#scrapy API integration
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
Hire Expert Scrapy Developers for Scalable Web Scraping & Data Automation
Looking to extract high-value data from the web quickly and accurately? At Prospera Soft, we offer top-tier Scrapy development services to help businesses automate data collection, gain market insights, and scale operations with ease.
Our team of Scrapy experts specializes in building robust, Python-based web scrapers that deliver 10X faster data extraction, 99.9% accuracy, and full cloud scalability. From price monitoring and sentiment analysis to lead generation and product scraping, we design intelligent, secure, and GDPR-compliant scraping solutions tailored to your business needs.
Why Choose Our Scrapy Developers?
✅ Custom Scrapy Spider Development for complex and dynamic websites
✅ AI-Optimized Data Parsing to ensure clean, structured output
✅ Middleware & Proxy Rotation to bypass anti-bot protections
✅ Seamless API Integration with BI tools and databases
✅ Cloud Deployment via AWS, Azure, or GCP for high availability
Whether you're in e-commerce, finance, real estate, or research, our scalable Scrapy solutions power your data-driven decisions.
#Hire Expert Scrapy Developers#scrapy development company#scrapy development services#scrapy web scraping#scrapy data extraction#scrapy automation#hire scrapy developers#scrapy company#scrapy consulting#scrapy API integration#scrapy experts#scrapy workflow automation#best scrapy development company#scrapy data mining#hire scrapy experts#scrapy scraping services#scrapy Python development#scrapy no-code scraping#scrapy enterprise solutions
0 notes
Text
Why Should You Do Web Scraping for python

Web scraping is a valuable skill for Python developers, offering numerous benefits and applications. Here’s why you should consider learning and using web scraping with Python:
1. Automate Data Collection
Web scraping allows you to automate the tedious task of manually collecting data from websites. This can save significant time and effort when dealing with large amounts of data.
2. Gain Access to Real-World Data
Most real-world data exists on websites, often in formats that are not readily available for analysis (e.g., displayed in tables or charts). Web scraping helps extract this data for use in projects like:
Data analysis
Machine learning models
Business intelligence
3. Competitive Edge in Business
Businesses often need to gather insights about:
Competitor pricing
Market trends
Customer reviews Web scraping can help automate these tasks, providing timely and actionable insights.
4. Versatility and Scalability
Python’s ecosystem offers a range of tools and libraries that make web scraping highly adaptable:
BeautifulSoup: For simple HTML parsing.
Scrapy: For building scalable scraping solutions.
Selenium: For handling dynamic, JavaScript-rendered content. This versatility allows you to scrape a wide variety of websites, from static pages to complex web applications.
5. Academic and Research Applications
Researchers can use web scraping to gather datasets from online sources, such as:
Social media platforms
News websites
Scientific publications
This facilitates research in areas like sentiment analysis, trend tracking, and bibliometric studies.
6. Enhance Your Python Skills
Learning web scraping deepens your understanding of Python and related concepts:
HTML and web structures
Data cleaning and processing
API integration
Error handling and debugging
These skills are transferable to other domains, such as data engineering and backend development.
7. Open Opportunities in Data Science
Many data science and machine learning projects require datasets that are not readily available in public repositories. Web scraping empowers you to create custom datasets tailored to specific problems.
8. Real-World Problem Solving
Web scraping enables you to solve real-world problems, such as:
Aggregating product prices for an e-commerce platform.
Monitoring stock market data in real-time.
Collecting job postings to analyze industry demand.
9. Low Barrier to Entry
Python's libraries make web scraping relatively easy to learn. Even beginners can quickly build effective scrapers, making it an excellent entry point into programming or data science.
10. Cost-Effective Data Gathering
Instead of purchasing expensive data services, web scraping allows you to gather the exact data you need at little to no cost, apart from the time and computational resources.
11. Creative Use Cases
Web scraping supports creative projects like:
Building a news aggregator.
Monitoring trends on social media.
Creating a chatbot with up-to-date information.
Caution
While web scraping offers many benefits, it’s essential to use it ethically and responsibly:
Respect websites' terms of service and robots.txt.
Avoid overloading servers with excessive requests.
Ensure compliance with data privacy laws like GDPR or CCPA.
If you'd like guidance on getting started or exploring specific use cases, let me know!
2 notes
·
View notes
Text

Python is no longer just a programming language for developers; it’s becoming an invaluable tool for SEO looking to sharpen their strategies. Imagine wielding the power of automation and data analysis to elevate your search engine optimization efforts. With Python, you can dive deep into keyword relevance and search intent, unraveling mysteries that traditional methods might overlook.
As the digital landscape evolves, so too must our approaches to SEO. Understanding what users want when they type a query into Google is crucial. The right keywords can make or break your online visibility. That’s where Python comes in—streamlining processes and providing insights that drive results.
Ready to unlock new possibilities? Let’s explore how Python can transform your SEO game by offering innovative ways to track keyword relevance and decode search intent with ease. Whether you’re a seasoned pro or just starting out, this journey promises valuable tools tailored for modern SEO challenges.
Understanding Keyword Relevance and Search Intent
Keyword relevance is the heart of effective SEO. It refers to how closely a keyword matches the content on your page. Choosing relevant keywords helps search engines understand what your site offers.
Search intent goes deeper. It’s about understanding why users perform a specific query. Are they looking for information, trying to make a purchase, or seeking navigation? Grasping this concept is crucial for creating content that resonates with audiences.
Different types of search intents exist: informational, transactional, navigational, and commercial investigation. Each type requires tailored strategies to meet user expectations effectively.
By aligning keyword relevance with search intent, you can craft content that not only attracts visitors but also engages them meaningfully. This dual focus enhances user experience and boosts rankings in SERPs over time.
Using Python for Keyword Research
Keyword research is a crucial step in any SEO strategy. Python simplifies this process significantly, allowing you to analyze large datasets efficiently.
With libraries like Pandas and NumPy, you can manipulate and clean keyword data quickly. These tools help you uncover valuable insights that drive content creation.
You can also use the Beautiful Soup library for web scraping. This enables you to gather keywords from competitor sites or industry forums effortlessly.
Additionally, integrating Google Trends API within your scripts offers real-time keyword popularity metrics. This feature helps identify rising trends that are relevant to your niche.
Python scripts automate repetitive tasks, freeing up time for more strategic initiatives. By leveraging these capabilities, you’re better equipped to optimize your campaigns effectively without getting bogged down by manual processes.
Tracking Search Intent with Python Scripts
Understanding search intent is crucial for any SEO strategy. With Python, you can automate the process of analyzing user queries and determining their underlying motivations.
Using libraries like BeautifulSoup or Scrapy, you can scrape SERPs to gather data on keyword rankings and associated content. This helps identify patterns in how users interact with different topics.
Additionally, Natural Language Processing (NLP) tools such as NLTK or spaCy can assist in categorizing keywords based on intent—whether informational, transactional, or navigational.
By implementing custom scripts, you can quickly assess which keywords align best with your audience’s needs. This not only saves time but also enhances your ability to target content effectively.
Automating this analysis allows for regular updates on changing search behaviors. Staying ahead of trends means better optimization strategies that resonate with real user intent.
Integrating Python into your SEO Workflow
Integrating Python into your SEO workflow can transform how you approach data analysis and keyword tracking. By automating repetitive tasks, you free up valuable time for strategic thinking and creative exploration.
Start by leveraging libraries like Pandas to analyze large datasets efficiently. This helps in identifying trends or anomalies that might be missed with traditional methods.
You can also use Beautiful Soup for web scraping, allowing you to gather competitor insights directly from their sites. Extracting relevant information becomes a breeze, enhancing your research capabilities.
Consider creating custom scripts tailored to your specific needs. Whether it’s monitoring rankings or analyzing backlinks, Python allows unprecedented flexibility.
Incorporate visualizations using Matplotlib or Seaborn to present data clearly. These visuals make it easier to share findings with team members or stakeholders who may not be as familiar with the technical aspects of SEO.
Tips and Tricks for Mastering Search Intent Analysis with Python
Mastering search intent analysis with Python can elevate your SEO strategy. Start by leveraging libraries like Pandas and Beautiful Soup for efficient data manipulation and web scraping.
Utilize Natural Language Processing (NLP) techniques to understand user queries better. Libraries such as NLTK or SpaCy can help you analyze keywords, phrases, and their contexts.
Make your code modular. Break down functions into smaller components for cleaner debugging and easier updates in the future.
Experiment with machine learning models to predict user behavior based on historical data. Tools like Scikit-learn offer a range of algorithms that can enhance your insights dramatically.
Stay updated with SEO trends. Adapt your scripts regularly to reflect changes in search engine algorithms and user preferences. Continuous learning is key in this ever-evolving field!
Conclusion
As the digital landscape continues to evolve, SEO professionals must adapt and innovate. Python has emerged as a powerful tool that can transform how you approach keyword relevance and search intent.
With Python, you can streamline your keyword research process, analyze massive datasets quickly, and effectively interpret user intent behind searches. The ability to automate repetitive tasks frees up time for deeper strategic thinking.
Integrating Python into your SEO workflow enhances efficiency and results in more targeted strategies. Real-world applications showcase its versatility—from scraping data from SERPs to analyzing trends over time.
By leveraging Python for SEO activities, you’re not only keeping pace with the industry but also setting yourself apart as a forward-thinking professional ready to tackle the challenges of tomorrow’s search engines. Embrace this technology; it could very well be your secret weapon in achieving online success.
0 notes
Text
Tools to Scrape Amazon Product Offers and Sellers Data

Introduction
Scraping Amazon product offers and seller information can provide valuable insights for businesses, developers, and researchers. Whether you're analyzing competitor pricing, monitoring market trends, or building a price comparison tool, Scrape Amazon Product Offers and Sellers Data is crucial for staying competitive. This guide will walk you through code-based and no-code methods for extracting Amazon data, making it suitable for beginners and experienced developers. We'll cover the best tools, techniques, and practices to ensure practical and ethical data extraction. One key aspect is learning how to Extract Amazon Seller Prices Data accurately, allowing you to track and analyze pricing trends across various sellers. Additionally, we will delve into how to Scrape Amazon Seller Information, ensuring that all data is collected efficiently while staying within legal boundaries. By following the right approaches, you can access valuable data insights without facing potential legal or technical challenges, ensuring long-term success in your data-driven projects.
Why Scrape Amazon Product Offers and Sellers?

Amazon is a treasure trove of e-commerce data. Scraping product offers and seller information, Amazon is a goldmine of e-commerce data, offering valuable insights for businesses looking to gain a competitive edge. By Scraping Amazon Seller Listings Data, you can collect crucial information that helps in several areas:
Monitor pricing trends: Track the price changes for specific products or categories over time. This allows you to understand market dynamics and adjust your pricing strategy accordingly.
Analyze seller performance: Evaluate key metrics such as seller ratings, shipping options, and inventory availability. This data can help you understand how top-performing sellers operate and what factors contribute to their success.
Competitor analysis: Scrape Amazon Offer Listings with Selenium Data to compare your offerings against your competitors. You can identify pricing gaps, product availability, and more, which helps refine your market positioning.
Market research: By examining Amazon Seller Scraping API Integration data, you can identify high-demand products, emerging niches, and customer preferences. This information can guide your product development and marketing strategies.
Build tools: Use the scraped data to create practical applications like price comparison tools or inventory management systems. With the right dataset, you can automate and optimize various business processes.
However, scraping Amazon's vast marketplace comes with challenges. Its dynamic website structure, sophisticated anti-scraping measures (like CAPTCHAs), and strict legal policies create barriers. To overcome these obstacles, you must implement strategies that include using advanced tools to Extract Amazon E-Commerce Product Data. Success requires a tailored approach that matches your skill level and resource availability.
Legal and Ethical Considerations

Before diving into scraping, understand the legal and ethical implications:
Amazon's Terms of Service (ToS): Amazon prohibits scraping without permission. Violating ToS can lead to IP bans or legal action.
Data Privacy: Avoid collecting personal information about sellers or customers.
Rate Limiting: Excessive requests can overload Amazon's servers, violating ethical scraping practices.
robots.txt: Look for Amazon's robots.txt file to see which pages are disallowed for scraping.
To stay compliant:
Use Amazon's official Product Advertising API: for authorized data access (if applicable).
Scrape publicly available data sparingly: and respect rate limits.
Consult a legal expert: if you're building a commercial tool.
Code-Based Approach: Scraping with Python

For developers skilled in coding, Python provides robust libraries such as BeautifulSoup, Scrapy, and Selenium to Scrape Amazon E-Commerce Product Data efficiently. Using libraries like BeautifulSoup and Requests, you can easily extract product offers and seller details. Combining these tools allows you to navigate Amazon's complex structure and gather valuable insights. Whether you're looking to Scrape Amazon ecommerce Product Data for pricing trends or competitor analysis, this approach allows for streamlined data extraction. With the proper script, you can automate the process, gather vast datasets, and leverage them for various business strategies.
Prerequisites
Python 3.x installed.
Libraries: Install via pip:
Basic understanding of HTML/CSS selectors.
Sample Python Script

This script scrapes product titles, prices, and seller names from an Amazon search results page.
How It Works?

Headers: The script uses a User-Agent to mimic a browser, reducing the chance of being blocked.
Request: Sends an HTTP GET request to Amazon's search page for the query (e.g., "wireless earbuds").
Parsing: BeautifulSoup parses the HTML to locate product containers using Amazon's class names.
Extraction: Extracts the title, price, and seller for each product.
Error Handling: Handles network errors gracefully.
Challenges and Solutions
Dynamic Content: Some Amazon pages load data via JavaScript. Use Selenium or Playwright for dynamic scraping.
CAPTCHAs: Rotate proxies or use CAPTCHA-solving services.
IP Bans: Implement delays (time.sleep(5)) or use proxy services.
Rate Limits: Limit requests to 1–2 per second to avoid detection.
Scaling with Scrapy
For large-scale scraping, use Scrapy, a Python framework for building web crawlers. Scrapy supports:
Asynchronous requests for faster scraping.
Middleware for proxy rotation and user-agent switching.
Pipelines for storing data in databases like MySQL or MongoDB.
No-Code Approach: Using Web Scraping Tools
For non-developers or those looking for fast solutions, no-code tools provide an easy way to Extract Popular E-Commerce Website Data without needing to write any code. These tools offer visual interfaces allowing users to select webpage elements and automate data extraction. Common types of no-code tools include web scraping platforms, browser extensions, and API-based solutions. With these tools, you can quickly collect product offers, seller information, and more. Many businesses rely on Ecommerce Data Scraping Services to simplify gathering data from websites like Amazon, enabling efficient analysis and decision-making.
1. Visual Scraping Tool
Features: A desktop or cloud-based tool with a point-and-click interface, supports exporting data to CSV/Excel, and handles pagination.
Install the tool and start a new project.
Enter the Amazon search URL (e.g., https://www.amazon.com/s?k=laptop).
Use the visual editor to select elements like product title, price, or seller name.
Configure pagination to scrape multiple pages.
Run the task locally or in the cloud and export the data.
Pros: User-friendly, handles dynamic content, supports scheduling.
Cons: Free plans often have limits; premium plans may be required for large-scale scraping.
2. Cloud-Based Scraping Platform
Features: A free or paid platform with cloud scraping, API integration, and support for JavaScript-rendered pages.
Load the Amazon page in the platform's built-in browser.
Click on elements to extract (e.g., price, seller name).
Add logic to handle missing or inconsistent data.
Export results as JSON or CSV.
Pros: Free tiers often support small projects; intuitive for beginners.
Cons: Advanced features may require learning or paid plans.
3. Browser Extension Scraper
Features: A free browser-based extension for simple scraping tasks.
Install the extension in your browser.
Create a scraping template by selecting elements on the Amazon page (e.g., product title, price).
Run the scraper and download data as CSV.
Pros: Free, lightweight, and easy to set up.
Cons: Limited to static content; lacks cloud or automation features.
Choosing a No-Code Tool
Small Projects: Browser extension scrapers are ideal for quick, one-off tasks.
Regular Scraping: Visual scraping tools or cloud-based platforms offer automation and cloud support.
Budget: Start with free tiers, but expect to upgrade for large-scale or frequent scraping.
Start extracting valuable insights today with our powerful and easy-to-use scraping tools!
Best Practices for Scraping Amazon

1. Respect Robots.txt: Avoid scraping disallowed pages.
2. Use Proxies: Rotate IPs to prevent bans. Proxy services offer residential proxies for reliable scraping.
3. Randomize Requests: Add delays and vary user agents to mimic human behavior.
4. Handle Errors: Implement retries for failed requests.
5. Store Data Efficiently: Use databases (e.g., SQLite, MongoDB) for large datasets.
6. Monitor Changes: Amazon's HTML structure changes frequently. Regularly update selectors.
7. Stay Ethical: Scrape only what you need and avoid overloading servers.
Alternative: Amazon Product Advertising API

Instead of scraping, consider Amazon's Product Advertising API for authorized access to product data. Benefits include:
Legal Compliance: Fully compliant with Amazon's ToS.
Rich Data: Access to prices, offers, reviews, and seller info.
Reliability: No risk of IP bans or CAPTCHAs.
Drawbacks:
Requires an Amazon Associate account with qualifying sales.
Limited to specific data points.
Rate limits apply.
To use the API:
1. Sign up for the Amazon Associates Program.
2. Generate API keys.
3. Use a library like boto3 (Python) to query the API.
How Product Data Scrape Can Help You?
Customizable Data Extraction: Our tools are built to adapt to various website structures, allowing you to extract exactly the data you need—whether it's product listings, prices, reviews, or seller details.
Bypass Anti-Scraping Measures: With features like CAPTCHA solving, rotating proxies, and user-agent management, our tools effectively overcome restrictions set by platforms like Amazon.
Supports Code and No-Code Users: Whether you're a developer or a non-technical user, our scraping solutions offer code-based flexibility and user-friendly no-code interfaces.
Real-Time and Scheduled Scraping: Automate your data collection with scheduling features and receive real-time updates, ensuring you always have the latest information at your fingertips.
Clean and Structured Output: Our tools deliver data in clean formats like JSON, CSV, or Excel, making it easy to integrate into analytics tools, dashboards, or custom applications.
Conclusion
Scraping Amazon product offers and seller information is a powerful way to Extract E-commerce Data��and gain valuable business insights. However, thoughtful planning is required to address technical barriers and legal considerations. Code-based methods using Python libraries like BeautifulSoup or Scrapy provide developers with flexibility and control. Meanwhile, no-code tools with visual interfaces or browser extensions offer user-friendly options for non-coders to use Web Scraping E-commerce Websites .
For compliant access, the Amazon Product Advertising API remains the safest route. Regardless of the method, always follow ethical scraping practices, implement proxies, and handle errors effectively. Combining the right tools with innovative techniques can help you build an insightful Ecommerce Product & Review Dataset for business or academic use.
At Product Data Scrape, we strongly emphasize ethical practices across all our services, including Competitor Price Monitoring and Mobile App Data Scraping. Our commitment to transparency and integrity is at the heart of everything we do. With a global presence and a focus on personalized solutions, we aim to exceed client expectations and drive success in data analytics. Our dedication to ethical principles ensures that our operations are both responsible and effective.
Source >>https://www.productdatascrape.com/amazon-product-seller-scraping-tools.php
#ScrapeAmazonProductOffersAndSellersData#ExtractAmazonSellerPricesData#AmazonSellerScrapingAPI#ExtractAmazonECommerceProductData#ScrapeAmazonEcommerceProductData#ExtractPopularECommerceWebsiteData#EcommerceDataScrapingServices
0 notes
Text
Automating Restaurant Menu Data Extraction Using Web Scraping APIs
Introduction
The food and restaurant business sector is going very heavily digital with millions of restaurant menus being made available through online platforms. Companies that are into food delivery, restaurant aggregation, and market research require menu data on a real-time basis for competition analysis, pricing strategies, and enhancement of customer experience. Manually collecting and updating this information is time-consuming and a laborious endeavor. This is where web scraping APIs come into play with the automated collection of such information to scrape restaurant menu data efficiently and accurately.
This guide discusses the importance of extracting restaurant menu data, how web scraping works for this use case, some challenges to expect, the best practices in dealing with such issues, and the future direction of menu data automation.
Why Export Restaurant Menu Data?
1. Food Delivery Service
Most online food delivery services, like Uber Eats, DoorDash, and Grubhub, need real-time menu updates for accurate pricing or availability. With the extraction of restaurant menu data, at least those online platforms are kept updated and discrepancies avoidable.
2. Competitive Pricing Strategy
Restaurants and food chains make use of web scraping restaurant menu data to determine their competitors' price positions. By tracking rival menus, they will know how they should price their products to remain competitive in the marketplace.
3. Nutritional and Dietary Insights
Health and wellness platforms utilize menu data for dietary recommendations to customers. By scraping restaurant menu data, these platforms can classify foods according to calorie levels, ingredients, and allergens.
4. Market Research and Trend Analysis
This is the group of data analysts and research firms collecting restaurant menu data to analyze consumer behavior about cuisines and track price variations with time.
5. Personalized Food Recommendations
Machine learning and artificial intelligence now provide food apps with the means to recommend meals according to user preferences. With restaurant menu data web scraping, food apps can access updated menus and thus afford personalized suggestions on food.
How Web Scraping APIs Automate Restaurant Menu Data Extraction
1. Identifying Target Websites
The first step is selecting restaurant platforms such as:
Food delivery aggregators (Uber Eats, DoorDash, Grubhub)
Restaurant chains' official websites (McDonald's, Subway, Starbucks)
Review sites (Yelp, TripAdvisor)
Local restaurant directories
2. Sending HTTP Requests
Scraping APIs send HTTP requests to restaurant websites to retrieve HTML content containing menu information.
3. Parsing HTML Data
The extracted HTML is parsed using tools like BeautifulSoup, Scrapy, or Selenium to locate menu items, prices, descriptions, and images.
4. Structuring and Storing Data
Once extracted, the data is formatted into JSON, CSV, or databases for easy integration with applications.
5. Automating Data Updates
APIs can be scheduled to run periodically, ensuring restaurant menus are always up to date.
Data Fields Extracted from Restaurant Menus
1. Restaurant Information
Restaurant Name
Address & Location
Contact Details
Cuisine Type
Ratings & Reviews
2. Menu Items
Dish Name
Description
Category (e.g., Appetizers, Main Course, Desserts)
Ingredients
Nutritional Information
3. Pricing and Discounts
Item Price
Combo Offers
Special Discounts
Delivery Fees
4. Availability & Ordering Information
Available Timings
In-Stock/Out-of-Stock Status
Delivery & Pickup Options
Challenges in Restaurant Menu Data Extraction
1. Frequent Menu Updates
Restaurants frequently update their menus, making it challenging to maintain up-to-date data.
2. Anti-Scraping Mechanisms
Many restaurant websites implement CAPTCHAs, bot detection, and IP blocking to prevent automated data extraction.
3. Dynamic Content Loading
Most restaurant platforms use JavaScript to load menu data dynamically, requiring headless browsers like Selenium or Puppeteer for scraping.
4. Data Standardization Issues
Different restaurants structure their menu data in various formats, making it difficult to standardize extracted information.
5. Legal and Ethical Considerations
Extracting restaurant menu data must comply with legal guidelines, including robots.txt policies and data privacy laws.
Best Practices for Scraping Restaurant Menu Data
1. Use API-Based Scraping
Leveraging dedicated web scraping APIs ensures more efficient and reliable data extraction without worrying about website restrictions.
2. Rotate IP Addresses & Use Proxies
Avoid IP bans by using rotating proxies or VPNs to simulate different users accessing the website.
3. Implement Headless Browsers
For JavaScript-heavy pages, headless browsers like Puppeteer or Selenium can load and extract dynamic content.
4. Use AI for Data Cleaning
Machine learning algorithms help clean and normalize menu data, making it structured and consistent across different sources.
5. Schedule Automated Scraping Jobs
To maintain up-to-date menu data, set up scheduled scraping jobs that run daily or weekly.
Popular Web Scraping APIs for Restaurant Menu Data Extraction
1. Scrapy Cloud API
A powerful cloud-based API that allows automated menu data scraping at scale.
2. Apify Restaurant Scraper
Apify provides pre-built restaurant scrapers that can extract menu details from multiple platforms.
3. Octoparse
A no-code scraping tool with API integration, ideal for businesses that require frequent menu updates.
4. ParseHub
A flexible API that extracts structured restaurant menu data with minimal coding requirements.
5. CrawlXpert API
A robust and scalable solution tailored for web scraping restaurant menu data, offering real-time data extraction with advanced anti-blocking mechanisms.
Future of Restaurant Menu Data Extraction
1. AI-Powered Menu Scraping
Artificial intelligence will improve data extraction accuracy, enabling automatic menu updates without manual intervention.
2. Real-Time Menu Synchronization
Restaurants will integrate web scraping APIs to sync menu data instantly across platforms.
3. Predictive Pricing Analysis
Machine learning models will analyze scraped menu data to predict price fluctuations and customer demand trends.
4. Enhanced Personalization in Food Apps
By leveraging scraped menu data, food delivery apps will provide more personalized recommendations based on user preferences.
5. Blockchain for Menu Authentication
Blockchain technology may be used to verify menu authenticity, preventing fraudulent modifications in restaurant listings.
Conclusion
Automating the extraction of restaurant menus from the web through scraping APIs has changed the food industry by offering real-time prices, recommendations for food based on liking, and analysis of competitors. With advances in technology, more AI-driven scraping solutions will further improve the accuracy and speed of data collection.
Know More : https://www.crawlxpert.com/blog/restaurant-menu-data-extraction-using-web-scraping-apis
#RestaurantMenuDataExtraction#ScrapingRestaurantMenuData#ExtractRestaurantMenus#ScrapeRestaurantMenuData
0 notes
Text
NLP Sentiment Analysis | Reviews Monitoring for Actionable Insights
NLP Sentiment Analysis-Powered Insights from 1M+ Online Reviews

Business Challenge

A global enterprise with diversified business units in retail, hospitality, and tech was inundated with customer reviews across dozens of platforms:
Amazon, Yelp, Zomato, TripAdvisor, Booking.com, Google Maps, and more. Each platform housed thousands of unstructured reviews written in multiple languages — making it ideal for NLP sentiment analysis to extract structured value from raw consumer feedback.
The client's existing review monitoring efforts were manual, disconnected, and slow. They lacked a modern review monitoring tool to streamline analysis. Key business leaders had no unified dashboard for customer experience (CX) trends, and emerging issues often went unnoticed until they impacted brand reputation or revenue.
The lack of a central sentiment intelligence system meant missed opportunities not only for service improvements, pricing optimization, and product redesign — but also for implementing a robust Brand Reputation Management Service capable of safeguarding long-term consumer trust.
Key pain points included:
No centralized system for analyzing cross-platform review data
Manual tagging that lacked accuracy and scalability
Absence of real-time CX intelligence for decision-makers
Objective
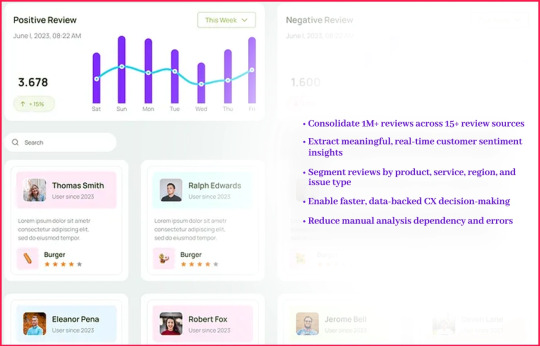
The client set out to:
Consolidate 1M+ reviews across 15+ review sources
Extract meaningful, real-time customer sentiment insights
Segment reviews by product, service, region, and issue type
Enable faster, data-backed CX decision-making
Reduce manual analysis dependency and errors
Their goal: Build a scalable sentiment analysis system using a robust Sentiment Analysis API to drive operational, marketing, and strategic decisions across business units.
Our Approach

DataZivot designed and deployed a fully-managed NLP-powered review analytics pipeline, customized for the client's data structure and review volume. Our solution included:
1. Intelligent Review Scraping
Automated scraping from platforms like Zomato, Yelp, Amazon, Booking.com
Schedule-based data refresh (daily & weekly)
Multi-language support (English, Spanish, German, Hindi)
2. NLP Sentiment Analysis
Hybrid approach combining rule-based tagging with transformer-based models (e.g., BERT, RoBERTa)
Sentiment scores (positive, neutral, negative) and sub-tagging (service, delivery, product quality)
Topic modeling to identify emerging concerns
3. Categorization & Tagging
Entity recognition (locations, product names, service mentions)
Keyword extraction for trend tracking
Complaint type detection (delay, quality, attitude, etc.)
4. Insights Dashboard Integration
Custom Power BI & Tableau dashboards
Location, time, sentiment, and keyword filters
Export-ready CSV/JSON options for internal analysts
Results & Competitive Insights

DataZivot's solution produced measurable results within the first month:
These improvements gave the enterprise:
Faster product feedback loops
Better pricing and menu optimization for restaurants
Localized insights for store/service operations
Proactive risk mitigation (e.g., before issues trended on social media)
Want to See the Dashboard in Action?
Book a demo or download a Sample Reviews Dataset to experience the power of our sentiment engine firsthand.
Contact Us Today!
Dashboard Highlights

The custom dashboard provided by DataZivot enabled:
Review Sentiment Dashboard featuring sentiment trend graphs (daily, weekly, monthly)
Top Keywords by Sentiment Type ("slow service", "friendly staff")
Geo Heatmaps showing regional sentiment fluctuations
Comparative Brand Insights (across subsidiaries or competitors)
Dynamic Filters by platform, region, product, date, language
Tools & Tech Stack

To deliver the solution at scale, we utilized:
Scraping Frameworks: Scrapy, Selenium, BeautifulSoup
NLP Libraries: spaCy, TextBlob, Hugging Face Transformers (BERT, RoBERTa)
Cloud Infrastructure: AWS Lambda, S3, EC2, Azure Functions
Dashboards & BI: Power BI, Tableau, Looker
Languages Used: Python, SQL, JavaScript (for dashboard custom scripts)
Strategic Outcome

By leveraging DataZivot’s NLP infrastructure, the enterprise achieved:
Centralized CX Intelligence: CX leaders could make decisions based on real-time, data-backed feedback
Cross-Industry Alignment: Insights across retail, hospitality, and tech units led to unified improvement strategies
Brand Perception Tracking: Marketing teams tracked emotional tone over time and correlated with ad campaigns
Revenue Impact: A/B-tested updates (product tweaks, price changes) showed double-digit improvements in review sentiment and NPS
Conclusion
This case study proves that large-scale review analytics is not only possible — it’s essential for modern enterprises managing multiple consumer-facing touchpoints. DataZivot’s approach to scalable NLP and real-time sentiment tracking empowered the client to proactively manage their brand reputation, uncover hidden customer insights, and drive growth across verticals.
If your organization is facing similar challenges with fragmented review data, inconsistent feedback visibility, or a slow response to customer sentiment — DataZivot’s sentiment intelligence platform is your solution.
#NLPSentimentAnalysis#CrossPlatformReviewData#SentimentAnalysisAPI#BrandReputationManagement#ReviewMonitoringTool#IntelligentReviewScraping#ReviewSentimentDashboard#RealTimeSentimentTracking#ReviewAnalytics
0 notes
Text
Travel Data Scraping Tools And Techniques For 2025
Introduction
The travel industry generates massive amounts of data every second, from fluctuating flight prices to real-time hotel availability. Businesses harnessing this information effectively gain a significant competitive advantage in the market. Travel Data Scraping has emerged as a crucial technique for extracting valuable insights from various travel platforms, enabling companies to make informed decisions and optimize their strategies.
Modern travelers expect transparency, competitive pricing, and comprehensive options when planning their journeys. To meet these demands, travel companies must continuously monitor competitor pricing, track market trends, and analyze consumer behavior patterns. Given the scale and speed at which travel data changes, extracting this information manually would be impossible.
Understanding the Fundamentals of Travel Data Extraction

Car Rental Data Scraping involves automated information collection from travel websites, booking platforms, and related online sources. This process utilizes specialized software and programming techniques to navigate through web pages, extract relevant data points, and organize them into structured formats for analysis.
The complexity of travel websites presents unique challenges for data extraction. Many platforms implement dynamic pricing algorithms, use JavaScript-heavy interfaces, and employ anti-bot measures to protect their data. Successfully navigating these obstacles requires sophisticated Travel Data Intelligence systems that can adapt to changing website structures and security measures.
Key components of effective travel data extraction include:
Target identification: Determining which websites and data points are most valuable for your business objectives.
Data parsing: Converting unstructured web content into organized, analyzable formats.
Quality assurance: Implementing validation mechanisms to ensure data accuracy and completeness.
Scalability management: Handling large volumes of requests without overwhelming target servers.
The extracted information typically includes pricing data, availability schedules, customer reviews, amenities descriptions, and geographical information. This comprehensive dataset enables businesses to analyze competition, identify market opportunities, and develop data-driven strategies.
Essential Tools and Technologies for 2025

The landscape of modern data extraction has evolved significantly, with advanced solutions offering enhanced capabilities for handling complex travel websites. Python-based frameworks like Scrapy and BeautifulSoup remain popular for custom development, while cloud-based platforms provide scalable solutions for enterprise-level operations.
Vacation Rental Data Scraping services have gained prominence by offering pre-built integrations with major travel platforms. These APIs handle the technical complexities of data extraction while providing standardized access to travel information. Popular providers include RapidAPI, Amadeus, and specialized travel data services focusing on industry needs.
Browser automation tools such as Selenium and Playwright excel at handling JavaScript-heavy websites that traditional scraping methods cannot access. These tools simulate human browsing behavior, making them particularly effective for sites with dynamic content loading and complex user interactions.
Advanced practitioners increasingly adopt machine learning approaches to improve Real-Time Travel Data Extraction accuracy. These systems can adapt to website changes automatically, recognize content patterns more effectively, and handle anti-bot measures with greater sophistication.
Flight Price Data Collection Strategies
Airlines constantly adjust their pricing based on demand, seasonality, route popularity, and competitive factors. Flight Price Data Scraping enables businesses to track these fluctuations across multiple carriers and booking platforms simultaneously. This information proves invaluable for travel agencies, price comparison sites, and market researchers.
Effective flight data collection requires monitoring multiple sources, including airline websites, online travel agencies, and metasearch engines. Each platform may display prices for identical flights due to exclusive deals, booking fees, or promotional campaigns. Comprehensive coverage ensures accurate market representation through Web Scraping Tools For Travel.
Key considerations for flight data extraction include:
Timing optimization: Prices change frequently, requiring strategic scheduling of data collection activities.
Route coverage: Monitoring popular routes while also tracking emerging destinations.
Fare class differentiation: Distinguishing between economy, business, and first-class offerings.
Additional fees tracking: Capturing baggage costs, seat selection charges, and other ancillary fees.
The challenge lies in handling the dynamic nature of flight search results. Many websites generate prices on demand based on search parameters, requiring sophisticated query management and result processing capabilities.
Hotel Industry Data Mining Techniques
The hospitality sector presents unique opportunities for data extraction, with thousands of properties across various booking platforms offering different rates, amenities, and availability windows. Hotel Data Scraping involves collecting information from major platforms like Booking.com, Expedia, Hotels.com, and individual hotel websites.
Property data encompasses room types, pricing structures, guest reviews, amenities lists, location details, and availability calendars. This comprehensive information enables competitive analysis, market positioning, and customer preference identification. Revenue management teams benefit from understanding competitor pricing strategies and occupancy patterns through Travel Scraping API solutions.
Modern hotel data extraction must account for the following:
Multi-platform presence: Hotels often list varying information on multiple booking sites.
Dynamic pricing models: Rates change based on demand, events, and seasonal factors.
Review authenticity: Filtering genuine customer feedback from promotional content.
Geographic clustering: Understanding local market dynamics and competitive landscapes.
These solutions incorporate advanced filtering and categorization features to handle the complexity of hotel data effectively.
Car Rental Market Intelligence
The car rental industry operates with complex pricing models influenced by vehicle availability, location demand, seasonal patterns, and local events. Modern data extraction provides insights into fleet availability, pricing strategies, and market trends across different geographic regions.
Major rental companies like Hertz, Avis, Enterprise, and Budget maintain extensive online presence with real-time inventory management systems. Extracting data from these platforms requires understanding their booking workflows and availability calculation methods using Best Travel Data Extraction Software.
Essential data points for car rental analysis include:
Vehicle categories: From economy cars to luxury vehicles and specialty equipment.
Location-based pricing: Airport versus city locations often have different rate structures.
Seasonal variations: Holiday periods and local events significantly impact availability and costs.
Add-on services: Insurance options, GPS rentals, and additional driver fees.
The challenge is the relationship between pickup/dropoff locations, rental duration, and vehicle availability. These factors interact in complex ways that require sophisticated data modeling approaches supported by Travel Data Intelligence systems.
Vacation Rental Platform Analysis
The rise of platforms like Airbnb, VRBO, and HomeAway has created new opportunities for travel data extraction. These platforms collect information about property listings, host profiles, guest reviews, pricing calendars, and booking availability.
Unlike traditional hotels, vacation rentals operate with unique pricing models, often including cleaning fees, security deposits, and variable nightly rates. Understanding these cost structures requires comprehensive Travel Data Scraping capabilities and analysis.
Key aspects of vacation rental data include:
Property characteristics: Number of bedrooms, amenities, location ratings, and unique features.
Host information: Response times, acceptance rates, and guest communication patterns.
Pricing strategies: Base rates, seasonal adjustments, and additional fee structures.
Market saturation: Understanding supply and demand dynamics in specific locations.
Real-Time Travel Data Extraction becomes particularly important for vacation rentals due to the personal nature of these properties and the impact of local events on availability and pricing.
Building Effective Data Intelligence Systems

Modern intelligence systems transform raw extracted information into actionable business insights. This process involves data cleaning, normalization, analysis, and visualization to support decision-making across various business functions.
Successful intelligence systems integrate data from multiple sources to provide comprehensive market views. They combine pricing information with availability data, customer sentiment analysis, and competitive positioning metrics to create holistic business intelligence dashboards using Web Scraping Tools For Travel.
Key components of effective systems include:
Data quality management: Ensuring accuracy, completeness, and consistency across all data sources.
Automated analysis: Implementing algorithms to identify trends, anomalies, and opportunities.
Customizable reporting: Providing stakeholders with relevant, timely, and actionable information.
Predictive modeling: Using historical data to forecast future trends and market conditions.
The integration of artificial intelligence and machine learning technologies enhances the capability of Travel Scraping API systems to provide deeper insights and more accurate predictions.
Real-Time Data Processing Capabilities
Modern travel businesses require up-to-the-minute information to remain competitive in fast-paced markets. Advanced processing systems operate continuously, monitoring changes across multiple platforms and updating business intelligence systems accordingly.
The technical infrastructure for real-time processing must handle high-frequency data updates while maintaining system performance and reliability. This requires distributed computing approaches, efficient data storage solutions, and robust error handling mechanisms Best Travel Data Extraction Software supports.
Critical aspects of real-time systems include:
Low-latency processing: Minimizing delays between data availability and business intelligence updates.
Scalable architecture: Handling varying data volumes and processing demands.
Fault tolerance: Maintaining operations despite individual component failures.
Data freshness: Ensuring information accuracy and relevance for time-sensitive decisions.
Advanced Flight Price Data Scraping systems exemplify these capabilities by providing instant updates on pricing changes across multiple airlines and booking platforms.
Legal and Ethical Considerations
Modern Hotel Data Scraping tools must navigate legal boundaries, adhering to website terms of service and data protection laws. As data extraction regulations evolve, businesses must stay compliant while gathering valuable travel insights.
Best practices include respecting robots.txt files, implementing reasonable request rates, and avoiding actions that could disrupt website operations. Many travel companies now offer official APIs as alternatives to scraping, providing structured access to their data while maintaining control over usage terms.
Important considerations include:
Terms of service compliance: Understanding and adhering to platform-specific usage policies.
Data privacy regulations: Ensuring compliance with GDPR, CCPA, and other privacy laws.
Rate limiting: Implementing respectful crawling practices that don't overwhelm target servers.
Attribution requirements: Properly crediting data sources when required.
Data scraping in the hotel sector must prioritize guest privacy and protect reservation confidentiality. Similarly, Car Rental Data Scraping should consider competitive pricing and ensure it doesn't interfere with booking platforms.
Future Trends and Innovations

The evolution of travel data extraction is rapidly advancing, driven by AI, machine learning, and cloud innovations. Amid this progress, Travel Data Intelligence unlocks deeper insights, greater accuracy, and scalable solutions for travel businesses.
Emerging trends such as natural language processing for review analysis, computer vision for extracting image-based data, and blockchain for secure data verification and sharing are transforming the landscape. These innovations enhance the value and scope of Vacation Rental Data Scraping systems across all market segments.
How Travel Scrape Can Help You?
We provide comprehensive data extraction solutions tailored to your business needs. Our expert team understands the complexities of Travel Data Scraping and offers cutting-edge tools to give you a competitive advantage.
Custom API Development: We create specialized solutions that integrate seamlessly with your existing systems and workflows.
Multi-Platform Coverage: Our services encompass data collection across hundreds of travel websites and booking platforms.
Real-Time Intelligence: Implement continuous monitoring capabilities that keep your business informed of market changes as they happen.
Advanced Analytics: Transform raw data into actionable insights using sophisticated analysis and reporting tools.
Scalable Infrastructure: Our solutions grow with your business, handling increased data volumes and additional platforms.
Compliance Management: We ensure all data collection activities adhere to legal requirements and industry best practices.
24/7 Support: Our dedicated team provides continuous monitoring and technical support to maintain optimal system performance.
Conclusion
The travel industry's data-driven transformation requires sophisticated information collection and analysis approaches. Travel Data Scraping has become an essential capability for businesses seeking to understand market dynamics, optimize pricing strategies, and deliver superior customer experiences. Modern Travel Aggregators rely heavily on comprehensive data extraction systems to provide accurate, timely information to their users.
Success in today's competitive environment demands robust Travel Industry Web Scraping capabilities that can adapt to changing technologies and market conditions. By implementing the right tools, strategies, and partnerships, travel businesses can harness the power of data to drive growth and innovation.
Ready to transform your travel business with comprehensive data intelligence? Contact Travel Scrape today to discover how we can provide the competitive advantage you need.
Read More :- https://www.travelscrape.com/how-travel-data-scraping-works-2025.php
#TravelDataScrapingWork#TheBestToolsToUseIn2025#TravelDataIntelligence#VacationRentalDataScraping#FlightPriceDataScraping#TravelScrapingAPI#HotelDataScraping#TravelIndustryWebScraping#TravelAggregators
0 notes
Text
How to Integrate WooCommerce Scraper into Your Business Workflow
In today’s fast-paced eCommerce environment, staying ahead means automating repetitive tasks and making data-driven decisions. If you manage a WooCommerce store, you’ve likely spent hours handling product data, competitor pricing, and inventory updates. That’s where a WooCommerce Scraper becomes a game-changer. Integrated seamlessly into your workflow, it can help you collect, update, and analyze data more efficiently, freeing up your time and boosting operational productivity.

In this blog, we’ll break down what a WooCommerce scraper is, its benefits, and how to effectively integrate it into your business operations.
What is a WooCommerce Scraper?
A WooCommerce scraper is a tool designed to extract data from WooCommerce-powered websites. This data could include:
Product titles, images, descriptions
Prices and discounts
Reviews and ratings
Stock status and availability
Such a tool automates the collection of this information, which is useful for e-commerce entrepreneurs, data analysts, and digital marketers. Whether you're monitoring competitors or syncing product listings across multiple platforms, a WooCommerce scraper can save hours of manual work.
Why Businesses Use WooCommerce Scrapers
Before diving into the integration process, let’s look at the key reasons businesses rely on scraping tools:
Competitor Price Monitoring
Stay competitive by tracking pricing trends across similar WooCommerce stores. Automated scrapers can pull this data daily, helping you optimize your pricing strategy in real time.
Bulk Product Management
Import product data at scale from suppliers or marketplaces. Instead of manually updating hundreds of SKUs, use a scraper to auto-populate your database with relevant information.
Enhanced Market Research
Get a snapshot of what’s trending in your niche. Use scrapers to gather data about top-selling products, customer reviews, and seasonal demand.
Inventory Tracking
Avoid stockouts or overstocking by monitoring inventory availability from your suppliers or competitors.
How to Integrate a WooCommerce Scraper Into Your Workflow
Integrating a WooCommerce scraper into your business processes might sound technical, but with the right approach, it can be seamless and highly beneficial. Whether you're aiming to automate competitor tracking, streamline product imports, or maintain inventory accuracy, aligning your scraper with your existing workflow ensures efficiency and scalability. Below is a step-by-step guide to help you get started.
Step 1: Define Your Use Case
Start by identifying what you want to achieve. Is it competitive analysis? Supplier data syncing? Or updating internal catalogs? Clarifying this helps you choose the right scraping strategy.
Step 2: Choose the Right Scraper Tool
There are multiple tools available, ranging from browser-based scrapers to custom-built Python scripts. Some popular options include:
Octoparse
ParseHub
Python-based scrapers using BeautifulSoup or Scrapy
API integrations for WooCommerce
For enterprise-level needs, consider working with a provider like TagX, which offers custom scraping solutions with scalability and accuracy in mind.
Step 3: Automate with Cron Jobs or APIs
For recurring tasks, automation is key. Set up cron jobs or use APIs to run scrapers at scheduled intervals. This ensures that your database stays up-to-date without manual intervention.
Step 4: Parse and Clean Your Data
Raw scraped data often contains HTML tags, formatting issues, or duplicates. Use tools or scripts to clean and structure the data before importing it into your systems.
Step 5: Integrate with Your CMS or ERP
Once cleaned, import the data into your WooCommerce backend or link it with your ERP or PIM (Product Information Management) system. Many scraping tools offer CSV or JSON outputs that are easy to integrate.
Common Challenges in WooCommerce Scraping (And Solutions)
Changing Site Structures
WooCommerce themes can differ, and any update might break your script. Solution: Use dynamic selectors or AI-powered tools that adapt automatically.
Rate Limiting and Captchas
Some sites use rate limiting or CAPTCHAs to block bots. Solution: Use rotating proxies, headless browsers like Puppeteer, or work with scraping service providers.
Data Duplication or Inaccuracy
Messy data can lead to poor business decisions. Solution: Implement deduplication logic and validation rules before importing data.
Tips for Maintaining an Ethical Scraping Strategy
Respect Robots.txt Files: Always check the site’s scraping policy.
Avoid Overloading Servers: Schedule scrapers during low-traffic hours.
Use the Data Responsibly: Don’t scrape copyrighted or sensitive data.
Why Choose TagX for WooCommerce Scraping?
While it's possible to set up a basic WooCommerce scraper on your own, scaling it, maintaining data accuracy, and handling complex scraping tasks require deep technical expertise. TagX’s professionals offer end-to-end scraping solutions tailored specifically for e-commerce businesses. Whether you're looking to automate product data extraction, monitor competitor pricing, or implement web scraping using AI at scale. Key Reasons to Choose TagX:
AI-Powered Scraping: Go beyond basic extraction with intelligent scraping powered by machine learning and natural language processing.
Scalable Infrastructure: Whether you're scraping hundreds or millions of pages, TagX ensures high performance and minimal downtime.
Custom Integration: TagX enables seamless integration of scrapers directly into your CMS, ERP, or PIM systems, ensuring a streamlined workflow.
Ethical and Compliant Practices: All scraping is conducted responsibly, adhering to industry best practices and compliance standards.
With us, you’re not just adopting a tool—you’re gaining a strategic partner that understands the nuances of modern eCommerce data operations.
Final Thoughts
Integrating a WooCommerce scraper into your business workflow is no longer just a technical choice—it’s a strategic advantage. From automating tedious tasks to extracting market intelligence, scraping tools empower businesses to operate faster and smarter.
As your data requirements evolve, consider exploring web scraping using AI to future-proof your automation strategy. And for seamless implementation, TagX offers the technology and expertise to help you unlock the full value of your data.
0 notes
Text
Scraping Cryptocurrency Price Trends for Investment Insights | Actowiz Solutions
Introduction
The cryptocurrency market is highly volatile, making real-time data crucial for investors. By leveraging web scraping, traders can extract cryptocurrency price trends to make informed decisions. Actowiz Solutions provides robust cryptocurrency data scraping services to help investors, financial analysts, and businesses gain actionable insights. In this blog, we will explore how cryptocurrency price trend scraping works, its benefits, and how Actowiz Solutions can empower your investment strategies.
Why Scrape Cryptocurrency Price Trends?
Cryptocurrency prices fluctuate rapidly due to market demand, news, regulations, and investor sentiment. Scraping real-time and historical price trends allows investors to:
Analyze market trends and price patterns
Identify arbitrage opportunities
Track price movements across multiple exchanges
Enhance algorithmic trading models
Gain insights into market liquidity and volatility

Key Data Points in Cryptocurrency Price Scraping
When scraping cryptocurrency prices, the essential data points include:
Current price: Real-time value of the cryptocurrency
Historical price data: Past trends for analysis
Market capitalization: Total market value of the cryptocurrency
Trading volume: Amount of cryptocurrency traded over a period
Exchange rates: Price differences across various exchanges
Price changes: Hourly, daily, and weekly price fluctuations

How Web Scraping Works for Cryptocurrency Data Extraction
Actowiz Solutions implements advanced web scraping techniques to collect cryptocurrency price trends efficiently. The process involves:
1. Identifying Data Sources
We scrape data from cryptocurrency exchanges like Binance, Coinbase, Kraken, and CoinMarketCap to obtain real-time and historical prices.
2. Using Web Scraping Tools and APIs
Actowiz Solutions employs Python-based scraping frameworks like Scrapy, BeautifulSoup, and Selenium, along with official APIs of exchanges, to extract accurate data.
3. Data Cleaning and Structuring
Extracted data is processed, structured, and stored in databases for further analysis.
4. Analyzing and Visualizing Trends

Benefits of Cryptocurrency Price Scraping
1. Real-time Market Insights
Scraping enables access to real-time price data, helping investors make quick decisions.
2. Competitive Advantage
Traders can use price trends to develop winning trading strategies.
3. Enhanced Decision-Making
Historical price data allows backtesting of trading algorithms.
4. Risk Management

How Actowiz Solutions Enhances Cryptocurrency Data Scraping
Actowiz Solutions offers specialized cryptocurrency data scraping services with:
High-speed data extraction to ensure real-time updates
Reliable and secure data collection using proxies and CAPTCHA-solving techniques
Custom API integrations for seamless data delivery
AI-driven analytics for predictive market insights

Use Cases of Cryptocurrency Price Trend Scraping
1. Algorithmic Trading
Traders use scraped data to develop automated trading strategies.
2. Arbitrage Analysis
Investors analyze price differences between exchanges to maximize profits.
3. Portfolio Management
Historical price trends assist in optimizing cryptocurrency portfolios.
4. Sentiment Analysis

Conclusion
Scraping cryptocurrency price trends is essential for making data-driven investment decisions. Actowiz Solutions provides powerful cryptocurrency data scraping services to help investors gain actionable insights. Contact us today to enhance your investment strategies with accurate market data. Learn More
#RealTimePriceData#PriceDataWithNewsScraping#CryptocurrencyDataScraping#ScrapingCryptocurrencyPriceTrends
0 notes
Text
Unlock SEO & Automation with Python
In today’s fast-paced digital world, marketers are under constant pressure to deliver faster results, better insights, and smarter strategies. With automation becoming a cornerstone of digital marketing, Python has emerged as one of the most powerful tools for marketers who want to stay ahead of the curve.
Whether you’re tracking SEO performance, automating repetitive tasks, or analyzing large datasets, Python offers unmatched flexibility and speed. If you're still relying solely on traditional marketing platforms, it's time to step up — because Python isn't just for developers anymore.
Why Python Is a Game-Changer for Digital Marketers
Python’s growing popularity lies in its simplicity and versatility. It's easy to learn, open-source, and supports countless libraries that cater directly to marketing needs. From scraping websites for keyword data to automating Google Analytics reports, Python allows marketers to save time and make data-driven decisions faster than ever.
One key benefit is how Python handles SEO tasks. Imagine being able to monitor thousands of keywords, track competitors, and audit websites in minutes — all without manually clicking through endless tools. Libraries like BeautifulSoup, Scrapy, and Pandas allow marketers to extract, clean, and analyze SEO data at scale. This makes it easier to identify opportunities, fix issues, and outrank competitors efficiently.
Automating the Routine, Empowering the Creative
Repetitive tasks eat into a marketer's most valuable resource: time. Python helps eliminate the grunt work. Need to schedule social media posts, generate performance reports, or pull ad data across platforms? With just a few lines of code, Python can automate these tasks while you focus on creativity and strategy.
In Dehradun, a growing hub for tech and education, professionals are recognizing this trend. Enrolling in a Python Course in Dehradun not only boosts your marketing skill set but also opens up new career opportunities in analytics, SEO, and marketing automation. Local training programs often offer real-world marketing projects to ensure you gain hands-on experience with tools like Jupyter, APIs, and web scrapers — critical assets in the digital marketing toolkit.
Real-World Marketing Use Cases
Python's role in marketing isn’t just theoretical — it’s practical. Here are a few real-world scenarios where marketers are already using
Python to their advantage:
Content Optimization: Automate keyword research and content gap analysis to improve your blog and web copy.
Email Campaign Analysis: Analyze open rates, click-throughs, and conversions to fine-tune your email strategies.
Ad Spend Optimization: Pull and compare performance data from Facebook Ads, Google Ads, and LinkedIn to make smarter budget decisions.
Social Listening: Monitor brand mentions or trends across Twitter and Reddit to stay responsive and relevant.
With so many uses, Python is quickly becoming the Swiss army knife for marketers. You don’t need to become a software engineer — even a basic understanding can dramatically improve your workflow.
Getting Started with Python
Whether you're a fresh graduate or a seasoned marketer, investing in the right training can fast-track your career. A quality Python training in Dehradun will teach you how to automate marketing workflows, handle SEO analytics, and visualize campaign performance — all with practical, industry-relevant projects.
Look for courses that include modules on digital marketing integration, data handling, and tool-based assignments. These elements ensure you're not just learning syntax but applying it to real marketing scenarios. With Dehradun's increasing focus on tech education, it's a great place to gain this in-demand skill.
Python is no longer optional for forward-thinking marketers. As SEO becomes more data-driven and automation more essential, mastering Python gives you a clear edge. It simplifies complexity, drives efficiency, and helps you make smarter, faster decisions.
Now is the perfect time to upskill. Whether you're optimizing search rankings or building powerful marketing dashboards, Python is your key to unlocking smarter marketing in 2025 and beyond.
Python vs Ruby, What is the Difference? - Pros & Cons
youtube
#python course#python training#education#python#pythoncourseinindia#pythoninstitute#pythoninstituteinindia#pythondeveloper#Youtube
0 notes
Text
Scraping Chipotle Menu Data from All US Locations

Why Scraping Chipotle Menu Data from All US Locations Matters for Market Insights?
Introduction
Chipotle Mexican Grill, one of the fast-casual dining brands at the forefront, is well known for its customizable burritos, bowls, tacos, and salads. With its thousands of branches dispersed throughout the United States, every outlet can have minor differences in menu offerings, regional pricing, and ingredient variations. It is an otherwise novel opportunity for businesses, researchers, and data analysts seeking to understand food trends and consumer behavior. Scraping Chipotle Menu Data from All US Locations is an excellent means of gathering and consolidating such valuable data. From monitoring protein trends to listing regional menu variations, such information provides profound insights into Chipotle's business models and customer preferences. The procedure entails applying sophisticated web scraping techniques and tools to accurately gather menu items, prices, and item descriptions from each outlet. Whether for competitive comparison, menu optimization, or market analysis, Chipotle Menu Data Extraction for All U.S. Branches unmasks significant patterns and regional preferences. This article explores such a task's methodologies, tools, and findings. It demonstrates how to Extract Chipotle Menu Listings Across US States and aggregate them into actionable information that can guide strategic business decision-making.
Understanding the Scope of Chipotle's US Presence
Chipotle operates over 3,000 locations across the United States, from busy city centers to suburban shopping areas. While all locations offer a consistent core menu, factors such as regional economics, ingredient availability, and local customer preferences can lead to pricing and item availability variations. To Scrape Chipotle's Menu and Pricing from the US Store, one must first identify each location's unique digital presence, typically found through Chipotle's official website or mobile app. These platforms offer location-specific menus and ordering options essential for accurate data collection.
This effort aims to capture detailed information such as item names, descriptions, pricing, customization choices, and any unique specials offered at specific locations. Given the scale—over 3,000 branches—automation is critical. Web Scraping Chipotle Menu Items from USA requires advanced tools or APIs to systematically pull data from Chipotle's dynamic online ordering system, which updates menus based on the selected location.
Through this approach, Chipotle Food Delivery App Data Scraping Services can extract comprehensive data from across the nation, offering valuable insights into regional trends, pricing strategies, and consumer preferences that shape the brand's success in diverse markets.
Tools and Technologies for Scraping

A combination of programming languages, libraries, and tools is typically employed to scrape Chipotle's menu data. Python is popular due to its robust ecosystem of scraping libraries like BeautifulSoup, Scrapy, and Selenium. These libraries are well-suited for parsing HTML, navigating dynamic web pages, and handling JavaScript-rendered content, which is common on modern websites like Chipotle's. For large-scale and efficient data extraction, Chipotle Food Delivery Scraping API Services can also be integrated to streamline access to location-specific menu data and ensure reliable data collection across all U.S. locations.
BeautifulSoup: Ideal for parsing static HTML content, such as menu item names and descriptions.
Scrapy: A robust framework for large-scale scraping, capable of crawling multiple pages and handling pagination or location-based redirects.
Selenium: Useful for interacting with dynamic elements, like dropdowns for selecting store locations or loading menu data via AJAX requests.
Requests: A library for making HTTP requests to fetch raw HTML or API responses.
Tools like Pandas can also be used for data cleaning and structuring, while databases like SQLite or MongoDB store the scraped data for analysis. For geolocation-based scraping, APIs like Google Maps or Chipotle's store locator API can help identify all US locations by ZIP code or city.
Structuring the Scraping Process
The scraping process begins with identifying all Chipotle locations. Chipotle's website features a store locator that lists addresses, hours, and links to location-specific menus. By sending HTTP requests to the store locator page, you can extract details for each restaurant, such as its unique store ID, address, and coordinates. These identifiers are critical for accessing the correct menu data, as Chipotle's online ordering system uses store IDs to load location-specific information.
Once locations are cataloged, the scraper navigates to each store's menu page or API endpoint. Chipotle's menu is typically categorized as entrees (burritos, bowls, tacos), sides, drinks, and kids' meals. For each category, the scraper captures:
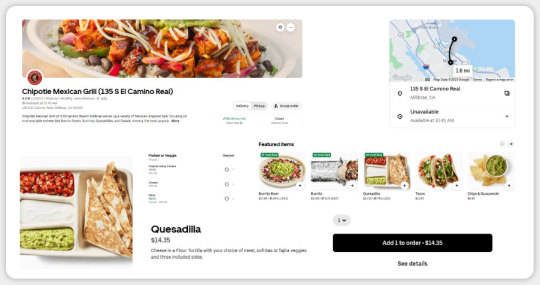
Item Name: E.g., "Chicken Burrito," "Chips & Guacamole."
Price: Base price and any variations based on protein or add-ons.
Description: Ingredients or customization options, such as salsas or toppings.
Availability: Whether the item is available at the specific location.
Specials: Limited-time offerings or regional exclusives.
To handle the volume, the scraper can run in parallel using multiprocessing or asynchronous libraries like asyncio, processing multiple locations simultaneously. Error handling is crucial to managing network issues, rate limits, or temporary site changes, ensuring the scraper retries failed requests or skips problematic locations.
Start extracting accurate and insightful food menu data today with our expert Food Delivery Data Scraping Services!
Contact us today!
Data Storage and Organization
Scraped data must be stored in a structured format for analysis. A relational database like SQLite is suitable for organizing menu data, with tables for locations, menu items, prices, and customizations. For example:
Locations Table: Store ID, address, city, state, ZIP code, latitude, longitude.
Menu Items Table: Item ID, name, category, description, store ID.
Prices Table: Item ID, store ID, base price, customization price (e.g., extra guacamole).
Customizations Table: Item ID, customization options (e.g., salsa types, proteins).
Alternatively, a NoSQL database like MongoDB can store semi-structured JSON data, which is valid if menu formats vary significantly across locations. After scraping, Pandas can clean the data by removing duplicates, standardizing item names, and handling missing values. The cleaned dataset is then ready for analysis or visualization.
Insights from Chipotle's Menu Data
Analyzing menu data from all US Chipotle locations reveals patterns and trends that offer valuable insights. Here are some key findings that typically emerge from such a dataset:
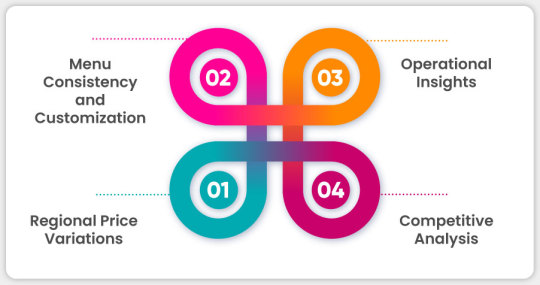
Regional Price Variations: One of the key insights gathered through Food Delivery Data Scraping Services is the variation in pricing for identical menu items across different geographic regions. For example, a chicken burrito at a Chipotle location in New York City or San Francisco is likely more expensive than the same item in a rural town in the Midwest. These differences stem from regional economic factors such as rent, labor costs, and supply chain logistics. By mapping this price data against geographic coordinates, analysts can visualize how Chipotle adjusts its pricing strategy based on location-specific economic pressures.
Menu Consistency and Customization: Through Restaurant Menu Data Scraping , it becomes clear that Chipotle maintains a highly consistent core menu nationwide, including burritos, bowls, tacos, and salads. However, depending on the store, customization options such as guacamole, queso, and double meat portions may vary in price or availability. Some locations even feature exclusive items like plant-based proteins or limited-time seasonal salsas, catering to local preferences and ingredient availability.
Operational Insights: Using Food Delivery Scraping API Services , data can be cross-referenced with store operation hours to uncover deeper insights. For instance, some locations may offer a limited breakfast menu or have shortened hours, affecting the availability of certain menu items. This information reveals how Chipotle adapts its offerings based on local demand and operational feasibility.
Competitive Analysis: Restaurant Data Intelligence Services can help compare Chipotle's menu data with competitors such as Qdoba or Taco Bell. These comparisons highlight strategic distinctions—for example, Chipotle's focus on high-quality, fresh ingredients and customizable meals versus competitors' emphasis on value combos or fixed-price meals. Pricing data further clarifies how Chipotle positions itself in the competitive landscape of fast-casual dining, offering a unique balance between quality and affordability.
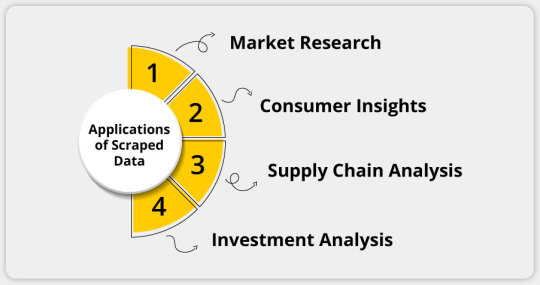
Applications of Scraped Data
The scraped menu data has numerous applications across industries:
Market Research: Restaurants and food chains can use the data to benchmark pricing, menu diversity, or regional preferences against Chipotle.
Consumer Insights: Based on customization data, analysts can study how Chipotle caters to dietary trends, such as vegan or low-carb options.
Supply Chain Analysis: Ingredient lists and availability can provide clues about Chipotle's sourcing and logistics, especially for items like avocados or organic produce.
Investment Analysis: Investors can use pricing and menu trends to assess Chipotle's market positioning and growth potential.
Visualizations, such as heat maps of price variations or bar charts of item popularity, can make these insights more accessible. Tools like Matplotlib or Tableau can transform raw data into compelling graphics for reports or presentations.
Scaling and Maintaining the Scraper

The scraper must be maintained and periodically rerun to keep the menu data current. Chipotle's website may undergo updates, requiring adjustments to the scraper's logic, such as new CSS selectors or API endpoints. Scheduling the scraper to run weekly or monthly ensures the dataset reflects changes like price adjustments, new menu items, or store openings/closures.
For scalability, deploying the scraper on a cloud platform like AWS or Google Cloud allows for distributed processing and storage. Containerization with Docker can simplify deployment while monitoring tools track the scraper's performance and alert developers to failures. Over time, the dataset becomes a longitudinal record of Chipotle's menu evolution, offering more profound insights into its business strategy.
How Food Data Scrape Can Help You?
Custom Web Scraping Solutions: We build tailored scraping tools to extract detailed menu data, including item names, descriptions, prices, and customization options from any food delivery platform or restaurant website.
Scalable Data Collection: Our infrastructure simultaneously supports scraping data from thousands of locations, which is ideal for national chains like Chipotle and ensures fast and reliable data delivery.
Data Cleaning & Structuring: We deliver clean, structured, and ready-to-use datasets formatted in JSON or CSV or integrated into databases for seamless use in analytics or dashboards.
Real-Time & Scheduled Updates: Access real-time or scheduled scraping to track menu changes, pricing updates, and new item launches without missing critical information.
Insight-Driven Analytics Support: Beyond data extraction, we help you integrate the results into dashboards or analytical tools, offering insights through Food Delivery Intelligence Services .
Conclusion
Scraping Chipotle's menu data from all US locations is a complex yet enriching task, offering deep insights into one of America's leading fast-casual dining brands. By utilizing Python, advanced scraping libraries, and structured storage methods, businesses can build detailed Food Delivery Datasets that uncover pricing trends, menu consistency, and regional differences. This information is invaluable for Food Delivery Intelligence Services, enabling data-driven decisions for market research and competitive benchmarking. Integrating the results into a Food Price Dashboard allows for real-time analysis of menu variations, helping businesses understand Chipotle's strategic positioning and adapt to evolving consumer preferences across the U.S.
Are you in need of high-class scraping services? Food Data Scrape should be your first point of call. We are undoubtedly the best in Food Data Aggregator and Mobile Grocery App Scraping service and we render impeccable data insights and analytics for strategic decision-making. With a legacy of excellence as our backbone, we help companies become data-driven, fueling their development. Please take advantage of our tailored solutions that will add value to your business. Contact us today to unlock the value of your data.
Source>> https://www.fooddatascrape.com/scraping-chipotle-menu-data-us-locations.php
#ScrapingChipotleMenuDatafromAllUSLocations#ChipotleMenuDataExtractionforAllUSBranches#ExtractChipotleMenuListingsAcrossUSStates#ScrapeChipotleMenuandPricingfromUSStore#WebScrapingChipotleMenuItemsfromUSA
0 notes
Text
Web Scraping 101: Everything You Need to Know in 2025

🕸️ What Is Web Scraping? An Introduction
Web scraping—also referred to as web data extraction—is the process of collecting structured information from websites using automated scripts or tools. Initially driven by simple scripts, it has now evolved into a core component of modern data strategies for competitive research, price monitoring, SEO, market intelligence, and more.
If you’re wondering “What is the introduction of web scraping?” — it’s this: the ability to turn unstructured web content into organized datasets businesses can use to make smarter, faster decisions.
💡 What Is Web Scraping Used For?
Businesses and developers alike use web scraping to:
Monitor competitors’ pricing and SEO rankings
Extract leads from directories or online marketplaces
Track product listings, reviews, and inventory
Aggregate news, blogs, and social content for trend analysis
Fuel AI models with large datasets from the open web
Whether it’s web scraping using Python, browser-based tools, or cloud APIs, the use cases are growing fast across marketing, research, and automation.
🔍 Examples of Web Scraping in Action
What is an example of web scraping?
A real estate firm scrapes listing data (price, location, features) from property websites to build a market dashboard.
An eCommerce brand scrapes competitor prices daily to adjust its own pricing in real time.
A SaaS company uses BeautifulSoup in Python to extract product reviews and social proof for sentiment analysis.
For many, web scraping is the first step in automating decision-making and building data pipelines for BI platforms.
⚖️ Is Web Scraping Legal?
Yes—if done ethically and responsibly. While scraping public data is legal in many jurisdictions, scraping private, gated, or copyrighted content can lead to violations.
To stay compliant:
Respect robots.txt rules
Avoid scraping personal or sensitive data
Prefer API access where possible
Follow website terms of service
If you’re wondering “Is web scraping legal?”—the answer lies in how you scrape and what you scrape.
🧠 Web Scraping with Python: Tools & Libraries
What is web scraping in Python? Python is the most popular language for scraping because of its ease of use and strong ecosystem.
Popular Python libraries for web scraping include:
BeautifulSoup – simple and effective for HTML parsing
Requests – handles HTTP requests
Selenium – ideal for dynamic JavaScript-heavy pages
Scrapy – robust framework for large-scale scraping projects
Puppeteer (via Node.js) – for advanced browser emulation
These tools are often used in tutorials like “Web scraping using Python BeautifulSoup” or “Python web scraping library for beginners.”
⚙️ DIY vs. Managed Web Scraping
You can choose between:
DIY scraping: Full control, requires dev resources
Managed scraping: Outsourced to experts, ideal for scale or non-technical teams
Use managed scraping services for large-scale needs, or build Python-based scrapers for targeted projects using frameworks and libraries mentioned above.
🚧 Challenges in Web Scraping (and How to Overcome Them)
Modern websites often include:
JavaScript rendering
CAPTCHA protection
Rate limiting and dynamic loading
To solve this:
Use rotating proxies
Implement headless browsers like Selenium
Leverage AI-powered scraping for content variation and structure detection
Deploy scrapers on cloud platforms using containers (e.g., Docker + AWS)
🔐 Ethical and Legal Best Practices
Scraping must balance business innovation with user privacy and legal integrity. Ethical scraping includes:
Minimal server load
Clear attribution
Honoring opt-out mechanisms
This ensures long-term scalability and compliance for enterprise-grade web scraping systems.
🔮 The Future of Web Scraping
As demand for real-time analytics and AI training data grows, scraping is becoming:
Smarter (AI-enhanced)
Faster (real-time extraction)
Scalable (cloud-native deployments)
From developers using BeautifulSoup or Scrapy, to businesses leveraging API-fed dashboards, web scraping is central to turning online information into strategic insights.
📘 Summary: Web Scraping 101 in 2025
Web scraping in 2025 is the automated collection of website data, widely used for SEO monitoring, price tracking, lead generation, and competitive research. It relies on powerful tools like BeautifulSoup, Selenium, and Scrapy, especially within Python environments. While scraping publicly available data is generally legal, it's crucial to follow website terms of service and ethical guidelines to avoid compliance issues. Despite challenges like dynamic content and anti-scraping defenses, the use of AI and cloud-based infrastructure is making web scraping smarter, faster, and more scalable than ever—transforming it into a cornerstone of modern data strategies.
🔗 Want to Build or Scale Your AI-Powered Scraping Strategy?
Whether you're exploring AI-driven tools, training models on web data, or integrating smart automation into your data workflows—AI is transforming how web scraping works at scale.
👉 Find AI Agencies specialized in intelligent web scraping on Catch Experts,
📲 Stay connected for the latest in AI, data automation, and scraping innovation:
💼 LinkedIn
🐦 Twitter
📸 Instagram
👍 Facebook
▶️ YouTube
#web scraping#what is web scraping#web scraping examples#AI-powered scraping#Python web scraping#web scraping tools#BeautifulSoup Python#web scraping using Python#ethical web scraping#web scraping 101#is web scraping legal#web scraping in 2025#web scraping libraries#data scraping for business#automated data extraction#AI and web scraping#cloud scraping solutions#scalable web scraping#managed scraping services#web scraping with AI
0 notes
Text
Tools to Scrape Amazon Product Offers and Sellers Data

Introduction
Scraping Amazon product offers and seller information can provide valuable insights for businesses, developers, and researchers. Whether you're analyzing competitor pricing, monitoring market trends, or building a price comparison tool, Scrape Amazon Product Offers and Sellers Data is crucial for staying competitive. This guide will walk you through code-based and no-code methods for extracting Amazon data, making it suitable for beginners and experienced developers. We'll cover the best tools, techniques, and practices to ensure practical and ethical data extraction. One key aspect is learning how to Extract Amazon Seller Prices Data accurately, allowing you to track and analyze pricing trends across various sellers. Additionally, we will delve into how to Scrape Amazon Seller Information, ensuring that all data is collected efficiently while staying within legal boundaries. By following the right approaches, you can access valuable data insights without facing potential legal or technical challenges, ensuring long-term success in your data-driven projects.
Why Scrape Amazon Product Offers and Sellers?
Amazon is a treasure trove of e-commerce data. Scraping product offers and seller information, Amazon is a goldmine of e-commerce data, offering valuable insights for businesses looking to gain a competitive edge. By Scraping Amazon Seller Listings Data, you can collect crucial information that helps in several areas:
Monitor pricing trends: Track the price changes for specific products or categories over time. This allows you to understand market dynamics and adjust your pricing strategy accordingly.
Analyze seller performance: Evaluate key metrics such as seller ratings, shipping options, and inventory availability. This data can help you understand how top-performing sellers operate and what factors contribute to their success.
Competitor analysis: Scrape Amazon Offer Listings with Selenium Data to compare your offerings against your competitors. You can identify pricing gaps, product availability, and more, which helps refine your market positioning.
Market research: By examining Amazon Seller Scraping API Integration data, you can identify high-demand products, emerging niches, and customer preferences. This information can guide your product development and marketing strategies.
Build tools: Use the scraped data to create practical applications like price comparison tools or inventory management systems. With the right dataset, you can automate and optimize various business processes.
However, scraping Amazon's vast marketplace comes with challenges. Its dynamic website structure, sophisticated anti-scraping measures (like CAPTCHAs), and strict legal policies create barriers. To overcome these obstacles, you must implement strategies that include using advanced tools to Extract Amazon E-Commerce Product Data. Success requires a tailored approach that matches your skill level and resource availability.
Legal and Ethical Considerations
Before diving into scraping, understand the legal and ethical implications:
Amazon's Terms of Service (ToS): Amazon prohibits scraping without permission. Violating ToS can lead to IP bans or legal action.
Data Privacy: Avoid collecting personal information about sellers or customers.
Rate Limiting: Excessive requests can overload Amazon's servers, violating ethical scraping practices.
robots.txt: Look for Amazon's robots.txt file to see which pages are disallowed for scraping.
To stay compliant:
Use Amazon's official Product Advertising API: for authorized data access (if applicable).
Scrape publicly available data sparingly: and respect rate limits.
Consult a legal expert: if you're building a commercial tool.
Code-Based Approach: Scraping with Python
For developers skilled in coding, Python provides robust libraries such as BeautifulSoup, Scrapy, and Selenium to Scrape Amazon E-Commerce Product Data efficiently. Using libraries like BeautifulSoup and Requests, you can easily extract product offers and seller details. Combining these tools allows you to navigate Amazon's complex structure and gather valuable insights. Whether you're looking to Scrape Amazon ecommerce Product Data for pricing trends or competitor analysis, this approach allows for streamlined data extraction. With the proper script, you can automate the process, gather vast datasets, and leverage them for various business strategies.
Prerequisites
Python 3.x installed.
Libraries: Install via pip:
Basic understanding of HTML/CSS selectors.
Sample Python Script
This script scrapes product titles, prices, and seller names from an Amazon search results page.
How It Works?
Headers: The script uses a User-Agent to mimic a browser, reducing the chance of being blocked.
Request: Sends an HTTP GET request to Amazon's search page for the query (e.g., "wireless earbuds").
Parsing: BeautifulSoup parses the HTML to locate product containers using Amazon's class names.
Extraction: Extracts the title, price, and seller for each product.
Error Handling: Handles network errors gracefully.
Challenges and Solutions
Dynamic Content: Some Amazon pages load data via JavaScript. Use Selenium or Playwright for dynamic scraping.
CAPTCHAs: Rotate proxies or use CAPTCHA-solving services.
IP Bans: Implement delays (time.sleep(5)) or use proxy services.
Rate Limits: Limit requests to 1–2 per second to avoid detection.
Scaling with Scrapy
For large-scale scraping, use Scrapy, a Python framework for building web crawlers. Scrapy supports:
Asynchronous requests for faster scraping.
Middleware for proxy rotation and user-agent switching.
Pipelines for storing data in databases like MySQL or MongoDB.
No-Code Approach: Using Web Scraping Tools
For non-developers or those looking for fast solutions, no-code tools provide an easy way to Extract Popular E-Commerce Website Data without needing to write any code. These tools offer visual interfaces allowing users to select webpage elements and automate data extraction. Common types of no-code tools include web scraping platforms, browser extensions, and API-based solutions. With these tools, you can quickly collect product offers, seller information, and more. Many businesses rely on Ecommerce Data Scraping Services to simplify gathering data from websites like Amazon, enabling efficient analysis and decision-making.
1. Visual Scraping Tool
Features: A desktop or cloud-based tool with a point-and-click interface, supports exporting data to CSV/Excel, and handles pagination.
Install the tool and start a new project.
Enter the Amazon search URL (e.g., https://www.amazon.com/s?k=laptop).
Use the visual editor to select elements like product title, price, or seller name.
Configure pagination to scrape multiple pages.
Run the task locally or in the cloud and export the data.
Pros: User-friendly, handles dynamic content, supports scheduling.
Cons: Free plans often have limits; premium plans may be required for large-scale scraping.
2. Cloud-Based Scraping Platform
Features: A free or paid platform with cloud scraping, API integration, and support for JavaScript-rendered pages.
Load the Amazon page in the platform's built-in browser.
Click on elements to extract (e.g., price, seller name).
Add logic to handle missing or inconsistent data.
Export results as JSON or CSV.
Pros: Free tiers often support small projects; intuitive for beginners.
Cons: Advanced features may require learning or paid plans.
3. Browser Extension Scraper
Features: A free browser-based extension for simple scraping tasks.
Install the extension in your browser.
Create a scraping template by selecting elements on the Amazon page (e.g., product title, price).
Run the scraper and download data as CSV.
Pros: Free, lightweight, and easy to set up.
Cons: Limited to static content; lacks cloud or automation features.
Choosing a No-Code Tool
Small Projects: Browser extension scrapers are ideal for quick, one-off tasks.
Regular Scraping: Visual scraping tools or cloud-based platforms offer automation and cloud support.
Budget: Start with free tiers, but expect to upgrade for large-scale or frequent scraping.
Start extracting valuable insights today with our powerful and easy-to-use scraping tools!
Contact Us Today!
Best Practices for Scraping Amazon
1. Respect Robots.txt: Avoid scraping disallowed pages.
2. Use Proxies: Rotate IPs to prevent bans. Proxy services offer residential proxies for reliable scraping.
3. Randomize Requests: Add delays and vary user agents to mimic human behavior.
4. Handle Errors: Implement retries for failed requests.
5. Store Data Efficiently: Use databases (e.g., SQLite, MongoDB) for large datasets.
6. Monitor Changes: Amazon's HTML structure changes frequently. Regularly update selectors.
7. Stay Ethical: Scrape only what you need and avoid overloading servers.
Alternative: Amazon Product Advertising API
Instead of scraping, consider Amazon's Product Advertising API for authorized access to product data. Benefits include:
Legal Compliance: Fully compliant with Amazon's ToS.
Rich Data: Access to prices, offers, reviews, and seller info.
Reliability: No risk of IP bans or CAPTCHAs.
Drawbacks:
Requires an Amazon Associate account with qualifying sales.
Limited to specific data points.
Rate limits apply.
To use the API:
1. Sign up for the Amazon Associates Program.
2. Generate API keys.
3. Use a library like boto3 (Python) to query the API.
How Product Data Scrape Can Help You?
Customizable Data Extraction: Our tools are built to adapt to various website structures, allowing you to extract exactly the data you need—whether it's product listings, prices, reviews, or seller details.
Bypass Anti-Scraping Measures: With features like CAPTCHA solving, rotating proxies, and user-agent management, our tools effectively overcome restrictions set by platforms like Amazon.
Supports Code and No-Code Users: Whether you're a developer or a non-technical user, our scraping solutions offer code-based flexibility and user-friendly no-code interfaces.
Real-Time and Scheduled Scraping: Automate your data collection with scheduling features and receive real-time updates, ensuring you always have the latest information at your fingertips.
Clean and Structured Output: Our tools deliver data in clean formats like JSON, CSV, or Excel, making it easy to integrate into analytics tools, dashboards, or custom applications.
Conclusion
Scraping Amazon product offers and seller information is a powerful way to Extract E-commerce Data and gain valuable business insights. However, thoughtful planning is required to address technical barriers and legal considerations. Code-based methods using Python libraries like BeautifulSoup or Scrapy provide developers with flexibility and control. Meanwhile, no-code tools with visual interfaces or browser extensions offer user-friendly options for non-coders to use Web Scraping E-commerce Websites .
For compliant access, the Amazon Product Advertising API remains the safest route. Regardless of the method, always follow ethical scraping practices, implement proxies, and handle errors effectively. Combining the right tools with innovative techniques can help you build an insightful Ecommerce Product & Review Dataset for business or academic use.
At Product Data Scrape, we strongly emphasize ethical practices across all our services, including Competitor Price Monitoring and Mobile App Data Scraping. Our commitment to transparency and integrity is at the heart of everything we do. With a global presence and a focus on personalized solutions, we aim to exceed client expectations and drive success in data analytics. Our dedication to ethical principles ensures that our operations are both responsible and effective.
Source>>https://www.productdatascrape.com/amazon-product-seller-scraping-tools.php
#ScrapeAmazonProductOffersAndSellersData#ExtractAmazonSellerPricesData#ScrapingAmazonSellerListingsData#AmazonSellerScrapingAPIIntegrationData#ExtractAmazonECommerceProductData
0 notes
Text
How to optimize your SEO marketing results? Get data through unlimited anti-detection browsers via proxy IP

In today's era of information, "data determines the fate" is no longer an empty slogan, but is actually changing the business situation with a thunderous force. In order to stand out in this data competition, many companies have turned their attention to advanced data collection methods. Among them, web crawling technology has become the only choice for many companies due to its excellence.
Role of web crawling:
Web crawling, a treasure of technology, perfectly integrates automated processes, data analysis and in-depth exploration of the Internet. It is like a wise explorer, swimming in the boundless ocean of the Internet, accurately obtaining target information, and injecting strong data power into SEO strategies. Through carefully designed web crawling plans, companies can not only gain insight into the actions of competitors, but also deeply analyze the market trends and inject strong power into their own digital marketing.

The perfect combination of SEO and web crawling
SEO, as the key cornerstone of digital marketing, its position is unshakable. And web crawling is a magical weapon in SEO optimization. It can not only collect and analyze the core data of competitors such as keyword distribution and page quality, but also help find and solve potential hidden dangers within the website, such as broken links, pages with high bounce rates, etc. With the synergy of SEO and web crawling, enterprises can quickly surpass competitors and seize the commanding heights of the market.
Legality and Compliance
While enjoying the convenience brought by web crawling, we must attach great importance to the legal norms and ethical standards behind it. Responsible web crawling operations should strictly follow the regulations and terms of the target website and respect copyright and privacy. Any infringement of the legitimate rights and interests of others may bring immeasurable legal risks to the enterprise. Therefore, when carrying out web crawling, enterprises must adhere to the principle of integrity and ensure that the operation is legal and compliant.
In order to help you master the skills of SEO web crawling, the following is a practical strategy for you:
Clear goals and detailed planning: Before starting crawling, you must clearly define your goals and needs. Develop a detailed crawling plan that covers elements such as the target website, the required data categories, and the expected results.
Selected tools and cutting-edge technologies: There are many web crawling tools on the market, such as BeautifulSoup, Scrapy, etc. It is crucial to choose the right tool according to your actual needs and technical level.
Implement crawling strategy: Execute crawling strategy according to your plan and technical selection. Be sure to comply with the regulations of the target website's robots.txt file and the use restrictions of the API.
Data processing and in-depth analysis: After the crawling is completed, the raw data needs to be cleaned, integrated and analyzed. Use data analysis tools to deeply explore the value of data, gain insights into market trends and SEO optimization points.
Strategy optimization and implementation: Adjust SEO strategy and digital marketing plan based on analysis results. Translate deep insights into practical actions, and continuously optimize the content and structure of the website to improve rankings in search engines.
Effect evaluation and flexible adjustment: Regularly evaluate the effectiveness of SEO and adjust strategies in a timely manner according to market changes. Maintaining a keen sense of data and accurate insight into the market is the key to success.
How does the proxy IP unlimited anti-detection browser empower web crawling
Proxy IP unlimited anti-detection browsers, such as Bit Browser, play an important role in the operation of web crawling. Their unique function settings make web crawling more covert and efficient when collecting data. Let's take a look at the advantages that the proxy IP unlimited anti-detection browser brings to web crawling:
High camouflage
Proxy IP unlimited anti-detection browser can simulate a variety of hardware and software environments. Not only can it cover a variety of operating systems, different browsers and their versions, various kernels, but also user agents (User-Agent), etc. Even subtle features such as fonts, languages, and resolutions can be simulated. Such a powerful simulation ability allows web crawlers to appear in a new "identity" every time a request is made, greatly reducing the possibility of being detected and blocked by the target website.
Captcha processing ability
Facing those websites that use captchas to prevent crawlers, the proxy IP unlimited anti-detection browser has a clever way to deal with it. It can automatically identify and process verification codes. When web crawling encounters verification links, it can respond quickly and continue data crawling, thereby effectively improving the efficiency of crawlers.
Independent session control
Proxy IP unlimited anti-detection browser provides a separate data storage area, cookies, cache, and session information for each web crawling task. This is like each task comes from a completely different user. This design not only avoids being identified as a duplicate or abnormal user by the target website, but also allows web crawlers to manage multiple accounts at the same time, thereby collecting richer and more personalized data.
Flexible IP allocation
Proxy IP unlimited anti-detection browser supports the configuration of multiple IP addresses. This means that web crawlers can make requests from different network locations. This strategy effectively reduces the risk of being blocked due to excessive requests from a single IP. Even if an IP is restricted, web crawlers can quickly switch to other available IP addresses and continue to work.
Automated script operation
Relying on the automation function of the proxy IP unlimited anti-detection browser, users can write scripts to automatically execute a series of complex web crawling tasks. From browsing pages, clicking links, to crawling data and filling out forms, all operation steps can be automated, which greatly speeds up the work speed of web crawling and improves accuracy.
Summary:
With the continuous innovation of technology and the increasingly fierce market competition, web crawling technology will play a pivotal role in the field of digital marketing. It can not only provide enterprises with valuable data support and deep insights, but also help enterprises to stand out in the fierce market competition. Mastering web crawling technology will open a new chapter for your digital marketing journey. In addition, it should be pointed out that in the process of pursuing efficient data crawling, we should also pay attention to the use of anti-detection technology. Top proxy IP unlimited anti-detection browsers such as Bit Browser can help you break through the restrictions and detection mechanisms of the website and achieve efficient and safe web crawling. Combining powerful web crawling with proxy IP unlimited anti-detection browsers, you will move forward courageously and unstoppably on the road of digital marketing!
0 notes
Text
Understanding Web Scraping: Techniques, Ethics & Professional Guidance

Web scraping is a widely-used method for automatically extracting information from websites. It allows users to programmatically gather large volumes of data without manual copying and pasting. This technology has become essential for professionals in fields like market research, journalism, and e-commerce. In this blog, we’ll explore what web scraping is, how it works, and why practicing it ethically matters—along with how partnering with experts in web development can enhance your data strategy.
What Is Web Scraping?
At its core, web scraping is a digital technique that simulates human browsing to extract useful information from websites. It involves writing scripts that send requests to web pages, parse the HTML code, and organize extracted content—such as prices, reviews, or contact info—into structured formats like spreadsheets or databases.
Many developers choose languages like Python for web scraping due to its clean syntax and powerful libraries like Beautiful Soup and Scrapy. These tools make it easier to navigate and extract data from complex websites efficiently.
Common Applications of Web Scraping
Web scraping serves a wide variety of purposes across different industries:
Market Research: Businesses collect consumer feedback and competitor pricing to understand market trends.
E-commerce Monitoring: Online stores track product availability and prices across multiple platforms.
News & Journalism: Reporters gather public data or breaking information to support their stories.
Academic Research: Analysts compile datasets for large-scale studies or surveys.
By leveraging these insights, companies can fine-tune their strategies and stay ahead of the competition.
Why Ethical Web Scraping Matters
While web scraping can be incredibly useful, it must be done responsibly. Key ethical considerations include:
Respect for Consent: Many websites specify in their terms of service whether scraping is allowed. Ignoring these terms may result in legal issues or damage to your reputation.
Robots.txt Compliance: Most websites use a file called robots.txt to control which parts of their site are accessible to bots. Ethical scrapers always check and follow these rules.
Data Usage Responsibility: Scraped data must be handled with care, especially if it contains personal or sensitive information. It should never be exposed or misused.
Maintaining an ethical stance helps preserve trust across the digital ecosystem and ensures long-term viability of web scraping as a business tool.
How to Practice Ethical Web Scraping
To make your web scraping efforts both effective and ethical, consider the following best practices:
Review Website Policies: Always check the site’s terms of service and robots.txt file before scraping.
Limit Request Frequency: Sending too many requests at once can overload a website’s server. Adding delays between requests is a respectful practice.
Anonymize Sensitive Data: If your project involves sharing scraped data, make sure it does not expose personal information.
Use Reliable Tools and Secure Platforms: Implement scraping on well-developed systems that adhere to best practices in coding and data security.
Get Professional Help with Ethical Web Development
While scraping tools are powerful, integrating them into a secure and compliant workflow requires professional expertise. That’s where a reliable partner like Dzinepixel comes in. As a leading web development company in India, Dzinepixel has worked with a wide range of businesses to create customized, secure, and ethical digital solutions.
Whether you need assistance building an efficient scraping tool or a full-fledged data dashboard, their expert developers can help you:
Create scalable and secure backend systems
Ensure compliance with data protection laws
Develop user-friendly interfaces for visualizing scraped data
Build APIs and data integration pipelines
By relying on an experienced web development team, you can streamline your scraping workflows while avoiding legal or technical pitfalls.
Final Thoughts
Web scraping is a valuable technique that helps individuals and organizations access critical data quickly and efficiently. However, it’s essential to approach it with caution and ethics. By understanding how scraping works, respecting website policies, and managing data responsibly, you ensure long-term success and sustainability.
If you're considering a web scraping project, or if you want to build a robust and secure platform for your business, explore the services offered by Dzinepixel’s web development team. Their expertise in building high-performance digital systems can give you a competitive edge while staying compliant with all ethical and legal standards.
Start small—review a website’s policies, test your scraping tool responsibly, or consult a professional. The right foundation today ensures scalable, secure success tomorrow.
#best web development agencies india#website design and development company in india#website development company in india#web design company india#website designing company in india#digital marketing agency india
0 notes
Text
Understanding Web Scraping: Techniques, Ethics & Professional Guidance

Web scraping is a widely-used method for automatically extracting information from websites. It allows users to programmatically gather large volumes of data without manual copying and pasting. This technology has become essential for professionals in fields like market research, journalism, and e-commerce. In this blog, we’ll explore what web scraping is, how it works, and why practicing it ethically matters—along with how partnering with experts in web development can enhance your data strategy.
What Is Web Scraping?
At its core, web scraping is a digital technique that simulates human browsing to extract useful information from websites. It involves writing scripts that send requests to web pages, parse the HTML code, and organize extracted content—such as prices, reviews, or contact info—into structured formats like spreadsheets or databases.
Many developers choose languages like Python for web scraping due to its clean syntax and powerful libraries like Beautiful Soup and Scrapy. These tools make it easier to navigate and extract data from complex websites efficiently.
Common Applications of Web Scraping
Web scraping serves a wide variety of purposes across different industries:
Market Research: Businesses collect consumer feedback and competitor pricing to understand market trends.
E-commerce Monitoring: Online stores track product availability and prices across multiple platforms.
News & Journalism: Reporters gather public data or breaking information to support their stories.
Academic Research: Analysts compile datasets for large-scale studies or surveys.
By leveraging these insights, companies can fine-tune their strategies and stay ahead of the competition.
Why Ethical Web Scraping Matters
While web scraping can be incredibly useful, it must be done responsibly. Key ethical considerations include:
Respect for Consent: Many websites specify in their terms of service whether scraping is allowed. Ignoring these terms may result in legal issues or damage to your reputation.
Robots.txt Compliance: Most websites use a file called robots.txt to control which parts of their site are accessible to bots. Ethical scrapers always check and follow these rules.
Data Usage Responsibility: Scraped data must be handled with care, especially if it contains personal or sensitive information. It should never be exposed or misused.
Maintaining an ethical stance helps preserve trust across the digital ecosystem and ensures long-term viability of web scraping as a business tool.
How to Practice Ethical Web Scraping
To make your web scraping efforts both effective and ethical, consider the following best practices:
Review Website Policies: Always check the site’s terms of service and robots.txt file before scraping.
Limit Request Frequency: Sending too many requests at once can overload a website’s server. Adding delays between requests is a respectful practice.
Anonymize Sensitive Data: If your project involves sharing scraped data, make sure it does not expose personal information.
Use Reliable Tools and Secure Platforms: Implement scraping on well-developed systems that adhere to best practices in coding and data security.
Get Professional Help with Ethical Web Development
While scraping tools are powerful, integrating them into a secure and compliant workflow requires professional expertise. That’s where a reliable partner like Dzinepixel comes in. As a leading web development company in India, Dzinepixel has worked with a wide range of businesses to create customized, secure, and ethical digital solutions.
Whether you need assistance building an efficient scraping tool or a full-fledged data dashboard, their expert developers can help you:
Create scalable and secure backend systems
Ensure compliance with data protection laws
Develop user-friendly interfaces for visualizing scraped data
Build APIs and data integration pipelines
By relying on an experienced web development team, you can streamline your scraping workflows while avoiding legal or technical pitfalls.
Final Thoughts
Web scraping is a valuable technique that helps individuals and organizations access critical data quickly and efficiently. However, it’s essential to approach it with caution and ethics. By understanding how scraping works, respecting website policies, and managing data responsibly, you ensure long-term success and sustainability.
If you're considering a web scraping project, or if you want to build a robust and secure platform for your business, explore the services offered by Dzinepixel’s web development team. Their expertise in building high-performance digital systems can give you a competitive edge while staying compliant with all ethical and legal standards.
Start small—review a website’s policies, test your scraping tool responsibly, or consult a professional. The right foundation today ensures scalable, secure success tomorrow.
#website development company in india#web design company india#website designing company in india#best web development agencies india#digital marketing agency india#online reputation management companies in india
0 notes