#scrapy Python development
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Hire Expert Scrapy Developers for Scalable Web Scraping & Data Automation
Looking to extract high-value data from the web quickly and accurately? At Prospera Soft, we offer top-tier Scrapy development services to help businesses automate data collection, gain market insights, and scale operations with ease.
Our team of Scrapy experts specializes in building robust, Python-based web scrapers that deliver 10X faster data extraction, 99.9% accuracy, and full cloud scalability. From price monitoring and sentiment analysis to lead generation and product scraping, we design intelligent, secure, and GDPR-compliant scraping solutions tailored to your business needs.
Why Choose Our Scrapy Developers?
✅ Custom Scrapy Spider Development for complex and dynamic websites
✅ AI-Optimized Data Parsing to ensure clean, structured output
✅ Middleware & Proxy Rotation to bypass anti-bot protections
✅ Seamless API Integration with BI tools and databases
✅ Cloud Deployment via AWS, Azure, or GCP for high availability
Whether you're in e-commerce, finance, real estate, or research, our scalable Scrapy solutions power your data-driven decisions.
#Hire Expert Scrapy Developers#scrapy development company#scrapy development services#scrapy web scraping#scrapy data extraction#scrapy automation#hire scrapy developers#scrapy company#scrapy consulting#scrapy API integration#scrapy experts#scrapy workflow automation#best scrapy development company#scrapy data mining#hire scrapy experts#scrapy scraping services#scrapy Python development#scrapy no-code scraping#scrapy enterprise solutions
0 notes
Text
Unlock the Secrets of Python Web Scraping for Data-Driven Success
Ever wondered how to extract data from websites without manual effort? Python web scraping is the answer!
This blog covers everything you need to know to harness Python’s powerful libraries like BeautifulSoup, Scrapy, and Requests.
Whether you're scraping for research, monitoring prices, or gathering content, this guide will help you turn the web into a vast source of structured data.
Learn how to set up Python for scraping, handle errors, and ensure your scraping process is both legal and efficient.
If you're ready to dive into the world of information mining, this article is your go-to resource.
0 notes
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text
Tapping into Fresh Insights: Kroger Grocery Data Scraping
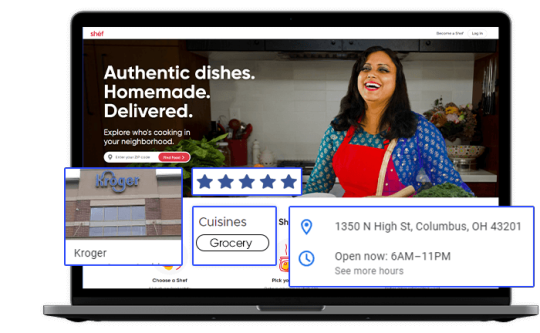
In today's data-driven world, the retail grocery industry is no exception when it comes to leveraging data for strategic decision-making. Kroger, one of the largest supermarket chains in the United States, offers a wealth of valuable data related to grocery products, pricing, customer preferences, and more. Extracting and harnessing this data through Kroger grocery data scraping can provide businesses and individuals with a competitive edge and valuable insights. This article explores the significance of grocery data extraction from Kroger, its benefits, and the methodologies involved.
The Power of Kroger Grocery Data
Kroger's extensive presence in the grocery market, both online and in physical stores, positions it as a significant source of data in the industry. This data is invaluable for a variety of stakeholders:
Kroger: The company can gain insights into customer buying patterns, product popularity, inventory management, and pricing strategies. This information empowers Kroger to optimize its product offerings and enhance the shopping experience.
Grocery Brands: Food manufacturers and brands can use Kroger's data to track product performance, assess market trends, and make informed decisions about product development and marketing strategies.
Consumers: Shoppers can benefit from Kroger's data by accessing information on product availability, pricing, and customer reviews, aiding in making informed purchasing decisions.
Benefits of Grocery Data Extraction from Kroger
Market Understanding: Extracted grocery data provides a deep understanding of the grocery retail market. Businesses can identify trends, competition, and areas for growth or diversification.
Product Optimization: Kroger and other retailers can optimize their product offerings by analyzing customer preferences, demand patterns, and pricing strategies. This data helps enhance inventory management and product selection.
Pricing Strategies: Monitoring pricing data from Kroger allows businesses to adjust their pricing strategies in response to market dynamics and competitor moves.
Inventory Management: Kroger grocery data extraction aids in managing inventory effectively, reducing waste, and improving supply chain operations.
Methodologies for Grocery Data Extraction from Kroger
To extract grocery data from Kroger, individuals and businesses can follow these methodologies:
Authorization: Ensure compliance with Kroger's terms of service and legal regulations. Authorization may be required for data extraction activities, and respecting privacy and copyright laws is essential.
Data Sources: Identify the specific data sources you wish to extract. Kroger's data encompasses product listings, pricing, customer reviews, and more.
Web Scraping Tools: Utilize web scraping tools, libraries, or custom scripts to extract data from Kroger's website. Common tools include Python libraries like BeautifulSoup and Scrapy.
Data Cleansing: Cleanse and structure the scraped data to make it usable for analysis. This may involve removing HTML tags, formatting data, and handling missing or inconsistent information.
Data Storage: Determine where and how to store the scraped data. Options include databases, spreadsheets, or cloud-based storage.
Data Analysis: Leverage data analysis tools and techniques to derive actionable insights from the scraped data. Visualization tools can help present findings effectively.
Ethical and Legal Compliance: Scrutinize ethical and legal considerations, including data privacy and copyright. Engage in responsible data extraction that aligns with ethical standards and regulations.
Scraping Frequency: Exercise caution regarding the frequency of scraping activities to prevent overloading Kroger's servers or causing disruptions.
Conclusion
Kroger grocery data scraping opens the door to fresh insights for businesses, brands, and consumers in the grocery retail industry. By harnessing Kroger's data, retailers can optimize their product offerings and pricing strategies, while consumers can make more informed shopping decisions. However, it is crucial to prioritize ethical and legal considerations, including compliance with Kroger's terms of service and data privacy regulations. In the dynamic landscape of grocery retail, data is the key to unlocking opportunities and staying competitive. Grocery data extraction from Kroger promises to deliver fresh perspectives and strategic advantages in this ever-evolving industry.
#grocerydatascraping#restaurant data scraping#food data scraping services#food data scraping#fooddatascrapingservices#zomato api#web scraping services#grocerydatascrapingapi#restaurantdataextraction
4 notes
·
View notes
Text

Python is no longer just a programming language for developers; it’s becoming an invaluable tool for SEO looking to sharpen their strategies. Imagine wielding the power of automation and data analysis to elevate your search engine optimization efforts. With Python, you can dive deep into keyword relevance and search intent, unraveling mysteries that traditional methods might overlook.
As the digital landscape evolves, so too must our approaches to SEO. Understanding what users want when they type a query into Google is crucial. The right keywords can make or break your online visibility. That’s where Python comes in—streamlining processes and providing insights that drive results.
Ready to unlock new possibilities? Let’s explore how Python can transform your SEO game by offering innovative ways to track keyword relevance and decode search intent with ease. Whether you’re a seasoned pro or just starting out, this journey promises valuable tools tailored for modern SEO challenges.
Understanding Keyword Relevance and Search Intent
Keyword relevance is the heart of effective SEO. It refers to how closely a keyword matches the content on your page. Choosing relevant keywords helps search engines understand what your site offers.
Search intent goes deeper. It’s about understanding why users perform a specific query. Are they looking for information, trying to make a purchase, or seeking navigation? Grasping this concept is crucial for creating content that resonates with audiences.
Different types of search intents exist: informational, transactional, navigational, and commercial investigation. Each type requires tailored strategies to meet user expectations effectively.
By aligning keyword relevance with search intent, you can craft content that not only attracts visitors but also engages them meaningfully. This dual focus enhances user experience and boosts rankings in SERPs over time.
Using Python for Keyword Research
Keyword research is a crucial step in any SEO strategy. Python simplifies this process significantly, allowing you to analyze large datasets efficiently.
With libraries like Pandas and NumPy, you can manipulate and clean keyword data quickly. These tools help you uncover valuable insights that drive content creation.
You can also use the Beautiful Soup library for web scraping. This enables you to gather keywords from competitor sites or industry forums effortlessly.
Additionally, integrating Google Trends API within your scripts offers real-time keyword popularity metrics. This feature helps identify rising trends that are relevant to your niche.
Python scripts automate repetitive tasks, freeing up time for more strategic initiatives. By leveraging these capabilities, you’re better equipped to optimize your campaigns effectively without getting bogged down by manual processes.
Tracking Search Intent with Python Scripts
Understanding search intent is crucial for any SEO strategy. With Python, you can automate the process of analyzing user queries and determining their underlying motivations.
Using libraries like BeautifulSoup or Scrapy, you can scrape SERPs to gather data on keyword rankings and associated content. This helps identify patterns in how users interact with different topics.
Additionally, Natural Language Processing (NLP) tools such as NLTK or spaCy can assist in categorizing keywords based on intent—whether informational, transactional, or navigational.
By implementing custom scripts, you can quickly assess which keywords align best with your audience’s needs. This not only saves time but also enhances your ability to target content effectively.
Automating this analysis allows for regular updates on changing search behaviors. Staying ahead of trends means better optimization strategies that resonate with real user intent.
Integrating Python into your SEO Workflow
Integrating Python into your SEO workflow can transform how you approach data analysis and keyword tracking. By automating repetitive tasks, you free up valuable time for strategic thinking and creative exploration.
Start by leveraging libraries like Pandas to analyze large datasets efficiently. This helps in identifying trends or anomalies that might be missed with traditional methods.
You can also use Beautiful Soup for web scraping, allowing you to gather competitor insights directly from their sites. Extracting relevant information becomes a breeze, enhancing your research capabilities.
Consider creating custom scripts tailored to your specific needs. Whether it’s monitoring rankings or analyzing backlinks, Python allows unprecedented flexibility.
Incorporate visualizations using Matplotlib or Seaborn to present data clearly. These visuals make it easier to share findings with team members or stakeholders who may not be as familiar with the technical aspects of SEO.
Tips and Tricks for Mastering Search Intent Analysis with Python
Mastering search intent analysis with Python can elevate your SEO strategy. Start by leveraging libraries like Pandas and Beautiful Soup for efficient data manipulation and web scraping.
Utilize Natural Language Processing (NLP) techniques to understand user queries better. Libraries such as NLTK or SpaCy can help you analyze keywords, phrases, and their contexts.
Make your code modular. Break down functions into smaller components for cleaner debugging and easier updates in the future.
Experiment with machine learning models to predict user behavior based on historical data. Tools like Scikit-learn offer a range of algorithms that can enhance your insights dramatically.
Stay updated with SEO trends. Adapt your scripts regularly to reflect changes in search engine algorithms and user preferences. Continuous learning is key in this ever-evolving field!
Conclusion
As the digital landscape continues to evolve, SEO professionals must adapt and innovate. Python has emerged as a powerful tool that can transform how you approach keyword relevance and search intent.
With Python, you can streamline your keyword research process, analyze massive datasets quickly, and effectively interpret user intent behind searches. The ability to automate repetitive tasks frees up time for deeper strategic thinking.
Integrating Python into your SEO workflow enhances efficiency and results in more targeted strategies. Real-world applications showcase its versatility—from scraping data from SERPs to analyzing trends over time.
By leveraging Python for SEO activities, you’re not only keeping pace with the industry but also setting yourself apart as a forward-thinking professional ready to tackle the challenges of tomorrow’s search engines. Embrace this technology; it could very well be your secret weapon in achieving online success.
0 notes
Text
Tools to Scrape Amazon Product Offers and Sellers Data

Introduction
Scraping Amazon product offers and seller information can provide valuable insights for businesses, developers, and researchers. Whether you're analyzing competitor pricing, monitoring market trends, or building a price comparison tool, Scrape Amazon Product Offers and Sellers Data is crucial for staying competitive. This guide will walk you through code-based and no-code methods for extracting Amazon data, making it suitable for beginners and experienced developers. We'll cover the best tools, techniques, and practices to ensure practical and ethical data extraction. One key aspect is learning how to Extract Amazon Seller Prices Data accurately, allowing you to track and analyze pricing trends across various sellers. Additionally, we will delve into how to Scrape Amazon Seller Information, ensuring that all data is collected efficiently while staying within legal boundaries. By following the right approaches, you can access valuable data insights without facing potential legal or technical challenges, ensuring long-term success in your data-driven projects.
Why Scrape Amazon Product Offers and Sellers?

Amazon is a treasure trove of e-commerce data. Scraping product offers and seller information, Amazon is a goldmine of e-commerce data, offering valuable insights for businesses looking to gain a competitive edge. By Scraping Amazon Seller Listings Data, you can collect crucial information that helps in several areas:
Monitor pricing trends: Track the price changes for specific products or categories over time. This allows you to understand market dynamics and adjust your pricing strategy accordingly.
Analyze seller performance: Evaluate key metrics such as seller ratings, shipping options, and inventory availability. This data can help you understand how top-performing sellers operate and what factors contribute to their success.
Competitor analysis: Scrape Amazon Offer Listings with Selenium Data to compare your offerings against your competitors. You can identify pricing gaps, product availability, and more, which helps refine your market positioning.
Market research: By examining Amazon Seller Scraping API Integration data, you can identify high-demand products, emerging niches, and customer preferences. This information can guide your product development and marketing strategies.
Build tools: Use the scraped data to create practical applications like price comparison tools or inventory management systems. With the right dataset, you can automate and optimize various business processes.
However, scraping Amazon's vast marketplace comes with challenges. Its dynamic website structure, sophisticated anti-scraping measures (like CAPTCHAs), and strict legal policies create barriers. To overcome these obstacles, you must implement strategies that include using advanced tools to Extract Amazon E-Commerce Product Data. Success requires a tailored approach that matches your skill level and resource availability.
Legal and Ethical Considerations

Before diving into scraping, understand the legal and ethical implications:
Amazon's Terms of Service (ToS): Amazon prohibits scraping without permission. Violating ToS can lead to IP bans or legal action.
Data Privacy: Avoid collecting personal information about sellers or customers.
Rate Limiting: Excessive requests can overload Amazon's servers, violating ethical scraping practices.
robots.txt: Look for Amazon's robots.txt file to see which pages are disallowed for scraping.
To stay compliant:
Use Amazon's official Product Advertising API: for authorized data access (if applicable).
Scrape publicly available data sparingly: and respect rate limits.
Consult a legal expert: if you're building a commercial tool.
Code-Based Approach: Scraping with Python

For developers skilled in coding, Python provides robust libraries such as BeautifulSoup, Scrapy, and Selenium to Scrape Amazon E-Commerce Product Data efficiently. Using libraries like BeautifulSoup and Requests, you can easily extract product offers and seller details. Combining these tools allows you to navigate Amazon's complex structure and gather valuable insights. Whether you're looking to Scrape Amazon ecommerce Product Data for pricing trends or competitor analysis, this approach allows for streamlined data extraction. With the proper script, you can automate the process, gather vast datasets, and leverage them for various business strategies.
Prerequisites
Python 3.x installed.
Libraries: Install via pip:
Basic understanding of HTML/CSS selectors.
Sample Python Script

This script scrapes product titles, prices, and seller names from an Amazon search results page.
How It Works?

Headers: The script uses a User-Agent to mimic a browser, reducing the chance of being blocked.
Request: Sends an HTTP GET request to Amazon's search page for the query (e.g., "wireless earbuds").
Parsing: BeautifulSoup parses the HTML to locate product containers using Amazon's class names.
Extraction: Extracts the title, price, and seller for each product.
Error Handling: Handles network errors gracefully.
Challenges and Solutions
Dynamic Content: Some Amazon pages load data via JavaScript. Use Selenium or Playwright for dynamic scraping.
CAPTCHAs: Rotate proxies or use CAPTCHA-solving services.
IP Bans: Implement delays (time.sleep(5)) or use proxy services.
Rate Limits: Limit requests to 1–2 per second to avoid detection.
Scaling with Scrapy
For large-scale scraping, use Scrapy, a Python framework for building web crawlers. Scrapy supports:
Asynchronous requests for faster scraping.
Middleware for proxy rotation and user-agent switching.
Pipelines for storing data in databases like MySQL or MongoDB.
No-Code Approach: Using Web Scraping Tools
For non-developers or those looking for fast solutions, no-code tools provide an easy way to Extract Popular E-Commerce Website Data without needing to write any code. These tools offer visual interfaces allowing users to select webpage elements and automate data extraction. Common types of no-code tools include web scraping platforms, browser extensions, and API-based solutions. With these tools, you can quickly collect product offers, seller information, and more. Many businesses rely on Ecommerce Data Scraping Services to simplify gathering data from websites like Amazon, enabling efficient analysis and decision-making.
1. Visual Scraping Tool
Features: A desktop or cloud-based tool with a point-and-click interface, supports exporting data to CSV/Excel, and handles pagination.
Install the tool and start a new project.
Enter the Amazon search URL (e.g., https://www.amazon.com/s?k=laptop).
Use the visual editor to select elements like product title, price, or seller name.
Configure pagination to scrape multiple pages.
Run the task locally or in the cloud and export the data.
Pros: User-friendly, handles dynamic content, supports scheduling.
Cons: Free plans often have limits; premium plans may be required for large-scale scraping.
2. Cloud-Based Scraping Platform
Features: A free or paid platform with cloud scraping, API integration, and support for JavaScript-rendered pages.
Load the Amazon page in the platform's built-in browser.
Click on elements to extract (e.g., price, seller name).
Add logic to handle missing or inconsistent data.
Export results as JSON or CSV.
Pros: Free tiers often support small projects; intuitive for beginners.
Cons: Advanced features may require learning or paid plans.
3. Browser Extension Scraper
Features: A free browser-based extension for simple scraping tasks.
Install the extension in your browser.
Create a scraping template by selecting elements on the Amazon page (e.g., product title, price).
Run the scraper and download data as CSV.
Pros: Free, lightweight, and easy to set up.
Cons: Limited to static content; lacks cloud or automation features.
Choosing a No-Code Tool
Small Projects: Browser extension scrapers are ideal for quick, one-off tasks.
Regular Scraping: Visual scraping tools or cloud-based platforms offer automation and cloud support.
Budget: Start with free tiers, but expect to upgrade for large-scale or frequent scraping.
Start extracting valuable insights today with our powerful and easy-to-use scraping tools!
Best Practices for Scraping Amazon

1. Respect Robots.txt: Avoid scraping disallowed pages.
2. Use Proxies: Rotate IPs to prevent bans. Proxy services offer residential proxies for reliable scraping.
3. Randomize Requests: Add delays and vary user agents to mimic human behavior.
4. Handle Errors: Implement retries for failed requests.
5. Store Data Efficiently: Use databases (e.g., SQLite, MongoDB) for large datasets.
6. Monitor Changes: Amazon's HTML structure changes frequently. Regularly update selectors.
7. Stay Ethical: Scrape only what you need and avoid overloading servers.
Alternative: Amazon Product Advertising API

Instead of scraping, consider Amazon's Product Advertising API for authorized access to product data. Benefits include:
Legal Compliance: Fully compliant with Amazon's ToS.
Rich Data: Access to prices, offers, reviews, and seller info.
Reliability: No risk of IP bans or CAPTCHAs.
Drawbacks:
Requires an Amazon Associate account with qualifying sales.
Limited to specific data points.
Rate limits apply.
To use the API:
1. Sign up for the Amazon Associates Program.
2. Generate API keys.
3. Use a library like boto3 (Python) to query the API.
How Product Data Scrape Can Help You?
Customizable Data Extraction: Our tools are built to adapt to various website structures, allowing you to extract exactly the data you need—whether it's product listings, prices, reviews, or seller details.
Bypass Anti-Scraping Measures: With features like CAPTCHA solving, rotating proxies, and user-agent management, our tools effectively overcome restrictions set by platforms like Amazon.
Supports Code and No-Code Users: Whether you're a developer or a non-technical user, our scraping solutions offer code-based flexibility and user-friendly no-code interfaces.
Real-Time and Scheduled Scraping: Automate your data collection with scheduling features and receive real-time updates, ensuring you always have the latest information at your fingertips.
Clean and Structured Output: Our tools deliver data in clean formats like JSON, CSV, or Excel, making it easy to integrate into analytics tools, dashboards, or custom applications.
Conclusion
Scraping Amazon product offers and seller information is a powerful way to Extract E-commerce Data and gain valuable business insights. However, thoughtful planning is required to address technical barriers and legal considerations. Code-based methods using Python libraries like BeautifulSoup or Scrapy provide developers with flexibility and control. Meanwhile, no-code tools with visual interfaces or browser extensions offer user-friendly options for non-coders to use Web Scraping E-commerce Websites .
For compliant access, the Amazon Product Advertising API remains the safest route. Regardless of the method, always follow ethical scraping practices, implement proxies, and handle errors effectively. Combining the right tools with innovative techniques can help you build an insightful Ecommerce Product & Review Dataset for business or academic use.
At Product Data Scrape, we strongly emphasize ethical practices across all our services, including Competitor Price Monitoring and Mobile App Data Scraping. Our commitment to transparency and integrity is at the heart of everything we do. With a global presence and a focus on personalized solutions, we aim to exceed client expectations and drive success in data analytics. Our dedication to ethical principles ensures that our operations are both responsible and effective.
Source >>https://www.productdatascrape.com/amazon-product-seller-scraping-tools.php
#ScrapeAmazonProductOffersAndSellersData#ExtractAmazonSellerPricesData#AmazonSellerScrapingAPI#ExtractAmazonECommerceProductData#ScrapeAmazonEcommerceProductData#ExtractPopularECommerceWebsiteData#EcommerceDataScrapingServices
0 notes
Text
How to Scrape Data from Amazon: A Quick Guide
How to scrape data from Amazon is a question asked by many professionals today. Whether you’re a data analyst, e-commerce seller, or startup founder, Amazon holds tons of useful data — product prices, reviews, seller info, and more. Scraping this data can help you make smarter business decisions.

In this guide, we’ll show you how to do it the right way: safely, legally, and without getting blocked. You’ll also learn how to deal with common problems like IP bans, CAPTCHA, and broken scrapers.
Is It Legal to Scrape Data from Amazon?
This is the first thing you should know.
Amazon’s Terms of Service (TOS) say you shouldn’t access their site with bots or scrapers. So technically, scraping without permission breaks their rules. But the laws on scraping vary depending on where you live.
Safer alternatives:
Use the Amazon Product Advertising API (free but limited).
Join Amazon’s affiliate program.
Buy clean data from third-party providers.
If you still choose to scrape, make sure you’re not collecting private data or hurting their servers. Always scrape responsibly.
What Kind of Data Can You Scrape from Amazon?
Here are the types of data most people extract:
1. Product Info:
You can scrape Amazon product titles, prices, descriptions, images, and availability. This helps with price tracking and competitor analysis.
2. Reviews and Ratings:
Looking to scrape Amazon reviews and ratings? These show what buyers like or dislike — great for product improvement or market research.
3. Seller Data:
Need to know who you’re competing with? Scrape Amazon seller data to analyze seller names, fulfillment methods (like FBA), and product listings.
4. ASINs and Rankings:
Get ASINs, category info, and product rankings to help with keyword research or SEO.
What Tools Can You Use to Scrape Amazon?
You don’t need to be a pro developer to start. These tools and methods can help:
For Coders:
Python + BeautifulSoup/Scrapy: Best for basic HTML scraping.
Selenium: Use when pages need to load JavaScript.
Node.js + Puppeteer: Another great option for dynamic content.
For Non-Coders:
Octoparse and ParseHub: No-code scraping tools.
Just point, click, and extract!
Don’t forget:
Use proxies to avoid IP blocks.
Rotate user-agents to mimic real browsers.
Add delays between page loads.
These make scraping easier and safer, especially when you’re trying to scrape Amazon at scale.
How to Scrape Data from Amazon — Step-by-Step
Let’s break it down into simple steps:
Step 1: Pick a Tool
Choose Python, Node.js, or a no-code platform like Octoparse based on your skill level.
Step 2: Choose URLs
Decide what you want to scrape — product pages, search results, or seller profiles.
Step 3: Find HTML Elements
Right-click > “Inspect” on your browser to see where the data lives in the HTML code.
Step 4: Write or Set Up the Scraper
Use tools like BeautifulSoup or Scrapy to create scripts. If you’re using a no-code tool, follow its visual guide.
Step 5: Handle Pagination
Many listings span multiple pages. Be sure your scraper can follow the “Next” button.
Step 6: Save Your Data
Export the data to CSV or JSON so you can analyze it later.
This is the best way to scrape Amazon if you’re starting out.
How to Avoid Getting Blocked by Amazon
One of the biggest problems? Getting blocked. Amazon has smart systems to detect bots.
Here’s how to avoid that:
1. Use Proxies:
They give you new IP addresses, so Amazon doesn’t see repeated visits from one user.
2. Rotate User-Agents:
Each request should look like it’s coming from a different browser or device.
3. Add Time Delays:
Pause between page loads. This helps you look like a real human, not a bot.
4. Handle CAPTCHAs:
Use services like 2Captcha, or manually solve them when needed.
Following these steps will help you scrape Amazon products without being blocked.
Best Practices for Safe and Ethical Scraping
Scraping can be powerful, but it must be used wisely.
Always check the site’s robots.txt file.
Don’t overload the server by scraping too fast.
Never collect sensitive or private information.
Use data only for ethical and business-friendly purposes.
When you’re learning how to get product data from Amazon, ethics matter just as much as technique.
Are There Alternatives to Scraping?
Yes — and sometimes they’re even better:
Amazon API:
This is a legal, developer-friendly way to get product data.
Third-Party APIs:
These services offer ready-made solutions and handle proxies and errors for you.
Buy Data:
Some companies sell clean, structured data — great for people who don’t want to build their own tools.
Common Errors and Fixes
Scraping can be tricky. Here are a few common problems:
Error 503:
This usually means Amazon is blocking you. Fix it by using proxies and delays.
Missing Data:
Amazon changes its layout often. Re-check the HTML elements and update your script.
JavaScript Not Loading:
Switch from BeautifulSoup to Selenium or Puppeteer to load dynamic content.
The key to Amazon product scraping success is testing, debugging, and staying flexible.
Conclusion:
To scrape data from Amazon, use APIs or scraping tools with care. While it violates Amazon’s Terms of Service, it’s not always illegal. Use ethical practices: avoid private data, limit requests, rotate user-agents, use proxies, and solve CAPTCHAs to reduce detection risk.
Looking to scale your scraping efforts or need expert help? Whether you’re building your first script or extracting thousands of product listings, you now understand how to scrape data from Amazon safely and smartly. Let Iconic Data Scrap help you get it done right.
Contact us today for custom tools, automation services, or scraping support tailored to your needs.
#iconicdatascrap#howtoscrapedatafromamazon#amazondatascraping#amazonwebscraping#scrapeamazonproducts#extractdatafromamazon#amazonscraper#amazonproductscraper#bestwaytoscrapeamazon#scrapeamazonreviews#scrapeamazonprices#scrapeamazonsellerdata#extractproductinfofromamazon#howtogetproductdatafromamazon#webscrapingtools#pythonscraping#beautifulsoupamazon#amazonapialternative#htmlscraping#dataextraction#scrapingscripts#automateddatascraping#howtoscrapedatafromamazonusingpython#isitlegaltoscrapeamazondata#howtoscrapeamazonreviewsandratings#toolstoscrapeamazonproductlistings#scrapeamazonatscale
1 note
·
View note
Text
Travel Data Scraping Tools And Techniques For 2025
Introduction
The travel industry generates massive amounts of data every second, from fluctuating flight prices to real-time hotel availability. Businesses harnessing this information effectively gain a significant competitive advantage in the market. Travel Data Scraping has emerged as a crucial technique for extracting valuable insights from various travel platforms, enabling companies to make informed decisions and optimize their strategies.
Modern travelers expect transparency, competitive pricing, and comprehensive options when planning their journeys. To meet these demands, travel companies must continuously monitor competitor pricing, track market trends, and analyze consumer behavior patterns. Given the scale and speed at which travel data changes, extracting this information manually would be impossible.
Understanding the Fundamentals of Travel Data Extraction

Car Rental Data Scraping involves automated information collection from travel websites, booking platforms, and related online sources. This process utilizes specialized software and programming techniques to navigate through web pages, extract relevant data points, and organize them into structured formats for analysis.
The complexity of travel websites presents unique challenges for data extraction. Many platforms implement dynamic pricing algorithms, use JavaScript-heavy interfaces, and employ anti-bot measures to protect their data. Successfully navigating these obstacles requires sophisticated Travel Data Intelligence systems that can adapt to changing website structures and security measures.
Key components of effective travel data extraction include:
Target identification: Determining which websites and data points are most valuable for your business objectives.
Data parsing: Converting unstructured web content into organized, analyzable formats.
Quality assurance: Implementing validation mechanisms to ensure data accuracy and completeness.
Scalability management: Handling large volumes of requests without overwhelming target servers.
The extracted information typically includes pricing data, availability schedules, customer reviews, amenities descriptions, and geographical information. This comprehensive dataset enables businesses to analyze competition, identify market opportunities, and develop data-driven strategies.
Essential Tools and Technologies for 2025

The landscape of modern data extraction has evolved significantly, with advanced solutions offering enhanced capabilities for handling complex travel websites. Python-based frameworks like Scrapy and BeautifulSoup remain popular for custom development, while cloud-based platforms provide scalable solutions for enterprise-level operations.
Vacation Rental Data Scraping services have gained prominence by offering pre-built integrations with major travel platforms. These APIs handle the technical complexities of data extraction while providing standardized access to travel information. Popular providers include RapidAPI, Amadeus, and specialized travel data services focusing on industry needs.
Browser automation tools such as Selenium and Playwright excel at handling JavaScript-heavy websites that traditional scraping methods cannot access. These tools simulate human browsing behavior, making them particularly effective for sites with dynamic content loading and complex user interactions.
Advanced practitioners increasingly adopt machine learning approaches to improve Real-Time Travel Data Extraction accuracy. These systems can adapt to website changes automatically, recognize content patterns more effectively, and handle anti-bot measures with greater sophistication.
Flight Price Data Collection Strategies
Airlines constantly adjust their pricing based on demand, seasonality, route popularity, and competitive factors. Flight Price Data Scraping enables businesses to track these fluctuations across multiple carriers and booking platforms simultaneously. This information proves invaluable for travel agencies, price comparison sites, and market researchers.
Effective flight data collection requires monitoring multiple sources, including airline websites, online travel agencies, and metasearch engines. Each platform may display prices for identical flights due to exclusive deals, booking fees, or promotional campaigns. Comprehensive coverage ensures accurate market representation through Web Scraping Tools For Travel.
Key considerations for flight data extraction include:
Timing optimization: Prices change frequently, requiring strategic scheduling of data collection activities.
Route coverage: Monitoring popular routes while also tracking emerging destinations.
Fare class differentiation: Distinguishing between economy, business, and first-class offerings.
Additional fees tracking: Capturing baggage costs, seat selection charges, and other ancillary fees.
The challenge lies in handling the dynamic nature of flight search results. Many websites generate prices on demand based on search parameters, requiring sophisticated query management and result processing capabilities.
Hotel Industry Data Mining Techniques
The hospitality sector presents unique opportunities for data extraction, with thousands of properties across various booking platforms offering different rates, amenities, and availability windows. Hotel Data Scraping involves collecting information from major platforms like Booking.com, Expedia, Hotels.com, and individual hotel websites.
Property data encompasses room types, pricing structures, guest reviews, amenities lists, location details, and availability calendars. This comprehensive information enables competitive analysis, market positioning, and customer preference identification. Revenue management teams benefit from understanding competitor pricing strategies and occupancy patterns through Travel Scraping API solutions.
Modern hotel data extraction must account for the following:
Multi-platform presence: Hotels often list varying information on multiple booking sites.
Dynamic pricing models: Rates change based on demand, events, and seasonal factors.
Review authenticity: Filtering genuine customer feedback from promotional content.
Geographic clustering: Understanding local market dynamics and competitive landscapes.
These solutions incorporate advanced filtering and categorization features to handle the complexity of hotel data effectively.
Car Rental Market Intelligence
The car rental industry operates with complex pricing models influenced by vehicle availability, location demand, seasonal patterns, and local events. Modern data extraction provides insights into fleet availability, pricing strategies, and market trends across different geographic regions.
Major rental companies like Hertz, Avis, Enterprise, and Budget maintain extensive online presence with real-time inventory management systems. Extracting data from these platforms requires understanding their booking workflows and availability calculation methods using Best Travel Data Extraction Software.
Essential data points for car rental analysis include:
Vehicle categories: From economy cars to luxury vehicles and specialty equipment.
Location-based pricing: Airport versus city locations often have different rate structures.
Seasonal variations: Holiday periods and local events significantly impact availability and costs.
Add-on services: Insurance options, GPS rentals, and additional driver fees.
The challenge is the relationship between pickup/dropoff locations, rental duration, and vehicle availability. These factors interact in complex ways that require sophisticated data modeling approaches supported by Travel Data Intelligence systems.
Vacation Rental Platform Analysis
The rise of platforms like Airbnb, VRBO, and HomeAway has created new opportunities for travel data extraction. These platforms collect information about property listings, host profiles, guest reviews, pricing calendars, and booking availability.
Unlike traditional hotels, vacation rentals operate with unique pricing models, often including cleaning fees, security deposits, and variable nightly rates. Understanding these cost structures requires comprehensive Travel Data Scraping capabilities and analysis.
Key aspects of vacation rental data include:
Property characteristics: Number of bedrooms, amenities, location ratings, and unique features.
Host information: Response times, acceptance rates, and guest communication patterns.
Pricing strategies: Base rates, seasonal adjustments, and additional fee structures.
Market saturation: Understanding supply and demand dynamics in specific locations.
Real-Time Travel Data Extraction becomes particularly important for vacation rentals due to the personal nature of these properties and the impact of local events on availability and pricing.
Building Effective Data Intelligence Systems

Modern intelligence systems transform raw extracted information into actionable business insights. This process involves data cleaning, normalization, analysis, and visualization to support decision-making across various business functions.
Successful intelligence systems integrate data from multiple sources to provide comprehensive market views. They combine pricing information with availability data, customer sentiment analysis, and competitive positioning metrics to create holistic business intelligence dashboards using Web Scraping Tools For Travel.
Key components of effective systems include:
Data quality management: Ensuring accuracy, completeness, and consistency across all data sources.
Automated analysis: Implementing algorithms to identify trends, anomalies, and opportunities.
Customizable reporting: Providing stakeholders with relevant, timely, and actionable information.
Predictive modeling: Using historical data to forecast future trends and market conditions.
The integration of artificial intelligence and machine learning technologies enhances the capability of Travel Scraping API systems to provide deeper insights and more accurate predictions.
Real-Time Data Processing Capabilities
Modern travel businesses require up-to-the-minute information to remain competitive in fast-paced markets. Advanced processing systems operate continuously, monitoring changes across multiple platforms and updating business intelligence systems accordingly.
The technical infrastructure for real-time processing must handle high-frequency data updates while maintaining system performance and reliability. This requires distributed computing approaches, efficient data storage solutions, and robust error handling mechanisms Best Travel Data Extraction Software supports.
Critical aspects of real-time systems include:
Low-latency processing: Minimizing delays between data availability and business intelligence updates.
Scalable architecture: Handling varying data volumes and processing demands.
Fault tolerance: Maintaining operations despite individual component failures.
Data freshness: Ensuring information accuracy and relevance for time-sensitive decisions.
Advanced Flight Price Data Scraping systems exemplify these capabilities by providing instant updates on pricing changes across multiple airlines and booking platforms.
Legal and Ethical Considerations
Modern Hotel Data Scraping tools must navigate legal boundaries, adhering to website terms of service and data protection laws. As data extraction regulations evolve, businesses must stay compliant while gathering valuable travel insights.
Best practices include respecting robots.txt files, implementing reasonable request rates, and avoiding actions that could disrupt website operations. Many travel companies now offer official APIs as alternatives to scraping, providing structured access to their data while maintaining control over usage terms.
Important considerations include:
Terms of service compliance: Understanding and adhering to platform-specific usage policies.
Data privacy regulations: Ensuring compliance with GDPR, CCPA, and other privacy laws.
Rate limiting: Implementing respectful crawling practices that don't overwhelm target servers.
Attribution requirements: Properly crediting data sources when required.
Data scraping in the hotel sector must prioritize guest privacy and protect reservation confidentiality. Similarly, Car Rental Data Scraping should consider competitive pricing and ensure it doesn't interfere with booking platforms.
Future Trends and Innovations

The evolution of travel data extraction is rapidly advancing, driven by AI, machine learning, and cloud innovations. Amid this progress, Travel Data Intelligence unlocks deeper insights, greater accuracy, and scalable solutions for travel businesses.
Emerging trends such as natural language processing for review analysis, computer vision for extracting image-based data, and blockchain for secure data verification and sharing are transforming the landscape. These innovations enhance the value and scope of Vacation Rental Data Scraping systems across all market segments.
How Travel Scrape Can Help You?
We provide comprehensive data extraction solutions tailored to your business needs. Our expert team understands the complexities of Travel Data Scraping and offers cutting-edge tools to give you a competitive advantage.
Custom API Development: We create specialized solutions that integrate seamlessly with your existing systems and workflows.
Multi-Platform Coverage: Our services encompass data collection across hundreds of travel websites and booking platforms.
Real-Time Intelligence: Implement continuous monitoring capabilities that keep your business informed of market changes as they happen.
Advanced Analytics: Transform raw data into actionable insights using sophisticated analysis and reporting tools.
Scalable Infrastructure: Our solutions grow with your business, handling increased data volumes and additional platforms.
Compliance Management: We ensure all data collection activities adhere to legal requirements and industry best practices.
24/7 Support: Our dedicated team provides continuous monitoring and technical support to maintain optimal system performance.
Conclusion
The travel industry's data-driven transformation requires sophisticated information collection and analysis approaches. Travel Data Scraping has become an essential capability for businesses seeking to understand market dynamics, optimize pricing strategies, and deliver superior customer experiences. Modern Travel Aggregators rely heavily on comprehensive data extraction systems to provide accurate, timely information to their users.
Success in today's competitive environment demands robust Travel Industry Web Scraping capabilities that can adapt to changing technologies and market conditions. By implementing the right tools, strategies, and partnerships, travel businesses can harness the power of data to drive growth and innovation.
Ready to transform your travel business with comprehensive data intelligence? Contact Travel Scrape today to discover how we can provide the competitive advantage you need.
Read More :- https://www.travelscrape.com/how-travel-data-scraping-works-2025.php
#TravelDataScrapingWork#TheBestToolsToUseIn2025#TravelDataIntelligence#VacationRentalDataScraping#FlightPriceDataScraping#TravelScrapingAPI#HotelDataScraping#TravelIndustryWebScraping#TravelAggregators
0 notes
Text
Scrape Product Info, Images & Brand Data from E-commerce | Actowiz
Introduction
In today’s data-driven world, e-commerce product data scraping is a game-changer for businesses looking to stay competitive. Whether you're tracking prices, analyzing trends, or launching a comparison engine, access to clean and structured product data is essential. This article explores how Actowiz Solutions helps businesses scrape product information, images, and brand details from e-commerce websites with precision, scalability, and compliance.
Why Scraping E-commerce Product Data Matters

E-commerce platforms like Amazon, Walmart, Flipkart, and eBay host millions of products. For retailers, manufacturers, market analysts, and entrepreneurs, having access to this massive product data offers several advantages:
- Price Monitoring: Track competitors’ prices and adjust your pricing strategy in real-time.
- Product Intelligence: Gain insights into product listings, specs, availability, and user reviews.
- Brand Visibility: Analyze how different brands are performing across marketplaces.
- Trend Forecasting: Identify emerging products and customer preferences early.
- Catalog Management: Automate and update your own product listings with accurate data.
With Actowiz Solutions’ eCommerce data scraping services, companies can harness these insights at scale, enabling smarter decision-making across departments.
What Product Data Can Be Scraped?

When scraping an e-commerce website, here are the common data fields that can be extracted:
✅ Product Information
Product name/title
Description
Category hierarchy
Product specifications
SKU/Item ID
Price (Original/Discounted)
Availability/Stock status
Ratings & reviews
✅ Product Images
Thumbnail URLs
High-resolution images
Zoom-in versions
Alternate views or angle shots
✅ Brand Details
Brand name
Brand logo (if available)
Brand-specific product pages
Brand popularity metrics (ratings, number of listings)
By extracting this data from platforms like Amazon, Walmart, Target, Flipkart, Shopee, AliExpress, and more, Actowiz Solutions helps clients optimize product strategy and boost performance.
Challenges of Scraping E-commerce Sites

While the idea of gathering product data sounds simple, it presents several technical challenges:
Dynamic Content: Many e-commerce platforms load content using JavaScript or AJAX.
Anti-bot Mechanisms: Rate-limiting, captchas, IP blocking, and login requirements are common.
Frequent Layout Changes: E-commerce sites frequently update their front-end structure.
Pagination & Infinite Scroll: Handling product listings across pages requires precise navigation.
Image Extraction: Downloading, renaming, and storing image files efficiently can be resource-intensive.
To overcome these challenges, Actowiz Solutions utilizes advanced scraping infrastructure and intelligent algorithms to ensure high accuracy and efficiency.
Step-by-Step: How Actowiz Solutions Scrapes E-commerce Product Data

Let’s walk through the process that Actowiz Solutions follows to scrape and deliver clean, structured, and actionable e-commerce data:
1. Define Requirements
The first step involves understanding the client’s specific data needs:
Target websites
Product categories
Required data fields
Update frequency (daily, weekly, real-time)
Preferred data delivery formats (CSV, JSON, API)
2. Website Analysis & Strategy Design
Our technical team audits the website’s structure, dynamic loading patterns, pagination system, and anti-bot defenses to design a customized scraping strategy.
3. Crawler Development
We create dedicated web crawlers or bots using tools like Python, Scrapy, Playwright, or Puppeteer to extract product listings, details, and associated metadata.
4. Image Scraping & Storage
Our bots download product images, assign them appropriate filenames (using SKU or product title), and store them in cloud storage like AWS S3 or GDrive. Image URLs can also be returned in the dataset.
5. Brand Attribution
Products are mapped to brand names by parsing brand tags, logos, and using NLP-based classification. This helps clients build brand-level dashboards.
6. Data Cleansing & Validation
We apply validation rules, deduplication, and anomaly detection to ensure only accurate and up-to-date data is delivered.
7. Data Delivery
Data can be delivered via:
REST APIs
S3 buckets or FTP
Google Sheets/Excel
Dashboard integration
All data is made ready for ingestion into CRMs, ERPs, or BI tools.
Supported E-Commerce Platforms

Actowiz Solutions supports product data scraping from a wide range of international and regional e-commerce websites, including:
Amazon
Walmart
Target
eBay
AliExpress
Flipkart
BigCommerce
Magento
Rakuten
Etsy
Lazada
Wayfair
JD.com
Shopify-powered sites
Whether you're focused on electronics, fashion, grocery, automotive, or home décor, Actowiz can help you extract relevant product and brand data with precision.
Use Cases: How Businesses Use Scraped Product Data

Retailers
Compare prices across platforms to remain competitive and win the buy-box.
🧾 Price Aggregators
Fuel price comparison engines with fresh, accurate product listings.
📈 Market Analysts
Study trends across product categories and brands.
🎯 Brands
Monitor third-party sellers, counterfeit listings, or unauthorized resellers.
🛒 E-commerce Startups
Build initial catalogs quickly by extracting competitor data.
📦 Inventory Managers
Sync product stock and images with supplier portals.
Actowiz Solutions tailors the scraping strategy according to the use case and delivers the highest ROI on data investment.
Benefits of Choosing Actowiz Solutions

✅ Scalable Infrastructure
Scrape millions of products across multiple websites simultaneously.
✅ IP Rotation & Anti-Bot Handling
Bypass captchas, rate-limiting, and geolocation barriers with smart proxies and user-agent rotation.
✅ Near Real-Time Updates
Get fresh data updated daily or in real-time via APIs.
✅ Customization & Flexibility
Select your data points, target pages, and preferred delivery formats.
✅ Compliance-First Approach
We follow strict guidelines and ensure scraping methods respect site policies and data usage norms.
Security and Legal Considerations
Actowiz Solutions emphasizes ethical scraping practices and ensures compliance with data protection laws such as GDPR, CCPA, and local regulations. Additionally:
Only publicly available data is extracted.
No login-restricted or paywalled content is accessed without consent.
Clients are guided on proper usage and legal responsibility for the scraped data.
Frequently Asked Questions
❓ Can I scrape product images in high resolution?
Yes. Actowiz Solutions can extract multiple image formats, including zoomable HD product images and thumbnails.
❓ How frequently can data be updated?
Depending on the platform, we support real-time, hourly, daily, or weekly updates.
❓ Can I scrape multiple marketplaces at once?
Absolutely. We can design multi-site crawlers that collect and consolidate product data across platforms.
❓ Is scraped data compatible with Shopify or WooCommerce?
Yes, we can deliver plug-and-play formats for Shopify, Magento, WooCommerce, and more.
❓ What if a website structure changes?
We monitor site changes proactively and update crawlers to ensure uninterrupted data flow.
Final Thoughts
Scraping product data from e-commerce websites unlocks a new layer of market intelligence that fuels decision-making, automation, and competitive strategy. Whether it’s tracking competitor pricing, enriching your product catalog, or analyzing brand visibility — the possibilities are endless.
Actowiz Solutions brings deep expertise, powerful infrastructure, and a client-centric approach to help businesses extract product info, images, and brand data from e-commerce platforms effortlessly. Learn More
0 notes
Text
🏡 Real Estate Web Scraping — A Simple Way to Collect Property Info Online

Looking at houses online is fun… but trying to keep track of all the details? Not so much.
If you’ve ever searched for homes or rental properties, you know how tiring it can be to jump from site to site, writing down prices, addresses, and details. Now imagine if there was a way to automatically collect that information in one place. Good news — there is!
It’s called real estate web scraping, and it makes life so much easier.
🤔 What Is Real Estate Web Scraping?
Real estate web scraping is a tool that helps you gather information from property websites — like Zillow, Realtor.com, Redfin, or local listing sites — all without doing it by hand.
Instead of copying and pasting, the tool goes to the website, reads the page, and pulls out things like:
The home’s price
Location and zip code
Square footage and number of rooms
Photos
Description
Contact info for the seller or agent
And it puts all that data in a nice, clean file you can use.
🧑💼 Who Is It For?
Real estate web scraping is useful for anyone who wants to collect a lot of property data quickly:
Buyers and investors looking for the best deals
Real estate agents tracking listings in their area
Developers building property websites or apps
People comparing prices in different cities
Marketing teams trying to find leads
It saves time and gives you a better view of what’s happening in the market.
🛠️ How Can You Do It?
If you’re good with code, there are tools like Python, Scrapy, and Selenium that let you build your own scraper.
But if you’re not into tech stuff, no worries. There are ready-made tools that do everything for you. One of the easiest options is this real estate web scraping solution. It works in the cloud, is beginner-friendly, and gives you the data you need without the stress.
🛑 Is It Legal?
Great question — and yes, as long as you’re careful.
Scraping public information (like listings on a website) is generally okay. Just make sure to:
Don’t overload the website with too many requests
Avoid collecting private info
Follow the website’s rules (terms of service)
Be respectful — don’t spam or misuse the data
Using a trusted tool (like the one linked above) helps keep things safe and easy.
💡 Why Use Real Estate Scraping?
Here are some real-life examples:
You’re a property investor comparing house prices in 10 cities — scraping gives you all the prices in one spreadsheet.
You’re a developer building a housing app — scraping provides live listings to show your users.
You’re just curious about trends — scraping lets you track how prices change over time.
It’s all about saving time and seeing the full picture.
✅ In Short…
Real estate web scraping helps you collect a lot of property data from the internet without doing it all manually. It’s fast, smart, and incredibly helpful—whether you’re buying, building, or just exploring.
And the best part? You don’t need to be a tech expert. This real estate web scraping solution makes it super simple to get started.
Give it a try and see how much easier your real estate research can be.
1 note
·
View note
Text
Unlock SEO & Automation with Python
In today’s fast-paced digital world, marketers are under constant pressure to deliver faster results, better insights, and smarter strategies. With automation becoming a cornerstone of digital marketing, Python has emerged as one of the most powerful tools for marketers who want to stay ahead of the curve.
Whether you’re tracking SEO performance, automating repetitive tasks, or analyzing large datasets, Python offers unmatched flexibility and speed. If you're still relying solely on traditional marketing platforms, it's time to step up — because Python isn't just for developers anymore.
Why Python Is a Game-Changer for Digital Marketers
Python’s growing popularity lies in its simplicity and versatility. It's easy to learn, open-source, and supports countless libraries that cater directly to marketing needs. From scraping websites for keyword data to automating Google Analytics reports, Python allows marketers to save time and make data-driven decisions faster than ever.
One key benefit is how Python handles SEO tasks. Imagine being able to monitor thousands of keywords, track competitors, and audit websites in minutes — all without manually clicking through endless tools. Libraries like BeautifulSoup, Scrapy, and Pandas allow marketers to extract, clean, and analyze SEO data at scale. This makes it easier to identify opportunities, fix issues, and outrank competitors efficiently.
Automating the Routine, Empowering the Creative
Repetitive tasks eat into a marketer's most valuable resource: time. Python helps eliminate the grunt work. Need to schedule social media posts, generate performance reports, or pull ad data across platforms? With just a few lines of code, Python can automate these tasks while you focus on creativity and strategy.
In Dehradun, a growing hub for tech and education, professionals are recognizing this trend. Enrolling in a Python Course in Dehradun not only boosts your marketing skill set but also opens up new career opportunities in analytics, SEO, and marketing automation. Local training programs often offer real-world marketing projects to ensure you gain hands-on experience with tools like Jupyter, APIs, and web scrapers — critical assets in the digital marketing toolkit.
Real-World Marketing Use Cases
Python's role in marketing isn’t just theoretical — it’s practical. Here are a few real-world scenarios where marketers are already using
Python to their advantage:
Content Optimization: Automate keyword research and content gap analysis to improve your blog and web copy.
Email Campaign Analysis: Analyze open rates, click-throughs, and conversions to fine-tune your email strategies.
Ad Spend Optimization: Pull and compare performance data from Facebook Ads, Google Ads, and LinkedIn to make smarter budget decisions.
Social Listening: Monitor brand mentions or trends across Twitter and Reddit to stay responsive and relevant.
With so many uses, Python is quickly becoming the Swiss army knife for marketers. You don’t need to become a software engineer — even a basic understanding can dramatically improve your workflow.
Getting Started with Python
Whether you're a fresh graduate or a seasoned marketer, investing in the right training can fast-track your career. A quality Python training in Dehradun will teach you how to automate marketing workflows, handle SEO analytics, and visualize campaign performance — all with practical, industry-relevant projects.
Look for courses that include modules on digital marketing integration, data handling, and tool-based assignments. These elements ensure you're not just learning syntax but applying it to real marketing scenarios. With Dehradun's increasing focus on tech education, it's a great place to gain this in-demand skill.
Python is no longer optional for forward-thinking marketers. As SEO becomes more data-driven and automation more essential, mastering Python gives you a clear edge. It simplifies complexity, drives efficiency, and helps you make smarter, faster decisions.
Now is the perfect time to upskill. Whether you're optimizing search rankings or building powerful marketing dashboards, Python is your key to unlocking smarter marketing in 2025 and beyond.
Python vs Ruby, What is the Difference? - Pros & Cons
youtube
#python course#python training#education#python#pythoncourseinindia#pythoninstitute#pythoninstituteinindia#pythondeveloper#Youtube
0 notes
Text
Tools to Scrape Amazon Product Offers and Sellers Data

Introduction
Scraping Amazon product offers and seller information can provide valuable insights for businesses, developers, and researchers. Whether you're analyzing competitor pricing, monitoring market trends, or building a price comparison tool, Scrape Amazon Product Offers and Sellers Data is crucial for staying competitive. This guide will walk you through code-based and no-code methods for extracting Amazon data, making it suitable for beginners and experienced developers. We'll cover the best tools, techniques, and practices to ensure practical and ethical data extraction. One key aspect is learning how to Extract Amazon Seller Prices Data accurately, allowing you to track and analyze pricing trends across various sellers. Additionally, we will delve into how to Scrape Amazon Seller Information, ensuring that all data is collected efficiently while staying within legal boundaries. By following the right approaches, you can access valuable data insights without facing potential legal or technical challenges, ensuring long-term success in your data-driven projects.
Why Scrape Amazon Product Offers and Sellers?
Amazon is a treasure trove of e-commerce data. Scraping product offers and seller information, Amazon is a goldmine of e-commerce data, offering valuable insights for businesses looking to gain a competitive edge. By Scraping Amazon Seller Listings Data, you can collect crucial information that helps in several areas:
Monitor pricing trends: Track the price changes for specific products or categories over time. This allows you to understand market dynamics and adjust your pricing strategy accordingly.
Analyze seller performance: Evaluate key metrics such as seller ratings, shipping options, and inventory availability. This data can help you understand how top-performing sellers operate and what factors contribute to their success.
Competitor analysis: Scrape Amazon Offer Listings with Selenium Data to compare your offerings against your competitors. You can identify pricing gaps, product availability, and more, which helps refine your market positioning.
Market research: By examining Amazon Seller Scraping API Integration data, you can identify high-demand products, emerging niches, and customer preferences. This information can guide your product development and marketing strategies.
Build tools: Use the scraped data to create practical applications like price comparison tools or inventory management systems. With the right dataset, you can automate and optimize various business processes.
However, scraping Amazon's vast marketplace comes with challenges. Its dynamic website structure, sophisticated anti-scraping measures (like CAPTCHAs), and strict legal policies create barriers. To overcome these obstacles, you must implement strategies that include using advanced tools to Extract Amazon E-Commerce Product Data. Success requires a tailored approach that matches your skill level and resource availability.
Legal and Ethical Considerations
Before diving into scraping, understand the legal and ethical implications:
Amazon's Terms of Service (ToS): Amazon prohibits scraping without permission. Violating ToS can lead to IP bans or legal action.
Data Privacy: Avoid collecting personal information about sellers or customers.
Rate Limiting: Excessive requests can overload Amazon's servers, violating ethical scraping practices.
robots.txt: Look for Amazon's robots.txt file to see which pages are disallowed for scraping.
To stay compliant:
Use Amazon's official Product Advertising API: for authorized data access (if applicable).
Scrape publicly available data sparingly: and respect rate limits.
Consult a legal expert: if you're building a commercial tool.
Code-Based Approach: Scraping with Python
For developers skilled in coding, Python provides robust libraries such as BeautifulSoup, Scrapy, and Selenium to Scrape Amazon E-Commerce Product Data efficiently. Using libraries like BeautifulSoup and Requests, you can easily extract product offers and seller details. Combining these tools allows you to navigate Amazon's complex structure and gather valuable insights. Whether you're looking to Scrape Amazon ecommerce Product Data for pricing trends or competitor analysis, this approach allows for streamlined data extraction. With the proper script, you can automate the process, gather vast datasets, and leverage them for various business strategies.
Prerequisites
Python 3.x installed.
Libraries: Install via pip:
Basic understanding of HTML/CSS selectors.
Sample Python Script
This script scrapes product titles, prices, and seller names from an Amazon search results page.
How It Works?
Headers: The script uses a User-Agent to mimic a browser, reducing the chance of being blocked.
Request: Sends an HTTP GET request to Amazon's search page for the query (e.g., "wireless earbuds").
Parsing: BeautifulSoup parses the HTML to locate product containers using Amazon's class names.
Extraction: Extracts the title, price, and seller for each product.
Error Handling: Handles network errors gracefully.
Challenges and Solutions
Dynamic Content: Some Amazon pages load data via JavaScript. Use Selenium or Playwright for dynamic scraping.
CAPTCHAs: Rotate proxies or use CAPTCHA-solving services.
IP Bans: Implement delays (time.sleep(5)) or use proxy services.
Rate Limits: Limit requests to 1–2 per second to avoid detection.
Scaling with Scrapy
For large-scale scraping, use Scrapy, a Python framework for building web crawlers. Scrapy supports:
Asynchronous requests for faster scraping.
Middleware for proxy rotation and user-agent switching.
Pipelines for storing data in databases like MySQL or MongoDB.
No-Code Approach: Using Web Scraping Tools
For non-developers or those looking for fast solutions, no-code tools provide an easy way to Extract Popular E-Commerce Website Data without needing to write any code. These tools offer visual interfaces allowing users to select webpage elements and automate data extraction. Common types of no-code tools include web scraping platforms, browser extensions, and API-based solutions. With these tools, you can quickly collect product offers, seller information, and more. Many businesses rely on Ecommerce Data Scraping Services to simplify gathering data from websites like Amazon, enabling efficient analysis and decision-making.
1. Visual Scraping Tool
Features: A desktop or cloud-based tool with a point-and-click interface, supports exporting data to CSV/Excel, and handles pagination.
Install the tool and start a new project.
Enter the Amazon search URL (e.g., https://www.amazon.com/s?k=laptop).
Use the visual editor to select elements like product title, price, or seller name.
Configure pagination to scrape multiple pages.
Run the task locally or in the cloud and export the data.
Pros: User-friendly, handles dynamic content, supports scheduling.
Cons: Free plans often have limits; premium plans may be required for large-scale scraping.
2. Cloud-Based Scraping Platform
Features: A free or paid platform with cloud scraping, API integration, and support for JavaScript-rendered pages.
Load the Amazon page in the platform's built-in browser.
Click on elements to extract (e.g., price, seller name).
Add logic to handle missing or inconsistent data.
Export results as JSON or CSV.
Pros: Free tiers often support small projects; intuitive for beginners.
Cons: Advanced features may require learning or paid plans.
3. Browser Extension Scraper
Features: A free browser-based extension for simple scraping tasks.
Install the extension in your browser.
Create a scraping template by selecting elements on the Amazon page (e.g., product title, price).
Run the scraper and download data as CSV.
Pros: Free, lightweight, and easy to set up.
Cons: Limited to static content; lacks cloud or automation features.
Choosing a No-Code Tool
Small Projects: Browser extension scrapers are ideal for quick, one-off tasks.
Regular Scraping: Visual scraping tools or cloud-based platforms offer automation and cloud support.
Budget: Start with free tiers, but expect to upgrade for large-scale or frequent scraping.
Start extracting valuable insights today with our powerful and easy-to-use scraping tools!
Contact Us Today!
Best Practices for Scraping Amazon
1. Respect Robots.txt: Avoid scraping disallowed pages.
2. Use Proxies: Rotate IPs to prevent bans. Proxy services offer residential proxies for reliable scraping.
3. Randomize Requests: Add delays and vary user agents to mimic human behavior.
4. Handle Errors: Implement retries for failed requests.
5. Store Data Efficiently: Use databases (e.g., SQLite, MongoDB) for large datasets.
6. Monitor Changes: Amazon's HTML structure changes frequently. Regularly update selectors.
7. Stay Ethical: Scrape only what you need and avoid overloading servers.
Alternative: Amazon Product Advertising API
Instead of scraping, consider Amazon's Product Advertising API for authorized access to product data. Benefits include:
Legal Compliance: Fully compliant with Amazon's ToS.
Rich Data: Access to prices, offers, reviews, and seller info.
Reliability: No risk of IP bans or CAPTCHAs.
Drawbacks:
Requires an Amazon Associate account with qualifying sales.
Limited to specific data points.
Rate limits apply.
To use the API:
1. Sign up for the Amazon Associates Program.
2. Generate API keys.
3. Use a library like boto3 (Python) to query the API.
How Product Data Scrape Can Help You?
Customizable Data Extraction: Our tools are built to adapt to various website structures, allowing you to extract exactly the data you need—whether it's product listings, prices, reviews, or seller details.
Bypass Anti-Scraping Measures: With features like CAPTCHA solving, rotating proxies, and user-agent management, our tools effectively overcome restrictions set by platforms like Amazon.
Supports Code and No-Code Users: Whether you're a developer or a non-technical user, our scraping solutions offer code-based flexibility and user-friendly no-code interfaces.
Real-Time and Scheduled Scraping: Automate your data collection with scheduling features and receive real-time updates, ensuring you always have the latest information at your fingertips.
Clean and Structured Output: Our tools deliver data in clean formats like JSON, CSV, or Excel, making it easy to integrate into analytics tools, dashboards, or custom applications.
Conclusion
Scraping Amazon product offers and seller information is a powerful way to Extract E-commerce Data and gain valuable business insights. However, thoughtful planning is required to address technical barriers and legal considerations. Code-based methods using Python libraries like BeautifulSoup or Scrapy provide developers with flexibility and control. Meanwhile, no-code tools with visual interfaces or browser extensions offer user-friendly options for non-coders to use Web Scraping E-commerce Websites .
For compliant access, the Amazon Product Advertising API remains the safest route. Regardless of the method, always follow ethical scraping practices, implement proxies, and handle errors effectively. Combining the right tools with innovative techniques can help you build an insightful Ecommerce Product & Review Dataset for business or academic use.
At Product Data Scrape, we strongly emphasize ethical practices across all our services, including Competitor Price Monitoring and Mobile App Data Scraping. Our commitment to transparency and integrity is at the heart of everything we do. With a global presence and a focus on personalized solutions, we aim to exceed client expectations and drive success in data analytics. Our dedication to ethical principles ensures that our operations are both responsible and effective.
Source>>https://www.productdatascrape.com/amazon-product-seller-scraping-tools.php
#ScrapeAmazonProductOffersAndSellersData#ExtractAmazonSellerPricesData#ScrapingAmazonSellerListingsData#AmazonSellerScrapingAPIIntegrationData#ExtractAmazonECommerceProductData
0 notes
Text
Web Scraping Blinkit Reviews Data: Unlocking Real-Time Customer Insights

In today’s data-driven age, customer reviews are invaluable assets. For businesses looking to understand real-time consumer sentiment, Web Scraping Blinkit Reviews Data offers a goldmine of insights. As Blinkit (formerly Grofers) continues to dominate the hyperlocal delivery space in India, its user-generated reviews reveal what customers genuinely feel about products, pricing, and service quality.
Why Scrape Blinkit Reviews Data?

Collecting and analyzing reviews manually is inefficient. Instead, using a Blinkit Reviews Scraper enables you to extract large volumes of structured, relevant feedback in real time. Whether you’re an FMCG brand, data analyst, or eCommerce strategist, scraping Blinkit reviews data helps uncover product strengths, detect recurring complaints, and track market trends.
With a robust Blinkit Reviews Data Extractor, businesses gain access to:
Star ratings and review text
Customer sentiment over time
Localized purchasing patterns
Pricing feedback and perceived value
Feature requests and product improvement areas
These insights can power everything from smarter product development to targeted marketing campaigns.
Tools to Scrape Blinkit Reviews Data

To efficiently scrape Blinkit reviews data, businesses can rely on tools like:
Python + BeautifulSoup: Great for small-scale extraction
Selenium or Puppeteer: Ideal for dynamic, JavaScript-heavy pages
Scrapy: For scalable, robust data pipelines
Third-party APIs: For faster deployment without coding
With the right tool, you can automate the entire extraction process and store the reviews in formats like CSV or JSON for deeper analysis.
Real-World Benefits of Blinkit Reviews Data Scraping

Product Innovation: Use customer suggestions to launch better products.
Market Trend Detection: Spot rising product categories or shifting customer preferences.
Localized Campaigns: Analyze reviews city-wise using a tailored Blinkit Reviews Data strategy.
Competitive Benchmarking: See how your brand stacks up against competitors.
Legal and Ethical Considerations

Before deploying a Blinkit Reviews Scraper, always review Blinkit’s Terms of Service and robots.txt file. Respect rate limits and ensure your scraping practices are ethical and compliant. For internal research and analytics, data extraction is typically allowed — but redistribution of scraped content may have restrictions.
Conclusion With customer feedback shaping modern commerce, Web Scraping Blinkit Reviews Data is no longer optional — it’s essential. Whether you use a custom script or a ready-to-use Blinkit Reviews Data Extractor, you’re opening the door to deeper customer understanding and smarter decisions. Don’t just guess what your users want — scrape Blinkit reviews data and know for sure.
Ready to extract insights from reviews?
Let Datazivot help you get started with the right tools today.
#BlinkitReviews#WebScraping#DataScraping#ReviewData#SentimentAnalysis#EcommerceData#DataExtractor#ScrapeReviews
0 notes
Text
Integration of AI and Machine Learning into Web Scraping APIs

Introduction
Artificial Intelligence (AI) and Machine Learning (ML) have recently advanced rapidly and revolutionized several industries. One of the most dramatic changes with these advancements is the transformation of web scraping. Web scraping was considered the traditional coding suite for data extraction from websites. However, the latest developments in AI and ML have turned this into something much more efficient, accurate, and adaptable. This blog will venture into the integration of AI and ML into Web Scraping APIs, along with discussing its advantages, challenges, and prospects for the future.
Understanding the Web Scraping APIs
Web Scraping APIs are specialized tools that give access to developers for extracting data from a website in a programmatic manner. These APIs considerably simplify the web scraping process by allowing automated mechanisms to fetch, parse, and structure data. Conventional web scraping is dependent upon static scripts able to parse HTML structures to retrieve specific data. However, because of the dynamic nature of today's web, classical methods struggle in the face of dealing with contemporary JavaScript-powered web pages, CAPTCHAs, and anti-scraping mechanisms.
The Role of AI in Web Scraping APIs
Artificial Intelligence within Web Scraping APIs has been a game changer for data collection, data processing, and data use. AI-powered scraping tools are able to withstand complex challenges such as modification in website structure, dynamic content load, and anti-scraping mechanisms. How AI supports Web Scraping APIs are:
1. Pre-empt Data Extraction
AI-enabled web scrapers may analyze page structures and extract relevant data without any predefined rules.
ML models may recognize patterns that help them to make changes according to the changes in website layouts.
2. Counter Anti-Scraping Measures
To prevent automated access, websites implement various anti-scraping measures, including CAPTCHA, blocking specific IP addresses, and user-agent detection.
AI bots could use CAPTCHA solvers, IP rotation, and human-like patterns to bypass these barriers.
3. Understanding the Data with Natural Language Processing (NLP)
NLP models enable scrapers to comprehend unstructured text, extract relevant information, and even summarize content.
While sentiment analysis, keyword extraction, and named entity recognition can enhance the usability of data successfully scraped otherwise.
4. Adaptive Learning for Changing Web Structures
Machine learning algorithms can track and learn from ongoing changes in a concerned website so that data can be collected freely without constant script updating.
Deep learning models can also analyze DOM elements and infer patterns dynamically.
5. Intelligent Data Cleaning and Pre-Processing
AI techniques will delete duplicates, fix inconsistencies, and fill in missing values from scraped data.
Anomaly detection identifies and corrects erroneous data points.
Key Technologies Enabling AI and ML in Web Scraping APIs
Several technologies and frameworks empower AI and ML in Web Scraping APIs:
Python libraries: BeautifulSoup, Scrapy, or Selenium, combined with TensorFlow, PyTorch, or Scikit-learn.
AI-Based Browsers: Puppeteer and Playwright for headless browsing with ML enhancements.
Cloud Computing and APIs: Google Cloud AI, AWS AI services, and OpenAI APIs for intelligent scraping.
Data Annotation and Reinforcement Learning: Using human-labeled datasets to train ML models for better accuracy.
Benefits of AI and ML in Web Scraping APIs
Applications of AI and ML in Web Scraping APIs bring advantages, including:
Faster- AI-based scrapers can deliver results in an instant.
Scalability- ML algorithms enable web scraping tools to scale to various domains and handle huge datasets.
Reduced Maintenance- Reinforced learning will lead to reduced script-update requirements.
Better Accuracy- AI filtering can effectively sort noise and deliver upper-rend data.
Even exploitable security- AI approaches help avoid any anti-bot mechanisms and follow the principle of ethical scraping.
Challenges and Ethical Considerations
However, AI web scraping challenges are offset by apparent advantages:
1. Legal and Ethical Issues Unsurprisingly
Most web places deny scraping in their terms of service.
Any scraping carried out by AI needs to be mindful of data privacy issues such as GDPR and CCPA.
2. Complex Website Structures
AI scrapers need to cope with dynamic page rendering with JavaScript and AJAX-based content or rendering.
3. Computational Costs
Running ML models for web scraping entails high computational costs and therefore running costs.
4. Validation and Data Quality
The AI scrapers need to have a strong mechanism for validation to confirm the accuracy of the data being extracted.
Best Practices for Using AI in Web Scraping APIs
To get the best out of AI in Web Scraping APIs, developers are expected to follow these best practices:
Respect Website Terms and Policies- Always check the site's robots.txt file, and respect its rules.
Implement Conscious Scraping Approach- Avoid hammering the website with too many requests; set limits for the bot to follow.
Implement Smart Proxy Rotations and User Agents- Rotate IP addresses and user-agent strings that mirror real users.
Monitor Pageload Activities- Have some ML-powered monitoring to track alterations to websites' structures.
Ensure Data Privacy- Follow the existing legal regimes to protect user data and avoid unauthorized collection of data.
Future Possibilities of AI and ML in Web Scraping APIs
The integration of AI and ML into Web Scraping APIs would expand with improvements in:
Self-Learning Web Scrapers- Full autonomic scrapers learning & adapting without human help.
AI-Powered Semantic Understanding- In other words, using more advanced NLP paradigms like GPT-4 for extracting context insight.
Decentralized Scrapping Networks- A distributed AI-driven scraping that minimizes the risk of detection and scales up easily.
Frameworks for Ethical AI Scraping- Formulating common norms for responsible web scraping practices.
Conclusion
AI and ML in Web Scraping APIs have transformed data extraction, making it more intelligent, resilient, and efficient. Despite challenges such as legal concerns and computational demands, AI-powered web scraping is set to become an indispensable tool for businesses and researchers. By leveraging adaptive learning, NLP, and automation, the future of Web Scraping APIs will be more sophisticated, ensuring seamless data extraction while adhering to ethical standards.
Know More : https://www.crawlxpert.com/blog/ai-and-machine-learning-into-web-scraping-apis
0 notes
Text
Data Scraping Made Simple: What It Really Means
Data Scraping Made Simple: What It Really Means
In the digital world, data scraping is a powerful way to collect information from websites automatically. But what exactly does that mean—and why is it important?
Let’s break it down in simple terms.
What Is Data Scraping?
Data scraping (also called web scraping) is the process of using bots or scripts to extract data from websites. Instead of copying and pasting information manually, scraping tools do the job automatically—much faster and more efficiently.
You can scrape product prices, news headlines, job listings, real estate data, weather reports, and more.
Imagine visiting a website with hundreds of items. Now imagine a tool that can read all that content and save it in a spreadsheet in seconds. That’s what data scraping does.
Why Is It So Useful?
Businesses, researchers, and marketers use data scraping to:
Track competitors' prices
Monitor customer reviews
Gather contact info for leads
Collect news for trend analysis
Keep up with changing market data
In short, data scraping helps people get useful information without wasting time.
Is Data Scraping Legal?
It depends. Public data (like product prices or news articles) is usually okay to scrape, but private or copyrighted content is not. Always check a website’s terms of service before scraping it.
Tools for Data Scraping
There are many tools that make data scraping easy:
Beautiful Soup (for Python developers)
Octoparse (no coding needed)
Scrapy (for advanced scraping tasks)
SERPHouse APIs (for SEO and search engine data)
Some are code-based, others are point-and-click tools. Choose what suits your need and skill level.
Final Thoughts
What is data scraping? It’s the smart way to extract website content for business, research, or insights. With the right tools, it saves time, increases productivity, and opens up access to valuable online data.
Just remember: scrape responsibly.
#serphouse#google serp api#serp scraping api#google search api#seo#api#google#bing#data scraping#web scraping
0 notes
Text
How to Leverage Python Skills to Launch a Successful Freelance Career
The demand for Python developers continues to grow in 2025, opening exciting opportunities—not just in full-time employment, but in freelancing as well. Thanks to Python’s versatility, freelancers can offer services across multiple industries, from web development and data analysis to automation and AI.
Whether you're looking to supplement your income or transition into full-time freelancing, here's how you can use Python to build a thriving freelance career.
Master the Core Concepts
Before stepping into the freelance market, it's essential to build a solid foundation in Python. Make sure you're comfortable with:
Data types and structures (lists, dictionaries, sets)
Control flow (loops, conditionals)
Functions and modules
Object-oriented programming
File handling and error management
Once you’ve nailed the basics, move on to specialized areas based on your target niche.
Choose a Niche That Suits You
Python is used in many domains, but as a freelancer, it helps to specialize. Some profitable freelance niches include:
Web Development: Use frameworks like Django or Flask to build custom websites and web apps.
Data Analysis: Help clients make data-driven decisions using tools like Pandas and Matplotlib.
Automation Scripts: Streamline repetitive client tasks by developing efficient Python automation tools.
Web Scraping: Use tools such as BeautifulSoup or Scrapy to extract data from websites quickly and effectively.
Machine Learning: Offer insights, models, or prototypes using Scikit-learn or TensorFlow.
Choosing a niche allows you to brand yourself as an expert rather than a generalist, which can attract higher-paying clients.
Build a Portfolio
A portfolio is your online resume and a powerful trust builder. Create a personal website or use GitHub to showcase projects that demonstrate your expertise. Some project ideas include:
A simple blog built with Flask
A script that scrapes data and exports it to Excel
A dashboard that visualizes data from a CSV file
An automated email responder
The key is to show clients that you can solve real-world problems using Python.
Create Profiles on Freelance Platforms
Once your portfolio is ready, the next step is to start reaching out to potential clients. Create profiles on platforms like:
Upwork
Freelancer
Fiverr
Toptal
PeoplePerHour
When setting up your profile, write a compelling bio, list your skills, and upload samples from your portfolio. Use keywords clients might search for, like "Python automation," "Django developer," or "data analyst."
Start Small and Build Your Reputation
Landing your first few clients as a new freelancer can take some patience and persistence. Consider offering competitive rates or working on smaller projects initially to gain reviews and build credibility. Positive feedback and completed jobs on your profile will help you attract better clients over time. Deliver quality work, communicate clearly, and meet deadlines—these soft skills matter as much as your technical expertise.
Upskill with Online Resources
The tech landscape changes fast, and staying updated is crucial.Set aside time to explore new tools, frameworks, and libraries, ensuring you stay up-to-date and continuously grow your skill set. Many freelancers also benefit from taking structured courses that help them level up efficiently. If you're serious about freelancing as a Python developer, enrolling in a comprehensive python training course in Pune can help solidify your knowledge. A trusted python training institute in Pune will offer hands-on projects, expert mentorship, and practical experience that align with the demands of the freelance market.
Market Yourself Actively
Don’t rely solely on freelance platforms. Expand your reach by: Sharing coding tips or projects on LinkedIn and Twitter
Writing blog posts about your Python solutions
Networking in communities like Reddit, Stack Overflow, or Discord
Attend local freelancing or tech meetups in your area to network and connect with like-minded professionals. The more visible you are, the more likely clients will find you organically.
Set Your Rates Wisely
Pricing is a common challenge for freelancers. Begin by exploring the rates others in your field are offering to get a sense of standard pricing. Factor in your skill level, project complexity, and market demand. You can charge hourly, per project, or even offer retainer packages for ongoing work. As your skills and client list grow, don’t hesitate to increase your rates.
Stay Organized and Professional
Treat freelancing like a business.Utilize productivity tools to streamline time tracking, invoicing, and client communication.Apps like Trello, Notion, and Toggl can help you stay organized. Create professional invoices, use contracts, and maintain clear communication with clients to build long-term relationships.
Building a freelance career with Python is not only possible—it’s a smart move in today’s tech-driven world. With the right skills, mindset, and marketing strategy, you can carve out a successful career that offers flexibility, autonomy, and unlimited growth potential.
Start by mastering the language, building your portfolio, and gaining real-world experience. Whether you learn through self-study or a structured path like a python training institute in Pune, your efforts today can lead to a rewarding freelance future.
0 notes