#scrapy automation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a 66 index score for customer satisfaction in the US.
Text
Hire Expert Scrapy Developers for Scalable Web Scraping & Data Automation
Looking to extract high-value data from the web quickly and accurately? At Prospera Soft, we offer top-tier Scrapy development services to help businesses automate data collection, gain market insights, and scale operations with ease.
Our team of Scrapy experts specializes in building robust, Python-based web scrapers that deliver 10X faster data extraction, 99.9% accuracy, and full cloud scalability. From price monitoring and sentiment analysis to lead generation and product scraping, we design intelligent, secure, and GDPR-compliant scraping solutions tailored to your business needs.
Why Choose Our Scrapy Developers?
✅ Custom Scrapy Spider Development for complex and dynamic websites
✅ AI-Optimized Data Parsing to ensure clean, structured output
✅ Middleware & Proxy Rotation to bypass anti-bot protections
✅ Seamless API Integration with BI tools and databases
✅ Cloud Deployment via AWS, Azure, or GCP for high availability
Whether you're in e-commerce, finance, real estate, or research, our scalable Scrapy solutions power your data-driven decisions.
#Hire Expert Scrapy Developers#scrapy development company#scrapy development services#scrapy web scraping#scrapy data extraction#scrapy automation#hire scrapy developers#scrapy company#scrapy consulting#scrapy API integration#scrapy experts#scrapy workflow automation#best scrapy development company#scrapy data mining#hire scrapy experts#scrapy scraping services#scrapy Python development#scrapy no-code scraping#scrapy enterprise solutions
0 notes
Text

Web Scraping 101: How Machines Read the Web
Ever wondered how data from your favorite websites gets pulled into apps, research tools, or dashboards? 🤖 This infographic breaks it down step-by-step — from crawling pages to parsing HTML and storing structured data.
Whether you're a beginner curious about automation or a developer diving into data collection, this visual guide will make the process crystal clear! 💡
From bots to parsing logic, it's all here. Ready to see how the web talks to machines?
👉 Check it out now and boost your data game!
#WebScraping#DataScience#Automation#Infographic#CodingLife#WebDevelopment#MachineLearning#BeautifulSoup#Scrapy#PythonDeveloper
0 notes
Text
AI Automated Testing Course with Venkatesh (Rahul Shetty) Join our AI Automated Testing Course with Venkatesh (Rahul Shetty) and learn how to test software using smart AI tools. This easy-to-follow course helps you save time, find bugs faster, and grow your skills for future tech jobs. To know more about us visit https://rahulshettyacademy.com/
#ai generator tester#ai software testing#ai automated testing#ai in testing software#playwright automation javascript#playwright javascript tutorial#playwright python tutorial#scrapy playwright tutorial#api testing using postman#online postman api testing#postman automation api testing#postman automated testing#postman performance testing#postman tutorial for api testing#free api for postman testing#api testing postman tutorial#postman tutorial for beginners#postman api performance testing#automate api testing in postman#java automation testing#automation testing selenium with java#automation testing java selenium#java selenium automation testing#python selenium automation#selenium with python automation testing#selenium testing with python#automation with selenium python#selenium automation with python#python and selenium tutorial#cypress automation training
0 notes
Text
Master Web Scraping with Python: Beautiful Soup, Scrapy, and More
Learn web scraping with Python using Beautiful Soup, Scrapy, and other tools. Extract and automate data collection for your projects seamlessly.
#WebScraping#Python#BeautifulSoup#Scrapy#Automation#PythonProgramming#DataScience#TechLearning#PythonDevelopment
0 notes
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text
Zillow Scraping Mastery: Advanced Techniques Revealed

In the ever-evolving landscape of data acquisition, Zillow stands tall as a treasure trove of valuable real estate information. From property prices to market trends, Zillow's extensive database holds a wealth of insights for investors, analysts, and researchers alike. However, accessing this data at scale requires more than just a basic understanding of web scraping techniques. It demands mastery of advanced methods tailored specifically for Zillow's unique structure and policies. In this comprehensive guide, we delve into the intricacies of Zillow scraping, unveiling advanced techniques to empower data enthusiasts in their quest for valuable insights.
Understanding the Zillow Scraper Landscape
Before diving into advanced techniques, it's crucial to grasp the landscape of zillow scraper. As a leading real estate marketplace, Zillow is equipped with robust anti-scraping measures to protect its data and ensure fair usage. These measures include rate limiting, CAPTCHA challenges, and dynamic page rendering, making traditional scraping approaches ineffective. To navigate this landscape successfully, aspiring scrapers must employ sophisticated strategies tailored to bypass these obstacles seamlessly.
Advanced Techniques Unveiled
User-Agent Rotation: One of the most effective ways to evade detection is by rotating User-Agent strings. Zillow's anti-scraping mechanisms often target commonly used User-Agent identifiers associated with popular scraping libraries. By rotating through a diverse pool of User-Agent strings mimicking legitimate browser traffic, scrapers can significantly reduce the risk of detection and maintain uninterrupted data access.
IP Rotation and Proxies: Zillow closely monitors IP addresses to identify and block suspicious scraping activities. To counter this, employing a robust proxy rotation system becomes indispensable. By routing requests through a pool of diverse IP addresses, scrapers can distribute traffic evenly and mitigate the risk of IP bans. Additionally, utilizing residential proxies offers the added advantage of mimicking genuine user behavior, further enhancing scraping stealth.
Session Persistence: Zillow employs session-based authentication to track user interactions and identify potential scrapers. Implementing session persistence techniques, such as maintaining persistent cookies and managing session tokens, allows scrapers to simulate continuous user engagement. By emulating authentic browsing patterns, scrapers can evade detection more effectively and ensure prolonged data access.
JavaScript Rendering: Zillow's dynamic web pages rely heavily on client-side JavaScript to render content dynamically. Traditional scraping approaches often fail to capture dynamically generated data, leading to incomplete or inaccurate results. Leveraging headless browser automation frameworks, such as Selenium or Puppeteer, enables scrapers to execute JavaScript code dynamically and extract fully rendered content accurately. This advanced technique ensures comprehensive data coverage across Zillow's dynamic pages, empowering scrapers with unparalleled insights.
Data Parsing and Extraction: Once data is retrieved from Zillow's servers, efficient parsing and extraction techniques are essential to transform raw HTML content into structured data formats. Utilizing robust parsing libraries, such as BeautifulSoup or Scrapy, facilitates seamless extraction of relevant information from complex web page structures. Advanced XPath or CSS selectors further streamline the extraction process, enabling scrapers to target specific elements with precision and extract valuable insights efficiently.
Ethical Considerations and Compliance
While advanced scraping techniques offer unparalleled access to valuable data, it's essential to uphold ethical standards and comply with Zillow's terms of service. Scrapers must exercise restraint and avoid overloading Zillow's servers with excessive requests, as this may disrupt service for genuine users and violate platform policies. Additionally, respecting robots.txt directives and adhering to rate limits demonstrates integrity and fosters a sustainable scraping ecosystem beneficial to all stakeholders.
Conclusion
In the realm of data acquisition, mastering advanced scraping techniques is paramount for unlocking the full potential of platforms like Zillow. By employing sophisticated strategies tailored to bypass anti-scraping measures seamlessly, data enthusiasts can harness the wealth of insights hidden within Zillow's vast repository of real estate data. However, it's imperative to approach scraping ethically and responsibly, ensuring compliance with platform policies and fostering a mutually beneficial scraping ecosystem. With these advanced techniques at their disposal, aspiring scrapers can embark on a journey of exploration and discovery, unraveling valuable insights to inform strategic decisions and drive innovation in the real estate industry.
2 notes
·
View notes
Text
"Look at this really badly run zoo" could have been the subtitle of the book, honestly. That's the premise behind most of my favorite moments in the books.
Velociraptors are social animals, with learned traits they didn't learn at the park. The park's raptors don't know how to work as a team or live in a pack, because they had no adults to teach them. That's why you have adult raptors keeping the juveniles away from the food, or attacking baby raptors.
The deterioration of the 2nd island's dinosaur population was due to a prion disease. Park organisers bought the cheapest feed (derived from scrapie infected sheep) without considering the consequences, and the populations were collapsing because a prion disease called DX had become endemic.
None of the people running the park understood the biology of the animals they were keeping. They were concerned with having a static, point-in-time population, not a functioning ecosystem. So when the dinosaurs started breeding, they had no idea what to do.
Similarly, they were more interested in the environments as dioramas for visitor viewing than as ecosystems for the animals. They kept predators isolated and tossed all the herbivores together ("it's not like they're gonna eat each other!") rather than studying their behavior to decide which dinosaurs to put where.
They picked plants based on the prehistoric aesthetic they wanted rather than their actual properties. Remember the sick triceratops? It was sick because it ate a poisonous plant. Ellie figured that out because her area of study was paleobotany. She also figured out that some of the plants around the family-friendly swimming pool were highly toxic. Nobody double checked the plants they used for their impacts on visitors or the dinosaurs.
They had hundreds of animals and no staff ecologists. They had 1 veterinarian. Instead of having paleontologists on staff, they had a big game hunter. All their biologists worked in the lab. They built everything like theme park rides because automation kept labor costs down and made secrecy easier.
The whole point was to demonstrate how spectacularly a project can fail if new scientific advances are used for profit before they're properly understood. That said, you could make an argument for dinosaurs being a novel way to highlight the shortcomings of for-profit zoos in general. A tiger eating the visitors isn't as headline-grabbing as a T-Rex, but it's still very much a possibility if you decide to show tigers without any understanding of their behavior or ecology.
Watching Jurassic Park and I have Opinions on this place as a zoo. Feeding the predators live prey?? There's other ways to provide enrichment! Also that enclosure is way too small for multiple large animals like that! Electric fences? Ha! Electric fences won't stop a fucking goat! Where's the zoo experts? Who designed these enclosures?? Were all zoos this shitty in the 90s???
#Jurassic park#worst zoo ever#guys can you tell this is one of my favorite books of all time?#see also: Hammond's skeezy marketing tactics in the books#where he packed around a miniature elephant to get investment in his genetics projects#but it wasn't even genetically manipulated it was from a traditional selective breeding project#and it was so mean you couldn't take it out of the cage#crichton wasn't saying don't clone dinosaurs#he was saying don't treat every cool new discovery as a cash grab#see also: his work on gene patents and science as political talking points#dude straight up got an MD and a law degree and then used them to write books#and we're kind of lucky he did
106K notes
·
View notes
Text

Python is no longer just a programming language for developers; it’s becoming an invaluable tool for SEO looking to sharpen their strategies. Imagine wielding the power of automation and data analysis to elevate your search engine optimization efforts. With Python, you can dive deep into keyword relevance and search intent, unraveling mysteries that traditional methods might overlook.
As the digital landscape evolves, so too must our approaches to SEO. Understanding what users want when they type a query into Google is crucial. The right keywords can make or break your online visibility. That’s where Python comes in—streamlining processes and providing insights that drive results.
Ready to unlock new possibilities? Let’s explore how Python can transform your SEO game by offering innovative ways to track keyword relevance and decode search intent with ease. Whether you’re a seasoned pro or just starting out, this journey promises valuable tools tailored for modern SEO challenges.
Understanding Keyword Relevance and Search Intent
Keyword relevance is the heart of effective SEO. It refers to how closely a keyword matches the content on your page. Choosing relevant keywords helps search engines understand what your site offers.
Search intent goes deeper. It’s about understanding why users perform a specific query. Are they looking for information, trying to make a purchase, or seeking navigation? Grasping this concept is crucial for creating content that resonates with audiences.
Different types of search intents exist: informational, transactional, navigational, and commercial investigation. Each type requires tailored strategies to meet user expectations effectively.
By aligning keyword relevance with search intent, you can craft content that not only attracts visitors but also engages them meaningfully. This dual focus enhances user experience and boosts rankings in SERPs over time.
Using Python for Keyword Research
Keyword research is a crucial step in any SEO strategy. Python simplifies this process significantly, allowing you to analyze large datasets efficiently.
With libraries like Pandas and NumPy, you can manipulate and clean keyword data quickly. These tools help you uncover valuable insights that drive content creation.
You can also use the Beautiful Soup library for web scraping. This enables you to gather keywords from competitor sites or industry forums effortlessly.
Additionally, integrating Google Trends API within your scripts offers real-time keyword popularity metrics. This feature helps identify rising trends that are relevant to your niche.
Python scripts automate repetitive tasks, freeing up time for more strategic initiatives. By leveraging these capabilities, you’re better equipped to optimize your campaigns effectively without getting bogged down by manual processes.
Tracking Search Intent with Python Scripts
Understanding search intent is crucial for any SEO strategy. With Python, you can automate the process of analyzing user queries and determining their underlying motivations.
Using libraries like BeautifulSoup or Scrapy, you can scrape SERPs to gather data on keyword rankings and associated content. This helps identify patterns in how users interact with different topics.
Additionally, Natural Language Processing (NLP) tools such as NLTK or spaCy can assist in categorizing keywords based on intent—whether informational, transactional, or navigational.
By implementing custom scripts, you can quickly assess which keywords align best with your audience’s needs. This not only saves time but also enhances your ability to target content effectively.
Automating this analysis allows for regular updates on changing search behaviors. Staying ahead of trends means better optimization strategies that resonate with real user intent.
Integrating Python into your SEO Workflow
Integrating Python into your SEO workflow can transform how you approach data analysis and keyword tracking. By automating repetitive tasks, you free up valuable time for strategic thinking and creative exploration.
Start by leveraging libraries like Pandas to analyze large datasets efficiently. This helps in identifying trends or anomalies that might be missed with traditional methods.
You can also use Beautiful Soup for web scraping, allowing you to gather competitor insights directly from their sites. Extracting relevant information becomes a breeze, enhancing your research capabilities.
Consider creating custom scripts tailored to your specific needs. Whether it’s monitoring rankings or analyzing backlinks, Python allows unprecedented flexibility.
Incorporate visualizations using Matplotlib or Seaborn to present data clearly. These visuals make it easier to share findings with team members or stakeholders who may not be as familiar with the technical aspects of SEO.
Tips and Tricks for Mastering Search Intent Analysis with Python
Mastering search intent analysis with Python can elevate your SEO strategy. Start by leveraging libraries like Pandas and Beautiful Soup for efficient data manipulation and web scraping.
Utilize Natural Language Processing (NLP) techniques to understand user queries better. Libraries such as NLTK or SpaCy can help you analyze keywords, phrases, and their contexts.
Make your code modular. Break down functions into smaller components for cleaner debugging and easier updates in the future.
Experiment with machine learning models to predict user behavior based on historical data. Tools like Scikit-learn offer a range of algorithms that can enhance your insights dramatically.
Stay updated with SEO trends. Adapt your scripts regularly to reflect changes in search engine algorithms and user preferences. Continuous learning is key in this ever-evolving field!
Conclusion
As the digital landscape continues to evolve, SEO professionals must adapt and innovate. Python has emerged as a powerful tool that can transform how you approach keyword relevance and search intent.
With Python, you can streamline your keyword research process, analyze massive datasets quickly, and effectively interpret user intent behind searches. The ability to automate repetitive tasks frees up time for deeper strategic thinking.
Integrating Python into your SEO workflow enhances efficiency and results in more targeted strategies. Real-world applications showcase its versatility—from scraping data from SERPs to analyzing trends over time.
By leveraging Python for SEO activities, you’re not only keeping pace with the industry but also setting yourself apart as a forward-thinking professional ready to tackle the challenges of tomorrow’s search engines. Embrace this technology; it could very well be your secret weapon in achieving online success.
0 notes
Text
Extract Laptop Resale Value from Cashify

Introduction
In India’s fast-evolving second-hand electronics market, Cashify has emerged as a leading platform for selling used gadgets, especially laptops. This research report investigates how to Extract laptop resale value from Cashify, using data-driven insights derived from Web scraping laptop listings from Cashify and analyzing multi-year pricing trends.
This report also explores the potential of building a Cashify product data scraping tool, the benefits of Web Scraping E-commerce Websites, and how businesses can leverage a Custom eCommerce Dataset for strategic pricing.
Market Overview: The Rise of Second-Hand Laptops in India
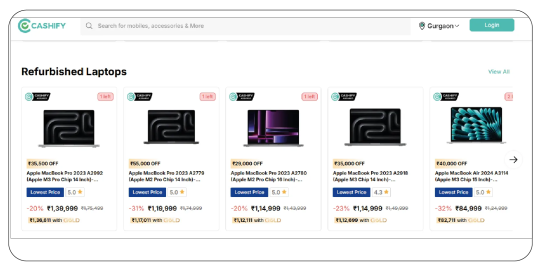
In India, the refurbished and second-hand electronics segment has witnessed double-digit growth over the last five years. Much of this boom is driven by the affordability crisis for new electronics, inflationary pressure, and the rising acceptance of certified pre-owned gadgets among Gen Z and millennials. Platforms like Cashify have revolutionized this space by building trust through verified listings, quality checks, and quick payouts. For brands, resellers, or entrepreneurs, the ability to extract laptop resale value from Cashify has become crucial for shaping buyback offers, warranty pricing, and trade-in deals.
Web scraping laptop listings from Cashify allows stakeholders to get a clear, real-time snapshot of average selling prices across brands, conditions, and configurations. Unlike OLX or Quikr, where listings can be inconsistent or scattered, Cashify offers structured data points — model, age, wear and tear, battery health, and more — making it a goldmine for second-hand market intelligence. By combining this structured data with a Cashify product data scraping tool, businesses can identify underpriced segments, negotiate better supplier rates, and create competitive refurbished offerings.
With millions of laptops entering the resale loop every year, the scope of scraping and analyzing Cashify’s data goes far beyond academic interest. For retailers, this data can translate into practical business actions — from customizing trade-in bonuses to launching flash sale campaigns for old stock. The bigger goal is to build an adaptive pricing model that updates dynamically. This is where Web Scraping Cashify.in E-Commerce Product Data proves indispensable for data-driven decision-making.
Technology & Tools: How to Scrape Laptop Prices from Cashify India
Building an efficient pipeline to scrape laptop prices from Cashify India demands more than just basic scraping scripts. Cashify uses dynamic content loading, pagination, and real-time pricing updates, which means your scraper must be robust enough to handle AJAX calls, handle IP blocks, and store large datasets securely. Many modern scraping stacks use Python libraries like Scrapy, Selenium, or Puppeteer, which can render JavaScript-heavy pages and pull detailed product listings, price fluctuations, and time-stamped snapshots.
Setting up a Cashify web scraper for laptop prices India can help businesses automate daily price checks, generate real-time price drop alerts, and spot sudden changes in average resale value. Combining this with a smart notification system ensures refurbishers and second-hand retailers stay one step ahead of market fluctuations.
Additionally, deploying a custom eCommerce dataset extracted from Cashify helps link multiple data points: for example, pairing model resale values with the original launch price, warranty status, or historical depreciation. This layered dataset supports advanced analytics, like predicting when a specific model’s resale value will hit rock bottom — an insight invaluable for maximizing margins on bulk procurement.
A good Cashify product data scraping tool should include error handling, proxy rotation, and anti-bot bypass methods. For larger operations, integrating this tool with CRM or ERP software automates workflows — from setting competitive buyback quotes to updating storefront listings. Ultimately, the technical strength behind web scraping e-commerce websites is what makes data actionable, turning raw pricing into real profit.
Opportunities: Turning Scraped Cashify Data into Business Strategy
Once you extract laptop resale value from Cashify, the next step is turning this raw pricing intelligence into a clear business advantage. For individual resellers, knowing the exact resale price of a MacBook Air or HP Pavilion in real-time can mean the difference between a profit and a loss. For larger refurbishing chains or online marketplaces, scraped data powers dynamic pricing engines, localized offers, and even targeted marketing campaigns for specific models or city clusters.
For instance, with a robust Cashify.com laptop pricing dataset India, a company can forecast upcoming spikes in demand — say during the start of the academic year when students buy affordable laptops — and stock up on popular mid-range models in advance. Additionally, trends in price drop alerts help predict when it’s cheaper to buy in bulk. With a Cashify web scraper for laptop prices India, these insights update automatically, ensuring no opportunity is missed.
Beyond pricing, the data can reveal supply gaps — like when certain brands or specs become scarce in specific cities. Using Web Scraping Solutions, retailers can then launch hyperlocal campaigns, offering better trade-in deals or doorstep pickups in under-supplied zones. This level of precision turns simple scraping into a strategic tool for growth.
In summary, the real power of web scraping laptop listings from Cashify lies not just in collecting prices, but in transforming them into a sustainable, profitable second-hand business model. With a solid scraping stack, well-defined use cases, and data-driven action plans, businesses can stay ahead in India’s booming refurbished laptop market.
Key Insights
Growing Popularity of Used Laptops
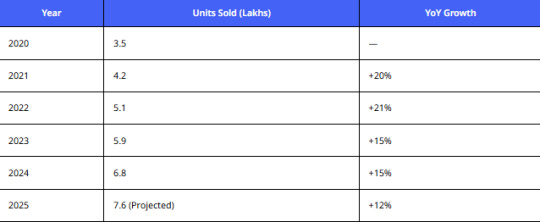
Analysis:
With over 7 million units projected for 2025, there’s a clear demand for affordable laptops, boosting the need to extract laptop resale value from Cashify for resale arbitrage and trade-in programs.
Average Resale Value Trend
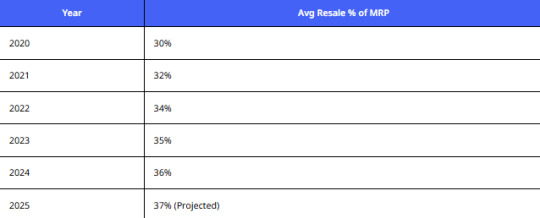
Analysis:
Consumers get back an average of 30–37% of the original price. This data justifies why many refurbishers and dealers scrape laptop prices from Cashify India to negotiate smarter buyback deals.
Brand-wise Resale Premium
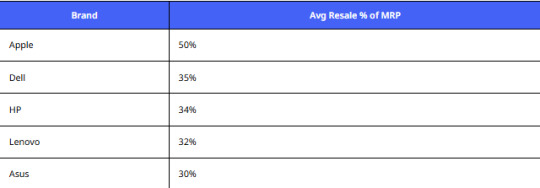
Analysis:
Apple retains the highest value — a key insight for businesses using a Cashify.com laptop pricing dataset India to optimize refurbished stock.
Price Drop Alerts Influence
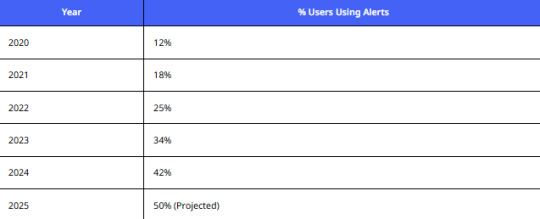
Analysis:
More users want real-time price drop alerts for laptops on Cashify, pushing resellers to deploy a Cashify web scraper for laptop prices India to monitor and react instantly.
Average Listing Time Before Sale
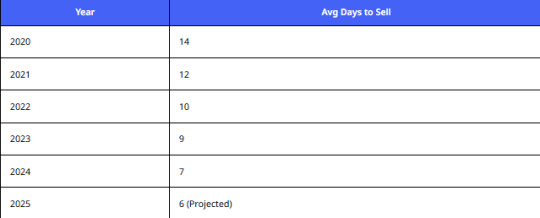
Analysis:
Faster selling cycles demand real-time tracking. Extract laptop resale value from Cashify in near real-time with a robust Cashify product data scraping tool.
Popular Price BracketsPrice Band (INR)% Share< 10,00020%10,000–20,00045%20,000–30,00025%>30,00010%
Analysis:
The ₹10k–₹20k band dominates, highlighting why Web Scraping Cashify.in E-Commerce Product Data is crucial for budget-focused segments.
Urban vs Rural Split

Analysis:
Growth in rural demand shows the need for local price intelligence via Web Scraping Solutions tailored for regional buyers.
Top Cities by Resale Listings
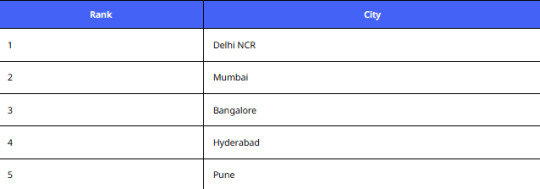
Analysis:
A Custom eCommerce Dataset from Cashify helps brands target these hubs with region-specific offers.
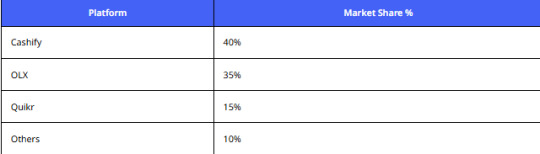
Analysis:
Cashify’s stronghold makes web scraping laptop listings from Cashify vital for second-hand market trend research.
Projected Market Value
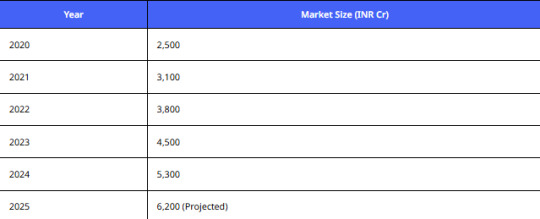
Analysis:
The second-hand laptop market will surpass INR 6,000 Cr by 2025 — a clear opportunity to build a Cashify web scraper for laptop prices India and lead the arbitrage game.
Conclusion
From real-time price tracking to building custom pricing datasets, this research shows that to stay ahead in the resale game, businesses must extract laptop resale value from Cashify with smart Web Scraping E-commerce Websites strategies. Ready to unlock hidden profits? Start scraping smarter with a custom Cashify product data scraping tool today!
Know More >> https://www.productdatascrape.com/extract-laptop-resale-value-cashify-market-trends.php
#ExtractLaptopResaleValueFromCashify#WebScrapingLaptopListingsFromCashify#ScrapeLaptopPricesFromCashifyIndia#CashifyComLaptopPricingDatasetIndia#CashifyProductDataScrapingTool#WebScrapingEcommerceWebsites
0 notes
Text
💻 Struggling to Pick the Right Open-Source Web Scraping Tool? You're Not Alone.
Choosing the right #WebScrapingTool can be overwhelming—especially when open-source libraries offer so many options. Whether you're working with Scrapy, BeautifulSoup, Selenium, or more advanced headless browsers and automation tools, knowing what to use and when is essential for scalable, #ReliableDataExtraction.
🔍 Our expert breakdown covers:
✅ The pros and cons of the top open-source libraries
✅ Best tools for dynamic websites, AJAX content, and login sessions
✅ Use cases by industry (e.g., travel, eCommerce, real estate, finance)
✅ Security, ethics, and compliance best practices
✅ When to upgrade from DIY to managed scraping solutions
🧠 Whether you're a developer, data scientist, or startup founder, this resource will help you avoid costly trial-and-error.
📎 Get expert insights with iWeb Data Scraping.

0 notes
Text
Python Automation Ideas: Save Hours Every Week with These Scripts
Tired of repeating the same tasks on your computer? With just a bit of Python knowledge, you can automate routine work and reclaim your time. Here are 10 Python automation ideas that can help you boost productivity and eliminate repetitive tasks.
1. Auto Email Sender
Use Python’s smtplib and email modules to send customized emails in bulk—perfect for reminders, reports, or newsletters.
2. File Organizer Script
Tired of a messy Downloads folder? Automate the sorting of files by type, size, or date using os and shutil.
3. PDF Merger/Splitter
Automate document handling by merging or splitting PDFs using PyPDF2 or pdfplumber.
4. Rename Files in Bulk
Rename multiple files based on patterns or keywords using os.rename()—great for photos, reports, or datasets.
5. Auto Backup Script
Schedule Python to back up files and folders to another directory or cloud with shutil or third-party APIs.
6. Instagram or Twitter Bot
Use automation tools like Selenium or APIs to post, like, or comment—ideal for marketers managing multiple accounts.
7. Invoice Generator
Automate invoice creation from Excel or CSV data using reportlab or docx. Perfect for freelancers and small businesses.
8. Weather Notifier
Set up a daily weather alert using the OpenWeatherMap API and send it to your phone or email each morning.
9. Web Scraper
Extract data from websites (news, prices, job listings) using BeautifulSoup or Scrapy. Automate market research or data collection.
10. Keyboard/Mouse Automation
Use pyautogui to simulate mouse clicks, keystrokes, and automate desktop workflows—great for repetitive UI tasks.
🎯 Want help writing these automation scripts or need hands-on guidance? Visit AllHomeworkAssignments.com for expert support, script writing, and live Python tutoring.
#PythonAutomation#TimeSavingScripts#LearnPython#ProductivityHacks#PythonProjects#AllHomeworkAssignments#AutomateWithPython
0 notes
Text
Automating Restaurant Menu Data Extraction Using Web Scraping APIs
Introduction
The food and restaurant business sector is going very heavily digital with millions of restaurant menus being made available through online platforms. Companies that are into food delivery, restaurant aggregation, and market research require menu data on a real-time basis for competition analysis, pricing strategies, and enhancement of customer experience. Manually collecting and updating this information is time-consuming and a laborious endeavor. This is where web scraping APIs come into play with the automated collection of such information to scrape restaurant menu data efficiently and accurately.
This guide discusses the importance of extracting restaurant menu data, how web scraping works for this use case, some challenges to expect, the best practices in dealing with such issues, and the future direction of menu data automation.
Why Export Restaurant Menu Data?
1. Food Delivery Service
Most online food delivery services, like Uber Eats, DoorDash, and Grubhub, need real-time menu updates for accurate pricing or availability. With the extraction of restaurant menu data, at least those online platforms are kept updated and discrepancies avoidable.
2. Competitive Pricing Strategy
Restaurants and food chains make use of web scraping restaurant menu data to determine their competitors' price positions. By tracking rival menus, they will know how they should price their products to remain competitive in the marketplace.
3. Nutritional and Dietary Insights
Health and wellness platforms utilize menu data for dietary recommendations to customers. By scraping restaurant menu data, these platforms can classify foods according to calorie levels, ingredients, and allergens.
4. Market Research and Trend Analysis
This is the group of data analysts and research firms collecting restaurant menu data to analyze consumer behavior about cuisines and track price variations with time.
5. Personalized Food Recommendations
Machine learning and artificial intelligence now provide food apps with the means to recommend meals according to user preferences. With restaurant menu data web scraping, food apps can access updated menus and thus afford personalized suggestions on food.
How Web Scraping APIs Automate Restaurant Menu Data Extraction
1. Identifying Target Websites
The first step is selecting restaurant platforms such as:
Food delivery aggregators (Uber Eats, DoorDash, Grubhub)
Restaurant chains' official websites (McDonald's, Subway, Starbucks)
Review sites (Yelp, TripAdvisor)
Local restaurant directories
2. Sending HTTP Requests
Scraping APIs send HTTP requests to restaurant websites to retrieve HTML content containing menu information.
3. Parsing HTML Data
The extracted HTML is parsed using tools like BeautifulSoup, Scrapy, or Selenium to locate menu items, prices, descriptions, and images.
4. Structuring and Storing Data
Once extracted, the data is formatted into JSON, CSV, or databases for easy integration with applications.
5. Automating Data Updates
APIs can be scheduled to run periodically, ensuring restaurant menus are always up to date.
Data Fields Extracted from Restaurant Menus
1. Restaurant Information
Restaurant Name
Address & Location
Contact Details
Cuisine Type
Ratings & Reviews
2. Menu Items
Dish Name
Description
Category (e.g., Appetizers, Main Course, Desserts)
Ingredients
Nutritional Information
3. Pricing and Discounts
Item Price
Combo Offers
Special Discounts
Delivery Fees
4. Availability & Ordering Information
Available Timings
In-Stock/Out-of-Stock Status
Delivery & Pickup Options
Challenges in Restaurant Menu Data Extraction
1. Frequent Menu Updates
Restaurants frequently update their menus, making it challenging to maintain up-to-date data.
2. Anti-Scraping Mechanisms
Many restaurant websites implement CAPTCHAs, bot detection, and IP blocking to prevent automated data extraction.
3. Dynamic Content Loading
Most restaurant platforms use JavaScript to load menu data dynamically, requiring headless browsers like Selenium or Puppeteer for scraping.
4. Data Standardization Issues
Different restaurants structure their menu data in various formats, making it difficult to standardize extracted information.
5. Legal and Ethical Considerations
Extracting restaurant menu data must comply with legal guidelines, including robots.txt policies and data privacy laws.
Best Practices for Scraping Restaurant Menu Data
1. Use API-Based Scraping
Leveraging dedicated web scraping APIs ensures more efficient and reliable data extraction without worrying about website restrictions.
2. Rotate IP Addresses & Use Proxies
Avoid IP bans by using rotating proxies or VPNs to simulate different users accessing the website.
3. Implement Headless Browsers
For JavaScript-heavy pages, headless browsers like Puppeteer or Selenium can load and extract dynamic content.
4. Use AI for Data Cleaning
Machine learning algorithms help clean and normalize menu data, making it structured and consistent across different sources.
5. Schedule Automated Scraping Jobs
To maintain up-to-date menu data, set up scheduled scraping jobs that run daily or weekly.
Popular Web Scraping APIs for Restaurant Menu Data Extraction
1. Scrapy Cloud API
A powerful cloud-based API that allows automated menu data scraping at scale.
2. Apify Restaurant Scraper
Apify provides pre-built restaurant scrapers that can extract menu details from multiple platforms.
3. Octoparse
A no-code scraping tool with API integration, ideal for businesses that require frequent menu updates.
4. ParseHub
A flexible API that extracts structured restaurant menu data with minimal coding requirements.
5. CrawlXpert API
A robust and scalable solution tailored for web scraping restaurant menu data, offering real-time data extraction with advanced anti-blocking mechanisms.
Future of Restaurant Menu Data Extraction
1. AI-Powered Menu Scraping
Artificial intelligence will improve data extraction accuracy, enabling automatic menu updates without manual intervention.
2. Real-Time Menu Synchronization
Restaurants will integrate web scraping APIs to sync menu data instantly across platforms.
3. Predictive Pricing Analysis
Machine learning models will analyze scraped menu data to predict price fluctuations and customer demand trends.
4. Enhanced Personalization in Food Apps
By leveraging scraped menu data, food delivery apps will provide more personalized recommendations based on user preferences.
5. Blockchain for Menu Authentication
Blockchain technology may be used to verify menu authenticity, preventing fraudulent modifications in restaurant listings.
Conclusion
Automating the extraction of restaurant menus from the web through scraping APIs has changed the food industry by offering real-time prices, recommendations for food based on liking, and analysis of competitors. With advances in technology, more AI-driven scraping solutions will further improve the accuracy and speed of data collection.
Know More : https://www.crawlxpert.com/blog/restaurant-menu-data-extraction-using-web-scraping-apis
#RestaurantMenuDataExtraction#ScrapingRestaurantMenuData#ExtractRestaurantMenus#ScrapeRestaurantMenuData
0 notes
Text
The Role of AI in Modern Software Testing Practices
AI is reshaping the way software testing is done. With AI automated testing, businesses can achieve higher efficiency, better accuracy, and faster software releases. Whether it’s AI software testing, AI generator testers, or AI-driven automation, the future of software testing is AI-powered.
#ai generator tester#ai software testing#ai automated testing#ai in testing software#playwright automation javascript#playwright javascript tutorial#playwright python tutorial#scrapy playwright tutorial#api testing using postman#online postman api testing#postman automation api testing#postman automated testing#postman performance testing#postman tutorial for api testing#free api for postman testing#api testing postman tutorial#postman tutorial for beginners#postman api performance testing#automate api testing in postman#java automation testing#automation testing selenium with java#automation testing java selenium#java selenium automation testing#python selenium automation#selenium with python automation testing#selenium testing with python#automation with selenium python#selenium automation with python#python and selenium tutorial#cypress automation training
0 notes
Text
Python for Data Mining: Web Scraping to Deep Insights
Data is the new oil, and extracting valuable insights from it is a skill that can set you apart in today’s competitive landscape. Python, with its simplicity and powerful libraries, has become the go-to tool for data mining — a process that transforms raw data into meaningful information. In this blog, we’ll explore how Python takes you from collecting data via web scraping to deriving deep, actionable insights.
Why Python Dominates Data Mining
Python's popularity in data mining stems from its vast ecosystem of libraries, flexibility, and ease of learning. Whether you're a beginner or a seasoned programmer, Python offers a seamless learning curve and powerful tools like Pandas, NumPy, BeautifulSoup, Scrapy, Scikit-learn, and TensorFlow that make data mining efficient and effective.
Its versatility allows professionals to handle a full data pipeline: collecting, cleaning, analyzing, and visualizing data — all within a single environment.
Web Scraping: The Gateway to Raw Data
Before any analysis can happen, you need data. Often, the most valuable data isn’t readily available in clean datasets but is scattered across websites. That’s where web scraping becomes essential.
Web scraping involves programmatically extracting data from web pages. Python simplifies this process with libraries like:
BeautifulSoup: For parsing HTML and XML documents.
Scrapy: A more advanced framework for large-scale web crawling.
Selenium: For scraping dynamic content rendered by JavaScript.
For instance, if you’re researching consumer reviews or competitor pricing, Python can automate the extraction of this data from multiple web pages in a matter of minutes — a task that would take days manually.
Note: Always make sure your web scraping practices align with the site's terms of service to prevent legal issues.
Data Cleaning: Preparing for Analysis
After data collection, it often requires preparation before analysis can begin. You’ll often encounter missing values, duplicates, and inconsistencies. The Pandas library in Python proves essential, providing functions to:
Handle missing data
Remove duplicates
Convert data types
Normalize values
Proper data cleaning ensures your insights are based on reliable, high-quality information, reducing the risk of misleading conclusions.
Analyzing the Data: From Patterns to Predictions
After cleaning, the real magic begins. Python allows you to explore the data through:
Descriptive statistics: Mean, median, mode, standard deviation, etc.
Data visualization: Using Matplotlib and Seaborn for creating insightful graphs and plots.
Machine Learning models: Employing Scikit-learn for predictive modeling, clustering, classification, and regression.
For example, a retailer might use clustering to segment customers into distinct groups based on buying habits, enabling targeted marketing strategies that boost sales.
Deep Insights: Leveraging Machine Learning
When you're ready to go beyond basic analysis, Python’s deep learning libraries like TensorFlow and Keras open doors to more advanced insights. These tools can:
Predict future trends based on historical data
Recognize patterns in complex datasets
Automate decision-making processes
Imagine being able to forecast sales trends or customer churn rates with high accuracy, allowing businesses to make proactive, data-driven decisions.
Real-World Application: Training for the Future
Becoming proficient in data mining with Python is more than a skill — it’s a catalyst for career growth. As industries across healthcare, finance, e-commerce, and manufacturing increasingly rely on data, the demand for skilled data professionals continues to rise.
If you’re looking to build expertise, consider enrolling in a Python training in Aurangabad. Such programs provide hands-on experience, real-world projects, and expert mentorship, giving you the competitive edge needed in today’s data-centric job market.
Python offers a complete toolkit for data mining — from scraping raw data off the web to analyzing it for deep, actionable insights. As businesses continue to recognize the value of data-driven decision-making, mastering these skills can open countless doors. Whether you're an aspiring data scientist or a business professional looking to harness the power of data, Python stands ready to help you turn information into innovation.
At DataMites Institute, we empower individuals with crucial, industry-aligned data skills. Our courses cover core areas such as Data Science, Python, Machine Learning, and more, blending global certifications with hands-on project experience. Guided by experts and offering flexible learning options, we equip professionals for the dynamic world of analytics careers.
#python certification#python course#python training#python#python course in india#python training in india#python institute in india#pythonprogramming#python developers#python programming#python programming course#python programming language#course#certification#education
0 notes
Text
So. So. So.
(a bit of hyping myself up, a bit of a plannin, a bit of a ranting on the day, so trust me the chance that you'd find something personally relevant isn't much)
I added an empty poll by accident.
i see, you cannot add the poll empty to the post. I do not see how to remove it, too.
Also turns out those run either for one day or for 1 week, I see I see.
I have only just one thing on my menu for today. And it's killing me softly
Writing a scraper for a website that requires me to automate a browserrrrr.
Also has cut ties with the person with whom I didn't know how to continue having contact today. So, yay there.
all in all, great day. Coming back to the question..
In order to automate the browser. Several parts. just technical scrapy breking problem into parts stuff below
- detect when captcha turns out
- bypass captcha
---------
- detect cookie pop up
- accept cookies
+ find out what other popups might happen on the website
- detect pop ups
- remove pop ups
---------
- set the search: min to prev max price, max to nex max price. If >1k results, manually input max price broken in half
- check amount of results
- manual price inputter
- after price is over certain treshold test is removing max price is <1k
---------
- add scrolling down to the pagination
- add pressing 'next' button
---------
- add saving response to a particular type of request
--------------------------------
see how long one vpn address would live through all this?
dude that created that scraping browser when he's nineteen and disabled is a legend and someone to aspire to
1 note
·
View note
Text
Top Options To Scrape Hotel Data From Agoda Without Coding
Introduction
In today's competitive hospitality landscape, accessing comprehensive hotel information has become crucial for businesses, researchers, and travel enthusiasts. The ability to Scrape Hotel Data From Agoda opens doors to valuable insights about pricing trends, room availability, customer reviews, and market dynamics. However, many individuals and organizations hesitate to pursue data extraction due to concerns about technical complexity and programming requirements.
The good news is that modern technology has democratized data scraping, making it accessible to users without extensive coding knowledge. This comprehensive guide explores various methods and tools that enable efficient Agoda Hotel Data Extraction while maintaining simplicity and effectiveness for non-technical users.
Understanding the Value of Agoda Hotel Data
Agoda, one of Asia's leading online travel agencies, hosts millions of hotel listings worldwide. The platform contains a treasure trove of information that can benefit various stakeholders in the tourism industry. Market researchers can analyze pricing patterns through Hotel Price Scraping , business owners can monitor competitor rates, and travel agencies can enhance their service offerings through comprehensive data analysis.
The platform's extensive database includes room rates, availability calendars, guest reviews, hotel amenities, location details, and booking policies. Extracting this information systematically allows businesses to make informed decisions about pricing strategies, marketing campaigns, and customer service improvements.
Real-Time Hotel Data from Agoda provides market intelligence that helps businesses stay competitive. By monitoring price fluctuations across different seasons, locations, and property types, stakeholders can optimize their revenue management strategies and identify market opportunities.
No-Code Solutions for Hotel Data Extraction
No-Code Solutions for Hotel Data Extraction refer to user-friendly platforms and tools that enable hotel data scraping—like reviews, room availability, and pricing—without requiring programming skills. These solutions are ideal for marketers, analysts, and business users.
1. Browser-Based Scraping Tools
Modern web scraping has evolved beyond command-line interfaces and complex programming languages. Several browser-based tools now offer intuitive interfaces that allow users to extract data through simple point-and-click operations. These tools typically record user interactions with web pages and automate repetitive tasks.
Popular browser extensions like Web Scraper, Data Miner, and Octoparse provide user-friendly interfaces where users can select specific elements on Agoda's website and configure extraction parameters. These tools automatically handle the technical aspects of data collection while presenting results in accessible formats like CSV or Excel files.
1. Cloud-Based Scraping Platforms
Cloud-based scraping services represent another excellent option for non-technical users seeking Agoda Room Availability Scraping capabilities. These platforms offer pre-built templates specifically designed for popular websites like Agoda, eliminating the need for manual configuration.
Services like Apify, Scrapy Cloud, and ParseHub provide ready-to-use scraping solutions that can be customized through simple form interfaces. Users can specify search criteria, select data fields, and configure output formats without writing a single line of code.
Key advantages of cloud-based solutions include:
Scalability to handle large-scale data extraction projects
Automatic handling of website changes and anti-scraping measures
Built-in data cleaning and formatting capabilities
Integration with popular business intelligence tools
Reliable uptime and consistent performance
Desktop Applications for Advanced Data Extraction
Desktop scraping applications offer another viable path for users seeking to extract hotel information without programming knowledge. These software solutions provide comprehensive interfaces with drag-and-drop functionality, making data extraction as simple as building a flowchart.
Applications like FMiner, WebHarvy, and Visual Web Ripper offer sophisticated features wrapped in user-friendly interfaces. These tools can handle complex scraping scenarios, including dealing with JavaScript-heavy pages, managing login sessions, and handling dynamic content loading.
Desktop applications' advantage is their ability to provide more control over the scraping process while maintaining ease of use. Users can set up complex extraction workflows, implement data validation rules, and export results in multiple formats. These applications also include scheduling capabilities for automated Hotel Booking Data Scraping operations.
API-Based Solutions and Third-Party Services
Modern automation platforms like Zapier, Microsoft Power Automate, and IFTTT have expanded to include web scraping capabilities. These platforms allow users to create automated workflows to Extract Hotel Reviews From Agoda and integrate them directly into their existing business systems.
Companies specializing in travel data extraction often provide dedicated Agoda scraping services that can be accessed through simple web forms or API endpoints. Users can specify their requirements, such as location, date ranges, and property types, and receive Real-Time Hotel Data in return.
Benefits of API-based solutions include:
Immediate access to data without setup time
Professional-grade reliability and accuracy
Compliance with website terms of service
Regular updates to handle website changes
Customer support for troubleshooting
Automated Workflow Tools and Integrations
Modern automation platforms like Zapier, Microsoft Power Automate, and IFTTT have expanded to include web scraping capabilities. These platforms allow users to create automated workflows to Extract Hotel Reviews From Agoda and integrate them directly into their existing business systems.
These tools are particularly valuable for businesses that must incorporate hotel data into their operations. For example, a travel agency could set up an automated workflow that scrapes Agoda data daily and updates its internal pricing database, enabling dynamic pricing strategies based on Agoda Room Availability Scraping insights.
The workflow approach seamlessly integrates with popular business tools like Google Sheets, CRM systems, and email marketing platforms. This integration capability makes it easier to act on the extracted data immediately rather than manually processing exported files.
Data Quality and Validation Considerations
Ensure data quality when implementing any Hotel Data Intelligence strategy. Non-coding solutions often include built-in validation features that help maintain data accuracy and consistency. These features typically include duplicate detection, format validation, and completeness checks.
Users should establish data quality standards before beginning extraction projects. This includes defining acceptable ranges for numerical data, establishing consistent formatting for text fields, and implementing verification procedures for critical information like pricing and availability.
Regular monitoring of extracted data helps identify potential issues early in the process. Many no-code tools provide notification systems that alert users to unusual patterns or extraction failures, enabling quick resolution of data quality issues.
Legal and Ethical Considerations
Before implementing any data extraction strategy, users must understand the legal and ethical implications of web scraping. Agoda's terms of service, robots.txt file, and rate-limiting policies should be carefully reviewed to ensure compliance.
Responsible scraping practices include:
Respecting website rate limits and implementing appropriate delays
Using data only for legitimate business purposes
Avoiding excessive server load that could impact website performance
Implementing proper data security measures for extracted information
Regularly reviewing and updating scraping practices to maintain compliance
Advanced Features and Customization Options
Modern no-code scraping solutions offer sophisticated customization options that rival traditional programming approaches. These features enable users to handle complex scenarios like multi-page data extraction, conditional logic implementation, and dynamic content handling.
Advanced filtering capabilities allow users to extract only relevant information based on specific criteria such as price ranges, star ratings, or geographic locations. This targeted approach reduces data processing time and focuses analysis on the most valuable insights.
Many platforms also offer data transformation features that can clean, format, and structure extracted information according to business requirements. These capabilities eliminate additional data processing steps and provide ready-to-use datasets.
Monitoring and Maintenance Strategies
Successful Travel Industry Web Scraping requires ongoing monitoring and maintenance to ensure consistent performance. No-code solutions typically include dashboard interfaces that provide visibility into scraping performance, success rates, and data quality metrics.
Users should establish regular review processes to validate data accuracy and identify potential issues. This includes monitoring for website changes that might affect extraction accuracy, validating data completeness, and ensuring compliance with updated service terms.
Automated alerting systems can notify users of extraction failures, data quality issues, or significant changes in scraped information. These proactive notifications enable quick responses to potential problems and maintain data reliability.
Future Trends in No-Code Data Extraction
The landscape of no-code data extraction continues to evolve rapidly, with new tools and capabilities emerging regularly. Artificial intelligence and machine learning technologies are increasingly integrated into scraping platforms, enabling more intelligent data extraction and automatic application to website changes.
These technological advances make Hotel Booking Data Scraping more accessible and reliable for non-technical users. Future developments will likely include enhanced natural language processing capabilities, improved visual recognition for data element selection, and more sophisticated automation features.
How Travel Scrape Can Help You?
We provide comprehensive hotel data extraction services that eliminate the technical barriers typically associated with web scraping. Our platform is designed specifically for users who need reliable Real-Time Hotel Data without the complexity of coding or managing technical infrastructure.
Our services include:
Custom Agoda scraping solutions tailored to your specific business requirements and data needs.
Automated data collection schedules that ensure you always have access to the most current hotel information.
Advanced data filtering and cleaning processes that deliver high-quality, actionable insights.
Multiple export formats, including CSV, Excel, JSON, and direct database integration options.
Compliance management ensures all data extraction activities adhere to legal and ethical standards.
Scalable solutions that grow with your business needs, from small-scale projects to enterprise-level operations.
Integration capabilities with popular business intelligence tools and CRM systems.
Our platform handles the technical complexities of Hotel Price Scraping while providing clean, structured data that can be immediately used for analysis and decision-making.
Conclusion
The democratization of data extraction technology has made it possible for anyone to Scrape Hotel Data From Agoda without extensive programming knowledge. Users can access valuable hotel information that drives informed business decisions through browser extensions, cloud-based platforms, desktop applications, and API services.
As the Travel Industry Web Scraping landscape evolves, businesses embracing these accessible technologies will maintain competitive advantages through better market intelligence and data-driven decision-making.
Don't let technical barriers prevent you from accessing valuable market insights; Contact Travel Scrape now to learn more about our comprehensive Travel Aggregators data extraction services and take the first step toward data-driven success.
Read More :- https://www.travelscrape.com/scrape-agoda-hotel-data-no-coding.php
#ScrapeHotelDataFromAgoda#AgodaHotelDataExtraction#HotelPriceScraping#RealTimeHotelData#HotelDataIntelligence#TravelIndustryWebScraping#HotelBookingDataScraping#TravelAggregators
0 notes