
Statistics
We looked inside some of the posts by xeektech and here's what we found interesting.
Average Info
Notes Per Post
8
Likes Per Post
8
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
2 months
Number of Posts By Type
Text
14
Link
3
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
Difference between “var” and “let” in JavaScript
Understanding var
Right off the bat, let’s take an example here
for (var i=0; i<10; i++){ console.log('i is: ' + i); }
Here I have declared var i as the for loop counter but an important consideration here is the scope of this variable i. If you take a moment and think closely, it’s part of the enclosing scope (which in this case is the global scope) and not that of the for loop itself. In order to test this premise, lets look at the following line of code (to be executed after the execution of the for loop mentioned earlier):
console.log('i outside of the for loop is: ' + i);
its output is:
i outside of the for loop is: 10
Whoa? Exactly, as this doesn’t happen in some of the other programming languages such as Java.
This behavior is dangerous especially if the developers tend to use and reuse already declared variables and they don’t have solid understanding of how the scope works in JavaScript.
Let’s expand this example a little further, consider the following:
var check = true; if(check){ for (var i=0; i<10; i++){ console.log('i is: ' + i); } } console.log('i outside of the for loop is: ' + i);
Just by looking at the code, it appears that the last line should throw the ReferenceError since var i is declared in the scope of the “if” block but wait, this code still works, try it out.
Why? This piece of code behaves exactly the same way as the one before because JavaScript doesn’t support block scopes. This is an important consideration.
How to get around this ungainly JS behavior? Luckily in ES6 we can now declare variables using the “let” keyword.
Enter let As already mentioned, it lets the developer declare variables just like var but it goes on up on var i.e. it attaches the variable to the scope it’s contained in hence achieving the missing block scoping.
Let’s refactor the existing example with “let”
for (let i=0; i<10; i++){ console.log('i is: ' + i); } console.log('i outside of the for loop is: ' + i);
In this case, you will get the ReferenceError instead as “i” isn’t accessible outside the scope of the for loop.
Besides, you can also create any scope (code inside the curly braces {}) and attach variables to it.
Yet another example
{ let somevar = 'some value'; console.log('some var inside the block scope: ' + somevar); } //console.log('some var outside the block scope: ' + somevar);
In the above code snippet, I have declared a variable by the name of somevar inside a block scope (pay attention to the curly braces). Its accessible only inside the given scope and not outside (as can be confirmed using the console.log statement inside the scope which works but the one outside doesn’t work when the comments are removed and a ReferenceError is encountered instead).
Bonus, the const keyword.
It’s the same as let but once declared its value cannot be changed thereafter in the code.
Here’s an example:
const pi=3.14; pi = 6.26; //TypeError: Assignment to constant variable.
2 notes
·
View notes
Text
Running a mongoDB docker container

Creating and setting up a MongoDB docker container is really easy and straight forward. First off, here's an overview of the environment I am using:
Docker host: Ubuntu 16.04 LTS (Xenial) Docker version: 1.12.1 (both client and server) MongoDB docker image: "mongo" the official image available on dockerhub
Before we delve into setting things up, here is a little something about the storage, important IMO:
There are basically two options:
1- Docker Managed:
As the name implies, docker manages the storage on host's filesystem using its internal volume management.
This is the default option
Pro: Fairly transparent and easy for the user (no setup hassle required)
Con: The files may be hard to locate for tools & apps that run directly on the host system (outside the container)
2- Manual Setup (with attached storage):
Requires creating a directory on the host's filesystem, outside the container
Mounting the directory created in the above step to a directory that is visible from inside the container
Pro: Taking this option will help in keeping the files in a known location on the host
Con: The usual hassle: the user needs to ensure the directory exists & the permissions on it are set up correctly
For the purpose of this blog, I am taking the second option.
Right, with everything else settled, let's get rolling now:
1- Create a directory on the host system:
$ sudo mkdir ~/mongoData
2- Installing the container:
$ sudo docker run -d --name mongo -p 27017:27017 -v ~/home/sam/mongoData:/data/db mongo
This command will start off the container if the image is available locally, if not, it will pull it off dockerhub and then run it.
Pay attention to different switches/flags/parameters of this docker run command:
-d: runs the container in the background.
--name: assigns the name to the container (e.g. --name mongo, assigns the string "mongo" as the container name)
-p: port mapping from container to the host system [format: -p (host port):(container port)]. Putting it in another way, this flag exposes the container's port to the host. If the port isn't exposed, any external client application won't be able to access the container running inside the given host. In this example I have kept the host's port same as MongoDB's default port
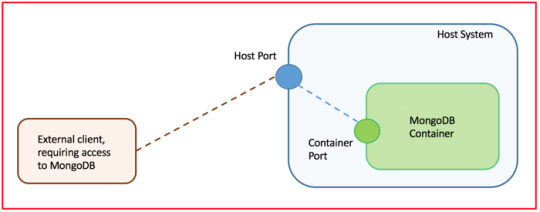
-v: maps the directory on the container to the one on the host (ex: -v ~/home/sam/mongoData:/data/db. The first part /home/sam/mongoData is the host's directory and this one data/db is the container's directory). This is the principal mechanism to import/export in & out of the container
mongo: is the name of the image on dockerhub
3- After the container is all set and running (can be verified by running $ docker ps -a), its time to connect to mongoDB running inside the newly created container
Install the MongoDB client tools
$ sudo apt-get install mongodb-clients
Connect to MongoDB using the 'mongo' shell which should be available now because of the command executed in the previous step:
> mongo localhost/testDB
Note: If connecting from an external system, outside the docker host, then specify the IP address of the docker host system. Besides, you can choose any name for the database, I have chosen testDB in this example
Lets's create a collection and a few documents inside. In this example I am storing info related to books (run these commands one after the other)
The results can be seen in the following screenshot

Notes:
In case you wish to stop the container, run the following command:
$ docker stop mongo
Removing the container would require the execution of this command:
$ docker rm mongo
A few helpful links:
https://www.thachmai.info/2015/04/30/running-mongodb-container/
https://hub.docker.com/_/mongo/
https://docs.mongodb.com/manual/tutorial/insert-documents/
0 notes
Text
Setting static ip on Ubuntu Server 16.04 guest VM running inside Oracle Virtualbox
In some cases it becomes imperative to make the IP static, of the system that one is using as the hosting platform of the solution. It is done to maintain the host’s/server’s connectivity profile consistent otherwise it will keep on acquiring a new IP address every time its bounced off. The latter scenario (DHCP) requires adjusting the connectivity setting of all the dependent resources/apps after every reboot. Too much effort and that too error prone, isn’t it?
This post is going to focus mainly on making the IP static of the ubuntu server (16.04), running as a guest vm inside Virtualbox.
System Specification:
Virtualization Software: Oracle Virtualbox version 5.1.6 r110634 (Qt5.5.1)
Guest OS: Ubuntu 16.04.1 LTS [Server, codename: Xenial]
Host OS: OSX El Capitan version 10.11.4
Steps:
- Stop the guest vm
- Open Virtulabox > Preferences > Network > Host-only Networks
- Click the add button, vboxnet0 network adapter will be added

- Click the edit button to pop open the adapter's config. Leave the defaults as they are (but if need be, make the necessary amendments here)

- Click on the DHCP Server tab and disable the Enable Server checkbox

- Now open the vm's network settings: Settings > Network
- Specify Adapter 1 as Host-only Adapter and also choose its Name as vboxnet0 (if its not already selected)

- Click on the Adapter 2 tab and specify NAT as the adapter

- Start the VM
- On the terminal, run this to see your adapters:
$ ls /sys/class/net

(Note: Since I have docker installed on the vm hence docker0 is also returned by the command)
- Open the interface file on the vm:
$ sudo vim /etc/network/interfaces
- Change the settings of enp0s3 (the primary adapter) and enp0s8 (if its already not configured properly). Here is how the interface file looks like on my guest vm:
auto lo
iface lo inet loopback
# The primary network interface, Host-only adapter
auto enp0s3
iface enp0s3 inet static #change from dhcp to static
address 192.168.56.20 #static IP of this VM
netmask 255.255.255.0
network 192.168.56.0
broadcast 192.168.56.255
# NAT dhcp adapter
auto enp0s8
iface enp0s8 inet dhcp
(Note: you can change these entries as per your environment/preferences)
- Save this file (hit esc then type in :wq and hit enter)
- Open the hosts file on the vm::
$ sudo vim /etc/hosts
- Add this entry, under the localhost entry:
192.168.56.20 rn-ubuntu-sbx
Note: rn-ubuntu-sbx is the name of the host the ip would resolve to
- Save this file (hit esc then type in :wq and hit enter)
- Restart the network adapters by running either of the following commands:
$ sudo service networking restart
or
$ sudo /etc/init.d/networking restart
Note: If either of the above commands are not having the desired effect, then bounce off the vm by running $ sudo reboot
- Run this command to verify the changes being made to the network configs:
$ ifconfig
- Here is a snippet of that (inside my guest vm):

- Verify the following:
If the internet inside the vm is working:
$ ping google.com
If the host (osx) is reachable:
$ ping 192.168.56.1
Note: Recall, this is specified as a vboxnet0 config. This can also be retrieved by running $ ifconfig on the host’s (osx) terminal. It can be seen under the vboxnet0 head. Here is the screenshot for reference:

If the vm is accessible via the host (osx). Run this command on the mac’s terminal
$ ping 192.168.56.20
- If everything checks out fine then that’s it, you now have successfully assigned a static IP to your Ubuntu 16.04 server running as a Virtualbox vm
1 note
·
View note
Text
Sharing folders between OSX host and Ubuntu (16.04.1 LTS - Server) guest vm running inside Virutalbox
Another quick tip.
- Open Virtualbox on the host osx system. Choose: Settings > Shared Folders.
- Click the Add button and select the folder on the host’s file system that needs to be shared with the VM and then choose Auto-mount. The Auto-mount setting will mount the shared folder on the guest vm, every time it’s started.

Run the VM and install guest additions by running these commands in the terminal:
$ sudo apt-get update
$ sudo apt-get install virtualbox-guest-dkms
- Reboot VM: $ sudo reboot
- Add the vm’s user to the vboxsf group: $sudo adduser <username> vboxsf
- Reboot VM: sudo reboot.
- That’s it, you can now access the shared folder (prefixed with ‘sf_’) inside the media folder: $ cd /media

1 note
·
View note
Text
SSH into Ubuntu guest vm from OSX host
Here is a quickie after a while.
Virtualization Software: Oracle Virtualbox version 5.1.6 r110634 (Qt5.5.1)
Guest OS: Ubuntu 16.04.1 LTS [Server, codename: Xenial]
Host OS: OSX El Capitan version 10.11.4
After installing Ubuntu inside the vm, shut it down and change it’s network config as per the screenshot below:

Also verify Settings > System > “Enable I/O APIC” property is ticked.
Start off the VM and perform the following steps on the terminal/console:
$ sudo apt-get update
Install ssh (both ssh client and ssh server): $ sudo apt-get install ssh
Note down the ip address of the ubuntu guest VM after obtaining it by running this command: $ ifconfig
Now pop open the terminal on the host OSX and try this command and run: $ ssh <ubuntuUser>@<VM IP>
example: ssh [email protected]
Enter the user’s password when prompted.
That’s it, you now have access to the Ubuntu vm from the OSX terminal.
Tip: Verify the access by running the pwd command to output the current directory structure insider the vm
0 notes
Text
Prototypal Inheritance in JavaScript
This article is moved to my new website
0 notes
Text
The three Vs of Supply Chain Management
Of late, I've picked up on reading about Supply Chain Management (SCM). One interesting realization thus far has been somewhat knowing the “value” we, as in the tech team responsible for integrating the enterprise systems for the eventual realization of the given business processes, are providing to our business along-with gaining in-depth knowledge about the inner mechanics of how this world operates. I thought about sharing some insights on the subject matter and this article is one such attempt.
These three Vs are: Velocity, Variability and Visibility. This article focuses on: what they are, their relationship among each other and their significance.
Velocity: This, simply put, is the pace of doing business which ideally should remain on the upwardly curve. To elaborate this point a little further, this term indicates the relative speed of all transactions made collectively within the supply chain community. Maximum velocity is most desirable because it indicates a higher asset turnover for stockholders and faster order to delivery response for customers. Velocity is enhanced by the supply chain running efficiently. Methods of increasing the velocity of transactions along the supply chain include factors such as:
Relying on rapid transportation
Reducing the time in which the inventory isn't moving by employing Just-In-Time delivery and Lean Manufacturing methodologies
Eliminating activities that don't add value. And so on
Variability: It's the natural tendency of the results of all business activities to fluctuate above and below an average value. Wait, what? A few examples might help here, fluctuations around: average time to completion, average number of defects, average daily sales, average production yields etc. Now the goal here is ensuring reduced variability to increase high velocity. Putting it another way, both variability and velocity have an inverse relationship. An improved supply chain is the one in which there is reduced supply and demand variability. One way to handle this phenomenon traditionally has been keeping safety stock to match supply to spikes in demand. This dovetails into a related point that is inventory management. Remember one thing, inventory is a killer, it has to be handled meticulously; meaning the priority should always be to ensure a) no stock-outs coz stockouts lead to the retailer losing competitive advantage, simply because of not having the items to sell when the customer demands for them and b) avoid filling up of the inventory which happens during receding demand (one of the key indicators of recession) both situations are bad for the overall business.
Let’s bring out the third V, i.e. Visibility
Visibility: Refers to the ability to view and access important information throughout the functioning of supply chain, at any given point in time. Increased visibility is very beneficial to the supply chain partners and the end customers. With better visibility stakeholders/partners can see the results of activities happening in the chain. Minor incremental changes are also spotted via technological means/processes. An example here: POS (point of sale) data is visible to systems running in warehouses, the manufacturing plants and supplier facilities. Now the data about the sale can instantaneously trigger appropriate actions in all those places automatically, i.e. shipments are scheduled from the warehouse to replenish the retailer's shelf, manufacturing produces another unit and the suppliers releases parts to the manufacturer. With the whole process working automatically as enabled by the technology, the supply chain partners can see savings in cost and time.
Greater visibility into the supply chain results in higher velocity which is one of the primary goals of having a supply chain in the first place. It also helps in reducing the safety stocks which is yet another avenue of achieving more savings.
Simply put, visibility is the friend of velocity to the bane of variability.
Another related and noteworthy concept to mention here is that of Integrated Operations (even though, it doesn’t start with a V :) )
Integrated Operations: Relate to requiring everyone in the chain to form partnerships and foster collaboration. Technology/connectivity plays a very important role in forming these collaborations. SCM benefits from integrating technologies associated with specific activities in the supply chain processes. ERP systems enable companies to not only manage their operations in one plant but to facilitate enterprise-wide integration and even cross company functionality. In addition to automation and networking, integrated ops use other technologies that make the information instantly accessible to various users within the supply chain, example: barcode scanners and RFID devices can pick up sales data that is sent over instantaneously for use in revising forecast and triggering subsequent operations along the chain.
Business Intelligence tools help to enable visibility into various aspects of the running business/integrated ops by making a plethora of information from various, disparate and scattered sources which is very difficult to fathom, available in meaningful and easily consumable ways through the means of reporting utilities.
1 note
·
View note
Text
MongoDB - An Overview
Well we are all familiar with RDBMS (Relational Database Management Systems) that have been around for over 2 decades now. Here I won't get into to details of what these systems are and the problems they aim to solve, what I will be emphasizing on rather are some of the challenges that we are faced with while dealing with RDBMS:
Data storage and related processing overhead growing exponentially: We are living in the age of data explosion. The trend was set in motion the moment machines started generating data a few years back. In the bygone era, humans were entering data into the DBs manually (more commonly known as data entry operations) and the load pretty much remained manageable. Now we are talking about terabyte to petabyte scale data being generated by systems everyday and that has happened in large part due to the advancement and consumability of technology by means of mobile apps, IoT and their backends running in cloud. Millions of apps making billions of transactions a day and the situation demands storage and processing of huge/extreme amounts of data (this phenomenon is generally referred to as Big Data) and the trend is growing by the day. Imagine dealing with such data driven operations in normalized data models and the answer will become obvious, i.e. hitting a brick wall :)
Scaling issues: A related point, RDBM systems by design are not suitable for distributed environments, meaning they are not cluster friendly and therefore have issues scaling up/out to big data demands. This means that RDBMS isn’t the answer when it comes to handing extreme amounts of data.
The rigidity of the data model: Yet another related point is the schema that is the blueprint of the data model in RDBMS becomes too rigid overtime and especially if it's holding too much data therefore it becomes a big consideration in the face of imminent changes in applications which are built on top of such data models. Modern apps are flexible, think Salesforce, coz it gives the flexibility to its customers to define its own business entities as desired; putting it in another way: it's like giving the pencil to the customer and let the customer draw the entities as desired without going through code modifications and deployment cycles. Now if such applications were running on top of relational models, they wouldn't be as flexible.
So what is the remedy to such headaches? the answer: there isn’t a single silver bullet and the answer is always a well researched and experimented blend of multiple technologies that may work for a given scenario.
Anyhow, one possible solution to address the above concerns is the use of NoSQL databases. These are cluster friendly stores of data. Some of them are key value data stores, some are document stores and some are graph based. I am going to focus here on MongoDB which is an open source, document based NoSQL database.
It derives its name from the term “Humongous” and just as the term implies, it allows for the management of humongous amounts of data in a relatively simple and efficient way.
Instead of tables and columns, you can store data in the form of documents in key value pairs. These documents are structured in BSON format (MongoDB represents JSON documents in binary encoded format called BSON behind the scenes. BSON extends the JSON model to provide additional data types. More info can be found here). For all practical purposes think of BSON as JSON here.
Here is a sample of how a record is formatted:

Bringing back our friend "flexibility" here. Consider the following example:

The above screenshot shows two records that are following a certain model, (_id, name and email), now if my web app needs to store a new record that has an additional field “phone” then I can manage the situation very easily without having to break the data model at all as would be the case in a fixed table structure based design. Here is how the new record with the additional field would look like:

Please take note of another interesting fact, every record in MongoDB has a unique ID, MongoDB takes care of that without the developer having to resort to convoluted ways of generating unique keys.
The following table shows the comparison of terminologies that are used in both SQL and MongoDB contexts:

Following table shows the query comparisons in both SQL and MongoDB contexts:

Another strength of MongoDB is scaling. Here is what I mean by that: the term scaling or sharding means horizontally adding more servers to handle the load/data volume. These machines/nodes are cheap commodity machines (with each node not necessarily running on extremely high specs). Through the sharding process MongoDB automatically distributes data across these machines to horizontally scale efficiently.
From the deployment standpoint you can consider hosting MongoDB yourself or use the services of Database-As-A-Service vendors that make deployment very easy (but the services come at a cost). One of the well known vendors in this space is Mongolab.com (you get 500 mb free upon sign up which is good enough for playing around).
Accessing MongoDB from different languages/platforms, drivers are used that help in providing the interface to MongoDB. However, once MongoDB is installed, its interactive shell called Mongo is also installed (this is based on V8 engine), it's handy for playing around with the database but there are numerous UI tools available also that help in accessing and managing MongoDB.
Here are some benefits of using MongoDB:
Efficient/high performance I/O
Highly scalable
Schema-less (well pretty much all NoSQL DBs are schema-less. Martin Fowler has an interesting insight on this aspect. Please take a look at his session on NoSQL on youtube. You can find the link to the session under the extra study section)
JSON style documents make it easy to work with JavaScript based technologies such as Node.js (in fact MongoDB is the "M" part in the very popular MEAN stack)
Extra Study:
https://www.mongodb.org/
https://docs.mongodb.org/manual/
https://mongolab.com/home
http://docs.mongolab.com/
http://mean.io/
Introduction to NoSQL by Martin Fowler: https://www.youtube.com/watchv=qI_g07C_Q5I
All about NodeJS - Udemy course by Sachin Bhatnagar: https://www.udemy.com/all-about-nodejs/
1 note
·
View note
Text
Key takeaways from AWS re:invent 2015
Well this year's re:invent has come to a close. This was a fun event where I attended a number of very informative sessions and also got to spend some time with AWS partners for various kinds. There is so much going on in the cloud world, here are a few noteworthy observations:
System Integrators/Outsourcing Partners: It was interesting to see what game did the outsourcing and IT services companies bring to the table in the premier cloud computing event as its generally believed that these companies along-with internal enterprise IT divisions are in the cross hairs with the fast cloud adoption. Guess what, they are transforming as well by building core competencies around cloud transformation, data migration, IoT and enterprise cloud readiness services. Infosys even has a product that scours the locally deployed apps and give recommendations on how ready these apps are for going the cloud way. An important aspect of this transformation that remains to be seen is the affect of the sheer volume of work that used to be outsourced getting smaller overtime (it is widely believed that this trend will play itself out over the course of time) along-with thinning margins. How these big behemoths like TCS, Infosys, Accenture to name a few, change this around quickly as the whole promise of cloud is agility, flexibility and cost efficiency (more bang for the buck) by the adoption of frugal architectures and these trends may not be in favor of such SIs. For the moment there is still some juice left for these companies because most of the enterprises aren't transformed fully yet and currently operating under the hybrid model and the journey to cloud is a long one. There is also an opportunity for these companies to offer cloud transformation services to their customers. Enterprise IT: Very important component of corporate America is also undergoing change. It has to, otherwise it is going to get wiped out. After attending the AWS enterprise customer sessions i think they have pretty much found a place for themselves by basically becoming the gatekeepers on the enterprise's path to cloud. Internal IT folks have essentially become the brokers working on behalf of the company to help in selection of the "right" cloud vendor, they then assume total control over the services on offer and then hand out computing resources to the enterprise customers. This is a new flavor of what used to happen before with the only difference being the apps that are now hosted on cloud as opposed to them running internally. The role of EI will become even critical as the spread of cloud apps becomes more and more disparate overtime with increasing demand from business.
Startups: A lot of interesting activity is going on in that space as so many small companies are offering a variety of services such as storage, backups, reporting, log management, monitoring, automation, IoT etc. The interesting thing to note is that in most cases these companies are providing core AWS functionality that is available as a platform service (such as storage) by just creating wrappers (apps: both web and mobile) around them and offering the whole affair as a managed service for their customers. Really keeping things simple here as most of the underlying application infrastructure has now been commoditized (even though AWS doesn't like this term for their own good reasons) the time to bootstrap functionality is reduced exponentially. A trickle down effect of this phenomenon is that it provides an opportunity to mix and match the underlying functionality to create something new, just like using the cloud infrastructure as lego blocks, all that while remaining lean. Another aspect: the cost of failure for a startup has also drastically reduced, meaning its really cheap to fail and by the same token very cheap to have another shot at making something else work without going complete broke :) There was also a lot of redundant functionality on offer, maybe that's a good thing as it gives the customers the peace of mind as they can see that all is not Amazon, i.e. they don’t have to go to and depend on AWS for every single thing and having a competitive market works to their advantage Partnering with AWS also provides safety to the startups, especially when their customer/subscriber base shoots through the roof instantly, the experience that AWS brings to the fold really benefits the companies manage the load once they are able to find success (ask Tinder) Enterprise Application Integration: The subject is close to my heart, hence a section dedicated here. EAI/ESB (I have a loosely clubbed both together here) is a middleware discipline which many believe has matured overtime and kind of saturated. The technologies built around this principle have served their purpose and that too, really well within the enterprise when the apps were pretty much hosted internally (initially in a single DC and to multi DCs overtime). EAI and then later ESB provided flexibility of connecting up-to a myriad of apps because it came with out-of-the-box set of connectors/adapters for most of the apps on the market and it also provided an opportunity to create intelligent middleware but in today's world where cloud (on all fronts, Infrastructure, Platform and Software) is promising utmost flexibility with continuous deployment mechanisms built into it. On the other hand the flexibility that once tested and proven off the shelf ESB platforms provided, is becoming a bottleneck now simply because the tested-and-proven systems are finding it difficult to keep pace with cloud's flexibility and in most cases ESB is becoming just another point of failure. ESB is also somewhat of an anti pattern to Microservices based architectures. This subject requires a dedicated blog that I will publish in the near future. Don't get me wrong here, the need for integration is still there (as the apps landscape is becoming more and more diverse and hence it is also required of them to be talking to each other for various reasons), the question is: which technology and methodology would work well in this eco system; the answer: cloud friendly, lightweight, super fast and not so complicated middleware :) That is the direction that TIBCO is taking with simplr (the whole solution is hosted on AWS), WebMethods is also fully cloud now, Mulesoft has already become a household name in this arena and there are some startups also trying their luck out in this space.
The winners:
Startups: As mentioned already, the cost of failure is extremely low and hence the opportunities are multifold
Open source Software: Open source is extremely hot and sexy these days; darling of the developers. The surge in the adoption has really got the big software vendors grappling to maintain their space and hegemony. The ability to purchase rather rent the software pennies on the dollar is also levelling the field for open source software.
Managed Services: Companies who are providing managed services, especially the open source software, are making a killing these days, for obvious reasons
Of course AWS :)
The strugglers:
Hardware Companies: Things are consolidating big-time. The industry vertical is already stagnating and is looking for a breakthrough or a disruptive trend that could help spur the growth. Cloud computing gaining territory isn't helping matter much in my view as most of the high powered computing is needed only by the likes of Amazon and other top cloud vendors, the consumers just need thin clients to interface with the processing backend running in the cloud. This trend is very similar to how things worked in the past where the users entered commands through the terminal (thin client), the CPU processed the requests and sent the results back to the terminal for the user's consumption. In today's world the thin client is your mobile device and the CPU is your cloud backend. This is pretty much a trend reversal for the hardware companies that saw major gains during the PC days. All is not lost here either as most of these companies are hoping for the IoT windfall. Well just wait and watch for that to happen, for now, at-least.
Big software vendors: read IBM (especially), SAP et. al with the exception of Microsoft that is second best to AWS when it comes to IaaS (Infrastructure-as-a-Service) plus its a major platform company and having this diversity helps it steer it's ways better than its competitors. Most of these big software companies used to make top dollar by licensing their software, well that space has changed dramatically. Even though these companies have made significant investments into bringing the much needed change and cloudify themselves but so far, they have been playing catchup.
0 notes
Text
A few thoughts on AWS Lambda
Attended a session on Lambda earlier in the day (at AWS re:invent 2015) and found it very interesting. Apparently it seems to bring the platform closer to the developer, basically relieving him somewhat from worrying too much about the underlying infrastructure which is a fairly complicated affair that relates to VPCs, subnets, security groups, NACLs, IP ranges, complex scaling and security architectures and a ton of other things. Lambda is essentially a compute service that runs your code and automatically manages the resources and the scale it needs while servicing requests in response to events.
Events could be DynamoDB table updates, SNS notifications, object modifications in S3 etc. This service seems very useful and is promising that folks like us who are more development oriented can really focus on our development work. Using Lambda the developer can develop serverless backends for APIs that can then be consumed by clients of various types (mobile, web, IoT etc.). The term "serverless" in this context refers to your app running inside a container (another layer of abstract runtime ecosystem on top of the underlying OS that becomes the app's runtime). Its pricing model is also very appealing as you pay only when your code runs i.e. $0.20 per 1 million requests and that too on top of free first million requests (this also means that you are not being charged on per hour basis as is the case in EC2 pricing).
I also had a chat with the Heroku team here at re:invent last evening. They are running on AWS as well. For those who are unfamiliar with the name, they are Salesforce.com's Platform-as-a-Service offering (SFDC acquired
Heroku back in 2010). Both AWS Lambda and Heroku are polyglot services (as they both support: Ruby, Python, Nodel.js, Java etc.)
I haven't done much research on Heroku's pricing model as yet but Lambda's seems more competitive at the outset. I wanted to attend the session on JAWS but couldn't as I got busy with something else. Here are the only few things I know about JAWS (so far that is): - Its Open Source - Its an npm package - It's a serverless application framework (much like AWS Lambda)
The above bits of info are not much but I was able to find the link to their presentation on slideshare, here it is.
I have a few ideas that I want to implement as APIs. Based on the info I currently have, Lambda seems the most suitable option.
I will keep sharing updates in this regard.
0 notes
Text
Testing Salesforce.com credentials for the purpose of REST API integration using Postman (a chrome extension)
I am using OAuth 2.0 Username-Password Flow for this example (click here for more info on this topic)
Have the following bits of info handy:
grant_type—Value must be password (string value) for this flow.
client_id—Consumer key from the connected app definition.
client_secret—Consumer secret from the connected app definition.
username—End-user username.
password—End-user password+security token
The eventual content that needs to be posted out to SFDC should take this form (I have highlighted the params for better readability):
grant_type=password&client_id=3MVG9lKcPoNINVBIPJjdw1J9LLM82Hn FVVX19KY1uA5mu0QqEWhqKpoW3svG3XHrXDiCQjK1mdgAvhCscA9GE&client_secret= 1955279925675241571&[email protected]&password=mypassword
Following are the steps needed to make things work via Postman
- Install Postman in Chrome if you haven’t already
- Open Apps in Chrome:

- Click Postman

- Select the POST method

- Furnish the following pieces of information:
Request URL: https://login.salesforce.com/services/oauth2/token
Add this header (in the header key/value:
Key: Content-Type
Value: application/x-www-form-urlencoded

- Click Body, put the POST content (with your params) in the editor with the raw option selected and then press the blue Send button (I have obfuscated the information in the screenshot below to protect my SFDC credentials)

- If the params provided in the given format properly then you should see the successful SFDC login response

0 notes
Link
Linux Quick Reference: Useful Commands
This PDF is really handy
0 notes
Text
Debugging node.js using node-inspector and Chrome on Mac
Download node-inspector:
Open terminal and type sudo npm install -g node-inspector
Enter the password when prompted
Note: If you encounter this exception: gyp WARN EACCES user “root” does not have permission to access the dev dir then type that command instead:
sudo npm install --unsafe-perm --verbose -g node-inspector
Run your js code with node using the debug-brk param:
node --debug-brk TestWebServer.js

Open a new terminal window and run node inspector:
node-inspector
Copy the URL

Open Chrome and run the already copied URL
There you are, Chrome opens up the javascript code you are looking to debug

Put a breakpoint in the code and issue a request, e.g. http://localhost:3000 and the debugger stops the execution at the breakpoint in the code and you can take it from there

0 notes
Text
gyp WARN EACCES user "root" does not have permission to access the dev dir
I encountered this problem while installing node-inspector on my mac (OSX Yosemite version 10.10.5) via terminal while issuing the following command:
sudo npm install -g node-inspector
Solution:
change the command to by adding --unsafe perm to the command:
sudo npm install --unsafe-perm --verbose -g node-inspector
This thread also contains helpful material on the subject matter
0 notes
Text
Vi Tips
To open a file: vi filename
Modes of Vi: command mode and edit mode
Command mode: press <ESC> on the keyboard
Edit mode: press i or a on the keyboard
The following actions can only take place in command mode:
Exiting Vi: press :q on the keyboard
Exiting Vi without saving changes: press :q! on the keyboard
Save: press :w on the keyboard
Save and Exit: press :wq on the keyboard
0 notes