#rabbitMQ
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile US users spent an average of 115.8 minutes on Tumblr app monthly.
Text
The connection with #RabbitMQ isn't always stable using #CSharp. The reconnection not always is working. I want to create a resilient connection to RabbitMQ
0 notes
Text
rabbitmq quickstart
download rabbitmq zip
download compatible erlang.exe
install erlang
in system variables add ERLANG_HOME and point to erlang installation directory (ex. C:\Program Files\Erlang OTP)
in system variables Path, add %ERLANG_HOME%\bin
unzip rabbitmq zip
go to sbin folder and open cmd prompt
in cmd prompt run > rabbitmq-plugins.bat enable rabbitmq_management

9. in (another) cmd prompt, start mq by running > rabbitmq-server.bat

10. after startup, open browser and access http://localhost:15672/
11. login as guest/guest
0 notes
Text

#PollTime
Which is your favorite middleware tool?
A) Kafka 📡
B) RabbitMQ 🐇
C) Redis ⚡
D) Nginx 🌐
Comments your answer below👇
💻 Explore insights on the latest in #technology on our Blog Page 👉 https://simplelogic-it.com/blogs/
🚀 Ready for your next career move? Check out our #careers page for exciting opportunities 👉 https://simplelogic-it.com/careers/
#simplelogic#makingitsimple#itcompany#dropcomment#manageditservices#itmanagedservices#poll#polls#Middleware#middlewareservices#kafka#rabbitmq#redis#nginx#itservices#itserviceprovider#managedservices#testyourknowledge#makeitsimple#simplelogicit
0 notes
Text

Apache Kafka . . . . for more information & tutorial https://bit.ly/3QjRtaN check the above link
0 notes
Text
RabbitMQ on Kubernetes

RabbitMQ and Kubernetes together offer a powerful platform for building scalable and resilient message-driven applications. However, like any integration, it has its pros and cons.
Benefits: RabbitMQ Shines on Kubernetes
Deploying RabbitMQ on Kubernetes provides numerous benefits. Leveraging Kubernetes' orchestration capabilities, you can easily scale RabbitMQ clusters to handle varying workloads. Automated deployment, management, and scaling become a reality, saving time and reducing errors. The Kubernetes RabbitMQ Operator is a game-changer, simplifying these processes even further.
Challenges: Overcoming Hurdles
While the advantages are clear, there are challenges to consider. Ensuring high availability and data durability in a dynamic Kubernetes environment requires careful planning. Configuring RabbitMQ to work seamlessly with Kubernetes can be complex, and effective resource management is crucial. Additionally, monitoring and troubleshooting RabbitMQ in a containerized environment demands specific tools and expertise.
The key to success lies in understanding both the strengths and weaknesses of RabbitMQ on Kubernetes. The Kubernetes RabbitMQ Operator can be a valuable tool in addressing many of the challenges. By carefully planning and implementing best practices, organizations can build robust and scalable message-driven architectures.
1 note
·
View note
Text
November 2023 - New Additions
Sorry for the delay this month; things have been more than a little hectic. This month, we have content from the usual suspects, but the Oracle A-Team has also been very busy publishing details on connecting Oracle Fusion Cloud with Microsoft Teams. It may not be as groundbreaking as the recent news about the Oracle database in Azure, but for many, this will make a lot of difference. Article /…
View On WordPress
0 notes
Text
Streamlining Order Processing with RabbitMQ
Discover how RabbitMQ, a powerful messaging queue system, can transform your e-commerce order management to enhance customer satisfaction and improve scalability.
Businesses often find themselves grappling with a myriad of challenges that hinder the smooth flow of orders, leading to delays, errors, and dissatisfied customers. From manual intervention to complex communication systems, these hurdles can impede productivity and compromise the overall customer experience. Fortunately, there is a solution that holds the potential to revolutionize order management: RabbitMQ, a powerful messaging queue system designed to streamline and optimize the order process. By leveraging the capabilities of RabbitMQ, businesses can overcome these obstacles and unlock a new level of efficiency, scalability, and customer satisfaction.
In travel booking systems, RabbitMQ facilitates seamless communication for tasks such as payment processing and reservation updates. In financial trading systems, RabbitMQ enhances real-time data flow between modules, supporting trade execution, risk management, and reporting for improved system performance. RabbitMQ optimizes e-commerce order processing by coordinating messages between services, ensuring efficient handling of tasks like inventory management and payment processing.
RabbitMQ : an essential tool for streamlining ecommerce order processing
RabbitMQ is a powerful open-source message-broker software based on the Advanced Message Queuing Protocol (AMQP), a messaging standard designed for seamless interoperability between applications and services.
RabbitMQ acts as a mediator or middleman between producers and consumers of messages. Producers create messages and publish them to RabbitMQ, while consumers retrieve and process these messages. The queue ensures that messages are stored until they are consumed, ensuring a smooth flow of information.
RabbitMQ enhances e-commerce efficiency by managing seamless communication between order processing services, ensuring timely and independent handling of tasks such as inventory management and payment processing.
Order Placement: When a customer places an order on the ecommerce platform, the order details are sent to RabbitMQ as a message.
Order Queue: RabbitMQ stores the order message in an order queue. This queue acts as a central hub for processing incoming orders.
Order Processing: Different components involved in order processing, such as inventory management, payment processing, and shipping, connect to RabbitMQ and consume messages from the order queue. Each component retrieves the order details from the message and performs its specific tasks asynchronously, independent of each other.
RabbitMQ facilitates seamless communication between various components of an order management system, ensuring messages are delivered in a timely and efficient manner. Its relevance lies in its ability to handle large volumes of orders and provide fault tolerance to ensure no orders are lost or overlooked. With RabbitMQ as a foundational element, businesses can overcome traditional bottlenecks, improve scalability, and elevate the overall efficiency of their order management systems.
Feature highlights
Asynchronous and parallel processing
With RabbitMQ’s message queuing mechanism, asynchronous processing is achieved by storing order details in a queue, allowing components like inventory management, payment processing, and shipping to handle tasks independently, ensuring smoother performance during peak times. Additionally, RabbitMQ facilitates parallel processing by distributing messages among multiple consumers, enabling tasks to be executed simultaneously on different threads or processes. This efficient approach ensures faster order processing and seamless user experiences in e-commerce applications.
Reliability
It supports message durability, persisting vital messages to disk to survive failures. Acknowledgment and rejection mechanisms prevent message loss during processing, while clustering and replication enable high availability. Queuing and publisher confirms and high availability further enhance reliability by decoupling producers and consumers and handling failed deliveries.
Scalability and Load balancing
RabbitMQ’s distributed nature allows for scalability and load balancing. By utilizing multiple instances or nodes, RabbitMQ can handle high order volumes and distribute the processing load across different components, ensuring optimal performance.
Message Routing and Filtering
RabbitMQ provides routing capabilities that enable selective message delivery to specific processing components based on predefined rules. For example, orders containing international shipping may be routed to a different component than local orders. This routing mechanism streamlines order processing by ensuring that each component receives relevant orders.
Clustering
It involves setting up a group of interconnected RabbitMQ nodes to enhance reliability and scalability. In a cluster, multiple RabbitMQ instances work together, sharing the message processing load and providing fault tolerance. This ensures high availability, load balancing, and fault tolerance, enabling the system to handle large workloads and remain operational even during node failures. Clustering allows for seamless communication and synchronization between nodes, making RabbitMQ a robust choice for critical e-commerce applications where message delivery and processing are vital.
Replicated queues
Replicated queues spread across multiple nodes in a cluster, ensuring continuous availability and fault tolerance. These mirrored queues prevent message loss and maintain service operation even during node failures, as messages can be handled by the mirrored queue on an available node. This feature is vital for critical parts of e-commerce systems, guaranteeing uninterrupted message processing and delivery in the event of disruptions or hardware failures.
Conclusion
RabbitMQ proves to be a valuable addition to the e-commerce platform, enhancing its reliability and scalability. RabbitMQ’s features like message durability, acknowledgment, and clustering provide a robust foundation for handling critical data and ensuring continuous operation, even during system failures or high traffic.
By integrating RabbitMQ Spurtcommerce gains access to a powerful message queuing system, enabling efficient communication between various components of the platform. Ultimately, this integration empowers Spurtcommerce to offer a seamless and responsive shopping experience for customers while facilitating seamless and reliable communication between different modules within the platform.
1 note
·
View note
Text
In Part 1, you heard the story of Picco Talent Developer, who shared their journey of enhancing coding capabilities to delve into the world of printing. Now, in Part 2, we dive deeper with a detailed, step-by-step guide on how to achieve seamless and efficient printing using the powerful tech stack of Angular + Electron with RabbitMQ and Node.js. Get ready to transform the whole printing experience.
0 notes
Text
Instalar un cluster de RabbitMQ en Rocky Linux o distribuciones RHEL
RabbitMQ es un sistema de mensajería de código abierto basado en el protocolo AMQP (Advanced Message Queuing Protocol) que permite la comunicación entre diferentes aplicaciones y servicios de manera eficiente y confiable. Es ampliamente utilizado en entornos de microservicios, sistemas de intercambio de mensajes y aplicaciones distribuidas para manejar tareas asincrónicas y colas de…

View On WordPress
#Instalar RabbitMQ en Rocky Linux o distribuciones RHEL#Instalar un cluster de RabbitMQ en Rocky Linux o distribuciones RHEL
0 notes
Text
BRB... just upgrading Python
CW: nerdy, technical details.
Originally, MLTSHP (well, MLKSHK back then) was developed for Python 2. That was fine for 2010, but 15 years later, and Python 2 is now pretty ancient and unsupported. January 1st, 2020 was the official sunset for Python 2, and 5 years later, we’re still running things with it. It’s served us well, but we have to transition to Python 3.
Well, I bit the bullet and started working on that in earnest in 2023. The end of that work resulted in a working version of MLTSHP on Python 3. So, just ship it, right? Well, the upgrade process basically required upgrading all Python dependencies as well. And some (flyingcow, torndb, in particular) were never really official, public packages, so those had to be adopted into MLTSHP and upgraded as well. With all those changes, it required some special handling. Namely, setting up an additional web server that could be tested against the production database (unit tests can only go so far).
Here’s what that change comprised: 148 files changed, 1923 insertions, 1725 deletions. Most of those changes were part of the first commit for this branch, made on July 9, 2023 (118 files changed).
But by the end of that July, I took a break from this task - I could tell it wasn’t something I could tackle in my spare time at that time.
Time passes…
Fast forward to late 2024, and I take some time to revisit the Python 3 release work. Making a production web server for the new Python 3 instance was another big update, since I wanted the Docker container OS to be on the latest LTS edition of Ubuntu. For 2023, that was 20.04, but in 2025, it’s 24.04. I also wanted others to be able to test the server, which means the CDN layer would have to be updated to direct traffic to the test server (without affecting general traffic); I went with a client-side cookie that could target the Python 3 canary instance.
In addition to these upgrades, there were others to consider — MySQL, for one. We’ve been running MySQL 5, but version 9 is out. We settled on version 8 for now, but could also upgrade to 8.4… 8.0 is just the version you get for Ubuntu 24.04. RabbitMQ was another server component that was getting behind (3.5.7), so upgrading it to 3.12.1 (latest version for Ubuntu 24.04) seemed proper.
One more thing - our datacenter. We’ve been using Linode’s Fremont region since 2017. It’s been fine, but there are some emerging Linode features that I’ve been wanting. VPC support, for one. And object storage (basically the same as Amazon’s S3, but local, so no egress cost to-from Linode servers). Both were unavailable to Fremont, so I decided to go with their Chicago region for the upgrade.
Now we’re talking… this is now not just a “push a button” release, but a full-fleged, build everything up and tear everything down kind of release that might actually have some downtime (while trying to keep it short)!
I built a release plan document and worked through it. The key to the smooth upgrade I want was to make the cutover as seamless as possible. Picture it: once everything is set up for the new service in Chicago - new database host, new web servers and all, what do we need to do to make the switch almost instant? It’s Fastly, our CDN service.
All traffic to our service runs through Fastly. A request to the site comes in, Fastly routes it to the appropriate host, which in turns speaks to the appropriate database. So, to transition from one datacenter to the other, we need to basically change the hosts Fastly speaks to. Those hosts will already be set to talk to the new database. But that’s a key wrinkle - the new database…
The new database needs the data from the old database. And to make for a seamless transition, it needs to be up to the second in step with the old database. To do that, we have take a copy of the production data and get it up and running on the new database. Then, we need to have some process that will copy any new data to it since the last sync. This sounded a lot like replication to me, but the more I looked at doing it that way, I wasn’t confident I could set that up without bringing the production server down. That’s because any replica needs to start in a synchronized state. You can’t really achieve that with a live database. So, instead, I created my own sync process that would copy new data on a periodic basis as it came in.
Beyond this, we need a proper replication going in the new datacenter. In case the database server goes away unexpectedly, a replica of it allows for faster recovery and some peace of mind. Logical backups can be made from the replica and stored in Linode’s object storage if something really disastrous happens (like tables getting deleted by some intruder or a bad data migration).
I wanted better monitoring, too. We’ve been using Linode’s Longview service and that’s okay and free, but it doesn’t act on anything that might be going wrong. I decided to license M/Monit for this. M/Monit is so lightweight and nice, along with Monit running on each server to keep track of each service needed to operate stuff. Monit can be given instructions on how to self-heal certain things, but also provides alerts if something needs manual attention.
And finally, Linode’s Chicago region supports a proper VPC setup, which allows for all the connectivity between our servers to be totally private to their own subnet. It also means that I was able to set up an additional small Linode instance to serve as a bastion host - a server that can be used for a secure connection to reach the other servers on the private subnet. This is a lot more secure than before… we’ve never had a breach (at least, not to my knowledge), and this makes that even less likely going forward. Remote access via SSH is now unavailable without using the bastion server, so we don’t have to expose our servers to potential future ssh vulnerabilities.
So, to summarize: the MLTSHP Python 3 upgrade grew from a code release to a full stack upgrade, involving touching just about every layer of the backend of MLTSHP.
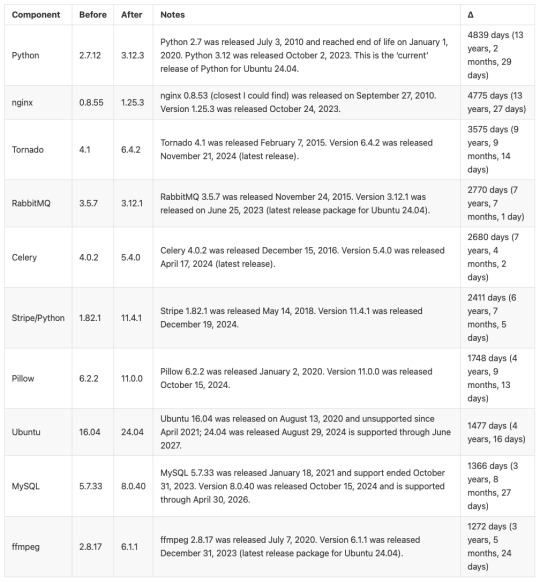
Here’s a before / after picture of some of the bigger software updates applied (apologies for using images for these tables, but Tumblr doesn’t do tables):
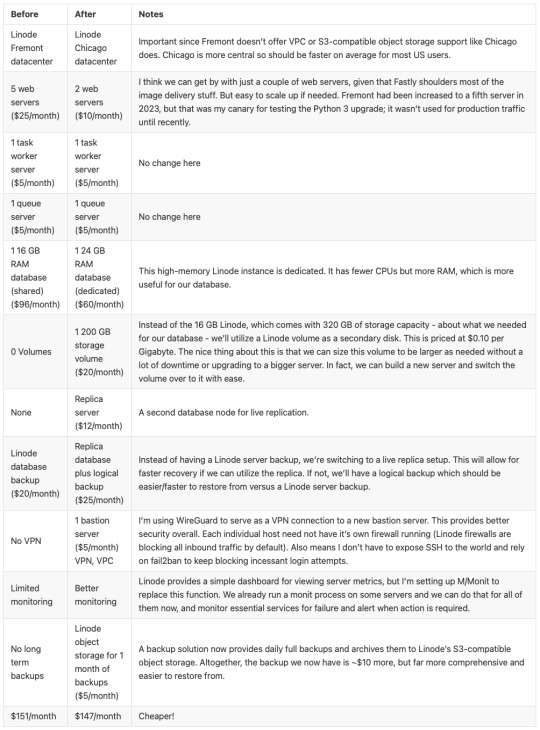
And a summary of infrastructure updates:
I’m pretty happy with how this has turned out. And I learned a lot. I’m a full-stack developer, so I’m familiar with a lot of devops concepts, but actually doing that role is newish to me. I got to learn how to set up a proper secure subnet for our set of hosts, making them more secure than before. I learned more about Fastly configuration, about WireGuard, about MySQL replication, and about deploying a large update to a live site with little to no downtime. A lot of that is due to meticulous release planning and careful execution. The secret for that is to think through each and every step - no matter how small. Document it, and consider the side effects of each. And with each step that could affect the public service, consider the rollback process, just in case it’s needed.
At this time, the server migration is complete and things are running smoothly. Hopefully we won’t need to do everything at once again, but we have a recipe if it comes to that.
15 notes
·
View notes
Text
Can Open Source Integration Services Speed Up Response Time in Legacy Systems?
Legacy systems are still a key part of essential business operations in industries like banking, logistics, telecom, and manufacturing. However, as these systems get older, they become less efficient—slowing down processes, creating isolated data, and driving up maintenance costs. To stay competitive, many companies are looking for ways to modernize without fully replacing their existing systems. One effective solution is open-source integration, which is already delivering clear business results.

Why Faster Response Time Matters
System response time has a direct impact on business performance. According to a 2024 IDC report, improving system response by just 1.5 seconds led to a 22% increase in user productivity and a 16% rise in transaction completion rates. This means increased revenue, customer satisfaction as well as scalability in industries where time is of great essence.
Open-source integration is prominent in this case. It can minimize latency, enhance data flow and make process automation easier by allowing easier communication between legacy systems and more modern applications. This makes the systems more responsive and quick.
Key Business Benefits of Open-Source Integration
Lower Operational Costs
Open-source tools like Apache Camel and Mule eliminate the need for costly software licenses. A 2024 study by Red Hat showed that companies using open-source integration reduced their IT operating costs by up to 30% within the first year.
Real-Time Data Processing
Traditional legacy systems often depend on delayed, batch-processing methods. With open-source platforms using event-driven tools such as Kafka and RabbitMQ, businesses can achieve real-time messaging and decision-making—improving responsiveness in areas like order fulfillment and inventory updates.
Faster Deployment Cycles: Open-source integration supports modular, container-based deployment. The 2025 GitHub Developer Report found that organizations using containerized open-source integrations shortened deployment times by 43% on average. This accelerates updates and allows faster rollout of new services.
Scalable Integration Without Major Overhauls
Open-source frameworks allow businesses to scale specific parts of their integration stack without modifying the core legacy systems. This flexibility enables growth and upgrades without downtime or the cost of a full system rebuild.
Industry Use Cases with High Impact
Banking
Integrating open-source solutions enhances transaction processing speed and improves fraud detection by linking legacy banking systems with modern analytics tools.
Telecom
Customer service becomes more responsive by synchronizing data across CRM, billing, and support systems in real time.
Manufacturing
Real-time integration with ERP platforms improves production tracking and inventory visibility across multiple facilities.
Why Organizations Outsource Open-Source Integration
Most internal IT teams lack skills and do not have sufficient resources to manage open-source integration in a secure and efficient manner. Businesses can also guarantee trouble-free setup and support as well as improved system performance by outsourcing to established providers. Top open-source integration service providers like Suma Soft, Red Hat Integration, Talend, TIBCO (Flogo Project), and Hitachi Vantara offer customized solutions. These help improve system speed, simplify daily operations, and support digital upgrades—without the high cost of replacing existing systems.
2 notes
·
View notes
Text

Apache Kafka . . . . for more information & tutorial https://bit.ly/40SJR3K check the above link
0 notes
Text
Integrating Third-Party Tools into Your CRM System: Best Practices
A modern CRM is rarely a standalone tool — it works best when integrated with your business's key platforms like email services, accounting software, marketing tools, and more. But improper integration can lead to data errors, system lags, and security risks.

Here are the best practices developers should follow when integrating third-party tools into CRM systems:
1. Define Clear Integration Objectives
Identify business goals for each integration (e.g., marketing automation, lead capture, billing sync)
Choose tools that align with your CRM’s data model and workflows
Avoid unnecessary integrations that create maintenance overhead
2. Use APIs Wherever Possible
Rely on RESTful or GraphQL APIs for secure, scalable communication
Avoid direct database-level integrations that break during updates
Choose platforms with well-documented and stable APIs
Custom CRM solutions can be built with flexible API gateways
3. Data Mapping and Standardization
Map data fields between systems to prevent mismatches
Use a unified format for customer records, tags, timestamps, and IDs
Normalize values like currencies, time zones, and languages
Maintain a consistent data schema across all tools
4. Authentication and Security
Use OAuth2.0 or token-based authentication for third-party access
Set role-based permissions for which apps access which CRM modules
Monitor access logs for unauthorized activity
Encrypt data during transfer and storage
5. Error Handling and Logging
Create retry logic for API failures and rate limits
Set up alert systems for integration breakdowns
Maintain detailed logs for debugging sync issues
Keep version control of integration scripts and middleware
6. Real-Time vs Batch Syncing
Use real-time sync for critical customer events (e.g., purchases, support tickets)
Use batch syncing for bulk data like marketing lists or invoices
Balance sync frequency to optimize server load
Choose integration frequency based on business impact
7. Scalability and Maintenance
Build integrations as microservices or middleware, not monolithic code
Use message queues (like Kafka or RabbitMQ) for heavy data flow
Design integrations that can evolve with CRM upgrades
Partner with CRM developers for long-term integration strategy
CRM integration experts can future-proof your ecosystem
#CRMIntegration#CRMBestPractices#APIIntegration#CustomCRM#TechStack#ThirdPartyTools#CRMDevelopment#DataSync#SecureIntegration#WorkflowAutomation
2 notes
·
View notes