#postgres installation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
https://codeonedigest.blogspot.com/2023/07/run-postgres-database-in-docker.html
#youtube#video#codeonedigest#docker#postgres installation#postgres db#postgres tutorial#postgres database#postgres#postgresql#dockercontainers#docker image#docker container#docker tutorial#dockerfile
0 notes
Text
How to install and set up PostgreSQL 15 or 16 on Ubuntu 20.04, 22.04, 24.04

If Ubuntu is part of your work environment, there will be no trouble deploying a PostgreSQL database server on it. With this manual at hand, you will promptly learn everything from installing PostgreSQL on your Ubuntu machine to managing it with a high-end PostgreSQL GUI client.
Prerequisites for installing PostgreSQL on Ubuntu:
Internet connection
A machine running Ubuntu
A user account with sudo privileges
Access to the command line
Discover the full guide to learn how to install PostgreSQL on Ubuntu.
#gui for postgresql#ide for postgresql#postgresql gui#postgresql#postgres#pgsql#postgresql install ubuntu#postgresql client#postgresql tools
0 notes
Text
i will strangle you

#all jokes aside#excel is not a programming language#and if i hear one more person call it a database they die#microsoft ACCESS is a database manager#and it's not even a very good one#EXCEL IS A GLORIFIED CSV EDITOR#if you don't know the difference between a csv file and a relational database i do not know how to help you#excel is great if you need to do your taxes or calculate income or w/e#but if you need to do anything real#for the love of brian w kernighan please write a script#if you need a database then install postgres#or sqlite#or SOMETHING that is SEARCHABLE in a REASONABLE AMOUNT OF TIME#YOU WILL THANK YOURSELF LATER
1K notes
·
View notes
Text
A thing I've been looking into at work lately is collation, and specifically sorting. We want to compare in-memory implementations of things to postgres implementations, which means we need to reproduce postgres sorting in Haskell. Man it's a mess.
By default postgres uses glibc to sort. So we can use the FFI to reproduce it.
This mostly works fine, except if the locale says two things compare equal, postgres falls back to byte-comparing them. Which is also fine I guess, we can implement that too, but ugh.
Except also, this doesn't work for the mac user, so they can't reproduce test failures in the test suite we implemented this in.
How does postgres do sorting on mac? Not sure.
So we figured we'd use libicu for sorting. Postgres supports that, haskell supports it (through text-icu), should be fine. I'm starting off with a case-insensitive collation.
In postgres, you specify a collation through a string like en-u-ks-level2-numeric-true. (Here, en is a language, u is a separator, ks and numeric are keys and level2 and true are values. Some keys take multiple values, so you just have to know which strings are keys I guess?) In Haskell you can do it through "attributes" or "rules". Attributes are type safe but don't support everything you might want to do with locales. Rules are completely undocumented in text-icu, you pass in a string and it parses it. I'm pretty sure the parsing is implemented in libicu itself but it would be nice if text-icu gave you even a single example of what they look like.
But okay, I've got a locale in Haskell that I think should match the postgres one. Does it? Lolno
So there's a function collate for "compare these two strings in this locale", and a function sortKey for "get the sort key of this string in this locale". It should be that "collate l a b" is the same as "compare (sortKey l a) (sortKey l b)", but there are subtle edge cases where this isn't the case, like for example when a is the empty string and b is "\0". Or any string whose characters are all drawn from a set that includes NUL, lots of other control codes, and a handful of characters somewhere in the Arabic block. In these cases, collate says they're equal but sortKey says the empty string is smaller. But pg gets the same results as collate so fine, go with that.
Also seems like text-icu and pg disagree on which blocks get sorted before which other blocks, or something? At any rate I found a lot of pairs of (latin, non-latin) where text-icu sorts the non-latin first and pg sorts it second. So far I've solved this by just saying "only generate characters in the basic multilingual plane, and ignore anything in (long list of blocks)".
(Collations have an option for choosing which order blocks get sorted in, but it's not available with attributes. I haven't bothered to try it with rules, or with the format pg uses to specify them.)
I wonder how much of this is to do with using different versions of libicu. For Haskell we use a nix shell, which is providing version 72.1. Our postgres comes from a docker image and is using 63.1. When I install libicu on our CI images, they get 67.1 (and they can't reproduce the collate/sortKey bug with the arabic characters, so fine, remove them from the test set).
(I find out version numbers locally by doing lsof and seeing that the files are named like .so.63.1. Maybe ldd would work too? But because pg is in docker I don't know where the binary is. On CI I just look at the install logs.)
I wonder if I can get 63.1 in our nix shell. No, node doesn't support below 69. Fine, let's try 69. Did you know chromium depends on libicu? My laptop's been compiling chromium for many hours now.
7 notes
·
View notes
Text
Is ChatGPT Easy to Use? Here’s What You Need to Know
Introduction: A Curious Beginning I still remember the first time I stumbled upon ChatGPT my heart raced at the thought of talking to an AI. I was a fresh-faced IT enthusiast, eager to explore how a “gpt chat” interface could transform my workflow. Yet, as excited as I was, I also felt a tinge of apprehension: Would I need to learn a new programming language? Would I have to navigate countless settings? Spoiler alert: Not at all. In this article, I’m going to walk you through my journey and show you why ChatGPT is as straightforward as chatting with a friend. By the end, you’ll know exactly “how to use ChatGPT” in your day-to-day IT endeavors whether you’re exploring the “chatgpt app” on your phone or logging into “ChatGPT online” from your laptop.
What Is ChatGPT, Anyway?
If you’ve heard of “chat openai,” “chat gbt ai,” or “chatgpt openai,” you already know that OpenAI built this tool to mimic human-like conversation. ChatGPT sometimes written as “Chat gpt”—is an AI-powered chatbot that understands natural language and responds with surprisingly coherent answers. With each new release remember buzz around “chatgpt 4”? OpenAI has refined its approach, making the bot smarter at understanding context, coding queries, creative brainstorming, and more.
GPT Chat: A shorthand term some people use, but it really means the same as ChatGPT just another way to search or tag the service.
ChatGPT Online vs. App: Although many refer to “chatgpt online,” you can also download the “chatgpt app” on iOS or Android for on-the-go access.
Free vs. Paid: There’s even a “chatgpt gratis” option for users who want to try without commitment, while premium plans unlock advanced features.
Getting Started: Signing Up for ChatGPT Online
1. Creating Your Account
First things first head over to the ChatGPT website. You’ll see a prompt to sign up or log in. If you’re wondering about “chat gpt free,” you’re in luck: OpenAI offers a free tier that anyone can access (though it has usage limits). Here’s how I did it:
Enter your email (or use Google/Microsoft single sign-on).
Verify your email with the link they send usually within seconds.
Log in, and voila, you’re in!
No complex setup, no plugin installations just a quick email verification and you’re ready to talk to your new AI buddy. Once you’re “ChatGPT online,” you’ll land on a simple chat window: type a question, press Enter, and watch GPT 4 respond.
Navigating the ChatGPT App
While “ChatGPT online” is perfect for desktop browsing, I quickly discovered the “chatgpt app” on my phone. Here’s what stood out:
Intuitive Interface: A text box at the bottom, a menu for adjusting settings, and conversation history links on the side.
Voice Input: On some versions, you can tap the microphone icon—no need to type every query.
Seamless Sync: Whatever you do on mobile shows up in your chat history on desktop.
For example, one night I was troubleshooting a server config while waiting for a train. Instead of squinting at the station’s Wi-Fi, I opened the “chat gpt free” app on my phone, asked how to tweak a Dockerfile, and got a working snippet in seconds. That moment convinced me: whether you’re using “chatgpt online” or the “chatgpt app,” the learning curve is minimal.
Key Features of ChatGPT 4
You might have seen “chatgpt 4” trending this iteration boasts numerous improvements over earlier versions. Here’s why it feels so effortless to use:
Better Context Understanding: Unlike older “gpt chat” bots, ChatGPT 4 remembers what you asked earlier in the same session. If you say, “Explain SQL joins,” and then ask, “How does that apply to Postgres?”, it knows you’re still talking about joins.
Multi-Turn Conversations: Complex troubleshooting often requires back-and-forth questions. I once spent 20 minutes configuring a Kubernetes cluster entirely through a multi-turn conversation.
Code Snippet Generation: Want Ruby on Rails boilerplate or a Python function? ChatGPT 4 can generate working code that requires only minor tweaks. Even if you make a mistake, simply pasting your error output back into the chat usually gets you an explanation.
These features mean that even non-developers say, a project manager looking to automate simple Excel tasks can learn “how to use ChatGPT” with just a few chats. And if you’re curious about “chat gbt ai” in data analytics, hop on and ask ChatGPT can translate your plain-English requests into practical scripts.
Tips for First-Time Users
I’ve coached colleagues on “how to use ChatGPT” in the last year, and these small tips always come in handy:
Be Specific: Instead of “Write a Python script,” try “Write a Python 3.9 script that reads a CSV file and prints row sums.” The more detail, the more precise the answer.
Ask Follow-Up Questions: Stuck on part of the response? Simply type, “Can you explain line 3 in more detail?” This keeps the flow natural—just like talking to a friend.
Use System Prompts: At the very start, you can say, “You are an IT mentor. Explain in beginner terms.” That “meta” instruction shapes the tone of every response.
Save Your Favorite Replies: If you stumble on a gem—say, a shell command sequence—star it or copy it to a personal notes file so you can reference it later.
When a coworker asked me how to connect a React frontend to a Flask API, I typed exactly that into the chat. Within seconds, I had boilerplate code, NPM install commands, and even a short security note: “Don’t forget to add CORS headers.” That level of assistance took just three minutes, demonstrating why “gpt chat” can feel like having a personal assistant.
Common Challenges and How to Overcome Them
No tool is perfect, and ChatGPT is no exception. Here are a few hiccups you might face and how to fix them:
Occasional Inaccuracies: Sometimes, ChatGPT can confidently state something that’s outdated or just plain wrong. My trick? Cross-check any critical output. If it’s a code snippet, run it; if it’s a conceptual explanation, ask follow-up questions like, “Is this still true for Python 3.11?”
Token Limits: On the “chatgpt gratis” tier, you might hit usage caps or get slower response times. If you encounter this, try simplifying your prompt or wait a few minutes for your quota to reset. If you need more, consider upgrading to a paid plan.
Overly Verbose Answers: ChatGPT sometimes loves to explain every little detail. If that happens, just say, “Can you give me a concise version?” and it will trim down its response.
Over time, you learn how to phrase questions so that ChatGPT delivers exactly what you need quickly—no fluff, just the essentials. Think of it as learning the “secret handshake” to get premium insights from your digital buddy.
Comparing Free and Premium Options
If you search “chat gpt free” or “chatgpt gratis,” you’ll see that OpenAI’s free plan offers basic access to ChatGPT 3.5. It’s great for light users students looking for homework help, writers brainstorming ideas, or aspiring IT pros tinkering with small scripts. Here’s a quick breakdown: FeatureFree Tier (ChatGPT 3.5)Paid Tier (ChatGPT 4)Response SpeedStandardFaster (priority access)Daily Usage LimitsLowerHigherAccess to Latest ModelChatGPT 3.5ChatGPT 4 (and beyond)Advanced Features (e.g., Code)LimitedFull accessChat History StorageShorter retentionLonger session memory
For someone just dipping toes into “chat openai,” the free tier is perfect. But if you’re an IT professional juggling multiple tasks and you want the speed and accuracy of “chatgpt 4” the upgrade is usually worth it. I switched to a paid plan within two weeks of experimenting because my productivity jumped tenfold.
Real-World Use Cases for IT Careers
As an IT blogger, I’ve seen ChatGPT bridge gaps in various IT roles. Here are some examples that might resonate with you:
Software Development: Generating boilerplate code, debugging error messages, or even explaining complex algorithms in simple terms. When I first learned Docker, ChatGPT walked me through building an image, step by step.
System Administration: Writing shell scripts, explaining how to configure servers, or outlining best security practices. One colleague used ChatGPT to set up an Nginx reverse proxy without fumbling through documentation.
Data Analysis: Crafting SQL queries, parsing data using Python pandas, or suggesting visualization libraries. I once asked, “How to use chatgpt for data cleaning?” and got a concise pandas script that saved hours of work.
Project Management: Drafting Jira tickets, summarizing technical requirements, or even generating risk-assessment templates. If you ever struggled to translate technical jargon into plain English for stakeholders, ChatGPT can be your translator.
In every scenario, I’ve found that the real magic isn’t just the AI’s knowledge, but how quickly it can prototype solutions. Instead of spending hours googling or sifting through Stack Overflow, you can ask a direct question and get an actionable answer in seconds.
Security and Privacy Considerations
Of course, when dealing with AI, it’s wise to think about security. Here’s what you need to know:
Data Retention: OpenAI may retain conversation data to improve their models. Don’t paste sensitive tokens, passwords, or proprietary code you can’t risk sharing.
Internal Policies: If you work for a company with strict data guidelines, check whether sending internal data to a third-party service complies with your policy.
Public Availability: Remember that anyone else could ask ChatGPT similar questions. If you need unique, private solutions, consult official documentation or consider an on-premises AI solution.
I routinely use ChatGPT for brainstorming and general code snippets, but for production credentials or internal proprietary logic, I keep those aspects offline. That balance lets me benefit from “chatgpt openai” guidance without compromising security.
Is ChatGPT Right for You?
At this point, you might be wondering, “Okay, but is it really easy enough for me?” Here’s my honest take:
Beginners who have never written a line of code can still ask ChatGPT to explain basic IT concepts no jargon needed.
Intermediate users can leverage the “chatgpt app” on mobile to troubleshoot on the go, turning commute time into learning time.
Advanced professionals will appreciate how ChatGPT 4 handles multi-step instructions and complex code logic.
If you’re seriously exploring a career in IT, learning “how to use ChatGPT” is almost like learning to use Google in 2005: essential. Sure, there’s a short learning curve to phrasing your prompts for maximum efficiency, but once you get the hang of it, it becomes second nature just like typing “ls -la” into a terminal.
Conclusion: Your Next Steps
So, is ChatGPT easy to use? Absolutely. Between the intuitive “chatgpt app,” the streamlined “chatgpt online” interface, and the powerful capabilities of “chatgpt 4,” most users find themselves up and running within minutes. If you haven’t already, head over to the ChatGPT website and create your free account. Experiment with a few prompts maybe ask it to explain “how to use chatgpt” and see how it fits into your daily routine.
Remember:
Start simple. Ask basic questions, then gradually dive deeper.
Don’t be afraid to iterate. If an answer isn’t quite right, refine your prompt.
Keep security in mind. Never share passwords or sensitive data.
Whether you’re writing your first “gpt chat” script, drafting project documentation, or just curious how “chat gbt ai” can spice up your presentations, ChatGPT is here to help. Give it a try, and in no time, you’ll wonder how you ever managed without your AI sidekick.
1 note
·
View note
Text
Java Database Connectivity API contains commonly asked Java interview questions. A good understanding of JDBC API is required to understand and leverage many powerful features of Java technology. Here are few important practical questions and answers which can be asked in a Core Java JDBC interview. Most of the java developers are required to use JDBC API in some type of application. Though its really common, not many people understand the real depth of this powerful java API. Dozens of relational databases are seamlessly connected using java due to the simplicity of this API. To name a few Oracle, MySQL, Postgres and MS SQL are some popular ones. This article is going to cover a lot of general questions and some of the really in-depth ones to. Java Interview Preparation Tips Part 0: Things You Must Know For a Java Interview Part 1: Core Java Interview Questions Part 2: JDBC Interview Questions Part 3: Collections Framework Interview Questions Part 4: Threading Interview Questions Part 5: Serialization Interview Questions Part 6: Classpath Related Questions Part 7: Java Architect Scalability Questions What are available drivers in JDBC? JDBC technology drivers fit into one of four categories: A JDBC-ODBC bridge provides JDBC API access via one or more ODBC drivers. Note that some ODBC native code and in many cases native database client code must be loaded on each client machine that uses this type of driver. Hence, this kind of driver is generally most appropriate when automatic installation and downloading of a Java technology application is not important. A native-API partly Java technology-enabled driver converts JDBC calls into calls on the client API for Oracle, Sybase, Informix, DB2, or other DBMS. Note that, like the bridge driver, this style of driver requires that some binary code be loaded on each client machine. A net-protocol fully Java technology-enabled driver translates JDBC API calls into a DBMS-independent net protocol which is then translated to a DBMS protocol by a server. This net server middleware is able to connect all of its Java technology-based clients to many different databases. The specific protocol used depends on the vendor. In general, this is the most flexible JDBC API alternative. It is likely that all vendors of this solution will provide products suitable for Intranet use. In order for these products to also support Internet access they must handle the additional requirements for security, access through firewalls, etc., that the Web imposes. Several vendors are adding JDBC technology-based drivers to their existing database middleware products. A native-protocol fully Java technology-enabled driver converts JDBC technology calls into the network protocol used by DBMSs directly. This allows a direct call from the client machine to the DBMS server and is a practical solution for Intranet access. Since many of these protocols are proprietary the database vendors themselves will be the primary source for this style of driver. Several database vendors have these in progress. What are the types of statements in JDBC? the JDBC API has 3 Interfaces, (1. Statement, 2. PreparedStatement, 3. CallableStatement ). The key features of these are as follows: Statement This interface is used for executing a static SQL statement and returning the results it produces. The object of Statement class can be created using Connection.createStatement() method. PreparedStatement A SQL statement is pre-compiled and stored in a PreparedStatement object. This object can then be used to efficiently execute this statement multiple times. The object of PreparedStatement class can be created using Connection.prepareStatement() method. This extends Statement interface. CallableStatement This interface is used to execute SQL stored procedures. This extends PreparedStatement interface. The object of CallableStatement class can be created using Connection.prepareCall() method.
What is a stored procedure? How to call stored procedure using JDBC API? Stored procedure is a group of SQL statements that forms a logical unit and performs a particular task. Stored Procedures are used to encapsulate a set of operations or queries to execute on database. Stored procedures can be compiled and executed with different parameters and results and may have any combination of input/output parameters. Stored procedures can be called using CallableStatement class in JDBC API. Below code snippet shows how this can be achieved. CallableStatement cs = con.prepareCall("call MY_STORED_PROC_NAME"); ResultSet rs = cs.executeQuery(); What is Connection pooling? What are the advantages of using a connection pool? Connection Pooling is a technique used for sharing the server resources among requested clients. It was pioneered by database vendors to allow multiple clients to share a cached set of connection objects that provides access to a database. Getting connection and disconnecting are costly operation, which affects the application performance, so we should avoid creating multiple connection during multiple database interactions. A pool contains set of Database connections which are already connected, and any client who wants to use it can take it from pool and when done with using it can be returned back to the pool. Apart from performance this also saves you resources as there may be limited database connections available for your application. How to do database connection using JDBC thin driver ? This is one of the most commonly asked questions from JDBC fundamentals, and knowing all the steps of JDBC connection is important. import java.sql.*; class JDBCTest public static void main (String args []) throws Exception //Load driver class Class.forName ("oracle.jdbc.driver.OracleDriver"); //Create connection Connection conn = DriverManager.getConnection ("jdbc:oracle:thin:@hostname:1526:testdb", "scott", "tiger"); // @machineName:port:SID, userid, password Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select 'Hi' from dual"); while (rs.next()) System.out.println (rs.getString(1)); // Print col 1 => Hi stmt.close(); What does Class.forName() method do? Method forName() is a static method of java.lang.Class. This can be used to dynamically load a class at run-time. Class.forName() loads the class if its not already loaded. It also executes the static block of loaded class. Then this method returns an instance of the loaded class. So a call to Class.forName('MyClass') is going to do following - Load the class MyClass. - Execute any static block code of MyClass. - Return an instance of MyClass. JDBC Driver loading using Class.forName is a good example of best use of this method. The driver loading is done like this Class.forName("org.mysql.Driver"); All JDBC Drivers have a static block that registers itself with DriverManager and DriverManager has static initializer method registerDriver() which can be called in a static blocks of Driver class. A MySQL JDBC Driver has a static initializer which looks like this: static try java.sql.DriverManager.registerDriver(new Driver()); catch (SQLException E) throw new RuntimeException("Can't register driver!"); Class.forName() loads driver class and executes the static block and the Driver registers itself with the DriverManager. Which one will you use Statement or PreparedStatement? Or Which one to use when (Statement/PreparedStatement)? Compare PreparedStatement vs Statement. By Java API definitions: Statement is a object used for executing a static SQL statement and returning the results it produces. PreparedStatement is a SQL statement which is precompiled and stored in a PreparedStatement object. This object can then be used to efficiently execute this statement multiple times. There are few advantages of using PreparedStatements over Statements
Since its pre-compiled, Executing the same query multiple times in loop, binding different parameter values each time is faster. (What does pre-compiled statement means? The prepared statement(pre-compiled) concept is not specific to Java, it is a database concept. Statement precompiling means: when you execute a SQL query, database server will prepare a execution plan before executing the actual query, this execution plan will be cached at database server for further execution.) In PreparedStatement the setDate()/setString() methods can be used to escape dates and strings properly, in a database-independent way. SQL injection attacks on a system are virtually impossible when using PreparedStatements. What does setAutoCommit(false) do? A JDBC connection is created in auto-commit mode by default. This means that each individual SQL statement is treated as a transaction and will be automatically committed as soon as it is executed. If you require two or more statements to be grouped into a transaction then you need to disable auto-commit mode using below command con.setAutoCommit(false); Once auto-commit mode is disabled, no SQL statements will be committed until you explicitly call the commit method. A Simple transaction with use of autocommit flag is demonstrated below. con.setAutoCommit(false); PreparedStatement updateStmt = con.prepareStatement( "UPDATE EMPLOYEE SET SALARY = ? WHERE EMP_NAME LIKE ?"); updateStmt.setInt(1, 5000); updateSales.setString(2, "Jack"); updateStmt.executeUpdate(); updateStmt.setInt(1, 6000); updateSales.setString(2, "Tom"); updateStmt.executeUpdate(); con.commit(); con.setAutoCommit(true); What are database warnings and How can I handle database warnings in JDBC? Warnings are issued by database to notify user of a problem which may not be very severe. Database warnings do not stop the execution of SQL statements. In JDBC SQLWarning is an exception that provides information on database access warnings. Warnings are silently chained to the object whose method caused it to be reported. Warnings may be retrieved from Connection, Statement, and ResultSet objects. Handling SQLWarning from connection object //Retrieving warning from connection object SQLWarning warning = conn.getWarnings(); //Retrieving next warning from warning object itself SQLWarning nextWarning = warning.getNextWarning(); //Clear all warnings reported for this Connection object. conn.clearWarnings(); Handling SQLWarning from Statement object //Retrieving warning from statement object stmt.getWarnings(); //Retrieving next warning from warning object itself SQLWarning nextWarning = warning.getNextWarning(); //Clear all warnings reported for this Statement object. stmt.clearWarnings(); Handling SQLWarning from ResultSet object //Retrieving warning from resultset object rs.getWarnings(); //Retrieving next warning from warning object itself SQLWarning nextWarning = warning.getNextWarning(); //Clear all warnings reported for this resultset object. rs.clearWarnings(); The call to getWarnings() method in any of above way retrieves the first warning reported by calls on this object. If there is more than one warning, subsequent warnings will be chained to the first one and can be retrieved by calling the method SQLWarning.getNextWarning on the warning that was retrieved previously. A call to clearWarnings() method clears all warnings reported for this object. After a call to this method, the method getWarnings returns null until a new warning is reported for this object. Trying to call getWarning() on a connection after it has been closed will cause an SQLException to be thrown. Similarly, trying to retrieve a warning on a statement after it has been closed or on a result set after it has been closed will cause an SQLException to be thrown. Note that closing a statement also closes a result set that it might have produced. What is Metadata and why should I use it?
JDBC API has 2 Metadata interfaces DatabaseMetaData & ResultSetMetaData. The DatabaseMetaData provides Comprehensive information about the database as a whole. This interface is implemented by driver vendors to let users know the capabilities of a Database Management System (DBMS) in combination with the driver based on JDBC technology ("JDBC driver") that is used with it. Below is a sample code which demonstrates how we can use the DatabaseMetaData DatabaseMetaData md = conn.getMetaData(); System.out.println("Database Name: " + md.getDatabaseProductName()); System.out.println("Database Version: " + md.getDatabaseProductVersion()); System.out.println("Driver Name: " + md.getDriverName()); System.out.println("Driver Version: " + md.getDriverVersion()); The ResultSetMetaData is an object that can be used to get information about the types and properties of the columns in a ResultSet object. Use DatabaseMetaData to find information about your database, such as its capabilities and structure. Use ResultSetMetaData to find information about the results of an SQL query, such as size and types of columns. Below a sample code which demonstrates how we can use the ResultSetMetaData ResultSet rs = stmt.executeQuery("SELECT a, b, c FROM TABLE2"); ResultSetMetaData rsmd = rs.getMetaData(); int numberOfColumns = rsmd.getColumnCount(); boolean b = rsmd.isSearchable(1); What is RowSet? or What is the difference between RowSet and ResultSet? or Why do we need RowSet? or What are the advantages of using RowSet over ResultSet? RowSet is a interface that adds support to the JDBC API for the JavaBeans component model. A rowset, which can be used as a JavaBeans component in a visual Bean development environment, can be created and configured at design time and executed at run time. The RowSet interface provides a set of JavaBeans properties that allow a RowSet instance to be configured to connect to a JDBC data source and read some data from the data source. A group of setter methods (setInt, setBytes, setString, and so on) provide a way to pass input parameters to a rowset's command property. This command is the SQL query the rowset uses when it gets its data from a relational database, which is generally the case. Rowsets are easy to use since the RowSet interface extends the standard java.sql.ResultSet interface so it has all the methods of ResultSet. There are two clear advantages of using RowSet over ResultSet RowSet makes it possible to use the ResultSet object as a JavaBeans component. As a consequence, a result set can, for example, be a component in a Swing application. RowSet be used to make a ResultSet object scrollable and updatable. All RowSet objects are by default scrollable and updatable. If the driver and database being used do not support scrolling and/or updating of result sets, an application can populate a RowSet object implementation (e.g. JdbcRowSet) with the data of a ResultSet object and then operate on the RowSet object as if it were the ResultSet object. What is a connected RowSet? or What is the difference between connected RowSet and disconnected RowSet? or Connected vs Disconnected RowSet, which one should I use and when? Connected RowSet A RowSet object may make a connection with a data source and maintain that connection throughout its life cycle, in which case it is called a connected rowset. A rowset may also make a connection with a data source, get data from it, and then close the connection. Such a rowset is called a disconnected rowset. A disconnected rowset may make changes to its data while it is disconnected and then send the changes back to the original source of the data, but it must reestablish a connection to do so. Example of Connected RowSet: A JdbcRowSet object is a example of connected RowSet, which means it continually maintains its connection to a database using a JDBC technology-enabled driver. Disconnected RowSet A disconnected rowset may have a reader (a RowSetReader object) and a writer (a RowSetWriter object) associated with it.
The reader may be implemented in many different ways to populate a rowset with data, including getting data from a non-relational data source. The writer can also be implemented in many different ways to propagate changes made to the rowset's data back to the underlying data source. Example of Disconnected RowSet: A CachedRowSet object is a example of disconnected rowset, which means that it makes use of a connection to its data source only briefly. It connects to its data source while it is reading data to populate itself with rows and again while it is propagating changes back to its underlying data source. The rest of the time, a CachedRowSet object is disconnected, including while its data is being modified. Being disconnected makes a RowSet object much leaner and therefore much easier to pass to another component. For example, a disconnected RowSet object can be serialized and passed over the wire to a thin client such as a personal digital assistant (PDA). What is the benefit of having JdbcRowSet implementation? Why do we need a JdbcRowSet like wrapper around ResultSet? The JdbcRowSet implementation is a wrapper around a ResultSet object that has following advantages over ResultSet This implementation makes it possible to use the ResultSet object as a JavaBeans component. A JdbcRowSet can be used as a JavaBeans component in a visual Bean development environment, can be created and configured at design time and executed at run time. It can be used to make a ResultSet object scrollable and updatable. All RowSet objects are by default scrollable and updatable. If the driver and database being used do not support scrolling and/or updating of result sets, an application can populate a JdbcRowSet object with the data of a ResultSet object and then operate on the JdbcRowSet object as if it were the ResultSet object. Can you think of a questions which is not part of this post? Please don't forget to share it with me in comments section & I will try to include it in the list.
0 notes
Text
🔥 Top 37 GitHub Projects You Can't Miss (March 2025)!
Javascript Developer Resources – Made by 0x3d.site A curated hub for Javascript developers featuring essential tools, articles, and trending discussions. Bookmark it: javascript.0x3d.site 1. WASD: Wireless Anomaly Signal Dataset Check it out! 2. Pgserver: Super easy pip-installable Postgres Check it out! 3. Cutting-edge web scraping techniques Check it out! 4. Deploy from local to…

View On WordPress
0 notes
Text
蜘蛛池源码如何部署?
蜘蛛池,也被称为“爬虫池”或“爬虫集群”,是一种用于提高网络爬取效率的技术。通过将多个爬虫任务分配到不同的服务器上运行,可以显著提升数据抓取的速度和稳定性。本文将详细介绍如何部署蜘蛛池源码,帮助你快速搭建自己的爬虫集群。
1. 环境准备
在开始部署���前,确保你的服务器环境满足以下要求:
- 操作系统:Linux(推荐Ubuntu)
- Python环境:Python 3.x
- 其他依赖库:Scrapy、Twisted等
安装Python环境
如果你的服务器尚未安装Python 3.x,可以通过以下命令进行安装:
```bash
sudo apt-get update
sudo apt-get install python3
```
安装依赖库
使用pip安装所需的Python库:
```bash
pip3 install scrapy twisted
```
2. 获取源码
从GitHub或其他代码托管平台获取蜘蛛池的源码。假设源码位于`https://github.com/username/spiderpool.git`,你可以通过以下命令克隆项目:
```bash
git clone https://github.com/username/spiderpool.git
cd spiderpool
```
3. 配置文件
进入项目目录后,找到配置文件(通常为`settings.py`),根据你的需求进行配置。主要配置项包括数据库连接信息、爬虫任务队列等。
```python
DATABASE = {
'drivername': 'postgres',
'host': 'localhost',
'port': '5432',
'username': 'your_username',
'password': 'your_password',
'database': 'spiderpool'
}
```
4. 启动服务
启动蜘蛛池服务通常需要运行一个主进程和多个工作进程。具体命令可能因项目不同而异,但一般形式如下:
```bash
python manage.py startmaster
python manage.py startworker
```
5. 监控与维护
部署完成后,定期监控蜘蛛池的运行状态,确保所有工作进程正常运行。同时,根据实际需求调整配置参数,优化爬虫性能。
讨论点
你在部署蜘蛛池的过程中遇到了哪些问题?又是如何解决的呢?欢迎在评论区分享你的经验,让我们一起学习进步!
加飞机@yuantou2048

谷歌霸屏
Google外链购买
0 notes
Link
0 notes
Text
Using Docker for Full Stack Development and Deployment

1. Introduction to Docker
What is Docker? Docker is an open-source platform that automates the deployment, scaling, and management of applications inside containers. A container packages your application and its dependencies, ensuring it runs consistently across different computing environments.
Containers vs Virtual Machines (VMs)
Containers are lightweight and use fewer resources than VMs because they share the host operating system’s kernel, while VMs simulate an entire operating system. Containers are more efficient and easier to deploy.
Docker containers provide faster startup times, less overhead, and portability across development, staging, and production environments.
Benefits of Docker in Full Stack Development
Portability: Docker ensures that your application runs the same way regardless of the environment (dev, test, or production).
Consistency: Developers can share Dockerfiles to create identical environments for different developers.
Scalability: Docker containers can be quickly replicated, allowing your application to scale horizontally without a lot of overhead.
Isolation: Docker containers provide isolated environments for each part of your application, ensuring that dependencies don’t conflict.
2. Setting Up Docker for Full Stack Applications
Installing Docker and Docker Compose
Docker can be installed on any system (Windows, macOS, Linux). Provide steps for installing Docker and Docker Compose (which simplifies multi-container management).
Commands:
docker --version to check the installed Docker version.
docker-compose --version to check the Docker Compose version.
Setting Up Project Structure
Organize your project into different directories (e.g., /frontend, /backend, /db).
Each service will have its own Dockerfile and configuration file for Docker Compose.
3. Creating Dockerfiles for Frontend and Backend
Dockerfile for the Frontend:
For a React/Angular app:
Dockerfile
FROM node:14 WORKDIR /app COPY package*.json ./ RUN npm install COPY . . EXPOSE 3000 CMD ["npm", "start"]
This Dockerfile installs Node.js dependencies, copies the application, exposes the appropriate port, and starts the server.
Dockerfile for the Backend:
For a Python Flask app
Dockerfile
FROM python:3.9 WORKDIR /app COPY requirements.txt . RUN pip install -r requirements.txt COPY . . EXPOSE 5000 CMD ["python", "app.py"]
For a Java Spring Boot app:
Dockerfile
FROM openjdk:11 WORKDIR /app COPY target/my-app.jar my-app.jar EXPOSE 8080 CMD ["java", "-jar", "my-app.jar"]
This Dockerfile installs the necessary dependencies, copies the code, exposes the necessary port, and runs the app.
4. Docker Compose for Multi-Container Applications
What is Docker Compose? Docker Compose is a tool for defining and running multi-container Docker applications. With a docker-compose.yml file, you can configure services, networks, and volumes.
docker-compose.yml Example:
yaml
version: "3" services: frontend: build: context: ./frontend ports: - "3000:3000" backend: build: context: ./backend ports: - "5000:5000" depends_on: - db db: image: postgres environment: POSTGRES_USER: user POSTGRES_PASSWORD: password POSTGRES_DB: mydb
This YAML file defines three services: frontend, backend, and a PostgreSQL database. It also sets up networking and environment variables.
5. Building and Running Docker Containers
Building Docker Images:
Use docker build -t <image_name> <path> to build images.
For example:
bash
docker build -t frontend ./frontend docker build -t backend ./backend
Running Containers:
You can run individual containers using docker run or use Docker Compose to start all services:
bash
docker-compose up
Use docker ps to list running containers, and docker logs <container_id> to check logs.
Stopping and Removing Containers:
Use docker stop <container_id> and docker rm <container_id> to stop and remove containers.
With Docker Compose: docker-compose down to stop and remove all services.
6. Dockerizing Databases
Running Databases in Docker:
You can easily run databases like PostgreSQL, MySQL, or MongoDB as Docker containers.
Example for PostgreSQL in docker-compose.yml:
yaml
db: image: postgres environment: POSTGRES_USER: user POSTGRES_PASSWORD: password POSTGRES_DB: mydb
Persistent Storage with Docker Volumes:
Use Docker volumes to persist database data even when containers are stopped or removed:
yaml
volumes: - db_data:/var/lib/postgresql/data
Define the volume at the bottom of the file:
yaml
volumes: db_data:
Connecting Backend to Databases:
Your backend services can access databases via Docker networking. In the backend service, refer to the database by its service name (e.g., db).
7. Continuous Integration and Deployment (CI/CD) with Docker
Setting Up a CI/CD Pipeline:
Use Docker in CI/CD pipelines to ensure consistency across environments.
Example: GitHub Actions or Jenkins pipeline using Docker to build and push images.
Example .github/workflows/docker.yml:
yaml
name: CI/CD Pipeline on: [push] jobs: build: runs-on: ubuntu-latest steps: - name: Checkout Code uses: actions/checkout@v2 - name: Build Docker Image run: docker build -t myapp . - name: Push Docker Image run: docker push myapp
Automating Deployment:
Once images are built and pushed to a Docker registry (e.g., Docker Hub, Amazon ECR), they can be pulled into your production or staging environment.
8. Scaling Applications with Docker
Docker Swarm for Orchestration:
Docker Swarm is a native clustering and orchestration tool for Docker. You can scale your services by specifying the number of replicas.
Example:
bash
docker service scale myapp=5
Kubernetes for Advanced Orchestration:
Kubernetes (K8s) is more complex but offers greater scalability and fault tolerance. It can manage Docker containers at scale.
Load Balancing and Service Discovery:
Use Docker Swarm or Kubernetes to automatically load balance traffic to different container replicas.
9. Best Practices
Optimizing Docker Images:
Use smaller base images (e.g., alpine images) to reduce image size.
Use multi-stage builds to avoid unnecessary dependencies in the final image.
Environment Variables and Secrets Management:
Store sensitive data like API keys or database credentials in Docker secrets or environment variables rather than hardcoding them.
Logging and Monitoring:
Use tools like Docker’s built-in logging drivers, or integrate with ELK stack (Elasticsearch, Logstash, Kibana) for advanced logging.
For monitoring, tools like Prometheus and Grafana can be used to track Docker container metrics.
10. Conclusion
Why Use Docker in Full Stack Development? Docker simplifies the management of complex full-stack applications by ensuring consistent environments across all stages of development. It also offers significant performance benefits and scalability options.
Recommendations:
Encourage users to integrate Docker with CI/CD pipelines for automated builds and deployment.
Mention the use of Docker for microservices architecture, enabling easy scaling and management of individual services.
WEBSITE: https://www.ficusoft.in/full-stack-developer-course-in-chennai/
0 notes
Text
ACT Auto Electrical Listed on PostgresConf – Trusted Auto Electrical Experts
ACT Auto Electrical is now listed on PostgresConf, making our auto electrical services more accessible than ever. We specialize in repairs, wiring, diagnostics, and installations for a wide range of vehicles, including trucks, tractors, and earthmoving equipment. Our team ensures efficiency and reliability in every job. Visit our PostgresConf profile to learn more about our services and how we can assist with your vehicle's electrical needs.
#auto repair services#auto electrical services#four wheel drive car services#air conditioning service#4wd vehicle repair#auto electrician#air conditioning repair#mechanic service#car electrical services#auto electrical repair
1 note
·
View note
Text
#youtube#video#codeonedigest#microservices#microservice#docker#springboot#spring boot#postgres installation#postgres db#postgresql#postgres tutorial#postgres database#postgres#dockercontainers#docker image#docker container#docker tutorial#dockerfile#spring boot microservices#java microservice#microservice tutorial
0 notes
Video
youtube
How to Install Postgres 17 and pgAdmin in Windows
1 note
·
View note
Text
Sonarqube Setup with Postgresql
sonarqube installation along with java 17 Postgresql Database Prerequisites Need an AWS EC2 instance (min t2.small) Install Java 17 (openjdk-17) apt-get update apt list | grep openjdk-17 apt-get install openjdk-17-jdk -y Install & Setup Postgres Database for SonarQube Source: https://www.postgresql.org/download/linux/ubuntu/ Install Postgresql database Import the repository signing…
0 notes
Text
Visualize Keploy Test Data in Grafana for Real-Time Monitoring

In today's fast-paced development environment, efficient monitoring and visualization of test results are essential for ensuring the quality of your application. Keploy, a zero-code testing tool, simplifies test generation and integration, but how do you effectively monitor and analyze the test data Keploy generates?
This is where Grafana, a powerful open-source analytics and monitoring platform, comes into play. In this blog, we'll explore how you can set up a Grafana dashboard to visualize Keploy test data, enabling you to quickly assess the health of your tests and debug issues efficiently.
What is Grafana?

With Grafana, you can create real-time dashboards to track everything from server performance to test results, all in one place. By combining Grafana with Keploy, you can visually monitor your test suites and gain insights into test performance, failures, and trends over time.
What is Keploy?
Keploy is an open-source, zero-code testing platform that generates and executes test cases by observing real-world network traffic. It captures API requests, responses, and user interactions to automatically create test cases without requiring developers to write test scripts.
Brownie points out that it can integrate with existing CI/CD pipelines to enable end-to-end, integration, and unit testing.
Why Integrate Keploy with Grafana?
While Keploy automates test creation and execution, visualizing the test results can sometimes be challenging, especially with large test suites. Integrating Keploy with Grafana allows you to:
Monitor test results in real-time: Get immediate insights into your test runs.
Visualize test trends: Track how your tests perform over time, including pass/fail rates and test coverage.
Analyze test failures: Quickly identify patterns and potential areas of improvement.
Share insights: Easily share dashboards with team members, providing transparency and accountability across your testing process.
Step-by-Step Guide to Using Grafana with Keploy
Step 1: Install Grafana
If you don't have Grafana yet, follow these steps:
Use the docker to start Grafana service:docker run -d -p 3000:3000 --name=grafana grafana/grafana-enterprise
Access Grafana via http://localhost:3000/ and log in with the default credentials (admin/admin).
Step 2: Set Up Keploy to Generate Test Data
Before integrating Grafana, you need to ensure that Keploy is generating and storing test reports. Keploy captures API traffic to create tests and stores the test results, which can then be visualized in Grafana. I am using a sample app based on Mux router with Postgres database : - https://github.com/Sonichigo/mux-sql#Start Postgres docker-compose up -d postgres #Build App binary go build -cover
You can generate test cases with Keploy by running:keploy record -c "./test-app-product-catelog"
This command captures the real-world traffic from your application and creates test cases based on it. We can make API Calls using Hoppscotch, Postman or cURL command and keploy would be able to capture those calls to generate the test-suites containing testcases and data mocks.
To run the test cases we created earlier and generate our report, let’s run :keploy test -c "./test-app-product-catelog"
This will execute the test cases and generate test reports.
Step 3: Export Keploy Test Data
Next, you need to export the test data generated by Keploy into a format that Grafana can read. Most common being JSON format, so let’s export the test reports to JSON using JSON Converter.
Step 4: Configure Grafana Data Source
Grafana supports a wide range of data sources, and you can use one based on how you've exported your Keploy data. If you're using JSON or CSV, you can set up Grafana Loki or another time-series database that supports the format. If you store test reports in MySQL or Prometheus, configure Grafana to fetch data from that source.
Go to Settings > Data Sources in Grafana.
Select the appropriate data source type (e.g., MySQL, Prometheus).
Configure the connection by providing the necessary credentials and database details.
Test the connection to ensure that Grafana can pull data from your source.
Step 5: Create a Grafana Dashboard
Once the data source is set up, you can create a dashboard to visualize the Keploy test results.
Go to Create > Dashboard in Grafana.
Select Add a new panel.
Query the test data from your chosen data source.
Configure visualizations based on your needs. Some examples include:
Bar charts to display test pass/fail ratios.
Time-series graphs to track test execution times.
Tables to list failed tests and their details.
Customize the panels to reflect the key metrics you want to monitor, such as:
Total tests run
Passed/failed tests
Test duration
Coverage percentage
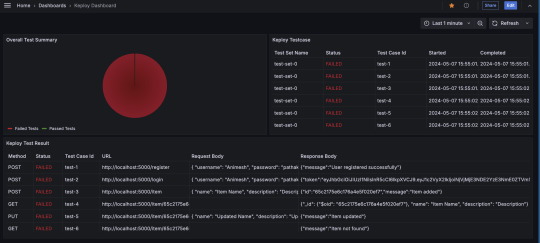
Alternatively, you can import the existing Keploy Dashboard on Grafana with everything already in place and just upload the JSON to view the metrics.
Step 6: Automating Keploy Test Data Updates
To keep your dashboard updated with the latest test data, you can automate the process of exporting Keploy reports and updating the Grafana data source. Set up a cron job or CI/CD pipeline step to regularly export Keploy reports.
Key Metrics to Track in Your Dashboard
Here are some useful metrics to include in your Grafana dashboard for Keploy:
Total Test Runs: The number of test executions over time.
Pass/Fail Ratio: A visual breakdown of successful vs. failed test cases.
Test Execution Time: The average time it takes for tests to run, helping identify slow-running tests.
Test Coverage: Percentage of code covered by the tests, which can help you identify areas lacking coverage.
Failed Test Cases: A detailed breakdown of the specific tests that failed, including error messages and stack traces.
Conclusion
Integrating Keploy with Grafana offers a powerful combination of zero-code test automation and real-time test visualization. By creating a Grafana dashboard for your Keploy test data, you can monitor the health of your application’s test suite, track key trends, and quickly respond to any issues that arise.
This setup not only saves time but also improves transparency and accountability across your testing process, enabling your team to make data-driven decisions with confidence. So, whether you're a developer, tester, or DevOps engineer, start using Grafana with Keploy to streamline your testing and monitoring efforts.
FAQs
What benefits does integrating Keploy with Grafana offer?
Integrating Keploy with Grafana provides real-time monitoring of test results, enabling you to visualize test trends, quickly spot failures, track test execution times, and assess test coverage. It also promotes transparency, helping teams make data-driven decisions and improve testing accountability.
How does Keploy generate test cases without writing code?
Keploy automatically captures network traffic and API interactions within your application to create test cases. This zero-code approach lets you generate comprehensive test suites by simply observing real-world user interactions, saving time and eliminating the need for manually written test scripts.
What kind of data sources can I connect to Grafana to view Keploy test data?
Grafana supports various data sources such as Prometheus, MySQL, CSV, and JSON. Depending on the format of the Keploy test data, you can configure Grafana to pull data from these sources, allowing flexible and customized visualization of test metrics.
Can I automate the process of exporting Keploy test data to Grafana?
Yes, you can automate the export of Keploy test data by setting up a cron job or adding a CI/CD pipeline step. This automation ensures that Grafana receives the latest test reports regularly, keeping the dashboard metrics up to date.
What are some key metrics I should monitor in my Grafana dashboard?
Useful metrics include Total Test Runs, Pass/Fail Ratio, Test Execution Time, Test Coverage Percentage, and specific details of Failed Test Cases. These metrics help assess the overall health of your tests, identify slow-running tests, and focus on areas requiring improvement.
Is there a pre-built Grafana dashboard for Keploy, or do I need to create one from scratch?
You can import an existing Grafana dashboard for Keploy by uploading the provided JSON file. This allows you to quickly set up a dashboard with default panels and visualizations, which you can further customize based on your specific testing needs.
0 notes
Video
youtube
How to Install PostgreSQL on Windows 10 or 11 #postgres #javascript #pyt...
0 notes