RooCline/Code) を使用することで、Cline で解決できることがよくあります。
Why I use Cline for AI Engineering - by Addy Osmani
0 notes
Text

Verbessertes Publishing mit ZimmWriter: Systemaktualisierungen verbessern die Leistung und beheben Probleme. Erweiterte Funktionen, wie die Zitatfunktionalität, unterstützen Inhalts-Ersteller. Systemaktualisierungen und Fehlerbehebungen Das Entwicklungsteam hat hart gearbeitet und eine Reihe von Systemupdates und Fehlerbehebungen sorgfältig implementiert, um Ihr Veröffentlichungserlebnis zu verbessern. Zu den wirkungsvollsten Verbesserungen zählt die Behebung von Problemen im Zusammenhang mit dem Profil-Loading, ein Schlüsselelement zur Gewährleistung eines reibungslosen Workflows. Diese Verbesserung ist Teil einer umfassenderen Anstrengung, die Gesamtleistung des Systems zu steigern, was Sie letztlich befähigt, Ihre Zeit und Energie der Erstellung ansprechender Inhalte zu widmen. Stellen Sie sich die Freiheit des Veröffentlichens ohne technische Pannen vor. Diese Verbesserungen sind darauf ausgelegt, Ihnen diese Freiheit zu bieten, mit dem Fokus auf die Schaffung eines flüssigeren und effizienteren Erlebnisses. Indem diese rauen Kanten geglättet werden, wird der Weg, Ihre Arbeit mit der Welt zu teilen, weniger zu einer entmutigenden Reise und mehr zu einem angenehmen, erfüllenden Prozess. Jedes Update ist ein Schritt hin zu einem System, das Ihre kreativen Bestrebungen respektiert und Hindernisse minimiert, sodass Sie sich auf das konzentrieren können, was wirklich zählt: Ihren Inhalt. Modellverbesserungen für OpenRouter und Perplexity Die Erstellung von Inhalten verändert sich ständig, wobei Modellverbesserungen für OpenRouter und Perplexity die Führung übernehmen. Diese Updates sind darauf ausgelegt, die Modelleistung und Benutzerzuverlässigkeit zu verbessern, was den Veröffentlichungsprozess effizienter macht. Durch das Ausphasen veralteter Modelle können wir uns nun auf neue, fortschrittlichere Versionen konzentrieren, die einen reibungslosen Content-Erstellungsprozess gewährleisten. Autoren können ihre Ideen frei ausdrücken, ohne technische Hindernisse, dank dieses optimierten Ansatzes. Dieser Fortschritt dreht sich nicht nur um Veränderungen – es geht darum, die Werkzeuge, die wir haben, zu verfeinern, um unseren Bedürfnissen besser gerecht zu werden. Die Updates für OpenRouter und Perplexity zielen darauf ab, die Verlagswelt zu vereinfachen, indem sie den Weg optimieren, auf dem wir Inhalte erstellen, bearbeiten und verteilen. Benutzer werden schnellere Antwortzeiten, verbesserte Genauigkeit und eine intuitivere Benutzeroberfläche bemerken, die alle zu einem reibungsloseren Erlebnis beitragen. In dieser Ära des rasanten technologischen Fortschritts ist es entscheidend, Werkzeuge zu priorisieren, die Kreativität fördern, anstatt sie zu behindern. Indem die Software agil und auf dem neuesten Stand gehalten wird, werden Schöpfer befähigt, sich voll und ganz auszudrücken, ohne von technischen Schwierigkeiten behindert zu werden. Diese Verbesserungen zu akzeptieren bedeutet, eine Zukunft zu umarmen, in der die Erstellung von Inhalten nicht nur einfacher ist, sondern auch innovativer und wirkungsvoller. Konfigurieren der Zeitzoneneinstellungen für WordPress-Websites Die Aktualisierung der Zeitzoneneinstellungen in WordPress ist entscheidend, um sicherzustellen, dass Ihre Inhalte immer zeitgemäß und präzise sind. Lassen Sie uns darauf eingehen, warum dies wichtig ist und wie Sie es effizient einrichten können. Zunächst wird empfohlen, die Standardzeitzone auf UTC+0 einzustellen. Die koordinierte Weltzeit (Universal Time Coordinated, UTC) bietet einen neutralen Ausgangspunkt. Für Sie bedeutet das Einheitlichkeit bei Ihren geplanten Beiträgen und ein breiteres Publikum erreicht die Inhalte wie beabsichtigt. Richten Sie als Nächstes Ihre Website-Einstellungen nach Ihrer lokalen Zeitzone aus. Dies ermöglicht eine nahtlose Integration zwischen Ihrem Veröffentlichungszeitplan und den Erwartungen Ihres Publikums. Wenn Ihre lokale Zeit in Ihren WordPress-Einstellungen widergespiegelt wird, reduziert dies Verwirrung und minimiert Fehler bei der Veröffentlichungszeit. Schließlich ist eine genaue Planung entscheidend. Die Implementierung dieser Zeitzoneneinstellungen ermöglicht es Ihnen, flexibel zu wählen, wann Sie Ihre Beiträge veröffentlichen, und bewahrt die kreative Freiheit, um ohne Probleme auf verschiedene Spitzenzeiten des Publikums einzugehen. Optimierung der Artikelveröffentlichungsstrategie Zu wissen, wann man einen Artikel veröffentlichen sollte, kann erheblichen Einfluss darauf haben, wie er die Leser anspricht. Die Faktoren, die diesen Zeitpunkt beeinflussen, können einen mittelmäßigen Beitrag in einen verwandeln, der Interesse weckt. Einfach ausgedrückt: Zur richtigen Zeit zu veröffentlichen ist entscheidend. Indem Autoren die besten Zeiten zum Veröffentlichen und die Häufigkeit, in der neue Inhalte geteilt werden, verstehen, können sie besser mit ihrem Publikum in Kontakt treten und die kreative Freiheit genießen, die damit einhergeht. Beispielsweise zeigen Untersuchungen, dass Artikel, die zu Stoßzeiten der Online-Aktivität – typischerweise späte Vormittage oder frühe Nachmittage an Wochentagen – veröffentlicht werden, tendenziell höhere Interaktion erzielen. Das bedeutet mehr Teilen, Kommentieren und Lesen. Außerdem ist Konsistenz wichtig. Regelmäßig Inhalte zu veröffentlichen, sei es täglich, wöchentlich oder zweiwöchentlich, hilft, das Interesse der Leser aufrechtzuerhalten und ein treues Publikum aufzubauen. Das richtige Gleichgewicht zwischen Qualität und Quantität zu finden, kann sich wie eine Herausforderung anfühlen, ist jedoch essentiell. Hochwertige Artikel, die zu optimalen Zeiten veröffentlicht werden, können die Präsenz eines Autors festigen. Viele erfolgreiche Kreatoren konzentrieren sich auf diese Strategien, was ihnen ermöglicht, sich authentisch auszudrücken und effektiv mit ihrem Publikum zu interagieren. In einem Umfeld, in dem Inhalte zahlreich und vielfältig sind, kann das Verständnis, wann zu veröffentlichen ist, den entscheidenden Unterschied machen. Berücksichtigen Sie diese Einblicke, wenn Sie Ihren nächsten Artikel planen, und beobachten Sie, wie sich Ihre Veröffentlichungserfahrung entwickelt. Mit der Zeit und ein wenig Übung werden Sie wahrscheinlich einen Rhythmus finden, der sowohl Ihre kreativen Ziele unterstützt als auch die Leser dort abholt, wo sie sind. Verbesserte Blockzitat-Funktionalität und Anpassung Wenn Sie daran denken, die Aufmerksamkeit Ihrer Leser zu gewinnen, ist es wichtig, sich nicht nur auf den Zeitpunkt der Veröffentlichung Ihres Inhalts zu konzentrieren, sondern auch darauf, wie er visuell präsentiert wird. Stellen Sie sich vor, die Wirkung Ihrer Worte wird durch verbesserte Zitatfunktionalität verstärkt und verleiht Ihrem Inhalt ein einzigartiges und ansprechendes Erscheinungsbild. Mit flexiblen Platzierungsoptionen können Sie Zitate kunstvoll positionieren, um die Augen der Leser auf natürliche Weise auf die relevantesten Teile Ihrer Nachricht zu lenken. Diese strategische Platzierung hilft, den Lesefluss zu erhalten und sicherzustellen, dass deren Aufmerksamkeit genau dort bleibt, wo Sie sie haben möchten. Die visuelle Attraktivität wird weiter durch anpassbare Stile verstärkt, die Ihnen die Freiheit bieten, das Aussehen an den Ton und die Identität Ihres Stücks anzupassen. Personalisierung steht im Zentrum des effektiven Schreibens und benutzerdefinierte Zitate ermöglichen es Ihnen, Ihrer Arbeit Ihre einzigartige Stimme zu verleihen. Diese Ebene der Anpassung zeigt nicht nur Ihre Individualität, sondern verbessert auch das Leseerlebnis, indem sie Ihre Erzählung nachvollziehbarer und authentischer macht. Effektives Schreiben zeigt Individualität durch Anpassung und nachvollziehbare Erzählstimmen. Inhalt zu erstellen, der resoniert, erfordert mehr als Worte; es geht darum, eine Umgebung zu schaffen, in der Ihre Ideen mit Klarheit und Kreativität strahlen können. Durch die Nutzung fortschrittlicher Benutzerzitat-Funktionen können Sie Ihr Schreiben in eine nahtlose Verbindung von Kunst und Information transformieren, die Ihr Publikum von Anfang bis Ende fesselt. Read the full article
0 notes
Text
To answer your question, yes, they can and do search the internet (if asked, and if the specific bot supports it).
The llm itself, in most reasonable setups, is basically a parser for user intent. That's why it's not really that big of a deal that they guess the next token - that's the best thing they *could* do. They don't need to "know" things. They just need to be able to guess what the user means without expecting exact string literals, and be able to guess tokens to put together useable language, and synthesize data fed to them from other functions.
User asks a question, optionally telling the llm to search online. The llm outputs a function call requesting internet search of the inference code. Inference code catches this, runs a number of searches (anywhere from one to several tens, depending on the bot, the user, and the content), related data is sniffed from the search, usually by a smaller model, and passed back to the llm, who's job is then to summarize for the user. This isn't the only way they can reference data, but is in a sense a sort of web-mediated Retrieval Augmented Generation, which works the same way - documents are converted into a vector database for fast indexing of "what" and "where". User asks a question. Smaller model queries vector DB for relation to user input. If matches are found, relevant text is passed to the llm to summarise back to the user. This is one way that LLMs can be adapted to certain domains - by making domain specific data available to them. (and finetuning but thats in the weeds from here)
and on the topic of internet search and RAG, small local models can do this, as well, with plugins to search the internet, as can the models of most inference providers.
Though, depending on what the model has been trained on, it can sometimes have a useable knowledge for certain domains without access to the internet, but, in general, yes, the llm itself is a 3 dimensional array of floating point values that spits a response. a text engine. But it's only the language core. Which is adapted for different use cases by inference code. This is one reason LLMs and AI based on them are difficult to discourse about meaningfully, because we could be talking about the model (a set of frozen floating point values in memory) or its interface, or the functions made available to it, or the output of all of that, together, and most people only have the barest grasp of what the model even is, let alone to throw in the complexity of functions that may or may not be there depending on the software surrounding the model in the implementation.
tldr; yes they can google and how much they can google is alterable at inference time in code. The default for openrouter is five max searches per query but this can be changed by passing a parameter to the models api at inference time.
one of the things that really pisses me off about how companies are framing the narrative on text generators is that they've gone out of their way to establish that the primary thing they are For is to be asked questions, like factual questions, when this is in no sense what they're inherently good at and given how they work it's miraculous that it ever works at all.
They've even got people calling it a "ChatGPT search". Now, correct me if I'm wrong software mutuals, but as i understand it, no searching is actually happening, right? Not in the moment when you ask the question. Maybe this varies across interfaces; maybe the one they've got plugged into Google is in some sense responding to content fed to it in the moment out of a conventional web search, but your like chatbot interface LLM isn't searching shit is it, it's working off data it's already been trained on and it can only work off something that isn't in there if you feed it the new text
i would be far less annoyed if they were still pitching them as like virtual buddies you can talk to or short story generators or programs that can rephrase and edit text that you feed to them
76 notes
·
View notes
Text
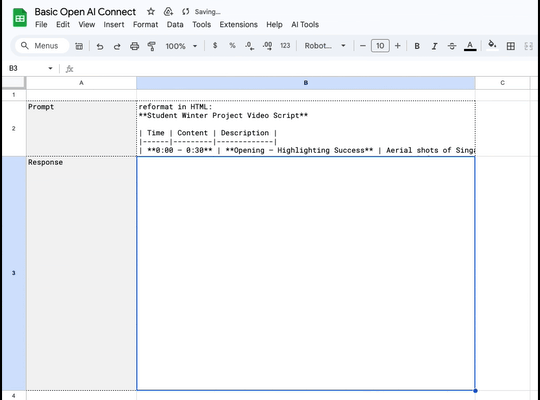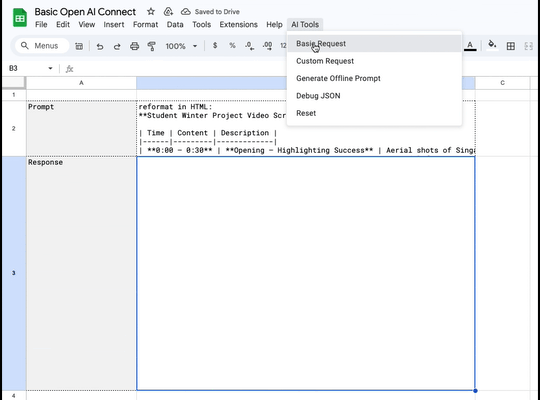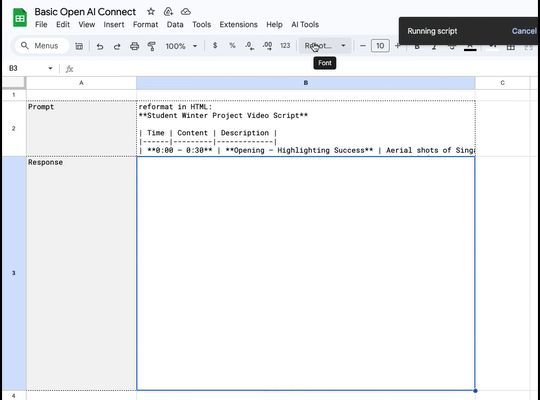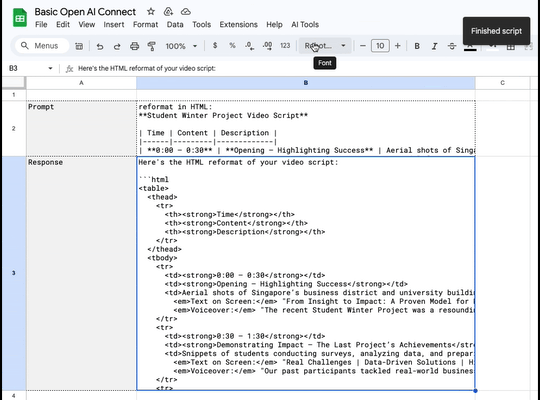
Things I'm working on. Custom requests via AppScript and Google Spreadsheets.
0 notes
Photo

Coming Yo Way VicksBurg💯💯. #KvngLee #AbandonedRoyaltyTour #Mississippi #OpenRoute #SoloDolo
1 note
·
View note
Text
llm command line with openrouter keys
Quite enjoying this command line tool. (llm)[https://github.com/simonw/llm]
pip install llm
llm install llm-openrouter
llm keys set openrouter
Enter key:
Then to set your fave model, see what your options are
llm models list
And (this week) i like to use Gemini Flash
llm models default openrouter/google/gemini-2.0-flash-001
Then you can have crazy thoughts and just ask on the command line
llm 'what is new wave music?'
0 notes