#subclassing keras
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
Day 14 _ sequential , functional and model subclassing API in Keras
In our last blog on day 13 we explained what’s Karas and we showed a code example which was using sequential api but have not discuss about its api type . Sequential API The Sequential API is the simplest and most straightforward way to build a neural network in Keras. It allows you to create a model layer-by-layer in a linear stack. This method is best suited for models where each layer has one…
#functional and model subclassing API in Keras#keras#keras API#sequential#sequential keras#subclassing api keras#subclassing keras
0 notes
Text
the scikit-learn cargo cults
People who design machine learning frameworks love the scikit-learn estimator interface. We can tell they love it, because they keep trying to imitate it.
But love and understanding are not the same -- and none of these designers seem to understand what the sklearn estimator interface is. This failure is
inexplicable, because the concept is very simple
utterly disastrous in its consequences
-----
Specifically, no one seems to get that the sklearn estimator interface is . . . wait for it . . . an interface.
That is: it specifies a standard way for objects to communicate with one another. It doesn't specify what the objects are, themselves.
That's the whole point. Anything can be an sklearn estimator, as long as it conforms to the rules that sklearn lays down for estimators.
Aside from that, it can contain anything, do anything. It's very easy to write a whole new sklearn estimator that no one has ever thought of before: the docs tell you exactly how an estimator is expected to behave, and as long as your object plays by those simple rules, it's allowed to join the game. (What's more, you can a lot of the rules for free, just by inheriting from the base classes and mixins sklearn provides.)
The simple rules include having a method called "fit," which takes one or two inputs and ought to set some internal state. For predictors, the most famous type of estimator, you need a method called "predict." This will matter in a moment.
(Sidenote: the sklearn estimator interface is really not a great example of an interface, because it actually does care about internals. It inspects attribute names and requires them to follow their own rules, and it has a not fully explicit expectation that estimators can be serialized with pickle.
However, these requirements are still interface-y in the sense that they only constrain estimators along a few well-defined dimensions, leaving everything else free. Anything that plays by the rules can still join the game, and play it just as well as the "official" estimators built in to sklearn.)
-----
Interfaces are great. They are one of the foundations of modern software. You would think people who loved an interface would learn the lesson "interfaces are great, and we should use them."
Here is what developers of keras, tensorflow, and Sagemaker learned from that beloved estimator interface:
Data scientists love typing the words "fit" and "predict."
It is, in fact, possible -- one cannot rule it out -- that data scientists do not know how to do anything other than type the words "fit" and "predict."
An "easy to use" ML library is one where you can make the work happen by typing "fit" and "predict." This is basically what usability is; the rest is details.
-----
Keras: patient zero
The first casualty of this odd disease -- indeed, perhaps the patient zero from whom all the rest sprang -- was François Chollet, creator of Keras.
Chollet says that sklearn was a "huge influence" on keras. "From Sklearn, I borrowed 'fit', but more generally best practices around usability."
(Note that the claim in the first tweet is false: Keras models have never been valid sklearn estimators, because they do not follow the parameter naming rule. In many versions of Keras they are also not pickleable. Indeed, the tweet itself is about about a wrapping layer meant to add this missing compatibility, so I have no idea what "compatibility since 2015" is supposed to mean.)
The "Model" objects in Keras look deceptively like sklearn estimators. They have "fit" and "predict." The methods do roughly the same things they do in sklearn.
But there is no "Keras estimator interface." There is only one known valid species of the Keras fit/predict gizmo, namely "Model," the one built into Keras.
The only way to roll your own thing that behaves like "Model" is to subclass "Model." With sklearn, it's helpful to inherit from BaseEstimator, but that just helps you follow a few rules, and you can easily follow them on your own. There is no set of rules that "Model" is following. It doesn't follow the law, it is the law.
"I have in hand an sklearn estimator. What does that mean?" Just read this page: that is literally all there is to know.
"I have in hand a Keras model. What does that mean?" Read this labyrinthine piece of code, and also read everything it imports. That's what a model does. Yes, you have to read the code — the docs tell you how to subclass Model, not what Model is.
-----
Tensorflow gets a fit/predict gizmo
Keras started out as a 3rd-party library, but was incorporated into tensorflow at some point, and was pushed as the standard way to develop neural nets in tf.
This is unfortunate, because Keras objects are complex beasts and no one really knows how to decompose one fully into primitives of tensorflow (or of anything). Nothing can be a Keras object that was not built as one from the ground up.
Thus, read any tensorflow doc and you're likely to run into a strange split: "if you're using Keras, then do X..." "...otherwise, do Y." There has to be a generic path because you might not be using Keras, and if you aren't, you're stuck there. Thus everything gets done twice, often different ways.
All for poor, little "fit" and "predict"!
-----
Tensorflow makes another one
That is not the end of the story. No, at some later date tensorflow decided one fit/predict wasn't enough. ("The more fit/predict-y a library is, the more usable it is," to adapt a meme.)
Thus, tensorflow introduced a new thing called -- of course -- "Estimator."
What the fuck is an Estimator (tensorflow flavor)? Well, it's yet another gizmo with "fit" and "predict."
It's not a Keras model, but is more generic than a Keras model, and indeed closer to the spirit of sklearn. Its "fit" and "predict" can wrap almost arbitrary tensorflow code.
I suppose this may be one of the reasons they created it in the first place. But they didn't get rid of Keras' fit/predict thing, they just confusingly had two at once -- and indeed the Keras gizmo both predated Estimator, and outlived it. (Like all reliable tensorflow features, Estimator has been officially deprecated and dis-recommended outside some specific legacy cases; references to Estimator are being slowly scrubbed out of the official guides as we speak.)
Estimator has (had?) its own complex ecosystem of helpers, most of them only "internal" and documented in code, just like Keras, but all over again. (Right before starting this post, I was trying to wrap my head around one called "MonitoredSession.")
What really made Estimator different, though, was its support for distributed/cloud computing.
Elaborating on the theme that users cannot do anything but type "fit" and "predict," Estimator aspires to make even such fearsome tasks as "training on multiple GPUs," "training on cloud TPUs," and even "deploying to a cloud service" into a call to either "fit" or "predict."
Amusingly, Estimator was the primary supported way to take these actions for a while, and certainly the least painful. Thus, any code you wanted to distribute had to be wrapped in a "fit" or a "predict," for the sake of letting an Estimator be the thing that calls it.
Perhaps (?) because the devs have noticed how unnecessary this is, tensorflow is now trying to ditch Estimator in favor of "Strategy," a more generic wrapper for distributing arbitrary tf code.
Before this, Estimator and Strategy sat alongside one another awkwardly, just like Estimator and Keras did. Indeed, Estimator seems more reliable than Strategy, and continues to see use in official spin-offs like Mesh Tensorflow, presumably because people know it actually works, and know how to use it in real life.
Meanwhile, Strategy . . . well, the guide for Strategy contains this mind-melting compatibility table:
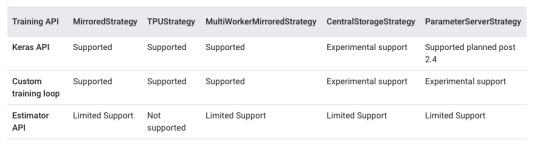
I remember this table from way back in Dec 2019, when I wrote my tensorflow rant. I am perversely pleased to see it still there in April 2021, with about as many "Experimental" and "Limited" cells as I remember.
(Note that this table's rows include Keras, a model API, and Estimator, a model-and-distribution API, and compare these for compatibility with Strategy, a distribution API.
If you understood that sentence, I fear you.)
I have spent countless hours trying to understand this kind of nonsense. One might find oneself asking where the "usability" has gone, and where it was supposed to come from in the first place.
Sagemaker: a copy of a copy
Sagemaker is one of the zillions of AWS products.
It's a "platform for machine learning," which in practice means it's Yet Another Complicated Wrapper Around Running Docker Containers On EC2™.
Like any AWS product, Sagemaker has API endpoints, and in python you can call these through the generic client boto3. To serve "high-level" "usability" needs, though, there is also a dedicated python SDK.
I bet you can guess what's in it.

Estimator (Sagemaker flavor) takes the cloud computing focus of Estimator (tensorflow flavor) to its logical conclusion.
Sagemaker "Estimators" do not have anything to do with fitting or predicting anything. The SDK is not supplying you with any machine learning code here. The only vestige of the original meanings attached to these words is that "fit" is expected to modify a state (hence it downloads an artifact from the cloud when it completes), while "predict" should be stateless.
Instead, "fit" and "predict" here are wrappers for pushing and running an arbitrary Docker image. "Fit" runs it with an entrypoint called "train," while "predict" runs it with one called "serve."
There are some surrounding helpers with an ML flavor, but they are similarly generic. There's something called "hyperparameters" which actually means "a json dict with string-only values injected into the container as a file before it runs," and something called "training data" which actually means "an S3 path the container can read."
It is impossible to understand what's going on outside of the "built-in" Estimators without remembering that actually "fit" and "predict" are lies and you are just using Docker.
This is the furthest thing from an interface! Anyone who can make their own Estimator (Sagemaker flavor) also has no reason to do so; if you know how to write Dockerfiles for ECS/EC2, you can just do that without tacking on this extra SDK.
Indeed, Estimator (Sagemaker flavor) is so far from the sklearn original that it is hard to imagine its developers had sklearn clearly in mind when they wrote. More likely, they were trying to imitate the earlier imitators.
Epilogue: pytorch
Pytorch is by far the most user-friendly neural network library available in 2021.
Pytorch does not have "fit" or "predict."
93 notes
·
View notes
Text
What is PyTorch, and How Does It Work: All You Need to Know
PyTorch is an upgraded Deep Learning tensor library in view of Python and Torch and is chiefly utilized for applications utilizing GPUs and CPUs. PyTorch is preferred over other Deep Learning structures like TensorFlow and Keras since it utilizes dynamic calculation charts and is totally Pythonic.

What Is PyTorch, and How Does It Work?
It permits researchers, designers, and brain network debuggers to run and test bits of the code progressively. Along these lines, clients don’t need to trust that the whole code will be carried out to check in the event that a piece of the code works or not.
The two primary elements of PyTorch are:
Tensor Computation (like NumPy) with solid GPU (Graphical Processing Unit) speed increase support Programmed Differentiation for making and preparing profound brain organizations Rudiments of PyTorch
The fundamental PyTorch tasks are really like Numpy. How about we get the fundamentals first.
Basics of PyTorch
In AI, when we address information, we really want to mathematically do that. A tensor is essentially a compartment that can hold information in various aspects. In numerical terms, notwithstanding, a tensor is a major unit of information that can be utilized as the establishment for cutting edge numerical activities. It very well may be a number, vector, grid, or complex cluster like Numpy exhibits. Tensors can likewise be taken care of by the CPU or GPU to make tasks quicker.
There are different kinds of tensors like Float Tensor, Double Tensor, Half Tensor, Int Tensor, and Long Tensor, yet PyTorch utilizes the 32-digit Float Tensor as the default type.
Mathematical Operations
The codes to perform numerical activities are something very similar in PyTorch as in Numpy. Clients need to introduce two tensors and afterward perform tasks like expansion, deduction, increase, and division on them.
Matrix Initialization and Matrix Operations
To instate a framework with arbitrary numbers in PyTorch, utilize the capacity randn() that gives a tensor loaded up with irregular numbers from a standard ordinary appropriation. Setting the irregular seed toward the starting will create similar numbers each time you run this code. Fundamental framework activities and translate activity in PyTorch are additionally like NumPy.
Common PyTorch Modules
In PyTorch, modules are utilized to address brain organizations.
Autograd
The autograd module is PyTorch’s programmed separation motor that assists with registering the angles in the forward sit back. Autograd creates a coordinated non-cyclic chart where the leaves are the information tensors while the roots are the result tensors.
Optim
The Optim module is a bundle with pre-composed calculations for enhancers that can be utilized to construct brain organizations.
nn
The nn module incorporates different classes that assistance to assemble brain network models. All modules in PyTorch subclass the nn module.
Dynamic Computation Graph
Computational diagrams in PyTorch permit the system to work out angle values for the brain networks fabricated. PyTorch utilizes dynamic computational charts. The diagram is characterized by implication utilizing administrator over-burdening while the forward calculation gets executed. Dynamic charts are more adaptable than static diagrams, wherein clients can make interleaved development and valuation of the chart. These are investigate agreeable as it permits line-by-line code execution. Observing issues in code is much simpler with PyTorch Dynamic diagrams — a significant element that pursues PyTorch such a favored decision in the business.
Computational diagrams in PyTorch are remade without any preparation at each cycle, permitting the utilization of irregular Python control stream proclamations, which can affect the general shape and size of the chart each time an emphasis happens. The benefit is — there’s compelling reason need to encode all potential ways prior to sending off the preparation. You run what you separate.
Data Loader
Working with huge datasets requires stacking all information into memory in one go. This causes memory blackout, and projects run gradually. Plus, it’s difficult to keep up with information tests handling code. PyTorch offers two information natives — DataLoader and Dataset — for parallelizing information stacking with mechanized grouping and better coherence and particularity of codes. Datasets and DataLoader permit clients to involve their own information as well as pre-stacked datasets. While Dataset houses the examples and the individual names, DataLoader joins dataset and sampler and executes an iterable around the Dataset so clients can undoubtedly get to tests.
Solving an Image Classification Problem Using PyTorch Have you at any point fabricated a brain network without any preparation in PyTorch? In the event that not, then this guide is for you.
Stage 1 — Initialize the info and result utilizing tensor.
Stage 2 — Define the sigmoid capacity that will go about as an enactment work. Utilize a subordinate of the sigmoid capacity for the backpropagation step.
Stage 3 — Initialize the boundaries like the quantity of ages, loads, predispositions, learning rate, and so on, utilizing the randn() work. This finishes the formation of a straightforward brain network comprising of a solitary secret layer and an information layer, and a result layer.
The forward spread advance is utilized to compute yield, while the retrogressive engendering step is utilized for blunder estimation. The blunder is utilized to refresh the loads and inclinations.
Then, we have our last brain network model in view of a certifiable contextual investigation, where the PyTorch system makes a profound learning model.
The main job is a picture characterization issue, where we figure out the sort of attire by taking a gander at various clothing pictures.
Stage 1 — Classify the picture of attire into various classes.
There are two organizers in the dataset — one for the preparation set and the other for the test set. Every organizer contains a .csv document that has the picture id of any picture and the relating name. Another envelope contains the pictures of the particular set.
Stage 2 — Load the Data
Import the expected libraries and afterward read the .csv record. Plot a haphazardly chosen picture to all the more likely comprehend how the information looks. Load all preparing pictures with the assistance of the train.csv document.
Stage 3 — Train the Model
Assemble an approval set to actually look at the presentation of the model on inconspicuous information. Characterize the model utilizing the import light bundle and the required modules. Characterize boundaries like the quantity of neurons, ages, and learning rate. Assemble the model, and afterward train it for a specific number of ages. Save preparing and approval misfortune if there should be an occurrence of every age plot, the preparation, and approval misfortune, to check assuming they are in a state of harmony.
Stage 4 — Getting Predictions
At long last, load the test pictures, make expectations, and present the forecasts. When the expectations are submitted, utilize the exactness rate as a benchmark to attempt to improve by changing the various boundaries of the model. Remain Updated With Developments in the Field of Deep Learning Summarizing, PyTorch is a fundamental profound learning structure and a fantastic decision as the primary profound learning system to learn. Assuming that you’re keen on PC vision and profound learning, look at our instructional exercises on Deep Learning applications and brain organizations.
0 notes
Video
youtube

custom writers
About me
Custom Writing Service
Custom Writing Service Nix Solutions Ltd. has delivered support for all our servers in the cloud for several years now and they're wonderful. As I talked to different service providers who wished to charge me 10X more I was shocked and pleasantly shocked to find Nix Solutions Ltd at their low costs. They have repeatedly provided outstanding service 24/7 which I am forever grateful. These guys do it all and I would advise any CEO that Nix Solutions Ltd. will exceed their expectations. And our full library of apply tools, aligned to educational requirements, helps your scholar do it at their own pace. For your convenience, we provide multiple claims reporting options that allow you to promptly report losses to our Claims Immediate Solutions group. I ordered three shirts with separate designs. The turned out nice and had been obtained days ahead of the expected supply date. Their assist chat service was extremely helpful. We use this info to make the web site work as well as potential and enhance government companies. Get answers, offer help, and share your pleasure with our engaged neighborhood of fellow entrepreneurs, consultants and influencers. Let Kajabi Pipelines optimize, automate, and scale your small business so you'll be able to focus on what fuels you as a substitute. Website was easy to use and created my custom T-shirts. Great that they allow you to buy in small quantities as not everybody desires 250 shirts! Delivery was quick and shorts are good high quality. I've ordered from these guys twice already and received my shirts faster than I thought I would. Our dedicated help team works 24/7 to resolve all your queries over the phone or e mail, irrespective of where you are situated. We verify Freelancers, publish their feedback scores and All-Time Transaction Data that will help you determine time-examined professionals throughout the globe. The Keras useful and subclassing APIs provide a outline-by-run interface for personalization and superior research. Build your mannequin, then write the forward and backward cross. Instructors are unbiased contractors who tailor their services to each consumer, utilizing their very own type, methods and materials. The Learning Lab provides adaptive assessments and personalized learning plans to assist focus the place essentially the most improvement is needed. Create custom layers, activations, and coaching loops. Varsity Tutors connects learners with specialists. With customized automation triggers and full platform integration, you’ll be able to create personal experiences in your viewers without additional effort for you and your staff. As the CEO of , I looked all around the world for somebody I may trust to handle our servers and databases. They look exactly like how they were designed online. RegExr was created by gskinner.com, and is proudly hosted by Media Temple. Roll over matches or the expression for particulars. Also, I should add we discovered Nix Solutions Ltd. only by way of Guru.com which makes me very joyful along with your group, too. Scopic Software has been on Guru since its founding in 2006. We are actually over 200 staff and Guru remains to be our primary supply of new clients. We wouldn't be the place we're at present without Guru. It is certainly the best service marketplace on the market if you are trying to develop an organization, both as a purchaser or provider.
0 notes
Photo

"[N] TensorFlow 2.0 (Beta) is Here!"- Detail: TensorFlow 2.0 Beta is officially out. Here are a few relavent links:Official documentationOfficial announcement on TwitterOfficial demo notebookOfficial announcement article on MediumI also received a notification via email. Here's one section of it:What's new in beta?In this beta release you'll find a final API surface, also available as part of the v2 compatibility module inside the TensorFlow 1.14 release. We have also added 2.0 support for Keras features like model subclassing, simplified the API for custom training loops, added distribution strategy support for most kinds of hardware, and lots more. You can see a list of all symbol changes here, and check out the link below for a collection of tutorials and getting started guides.See documentation. Caption by iyaja. Posted By: www.eurekaking.com
0 notes
Text
Phylogenetic Convolutional Neural Networks in Metagenomics. (arXiv:1709.02268v1 [q-bio.QM])
Background: Convolutional Neural Networks can be effectively used only when data are endowed with an intrinsic concept of neighbourhood in the input space, as is the case of pixels in images. We introduce here Ph-CNN, a novel deep learning architecture for the classification of metagenomics data based on the Convolutional Neural Networks, with the patristic distance defined on the phylogenetic tree being used as the proximity measure. The patristic distance between variables is used together with a sparsified version of MultiDimensional Scaling to embed the phylogenetic tree in a Euclidean space. Results: Ph-CNN is tested with a domain adaptation approach on synthetic data and on a metagenomics collection of gut microbiota of 38 healthy subjects and 222 Inflammatory Bowel Disease patients, divided in 6 subclasses. Classification performance is promising when compared to classical algorithms like Support Vector Machines and Random Forest and a baseline fully connected neural network, e.g. the Multi-Layer Perceptron. Conclusion: Ph-CNN represents a novel deep learning approach for the classification of metagenomics data. Operatively, the algorithm has been implemented as a custom Keras layer taking care of passing to the following convolutional layer not only the data but also the ranked list of neighbourhood of each sample, thus mimicking the case of image data, transparently to the user. Keywords: Metagenomics; Deep learning; Convolutional Neural Networks; Phylogenetic trees http://dlvr.it/PlZTQc
0 notes
Text
Day 15 _ Sequential vs Functional Keras API Part 2 explanation
Part 1: Understanding Sequential vs. Functional API in Keras with a Simple Example When building neural networks in Keras, there are two main ways to define models: the Sequential API and the Functional API. In this post, we’ll explore the differences between these two approaches using a simple mathematical example. Sequential API The Sequential API in Keras is a linear stack of layers. It’s easy…

View On WordPress
#functional and model subclassing API in Keras#functional Keras api#functional vs sequential Keras api#keras#keras API#machine learning#sequential keras
0 notes
Photo

"[Project] A Transformer implementation in Keras' Imperative (Subclassing) API for TensorFlow."- Detail: https://ift.tt/2J4PHdP I have a sentiment analysis demo working. Training for machine translation seems to require longer time and effort.For attention visualization, couldn't get the visualization in https://ift.tt/2TI1Ol6 to work, so just using heatmaps.. Caption by suyash93. Posted By: www.eurekaking.com
0 notes
Photo

"[D] Deep Reinforcement Learning with TensorFlow 2.0"- Detail: Seems there's quite a bit of confusion about what exactly does TensorFlow 2.0 bring to the table so I wrote a overview blog post, sharing my experiences with TensorFlow 2.0 by implementing a popular DRL algorithm (A2C) from scratch. I provide an overview of the Keras subclassing API, eager execution, session replacements, and some general tricks to make life easier. I've also tried to make the blog post self-contained with regards to theory, so if you need a refresher on DRL - check it out as well :)You can read the blog post here: http://bit.ly/2W3aErX you want to skip directly to source code, it's available here: http://bit.ly/2R1f7HP if you want to play with source code online, it's available on Google Colab: http://bit.ly/2W7ZiD1. Caption by Inori. Posted By: www.eurekaking.com
0 notes