#hire scrapy developers
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is funded by 13 investors.
Text
Hire Expert Scrapy Developers for Scalable Web Scraping & Data Automation
Looking to extract high-value data from the web quickly and accurately? At Prospera Soft, we offer top-tier Scrapy development services to help businesses automate data collection, gain market insights, and scale operations with ease.
Our team of Scrapy experts specializes in building robust, Python-based web scrapers that deliver 10X faster data extraction, 99.9% accuracy, and full cloud scalability. From price monitoring and sentiment analysis to lead generation and product scraping, we design intelligent, secure, and GDPR-compliant scraping solutions tailored to your business needs.
Why Choose Our Scrapy Developers?
✅ Custom Scrapy Spider Development for complex and dynamic websites
✅ AI-Optimized Data Parsing to ensure clean, structured output
✅ Middleware & Proxy Rotation to bypass anti-bot protections
✅ Seamless API Integration with BI tools and databases
✅ Cloud Deployment via AWS, Azure, or GCP for high availability
Whether you're in e-commerce, finance, real estate, or research, our scalable Scrapy solutions power your data-driven decisions.
#Hire Expert Scrapy Developers#scrapy development company#scrapy development services#scrapy web scraping#scrapy data extraction#scrapy automation#hire scrapy developers#scrapy company#scrapy consulting#scrapy API integration#scrapy experts#scrapy workflow automation#best scrapy development company#scrapy data mining#hire scrapy experts#scrapy scraping services#scrapy Python development#scrapy no-code scraping#scrapy enterprise solutions
0 notes
Text
Web Scraping CareerBuilder Reviews Data for Insights
Web Scraping CareerBuilder Reviews Data for Insights

Introduction
In the digital age, job boards are more than just platforms to apply for work—they're ecosystems of user-generated content, especially in the form of company reviews. Among the most recognized job sites is CareerBuilder, a platform with thousands of reviews by job seekers and employees. For HR tech firms, market analysts, and competitive intelligence teams, these reviews represent a treasure trove of insights. But how can you harness this at scale?
The answer lies in Web Scraping CareerBuilder Reviews Data.
This guide is a deep-dive into the CareerBuilder Reviews Data Scraping process—covering the what, why, and how of extracting review data to make smarter business, hiring, and research decisions. We'll walk you through the tools and techniques to Scrape CareerBuilder Reviews Data, build your own CareerBuilder Reviews Data Extractor, and deploy a powerful CareerBuilder Reviews Scraper to stay ahead of market dynamics.
Why Scrape CareerBuilder Reviews Data?

CareerBuilder features reviews on companies from employees and candidates. These reviews typically include feedback on work culture, compensation, management, growth opportunities, and interview experiences.
Here’s why extracting this data is vital:
1. Employee Sentiment Analysis
Discover how employees feel about companies, departments, or locations. Sentiment trends help you understand real-time workforce satisfaction.
2. Employer Branding Benchmarking
Compare company reputations side-by-side. This is key for companies improving their online image.
3. Candidate Experience Feedback
Find what candidates say about interview processes, hiring practices, and recruiter behavior.
4. HR Strategy Development
HR departments can use insights to revamp workplace policies, adjust compensation, and improve employee engagement.
5. Competitive Intelligence
Analyze reviews of competitors to understand where they excel—or fall short—in employee satisfaction.
What Information Can You Extract?

A comprehensive CareerBuilder Reviews Data Extractor can pull the following elements:
Star ratings (overall, culture, management, etc.)
Review title and content
Date of review
Company name
Location
Reviewer's job title or department
Length of employment
Pros and Cons sections
Advice to management (if available)
Job seeker or employee tag
This structured data gives an all-around view of the employer landscape across industries and geographies.
Tools to Scrape CareerBuilder Reviews Data

To create a scalable CareerBuilder Reviews Scraper, here’s a reliable tech stack:
Python Libraries:
Requests – for HTTP requests
BeautifulSoup – for HTML parsing
Selenium – for dynamic content and rendering JavaScript
Scrapy – for scalable crawling
Data Handling & Analysis:
pandas, NumPy – data wrangling
TextBlob, NLTK, spaCy – sentiment analysis
matplotlib, seaborn, Plotly – for visualization
Storage:
CSV, JSON – quick exports
PostgreSQL, MongoDB – structured storage
Elasticsearch – for full-text search indexing
Sample Python Script to Scrape CareerBuilder Reviews
Here’s a simplified script using BeautifulSoup:
import requests
from bs4 import BeautifulSoup
url = 'https://www.careerbuilder.com/company/...views';
headers = {
'User-Agent': 'Mozilla/5.0
'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
reviews = soup.find_all('div', class_='review-card')
for review in reviews:
rating = review.find('div', class_='stars').text title = review.find('h3').text
body = review.find('p', class_='review-content').text
print(f'Title: {title}, Rating: {rating}, Review: {body}')
Disclaimer: Actual class names and review structures may differ. You may need to adapt this code for dynamic pages using Selenium.
Real-World Applications of Review Data Scraping

Let’s explore some practical use cases of CareerBuilder Reviews Data Scraping:
For Employers:
Compare your brand reputation to competitors
Monitor changes in employee satisfaction post-policy updates
Identify office locations with poor feedback
For HR SaaS Companies:
Enrich product dashboards with scraped review insights
Train machine learning models on employee sentiment data
For Market Researchers:
Study employee satisfaction trends across industries
Track labor issues, such as mass layoffs or toxic work culture indicators
For Job Portals:
Provide aggregated ratings to users
Personalize job suggestions based on culture-fit reviews
Ethical & Legal Guidelines for Scraping

While Scraping CareerBuilder Reviews Data offers great value, you must follow best practices:
Respect robots.txt directives
Avoid personal or sensitive data
Include crawl delays and request throttling
Refrain from scraping at disruptive frequencies
Use proxies/IP rotation to avoid blocking
Also, check CareerBuilder’s Terms of Use to ensure compliance.
Building Your CareerBuilder Reviews Scraper Pipeline

Here’s a production-grade pipeline for CareerBuilder Reviews Data Scraping:
1. URL Discovery
Identify companies or categories you want to scrape. Use sitemaps or search patterns.
2. Page Crawling
Scrape multiple pages of reviews using pagination logic.
3. Data Extraction
Pull fields like rating, content, date, title, pros, and cons using HTML selectors.
4. Storage
Use databases or export to JSON/CSV for quick access.
5. Analysis Layer
Add a sentiment analyzer, keyword extractor, and visual dashboards.
6. Scheduling
Automate scraping at regular intervals using cron jobs or Airflow.
How to Analyze Scraped CareerBuilder Review Data?

Once you’ve scraped data, here are some advanced analytical strategies:
1. Sentiment Classification
Use models like VADER or BERT to classify sentiment into:
Positive
Neutral
Negative
2. Time-Series Analysis
Track how ratings evolve monthly or quarterly—especially during key events like CEO changes or layoffs.
3. Topic Modeling
Use NLP techniques like LDA to surface common themes (e.g., “work-life balance”, “micromanagement”, “career growth”).
4. Word Clouds
Visualize the most frequently used words across thousands of reviews.
5. Company Comparisons
Benchmark companies across industries by average rating, sentiment, and keyword frequency.
Using Machine Learning on CareerBuilder Review Data
Once you’ve scraped thousands of reviews, you can apply ML to:
Predict employee churn risk based on review patterns
Categorize reviews automatically
Identify toxic management patterns
Personalize job recommendations based on review preferences
Insightful Metrics You Can Derive
Here’s what you can uncover with a solid CareerBuilder Reviews Scraper:MetricDescriptionAverage Company RatingTrack overall satisfactionSentiment Score % Positive vs.Negative reviewsTop Complaints"Most frequent "Cons"Top PraisesMost frequent "Pros"Review Volume by LocationPopularity by regionCEO Approval TrendsBased on keywords and sentimentIndustry BenchmarkingCompare firms within same field
Sample Dashboards for Review Analysis

You can visualize the data through dashboards built with tools like:
Tableau
Power BI
Looker
Plotly Dash
Streamlit
Example KPIs to showcase:
Average review score by location
Negative review spike alerts
Pie chart of top "Pros" and "Cons"
Line chart of review sentiment over time
Automating and Scaling the Process

To scale your CareerBuilder Reviews Scraper, use:
Scrapy + Splash: For JS-rendered pages
Rotating Proxies + User Agents: To avoid detection
Airflow: For scheduling and workflow management
Docker: For containerizing your scraper
Cloud (AWS, GCP): For deployment and scalability
Example Findings from Scraping 50,000 Reviews

If you scraped 50K reviews across 1,000 companies, you might find:
68% mention work-life balance as a top concern
Only 40% express satisfaction with upper management
Healthcare and tech have highest approval ratings
Locations in California show lower satisfaction vs. Texas
Top complaint keywords: “no growth”, “toxic environment”, “low pay”
Why Choose Datazivot?

At Datazivot, we deliver precise and reliable Web Scraping Job Posting Reviews Data to help you uncover genuine insights from job seekers and employees. Our expert CareerBuilder reviews data scraping services enable you to scrape CareerBuilder reviews data efficiently for market analysis, HR strategy, and reputation management. With our advanced CareerBuilder reviews data extractor, you get structured and scalable data tailored to your needs. Trust our robust CareerBuilder reviews scraper to capture real-time feedback and sentiment from CareerBuilder users. Choose Datazivot for accurate, secure, and high-performance review data solutions that give your organization a competitive advantage.
Conclusion
As the HR landscape becomes more data-driven, Web Scraping CareerBuilder Reviews Data is no longer optional—it’s essential. With the right tools and compliance measures, you can unlock invaluable insights hidden in thousands of employee and candidate reviews.
From improving workplace culture to optimizing recruitment strategies, CareerBuilder Reviews Data Scraping enables better decisions across industries. If you're ready to Scrape CareerBuilder Reviews Data, build a CareerBuilder Reviews Data Extractor, or deploy a CareerBuilder Reviews Scraper, now’s the time to act. Ready to harness the power of reviews?
Partner with Datazivot today and turn CareerBuilder feedback into actionable insights!
Originally published by https://www.datazivot.com/careerbuilder-reviews-data-scraping-insights.php
#Web Scraping CareerBuilder Reviews#CareerBuilder Reviews Scraping#Scrape CareerBuilder Reviews Data#CareerBuilder Reviews Data Extractor#CareerBuilder Reviews Scraper
0 notes
Text
Master In Data Science
MASTER IN DATA SCIENCE
Data science is the study of data to extract meaningful insights for business. It is a multidisciplinary approach that combines principles and practices from the fields of mathematics, statistics, artificial intelligence, and computer engineering to analyze large amounts of data. This analysis helps data scientists to ask and answer questions like what happened, why it happened, what will happen, and what can be done with the results.
HOW TO EARN MONEY WITH DATA SCIENCE?
There are many several ways to earn money with data science skills.
Data Scientist positions, many company hires data scientists to analyze their data, extract insights, and inform decision-making processes. Job roles can include machine learning engineer, data analyst, or business intelligence analyst.
Various industries, such as finance, healthcare, e-commerce, and technology, have a growing demand for data scientists with domain-specific knowledge
INNOVATION AND AUTOMATION
Innovation and automation play crucial roles in advancing the field of data science, enhancing efficiency. Innovation and automation in data science are pivotal for maximizing the value of data, reducing manual effort, and empowering organizations to make informed decisions in a rapidly evolving technological landscape..
Automated Data Collection and Cleaning: Automated tools can be extract data from websites, and other online sources. Web scraping libraries, such as Scrapy in Python, help automate this process.
Automated data cleaning tools help in identifying and handling missing values, outliers, and inconsistencies, saving time and improving data quality.
Some examples of innovation in data science include the development of deep learning algorithms, the use of natural language processing in sentiment analysis and the creation of interactive data dashboards for easier access to insights. These innovations are helping organizations to make better decisions, gain deeper insights into their data, and drive business growth.
DEMAND AND SUPPLY
The demand and supply of data science have experienced significant shifts in recent years. Data science is a multidisciplinary field that combines techniques from statistics, mathematics, computer science, and domain-specific knowledge to extract valuable insights and knowledge from data.
Demand for Data Science:
Artificial Intelligence and Machine Learning: The integration of artificial intelligence and machine learning in various applications has driving the demand for data scientists who can develop and implement advanced algorithms.
Industry adoption: Data science has gained widespread adoption across the industry such as finance, marketing and technology. As businesses recognize the value of data-driven insights, the demand for skilled data scientists has increased.
Supply for Data Science:
Online Learning Platforms: The availability of online courses and certifications has made it easier for individuals to obtain data science skills. Platforms like Datacamp, edX and many more, making education more accessible.
Self Learning Resources: The quantity of online resources, including tutorials, and open- source tools, it allows individuals to learn and practice data science skills.
HIGH PAYING JOB OPPORTUNITIES
Data science is valid field that offers various high- paying job opportunities due to its increasing demand, here are some high paying jobs role in data science:
Data Scientist: Data scientists gather and analyze huge sets of structured as well as unstructured data. They use unstructured data from sources like emails, social media feeds, and smart devices. Usually, they need to combine concepts of mathematics, statistics, and science. The reason behind data scientist highest salary in India is that they are also analytical experts who employ their skills in both social science and technical domains to determine trends and handle data.
Data Engineer: Data Engineers focus on designing, constructing, and maintaining the systems and architectures necessary for large-scale data processing. They play a crucial role in the data pipeline. Skilled Data Engineers are in demand as organizations seek to manage and process vast amounts of data efficiently.
Machine Learning Engineer: As a machine learning engineer, design and implement machine learning algorithms and models. They work on creating systems that can learn and improve from experience.
Salaries for Machine Learning Engineers are often among the highest in the data science field due to the specialized knowledge and required.
Data Science Manager: A data science manager is a professional who oversees the data analysis and management within an organization. They lead and direct a team of data scientists, analysts, and engineers to gather, process, analyze, and interpret large and complex datasets.
A data science manager provides guidance, support, and mentorship to team members, ensuring that projects are completed on track and meet the organization's goals. They also help to identify areas where data can be used to gain insights and drive decision-making.
Quantitative Analyst: A quantitative analyst is a professional who applies quantitative methods to help businesses and organizations make better decisions. They can work in a variety of fields, including finance, healthcare, and technology. In finance, a quantitative analyst might use mathematical models to price financial instruments or assess risk. In healthcare, they might analyze patient data to predict outcomes or identify trends. The job requires a strong background in mathematics, statistics and computer science, as well as practical knowledge of finance markets and instruments.
FLEXIBILITY
Flexibility in data science refers to the ability to adapt to changes in data, or tools. It involves being able to work with different data types, structures and sources, as well as adjusting analysis methods and techniques to suit the specific needs of a project. Here are several aspects highlighting the flexibility within the realm of data science:-
Problem-Solving Orientation: Data scientists are trained to approach problems analytically and find data-driven solutions. This problem-solving orientation is applicable across different scenarios and industries, making them valuable contributors to various projects.
Application Across Industries: Professionals in this field can apply their expertise in finance, healthcare, marketing, e-commerce, technology, and many other sectors. This industry nature allows for career flexibility and the opportunity to work in various domains.
Project Flexibility: Project Diversity in Data scientists may work on a variety of projects, from exploratory data analysis and predictive modeling to designing. The ability to adapt to different project requirements is valuable.
Work Arrangement Flexibility:
Remote Work- Remote work provides data scientists work with flexibility to collaborate with teams globally, contributing to projects without geographical constraints.
Freelancing- Some data scientists opt for freelancing or consulting roles, providing services to multiple clients or organizations. This allows for flexibility in choosing projects and managing work schedules.
0 notes
Text
A Comprehensive Guide to Grubhub Data Scraping and Grubhub API
Grubhub is a popular online food ordering and delivery platform that connects hungry customers with local restaurants. With over 300,000 restaurants listed on the platform, Grubhub has become a go-to for many people looking for a quick and convenient meal. As a business owner, it's important to stay on top of the competition and understand the market trends. This is where Grubhub data scraping and the Grubhub API come into play.
What is Grubhub Data Scraping?
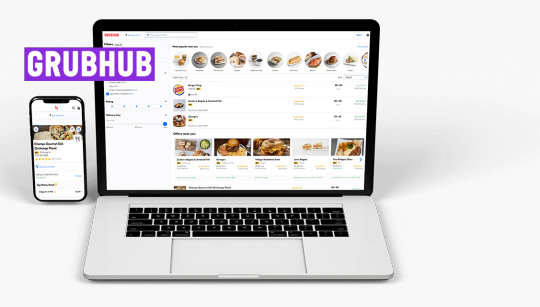
Grubhub data scraping is the process of extracting data from the Grubhub website. This data can include information such as restaurant names, menus, prices, ratings, and reviews. By scraping this data, businesses can gain valuable insights into their competitors' offerings and customer preferences. This information can then be used to make informed decisions about pricing, menu items, and marketing strategies.
How to Scrape Data from Grubhub
There are a few different methods for scraping data from Grubhub. One option is to use a web scraping tool, such as Octoparse or Scrapy, which allows you to extract data from websites without any coding knowledge. These tools have pre-built templates for scraping Grubhub data, making the process quick and easy.
Another option is to hire a professional data scraping service. These services have the expertise and resources to scrape large amounts of data from Grubhub efficiently and accurately. They can also provide the data in a structured format, making it easier to analyze and use for business purposes.
What is the Grubhub API?
The Grubhub API (Application Programming Interface) is a set of tools and protocols that allow developers to access data from the Grubhub platform. This data can include restaurant information, menus, and orders. The API also allows developers to integrate foods data services into their own applications, such as restaurant websites or mobile apps.
How to Use the Grubhub API
To use the Grubhub API, you will need to register for a Grubhub developer account and obtain an API key. This key will be used to authenticate your requests to the API. Once you have your API key, you can use it to make requests for data from the Grubhub platform. The API documentation provides detailed instructions on how to make these requests and how to handle the data returned.
Benefits of Grubhub Data Scraping and API
By utilizing Grubhub data scraping and the Grubhub API, businesses can gain a competitive edge in the market. They can gather valuable insights into their competitors' offerings and customer preferences, allowing them to make informed decisions about their own business strategies. Additionally, by integrating the Grubhub API into their own applications, businesses can provide a more seamless and convenient experience for their customers.
Conclusion
In today's competitive market, it's important for businesses to stay on top of the latest trends and understand their competitors. Grubhub data scraping and the Grubhub API provide valuable tools for gathering and utilizing this information. By utilizing these tools, businesses can make data-driven decisions and stay ahead of the competition. Have you used Grubhub data scraping or the Grubhub API for your business? Let us know in the comments.
#food data scraping#food data scraping services#restaurant data scraping#web scraping services#restaurantdataextraction#zomato api#fooddatascrapingservices#grocerydatascraping#grocerydatascrapingapi
0 notes
Text
In this blog, you are going to learn about why you should choose Scrapy over Beautiful Soup for web scraping in Python language. Start reading now.
#scrapy#scrapy for web scraping#scrapy in python#python technology#python development#hire python developer#innvonix
1 note
·
View note
Link
Python web Development
Website: http://www.connectinfosoft.com/
Our Services: https://www.connectinfosoft.com/python-web-development

THERE ARE REASONS FOR MAKING IT ONE OF THE MOST POPULAR CHOICES.
1. Python Game Development
2. Python Software Development
3. Web Development Using Python
4. Python Mobile App Development
5. Python Android App Development
6. Python Web Application Development
7. Python Desktop Application Development
8. Integration of OAuth 2 & JWT For Data Authentication.
9. Core Python Programming.
10. Docker Based Deployment.
11. Scrapy Framework For Web Scraping
#DjangoWebDevelopmentServices#PythonDevelopmentServices#PythonWebDevelopersInUSA#DjangoWebDevelopmentCompany#PythonWebDevelopmentCompany#PythonWebDeveloper#hiredjangodeveloper
3 notes
·
View notes
Link
THERE ARE REASONS FOR MAKING IT ONE OF THE MOST POPULAR CHOICES.
1. Python Game Development
2. Python Software Development
3. Web Development Using Python
4. Python Mobile App Development
5. Python Android App Development
6. Python Web Application Development
7. Python Desktop Application Development
8. Integration of OAuth 2 & JWT For Data Authentication.
9. Core Python Programming.
10. Docker Based Deployment.
11. Scrapy Framework For Web Scraping
Want to learn what we can do for you?
Let's talk
Contact us:
Visit us: http://www.connectinfosoft.com/contact_us.php
Our Services: http://www.connectinfosoft.com/service.php
Phone: (225) 361-2741
Connect InfoSoft Technologies Pvt.Ltd
#HireDjangoDeveloper#PythonWebDeveloper#PythonWebDevelopmentCompany#DjangoWebDevelopmentCompany#PythonWebDevelopersInUSA#PythonDevelopmentServices#DjangoWebDevelopmentServices
2 notes
·
View notes
Text
10 Best Practices for Implementing Automated Web Data Mining Using Web Scraping Tools
A famous manufacturer of household products, working with a number of retailers across the globe, wanted to capture product reviews from retail websites. The objective was to understand consumer satisfaction levels and identify retailers violating the MAP (Minimum Advertised Policy) policy. The manufacturer partnered with a web scraping and distributed server technology expert to get an accurate, comprehensive, and real-time overview of their requirements. It took them no time to get complete control over the retailers and pre-empt competitors with a continuous sneak peek into their activities. This example underscores the importance of web scraping as a strategic business planning tool.
Web scraping is the process of extracting unique, rich, proprietary, and time-sensitive data from websites for meeting specific business objectives such as data mining, price change monitoring, contact scrapping, product review scrapping, and so on. The data to be extracted is primarily contained in a PDF or a table format which renders it unavailable for reuse. While there are many ways to accomplish web data scraping, most of them are manual, and so tedious and time-consuming. However, in the age of automation, automated web data mining has replaced the obsolete methods of data extraction and transformed it into a time-saving and effortless process.
How is Web Data Scraping Done
Web data scraping is done either by using software or writing codes. The software used to scrap can be locally installed in the targeted computer or run in Cloud. Yet another technique is hiring a developer to build highly customised data extraction software to execute specific requirements. The most common technologies used for scraping are Wget, cURL, HTTrack, Selenium, Scrapy, PhantomJS, and Node.js.
Best Practice for Web Data Mining
1) Begin With Website Analysis and Background Check
To start with, it is very important to develop an understanding of the structure and scale of the target website. An extensive background check helps check robot.txt and minimise the chance of getting detected and blocked; examine the sitemap for well-defined and detailed crawling; estimate the size of the website to understand the effort and time required; identify the technology used to build the website for seamless crawling and more.
2) Treat Robot.txt -Terms, and Conditions
The robots.txt file is a valuable resource that helps the web crawler eliminate the chances of being spotted, as well as uncover the structure of a website. It’s important to understand and follow the protocol of robot.txt files to avoid legal ramifications. Complying with access rules, visit times, crawl rate limiting, request rate helps to adhere to the best crawling practises and carry out ethical scrapping. Web scraping bots studiously read and follow all the terms and conditions.
3) Use Rotating IPs and Minimise the Loads
More requests from a single IP address alert a site and induce it to block the IP address. To escape this possibility, it’s important to create a pool of IP addresses and route requests randomly through the pool of IP addresses. As requests on the target website come through different IPs, the load of requests from a single IP gets minimised, thereby minimising the chances of being spotted and blacklisted. With automated data mining, however, this problem stands completely eliminated.
4) Set Right Frequency to Hit Servers
In a bid to fetch data as fast as possible most web scraping activities send more requests to the host server than normal. This triggers suspicion about unhuman-like activity leading to being blocked. Sometimes it even leads to server overloads causing the server to fail. This can be avoided by having random time delay between requests and limiting page access requests to 1-2 pages every time.
5) Use Dynamic Crawling Pattern
Web data scraping activities usually follow a pattern. The anti-crawling mechanisms of sites can detect such patterns without much effort because the patterns keep repeating at a particular speed. Changing the regular design of extracting information helps to escape a crawler from being detected by the site. Therefore, having a dynamic web data crawling pattern for extracting information makes the site’s anti-crawling mechanism believe that the activity is being performed by humans. Automated web data scraping ensures patterns are repeatedly changed.
6) Avoid Web Scraping During Peak Hours
Scheduling web crawling during off-peak hours is always a good practice. It ensures data collection without overwhelming the website’s server and triggering any suspicion. Besides, off-peak scrapping also helps to improve the speed of data extraction. Even though waiting for off-peak hours slows down the overall data collection process, it’s a practice worth implementing.
7) Leverage Right Tools Libraries and Framework
There are many types of web scraping tools. But it’s important to pick the right software, based upon technical ability and specific use case. For instance, web scraping browser extensions have less advanced features compared to open-source programming technologies. Likewise smaller web data scraping tools can be run effectively from within a browser, whereas large suites of web scraping tools are more effective and economical as standalone programs.
8) Treat Canonical URLs
Sometimes, a single website can have multiple URLs with the same data. Scraping data from these websites leads to a collection of duplicate data from duplicate URLs. This leads to a waste of time and effort. The duplicate URL, however, will have a canonical URL mentioned. The canonical URL points the web crawler to the original URL. Giving due importance to canonical URLs during the scrapping process ensures there is no scraping of duplicate contents.
9) Set a Monitoring Mechanism
An important aspect of web scraping bots is to find the right and most reliable websites to crawl. The right kind of monitoring mechanism helps to identify the most reliable website. A robust monitoring mechanism helps to identify sites with too many broken links, spot sites with fast-changing coding practises, and discover sites with fresh and top-quality data.
10) Respect the Law
Web scraping should be carried out in ethical ways. It’s never right to misrepresent the purpose of scrapping. Likewise, it’s wrong to use deceptive methods to gain access. Always request data at a reasonable rate and seek data that is absolutely needed. Similarly, never reproduce copyrighted web content and instead strive to create new value from it. Yet another important requirement is to respond in a timely fashion to any targeted website outreach and work amicably towards a resolution.
Conclusion
While the scope of web data scraping is immense for any business, it needs to be borne in mind that data scraping is an expert activity and has to be done mindfully. The above-mentioned practises will ensure the right game plan to scrap irrespective of the scale and challenges involved.
0 notes
Text
What is Hire Scrapy Developer for Web Scraping Services?
iWeb Scraping provides the best Scrapy Web Scraping developer services at affordable prices. Quickly growing companies select iWeb Scraping to increase their Scrapy developers team.
Scrapy Developers for Hire
Scrapy framework is the framework written using Python to crawl websites. The Scrapy framework is specially designed to scrape an extensive range of well-structured data that could be applied in different areas like data mining, information processing, etc. This is an open-source program presently managed by Scrapinghub. Scrapy framework is very easy-to-utilize by the developers because it permits them to re-use the code. This also helps developers in testing a website on different assumptions using a web crawling shell. As Scrapy is a productive and user-friendly program, a lot of well-known companies are utilizing a Scrapy framework. iWeb Scraping provides Hire Scrapy Developer services as per your requirements.
Scrapy framework allows you to perform fast crawling. This is to send numerous requests alongside with the most nominal error acceptance. This crawling framework also provides options to get complete control of all crawling operations. Scrapy will permit you to create a delay in the download for every two requests as well as limits the volumes of requests for every domain. This comes with an extension that regulates the operations inevitably. You can schedule or process requests on Scrapy. It suggests that a framework could perform other functions whereas other requests are getting processed, although some requests have errors. Hire the best Scrapy developer having industry’s leading experiences in Scrapy framework at a location you wish as well as at a price which is the best for you.
iWeb Scraping - Scrapy Developers for Hire
Our ability to hire the best Scrapy developer couldn't be easier with our smart matching structure. We've lessened the hiring procedure down so that it takes days and not weeks for locating a professional Scrapy developer. Our corresponding system as well as expert team could save time as well as gets any projects started quickly. Every reflection has been considered from time zone overlapping to developer’s availability. It's very important to get the businesses an ideal developer’s fit, not any programmers would do and we know that. When our iWeb Scraping professional Scrapy developer contacts you, we would have you with contact with ideal developer within hours and not weeks.
1 note
·
View note
Text
Building A Web Scraper

Create A Web Scraper
Web Scraper Google Chrome
Web Scraper Lite
Web Scraper allows you to build Site Maps from different types of selectors. This system makes it possible to tailor data extraction to different site structures. Export data in CSV, XLSX and JSON formats. Build scrapers, scrape sites and export data in CSV format directly from your browser. Use Web Scraper Cloud to export data in CSV, XLSX. It also has a number of built-in extensions for tasks like cookie handling, user-agent spoofing, restricting crawl depth, and others, as well as an API for easily building your own additions. For an introduction to Scrapy, check out the online documentation or one of their many community resources, including an IRC channel, Subreddit, and a. This question is related to link building method i am doing seo for web development company and website has more than 2lac backlinks, majority of backlinks come from social bookmarking, article and press release submission. In this recent penguin 2.0 update, i lost my ranking on majority of keywords. Advanced tactics 1. Customizing web query. Once you create a Web Query, you can customize it to suit your needs. To access Web query properties, right-click on a cell in the query results and choose Edit Query.; When the Web page you’re querying appears, click on the Options button in the upper-right corner of the window to open the dialog box shown in screenshot given below.
What Are Web Scrapers And Benefits Of Using Them?

A Web Scraper is a data scraping tool that quite literally scrapes or collects data off from websites. Microsoft office for mac catalina. It is the process of extracting information and data from a website, transforming the information on a web-page into a structured format for further analysis. Web Scraper is a term for various methods used to extract and collect information from thousands of websites across the Internet. Generally, you can get rid of copy-pasting work by using the data scrapers. Those who use web scraping tools may be looking to collect certain data to sell to other users or to use for promotional purposes on a website. Web Data Scrapers also called Web data extractors, screen scrapers, or Web harvesters. one of the great things about the online web data scrapers is that they give us the ability to not only identify useful and relevant information but allow us to store that information for later use.
Create A Web Scraper
How To Build Your Own Custom Scraper Without Any Skill And Programming Knowledge?
Modern post boxes uk. Sep 02, 2016 This question is related to link building method i am doing seo for web development company and website has more than 2lac backlinks, majority of backlinks come from social bookmarking, article and press release submission. In this recent penguin 2.0 update, i lost my ranking on majority of keywords.
Web Scraper Google Chrome
If you want to build your own scraper for any website and want to do this without coding then you are lucky you found this article. Making your own web scraper or web crawler is surprisingly easy with the help of this data miner. It can also be surprisingly useful. Now, it is possible to make multiple websites scrapers with a single click of a button with Any Site Scraper and you don’t need any programming for this. Any Site Scraper is the best scraper available on the internet to scrape any website or to build a scraper for multiple websites. Now you don’t need to buy multiple web data extractors to collect data from different websites. If you want to build Yellow Pages Data Extractor, Yelp Data Scraper, Facebook data scraper, Ali Baba web scraper, Olx Scraper, and many web scrapers like these websites then it is all possible with AnySite Scraper. Over, If you want to build your own database from a variety of websites or you want to build your own custom scraper then Online Web Scraper is the best option for you.
Build a Large Database Easily With Any site Scraper
In this modern age of technology, All businesses' success depends on big data and the Businesses that don’t rely on data have a meager chance of success in a data-driven world. One of the best sources of data is the data available publicly online on social media sites and business directories websites and to get this data you have to employ the technique called Web Data Scraping or Data Scraping. Building and maintaining a large number of web scrapers is a very a complex project that like any major project requires planning, personnel, tools, budget, and skills.
Web scraping with django python. Web Scraping using Django and Selenium # django # selenium # webscraping. Muhd Rahiman Feb 25 ・13 min read. This is a mini side project to tinker around with Django and Selenium by web scraping FSKTM course timetable from MAYA UM as part of my self-learning prior to FYP. Automated web scraping with Python and Celery is available here. Making a web scraping application with Python, Celery, and Django here. Django web-scraping. Improve this question. Follow asked Apr 7 '19 at 6:14. User9615577 user9615577. Add a comment 2 Answers Active Oldest Votes. An XHR GET request is sent to the url via requests library. The response object html is. If your using django, set up a form with a text input field for the url on your html page. On submission this url will appear in the POST variables if you've set it up correctly.
Jul 10, 2019 The Switch itself (just the handheld screen) includes a slot for a microSD Card and a USB Type-C Connector. The Nintendo Switch Dock includes two USB 2.0 Ports and a TV Output LED in the front. The 'Switch tax' also applies to many games that had been previously released on other platforms ported later to the Switch, where the Switch game price reflects the original price of the game when it was first released rather than its current price. It is estimated that the cost of Switch games is an average of 10% over other formats. Get the detailed specs for the Nintendo Switch console, the Joy-Con controllers, and more. Switch specs. The S5200-ON is a complete family of switches:12-port, 24-port, and 48-port 25GbE/100GbE ToR switches, 96-port 25GbE/100GbE Middle of Row (MoR)/End of Row (EoR) switch, and a 32-port 100GbE Multi-Rate Spine/Leaf switch. From the compact half-rack width S5212F-ON providing an ideal form factor. Switch resistance is referred to the resistance introduced by the switch into the circuit irrespective of its contact state. The resistance will be extremely high (ideally infinite) when the switch is open and a finite very low value (ideally zero) when the switch is closed. 2: Graph Showing Typical Switch Resistance Pattern.
Web Scraper Lite
You will most likely be hiring a few developers who know-how to build scale-able scrapers and setting up some servers and related infrastructure to run these scrapers without interruption and integrating the data you extract into your business process. You can use full-service professionals such as Anysite Scraper to do all this for you or if you feel brave enough, you can tackle this yourself.
Apr 15, 2021 Currently, you cannot stream Disney Plus on Switch, however, there is a piece of good news for Nintendo Switch users. It seems that Disney lately announced that Disney Plus streaming service will be accessible on Nintendo’s handheld console. The news originates from a presentation slide revealing the new streaming service available on consoles. Disney plus on switch. Mar 15, 2021 Though mentioned earlier, Disney Plus is available on few gaming consoles. Unfortunately, it is not available on Nintendo Switch as of now. Chances are there to bring it in on the future updates as Nintendo Switch is getting popular day by day. Despite the own store by Nintendo switch, it has only a few apps present. No, there is no Disney Plus app on the Nintendo Switch. If you want to stream movies or shows on your Switch, you can instead download the Hulu or YouTube apps. Visit Business Insider's homepage. Nov 30, 2020 Disney Plus is not available on the handheld console. The Switch only offers YouTube and Hulu as of now, not even Netflix. This tells us that the Nintendo Switch is indeed capable of hosting a.
0 notes
Text
A Complete Guide on Offering Web Scraping Services

Web scraping could unlock the invaluable insights for all types of businesses. So, a lot of companies hire somebody to handle their web data scraping projects. In case, you’re interested in providing this service, X-Byte Enterprise Crawling is the right place for you! We’ve made a complete guide here about how to provide web scraping services to your clients.
Before getting started, let’s revise a few basics.
What is Web Scraping?
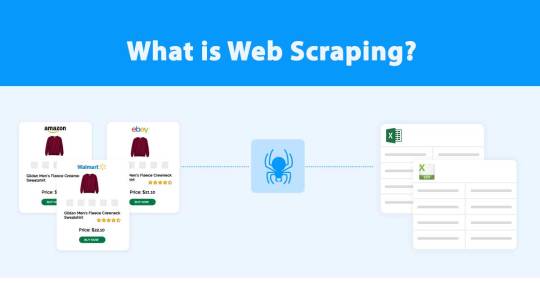
Web scraping is the term used to collect data from websites using the internet. Mainly it is done using automated bots or tools.
Clients interested in the data scraping services will usually have the objective in mind to have all the names, addresses, phone numbers, and email IDs for all contacts on the directory. Then, a scraping tool will crawl the website to scrape that data and spread it to the required format like Excel, XML, JSON, etc.
Why People Scrape Data?
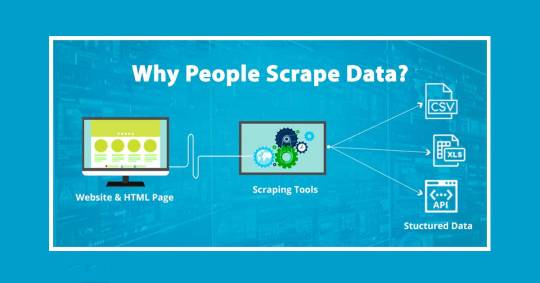
There are a lot of reasons why people, as well as businesses, scrape or extract data from any website. Let’s go through some general use cases:
Scraping lead data from directories: Either specific contact data or company data to occupy CRMs. For instance, scraping platforms like Yellow Pages or Yelp.
Market Research: Scraping pricing and other data on the products from vehicles or dealership sites, e-commerce websites, travel or trips sites or property data from the real estate websites.
Create aggregators which gather classified ads, blog posts, or jobs
Extract data from the old website for moving the content to new websites, where transfer or API is not accessible
Scrape comments and reviews to do sentiment analysis
Scrape cryptocurrency or stock rates frequently
Scrape data from websites for different research objectives
How to Scrape Data from the Web?
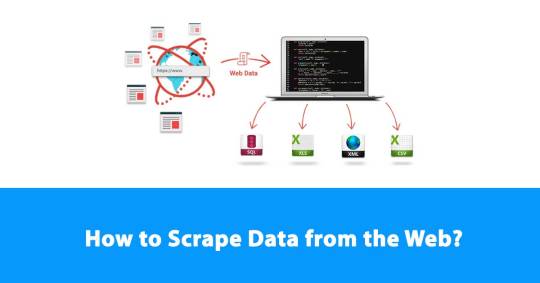
Different ways are there of scraping data:
Custom Web Scrapers
They are usually created by the programmers indifferent languages. People generally use libraries like Beautiful Soup, Scrapy, and Selenium for building them.
Pros:
Tailor-made and highly customized as per your requirements
If you employ somebody to create it, very little investment of time at your part
Cons:
Hard to maintain if you don’t have programming knowledge
If you hire somebody, you have to contact as well as pay them every time a problem arises or changes required
Every the website needs that a completely new scraper built for that
Web Scraping Software
A lot of software companies are there which offer software, which allows you to extract data without any knowledge of programming. A few examples consist of Diffbot, Portia, Import.io, and our software at X-Byte Enterprise Crawling.
Pros:
Pricing may start off very low, having some providers giving a free version
Support is available for setting up the scraping projects
Users can maintain their projects without the need to contact the developer
Users can set up the web scrapers having little or no mechanical knowledge
You may use a similar piece of software for scraping different websites rather than creating new scraper for every new website you need to scrape.
Cons:
In a few cases, you need to become more technical while using more advanced features.
Some scraping software could not deal with more complex websites.
You need to devote more time to discover how to utilize the software. In a few cases, it can be very easy according to the software.
How Much Do People Generally Charge for Web Scraping Services?

The costing for web scraping depends on online freelancers providing as many low prices at $10/website! Though, scraping companies charge higher prices.
We have done an experiment for web scraping service pricing.
We have contacted many scraping companies having a quote request for a weekly scraping of 12000 products on Amazon in different four categories for scraping title, brand, description, pricing, ASIN, ratings, number of reviews, "Sold by" name, as well as URL.
Here are some quotes that we have received:
$800 for initial setup as well as $9000 - $9500 USD every year for managed services (supposing the middle ground of $5000, it is $415/month for maintenance)
$199 initial setup, $149/month for monthly maintenance as well as $5 for every 10000 records every month (assuming that 12000 records every week.
$249 initial setup and $200/month for maintenance
$649 for initial setup as well as data for the first 10,000 lines. After that, every additional record gets charged at $0.005 per line. At 48,000 products every month, it is about $240/month for maintenance
X-Byte Enterprise Crawling provides a free plan if you have one-time scraping requirements, moreover, we could set up as well as run the whole scraping job. Contact us and get a quote!
What Questions We Need to Ask to a Potential Client?

To recognize the difficulty of a data scraping the project, usually, we ask:
Which website they want to scrape?
In that website, which particular elements they are interested in?
Roughly how many pages will they need to get scrapped?
Which the format they would like the data to get extracted to as well as in which format they need data?
Wrapping Up
Web scraping is an extremely in-demand skills which you can discover very easily. It is a wonderful opportunity for consultants, agencies, as well as freelancers for adding web scraping in their services line-up.
Visit Us: www.xbyte.io
#web scraping#web scraping services#data scraping#DataExtraction#web crawler#Python Web Scraping#data extraction#xbyteio#xbytecrawling#xbyteenterprisecrawling#usa#canada#india#website data scraping#web scraping software
0 notes
Text
How Can Python Development Help Your Business In Staying Ahead of the competition?

Being one of the recognized, finest and user-friendly programming languages that can be grouped easily with other ground-breaking platforms, Python allows experts and professionals to easily express their core concepts that too just in fewer lines of code. Since its integration with the highly scalable and dynamic type system along with the highly efficient and automated memory management. We, at OnGraph, possess expertise in delivering top-notch Python development services. Since inception, we are exceptionally providing highly customized and bespoke programming solutions, which are based on the customized client’s business requirements. We have a team of adept and experienced software professionals, who are flawlessly providing modern programming solutions in Python. If you are looking to Hire Offshore Python Developer, then you can consider us as we are known in the industry to deliver client-centric Python-based solutions, which help our clients in meeting their business goals with full quality assurance. Let’s take a look at our key offerings in Python development:
We always keep ourselves updated and with the emerging technologies, which in turn, will help us in delivering a wide variety of Python web design & development services including:
Web Application Development
We are expert in turning client’s business ideas into reality through our tailor-made Python solutions. Our experienced and professional Python experts are successfully providing ultimate and tailor-made web applications with exceptional and unique features.
Prototype Development
Our experts have the rich expertise and experience of working on a wide range of web development services, which are based on the high-level programming language. And our unique and competent approach enables us to create a competent design prototype.
Migration
Our proficient Python developers and experts are well-equipped and acquainted with the Python programming and migration services. Since inception, we are proficiently offering Python migration services to serve our clients across the globe.
Support & Maintenance
Our key goal and prime objective are to successfully deliver best-in-class and state-of-the-art solutions and services, thus providing instant support and maintenance majority related to Python web services.
Our Expertise and Experience
Let’s take a look at a few of our Python dynamic website development services:
Web application Development by using Python-based web frameworks Django & Flask
Developing a Python-based Content Management System
Mobile responsive website design & development.
Flawlessly integrating the existing web applications which are compatible with python
Working on core Python programming
For data authentication, successfully integrating OAuth 2 & JWT
Using scrapy Framework for successful Web Scraping
Why Should You Choose OnGraph for Python Development?
Our professionals with sound industry knowledge & years of experience and expertise ensure that our client’s business reaches higher position & could set a new level of benchmark to its competitors.
10+ years of experience in the industry
Client Base: Singapore, USA, UK, Middle East, Australia and other Asian and European countries
1200+ projects delivered successfully
200+ industry experts
Nasscom certified
ISO 9001:2015 certified company
We are known for delivering top-notch offshore Python development services as we excel in developing user-friendly, and browser and device compatible websites.
We provide real-time maintenance & support during entire development
We offer highly scalable and flexible engagement models for our clients
We adhere strictly to international coding standards, guidelines, quality, and timely delivery of projects
Our solutions offer exceptional and seamless integration with other kink-free codes and APIs
We thoroughly discuss our client’s goals & requirements to ensure that we deliver the precise and customized solutions
Being the recognized and certified Python expert, we are helping brands and business in earning value and revenue, both. If you are looking for offshore Python development services, shoot us an email at [email protected] to share your project requirements with us.
0 notes
Link
Location : London, United Kingdom, London Company: Durlston Partners Description: Experience in a front office environment Good financial product knowledge, Commodities a plus WCF/Sockets/Data Scrape (Scrapy, Webkit, PhantomJS, CasperJS) Big Data experience (Cassandra, Hadoop Apply Now ➣ Search for free, we have thousands of recent jobs in your area. Search Now #jobseekers #nowhiring

Our Free job search portal has complete details to apply online for the C# Developer – Front Office – Commodities Desk – Hedge Fund – Mayfair. position.
0 notes
Text
How (and Why) We’re Collecting Cook County Jail Data
figure.article-inline-image { display: none; } div.sidebar-inject { display: none; } body #page.article > .wrapper > article > section.bodytext .callout-ad { clear: none; } div.callout { border-top: 1px solid #ddd; display: inline-block; line-height: 1.4; padding: 0.8em; font-style: normal; font-size: 14px; font-family: Arial, sans-serif; z-index: 10; box-sizing: border-box; width: 300px; float: right; margin: 1em 2em; } div.callout img { width: 100%; } div.callout h3 { font-weight: bold; font-size: 1.3em; margin-top: 1.25em; margin-bottom: 1em; } div.callout-dek { margin-bottom: 1em; } div.callout-source { color: #999; margin-top: 1em; font-size: 13px; } .bodytext hr { width: 33%; height: 0; border: 0; border-top: 1px solid rgb(204, 204, 204); margin: 1.75em auto; text-align: center; } .bodytext h3 { font-family: "ff-meta-serif-web-pro","Georgia",serif; font-size: 18px; font-weight: bold; margin: 25px 0 15px 0; } div.pp-interactive { border-top: 1px solid #ddd; display: inline-block; line-height: 1.4; padding: 0.8em; font-style: normal; font-size: 14px; font-family: Arial, sans-serif; z-index: 10; box-sizing: border-box; width: 400px; float: right; margin: 1em -200px 1em 30px; } .pp-interactive h2 { font-family: "ff-meta-serif-web-pro", "Georgia", serif; font-weight: bold; font-size: 1.3em; margin: 10px 0 10px 0; } .pp-int-dek { margin-bottom: 1em; font-size: 0.9em; line-height: 1.35em !important; } .pp-interactive-source { color: #999; font-family: Arial; font-size: 0.7em; padding: 0 0 30px 0.8em; } .graphic-promo { float: right; padding: 10px 0 25px; position: relative; width: 500px; margin: 0 -200px 0 30px; /* border-top: 1px solid #ddd; */ } .graphic-promo-full { width: 100%; float: left; padding: 10px 0 25px; /*border-top: 1px solid #ddd;*/ } .graphic-promo-vertical { position: relative; z-index: 1000; width: 300px; float: right; padding: 10px 0 25px; border-top: 1px solid #ddd; margin-left: 30px; } .graphic-promo-full img.border { border: 1px solid #ddd; } .pp-interactive img, .graphic-promo img, .graphic-promo-full img, .graphic-promo-vertical img { max-width: 100%; } .data-store-promo .badge { display: block; width: 60%; } div.pp-app-promo { border-top: 1px solid #ddd; display: inline-block; line-height: 1.4; padding: 0.8em; font-style: normal; font-size: 14px; font-family: Arial, sans-serif !important; z-index: 1; box-sizing: border-box; width: 320px; float: right; margin: 1em 0 1em 2em; clear: none; } .pp-app-promo img { width: 100%; -webkit-transition-property: opacity, left, top, height; transition-property: opacity, left, top, height; -webkit-transition-duration: 0.5s, 2s; transition-duration: 0.5s, 2s; } body #page.article > .wrapper > article .ad { display: none; } @media screen and (max-width: 800px) and (min-width:481px) { div.pp-interactive { padding: 0px; } div.pp-interactive, .graphic-promo { /*float: none;*/ margin: 10px 0 0px 30px; width: 400px; } div.callout { margin-right: 0px; } } @media screen and (max-width: 480px) { div.pp-interactive { padding: 0px; } div.callout, div.pp-interactive, .graphic-promo, .graphic-promo-full { float: none; margin: 10px 0 0 0; width: 300px; } #page > div > article > section > div.graphic-promo > figure, #page > div > article > section > div.graphic-promo-full > figure { float: none; } .graphic-promo .photo-caption { width: 300px !important; } div.pp-app-promo { width: 100%; margin: 0 auto; float: none; } } @media print { .graphic-promo { margin-right: 0px; } } .cf:before, .cf:after { content: " "; /* 1 */ display: table; /* 2 */ } .cf:after { clear: both; }
At ProPublica Illinois, we’ve just restarted a data collection project to get new information about what happens to inmates at one of the country’s largest and most notorious jails.
Cook County Jail has been the subject of national attention and repeated reform efforts since its earliest days. Al Capone famously had “VIP accommodations” there in 1931, with homemade meals and a large cell in the hospital ward that he shared only with his bodyguard. Other prisoners have been more poorly accommodated: In the 1970s, the warden was fired for allegedly beating inmates with his own hands, and the facility was placed under federal oversight in 1974. During the 1980s, the federal government forced the jail to release inmates because of overcrowding. In 2008, the Department of Justice found systematic violation of inmates’ 8th Amendment rights and once again pushed for reforms.
These days, the jail, which has just recently been taken out of the federal oversight program, is under new management. Tom Dart, the charismatic and media-savvy sheriff of Cook County, oversees the facility. Dart has argued publicly for reducing the population and improving conditions at the jail. He’s also called the facility a de facto mental hospital, and said inmates should be considered more like patients, even hiring a clinical psychologist to run the jail.
Efforts to study the jail’s problems date back decades. A 1923 report on the jail by the Chicago Community Trust says, “Indifference of the public to jail conditions is responsible for Chicago’s jail being forty years behind the time.”
The promises to fix it go back just as far. The same 1923 report continues, “But at last the scientific method which has revolutionized our hospitals and asylums is making inroads in our prisons, and Chicago will doubtless join in the process.”
Patterns in the data about the inmate population could shed light on the inner workings of the jail, and help answer urgent questions, such as: How long are inmates locked up? How many court dates do they have? What are the most common charges? Are there disparities in the way inmates are housed or disciplined?
Such detailed data about the inmate population has been difficult to obtain, even though it is a matter of public record. The Sheriff’s Department never answered my FOIA request in 2012 when I worked for the Chicago Tribune.
Around the same time, I started a project at FreeGeek Chicago to teach basic coding skills to Chicagoans through working on data journalism projects. Our crew of aspiring coders and pros wrote code that scraped data from the web we couldn’t get other ways. Our biggest scraping project was the Cook County Jail website.
Over the years, the project lost momentum. I moved on and out of Chicago and the group dispersed. I turned off the scraper, which had broken for inexplicable reasons, last August.
I moved back home to Chicago earlier this month and found the data situation has improved a little. The Chicago Data Cooperative, a coalition of local newsrooms and civic-data organizations, is starting to get detailed inmate data via Freedom of Information requests. But there’s even more information to get.
So for my first project at ProPublica Illinois, I’m bringing back the Cook County Jail scraper. Along with Wilberto Morales, one of the original developers, we are rebuilding the scraper from scratch to be faster, more accurate and more useful to others interested in jail data. The scraper tracks inmates’ court dates over time and when and where they are moved within the jail complex, among other facts.
Our project complements the work of the Data Cooperative. Their efforts enable the public to understand the flow of people caught up in the system from arrest to conviction. What we’re adding will extend that understanding to what happens during inmates’ time in jail. It’s not clear yet if we’ll be able to track an individual inmate from the Data Cooperative’s data into ours. There’s no publicly available, stable and universal identifier for people arrested in Cook County.
The old scraper ran from June 5, 2014, until July 24, 2016. The new scraper has been running consistently since June 20, 2017. It is nearly feature-complete and robust, writing raw CSVs with all inmates found in the jail on a given day.
Wilberto will lead the effort to develop scripts and tools to take the daily CSVs and load them into a relational database.
We plan to analyze the data with tools such as Jupyter and R and use the data for reporting.
A manifest of daily snapshot files (for more information about those, read on) is available at http://ift.tt/2tv2qdB
How Our Scraper Works, a High-Level Overview
The scraper harvests the original inmate pages from the Cook County Jail website, mirrors those pages and processes them to create daily snapshots of the jail population. Each record in the daily snapshots data represents a single inmate on a single day.
The daily snapshots are anonymized. Names are stripped out, date of birth is converted to age at booking, and a one-way hash is generated from name, birth date and other personal details, so researchers can study recidivism. The snapshot data also contains the booking ID, booking date, race, gender, height, weight, housing location, charges, bail amount, next court data and next court location.
We don’t make the mirrored inmate pages public, to avoid misuse of personal data for things like predatory mugshot or background check websites.
How Our Scraper Works, the Nerdy Parts
The new scraper code is available on Github. It’s written in Python 3 and uses the Scrapy library for scraping.
Data Architecture
When we built our first version of the scraper in 2012, we could use the web interface to search for all inmates whose last name started with a given letter. Our code took advantage of this to collect the universe of inmates in the data management system, simply by running 26 searches and stashing the results.
Later, the Sheriff's Department tightened the possible search inputs and added a CAPTCHA. However, we were still able to access individual inmate pages via their Booking ID. This identifier follows a simple and predictable pattern: YYYY-MMDDXXX where XXX is a zero-padded number corresponding to the order that the inmate arrived that day. For example, an inmate with Booking ID “2017-0502016” would be the 16th inmate booked on May 2, 2017. When an inmate leaves the jail, the URL with that Booking ID starts returning a 500 HTTP status code.
The old scraper scanned the inmate locator and harvested URLs by checking all of the inmate URLs it already knew about and then incrementing the Booking ID until the server returned a 500 response. The new scraper works much the same way, though we’ve added some failsafes in case our scraper misses one or more days.
The new scraper can also use older data to seed scrapes. This reduces the number of requests we need to send and gives us the ability to compare newer records to older ones, even if our data set has missing days.
Scraping With Scrapy
We’ve migrated from a hodgepodge of Python libraries and scripts to Scrapy. Scrapy’s architecture makes scraping remarkably fast, and it includes safeguards to avoid overwhelming the servers we’re scraping.
Most of the processing is handled by inmate_spider.py. Spiders are perhaps the most fundamental elements that Scrapy helps you create. A spider handles generating URLs for scraping, follows links and parses HTML into structured data.
Scrapy also has a way to create data models, which it calls “Items.” Items are roughly analogous to Django models, but I found Scrapy’s system underdeveloped and difficult to test. It was never clear to me if Items should be used to store raw data and to process data during serialization or if they were basically fancy dicts that I should put clean data into.
Instead, I used a pattern I learned from Norbert Winklareth, one of the collaborators on the original scraper. I wrote about the technique in detail for NPR last year. Essentially, you create an object class that takes a raw HTML string in its constructor. The data model object then exposes parsed and calculated fields suitable for storage.
Despite several of its systems being a bit clumsy, Scrapy really shines due to its performance. Our original scraper worked sequentially and could harvest pages for the approximately 10,000 inmates under jail supervision in about six hours, though sometimes it took longer. Improvements we made to the scraper got this down to a couple hours. But in my tests, Scrapy was able to scrape 10,000 URLs in less than 30 minutes.
We follow the golden rule at ProPublica when we’re web scraping: “Do unto other people’s servers as you’d have them do unto yours.” Scrapy’s “autothrottle” system will back off if the server starts to lag, though we haven’t seen any effect so far on the server we’re scraping.
Scrapy’s speed gains are remarkable. It’s possible that these are due in part to increases in bandwidth, server capacity and in web caching at the Cook County Jail’s site, but in any event, it’s now possible to scrape the data multiple times every day for even higher accuracy.
Pytest
I also started using a test framework for this project I haven’t used before.
I’ve mostly used Nose, Unittest and occasionally Doctests for testing in Python. But people seem to like Pytest (including several of the original jail scraper developers) and the output is very nice, so I tried it this time around.
Pytest is pretty slick! You don’t have to write any boilerplate code, so it’s easy to start writing tests quickly. What I found particularly useful is the ability to parameterize tests over multiple inputs.
Take this abbreviated code sample:
testdata = ( (get_inmate('2015-0904292'), { 'bail_amount': '50,000.00', }), (get_inmate('2017-0608010'), { 'bail_amount': '*NO BOND*', }), (get_inmate('2017-0611015'), { 'bail_amount': '25,000', }), )
@pytest.mark.parametrize("inmate,expected", testdata) def test_bail_amount(inmate,expected): assert inmate.bail_amount == expected['bail_amount']
In the testdata variable assignment, the get_inmate function loads an Inmate model instance from sample data and then defines some expected values based on direct observation of the scraped pages. Then, by using the @pytest.mark.parameterize(...) decorator and passing it the testdata variable, the test function is run for all the defined values.
There might be a more effective way to do this with Pytest fixtures. Even so, this is a significant improvement over using metaclasses and other fancy Python techniques to parameterize tests as I did here. Those techniques yield practically unreadable test code, even if they do manage to provide good test coverage for real-world scenarios.
In the future, we hope to use the Moto library to mock out the complex S3 interactions used by the scraper.
How You Can Contribute
We welcome collaborators! Check out the contributing section of the project README for the latest information about contributing. You can check out the issue queue, fork the project, make your contributions and submit a pull request on Github!
And if you’re not a coder but you notice something in our approach to the data that we could be doing better, don’t be shy about submitting an issue.
from The ProPublica Nerd Blog http://ift.tt/2uRJ8CN via IFTTT
0 notes
Text
10 Best Practices for Implementing Automated Web Data Mining Using Web Scraping Tools
A famous manufacturer of household products, working with a number of retailers across the globe, wanted to capture product reviews from retail websites. The objective was to understand consumer satisfaction levels and identify retailers violating the MAP (Minimum Advertised Policy) policy. The manufacturer partnered with a web scraping and distributed server technology expert to get an accurate, comprehensive, and real-time overview of their requirements. It took them no time to get complete control over the retailers and pre-empt competitors with a continuous sneak peek into their activities. This example underscores the importance of web scraping as a strategic business planning tool.
Web scraping is the process of extracting unique, rich, proprietary, and time-sensitive data from websites for meeting specific business objectives such as data mining, price change monitoring, contact scrapping, product review scrapping, and so on. The data to be extracted is primarily contained in a PDF or a table format which renders it unavailable for reuse. While there are many ways to accomplish web data scraping, most of them are manual, and so tedious and time-consuming. However, in the age of automation, automated web data mining has replaced the obsolete methods of data extraction and transformed it into a time-saving and effortless process.
How is Web Data Scraping Done
Web data scraping is done either by using software or writing codes. The software used to scrap can be locally installed in the targeted computer or run in Cloud. Yet another technique is hiring a developer to build highly customised data extraction software to execute specific requirements. The most common technologies used for scraping are Wget, cURL, HTTrack, Selenium, Scrapy, PhantomJS, and Node.js.
Best Practice for Web Data Mining
1) Begin With Website Analysis and Background Check
To start with, it is very important to develop an understanding of the structure and scale of the target website. An extensive background check helps check robot.txt and minimise the chance of getting detected and blocked; examine the sitemap for well-defined and detailed crawling; estimate the size of the website to understand the effort and time required; identify the technology used to build the website for seamless crawling and more.
2) Treat Robot.txt -Terms, and Conditions
The robots.txt file is a valuable resource that helps the web crawler eliminate the chances of being spotted, as well as uncover the structure of a website. It’s important to understand and follow the protocol of robot.txt files to avoid legal ramifications. Complying with access rules, visit times, crawl rate limiting, request rate helps to adhere to the best crawling practises and carry out ethical scrapping. Web scraping bots studiously read and follow all the terms and conditions.
3) Use Rotating IPs and Minimise the Loads
More requests from a single IP address alert a site and induce it to block the IP address. To escape this possibility, it’s important to create a pool of IP addresses and route requests randomly through the pool of IP addresses. As requests on the target website come through different IPs, the load of requests from a single IP gets minimised, thereby minimising the chances of being spotted and blacklisted. With automated data mining, however, this problem stands completely eliminated.
4) Set Right Frequency to Hit Servers
In a bid to fetch data as fast as possible most web scraping activities send more requests to the host server than normal. This triggers suspicion about unhuman-like activity leading to being blocked. Sometimes it even leads to server overloads causing the server to fail. This can be avoided by having random time delay between requests and limiting page access requests to 1-2 pages every time.
5) Use Dynamic Crawling Pattern
Web data scraping activities usually follow a pattern. The anti-crawling mechanisms of sites can detect such patterns without much effort because the patterns keep repeating at a particular speed. Changing the regular design of extracting information helps to escape a crawler from being detected by the site. Therefore, having a dynamic web data crawling pattern for extracting information makes the site’s anti-crawling mechanism believe that the activity is being performed by humans. Automated web data scraping ensures patterns are repeatedly changed.
6) Avoid Web Scraping During Peak Hours
Scheduling web crawling during off-peak hours is always a good practice. It ensures data collection without overwhelming the website’s server and triggering any suspicion. Besides, off-peak scrapping also helps to improve the speed of data extraction. Even though waiting for off-peak hours slows down the overall data collection process, it’s a practice worth implementing.
7) Leverage Right Tools Libraries and Framework
There are many types of web scraping tools. But it’s important to pick the right software, based upon technical ability and specific use case. For instance, web scraping browser extensions have less advanced features compared to open-source programming technologies. Likewise smaller web data scraping tools can be run effectively from within a browser, whereas large suites of web scraping tools are more effective and economical as standalone programs.
8) Treat Canonical URLs
Sometimes, a single website can have multiple URLs with the same data. Scraping data from these websites leads to a collection of duplicate data from duplicate URLs. This leads to a waste of time and effort. The duplicate URL, however, will have a canonical URL mentioned. The canonical URL points the web crawler to the original URL. Giving due importance to canonical URLs during the scrapping process ensures there is no scraping of duplicate contents.
9) Set a Monitoring Mechanism
An important aspect of web scraping bots is to find the right and most reliable websites to crawl. The right kind of monitoring mechanism helps to identify the most reliable website. A robust monitoring mechanism helps to identify sites with too many broken links, spot sites with fast-changing coding practises, and discover sites with fresh and top-quality data.
10) Respect the Law
Web scraping should be carried out in ethical ways. It’s never right to misrepresent the purpose of scrapping. Likewise, it’s wrong to use deceptive methods to gain access. Always request data at a reasonable rate and seek data that is absolutely needed. Similarly, never reproduce copyrighted web content and instead strive to create new value from it. Yet another important requirement is to respond in a timely fashion to any targeted website outreach and work amicably towards a resolution.
Conclusion
While the scope of web data scraping is immense for any business, it needs to be borne in mind that data scraping is an expert activity and has to be done mindfully. The above-mentioned practises will ensure the right game plan to scrap irrespective of the scale and challenges involved.
0 notes
Text
10 Best Practices for Implementing Automated Web Data Mining Using Web Scraping Tools
A famous manufacturer of household products, working with a number of retailers across the globe, wanted to capture product reviews from retail websites. The objective was to understand consumer satisfaction levels and identify retailers violating the MAP (Minimum Advertised Policy) policy. The manufacturer partnered with a web scraping and distributed server technology expert to get an accurate, comprehensive, and real-time overview of their requirements. It took them no time to get complete control over the retailers and pre-empt competitors with a continuous sneak peek into their activities. This example underscores the importance of web scraping as a strategic business planning tool.
Web scraping is the process of extracting unique, rich, proprietary, and time-sensitive data from websites for meeting specific business objectives such as data mining, price change monitoring contact scrapping, product review scrapping, and so on. The data to be extracted is primarily contained in a PDF or a table format which renders it unavailable for reuse. While there are many ways to accomplish web data scraping, most of them are manual, and so, tedious and time-consuming. However, in the age of automation, automated web data mining has replaced the obsolete methods of data extraction and transformed it into a time-saving and effortless process.
How is Web Data Scraping Done
Web data scraping is done either by using software or writing codes. The software used to scrap can be locally installed in the targeted computer or run in Cloud. Yet another technique is hiring a developer to build highly customized data extraction software to execute specific requirements. The most common technologies used for scraping are Wget, cURL, HTTrack, Selenium, Scrapy, PhantomJS, and Node.js.
Best Practice for Web Data Mining
1) Begin With Website Analysis and Background Check
To start with, it is very important to develop an understanding of the structure and scale of the target website. An extensive background check helps check robot.txt and minimize the chance of getting detected and blocked; examine the sitemap for well-defined and detailed crawling; estimate the size of the website to understand the effort and time required; identify the technology used to build the website for seamless crawling and more.
2) Treat Robot.txt -Terms, and Conditions
The robots.txt file is a valuable resource that helps the web crawler eliminate the chances of being spotted, as well as uncover the structure of a website. It’s important to understand and follow the protocol of robot.txt files to avoid legal ramifications. Complying with access rules, visit times, crawl rate limiting, request rate helps to adhere to the best crawling practices and carry out ethical scrapping. Web scraping bots studiously read and follow all the terms and conditions.
3) Use Rotating IPs and Minimize the Loads
More requests from a single IP address alert a site and induces it to block the IP address. To escape this possibility, it’s important to create a pool of IP addresses and route requests randomly through the pool of IP addresses. As requests on the target website come through different IPs, the load of requests from a single IP gets minimized, thereby minimizing the chances of being spotted and blacklisted. With automated data mining, however, this problem stands completely eliminated.
4) Set Right Frequency to Hit Servers
In a bid to fetch data as fast as possible most web scraping activities send more requests to the host server than normal. This triggers suspicion about unhuman-like activity leading to being blocked. Sometimes it even leads to server overloads causing the server to fail. This can be avoided by having random time delay between requests and limit page access requests to 1-2 pages every time.
5) Use Dynamic Crawling Pattern
Web data scraping activities usually follow a pattern. The anti-crawling mechanisms of sites can detect such patterns without much effort because the patterns keep repeating at a particular speed. Changing the regular design of extracting information helps to escape a crawler from being detected by the site. Therefore, having a dynamic web data crawling pattern for extracting information makes the site’s anti-crawling mechanism believe that the activity is being performed by humans. Automated web data scraping ensures patterns are repeatedly changed.
6) Avoid Web Scraping During Peak Hours
Scheduling web crawling during off-peak hours is always a good practice. It ensures data collection without overwhelming the website’s server and triggering any suspicion. Besides, off-peak scrapping also helps to improve the speed of data extraction. Even though waiting for off-peak hours slows down the overall data collection process, it’s a practice worth implementing.
7) Leverage Right Tools Libraries and Framework
There are many types of web scraping tools. But it’s important to pick the right software, based upon technical ability and specific use case. For instance, web scraping browser extensions have less advanced features compared to open-source programming technologies. Likewise smaller web data scraping tools can be run effectively from within a browser, whereas large suites of web scraping tools are more effective and economical as standalone programs.
8) Treat Canonical URLs
Sometimes, a single website can have multiple URLs with the same data. Scraping data from these websites leads to a collection of duplicate data from duplicate URLs. This leads to a waste of time and effort. The duplicate URL, however, will have a canonical URL mentioned. The canonical URL points the web crawler to the original URL. Giving due importance to canonical URLs during the scrapping process ensures there is no scraping of duplicate contents.
9) Set a Monitoring Mechanism
An important aspect of web scraping bots is to find the right and most reliable websites to crawl. The right kind of monitoring mechanism helps to identify the most reliable website. A robust monitoring mechanism helps to identify sites with too many broken links, spot sites with fast-changing coding practices, and discover sites with fresh and top-quality data.
10) Respect the Law
Web scraping should be carried out in ethical ways. It’s never right to misrepresent the purpose of scrapping. Likewise, it’s wrong to use deceptive methods to gain access. Always request data at a reasonable rate and seek data that is absolutely needed. Similarly, never reproduce copyrighted web content and instead strive to create new value from it. Yet another important requirement is to respond in a timely fashion to any targeted website outreach and work amicably towards a resolution.
Conclusion
While the scope of web data scraping is immense for any business, it needs to be borne in mind that data scraping is an expert activity and has to be done mindfully. The above-mentioned practices will ensure the right game plan to scrap irrespective of the scale and challenges involved.
0 notes