#wow html in text posts is very limiting in general
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text
aw man
inline css styling doesn't work on the html editor :(
0 notes
Text
ever since i made THIS POST a lot of people have been asking for a tutorial, even though in pretty much all of the screenshots i included the specific part of inspect element showing exactly what i edited.
so buckle the fuck up I guess because the tumblr userbase want to find out how to make html pages unusable and who am I to deny you.
get ready for Baby's First HTML and CSS tutorial lmao
ok so first things first we need to go over BASIC HTML
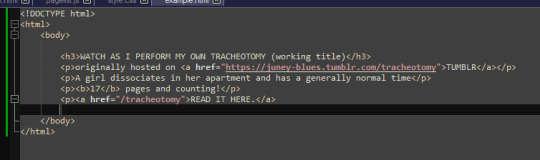
html is made up of these things called "tags" which specify certain parts of the web page, such as
HEADERS (<h1> through <h6> in terms of importance)
PARAGRAPHS (<p>paragraph here</p>)
LINKS (<a href="linkhere"></a>)
BOLDED SECTIONS OF TEXT(<b>bold here</b>)
and a bunch of other stuff,
by default however, specifying all of this just gives us a plain white page with plain black text of varying sizes

that's of course, no fucking good, and sucks shit, so the arbiters of html decided to let us STYLE certain elements, by adding a STYLE parameter to the tag

this can change any number of elements about how things are formatted.
text colour, page colour, font, size, spacing between elements, text alignment, you name it? you can change it!


you might've noticed that, certain elements are nested in other elements

and that any changes that apply to one element, apply to everything included under that element!


how convenient!
anyway this method of styling things by adding a style=" " to their tags is called "in-line style"
i think because the "style" goes "in" the "line"
it's generally ALSO a pain in the ass to style an entire website like this and should be exclusively reserved for small changes that you only want to apply to specific parts of the page.
for any real change in style you want to create a <style> section in your page's header!
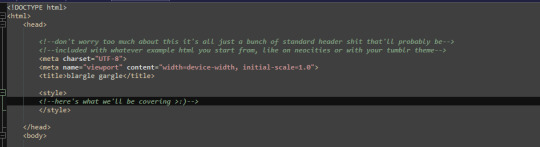
this can be used to make changes to how all elements of a type in your page are displayed

or even add new elements with whatever wacky styling you want that can be used with the <div> tag!


wow! isn't css just dandy!
and hell you can even use External CSS™ if you're making multiple pages and want them all to have a consistent theme, by pointing to a .CSS file (which is basically just a <style> header without the <style> tags lmao


ok this is all well and good and very interesting if, say, you're making your own website
*cough*neocities*cough*itsreallycoolandfree*cough*
but you came here because you want to FUCK UP A WEBSITE and make it look STUPID!!
so this is where the transform css property comes in~
you can read up on it HERE if you want the details but basically it allows you to apply mathematical transformations to any html element you want,

all of these fun bastards,
they can be really useful if you're doing some complicated stupid bullshit like me

OR for having fun >:)
if you'll remember, earlier i said that css properties apply to literally everything nested in an element,
and you MIGHT notice, that literally everything in pretty much all html files, is nested in an <html> tag

you can use style=" " or regular css on pretty much ANY html tag,


INCLUDING HTML!


ok ok that was a lot of buildup for something that i could've explained in one or two lines, but i gave you all this fundamental knowledge for a reason,
well, two reasons, go make a neocities
CHAPTER 2: THIS POST HAS CHAPTERS NOW
CSS KEY FRAMES BABYYYY
THESE FUCKERS DON'T WORK AS INLINE STYLING
I HAD TO TEACH YOU HOW CSS WORKED, TO GIVE YOU THE KNOWLEDGE YOU NEED, TO ANIMATE PAGES. TO MAKE THE FUCKERY COMPLETE!!!!
OKAY SO AGAIN READ UP ON THIS IF YOU WANT THE FULLEST POSSIBLE UNDERSTANDING
BUT WHAT KEYFRAMES ALLOW YOU TO DO, IS ANIMATE CSS PROPERTIES

and then make a class, which calls that animation...

and then assign that class. to your html tag.
and then vomit forever
we can do it in 3d too,
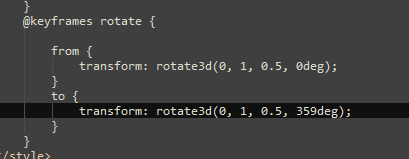

the only limit is your imagination... (and how many parameters you want to look up on w3schools and mozilla mdn web docs)
CHAPTER 3: APPLYING IN PRACTICE
ok now the fun thing about all of this, is you can apply it to your blog theme, literally right now
like literally RIGHT now
like step one, make sure you have a custom blog theme enabled in your settings, because that's turned off by default for some reason

step 2: edit theme

step 3: edit html:
step 4: apply knowledge in practice >:)
437 notes
·
View notes
Text
January 10th; so many cacti. cactuses. cactiuses. MULTIPLE CACTUS!
(squints) CACTUS?? THERE ARE SO MANY TYPES WTF

Anyhoo! There are (checks notes).. mainly four? Cacti I will be talking about today, so this will be A Long Post. Are you all ready? Okay! As a blanket rule, cacti are generally under mars, element fire, which you'll see why later.

First off, the common cactus (cactaceae). This is the one that most of the Victorian-era mostly talked about- actually, that's not really... true, I guess, they mention everything except for the optunia, (editor cyg here; i'm a buffoon, i lied) I suppose. But!
I'm sure you know what cactuses are. If not, then... what are you doing here? Anyway. These are the 'trademark desert plant'. They're like camels, except a plant, and spiky.
Also, it's in a Dr Seuss book- oh, wait, camels are also in there. Stream of consciousness, am I right?
Anyhoo. They conserve the little bit of water they get. They're very cool.

I almost put a normal picture, until I remember this beautiful thing exists. Say hi to the middle finger cactus.
As 'cactus', it takes most of the fall for definitions. So. There's gonna be a few.
Including but not limited to: Ardent love, warmth, I burn, burn with love, chastity, endurance, lust, maternal love, protection, sex, you left me.
Told you there were many definitions. I had to look up what 'ardent' meant, so..
In most of the really old sources, it just means 'I burn' and 'warmth', but it's not clear whether this is referring to a prickly pear cactus or not, so better to err on the side of caution.
In more of the modern sources, it also means 'our love shall endure', which seems to be a more inferential definition (one that I can definitely get behind). Also coming with age is the definition 'endurance'.
html im coming for you (shakes my fist @ you) how do i do it in rich text hold on.
mobile viewers, you guys'll just have to suffer for this one, sorry. tumblr formatting can suffer in a hole.
The serpentine cactus (stenocereus eruca), or creeping devil cactus (as the term serpentine cactus is hardly used these days). As you can probably guess, from it's name and the fact that it includes 'serpent', this cactus is *not *the best of meanings. It gets it's name from the trailing roots it throws out, which resembles snakes.
It's commonly meaning 'horror' because of this. Modest genius, modest gain. Also, it's kinda terrifying. But also... DANGEROUSLY PHALLIC- yeah, okay, I'll leave. My bad.
(tw for uh. fuckin. snake cacti. yeah.)

Wow, okay, that's... uncomfortable. Oh, I hate that, hell.
The night-blooming cactus (selenicereus grandi-florus), also called the grand cactus, vanilla cactus, sweet-smelling cactus, is the one most talked about in Ye Olden Sources. It's gone through, like, so many scientific names, but I'll settle on this one.

So! This plant is called night-blooming because it's flowers open only at night. When they do, they emit a vanilla-like sweet scent, which 'reaches a considerable distance'. The flowers can be very large, spanning up to 5 feet.
Native to Jamaica, this plant's flowers open after dark, and close by the first light of dawn (I had to look that one up, because I had a bit of confusion as to why the Victorian sources said 'dies off completely'. Thanks, discernment.)
There are some medical stuff mixed in with the properties of this bitch, but I am SO not going to delve into that because a) too long b) too hard to explain. so with that in mind.
Night-blooming cactus: transient beauty. (Also grandeur, because of it's grandness. Is that a word? It is now.)
The prickly pear cactus (optunia ficus-indica)- possibly one you've seen as a 'stereotypical cactus', if ever that were a thing. It's shaped like- you guessed it- a pear. Huh. Weird (imagine me giving you the most sarcastic look rn).

There's actually not much backstory for this one, but it is unanimously agreed that it means 'satire'. Other sources mention it also as 'I burn', with another one quoting 'I did not forget'. Also, 'chastity' and endurance. Yeah, man, I don't know the flore (flower lore) either.
But! Here are some interesting tidbits, if you're so inclined.
"Opuntia is native to the Americas, with samples being brought home by the Spanish, where it spread from Spain to all parts of the Mediterranean and North Africa. • The Aztecs grew Opuntia for the purpose of harvesting the cochineal scale it would be infested with, using it to produce red dye that was eventually worth more than gold, to ultimately be the same scarlet dye that was used to to color the fabric used *for British soldiers’ “redcoat” uniforms."
^ obviously not my own my words. you really think i'm scholarly enough to type all that up? because i am.
Anyway. Prickly pear; satire, I burn, chastity, endurance.
Oh, and here are a couple of other species of cacti's definitions, but I'm not going to go deep into them, because this is already a long post.
Crab cactus (Schlumbergera russelliana)- Dependability, loyalty
Chainlike cactus (Cylindropuntia imbricata)- sentiments of honour, uprightness
Neoporteria cactus (Neoporteria paucicostata)- motivation
Noble star cactus (Stapelia nobilis)- compassion, service
Saguaro Cactus Blossom (Carnegiea gigantean) » will to live, inner wisdom, compassion, endurance, self-empowerment

I have a floriography blog! @bloomsong-from-a-swans-breath :D
0 notes
Link
The Jamstack way of thinking and building websites is becoming more and more popular. Have you already tried Gatsby, Nuxt, or Gridsome (to cite only a few)? Chances are that your first contact was a “Wow!” moment — so many things are automatically set up and ready to use. There are some challenges, though, one of which is search functionality. If you’re working on any sort of content-driven site, you’ll likely run into search and how to handle it. Can it be done without any external server-side technology? Search is not one of those things that come out of the box with Jamstack. Some extra decisions and implementation are required. Fortunately, we have a bunch of options that might be more or less adapted to a project. We could use Algolia’s powerful search-as-service API. It comes with a free plan that is restricted to non-commercial projects with a limited capacity. If we were to use WordPress with WPGraphQL as a data source, we could take advantage of WordPress native search functionality and Apollo Client. Raymond Camden recently explored a few Jamstack search options, including pointing a search form directly at Google. In this article, we will build a search index and add search functionality to a Gatsby website with Lunr, a lightweight JavaScript library providing an extensible and customizable search without the need for external, server-side services. We used it recently to add “Search by Tartan Name” to our Gatsby project tartanify.com. We absolutely wanted persistent search as-you-type functionality, which brought some extra challenges. But that’s what makes it interesting, right? I’ll discuss some of the difficulties we faced and how we dealt with them in the second half of this article.

Getting started
For the sake of simplicity, let’s use the official Gatsby blog starter. Using a generic starter lets us abstract many aspects of building a static website. If you’re following along, make sure to install and run it:
gatsby new gatsby-starter-blog https://github.com/gatsbyjs/gatsby-starter-blog cd gatsby-starter-blog gatsby develop
It’s a tiny blog with three posts we can view by opening up http://localhost:8000/___graphql in the browser.
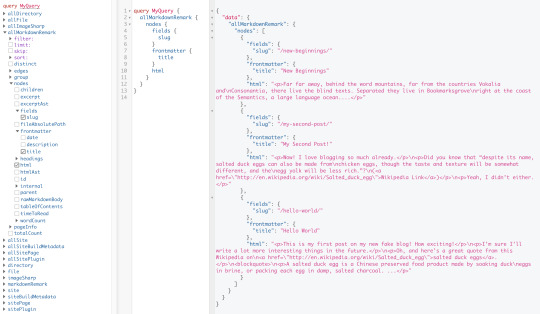
Inverting index with Lunr.js 🙃
Lunr uses a record-level inverted index as its data structure. The inverted index stores the mapping for each word found within a website to its location (basically a set of page paths). It’s on us to decide which fields (e.g. title, content, description, etc.) provide the keys (words) for the index. For our blog example, I decided to include all titles and the content of each article. Dealing with titles is straightforward since they are composed uniquely of words. Indexing content is a little more complex. My first try was to use the rawMarkdownBody field. Unfortunately, rawMarkdownBody introduces some unwanted keys resulting from the markdown syntax.

I obtained a “clean” index using the html field in conjunction with the striptags package (which, as the name suggests, strips out the HTML tags). Before we get into the details, let’s look into the Lunr documentation. Here’s how we create and populate the Lunr index. We will use this snippet in a moment, specifically in our gatsby-node.js file.
const index = lunr(function () { this.ref('slug') this.field('title') this.field('content') for (const doc of documents) { this.add(doc) } })
documents is an array of objects, each with a slug, title and content property:
{ slug: '/post-slug/', title: 'Post Title', content: 'Post content with all HTML tags stripped out.' }
We will define a unique document key (the slug) and two fields (the title and content, or the key providers). Finally, we will add all of the documents, one by one. Let’s get started.
Creating an index in gatsby-node.js
Let’s start by installing the libraries that we are going to use.
yarn add lunr graphql-type-json striptags
Next, we need to edit the gatsby-node.js file. The code from this file runs once in the process of building a site, and our aim is to add index creation to the tasks that Gatsby executes on build. CreateResolvers is one of the Gatsby APIs controlling the GraphQL data layer. In this particular case, we will use it to create a new root field; Let’s call it LunrIndex. Gatsby’s internal data store and query capabilities are exposed to GraphQL field resolvers on context.nodeModel. With getAllNodes, we can get all nodes of a specified type:
/* gatsby-node.js */ const { GraphQLJSONObject } = require(`graphql-type-json`) const striptags = require(`striptags`) const lunr = require(`lunr`) exports.createResolvers = ({ cache, createResolvers }) => { createResolvers({ Query: { LunrIndex: { type: GraphQLJSONObject, resolve: (source, args, context, info) => { const blogNodes = context.nodeModel.getAllNodes({ type: `MarkdownRemark`, }) const type = info.schema.getType(`MarkdownRemark`) return createIndex(blogNodes, type, cache) }, }, }, }) }
Now let’s focus on the createIndex function. That’s where we will use the Lunr snippet we mentioned in the last section.
/* gatsby-node.js */ const createIndex = async (blogNodes, type, cache) => { const documents = [] // Iterate over all posts for (const node of blogNodes) { const html = await type.getFields().html.resolve(node) // Once html is resolved, add a slug-title-content object to the documents array documents.push({ slug: node.fields.slug, title: node.frontmatter.title, content: striptags(html), }) } const index = lunr(function() { this.ref(`slug`) this.field(`title`) this.field(`content`) for (const doc of documents) { this.add(doc) } }) return index.toJSON() }
Have you noticed that instead of accessing the HTML element directly with const html = node.html, we’re using an await expression? That’s because node.html isn’t available yet. The gatsby-transformer-remark plugin (used by our starter to parse Markdown files) does not generate HTML from markdown immediately when creating the MarkdownRemark nodes. Instead, html is generated lazily when the html field resolver is called in a query. The same actually applies to the excerpt that we will need in just a bit. Let’s look ahead and think about how we are going to display search results. Users expect to obtain a link to the matching post, with its title as the anchor text. Very likely, they wouldn’t mind a short excerpt as well. Lunr’s search returns an array of objects representing matching documents by the ref property (which is the unique document key slug in our example). This array does not contain the document title nor the content. Therefore, we need to store somewhere the post title and excerpt corresponding to each slug. We can do that within our LunrIndex as below:
/* gatsby-node.js */ const createIndex = async (blogNodes, type, cache) => { const documents = [] const store = {} for (const node of blogNodes) { const {slug} = node.fields const title = node.frontmatter.title const [html, excerpt] = await Promise.all([ type.getFields().html.resolve(node), type.getFields().excerpt.resolve(node, { pruneLength: 40 }), ]) documents.push({ // unchanged }) store[slug] = { title, excerpt, } } const index = lunr(function() { // unchanged }) return { index: index.toJSON(), store } }
Our search index changes only if one of the posts is modified or a new post is added. We don’t need to rebuild the index each time we run gatsby develop. To avoid unnecessary builds, let’s take advantage of the cache API:
/* gatsby-node.js */ const createIndex = async (blogNodes, type, cache) => { const cacheKey = `IndexLunr` const cached = await cache.get(cacheKey) if (cached) { return cached } // unchanged const json = { index: index.toJSON(), store } await cache.set(cacheKey, json) return json }
Enhancing pages with the search form component
We can now move on to the front end of our implementation. Let’s start by building a search form component.
touch src/components/search-form.js
I opt for a straightforward solution: an input of type="search", coupled with a label and accompanied by a submit button, all wrapped within a form tag with the search landmark role. We will add two event handlers, handleSubmit on form submit and handleChange on changes to the search input.
/* src/components/search-form.js */ import React, { useState, useRef } from "react" import { navigate } from "@reach/router" const SearchForm = ({ initialQuery = "" }) => { // Create a piece of state, and initialize it to initialQuery // query will hold the current value of the state, // and setQuery will let us change it const [query, setQuery] = useState(initialQuery) // We need to get reference to the search input element const inputEl = useRef(null) // On input change use the current value of the input field (e.target.value) // to update the state's query value const handleChange = e => { setQuery(e.target.value) } // When the form is submitted navigate to /search // with a query q paramenter equal to the value within the input search const handleSubmit = e => { e.preventDefault() // `inputEl.current` points to the mounted search input element const q = inputEl.current.value navigate(`/search?q=${q}`) } return ( <form role="search" onSubmit={handleSubmit}> <label htmlFor="search-input" style=> Search for: </label> <input ref={inputEl} id="search-input" type="search" value={query} placeholder="e.g. duck" onChange={handleChange} /> <button type="submit">Go</button> </form> ) } export default SearchForm
Have you noticed that we’re importing navigate from the @reach/router package? That is necessary since neither Gatsby’s <Link/> nor navigate provide in-route navigation with a query parameter. Instead, we can import @reach/router — there’s no need to install it since Gatsby already includes it — and use its navigate function. Now that we’ve built our component, let’s add it to our home page (as below) and 404 page.
/* src/pages/index.js */ // unchanged import SearchForm from "../components/search-form" const BlogIndex = ({ data, location }) => { // unchanged return ( <Layout location={location} title={siteTitle}> <SEO title="All posts" /> <Bio /> <SearchForm /> // unchanged
Search results page
Our SearchForm component navigates to the /search route when the form is submitted, but for the moment, there is nothing behing this URL. That means we need to add a new page:
touch src/pages/search.js
I proceeded by copying and adapting the content of the the index.js page. One of the essential modifications concerns the page query (see the very bottom of the file). We will replace allMarkdownRemark with the LunrIndex field.
/* src/pages/search.js */ import React from "react" import { Link, graphql } from "gatsby" import { Index } from "lunr" import Layout from "../components/layout" import SEO from "../components/seo" import SearchForm from "../components/search-form"
// We can access the results of the page GraphQL query via the data props const SearchPage = ({ data, location }) => { const siteTitle = data.site.siteMetadata.title // We can read what follows the ?q= here // URLSearchParams provides a native way to get URL params // location.search.slice(1) gets rid of the "?" const params = new URLSearchParams(location.search.slice(1)) const q = params.get("q") || ""
// LunrIndex is available via page query const { store } = data.LunrIndex // Lunr in action here const index = Index.load(data.LunrIndex.index) let results = [] try { // Search is a lunr method results = index.search(q).map(({ ref }) => { // Map search results to an array of {slug, title, excerpt} objects return { slug: ref, ...store[ref], } }) } catch (error) { console.log(error) } return ( // We will take care of this part in a moment ) } export default SearchPage export const pageQuery = graphql` query { site { siteMetadata { title } } LunrIndex } `
Now that we know how to retrieve the query value and the matching posts, let’s display the content of the page. Notice that on the search page we pass the query value to the <SearchForm /> component via the initialQuery props. When the user arrives to the search results page, their search query should remain in the input field.
return ( <Layout location={location} title={siteTitle}> <SEO title="Search results" /> {q ? <h1>Search results</h1> : <h1>What are you looking for?</h1>} <SearchForm initialQuery={q} /> {results.length ? ( results.map(result => { return ( <article key={result.slug}> <h2> <Link to={result.slug}> {result.title || result.slug} </Link> </h2> <p>{result.excerpt}</p> </article> ) }) ) : ( <p>Nothing found.</p> )} </Layout> )
You can find the complete code in this gatsby-starter-blog fork and the live demo deployed on Netlify.
Instant search widget
Finding the most “logical” and user-friendly way of implementing search may be a challenge in and of itself. Let’s now switch to the real-life example of tartanify.com — a Gatsby-powered website gathering 5,000+ tartan patterns. Since tartans are often associated with clans or organizations, the possibility to search a tartan by name seems to make sense. We built tartanify.com as a side project where we feel absolutely free to experiment with things. We didn’t want a classic search results page but an instant search “widget.” Often, a given search keyword corresponds with a number of results — for example, “Ramsay” comes in six variations. We imagined the search widget would be persistent, meaning it should stay in place when a user navigates from one matching tartan to another.
Let me show you how we made it work with Lunr. The first step of building the index is very similar to the gatsby-starter-blog example, only simpler:
/* gatsby-node.js */ exports.createResolvers = ({ cache, createResolvers }) => { createResolvers({ Query: { LunrIndex: { type: GraphQLJSONObject, resolve(source, args, context) { const siteNodes = context.nodeModel.getAllNodes({ type: `TartansCsv`, }) return createIndex(siteNodes, cache) }, }, }, }) } const createIndex = async (nodes, cache) => { const cacheKey = `LunrIndex` const cached = await cache.get(cacheKey) if (cached) { return cached } const store = {} const index = lunr(function() { this.ref(`slug`) this.field(`title`) for (node of nodes) { const { slug } = node.fields const doc = { slug, title: node.fields.Unique_Name, } store[slug] = { title: doc.title, } this.add(doc) } }) const json = { index: index.toJSON(), store } cache.set(cacheKey, json) return json }
We opted for instant search, which means that search is triggered by any change in the search input instead of a form submission.
/* src/components/searchwidget.js */ import React, { useState } from "react" import lunr, { Index } from "lunr" import { graphql, useStaticQuery } from "gatsby" import SearchResults from "./searchresults"
const SearchWidget = () => { const [value, setValue] = useState("") // results is now a state variable const [results, setResults] = useState([])
// Since it's not a page component, useStaticQuery for quering data // https://www.gatsbyjs.org/docs/use-static-query/ const { LunrIndex } = useStaticQuery(graphql` query { LunrIndex } `) const index = Index.load(LunrIndex.index) const { store } = LunrIndex const handleChange = e => { const query = e.target.value setValue(query) try { const search = index.search(query).map(({ ref }) => { return { slug: ref, ...store[ref], } }) setResults(search) } catch (error) { console.log(error) } } return ( <div className="search-wrapper"> // You can use a form tag as well, as long as we prevent the default submit behavior <div role="search"> <label htmlFor="search-input" className="visually-hidden"> Search Tartans by Name </label> <input id="search-input" type="search" value={value} onChange={handleChange} placeholder="Search Tartans by Name" /> </div> <SearchResults results={results} /> </div> ) } export default SearchWidget
The SearchResults are structured like this:
/* src/components/searchresults.js */ import React from "react" import { Link } from "gatsby" const SearchResults = ({ results }) => ( <div> {results.length ? ( <> <h2>{results.length} tartan(s) matched your query</h2> <ul> {results.map(result => ( <li key={result.slug}> <Link to={`/tartan/${result.slug}`}>{result.title}</Link> </li> ))} </ul> </> ) : ( <p>Sorry, no matches found.</p> )} </div> ) export default SearchResults
Making it persistent
Where should we use this component? We could add it to the Layout component. The problem is that our search form will get unmounted on page changes that way. If a user wants to browser all tartans associated with the “Ramsay” clan, they will have to retype their query several times. That’s not ideal. Thomas Weibenfalk has written a great article on keeping state between pages with local state in Gatsby.js. We will use the same technique, where the wrapPageElement browser API sets persistent UI elements around pages. Let’s add the following code to the gatsby-browser.js. You might need to add this file to the root of your project.
/* gatsby-browser.js */ import React from "react" import SearchWrapper from "./src/components/searchwrapper" export const wrapPageElement = ({ element, props }) => ( <SearchWrapper {...props}>{element}</SearchWrapper> )
Now let’s add a new component file:
touch src/components/searchwrapper.js
Instead of adding SearchWidget component to the Layout, we will add it to the SearchWrapper and the magic happens. ✨
/* src/components/searchwrapper.js */ import React from "react" import SearchWidget from "./searchwidget"
const SearchWrapper = ({ children }) => ( <> {children} <SearchWidget /> </> ) export default SearchWrapper
Creating a custom search query
At this point, I started to try different keywords but very quickly realized that Lunr’s default search query might not be the best solution when used for instant search. Why? Imagine that we are looking for tartans associated with the name MacCallum. While typing “MacCallum” letter-by-letter, this is the evolution of the results:
m – 2 matches (Lyon, Jeffrey M, Lyon, Jeffrey M (Hunting))
ma – no matches
mac – 1 match (Brighton Mac Dermotte)
macc – no matches
macca – no matches
maccal – 1 match (MacCall)
maccall – 1 match (MacCall)
maccallu – no matches
maccallum – 3 matches (MacCallum, MacCallum #2, MacCallum of Berwick)
Users will probably type the full name and hit the button if we make a button available. But with instant search, a user is likely to abandon early because they may expect that the results can only narrow down letters are added to the keyword query. That’s not the only problem. Here’s what we get with “Callum”:
c – 3 unrelated matches
ca – no matches
cal – no matches
call – no matches
callu – no matches
callum – one match
You can see the trouble if someone gives up halfway into typing the full query. Fortunately, Lunr supports more complex queries, including fuzzy matches, wildcards and boolean logic (e.g. AND, OR, NOT) for multiple terms. All of these are available either via a special query syntax, for example:
index.search("+*callum mac*")
We could also reach for the index query method to handle it programatically. The first solution is not satisfying since it requires more effort from the user. I used the index.query method instead:
/* src/components/searchwidget.js */ const search = index .query(function(q) { // full term matching q.term(el) // OR (default) // trailing or leading wildcard q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, }) }) .map(({ ref }) => { return { slug: ref, ...store[ref], } })
Why use full term matching with wildcard matching? That’s necessary for all keywords that “benefit” from the stemming process. For example, the stem of “different” is “differ.” As a consequence, queries with wildcards — such as differe*, differen* or different* — all result in no matches, while the full term queries differe, differen and different return matches. Fuzzy matches can be used as well. In our case, they are allowed uniquely for terms of five or more characters:
q.term(el, { editDistance: el.length > 5 ? 1 : 0 }) q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, })
The handleChange function also “cleans up” user inputs and ignores single-character terms:
/* src/components/searchwidget.js */ const handleChange = e => { const query = e.target.value || "" setValue(query) if (!query.length) { setResults([]) } const keywords = query .trim() // remove trailing and leading spaces .replace(/\*/g, "") // remove user's wildcards .toLowerCase() .split(/\s+/) // split by whitespaces // do nothing if the last typed keyword is shorter than 2 if (keywords[keywords.length - 1].length < 2) { return } try { const search = index .query(function(q) { keywords // filter out keywords shorter than 2 .filter(el => el.length > 1) // loop over keywords .forEach(el => { q.term(el, { editDistance: el.length > 5 ? 1 : 0 }) q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, }) }) }) .map(({ ref }) => { return { slug: ref, ...store[ref], } }) setResults(search) } catch (error) { console.log(error) } }
Let’s check it in action:
m – pending
ma – 861 matches
mac – 600 matches
macc – 35 matches
macca – 12 matches
maccal – 9 matches
maccall – 9 matches
maccallu – 3 matches
maccallum – 3 matches
Searching for “Callum” works as well, resulting in four matches: Callum, MacCallum, MacCallum #2, and MacCallum of Berwick. There is one more problem, though: multi-terms queries. Say, you’re looking for “Loch Ness.” There are two tartans associated with that term, but with the default OR logic, you get a grand total of 96 results. (There are plenty of other lakes in Scotland.) I wound up deciding that an AND search would work better for this project. Unfortunately, Lunr does not support nested queries, and what we actually need is (keyword1 OR *keyword*) AND (keyword2 OR *keyword2*). To overcome this, I ended up moving the terms loop outside the query method and intersecting the results per term. (By intersecting, I mean finding all slugs that appear in all of the per-single-keyword results.)
/* src/components/searchwidget.js */ try { // andSearch stores the intersection of all per-term results let andSearch = [] keywords .filter(el => el.length > 1) // loop over keywords .forEach((el, i) => { // per-single-keyword results const keywordSearch = index .query(function(q) { q.term(el, { editDistance: el.length > 5 ? 1 : 0 }) q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, }) }) .map(({ ref }) => { return { slug: ref, ...store[ref], } }) // intersect current keywordSearch with andSearch andSearch = i > 0 ? andSearch.filter(x => keywordSearch.some(el => el.slug === x.slug)) : keywordSearch }) setResults(andSearch) } catch (error) { console.log(error) }
The source code for tartanify.com is published on GitHub. You can see the complete implementation of the Lunr search there.
Final thoughts
Search is often a non-negotiable feature for finding content on a site. How important the search functionality actually is may vary from one project to another. Nevertheless, there is no reason to abandon it under the pretext that it does not tally with the static character of Jamstack websites. There are many possibilities. We’ve just discussed one of them. And, paradoxically in this specific example, the result was a better all-around user experience, thanks to the fact that implementing search was not an obvious task but instead required a lot of deliberation. We may not have been able to say the same with an over-the-counter solution.
0 notes
Text
How to Add Lunr Search to your Gatsby Website
The Jamstack way of thinking and building websites is becoming more and more popular.
Have you already tried Gatsby, Nuxt, or Gridsome (to cite only a few)? Chances are that your first contact was a “Wow!” moment — so many things are automatically set up and ready to use.
There are some challenges, though, one of which is search functionality. If you’re working on any sort of content-driven site, you’ll likely run into search and how to handle it. Can it be done without any external server-side technology?
Search is not one of those things that come out of the box with Jamstack. Some extra decisions and implementation are required.
Fortunately, we have a bunch of options that might be more or less adapted to a project. We could use Algolia’s powerful search-as-service API. It comes with a free plan that is restricted to non-commercial projects with a limited capacity. If we were to use WordPress with WPGraphQL as a data source, we could take advantage of WordPress native search functionality and Apollo Client. Raymond Camden recently explored a few Jamstack search options, including pointing a search form directly at Google.
In this article, we will build a search index and add search functionality to a Gatsby website with Lunr, a lightweight JavaScript library providing an extensible and customizable search without the need for external, server-side services. We used it recently to add “Search by Tartan Name” to our Gatsby project tartanify.com. We absolutely wanted persistent search as-you-type functionality, which brought some extra challenges. But that’s what makes it interesting, right? I’ll discuss some of the difficulties we faced and how we dealt with them in the second half of this article.

Getting started
For the sake of simplicity, let’s use the official Gatsby blog starter. Using a generic starter lets us abstract many aspects of building a static website. If you’re following along, make sure to install and run it:
gatsby new gatsby-starter-blog https://github.com/gatsbyjs/gatsby-starter-blog cd gatsby-starter-blog gatsby develop
It’s a tiny blog with three posts we can view by opening up http://localhost:8000/___graphql in the browser.

Inverting index with Lunr.js 🙃
Lunr uses a record-level inverted index as its data structure. The inverted index stores the mapping for each word found within a website to its location (basically a set of page paths). It’s on us to decide which fields (e.g. title, content, description, etc.) provide the keys (words) for the index.
For our blog example, I decided to include all titles and the content of each article. Dealing with titles is straightforward since they are composed uniquely of words. Indexing content is a little more complex. My first try was to use the rawMarkdownBody field. Unfortunately, rawMarkdownBody introduces some unwanted keys resulting from the markdown syntax.

I obtained a “clean” index using the html field in conjunction with the striptags package (which, as the name suggests, strips out the HTML tags). Before we get into the details, let’s look into the Lunr documentation.
Here’s how we create and populate the Lunr index. We will use this snippet in a moment, specifically in our gatsby-node.js file.
const index = lunr(function () { this.ref('slug') this.field('title') this.field('content') for (const doc of documents) { this.add(doc) } })
documents is an array of objects, each with a slug, title and content property:
{ slug: '/post-slug/', title: 'Post Title', content: 'Post content with all HTML tags stripped out.' }
We will define a unique document key (the slug) and two fields (the title and content, or the key providers). Finally, we will add all of the documents, one by one.
Let’s get started.
Creating an index in gatsby-node.js
Let’s start by installing the libraries that we are going to use.
yarn add lunr graphql-type-json striptags
Next, we need to edit the gatsby-node.js file. The code from this file runs once in the process of building a site, and our aim is to add index creation to the tasks that Gatsby executes on build.
CreateResolvers is one of the Gatsby APIs controlling the GraphQL data layer. In this particular case, we will use it to create a new root field; Let’s call it LunrIndex.
Gatsby’s internal data store and query capabilities are exposed to GraphQL field resolvers on context.nodeModel. With getAllNodes, we can get all nodes of a specified type:
/* gatsby-node.js */ const { GraphQLJSONObject } = require(`graphql-type-json`) const striptags = require(`striptags`) const lunr = require(`lunr`) exports.createResolvers = ({ cache, createResolvers }) => { createResolvers({ Query: { LunrIndex: { type: GraphQLJSONObject, resolve: (source, args, context, info) => { const blogNodes = context.nodeModel.getAllNodes({ type: `MarkdownRemark`, }) const type = info.schema.getType(`MarkdownRemark`) return createIndex(blogNodes, type, cache) }, }, }, }) }
Now let’s focus on the createIndex function. That’s where we will use the Lunr snippet we mentioned in the last section.
/* gatsby-node.js */ const createIndex = async (blogNodes, type, cache) => { const documents = [] // Iterate over all posts for (const node of blogNodes) { const html = await type.getFields().html.resolve(node) // Once html is resolved, add a slug-title-content object to the documents array documents.push({ slug: node.fields.slug, title: node.frontmatter.title, content: striptags(html), }) } const index = lunr(function() { this.ref(`slug`) this.field(`title`) this.field(`content`) for (const doc of documents) { this.add(doc) } }) return index.toJSON() }
Have you noticed that instead of accessing the HTML element directly with const html = node.html, we’re using an await expression? That’s because node.html isn’t available yet. The gatsby-transformer-remark plugin (used by our starter to parse Markdown files) does not generate HTML from markdown immediately when creating the MarkdownRemark nodes. Instead, html is generated lazily when the html field resolver is called in a query. The same actually applies to the excerpt that we will need in just a bit.
Let’s look ahead and think about how we are going to display search results. Users expect to obtain a link to the matching post, with its title as the anchor text. Very likely, they wouldn’t mind a short excerpt as well.
Lunr’s search returns an array of objects representing matching documents by the ref property (which is the unique document key slug in our example). This array does not contain the document title nor the content. Therefore, we need to store somewhere the post title and excerpt corresponding to each slug. We can do that within our LunrIndex as below:
/* gatsby-node.js */ const createIndex = async (blogNodes, type, cache) => { const documents = [] const store = {} for (const node of blogNodes) { const {slug} = node.fields const title = node.frontmatter.title const [html, excerpt] = await Promise.all([ type.getFields().html.resolve(node), type.getFields().excerpt.resolve(node, { pruneLength: 40 }), ]) documents.push({ // unchanged }) store[slug] = { title, excerpt, } } const index = lunr(function() { // unchanged }) return { index: index.toJSON(), store } }
Our search index changes only if one of the posts is modified or a new post is added. We don’t need to rebuild the index each time we run gatsby develop. To avoid unnecessary builds, let’s take advantage of the cache API:
/* gatsby-node.js */ const createIndex = async (blogNodes, type, cache) => { const cacheKey = `IndexLunr` const cached = await cache.get(cacheKey) if (cached) { return cached } // unchanged const json = { index: index.toJSON(), store } await cache.set(cacheKey, json) return json }
Enhancing pages with the search form component
We can now move on to the front end of our implementation. Let’s start by building a search form component.
touch src/components/search-form.js
I opt for a straightforward solution: an input of type="search", coupled with a label and accompanied by a submit button, all wrapped within a form tag with the search landmark role.
We will add two event handlers, handleSubmit on form submit and handleChange on changes to the search input.
/* src/components/search-form.js */ import React, { useState, useRef } from "react" import { navigate } from "@reach/router" const SearchForm = ({ initialQuery = "" }) => { // Create a piece of state, and initialize it to initialQuery // query will hold the current value of the state, // and setQuery will let us change it const [query, setQuery] = useState(initialQuery) // We need to get reference to the search input element const inputEl = useRef(null) // On input change use the current value of the input field (e.target.value) // to update the state's query value const handleChange = e => { setQuery(e.target.value) } // When the form is submitted navigate to /search // with a query q paramenter equal to the value within the input search const handleSubmit = e => { e.preventDefault() // `inputEl.current` points to the mounted search input element const q = inputEl.current.value navigate(`/search?q=${q}`) } return ( <form role="search" onSubmit={handleSubmit}> <label htmlFor="search-input" style=> Search for: </label> <input ref={inputEl} id="search-input" type="search" value={query} placeholder="e.g. duck" onChange={handleChange} /> <button type="submit">Go</button> </form> ) } export default SearchForm
Have you noticed that we’re importing navigate from the @reach/router package? That is necessary since neither Gatsby’s <Link/> nor navigate provide in-route navigation with a query parameter. Instead, we can import @reach/router — there’s no need to install it since Gatsby already includes it — and use its navigate function.
Now that we’ve built our component, let’s add it to our home page (as below) and 404 page.
/* src/pages/index.js */ // unchanged import SearchForm from "../components/search-form" const BlogIndex = ({ data, location }) => { // unchanged return ( <Layout location={location} title={siteTitle}> <SEO title="All posts" /> <Bio /> <SearchForm /> // unchanged
Search results page
Our SearchForm component navigates to the /search route when the form is submitted, but for the moment, there is nothing behing this URL. That means we need to add a new page:
touch src/pages/search.js
I proceeded by copying and adapting the content of the the index.js page. One of the essential modifications concerns the page query (see the very bottom of the file). We will replace allMarkdownRemark with the LunrIndex field.
/* src/pages/search.js */ import React from "react" import { Link, graphql } from "gatsby" import { Index } from "lunr" import Layout from "../components/layout" import SEO from "../components/seo" import SearchForm from "../components/search-form"
// We can access the results of the page GraphQL query via the data props const SearchPage = ({ data, location }) => { const siteTitle = data.site.siteMetadata.title // We can read what follows the ?q= here // URLSearchParams provides a native way to get URL params // location.search.slice(1) gets rid of the "?" const params = new URLSearchParams(location.search.slice(1)) const q = params.get("q") || ""
// LunrIndex is available via page query const { store } = data.LunrIndex // Lunr in action here const index = Index.load(data.LunrIndex.index) let results = [] try { // Search is a lunr method results = index.search(q).map(({ ref }) => { // Map search results to an array of {slug, title, excerpt} objects return { slug: ref, ...store[ref], } }) } catch (error) { console.log(error) } return ( // We will take care of this part in a moment ) } export default SearchPage export const pageQuery = graphql` query { site { siteMetadata { title } } LunrIndex } `
Now that we know how to retrieve the query value and the matching posts, let’s display the content of the page. Notice that on the search page we pass the query value to the <SearchForm /> component via the initialQuery props. When the user arrives to the search results page, their search query should remain in the input field.
return ( <Layout location={location} title={siteTitle}> <SEO title="Search results" /> {q ? <h1>Search results</h1> : <h1>What are you looking for?</h1>} <SearchForm initialQuery={q} /> {results.length ? ( results.map(result => { return ( <article key={result.slug}> <h2> <Link to={result.slug}> {result.title || result.slug} </Link> </h2> <p>{result.excerpt}</p> </article> ) }) ) : ( <p>Nothing found.</p> )} </Layout> )
You can find the complete code in this gatsby-starter-blog fork and the live demo deployed on Netlify.
Instant search widget
Finding the most “logical” and user-friendly way of implementing search may be a challenge in and of itself. Let’s now switch to the real-life example of tartanify.com — a Gatsby-powered website gathering 5,000+ tartan patterns. Since tartans are often associated with clans or organizations, the possibility to search a tartan by name seems to make sense.
We built tartanify.com as a side project where we feel absolutely free to experiment with things. We didn’t want a classic search results page but an instant search “widget.” Often, a given search keyword corresponds with a number of results — for example, “Ramsay” comes in six variations. We imagined the search widget would be persistent, meaning it should stay in place when a user navigates from one matching tartan to another.
Let me show you how we made it work with Lunr. The first step of building the index is very similar to the gatsby-starter-blog example, only simpler:
/* gatsby-node.js */ exports.createResolvers = ({ cache, createResolvers }) => { createResolvers({ Query: { LunrIndex: { type: GraphQLJSONObject, resolve(source, args, context) { const siteNodes = context.nodeModel.getAllNodes({ type: `TartansCsv`, }) return createIndex(siteNodes, cache) }, }, }, }) } const createIndex = async (nodes, cache) => { const cacheKey = `LunrIndex` const cached = await cache.get(cacheKey) if (cached) { return cached } const store = {} const index = lunr(function() { this.ref(`slug`) this.field(`title`) for (node of nodes) { const { slug } = node.fields const doc = { slug, title: node.fields.Unique_Name, } store[slug] = { title: doc.title, } this.add(doc) } }) const json = { index: index.toJSON(), store } cache.set(cacheKey, json) return json }
We opted for instant search, which means that search is triggered by any change in the search input instead of a form submission.
/* src/components/searchwidget.js */ import React, { useState } from "react" import lunr, { Index } from "lunr" import { graphql, useStaticQuery } from "gatsby" import SearchResults from "./searchresults"
const SearchWidget = () => { const [value, setValue] = useState("") // results is now a state variable const [results, setResults] = useState([])
// Since it's not a page component, useStaticQuery for quering data // https://www.gatsbyjs.org/docs/use-static-query/ const { LunrIndex } = useStaticQuery(graphql` query { LunrIndex } `) const index = Index.load(LunrIndex.index) const { store } = LunrIndex const handleChange = e => { const query = e.target.value setValue(query) try { const search = index.search(query).map(({ ref }) => { return { slug: ref, ...store[ref], } }) setResults(search) } catch (error) { console.log(error) } } return ( <div className="search-wrapper"> // You can use a form tag as well, as long as we prevent the default submit behavior <div role="search"> <label htmlFor="search-input" className="visually-hidden"> Search Tartans by Name </label> <input id="search-input" type="search" value={value} onChange={handleChange} placeholder="Search Tartans by Name" /> </div> <SearchResults results={results} /> </div> ) } export default SearchWidget
The SearchResults are structured like this:
/* src/components/searchresults.js */ import React from "react" import { Link } from "gatsby" const SearchResults = ({ results }) => ( <div> {results.length ? ( <> <h2>{results.length} tartan(s) matched your query</h2> <ul> {results.map(result => ( <li key={result.slug}> <Link to={`/tartan/${result.slug}`}>{result.title}</Link> </li> ))} </ul> </> ) : ( <p>Sorry, no matches found.</p> )} </div> ) export default SearchResults
Making it persistent
Where should we use this component? We could add it to the Layout component. The problem is that our search form will get unmounted on page changes that way. If a user wants to browser all tartans associated with the “Ramsay” clan, they will have to retype their query several times. That’s not ideal.
Thomas Weibenfalk has written a great article on keeping state between pages with local state in Gatsby.js. We will use the same technique, where the wrapPageElement browser API sets persistent UI elements around pages.
Let’s add the following code to the gatsby-browser.js. You might need to add this file to the root of your project.
/* gatsby-browser.js */ import React from "react" import SearchWrapper from "./src/components/searchwrapper" export const wrapPageElement = ({ element, props }) => ( <SearchWrapper {...props}>{element}</SearchWrapper> )
Now let’s add a new component file:
touch src/components/searchwrapper.js
Instead of adding SearchWidget component to the Layout, we will add it to the SearchWrapper and the magic happens. ✨
/* src/components/searchwrapper.js */ import React from "react" import SearchWidget from "./searchwidget"
const SearchWrapper = ({ children }) => ( <> {children} <SearchWidget /> </> ) export default SearchWrapper
Creating a custom search query
At this point, I started to try different keywords but very quickly realized that Lunr’s default search query might not be the best solution when used for instant search.
Why? Imagine that we are looking for tartans associated with the name MacCallum. While typing “MacCallum” letter-by-letter, this is the evolution of the results:
m – 2 matches (Lyon, Jeffrey M, Lyon, Jeffrey M (Hunting))
ma – no matches
mac – 1 match (Brighton Mac Dermotte)
macc – no matches
macca – no matches
maccal – 1 match (MacCall)
maccall – 1 match (MacCall)
maccallu – no matches
maccallum – 3 matches (MacCallum, MacCallum #2, MacCallum of Berwick)
Users will probably type the full name and hit the button if we make a button available. But with instant search, a user is likely to abandon early because they may expect that the results can only narrow down letters are added to the keyword query.
That’s not the only problem. Here’s what we get with “Callum”:
c – 3 unrelated matches
ca – no matches
cal – no matches
call – no matches
callu – no matches
callum – one match
You can see the trouble if someone gives up halfway into typing the full query.
Fortunately, Lunr supports more complex queries, including fuzzy matches, wildcards and boolean logic (e.g. AND, OR, NOT) for multiple terms. All of these are available either via a special query syntax, for example:
index.search("+*callum mac*")
We could also reach for the index query method to handle it programatically.
The first solution is not satisfying since it requires more effort from the user. I used the index.query method instead:
/* src/components/searchwidget.js */ const search = index .query(function(q) { // full term matching q.term(el) // OR (default) // trailing or leading wildcard q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, }) }) .map(({ ref }) => { return { slug: ref, ...store[ref], } })
Why use full term matching with wildcard matching? That’s necessary for all keywords that “benefit” from the stemming process. For example, the stem of “different” is “differ.” As a consequence, queries with wildcards — such as differe*, differen* or different* — all result in no matches, while the full term queries differe, differen and different return matches.
Fuzzy matches can be used as well. In our case, they are allowed uniquely for terms of five or more characters:
q.term(el, { editDistance: el.length > 5 ? 1 : 0 }) q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, })
The handleChange function also “cleans up” user inputs and ignores single-character terms:
/* src/components/searchwidget.js */ const handleChange = e => { const query = e.target.value || "" setValue(query) if (!query.length) { setResults([]) } const keywords = query .trim() // remove trailing and leading spaces .replace(/\*/g, "") // remove user's wildcards .toLowerCase() .split(/\s+/) // split by whitespaces // do nothing if the last typed keyword is shorter than 2 if (keywords[keywords.length - 1].length < 2) { return } try { const search = index .query(function(q) { keywords // filter out keywords shorter than 2 .filter(el => el.length > 1) // loop over keywords .forEach(el => { q.term(el, { editDistance: el.length > 5 ? 1 : 0 }) q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, }) }) }) .map(({ ref }) => { return { slug: ref, ...store[ref], } }) setResults(search) } catch (error) { console.log(error) } }
Let’s check it in action:
m – pending
ma – 861 matches
mac – 600 matches
macc – 35 matches
macca – 12 matches
maccal – 9 matches
maccall – 9 matches
maccallu – 3 matches
maccallum – 3 matches
Searching for “Callum” works as well, resulting in four matches: Callum, MacCallum, MacCallum #2, and MacCallum of Berwick.
There is one more problem, though: multi-terms queries. Say, you’re looking for “Loch Ness.” There are two tartans associated with that term, but with the default OR logic, you get a grand total of 96 results. (There are plenty of other lakes in Scotland.)
I wound up deciding that an AND search would work better for this project. Unfortunately, Lunr does not support nested queries, and what we actually need is (keyword1 OR *keyword*) AND (keyword2 OR *keyword2*).
To overcome this, I ended up moving the terms loop outside the query method and intersecting the results per term. (By intersecting, I mean finding all slugs that appear in all of the per-single-keyword results.)
/* src/components/searchwidget.js */ try { // andSearch stores the intersection of all per-term results let andSearch = [] keywords .filter(el => el.length > 1) // loop over keywords .forEach((el, i) => { // per-single-keyword results const keywordSearch = index .query(function(q) { q.term(el, { editDistance: el.length > 5 ? 1 : 0 }) q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, }) }) .map(({ ref }) => { return { slug: ref, ...store[ref], } }) // intersect current keywordSearch with andSearch andSearch = i > 0 ? andSearch.filter(x => keywordSearch.some(el => el.slug === x.slug)) : keywordSearch }) setResults(andSearch) } catch (error) { console.log(error) }
The source code for tartanify.com is published on GitHub. You can see the complete implementation of the Lunr search there.
Final thoughts
Search is often a non-negotiable feature for finding content on a site. How important the search functionality actually is may vary from one project to another. Nevertheless, there is no reason to abandon it under the pretext that it does not tally with the static character of Jamstack websites. There are many possibilities. We’ve just discussed one of them.
And, paradoxically in this specific example, the result was a better all-around user experience, thanks to the fact that implementing search was not an obvious task but instead required a lot of deliberation. We may not have been able to say the same with an over-the-counter solution.
The post How to Add Lunr Search to your Gatsby Website appeared first on CSS-Tricks.
How to Add Lunr Search to your Gatsby Website published first on https://deskbysnafu.tumblr.com/
0 notes
Text
How to Add Lunr Search to your Gatsby Website
The Jamstack way of thinking and building websites is becoming more and more popular.
Have you already tried Gatsby, Nuxt, or Gridsome (to cite only a few)? Chances are that your first contact was a “Wow!” moment — so many things are automatically set up and ready to use.
There are some challenges, though, one of which is search functionality. If you’re working on any sort of content-driven site, you’ll likely run into search and how to handle it. Can it be done without any external server-side technology?
Search is not one of those things that come out of the box with Jamstack. Some extra decisions and implementation are required.
Fortunately, we have a bunch of options that might be more or less adapted to a project. We could use Algolia’s powerful search-as-service API. It comes with a free plan that is restricted to non-commercial projects with a limited capacity. If we were to use WordPress with WPGraphQL as a data source, we could take advantage of WordPress native search functionality and Apollo Client. Raymond Camden recently explored a few Jamstack search options, including pointing a search form directly at Google.
In this article, we will build a search index and add search functionality to a Gatsby website with Lunr, a lightweight JavaScript library providing an extensible and customizable search without the need for external, server-side services. We used it recently to add “Search by Tartan Name” to our Gatsby project tartanify.com. We absolutely wanted persistent search as-you-type functionality, which brought some extra challenges. But that’s what makes it interesting, right? I’ll discuss some of the difficulties we faced and how we dealt with them in the second half of this article.

Getting started
For the sake of simplicity, let’s use the official Gatsby blog starter. Using a generic starter lets us abstract many aspects of building a static website. If you’re following along, make sure to install and run it:
gatsby new gatsby-starter-blog https://github.com/gatsbyjs/gatsby-starter-blog cd gatsby-starter-blog gatsby develop
It’s a tiny blog with three posts we can view by opening up http://localhost:8000/___graphql in the browser.

Inverting index with Lunr.js

Lunr uses a record-level inverted index as its data structure. The inverted index stores the mapping for each word found within a website to its location (basically a set of page paths). It’s on us to decide which fields (e.g. title, content, description, etc.) provide the keys (words) for the index.
For our blog example, I decided to include all titles and the content of each article. Dealing with titles is straightforward since they are composed uniquely of words. Indexing content is a little more complex. My first try was to use the rawMarkdownBody field. Unfortunately, rawMarkdownBody introduces some unwanted keys resulting from the markdown syntax.

I obtained a “clean” index using the html field in conjunction with the striptags package (which, as the name suggests, strips out the HTML tags). Before we get into the details, let’s look into the Lunr documentation.
Here’s how we create and populate the Lunr index. We will use this snippet in a moment, specifically in our gatsby-node.js file.
const index = lunr(function () { this.ref('slug') this.field('title') this.field('content') for (const doc of documents) { this.add(doc) } })
documents is an array of objects, each with a slug, title and content property:
{ slug: '/post-slug/', title: 'Post Title', content: 'Post content with all HTML tags stripped out.' }
We will define a unique document key (the slug) and two fields (the title and content, or the key providers). Finally, we will add all of the documents, one by one.
Let’s get started.
Creating an index in gatsby-node.js
Let’s start by installing the libraries that we are going to use.
yarn add lunr graphql-type-json striptags
Next, we need to edit the gatsby-node.js file. The code from this file runs once in the process of building a site, and our aim is to add index creation to the tasks that Gatsby executes on build.
CreateResolvers is one of the Gatsby APIs controlling the GraphQL data layer. In this particular case, we will use it to create a new root field; Let’s call it LunrIndex.
Gatsby’s internal data store and query capabilities are exposed to GraphQL field resolvers on context.nodeModel. With getAllNodes, we can get all nodes of a specified type:
/* gatsby-node.js */ const { GraphQLJSONObject } = require(`graphql-type-json`) const striptags = require(`striptags`) const lunr = require(`lunr`) exports.createResolvers = ({ cache, createResolvers }) => { createResolvers({ Query: { LunrIndex: { type: GraphQLJSONObject, resolve: (source, args, context, info) => { const blogNodes = context.nodeModel.getAllNodes({ type: `MarkdownRemark`, }) const type = info.schema.getType(`MarkdownRemark`) return createIndex(blogNodes, type, cache) }, }, }, }) }
Now let’s focus on the createIndex function. That’s where we will use the Lunr snippet we mentioned in the last section.
/* gatsby-node.js */ const createIndex = async (blogNodes, type, cache) => { const documents = [] // Iterate over all posts for (const node of blogNodes) { const html = await type.getFields().html.resolve(node) // Once html is resolved, add a slug-title-content object to the documents array documents.push({ slug: node.fields.slug, title: node.frontmatter.title, content: striptags(html), }) } const index = lunr(function() { this.ref(`slug`) this.field(`title`) this.field(`content`) for (const doc of documents) { this.add(doc) } }) return index.toJSON() }
Have you noticed that instead of accessing the HTML element directly with const html = node.html, we’re using an await expression? That’s because node.html isn’t available yet. The gatsby-transformer-remark plugin (used by our starter to parse Markdown files) does not generate HTML from markdown immediately when creating the MarkdownRemark nodes. Instead, html is generated lazily when the html field resolver is called in a query. The same actually applies to the excerpt that we will need in just a bit.
Let’s look ahead and think about how we are going to display search results. Users expect to obtain a link to the matching post, with its title as the anchor text. Very likely, they wouldn’t mind a short excerpt as well.
Lunr’s search returns an array of objects representing matching documents by the ref property (which is the unique document key slug in our example). This array does not contain the document title nor the content. Therefore, we need to store somewhere the post title and excerpt corresponding to each slug. We can do that within our LunrIndex as below:
/* gatsby-node.js */ const createIndex = async (blogNodes, type, cache) => { const documents = [] const store = {} for (const node of blogNodes) { const {slug} = node.fields const title = node.frontmatter.title const [html, excerpt] = await Promise.all([ type.getFields().html.resolve(node), type.getFields().excerpt.resolve(node, { pruneLength: 40 }), ]) documents.push({ // unchanged }) store[slug] = { title, excerpt, } } const index = lunr(function() { // unchanged }) return { index: index.toJSON(), store } }
Our search index changes only if one of the posts is modified or a new post is added. We don’t need to rebuild the index each time we run gatsby develop. To avoid unnecessary builds, let’s take advantage of the cache API:
/* gatsby-node.js */ const createIndex = async (blogNodes, type, cache) => { const cacheKey = `IndexLunr` const cached = await cache.get(cacheKey) if (cached) { return cached } // unchanged const json = { index: index.toJSON(), store } await cache.set(cacheKey, json) return json }
Enhancing pages with the search form component
We can now move on to the front end of our implementation. Let’s start by building a search form component.
touch src/components/search-form.js
I opt for a straightforward solution: an input of type="search", coupled with a label and accompanied by a submit button, all wrapped within a form tag with the search landmark role.
We will add two event handlers, handleSubmit on form submit and handleChange on changes to the search input.
/* src/components/search-form.js */ import React, { useState, useRef } from "react" import { navigate } from "@reach/router" const SearchForm = ({ initialQuery = "" }) => { // Create a piece of state, and initialize it to initialQuery // query will hold the current value of the state, // and setQuery will let us change it const [query, setQuery] = useState(initialQuery) // We need to get reference to the search input element const inputEl = useRef(null) // On input change use the current value of the input field (e.target.value) // to update the state's query value const handleChange = e => { setQuery(e.target.value) } // When the form is submitted navigate to /search // with a query q paramenter equal to the value within the input search const handleSubmit = e => { e.preventDefault() // `inputEl.current` points to the mounted search input element const q = inputEl.current.value navigate(`/search?q=${q}`) } return ( <form role="search" onSubmit={handleSubmit}> <label htmlFor="search-input" style=> Search for: </label> <input ref={inputEl} id="search-input" type="search" value={query} placeholder="e.g. duck" onChange={handleChange} /> <button type="submit">Go</button> </form> ) } export default SearchForm
Have you noticed that we’re importing navigate from the @reach/router package? That is necessary since neither Gatsby’s <Link/> nor navigate provide in-route navigation with a query parameter. Instead, we can import @reach/router — there’s no need to install it since Gatsby already includes it — and use its navigate function.
Now that we’ve built our component, let’s add it to our home page (as below) and 404 page.
/* src/pages/index.js */ // unchanged import SearchForm from "../components/search-form" const BlogIndex = ({ data, location }) => { // unchanged return ( <Layout location={location} title={siteTitle}> <SEO title="All posts" /> <Bio /> <SearchForm /> // unchanged
Search results page
Our SearchForm component navigates to the /search route when the form is submitted, but for the moment, there is nothing behing this URL. That means we need to add a new page:
touch src/pages/search.js
I proceeded by copying and adapting the content of the the index.js page. One of the essential modifications concerns the page query (see the very bottom of the file). We will replace allMarkdownRemark with the LunrIndex field.
/* src/pages/search.js */ import React from "react" import { Link, graphql } from "gatsby" import { Index } from "lunr" import Layout from "../components/layout" import SEO from "../components/seo" import SearchForm from "../components/search-form"
// We can access the results of the page GraphQL query via the data props const SearchPage = ({ data, location }) => { const siteTitle = data.site.siteMetadata.title // We can read what follows the ?q= here // URLSearchParams provides a native way to get URL params // location.search.slice(1) gets rid of the "?" const params = new URLSearchParams(location.search.slice(1)) const q = params.get("q") || ""
// LunrIndex is available via page query const { store } = data.LunrIndex // Lunr in action here const index = Index.load(data.LunrIndex.index) let results = [] try { // Search is a lunr method results = index.search(q).map(({ ref }) => { // Map search results to an array of {slug, title, excerpt} objects return { slug: ref, ...store[ref], } }) } catch (error) { console.log(error) } return ( // We will take care of this part in a moment ) } export default SearchPage export const pageQuery = graphql` query { site { siteMetadata { title } } LunrIndex } `
Now that we know how to retrieve the query value and the matching posts, let’s display the content of the page. Notice that on the search page we pass the query value to the <SearchForm /> component via the initialQuery props. When the user arrives to the search results page, their search query should remain in the input field.
return ( <Layout location={location} title={siteTitle}> <SEO title="Search results" /> {q ? <h1>Search results</h1> : <h1>What are you looking for?</h1>} <SearchForm initialQuery={q} /> {results.length ? ( results.map(result => { return ( <article key={result.slug}> <h2> <Link to={result.slug}> {result.title || result.slug} </Link> </h2> <p>{result.excerpt}</p> </article> ) }) ) : ( <p>Nothing found.</p> )} </Layout> )
You can find the complete code in this gatsby-starter-blog fork and the live demo deployed on Netlify.
Instant search widget
Finding the most “logical” and user-friendly way of implementing search may be a challenge in and of itself. Let’s now switch to the real-life example of tartanify.com — a Gatsby-powered website gathering 5,000+ tartan patterns. Since tartans are often associated with clans or organizations, the possibility to search a tartan by name seems to make sense.
We built tartanify.com as a side project where we feel absolutely free to experiment with things. We didn’t want a classic search results page but an instant search “widget.” Often, a given search keyword corresponds with a number of results — for example, “Ramsay” comes in six variations. We imagined the search widget would be persistent, meaning it should stay in place when a user navigates from one matching tartan to another.
Let me show you how we made it work with Lunr. The first step of building the index is very similar to the gatsby-starter-blog example, only simpler:
/* gatsby-node.js */ exports.createResolvers = ({ cache, createResolvers }) => { createResolvers({ Query: { LunrIndex: { type: GraphQLJSONObject, resolve(source, args, context) { const siteNodes = context.nodeModel.getAllNodes({ type: `TartansCsv`, }) return createIndex(siteNodes, cache) }, }, }, }) } const createIndex = async (nodes, cache) => { const cacheKey = `LunrIndex` const cached = await cache.get(cacheKey) if (cached) { return cached } const store = {} const index = lunr(function() { this.ref(`slug`) this.field(`title`) for (node of nodes) { const { slug } = node.fields const doc = { slug, title: node.fields.Unique_Name, } store[slug] = { title: doc.title, } this.add(doc) } }) const json = { index: index.toJSON(), store } cache.set(cacheKey, json) return json }
We opted for instant search, which means that search is triggered by any change in the search input instead of a form submission.
/* src/components/searchwidget.js */ import React, { useState } from "react" import lunr, { Index } from "lunr" import { graphql, useStaticQuery } from "gatsby" import SearchResults from "./searchresults"
const SearchWidget = () => { const [value, setValue] = useState("") // results is now a state variable const [results, setResults] = useState([])
// Since it's not a page component, useStaticQuery for quering data // https://www.gatsbyjs.org/docs/use-static-query/ const { LunrIndex } = useStaticQuery(graphql` query { LunrIndex } `) const index = Index.load(LunrIndex.index) const { store } = LunrIndex const handleChange = e => { const query = e.target.value setValue(query) try { const search = index.search(query).map(({ ref }) => { return { slug: ref, ...store[ref], } }) setResults(search) } catch (error) { console.log(error) } } return ( <div className="search-wrapper"> // You can use a form tag as well, as long as we prevent the default submit behavior <div role="search"> <label htmlFor="search-input" className="visually-hidden"> Search Tartans by Name </label> <input id="search-input" type="search" value={value} onChange={handleChange} placeholder="Search Tartans by Name" /> </div> <SearchResults results={results} /> </div> ) } export default SearchWidget
The SearchResults are structured like this:
/* src/components/searchresults.js */ import React from "react" import { Link } from "gatsby" const SearchResults = ({ results }) => ( <div> {results.length ? ( <> <h2>{results.length} tartan(s) matched your query</h2> <ul> {results.map(result => ( <li key={result.slug}> <Link to={`/tartan/${result.slug}`}>{result.title}</Link> </li> ))} </ul> </> ) : ( <p>Sorry, no matches found.</p> )} </div> ) export default SearchResults
Making it persistent
Where should we use this component? We could add it to the Layout component. The problem is that our search form will get unmounted on page changes that way. If a user wants to browser all tartans associated with the “Ramsay” clan, they will have to retype their query several times. That’s not ideal.
Thomas Weibenfalk has written a great article on keeping state between pages with local state in Gatsby.js. We will use the same technique, where the wrapPageElement browser API sets persistent UI elements around pages.
Let’s add the following code to the gatsby-browser.js. You might need to add this file to the root of your project.
/* gatsby-browser.js */ import React from "react" import SearchWrapper from "./src/components/searchwrapper" export const wrapPageElement = ({ element, props }) => ( <SearchWrapper {...props}>{element}</SearchWrapper> )
Now let’s add a new component file:
touch src/components/searchwrapper.js
Instead of adding SearchWidget component to the Layout, we will add it to the SearchWrapper and the magic happens.

/* src/components/searchwrapper.js */ import React from "react" import SearchWidget from "./searchwidget"
const SearchWrapper = ({ children }) => ( <> {children} <SearchWidget /> </> ) export default SearchWrapper
Creating a custom search query
At this point, I started to try different keywords but very quickly realized that Lunr’s default search query might not be the best solution when used for instant search.
Why? Imagine that we are looking for tartans associated with the name MacCallum. While typing “MacCallum” letter-by-letter, this is the evolution of the results:
m – 2 matches (Lyon, Jeffrey M, Lyon, Jeffrey M (Hunting))
ma – no matches
mac – 1 match (Brighton Mac Dermotte)
macc – no matches
macca – no matches
maccal – 1 match (MacCall)
maccall – 1 match (MacCall)
maccallu – no matches
maccallum – 3 matches (MacCallum, MacCallum #2, MacCallum of Berwick)
Users will probably type the full name and hit the button if we make a button available. But with instant search, a user is likely to abandon early because they may expect that the results can only narrow down letters are added to the keyword query.
That’s not the only problem. Here’s what we get with “Callum”:
c – 3 unrelated matches
ca – no matches
cal – no matches
call – no matches
callu – no matches
callum – one match
You can see the trouble if someone gives up halfway into typing the full query.
Fortunately, Lunr supports more complex queries, including fuzzy matches, wildcards and boolean logic (e.g. AND, OR, NOT) for multiple terms. All of these are available either via a special query syntax, for example:
index.search("+*callum mac*")
We could also reach for the index query method to handle it programatically.
The first solution is not satisfying since it requires more effort from the user. I used the index.query method instead:
/* src/components/searchwidget.js */ const search = index .query(function(q) { // full term matching q.term(el) // OR (default) // trailing or leading wildcard q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, }) }) .map(({ ref }) => { return { slug: ref, ...store[ref], } })
Why use full term matching with wildcard matching? That’s necessary for all keywords that “benefit” from the stemming process. For example, the stem of “different” is “differ.” As a consequence, queries with wildcards — such as differe*, differen* or different* — all result in no matches, while the full term queries differe, differen and different return matches.
Fuzzy matches can be used as well. In our case, they are allowed uniquely for terms of five or more characters:
q.term(el, { editDistance: el.length > 5 ? 1 : 0 }) q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, })
The handleChange function also “cleans up” user inputs and ignores single-character terms:
/* src/components/searchwidget.js */ const handleChange = e => { const query = e.target.value || "" setValue(query) if (!query.length) { setResults([]) } const keywords = query .trim() // remove trailing and leading spaces .replace(/\*/g, "") // remove user's wildcards .toLowerCase() .split(/\s+/) // split by whitespaces // do nothing if the last typed keyword is shorter than 2 if (keywords[keywords.length - 1].length < 2) { return } try { const search = index .query(function(q) { keywords // filter out keywords shorter than 2 .filter(el => el.length > 1) // loop over keywords .forEach(el => { q.term(el, { editDistance: el.length > 5 ? 1 : 0 }) q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, }) }) }) .map(({ ref }) => { return { slug: ref, ...store[ref], } }) setResults(search) } catch (error) { console.log(error) } }
Let’s check it in action:
m – pending
ma – 861 matches
mac – 600 matches
macc – 35 matches
macca – 12 matches
maccal – 9 matches
maccall – 9 matches
maccallu – 3 matches
maccallum – 3 matches
Searching for “Callum” works as well, resulting in four matches: Callum, MacCallum, MacCallum #2, and MacCallum of Berwick.
There is one more problem, though: multi-terms queries. Say, you’re looking for “Loch Ness.” There are two tartans associated with that term, but with the default OR logic, you get a grand total of 96 results. (There are plenty of other lakes in Scotland.)
I wound up deciding that an AND search would work better for this project. Unfortunately, Lunr does not support nested queries, and what we actually need is (keyword1 OR *keyword*) AND (keyword2 OR *keyword2*).
To overcome this, I ended up moving the terms loop outside the query method and intersecting the results per term. (By intersecting, I mean finding all slugs that appear in all of the per-single-keyword results.)
/* src/components/searchwidget.js */ try { // andSearch stores the intersection of all per-term results let andSearch = [] keywords .filter(el => el.length > 1) // loop over keywords .forEach((el, i) => { // per-single-keyword results const keywordSearch = index .query(function(q) { q.term(el, { editDistance: el.length > 5 ? 1 : 0 }) q.term(el, { wildcard: lunr.Query.wildcard.LEADING | lunr.Query.wildcard.TRAILING, }) }) .map(({ ref }) => { return { slug: ref, ...store[ref], } }) // intersect current keywordSearch with andSearch andSearch = i > 0 ? andSearch.filter(x => keywordSearch.some(el => el.slug === x.slug)) : keywordSearch }) setResults(andSearch) } catch (error) { console.log(error) }
The source code for tartanify.com is published on GitHub. You can see the complete implementation of the Lunr search there.
Final thoughts
Search is often a non-negotiable feature for finding content on a site. How important the search functionality actually is may vary from one project to another. Nevertheless, there is no reason to abandon it under the pretext that it does not tally with the static character of Jamstack websites. There are many possibilities. We’ve just discussed one of them.
And, paradoxically in this specific example, the result was a better all-around user experience, thanks to the fact that implementing search was not an obvious task but instead required a lot of deliberation. We may not have been able to say the same with an over-the-counter solution.
The post How to Add Lunr Search to your Gatsby Website appeared first on CSS-Tricks.
source https://css-tricks.com/how-to-add-lunr-search-to-your-gatsby-website/
from WordPress https://ift.tt/3eKOx2M via IFTTT
0 notes
Photo

New Post has been published on https://travelonlinetips.com/bannock-indigenous-bread-is-having-a-moment-in-toronto-2/
Bannock – indigenous bread – is having a moment in Toronto
Virtually every culture on earth has its own special relationship with bread. While the Old World was baking baguettes and sourdough, the Indigenous peoples of the New World were handcrafting skaan and frybread. During North American colonization, sadly, the Europeans imposed their will over the First Nations with a heavy hand. In Toronto, bannock exists as a reminder of that lamentable past. It is as much a local delicacy as it is a cultural touchstone.
“The roots of bannock trace back to scones in Scotland,” explains Shawn Adler, owner of the Pow Wow Cafe in the Kensington Market neighborhood of Toronto. “It is full of things that were brought over post-colonization, like white sugar, and baking powder. But it’s born of indigenous ingenuity. It’s a bread of oppression that was turned into a delicious treat.”
Adler traces his roots back to the Ojibway – a large Indigenous ethnic group spread out across much of Ontario province. In 2016, he opened Pow Wow as a way to bring the food he grew up with to a broader audience.
He gained an immediate following with his ‘Indian taco,’ which has familiar ingredients such as chili and shredded cheddar wrapped in bannock instead of a traditional tortilla. According to him, in his youth, “everyone had a story about bannock, like what grandma used to make.” It was comfort food with a crunch.
Although it’s virtually unseen on American menus these days, bannock has morphed into a reliable specialty in this part of Ontario. At Kukum Kitchen, a popular First Nations outpost helmed by Indigenous chef Joseph Shawana, it appears in crostini form beneath a smattering of pan-seared seal loin.
Tea-N-Bannock gives the carb the cafe treatment and bakes a take-home iteration while you wait. In the heart of downtown, a hip eatery even named itself after Toronto’s trendiest bread.
How’s it made? Well, that can vary, depending on who you ask. “There are a bunch of recipes, but I try to make it dense like a biscuit,” notes Adler. “I use wheat flour, sugar, lard – or sometimes butter – baking powder and milk. But you can use duck fat, bacon, cheddar cheese. It can be very versatile.”
Although Adler relies on what he considers a more traditional recipe, it can change with the seasons, or with what he feels like topping it with on any particular day. He might make it lighter and less dense in consistency, for example, if using something like fish or vegetables as opposed to heartier meats. Bannock can also arrive in either baked or fried form depending on the vendor; chewier from some, extra crispy from others.
Bannock at Pow Wow — Photo courtesy of Pow Wow Cafe
But whatever the texture it exhibits or ingredients it carries, bannock is loaded heavy with the tales of a proud people that persevered in the face of adversity. As the Indigenous were ripped from their lands in generations past, they were left with limited feeding options. In Canada, the government provided rations to displaced natives. This included flour, eggs, lard, sugar: the building blocks of what became bannock.
“I always tell people you can compare it to Jewish people’s matzoh,” says Adler. “They made it when running away from their oppressors. It’s the same with bannock. Indigenous people created it by rationing from the land.”
In sharing that legacy with modern diners, the Indigenous chefs of Toronto are dishing out more than just Indian tacos and high-minded crostini. They are offering a measure of virtue in every bite. Across a cultural divide, breaking bread assumes a more fulfilling role than any one meal can provide.
var gci_10b = ; gci_10b.content_type="Article";
var googletag = googletag || ; googletag.cmd = googletag.cmd || []; (function() var gads = document.createElement('script'); gads.async = true; gads.type = 'text/javascript'; var useSSL = 'https:' == document.location.protocol; gads.src = (useSSL ? 'https:' : 'http:') + '//www.googletagservices.com/tag/js/gpt.js'; var node = document.getElementsByTagName('script')[0]; node.parentNode.insertBefore(gads, node); )();
window.fbAsyncInit = function() FB.init( appId : '213816218687991', xfbml : true, version : 'v2.0' ); ;
(function(d, s, id) var js, fjs = d.getElementsByTagName(s)[0]; if (d.getElementById(id)) return; js = d.createElement(s); js.id = id; js.src = "http://connect.facebook.net/en_US/sdk.js"; fjs.parentNode.insertBefore(js, fjs); (document, 'script', 'facebook-jssdk'));
$(document).ready(function()
$(".slidingDiv").hide(); $(".show_hide").show();
$('.show_hide').click(function() $(".slidingDiv").slideToggle(); );
);
$(window).scroll(function() var scroll_top = $(this).scrollTop(); // get scroll position top var height_element_parent = $(".vert-social-sharing-bar").parent().outerHeight(); //get high parent element var height_element = $(".vert-social-sharing-bar").height(); //get high of elemeneto var position_fixed_max = height_element_parent - height_element; // get the maximum position of the elemen var position_fixed = scroll_top < 30 ? 30 - scroll_top : position_fixed_max > scroll_top ? 0 : position_fixed_max - scroll_top ; $(".vert-social-sharing-bar").css("top",position_fixed); );
/* ----- Begin Step 1 ----- */ //Load the APS JavaScript Library !function(a9,a,p,s,t,A,g)if(a[a9])return;function q(c,r)a[a9]._Q.push([c,r])a[a9]=init:function() q("i",arguments),fetchBids:function()q("f",arguments),setDisplayBids:function() ,targetingKeys:function()return[],_Q:[];A=p.createElement(s);A .async=!0;A.src=t;g=p.getElementsByTagName(s)[0];g.parentNode.insertBefore(A,g) ("apstag",window,document,"script","//c.amazon-adsystem.com/aax2/apstag.js"); //Initialize the Library apstag.init( pubID: '3090', adServer: 'googletag' ); /* ----- End Step 1 ----- */
$(function() $(".th-slide").jCarouselLite( btnNext: ".next", btnPrev: ".prev", scroll: 1, circular: false ); );
$(document).ready(function()
$(".scrollToTop").hide();
//Check to see if the window is top if not then display button $(window).scroll(function() if ($(this).scrollTop() > 100) $('.scrollToTop').fadeIn(); else $('.scrollToTop').fadeOut(); );
//Click event to scroll to top $('.scrollToTop').click(function() $('html, body').animate(scrollTop : 0,800); return false; );
);
Source link
0 notes