
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by objectwaysblog and here's what we found interesting.
Average Info
Notes Per Post
3
Likes Per Post
3
Reblog Per Post
0
Reply Per Post
0
Time Between Posts
4 days
Number of Posts By Type
Text
10
Last Seen Tumblr Blogs





Fun Fact
130K people were victims of a chain letter scam that affected Tumblr in May 2011.
Text

Extensive testing of AI is necessary to prevent diagnostic errors, which account for a significant portion of medical errors and result in numerous deaths each year. While AI shows promise for accurate diagnostics, concerns remain regarding potential mistakes. Ensuring representative training data and effective model generalization are crucial for successful AI integration in healthcare.
Learn More: https://lnkd.in/dDK_5DfS
In the healthcare sector, ensuring the privacy and security of patient data is paramount, as it not only fosters trust between healthcare providers and patients, but also complies with stringent regulatory standards such as HIPAA, promoting ethical, responsible data handling practices.
Reach out to us to learn more [email protected].
#aiinhealthcare#healthcare#medicallabeling#hipaa#medicaldevices#drugdiscovery#datalabeling#dataannotation#annotation#objectways#qualitycontrol#datasecurity
0 notes
Text
Real-time Model Oversight: Amazon SageMaker vs Databricks ML Monitoring Features
Model monitoring is crucial in the lifecycle of machine learning models, especially for models deployed in production environments. Model monitoring is not just a "nice-to-have" but is essential to ensure the models' robustness, accuracy, fairness, and reliability in real-world applications. Without monitoring, model predictions can be unreliable, or even detrimental to the business or end-users. As a model builder, how often have you thought about how models’ behavior will change over time? In my professional life, I have seen many production systems managing model retraining life cycle using heuristic, gut feel or scheduled basis, either leading to the wastage of precious resources or performing retraining too late.

This is a ripe problem space as many models have been deployed in production. Hence there are many point solutions such as Great Expectations, Neptune.ai, Fiddler.ai who all boast really cool features either in terms of automatic metrics computation, differentiated statistical methods or Responsible AI hype that has become a real need of time (Thanks to ChatGPT and LLMs). In this Op-ed, I would like to touch upon two systems that I am familiar with and are widely used.
Amazon SageMaker Model Monitor
Amazon SageMaker is AWS’s flagship fully managed ML service to Build, Train, Deploy & “Monitor” Machine Learning models. The service provides click through experience for set up using SageMaker Studio or API experience using SageMaker SDK. SageMaker assumes you to have clean datasets for training and can capture inference request/response based on user defined time interval. The system works for model monitoring if models are the problem, BUT What if Data that is fed to the model is a problem or a pipeline well upstream in ETL pipeline is a problem. AWS provides multiple Data Lake architectures and patterns to stitch end-2-end data and AI systems together but tracking data lineage is easy if not impossible.
The monitoring solution is flexible thanks to SageMaker processing job which is underlying mechanism to execute underlying metrics. SageMaker processing also lets you build your custom container. SageMaker model monitoring is integrated with Amazon SageMaker Clarify and can provide Bias Drift which is important for Responsible AI. Overall SageMaker monitoring does a decent job of alerting when model drifts.

Databricks Lakehouse Monitoring
Let's look at the second contender. Databricks is a fully managed Data and AI platform available across all major clouds and also boasts millions of downloads of MLFlow OSS. I have recently come across Databricks Lakehouse Monitoring which IMO is a really cool paradigm of Monitoring your Data assets.
Let me explain why you should care if you are an ML Engineer or Data Scientist?
Let's say you have built a cool customer segmentation model and deployed it in production. You have started monitoring the model using one of the cool bespoke tools I mentioned earlier which may pop up an alert blaming a Data field. Now What?
✔ How do you track where that field came from cobweb of data ETL pipeline?
✔ How do you find the root cause of the drift?
✔ How do you track where that field came from cobweb of data ETL pipeline?
Here comes Databricks Lakehouse Monitoring to the rescue. Databricks Lakehouse Monitoring lets you monitor all of the tables in your account. You can also use it to track the performance of machine learning models and model-serving endpoints by monitoring inference tables created by the model’s output.
Let's put this in perspective, Data Layer is a foundation of AI. When teams across data and AI portfolios work together in a single platform, productivity of ML Teams, Access to Data assets and Governance is much superior compared to siloed or point solution.
The Vision below essentially captures an ideal Data and Model Monitoring solution. The journey starts with raw data with Bronze -> Silver -> Golden layers. Moreover, Features are also treated as another table (That’s refreshing and new paradigm, Goodbye feature stores). Now you get down to ML brass tacks by using Golden/Feature Tables for Model training and serve that model up.
Databricks recently launched in preview awesome Inference table feature. Imagine all your requests/responses captured as a table than raw files in your object store. Possibilities are limitless if the Table can scale. Once you have ground truth after the fact, just start logging it in Groundtruth Table. Since all this data is being ETLed using Databricks components, the Unity catalog offers nice end-2-end data lineage similar to Delta Live Tables.
Now you can turn on Monitors, and Databricks start computing metrics. Any Data Drift or Model Drift can be root caused to upstream ETL tables or source code. Imagine that you love other tools in the market for monitoring, then just have them crawl these tables and get your own insights.

Looks like Databricks want to take it up the notch by extending Expectations framework in DLT to extend to any Delta Table. Imagine the ability to set up column level constraints and instructing jobs to fail, rollback or default. So, it means problems can be pre-empted before they happen. Can't wait to see this evolution in the next few months.

To summarize, I came up with the following comparison between SageMaker and Databricks Model Monitoring.CapabilityWinnerSageMakerDatabricksRoot cause AnalysisDatabricksConstraint and violations due to concept and model driftExtends RCA to upstream ETL pipelines as lineage is maintainedBuilt-in statisticsSageMakerUses Deque Spark library and SageMaker Clarify for Bias driftUnderlying metrics library is not exposed but most likely Spark libraryDashboardingDatabricksAvailable using SageMaker Studio so it is a mustRedash dashboards are built and can be customized or use your favorite BI tool.AlertingDatabricksNeeds additional configuration using Event BridgeBuilt in alertingCustomizabilityBothUses Processing jobs so customization of your own metricsMost metrics are built-in, but dashboards can be customizedUse case coverageSageMakerCoverage for Tabular and NLP use casesCoverage for tabular use casesEase of UseDatabricksOne-click enablementOne-click enablement but bonus for monitoring upstream ETL tables
Hope you enjoyed the quick read. Hope you can engage Propensity Labs for your next Machine Learning project no matter how hard the problem is, we have a solution. Keep monitoring.
0 notes
Text
Guideline Adherence for Accurate Medical Data Labeling

The healthcare industry has witnessed the remarkable growth of artificial intelligence (AI), which has found diverse applications. As technology advances, AI’s potential in healthcare continues to expand. Nevertheless, certain limitations currently hinder the seamless integration of AI into existing healthcare systems.
AI is used in healthcare datasets to analyze data, provide clinical decision support, detect diseases, personalize treatment, monitor health, and aid in drug discovery. It enhances patient care, improves outcomes, and drives advancements in the healthcare industry. Many AI services such as Amazon Comprehend Medical, Google Cloud Healthcare API, John Snow Labs provide pre-built models. Due to the variety of medical data and requirements for accuracy human in the loop techniques are important to safeguard accuracy. However, the success of AI and ML models largely depends on the quality of the data they are trained on, necessitating reliable and accurate data labelling services.
Challenges in applying AI in Healthcare
Extensive testing of AI is necessary to prevent diagnostic errors, which account for a significant portion of medical errors and result in numerous deaths each year. While AI shows promise for accurate diagnostics, concerns remain regarding potential mistakes. Ensuring representative training data and effective model generalization are crucial for successful AI integration in healthcare.
In the healthcare sector, ensuring the privacy and security of patient data is paramount, as it not only fosters trust between healthcare providers and patients, but also complies with stringent regulatory standards such as HIPAA, promoting ethical, responsible data handling practices.
Lack of High-Quality Labeled datasets
Achieving a high quality labeled medical dataset poses several challenges, including:
Medical Labeling Skills: -Properly labeling medical data requires specialized domain knowledge and expertise. Medical professionals or trained annotators with a deep understanding of medical terminology and concepts are necessary to ensure accurate and meaningful annotations.
Managing Labeling Quality: -Maintaining high-quality labeling is crucial for reliable and trustworthy datasets. Ensuring consistency, accuracy, and minimizing annotation errors is challenging, as medical data can be complex and subject to interpretation. Robust quality control measures, including double-checking annotations and inter-annotator agreement, are necessary to mitigate labeling inconsistencies.
Managing the Cost of Labeling: -Labeling medical datasets can be a resource-intensive process, both in terms of time and cost. Acquiring sufficient labeled data may require significant financial investment, especially when specialized expertise is involved. Efficient labeling workflows, leveraging automation when feasible, can help manage throughput and reduce costs without compromising data quality.
Data Privacy and Security: -Safeguarding patient privacy and ensuring secure handling of sensitive medical data is crucial when collecting and labeling datasets.
Data Diversity and Representativeness: -Ensuring that the dataset captures the diversity of medical conditions, demographics, and healthcare settings is essential for building robust and unbiased AI models.
Best practices to manage medical labeling projects
Addressing these challenges requires a combination of domain expertise, quality control measures, and optimizing labeling processes to strike a balance between accuracy, cost-effectiveness, and dataset scale.
At Objectways we follow the Best Practices in medical labeling which include
Adherence to Guidelines: -Familiarize labeling teams with clear and comprehensive guidelines specific to the medical domain. Thoroughly understanding the guidelines ensures consistent and accurate labeling.
Conducting KPT (Knowledge, Process, Test): -Provide comprehensive training to labeling teams on medical concepts, terminology, and labeling procedures. Regular knowledge assessments and testing help evaluate proficiency of labeling teams and ensure continuous improvement.
Robust Team Structure: -We have established a structured team comprising labeling personnel, spot Quality Assurance (QA) reviewers, and dedicated QA professionals. This structure promotes accountability, efficient workflow, and consistent quality.
Quality Metrics: -We have implemented appropriate quality metrics such as precision, recall, and F1 score to assess labeling accuracy. We regularly monitor and track these metrics to identify areas for improvement and maintain high-quality standards.
Continuous Feedback Loop: -We have established a feedback mechanism where labeling teams receive regular feedback on their performance. This helps address any inconsistencies, clarify guidelines, and improve overall labeling accuracy.
Quality Control and Spot QA: - By implementing robust quality control measures, including periodic spot QA reviews by experienced reviewers, helps identify and rectify any labeling errors, ensures adherence to guidelines, and maintains high labeling quality.
Data Security and Privacy: - To validate our commitment to security and privacy controls, we have obtained the following formal certifications SOC2 Type2, ISO 27001, HIPAA, and GDPR. These certifications affirm our dedication to safeguarding customer data. Our privacy and security programs continue to expand, adhering to Privacy by Design principles and incorporating industry standards and customer requirements from various sectors.
Summary
At Objectways we have a team of certified annotators, including medical professionals such as nurses, doctors, and medical coders. Our experience includes working with top Cloud Medical AI providers, Healthcare providers and Insurance companies, utilizing advanced NLP techniques to create top-notch training sets and conduct human reviews of pre-labels across a wide variety of document formats and ontologies, such as call transcripts, patient notes, and ICD documents. Our DICOM data labeling services for computer vision cover precise annotation of medical images, including CT scans, MRIs, and X-rays and expert domain knowledge in radiology to ensure the accuracy and quality of labeled data.
In summary, the effectiveness of AI and ML models hinges significantly on the calibre of the data used for training, underscoring the need for dependable and precise data labeling services. Please contact [email protected] to enhance your AI Model Performance
#Objectways#Artificial Intelligence#Machine Learning#Data Science#Data Labeling#Data Annotation#Ai in Healthcare#Artificial Intelligence in Healthcare#Healthcare#Medical Labeling
0 notes
Text
Medical Labeling: Best Practices for High-Quality Datasets
ChatGPT has made AI a sensation among all enterprises and the everyday common man. It surpassed the user base to 1M within a week and broke many records. Even Bill gates' compared the success of ChatGPT to the most important milestones such as the birth of the internet, personal computers, and GUI. “This will change our world,” he continued. The applications of generative AI like OpenAI’s ChatGPT could improve office efficiency, drafting invoices and letters, Gates said in a podcast conversation with the German-language business paper.

Large Language Models (LLMs) are becoming increasingly popular for natural language processing (NLP) tasks, such as language translation, text summarization, and text generation. While LLMs have shown remarkable performance in these tasks, they are not without their limitations and potential drawbacks. LLMs are often trained on large datasets of text, which may contain biased or sensitive information. If these biases are not corrected, the LLM may perpetuate or amplify them in its language generation. Human reviewers are needed to evaluate the quality and appropriateness of LLM-generated text and to correct any errors or biases that are identified. LLMs are not yet capable of understanding the nuances and complexities of human language in the same way that humans can. Human reviewers are needed to ensure that LLM-generated text is understandable, coherent, and consistent with the intended meaning.
What is LLM Reinforcement Learning Human Feedback (RLHF)
LLM reinforcement learning human feedback (LLM RHLF) refers to a method of training large language models (LLMs) using a combination of reinforcement learning and human feedback. Reinforcement learning is a type of machine learning where an algorithm learns to make decisions by trial and error. In the context of LLMs, reinforcement learning can be used to optimize the performance of the LLM by providing it with feedback on the quality of its generated text.

Human feedback, on the other hand, is provided by human reviewers who evaluate the quality and appropriateness of LLM-generated text. Human feedback can be used to correct any errors or biases in the LLM-generated text and to improve the overall performance of the LLM.
LLM RHLF combines these two approaches by training the LLM using reinforcement learning and then using human feedback to evaluate and improve the quality of the LLM-generated text. This approach can help to improve the accuracy, quality, and appropriateness of LLM-generated text and to reduce any biases or errors that may be present in the training data.
How LLMs are augmented by Human Reviewers
There are several typical human review tasks for Large Language Models (LLMs):
Bias Evaluation: -One of the main concerns with LLMs is their potential to perpetuate or amplify biases present in the training data. Human reviewers can evaluate LLM-generated text for any biases or stereotypes that may have been introduced.
Accuracy Checking: -LLMs are not always accurate in their language generation, especially when faced with complex or nuanced language. Human reviewers can check LLM-generated text for accuracy and correct any errors that are identified.
Style and Tone Evaluation: -LLMs may not always generate text that is appropriate for the intended audience or purpose. Human reviewers can evaluate LLM-generated text for style, tone, and appropriateness.
Contextual Evaluation: -LLM-generated text may not always be suitable for a given context or situation. Human reviewers can evaluate LLM-generated text for context and ensure that it is appropriate for its intended use.
Content Verification: - LLMs may generate text that contains false or misleading information. Human reviewers can verify the accuracy of LLM-generated content and correct any errors that are identified.
Human Reviewers’ Skills
Human reviewers for Large Language Models (LLMs) need to have specific skills and experience to effectively evaluate and correct LLM-generated text. Here are some of the key skills and experience needed:
Language Skills: - Human reviewers need to have a strong command of the language(s) in which the LLM is generating text. They need to be able to understand the nuances of the language and ensure that LLM-generated text is grammatically correct, coherent, and appropriate for its intended audience and purpose.
Subject Matter Expertise: - Depending on the domain for which the LLM is generating text, human reviewers may need to have subject matter expertise in that area. For example, human reviewers working on LLM-generated medical text may need to have a background in medicine or healthcare.
Analytical Skills: -Human reviewers need to be able to critically evaluate LLM-generated text for accuracy, bias, style, tone, and context. They need to be able to identify errors and biases and correct them as needed.
Attention to Detail: - Human reviewers need to be detail-oriented and meticulous in their review of LLM-generated text. They need to be able to identify even small errors or inconsistencies and correct them as needed.
Cultural Competence: - Human reviewers need to be aware of cultural differences and sensitivities in the language(s) for which the LLM is generating text. They need to ensure that LLM-generated text is appropriate for its intended audience and does not offend or marginalize any group. Overall, human reviewers for LLM tasks need to have a combination of language skills, subject matter expertise, analytical skills, attention to detail, and cultural competence. They play a critical role in ensuring the accuracy, quality, and appropriateness of LLM-generated text, and their skills and experience are essential to the success of LLM-based language processing
Summary
At Objectways, we have a team of highly skilled human reviewers with education in creative writing, literature, journalism, and arts. They have deep expertise in natural language processing, and the ability to evaluate and correct the output of large language models (LLMs). Our team is experienced in working with a wide range of LLMs summarization, prompt generation, creative writing (movie, story, poem, code, essays, etc.), question & answer generation and is equipped with the knowledge and tools necessary to identify and correct any errors, biases, or inconsistencies in LLM-generated text. We have worked with companies who have generated foundational LLMs and improved on a variety of domains such as legal, chatbots, insurance, finance, medical, and hospitality to name a few. In summary, while LLMs are a powerful tool for natural language processing tasks, they are not a replacement for skilled human reviewers. Human reviewers are needed to ensure the accuracy, appropriateness, and quality of LLM-generated text, and to correct any errors or biases that may arise. Please contact [email protected] to harness the power of LLMs
#Objectways#Artificial Intelligence#Machine Learning#Data Science#Data Labeling#Data Annotation#Large Language Model#LLM#ChatGPT#Reinforcement Learning#NLP#GPT4
0 notes
Text
Balancing Automation and Human Review in Content Moderation

User-generated content (UGC) can be a valuable asset for digital platforms and businesses, providing an opportunity for users to engage with content and each other. However, UGC can also present several challenges and issues, including:
Legal and regulatory compliance: -UGC can sometimes infringe on legal and regulatory requirements, such as copyright, privacy, or advertising standards. Digital platforms and businesses need to ensure that the UGC posted by users is compliant with these requirements to avoid legal or regulatory repercussions.
Offensive or harmful content: -UGC can include content that is offensive, hateful, or harmful, such as hate speech, discriminatory language, or graphic violence. This type of content can lead to a negative user experience and may even damage brand reputation.
Inappropriate content: -UGC can also include inappropriate or irrelevant content, such as spam, fake reviews, or irrelevant comments. This can affect the overall quality of the content and make it difficult for users to find relevant and useful information.
Misinformation: -UGC can also include false or misleading information, which can be harmful to users and to the platform or business. Digital platforms and businesses must take steps to ensure that UGC is accurate and truthful.
Brand safety: -UGC can also pose a risk to brand safety, particularly if the content includes references to competitors or is critical of the platform or business. Digital platforms and businesses need to monitor UGC to ensure that it is not damaging to their brand image.
Moderation cost and scalability: -UGC can be difficult and expensive to moderate at scale. Digital platforms and businesses may need to invest in moderation tools, processes, and personnel to ensure that UGC is reviewed and moderated effectively.
Overall, UGC presents a number of challenges and issues that must be addressed by digital platforms and businesses. By implementing appropriate moderation processes, tools, and guidelines, these challenges can be mitigated, and UGC can continue to provide value to both users and the platform or business.
Best Practices to Manage Content Moderation Processes
Best Practices to Manage Content Moderation Processes Content moderation best practices involve a combination of human and automated moderation techniques, clear and transparent policies, and effective communication with users. By implementing these practices, digital platforms and businesses can provide a safe and positive user experience while complying with legal and regulatory requirements.
Objectways Content Moderation Human Review workflows involve following best practices:
User report or flagging: -The first step in the human content moderation workflow is for users to report or flag content that they believe violates platform policies or community guidelines.
Review content: -Once the content is flagged, it is then reviewed by a human content moderator. The moderator will evaluate the content to determine if it violates any platform policies or community guidelines.
Categorize the content: -The moderator will categorize the content based on the type of violation, such as hate speech, graphic violence, or adult content.
Take action: -The moderator will then take appropriate action depending on the type of violation. This can include removing the content, warning the user, or escalating the issue to a higher authority.
Appeal process: -Platforms often provide an appeal process for users to dispute moderation decisions. If a user appeals, the content will be reviewed by a different moderator or team.
Monitoring and continuous improvement: - After content is moderated, it is important to monitor the platform for repeat offenses or new types of violations. This helps to identify new patterns and improve the moderation process.
Choose the Right Moderation Tool
There are many tools available to help digital platforms and businesses with content moderation. Here are some leading tools for content moderation:
Google Perspective API: -Google Perspective API uses machine learning to identify and score the level of toxicity in a piece of content, making it easier for moderators to identify content that may violate community guidelines.
Amazon Rekognition:-Amazon Rekognition is a powerful image and video analysis tool that can be used to automatically identify and moderate content that violates community guidelines.
OpenAI GPT-3:-OpenAI GPT-3 is a natural language processing tool that can be used to analyze and moderate user-generated content, such as comments and reviews.
Besedo:-Besedo is a content moderation platform that uses a combination of AI and human moderators to review and moderate user-generated content.
We typically work with tools chosen by our customer partners or use Amazon Rekognition for our Turnkey Content Moderation offering as it is easy to use, provides nice integration and human in the loop capabilities.

Quality Service Level Agreements
Service Level Agreements (SLAs) are agreements between our customers who are digital platforms, businesses and Objectways content moderation team. The SLAs specify the expected quality and quantity of content moderation services and set out the penalties for failure to meet those expectations. Our SLAS can include:
Turnaround time: -Google Perspective API uses machine learning to identify and score the level of toxicity in a piece of content, making it easier for moderators to identify content that may violate community guidelines.
Accuracy rate: -Amazon Rekognition is a powerful image and video analysis tool that can be used to automatically identify and moderate content that violates community guidelines.
Rejection rate: -OpenAI GPT-3 is a natural language processing tool that can be used to analyze and moderate user-generated content, such as comments and reviews.
Escalation process: -Besedo is a content moderation platform that uses a combination of AI and human moderators to review and moderate user-generated content.
Availability: -This specifies the availability of content moderation services, such as 24/7 or during specific business hours.
Reporting and communication: -This specifies the frequency and format of reporting on content moderation activities, as well as the communication channels for raising issues or concerns.
Penalties and incentives: -This specifies the penalties or incentives for failing to meet or exceeding the SLA targets, such as financial penalties or bonuses.
By establishing clear SLAs for human content moderation, digital platforms and businesses can ensure that the quality and quantity of content moderation services meet their requirements and standards. It also allows them to hold our content moderation teams accountable for meeting performance targets and provide transparency to their users.
Conclusion
In conclusion, content moderation human review plays a critical role in maintaining the safety, security, and trustworthiness of online platforms and communities. By providing a human layer of review and oversight, content moderation helps to ensure that inappropriate or harmful content is removed, while legitimate and valuable content is allowed to thrive.
However, content moderation human review is a complex and challenging process, requiring careful planning, organization, and management. It also requires a deep understanding of the cultural, linguistic, and social nuances of the communities being moderated, as well as a commitment to transparency, fairness, and accountability.
By leveraging best practices, advanced technologies, and human expertise, it is possible to create effective and efficient content moderation human review workflows that support the goals and values of online platforms and communities. Whether it’s combating hate speech, preventing cyberbullying, or ensuring the safety of children, content moderation human review is a critical tool in creating a safer and more trustworthy online world for everyone.
Please contact Objectways Content Moderation experts to plan your next Content Moderation project.
#Objectways#Artificial Intelligence#Machine Learning#Data Science#Data Labeling#Data Annotation#COntent Moderation#Content
0 notes
Text
The Future is Lidar: Unlocking Possibilities with Precise Labeling

Lidar (which stands for Light Detection and Ranging) is a type of 3D sensing technology that uses laser light to measure distances and create detailed 3D maps of objects and environments. Lidar has a wide range of applications, including self-driving cars, robotics, virtual reality, and geospatial mapping.
Lidar works by emitting laser light pulses and measuring the time it takes for the light to bounce back after hitting an object or surface. This data is then used to create a precise 3D map of the surrounding environment, with detailed information about the size, shape, and distance of objects within the map. Lidar sensors can vary in their range and resolution, with some sensors able to measure distances up to several hundred meters, and others able to detect fine details as small as a few centimeters.
One of the primary applications of lidar is in autonomous vehicles, where lidar sensors can be used to create a detailed 3D map of the surrounding environment, allowing the vehicle to detect and avoid obstacles in real-time. Lidar is also used in robotics for navigation and obstacle avoidance, and in virtual reality for creating immersive, 3D environments. https://www.youtube.com/embed/BVRMh9NO9Cs
In addition, lidar is used in geospatial mapping and surveying, where it can be used to create highly accurate 3D maps of terrain and buildings for a variety of applications, including urban planning, disaster response, and natural resource management.
Overall, lidar is a powerful and versatile technology that is driving advances in a wide range of fields, from autonomous vehicles to robotics to geospatial mapping.
Choosing your labeling modality
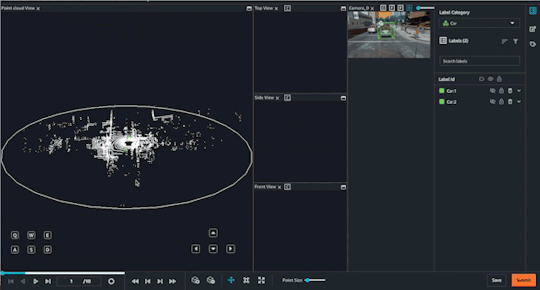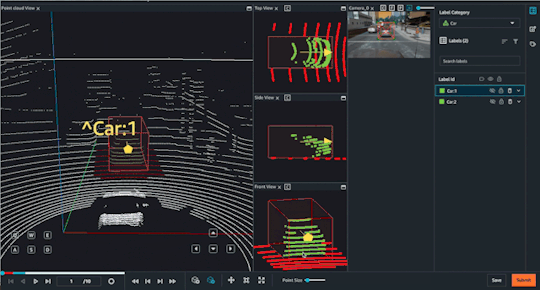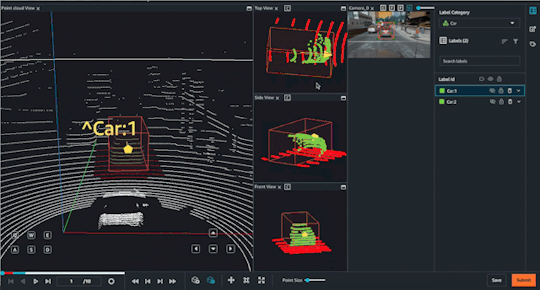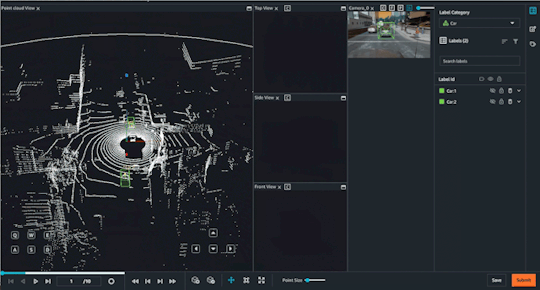
Object Tracking
Computer vision techniques are often used in combination with lidar 3D point cloud data to extract information and insights from the data. Here are some of the different computer vision techniques that can be used with lidar 3D point cloud data:
Object detection and recognition:-This involves using computer vision algorithms to detect and identify objects within the point cloud data, such as cars, buildings, and trees. Object detection and recognition can be useful for a wide range of applications, from urban planning to autonomous driving.
Object tracking:-This involves tracking the movement and trajectory of objects within the point cloud data over time. Object tracking can be used for applications such as crowd monitoring or autonomous vehicle navigation.
Segmentation:-This involves dividing the point cloud data into different segments based on the properties of the points, such as color or reflectivity. Segmentation can be used to identify regions of interest within the data, such as road surfaces or building facades.
Overall, these computer vision techniques can help to extract valuable information and insights from lidar 3D point cloud data and enable a wide range of applications and use cases. By combining lidar data with computer vision techniques, it is possible to create highly accurate and detailed 3D models of objects and environments, with a wide range of potential applications.
Why High-Quality labeling is important
High-quality lidar 3D point cloud labels are important for creating accurate and reliable 3D models of objects and environments. Here are some reasons why high-quality lidar 3D point cloud labels matter for a high-quality model:
Accuracy:-High-quality lidar 3D point cloud labels ensure that objects are accurately and consistently identified and labeled within the data. This is important for applications such as autonomous vehicles or robotics, where accurate and reliable information about objects in the environment is critical.
Consistency:-High-quality lidar 3D point cloud labels ensure that objects are labeled consistently across the data, with no variations in naming or identification. This is important for applications such as object detection or segmentation, where consistent labels are necessary for accurate and reliable results.
Completeness:-High-quality lidar 3D point cloud labels ensure that all objects within the data are identified and labeled, with no missing or incomplete information. This is important for applications such as geospatial mapping or urban planning, where complete and comprehensive information about objects in the environment is necessary.
Cost-effectiveness:-While high-quality lidar 3D point cloud labels may be more expensive to acquire or process initially, they can actually be more cost-effective in the long run, as they may require fewer resources to process or analyze and may be more suitable for a wider range of applications.
Overall, high-quality lidar 3D point cloud labels are critical for creating accurate and reliable 3D models of objects and environments, with a wide range of potential applications and benefits. By investing in high-quality labeling and processing, it is possible to create more accurate, detailed, and valuable 3D models that can be used in a wide range of applications, from autonomous vehicles to urban planning to robotics.
Best Practices to Manage Large Scale Lidar 3D Point Cloud Labeling Projects
Planning your lidar 3D point cloud labeling project is an important step in ensuring that the project is completed on time, on budget, and with the desired level of quality. Here are some key considerations to keep in mind when planning your lidar 3D point cloud labeling project:
Project scope:-Define the scope of the project, including the size of the dataset, the types of objects to be labeled, and the level of detail required. This will help to ensure that the project is focused and well-defined.
Labeling requirements:-Define the labeling requirements for the project, including the labeling schema, the labeling accuracy, and the level of detail required. This will help to ensure that the labeling process is consistent and produces high-quality results.
Labeling team:-Define the size and composition of the labeling team, including the number of labelers, their expertise, and their availability. Objectways can provide 1000s of trained Lidar labeling experts to match the throughput demand.
Tools and resources:-Identify the tools and resources required for the labeling project, including software, hardware, and data storage. This will help to ensure that the labeling process is efficient and that the results are consistent and of high quality.
Timeline and budget:-Define the timeline and budget for the labeling project, including the estimated time required for labeling, the cost of resources, and the expected deliverables. This will help to ensure that the project is completed on time and within budget.
Use Pre-labeling or downsampling to Save Cost:-There are many SOTA models available for pre-labeling that can provide starting point for labeling to save human labeling cost. Other approach in object tracking is to downsample frames at lower rate to reduce labeling effort
Overall, careful planning is key to the success of any lidar 3D point cloud labeling project. By taking the time to define the scope, requirements, team, tools, timeline, and budget for the project, it is possible to ensure that the project is completed with the desired level of quality and within the allotted resources.
At Objectways, we have worked on 100s of Lidar 3D point Cloud labeling projects across Autonomous Vehicles, Robotics, Agriculture and Geospatial domains. Contact Objectways for planning your next Lidar 3D point cloud labeling project
Lidar 3D Object Detection
Computer Vision
Autonomous Vehicle
Self Driving Cars
Tesla
#artificial intelligence#data annotation#data labeling#data science#machine learning#objectways#Lidar#Lidar 3d#Cloud Lableing#Cloud Labeling
0 notes
Text
Unleashing Hidden Data: Extracting Insights with Annotation Tools for PDFs
In today's digital age, businesses generate and process a large volume of documents. These documents can be in a variety of formats, including PDFs, images, and scanned documents. Extracting data from these documents can be a challenge, but it is essential for many business processes.
One way to extract data from documents is to use optical character recognition (OCR) software. OCR software can automatically read and convert text from images and scanned documents into a machine-readable format. However, OCR software is not always accurate, and it can be difficult to extract structured data from unstructured text.
Another way to extract data from documents is to use a purpose-built annotation tool. Annotation tools allow users to highlight and annotate specific parts of a document. This can be helpful for identifying important information and for extracting structured data.
There are a number of purpose-built annotation tools available, including Amazon Textract, Google Cloud Vision API, and Microsoft Azure Cognitive Services. These tools offer a variety of features, including the ability to extract text, identify entities, and extract tables.
In addition to extracting data, annotation tools can also be used to improve the quality of OCR results. By highlighting and annotating specific parts of a document, users can help OCR software to better understand the context of the text. This can lead to more accurate OCR results.
Annotation tools can be a valuable tool for extracting data from PDFs and other documents. By using a purpose-built annotation tool, businesses can improve the accuracy of their OCR results and extract structured data from unstructured text.
Here are some of the benefits of using a purpose-built annotation tool:
Improved accuracy of OCR results
Ability to extract structured data from unstructured text
Easier to identify important information
Improved efficiency of document processing
If you are looking for a way to extract data from PDFs and other documents, a purpose-built annotation tool is a good option. These tools can help you to improve the accuracy of your OCR results, extract structured data from unstructured text, and identify important information.
Here are some of the steps involved in using a purpose-built annotation tool to extract data from PDFs:
Upload the PDF to the annotation tool.
Highlight and annotate the text that you want to extract.
Save the annotated PDF.
Run the OCR software on the annotated PDF.
The OCR software will extract the text from the annotated PDF.
Here are some of the considerations when choosing a purpose-built annotation tool:
The features offered by the tool.
The accuracy of the OCR results.
The ease of use of the tool.
The price of the tool.
Summary:
The blog provides a step-by-step guide on using a purpose-built annotation tool to extract data from PDFs, which includes uploading the PDF, highlighting and annotating the text, and running OCR software on the annotated PDF.
Overall, purpose-built annotation tools offer improved accuracy of OCR results, the ability to extract structured data from unstructured text, ease of identifying important information, and increased efficiency in document processing. They prove to be a valuable solution for businesses seeking to enhance data extraction from PDFs and other documents. Contact us [email protected] for more details.

0 notes
Text
How AI and Deep Learning Are Revolutionizing Insurance

The use of artificial intelligence (AI) in the insurance industry has gained considerable momentum in recent years, revolutionizing various aspects of insurance operations and customer experience. AI technologies, such as machine learning, natural language processing, and predictive analytics, are being employed to streamline processes, enhance risk assessment, automate claims processing, detect fraud, and personalize policies, among other applications. By leveraging AI, insurance companies can make data-driven decisions, improve operational efficiency, mitigate risks, and deliver more tailored products and services to policyholders also utilizing AI in these insurance processes can enhance precision and result in cost savings.
However, there are some obstacles that currently make it difficult to fully integrate AI into existing insurance systems.
Challenges to incorporate AI into the insurance industry
Managing Data Quality and Availability: ML models and algorithms heavily rely on high-quality and diverse data. However, insurance companies may encounter challenges in ensuring the accuracy, completeness, and accessibility of data. Inconsistent or fragmented data sources can hinder models' effectiveness.
Data Privacy and Security: Data privacy and security pose concerns in the insurance industry due to the sensitive customer information involved. Integrating AI requires robust measures to protect data and comply with regulatory requirements, such as HIPAA and GDPR, to maintain trust and confidentiality.
Domain Expertise: Insurance-specific knowledge and expertise are required to label insurance-related documents and data correctly. It can be challenging to find labeling resources with deep understanding of insurance terminology, policies, and regulations.
Scalability and Volume: Insurance companies handle large volumes of data and documents that need to be labelled. Scaling labeling operations to handle such volumes while maintaining accuracy and efficiency can be a significant challenge.
Adapting to Evolving Insurance Requirements: Insurance practices, regulations, and products continuously evolve. Keeping the practices up to date and adaptable to changing insurance requirements can be a challenge. Continuous monitoring, feedback loops, and iterative improvements are essential to address evolving needs.
Managing the cost: Building infrastructure and technology costs, data acquisition and management expenses, talent acquisition, training and model development costs (the time and costs of labeling data, and slow iteration cycles)
Ethical and Bias Concerns: A growing challenge is the ethical considerations surrounding AI. The effectiveness of AI algorithms heavily relies on the quality of the data used for training, as biased data can result in biased outcomes that perpetuate discrimination and can impact the lives and financial security of people and their businesses.
Best practices to manage insurance AI projects
To overcome these challenges requires a combination of industry and domain expertise, quality control measures, and optimizing labeling processes to strike a balance between accuracy, cost-efficiency, and scalability of datasets
At Objectways we follow the Best Practices in labeling which include
Adherence to precise guidelines: We establish well-defined guidelines that outline the criteria and instructions for labeling data. Clearly communicate the labeling process, including the types of labels required, the context in which labels should be applied, and any specific rules or conventions to follow.
Executing KPT (Knowledge, Process, Test): Firstly, we establish a deep understanding of the insurance domain and its terminology to our team. Next, we define a standardized labeling process with clear guidelines for consistent and accurate labeling. Then there is regular testing and quality assurance to ensure the effectiveness of the process, allowing for continuous improvement and adaptation to changing insurance requirements.
Strong Team Organization: Our team has implemented a well-organized structure consisting of labeling personnel, spot Quality Assurance (QA) reviewers, and dedicated QA professionals. This framework promotes responsibility, streamlined workflow, and unwavering quality.
Performance Measures: We have established suitable quality indicators, including precision, recall, and F1 score, to evaluate the accuracy of labeling. We consistently monitor and analyse these measures to identify areas for enhancement and uphold exceptional quality standards.
Continuous Feedback Loop: We have implemented a system for providing consistent feedback to labeling teams regarding their performance. This facilitates the resolution of any discrepancies, clarifies guidelines, and enhances the overall accuracy of labeling.
Quality Control and Spot QA: By implementing robust quality control measures, including periodic spot QA reviews by experienced reviewers, helps identify and rectify any labeling errors, ensures adherence to guidelines, and maintains high labeling quality.
Data Security and Privacy: Data security and privacy are of paramount importance in the insurance industry, necessitating stringent measures to safeguard sensitive information and protect customer confidentiality. Therefore, to validate our commitment to security and privacy controls, we have obtained the following formal certifications SOC2 Type2, ISO 27001, HIPAA, and GDPR. These certifications affirm our dedication to safeguarding customer data and they continue to expand, adhering to Privacy by Design principles and incorporating industry standards and customer requirements from various sectors.
Below are some of the representative use cases for our clients:
Expediting and streamlining claims processing: Developing AI-powered claims processing and adjustment systems for insurance companies face challenges such as establishing human in the loop system, dealing with the time and cost-intensive process of labeling data, and facing slow iteration cycles. At Objectways we offer comprehensive support for all aspects of claims adjustment AI projects, offering solutions that enhance model performance and accelerate time to market, thereby helping insurers overcome these obstacles.
Accelerating insurance documents faster with AI and human in the loop: Expediting the processing of insurance documents by utilizing AI in combination with human expertise. AI technologies like OCR and NER enable efficient information retrieval, document understanding, and automated decision-making. Objectways human-in-the-loop workflows ensures accuracy, quality control, in the above cases, enabling faster processing while maintaining precision and compliance.
Fast and Precise Underwriting: By training computer vision models on geospatial data, underwriters can assess risks and property values without the need for human inspection. At Objectways we offer comprehensive support for geospatial data within all its products, enabling teams to visualize raw data, annotate information, and curate location data for spatial analysis. This native support empowers teams to leverage geospatial data effectively and make informed decisions based on accurate insights.
Driving language and text AI development: At Objectways we offer cutting-edge text labeling services to insurers, enabling them to harness the power of large language models for enhancing recommendations, chatbots (Providing automated customer service, answering frequently asked questions with personalization and empathy. Enabling multi-lingual customer service by translating customers queries and responding in the customers preferred language), risk assessments, and other applications. With our services, insurers can accelerate and optimize the development of NLP-based AI, propelling advancements in language and text processing.
Summary
At Objectways, our team consists of over 1000 experts specializing in Computer Vision, Natural Language Processing (NLP), and prompt engineering. They bring extensive experience in tasks like object detection, such as image segmentation and classification, as well as common language tasks like named entity recognition (NER), optical character recognition (OCR), and LLM prompt engineering.
In summary while there are challenges to fully integrating AI into the insurance industry, Objectways follows best practices in labeling to overcome these obstacles and ensure accuracy, cost-efficiency, and scalability of datasets. To learn more about how Objectways can revolutionize your insurance processes with AI, contact [email protected] to provide feedback or have any questions.
#artificial intelligence#data annotation#data labeling#data science#machine learning#objectways#Ai in Insurance#Artificial Intelligence in Insurance
1 note
·
View note
Text
Data Labeling Strategies for Cutting-Edge Segmentation Projects

Deep learning has been very successful when working with images as data and is currently at a stage where it works better than humans on multiple use-cases. The most important problems that humans have been interested in solving with computer vision are image classification, object detection and segmentation in the increasing order of their difficulty.
While there in the plain old task of image classification we are just interested in getting the labels of all the objects that are present in an image. In object detection we come further and try to know along with what all objects that are present in an image, the location at which the objects are present with the help of bounding boxes. Image segmentation takes it to a new level by trying to find out accurately the exact boundary of the objects in the image.
What is image segmentation?
We know an image is nothing but a collection of pixels. Image segmentation is the process of classifying each pixel in an image belonging to a certain class and hence can be thought of as a classification problem per pixel. There are two types of segmentation techniques
segmentation: - Semantic segmentation is the process of classifying each pixel belonging to a particular label. It doesn’t different across different instances of the same object. For example, if there are 2 cats in an image, semantic segmentation gives same label to all the pixels of both cats
Instance segmentation: - Instance segmentation differs from semantic segmentation in the sense that it gives a unique label to every instance of a particular object in the image. As can be seen in the image above all 3 dogs are assigned different colors i.e different labels. With semantic segmentation all of them would have been assigned the same color.
There are numerous advances in Segmentation algorithms and open-source datasets. But to solve a particular problem in your domain, you will still need human labeled images or human based verification. In this article, we will go through some of the nuances in segmentation task labeling and how human based workforce can work in tandem with machine learning based approaches.
To train your machine learning model, you need high quality labels. For a successful data labeling project for segmentation depends on three key ingredients.
Labeling Tools
Training
Quality Management
Labeling Tools
There are many open source and commercially available tools on the market. At objectways, we train our workforce using Open CVAT that provides a polygon tool with interpolation and assistive tooling that gives 4x better speed at labeling and then we use a tool that fits the use case.
Here are the leading tools that we recommend for labeling. For efficient labeling, prefer a tool that allows pre-labeling and assistive labeling using techniques like Deep Extreme Cut or Grab cut and good review capabilities such as per label opacity controls.
Workforce training
While it is easier to train a resource to perform simple image tasks such as classification or bounding boxes, segmentation tasks require more training as it involves multiple mechanisms to optimize time, increase efficiency and reduce worker fatigue. Here are some simple training techniques
Utilize Assistive Tooling: An annotator may start with a simple brush or polygon tool which they find easy to pick up. But at volume, these tools tend to induce muscle fatigue hence it is important to make use of assistive tooling.
Gradually introduce complex tasks: Annotators are always good at doing the same task more efficiently with time and should be part of the training program. At Objectways, we tend to start training by introducing annotators with simple images with relatively easy shapes (Cars/Buses/Roads) and migrate them to using complex shapes such as vegetation, barriers.
Use variety of available open-source pre-labeled datasets: It is also important to train the workforce using different datasets and we use PascalVoc, Coco, Cityscapes, Lits, CCP, Pratheepan, Inria Aerial Image Labeling.
Provide Feedback: It is also important to provide timely feedback about their work and hence we use the golden set technique that is created by our senior annotators with 99.99% accuracy and use it to provide feedback for annotators during the training.
Quality Management
In Machine Learning, there are different techniques to understand and evaluate the results of a model.
Pixel accuracy: Pixel accuracy is the most basic metric which can be used to validate the results. Accuracy is obtained by taking the ratio of correctly classified pixels w.r.t total pixels.
Intersection over Union: IOU is defined as the ratio of intersection of ground truth and predicted segmentation outputs over their union. If we are calculating for multiple classes, the IOU of each class is calculated, and their meaning is taken. It is a better metric compared to pixel accuracy as if every pixel is given as background in a 2-class input the IOU value is (90/100+0/100)/2 i.e 45% IOU which gives a better representation as compared to 90% accuracy.
F1 Score: The metric popularly used in classification F1 Score can be used for segmentation tasks as well to deal with class imbalance.
If you have a labeled dataset, you can introduce a golden set in the labeling pipeline and use one of the scores to compare labels against your own ground truth. We focus on following aspects to improve quality of labeling
Understand labeling instructions: Never underestimate the importance of good labeling instructions. Typically, instructions are authored by data scientists who are good at expressing what they want with examples. The human brain has a natural tendency to give weight to (and remember) negative experiences or interactions more than positive ones — they stand out more. So, it is important to provide bad labeling examples. Reading instructions carefully often weeds out many systemic errors across tasks.
Provide timely feedback: While many workforces use tiered skilled workforce where level1 workforce are less experienced than quality control team, it is important to provide timely feedback to level1 annotators, so they understand unintentional labeling errors, so they do not make those errors in the future tasks
Rigorous Quality audits: Many tools provide nice metrics to track label addition/deletion or change over time. Just as algorithms should converge and reduce the loss function, the time to QC a particular task and suggested changes should converge to less than .01% error rate. At objectways, we have dedicated QC and super QC teams who have a consistent track record to achieve over 99% accuracy.
Summary
We have discussed best practices to manage complex large scale segmentation projects and provided guidance for tooling, workforce upskilling and quality management. Please contact [email protected] to provide feedback or if you have any questions.
#Objectways#Artificial Intelligence#Machine Learning#Data Science#Data Labeling#Data Annotation#Human in the Loop
0 notes
Text
The Power of AI and Human Collaboration in Media Content Analysis

In today’s world binge watching has become a way of life not just for Gen-Z but also for many baby boomers. Viewers are watching more content than ever. In particular, Over-The-Top (OTT) and Video-On-Demand (VOD) platforms provide a rich selection of content choices anytime, anywhere, and on any screen. With proliferating content volumes, media companies are facing challenges in preparing and managing their content. This is crucial to provide a high-quality viewing experience and better monetizing content.
Some of the use cases involved are,
Finding opening of credits, Intro start, Intro end, recap start, recap end and other video segments
Choosing the right spots to insert advertisements to ensure logical pause for users
Creating automated personalized trailers by getting interesting themes from videos
Identify audio and video synchronization issues
While these approaches were traditionally handled by large teams of trained human workforces, many AI based approaches have evolved such as Amazon Rekognition’s video segmentation API. AI models are getting better at addressing above mentioned use cases, but they are typically pre-trained on a different type of content and may not be accurate for your content library. So, what if we use AI enabled human in the loop approach to reduce cost and improve accuracy of video segmentation tasks.
In our approach, the AI based APIs can provide weaker labels to detect video segments and send for review to be trained human reviewers for creating picture perfect segments. The approach tremendously improves your media content understanding and helps generate ground truth to fine-tune AI models. Below is workflow of end-2-end solution,
Raw media content is uploaded to Amazon S3 cloud storage. The content may need to be preprocessed or transcoded to make it suitable for streaming platform (e.g convert to .mp4, upsample or downsample)
AWS Elemental MediaConvert transcodes file-based content into live stream assets quickly and reliably. Convert content libraries of any size for broadcast and streaming. Media files are transcoded to .mp4 format
Amazon Rekognition Video provides an API that identifies useful segments of video, such as black frames and end credits.
Objectways has developed a Video segmentation annotator custom workflow with SageMaker Ground Truth labeling service that can ingest labels from Amazon Rekognition. Optionally, you can skip step#3 if you want to create your own labels for training custom ML model or applying directly to your content.
The content may have privacy and digitial rights management requirements and protection. The Objectway’s Video Segmentaton tool also supports Digital Rights Management provider integration to ensure only authorized analyst can look at the content. Moreover, the content analysts operate out of SOC2 TYPE2 compliant facilities where no downloads or screen capture are allowed.
The media analysts at Objectways’ are experts in content understanding and video segmentation labeling for a variety of use cases. Depending on your accuracy requirements, each video can be reviewed or annotated by two independent analysts and segment time codes difference thresholds are used for weeding out human bias (e.g., out of consensus if time code differs by 5 milliseconds). The out of consensus labels can be adjudicated by senior quality analyst to provide higher quality guarantees.
The Objectways Media analyst team provides throughput and quality gurantees and continues to deliver daily throughtput depending on your business needs. The segmented content labels are then saved to Amazon S3 as JSON manifest format and can be directly ingested into your Media streaming platform.
Conclusion
Artificial intelligence (AI) has become ubiquitous in Media and Entertainment to improve content understanding to increase user engagement and also drive ad revenue. The AI enabled Human in the loop approach outlined is best of breed solution to reduce the human cost and provide highest quality. The approach can be also extended to other use cases such as content moderation, ad placement and personalized trailer generation.
Contact [email protected] for more information.
2 notes
·
View notes