#tagx
Text
MLOps and ML Data pipeline: Key Takeaways

If you have ever worked with a Machine Learning (ML) model in a production environment, you might have heard of MLOps. The term explains the concept of optimizing the ML lifecycle by bridging the gap between design, model development, and operation processes.
As more teams attempt to create AI solutions for actual use cases, MLOps is now more than just a theoretical idea; it is a hotly debated area of machine learning that is becoming increasingly important. If done correctly, it speeds up the development and deployment of ML solutions for teams all over the world.
MLOps is frequently referred to as DevOps for Machine Learning while reading about the word. Because of this, going back to its roots and drawing comparisons between it and DevOps is the best way to comprehend the MLOps concept.
MLOps vs DevOps
DevOps is an iterative approach to shipping software applications into production. MLOps borrows the same principles to take machine learning models to production. Either Devops or MLOps, the eventual objective is higher quality and control of software applications/ML models.
What is MLOps?
Machine Learning Operations is referred to as MLOps. Therefore, the function of MLOps is to act as a communication link between the operations team overseeing the project and the data scientists who deal with machine learning data.
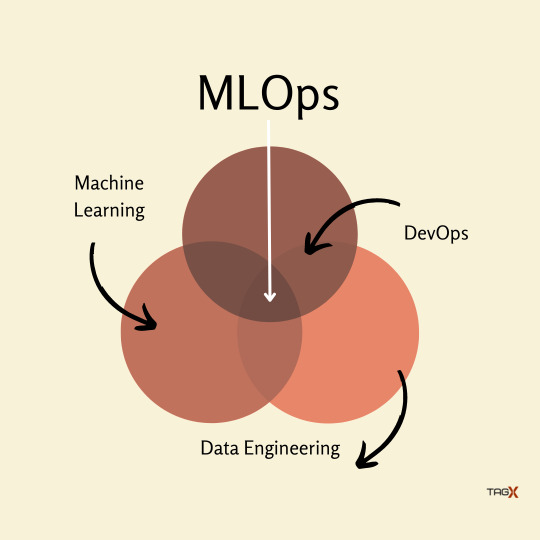
The key MLOps principles are:
Versioning – keeping track of the versions of data, ML model, code around it, etc.;
Testing – testing and validating an ML model to check whether it is working in the development environment;
Automation – trying to automate as many ML lifecycle processes as possible;
Reproducibility – we want to get identical results given the same input;
Deployment – deploying the model into production;
Monitoring – checking the model’s performance on real-world data.
What are the benefits of MLOps?
The primary benefits of MLOps are efficiency, scalability, and risk reduction.
Efficiency: MLOps allows data teams to achieve faster model development, deliver higher quality ML models, and faster deployment and production.
Scalability: Thousands of models may be supervised, controlled, managed, and monitored for continuous integration, continuous delivery, and continuous deployment thanks to MLOps’ extensive scalability and management capabilities. MLOps, in particular, makes ML pipelines reproducible, enables closer coordination between data teams, lessens friction between DevOps and IT, and speeds up release velocity.
Risk reduction: Machine learning models often need regulatory scrutiny and drift-check, and MLOps enables greater transparency and faster response to such requests and ensures greater compliance with an organization’s or industry’s policies.
Data pipeline for ML operations
One significant difference between DevOps and MLOps is that ML services require data–and lots of it. In order to be suitable for ML model training, most data has to be cleaned, verified, and tagged. Much of this can be done in a stepwise fashion, as a data pipeline, where unclean data enters the pipeline, and then the training, validating, and testing data exits the pipeline.
The data pipeline of a project involves several key steps:
Data collection:
Whether you source your data in-house, open-source, or from a third-party data provider, it’s important to set up a process where you can continuously collect data, as needed. You’ll not only need a lot of data at the start of the ML development lifecycle but also for retraining purposes at the end. Having a consistent, reliable source for new data is paramount to success.
Data cleansing:
This involves removing any unwanted or irrelevant data or cleaning up messy data. In some cases, it may be as simple as converting data into the format you need, such as a CSV file. Some steps of this may be automatable.
Data annotation:
Labeling your data is one of the most time-consuming, difficult, but crucial, phases of the ML lifecycle. Companies that try to take this step internally frequently struggle with resources and take too long. Other approaches give a wider range of annotators the chance to participate, such as hiring freelancers or crowdsourcing. Many businesses decide to collaborate with external data providers, who can give access to vast annotator communities, platforms, and tools for any annotating need. Depending on your use case and your need for quality, some steps in the annotation process may potentially be automated.
After the data has been cleaned, validated, and tagged, you can begin training the ML model to categorize, predict, or infer whatever it is that you want the model to do. Training, validation, and hold-out testing datasets are created out of the tagged data. The model architecture and hyperparameters are optimized many times using the training and validation data. Once that is finished, you test the algorithm on the hold-out test data one last time to check if it performs enough on the fresh data you need to release.
Setting up a continuous data pipeline is an important step in MLOps implementation. It’s helpful to think of it as a loop, because you’ll often realize you need additional data later in the build process, and you don’t want to have to start from scratch to find it and prepare it.
Conclusion
MLOps help ensure that deployed models are well maintained, performing as expected, and not having any adverse effects on the business. This role is crucial in protecting the business from risks due to models that drift over time, or that are deployed but unmaintained or unmonitored.
TagX is involved in delivering Data for each step of ML operations. At TagX, we provide high-quality annotated training data to power the world’s most innovative machine learning and business solutions. We can help your organization with data collection, Data cleaning, data annotation, and synthetic data to train your Machine learning models.
#annotation#data annotation for ml#it services#machine learning#viral topic#blog post#data annotation services#indore#india#instagram#tagx#service#ecommerce#digital marketing#seo service
5 notes
·
View notes


Text
Since it's been a hot minute
I love you persecutors
I love you persecutors trying to heal
I love you persecutors who are still hurting
I love you ex-persecutors
I love you persecutors who are called "evil"
I love you persecutors that are hosts
I love you persecutors that are caregivers
I love you persecutors that are littles
I love you "scary" persecutors
(feel free to add to this)
#🔥.txt#itx been a hot second#(cocon w someone who doesnt want to be named)#actually plural#persecutor alter#actually did#plural community#plural gang#idk what tagx to use here tbh#Awake to Post
28 notes
·
View notes
Text
Typing Quirk
S -> X
I juxt want to talk about my TranxIDx, like, expecially my tranxharmful onex!! I don’t want to harm people though xince none of them are baxed around hurting people vocally, but i juxt like talking about myxelf i have learned!!
Xhould i lixt my idx or have people guexx or? I don’t know, xtill trying to figure out xome of thix xtuff
#radqueer#rq 🌈🍓#pro transid#pro transx#transid#transx#transid safe#transid please interact#Alxo juxt xo everyone knowx i am NOT the one who made thexe tagx#that wax the hoxt <Arti> and not me#I’m juxt clicking the auto tagx#🎤⛓️
5 notes
·
View notes
Text
Expanding Your Data Labeling Process for Machine Learning
The victory of machine learning models depends intensely on the quality and amount of labeled information they are prepared on. Organizations are hooking with gigantic volumes of unstructured, unlabeled information, making a vigorous information labeling preparation significant. At TagX, we get the significant part information labeling plays in ML victory. Our multi-tiered approach starts with understanding clients' interesting needs to advise custom fitted workflows driving extended accomplishments.
Machine learning has changed problem-solving in computer vision and common dialect preparation. By leveraging endless information, calculations learn designs and make profitable forecasts without express programming. From protest acknowledgment to voice collaborators, ML models are vital however depend on high-quality labeled preparing information. Information labeling fastidiously structures crude information for machine comprehension - a basic, frequently ignored movement supporting ML venture success.
What is Data Labeling?
Data labeling is the process of assigning contextual meaning or annotations to raw data, enabling machine learning algorithms to learn from these labeled examples and achieve desired outcomes. At TagX, we understand the pivotal role data labeling plays in the success of any machine learning endeavor.
This process involves categorizing, classifying, and annotating various forms of data, such as images, text, audio, or video, according to predefined rules or guidelines. Tasks can include object detection and segmentation in images, sentiment analysis and named entity recognition in text, or speech recognition and transcription in audio data.
The labeled data is then used to train machine learning models, allowing them to recognize patterns, make predictions, and perform tasks with increasing accuracy and efficiency. Our team of skilled data annotators meticulously label vast amounts of data, ensuring the models our clients rely on are trained on high-quality, accurately labeled datasets.
Types of Data Labeling
Data labeling is a crucial process for various types of data, each requiring specific approaches and techniques. We have extensive experience in labeling diverse data formats, ensuring our clients' machine learning models are trained on accurate and high-quality labeled datasets. Here are some of the common types of data labeling we handle:
Image Labeling: This involves annotating image data with labels or bounding boxes to identify objects, classify scenes, or segment specific regions. Common tasks include object detection, instance segmentation, and pixel-level semantic segmentation.
Video Labeling: Similar to image labeling, video data is annotated frame by frame to identify and track objects, actions, or events across multiple frames. This type of labeling is essential for applications like autonomous vehicles, surveillance systems, and activity recognition.
3D Data Labeling: LiDAR (Light Detection and Ranging) and Radar data provide depth information and are labeled to create precise 3D representations of scenes. This data is crucial for applications like autonomous navigation, robotics, and environmental mapping.
Audio Labeling: Audio data, such as speech recordings or environmental sounds, is labeled for tasks like speech recognition, speaker identification, and audio event detection. This involves transcribing speech, annotating sound events, and identifying speakers.
Text Labeling: Text data is labeled for various natural language processing tasks, including sentiment analysis, named entity recognition, intent classification, and language translation. This involves annotating text with relevant labels, such as entities, sentiments, or intents.
Our team of skilled data annotators is well-versed in handling these diverse data types, ensuring that the labeled data adheres to industry-standard guidelines and meets the specific requirements of our clients' machine learning projects.
Importance of Data Labeling
Information labeling is the basic establishment that empowers machine learning models to learn and make exact expectations. Without high-quality labeled information, these models would be incapable of recognizing designs and extracting important insights.
Labeled information acts as the ground truth, giving the administered direction that machine learning calculations require to get it and generalize from illustrations amid the preparation. The quality and exactness of this labeled information straightforwardly impacts the execution of the coming about model.
Data labeling is especially pivotal for complex errands like computer vision, characteristic dialect preparing, and discourse acknowledgment. Clarifying information with objects, content substances, estimations, and other significant names permits models to learn modern concepts and relationships.
As datasets develop bigger and utilize cases that end up more complicated, the significance of a strong and versatile information labeling preparation escalates. Effective information labeling operations empower organizations to emphasize and refine their models quickly, driving development and keeping up a competitive edge.
At TagX, we recognize information labeling as a mission-critical component of effective machine learning activities. Our mastery in this space guarantees our clients have access to high-quality, precisely labeled datasets custom-made to their particular needs, engaging their models to accomplish ideal performance.
What is Data Labeling for Machine Learning?
Data labeling, also known as data annotation, is a critical process in the realm of machine learning, particularly for computer vision applications. It involves assigning labels or annotations to raw, unlabeled data, such as images, videos, text, or audio, to create high-quality training datasets for artificial intelligence models.
We understand the pivotal role that accurate data labeling plays in the success of machine learning endeavors. For computer vision use cases, data labeling encompasses tasks like applying bounding boxes or polygon annotations to identify objects, segmenting specific regions, or annotating intricate details like microcellular structures in healthcare projects. Regardless of the complexity, meticulous accuracy is essential in the labeling process to ensure optimal model performance.
Top 6 Tips for Better Data Labeling in Machine Learning
1. Define Clear Annotation Guidelines
Establish precise instructions and examples for annotators to follow. Clearly define label categories, annotation types (bounding boxes, polygons, etc.), and provide visual references. Consistent guidelines are crucial for creating high-quality, coherent datasets.
2. Implement Robust Quality Assurance
Data quality is paramount for model performance. Implement processes like manual reviews, automated checks, and consensus scoring to identify and correct labeling errors. Regular audits and providing annotator feedback helps maintain high standards.
3. Leverage Domain Expertise
For complex domains like healthcare or specialized tasks, involve subject matter experts in the labeling process. Their deep domain knowledge ensures accurate and meaningful annotations, reducing errors.
4. Choose Appropriate Annotation Tools
Select user-friendly annotation tools tailored to your data types and labeling needs. Tools with customizable workflows can significantly improve annotator efficiency and accuracy. Seamless integration with machine learning pipelines is a plus.
5. Prioritize Data Security and Privacy
When dealing with sensitive data like personal information or medical records, implement robust security measures. This includes access controls, encryption, anonymization, and adhering to data protection regulations.
6. Plan for Scalability
As your machine learning projects grow, so will the demand for labeled data. Implement processes and infrastructure to efficiently scale your data labeling operations. This may involve outsourcing, automating workflows, or building dedicated in-house teams.
We follow these best practices to deliver high-quality, accurately labeled datasets optimized for our clients' machine learning needs. Our expertise enables us to scale labeling operations while maintaining stringent quality standards, fueling the success of your AI initiatives.
Challenges of Data Labeling in Machine Learning
Volume and Variety of Data
Machine learning models require vast amounts of labeled data to achieve high accuracy. As datasets grow larger and more diverse, encompassing different data types (images, videos, text, audio), the labeling process becomes increasingly complex and time-consuming.
Quality and Consistency
Inaccurate or inconsistent labels can significantly degrade a model's performance. Ensuring high-quality, consistent labeling across large datasets is a major challenge, especially when involving multiple annotators for crowd-sourced labeling.
Domain Complexity
Certain domains like healthcare, finance, or highly specialized industries require a deep understanding of the subject matter to accurately label data. Finding annotators with the necessary expertise can be difficult and costly.
Scalability and Efficiency
As machine learning projects scale, the demand for labeled data increases exponentially. Scaling data labeling operations efficiently while maintaining quality and consistency is a significant challenge, often requiring robust processes, tools, and infrastructure.
Data Privacy and Security
When dealing with sensitive data, such as personal information or proprietary data, ensuring data privacy and security during the labeling process is crucial. Implementing robust security measures and adhering to data protection regulations can be complex.
Ambiguity and Edge Cases
Some data samples can be ambiguous or contain edge cases that are difficult to label consistently. Developing comprehensive guidelines and protocols to handle these situations is essential but can be time-consuming.
Cost and Resource Management
Data labeling is a labor-intensive and often expensive process. Managing costs and allocating resources efficiently while balancing quality, speed, and scalability requirements can be challenging, especially for small or medium-sized organizations.
We specialize in addressing these challenges head-on, enabling our clients to develop highly accurate machine learning models with efficiently labeled, high-quality datasets. Our expertise, processes, and tools are designed to tackle the complexities of data labeling, ensuring successful and scalable machine learning initiatives.
Final Thoughts
In conclusion, expanding your data labeling process for machine learning is not just about increasing the quantity of labeled data, but also about ensuring its quality, diversity, and relevance to the task at hand. By embracing innovative labeling techniques, leveraging domain expertise, and harnessing the power of crowdsourcing or automation where applicable, organizations can enhance the effectiveness and efficiency of their machine learning models, ultimately driving better decision-making and outcomes in various fields and industries.
TagX is at the forefront of this transformation, bringing innovation and change by providing top-notch data labeling services. Our expertise ensures that your data is accurately labeled, diverse, and relevant, empowering your machine learning models to perform at their best. With us, you can achieve superior results and stay ahead in the competitive landscape.
Visit us, www.tagxdata.com
Original Source, https://www.tagxdata.com/expanding-your-data-labeling-process-for-machine-learning
0 notes
Text
Intelligent Document Processing Workflow and Use cases

Artificial Intelligence has stepped up to the front line of real-world problem solving and business transformation with Intelligent Document Processing (IDP) becoming a vital component in the global effort to drive intelligent automation into corporations worldwide.
IDP solutions read the unstructured, raw data in complicated documents using a variety of AI-related technologies, including RPA bots, optical character recognition, natural language processing, computer vision, and machine learning. IDP then gathers the crucial data and transforms it into formats that are structured, pertinent, and usable for crucial processes including government, banking, insurance, orders, invoicing, and loan processing forms. IDP gathers the required data and forwards it to the appropriate department or place further along the line to finish the process.
Organizations can digitize and automate unstructured data coming from diverse documentation sources thanks to intelligent document processing (IDP). These consist of scanned copies of documents, PDFs, word-processing documents, online forms, and more. IDP mimics human abilities in document identification, contextualization, and processing by utilizing workflow automation, natural language processing, and machine learning technologies.
What exactly is Intelligent Document Processing?
A relatively new category of automation called “intelligent document processing” uses artificial intelligence services, machine learning, and natural language processing to help businesses handle their papers more effectively. Because it can read and comprehend the context of the information it extracts from documents, it marks a radical leap from earlier legacy automation systems and enables businesses to automate even more of the document processing lifecycle.
Data extraction from complicated, unstructured documents is automated by IDP, which powers both back office and front office business operations. Business systems can use data retrieved by IDP to fuel automation and other efficiencies, including the automated classification of documents. Enterprises must manually classify and extract data from these papers in the absence of IDP. They have a quick, affordable, and scalable option with IDP.
How does intelligent document processing work?
There are several steps a document goes through when processed with IDP software. Typically, these are:
Data collection
Intelligent document processing starts with ingesting data from various sources, both digital and paper-based. For taking in digitized data, most IDP solutions feature built-in integrations or allow developing custom interfaces to enterprise software. When it comes to collecting paper-based or handwritten documents, companies either relies on its internal data or outsource the collection requirement to third party vendor like TagX who can handle the whole collection process for a specific IDP usecase.
Pre-processing
Intelligent document processing (IDP) can only produce trustworthy results if the data it uses is well-structured, accurate, and clean. Because of this, intelligent document recognition software cleans and prepares the data it receives before actually extracting it. For that, a variety of techniques are employed, ranging from deskewing and noise reduction to cropping and binarization, and beyond. During this step, IDP aims to integrate, validate, fix/impute errors, split images, organise, and improve photos.
Classification & Extraction
Enterprise documentation typically has multiple pages and includes a variety of data. Additionally, the success of additional analysis depends on whether the various data types present in a document are processed according to the correct workflow. During the data extraction stage, knowledge from the documents is extracted. Machine learning models extract specific data from the pre-processed and categorised material, such as dates, names, or numbers. Large volumes of subject-matter data are used to train the machine learning models that run IDP software. Each document’s pertinent entities are retrieved and tagged for IDP model training.
Validation and Analytics
The retrieved data is available to ML models at the post-processing phase. To guarantee the accuracy of the processing results, the extracted data is subjected to a number of automated or manual validation tests. The collected data is now put together into a finished output file, which is commonly in JSON or XML format. A business procedure or a data repository receives the file. IDP can anticipate the optimum course of action. IDP can also turn data into insights, automation, recommendations, and forecasts by utilising its AI capabilities.
Top Use Cases of Intelligent Document Processing
Invoice Processing
With remote work, processing bills has never been simpler for the account payable and human resources staff. Invoice collection, routing, and posting via email and paper processes results in high costs, poor visibility, and compliance and fraud risks. Also, the HR and account payable staff shares the lion’s part of their day on manual repetitive chores like data input and chasing information that leads to delay and inaccurate payment. However, intelligent document processing makes sure that all information is gathered is in an organised fashion, and data extraction in workflow only concentrates on pertinent data. Intelligent document processing assists the account payable team in automating error reconciliation, data inputs, and the decision-making process from receipt to payment. IDP ensures organizations can limit errors and reduce manual intervention.
Claims Processing
Insurance companies frequently suffer with data processing because of unstructured data and varying formats, including PDF, email, scanned, and physical documents. These companies mainly rely on a paper-based system. Additionally, manual intervention causes convoluted workflows, sluggish processing, high expenses, increased mistake, and fraud. Both insurers and clients must wait a long time during this entire manual process. However, intelligent document processing is a cutting-edge method that enables insurers to swiftly examine the large amount of structured and unstructured data and spot fraudulent activity. Insurance companies can quickly identify, validate, and integrate the data automatically and offer quicker claims settlement by utilising AI technologies like OCR and NLP.
Fraud Detection
Document fraud instances are increasing as a result of the processing of a lot of data. Additionally, the manual inspection of fraudulent documents and invoices is a time-consuming traditional procedure. Any fraudulent financial activity involving paper records may result in diminished client confidence and higher operating expenses. Therefore, implementing automated workflows for transaction validation and verification is essential to preventing fraudulent transactions. Furthermore, intelligent document processing has the ability to automatically identify and annotate questionable transactions for the fraud team. Furthermore, IDP frees the operational team from manual labour while reducing fraud losses.
Logistics
Every step of the logistics process, including shipping, transportation, warehousing, and doorstep consumer delivery, involves thousands of hands exchanging data. For manual processing by outside parties, this information must be authenticated, verified, cross-checked, and sometimes even re-entered. Companies utilize IDP to send invoices, labels, and agreements to vendors, contractors, and transportation teams at the supply chain level. IDP enables to read unstructured data from many sources, which eliminates the need for manual processing and saves countless hours of work. It also helps to handle the issue of document variability. IDP keeps up with enterprises as they grow and scale to handle larger client user bases due to intelligent automation of various document processing workflow components.
Medical records
It is crucial to keep patient records in the healthcare sector. In a particular situation, quick and easy access to information may be essential; as a result, it is crucial to digitize all patient-related data. IDP can now be used to effectively manage a patient’s whole medical history and file. Many hospitals continue to save patient information in manual files and disorganised paper formats that are prone to being lost. So it becomes a challenge for a doctor to sort through all the papers in the files to find what they’re looking for when they need to access a specific file. All medical records and diagnostic data may be kept in one location using an IDP, and only pertinent data can be accessed when needed.
The technologies behind intelligent document processing
When it comes to processing documents in a new, smart way, it all heavily relies on three cornerstones: Artificial intelligence, optical character recognition, and robotic process automation. Let’s get into a bit more detail on each technology.
Optical Character Recognition
OCR is a narrowly focused technology that can recognize handwritten, typed, or printed text within scanned images and convert it into a machine-readable format. As a standalone solution, OCR simply “sees” what’s there on a document and pulls out the textual part of the image, but it doesn’t understand the meanings or context. That’s why the “brain” is needed. Thus OCR is trained using AI and deep learning algorithms to increase its accuracy.
Artificial intelligence
Artificial intelligence deals with designing, training, and deploying models that mimic human intelligence. AI/ML is used to train the system to identify, classify, and extract relevant information using tags, which can be linked to a position or visual elements or a key phrase. AI is a field of knowledge that focuses on creating algorithms and training models on data so that they can process new data inputs and make decisions by themselves. So, the models learn to “understand” imaging information and delve into the meaning of textual data the way humans do.IDP heavily relies on such ML-driven technologies as
Computer Vision (CV)
CV utilizes deep neural networks for image recognition. It identifies patterns in visual data say, document scans, and classifies them accordingly. Computer vision uses AI to enable automatic extraction, analysis, and understanding of useful information from digital images. Only a few solutions leverage computer vision technology to recognize images/pictures within documents.
Natural Language Processing (NLP)
NLP finds language elements such as separate sentences, words, symbols, etc., in documents, interprets them, and performs a linguistic-based document summary. With the help of NLP, IDP solutions can analyze the running text in documents, understand the context, consolidate the extracted data, and map the extracted fields to a defined taxonomy. It can help in recognizing the sentiments from the text (e.g., from emails and other unstructured data) and in classifying documents into different categories. It also assists in creating summaries of large documents or data from charts using NLG by capturing key data points.
Robotic Process Automation
RPA is designed to perform repetitive business tasks through the use of software bots. The technology has proved to be effective in working with data presented in a structured format. RPA software can be configured to capture information from certain sources, process and manipulate data, and communicate with other systems. Most importantly, since RPA bots are usually rule-based, if there are any changes in the structure of the input, they won’t be able to perform a task.RPA bots can extend the intelligent process automation pipeline, executing such tasks as processing transactions, manipulating the extracted data, triggering responses, or communicating with other enterprises IT systems.
Conclusion
It is needless to say; the number of such documents will keep on piling up and making it impossible for many organizations to manage effectively. Organizations should be able to make use of this data for the benefit of businesses, but when it becomes so voluminous in physical documents gleaning insights from it will become even more tedious. With the use of Intelligent Document Processing, the time-consuming, monotonous, and tedious process is made simpler without any risks of manual errors. This way, data becomes more powerful even in varying formats and also helps organizations to ensure enhanced productivity and operational efficiency.
The implementation of IDP is not as easy. The big challenge is a lack of training data. For an artificial intelligence model to operate effectively, it must be trained on large amounts of data. If you don’t have enough of it, you could still tap into document processing automation by relying on third-party vendors like Tagx who can help you with the collection, classification, Tagging, and data extraction. The more processes you automate, the more powerful AI will become, enabling it to find ways to automate even more.
0 notes
Photo

I asked my dog if she wanted to wear her pumpkin costume. She won't let me take it off. #dogsofinstagram #labsofinstagram #halloween https://www.instagram.com/p/CkWzWs-tAgx/?igshid=NGJjMDIxMWI=
0 notes
Text
What is Content Moderation and types of Moderation?

Successful brands all over the world have one thing in common: a thriving online community where the brand’s fans and influencers engage in online conversations that contribute high-value social media content, which in turn provides incredible insights into user behavior, preferences, and new business opportunities.
Content moderation is the process through which an online platform screens and monitors user-generated content to determine whether it should be published on the platform or not, based on platform-specific rules and guidelines. To put it another way, when a user submits content to a website, that content will go through a screening procedure (the moderation process) to make sure that the content upholds the regulations of the website, is not illegal, inappropriate, or harassing, etc.
From text-based content, ads, images, profiles, and videos to forums, online communities, social media pages, and websites, the goal of all types of content moderation is to maintain brand credibility and security for businesses and their followers online.
Types of content moderation
The content moderation method that you adopt should depend upon your business goals. At least the goal for your application or platform. Understanding the different kinds of content moderation, along with their strengths and weaknesses, can help you make the right decision that will work best for your brand and its online community.
Let’s discuss the different types of content moderation methods being used and then you can decide what is best for you.
Pre-moderation
All user submissions are placed in a queue for moderation before being presented on the platform, as the name implies. Pre-moderation ensures that no personally identifiable information, such as a comment, image, or video, is ever published on a website. However, for online groups that desire fast and unlimited involvement, this can be a barrier. Pre-moderation is best suited to platforms that require the highest levels of protection, like apps for children.
Post-moderation
Post-moderation allows users to publish their submissions immediately but the submissions are also added to a queue for moderation. If any sensitive content is found, it is taken down immediately. This increases the liability of the moderators because ideally there should be no inappropriate content on the platform if all content passes through the approval queue.
Reactive moderation
Platforms with a big community of cybercrime members allow users to flag any content that is offensive or violates community norms. This helps the moderators to concentrate on the content that has been flagged by the most people. However, this can enable for long-term distribution of sensitive content on a platform. It depends upon your business goals how long you can tolerate sensitive content to be on display.
Automated moderation
Automated moderation works by using specific content moderation applications to filter certain offensive words and multimedia content. Detecting inappropriate posts becomes automatic and more seamless. IP addresses of users classified as abusive can also be blocked through the help of automated moderation. Artificial intelligence systems can be used to analyze text, image, and video content. Finally, human moderators may be involved in the automated systems and flag something for their consideration.
Distributed moderation
Distributed moderation is accomplished by providing a rating system that allows the rest of the online community to score or vote on the content that has been uploaded. Although this is an excellent approach to crowdsourcing and ensuring that your community members are productive, it does not provide a high level of security.
Not only is your website exposed to abusive Internet trolls, it also relies on a slow self-moderation process that takes too much time for low-scoring harmful content to be brought to your attention.
TagX Content Moderation Services
At TagX, we strive to create the best possible content moderation solution by striking an optimum balance between your requirements and objectives.we understand that the future of content moderation involves an amalgamation of human judgment and evolving AI/ML capabilities.Our diverse workforce of data specialists, professional annotators, and social media experts come together to moderate a large volume of real-time content with the help of proven operational models.
Our content moderation services are designed to manage large volumes of real-time data in multiple languages while preserving quality, regulatory compliance, and brand reputation. TagX will build a dedicated team of content moderators who are trained and ready to be your brand advocates.
0 notes
Photo

What a day for this little dude! Best score of the day at TagX, then gets a trophy awarded by his football coaches for their choice of player of the year! #proudmum (at TAG X) https://www.instagram.com/p/CerBvSPsPhf/?igshid=NGJjMDIxMWI=
0 notes
Text
Queridos, postamos a proposta e história do rp! Agora queremos saber de vocês, alguém estaria interessado em participar? Nossa ask está aberta para o feedback de vocês.

1 note
·
View note
Photo

Tag X im Hambacher Forst !
Solidarität an alle die vor Ort sind!
4 notes
·
View notes
Text
Heute vor 1 Jahr hast du mich zerstört.
6 notes
·
View notes
Photo

+++ open from 4 pm 🌩 #AllCurrysAreBeautifull +++ wir #kochenvorwut weil die berliner rot-rot-grüne Regierung unsere Kiezkneipe - Das #SYNDIKAT - heute hat räumen lassen 👎..mit 700 #cops & übertrieben viel Gewalt 🤬 @polizeiberlin ihr wart mal wieder abscheulich! 👉Obwohl wir zugleich traurig & wütend sind haben wir heute geöffnet! #ohnemampfkeinkampf✊ In diesem Sinne - #rausausderdefensive - 🖤💜🖤💜🖤 #tschüsch uP your #revolution 💜🖤💜🖤💜 #syndibleibt #tagx #rebellfood #syndikatbleibt #acab #neukölln #schillerkiez #gentrificationsucks #fckpearsglobal #1312 #heiß #struggleberlin #syndikatberlin #b0708 (hier: Syndikat) https://www.instagram.com/p/CDlkHmRoA6A/?igshid=z8r6hlz66mtd
#allcurrysarebeautifull#kochenvorwut#syndikat#cops#ohnemampfkeinkampf✊#rausausderdefensive#tschüsch#revolution#syndibleibt#tagx#rebellfood#syndikatbleibt#acab#neukölln#schillerkiez#gentrificationsucks#fckpearsglobal#1312#heiß#struggleberlin#syndikatberlin#b0708
0 notes
Photo

Sag mal, was fragst du mich? Wie geht's mir wohl? Irgendwie bin ich am Arsch, diese Sache mit Tränen und so. Ich dachte immer, niemand kann die Nuss knacken. Nun hab ich immer wiederkehrende Vermissungsattacken. Es ist nicht mehr als ne beschissene Schnitzeljagd. Imme hinter dir herzurennen. Sagt wer bist du denn Fick dich ma, fuck! Erst mal die Wand anstarren, manchmal mit Tieren reden. Bettlaken riechen so, als wärst du grad noch hier gewesen. Das macht mir eh nichts aus, das kann jeder sagen. Am Ende des Tages hab ich 'n heftigen Leberschaden. Jedes Mal wenn etwas Wichtiges richtig ist, dann verliert man es. Dann wird der ganze Kitsch was Bitteres, was Wirkliches. Irgendwann ham wir nur teillos uns zum Leben genommen. Uns getrennt und weggerannt, unter die Räder gekommen. Bei uns war's dunkel, mal hell. Mal dunkel, mal hell, mal dunkel, mal hell, mal dunkel. Und alles Rundherum zu schnell. Ey, hab was geschrieben, Süßer, egal ob's gefällt. Briefmarke dran und schöne Grüße vom Arsch der Welt. Endlich mal ich selbst sein, nicht böse sein und verrückt. Denn bis jetzt hab ich das größte Schwein in mir drin unterdrückt. Aber es fehlt jemand, der mich im Zaum hält. Es fehlt ein Baustein, beschädigte Traumwelt. Nicht nur beschädigt, sondern mehr als zerstört. Nun bin ich ledig und muss täglich was von Aerosmith hören. Und hab den ganzen Tag lang nur schnulzigen Schlager im Ohr. Also war's nur warme Luft, unser Indianer-Ehrenwort. Und ab nun mach ich was Dummes, etwas Doffes, was Dämliches, Wie Huf, von nun an laber ich den Blues oder was Ähnliches. Irgendwie ist das Ganze voll aus dem Ruder gelaufen. Die Luft ist raus, hab kaum noch Puste um kurz unterzutauchen. Irgendwie ist es besser wenn unsre Wege sich trennen. Wir sparen uns das Reden, mach's gut und wir sehen uns, bis denne. #chakuza #dunkelmalhell #dunkelheit #freundschaft #kaputt #depression #fernweh #friendship #verletzt #vermissungsattacken #noah #off #tagx #sehnsucht #selbsthass #selfharn #brokenheart
#dunkelheit#friendship#off#chakuza#selbsthass#noah#verletzt#sehnsucht#brokenheart#kaputt#selfharn#depression#fernweh#vermissungsattacken#tagx#freundschaft#dunkelmalhell
3 notes
·
View notes
Text
Unlocking the Power of Smart Security Dataset: A Guide for Beginners

In today's world, where technology intertwines with almost every aspect of our lives, security has become a paramount concern. From protecting our homes to safeguarding our online identities, the need for smart security solutions has never been greater. But with the vast array of options available, navigating the landscape of security can be overwhelming. That's where the smart security dataset comes into play, offering a comprehensive approach to understanding and implementing effective security measures.
What is the Smart Security Dataset?
Put simply, the Smart Security Dataset is a collection of information and resources designed to help individuals and organizations enhance their security infrastructure intelligently. It encompasses a wide range of data, including but not limited to:
Threat Intelligence: Information about potential security threats, such as malware, phishing attempts, and hacking techniques.
Vulnerability Assessments: Analysis of weaknesses in systems or networks that could be exploited by attackers.
Security Best Practices: Guidelines and recommendations for implementing robust security measures.
Case Studies: Real-world examples of security incidents and how they were addressed.
Tools and Technologies: Software and hardware solutions for monitoring, detecting, and preventing security breaches.
Why is the Smart Security Dataset Important?
The importance of the Smart Security Dataset cannot be overstated. By leveraging the insights and resources it provides, individuals and organizations can:
Stay Ahead of Emerging Threats: With access to up-to-date threat intelligence, users can identify and mitigate potential risks before they escalate into full-blown security breaches.
Enhance Resilience: By conducting vulnerability assessments and implementing best practices, users can strengthen their security posture and minimize the impact of attacks.
Learn from Others' Experiences: Case studies offer valuable lessons from past security incidents, allowing users to learn from others' mistakes and successes.
Make Informed Decisions: With access to a diverse range of tools and technologies, users can make informed decisions about which security solutions best meet their needs and budget.
How Can You Get Started with the Smart Security Dataset?
Getting started with the Smart Security Dataset is easier than you might think. Here are a few simple steps to help you dive in:
Explore the Resources: Take some time to familiarize yourself with the various resources available in the dataset. This could include reading through threat intelligence reports, studying vulnerability assessments, or reviewing case studies.
Identify Your Security Needs: Assess your own security needs and priorities. Are you most concerned about protecting your home, your business, or your online accounts? Once you have a clear understanding of your goals, you can tailor your use of the dataset accordingly.
Implement Best Practices: Start implementing security best practices based on the recommendations provided in the dataset. This might include setting up strong passwords, enabling two-factor authentication, or regularly updating your software and firmware.
Stay Informed: Security threats are constantly evolving, so it's important to stay informed about the latest developments. Make a habit of regularly checking in on the Smart Security Dataset for updates and new resources.
Conclusion
In our world today, staying safe is super important. With tagX person detection dataset, everyone can protect themselves better. It doesn't matter if you're new to this or already know a lot. Just jump in and take charge of your security today!
Visit us, www.tagxdata.com
0 notes
Text
The Ultimate Guide to Data Ops for AI

Data is the fuel that powers AI and ML models. Without enough high-quality, relevant data, it is impossible to train and develop accurate and effective models.
DataOps (Data Operations) in Artificial Intelligence (AI) is a set of practices and processes that aim to optimize the management and flow of data throughout the entire AI development lifecycle. The goal of DataOps is to improve the speed, quality, and reliability of data in AI systems. It is an extension of the DevOps (Development Operations) methodology, which is focused on improving the speed and reliability of software development.
What is DataOps?
DataOps (Data Operations) is an automated and process-oriented data management practice. It tracks the lifecycle of data end-to-end, providing business users with predictable data flows. DataOps accelerate the data analytics cycle by automating data management tasks.
Let's take the example of a self-driving car. To develop a self-driving car, an AI model needs to be trained on a large amount of data that includes various scenarios, such as different weather conditions, traffic patterns, and road layouts. This data is used to teach the model how to navigate the roads, make decisions, and respond to different situations. Without enough data, the model would not have been exposed to enough diverse scenarios and would not be able to perform well in real-world situations. DataOps needs high-performance and scalable data lakes, which can handle mixed workloads, and different data types audio, video, text, and data from sensors and that have the performance capabilities needed to keep the compute layer fully utilized.
What is the data lifecycle?
Data Generation: There are various ways in which data can be generated within a business, be it through customer interactions, internal operations, or external sources. Data generation can occur through three main methods:
Data Entry: The manual input of new information into a system, often through the use of forms or other input interfaces.
Data Capture: The process of collecting information from various sources, such as documents, and converting it into a digital format that can be understood by computers.
Data Acquisition: The process of obtaining data from external sources, such as through partnerships or external data providers like Tagx.
Data Processing: Once data is collected, it must be cleaned, prepared, and transformed into a more usable format. This process is crucial to ensure the data's accuracy, completeness, and consistency.
Data Storage: After data is processed, it must be protected and stored for future use. This includes ensuring data security and compliance with regulations.
Data Management: The ongoing process of organizing, storing, and maintaining data, from the moment it is generated until it is no longer needed. This includes data governance, data quality assurance, and data archiving. Effective data management is crucial to ensure the data's accessibility, integrity, and security.
Advantages of Data Ops
DataOps enables organizations to effectively manage and optimize their data throughout the entire AI development lifecycle. This includes:
Identifying and Collecting Data from All Sources: DataOps is widely used to identify and collect data from a wide range of sources, including internal data, external data, and public data sets. This is helpful for organizations to have access to the data they need to train and test their AI models.
Automatically Integrating New Data: DataOps enables organizations to automatically integrate new data into their data pipelines. This ensures that data is consistently updated and that the latest information is always available to users.
Centralizing Data and Eliminating Data Silos: Companies focus on Dataops to centralize their data and eliminate data silos. This improves data accessibility and helps to ensure that data is used consistently across the organization.
Automating Changes to the Data Pipeline: DataOps implementation helps to automate changes to their data pipeline. This increases the speed and efficiency of data management and helps to ensure that data is used consistently across the organization.
By implementing DataOps, organizations can improve the speed, quality, and reliability of their data and AI models, and reduce the time and cost of developing and deploying AI systems. Additionally, by having proper data management and governance in place, the AI models developed can be explainable and trustworthy, which can be beneficial for regulatory and ethical considerations.
TagX Data as a Service
Data as a service (DaaS) refers to the provision of data by a company to other companies. TagX provides DaaS to AI companies by collecting, preparing, and annotating data that can be used to train and test AI models.
Here's a more detailed explanation of how TagX provides DaaS to AI companies:
Data Collection: TagX collects a wide range of data from various sources such as public data sets, proprietary data, and third-party providers. This data includes image, video, text, and audio data that can be used to train AI models for various use cases.
Data Preparation: Once the data is collected, TagX prepares the data for use in AI models by cleaning, normalizing, and formatting the data. This ensures that the data is in a format that can be easily used by AI models.
Data Annotation: TagX uses a team of annotators to label and tag the data, identifying specific attributes and features that will be used by the AI models. This includes image annotation, video annotation, text annotation, and audio annotation. This step is crucial for the training of AI models, as the models learn from the labeled data.
Data Governance: TagX ensures that the data is properly managed and governed, including data privacy and security. We follow data governance best practices and regulations to ensure that the data provided is trustworthy and compliant with regulations.
Data Monitoring: TagX continuously monitors the data and updates it as needed to ensure that it is relevant and up-to-date. This helps to ensure that the AI models trained using our data are accurate and reliable.
By providing data as a service, TagX makes it easy for AI companies to access high-quality, relevant data that can be used to train and test AI models. This helps AI companies to improve the speed, quality, and reliability of their models, and reduce the time and cost of developing AI systems. Additionally, by providing data that is properly annotated and managed, the AI models developed can be explainable and trustworthy, which can be beneficial for regulatory and ethical considerations.
Conclusion
Gaining the agility to boost the speed of data processing and increasing the quality of data to derive actionable insights is the focus of many businesses. This focus creates a need for an agile data management approach such as DataOps.
In addition to applying DataOps technologies, processes and people also need to be considered for better data operations. For example, it is important to set up new data governance practices that are compatible with DataOps. The human factor is also crucial. TagX can assist if you need help developing DataOps for your business and deciding which technologies to use
0 notes
Last Seen Blogs

everything-u-need-women
Swimsuits & Lingerie

anaolver
anaz

kaiaf123
Anotherone

hanl0nlawfl
Will Hanlon

little-l-and-big-l
Little L and Big L