#sstables
Link
#cornertable#endtable#Furniture#homedecor#homedecoration#Indiasofatable#interiordesign#luxuryhome#marbletop#PVDtable#sidetables#sstables
0 notes
Video
youtube
China stainless steel wokrtable
Hello everybody, this is Grace, from Qingdao Victory company Let me show our different kinds of stainless steel worktable with you~~Contact: Grace MaMob:+8618766999889(whatsapp/wechat)Email: [email protected]: www.qdvictory.com#Chinafactory #Chinamanufacturer #Chinasupplier #Chinaexporter #factorydirectsale #Chinafactorydirectsale #Chinafactorywholesale #commercialequipment #hotelequipment #restaurantequipment #cafeequipment #supermarketequipment #stainlesssteelworktable #ssworktable #sstable #stainlesssteelworkbench #ssworkbench #metalworktable #metalworkbench #stainlesssteelcabient #stainlesssteelcupboard #stainlesssteelsink #stainlesssteelwashsink #stainlesssteelbowlsink #singlesinkmetal #doublesinkmadeinstainlesssteel #triplesinkthreecompartment #kitchenbowlsink #washhandsink #Kneedpushsink #kitchenfurniture #metalfurniture #stainlesssteelfurniture
0 notes
Photo

Chester field sofa delivered ✅ #furnopolis #thefurniturediaries #thefurniturecity #thefurnituregallery #chesterfieldsofa #marbletable #homedecor #sstable Furnopolis The furniture city. #furniture #furnituremakeover #furnituredesign #delhi #delhincr #ncr #interiordesign #woodworking #furnitureonline #madeinindia #vocalforlocal #furnituremaker #Wood #madetoorder #wow #vocalforlocalindia #2020 #delhi #makeinindia #sale #newcollection #furniturelovers #furnishing (at Gurugram) https://www.instagram.com/p/CIkOSnqp3Gp/?igshid=19zoerh6g95j4
#furnopolis#thefurniturediaries#thefurniturecity#thefurnituregallery#chesterfieldsofa#marbletable#homedecor#sstable#furniture#furnituremakeover#furnituredesign#delhi#delhincr#ncr#interiordesign#woodworking#furnitureonline#madeinindia#vocalforlocal#furnituremaker#wood#madetoorder#wow#vocalforlocalindia#2020#makeinindia#sale#newcollection#furniturelovers#furnishing
0 notes
Photo

Large Stainless Steel Work Table - $100
https://fortcollins.craigslist.org/for/d/johnstown-large-stainless-steel-work/6914678908.html
0 notes
Text
@tenebres-champ // LA-04
〚 D. Ddd. Do excuse mm..me, ma’am, but dd. you--you hh-h.have thht.the tt-ttime? 〛
The machine slinks its way from the bushes, elegant and unusual in design but oh-so familiar at the same time. His eyes twist left and right, shimmering opalescent plates on his snout reflecting light in such a strange, bizarrely attractive way. It’s so pretty--
Tearing away one’s eyes is enough to snap out of it. The machine looks back and his snout cocks curiously, stepping back slightly.

〚 I-I-I dd.dd.ddon’t mee-meaan tto both-th-th-ther you, r.rr.rrr.really, but I ne-e-eed to know sus-ss.ss.Sun--SSs--[RKSSH] DUSK’S arr-rr.rrrar--arrival. It’s gg-g.g g.ggoing tt.o bbb.e a difficult ni-ni-night--oh, are you al.l.lone? 〛
He steps forward. What looked like loose fur instead shudders, revealing its nature as something organic.
〚 AhAA--Ah. All-ll.Alola isn’t ss.s.ss.ssrs..ss.--[KRSSSH--] sstabl..sstt--[KRSSHKK--!] DAMN IT! Alola IS DANGEROUS at n-nin.night these daysss s..s. 〛
1 note
·
View note
Text
Slow database? It might not be your fault
<rant>
Okay, it usually is your fault. If you logged the SQL your ORM was generating, or saw how you are doing joins in code, or realised what that indexed UUID does to your insert rate etc you’d probably admit it was all your fault. And the fault of your tooling, of course.
In my experience, most databases are tiny. Tiny tiny. Tables with a few thousand rows. If your web app is slow, its going to all be your fault. Stop building something webscale with microservices and just get things done right there in your database instead. Etc.
But, quite often, each company has one or two databases that have at least one or two large tables. Tables with tens of millions of rows. I work on databases with billions of rows. They exist. And that’s the kind of database where your database server is underserving you. There could well be a metric ton of actual performance improvements that your database is leaving on the table. Areas where your database server hasn’t kept up with recent (as in the past 20 years) of regular improvements in how programs can work with the kernel, for example.
Over the years I’ve read some really promising papers that have speeded up databases. But as far as I can tell, nothing ever happens. What is going on?
For example, your database might be slow just because its making a lot of syscalls. Back in 2010, experiments with syscall batching improved MySQL performance by 40% (and lots of other regular software by similar or better amounts!). That was long before spectre patches made the costs of syscalls even higher.
So where are our batched syscalls? I can’t see a downside to them. Why isn’t linux offering them and glib using them, and everyone benefiting from them? It’ll probably speed up your IDE and browser too.
Of course, your database might be slow just because you are using default settings. The historic defaults for MySQL were horrid. Pretty much the first thing any innodb user had to do was go increase the size of buffers and pools and various incantations they find by googling. I haven’t investigated, but I’d guess that a lot of the performance claims I’ve heard about innodb on MySQL 8 is probably just sensible modern defaults.
I would hold tokudb up as being much better at the defaults. That took over half your RAM, and deliberately left the other half to the operating system buffer cache.
That mention of the buffer cache brings me to another area your database could improve. Historically, databases did ‘direct’ IO with the disks, bypassing the operating system. These days, that is a metric ton of complexity for very questionable benefit. Take tokudb again: that used normal buffered read writes to the file system and deliberately left the OS half the available RAM so the file system had somewhere to cache those pages. It didn’t try and reimplement and outsmart the kernel.
This paid off handsomely for tokudb because they combined it with absolutely great compression. It completely blows the two kinds of innodb compression right out of the water. Well, in my tests, tokudb completely blows innodb right out of the water, but then teams who adopted it had to live with its incomplete implementation e.g. minimal support for foreign keys. Things that have nothing to do with the storage, and only to do with how much integration boilerplate they wrote or didn’t write. (tokudb is being end-of-lifed by percona; don’t use it for a new project 😞)
However, even tokudb didn’t take the next step: they didn’t go to async IO. I’ve poked around with async IO, both for networking and the file system, and found it to be a major improvement. Think how quickly you could walk some tables by asking for pages breath-first and digging deeper as soon as the OS gets something back, rather than going through it depth-first and blocking, waiting for the next page to come back before you can proceed.
I’ve gone on enough about tokudb, which I admit I use extensively. Tokutek went the patent route (no, it didn’t pay off for them) and Google released leveldb and Facebook adapted leveldb to become the MySQL MyRocks engine. That’s all history now.
In the actual storage engines themselves there have been lots of advances. Fractal Trees came along, then there was a SSTable+LSM renaissance, and just this week I heard about a fascinating paper on B+ + LSM beating SSTable+LSM. A user called Jules commented, wondered about B-epsilon trees instead of B+, and that got my brain going too. There are lots of things you can imagine an LSM tree using instead of SSTable at each level.
But how invested is MyRocks in SSTable? And will MyRocks ever close the performance gap between it and tokudb on the kind of workloads they are both good at?
Of course, what about Postgres? TimescaleDB is a really interesting fork based on Postgres that has a ‘hypertable’ approach under the hood, with a table made from a collection of smaller, individually compressed tables. In so many ways it sounds like tokudb, but with some extra finesse like storing the min/max values for columns in a segment uncompressed so the engine can check some constraints and often skip uncompressing a segment.
Timescaledb is interesting because its kind of merging the classic OLAP column-store with the classic OLTP row-store. I want to know if TimescaleDB’s hypertable compression works for things that aren’t time-series too? I’m thinking ‘if we claim our invoice line items are time-series data…’
Compression in Postgres is a sore subject, as is out-of-tree storage engines generally. Saying the file system should do compression means nobody has big data in Postgres because which stable file system supports decent compression? Postgres really needs to have built-in compression and really needs to go embrace the storage engines approach rather than keeping all the cool new stuff as second class citizens.
Of course, I fight the query planner all the time. If, for example, you have a table partitioned by day and your query is for a time span that spans two or more partitions, then you probably get much faster results if you split that into n queries, each for a corresponding partition, and glue the results together client-side! There was even a proxy called ShardQuery that did that. Its crazy. When people are making proxies in PHP to rewrite queries like that, it means the database itself is leaving a massive amount of performance on the table.
And of course, the client library you use to access the database can come in for a lot of blame too. For example, when I profile my queries where I have lots of parameters, I find that the mysql jdbc drivers are generating a metric ton of garbage in their safe-string-split approach to prepared-query interpolation. It shouldn’t be that my insert rate doubles when I do my hand-rolled string concatenation approach. Oracle, stop generating garbage!
This doesn’t begin to touch on the fancy cloud service you are using to host your DB. You’ll probably find that your laptop outperforms your average cloud DB server. Between all the spectre patches (I really don’t want you to forget about the syscall-batching possibilities!) and how you have to mess around buying disk space to get IOPs and all kinds of nonsense, its likely that you really would be better off perforamnce-wise by leaving your dev laptop in a cabinet somewhere.
Crikey, what a lot of complaining! But if you hear about some promising progress in speeding up databases, remember it's not realistic to hope the databases you use will ever see any kind of benefit from it. The sad truth is, your database is still stuck in the 90s. Async IO? Huh no. Compression? Yeah right. Syscalls? Okay, that’s a Linux failing, but still!
Right now my hopes are on TimescaleDB. I want to see how it copes with billions of rows of something that aren’t technically time-series. That hybrid row and column approach just sounds so enticing.
Oh, and hopefully MyRocks2 might find something even better than SSTable for each tier?
But in the meantime, hopefully someone working on the Linux kernel will rediscover the batched syscalls idea…? ;)
2 notes
·
View notes
Text
Как Apache Cassandra, Kafka, Storm и Hadoop формируют рекомендации пользователям Spotify

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS.
Рекомендательная система Spotify: зачем она нужна и что должна делать
Начнем с описания самого сервиса: Spotify – это интернет-ресурс потокового аудио (стриминговый), позволяющий легально и бесплатно прослушивать более 50 миллионов музыкальных композиций, аудиокниг и подкастов, в режиме онлайн, т.е. не загружая их на локальное устройство. Этот сервис доступен в США, Европе, Австралии и Новой Зеландии, а также в некоторых странах Азии и Африки. В общем случае доля сервиса составляет более 36 % мирового аудиостриминга, при этом большая часть (70%) прослушиваний выполняется через плейлисты, а не по поисковым запросам или авторским страницам [1]. С учетом большого числа пользователей (60 миллионов), огромного каталога всевозможного аудиоконтента и специфики прослушиваний через плейлисты (более 1,5 миллиардов плейлистов), тема рекомендательных систем для Spotify весьма актуальна. Главная задача любой рекомендательной системы – это проинформировать пользователя о продукте, который может быть ему интересен в данный момент времени. В результате этого клиент получает не навязчивую рекламу, а полезную информацию, а сервис зарабатывает на предоставлении качественных услуг [2]. Суть работы рекомендательной системы состоит в накоплении статистики по пользователям и продуктам с последующим формированием рекомендаций. Различают 2 основные стратегии создания рекомендательных систем [3]: · фильтрация на основе содержания (Content-based), когда по анализу данных о контенте создаются профили пользователей (включая демографический, географический и прочие признаки, описывающие потребителя) и объектов (жанр, артист и другие атрибуты, характеризующие продукт) с целью выявления предпочтений пользователя. коллаборативная фильтрация (User-based), основанная на ретроспективном анализе пользовательского поведения, независимо от рассматриваемого объекта. Это позволяет учитывать некоторые неявные характеристики, которые сложно выразить при создании профиля. При всех положительных свойствах рекомендательных систем этого типа, для них характерна проблема холодного старта, когда данных о новых пользователях или объектах еще недостаточно для формирования адекватных рекомендаций.

Основные стратегии создания рекомендательных систем
В случае Spotify больше подходит стратегия коллаборативной фильтрации, адаптированная к потребностям конкретного пользователя в зависимости от времени суток. Она учитывает не только общие клиентские интересы и предпочтения, но и временной контекст. Например, любитель тяжелой рок-музыки слушает ее по утрам, по пути на работу, а вечером укладывает детей спать под нежные музыкальные композиции совсем другого жанра [4]. Сформировать такую модель предиктивной аналитики, которая предугадывает поведение пользователя, помогают методы машинного обучения (Machine Learning). Таким образом, сервис Spotify поставил задачу разработки такой системы персональных рекомендаций, которая должна анализировать данные в реальном времени и историческую статистику, чтобы, соответственно понимая контекст и поведение пользователя, предлагать ему наиболее релевантные аудиозаписи [4].

Примеры рекомендаций Spotify в пользовательских интерфейсах мобильного приложения
Архитектура и основные возможности Big Data системы сервиса Spotify
Для достижения поставленной бизнес-цели была разработана рекомендательная система на базе эффективного сочетания соответствующих Big Data технологий: Apache Cassandra, Kafka, Storm и Hadoop. Каждый из компонентов отвечает за конкретную часть архитектуры: · брокер сообщений Apache Kafka обеспечивает сбор и агрегацию пользовательских логов; · распределенный потоковый фреймворк Apache Storm реализует обработку событий в реальном времени; · библиотека Apache Crunch используется для запуска пакетных заданий MapReduce в Hadoop и отправки данных в Cassandra для хранения атрибутов пользовательского профиля и метаданных об объектах (списки воспроизведения, исполнители и пр.). Эта Java-библиотека, работающая поверх Hadoop и Apache Spark, предоставляет среду для написания, тестирования и запуска конвейеров MapReduce, состоящих из множества пользовательских функций. Этот API особенно полезен при обработке данных, которые не вписываются в реляционную модель, в частности, временные ряды, сериализованные форматы объектов (protocol buffers или записи AVRO), а также строки и столбцы HBase [5]. · Распределенная файловая система Apache Hadoop HDFS хранит информацию о пользовательском поведении в виде записей о событиях и метаданные об объектах. Таким образом, Apache Kafka собирает и а��регирует данные по пользовательским событиям (завершение аудиозаписи, включение рекламы), откуда их считывают 2 группы подписчиков (consumer), подписанных на разные темы (topic) [4]: · все необработанные логи сперва записываются в распределенную файловую систему Apache Hadoop (HDFS), а затем обрабатываются с помощью Crunch, удаляя повторяющиеся события, отфильтровывая ненужные поля и преобразуя записи в формат AVRO. · подписчики Kafka в топологиях Storm используют информацию о пользовательских событиях для вычислений в реальном времени. Другие конвейеры Crunch принимают и генерируют метаданные объектов (жанр, темп, исполнители и пр.). Эта информация также хранится в HDFS и экспортируется с помощью Crunch в Cassandra для поиска в реальном времени в конвейерах Storm. Таким образом, кластер Cassandra обеспечивает хранение метаданных объектов. Конвейеры Storm обрабатывают исходные события из Kafka, отфильтровывая и обогащая их метаданными объектов, группируя по пользователям и определяя клиентские атрибуты с помощью специальных алгоритмов машинного обучения [6]. Такая комбинация пользовательских атрибутов представляет собой профиль пользователя, также хранящийся в кластере Cassandra [4].
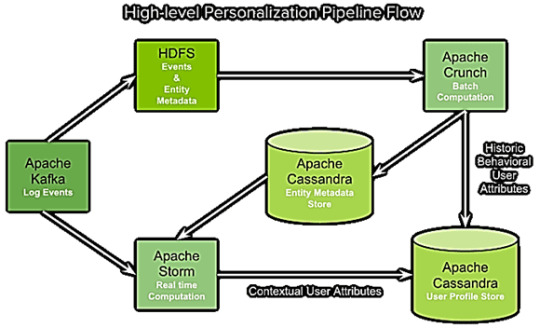
Архитектура рекомендательной Big Data системы стримингового сервиса Spotify
Роль Apache Cassandra в рекомендательной системе стримингового сервиса
Благодаря своим архитектурным особенностям и ключевым достоинствам, именно Apache Cassandra, в отличие других СУБД, используемых в Spotify (Memcached, Sparkey), смогла обеспечить следующие потребности рассматриваемой рекомендательной системы [4]: · горизонтальное масштабирование; · поддержка репликации; · отказоустойчивость и надежность; · низкая временная задержка (low latency) обработки данных с возможностью проведения операций практически в режиме онлайн; · возможность управлять согласованностью распределенных данных; · загрузка пакетных и потоковые данных из Crunch и Storm соответственно; · широкий набор схем данных для разных вариантов использования, в частности, метаданных для множества различных объектов, что позволило бы сократить эксплуатационные расходы. Также стоит отметить возможности Cassandra для массового импорта информации из других источников данных, в частности, HDFS, путем создания сохраненных таблиц (SSTable) и последующей потоковой передачи их в кластер. Это намного проще, быстрее и эффективнее, чем отправка множества отдельных операторов INSERT для всех данных, которые нужно загрузить в Кассандру [4]. По результатам тестирования описанного Big Data проекта Apache Cassandra показала высокую скорость обработки и надежность хранения данных, благодаря чему была успешно внедрена в production-версию разработанной системы персональных рекомендаций стримингового сервиса Spotify.

Рекомендательная Big Data система Spotify на базе Cassandra, Kafka, Storm и Hadoop
В следующей статье мы рассмотрим, чем отличается Apache Cassandra от другой популярной NoSQL-СУБД для Big Data, HBase, и что общего между этими нереляционными системами.
Источники 1. https://ru.wikipedia.org/wiki/Spotify 2. https://habr.com/ru/company/lanit/blog/420499/ 3. https://ru.wikipedia.org/wiki/Рекомендательная_система 4. https://labs.spotify.com/2015/01/09/personalization-at-spotify-using-cassandra/ 5. https://crunch.apache.org/ 6. https://hackernoon.com/spotifys-discover-weekly-how-machine-learning-finds-your-new-music-19a41ab76efe
Read the full article
#BigData#Cassandra#HBase#Kafka#MachineLearning#NoSQL#Spark#SQL#архитектура#Большиеданные#МашинноеОбучение#обработкаданных#предиктивнаяаналитика#Hadoop
0 notes
Text
300+ TOP CASSANDRA Interview Questions and Answers
CASSANDRA Interview Questions for freshers experienced :-
1. What is Cassandra?
Cassandra is an open source data storage system developed at Facebook for inbox search and designed for storing and managing large amounts of data across commodity servers. It can server as both
Real time data store system for online applications
Also as a read intensive database for business intelligence system
OR
Apache Cassandra is an open source, distributed and decentralized/distributed storage system (database), for managing very large amounts of structured data spread out across the world. It provides highly available service with no single point of failure.It was developed at Facebook for inbox search and it was open-sourced by Facebook in July 2008.
2. What was the design goal of Cassandra?
The design goal of Cassandra is to handle big data workloads across multiple nodes without any single point of failure.
3. What is NoSQLDatabase?
NoSQL database (sometimes called as Not Only SQL) is a database that provides a mechanism to store and retrieve data other than the tabular relations used in relational databases. These databases are schema-free, support easy replication, have simple API, eventually consistent, and can handle huge amounts of data.
4. Cassandra is written in which language?
Java
5. How many types of NoSQL databases?
Document Stores (MongoDB, Couchbase)
Key-Value Stores (Redis, Volgemort)
Column Stores (Cassandra)
Graph Stores (Neo4j, Giraph)
6. What do you understand by composite type?
Composite Type is a cool feature of Hector and Cassandra.It allow to define a key or a column name with a concatenation of data of different type.With CassanraUnit, you can use CompositeType in 2 places :
row key
column name
7. What is mandatory while creating a table in Cassandra?
While creating a table primary key is mandatory, it is made up of one or more columns of a table.
8. What is the relationship between Apache Hadoop, HBase, Hive and Cassandra?
Apache Hadoop, File Storage, Grid Compute processing via Map Reduce.
Apache Hive, SQL like interface ontop of hadoop.
Apache Hbase, Column Family Storage built like BigTable
Apache Cassandra, Column Family Storage build like BigTable with Dynamo topology and consistency.
9. List out some key features of Apache Cassandra?
It is scalable, fault-tolerant, and consistent.
It is a column-oriented database.
Its distribution design is based on Amazon’s Dynamo and its data model on Google’s Bigtable.
Created at Facebook, it differs sharply from relational database management systems.
Cassandra implements a Dynamo-style replication model with no single point of failure, but adds a more powerful “column family” data model.
Cassandra is being used by some of the biggest companies such as Facebook, Twitter, Cisco, Rackspace, ebay, Twitter, Netflix, and more.
10. What do you understand by Data Replication in Cassandra?
Database replication is the frequent electronic copying data from a database in one computer or server to a database in another so that all users share the same level of information.
Cassandra stores replicas on multiple nodes to ensure reliability and fault tolerance. A replication strategy determines the nodes where replicas are placed. The total number of replicas across the cluster is referred to as the replication factor. A replication factor of 1 means that there is only one copy of each row on one node. A replication factor of 2 means two copies of each row, where each copy is on a different node. All replicas are equally important; there is no primary or master replica. As a general rule, the replication factor should not exceed the number of nodes in the cluster. However, you can increase the replication factor and then add the desired number of nodes later.

CASSANDRA Interview Questions
11. What do you understand by Node in Cassandra?
Node is the place where data is stored.
12. What do you understand by Data center in Cassandra?
Data center is a collection of related nodes.
13. What do you understand by Cluster in Cassandra?
Cluster is a component that contains one or more data centers.
14. What do you understand by Commit log in Cassandra?
Commit log is a crash-recovery mechanism in Cassandra. Every write operation is written to the commit log.
15. What do you understand by Mem-table in Cassandra?
Mem-table is a memory-resident data structure. After commit log, the data will be written to the mem-table. Sometimes, for a single-column family, there will be multiple mem-tables.
16. What do you understand by SSTabl in Cassandra?
SSTable is a disk file to which the data is flushed from the mem-table when its contents reach a threshold value.
17. What do you understand by Bloom filter in Cassandra?
Bloom filter are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query.
18. What do you understand by CQL?
User can access Cassandra through its nodes using Cassandra Query Language (CQL. CQL treats the database (Keyspace) as a container of tables. Programmers use cqlsh: a prompt to work with CQL or separate application language drivers.
19. What do you understand by Column Family?
Column family is a container for an ordered collection of rows. Each row, in turn, is an ordered collection of columns.
20. What is the use of "void close()" method?
This method is used to close the current session instance.
21. What is the use of "ResultSet execute(Statement statement)" method?
This method is used to execute a query. It requires a statement object.
22. Which command is used to start the cqlsh prompt?
Cqlsh
23. What is the use of "cqlsh --version" command?
This command will provides the version of the cqlsh you are using.
24. What are the collection data types provided by CQL?
List : A list is a collection of one or more ordered elements.
Map : A map is a collection of key-value pairs.
Set : A set is a collection of one or more elements.
25. What is Cassandra database used for?
Apache Cassandra is a second-generation distributed database originally open-sourced by Facebook. Its write-optimized shared-nothing architecture results in excellent performance and scalability. The Cassandra storage cluster and S3 archival layer are designed to expand horizontally to any arbitrary size with linear cost.Cassandra’s memory footprint is more dependent on the number of column families than on the size of the data set. Cassandra scales pretty well horizontally for storage and IO, but not for memory footprint, which is tied to your schema and your cache settings regardless of the size of your cluster. some of the important link about casandara is available-here.
26. What is the syntax to create keyspace in Cassandra?
Syntax for creating keyspace in Cassandra is
CREATE KEYSPACE WITH
27. What is a keyspace in Cassandra?
In Cassandra, a keyspace is a namespace that determines data replication on nodes. A cluster consist of one keyspace per node.
28. What is cqlsh?
cqlsh is a Python-based command-line client for cassandra.
29. Does Cassandra works on Windows?
Yes, Cassandra works pretty well on windows. Right now we have linux and windows compatible versions available.
30. What do you understand by Consistency in Cassandra?
Consistency means to synchronize and how up-to-date a row of Cassandra data is on all of its replicas.
31. Explain Zero Consistency?
In this write operations will be handled in the background, asynchronously. It is the fastest way to write data, and the one that is used to offer the least confidence that operations will succeed.
32. What do you understand by Thrift?
Thrift is the name of the RPC client used to communicate with the Cassandra server.
33. What do you understand by Kundera?
Kundera is an object-relational mapping (ORM) implementation for Cassandra written using Java annotations.
34. JMX stands for?
Java Management Extension
35. How does Cassandra write?
Cassandra performs the write function by applying two commits-first it writes to a commit log on disk and then commits to an in-memory structured known as memtable. Once the two commits are successful, the write is achieved. Writes are written in the table structure as SSTable (sorted string table). Cassandra offers speedier write performance.
36. When to use Cassandra?
Being a part of NoSQL family Cassandra offers solution for problem where your requirement is to have very heavy write system and you want to have quite responsive reporting system on top of that stored data. Consider use case of Web analytic where log data is stored for each request and you want to built analytical platform around it to count hits by hour, by browser, by IP, etc in real time manner.
37. When should you not use Cassandra? OR When to use RDBMS instead of Cassandra?
Cassandra is based on NoSQL database and does not provide ACID and relational data property. If you have strong requirement of ACID property (for example Financial data), Cassandra would not be a fit in that case. Obviously, you can make work out of it, however you will end up writing lots of application code to handle ACID property and will loose on time to market badly. Also managing that kind of system with Cassandra would be complex and tedious for you.
38. What are secondary indexes?
Secondary indexes are indexes built over column values. In other words, let’s say you have a user table, which contains a user’s email. The primary index would be the user ID, so if you wanted to access a particular user’s email, you could look them up by their ID. However, to solve the inverse query given an email, fetch the user ID requires a secondary index.
39. When to use secondary indexes?
You want to query on a column that isn't the primary key and isn't part of a composite key. The column you want to be querying on has few unique values (what I mean by this is, say you have a column Town, that is a good choice for secondary indexing because lots of people will be form the same town, date of birth however will not be such a good choice).
40. When to avoid secondary indexes?
Try not using secondary indexes on columns contain a high count of unique values and that will produce few results.
41. I have a row or key cache hit rate of 0.XX123456789 reported by JMX. Is that XX% or 0.XX% ?
XX%
42. What happens to existing data in my cluster when I add new nodes?
When a new nodes joins a cluster, it will automatically contact the other nodes in the cluster and copy the right data to itself.
43. What are "Seed Nodes" in Cassandra?
A seed node in Cassandra is a node that is contacted by other nodes when they first start up and join the cluster. A cluster can have multiple seed nodes. Seed node helps the process of bootstrapping for a new node joining a cluster. Its recommended to use the 2 seed node per data center.
44. What are "Coordinator Nodes" in Cassandra?
Coordinator Nodes: Its a node which receive the request from client and send the request to the actual node depending upon the token. So all the nodes acts as coordinator node,because every node can receive a request and proxy that request.
45. What are the befefits of NoSQL over relational database?
NoSQL overcome the weaknesses that the relational data model does not address well, which are as follows:
Huge volume of sructured, semi-structured, and unstructured data
Flexible data model(schema) that is easy to change
Scalability and performance for web-scale applications
Lower cost
Impedance mismatch between the relational data model and object-oriented programming
Built-in replication
Support for agile software development
46. What ports does Cassandra use?
By default, Cassandra uses 7000 for cluster communication, 9160 for clients (Thrift), and 8080 for JMX. These are all editable in the configuration file or bin/cassandra.in.sh (for JVM options. All ports are TCP.
47. What do you understand by High availability?
A high availability system is the one that is ready to serve any request at any time. High avaliability is usually achieved by adding redundancies. So, if one part fails, the other part of the system can serve the request. To a client, it seems as if everything worked fine.
48. How Cassandra provide High availability feature?
Cassandra is a robust software. Nodes joining and leaving are automatically taken care of. With proper settings, Cassandra can be made failure resistant. That means that if some of the servers fail, the data loss will be zero. So, you can just deploy Cassandra over cheap commodity hardware or a cloud environment, where hardware or infrastructure failures may occur.
49. Who uses Cassandra?
Cassandra is in wide use around the world, and usage is growing all the time. Companies like Netflix, eBay, Twitter, Reddit, and Ooyala all use Cassandra to power pieces of their architecture, and it is critical to the day-to-da operations of those organizations. to date, the largest publicly known Cassandra cluster by machine count has over 300TB of data spanning 400 machines.
Because of Cassandra's ability to handle high-volume data, it works well for a myriad of applications. This means that it's well suited to handling projects from the high-speed world of advertising technology in real time to the high-volume world of big-data analytics and everything in between. It is important to know your use case before moving forward to ensure things like proper deployment and good schema design.
50. When to use secondary indexes?
You want to query on a column that isn't the primary key and isn't part of a composite key. The column you want to be querying on has few unique values (what I mean by this is, say you have a column Town, that is a good choice for secondary indexing because lots of people will be form the same town, date of birth however will not be such a good choice).
51. When to avoid secondary indexes?
Try not using secondary indexes on columns contain a high count of unique values and that will produce few results.
52. What do you understand by Snitches?
A snitch determines which data centers and racks nodes belong to. They inform Cassandra about the network topology so that requests are routed efficiently and allows Cassandra to distribute replicas by grouping machines into data centers and racks. Specifically, the replication strategy places the replicas based on the information provided by the new snitch. All nodes must return to the same rack and data center. Cassandra does its best not to have more than one replica on the same rack.
53. What is Hector?
Hector is an open source project written in Java using the MIT license. It was one of the early Cassandra clients and is used in production at Outbrain. It wraps Thrift and offers JMX, connection pooling, and failover.
54. What do you understand by NoSQL CAP theorem?
Consistency: means that data is the same across the cluster, so you can read or write to/from any node and get the same data.
Availability: means the ability to access the cluster even if a node in the cluster goes down.
Partition: Tolerance means that the cluster continues to function even if there is a "partition" (communications break) between two nodes (both nodes are up, but can't communicate).
In order to get both availability and partition tolerance, you have to give up consistency. Consider if you have two nodes, X and Y, in a master-master setup. Now, there is a break between network comms in X and Y, so they can't synch updates. At this point you can either:
A) Allow the nodes to get out of sync (giving up consistency), or
B) Consider the cluster to be "down" (giving up availability)
All the combinations available are:
CA - data is consistent between all nodes - as long as all nodes are online - and you can read/write from any node and be sure that the data is the same, but if you ever develop a partition between nodes, the data will be out of sync (and won't re-sync once the partition is resolved).
CP - data is consistent between all nodes, and maintains partition tolerance (preventing data desync) by becoming unavailable when a node goes down.
AP - nodes remain online even if they can't communicate with each other and will resync data once the partition is resolved, but you aren't guaranteed that all nodes will have the same data (either during or after the partition)
55. What is Keyspace in Cassandra?
Before doing any work with the tables in Cassandra, we have to create a container for them,
otherwise known as a keyspace. One of the main uses for keyspaces is defining a replication
mechanism for a group of tables.
Example:
CREATE KEYSPACE used_cars WITH replication = { 'class': 'SimpleStrategy',
'replication_factor' : 1};
56. Explain Cassandra data model?
The Cassandra data model has 4 main concepts which are cluster, keyspace, column, column family.
Clusters contain many nodes(machines) and can contain multiple keyspaces.
A keyspace is a namespace to group multiple column families, typically one per application.
A column contains a name, value and timestamp.
A column family contains multiple columns referenced by a row keys.
57. Can you add or remove Column Families in a working Cluster?
Yes, but keeping in mind the following processes.
Do not forget to clear the commitlog with ‘nodetool drain’
Turn off Cassandra to check that there is no data left in commitlog
Delete the sstable files for the removed CFs
58. What is Replication Factor in Cassandra?
ReplicationFactor is the measure of number of data copies existing. It is important to increase the replication factor to log into the cluster.
59. Can we change Replication Factor on a live cluster?
Yes, but it will require running repair to alter the replica count of existing data.
60. How to iterate all rows in ColumnFamily?
Using get_range_slices. You can start iteration with the empty string and after each iteration, the last key read serves as the start key for next iteration.
CASSANDRA Questions and Answers pdf Download
Read the full article
0 notes
Link
#bedsidetable#cornertable#endtable#Furniture#homedecor#India#interiordesign#marbletoptables#sidetable#sofatable#sstables
0 notes
Note
"How you feel isn't always easy to digest." The spirit sighed deeply , he knew the conversation topic wasn't pleasant for Godling so he put down the brochure he was holding and cupped the God's head. "There are many things I wish to know about him. I know he was important to you.. Rather than questioning, I'd prefer you to simply talk to me. Tell me what he was like and what he is to you."
"Then I will sssay the thingsss lesss, sso long ass you promissse not to forget that I feel them." He nodded and gave Kura's hands a tiny kiss.
"Okay. I will talk about him. Sssennen .. wass the firsst perssson I knew who didn't punish me for my failuresss. When I did sssomething wrong he didn't get angry or hurt me, he'd hold me and explain thingsss to me and tell me I could do better and he believed in me. I didn't underssstand him at all at firsst. Sssennen never yelled at me. He wass patient and he undersstood me. Ssso I entrusssted him with the care of mysself."
Godling paused to stare up at Kura. "That iss why you are like him. You are patient and kind too. But he wasssn't the ssame as you. You are .. excciting and quick and hot, where he wass sstable and sslow and warm. You are a bright hungry fire and he wasss warm glowing emberss."
2 notes
·
View notes
Text
LevelDB: SSTable and Log-Structured Storage (2012)
https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
Comments
0 notes
Text
February 11, 2020 at 10:00PM - The Big Data Bundle (93% discount) Ashraf
The Big Data Bundle (93% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
Hive is a Big Data processing tool that helps you leverage the power of distributed computing and Hadoop for analytical processing. Its interface is somewhat similar to SQL, but with some key differences. This course is an end-to-end guide to using Hive and connecting the dots to SQL. It’s perfect for both professional and aspiring data analysts and engineers alike. Don’t know SQL? No problem, there’s a primer included in this course!
Access 86 lectures & 15 hours of content 24/7
Write complex analytical queries on data in Hive & uncover insights
Leverage ideas of partitioning & bucketing to optimize queries in Hive
Customize Hive w/ user defined functions in Java & Python
Understand what goes on under the hood of Hive w/ HDFS & MapReduce
Big Data sounds pretty daunting doesn’t it? Well, this course aims to make it a lot simpler for you. Using Hadoop and MapReduce, you’ll learn how to process and manage enormous amounts of data efficiently. Any company that collects mass amounts of data, from startups to Fortune 500, need people fluent in Hadoop and MapReduce, making this course a must for anybody interested in data science.
Access 71 lectures & 13 hours of content 24/7
Set up your own Hadoop cluster using virtual machines (VMs) & the Cloud
Understand HDFS, MapReduce & YARN & their interaction
Use MapReduce to recommend friends in a social network, build search engines & generate bigrams
Chain multiple MapReduce jobs together
Write your own customized partitioner
Learn to globally sort a large amount of data by sampling input files
Analysts and data scientists typically have to work with several systems to effectively manage mass sets of data. Spark, on the other hand, provides you a single engine to explore and work with large amounts of data, run machine learning algorithms, and perform many other functions in a single interactive environment. This course’s focus on new and innovating technologies in data science and machine learning makes it an excellent one for anyone who wants to work in the lucrative, growing field of Big Data.
Access 52 lectures & 8 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & product ratings
Employ all the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming & GraphX
The functional programming nature and the availability of a REPL environment make Scala particularly well suited for a distributed computing framework like Spark. Using these two technologies in tandem can allow you to effectively analyze and explore data in an interactive environment with extremely fast feedback. This course will teach you how to best combine Spark and Scala, making it perfect for aspiring data analysts and Big Data engineers.
Access 51 lectures & 8.5 hours of content 24/7
Use Spark for a variety of analytics & machine learning tasks
Understand functional programming constructs in Scala
Implement complex algorithms like PageRank & Music Recommendations
Work w/ a variety of datasets from airline delays to Twitter, web graphs, & Product Ratings
Use the different features & libraries of Spark, like RDDs, Dataframes, Spark SQL, MLlib, Spark Streaming, & GraphX
Write code in Scala REPL environments & build Scala applications w/ an IDE
For Big Data engineers and data analysts, HBase is an extremely effective databasing tool for organizing and manage massive data sets. HBase allows an increased level of flexibility, providing column oriented storage, no fixed schema and low latency to accommodate the dynamically changing needs of applications. With the 25 examples contained in this course, you’ll get a complete grasp of HBase that you can leverage in interviews for Big Data positions.
Access 41 lectures & 4.5 hours of content 24/7
Set up a database for your application using HBase
Integrate HBase w/ MapReduce for data processing tasks
Create tables, insert, read & delete data from HBase
Get a complete understanding of HBase & its role in the Hadoop ecosystem
Explore CRUD operations in the shell, & with the Java API
Think about the last time you saw a completely unorganized spreadsheet. Now imagine that spreadsheet was 100,000 times larger. Mind-boggling, right? That’s why there’s Pig. Pig works with unstructured data to wrestle it into a more palatable form that can be stored in a data warehouse for reporting and analysis. With the massive sets of disorganized data many companies are working with today, people who can work with Pig are in major demand. By the end of this course, you could qualify as one of those people.
Access 34 lectures & 5 hours of content 24/7
Clean up server logs using Pig
Work w/ unstructured data to extract information, transform it, & store it in a usable form
Write intermediate level Pig scripts to munge data
Optimize Pig operations to work on large data sets
Data sets can outgrow traditional databases, much like children outgrow clothes. Unlike, children’s growth patterns, however, massive amounts of data can be extremely unpredictable and unstructured. For Big Data, the Cassandra distributed database is the solution, using partitioning and replication to ensure that your data is structured and available even when nodes in a cluster go down. Children, you’re on your own.
Access 44 lectures & 5.5 hours of content 24/7
Set up & manage a cluster using the Cassandra Cluster Manager (CCM)
Create keyspaces, column families, & perform CRUD operations using the Cassandra Query Language (CQL)
Design primary keys & secondary indexes, & learn partitioning & clustering keys
Understand restrictions on queries based on primary & secondary key design
Discover tunable consistency using quorum & local quorum
Learn architecture & storage components: Commit Log, MemTable, SSTables, Bloom Filters, Index File, Summary File & Data File
Build a Miniature Catalog Management System using the Cassandra Java driver
Working with Big Data, obviously, can be a very complex task. That’s why it’s important to master Oozie. Oozie makes managing a multitude of jobs at different time schedules, and managing entire data pipelines significantly easier as long as you know the right configurations parameters. This course will teach you how to best determine those parameters, so your workflow will be significantly streamlined.
Access 23 lectures & 3 hours of content 24/7
Install & set up Oozie
Configure Workflows to run jobs on Hadoop
Create time-triggered & data-triggered Workflows
Build & optimize data pipelines using Bundles
Flume and Sqoop are important elements of the Hadoop ecosystem, transporting data from sources like local file systems to data stores. This is an essential component to organizing and effectively managing Big Data, making Flume and Sqoop great skills to set you apart from other data analysts.
Access 16 lectures & 2 hours of content 24/7
Use Flume to ingest data to HDFS & HBase
Optimize Sqoop to import data from MySQL to HDFS & Hive
Ingest data from a variety of sources including HTTP, Twitter & MySQL
from Active Sales – SharewareOnSale https://ift.tt/2qeN7bl
https://ift.tt/eA8V8J
via Blogger https://ift.tt/37kIn4G
#blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
Zonefs FS: el sistema de archivos de Western Digital para unidades zonificadas
El director de desarrollo de software de Western Digital ha propuesto un nuevo sistema de archivos Zonefs en la lista de correo de desarrolladores de kernel de Linux, con el objetivo de simplificar el trabajo de bajo nivel con dispositivos de almacenamiento por zonas. Zonefs asocia cada zona en la unidad con un archivo separado que puede usarse para almacenar datos en modo sin procesar sin manipulación en el sector y el nivel de bloque.
Zonefs no es un FS compatible con POSIX y está limitado por un alcance bastante limitado que permite a las aplicaciones usar la API de archivo en lugar de acceder directamente a un dispositivo de bloque usando ioctl. Los archivos asociados con zonas requieren operaciones de escritura secuenciales que comienzan desde el final del archivo (escritura en modo de complemento).
(adsbygoogle = window.adsbygoogle || []).push({});
Los archivos proporcionados en Zonefs se pueden usar para colocar bases de datos en la parte superior de las unidades zonificadas utilizando estructuras de registro de fusión estructurada de registro (LSM), comenzando por el concepto de un archivo: una zona de almacenamiento.
Por ejemplo, se utilizan estructuras similares en las bases de datos RocksDB y LevelDB. El enfoque propuesto hace posible reducir el costo de portar código que fue diseñado originalmente para manipular archivos en lugar de bloquear dispositivos, así como organizar trabajos de bajo nivel con unidades zonificadas desde aplicaciones en lenguajes de programación que no sean C.
Bajo unidades divididas en zonas destinadas dispositivos para unidades de disco duro o NVMe SSD, espacio de almacenamiento que se divide en zonas, sectores o bloques que constituyen el grupo en el que solo se permite la actualización de datos secuencial además a lo largo de todo el grupo de bloques.
(adsbygoogle = window.adsbygoogle || []).push({});
Por ejemplo, la zonificación de grabación se usa en dispositivos con Shingled Magnetic Recording (SMR), en los que el ancho de la pista es menor que el ancho del cabezal magnético, y la grabación se realiza con una superposición parcial de la pista vecina, es decir, cualquier sobrescritura hace necesario sobrescribir todo el grupo de pistas.
Damien Le Moal de Western Digital describe Zonefs como
Zonefs no es un sistema de archivos compatible con POSIX. Su objetivo es simplificar la implementación del soporte de dispositivos de bloque zonificado en aplicaciones reemplazando los accesos de archivos de dispositivos de bloques sin procesar con una API basada en archivos más rica, evitando depender de ioctls de archivos de dispositivos de bloques directos que pueden ser más oscuros para los desarrolladores.
Un ejemplo de este enfoque es la implementación de estructuras de árbol LSM en dispositivos de bloques zonificados permitiendo que las SSTables se almacenen en un archivo de zona de manera similar a un sistema de archivos normal en lugar de una gama de sectores de un dispositivo zonal.
En cuanto a las unidades SSD, inicialmente tienen un enlace a operaciones de escritura secuenciales con limpieza preliminar de datos, pero estas operaciones están ocultas a nivel del controlador y la capa FTL (Capa de traducción Flash). Para aumentar la eficiencia bajo ciertos tipos de carga, NVMe ha estandarizado la interfaz ZNS (Zoned Namespaces), que permite el acceso directo a las zonas sin pasar por la capa FTL.
Linux para discos duros zonificados que comienzan con el núcleo 4.10 ofrece dispositivos de bloque ZBC (SCSI) y ZAC (ATA) y desde la versión 4.13, se ha agregado el módulo dm-zoned, que representa el disco zonificado como un dispositivo de bloque normal, ocultando las restricciones de escritura utilizadas durante el trabajo.
A nivel del sistema de archivos, el soporte de zonificación ya se ha integrado en el sistema de archivos F2FS y se está desarrollando un conjunto de parches para el sistema de archivos Btrfs, cuya adaptación para las unidades zonificadas se simplifica trabajando en modo CoW de copia en escritura. Ext4 y XFS que se ejecutan sobre unidades zonificadas se pueden organizar usando dm-zoned.
Para simplificar la traducción de los sistemas de archivos, se propone la interfaz ZBD, que traduce las operaciones de escritura aleatoria en archivos en secuencias de operaciones de escritura secuencial.
Fuente: https://blog.westerndigital.com
Fuente: Linux Adictos https://www.linuxadictos.com/zonefs-fs-el-sistema-de-archivos-de-western-digital-para-unidades-zonificadas.html
0 notes
Text
Summary for how databases handle storage and retrieval.
On a high level, we saw that storage engines fall into two broad categories: those opti‐ mized for transaction processing (OLTP), and those optimized for analytics (OLAP). There are big differences between the access patterns in those use cases:
OLTP systems are typically user-facing, which means that they may see a huge volume of requests. In order to handle the load, applications usually only touch a small number of records in each query. The application requests records using some kind of key, and the storage engine uses an index to find the data for the requested key. Disk seek time is often the bottleneck here.
Data warehouses and similar analytic systems are less well known, because they are primarily used by business analysts, not by end users. They handle a much lower volume of queries than OLTP systems, but each query is typically very demanding, requiring many millions of records to be scanned in a short time. Disk bandwidth (not seek time) is often the bottleneck here, and column- oriented storage is an increasingly popular solution for this kind of workload.
On the OLTP side, we saw storage engines from two main schools of thought:
The log-structured school, which only permits appending to files and deleting obsolete files, but never updates a file that has been written. Bitcask, SSTables, LSM-trees, LevelDB, Cassandra, HBase, Lucene, and others belong to this group.
The update-in-place school, which treats the disk as a set of fixed-size pages that can be overwritten. B-trees are the biggest example of this philosophy, being used in all major relational databases and also many nonrelational ones.
Log-structured storage engines are a comparatively recent development. Their key idea is that they systematically turn random-access writes into sequential writes on disk, which enables higher write throughput due to the performance characteristics of hard drives and SSDs.
0 notes
Text
Kitchen equipments,
Commercial kitchen equipments manufacturers,
Catering equipments,
Kitchen exhaust system manufacturers,
Kitchen trolley manufacturers,
Ss kitchen equipments,
Hotel kitchen equipments manufacturers,
Steam equipments,
Bakery equipments manufacturers
RAGHAVENDRA INDUSTRIES-Commercial Kitchen and Hotel Equipments,SS kitchen equipments, bakery equipments,catering equipment,steam equipments,kitchen trolley, kitchen exhaust manufacturers and suppliers Bangalore karnataka,india
Commercial Kitchen and Hotel Equipments,SS kitchen equipments, bakery equipments,catering equipment,steam equipments,kitchen trolley, kitchen exhaust manufacturers and suppliers Bangalore ,Single Door Stainless Steel Refrigerator Manufacturers in Bangalore, Stainless Steel Pizza Counter Manufacturers in Bangalore, Under Counter Stainless Steel Freezer Manufacturers in Bangalore, Double Door Stainless Steel Refrigerator Manufacturers in Bangalore, Display Equipments Manufacturers in Bangalore, Normal Display Counter Manufacturers in Bangalore, Cooling Display Counter Manufacturers in Bangalore, Pastry Chiller Counter Manufacturers in Bangalore, Ice cream Display Counter Manufacturers in Bangalore, Hot Display Counter Manufacturers in Bangalore, Front Bend Display Counter Manufacturers in Bangalore, Food Display Counter Manufacturers in Bangalore, Manufacturers of Commercial Kitchen Equipments, Steam Equipments, Gas Equipments, Display equipments manufacturers bangalore karnataka,india
commercial kitchen equipments,hotel kitchen equipments,catering equipments,hospital kitchen equipments,Kitchen equipment manufacturers, bakery equipment suppliers, Industrial Canteens, Hotels, Restaurants, Banquets, Resorts, Clubs, Hospitals, Educational Institutional & Bakeries equipments Manufacturers Bangalore Karnataka india,http://www.raghavendraindustries.co.in
http://www.raghavendraindustries.co.in
http://www.raghavendraindustries.co.in/index.html
http://www.raghavendraindustries.co.in/Kitchen-Equipment-Manufacturers-aboutus.html
http://www.raghavendraindustries.co.in/Bakery-Equipment-Manufacturers-products.html
http://www.raghavendraindustries.co.in/kitchen-equipments-steamequipments.html
http://www.raghavendraindustries.co.in/Commercial-kitchen-Exhaust-Systems-kitchenexhaust.html
http://www.raghavendraindustries.co.in/REFRIGERATOR-FREEZER-refrigerator-manufacturers.html
http://www.raghavendraindustries.co.in/Stainless-Steel-Burner-manufacturers.html
http://www.raghavendraindustries.co.in/ss-sinks-sstables-manufacturers-kitchensink.html
http://www.raghavendraindustries.co.in/Trolley-kitchen-kitchentrolly-sstrolly-manufacturers.html
http://www.raghavendraindustries.co.in/kitchen-equipment-contactus.html
https://plus.google.com/u/0/112199422406615043944
https://www.facebook.com/raghavendra.indus.7
0 notes
Text
New top story on Hacker News: LevelDB: SSTable and Log-Structured Storage (2012)
New top story on Hacker News: LevelDB: SSTable and Log-Structured Storage (2012)
LevelDB: SSTable and Log-Structured Storage (2012)
14 by jxub | 3 comments on Hacker News.
https://ClusterAssets.tk
View On WordPress
0 notes
Last Seen Blogs

mandopirata
Untitled

rashmeerl
Writer

loversofpanem
He’s a friend from work!!

sublimedinonuggies
My Mental Palace

calebduval
𝔩'𝔞𝔭𝔭𝔢𝔩 𝔡𝔲 𝔳𝔦𝔡𝔢.