
Fortnite ZeroBuilder. Omen & Cypher Main / Lover of Horror Games
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by d0nutzgg and here's what we found interesting.
Average Info
Notes Per Post
127K
Likes Per Post
73K
Reblog Per Post
54K
Reply Per Post
133
Time Between Posts
10 days
Number of Posts By Type
Text
16
Note
1
Last Seen Tumblr Blogs





Fun Fact
Hackers stole 65M passwords from Tumblr in 2013.
Text

Thank you @suunlite and everyone who got me to 50 reblogs!
Analyzing An Ataxic Dysarthria Patient's Speech with Computer Vision and Audio Processing
Hey everyone, so as you know I have been doing research on patients like myself who have Ataxic Dysarthria and other neurological speech disorders related to diseases and conditions that affect the brain. I was analyzing this file
with a few programs that I have written.
The findings are very informative and I am excited that I am able to explain this to my Tumblr following as I feel it not only promotes awareness but provides an understanding of what we go through with Ataxic Dysarthria.
Analysis of the audio file with an Intonation Visualizer I built
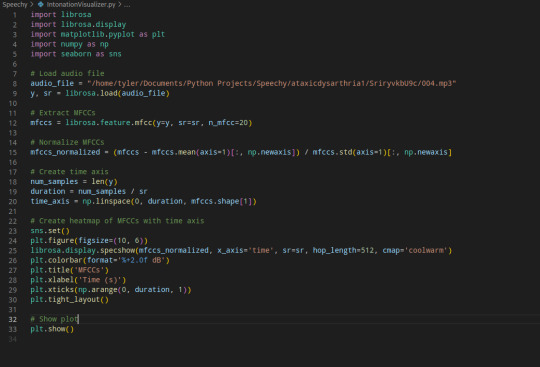
As you can tell this uses a heatmap to visualize loudness and softness of a speaker's voice. I used it to analyze the file and I found some really interesting and telling signs of Ataxic Dysarthria

At 0-1 seconds it is mostly pretty quiet (which is normal because it is harder for patients with AD to start their speaking off. You can notice that around 1-3 seconds it gets louder, and then when she speaks its clearer and louder than the patients voice. However the AD makes the patients speech constantly rise and fall in loudness from around -3 to 0 decibels most of the audio when the patient is speaking. The variation though between 0 and -3 varies quickly though which is a common characteristic in AD
The combination of the constant rising and falling in loudness and intonation as well as problems getting sentences started is one of the things that makes it so hard for people to understand those with Ataxic Dysarthria.
The second method I used is using a line graph (plotted) that gives an example of the rate of speech and elongated syllables of the patient.
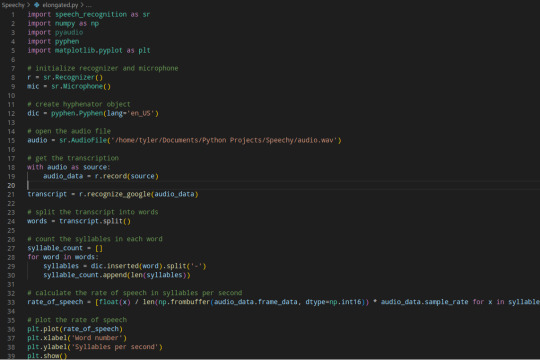
As you can see I primarily used the Google Speech Recognition library to transcribe and count the syllables using Pyphen via "hyphenated" (elongated) words in the speech of the patient. This isn't the most effective method but it worked well for this example and here is the results plotted out using Matplotlib:

As you can see when they started talking at first there was a rise from the softer speech, as the voice of the patient got louder, they were speaking faster (common for those with AD / and HD) my hypothesis (and personal experience) is that this is how we try to get our words out where we can be understood by "forcing" out words resulting in a rise and fall of syllables / rate of speech that we see at the first part. The other spikes typically happen when she speaks but there is another spike at the end which you can see as well when the patient tries to force more words out.
This research already indicates a pretty clear pattern what is going on in the patients speech. As they try to force out words, their speech gets faster and thus gets louder as they try to communicate.
I hope this has been informative for those who don't know much about speech pathology or neurological diseases. I know it's already showing a lot of exciting progress and I am continuing to develop scripts to further research on this subject so maybe we can all understand neurological speech disorders better.
As I said, I will be posting my research and findings as I go. Thank you for following me and keeping up with my posts!
41 notes
·
View notes
Text

It's been a whole year lol. Thank you all for following me even though I'm not as active.
0 notes
Text
Analyzing An Ataxic Dysarthria Patient's Speech with Computer Vision and Audio Processing
Hey everyone, so as you know I have been doing research on patients like myself who have Ataxic Dysarthria and other neurological speech disorders related to diseases and conditions that affect the brain. I was analyzing this file
with a few programs that I have written.
The findings are very informative and I am excited that I am able to explain this to my Tumblr following as I feel it not only promotes awareness but provides an understanding of what we go through with Ataxic Dysarthria.
Analysis of the audio file with an Intonation Visualizer I built
As you can tell this uses a heatmap to visualize loudness and softness of a speaker's voice. I used it to analyze the file and I found some really interesting and telling signs of Ataxic Dysarthria
At 0-1 seconds it is mostly pretty quiet (which is normal because it is harder for patients with AD to start their speaking off. You can notice that around 1-3 seconds it gets louder, and then when she speaks its clearer and louder than the patients voice. However the AD makes the patients speech constantly rise and fall in loudness from around -3 to 0 decibels most of the audio when the patient is speaking. The variation though between 0 and -3 varies quickly though which is a common characteristic in AD
The combination of the constant rising and falling in loudness and intonation as well as problems getting sentences started is one of the things that makes it so hard for people to understand those with Ataxic Dysarthria.
The second method I used is using a line graph (plotted) that gives an example of the rate of speech and elongated syllables of the patient.
As you can see I primarily used the Google Speech Recognition library to transcribe and count the syllables using Pyphen via "hyphenated" (elongated) words in the speech of the patient. This isn't the most effective method but it worked well for this example and here is the results plotted out using Matplotlib:
As you can see when they started talking at first there was a rise from the softer speech, as the voice of the patient got louder, they were speaking faster (common for those with AD / and HD) my hypothesis (and personal experience) is that this is how we try to get our words out where we can be understood by "forcing" out words resulting in a rise and fall of syllables / rate of speech that we see at the first part. The other spikes typically happen when she speaks but there is another spike at the end which you can see as well when the patient tries to force more words out.
This research already indicates a pretty clear pattern what is going on in the patients speech. As they try to force out words, their speech gets faster and thus gets louder as they try to communicate.
I hope this has been informative for those who don't know much about speech pathology or neurological diseases. I know it's already showing a lot of exciting progress and I am continuing to develop scripts to further research on this subject so maybe we can all understand neurological speech disorders better.
As I said, I will be posting my research and findings as I go. Thank you for following me and keeping up with my posts!
41 notes
·
View notes
Text
Recovering from COVID
Hey so I haven't been on in a while because I was sick with viral Encephalitis from COVID back in December, I've been battling a cold this month so far. Being terminal makes me pretty susceptible to illnesses and it takes me forever to recover. I'm currently working on a visual novel and studying for my ISC2 CC and Pentest+ but I just wanted to say I appreciate all the follows and reblogs even though I've been gone forever. I hope to get back to research in the future, I guess I've also been dealing with depression too because of SAD so I haven't had much motivation between being sick and depressed lol. I am trying to get back into programming though with this visual novel with RenPy so hopefully completing a project will boost my confidence again. :) Thanks once again!
#programming#programmer#artificial intelligence#coding#renpy#visual novel#game development#game developers#python 3#python#ai#health update#medical update#thank you
7 notes
·
View notes
Text
So I learned Bootstrap 5 in one night lol. This is what I have come up with so far for the organization's website. It's just the home page, but not bad for my first time making a website, eh? Let me know what you think? I could use some love because tonight has been like I got in a fistfight with my computer for 8 hours lol.
#programming#programmer#artificial intelligence#machine learning#python programming#technology#ai#coding#python#programmers#webdevelopment#web developer#web development#front end development#bootstrap
1 note
·
View note
Text
I made some updates and also today I have been researching pancreatic cancer urinary biomarkers! Had some interesting results that I will be sharing in another write up later! Right now I am just in the data analysis stage, but I am currently training the model that I am trying out on the data. It's a Random Forest classifier, not sure how it is going to do but we're going to see! I added some more stuff to the IndieGOGO and the initial write up on the data is there too right now. Go check it out:
Hey all, so the crowdfund is up for ReachAI. If anyone wants to go check it out it would mean a lot to me! Also you can watch the video there on IndieGOGO or here:
youtube
It should give you a bit of an idea on what ReachAI is and what the nonprofit will be doing as well as the benefits of becoming a donor (which there are even more than I talked about in the video including Webinars, 1-on-1 sessions with me, a newsletter update on research the organization is working on or right now that I am). I am excited to be bringing ReachAI closer to launch day, I am really hoping I can raise the money to get it started! I know it could do so much good in the world :3
#programming#programmer#artificial intelligence#machine learning#technology#python programming#coding#ai#python#programmers#data science#medical research#medical technology#aicommunity#aiinnovation
24 notes
·
View notes
Text
Hey all, so the crowdfund is up for ReachAI. If anyone wants to go check it out it would mean a lot to me! Also you can watch the video there on IndieGOGO or here:
youtube
It should give you a bit of an idea on what ReachAI is and what the nonprofit will be doing as well as the benefits of becoming a donor (which there are even more than I talked about in the video including Webinars, 1-on-1 sessions with me, a newsletter update on research the organization is working on or right now that I am). I am excited to be bringing ReachAI closer to launch day, I am really hoping I can raise the money to get it started! I know it could do so much good in the world :3
#programming#programmer#artificial intelligence#machine learning#technology#python programming#coding#ai#python#programmers#data science#medical research#medical technology#aicommunity#aiinnovation#Youtube
24 notes
·
View notes
Text
Q&A on the Anti-Hate Speech / Anti-Bullying / Anti-NSFW Photos Moderator Plug-in I am Making for Socials
I have gotten a lot of questions on things like the dataset, the software I am developing, and all that. Okay, so I want to start from the beginning. I am developing a tool / plug-in for social media sites / Discord that is powered by machine learning (Natural Language Processing).
Q1. Where Was The Dataset Collected From, Were Real People Being Harmed?
The dataset that I was originally going to use for the software can be found here:
It was generated dynamically by the Dynabench Project. It is realistic but not scraped from internet forums or things like Twitter, etc, although there are real datasets that are valuable to understanding why people act like psychos on socials that do contained scraped hate speech / bullying / toxicity that are usually used for psychological studies and content moderation similar to the thing that I am doing. I wanted to use this dataset first, to see if it would suffice for what I needed it for.
Issue #1
I initially was going to use a pre-trained BERT model via HuggingFaceTransformer library (compatible with PyTorch), but unfortunately BERT requires an exhaustive amount of data. I'm talking like.. scraping the entire Wikipedia site for every page amount, if that makes sense.
I tried to use TinyBERT but the results were not good despite Optuna hyperparameter tuning and it ate up 99% of my resources for this month of Google Colab+'s GPUs >_> Issue #2
It didn't have everything I wanted for what I was doing. I wanted it to be as accurate as possible, because what I am doing is incredibly important and involves very sensitive topics. It wasn't big enough to train on any actual real Transformers like GPT or BERT, so I moved on to the solution for this.
Solution
I am now using Azure AI's Content Moderation AI which is extremely advanced and finetuned to wipe out toxicity. It has customization and is easy to use. I can add a front-end to the back-end (Python Flask) which makes it reassuring that it will be easy to use when I implement a proper front-end. It allows you to auto-ban people (using logic I am developing) based on if they show you NSFW images that are unwanted, photos promoting violence / hate / animal abuse etc, it also allows you to auto-ban hate speech and bullying of ALL kinds.
Q2. Does It Protect Against Hate Speech Towards All Communities
This was actually not worded the way I am phrasing it but I wanted to rephrase it because it was off-putting and would upset some of my community. The answer to that, is that it protects ALL people from bullying and hate speech. If someone says hate speech directed at you / bullying towards you, the goal is to have the model autoban via backend logic (API calls / Webhooks, etc). I am Indigenous and white, I am non-binary (the people everyone swears don't exist, hi I exist), and I am married to a woman. I want to protect EVERYONE not just a few communities from targeted harassment.
I am going to analyze the amounts of hate speech on a scraped dataset with a correlation matrix and explain which communities are being targeted and to what degree just to prove a point later on because this question really did bother me on how it was worded. THIS is why - > Why would I choose to make a software that only detects hate speech / bullying towards only a "few" communities, it makes no sense. (-end rant-)
Anyways. Now that is over and out of my system, I am going to work on some things. I hope everyone has a great night and please take care of yourselves and be kind to each other (and yourselves!).
#programming#programmer#programmers#ai#machine learning#aicommunity#artificialintelligence#artificial intelligence#LGBTQplus#LGBTQIA#lgbtq#stopthehate#equality#gender equality#stop hate#endbullying#cyberbullying#support bipoc#black lives matter#racial justice#racial equality#trans equality#nonbinary
1 note
·
View note
Text
Understanding IHD with Data Science
Ischemic Heart Disease (IHD), more commonly recognized as coronary artery disease, is a profound health concern that stems from a decreased blood supply to the heart. Such a decrease is typically due to fatty deposits or plaques narrowing the coronary arteries. These arteries, as vital conduits delivering oxygen-rich blood to the heart, play a paramount role in ensuring the heart's efficient functioning. An obstruction or reduced flow within these arteries can usher in adverse outcomes, with heart attacks being the most dire. Given the gravity of IHD, the global medical community emphasizes the essence of early detection and prompt intervention to manage its repercussions effectively.
A New Age in Healthcare: Embracing Data Science
As we stand on the cusp of the fourth industrial revolution, technology's intertwining with every domain is evident. The healthcare sector is no exception. The integration of data science in healthcare is not merely an augmentation; it's a paradigm shift. Data science, with its vast array of tools and methodologies, is fostering new avenues to understand, diagnose, and even predict various health conditions long before they manifest pronounced symptoms.
Machine Learning: The Vanguard of Modern Medical Research
Among the myriad of tools under the vast umbrella of data science, Machine Learning (ML) shines exceptionally bright. An essential offshoot of artificial intelligence, ML capitalizes on algorithms and statistical models, granting computers the capability to process vast amounts of data and discern patterns without being explicitly programmed.
In the healthcare realm, the applications of ML are manifold. From predicting potential disease outbreaks based on global health data trends to optimizing patient flow in bustling hospitals, ML is progressively becoming a linchpin in medical operations. One of its most lauded applications, however, is its prowess in early disease prediction, and IHD detection stands as a testament to this.
Drawn to the immense potential ML holds, I ventured into a research project aimed at harnessing the RandomForestClassifier model's capabilities. Within the medical research sphere, this model is celebrated for its robustness and adaptability, making it a prime choice for my endeavor.
Deep Dive into the Findings
The results from the ML model were heartening. With an accuracy rate of 90%, the model’s prowess in discerning the presence of IHD based on an array of parameters was evident. Such a high accuracy rate is pivotal, considering the stakes at hand – the very health of a human heart. 9 times out of 10 the model is correct at its predictions.
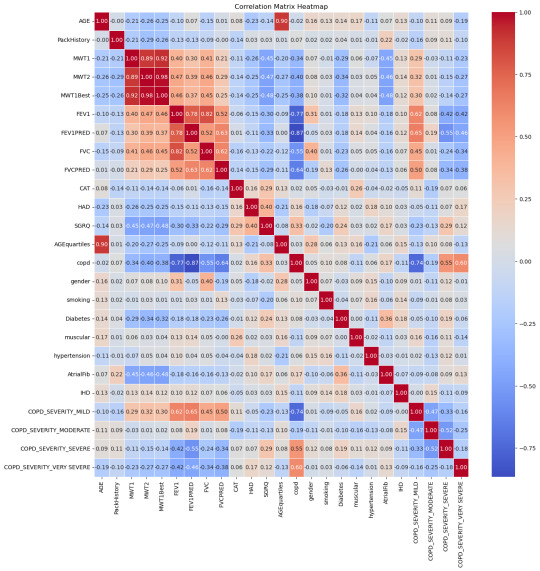
Breaking down the data, some correlations with IHD stood out prominently:
Moderate COPD (Chronic Obstructive Pulmonary Disease) – 15%: COPD's inclusion is noteworthy. While primarily a lung condition, its linkage with heart health has been a topic of numerous studies. A compromised respiratory system can inadvertently strain the heart, underscoring the interconnectedness of our bodily systems.
Diabetes – 18%: The correlation between diabetes and heart health isn't novel. Elevated blood sugar levels over extended periods can damage blood vessels, including the coronary arteries.
Age (segmented in quarterlies) – 15%: Age, as an immutable factor, plays a significant role. With age, several bodily systems gradually wear down, rendering individuals more susceptible to a plethora of conditions, IHD included.
Smoking habits – 14%: The deleterious effects of smoking on lung health are well-documented. However, its impact extends to the cardiovascular system, with nicotine and other chemicals adversely affecting heart functions.
MWT1 and MWT2 (indicators of physical endurance) – 13% and 14% respectively: Physical endurance and heart health share an intimate bond. These metrics, gauging one's physical stamina, can be precursors to potential heart-related anomalies.
Redefining Patient Care in the Machine Learning Era
Armed with these insights, healthcare can transcend its conventional boundaries. A deeper understanding of IHD's contributors empowers medical professionals to devise comprehensive care strategies that are both preventive and curative.
Moreover, the revelations from this study underscore the potential for proactive medical interventions. Instead of being reactive, waiting for symptoms to manifest, healthcare providers can now adopt a preventive stance. Patients exhibiting the highlighted risk factors can be placed under more meticulous observation, ensuring that potential IHD developments are nipped in the bud.
With the infusion of machine learning, healthcare is on the cusp of a personalized revolution. Gone are the days of one-size-fits-all medical approaches. Recognizing the uniqueness of each patient's health profile, machine learning models like the one employed in this study can pave the way for hyper-personalized care regimens.
As machine learning continues to entrench itself in healthcare, a future where disease predictions are accurate, interventions are timely, and patient care is unparalleled isn't merely a vision; it's an impending reality.
#heart disease#ihd#ischemic heart disease#programming#programmer#python#python programming#machine learning#data analysis#data science#data visualization#aicommunity#ai#artificial intelligence#medical research#medical technology
3 notes
·
View notes
Text
Autism Detection with Stacking Classifier
Introduction Navigating the intricate world of medical research, I've always been fascinated by the potential of artificial intelligence in health diagnostics. Today, I'm elated to unveil a project close to my heart, as I am diagnosed ASD, and my cousin who is 18 also has ASD. In my project, I employed machine learning to detect Adult Autism with a staggering accuracy of 95.7%. As followers of my blog know, my love for AI and medical research knows no bounds. This is a testament to the transformative power of AI in healthcare.
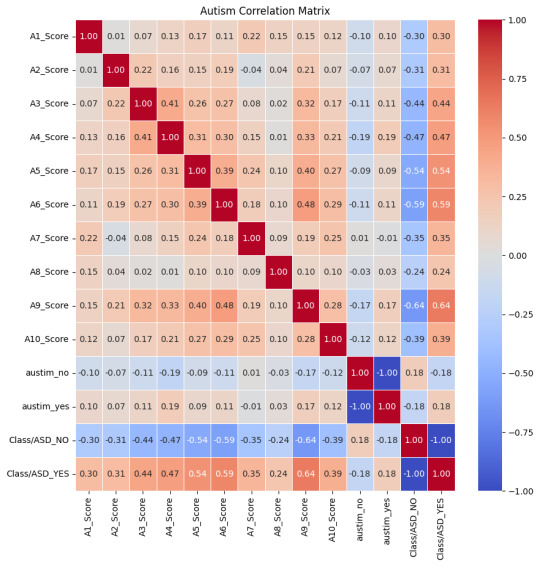
The Data My exploration commenced with a dataset (autism_screening.csv) which was full of scores and attributes related to Autism Spectrum Disorder (ASD). My initial step was to decipher the relationships between these scores, which I visualized using a heatmap. This correlation matrix was instrumental in highlighting the attributes most significantly associated with ASD.
The Process:
Feature Selection: Drawing insights from the correlation matrix, I pinpointed the following scores as the most correlated with ASD:
'A6_Score', 'A5_Score', 'A4_Score', 'A3_Score', 'A2_Score', 'A1_Score', 'A10_Score', 'A9_Score'
Data Preprocessing: I split the data into training and testing sets, ensuring a balanced representation. To guarantee the optimal performance of my model, I standardized the data using the StandardScaler.
Model Building: I opted for two powerhouse algorithms: RandomForest and XGBoost. With the aid of Optuna, a hyperparameter optimization framework, I fine-tuned these models.
Stacking for Enhanced Performance: To elevate the accuracy, I employed a stacking classifier. This technique combines the predictions of multiple models, leveraging the strengths of each to produce a final, more accurate prediction.
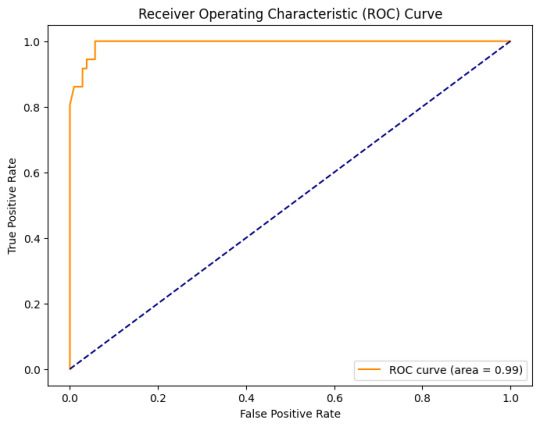
Evaluation: Testing my model, I was thrilled to achieve an accuracy of 95.7%. The Receiver Operating Characteristic (ROC) curve further validated the model's prowess, showcasing an area of 0.99.
Conclusion: This project's success is a beacon of hope and a testament to the transformative potential of AI in medical diagnostics. Achieving such a high accuracy in detecting Adult Autism is a stride towards early interventions and hope for many.
Note: For those intrigued by the technical details and eager to delve deeper, the complete code is available here. I would love to hear your feedback and questions!
Thank you for accompanying me on this journey. Together, let's keep pushing boundaries, learning, and making a tangible difference.
Stay curious, stay inspired.
#autism spectrum disorder#asd#autism#programming#python programming#python programmer#python#machine learning#ai#ai community#aicommunity#artificial intelligence#ai technology#prediction#data science#data analysis#neurodivergent
5 notes
·
View notes
Text
Buildspace: Business Plan
Over the weekend I am going to create a business plan for the nonprofit medical research organization I am creating during s4 of buildspace, just to prove I am serious and really want to do this. As you all know, I am incredibly passionate about helping potentially save lives and contributing to research in the medical field.
I hope by getting this plan on paper, I will solidify my idea and motivate myself even more in making my dream a reality.
#medical research#medical technology#huntingtons disease#business plan#business#nonprofit organization#nonprofit#machinelearning#machine learning#ai#aicommunity#ai technology#artificial intelligence
2 notes
·
View notes
Text
I was diagnosed with ADHD and ASD when I was young and the teachers just sat me in the hallway, desk and all. x.x It's okay I was already smarter than any of them anyways even at 8, I was reading college ecology and biology books that my grandma's friend would bring over for me by this time and had already learned how to build computers with my dad. I would have been better off homeschooling myself lol.

127K notes
·
View notes
Text

So I changed up my idea a bit on everything, BERT didn't train worth a damn unfortunately, so what I am going to do is use an LSTM model to identify spam and the rest I am going to use Azure AI's Content Moderation API (it's a very advanced API). Right here is some of the programming that analyzes images to make sure they are not profane / inappropriate. If they are, the person who sends them to your inbox gets blocked. Very useful for quite a few females who deal with sexual harassment over the internet. The next part of it will be on using the LSTM to detect scammers, phishers, and I will also probably introduce a cloud Antivirus API to the program to make sure that people can't send malware to a person :D
The idea is definitely evolving, I'm very happy with it. Also I completed my first assignment at my job yesterday as the head of the cybersec team there. I was very proud of myself and my bosses were impressed! :D I'm volunteering because I don't want to get in trouble for making money by disability again xD but it was still pretty cool to be able to help and my bosses be impressed with my skills.
#programming#programmer#artificial intelligence#machine learning#technology#coding#programmers#python programming#ai#python#azuredeveloper#azure#microsoft#tech
1 note
·
View note
Text
So the other day I posted my photo of the Snake dataset I had started collecting, this model on Microsoft Azure was trained on what I have right now (not much - 500 different pictures of different species of venomous snakes), and this was the result so far. I think it is turning out great and the dataset is really great! It only messed up on one snake that didn't have a really good picture of it, so that is actually really great already! Anyone else excited about the Snake Detective model? What snakes would you like to see in the dataset? Drop me a comment below and tell me your favorite slithering friends and I will add them to the database if I can find some pictures in Wikimedia Commons of them! I also plan to make a full website to host this machine learning model on eventually when I am done so people can analyze snakes in their yards to make sure they aren't venomous. I will also probably allow people to post their own comments under the snake pictures. The idea is to spread awareness and promote animal safety and respect for these misunderstood animals!
#programming#programmer#artificial intelligence#machine learning#python programming#technology#coding#python#ai#python 3#snakes#herpetology#reptiles#computer vision#artificialintelligence#aicommunity
2 notes
·
View notes
Text
So after mistaking forgetting to distribute BERT's training on GPU (BERT is a pretrained model made with PyTorch by META [PyTorch] by Google AI).
This is Pre-GPU distribution (as you can see it ate up my RAM, it originally crashed the entire thing before I switched to the high ram VM).
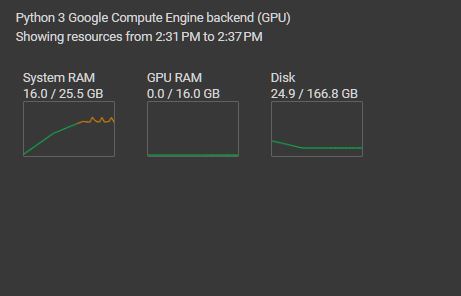
This is after GPU distribution which nearly also took up the entire GPU RAM.

I am on a V100 so this is pretty insane. Training BERT is incredibly demanding but it will be worth it when it helps stop bullying and hate speech. I will be making a separate app for Facebook and the Twitter API using BERT to help block people who are bullying people or spewing toxic hate speech.
I hope that this helps people a lot. I have been the target of cyberbullying / hate speech because I am non-binary (I don't really feel like either but I will go by either gender pronouns / my deadname if I have to). The last time I was on what is now X (Twitter), I ended up deleting it after getting a video from someone who was shooting an AR-15 at a LGBTQ+ flag.
That is what motivated me to develop something that could potentially help stop it as soon as it starts.
#programming#programmer#artificial intelligence#machine learning#python programming#coding#python#ai#python 3#stopthehate#nonbinary#trans equality#LGBTQIA#lgbtq community#lgbtqplus#technology#facebook#meta#google ai#google#PyTorch#BERT#NLP#natural language processing
2 notes
·
View notes
Text

This is part of a new project I am doing for a Facebook app that can alert someone when there is suspicious activity on their account, and block people who post rude comments and hate speech using a BERT model I am training on a dataset of hate speech. It automatically blocks people who are really rude / mean and keeps your feed clean of spam. I am developing it right now for work and for @emoryvalentine14 to test out and maybe in the future I will make it public.
I love NLP :D Also I plan to host this server probably on Heroku or something after it is done.
#machine learning#artificial intelligence#python programming#programmer#programming#technology#coding#python#ai#python 3#social media#stopthehate#lgbtq community#lgbtqia#lgbtqplus#gender equality
74 notes
·
View notes