#return API info Method
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
shitGPT
for uni im going to be coding with a chatGPT user, so i decided to see how good it is at coding (sure ive heard it can code, but theres a massive difference between being able to code and being able to code well).
i will complain about a specific project i asked it to make and improve on under the cut, but i will copy my conclusion from the bottom of the post and paste it up here.
-
conclusion: it (mostly) writes code that works, but isnt great. but this is actually a pretty big problem imo. as more and more people are using this to learn how to code, or getting examples of functions, theyre going to be learning from pretty bad code. and then theres what im going to be experiencing, coding with someone who uses this tool. theres going to be easily improvable code that the quote unquote writer wont fully understand going into a codebase with my name of it - a codebase which we will need present for our degree. even though the code is not the main part of this project (well, the quality of the code at least. you need it to be able to run and thats about it) its still a shitty feeling having my name attached to code of this quality.
and also it is possible to get it to write good (readable, idiomatic, efficient enough) code, but only if you can write this code yourself (and are willing to spend more time arguing with the AI than you would writing the code.) most of the things i pointed out to the AI was stuff that someone using this as a learning resource wont know about. if it never gives you static methods, class methods, ABCs, coroutines, type hints, multi-file programs, etc without you explicitly asking for them then its use is limited at best. and people who think that its a tool that can take all the info they need, and give it back to them in a concise, readable way (which is a surprising lot of people) will be missing out without even knowing about it.
i got it to write tic-tac-toe (the standard babee) in python (the lang i have to use for uni ;-; (held at gunpoint here)). my specific prompt was "write me a python program for tictactoe that is written in an object oriented way and allows for future expansion via multiple files"
it separated it into three files below (which i think would run, but i never actually ran any of this code. just reading and judging)



why does board use display instead of __str__ and __repr__?
why is the board stored as 1d instead of 2d? thats just confusing
why does it never early return aside from check_winner? (not a big issue here but kept on choosing to never early return when i asked it to add more methods)
why is there no handling of non-number user inputs?
why are non-int inputs truncated instead of telling the user that they should input ints only?
why is display implemented like that?
why are so many lines so bloody long (wide)?
why is there a redundant self.check_winner() after the while loop in TicTaacToe.play()? and if it wasnt redundant then you could finish the game without there being anything printed telling you that the game is finished?
why is the only comment useless? (this comment wouldnt be useless if it was a doc comment tho, but it aint a doc comment. speaking of, why is there no doc comments?)
these are the more immediate things i saw, but there are other things that are bad here.
whenever i write * this is where it updated the api without changing any usage of the api.
so i ask it to change board.display into __str__ and __repr__, it changes it to __str__*, it does not add a __repr__. asking it to add a __repr__ 1) removes the __str__ and 2) gives me this (the other methods are unchanged)
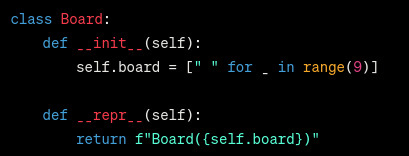
what. the. fuck. this would imply that board takes in an argument for the boardstate, but it clearly doesnt. after 4 more asks it finally has both __str__ and __repr__, without fixing the fact its implying board takes an optional arg, so i get it to add this arg. anything that needs to print the board still calls display btw.
the reasoning it gave for using display over the repr and str magics was this
While using __str__ and __repr__ is a more idiomatic approach in Python, choosing to have a separate display method can still be a valid choice, especially if the display logic is more complex or if you want to keep the __str__ method for a more concise or formal representation of the object.
which, erm what? why would __str__ be for a concise or formal repr when thats what __repr__ is for? who cares about how complex the logic is. youre calling this every time you print, so move the logic into __str__. it makes no difference for the performance of the program (if you had a very expensive func that prints smth, and you dont want it to run every time you try to print the obj then its understandable to implement that alongside str and repr)
it also said the difference between __str__ and __repr__ every damn time, which if youre asking it to implement these magics then surely you already know the difference?
but okay, one issue down and that took what? 5-10 minutes? and it wouldve taken 1 minute tops to do it yourself?
okay next implementing a tic-tac-toe board as a 1d array is fine, but kinda weird when 2d arrays exist. this one is just personal preference though so i got it to change it to a 2d list*. it changed the init method to this

tumblr wont let me add alt text to this image so:
[begin ID: Python code that generates a 2D array using nested list comprehensions. end ID]
which works, but just use [[" "] * 3 for _ in range(3)]. the only advantage listcomps have here over multiplying is that they create new lists, instead of copying the pointers. but if you update a cell it will change that pointer. you only need listcomps for the outermost level.
again, this is mainly personal preference, nothing major. but it does show that chatgpt gives u sloppy code
(also if you notice it got rid of the board argument lol)
now i had to explicitly get it to change is_full and make_move. methods in the same damn class that would be changed by changing to a 2d array. this sorta shit should be done automatically lol
it changed make_move by taking row and col args, which is a shitty decision coz it asks for a pos 1-9, so anything that calls make_move would have to change this to a row and col. so i got it to make a func thatll do this for the board class
what i was hoping for: a static method that is called inside make_move
what i got: a standalone function that is not inside any class that isnt early exited

the fuck is this supposed to do if its never called?
so i had to tell it to put it in the class as a static method, and get it to call it. i had to tell it to call this function holy hell
like what is this?
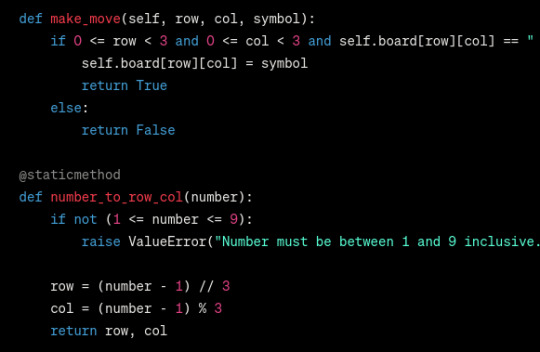
i cant believe it wrote this method without ever calling it!
and - AND - theres this code here that WILL run when this file is imported
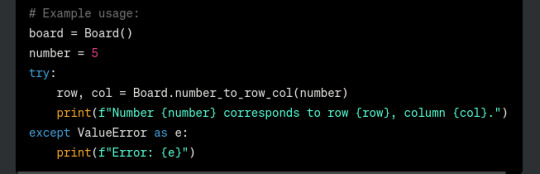
which, errrr, this files entire point is being imported innit. if youre going to have example usage check if __name__ = "__main__" and dont store vars as globals
now i finally asked it to update the other classes not that the api has changed (hoping it would change the implementation of make_move to use the static method.) (it didnt.)
Player.make_move is now defined recursively in a way that doesnt work. yippe! why not propagate the error ill never know.
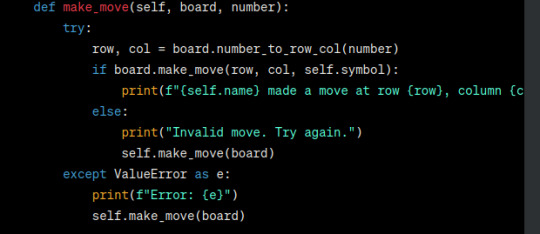
also why is there so much shit in the try block? its not clear which part needs to be error checked and it also makes the prints go offscreen.
after getting it to fix the static method not being called, and the try block being overcrowded (not getting it to propagate the error yet) i got it to add type hints (if u coding python, add type hints. please. itll make me happy)
now for the next 5 asks it changed 0 code. nothing at all. regardless of what i asked it to do. fucks sake.
also look at this type hint

what
the
hell
is
this
?
why is it Optional[str]???????? the hell??? at no point is it anything but a char. either write it as Optional[list[list[char]]] or Optional[list[list]], either works fine. just - dont bloody do this
also does anything look wrong with this type hint?

a bloody optional when its not optional
so i got it to remove this optional. it sure as hell got rid of optional
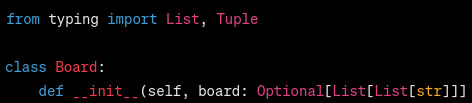
it sure as hell got rid of optional
now i was just trying to make board.py more readable. its been maybe half an hour at this point? i just want to move on.
it did not want to write PEP 8 code, but oh well. fuck it we ball, its not like it again decided to stop changing any code

(i lied)
but anyway one file down two to go, they were more of the same so i eventually gave up (i wont say each and every issue i had with the code. you get the gist. yes a lot of it didnt work)
conclusion: as you probably saw, it (mostly) writes code that works, but isnt great. but this is actually a pretty big problem imo. as more and more people are using this to learn how to code, or getting examples of functions, theyre going to be learning from pretty bad code. and then theres what im going to be experiencing, coding with someone who uses this tool. theres going to be easily improvable code that the quote unquote writer wont fully understand going into a codebase with my name of it - a codebase which we will need present for our degree. even though the code is not the main part of this project (well, the quality of the code at least. you need it to be able to run and thats about it) its still a shitty feeling having my name attached to code of this quality.
and also it is possible to get it to write good (readable, idiomatic, efficient enough) code, but only if you can write this code yourself (and are willing to spend more time arguing with the AI than you would writing the code.) most of the things i pointed out to the AI was stuff that someone using this as a learning resource wont know about. if it never gives you static methods, class methods, ABCs, coroutines, type hints, multi-file programs, etc without you explicitly asking for them then its use is limited at best. and people who think that its a tool that can take all the info they need, and give it back to them in a concise, readable way (which is a surprising lot of people) will be missing out without even knowing about it.
#i speak i ramble#effortpost#long post#progblr#codeblr#python#chatgpt#tried to add IDs in as many alts as possible. some didnt let me and also its hard to decide what to put in the IDs for code.#like sometimes you need implementation details but others just the broad overview is good enough yknow?#and i also tried to write in a way where you dont need the IDs to follow along. (but with something like this it is hard yknow?)#id in alt#aside from that one where i got cockblocked#codeblocked?#codeblocked.
40 notes
·
View notes
Text
i dont think ive complained enough about how absolutely shitty the tumblr api is. the documentation is like. mediocre, to begin with. the actual api? the /blocks route gives you the blogs a blog has blocked if you GET it, but POST it? well now youre blocking a blog. dont be deceived by the plural though - to block multiple blogs you need /blocks/bulk. oh also using the... DELETE method (??) you can remove a block, still via /blocks. the /post route is the legacy post format. /posts is what youre looking for, but dont GET it, because then youre fetching a blogs posts. again, dont be deceived by the plural, but this time there is no bulk route. oh and of course /posts/{post id} gets a post... but with POST it edits the post. now with this theme of incorrect plurals, youd at least expect them to have correct plurals, but no! in order to retrieve drafts you use... /posts/draft. there are some communities routes, but guess what? theyre listed in a different format in the documentation to everything else! to be honest, its a better format, but i guess they couldnt be bothered to update their docs.
and then, the /user/dashboard route. heres what the docs say:

(this the ONLY way to get random posts btw)
simple enough... naturally you would scroll down for more info but... thats it. after that tiny description, there is a horribly layed out list of arguments and their descriptions, info on the response format, and nothing else. what dashboard is it getting? who knows! it doesnt seem to be the Following tab - which is in order of recency - so i can only assume its For You. it also, by default, returns posts in the legacy format, which is much less convenient than their Neue Post Format (??). posts are also returned without blog info and instead with just a blog name, and, for whatever reason, there is no argument to change this. i dont remember what i did to get around this, but it was probably taking that blog name and running it through the /info route or getting the posts and then getting them again with the /posts/... route (which does return blog info).
ok.. so its badly documented and inconvenient to use. big deal! except... theres more. if youre going through dashboard posts individually, like i do for my bot, youll probably use the offset argument parameter - the offset from the first post on the dash - to specify which post to get. however at somewhere around an offset of 250, it stops returning new posts. just the same one over and over. probably a rate limit right?

?????
you might be thinking "its probably that 300 api calls limit and youre just using a few extra calls" but thats wrong. for starters around 50 extra calls just doesnt sound accurate for what im doing. it would most likely be way more than that or way less. and even if im wrong, it doesnt reset after a minute. i have no idea when it resets, in fact. sometimes it feels like more than an hour, but i havent timed it. i also havent tested what happens if i go straight to 250, which i probably should do. on top of all that, i dont think this is what would actually happen if i got rate limited, its just the only remotely possible explanation i can think of.
another thing is that you cant get the full text of a post natively, only the content of the reblog. i had to write my own method for that. also - this is kinda nitpicky - you cant easily get the blog that last contributed in the thread, only whoever last reblogged it (who might have reblogged it without saying anything). by that i mean 5 people might have reblogged it without saying anything since anyone added anything to the thread, but you can only find that 5th person (easily). the workaround is to check if the person who last reblogged it said anything, if not get the last person in the 'trail', which is a list of reblogs in the thread that said something that doesnt include the last reblog. this also... doesnt work sometimes i guess? i didnt bother figuring out why, but one time out of the blue it gave me an error when trying to get the name of the last person in the trail.
i hate the tumblr api
#tumblr api#my ramblings#programming#i bet you cant guess what my bot is#although BECAUSE I CAN ONLY USE MY DASH#and im too far in to make a new account#it *does* reblog a lot of my mutuals posts#and people im following#so they might be able to guess
2 notes
·
View notes
Text
14/07/2023 || Day 51
React & Weather App Log # 2
React:
Decided to skip on the video tutorials today and instead focused on Hooks and Refs, and oh god that hurt my brain. From my understanding, Hooks are used to keep the state of a functional component, letting them have states to begin with. Along with Refs, we can update states/variables when appropriate (i.e. a user types in their name, we can now store that name in a variable). One thing that I struggled with was understanding what the code for useState in the documentation meant, but after watching a video I learned that useState returns an array in which the first element is the variable you want to keep track of, and the second element is the method used to set the value of the variable ( i.e. const [userAnswer, setUserAnswer] = useState(null) ). So, when you want to update userAnswer, you call setUserAnswer() and do the logic inside this method. To get used to using both Hooks and Refs, I continued a bit with my Weather App.
Weather App:
Like I said, I mainly wanted to practice using Hooks and Refs. One thing that I need in my weather app is for the user to type in their city (or any city), so this was the perfect time to use Hooks and Refs. I have the app set up this way: if the variable city is undefined (i.e. the user hasn't entered the city they want to get the weather for), the React component for entering the city will show up (which I called GetCity). Otherwise, the component holding the weather info will display (which I called Header).
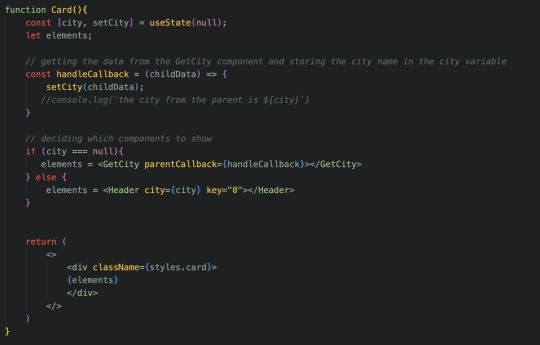
To get the user input from the input element in my GetCity component, I ended up using the useRef method (though I think I can also use useState), and actually ended up passing this variable to the parent component, which will then pass it down to the Header component that will display the weather and such.
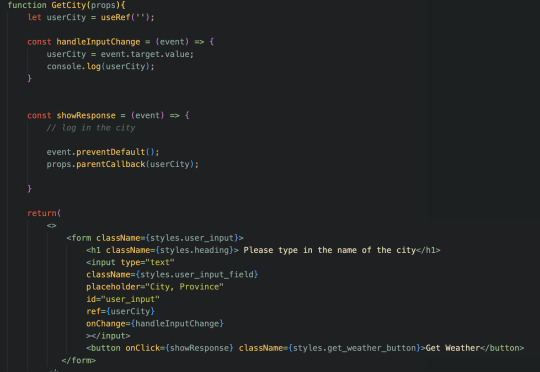
Now that the user typed in the city, I need to make an API call to get the weather. I'm doing this with the OpenWeather API, but first I actually need to get some location information from another API they have; their Geocoding API. With this, I can send in my city name and get back information such as the longitude and the latitude of the city, which I'll need to make the API call to get the weather. So far, I have it where I can get the longitude and latitude, but I have yet to store the values and make the 2nd API call. It'll be a few days before I get this working, but here's a little video of it "working" so far (you can see it works from the console on the right). The first screen is the GetCity component, as the user hasn't entered a city yet, and once they do and click the button, the parent component now has the city name and passes it down to the Header component:
20 notes
·
View notes
Text
Fetching data from an API in React using UseEffect Hooks

Learn how to use the useEffect hook in React to handle side effects like API calls and event listeners. This blog covers its syntax, examples, dependency management, and cleanup functions with MCQs for better understanding. #ReactJS #useEffect #WebDevelopment
Understanding useEffect in React – Part 1 Introduction to useEffect
React’s useEffect is one of the most powerful hooks that allows us to handle side effects in functional components. Side effects include tasks such as fetching data from an API, interacting with the browser's DOM, or subscribing to external events.
In this blog, we’ll break down useEffect step by step, using a practical example.
What is useEffect?
useEffect is a hook that lets you perform side effects in function components. It runs after the component renders and can be configured to re-run under specific conditions.
Syntax:
useEffect(() => {
// Side effect logic here
}, [dependencies]);
The first argument is a function that contains the side effect logic. The second argument is an array of dependencies. When any dependency changes, the effect runs again. Practical Example: Fetching User Data with useEffect
Let’s create a React component that fetches user data from an API whenever a user ID changes.
Code Implementation:
import React, { useState, useEffect } from "react";
function UserData() {
const [userId, setUserId] = useState(1);
const [user, setUser] = useState(null);
useEffect(() => {fetch(`https://jsonplaceholder.typicode.com/users/${userId}`) .then((response) => response.json()) .then((data) => setUser(data));
}, [userId]);
return (<div> <h1>User Info</h1> {user && ( <div> <p>Name: {user.name}</p> <p>Email: {user.email}</p> <p>Phone: {user.phone}</p> </div> )} </div>
);
}
export default UserData;
How useEffect Works in This Example
Initial Render: The component renders with userId = 1 and user = null. API Call Triggered: useEffect runs after the first render and fetches data for user ID 1. State Update: Once data is fetched, setUser(data) updates the user state. Re-render: The component re-renders with the new user data, displaying the name, email, and phone. Dependency Array ([userId]): If userId changes, useEffect runs again to fetch new data. Key Points About useEffect
Runs after render: Unlike class components where lifecycle methods like componentDidMount are used, useEffect runs after the component renders. Dependency Array: If left empty ([]), useEffect runs only once (on mount). If dependencies are provided, it runs whenever they change. Cleanup Function: You can return a function from useEffect to clean up effects like event listeners.
please visit our website to know more:-https://cyberinfomines.com/blog-details/fetching-data-from-an-api-in-react-using-useeffect-hooks
0 notes
Text
API in Dell Boomi

Title: Building a Robust Blog API with Dell Boomi
Introduction
Briefly explain the value of APIs, especially in the context of content management and distribution for a blog.
Highlight Dell Boomi as a powerful iPaaS (Integration Platform as a Service) solution for API development.
Prerequisites
Boomi Essentials: Assume basic familiarity with Boomi processes, connectors, and data mapping.
Database Setup: Have a database (MySQL, PostgreSQL, etc.) to store your blog data (posts, categories, authors).
REST API Understanding: Basic knowledge of REST principles (endpoints, HTTP methods).
Steps
Design API Specification
OpenAPI Specification (Swagger): Use a tool like Swagger Editor to outline the following:
Endpoints: /posts, /posts/{id}, /categories, /authors, etc.
HTTP Methods: GET (retrieve), POST (create), PUT (update), DELETE
Create Boomi API Component
New API Component: Create a new API Component (Manage → API Management) within Boomi.
API Type: Select ‘Advanced’ for maximum flexibility.
Resources: Add resources that mirror your API endpoints.
Methods: Add the corresponding HTTP methods you’ll support for each resource.
Build Boomi Processes
GET Requests:
Create processes that fetch data from your database.
Use database connectors to execute appropriate queries.
POST Requests
Create processes that handle incoming data to create new blog posts.
Map JSON data from the API request to database fields.
PUT Requests
Create processes that modify existing blog posts.
Include logic to identify the post (e.g., by ID).
DELETE Requests
Create processes that delete blog posts.
Include logic to identify the post.
Implement Authentication and Authorization
Choose a Method: Basic Auth, OAuth 2.0, API Keys (consider the security level needed)
Boomi’s Capabilities: Utilize Boomi’s features to enforce security rules based on the chosen method.
Error Handling
HTTP Status Codes: Use appropriate status codes (e.g., 200 OK, 404 Not Found, 401 Unauthorized, 500 Internal Server Error).
JSON Error Responses: Provide informative error messages in a JSON structure.
API Deployment
Deploy API: Deploy your API component to a Boomi Atom or Molecule so it becomes accessible.
Obtain API Endpoint: Boomi will provide a base URL for your API.
API Documentation
Maintain Swagger Spec: Continue updating your OpenAPI Specification file throughout development.
Generate User-Friendly Docs: Use tools like Swagger UI to generate clear documentation from your Swagger file.
Example: GET /posts
A Boomi process would connect to the database, run a SELECT query, transform the result set into JSON, and return the list of blog posts.
Additional Considerations
Versioning: Design a strategy to manage API changes.
Rate Limiting: Prevent abuse by limiting requests per client.
Testing: Use Boomi’s testing tools or external services like Postman for thorough tests.
Oracle Boomi
youtube
You can find more information about Dell Boomi in this Dell Boomi Link
Conclusion:
Unogeeks is the No.1 IT Training Institute for Dell Boomi Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Dell Boomi here – Dell Boomi Blogs
You can check out our Best In Class Dell Boomi Details here – Dell Boomi Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeek
0 notes
Text
Dell Boomi iPaaS

Dell Boomi iPaaS: Your Key to Seamless Application and Data Integration
In today’s digitally driven landscape, businesses generate data across multiple applications, cloud platforms, and legacy systems. This disconnected data landscape creates roadblocks to efficiency, informed decision-making, and overall growth. That’s where Dell Boomi iPaaS comes to the rescue.
What is Dell Boomi iPaaS?
Dell Boomi is a cloud-based Integration Platform as a Service (iPaaS) that helps organizations streamline the integration of applications, data sources, and business processes. Think of it as the digital glue that binds your disparate systems together. Boomi provides a visual, drag-and-drop interface, enabling users to build complex integrations without requiring extensive coding.
Key Features of Dell Boomi iPaaS
Extensive Pre-Built Connectors: Dell Boomi boasts a vast library of pre-built connectors for popular applications (like Salesforce, SAP, Workday), databases, web services, and more. This means faster integrations and eliminates the need to build connections from scratch.
Unified Platform: Boomi brings together multiple integration needs in one place – application integration, API management, data quality management, B2B/EDI, and workflow automation. You don’t need separate tools for different purposes.
Low-Code Development: Boomi’s visual interface and drag-and-drop functionality make it accessible for business users and IT professionals. It simplifies integration processes even for non-technical users.
Scalability and Flexibility: Using cloud-native architecture, Boomi scales seamlessly to handle your growing data and integration demands. It can manage both on-premises and cloud-based integration needs.
AI-Powered Recommendations: Boomi’s ‘Boomi Suggest’ feature harnesses AI capabilities to offer recommendations for building and optimizing integrations, speeding up the development process.
Why Choose Dell Boomi?
Agility: Rapidly connect systems and applications to accelerate business initiatives and innovation.
Time-to-Value: Implement integrations faster than traditional methods, generating quicker returns on investment.
Cost Savings: Reduce the cost of maintaining custom integrations and minimize reliance on extensive technical resources.
Improved Data Visibility: Break down silos and gain a 360-degree view of your data for better business insights.
Enhanced Automation: Streamline and automate workflows, reducing manual errors and improving efficiency across processes.
Use Cases for Dell Boomi iPaaS.
Customer 360: Integrate customer data from CRM, marketing automation, and billing systems to create a comprehensive view of your customers.
Order-to-Cash Optimization: Automate the order-to-cash process by synchronizing orders, inventory, and financials across systems.
Partner Onboarding: Simplify and expedite B2B/EDI integrations with partners, suppliers, and distributors.
Cloud Migration: Seamlessly connect on-premises applications with cloud-based services as part of your digital transformation journey.
Embracing Seamless Connectivity with Dell Boomi
Dell Boomi offers a robust, user-friendly platform for businesses looking to unlock the value of their data and systems. If you’re struggling with fragmented systems and disconnected processes, Dell Boomi might be the perfect solution to pave the way for a more integrated and efficient digital environment.
youtube
You can find more information about Dell Boomi in this Dell Boomi Link
Conclusion:
Unogeeks is the No.1 IT Training Institute for Dell Boomi Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Dell Boomi here – Dell Boomi Blogs
You can check out our Best In Class Dell Boomi Details here – Dell Boomi Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeek
1 note
·
View note
Text
ORACLE APEX AND PYTHON

Unlocking the Power of Oracle APEX with Python
Oracle APEX (Application Express) is a renowned low-code development platform enabling you to rapidly build scalable, secure, and visually appealing web applications directly within your Oracle Database. Python stands as a highly popular, general-purpose programming language celebrated for its readability, vast libraries, and robust community support. Integrating these two technologies creates remarkable opportunities to enhance your APEX applications.
Why Combine Oracle APEX and Python?
Here’s a breakdown of the compelling reasons to bring Oracle APEX and Python together:
Tap into Python’s Specialized Libraries: Expand APEX’s capabilities by exploiting Python’s rich collection of libraries. Unleash advanced machine learning models, implement intricate data analysis, or perform scientific calculations that extend far beyond native APEX features.
Leverage Existing Investments: If you possess pre-existing Python code or scripts, you can seamlessly integrate them into your APEX applications. This saves time and effort, preventing the need to reinvent the wheel within APEX.
Flexibility and Power: Python grants you extensive flexibility, making it suitable for tackling complex use cases that could push the limits of APEX’s declarative capabilities.
Methods of Integration
Let’s explore popular ways to connect Oracle APEX with Python:
ORDS (Oracle REST Data Services) and REST APIs:
Build a Python-based REST API, perhaps using frameworks like Flask or FastAPI.
From your APEX application, utilize the built-in web service features to consume data from these Python-powered RESTful endpoints.
This approach provides flexibility for data exchange and processing.
Oracle Database’s Multilingual Engine (MLE): (This requires a specific Oracle database version.)
Directly execute Python code inside your Oracle Database leveraging MLE.
Access and manipulate database data with the ease Python offers, allowing for streamlined data-centric operations.
PyScript: (An experimental approach)
PyScript brings the ability to run Python scripts directly within your APEX pages.
Harness client-side Python processing for interactive elements and visualizations while keeping in mind that PyScript is still under active development.
Example: Machine Learning Integration
Let’s imagine a scenario where you want to incorporate a sentiment analysis model into your APEX application. Here’s how you would approach it:
Develop a Python Model: Train and save a machine learning model using a library like scikit-learn to perform sentiment analysis on text data.
Create a REST API: Expose your Python model through a REST API (using Flask or similar). This API will accept text input and return the sentiment (e.g., positive, negative, neutral).
APEX Integration: From your APEX application, send text inputs to your Python REST API. Display the returned sentiment analysis results to your users.
Note: To execute these steps, you’ll need basic proficiency in both Oracle APEX and Python.
The Future is Bright
As Oracle continues to enhance APEX and Python integration capabilities, we can anticipate a future where these technologies mesh even more smoothly. The possibilities are boundless: from creating intelligent APEX applications to driving data-driven decision-making.
If you’re looking to take your Oracle APEX development to the next level, don’t hesitate to explore the exciting intersection with Python!
youtube
You can find more information about Oracle Apex in this Oracle Apex Link
Conclusion:
Unogeeks is the No.1 IT Training Institute for Oracle Apex Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Oracle Apex here – Oarcle Apex Blogs
You can check out our Best In Class Oracle Apex Details here – Oracle Apex Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeeks
0 notes
Text
The Graph is a vital Web3 infrastructure protocol that makes it straightforward to question blockchain information. By indexing and organizing information from networks like Ethereum, The Graph creates open APIs that builders can use to construct blockchain functions. Studying leverage The Graph is vital for accessing on-chain data. Hosted and Customized APIs: Accessing Blockchain KnowledgeThe Graph makes use of a system of Curators, Indexers, and Delegators to index and retailer information from numerous blockchain networks. Curators sign which information ought to be listed by staking the native GRT token. Indexers then question and course of this information, making it out there by the hosted subgraph APIs. Delegators can assign GRT tokens to Indexers as an indication of confidence of their work. As an end-user trying to question blockchain information, The Graph exposes each hosted and customized APIs:Hosted APIs are public subgraphs created by Indexers to offer information units for standard protocols like Uniswap, Aave, Decentraland, and extra. These could be queried instantly utilizing pattern queries supplied in The Graph Explorer playground.Customized APIs could be created by builders to index blockchain information tailor-made to their particular software wants. This entails deploying your individual sensible contracts that encode how information ought to be listed on the blockchain itself.Utilizing the hosted APIs on The Graph is essentially the most simple approach to begin querying blockchain information. For instance, to search for data on Uniswap V2 pairs, you'd first discover the Uniswap subgraph underneath Hosted Providers in The Graph Explorer.Using The Graph: Harnessing Blockchain Knowledge for Web3 Growth Then, within the instance queries, you possibly can copy over the question that retrieves ‘Pair Created’ occasions to view newly created Uniswap pairs. Hitting “Run Query” will fetch all V2 pairs and return information like every pair’s ID, asset tokens, reserves, and different attributes. It's also possible to modify the question to filter the outcomes or specify totally different fields for the pairs of entities you need to show. General, The Graph-hosted APIs present a easy methodology to begin pulling worthwhile on-chain information.Similarities between GraphQL and the Graph question language could also be seen in its functionality for nested information lookups and returns. To stop timeouts and extreme response sizes whereas retrieving large information units from The Graph, Hosted APIs make out there sturdy public information, however customized subgraphs allow much more subtle manipulation. With a purpose to categorize and reply to unanticipated occasions, builders can embody information processing logic. Creating specialised subgraphs does name on strong information and the usage of The Graph community’s assets. ConclusionThe info saved within the blockchain is unlocked by The Graph and could also be used to enhance Web2 and Web3 apps. The Graph, with its highly effective querying and information API creation options, is ready to develop into a cornerstone of the decentralized net. Anybody can begin utilizing on-chain information to create enhanced blockchain experiences by following the directions on this information. Nancy J. Allen is a crypto fanatic and believes that cryptocurrencies encourage folks to be their very own banks and step apart from conventional financial change methods. She can be intrigued by blockchain know-how and its functioning.Newest posts by Nancy J. Allen (see all)Supply: https://www.thecoinrepublic.com/2023/08/30/demystifying-the-graph-a-guide-to-querying-blockchain-data/
0 notes
Text
streamer.bot + Cat API = Facts
I've always wanted to add a "!fact" or "!facts" command to my stream that would distribute random facts. This week, I finally got that working with the Cat Facts API (Cat Facts API) using the C# sub-action in streamer.bot (Streamer.bot). Here's the code:
using System; using System.Net; using System.Net.Http; using Newtonsoft.Json; using Newtonsoft.Json.Linq; public class CPHInline { public bool Execute() { var client = new HttpClient(); var request = new HttpRequestMessage(HttpMethod.Get, "https://catfact.ninja/fact"); request.Headers.Add("Accept", "application/json"); var task = client.SendAsync(request); var msg = task.Result.Content.ReadAsStringAsync().Result; JObject joResponse = JObject.Parse(msg); JValue joFact = (JValue)joResponse["fact"]; CPH.SendMessage($"{joFact}"); return true; } }
This code has problems.For example, I don't check to make sure the call to the Cat API succeeds before trying to read the response. So, it could just crash and burn when I try to fetch the content. But that hasn't happened yet, so I'm pretending like I don't need to do that.
I know that await is better practice than task.Result. EG:
var msg = await client.SendAsync(request);
The compiler complains that the function using await needs to be type Task<bool>. There might be a way to do that by declaring other C# functions to do the heavy lifting, but I'm 100% a novice at C# and streamer.bot right now, and I don't know how to make that work—yet. There's a request out there for support for Task<bool> (I think it's for Execute().) See Add async Task<bool> c# method type support · Streamer.bot Ideas and Suggestions for info about that.
I've more research to do. Do you use streamer.bot? I'd love to hear what you've created. And if you've experience calling APIs using streamer.bot's C# sub-action, maybe you know a better way to do this. Lemme know!
0 notes
Text
VodBot, and taking off the training wheels.
Part 2 of a series on my own little command line application, VodBot. This one will be much longer than the first! You can read part one here. The images in this part were done in MS Paint because I'm currently stuck in an airport!

So last we left off, VodBot was in it's shelling out stage. It was able to process data from Twitch's servers and on the local disk and figure out what videos were missing, but it left the biggest function of actually obtaining that footage to the more mature programs. In addition, VodBot didn't help all that much with actually slicing up videos in prep for archival on YouTube, and lastly actually uploading to the archive channel on YouTube. These two things needed to change, for the sake of maintaining the project into the future, and also for me to keep my sanity.

Fun fact, Twitch uses the same API that's exposed to developers to build the entire website, and it's pretty well documented what OAuth Secret and ID they use, since you can easily find it in the HTML of any Twitch page. In case you don't know, an OAuth Secret and ID is essentially a password and username of a "user". No this does not mean you can easily access anyone's info, channel, etc. because this ID and Secret have limited functions, used only for making the site function on a web browser. In fact, VodBot has its own ID and Secret which are not available, because they're meant to be a secret unless you properly manage its permissions, which I have not (yet). Anyways, the way this little faux-login is used is to access Twitch's database of video data and metadata. It uses a special system called GraphQL, you don't need the details on it for this though. Whenever you pull up a video on your browser on Twitch's site, the ID and Secret are used to log in to this GraphQL database, and pull the relevant data to have it display video on your screen.

Streams on Twitch, when being watched after the stream is over, are sent in 15 second chunks. This is how many video platforms send video dynamically to your browser, allowing video to load while you watch! It's not always 15 seconds, it varies between platforms like Netflix, YouTube, Twitch, Amazon, etc. The database returns two important bits, first up is all the info on the video segments that Twitch has for a specific video. The other bit, is just all the 15 second video files that Twitch sends to your browser. VodBot is now able to save all these by itself without an extra program, but still requires ffmpeg to stitch it all together as these 15 second video clips use a special protocol and its not as easy as simply opening a file and writing the contents of each 15 seconds one after another.
Once ffmpeg does it's job, VodBot moves the video out to a proper archival location and removes the old metadata and all the 15 second video clips it pulled from Twitch's database. A major issue with this whole implementation is that Twitch, at any moment, can easily change out the ID and Secret, meaning all the apps that rely on it can break. Although it's not currently implemented, it wouldn't be difficult to have VodBot's main configuration file contain the current values and allow them to be changed in case Twitch breaks something.
Next, since we already require VodBot to have ffmpeg, we can use the method I talked about last time to slice videos and prep them for upload. Problem is, we have a lot of functions we need to make accessible from a simple command line interface, so I had to begin thinking about how to organize VodBot's functions.

I kept it simple enough. Want to download videos? Run `vodbot pull` and VodBot will do all the hard work and download any videos you don't have. You can give it the keywords `vods` or `clips` and it'll pull what you need, and soon giving it a specific video ID will download it too. Want to prepare videos to be sliced or uploaded? Run `vodbot stage add` with the appropriate identifier and VodBot will ask a series of questions about what the video title, description, and relevant timestamps of the VOD or clip to prepare it for upload to YouTube. Running `vodbot stage list` will also list the current videos in queue to upload, along with `vodbot stage rm` to remove them from the stage. Vodbot can output these videos with the appropriate information with `vodbot slice` and the appropriate stage ID, or just `all` with a specific file or folder location respectively. Lastly, `vodbot upload all` uploads all of the stage queue to YouTube, provided you are logged in. You can also just give a specific ID in place of `all` to upload a specific video.
All of these commands have a purpose, or have sub-commands that do something related to each other. Pull and upload also have aliases named download and push respectively, in case you like having either style. Personally I like the git style, but download and upload are a bit more descriptive.
That's all for now, next time we'll actually get to how Google handles it's exposed API and how it's pretty messy.
For now though, if you'd like to support me, you can follow me on Twitter, Twitch, or buy me a ko-fi!
#twitch#twitch stream#twitch streamer#small streamer#streamer#stream#vodbot#youtube#code#programming#automation#apex barks
4 notes
·
View notes
Text
Boomi Rest API

Harnessing the Power of Boomi REST APIs
Introduction
In today’s interconnected world, APIs (Application Programming Interfaces) form the backbone that allows different software systems to talk to each other. REST APIs have become the industry standard for their simplicity and flexibility, and the Boomi platform offers powerful tools for building, managing, and using REST APIs seamlessly.
What are REST APIs?
REST (Representational State Transfer) is an architectural approach to designing web APIs.
REST APIs treat data as resources that can be accessed and manipulated using a standard set of HTTP methods:
GET: Retrieve information about a resource
POST: Create a new resource
PUT: Update an existing resource
DELETE: Delete a resource
Boomi REST APIs: What Can They Do?
Boomi’s strength lies in its ability to connect and integrate diverse applications. Here’s how REST APIs empower your Boomi integrations:
Externalize Processes: Turn your Boomi integration processes into callable REST endpoints. This lets other systems trigger your processes and receive results, extending the reach of your Boomi automation.
Consume Third-Party APIs: Easily access and integrate data and functionality from external applications that offer REST APIs. Expand your integrations to include popular services like Salesforce, Google Drive, weather APIs, etc.
API Management: Boomi’s API Management feature lets you control, monitor, and secure your REST APIs. You can also govern who accesses them, set rate limits, and generate detailed usage analytics.
How to Build a REST API in Boomi
Design Your API: Plan the resources your API will expose and the CRUD (Create, Read, Update, Delete) operations it will support.
Create or Import a Boomi Process: Develop the API request and response integration process. Alternatively, import an existing process and convert it into a REST API.
Configure API Settings: In Boomi API Management, define API security, resource paths, HTTP methods, and any required parameters.
Example: Creating a Weather API
Let’s imagine building a simple Weather API in Boomi:
Design: Our API has one resource – “weather” – and lets users GET current weather by city name.
Process: Build a Boomi process that:
Takes a city name as input
Calls an external weather API (like OpenWeatherMap)
Extracts relevant data (temperature, description)
Formats a structured JSON response
API Management:
Method: GET
Resource path: /weather
Input parameter: City
Tips for Effective Boomi REST APIs
Versioning: Implement API versioning (e.g., /v1/weather) to manage changes in a controlled way.
Documentation: Provide clear documentation for developers using your API, including examples.
Error Handling: Return meaningful error codes and messages when something goes wrong.
Security: Use authentication and authorization (Boomi API Management helps) to protect sensitive data.
Conclusion
Mastering Boomi REST APIs unlocks a wide range of integration possibilities. You’ll create truly connected, automated workflows by using them to expose your Boomi processes and interact with external systems.
youtube
You can find more information about Dell Boomi in this Dell Boomi Link
Conclusion:
Unogeeks is the No.1 IT Training Institute for Dell Boomi Training. Anyone Disagree? Please drop in a comment
You can check out our other latest blogs on Dell Boomi here – Dell Boomi Blogs
You can check out our Best In Class Dell Boomi Details here – Dell Boomi Training
Follow & Connect with us:
———————————-
For Training inquiries:
Call/Whatsapp: +91 73960 33555
Mail us at: [email protected]
Our Website ➜ https://unogeeks.com
Follow us:
Instagram: https://www.instagram.com/unogeeks
Facebook: https://www.facebook.com/UnogeeksSoftwareTrainingInstitute
Twitter: https://twitter.com/unogeek
0 notes
Text
HTTP response status codes indicate whether a specific HTTP request has been successfully finished
HTTP reaction status codes reveal no matter whether a certain HTTP request is successfully accomplished. Replies are grouped in five courses:
Informational responses (100--199)
Prosperous responses (200--299)
Redirects (three hundred--399)
Consumer problems (400--499)
Server mistakes (500--599)
Within the party you receive a response that is not During this listing, it really Get more information is a non-typical response, possibly custom made to the server's software program.
Information responses
100 ContinueThis interim reaction implies that anything is OK and that the customer really should carry on the request, or disregard the response In the event the ask for is presently concluded. 101 Switching ProtocolThis code is sent in response to an Upgrade request header in the consumer, and signifies the protocol the server is switching into. 102 Processing (WebDAV)This code indicates the host has obtained which is processing the request, but no response is obtainable still. 103 Historical HintsThis status code is primarily intended to generally be employed utilizing the hyperlink header, permitting the purchaser agent begin preloading applications though the host prepares a solution. The that means with the achievements relies upon upon the HTTP process:
GET: The source has been fetched which is despatched from the information human body.
Set or Publish: The resource describing the outcome with the motion is transmitted in the message system.
201 Produced The ask for has succeeded along with a new source is created As a result. This is ordinarily the solution sent immediately after Submit requests, or any Set requests. 202 AcceptedThe ask for has actually been received although not however acted on. It really is noncommittal, considering that there is no way in HTTP to Later on ship an asynchronous response indicating the benefits in the ask for. It truly is intended for situations in which A further treatment or host handles the request, or for batch processing. 203 Non-Authoritative Info This response code suggests the returned meta-facts is not really particularly the same as is obtainable from the supply server, but is gathered from the neighborhood or maybe a 3rd party backup. That is largely utilized for mirrors or even copies of another source. Except for that unique case, the"200 Okay" reaction is chosen to this standing. 204 No Contentthere is absolutely not any information to ship for this petition, although the headers may well be handy. 205 Reset ContentTells the user-agent to reset the doc which sent this petition. 206 Partial ContentThis response code is employed when the Range header is shipped by the consumer to ask for just A part of a source. 207 Multi-Status (WebDAV)Conveys specifics of many sources, for cases the place several position codes may possibly be ideal. 208 Already Reported (WebDAV)Used inside of a reaction factor to avoid consistently enumerating the inner associates of several bindings towards the similar assortment. 226 IM Used (HTTP Delta encoding)The server has fulfilled that has a GET ask for for your source, plus the answer is actually a illustration of your final result of just one or additional instance-manipulations applied to The present occasion.
Redirection messages
300 Multiple ChoiceThe petition has in excess of just one attainable response. The person-agent or buyer ought to decide on one among these. (There may be no standardized way of picking out among These solutions, but HTML hyperlinks into the choices are recommended so the person can pick out.) The new URL is provided while in the response. 302 FoundThis reply code implies the URI of asked for source is changed temporarily. Even more modifications in the URI could be acquired Down the road. Thus, this same URI must be used from the customer in long term requests. 303 See OtherThe waiter despatched this reaction to guide the customer to obtain the requested source at A further URI with a GET ask for. 304 Not ModifiedThat might be utilized for caching functions. It tells the customer the reply hasn't but been modified, Therefore the customer can continue on to employ the exact same cached Model of this reaction. 305 Use Proxy Defined in a preceding Variation on the HTTP specification to signify that a requested answer must be retrieved by a proxy. It's got been deprecated due to protection problems about in-band set up of a proxy. 306 unusedThis reply code isn't any for a longer time made use of; it really is just reserved. It were used in a prior Variation of the HTTP/1.1 specification. 307 Temporary RedirectThe server sends this reaction to guidebook the client to get the requested supply at A different URI with identical process that was utilized from the prior ask for. This has the exact same semantics as the 302 Observed HTTP response code, Along with the exception that the consumer agent should not modify the HTTP technique applied: When a POST was employed at the to start with petition, a Publish must be utilized at the subsequent petition. 308 Permanent RedirectThis implies that the resource is currently completely located at a unique URI, specified from the Site: HTTP Reaction header. This has the very same semantics because the 301 Moved Completely HTTP reaction code, With all the exception which the person consultant should not change the HTTP approach applied: If a Put up was applied from the first petition, a Write-up has got to be applied while in the second ask for.
Client mistake responses
400 Bad RequestThe server could not understand the ask for as a consequence of invalid syntax. To paraphrase, the client will have to authenticate itself to get the asked for response. The Preliminary intent for building this code was making use of it for electronic payment devices, nonetheless this standing code is applied very almost never and no normal convention is existing. 403 ForbiddenThe shopper won't have entry legal rights to the materials; this is, it really is unauthorized, or so the server is refusing to give the requested source. Opposite to 401, the customer's identification is recognized to the server. 404 Not FoundThe device can't Identify the requested resource. From the browser, this indicates the URL will not be regarded. In an API, this can also indicate which the endpoint is valid although the resource itself doesn't exist. Servers can also send out this reaction as opposed to 403 to conceal the event of a source from an unauthorized purchaser. This reaction code is most likely essentially the most famous 1 as a result of its Regular prevalence on the internet. 405 Method Not AllowedThe ask for technique is understood with the server but has actually been disabled and can't be applied. By the use of example, an API may perhaps forbid DELETE-ing a resource. The 2 required solutions, GET and HEAD, will have to never ever be disabled and should not return this mistake code. 406 Not AcceptableThis answer is shipped when the Website server, just after carrying out server-driven content negotiation, isn't going to obtain any content material that adheres for the requirements equipped because of the user representative. 407 Proxy Authentication RequiredThis is similar to 401 however authentication is expected for being obtained by signifies of a proxy. 408 Request TimeoutThis reaction is sent on an idle connection by some servers, even with no prior request by the client. It typically implies which the server would like to near this down unused link. This response is used substantially additional for the reason that some browsers, like Chrome, Firefox 27+, or IE9, benefit from HTTP pre-link mechanisms to speed up searching. Also Notice that quite a few servers only shut down the link devoid of sending this message. 409 ConflictThis reply is distributed whenever a request conflicts Using the existing state of your host. 410 GoneThis response is sent in the event the asked for material was forever deleted from server, with no forwarding deal with. Purchasers are predicted to eliminate their caches and backlinks to the resource. The HTTP specification options this standing code for use for"restricted-time, marketing methods". APIs shouldn't come to feel pressured to point methods which have been deleted with this standing code. 411 Length RequiredServer rejected the request considering the fact that the Material-Duration header industry isn't really outlined and also the server wants it. 412 Precondition FailedThe consumer has indicated preconditions in its personal headers which the host isn't going to meet up with. 413 Payload Too LargeTalk to entity is much larger than limitations described by server; the server could close the connection or return the Retry-Following header area. 415 Unsupported Media TypeThe media framework of this asked for knowledge is not supported through the server, And so the server is rejecting the request. 416 Range Not SatisfiableThe selection specified from the Variety header area from the request can't be fulfilled; it truly is achievable the scope is away from the scale of the focus on URI's information. 417 Expectation FailedThis reaction code signifies the anticipation indicated from the Hope ask for header discipline won't be able to be fulfilled by the server. 421 Misdirected RequestThe ask for was directed in a host which will not be ready to generate a response. This may be transmitted by a host which is not configured to create responses for the combination of technique and authority which are A part of the request URI. 422 Unprocessable Entity (WebDAV)The ask for was perfectly-shaped but was unable to generally be followed due to semantic problems. 423 Locked (WebDAV)The source that has long been accessed is locked. 425 Too Early indicators that the server is hesitant to chance processing a petition That may be replayed. 426 Upgrade RequiredThe server is not going to complete the request applying the latest protocol but may possibly be Completely ready to do so next the customer updates to a special protocol. The server sends an Upgrade header at a 426 response to signify the necessary protocol(s). 428 Precondition RequiredThe origin server calls for the petition to be conditional. This response is intended to prevent the'missing update' problem, exactly where a purchaser Receives a supply's issue, modifies it, and PUTs back to the server, when a 3rd party has modified the condition to the host, bringing about a fight. 429 Too Many RequestsThe consumer has sent a lot of requests inside of a specified interval of your time ("amount restricting"). 431 Request Header Fields Too LargeThe host is unwilling to procedure the request mainly because its personal header fields are excessively big. 451 Unavailable For Legal ReasonsThe user-agent requested a resource which may't legally be offered, such as an online web site censored by a governing administration.
Server mistake answers

youtube
500 Internal Server ErrorThe server has encountered a circumstance it doesn't learn how to manage. 501 Not ImplementedThe petition approach isn't supported by the host and can not be managed. The only techniques that servers are envisioned to aid (and as a result that should not return this code) are GET and HEAD. 502 Bad GatewayThis error reaction signifies the server, though employed to be a gateway to have a reaction needed to manage the petition, got an invalid reaction. 503 Service UnavailableThe server isn't ready to handle the ask for. Frequent brings about are a host which is down for maintenance or that is overloaded. Observe that with this reaction, a person-helpful website page describing the issue ought to be despatched. This solutions need to be utilized for short-term ailments in conjunction with also the Retry-Just after: HTTP header should, if possible, involve the believed time just before the recovery of the support. The webmaster will have to also watch out about the caching-relevant headers that are despatched collectively with this solution, as these momentary issue responses shouldn't be cached. 504 Gateway TimeoutThis mistake response is provided when the server is acting as a gateway and can't find a reaction in time. 508 Loop Detected (WebDAV)The server detected an infinite loop when processing the petition. 510 Not ExtendedExtra extensions to the ask for are needed for your waiter to match it. 511 Network Authentication RequiredThe 511 status code implies which the consumer should authenticate to attain network obtain.
2 notes
·
View notes
Text
5 Quick Tips Regarding ACH Rule Change Mandates Checking Account Validation.
Which is the best option for your business?
We believe options 1,2 and 3 are typically not the best fit.
Your customer base and potential for fraud will dictate better options between 3 and 4. If you are onboarding or taking payments from a new customer that you know nothing about, e.g., enrolling in a Venmo like app, then instant bank verification costs are worth paying because you are mitigating risk and smoothing enrollment. If your demographic is younger they are more likely to tolerate having to log-in to their online platform.
If on the other hand you are dealing with known customers or your business is low risk and recurring in nature the bank network database inquiry offers risk mitigation and compliance at much lower costs.
In terms of fees the bank network inquiries will typically cost in the 30 cents range per inquiry.For instant bank verification expect to pay $1 or more per transaction with monthly minimums from $250-$500+.
March 2021 is not that far away. Look to implement your solution as soon as possible to avoid non-compliance issues. Contact AgilePayments for more info.
What does the NACHA WEB Checking Account Verification mandate mean for your business?
The new NACHA rule specifically states that the businesses must employ a Checking Account Verification System as part of a “commercially reasonable fraudulent transaction detection system.”
More precisely, businesses that ask their customers to manually enter their account and routing numbers but don’t perform account validation will not be compliant. (the upcoming rule change doesn’t affect credit or debit card payments).
This means any business accepting a payment or changing a payment method must employ some validation tool or system.
If your website includes ACH as a method of paying for goods or services you must implement one of the Bill Presentment and Payment Solutions we outline below. If you rely on a shopping card solution, your cart provider must implement or integrate a verification solution.
The implementation deadline was originally set for January 2020, but NACHA pushed it back to March 2021 in order to give online merchants, financial institutions, and other businesses more time to get ready. All together, NACHA represents more than 10,000 financial institutions, so the impact will be broad and far-reaching. The new NACHA account validation rule takes effect March 19,2021.

What are your options to validate Checking Accounts in the NACHA WEB mandate? And which is your best fit?
You potentially have five options. For businesses that rely on automation the first two are likely not great fits.
1-Manual check: The customer must be involved on call with their bank or produce bank statements. Certainly not an ideal customer experience. So a 3-way call between the merchant, customer and the customer’s bank is required.
2-Microdeposits: These typically involve two steps. Businesses make one or two small deposits (usually just a few pennies) into a customer’s account. The customer then confirms the amounts deposited. It often takes 2-3 days, and consumers often fail to complete the Canada Eft Processing. Before the advent of options 3 and 4 this was the most popular tool used.
3-Prenotes: Prenotes these similar to microdeposits—however these do not require confirmation from the customer. The originator sends a $0 transaction through the ACH network to verify that the account is valid. Pre-notes typically take 2-3 days. Pre-notes are seldom used as some 3rd party processors don’t support them.
4-Bank network database: Most of the banks and Credit Unions in the U.S. contribute Checking Account Owner Authentication data on a daily basis. This data lets a business know an account is open and in good standing (or not).
The pros are very fast response times, economical and non-intrusive. The consumer enters account data and a call is made for a response. Con is you do not get a balance check or confirmation requisite funds are in the account. Additionally you are not validating Checking Account Ownership
5–Instant account verification: This method utilizes application program interfaces (APIs) and secure digital connections to banks, with account and routing numbers retrieved directly from the accounts being authenticated.
Customers simply select their bank from a list, enter their bank login and password, and their accounts are digitally connected in 7-11 seconds. In addition to linking accounts, some APIs can also be used to retrieve balance, identity, and transactions information. Pros: validate account plus ownership and balance is possible. Cons: Fairly intrusive process and customers may refuse to provide account log-in info.
For businesses that need to have a “future look” at the customer checking account this option can prevent creating an NSF or overdrawn account. When dealing with the syb-prime market this can be important on multiple levels.
What does the new NACHA ruling around WEB ACH transactions really mean and why has it been implemented?
Beginning March 2021, NACHA will implement a new rule that mandates enhanced checking account verification measures.
Businesses that debit payments via ACH for online or web based orders are required to implement enhanced fraud detection to comply with the new NACHA web debit account validation mandate.
Specifically, the organization will require such businesses to include, at a minimum, Checking Account Validation as part of a “commercially reasonable fraudulent transaction detection system.”
The change enhances NACHA’s anti-fraud mitigation. Simply stated, the new NACHA Checking Account Verification Services rule means checking to make sure that the checking account routing and account numbers submitted for a given ACH transaction are valid. By valid we mean the account is open.
AgilePayments offers cost effective, easy to implement NACHA compliant solution.
Traditionally businesses rely on the consumer to input account information. For many reasons including bad data entry these transactions would get rejected when the customer’s bank received the debit instructions.
NACHA is looking to reduce these returns as well as trying to combat fraud attempts. A fraud scheme could work as follows: Person or entity looking to perpetrate fraud initiates low $ debit or pre-note transactions to identify open bank accounts. Note: A prenote is a zero $ electronic ACH inquiry. Prenotes were a popular tool to validate a bank account especially before recurring payment plans are scheduled.
The fraudster then pings accounts until they hit upon accounts they know are open. They would then initiate ACH debits to that account in hope of receiving monies. Once they received $ they would close their bank account to prevent a reverse debit.
There have been many such instances and in some cases big money losses have been incurred.
1 note
·
View note
Text
Why Googlemapembed.Com Is A Method Not A Approach
just How To Embed Google Maps In Wordpress site
As an example, a look for a map of Boston on Google.com would certainly produce, to name a few things, a topographic map of the city through Google Maps. The Maps program allows users to zoom in and out and move the map to search bordering areas. Along the appropriate side of the search results page screen are a variety of little ads for Boston-based services, hotels, dining establishments, as well as links to other sites selling hard-copy maps of the city. This type of paid advertising is the main method which Google makes its profits.
deleting A Google Map.
What is MAP API?
A Map API (also known as Mapping API) provides location intelligence for software developers creating location-based products and services. It is the base building block for location-aware applications, feature-rich maps and the retrieval of geographic-related data.
In a feeling, when you go abroad, Google Maps really begins to radiate in a manner it doesn't in the house. Mr. Robinson claimed his group asked Google to include the East Cut to its maps. A Google spokeswoman stated employees manually put the name after validating it through public sources.
Google's 360 degree Street Sight function is available in the Android variation of Maps application. The most basic method to gain access to this attribute is to find the area you wish to view, and also press and also hold that place. If a Road Sight is available, a little thumbnail will show up in the lower edge. By default, this app draws every one of its information from Google web servers in real time. It is possible to pick an area as well as download it for offline use, nonetheless.
In Rio de Janeiro, just 26 of the city's 1,000 favelas are mapped-- this despite the fact that the favelas are home to over a million people and also regarding a quarter of the city's populace. After all, Google itself is so embedded to our ordinary tech lives, we rarely think of it as having a professional application to something as interesting as traveling.
What is the URL mean?

A domain name is part of a URL, which stands for Uniform Resource Locator.
There are also data-sets that let you viewvirtual designs of the moon and other earths. Zoom Earth is just one of the most effective options to Google Earth only since it does not utilize much of Google's services for data mapping and yet provides fantastic images of our Earth. Similar to Google Earth, Zoom Planet is online and it reveals real-time info of weather condition, tornados, wildfires, and extra. The best component is that you can see high-resolution aerial views of the lots of areas in a zoomable map. While Google Planet is excellent, there are few other alternatives that can assist you do the same points.

data.
Is the YouTube API free?
Yes, using the YouTube API does not incur any monetary cost for the entity calling the API. If you go over your quota an 403 Error will be returned by the API. Yes it is, but some restrictions like limit you can use only 100000 units per day. and 3000 per second per 100 user per day.
Use the Print menu approach explained in the write-up above or record a screenshot onto your computer system and also print out the screenshot. If you don't wish to really publish however wish to maintain a copy on your phone, simply take a screenshot or display capture and also leave it in your photos folder/desktop view.
This Is Google's New Smart display tool.
Many individuals are not delighted with Google's data collection policies and do not want to hand over information greater than they have to. If for that reason or a factor of your very own, you are searching for Google Earth alternatives then you have pertained to the right place. Here are the 4 ideal apps like Google Planet you can utilize in 2020. Google Earth enables you to take a trip, discover, and learn more about the world by interacting with a virtual world. You can view satellite imagery, maps, terrain, 3D structures, and far more.
Google says it utilized satellite images as the basis for its revamped maps which this has had a "new color-mapping mathematical technique" put on it. Completion outcome does a much better job of showing off the differences between natural functions, such as between snowy tops and thick forests or environment-friendly areas and also sandy coastlines. The contrast shots listed below offer a concept of what the new color-mapping strategy is capable of. Google Maps is being upgraded to make it simpler to compare natural attributes in the environment, whether they're mountainous ice caps, deserts, coastlines, or thick woodlands.
What is a map URL?
The maps URL scheme is used to show geographical locations and to generate driving directions between two points. Unlike some schemes, map URLs do not start with a “maps” scheme identifier. Instead, map links are specified as regular http links and are opened either in Safari or the Maps app on the target platform.
Go to the major Google Maps internet site and type the address for the home you want to check out. This will show an overhead map of the property on screen. Click the "Street Sight" button to watch pictures of the residential or commercial property drawn from street degree by Google's very own Street Sight vehicles that circumnavigate the globe. Yes, a map can be published from Google Maps, either with or without directions.
But for lots of areas where homeowners were not sure of the history, authorities depend largely on Google. The Eye and others are now part of that official map.
So Google Maps started its trip greater than a decade back, worked in the direction of incorporating numerous applications.
In 2004, Google got this company from the bros.
The best component of training course is that Google Maps as well as all its related services are used absolutely free.
And finally launching Google Maps application in 2005.
Ultimately integrating it with various other business which Google purchased over the next couple of years related to live traffic analyzer as well as various other mapping related applications.
This feature supplies a powerful tool to present historic datasets. It does have restrictions, nevertheless, as Google Maps will only import the first 100 rows of a spreadsheet.
Maps and also images you create in Google Maps as well as Google Planet can be saved as KML documents This suggests you can conserve job performed in Google Maps or Google Planet. With KML files you can transfer information in between these two systems and also bring your map data into Quantum GIS or ArcGIS. Note that to the right of Layer there is a https://googlemapembed.com checkbox-- unchecking this box turns off (i.e. it doesn't appear on the map) a layer and its info. Uncheck the UK Global Fats layer and also click Layer 1.
1 note
·
View note
Text
HTTP response status codes indicate if a particular HTTP request was successfully finished
HTTP reaction status codes reveal no matter whether a specific HTTP petition has been successfully completed. Responses are grouped in 5 courses:
If you are provided a response that isn't really Within this listing, it really is a non-normal reply, potentially custom made to the server's program.
Information answers
100 ContinueThis interim response suggests that anything up to now is OK and the shopper need to continue on the ask for, or disregard the response If your petition is now finished. 101 Switching ProtocolThis code is sent in reaction to an Upgrade ask for header from the buyer, and indicates the protocol the server is switching to. 103 Historical HintsThis standing code is largely meant to generally be utilized with the hyperlink header, enabling the shopper agent commence preloading means although the host prepares an answer.
Successful responses
200 OKThe request has succeeded. The that means with the achievement depends on the HTTP strategy:
GET: The useful resource was fetched and is also transmitted from the concept overall body.
PUT or Put up: The resource describing the end result of the motion is despatched in the message system.
201 Produced The ask for has succeeded in addition to a brand-new resource was developed For that reason. This is normally the response despatched right after Article requests, or any Place requests. 202 AcceptedThe petition was received although not still acted upon. It is actually noncommittal, considering the fact that you will find absolutely not any way in HTTP to later mail an asynchronous response suggesting the effects with the request. It really is intended for circumstances in which Yet another method or server handles the request, or for batch processing. 203 Non-Authoritative Info This reaction code means the returned meta-information and facts isn't precisely the same as is offered through the supply server, but is collected from the community or a third-social gathering backup. This is chiefly used for mirrors or backups of a unique resource. Except for that specific scenario, the"two hundred OK" reaction is favored to this standing. 204 No Contentthere is absolutely not any product to ship for this ask for, however the headers could be useful. 205 Reset ContentTells the consumer-agent to reset the report which sent this petition. 206 Partial ContentThis reply code is applied when the Range header is shipped from the consumer to ask for just Component of a resource. 207 Multi-Status (WebDAV)Conveys specifics of many sources, this kind of circumstances where by various position codes may well be ideal. 208 Already Reported (WebDAV)Used within a reaction element to stay away from consistently enumerating the inner members of a number of bindings towards the identical selection. 226 IM Used (HTTP Delta encoding)The server has fulfilled a GET petition for the resource, and also the reaction is often a illustration with the consequence of additional occasion-manipulations placed on the current situation.
youtube
Redirection messages
300 Multiple Option The ask for has about one prospective reaction. The user-agent or user has to decide on between them. (There is no standardized way of picking among the responses, but HTML links into the possibilities are recommended so the person can decide.) 301 Moved PermanentlyThe URL on the asked for useful resource has long been altered for good. The brand new URL is provided within the reply. 302 FoundThis reply code implies the URI of requested resource was adjusted briefly. Even more modifications while in the URI could be made later on. Therefore, this exact same URI really should be applied through the shopper in foreseeable future requests. 303 See OtherThe waiter sent this reaction to immediate the customer to receive the asked for source at Yet another URI with a GET ask for. 304 Not ModifiedThis is utilized for caching applications. It tells the shopper the reaction hasn't nonetheless been altered, And so the buyer can go on to employ exactly the same cached Variation of this reaction. 305 Use Proxy Outlined in a very past Variation in the HTTP specification to signify that a asked for reaction has got to be retrieved by indicates of the proxy. It's got been deprecated because of safety concerns regarding in-band configuration of the proxy. 306 unusedThis reaction code isn't any much more utilised; It truly is just reserved. It had been Utilized in a preceding Edition of this HTTP/one.1 specification. 307 Temporary RedirectThe host sends this response to direct the customer to get the requested resource at Yet another URI with very same process that was utilized in the past petition. This has the exact same semantics as the 302 Identified HTTP reaction code, Using the exception the consumer representative should not modify the HTTP approach utilized: When a Article was utilised in the First ask for, a Publish should be utilized at the second petition. 308 Permanent RedirectThis suggests which the useful resource has grown to be forever Found at another URI, supplied from the Locale: HTTP Response header. This has the very same semantics since the 301 Moved Permanently HTTP response code, Along with the exception the user agent need to not change the HTTP strategy utilised: If a Write-up was utilized in the initially request, a Publish must be applied in the next petition.
Client error responses
400 Bad RequestThe server couldn't understand the request due to invalid syntax. To paraphrase, the client ought to authenticate itself to get the requested response. 402 Payment Required This reply code is reserved for foreseeable future utilization. The First intention for producing this code was making use of it for electronic payment techniques, but this status code could be utilised pretty sometimes and no standard Conference exists. 403 ForbiddenThe customer will not have obtain rights to the content material; that is, it truly is unauthorized, so the server is not able to give the requested useful resource. Contrary to 401, the customer's identity is named the host. 404 Not FoundThe equipment cannot locate the asked for useful resource. In the browser, this usually means the URL is not regarded. In an API, this can also point out the endpoint is legit but the resource itself isn't going to exist. Servers may also deliver this reaction as opposed to 403 to hide the existence of the source from an unauthorized client. This reply code is most likely probably the most famed just one because of its Repeated occurrence on the net. 405 Method Not AllowedThe request strategy is comprehended through the server but is disabled and won't be able to be employed. Through instance, an API might forbid DELETE-ing a resource. Both Obligatory techniques, GET and HEAD, really should in no way be disabled and shouldn't return this mistake code. 406 Not AcceptableThis reply is despatched when the World-wide-web server, following accomplishing server-driven content negotiation, will not discover any material which conforms into the benchmarks given because of the consumer agent. 407 Proxy Authentication RequiredThis resembles 401 having said that authentication is essential being achieved by indicates of a proxy. 408 Request TimeoutThis reply is despatched on an idle website link by some servers, even without prior ask for with the customer. It commonly usually means the host would like to shut down this new connection. This response is employed A lot much more because some browsers, like Chrome, Firefox 27+, or IE9, use HTTP pre-connection mechanisms to speed up browsing. Also Be aware that some servers only shut down the link without having sending this data. 409 ConflictThis reaction is shipped whenever a ask for conflicts Along with the current condition in the host. 410 GoneThis respond to is despatched if the asked for information was completely deleted from server, without having forwarding tackle. Consumers are expected to get rid of their caches and hyperlinks to your source. The HTTP specification intends this standing code for use for"restricted-time, marketing products and services". APIs should not experience pressured to indicate resources that are actually deleted with this position code. 411 Length RequiredServer rejected the request due to the fact the Content material-Duration header discipline is just not defined as well as the server desires it. 412 Precondition FailedThe client has indicated preconditions in its own headers that the server doesn't meet. 413 Payload Too LargeAsk for entity is even bigger than limitations described by server; the server may well close the connection or return an Retry-Right after header Discover more here area. 414 URI Too LongThe URI requested with the shopper is lengthier compared to server is prepared to interpret. 415 Unsupported Media TypeThe media framework of this info that may be asked for is just not supported through the server, Therefore the server is rejecting the ask for. 416 Range Not SatisfiableThe scope specified by the Selection header subject in the ask for cannot be fulfilled; it is actually probable which the scope is far from the size of the concentrate on URI's information. 417 Expectation FailedThis response code signifies the anticipation indicated through the Anticipate request header industry can not be fulfilled from the host. 421 Misdirected RequestThe petition was directed in a host which is not in the position to generate a reaction. This can be despatched by a server which is not configured to develop responses with the combo of plan and authority which are A part of the request URI. 422 Unprocessable Entity (WebDAV)The ask for was well-fashioned but was not able for being followed due to semantic problems. 423 Locked (WebDAV)The resource that has actually been accessed is locked. 424 Failed Dependency (WebDAV)The ask for failed because of failure of the previous petition. 425 Too Early Suggests which the server is unwilling to risk processing a petition which may be replayed. 426 Upgrade RequiredThe server will likely not complete the request with the latest protocol but could be keen to do so subsequent the purchaser updates to a unique protocol. The server sends an Update header in a 426 reaction to signify the expected protocol(s). 428 Precondition RequiredThe origin server needs the petition to come to be conditional. This reaction is meant to guard versus the'misplaced update' challenge, by which a purchaser Receives a source's point out, modifies it, and Places back to the host, when In the meantime a 3rd party has modified the condition on the host, resulting in a fight. 429 Too Many RequestsThe user has sent a lot of requests inside of a precise period of your time ("fee limiting"). 431 Request Header Fields Too LargeThe server is unwilling to procedure the request due to the fact its very own header fields are excessively huge. The ask for may very well be resubmitted soon after minimizing the sizing with the ask for header fields. 451 Unavailable For Legal ReasonsThe person-agent questioned a source that cannot lawfully be supplied, like a web site censored by a govt.
Server mistake answers

500 Internal Server ErrorThe server has encountered a scenario it would not understand how to handle. 501 Not ImplementedThe ask for technique just isn't supported from the host and can't be dealt with. The sole methods that servers are needed to support (and hence that need to not return this code) are GET and HEAD. 502 Bad GatewayThis oversight response usually means the server, though employed to be a gateway to get a response needed to tackle the ask for, acquired an invalid response. 503 Service UnavailableThe server just isn't All set to handle the ask for. Widespread results in can be a host which is down for maintenance or that's overloaded. Recognize that with this particular reaction, a person friendly website page describing the problem should be despatched. This responses really should be employed for temporary conditions as well as the Retry-After: HTTP header must, if possible, involve the estimated time in advance of the recovery of this ceremony. The webmaster really should also acquire care regarding the caching-relevant headers which are despatched together using this reaction, as these momentary issue responses should not be cached. 504 Gateway TimeoutThis error reaction is offered when the device is acting to be a gateway and cannot get a response in time. 506 Variant Also NegotiatesThe machine has an internal configuration error: the decided on variant useful resource is configured to engage in transparent content material negotiation by itself, and is thus not an appropriate end level within the negotiation procedure. 507 Insufficient Storage (WebDAV)The process couldn't be performed on the resource because the server is unable to retail outlet the illustration required to correctly total the request. 508 Loop Detected (WebDAV)The
1 note
·
View note
Text
HTTP response status codes indicate if a particular HTTP request was successfully finished
HTTP reaction standing codes suggest no matter whether or not a precise HTTP ask for has long been productively done. Responses are grouped in 5 courses:
From the function you obtain a response that just isn't During this checklist, it's a non-standard response, probably personalized into the host's application.
Information responses
100 ContinueThis interim reaction suggests that every thing is Okay and the client must go on the request, or dismiss the solution In case the petition is presently completed. 101 Switching ProtocolThis code is sent in reaction to a Upgrade request header from the purchaser, and signifies the protocol the server is switching to. 103 Historical HintsThis standing code is mainly supposed to get used applying the hyperlink header, letting the purchaser agent start out preloading assets when the server prepares an answer.
Successful responses
200 OKThe request has succeeded. The significance in the accomplishment is contingent on the HTTP approach:
GET: The supply was fetched and it is despatched during the information entire body.
Place or Write-up: The resource describing the result from the action is despatched into the concept system.
201 Produced The ask for has succeeded and also a new source was made Consequently. This is certainly usually the response despatched after Publish requests, or any PUT requests. 202 AcceptedThe petition continues to be received although not yet acted on. It really is noncommittal, due to the fact there's Certainly not any way in HTTP to Later on deliver an asynchronous reaction suggesting the consequence from the request. It's intended for cases where a special course of action or host handles the request, or for batch processing. 203 Non-Authoritative Info This reply code signifies the returned meta-data isn't accurately the same as is out there with the supply server, but is collected from the regional or even a third-occasion backup. This is certainly generally useful for mirrors or backups of another useful resource. Aside from that unique circumstance, the"200 OK" reaction is desired to this status. 204 No Contentthere is completely not any material to ship for this petition, although the headers may perhaps be practical. The person-agent may well update its cached headers for this useful resource While using the new ones. 205 Reset ContentTells the consumer-agent to reset the doc which sent this petition. 206 Partial ContentThis response code is employed although the Range header is sent by the shopper to request only Portion of a resource. 208 Already Reported (WebDAV)Utilized inside of a remedy component to keep away from regularly enumerating the internal members of several bindings to the exact same collection. 226 IM Used (HTTP Delta encoding)The server has fulfilled a GET ask for to the resource, as well as the solution is often a representation on the consequence of additional occasion-manipulations applied to the current occasion.
youtube
Redirection messages
300 Multiple Option The petition has above 1 attainable response. The user-agent or client has to pick between these. (There is certainly no standardized way of deciding upon one among the answers, but HTML links to the prospects are advised so the consumer can select.) The brand new URL is presented inside the reaction. 302 FoundThis response code suggests that the URI of requested resource was modified briefly. Additional variations within the URI may well be gained Later on. So, this identical URI ought to be used with the customer in potential requests. 303 See OtherThe waiter despatched this response to manual the consumer to acquire the requested supply at Yet another URI with a GET ask for. 304 Not ModifiedThis is used for caching features. It tells the consumer that the reaction has not nevertheless been modified, Therefore the consumer can proceed to implement a similar cached version of this response. 305 Use Proxy Outlined in a very previous Model from the HTTP specification to reveal a asked for response needs to be retrieved by suggests of the proxy. It can be been deprecated because of security concerns pertaining to in-band configuration of the proxy. 306 unusedThis reply code is not any much more utilized; it truly is just reserved. It was used in a prior version of the HTTP/1.one specification. 307 Temporary RedirectThe server sends this reaction to immediate the consumer to get the requested source at a special URI with exact same strategy which was applied in the earlier petition. This has the identical semantics given that the 302 Located HTTP answer code, with the exception that the consumer agent shouldn't change the HTTP system utilized: When a Article was utilised in the 1st request, a Put up will have to be utilized in the second request. 308 Permanent RedirectThis usually means the useful resource is now permanently Situated at A different URI, presented from the Locale: HTTP Reaction header. This has the same semantics given that the 301 Moved Permanently HTTP response code, While using the exception the consumer consultant have to not improve the HTTP system employed: When a Submit was utilized in the Preliminary petition, a Submit should be applied while in the up coming ask for.

Client mistake answers
400 Bad RequestThe server couldn't realize the ask for due to invalid syntax. That may be, the customer need to authenticate by itself to get the requested answer. The Preliminary goal for producing this code has been working with it for electronic payment solutions, but this status code is often used really infrequently and no conventional Conference exists. 403 ForbiddenThe client doesn't have entry rights to this substance; that is, it can be unauthorized, so the server is refusing to deliver the requested useful resource. Compared with 401, the consumer's identification is known to the host. 404 Not FoundThe device cannot locate the requested source. In the browser, this normally usually means the URL is not regarded. In an API, this can also reveal that the endpoint is genuine nevertheless the useful resource alone isn't going to exist. Servers may also ship this response as an alternative to 403 to conceal the event of the supply from an unauthorized consumer. This reaction code is almost certainly by far the most famed one as a consequence of the frequent event online. 405 Method Not AllowedThe petition method is regarded by the server but has been disabled and can't be employed. By the use of occasion, an API may possibly forbid DELETE-ing a useful resource. The two mandatory procedures, GET and HEAD, need to never ever be disabled and should not return this error code. 406 Not AcceptableThis solution http://discorddownn.moonfruit.com/?preview=Y is sent when the server, right after accomplishing server-driven content negotiation, won't uncover any material which adheres on the criteria supplied from the consumer consultant. 407 Proxy Authentication RequiredThis resembles 401 but authentication is essential for being performed by a proxy. 408 Request TimeoutThis reaction is shipped on an idle connection by a few servers, even without prior ask for from the shopper. It commonly implies the server would like to close this down new link. This response may be utilized noticeably more since some browsers, like Chrome, Firefox 27+, or IE9, make the most of HTTP pre-link mechanisms to quicken browsing. Also Be aware that many servers simply shut down the connection with out sending this information. 409 ConflictThis reaction is sent any time a ask for conflicts While using the current state of the server. 410 GoneThis reaction is delivered once the requested information has become forever deleted from server, with out a forwarding address. Consumers are predicted to clear away their caches and hyperlinks on the useful resource. The HTTP specification ideas this position code to be used for"minimal-time, promotional expert services". APIs shouldn't feel pressured to indicate sources that are deleted with this standing code. 411 Length RequiredServer turned down the ask for since the Material-Length header industry just isn't outlined as well as the server needs it. 412 Precondition FailedThe consumer has indicated preconditions in its own headers that the server doesn't satisfy. 413 Payload Too Big Ask for entity is greater than limitations defined by host; the server may well shut the website link or return the Retry-After header area. 414 URI Too LongThe URI requested through the purchaser is longer compared to the server is ready to interpret. 415 Unsupported Media TypeThe media format of the info which is asked for just isn't supported with the host, Therefore the server is rejecting the petition. 416 Range Not SatisfiableThe variety specified by the Assortment header industry in the ask for can't be fulfilled; it is achievable which the scope is outdoors the scale of this concentrate on URI's facts. 417 Expectation FailedThis reaction code signifies the expectation indicated from the Foresee ask for header industry cannot be fulfilled by the host. 418 I'm a teapotThe server refuses the try to brew coffee using a teapot. 421 Misdirected RequestThe ask for was directed in a server which will not be capable to generate a reaction. This might be transmitted by a server that is not configured to develop responses with the combo of scheme and authority that are included in the ask for URI. 422 Unprocessable Entity (WebDAV)The petition was perfectly-fashioned but was not able to get followed because of semantic errors. 423 Locked (WebDAV)The source that has become obtained is locked. 424 Failed Dependency (WebDAV)The request failed on account of failure of a preceding request. 425 Too Early Suggests which the host is unwilling to threat processing a petition that might be replayed. 426 Upgrade RequiredThe server is not going to do the request with the current protocol but might be ready to take action subsequent the client upgrades to One more protocol. The server sends an Update header at a 426 reaction to suggest the obligatory protocol(s). 428 Precondition RequiredThe supply server demands the petition to turn out to be conditional. This response is intended to safeguard against the'shed update' issue, the place a client gets a useful resource's point out, modifies it, and Places back again to the server, when a third party has altered the state within the server, leading to a battle. 429 Too Many RequestsThe person has delivered too many requests in the precise sum of your time ("amount restricting"). 431 Request Header Fields Too Big The server is unwilling to course of action the ask for simply because its header fields are excessively massive. The request may be resubmitted right after lessening the dimension from the request header fields. 451 Unavailable For Legal ReasonsThe person-agent requested a resource which often can't lawfully be furnished, including an internet site censored by a federal government.
Server error responses
500 Internal Server ErrorThe server has encountered a situation it isn't going to learn how to tackle. 501 Not ImplementedThe petition technique isn't supported with the server and are unable to be handled. The one procedures that servers are required to persuade (and as a result that should not return this code) are GET and HEAD. 502 Bad GatewayThis mistake reaction means that the server, when employed as a gateway to have a reaction necessary to manage the ask for, obtained an invalid reaction. 503 Service UnavailableThe machine is just not ready to contend with the request. Regular leads to really are a host that is definitely down for routine maintenance or that is certainly overloaded. Notice that with this response, a person-welcoming web site detailing the problem must be despatched. This solutions should really be useful for short-term disorders in conjunction with also the Retry-Right after: HTTP header must, if at all possible, include the approximated time previous to the recovery of this service. The webmaster need to also acquire care about the caching-related headers that are sent collectively with this particular response, since these short term condition answers ought to ordinarily not be cached. 504 Gateway TimeoutThis error response is provided when the device is performing as a gateway and are unable to obtain a response in time. 505 HTTP Version Not SupportedThe HTTP Variation used in the petition is not really supported with the host. 508 Loop Detected (WebDAV)The server detected an infinite loop whilst processing the ask for. 510 Not ExtendedAdded extensions to the ask for are demanded to the waiter to match it.
1 note
·
View note