#MySQL 8 Failure
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
Top Tips to Build a Secure Website Backup Plans

Why Website Backup Is Crucial
Website backup is a critical aspect of website management, offering protection against various threats and ensuring smooth operations. Here's an in-depth look at why website backup is essential:
1. Protection Against Data Loss: During website development, frequent changes are made, including code modifications and content updates. Without proper backup, accidental deletions or code errors can lead to irrecoverable data loss.
2. Safeguarding Against Cyber Attacks: Malicious cyber attacks, including ransomware, pose a significant threat to websites. Regular backups provide a safety net, allowing businesses to restore their websites to a pre-attack state quickly.
3. Mitigating Risks of Hardware and Software Failures: Hardware failures or software glitches can occur unexpectedly, potentially resulting in data corruption or loss. Website backup ensures that data can be restored swiftly in such scenarios.
4. Facilitating Smoother Updates and Overhauls: Website updates and overhauls are inevitable for staying current and meeting evolving requirements. Having backups in place streamlines these processes by providing a fallback option in case of unforeseen issues.
Understanding Website Backup
What is Website Backup? Website backup involves creating duplicate copies of website data, including media, code, themes, and other elements, and storing them securely to prevent loss or damage.
Components of Website Backup:
Website Files: Includes all website data such as code files, media, plugins, and themes.
Databases: Backup of databases like MySQL or PostgreSQL, if utilized.
Email Sending: Backup of email forwarders and filters associated with the website.
Tips for Secure Website Backup Planning
1. Choose the Right Backup Frequency: Frequency depends on website traffic, update frequency, and content sensitivity.
2. Opt for Third-Party Backup Solutions: Consider factors like storage capacity, automation, security features, and user-friendliness.
3. Utilize Backup Plugins for WordPress: Plugins like UpdraftPlus, VaultPress, and others offer secure and automated backup solutions.
4. Maintain Offsite Backups: Store backups in remote data centers or cloud services for added security.
5. Test Your Backups: Regular testing ensures backup integrity and readiness for restoration.
6. Supplement Hosting Backup Services: While hosting providers offer backups, explore additional backup solutions for enhanced security and control.
7. Consider Manual Backups: Manual backups provide flexibility and control, especially for specific needs or scenarios.
8. Encrypt Backup Data: Encrypting backup files adds an extra layer of security, preventing unauthorized access.
9. Monitor Backup Processes: Regular monitoring helps identify issues promptly and ensures backup availability.
10. Implement Disaster Recovery Plans: Prepare for unforeseen events with comprehensive disaster recovery strategies.
Secure Website Backup Service with Servepoet
For comprehensive website backup solutions, consider CodeGuard Backup service, offering automated daily backups, robust encryption, and user-friendly management features.
Conclusion
Building a secure website backup plan is vital for protecting against data loss, cyber threats, and operational disruptions. By following best practices and leveraging reliable backup solutions, businesses can safeguard their websites and ensure continuity of operations.
#buy domain and hosting#best domain hosting service#domain hosting services#marketing#cloud vps providers#web hosting and server#shared web hosting
2 notes
·
View notes
Text
What Steps Should I Take for OpenEMR Installation Issues?
Introduction
The installation process of OpenEMR presents difficulties due to its power as an open-source Electronic Medical Records (EMR) system. The following section presents known OpenEMR installation issues with corresponding step-by-step solutions.
Common Installation Errors and Solutions
1.PHP Compatibility Issues
Error: OpenEMR installation fails due to compatibility issues with PHP version.
Solution: The installation process requires using PHP version 7.4 or newer versions. The php.ini file requires PHP configuration updates that match OpenEMR settings. Proper error prevention involves enabling Off for short_open_tag while setting the memory_limit to 512M in your php.ini file.
2.Database Connection Failure
Error: “Cannot connect to the MySQL database.”
Cause: This error arises when the OpenEMR installer cannot establish a connection to the MySQL database.
Solution:
· Ensure the MySQL service is running: sudo service mysql start.
· Verify that the credentials in the sqlconf.php file are correct:
Php: $host = 'localhost'; $port = '3306'; $login = 'your_username'; $pass = 'your_password'; $dbase = 'openemr';
3. Blank Page After Installation
Error: A blank screen is displayed after installing OpenEMR.
Cause: Typically caused by a missing PHP module or a permissions issue.
Solution:
· Check for missing PHP modules using php -m | grep -i <missing_module>.
· Install missing modules with sudo apt-get install php-<module_name>.
· Ensure correct file permissions: sudo chmod -R 755 /var/www/openemr.
4. Locale Errors
Error: “PHP Warning: Failed to setlocale…”
Cause: The locale settings on the server are not configured correctly.
Solution:
· Install the appropriate locales: sudo locale-gen en_US.UTF-8.
· Reconfigure locales: sudo dpkg-reconfigure locales.
5. SQL Error in OpenEMR Usage
Error: A fatal error occurred that showed “Uncaught Error: SQLSTATE[42S02]: Base table or view not found…”
Cause: The missing database table or improper database table creation process causes this error to appear.
Solution:
· Re-execute the SQL upgrade script through the command: mysql -u root -p openemr < sql/upgrade.sql.
· All database tables need to be imported correctly.
6. PDF Generation Failure
Error: The error message reads, “FPDF error: Unable to create output file.”
Cause: The file system write permissions create a cause that prevents OpenEMR from generating output files.
Solution:
· Users need write permissions in the sites/default/documents directory because of this command: sudo chmod -R777/var/www/openemr/sites/default/documents.
Common Mistakes During Setup
1.Inadequate System Requirements Assessment
· Performance problems emerge because organizations underestimate their hardware requirements along with their software needs.
· System requirements assessment needs to become a complete process done before any installation begins.
2.Neglecting Data Backup and Recovery Planning
· Failing to plan backup procedures and recovery strategies remains one of the main setup challenges.
· Planning for data backup becomes essential since the absence of planning may cause complete loss of information.
· Regular backups should be conducted either through OpenEMR’s tools or third-party scripting solutions.
3.Improper Configuration
· Incorrectly implemented settings result in both performance issues and system errors.
· Users should verify that both database and PHP settings align correctly with OpenEMR’s necessary requirements.
Real-World Examples and Case Studies
Cloud Success Story: Through OpenEMR Cloud on AWS, this Vermont clinic cut their server maintenance expenses by 70% and also gained better peak-season system capabilities.
On-Premises Example: A large Texas hospital chose on-premises deployment of OpenEMR to sustain whole authority over security standards while maintaining easy integration with current hospital information infrastructure.
Troubleshooting Tips for Windows Installation
· Check PHP settings because you must enable all required PHP extensions while following the correct settings in the php.ini configuration file.
· Check MySQL Connection by verifying the correct running of MySQL and sqlconf.php credentials.
· During installation, use a temporary disable of antivirus software to prevent interruptions.
· You should check OpenEMR directory permissions to stop unauthorized access to its files.
Future Trends in OpenEMR
OpenEMR will continue integrating modern features into its system as healthcare technology advances forward.
AI and Machine Learning
· OpenEMR will incorporate artificial intelligence-based clinical decision support systems and predictive analytics technology for patient care in future updates.
Telehealth Enhancements
· The telehealth system will receive updated modules that enable remote consultation access while offering better healthcare access to patients.
Interoperability Standards
· Additional FHIR technology support in the system will help different healthcare systems communicate their data more efficiently.
Conclusion
The resolution of OpenEMR installation problems requires a careful approach together with expertise in frequent installation barriers. Healthcare providers who focus on PHP compatibility along with database connections and permissions will establish a successful OpenEMR setup while maximizing its functionality. Continuous updates about the latest OpenEMR advancements enable healthcare professionals to achieve maximum performance and efficiency for their management tasks.
FAQs
What are the most common installation errors in OpenEMR?
During OpenEMR installation, you might encounter three major issues that include PHP version conflicts as well as database connection problems and unexplained blank pages showing up because of either missing components or access permission problems.
How do I troubleshoot a blank page error after OpenEMR installation?
Review both PHP module's presence and verify correct permissions for the OpenEMR directory files.
What are some common mistakes during OpenEMR setup?
The integration of insufficient system assessment with poor data backup and recovery planning along with unsuitable configuration represents the main mistakes that cause performance degradation and data loss.
0 notes
Text
Database Automation
Database automation with Ansible can significantly streamline the management and deployment of databases. Here are some specific subtopics and tasks you could explore within database automation:
1. Database Installation and Configuration
Task: Automate the installation of MySQL/PostgreSQL.
Playbooks:
Install database packages.
Initialize the database.
Configure the database server (e.g., set up users, configure authentication, modify configuration files).
2. Automating Database Backups
Task: Set up automated backups for databases.
Playbooks:
Create backup scripts for MySQL/PostgreSQL.
Schedule regular backups using cron jobs.
Store backups in remote locations (e.g., S3, FTP servers).
3. Database Replication Setup
Task: Automate the setup of database replication.
Playbooks:
Configure master and replica databases.
Set up replication users and permissions.
Handle failover configurations and testing.
4. Automating Database Migrations
Task: Manage database schema changes and migrations.
Playbooks:
Apply schema changes using tools like Alembic or Flyway.
Rollback migrations in case of failures.
Version control database schema changes.
5. Database Performance Tuning
Task: Optimize database performance automatically.
Playbooks:
Apply performance tuning parameters to configuration files.
Set up monitoring and alerting for performance metrics.
Automate index creation and maintenance tasks.
6. User and Permission Management
Task: Automate the creation and management of database users and permissions.
Playbooks:
Create database users with specific permissions.
Automate role assignments.
Implement security best practices for database access.
7. Automating Database Security
Task: Enhance database security through automation.
Playbooks:
Apply security patches and updates.
Configure firewalls and access controls.
Monitor and log database activity for suspicious behavior.
8. Disaster Recovery Planning
Task: Automate disaster recovery processes.
Playbooks:
Automate backup and restore procedures.
Test failover and recovery plans regularly.
Ensure data integrity and consistency across backups.
Sample Playbook for MySQL Installation and Basic Configuration
- name: Install and configure MySQL
hosts: database_servers
become: yes
vars:
mysql_root_password: "securepassword"
mysql_database: "myappdb"
mysql_user: "myappuser"
mysql_password: "myapppassword"
tasks:
- name: Install MySQL server
apt:
name: mysql-server
state: present
- name: Start MySQL service
service:
name: mysql
state: started
enabled: yes
- name: Set root password
mysql_user:
name: root
password: "{{ mysql_root_password }}"
login_user: root
login_password: ''
host_all: yes
when: ansible_os_family == "Debian"
- name: Remove anonymous users
mysql_user:
name: ''
host_all: yes
state: absent
- name: Remove test database
mysql_db:
name: test
state: absent
- name: Create application database
mysql_db:
name: "{{ mysql_database }}"
state: present
- name: Create application user
mysql_user:
name: "{{ mysql_user }}"
password: "{{ mysql_password }}"
priv: "{{ mysql_database }}.*:ALL"
state: present
- name: Apply basic security settings
mysql_variables:
- name: bind-address
value: 0.0.0.0
- name: max_connections
value: 150
This is a basic example, but it can be expanded to include more complex configurations and tasks as needed. You can also explore using Ansible roles for better organization and reusability of your playbooks.
For more details www.qcsdclabs.com
#linux#redhatcourses#information technology#containerorchestration#kubernetes#dockerswarm#aws#docker#container#containersecurity
0 notes
Text
"Mastering MySQL: Comprehensive Database Management Course"
I'm thrilled to address your inquiries about MySQL. My perspective and expertise have undergone significant growth in this field. MySQL enjoys widespread recognition and finds extensive applications across diverse industries.
MySQL is an open-source relational database management system (RDBMS) renowned for its versatility and utility in handling structured data. Initially developed by the Swedish company MySQL AB, it is presently under the ownership of Oracle Corporation. MySQL's reputation rests on its speed, reliability, and user-friendliness, which have fueled its adoption among developers and organizations of all sizes.

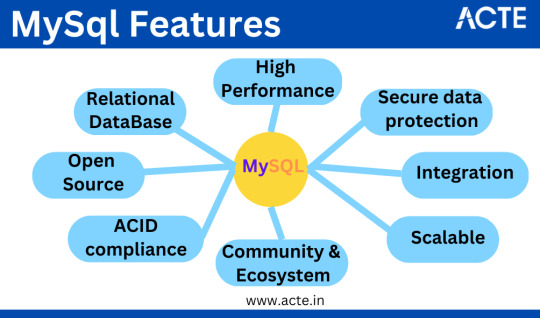
Key Attributes of MySQL:
1. Relational Database: MySQL organizes data into tables with rows and columns, facilitating efficient data retrieval and manipulation.
2. Open Source: Available under an open-source license, MySQL is freely accessible and modifiable, with commercial versions and support options for those requiring additional features.
3. Multi-Platform: MySQL caters to various operating systems, including Windows, Linux, macOS, and more, ensuring adaptability across diverse environments.
4.Scalability: MySQL seamlessly scales from small-scale applications to high-traffic websites and data-intensive enterprise systems, offering support for replication and clustering.
5. Performance: Recognized for high-performance capabilities, MySQL ensures swift data retrieval and efficient query execution, offering multiple storage engines with varying feature trade-offs.
6. Security: MySQL provides robust security features, encompassing user authentication, access control, encryption, and auditing to safeguard data and ensure compliance with security standards.
7. ACID Compliance: MySQL adheres to ACID principles, ensuring data integrity and reliability, even in the event of system failures.
8. SQL Support: Employing Structured Query Language (SQL), MySQL defines, manipulates, and queries data, aligning with a standard set of SQL commands for compatibility with various applications and development tools.
9. Community and Ecosystem: MySQL boasts a thriving user community, contributing to its development and offering extensive resources, including documentation, forums, and third-party extensions.
10.Integration: MySQL seamlessly integrates with multiple programming languages and development frameworks, making it a favored choice for web and application development.
MySQL finds widespread usage in web applications, content management systems, e-commerce platforms, and numerous other software projects where structured data storage and retrieval are imperative. It competes with other relational databases such as PostgreSQL, Oracle Database, and Microsoft SQL Server in the database management system arena.
Should you seek to delve deeper into MySQL Course, I strongly recommend reaching out to ACTE Technologies, a hub for certifications and job placement opportunities. Their experienced instructors can facilitate your learning journey, with both online and offline options available. Take a methodical approach, and contemplate enrolling in a course if your interest persists.
I trust that this response effectively addresses your inquiries. If not, please do not hesitate to voice your concerns in the comments section. I remain committed to continuous learning.
If you've found my insights valuable, consider following me on this platform and giving this content an upvote to encourage further MySQL-related content. Thank you for investing your time here, and I wish you a splendid day.
1 note
·
View note
Text
InnoDB Cluster (High Availability setup for MySQL)
InnoDB Cluster (High Availability setup for MySQL)

InnoDB cluster is a complete high availability solution for MySQL. It uses a group replication mechanism with the help of AdminAPI. We can configure the setup very easily by using the MySQL shell utility.
We can use MySQL Router on top of the cluster to route traffic to backend database nodes. It can be used to split READ and WRITE requests using different proxy ports. It can provide more…
View On WordPress
#mysql#MySQL 8 Failure#MySQL High availability#MySQL InnoDB Cluster#MySQL Router#MySQL Scalibility#Mysql shell#Mysql8
0 notes
Text
20 key points on becoming a Junior Full-Stack Web Developer | Resource ✨

I follow a user on Twitter called Swapna Kumar Panda! He's a tech educator and mentor from India. He tweeted a thread about mentoring someone into getting their first tech job. He laid out what he did to help him in the tweet and I thought I would bullet point them here for anyone interested!
But do go ahead and read the full thread because he does do into details on what he did!
20 key points on becoming a Junior Full-Stack Web Developer:
[ 1 ] Save time by being smart [ 2 ] Stop comparing Education [ 3 ] Practice during learning [ 4 ] Avoid Tutorial Hell & FOMO (Fear of Missing out) [ 5 ] Learn and start using Git as early as possible [ 6 ] Start with simple HTML & CSS (which he provides a roadmap) [ 7 ] Learn basic JavaScript (which he provides a roadmap) [ 8 ] Build small projects (he provides 150+ projects) [ 9 ] Learn TypeScript [ 10 ] Be modular [ 11 ] Learn React [ 12 ] Learn Next.js [ 13 ] Problem Solving Skills (which he provide practice Algorithms for various programming languages) [ 14 ] Back-End with Node.js & Express [ 15 ] Database with MySQL & MongoDB [ 16 ] Build complete projects (which he provides 150+ Full-Stack Web projects) [ 17 ] Make Personal Portfolio [ 18 ] Build Resume [ 19 ] Build Connections [ 20 ] Be ready for a few failures
Hope this helps people! But make sure to check out the full thread on Twitter! Have a nice day programming! (✿◡‿◡)
#computer science#big data#programming#AI#artificial intelligence#machine learning#deep learning#studying#studyblr#robotics#software developer#resources#backend#coding#100 days of code#projetcs#study plan#comp sci#python#how to code#web development#game dev#typescript#studyblr community#student#study tips#study motivation#programming resource#javascript
397 notes
·
View notes
Text
Excel, Word, Access, Outlook
Previously on computer literacy: A Test For Computer Literacy
If you’re a computer programmer, you sometimes hear other programmers complain about Excel, because it mixes data and code, or about Word, because it mixes text and formatting, and nobody ever uses Word and Excel properly.
If you’re a computer programmer, you frequently hear UX experts praise the way Excel allows non-programmers to write whole applications without help from the IT department. Excel is a great tool for normal people and power users, I often hear.
I have never seen anybody who wasn’t already versed in a real programming language write a complex application in an Excel spreadsheet. I have never seen anybody who was not a programmer or trained in Excel fill in a spreadsheet and send it back correctly.
Computer programmers complain about the inaccessibility of Excel, the lack of discoverability, the mixing of code and data in documents that makes versioning applications a proper nightmare, the influence of the cell structure on code structure, and the destructive automatic casting of cell data into datatypes.
UX experts praise Excel for giving power to non-programmers, but I never met a non-programmer who used Excel “properly”, never mind developed an application in it. I met non-programmers who used SPSS, Mathematica, or Matlab properly a handful of times, but even these people are getting rarer and rarer in the age of Julia, NumPy, SymPy, Octave, and R. Myself, I have actually had to learn how to use Excel in school, in seventh grade. I suspect that half of the “basic computer usage” curriculum was the result of a lobbying campaign by Microsoft’s German branch, because we had to learn about certain features in Word, Excel, and PowerPoint on Windows 95, and non-Microsoft applications were conspicuously absent.
Visual Basic and VBS seemed like a natural choice to give power to end users in the 90s. People who had already used a home computer during the 8-bit/16-bit era (or even an IBM-compatible PC) were familiar with BASIC because that was how end-users were originally supposed to interact with their computers. BASIC was for end users, and machine code/compiled languages were for “real programmers” - BASIC was documented in the manual that came with your home computer, machine code was documented in MOS data sheets. From today’s point of view, programming in BASIC is real programming. Calling Visual Basic or .Net scripting in Excel “not programming“ misrepresents what modern programmers do, and what GUI users have come to expect after the year 2000.
Excel is not very intuitive or beginner-friendly. The “basic computer usage” curriculum was scrapped shortly after I took it, so I had many opportunities to observe people who were two years younger than me try to use Excel by experimenting with the GUI alone.
The same goes fro Microsoft Word. A friend of mine insists that nobody ever uses Word properly, because Word can do ligatures and good typesetting now, as well as footnotes, chapters, outline note taking, and so on. You just need to configure it right. If people used Word properly, they wouldn’t need LaTeX or Markdown. That friend is already a programmer. All the people I know who use Word use WYSIWYG text styling, fonts, alignment, tables, that sort of thing. In order to use Word “properly“, you’d have to use footnotes, chapter marks, and style sheets. The most “power user” thing I have ever seen an end user do was when my father bought a CD in 1995 with 300 Word templates for all sorts of occasions - birthday party invitation, employee of the month certificate, marathon completion certificate, time table, cooking recipe, invoice, cover letter - to fill in and print out.
Unlike Excel, nobody even claims that non-programmer end users do great things in Word. Word is almost never the right program when you have email, calendars, wikis, to-do lists/Kanban/note taking, DTP, vector graphics, mind mapping/outline editors, programmer’s plain text editors, dedicated novelist/screenwriting software, and typesetting/document preparation systems like LaTeX. Nobody disputes that plain text, a wiki, or a virtual Kanban board is often preferable to a .doc or .docx file in a shared folder. Word is still ubiquitous, but so are browsers.
Word is not seen as a liberating tool that enables end-user computing, but as a program you need to have but rarely use, except when you write a letter you have to print out, or when you need to collaborate with people who insist on e-mailing documents back and forth.
I never met an end user who actually liked Outlook enough to use it for personal correspondence. It was always mandated by an institution or an employer, maintained by an IT department, and they either provided training or assumed you already had had training. Outlook has all these features, but neither IT departments nor end users seemed to like them. Outlook is top-down mandated legibility and uniformity.
Lastly, there is Microsoft Access. Sometimes people confused Excel and Access because both have tables, so at some point Microsoft caved in and made Excel understand SQL queries, but Excel is still not a database. Access is a database product, designed to compete with products like dBase, Cornerstone, and FileMaker. It has an integrated editor for the database schema and a GUI builder to create forms and reports. It is not a networked database, but it can be used to run SQL queries on a local database, and multiple users can open the same database file if it is on a shared SMB folder. It is not something you can pick up on one afternoon to code your company’s billing and invoicing system. You could probably use it to catalogue your Funko-Pop collection, or to keep track of the inventory, lending and book returns of a municipal library, as long as the database is only kept on one computer. As soon as you want to manage a mobile library or multiple branches, you would have to ditch Access for a real SQL RDBMS.
Microsoft Access was marketed as a tool for end-user computing, but nobody really believed it. To me, Access was SQL with training wheels in computer science class, before we graduated to MySQL and then later to Postgres and DB2. UX experts never tout Access as a big success story in end-user computing - yet they do so for Excel.
The narrative around Excel is quite different from the narrative around Yahoo Pipes, IFTTT, AppleScript, HyperCard, Processing, or LabView. The narrative goes like this: “Excel empowers users in big, bureaucratic organisations, and allows them to write limited applications to solve business problems, and share them with co-workers.”
Excel is not a good tool for finance, simulations, genetics, or psychology research, but it is most likely installed on every PC in your organisation already. You’re not allowed to share .exe files, but you are allowed to share spreadsheets. Excel is an exchange format for applications. Excel files are not centrally controlled, like Outlook servers or ERP systems, and they are not legible to management. Excel is ubiquitous. Excel is a ubiquitous runtime and development environment that allows end-users to create small applications to perform simple calculations for their jobs.
Excel is a tool for office workers to write applications to calculate things, but not without programming, but without involving the IT department. The IT department would like all forms to be running on some central platform, all data to be in the data warehouse/OLAP platform/ERP system - not because they want to make the data legible and accessible, but because they want to minimise the number of business-critical machines and points of failure, because important applications should either run on servers in a server rack, or be distributed to workstations by IT.
Management wants all knowledge to be formalised so the next guy can pick up where you left off when you quit. For this reason, wikis, slack, tickets and kanban boards are preferable to Word documents in shared folders. The IT department calls end-user computing “rogue servers“ or “shadow IT“. They want all IT to have version control, unit tests, backups, monitoring, and a handbook. Accounting/controlling thinks end-user computing is a compliance nightmare. They want all software to be documented, secured, and budgeted for. Upper management wants all IT to be run by the IT department, and all information integrated into their reporting solution that generates these colourful graphs. Middle management wants their people to get some work done.
Somebody somewhere in the C-suite is always viewing IT as a cost centre, trying to fire IT people and to scale down the server room. This looks great on paper, because the savings in servers, admins, and tech support are externalised to other departments in the form of increased paperwork, time wasted on help hotlines, and
Excel is dominating end-user computing because of social reasons and workplace politics. Excel is not dominating end-user computing because it is actually easy to pick up for end-users.
Excel is dominating end-user computing neither because it is actually easy to pick up for non-programmers nor easy to use for end-users.
This is rather obvious to all the people who teach human-computer interaction at universities, to the people who write books about usability, and the people who work in IT departments. Maybe it is not quite as obvious to people who use Excel. Excel is not easy to use. It’s not obvious when you read a book on human-computer interaction (HCI), industrial design, or user experience (UX). Excel is always used as the go-to example of end-user computing, an example of a tool that “empowers users”. If you read between the lines, you know that the experts know that Excel is not actually a good role model you should try to emulate.
Excel is often called a “no code“ tool to make “small applications“, but that is also not true. “No Code” tools usually require users to write code, but they use point-and-click, drag-and-drop, natural language programming, or connecting boxes by drawing lines to avoid the syntax of programming languages. Excel avoids complex syntax by breaking everything up into small cells. Excel avoids iteration or recursion by letting users copy-paste formulas into cells and filling formulas in adjacent cells automatically. Excel does not have a debugger, but shows you intermediate results by showing the numbers/values in the cells by default, and the code in the cells only if you click.
All this makes Excel more like GameMaker or ClickTeam Fusion than like Twine. Excel is a tool that doesn’t scare users away with text editors, but that’s not why people use it. It that were the reason, we would be writing business tools and productivity software in GameMaker.
The next time you read or hear about the amazing usability of Excel, take it with a grain of salt! It’s just barely usable enough.
128 notes
·
View notes
Text
My Own Blog by Laravel(1)
Make my own blog with Laravel!!
Hi guys, I will make my own blog by Laravel. I'm a Japanese cook in BC. But I don't work now because of COVID-19. So I have much time now. That's why I have started to learn Laravel. I'm not a good English writer. But I will do my best in English. Please correct my English if you would notice any wrong expressions. Thank you!
Anyway, I will post about making a blog by Laravel for a while. Let's get started!
All we have to do
Install Laravel
Create a Project
Database Setting
Migration
Create Models
Seeding
Routing
Make Controllers
Make Views
Agenda
Today's agenda is
Install Laravel
Create a Project
Database Setting
Migration
Create Models
Seeding
Install Laravel
Laravel utilizes Composer to manage its dependencies. So install Composer first if you have not installed Composer yet. Ok, now you can install Laravel using Composer.
% composer global require Laravel/installer
Here we go. So next step is to create a project named blog!
Create a project
Creating a project in Laravel is super easy. Just type a command like below.
% laravel new blog
That's it. So easy. That command bring every dependencies automatically. And you move to blog directory.
% cd blog
Now you can use a new command called 'artisan'. It's a command used for Laravel. For example, you can start server with this command.
% php artisan serve
Do you see command line like this?
% php artisan serve ~/workspace/blog Laravel development server started: http://127.0.0.1:8000 [Mon Apr 20 09:20:56 2020] PHP 7.4.5 Development Server (http://127.0.0.1:8000) started
You can access localhost:8000 to see the Laravel's welcome page! If you want to know the other arguments of artisan, just type like this.
% php artisan list
Then you can see all artisan commands. You can also display the commands for a specific namespace like this.
% php artisan list dusk ~/workspace/blog Laravel Framework 7.6.2 Usage: command [options] [arguments] Options: -h, --help Display this help message -q, --quiet Do not output any message -V, --version Display this application version --ansi Force ANSI output --no-ansi Disable ANSI output -n, --no-interaction Do not ask any interactive question --env[=ENV] The environment the command should run under -v|vv|vvv, --verbose Increase the verbosity of messages: 1 for normal output, 2 for more verbose output and 3 for debug Available commands for the "dusk" namespace: dusk:chrome-driver Install the ChromeDriver binary dusk:component Create a new Dusk component class dusk:fails Run the failing Dusk tests from the last run and stop on failure dusk:install Install Dusk into the application dusk:make Create a new Dusk test class dusk:page Create a new Dusk page class
So let's go to next step!
Database setting
Open .env located under root directory. And edit around DB setting.
DB_CONNECTION=mysql DB_HOST=127.0.0.1 DB_PORT=3306 DB_DATABASE=blog DB_USERNAME=root DB_PASSWORD=
Depends on your database. I use MySQL and I already create database named blog in MySQL. You should create user for only this project when you deploy.
Migration
Laravel supplies the migration system. It allow you to control database using php code. For example, when you want to create database, type the command like this.
% php artisan make:migration create_posts_table
You can see a new migration file database/migrations/xxxx_xx_xx_xxxxxx_create_posts_table.php. Write down columns you need in the function called up() and write down columns you want to delete in down(). Edit it.
public function up() { Schema::create('posts', function (Blueprint $table) { $table->increments('id'); $table->boolean('published'); $table->string('title'); $table->longText('body'); $table->string('tag')->nullable(); $table->timestamps(); }); }
It's ready! Execute this command.
% php artisan migrate
Here we go! Now you got some tables with columns! Let's check them out in MySQL console.
% mysql -uroot
And check tables and columns.
mysql> use blog; Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Database changed mysql> show tables; +----------------+ | Tables_in_blog | +----------------+ | failed_jobs | | migrations | | posts | | users | +----------------+ 4 rows in set (0.01 sec) mysql> desc posts; +------------+------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+------------------+------+-----+---------+----------------+ | id | int(10) unsigned | NO | PRI | NULL | auto_increment | | published | tinyint(1) | NO | | NULL | | | title | varchar(191) | NO | | NULL | | | body | longtext | NO | | NULL | | | tag | varchar(191) | YES | | NULL | | | created_at | timestamp | YES | | NULL | | | updated_at | timestamp | YES | | NULL | | | user_id | int(11) | NO | MUL | NULL | | +------------+------------------+------+-----+---------+----------------+ 8 rows in set (0.01 sec)
Good! You could create tables and columns by php. Next step is Create Model.
Create Model
Laravel Framework is MVC application model. MVC is Model, View and Controller. Application works with each role. View works for display to browsers. Controller works as a playmaker. It receives request from router and access databases to get some datas and pass the datas to views. Model connects to the database and gets, inserts, updates or deletes datas.
Now you create a Model.
% php artisan make:model Post
Then you will see the new Post model under app/Post.php.
<?php namespace App; use Illuminate\Database\Eloquent\Model; class Post extends Model { // }
This model has no code. But it's ok. You can leave it for now.
About a model name
A model name is important. A model connects to table of the database with the rule of the name. If you have a posts table, Post model is mapped with posts table automatically.
Seeding
Seeding is very useful function for preparing test datas or master datas. You can use it easily. All you need is just 1. making seeder file and 2. executing it. Let's do that.
Making seeder files
% php artisan make:seeder BooksTableSeeder Seeder created successfully.
Edit seeder files
public function run() { DB::table('posts')->truncate(); $posts = [ [ 'published' => true, 'title' => 'The First Post', 'body' => '1st Lorem ipsum...', 'tag' => 'laravel', 'user_id' => 1 ], [ 'published' => true, 'title' => 'The Second Post', 'body' => '2nd Lorem ipsum dolor sit amet...', 'tag' => 'shiba-inu', 'user_id' => 1 ], [ 'published' => false, 'title' => 'The Third Post', 'body' => '3rd Lorem ipsum dolor sit ...', 'tag' => 'laravel', 'user_id' => 1 ] ]; foreach($posts as $post) { \App\Post::create($post); } }
And edit DatabaseSeeder.php file.
public function run() { // $this->call(UserSeeder::class); $this->call(PostsTableSeeder::class); }
Execute seegding
% php artisan db:seed Seeding: PostsTableSeeder Database seeding completed successfully.
Sweet. Let's check out database.
mysql> select * from posts; +----+-----------+-----------------+-----------------------------------+---------------------------------+---------------------+---------+ | id | published | title | body | tag | created_at | updated_at | user_id | +----+-----------+-----------------+-----------------------------------+-----------+---------------------+---------------------+---------+ | 1 | 1 | The First Post | 1st Lorem ipsum... | laravel | 2020-04-19 19:16:18 | 2020-04-19 19:16:18 | 1 | | 2 | 1 | The Second Post | 2nd Lorem ipsum dolor sit amet... | shiba-inu | 2020-04-19 19:16:18 | 2020-04-19 19:16:18 | 1 | | 3 | 0 | The Third Post | 3rd Lorem ipsum dolor sit ... | laravel | 2020-04-19 19:16:18 | 2020-04-19 19:16:18 | 1 | +----+-----------+-----------------+-----------------------------------+-----------+---------------------+---------------------+---------+ 3 rows in set (0.00 sec)
Perfect! Now we can go next step!
So, see you next time!
References
Installation - Laravel - The PHP Framework For Web Artisans
1 note
·
View note
Text
Draconic tinkertool

DRACONIC TINKERTOOL HOW TO
DRACONIC TINKERTOOL INSTALL
DRACONIC TINKERTOOL REGISTRATION
DRACONIC TINKERTOOL SOFTWARE
It means porting a lot of database procedures to MySQL format which could take awhile, given KaniS's limited free time. Because a new host will save a lot of money vs running the dedicated server Draconic currently runs on, we're going to continue that move. It turned out that the hard drive that failed on the server was only used by the live snapshot backup system and that the main drive is still working after removing the failed drive.ĭuring the downtime, it was assumed the server was not easily recoverable and we began to move to a new web hosting provider. UPDATE: They extended the deadline so you now have about 26 days.Īround Nov 23rd, the Draconic server experienced a hard drive failure. It's pretty cheap to fund a copy for yourself and the author only gets the money if they reach their goal in the next 8 days, so spread the word. It looks a little hokey, but the artwork's decent and the humor looks reminiscent of the old text adventure games on DOS. Indiegogo has someone wanting to produce a dragon dating simulator game. I've imported the latest version of the database to the new server and am working on converting database logic.ġ2-10-14, 7:27am: Dragon Dating Simulator There was a nightly backup run that seems to be intact, so not much data should have been lost. I'll un-grey more links above as I restore various sections. That work is not complete, but I'm going to work on completing it rather than waste time and money on restoring to a new hard drive.įeatures on this page that aren't greyed-out have been converted. I've been wanting to move the site to a hosting service for a long time, but it requires converting the existing database to a new system. But we'll see.ĭraconic's hard drive died.
DRACONIC TINKERTOOL INSTALL
So at this point, I'm hoping most of the remaining 87 procs will install without many additional features to figure out, in which case the remaining site features should be ready in the next weekish.
DRACONIC TINKERTOOL HOW TO
Each time I figure out how to convert an obscure feature, I convert every use of that feature in every proc that uses it. Unfortunately the remaining 20% is the most obscure stuff that is harder to figure out how to convert.
DRACONIC TINKERTOOL SOFTWARE
This is a pretty complicated task, but I found conversion software that gets it about 80% of the way. Most of my time has been spent converting message bodies from flat-file storage to in-database storage, and stored procedures from one database format to another. If you notice any new bugs, especially critical things like duplicate messages appearing, messages being lost, linked out of order, etc, please email immediately because the longer such things propagate, the harder they are to fix. Going forward, messages won't be archived till they're 365 days old instead of 90 days. Search is now based on a different piece of software so I need to see what fields in advanced search will translate.Īlso, I un-archived messages posted in the last year so you can reply to them. Message search works, but advanced search fields do not. If you notice problems, let me know.Īfter many days of marathon coding, data conversion, importing, and testing, the forums are restored!Īmazingly, it all seems to work just as before, even obscure things like signature image resizing. Basically, everything should be working again. If anyone still has problems, please email users are now prompted to create a password instead of being sent a random password later.Ĭurrent password is now required to change account information via Edit account info.įind a Dragon is ported and tested, new user registration, Edit Account Info, forums advanced search, and all admin features. I never knew about the problem because my original test browser did not encounter the issue. I fixed a bug preventing new users from registering using certain web browsers.
DRACONIC TINKERTOOL REGISTRATION
Serving the dragon otherkin community since January 1998.Ĩ-10-18, 7:20pm: New user registration fixed
1 note
·
View note
Text
Application Performance Monitoring (APM) can be defined as the process of discovering, tracing, and performing diagnoses on cloud software applications in production. These tools enable better analysis of network topologies with improved metrics and user experiences. Pinpoint is an open-source Application Performance Management(APM) with trusted millions of users around the world. Pinpoint, inspired by Google Dapper is written in Java, PHP, and Python programming languages. This project was started in July 2012 and later released to the public in January 2015. Since then, it has served as the best solution to analyze the structure as well as the interconnection between components across distributed applications. Features of Pinpoint APM Offers Cloud and server Monitoring. Distributed transaction tracing to trace messages across distributed applications Overview of the application topology – traces transactions between all components to identify potentially problematic issues. Lightweight – has a minimal performance impact on the system. Provides code-level visibility to easily identify points of failure and bottlenecks Software as a Service. Offers the ability to add a new functionality without code modifications by using the bytecode instrumentation technique Automatically detection of the application topology that helps understand the configurations of an application Real-time monitoring – observe active threads in real-time. Horizontal scalability to support large-scale server group Transaction code-level visibility – response patterns and request counts. This guide aims to help you deploy Pinpoint APM (Application Performance Management) in Docker Containers. Pinpoint APM Supported Modules Below is a list of modules supported by Pinpoint APM (Application Performance Management): ActiveMQ, RabbitMQ, Kafka, RocketMQ Arcus, Memcached, Redis(Jedis, Lettuce), CASSANDRA, MongoDB, Hbase, Elasticsearch MySQL, Oracle, MSSQL(jtds), CUBRID, POSTGRESQL, MARIA Apache HTTP Client 3.x/4.x, JDK HttpConnector, GoogleHttpClient, OkHttpClient, NingAsyncHttpClient, Akka-http, Apache CXF JDK 7 and above Apache Tomcat 6/7/8/9, Jetty 8/9, JBoss EAP 6/7, Resin 4, Websphere 6/7/8, Vertx 3.3/3.4/3.5, Weblogic 10/11g/12c, Undertow Spring, Spring Boot (Embedded Tomcat, Jetty, Undertow), Spring asynchronous communication Thrift Client, Thrift Service, DUBBO PROVIDER, DUBBO CONSUMER, GRPC iBATIS, MyBatis log4j, Logback, log4j2 DBCP, DBCP2, HIKARICP, DRUID gson, Jackson, Json Lib, Fastjson Deploy Pinpoint APM (Application Performance Management) in Docker Containers Deploying the PInpoint APM docker container can be achieved using the below steps: Step 1 – Install Docker and Docker-Compose on Linux. Pinpoint APM requires a Docker version 18.02.0 and above. The latest available version of Docker can be installed with the aid of the guide below: How To Install Docker CE on Linux Systems Once installed, ensure that the service is started and enabled as below. sudo systemctl start docker && sudo systemctl enable docker Check the status of the service. $ systemctl status docker ● docker.service - Docker Application Container Engine Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2022-01-19 02:51:04 EST; 1min 4s ago Docs: https://docs.docker.com Main PID: 34147 (dockerd) Tasks: 8 Memory: 31.3M CGroup: /system.slice/docker.service └─34147 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock Verify the installed Docker version. $ docker version Client: Docker Engine - Community Version: 20.10.12 API version: 1.41 Go version: go1.16.12 Git commit: e91ed57 Built: Mon Dec 13 11:45:22 2021 OS/Arch: linux/amd64 Context: default Experimental: true
..... Now proceed and install Docker-compose using the dedicated guide below: How To Install Docker Compose on Linux Add your system user to the Docker group to be able to run docker commands without sudo sudo usermod -aG docker $USER newgrp docker Step 2 – Deploy the Pinpoint APM (Application Performance Management) The Pinpoint docker container can be deployed by pulling the official docker image as below. Ensure that git is installed on your system before you proceed. git clone https://github.com/naver/pinpoint-docker.git Once the image has been pulled, navigate into the directory. cd pinpoint-docker Now we will run the Pinpoint container that will have the following containers joined to the same network: The Pinpoint-Web Server Pinpoint-Agent Pinpoint-Collector Pinpoint-QuickStart(a sample application, 1.8.1+) Pinpoint-Mysql(to support certain feature) This may take several minutes to download all necessary images. Pinpoint-Flink(to support certain feature) Pinpoint-Hbase Pinpoint-Zookeeper All these components and their configurations are defined in the docker-compose YAML file that can be viewed below. cat docker-compose.yml Now start the container as below. docker-compose pull docker-compose up -d Sample output: ....... [+] Running 14/14 ⠿ Network pinpoint-docker_pinpoint Created 0.3s ⠿ Volume "pinpoint-docker_mysql_data" Created 0.0s ⠿ Volume "pinpoint-docker_data-volume" Created 0.0s ⠿ Container pinpoint-docker-zoo3-1 Started 3.7s ⠿ Container pinpoint-docker-zoo1-1 Started 3.0s ⠿ Container pinpoint-docker-zoo2-1 Started 3.4s ⠿ Container pinpoint-mysql Sta... 3.8s ⠿ Container pinpoint-flink-jobmanager Started 3.4s ⠿ Container pinpoint-hbase Sta... 4.0s ⠿ Container pinpoint-flink-taskmanager Started 5.4s ⠿ Container pinpoint-collector Started 6.5s ⠿ Container pinpoint-web Start... 5.6s ⠿ Container pinpoint-agent Sta... 7.9s ⠿ Container pinpoint-quickstart Started 9.1s Once the process is complete, check the status of the containers. $ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES cb17fe18e96d pinpointdocker/pinpoint-quickstart "catalina.sh run" 54 seconds ago Up 44 seconds 0.0.0.0:8000->8080/tcp, :::8000->8080/tcp pinpoint-quickstart 732e5d6c2e9b pinpointdocker/pinpoint-agent:2.3.3 "/usr/local/bin/conf…" 54 seconds ago Up 46 seconds pinpoint-agent 4ece1d8294f9 pinpointdocker/pinpoint-web:2.3.3 "sh /pinpoint/script…" 55 seconds ago Up 48 seconds 0.0.0.0:8079->8079/tcp, :::8079->8079/tcp, 0.0.0.0:9997->9997/tcp, :::9997->9997/tcp pinpoint-web 79f3bd0e9638 pinpointdocker/pinpoint-collector:2.3.3 "sh /pinpoint/script…" 55 seconds ago Up 47 seconds 0.0.0.0:9991-9996->9991-9996/tcp, :::9991-9996->9991-9996/tcp, 0.0.0.0:9995-9996->9995-9996/udp,
:::9995-9996->9995-9996/udp pinpoint-collector 4c4b5954a92f pinpointdocker/pinpoint-flink:2.3.3 "/docker-bin/docker-…" 55 seconds ago Up 49 seconds 6123/tcp, 0.0.0.0:6121-6122->6121-6122/tcp, :::6121-6122->6121-6122/tcp, 0.0.0.0:19994->19994/tcp, :::19994->19994/tcp, 8081/tcp pinpoint-flink-taskmanager 86ca75331b14 pinpointdocker/pinpoint-flink:2.3.3 "/docker-bin/docker-…" 55 seconds ago Up 51 seconds 6123/tcp, 0.0.0.0:8081->8081/tcp, :::8081->8081/tcp pinpoint-flink-jobmanager e88a13155ce8 pinpointdocker/pinpoint-hbase:2.3.3 "/bin/sh -c '/usr/lo…" 55 seconds ago Up 50 seconds 0.0.0.0:16010->16010/tcp, :::16010->16010/tcp, 0.0.0.0:16030->16030/tcp, :::16030->16030/tcp, 0.0.0.0:60000->60000/tcp, :::60000->60000/tcp, 0.0.0.0:60020->60020/tcp, :::60020->60020/tcp pinpoint-hbase 4a2b7dc72e95 zookeeper:3.4 "/docker-entrypoint.…" 56 seconds ago Up 52 seconds 2888/tcp, 3888/tcp, 0.0.0.0:49154->2181/tcp, :::49154->2181/tcp pinpoint-docker-zoo2-1 3ae74b297e0f zookeeper:3.4 "/docker-entrypoint.…" 56 seconds ago Up 52 seconds 2888/tcp, 3888/tcp, 0.0.0.0:49155->2181/tcp, :::49155->2181/tcp pinpoint-docker-zoo3-1 06a09c0e7760 zookeeper:3.4 "/docker-entrypoint.…" 56 seconds ago Up 52 seconds 2888/tcp, 3888/tcp, 0.0.0.0:49153->2181/tcp, :::49153->2181/tcp pinpoint-docker-zoo1-1 91464a430c48 pinpointdocker/pinpoint-mysql:2.3.3 "docker-entrypoint.s…" 56 seconds ago Up 52 seconds 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp, 33060/tcp pinpoint-mysql Access the Pinpoint APM (Application Performance Management) Web UI The Pinpoint Web run on the default port 8079 and can be accessed using the URL http://IP_address:8079. You will be granted the below page. Select the desired application to analyze. For this case, we will analyze our deployed Quickapp. Select the application and proceed. Here, click on inspector to view the detailed metrics. Here select the app-in-docker You can also make settings to Pinpoint such as setting user groups, alarms, themes e.t.c. Under administration, you can view agent statistics for your application Manage your applications under the agent management tab To set an alarm, you first need to have a user group created. you also need to create a pinpoint user and add them to the user group as below. With the user group, an alarm for your application can be created, a rule and notification methods to the group members added as shown. Now you will have your alarm configured as below. You can also switch to the dark theme which appears as below. View the Apache Flink Task manager page using the URL http://IP_address:8081. Voila! We have triumphantly deployed Pinpoint APM (Application Performance Management) in Docker Containers. Now you can discover, trace, and perform diagnoses on your applications.
0 notes
Text
Top 5 High Availability Dedicated Server Solutions
What Is a High Availability Dedicated Server?
A typical dedicated server is a powerful computer which is connected to a high-speed Internet connection, and housed in a state-of-the-art remote data center or optimized data facility.
A High Availability dedicated server is an advanced system equipped with redundant power supplies, a fully redundant network, RAID disk towers and backups, ensuring the highest uptime and the full reliability with no single point of failure.
Configuration For High Availability Dedicated Servers
As its name implies, high availability dedicated solutions are scalable and customized hosting solutions, designed to meet the unique needs of any business.
These configurations are carefully designed to provide fail-proof architecture to run the critical applications in your business – those that demand the highest availability.
Possible high availability server configurations might include multiple hosts managed by redundant load balancers and replication hosts. As well as redundant firewalls for added security and reliability.
Why High Availability Server Is Important for Business
Nowadays businesses rely on the Internet. Let’s face it – even the smallest downtime can cause huge losses to business. And not just financial losses. Loss of reputation can be equally devastating.
According to StrategicCompanies more than half of Fortune 500 companies experience a minimum of 1.6 hours of downtime each and every week. That amounts to huge losses of time, profit, and consumer confidence. If your customer can’t reach you online, you might as well be on the moon, as far as they are concerned.
Consider: In the year 2013, 30 minutes of an outage to Amazon.com reportedly cost the company nearly $2 million. That’s $66,240 per minute. Take a moment to drink that in. Even if you’re not Amazon, any unplanned downtime is harmful to your business.
Your regular hosting provider may provide 99% service availability. That might sound good, in theory. But think about that missing 1%… That’s 87 hours (3.62 days) of downtime per year! If the downtime hits during peak periods, the loss to your business can be disastrous.
The best way to prevent downtime and eliminate these losses is to opt for high availability hosting solutions.
Built on a complex architecture of hardware and software, all parts of this system work completely independently of each other. In other words – failure of any single component won’t collapse the entire system.
It can handle very large volume of requests or a sudden surge in traffic. It grows and shrinks with the size and needs of your organization. Your business is flexible, shouldn’t your computer systems be, as well? Following are some of the best high availability solutions you can use to host your business applications.
1. Ultra High Performance Dedicated Servers
High performance servers are high-end dedicated solutions with larger computing capacity, especially designed to achieve the maximum performance. They are an ideal solution to cater enterprise workloads.
A typical high performance dedicated server will consist of the following:
Single/Dual latest Intel Xeon E3 or E5 series processors.
64 GB to 256 GB RAM
8 to 24 TB SATA II HDD with RAID 10
Energy efficient and redundant power supply & cooling units
Offsite Backups
Note that the list above is just a sample configuration which can be customized/upgraded as per your unique requirements. If you need more power, we can build a setup with 96 drives, 3 TB RAM, and 40+ physical CPU cores.
Real World Applications (Case Study)Customer’s Requirement
One of our existing customers was looking for a high-end game server to host flash games with encoded PHP and MySQL server as a backend.
To achieve the highest availability, they demanded 2 load balancers with failover. Each of them contains 2 web servers and a database server.
Website Statistics
8000-10000 simultaneous players
100% uptime requirement
10 GB+ database size
Solution Proposed by AccuWebHosting
Our capacity planning team designed a fully redundant infrastructure with dual load balancers sitting in front of web and database servers.
This setup consists of 2 VMs with load balancers connected to a group of web servers through a firewall. The database server was built on ultra-fast SSD drives for the fastest disk I/O operations.
For a failover, we set up an exact replica of this architecture with real-time mirroring. Should the primary system fail, the secondary setup will seamlessly take over the workload. That’s right. Zero downtime.
Infrastructure Diagram

2. Load Balanced Dedicated Servers
Load Balancing
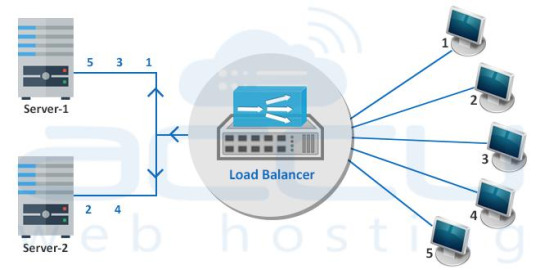
The process of distributing incoming web traffic across a group of servers efficiently and without intervention is called Load Balancing.
A hardware or software appliance which provides this load balancing functionality is known as a Load Balancer.
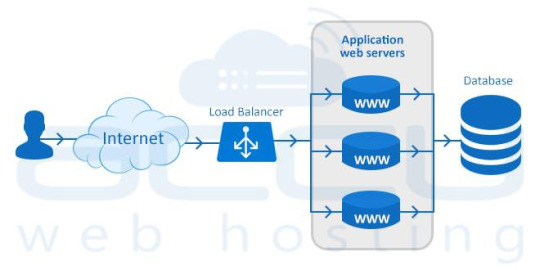
The dedicated servers equipped with a hardware/software load balancer are called Load Balanced Dedicated Servers.
How Load Balancing Works?
A load balancer sits in front of your servers and routes the visitor requests across the servers. It ensures even distribution, i.e., all requests must be fulfilled in a way that it maximizes speed and capacity utilization of all servers and none of them is over or under-utilized.
When your customers visit your website, they are first connected to load balancer and the load balancer routes them to one of the web servers in your infrastructure. If any server goes down, the load balancer instantly redirects the traffic to the remaining online servers.
As web traffic increases, you can add new servers quickly and easily to the existing pool of load-balanced servers. When a new server is added, the load balancer will start sending requests to new server automatically. That’s right – there’s no user-intervention required.
Types Of Load Balancing
Load balancing can be performed with one of the following methods.
Load Balancing Through DNS
Load Balancing Through Hardware
Load Balancing Through Software
Load Balancing With DNS
The DNS service balances the web traffic across the multiple servers. Note that when you perform the traffic load balancing through this method you cannot choose which load balancing algorithm. It always uses the Round Robin algorithm to balance the load.
Load Balancing Through Hardware
This is the most expensive way of load balancing. It uses a dedicated hardware device that handles traffic load balancing.
Most of the hardware based load balancer systems run embedded Linux distribution with a load balancing management tool that allows ease of access and a configuration overview.
Load Balancing Through Software
Software-based load balancing is one of the most reliable methods for distributing the load across servers. In this method, the software balances the incoming requests through a variety of algorithms.
Load Balancing Algorithms
There are a number of algorithms that can be used to achieve load balance on the inbound requests. The choice of load balancing method depends on the service type, load balancing type, network status and your own business requirements.
Typically, for low load systems, simple load balancing methods (i.e., Round Robin) will suffice, whereas, for high load systems, more complex methods should be used. Check out this link for more information on some industry standard Load Balancing Algorithms used by the load balancers.
Setup Load Balancing On Linux
HAProxy (High Availability Proxy) is the best available tool to set up a load balancer on Linux machines (web server, database server, etc).
It is an open-source TCP and HTTP load balancer used by some of the largest websites including Github, StackOverflow, Reddit, Tumblr and Twitter.
It is also used as a fast and lightweight proxy server software with a small memory footprint and low CPU usage.
Following are some excellent tutorials to setup a load balancing on Apache, NGINX and MySQL server.
Setup HAProxy as Load Balancer for Nginx on CentOS 7
Setup High-Availability Load Balancer for Apache with HAProxy
Setup MySQL Load Balancing with HAProxy
Setup Load Balancing On Windows
Check out below the official Microsoft document to setup load balancing with IIS web server.
Setup Load Balancing on IIS
3. Scalable Private Cloud
A scalable private cloud is a cloud-based system that gives you self-service, scalability, and elasticity through a proprietary architecture.
Private clouds are highly scalable that means whenever you need more resources, you can upgrade them, be it memory, storage space, CPU or bandwidth.
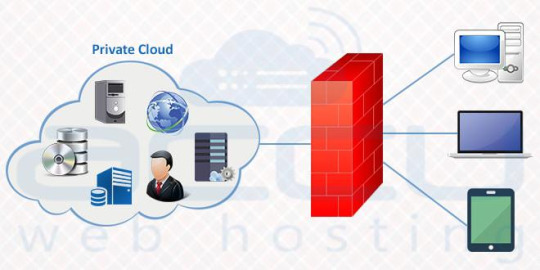
It gives the best level of security and control making it an ideal solution for a larger business. It enables you to customise computer, storage and networking components to best suit custom requirements.
Private Cloud Advantages
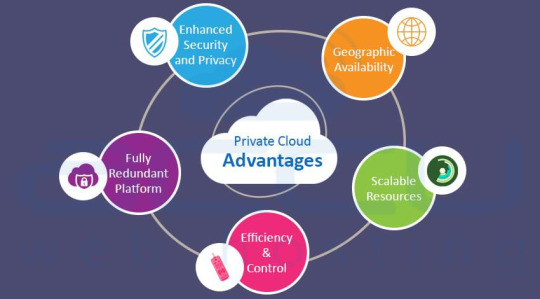
Enhanced Security & Privacy
All your data is stored and managed on dedicated servers with dedicated access. If your Cloud is on-site, the server will be monitored by your internal IT team and if it is at a datacenter, their technicians will monitor it. Thus, physical security is not your concern.
Fully Redundant Platform
A private cloud platform provides a level of redundancy to compensate from multiple failures of the hard drive, processing power etc. When you have a private cloud, you do not have to purchase any physical infrastructure to handle fluctuation in traffic.
Efficiency & Control
Private cloud gives you more control on your data and infrastructure. It has dedicated resources and no one else has access of the server except the owner of the server.
Scalable Resources
Each company has a set of technical and business requirements which usually differ from other companies based on company size, industry and business objectives etc.
A private cloud allows you to customize the server resources as per your unique requirements. It also allows you to upgrade the resources of the server when necessary.
Private Cloud DisadvantagesCost
As compared to the public cloud and simple dedicated server setup, a private cloud is more expensive. Investments in hardware and resources are also required.
You can also rent a private cloud, however the costs will likely be the same or even higher, so this might not be an advantage.
Maintenance
Purchasing or renting a private cloud is only one part of the cost. Obviously, for a purchase, you’ll have a large outlay of cash at the onset. If you are renting you’ll have continuous monthly fees.
But even beyond these costs, you will need to consider maintenance and accessories. Your private cloud will need enough power, cooling facilities, a technician to manage the server and so on.
Under-utilization
Even if you are not utilizing the server resources, you still need to pay the full cost of your private cloud. Whether owning or renting, the cost of capacity under-utilization can be daunting, so scale appropriately at the beginning of the process.
Complex Implementation
If you are not tech savvy, you may face difficulties maintaining a private cloud. You will need to hire a cloud expert to manage your infrastructure, yet another cost.
Linux & Windows Private Cloud Providers
Cloud providers give you an option to select your choice of OS: either Windows or any Linux distribution. Following are some of the private cloud solution providers.
AccuWebHosting
Amazon Web Services
Microsoft Azure
Rackspace
Setting Up Your Own Private Cloud
There are many paid and open source tools available to setup your own private cloud.
OpenStack
VMware vSphere
VMmanager
OnApp
OpenNode Cloud Platform
OpenStack is an open source platform that provides IAAS (Infrastructure As A Service) for both public and private cloud.
Click here to see the complete installation guide on how you can deploy your own private cloud infrastructure with OpenStack on a single node in CentOS or RHEL 7.
4. Failover
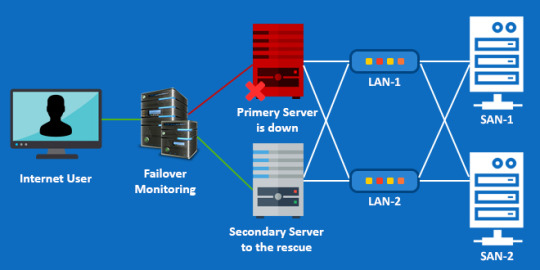
Failover means instantly switching to a standby server or a network upon the failure of the primary server/network.
When the primary host goes down or needs maintenance, the workload will be automatically switched to a secondary host. This should be seamless, with your users completely unaware that it happened.
Failover prevents a single point of failure (SPoF) and hence it is the most suitable option for mission critical applications where the system has to be online without even one second of downtime.
How Failover Works?
Surprisingly, automated failover system is quite easy to set up. A failover infrastructure consists of 2 identical servers, A primary server and a secondary. Both servers will serve the same data.
A third server will be used for monitoring. It continuously monitors the primary server and if it detects a problem, it will automatically update the DNS records for your website so that traffic will be diverted to the secondary server.
Once the primary server starts functioning again, traffic will be routed back to primary server. Most of the time your users won’t even notice a downtime or lag in server response.
Failover TypesCold Failover
A Cold Failover is a redundancy method that involves having one system as a backup for another identical primary system. The Cold Failover system is called upon only on failure of the primary system.
So, Cold Failover means that the second server is only started up after the first one has been shut down. Clearly this means you must be able to tolerate a small amount of downtime during the switch-over.
Hot Failover
Hot Failover is a redundant method in which one system runs simultaneously with an identical primary system.
Upon failure of the primary system, the Hot Failover system immediately takes over, replacing the primary system. However, data is still mirrored in real time ensuring both systems have identical data.
Setup Failover
Checkout the below tutorials to setup and deploy a failover cluster.
Setup Failover Cluster on Windows Server 2012
Configure High Avaliablity Cluster On CentOS
The Complete Guide on Setting up Clustering In Linux
Available Solutions
There are four major providers of failover clusters listed as below.
Microsoft Failover Cluster
RHEL Failover Cluster
VMWare Failover Cluster
Citrix Failover Cluster
Failover Advantages
Failover Server clustering is completely a scalable solution. Resources can be added or removed from the cluster.
If a dedicated server from the cluster requires maintenance, it can be stopped while other servers handle its load. Thus, it makes maintenance easier.
Failover Disadvantages
Failover Server clustering usually requires more servers and hardware to manage and monitor, thus, increases the infrastructure.
Failover Server clustering is not flexible, as not all the server types can be clustered.
There are many applications which are not supported by the clustered design.
It is not a cost-effective solution, as it needs a good server design which can be expensive.
5. High Availability Clusters

A high availability cluster is a group of servers that support server applications which can be utilized with a minimal amount of downtime when any server node fails or experiences overload.
You may require a high availability clusters for any of the reasons like load balancing, failover servers, and backup system. The most common types of Cluster configuration are active-active and active-passive.
Active-Active High Availability Cluster
It consists of at least two nodes, both actively running same the service. An active-active cluster is most suitable for achieving true load balancing. The workload is distributed across the nodes. Generally, significant improvement in response time and read/write speed is experienced.
Active-Passive High Availability Cluster
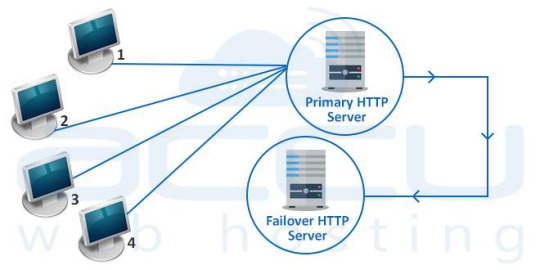
Active-passive also consists of at least two nodes. However, not all nodes remain active simultaneously. The secondary node remains in passive or standby mode. Generally, this cluster is more suitable for a failover cluster environment.
Setup A High Availability Cluster
Here are some excellent tutorials to setup a high availability cluster.
Configuring A High Availability Cluster On CentOS
Configure High-Availability Cluster on CentOS 7 / RHEL 7
Available Solutions
There are very well-known vendors out there, who are experts in high availability services. A few of them are listed below.
Dell Windows High Availability solutions
HP High Availability (HA) Solutions for Microsoft and Linux Clusters
VMware HA Cluster
High Availability Cluster Advantages
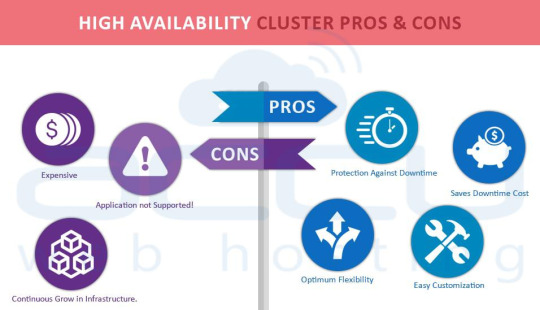
Protection Against Downtime
With HA solutions, if any server of a cluster goes offline, all the services are migrated to an active host. The quicker you get your server back online, the quicker you can get back to business. This prevents your business from remaining non-productive.
Optimum Flexibility
High availability solutions offer greater flexibility if your business demands 24×7 availability and security.
Saves Downtime Cost
The quicker you get your server back up online, the quicker you can get back to business.This prevents your business from remaining non-productive.
Easy Customization
With HA solutions, it is a matter of seconds to switch over to the failover server and continue production. You can customize your HA cluster as per your requirement. You can either set data to be up-to-date in minutes or within seconds. Moreover, the data replication scheme, versions can be specified as per your needs.
High Availability Cluster Disadvantages
Continuous Grow in infrastructure
It demands many servers and loads of hardware to deliver a failover and load balancing. This increases your infrastructure.
Application Not Supported!
HA clustering offers much flexibility at the hardware level but not all software applications support clustered environment.
Expensive
HA clustering is not a cost-effective solution, the more sophistication you need, the more money you need to invest.
6. Complex Configuration Built By AccuWebHosting
Customer’s Requirement
An eCommerce website that can handle the peak load of 1000 HTTP requests per second, more than 15,000 visitors per day and 3 times the load in less than 10 seconds. During the peak hours and new product launches, visits count to the website will be multiplied by 2.
Website Statistics
40K products and product related articles
40 GB of static contents (images and videos and website elements)
6 GB of database
Solution We Delivered
We suggested a high availability Cloud Infrastructure, to handle the load and ensure the maximum availability as well. To distribute the load, we mounted 2 load balancer servers in front of the setup with load balanced IP address on top of them.
We deployed a total of 8 web servers, 3 physical dedicated servers, and 5 Cloud instances to absorb the expected traffic. The setup was configured to get synchronized between the various components through the rsync cluster.
The Cloud instances were used in a way that they can be added or removed as per load of the peak traffic without incurring the costs associated with additional physical servers.
Each Cloud instance contained the entire website (40GB of static content) to give the user a smooth website experience.
The 6 GB database was hosted on a master dedicated server, which was replicated on a secondary slave server to take over when the master server fails. Both of these DB servers have SSD disks for better read/write performance.
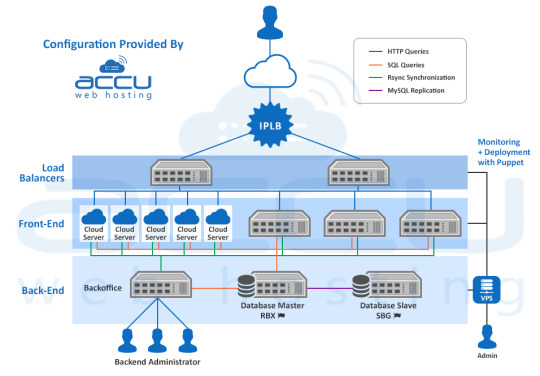
A team of 15 developers and content writers update the content through backoffice servers hosted on a dedicated server. Any changes made by the team are propagated by rsync on the production environment and the database.
The entire infrastructure was monitored by Zabbix, which is installed on a high availability Cloud VPS. Zabbix will monitor the data provided by the infrastructure servers and then generate a series of graphs to depict the RAM usage, load average, disk consumption and network stats. Zabbix will also send an alert when any of the usage reaches its threshold or if any of the services goes down.
0 notes
Text
8 Benefits Of Using MySQL

MySQL is an open-source RDBMS or relational database management system. Data is created, modified, and extracted from the relational database by programmers using SQL or structured query language. And data, including data types related to each other, are organized into data tables by a relational database. Though MySQL is mostly used with other programs, it has stand-alone clients as well. Moreover, many popular websites, as well as database-driven web applications, use MySQL. Here are the 8 benefits of MySQL installation and using MySQL.
Data Security
The first and foremost thing considered in any database management system is data security, and MySQL is one of the most secure database management systems. Besides, securing data is of utmost importance since your business could even get compromised without data security. What's more, MySQL is used by popular web applications like Drupal, Joomla, WordPress and popular websites like Facebook and Twitter. Further, it has security features to prevent unauthorized access to sensitive data and is suitable for businesses, especially those requiring frequent money transfers.
Scalability
MySQL also offers on-demand scalability, which can be beneficial with the growth of data and technology. So you can scale up or scale down your requirements as and when required. Thus, it facilitates the management of applications no matter the amount of data. For instance, it enables you to handle spreading databases, varying loads of application queries, etc with ease.
High Performance
The storage engine framework used in MySQL allows system managers to set up database servers that are high performing yet flawless. Hence, it can handle a large number of queries your business may receive and still ensure optimal speed. Database indexes, replication, clustering helps boost performance while managing heavy loads.
24x7 Uptime
Being available round the clock is significant for a business to generate revenue. However, MySQL ensures 24x7 uptime with its clustering and replication configurations. When a failure occurs, the cluster servers manage it and keep the system running. And if one server fails, the user will be redirected to another one to complete the query.
Transactional Support
MySQL provides all-inclusive transactional support with several transaction support features. It includes row-level locking, database transactions with ACID or atomicity, consistency, isolation, and durability, multi-version transaction support, and so on. After all, if you are looking for data integrity, MySQL gives that as well.
Workflow Control
Furthermore, MySQL comes with cross-platform capabilities, and the time required to download and install it is relatively low. Therefore, it can be used right away once the installation is complete, whether the system platform is Windows, Linux, macOS, or others. Also, everything is automated with its self-management features. Ultimately, it lets you keep complete workflow control.
Reduced Total Cost
MySQL offers reliability and is easily manageable with so many features. As a result, time and money used for troubleshooting, fixing downtimes or performance issues are saved, thus reducing the total cost involved.
Flexibility
MySQL makes debugging, upgrading, and maintenance effortless as well as enhances the end-user experience. Besides, it lets you customize configurations your way, making it a flexible open-source database management system.
#mysql server#mysql server service#manjaro mysql installation#mysql dats base#mysql service in calicut#mysql server service in kerala#web hosting support service#24x7 technical support company#hosting support services#Cloud Management Services
0 notes
Text
Free Download Tweaking Windows Repair

Tweaking Windows Repair Free
Free Download Tweaking Windows Repair All In One
Tweaking Windows Repair Review
With Tweaking.com Windows Repair pro you can restore windows original settings fixing many of these problems outright. Windows Repair fixes registry errors, file permissions, issues with Internet Explorer, Windows Updates, Windows Firewall and more. Descarga fiable para Windows (PC) de Tweaking.Com Windows Repair GRATIS-4.8. Descarga libre de virus y 100% limpia. Consigue Tweaking.Com Windows Repair descargas alternativas. Dec 03, 2020 Tweaking.Com Windows Repair 4.10 can be downloaded from our software library for free. The following versions: 4.9, 4.8 and 4.4 are the most frequently downloaded ones by the program users. This download was scanned by our built-in antivirus and was rated as clean. Nov 22, 2020 Tweaking.com - Windows Repair is an all-in-one repair tool to help fix many known Windows problems, including registry errors and file permissions. Video tutorial and portable are also available. Widespread use for Windows Repair is after a malware infection. While there are a lot of tools out there to help remove an infection.
How to fix corrupted files in Windows 10? This post covers the most effective ways to repair corrupted files with the top 5 Windows repair tools. Besides, you can also learn to fix corrupted system files in Windows 10 with simple methods.
PAGE CONTENT:
5 best Windows 10 file repair tools to fix corrupted files
How to fix corrupted system files in Windows 10
Files on Windows 10 can be divided into two types: Windows 10 system files, created when installing Windows operating system, and general files created by the user, which can be photos, videos, documents, emails, audio files, etc..
Either Windows system files or user files are likely to be corrupted due to various reasons, such as hardware damage, OS crash, software failure, virus attack, or human misoperation. File corruption is a very common and serious problem. If an important file is damaged, you need to do your best to repair the damaged file, or you will face data loss or worse.
In this tutorial, we will focus on how to fix corrupted files in Windows 10, 8, 7 with some efficient Windows 10 file repair tools. Besides, practical solutions to fix corrupted system files on Windows 10 are also introduced.
Top 5 Windows File Repair Tool to Fix Corrupted Files on Windows 10
Don't fret anymore when you suddenly get a pop-up message saying that your file has corrupted. Here come many Windows 10 repair tools that can help you fix damaged files effectively.
1. EaseUS Data Recovery Wizard
The most effective way to fix corrupted files on Windows 10 is by using a file repair utility. EaseUS Data Recovery Wizard, a professional data recovery and file repair tool, enables you to fix and restore lost/existing corrupted photos, videos, Word, Excel, PowerPoint, or other files in any case.
Repair corrupted Excel/Word file with free preview option
Repair corrupted videos in MP4 and MOV formats on Windows and Mac
Fix multiple broken files without limits
Repair damaged files from PC, laptop, external hard drive, SD card, USB flash drive, etc.
The free version allows repairing corrupted files up to 2GB
Now, download and use EaseUS Windows 10 repair tool to fix corrupted files in Windows 10, 8, and 7 with a few clicks.
Step 1. Select a disk location where the corrupt files are saved. Click 'Scan' to start finding the corrupt files and repairing.
Step 2. EaseUS data recovery software will run immediately to scan all over the selected drive to find lost and corrupted files as many as possible. After the scan, you'll go to the repair session as soon as the software detects corruption. Wait patiently until the repair ends. You can use the 'Filter' to quickly locate the specific file type you're trying to repair.
Step 3. Double-click on a file lets you preview the file quality. Select the target file and click 'Recover'. You should save the repaired corrupted files to a different location to avoid data overwriting.
Except for file repair, EaseUS Data Recovery Wizard also has a good reputation in data recovery. It can simply recover permanently deleted files in Windows 10 with advanced algorithm technology. Other outstanding functions are formatted recovery, RAW recovery, lost partition recovery, OS crash recovery, virus attack recovery, and more.
2. Piriform Recuva
As a famous data recovery tool, Recuva is also capable of repairing damaged files on Windows 10. This program allows you to scan your PC, storage media card, recycle bin, or a specific folder deeply to recover deleted files and repair damaged files as well.
Provides Recova Wizard that helps you choose files easily from a large number of data
A user-friendly interface that simplifies the recovery and file repair process
Recover all files, including pictures, music, documents, video, compressed files, and emails
Work with damaged hardware to recover files from damaged flash drives
3. Stellar Phoenix Video Repair Tool
Stellar Phoenix Video Repair tool is a competent tool to fix corrupted and damaged video files that are unplayable in QuickTime player on both Windows and macOS. It can fix multiple severely corrupted files simultaneously.
Support all the popular video formats, such as MP4, MOV, AVI, MKV, etc.
Fix several corrupted videos in batches
Preview repaired files for free before saving
Stellar File Repair Toolkit also supports Excel, PowerPoint, MySQL, Access, and so on
4. File Repair
File Repair can restore damaged files caused by a virus infection, application failures, system crashes, and network errors. It allows you to fix corrupted files in Windows 10 on all the common formats from your computer, SD card, iPhones, or Android smartphones.
Support repairing many types of files, such as pictures, PDF, office documents, emails, and, database
Support multiple image formats, such as JPEG, GIF, TIFF, BMP, PNG or RAW images
Fully compatible with Windows 10, 8, 7, and other versions
5. Digital Video Repair
Digital Video Repair allows you to fix corrupted Mpeg 4 and AVI videos in just a few clicks. Digital Video Repair can repair broken AVI files encoded with Xvid, DivX, MPEG4, 3ivx, and Angel Potion codecs. This tool can easily fix unfinished AVI files, MOV, and MP4 videos that haven’t been completely downloaded from the Internet or a local network.
Support popular video formats like MOV, MP4, AVI, FLV, etc.
Automatically delete the not important content from the video file
Fix multiple video files at once
Free file repair tool for any users
How to Fix Corrupted System Files in Windows 10 [5 Ways]
When we are using a Windows computer, there are often some problems appearing, such as system files corruption. Windows 10 corrupted system files may result from an abrupt power outage, hard drive damage, virus infection, or system failure. And it will lead to many issues. How to fix corrupted system files in Windows 10? Try several useful ways below.
Fix 1. Use SFC Scan
SFC checks system file integrity and replaces a corrupt or damaged system file with a cached copy. This system file checker helps fix the damaged or missing Windows system files that may cause drive corruption. Follow the steps below:
Step 1. Type Command Prompt in the search bar, right-click it, and choose 'Run as administrator'.
Step 2. Type the following cmd and hit 'Enter'.

sfc /scannow
If the drive is an external device, follow this command:
sfc /scannow /offbootdir=c: /offwindir=c:windows
Replace letter c: with your hard drive letter. Wait for the scan to finish and then restart the system. Check if you can access the drive.
After the repair process completes, you'll see 'Windows Resource Protection did not find any integrity violations' message if the system files aren't corrupted in Windows 10.
Fix 2. Use DISM Tool
When the SFC system file checker tool fails to repair corrupted system files in Windows 10, you can go on using the DISM tool instead, which is designed to fix any corruption problems that can prevent the SFC tool from running.
Step 1. Press Win + R to open Run dialog and type: cmd to open Command Prompt.
Step 2. Type the following command and hit 'Enter'.
Step 3. Reboot PC to keep all changes and repair sfc into working again.
Fix 3. Run SFC in Safe Mode
Safe Mode is a special mode that uses only default drivers and applications. If SFC can't fix corrupted Windows system files, you can try running the SFC tool from Safe Mode.
Tweaking Windows Repair Free
Step 1. Click Start Menu. Click the Power button.
Step 2. Hold the Shift key and choose the 'Restart' option. Select 'Troubleshoot'.
Step 3. Go to 'Advanced options' > 'Startup Settings'. Click the 'Restart' button.
Step 4. When your PC restarts, there will be a list of options. Select any version of Safe Mode by pressing the appropriate F key.
Step 5. When Safe Mode starts, use the SFC tool to repair damaged system files on Windows 10 by following the steps in Fix 1.
Fix 4. Use System Restore
With the Windows Restore feature, you can restore your PC to a previous point in time. However, you need to enable System Recovery on Windows 10 and create a recovery point in advance for using this function. If there are no recovery points, this method won't be valid.
Step 1. Type System Restore in the Searchbox. Click 'Create a restore point option'.
Step 2. Click the 'System Restore' button on the pop-up window.
Step 3. Check 'Show more restore points'. then, select an available restore point and click 'Next'.
Step 4. Follow the on-screen instructions to perform the restore. When your Windows 10 is restored, the system files should be intact, and your computer will work properly.
Fix 5. Reset Windows 10
When all the above solutions fail, you might reset your Windows and restore your computer to the factory state by reinstalling Windows 10. This process will delete all the installed programs and data. Therefore, make sure that you have backed up every critical file before resetting.
To reset your Windows 10 machine, follow these steps:
Step 1. Go to Start, click Power button > hold the shift key and click 'Restart'.
Step 2. Choose 'Troubleshoot' > 'Reset this PC'. You have two options - 'Keep my files' and 'Remove everything'. The former will reinstall Windows 10 and keep your personal files and settings. The latter will remove both personal files and settings. Choose either of the two.
Step 3. Enter your username and password, select the Windows version, and click 'Reset'. If you're asked to insert Windows 10 installation media, do as required.
Step 4. Follow the on-screen instructions to finish resetting Windows.
If there was a problem resetting your PC in Windows 10/8/7, read the article to check how to troubleshoot.
Final Verdict
As you can see, there are many different tools and approaches that you can use to fix corrupted data files and system files on Windows 10, Windows 8, and Windows 7. You may use different tools depending on the type of files that you want to repair.
To recover and repair damaged MP4, MOV, GIF, JPEG, Word, Excel, or other files, we highly recommend you try EaseUS data recovery software. It integrates data recovery and data repair capabilities and allows you to preview the repaired files for free. Using this tool, you can fix unlimited corrupted files in the simplest way.
Free Download Tweaking Windows Repair All In One
FAQs on How to Fix Corrupted Files on Windows 10/8/7
The following are the four frequently asked questions on how to fix corrupted files or repair damaged system files in Windows 10. Check the brief answers to these problems.
How do I do a repair install of Windows 10?
One of the solutions to fix corrupted system files is resetting your computer to the factory configurations and reinstalling Windows 10. Reinstalling Windows 10 can usually make your PC as good as new and performs as a method to figure out when your PC stop working or just doesn't work as well as normally. There are three ways to reinstall Windows 10 without CD, check the tutorial and details.
Does Windows 10 have a repair tool?
Windows 10 offers a fix-it tool to solve some problems. You can use the troubleshooters to help you solve problems with your PC. To run a troubleshooter: Select Start > Settings > Update & Security > Troubleshoot.
If you are having a problem with your Windows 10 computer, such as a reboot loop, corrupted Windows files, corrupted registry keys, corrupted registry driver or other Windows boot related issues, you can use the Windows Automatic Repair or Startup Repair tool.
Also read: How to fix Windows Automatic Repair Loop in Windows 10/8.1/8
How do I fix a corrupted Windows file?
Use EaseUS Data Recovery Wizard to fix corrupted Windows files easily in three steps:
Step 1. Choose the device to scan for corrupted files in Windows 10.
Step 2. Repair and preview the corrupted files.
Step 3. Restore the fixed files.
Is Windows 10 repair tool safe?
Windows 10 Troubleshooter, Automatic Repair, or Startup Repair tool is a free and useful Windows 10 repair tool you can use to repair many Windows 10 issues.
Tweaking Windows Repair Review
This Windows 10 repair tool may not fix all of your PC problems, but it is a good place to start. Running Startup Repair on your computer can fix problems that keep Windows from loading on your computer.
0 notes
Text
MySQL Connector/C++ 8.0.24 has been released
Dear MySQL users, MySQL Connector/C++ 8.0.24 is a new release version of the MySQLConnector/C++ 8.0 series. Connector/C++ 8.0 can be used to access MySQL implementing DocumentStore or in a traditional way, using SQL queries. It allows writingboth C++ and plain C applications using X DevAPI and X DevAPI for C.It also supports the legacy API of Connector/C++ 1.1 based on JDBC4. To learn more about how to write applications using X DevAPI, see“X DevAPI User Guide” at https://dev.mysql.com/doc/x-devapi-userguide/en/ See also “X DevAPI Reference” at https://dev.mysql.com/doc/dev/connector-cpp/devapi_ref.html and “X DevAPI for C Reference” at https://dev.mysql.com/doc/dev/connector-cpp/xapi_ref.html For generic information on using Connector/C++ 8.0, see https://dev.mysql.com/doc/dev/connector-cpp/ For general documentation about how to get started using MySQLas a document store, see http://dev.mysql.com/doc/refman/8.0/en/document-store.html To download MySQL Connector/C++ 8.0.24, see the “General Availability (GA)Releases” tab at https://dev.mysql.com/downloads/connector/cpp/ Changes in MySQL Connector/C++ 8.0.24 (2021-04-20, GeneralAvailability) Connection Management Notes * Previously, for client applications that use the legacy JDBC API (that is, not X DevAPI or X DevAPI for C), if the connection to the server was not used within the period specified by the wait_timeout system variable and the server closed the connection, the client received no notification of the reason. Typically, the client would see Lost connection to MySQL server during query (CR_SERVER_LOST) or MySQL server has gone away (CR_SERVER_GONE_ERROR). In such cases, the server now writes the reason to the connection before closing it, and client receives a more informative error message, The client was disconnected by the server because of inactivity. See wait_timeout and interactive_timeout for configuring this behavior. (ER_CLIENT_INTERACTION_TIMEOUT). The previous behavior still applies for client connections to older servers and connections to the server by older clients. * For connections made using X Plugin, if client with a connection to a server remains idle (not sending to the server) for longer than the relevant X Plugin timeout setting (read, write, or wait timeout), X Plugin closes the connection. If any of these timeouts occur, the plugin returns a warning notice with the error code ER_IO_READ_ERROR to the client application. For such connections, X Plugin now also sends a warning notice if a connection is actively closed due to a server shutdown, or by the connection being killed from another client session. In the case of a server shutdown, the warning notice is sent to all authenticated X Protocol clients with open connections, with the ER_SERVER_SHUTDOWN error code. In the case of a killed connection, the warning notice is sent to the relevant client with the ER_SESSION_WAS_KILLED error code, unless the connection was killed during SQL execution, in which case a fatal error is returned with the ER_QUERY_INTERRUPTED error code. If connection pooling is used and a connection close notice is received in a session as a result of a server shutdown, all other idle sessions that are connected to the same endpoint are removed from the pool. Client applications can use the warning notices to display to users, or to analyze the reason for disconnection and decide whether to attempt reconnection to the same server, or to a different server. Packaging Notes * Connector/C++ packages now include sasl2 modules due to connection failures for accounts that use the authentication_ldap_sasl authentication plugin. (Bug #32175836) Bugs Fixed * Upon connecting to the server, Connector/C++ executed a number of SHOW [SESSION] VARIABLES statements to retrieve system variable values. Such statements involve locking in the server, so they are now avoided in favor of SELECT @@var_name statements. Additionally, Connector/C++ was trying to fetch the value of the max_statement_time system variable, which has been renamed to max_execution_time. Connector/C++ now uses the correct variable name, with the result that getQueryTimeout() and setQueryTimeout() now work properly for both Statement and Prepared Statement objects. (Bug #28928712, Bug #93201) * DatabaseMetaData.getProcedures() failed when the metadataUseInfoSchema connection option was false. (Bug #24371558) On Behalf of the Oracle/MySQL Engineering Team,Tvarita Jain https://insidemysql.com/mysql-connector-cpp-8-0-24/
0 notes