#smalllanguagemodels
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Link
#AIagents#AISpecialization#computationalefficiency#edgecomputing#mobileoptimization#Privacy-PreservingAI#regionalinnovation#SmallLanguageModels
0 notes
Text
The Rise of Small Language Models: Are They the Future of NLP?
In recent years, large language models like GPT-4 and PaLM have dominated the field of NLP (Natural Language Processing). However, in 2025, we are witnessing a major shift: the rise of small language models (SLMs). Models like LLaMA 3, Mistral, and Gemma are proving that bigger isn't always better for NLP tasks.
Unlike their massive counterparts, small models are designed to be lightweight, faster, and cost-effective, making them ideal for a variety of NLP applications such as real-time translation, chatbots, and voice assistants. They require significantly less computing power, making them perfect for edge computing, mobile devices, and private deployments where traditional NLP systems were too heavy to operate.
Moreover, small language models offer better customization, privacy, and control over NLP systems, allowing businesses to fine-tune models for specific needs without relying on external cloud services.
While large models still dominate in highly complex tasks, small language models are shaping the future of NLP — bringing powerful language capabilities to every device and business, big or small.

#NLP#SmallLanguageModels#AI#MachineLearning#EdgeComputing#NaturalLanguageProcessing#AIFuture#TechInnovation#AIEfficiency#NLPTrends#FutureOfAI#ArtificialIntelligence#LanguageModels#AIin2025#TechForBusiness#AIandPrivacy#SustainableAI#ModelOptimization
0 notes
Text
AMD Introduces AMD-135M, First Small Language Model(SLM)

AMD Releases AMD-135M, its First Small Language Model. Large language models (LLMs) such as GPT-4 and Llama have attracted a lot of interest in the rapidly changing field of artificial intelligence because to their remarkable skills in natural language synthesis and processing. Small language models (SLMs), on the other hand, are becoming more and more important in the AI model community and provide a special benefit for certain use situations.
AMD is presenting AMD-135M with Speculative Decoding, its very first Small language model. This study shows the dedication to an open strategy to AI, which will promote more inventive, moral, and inclusive technological advancement and guarantee that its advantages are more freely distributed and its difficulties are more cooperatively handled.
AMD-135M Models
The first AMD small language model is AMD-135M
The first Small language model for the Llama family, AMD-135M, was split into two models: AMD-Llama-135M and AMD-Llama-135M-code. It was trained entirely from scratch on AMD Instinct MI250 accelerators using 670B tokens.
Pretraining: Using four MI250 nodes, 670 billion tokens of general data were used to train the AMD-Llama-135M model from scratch over the course of six days.
AMD-Llama-135M: AMD used 670B general data to train the model from scratch on the MI250 accelerator. Pretraining AMD-Llama-135M on four MI250 nodes, each with four MI250 accelerators (each with eight virtual GPU cards and 64G of RAM), took us six full days.
Code Finetuning: Using the same hardware, an extra 20 billion tokens of code data were added to the AMD-Llama-135M-code version, which took four days to complete.
AMD-code Llama-135M: It improved the AMD-Llama-135M further by adding 20B code data tokens to make it more precise and enable a certain code mode. The AMD-Llama-135M-code tuning process required four full days on four MI250 accelerators.
Code Dataset: To refine the 135M pretrained model, AMD used the Python part of the StarCoder dataset. The StarCoder dataset, which contains data from GitHub Issues, Jupyter notebooks, and GitHub contributions, totals over 250B tokens and consists of 783GB of code spanning 86 programming languages. Specifically, they concentrated on the Python programming language.
To enable developers to replicate the model and assist in training further SLMs and LLMs, the training code, dataset, and weights for this model are made available as open source.
Enhancement using Speculative Decoding
An autoregressive method is usually used for inference in large language models. This method’s primary drawback is that it can only produce one token each forward pass, which has a negative impact on total inference speed and memory access efficiency.
This issue has been resolved with the development of speculative decoding. The primary idea is to build a collection of candidate tokens using a tiny draft model and then validate them with a bigger target model. By generating several tokens on each forward pass without sacrificing performance, this method dramatically lowers the amount of memory access required and enables speed increases of many orders of magnitude.
Acceleration of Inference Performance
It evaluated the inference performance with and without speculative decoding on the MI250 accelerator for data centers and the Ryzen AI processor (with NPU) for AI PCs, using AMD-Llama-135M-code as a draft model for CodeLlama-7b. In comparison to the inference without speculative decoding, it saw speedups on the Instinct MI250 accelerator, Ryzen AI CPU, and Ryzen AI NPU for the specific setups that it evaluated utilizing AMD-Llama-135M-code as the draft model. On certain AMD systems, the AMD-135M SLM provides an end-to-end workflow that includes both training and inferencing.
In summary
AMD-135M SLM creates a complete workflow on AMD GPU accelerators and Ryzen AI processors that includes both training and inferencing. In order to achieve optimal performance in the data center as well as on power-limited edge devices like AI PC, this model helps ensure compliance with developer usability criteria by offering a reference implementation that follows best practices for model construction, pretraining, and deployment on AMD platforms. AMD is committed to providing new models to the open-source community, and it looks forward to seeing what ideas arise from this group.
Read more on govindhtech.com
#AMDIntroduces#AMD135M#FirstSmallLanguageModel#SLM#news#RyzenAI#AMDInstinct#Smalllanguagemodels#AMD135MModels#Python#AMDGPUaccelerators#technology#technews#govindhtech
0 notes
Text
Learn how MiniCPM3-4B is setting new standards in AI with its scalability in model and data dimensions. This Small Language Model (SLM), with it's function calling feature, is capable of performing a wider range of tasks faster than its predecessors, offering better mathematical ability and proficiency than GPT-3.5-Turbo.
#MiniCPM3-4B#Scalability#SmallLanguageModels#MachineLearning#ArtificialIntelligence#ai#artificial intelligence#open source#machine learning#software engineering#opensource#programming#python#nlp
0 notes
Text
Meta's New Focus: Smaller Language Models for Mobile Devices

While large language AI models continue to make headlines, small language models are where the action is. At least, that’s what Meta appears to be betting on, according to a team of its research scientists. https://tinyurl.com/mr3ja28s
0 notes
Text
0 notes
Text
How Small Language Models Boost Efficiency in Industries
In recent years, small language models (SLMs) have reshaped industries, streamlined customer service, and transformed workflows in fields like healthcare, education, and finance. While larger models like OpenAI’s GPT-3 and GPT-4 often steal the spotlight, SLMs are gaining traction for their efficiency, scalability, and practicality. These compact AI systems, designed to process and understand natural language with fewer parameters and less computing power, may be significantly smaller than their larger counterparts but still perform a wide range of tasks—text generation, translation, summarization, sentiment analysis, and more—with remarkable efficiency.
SLMs offer faster, cost-effective, and less resource-intensive solutions, making them ideal for businesses or applications with limited computing resources.
Why Small Language Models Matter
SLMs shine in several key areas:

In practice, SLMs don’t just automate tasks—they spark innovation across various fields.
Customer Support: Revolutionizing Service with AI

Customer service often involves repetitive, time-consuming tasks where agents answer similar questions repeatedly. Small language models, used in AI chatbots, allow businesses to manage thousands of customer inquiries with minimal human intervention. This delivers quick, accurate responses to common questions, freeing human agents to tackle more complex issues.
Behind the Scenes: SLMs process customer messages through natural language understanding, interpret intent, retrieve relevant information from databases or knowledge bases, and generate clear, accurate responses. They track customer interactions over time, enabling consistent replies across diverse inquiries. For complex issues, the ai services escalates to human agents and can analyse sentiment to adjust responses for a more personalised experience.
Example: Zendesk’s Answer Bot uses AI to address FAQs like “How do I reset my password?” or “Where is my order?” by pulling answers from a company’s knowledge base. This reduces wait times, improves customer satisfaction, and allows human agents to focus on intricate problems.
Healthcare: Streamlining Administration and Diagnostics
Healthcare providers handle massive datasets—patient records, test results, and research papers—that can overwhelm staff. SLMs simplify these tasks by quickly processing information, aiding diagnostics, conducting initial symptom checks, and documenting patient histories, allowing professionals to focus on patient care.
How They Operate: SLMs analyze extensive datasets, such as patient records or clinical summaries, to assist with scheduling, billing, and documentation. They support diagnostics by reviewing patient data, suggesting treatments, and flagging urgent issues. In some cases, SLMs perform symptom triage, provide preliminary diagnoses, and prioritize complex cases for physicians, even identifying early warning signs of potential health issues.
Example: IBM Watson for Health processes vast amounts of medical data. Watson for Oncology, for instance, reviews cancer research and patient records to help oncologists recommend personalized treatment plans, saving time and improving patient outcomes.
Education: Personalizing Learning Experiences
SLMs transform education by explaining complex concepts, acting as virtual tutors, and assessing student progress in real time, making learning more flexible and accessible for students at all levels.
Their Approach: SLMs analyze students’ learning patterns and adjust content accordingly. If a student struggles, the AI provides alternative explanations, additional examples, or extra practice. Real-time feedback, comprehension checks, and quizzes track progress, creating a customized learning experience that adapts to individual needs.
Example: Khan Academy uses AI to provide on-demand help, guiding students with hints and steps tailored to their pace. The system adjusts lessons based on performance, making education more accessible and effective, even in remote regions.
Marketing: Streamlining Content Creation and Targeting
Marketing teams need to produce engaging content quickly. SLMs automate content creation, allowing marketers to focus on strategy and campaign optimization for better results.
The Process: SLMs analyze customer data—demographics, purchase history, and browsing habits—to create personalized marketing content. They automate tasks like generating ad copy, emails, product descriptions, and social media posts. By analyzing campaign performance through A/B testing, SLMs refine strategies to improve engagement and conversions.
Example: Copy.ai acts as a virtual copywriter, producing high-quality blog posts, ad copy, and social media content. This reduces manual effort, allowing marketers to focus on creative strategy and targeted campaigns.
Finance: Automating Reports and Insights
Finance professionals manage vast datasets and require timely insights for decision-making. SLMs automate report generation, financial analysis, and client query responses, reducing manual work, minimizing errors, and speeding up decisions.
How It Functions: SLMs process financial data—transaction records, statements, and market trends—to generate reports like profit and loss statements or forecasts. They flag anomalies or unusual transactions for risk management, helping professionals address issues before they escalate.
Example: KPMG uses AI to streamline audits and compliance, analyzing financial data for discrepancies or risks. This saves time on manual checks, predicts market trends, and provides clients with actionable insights for better decisions.
Legal Services: Speeding Up Document Review and Contracts
The legal industry spends significant time reviewing contracts and documents. SLMs automate these tasks by scanning for key clauses, suggesting edits, and reducing time spent on routine work, freeing legal professionals for strategic tasks.
Their Mechanism: SLMs review large legal texts, identifying critical clauses or problematic wording in contracts and suggesting edits based on legal standards. They also assist with legal research by sifting through case law, statutes, and opinions to provide relevant precedents for complex questions.
Example: ROSS Intelligence uses AI to help lawyers research by answering specific questions, like “What are the precedents for breach of contract in this jurisdiction?” It retrieves relevant legal documents, saving time and improving efficiency.
Retail: Enhancing the Shopping Experience
SLMs improve retail by offering personalized product recommendations, managing inventory, and automating customer service, leading to better customer satisfaction and business performance.
How They Work: SLMs track customer behavior—purchase history, searches, and browsing patterns—to recommend relevant products. For example, a customer buying athletic wear might receive suggestions for matching accessories. SLMs also analyze trends to predict demand, optimizing inventory management.
Example: Amazon’s recommendation engine uses AI to suggest products based on browsing and purchase history. These recommendations evolve with each interaction, creating a personalized shopping experience that boosts sales and customer loyalty.
Human Resources: Simplifying Hiring and Management
HR departments handle repetitive tasks like resume screening and employee queries. SLMs automate these processes, allowing HR professionals to focus on talent development, employee engagement, and strategic goals.
Their Role: SLMs screen resumes by matching keywords, conduct initial candidate interviews, and answer common employee questions. They analyze performance data and feedback to identify improvement areas and recommend tailored training or support.
Example: HireVue uses AI to evaluate video interview responses, analyzing tone, word choice, and body language to assess candidate suitability. This reduces hiring time and allows HR teams to focus on final selections.

Conclusion
Small language models streamline operations by automating tasks, processing vast datasets, and generating human-like text, making them invaluable for businesses worldwide. Their ability to reduce costs, save time, and improve user experiences is transforming industries. From healthcare to retail, SLMs simplify complex processes, reduce human workload, and drive efficiency. As technology advances, these models will continue to reshape how businesses and industries operate, paving the way for a more efficient future.
0 notes
Text
Small Models, Big Impact: Transforming Tech Efficiently!
Small language models are revolutionizing the tech landscape by providing a more efficient alternative to larger counterparts.
Their ability to operate on modest hardware means they can run locally, making them perfect for industries like healthcare and finance where data privacy is crucial.
These models enable fast and secure processing of sensitive information, transforming how businesses manage data.
By addressing privacy concerns without compromising performance, small language models are paving the way for innovative solutions in various sectors. Discover how these advancements impact our world today!
#SmallLanguageModels #DataPrivacy
0 notes
Text
AMD Introduces AMD-135M, First Small Language Model(SLM)

AMD Releases AMD-135M, its First Small Language Model. Large language models (LLMs) such as GPT-4 and Llama have attracted a lot of interest in the rapidly changing field of artificial intelligence because to their remarkable skills in natural language synthesis and processing. Small language models (SLMs), on the other hand, are becoming more and more important in the AI model community and provide a special benefit for certain use situations.
AMD is presenting AMD-135M with Speculative Decoding, its very first Small language model. This study shows the dedication to an open strategy to AI, which will promote more inventive, moral, and inclusive technological advancement and guarantee that its advantages are more freely distributed and its difficulties are more cooperatively handled.
AMD-135M Models
The first AMD small language model is AMD-135M
The first Small language model for the Llama family, AMD-135M, was split into two models: AMD-Llama-135M and AMD-Llama-135M-code. It was trained entirely from scratch on AMD Instinct MI250 accelerators using 670B tokens.
Pretraining: Using four MI250 nodes, 670 billion tokens of general data were used to train the AMD-Llama-135M model from scratch over the course of six days.
AMD-Llama-135M: AMD used 670B general data to train the model from scratch on the MI250 accelerator. Pretraining AMD-Llama-135M on four MI250 nodes, each with four MI250 accelerators (each with eight virtual GPU cards and 64G of RAM), took us six full days.
Code Finetuning: Using the same hardware, an extra 20 billion tokens of code data were added to the AMD-Llama-135M-code version, which took four days to complete.
AMD-code Llama-135M: It improved the AMD-Llama-135M further by adding 20B code data tokens to make it more precise and enable a certain code mode. The AMD-Llama-135M-code tuning process required four full days on four MI250 accelerators.
Code Dataset: To refine the 135M pretrained model, AMD used the Python part of the StarCoder dataset. The StarCoder dataset, which contains data from GitHub Issues, Jupyter notebooks, and GitHub contributions, totals over 250B tokens and consists of 783GB of code spanning 86 programming languages. Specifically, they concentrated on the Python programming language.
To enable developers to replicate the model and assist in training further SLMs and LLMs, the training code, dataset, and weights for this model are made available as open source.
Enhancement using Speculative Decoding
An autoregressive method is usually used for inference in large language models. This method’s primary drawback is that it can only produce one token each forward pass, which has a negative impact on total inference speed and memory access efficiency.
This issue has been resolved with the development of speculative decoding. The primary idea is to build a collection of candidate tokens using a tiny draft model and then validate them with a bigger target model. By generating several tokens on each forward pass without sacrificing performance, this method dramatically lowers the amount of memory access required and enables speed increases of many orders of magnitude.
Acceleration of Inference Performance
It evaluated the inference performance with and without speculative decoding on the MI250 accelerator for data centers and the Ryzen AI processor (with NPU) for AI PCs, using AMD-Llama-135M-code as a draft model for CodeLlama-7b. In comparison to the inference without speculative decoding, it saw speedups on the Instinct MI250 accelerator, Ryzen AI CPU, and Ryzen AI NPU for the specific setups that it evaluated utilizing AMD-Llama-135M-code as the draft model. On certain AMD systems, the AMD-135M SLM provides an end-to-end workflow that includes both training and inferencing.
In summary
AMD-135M SLM creates a complete workflow on AMD GPU accelerators and Ryzen AI processors that includes both training and inferencing. In order to achieve optimal performance in the data center as well as on power-limited edge devices like AI PC, this model helps ensure compliance with developer usability criteria by offering a reference implementation that follows best practices for model construction, pretraining, and deployment on AMD platforms. AMD is committed to providing new models to the open-source community, and it looks forward to seeing what ideas arise from this group.
Read more on govindhtech.com
#AMD135M#FirstSmallLanguageModel#SLM#Largelanguagemodels#LLM#Smalllanguagemodels#AMDInstinct#InferencePerformance#Python#RyzenAI#AMDGPUaccelerators#SpeculativeDecoding#amd#technology#technews#news#govindhtech
0 notes
Text
AMD Instinct MI300X GPU Accelerators With Meta’s Llama 3.2

AMD applauds Meta for their most recent Llama 3.2 release. Llama 3.2 is intended to increase developer productivity by assisting them in creating the experiences of the future and reducing development time, while placing a stronger emphasis on data protection and ethical AI innovation. The focus on flexibility and openness has resulted in a tenfold increase in Llama model downloads this year over last, positioning it as a top option for developers looking for effective, user-friendly AI solutions.
Llama 3.2 and AMD Instinct MI300X GPU Accelerators
The world of multimodal AI models is changing with AMD Instinct MI300X accelerators. One example is Llama 3.2, which has 11B and 90B parameter models. To analyze text and visual data, they need a tremendous amount of processing power and memory capa
AMD and Meta have a long-standing cooperative relationship. Its is still working to improve AI performance for Meta models on all of AMD platforms, including Llama 3.2. AMD partnership with Meta allows Llama 3.2 developers to create novel, highly performant, and power-efficient agentic apps and tailored AI experiences on AI PCs and from the cloud to the edge.
AMD Instinct accelerators offer unrivaled memory capability, as demonstrated by the launch of Llama 3.1 in previous demonstrations. This allows a single server with 8 MI300X GPUs to fit the largest open-source project currently available with 405B parameters in FP16 datatype something that no other 8x GPU platform can accomplish. AMD Instinct MI300X GPUs are now capable of supporting both the latest and next iterations of these multimodal models with exceptional memory economy with the release of Llama 3.2.
By lowering the complexity of distributing memory across multiple devices, this industry-leading memory capacity makes infrastructure management easier. It also allows for quick training, real-time inference, and the smooth handling of large datasets across modalities, such as text and images, without compromising performance or adding network overhead from distributing across multiple servers.
With the powerful memory capabilities of the AMD Instinct MI300X platform, this may result in considerable cost savings, improved performance efficiency, and simpler operations for enterprises.
Throughout crucial phases of the development of Llama 3.2, Meta has also made use of AMD ROCm software and AMD Instinct MI300X accelerators, enhancing their long-standing partnership with AMD and their dedication to an open software approach to AI. AMD’s scalable infrastructure offers open-model flexibility and performance to match closed models, allowing developers to create powerful visual reasoning and understanding applications.
Developers now have Day-0 support for the newest frontier models from Meta on the most recent generation of AMD Instinct MI300X GPUs, with the release of the Llama 3.2 generation of models. This gives developers access to a wider selection of GPU hardware and an open software stack ROCm for future application development.
CPUs from AMD EPYC and Llama 3.2
Nowadays, a lot of AI tasks are executed on CPUs, either alone or in conjunction with GPUs. AMD EPYC processors provide the power and economy needed to power the cutting-edge models created by Meta, such as the recently released Llama 3.2. The rise of SLMs (small language models) is noteworthy, even if the majority of recent attention has been on LLM (long language model) breakthroughs with massive data sets.
These smaller models need far less processing resources, assist reduce risks related to the security and privacy of sensitive data, and may be customized and tailored to particular company datasets. These models are appropriate and well-sized for a variety of corporate and sector-specific applications since they are made to be nimble, efficient, and performant.
The Llama 3.2 version includes new capabilities that are representative of many mass market corporate deployment situations, particularly for clients investigating CPU-based AI solutions. These features include multimodal models and smaller model alternatives.
When consolidating their data center infrastructure, businesses can use the Llama 3.2 models’ leading AMD EPYC processors to achieve compelling performance and efficiency. These processors can also be used to support GPU- or CPU-based deployments for larger AI models, as needed, by utilizing AMD EPYC CPUs and AMD Instinct GPUs.
AMD AI PCs with Radeon and Ryzen powered by Llama 3.2
AMD and Meta have collaborated extensively to optimize the most recent versions of Llama 3.2 for AMD Ryzen AI PCs and AMD Radeon graphics cards, for customers who choose to use it locally on their own PCs. Llama 3.2 may also be run locally on devices accelerated by DirectML AI frameworks built for AMD on AMD AI PCs with AMD GPUs that support DirectML. Through AMD partner LM Studio, Windows users will soon be able to enjoy multimodal Llama 3.2 in an approachable package.
Up to 192 AI accelerators are included in the newest AMD Radeon, graphics cards, the AMD Radeon PRO W7900 Series with up to 48GB and the AMD Radeon RX 7900 Series with up to 24GB. These accelerators can run state-of-the-art models such Llama 3.2-11B Vision. Utilizing the same AMD ROCm 6.2 optimized architecture from the joint venture between AMD and Meta, customers may test the newest models on PCs that have these cards installed right now3.
AMD and Meta: Progress via Partnership
To sum up, AMD is working with Meta to advance generative AI research and make sure developers have everything they need to handle every new release smoothly, including Day-0 support for entire AI portfolio. Llama 3.2’s integration with AMD Ryzen AI, AMD Radeon GPUs, AMD EPYC CPUs, AMD Instinct MI300X GPUs, and AMD ROCm software offers customers a wide range of solution options to power their innovations across cloud, edge, and AI PCs.
Read more on govindhtech.com
#AMDInstinctMI300X#GPUAccelerators#AIsolutions#MetaLlama32#AImodels#aipc#AMDEPYCCPU#smalllanguagemodels#AMDEPYCprocessors#AMDInstinctMI300XGPU#AMDRyzenAI#LMStudio#graphicscards#AMDRadeongpu#amd#gpu#mi300x#technology#technews#govindhtech
0 notes
Text
Bezoku: Safe, Affordable And Reliable Gen AI For Everyone

Concerning Bezoku
A South Florida, USA-based AI start-up called Bezoku collaborates with local communities to create generative AI applications. consumer-focused linguists, mathematicians, machine learning experts, and software engineers make up the Bezoku development team. They provide commercial, no-code consumer interfaces, enabling communities to take charge of generative AI for the first time. The goal of it is to provide a human-level language system that is safe, dependable, and reasonably priced. This method, which is often the result of a personal connection to a place, links groups via a common cultural lexicon.
The Challenge
Come explore Bezoku, the state-of-the-art generative AI that understands social language. The goal of this advanced Natural Language Processing (NLP) system is to link people, not just technology.
Everyone’s access to private and secure language technologies
Bezoku develops generative AI in collaboration with communities. For the first time, communities will be in charge of generative AI thanks to Bezoku‘s team of consumer-focused linguists, mathematicians, machine learning, and software engineers who create commercial no-code user interfaces. It has the following cutting-edge AI capabilities:
Human-centered design includes safety elements that promote cognitive liberty and shield communities from discrimination based on dialect.
complete privacy data encryption, offering a first-of-its-kind generative AI system using sophisticated mathematical techniques.
It gives populations speaking “low resource languages” priority. The library will swiftly expand to include other Hispanic languages, such as Cuban and Honduran, in addition to Haitian Creole. This will enable bilingual speakers to engage in a process known as code switching.
Compared to rivals with trillion parameters, Bezoku requires 5,300 times less computing per model. Bezoku significantly reduces pollution, thus AI has less of an adverse effect on the planet’s limited resources.
The Solution
Large Language Models (LLMs) are true superpowers in terms of producing accurate and timely replies. but lack the in-depth, domain-specific expertise that, in certain use cases, is crucial. Not to mention the significant computational power and knowledge needed to create and implement them.
This is the situation where Small Language Models (SLMs) are increasingly being used for certain purposes. SLMs have a lower computational footprint and are more efficient than LLMs due to their more concentrated approach. They are thus better suited for local execution on workstations or on-premise servers.
The Resolution
It is a unique kind of artificial intelligence (AI) technology that is centered on people and has many security safeguards to guard against discrimination based on language and cognitive liberty. End-to-end encryption of private data is offering a first-of-its-kind solution for generative AI using sophisticated mathematics in order to do this.
For communities who speak “low resource languages,” it was created. They are beginning with Haitian Creole but will swiftly move on to many other Hispanic dialects and will support a bilingual speaker’s ability to switch between languages known as code switching. The Small Language Model (SML) method used by Bezoku requires 5,300 times less computing power per model than ChatGPT4. As a result, Bezoku emits significantly less pollution and has a much smaller environmental effect.
Bezoku core features are as follows:
Image credit to Intel
Safe Data Handling: Bezoku uses encryption to protect sensitive data, making sure that only authorized users may access it.
Customized linguistic Understanding: To guard against prejudice stemming from dialect bias, the pre-trained models are adapted to various dialects and linguistic styles.
Simple Adaptation: Bezoku‘s training using private data doesn’t need any code. Easy-to-use, user-friendly tools load personal data, and the models automatically pick it up. That is all.
Transparent Predictions: Bezoku builds trust by not just offering solutions but also explaining how it works, for as by letting you know if it is experiencing hallucinations.
Bezuko’s strategy is comprised on four primary differentiators:
Adding dialects will increase representation and allow for the participation of other populations.
Affordability at a small fraction of LLM expenses using one’s own models.
Encrypted security data that is private by design.
Utilizing 5,000 times less energy and water each model is better for the environment.
“Bezoku is pleased to announce that it has joined the Intel Liftoff Program. Being a member of this exclusive worldwide network of technological companies, the Bezoku team and its partners are eager to use the array of potent AI tools and Developer Cloud to expedite the development of our products.
This partnership not only helps us expand and become more visible, but it also creates special relationships inside the IT industry. They can’t wait to start this adventure, to make use of Intel’s vast resources, to get access to their knowledgeable insights, and to work with other AI-focused firms. Ian Gilmour, Bezoku’s Chief Customer Officer
In summary
Bezoku’s groundbreaking human-centric approach is made possible by its generative AI technology. Smaller AI models as a consequence preserve cognitive liberty, eliminate dialect bias, and provide understandable supporting output by tracking data and alerting users if hallucinations are suspected.
As a result, groups with “low resource languages” end up receiving priority. This includes Hispanic dialects and Haitian Creole, among other things, since they will support bilingual speakers’ language
Read more on govindhtech.com
#Bezoku#genai#generativeAIapplications#ConcerningBezoku#generativeAI#machinelearning#NaturalLanguageProcessing#LargeLanguageModels#cuttingedgeAIcapabilities#SmallLanguageModels#artificialintelligence#AI#intel#aitools#aimodels#aitechnology#technews#news#govindhtech
0 notes
Text
Lean AI Is Making Modern Technology Access To All Business

AI is changing thanks to open source and small language models. Lean AI is changing the business environment and democratizing cutting-edge technology for companies of all sizes by reducing costs and increasing productivity.
AI Lean
The term “lean” is frequently used in the IT business to refer to procedures that need to be more economical and efficient. This also applies to generative AI. In case you missed it, certain businesses demand gigawatts of grid power in addition to equipment that cost millions of dollars to operate. It seems sense that a lot of businesses approach AI architects to offer a leaner or more effective solution.
Businesses naturally turn to public cloud providers to accelerate their adoption of generative AI. Ultimately, public clouds provide entire ecosystems with a single dashboard button click. In fact, this initial wave of AI spending has increased income for major cloud providers.
Many businesses have discovered, nevertheless, that employing the cloud in their data centers might result in greater operational expenses than traditional systems. Companies are looking at ways to use cloud costs more efficiently because, in spite of this, using the cloud is still the major focus. This is where the idea of “lean AI” is useful.
How is lean AI implemented?
A strategic approach to artificial intelligence known as “lean AI” places an emphasis on productivity, economy, and resource efficiency while generating the most economic value possible. Lean approaches that were first applied in manufacturing and product development are the source of many lean AI techniques.
The goal of lean AI is to optimize AI system development, deployment, and operation. To cut down on waste, it uses smaller models, iterative development methods, and resource-saving strategies. Lean AI emphasizes continuous improvement and agile, data-driven decision-making to help firms scale and sustain AI. This ensures AI projects are impactful and profitable.
SLMs
Businesses are starting to realize that sometimes, bigger does not always mean better. A wave of open source advances and small language models (SLMs) characterize the evolving industrial AI ecosystem. Large language model (LLM) generative AI systems impose significant costs and resource demands, which have prompted its evolution. These days, a lot of businesses wish to reevaluate how expenses and business value are distributed.
The difficulties associated with LLMs
Big language models, like Meta’s Llama and OpenAI’s GPT-4, have shown remarkable powers in producing and comprehending human language. However, these advantages come with a number of difficulties that businesses are finding harder and harder to justify. The hefty cloud expenses and computational needs of these models impose a burden on budgets and prevent wider implementation. Then there is the problem of energy use, which has serious financial and environmental ramifications.
Another challenge is operational latency, which is particularly problematic for applications that need to respond quickly. Not to mention how difficult it is to manage and maintain these massive models, which call for infrastructure and specialized knowledge that not all organizations have access to.
What Are SLMs
Making the switch to SLMs
The deployment of tiny language models for generative AI in cloud and non-cloud systems has been expedited by this background. These are becoming more and more thought of as sensible substitutes. In terms of energy usage and the need for computational resources, SLMs are made to be substantially more efficient.
This translates into reduced operating expenses and an alluring return on investment for AI projects. Enterprises that require agility and responsiveness in a rapidly evolving market find SLMs more attractive due to their accelerated training and deployment cycles.
It is absurd to imply that enterprises will employ LLMs as they are not typically used by them. Rather, they will develop more tactically focused AI systems to address particular use cases, such factory optimization, logistics for transportation, and equipment maintenance areas where lean AI approaches can yield instant commercial value.
SLMs refine customisation as well. By fine-tuning these models for certain tasks and industry sectors, specialised apps that deliver quantifiable business outcomes can be produced. These slimmer models demonstrate their efficacy in customer support, financial analysis, and healthcare diagnosis.
The benefit of open source
The development and uptake of SLMs have been propelled by the open source community. Llama 3.1, the latest version of Meta, comes in a variety of sizes that provide strong functionality without putting too much strain on system resources. Other models show that the performance of smaller models can match or even exceed that of bigger models, particularly in domain-specific applications. Examples of these models are Stanford’s Alpaca and Stability AI’s StableLM.
Hugging Face, IBM’s Watsonx.ai, and other cloud platforms and tools are lowering entry barriers and increasing the accessibility of these models for businesses of all sizes. This is revolutionary AI capabilities are now accessible to everyone. Advanced AI can be included by more companies without requiring them to use proprietary, sometimes unaffordable technologies.
The business turn around
There are several benefits to using SLMs from an enterprise standpoint. These models enable companies to grow their AI implementations at a reasonable cost, which is crucial for startups and midsize firms looking to get the most out of their technological expenditures. As AI capabilities are more closely aligned with changing business needs through faster deployment timeframes and simpler customization, enhanced agility becomes a practical benefit.
SLMs hosted on-premises or in private clouds provide a superior solution for addressing data privacy and sovereignty, which are recurring problems in the enterprise environment. This method maintains strong security while meeting regulatory and compliance requirements. Furthermore, SLMs’ lower energy usage contributes to business sustainability programs. Isn’t that still significant?
The shift to more compact language models, supported by innovation in open source, changes how businesses approach artificial intelligence. SLMs provide an effective, affordable, and adaptable alternative to large-scale generative AI systems by reducing their cost and complexity. This change promotes scalable and sustainable growth and increases the business value of AI investments.
Read more on govindhtech.com
#LeanAI#MakingModernTechnology#AllBusiness#smalllanguagemodels#generativeAI#artificialintelligence#llm#slm#Largelanguagemodel#AIprojects#AIcapabilities#businessturnaround#AIimplemented#ai#technology#technews#news#govindhtech
0 notes
Text
Updates to Azure AI, Phi 3 Fine tuning, And gen AI models

Introducing new generative AI models, Phi 3 fine tuning, and other Azure AI enhancements to enable businesses to scale and personalise AI applications.
All sectors are being transformed by artificial intelligence, which also creates fresh growth and innovation opportunities. But developing and deploying artificial intelligence applications at scale requires a reliable and flexible platform capable of handling the complex and varied needs of modern companies and allowing them to construct solutions grounded on their organisational data. They are happy to share the following enhancements to enable developers to use the Azure AI toolchain to swiftly and more freely construct customised AI solutions:
Developers can rapidly and simply customise the Phi-3-mini and Phi-3-medium models for cloud and edge scenarios with serverless fine-tuning, eliminating the need to schedule computing.
Updates to Phi-3-mini allow developers to create with a more performant model without incurring additional costs. These updates include a considerable improvement in core quality, instruction-following, and organised output.
This month, OpenAI (GPT-4o small), Meta (Llama 3.1 405B), and Mistral (Large 2) shipped their newest models to Azure AI on the same day, giving clients more options and flexibility.
Value unlocking via customised and innovative models
Microsoft unveiled the Microsoft Phi-3 line of compact, open models in April. Compared to models of the same size and the next level up, Phi-3 models are their most powerful and economical small language models (SLMs). Phi 3 Fine tuning a tiny model is a wonderful alternative without losing efficiency, as developers attempt to customise AI systems to match unique business objectives and increase the quality of responses. Developers may now use their data to fine-tune Phi-3-mini and Phi-3-medium, enabling them to create AI experiences that are more affordable, safe, and relevant to their users.
Phi-3 models are well suited for fine-tuning to improve base model performance across a variety of scenarios, such as learning a new skill or task (e.g., tutoring) or improving consistency and quality of the response (e.g., tone or style of responses in chat/Q&A). This is because of their small compute footprint and compatibility with clouds and edges. Phi-3 is already being modified for new use cases.
Microsoft and Khan Academy are collaborating to enhance resources for educators and learners worldwide. As part of the partnership, Khan Academy is experimenting with Phi-3 to enhance math tutoring and leverages Azure OpenAI Service to power Khanmigo for Teachers, a pilot AI-powered teaching assistant for educators in 44 countries. A study from Khan Academy, which includes benchmarks from an improved version of Phi-3, shows how various AI models perform when assessing mathematical accuracy in tutoring scenarios.
According to preliminary data, Phi-3 fared better than the majority of other top generative AI models at identifying and fixing mathematical errors made by students.
Additionally, they have optimised Phi-3 for the gadget. To provide developers with a strong, reliable foundation for creating apps with safe, secure AI experiences, they launched Phi Silica in June. Built specifically for the NPUs in Copilot+ PCs, Phi Silica expands upon the Phi family of models. The state-of-the-art short language model (SLM) for the Neural Processing Unit (NPU) and shipping inbox is exclusive to Microsoft Windows.
Today, you may test Phi 3 fine tuning in Azure AI
Azure AI’s Models-as-a-Service (serverless endpoint) feature is now widely accessible. Additionally, developers can now rapidly and simply begin developing AI applications without having to worry about managing underlying infrastructure thanks to the availability of Phi-3-small via a serverless endpoint.
The multi-modal Phi-3 model, Phi-3-vision, was unveiled at Microsoft Build and may be accessed via the Azure AI model catalogue. It will also soon be accessible through a serverless endpoint. While Phi-3-vision (4.2B parameter) has also been optimised for chart and diagram interpretation and may be used to produce insights and answer queries, Phi-3-small (7B parameter) is offered in two context lengths, 128K and 8K.
The community’s response to Phi-3 is excellent. Last month, they launched an update for Phi-3-mini that significantly enhances the core quality and training after. After the model was retrained, support for structured output and instruction following significantly improved.They also added support for |system|> prompts, enhanced reasoning capability, and enhanced the quality of multi-turn conversations.
They also keep enhancing the safety of Phi-3. In order to increase the safety of the Phi-3 models, Microsoft used an iterative “break-fix” strategy that included vulnerability identification, red teaming, and several iterations of testing and improvement. This approach was recently highlighted in a research study. By using this strategy, harmful content was reduced by 75% and the models performed better on responsible AI benchmarks.
Increasing model selection; around 1600 models are already accessible in Azure AI They’re dedicated to providing the widest range of open and frontier models together with cutting-edge tooling through Azure AI in order to assist clients in meeting their specific cost, latency, and design requirements. Since the debut of the Azure AI model catalogue last year, over 1,600 models from providers such as AI21, Cohere, Databricks, Hugging Face, Meta, Mistral, Microsoft Research, OpenAI, Snowflake, Stability AI, and others have been added, giving us the widest collection to date. This month, they added Mistral Large 2, Meta Llama 3.1 405B, and OpenAI’s GPT-4o small via Azure OpenAI Service.
Keeping up the good work, they are happy to announce that Cohere Rerank is now accessible on Azure. Using Azure to access Cohere’s enterprise-ready language models Businesses can easily, consistently, and securely integrate state-of-the-art semantic search technology into their applications because to AI’s strong infrastructure. With the help of this integration, users may provide better search results in production by utilising the scalability and flexibility of Azure in conjunction with the highly effective and performant language models from Cohere.
With Cohere Rerank, Atomicwork, a digital workplace experience platform and a seasoned Azure user, has greatly improved its IT service management platform. Atomicwork has enhanced search relevancy and accuracy by incorporating the model into Atom AI, their AI digital assistant, hence offering quicker, more accurate responses to intricate IT help enquiries. Enterprise-wide productivity has increased as a result of this integration, which has simplified IT processes.
Read more on govindhtech.com
#AzureAI#Phi3#gen#AImodels#generativeAImodels#OpenAi#AzureAImodels#ai21#artificialintelligence#Llama31405B#slms#Phi3mini#smalllanguagemodels#AzureOpenAIService#npus#Databricks#technology#technews#news#govindhtech
0 notes
Text
Dive into the world of Phi-3, Microsoft’s innovative Small Language Model that’s challenging the status quo. Despite its smaller size, Phi-3 is outperforming models twice its size, all while being fine-tuned and open-source. Join us as we explore this exciting development in AI.
#Phi3#Microsoft#AI#ArtificialIntelligence#SLM#SmallLanguageModels#OpenSource#MachineLearning#DeepLearning#NLP#NaturalLanguageProcessing#DataScience#artificial intelligence#open source#machine learning#microsoft ai
0 notes
Text
How Small Language Models Are Reshaping AI: Smarter, Faster & More Accessible
Artificial Intelligence (AI) has transformed industries, from healthcare to education, by enabling machines to process and generate human-like text, answer questions, and perform complex tasks. At the heart of these advancements are language models, which are algorithms trained to understand and produce language. While large language models (LLMs) like GPT-4 or Llama have dominated headlines due to their impressive capabilities, they come with significant drawbacks, such as high computational costs and resource demands. Enter Small Language Models (SLMs)—compact, efficient alternatives that are reshaping how AI is developed, deployed, and accessed. This blog explores the technical foundations of SLMs, their role in making AI more accessible, and their impact on performance across various applications.
What Are Small Language Models?
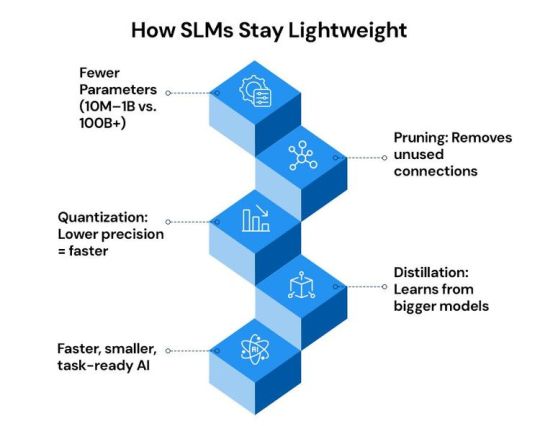
Why SLMs Matter for Accessibility
Accessibility in AI refers to the ability of individuals, businesses, and organizations—regardless of their resources—to use and benefit from AI technologies. SLMs are pivotal in this regard because they lower the barriers to entry in three keyways: cost, infrastructure, and usability.
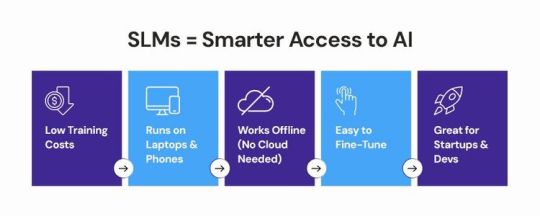
Lower Computational Costs
Training and running LLMs require vast computational resources, often involving clusters of high-end GPUs or TPUs that cost millions of dollars. For example, training a model like GPT-3 can consume energy equivalent to the annual usage of hundreds of households. SLMs, by contrast, require significantly less computing power. A model with 1 billion parameters can often be trained or fine-tuned on a single high-end GPU or even a powerful consumer-grade laptop. This reduced cost makes AI development feasible for startups, small businesses, and academic researchers who lack access to large-scale computing infrastructure.
Reduced Infrastructure Demands
Deploying LLMs typically involves cloud-based servers or specialized hardware, which can be expensive and complex to manage. SLMs, with their smaller footprint, can run on edge devices like smartphones, IoT devices, or low-cost servers. For instance, models like Google’s MobileBERT or Meta AI’s DistilBERT can perform tasks such as text classification or sentiment analysis directly on a mobile device without needing constant internet connectivity. This capability is transformative for applications in remote areas or industries where data privacy is critical, as it allows AI to function offline and locally.
Simplified Usability
SLMs are easier to fine-tune and deploy than LLMs, making them more approachable for developers with limited expertise. Fine-tuning an SLM for a specific task, such as summarizing medical records or generating customer support responses, requires less data and time compared to an LLM. Open-source SLMs, such as Hugging Face’s DistilBERT or Microsoft’s Phi-2, come with detailed documentation and community support, enabling developers to adapt these models to their needs without extensive machine learning knowledge. This democratization of AI tools empowers a broader range of professionals to integrate AI into their workflows.
Performance Advantages of SLMs
While SLMs are smaller than LLMs, they are not necessarily less capable in practical scenarios. Their performance is often comparable to larger models in specific tasks, and they offer unique advantages in efficiency, speed, and scalability.
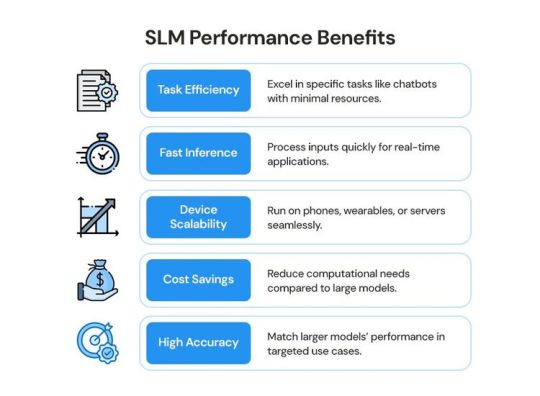
Task-Specific Efficiency
SLMs excel in targeted applications where a general-purpose, billion-parameter model is overkill. For example, in customer service chatbots, an SLM can be fine-tuned to handle common queries like order tracking or returns with accuracy comparable to an LLM but at a fraction of the computational cost. Studies have shown that models like DistilBERT achieve 97% of BERT’s performance on benchmark tasks like question answering while using half the parameters. This efficiency makes SLMs ideal for industries with well-defined AI needs, such as legal document analysis or real-time language translation.
Faster Inference Times
Inference—the process of generating predictions or responses—happens much faster with SLMs due to their compact size. For instance, an SLM running on a smartphone can process a user’s voice command in milliseconds, enabling real-time interactions. In contrast, LLMs often require server-side processing, introducing latency that can frustrate users. Faster inference is critical for applications like autonomous vehicles, where split-second decisions are necessary, or in healthcare, where real-time diagnostic tools can save lives.
Scalability Across Devices
The ability to deploy SLMs on a wide range of devices—from cloud servers to wearables—enhances their scalability. For example, an SLM embedded in a smartwatch can monitor a user’s health data and provide personalized feedback without relying on a cloud connection. This scalability also benefits businesses, as they can deploy SLMs across thousands of devices without incurring the prohibitive costs associated with LLMs. In IoT ecosystems, SLMs enable edge devices to collaborate, sharing lightweight models to perform distributed tasks like environmental monitoring or predictive maintenance.
Challenges and Limitations
Despite their advantages, SLMs have limitations that developers and organizations must consider. Their smaller size means they capture less general knowledge compared to LLMs. For instance, an SLM may struggle with complex reasoning tasks, such as generating detailed research papers or understanding nuanced cultural references, where LLMs excel. Additionally, while SLMs are easier to fine-tune, they may require more careful optimization to avoid overfitting, especially when training data is limited.
Another challenge is the trade-off between size and versatility. SLMs are highly effective for specific tasks but lack the broad, multi-domain capabilities of LLMs. Organizations must weigh whether an SLM’s efficiency justifies its narrower scope or if an LLM’s flexibility is worth the added cost. Finally, while open-source SLMs are widely available, proprietary models may still require licensing fees, which could limit accessibility for some users.
Real-World Applications
SLMs are already making a significant impact across industries, demonstrating their value in practical settings. Here are a few examples:
Healthcare: SLMs power portable diagnostic tools that analyze patient data, such as medical imaging or symptom reports, directly on devices like tablets. This is particularly valuable in rural or underserved areas with limited internet access.
Education: Language tutoring apps use SLMs to provide real-time feedback on pronunciation or grammar, running entirely on a student’s smartphone.
Retail: E-commerce platforms deploy SLMs for personalised product recommendations, analysing user behaviour locally to protect privacy and reduce server costs.
IoT and Smart Homes: SLMs enable voice assistants in smart speakers to process commands offline, improving response times and reducing reliance on cloud infrastructure.
The Future of SLMs
The rise of SLMs signals a shift toward more inclusive and practical AI development. As research continues, we can expect SLMs to become even more efficient through advancements in model compression and training techniques. For example, ongoing work in federated learning—where models are trained across distributed devices—could further reduce the resource demands of SLMs, making them accessible to even more users.
Moreover, the open-source community is driving innovation in SLMs, with platforms like Hugging Face and GitHub hosting a growing number of models tailored to specific industries. This collaborative approach ensures that SLMs will continue to evolve, addressing niche use cases while maintaining high performance.
Conclusion
Small Language Models are revolutionizing AI by making it more accessible and efficient without sacrificing performance in many practical applications. Their lower computational costs, reduced infrastructure demands, and simplified usability open the door for small businesses, individual developers, and underserved communities to adopt AI technologies. While they may not match the versatility of larger models, SLMs offer a compelling balance of speed, scalability, and task-specific accuracy. As industries increasingly prioritize efficiency and inclusivity, SLMs are poised to play a central role in the future of AI, proving that bigger isn’t always better.
0 notes
Text
Learn how Reader-LM, an open-source Small Language Model, is transforming the way we convert HTMLs into Markdowns. With multilingual support for use in different countries and the ability to handle long documents of up to 256K tokens, it outperforms much larger models in quantitative evaluations.
#ReaderLM#AI#SmallLanguageModel#OpenSource#JinaAI#AIModels#artificial intelligence#open source#Html to Markdown#markdown#ai technology#aitech
0 notes