#Decision Tree
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
Writing Game: Decision Tree chapter 6 (final!)
>> Funny place for signposts, he thought. They looked very out of place, but these were no earthly objects. They each had lettering that glowed faintly. Past… Present… and, fallen and partially obscured, Future. << ~ (quote from chapter 6)

Aziraphale Falls.
But Hell is in serious disarray, and as he goes looking for answers, which is equivalent to looking for Crowley… help could come from an unexpected quarter.
~~~
This story was created by playing a Collaboration Game of Ping Pong Writing 🏓🏓, where two authors write chapters alternately, picking up the thread where the other left off. It��s a bit like improv theatre, and the story develops as we go.
~~~
For the details and rules of this game, Ping Pong Writing, see:
https://archiveofourown.org/works/51987664
~~~
chapter overview with word counts:
(~100): Abyss
(~200): Hell of a Day to Fall
(~300): Temple of a Thousand Doors
(~400): Entrance of the Angel
(~500): Hecat
(~600 ~2000): Crossroads
chapters 1,3,5 by NaturallyTeal, chapters 2,4,6 by Jean_kimberley
This match of our writing game is now final! Check out how it ends!
There will probably be other matches in the future, and maybe YOU can play one of them? Take a look at these three beginnings of new matches I’ve already prepared, maybe one of them makes you want to write the next chapter?
Tagging List under the cut
Let me know if you want on it for future posts of mine!
Let me know if you want off the list:
@echogracebeloved @oxribs @copperplatebeech @thescholarlystrumpet @simonezitrone79
@siriosa @captainblou @alphacentaurinebula @ineffablefool @ashfae
@fellshish @vidavalor @thindarkdukewrites @crowleys-bright-red-hair-streak @kimberleyjean
@dragonfire42 @lickthecowhappy @ineffablenlghtingales @turquoisedata @di-42
@dierama-mojo
#good omens#good omens fanfiction#good omens writing game#ping pong writing#writing game#decision tree
15 notes
·
View notes
Text
2 notes
·
View notes
Text
[ID: decision tree with a red-yellow-gradient from left to right. The title is "Kate's Guide to the 10 Point Rating System" and subtitled "follow this chart to get a rating in 30 seconds or less! (*see usage footnote)"
Was your net reaction to this thing positive?
The root node asks "Was your net reaction to this thing positive?" If no, "Was your net reaction to this thing negative?" If yes, "Did you like it enough to revisit it?"
Was your net reaction to this thing negative?
If yes, then "Was it just dull overall or genuinely unpleasant?" If yes, then "Was it just a dull overall or genuinely unpleasant?" If no, then rate as a "4".
Was it just dull overall or genuinely unpleasant?
If "it hurt me", then "Did it have any redeeming sections or qualities to it?" If "it just kind of sucked", rate as a "3".
Did it have any redeeming qualities to it?
If "it really could not get worse", rate as a "1". If "maybe some stuff that wasn't quite as bad as the rest of it", rate as a "2".
Did you like it enough to want to revisit it?
If no, then "Was it cohesive, or were there parts of it that really didn't work?" If yes, then "Did it stand out or impress you with its quality?"
Was it cohesive, or were there parts of it that really didn't work?
If "parts that didn't work", rate as a "5". If "cohesive", then rate as a "6".
Did it stand out or impress you with its quality?
If "i mean i liked it but it didn't really stand out", then rate as a "7". If "my attention was grabbed", then
Did it REALLY blow you away???
If "I mean it was great!!!", then rate as an "8". If "YEAH!!!!" then
Is this an all-time personal favorite of yours?
If "maybe one day?" then rate as a "9". If "it really really is" then rate as a "10".
*usage note
this scale is not intended for anything resembling "objective" judgement. it is optimized to express the subjective feelings you came away from a piece of media with. and key aspect of it is that YOU RATINGS ARE MEANT TO CHANGE! a piece of media that has the POTENTIAL to be a 10 may come off as an 8 when you first engage with it, and then increase with each listen. ratings are subjective, there should be no pressure to determine the "correct" rating for a piece of media.
/end ID]
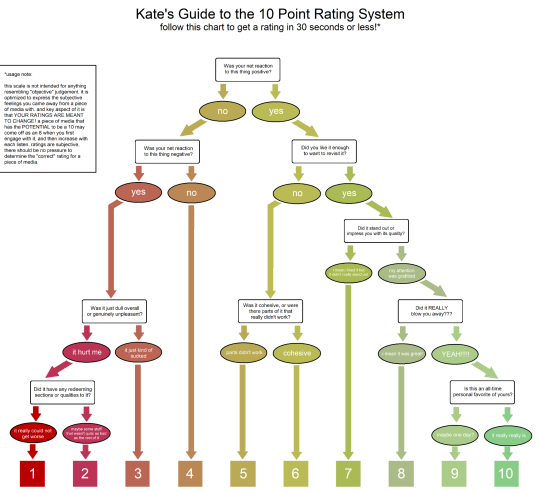
i just made this for myself, but multiple people have told me they find it really useful so i thought id share it!
#rating scale#decision tree#flowchart#trying to write an image description for a decision tree like this is a challenge#I decided to go with the order that I read it#used headers because screen readers should be able to jump to and from headers. I think.#id by me
18K notes
·
View notes
Text
Evaluating Where to Implement Agentic AI in Your Business
New Post has been published on https://thedigitalinsider.com/evaluating-where-to-implement-agentic-ai-in-your-business/
Evaluating Where to Implement Agentic AI in Your Business

Agentic AI has the potential to reshape several industries by enabling autonomous decision-making, real-time adaptability, and proactive problem-solving. As businesses strive to enhance operational efficiency, they face the challenge of deciding how and where to implement agentic AI for maximum impact. From supply chain optimization to predictive maintenance and customer experience enhancement, enterprise leaders must carefully evaluate which areas of their business stand to gain the most benefit from agentic AI. A strategic framework for assessing AI integration opportunities is critical to ensuring that investments align with business objectives, drive measurable outcomes, and maintain a balance between automation and human oversight.
Understanding AI Evolution
To understand the role of agentic AI, we must first distinguish it from traditional AI implementations. Historically, enterprises have leveraged AI to analyze historical data, generate insights, and even make recommendations. However, these systems generally require human intervention to execute decisions and workflows. For example, a machine learning algorithmic system generates new observations, refines its models, and improves over time but never makes decisions, whereas standard AI recommends actions based on its learned experiences, potentially generating one action to move ahead a single step.
Agentic AI introduces autonomy into the equation. Instead of merely suggesting actions, agentic AI executes them, acting in real-time to solve problems and optimize workflows with multiple AI agents operating in parallel. The key differentiator lies in the concept of agents—independent AI entities that take action based on learning mechanisms and real-world conditions. A single AI agent might reorder inventory when stock runs low, while agentic AI—comprising multiple agents—could coordinate an entire supply chain response, adjusting procurement, transportation, and storage conditions dynamically.
Instead of executing a decision tree, agentic AI adapts based on real-time inputs, learning from its ever-changing environment and modifying its actions accordingly. For example, in food retail, a rule-based system might follow a structured compliance workflow—such as alerting a manager when a refrigeration unit exceeds a set temperature threshold. An agentic AI system, on the other hand, could autonomously adjust refrigeration settings, reroute impacted shipments, and reorder inventory—all without human intervention.
In a highly dynamic environment like airline logistics, a fully agentic AI network simultaneously analyzes all affected travelers, rebooks flights, notifies ground services, and communicates seamlessly with customer service representatives—all in parallel, reducing disruptions and improving efficiency.
Managing Agentic AI Autonomy Levels
As the AI evolution continues, agentic AI will gain more autonomy and handle increasingly complex decision-making scenarios. In the future, AI agents will collaborate across industries and make context-aware decisions. The challenge moving forward will be determining the right balance between full automation and human oversight for excursion management, mistake prevention, and system lockdowns. Businesses must carefully consider the risk thresholds for different workflows, implementing safeguards to prevent unintended actions while maximizing the potential gains from AI-driven advancements.
Leaders across industries should consider the areas where agentic AI is particularly valuable, where decision-making needs to be real-time, adaptive, and highly scalable. Key business functions that stand to benefit the most include supply chain and inventory management. Fleets of AI agents are able to monitor stock levels, predict demand fluctuations, and autonomously reorder products to reduce waste, avoid unnecessary loss, and finetune logistics outcomes.
In predictive maintenance, agentic AI analyzes equipment health, detects potential failures, and proactively schedules maintenance to reduce downtime. Compliance and risk management functions can also benefit, as AI oversees compliance workflows in regulated industries, automatically adjusting SOPs to meet evolving requirements.
Steps to Successful Agentic AI Adoption
To ensure successful agentic AI adoption, business leaders should follow a structured evaluation process.
Identify high-impact use cases by assessing business functions where real-time decision-making improves efficiency and reduces the administrative burden on customers or employees.
Define risk tolerance and oversight mechanisms by establishing safeguards, approval processes, and intervention points to balance AI autonomy with human oversight.
Ensure AI investments align with business objectives, focusing on applications that deliver measurable ROI and support broader strategic goals.
Start small and scale gradually by launching pilot programs in controlled environments before expanding agentic AI deployment across the enterprise.
Evaluate agentic AI programs regularly, refining models based on outcomes and a continuous improvement approach.
With the move to agentic AI, we’ll see a significant leap forward in enterprise automation, enabling businesses to move beyond insights and recommendations into autonomous execution. Successful implementation of agentic AI will require strategic consideration of workflow design, risk management, and governance structures. Business leaders who move quickly and thoughtfully will maximize efficiency, enhance resilience, and future-proof their operations.
#adoption#agent#Agentic AI#Agentic AI applications#agents#ai#AI adoption#ai agent#AI AGENTS#AI Autonomy#AI integration#applications#approach#automation#autonomous#Business#challenge#collaborate#compliance#continuous#customer experience#customer service#data#Decision Tree#deployment#Design#digi#efficiency#employees#enterprise
0 notes
Text
Random Forest
Se realizó un análisis de bosque aleatorio para evaluar la importancia de una serie de variables explicativas en la predicción de una variable de respuesta binaria y categórica.
Se clasifican los cráteres de marte según su zona (latitud), que es nuestra variable de respuesta, con base en el diámetro y profundidad, las variables explicativas.
El código es el siguiente:



Los resultados:

La variable explicativa con la puntuación de importancia relativa más alta (0.9504) fue la profundidad del cráter. La precisión de bosque aleatorio fue del 74.39%, con el posterior crecimiento de múltiples árboles en lugar de un único árbol, añadiendo poco a la precisión general del modelo, y sugiriendo que la interpretación de un único árbol de decisión puede ser apropiada.
0 notes
Text
Decision Tree
from pandas import Series, DataFrame
import pandas as pd
import numpy as np
import os
import matplotlib.pylab as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
import sklearn.metrics
# Tree Model
data_clean = datosn.dropna()
data_clean.dtypes
data_clean.describe()
"""
Modeling and Prediction
"""
#Split into training and testing sets
#predictors = data_clean[['CODPERING', 'CODPRIPER', 'CODULTPER', 'CICREL', 'CRDKAPRACU',
# 'PPKAPRACU', 'CODPER5', 'RN', 'MODALIDADC', 'SEXOC']]
predictors = data_clean[[ 'CODPRIPER',
'CODULTPER', 'SEXOC']]
targets = data_clean.SITALUC
pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, targets, test_size=.4)
pred_train.shape
pred_test.shape
tar_train.shape
tar_test.shape
#Build model on training data
classifier=DecisionTreeClassifier(max_depth=3)
classifier=classifier.fit(pred_train,tar_train)
predictions=classifier.predict(pred_test)
sklearn.metrics.confusion_matrix(tar_test,predictions)
sklearn.metrics.accuracy_score(tar_test, predictions)
#Displaying the decision tree
from sklearn import tree
#from StringIO import StringIO
from io import StringIO
#from StringIO import StringIO
from IPython.display import Image
out = StringIO()
tree.export_graphviz(classifier, out_file=out)
import pydotplus
graph=pydotplus.graph_from_dot_data(out.getvalue())
Image(graph.create_png())

The root of the decision tree has divided the dataset of 8162 samples based on the condition x[0] <= 4365. The high gini value (0.784) indicates that there is a lot of mixing of classes in this node. The distribution of samples in the classes suggests that some classes (such as class 9 and class 0) have a significantly higher number of samples compared to other classes (such as class 2 and class 7). This is just the root node. The tree will continue to divide the data into successive nodes based on other conditions, with the goal of reducing impurity (gini) and separating classes more effectively.
0 notes
Link
#Data mining#Decision tree#K-nearest neighbor#Machine learning#Multilayer perceptron#Support vector machine#WEKA
1 note
·
View note
Text

Imperfect information and chance mean you’re never going to get "good" outcomes from all all your decisions. Instead, this book aims to help you improve the quality and consistency of your decision making over the longer term.
As it says on the cover, ‘How to Decide: Simple Tools for Making Better Decisions’ (‘HTD’) is a toolkit to help people become better at making decisions. Having a good process for making decisions is important. Just because you received a good or bad outcome from a decision in the past, doesn’t necessarily mean the decision itself was good or bad. Chance, imperfect information and other factors outside your control all play a role in determining the result.
With this in mind, the focus of ‘HTD’ is on the decision making process. It begins by examining how blind spots and hidden bias shape the way we view past decisions. The book then introduces a series of tools that can be used to help with decision making, such as how to use a simple ‘decision tree’ to visualise the range of possible outcomes from a decision. This model is then built on, and new tools added. The beauty of ‘HTD’ is it goes beyond the initial decision. The reader is offered tools to help them evaluate when to change goals, change their decision, and how to execute their decision better when a final decision is made.
When it comes to following through on decisions, I’d recommend people also check out one of my favorite books from last year, ‘Atomic Habits’.
The book concludes with a helpful chapter on how to effectively seek information and feedback from others in order to improve the quality of your decisions.
What I learned, what it got me thinking about
‘HTD’ is a book with a lot to offer. But perhaps reflecting how many business books and courses I’ve been through over the years, a lot of the individual concepts were already familiar to me. That said, it’s a well constructed book whether you’re new to the material or using it as a refresher.
If I had to narrow down to five things I liked, learned or started thinking about because of this book I’d say my list would be;
Getting better at thinking in terms of scenarios. Decision trees are built around imagining scenarios for how different decisions might play out and estimating how likely those outcomes are. That’s a handy decision making skill, but also helpful for the sort of analysis and insight generation I do for clients.
How to beat analysis paralysis. A good reminder that we can easily waste a lot of time and mental energy on decisions with a small impact. How much impact will this decision have on my happiness for the year? The month? The week? This is a good way to scale how much time you should be putting into a decision. Don’t waste time on small impact decisions.
Knowing when to lock in your decision. When you think you’ve reached a decision but aren’t sure if it’s time to stop analysing - ask these questions. Is there any piece of information that would change your mind? If not. Move on. Similarly, if you can’t obtain that information (unknowable) or too costly ( too expensive, too much time relative to the impact of the decision) then move on.
Pre-mortems and backcasting. These are two techniques I’ve had a fair bit of exposure to in the past. Both involve imagining yourself in the future and then looking backwards to the present to see either (1) what might have gone wrong and led to a bad outcome (pre-mortem) or (2) the things that went well and led to a good outcome (backcasting). This includes factors within your control and those outside of it. ‘HTD’ provides a great summary of how to use these techniques. It’s enough for newcomers to get the concept, but also provides a good refresher for those who already know the frameworks.
Throw out the "pros vs cons" list. As Annie Duke points out, these types of lists are at best a starting point for factors to consider in your decision tree. But at worst, our self-delusion and blind spots can lead us to making bad decisions if we rely solely on these lists.
Whether you’re looking to improve your decision making in your personal or professional life, you’re highly likely to find something of interest in ‘How to Decide’.
Note: I listened to this originally as an audiobook, but at time of writing (Feb-24) the Kindle edition is a bargain at less than five dollars.
0 notes
Text
HWM: Game Design Log (25) Finding the Right “AI” System
Hey! I’m Omer from Oba Games, and I’m in charge of the game design for Hakan’s War Manager. I share a weekly game design log, and this time, I’ll be talking about AI and AI systems. Since I’m learning as I go, I thought, why not learn together? So, let’s get into it! Do We Need AI? Starting off with a simple question: Do we need AI? Now, I didn’t ask the most fundamental concept in game history…

View On WordPress
#AI system#Artificial Intelligence#Bayesian networks#decision tree#FSM#game design#game designer#game development#game mechanics#Hakan&039;s War Manager#Neural networks#state#state machine#strategy game
0 notes
Text

Curtwen Week Day 4: Haunted
#fuck yall I really wasn’t sure about this last night but looking at it now I think it’s grown on me#I tried going for a 1960s comic book look#because I really like the vibes of old comics#they’re very cool#honestly this came out very different from what I had planned originally#but then I had this idea and ran with it#also I made the executive decision of doing long hair Curt because A) It’s my drawing and I can do what I want and B) I love the idea that#curt had the long hair like in SAD post fall#whoever originally had that idea is a genius- I wish I could remember who it was#but yeah I love doing stylized stuff like this#I don’t do it as often as I want to#I have another saf idea similar to this that I’ve had on the back burner that I might do soon ish#i suppose we’ll see#I’m not making any promises#but yeah this one is a bit different from the drawings for the other three days#I got a bit of reprieve from all the rendering I’ve been doing#fun fact: palm trees are technically a type of grass#because it doesn’t have bark and it doesn’t have rings to tell how old it is#curtwen week#Curtwen week 2024#Curtwen#spies are forever#tin can bros#tin can brothers#agent Curt mega#curt mega#owen carvour#Joey richter#my art#cw guns
1K notes
·
View notes
Text

Laurence upon being called a coward: "I am terribly offended and upset but simply cannot justify defending myself, thereby doing more damage than I already have 😞"
Laurence when someone implies Temeraire should die:

#temeraire#his majesty's dragon#victory of eagles#obsessed with him having a whole different decision making tree for when temeraire is involved#will laurence#temeraire lb
212 notes
·
View notes
Text
Writing Game: Decision Tree chapter 5
>> “But doesn’t a gathering of witches need at least three? We don’t have time! Where do we get a third witch in a hurry?” << ~ (quote from chapter 5)

~~~
Aziraphale Falls.
But Hell is in serious disarray, and as he goes looking for answers, which is equivalent to looking for Crowley… help could come from an unexpected quarter.
~~~
This story is being created by playing a Collaboration Game of Ping Pong Writing 🏓🏓, where two authors write chapters alternately, picking up the thread where the other left off. It’s a bit like improv theatre, and the story develops as we go. If you’re curious what will happen next, as are we: stay tuned!
~~~
For the details and rules of this game, Ping Pong Writing, see:
https://archiveofourown.org/works/51987664
~~~
chapter overview with word counts:
(~100): Abyss
(~200): Hell of a Day to Fall
(~300): Temple of a Thousand Doors
(~400): Entrance of the Angel
(~500): Hecat
(~600)
chapters 1,3,5 by NaturallyTeal, chapters 2,4,6 by Jean_kimberley
Tagging List under the cut
Let me know if you want on it for future posts of mine!
Let me know if you want off the list:
@echogracebeloved @oxribs @copperplatebeech @thescholarlystrumpet @simonezitrone79
@siriosa @captainblou @alphacentaurinebula @ineffablefool @ashfae
@fellshish @vidavalor @thindarkdukewrites @crowleys-bright-red-hair-streak @kimberleyjean
@dragonfire42 @lickthecowhappy @ineffablenlghtingales @turquoisedata @di-42
@dierama-mojo
#good omens#good omens fanfiction#good omens writing game#writing game#ping pong writing#decision tree
12 notes
·
View notes
Text
im gone cus im working on this very long last rejoice mini comic but i have an IDEA (ambitious)
what if i make my comic into a visual novel esque game instead.... i have this belief that it will actually take less time than a 400 page comic (or at least less drawing, but definitely more writing for me)... will that not be more fun and engaging!!
and get this.... you, the player, will be essentially writing your own fairytale based on choices you make! i'll make a fairytale retelling play out for every possible outcome that will get played by the end of it...!
i can do anything...(questionable)
#did this idea come to me because i couldn't choose an ending? yes.#is it because i want to create music for it? also yes#is making sprites fun..? yes#idk i feel like i can learn (has watched 4 tutorials)#im smart!! and ambitious#what do the people think?#also i want to do the whole decision tree thing. would be fun for me watching it connect#the visuals will carry though#there will be many cutscenes/slideshows thing going on cus..#i will not settle for one frame per scene#trust me i have the vision i just need to be smart about ut#it
181 notes
·
View notes
Text
Using AI to Predict a Blockbuster Movie
New Post has been published on https://thedigitalinsider.com/using-ai-to-predict-a-blockbuster-movie/
Using AI to Predict a Blockbuster Movie
Although film and television are often seen as creative and open-ended industries, they have long been risk-averse. High production costs (which may soon lose the offsetting advantage of cheaper overseas locations, at least for US projects) and a fragmented production landscape make it difficult for independent companies to absorb a significant loss.
Therefore, over the past decade, the industry has taken a growing interest in whether machine learning can detect trends or patterns in how audiences respond to proposed film and television projects.
The main data sources remain the Nielsen system (which offers scale, though its roots lie in TV and advertising) and sample-based methods such as focus groups, which trade scale for curated demographics. This latter category also includes scorecard feedback from free movie previews – however, by that point, most of a production’s budget is already spent.
The ‘Big Hit’ Theory/Theories
Initially, ML systems leveraged traditional analysis methods such as linear regression, K-Nearest Neighbors, Stochastic Gradient Descent, Decision Tree and Forests, and Neural Networks, usually in various combinations nearer in style to pre-AI statistical analysis, such as a 2019 University of Central Florida initiative to forecast successful TV shows based on combinations of actors and writers (among other factors):
A 2018 study rated the performance of episodes based on combinations of characters and/or writer (most episodes were written by more than one person). Source: https://arxiv.org/pdf/1910.12589
The most relevant related work, at least that which is deployed in the wild (though often criticized) is in the field of recommender systems:
A typical video recommendation pipeline. Videos in the catalog are indexed using features that may be manually annotated or automatically extracted. Recommendations are generated in two stages by first selecting candidate videos and then ranking them according to a user profile inferred from viewing preferences. Source: https://www.frontiersin.org/journals/big-data/articles/10.3389/fdata.2023.1281614/full
However, these kinds of approaches analyze projects that are already successful. In the case of prospective new shows or movies, it is not clear what kind of ground truth would be most applicable – not least because changes in public taste, combined with improvements and augmentations of data sources, mean that decades of consistent data is usually not available.
This is an instance of the cold start problem, where recommendation systems must evaluate candidates without any prior interaction data. In such cases, traditional collaborative filtering breaks down, because it relies on patterns in user behavior (such as viewing, rating, or sharing) to generate predictions. The problem is that in the case of most new movies or shows, there is not yet enough audience feedback to support these methods.
Comcast Predicts
A new paper from Comcast Technology AI, in association with George Washington University, proposes a solution to this problem by prompting a language model with structured metadata about unreleased movies.
The inputs include cast, genre, synopsis, content rating, mood, and awards, with the model returning a ranked list of likely future hits.
The authors use the model’s output as a stand-in for audience interest when no engagement data is available, hoping to avoid early bias toward titles that are already well known.
The very short (three-page) paper, titled Predicting Movie Hits Before They Happen with LLMs, comes from six researchers at Comcast Technology AI, and one from GWU, and states:
‘Our results show that LLMs, when using movie metadata, can significantly outperform the baselines. This approach could serve as an assisted system for multiple use cases, enabling the automatic scoring of large volumes of new content released daily and weekly.
‘By providing early insights before editorial teams or algorithms have accumulated sufficient interaction data, LLMs can streamline the content review process.
‘With continuous improvements in LLM efficiency and the rise of recommendation agents, the insights from this work are valuable and adaptable to a wide range of domains.’
If the approach proves robust, it could reduce the industry’s reliance on retrospective metrics and heavily-promoted titles by introducing a scalable way to flag promising content prior to release. Thus, rather than waiting for user behavior to signal demand, editorial teams could receive early, metadata-driven forecasts of audience interest, potentially redistributing exposure across a wider range of new releases.
Method and Data
The authors outline a four-stage workflow: construction of a dedicated dataset from unreleased movie metadata; the establishment of a baseline model for comparison; the evaluation of apposite LLMs using both natural language reasoning and embedding-based prediction; and the optimization of outputs through prompt engineering in generative mode, using Meta’s Llama 3.1 and 3.3 language models.
Since, the authors state, no publicly available dataset offered a direct way to test their hypothesis (because most existing collections predate LLMs, and lack detailed metadata), they built a benchmark dataset from the Comcast entertainment platform, which serves tens of millions of users across direct and third-party interfaces.
The dataset tracks newly-released movies, and whether they later became popular, with popularity defined through user interactions.
The collection focuses on movies rather than series, and the authors state:
‘We focused on movies because they are less influenced by external knowledge than TV series, improving the reliability of experiments.’
Labels were assigned by analyzing the time it took for a title to become popular across different time windows and list sizes. The LLM was prompted with metadata fields such as genre, synopsis, rating, era, cast, crew, mood, awards, and character types.
For comparison, the authors used two baselines: a random ordering; and a Popular Embedding (PE) model (which we will come to shortly).
The project used large language models as the primary ranking method, generating ordered lists of movies with predicted popularity scores and accompanying justifications – and these outputs were shaped by prompt engineering strategies designed to guide the model’s predictions using structured metadata.
The prompting strategy framed the model as an ‘editorial assistant’ assigned with identifying which upcoming movies were most likely to become popular, based solely on structured metadata, and then tasked with reordering a fixed list of titles without introducing new items, and to return the output in JSON format.
Each response consisted of a ranked list, assigned popularity scores, justifications for the rankings, and references to any prior examples that influenced the outcome. These multiple levels of metadata were intended to improve the model’s contextual grasp, and its ability to anticipate future audience trends.
Tests
The experiment followed two main stages: initially, the authors tested several model variants to establish a baseline, involving the identification of the version which performed better than a random-ordering approach.
Second, they tested large language models in generative mode, by comparing their output to a stronger baseline, rather than a random ranking, raising the difficulty of the task.
This meant the models had to do better than a system that already showed some ability to predict which movies would become popular. As a result, the authors assert, the evaluation better reflected real-world conditions, where editorial teams and recommender systems are rarely choosing between a model and chance, but between competing systems with varying levels of predictive ability.
The Advantage of Ignorance
A key constraint in this setup was the time gap between the models’ knowledge cutoff and the actual release dates of the movies. Because the language models were trained on data that ended six to twelve months before the movies became available, they had no access to post-release information, ensuring that the predictions were based entirely on metadata, and not on any learned audience response.
Baseline Evaluation
To construct a baseline, the authors generated semantic representations of movie metadata using three embedding models: BERT V4; Linq-Embed-Mistral 7B; and Llama 3.3 70B, quantized to 8-bit precision to meet the constraints of the experimental environment.
Linq-Embed-Mistral was selected for inclusion due to its top position on the MTEB (Massive Text Embedding Benchmark) leaderboard.
Each model produced vector embeddings of candidate movies, which were then compared to the average embedding of the top one hundred most popular titles from the weeks preceding each movie’s release.
Popularity was inferred using cosine similarity between these embeddings, with higher similarity scores indicating higher predicted appeal. The ranking accuracy of each model was evaluated by measuring performance against a random ordering baseline.
Performance improvement of Popular Embedding models compared to a random baseline. Each model was tested using four metadata configurations: V1 includes only genre; V2 includes only synopsis; V3 combines genre, synopsis, content rating, character types, mood, and release era; V4 adds cast, crew, and awards to the V3 configuration. Results show how richer metadata inputs affect ranking accuracy. Source: https://arxiv.org/pdf/2505.02693
The results (shown above), demonstrate that BERT V4 and Linq-Embed-Mistral 7B delivered the strongest improvements in identifying the top three most popular titles, although both fell slightly short in predicting the single most popular item.
BERT was ultimately selected as the baseline model for comparison with the LLMs, as its efficiency and overall gains outweighed its limitations.
LLM Evaluation
The researchers assessed performance using two ranking approaches: pairwise and listwise. Pairwise ranking evaluates whether the model correctly orders one item relative to another; and listwise ranking considers the accuracy of the entire ordered list of candidates.
This combination made it possible to evaluate not only whether individual movie pairs were ranked correctly (local accuracy), but also how well the full list of candidates reflected the true popularity order (global accuracy).
Full, non-quantized models were employed to prevent performance loss, ensuring a consistent and reproducible comparison between LLM-based predictions and embedding-based baselines.
Metrics
To assess how effectively the language models predicted movie popularity, both ranking-based and classification-based metrics were used, with particular attention to identifying the top three most popular titles.
Four metrics were applied: Accuracy@1 measured how often the most popular item appeared in the first position; Reciprocal Rank captured how high the top actual item ranked in the predicted list by taking the inverse of its position; Normalized Discounted Cumulative Gain (NDCG@k) evaluated how well the entire ranking matched actual popularity, with higher scores indicating better alignment; and Recall@3 measured the proportion of truly popular titles that appeared in the model’s top three predictions.
Since most user engagement happens near the top of ranked menus, the evaluation focused on lower values of k, to reflect practical use cases.
Performance improvement of large language models over BERT V4, measured as percentage gains across ranking metrics. Results were averaged over ten runs per model-prompt combination, with the top two values highlighted. Reported figures reflect the average percentage improvement across all metrics.
The performance of Llama model 3.1 (8B), 3.1 (405B), and 3.3 (70B) was evaluated by measuring metric improvements relative to the earlier-established BERT V4 baseline. Each model was tested using a series of prompts, ranging from minimal to information-rich, to examine the effect of input detail on prediction quality.
The authors state:
‘The best performance is achieved when using Llama 3.1 (405B) with the most informative prompt, followed by Llama 3.3 (70B). Based on the observed trend, when using a complex and lengthy prompt (MD V4), a more complex language model generally leads to improved performance across various metrics. However, it is sensitive to the type of information added.’
Performance improved when cast awards were included as part of the prompt – in this case, the number of major awards received by the top five billed actors in each film. This richer metadata was part of the most detailed prompt configuration, outperforming a simpler version that excluded cast recognition. The benefit was most evident in the larger models, Llama 3.1 (405B) and 3.3 (70B), both of which showed stronger predictive accuracy when given this additional signal of prestige and audience familiarity.
By contrast, the smallest model, Llama 3.1 (8B), showed improved performance as prompts became slightly more detailed, progressing from genre to synopsis, but declined when more fields were added, suggesting that the model lacked the capacity to integrate complex prompts effectively, leading to weaker generalization.
When prompts were restricted to genre alone, all models under-performed against the baseline, demonstrating that limited metadata was insufficient to support meaningful predictions.
Conclusion
LLMs have become the poster child for generative AI, which might explain why they’re being put to work in areas where other methods could be a better fit. Even so, there’s still a lot we don’t know about what they can do across different industries, so it makes sense to give them a shot.
In this particular case, as with stock markets and weather forecasting, there is only a limited extent to which historical data can serve as the foundation of future predictions. In the case of movies and TV shows, the very delivery method is now a moving target, in contrast to the period between 1978-2011, when cable, satellite and portable media (VHS, DVD, et al.) represented a series of transitory or evolving historical disruptions.
Neither can any prediction method account for the extent to which the success or failure of other productions may influence the viability of a proposed property – and yet this is frequently the case in the movie and TV industry, which loves to ride a trend.
Nonetheless, when used thoughtfully, LLMs could help strengthen recommendation systems during the cold-start phase, offering useful support across a range of predictive methods.
First published Tuesday, May 6, 2025
#2023#2025#Advanced LLMs#advertising#agents#ai#Algorithms#Analysis#Anderson's Angle#approach#Articles#Artificial Intelligence#attention#Behavior#benchmark#BERT#Bias#collaborative#Collections#comcast#Companies#comparison#construction#content#continuous#data#data sources#dates#Decision Tree#domains
0 notes
Text
Árbol de clasificación
Se usa para probar relaciones no lineales entre una serie de variables explicativas y una variable de respuesta binaria y categórica.
Se clasifican los cráteres de marte según su zona (latitud), que es nuestra variable de respuesta, con base en el diámetro y profundidad, las variables explicativas.
El código es el siguiente:


Los resultados:

De la matriz anterior podemos ver los resultados de la clasificación: *Verdaderos positivos: 48,696 *Verdaderos negativos: 65,558 *Falsos positivos: 28,035 *Falsos negativos: 11,449
Se clasificó con una precisión del 74.3% (según lo visto en los resultados).
y obtenemos el siguiente árbol de decisión:

El primer nodo empieza a clasificar con la variable x[1]=profundidad del cráter. Si este es menor que 1.5 (las variables son '1' y '2') ahora tenemos 115,441 muestras. Ahora tomando la variable x[0]=diámetro del cráter (la cual tiene las variables '1', '2', '3' y '4')
Si x[0]<=1.5 ahora tenemos 34,318 muestras. De aquí que los cráteres que tienen un diámetro pequeño de los que tienen poca profundidad: 12,148 están ubicados en el norte y 22,170 están ubicados en el sur.
Si x[0]>1.5 ahora tenemos 81,123 muestras. De aquí que los cráteres que tienen un diámetro mayor de los que tienen poca profundidad: 29,725 están ubicados en el norte y 51,398 están ubicados en el sur.
De esta manera podemos seguir interpretando los demás nodos.
0 notes
Text
https://1drv.ms/b/s!At_LC8QFhi4uhZ9pgyBY-ztRwdvS_w?e=7EwoBq
1 note
·
View note