#DataBricks ML
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
Real-time Model Oversight: Amazon SageMaker vs Databricks ML Monitoring Features
Model monitoring is crucial in the lifecycle of machine learning models, especially for models deployed in production environments. Model monitoring is not just a "nice-to-have" but is essential to ensure the models' robustness, accuracy, fairness, and reliability in real-world applications. Without monitoring, model predictions can be unreliable, or even detrimental to the business or end-users. As a model builder, how often have you thought about how models’ behavior will change over time? In my professional life, I have seen many production systems managing model retraining life cycle using heuristic, gut feel or scheduled basis, either leading to the wastage of precious resources or performing retraining too late.

This is a ripe problem space as many models have been deployed in production. Hence there are many point solutions such as Great Expectations, Neptune.ai, Fiddler.ai who all boast really cool features either in terms of automatic metrics computation, differentiated statistical methods or Responsible AI hype that has become a real need of time (Thanks to ChatGPT and LLMs). In this Op-ed, I would like to touch upon two systems that I am familiar with and are widely used.
Amazon SageMaker Model Monitor
Amazon SageMaker is AWS’s flagship fully managed ML service to Build, Train, Deploy & “Monitor” Machine Learning models. The service provides click through experience for set up using SageMaker Studio or API experience using SageMaker SDK. SageMaker assumes you to have clean datasets for training and can capture inference request/response based on user defined time interval. The system works for model monitoring if models are the problem, BUT What if Data that is fed to the model is a problem or a pipeline well upstream in ETL pipeline is a problem. AWS provides multiple Data Lake architectures and patterns to stitch end-2-end data and AI systems together but tracking data lineage is easy if not impossible.
The monitoring solution is flexible thanks to SageMaker processing job which is underlying mechanism to execute underlying metrics. SageMaker processing also lets you build your custom container. SageMaker model monitoring is integrated with Amazon SageMaker Clarify and can provide Bias Drift which is important for Responsible AI. Overall SageMaker monitoring does a decent job of alerting when model drifts.

Databricks Lakehouse Monitoring
Let's look at the second contender. Databricks is a fully managed Data and AI platform available across all major clouds and also boasts millions of downloads of MLFlow OSS. I have recently come across Databricks Lakehouse Monitoring which IMO is a really cool paradigm of Monitoring your Data assets.
Let me explain why you should care if you are an ML Engineer or Data Scientist?
Let's say you have built a cool customer segmentation model and deployed it in production. You have started monitoring the model using one of the cool bespoke tools I mentioned earlier which may pop up an alert blaming a Data field. Now What?
✔ How do you track where that field came from cobweb of data ETL pipeline?
✔ How do you find the root cause of the drift?
✔ How do you track where that field came from cobweb of data ETL pipeline?
Here comes Databricks Lakehouse Monitoring to the rescue. Databricks Lakehouse Monitoring lets you monitor all of the tables in your account. You can also use it to track the performance of machine learning models and model-serving endpoints by monitoring inference tables created by the model’s output.
Let's put this in perspective, Data Layer is a foundation of AI. When teams across data and AI portfolios work together in a single platform, productivity of ML Teams, Access to Data assets and Governance is much superior compared to siloed or point solution.
The Vision below essentially captures an ideal Data and Model Monitoring solution. The journey starts with raw data with Bronze -> Silver -> Golden layers. Moreover, Features are also treated as another table (That’s refreshing and new paradigm, Goodbye feature stores). Now you get down to ML brass tacks by using Golden/Feature Tables for Model training and serve that model up.
Databricks recently launched in preview awesome Inference table feature. Imagine all your requests/responses captured as a table than raw files in your object store. Possibilities are limitless if the Table can scale. Once you have ground truth after the fact, just start logging it in Groundtruth Table. Since all this data is being ETLed using Databricks components, the Unity catalog offers nice end-2-end data lineage similar to Delta Live Tables.
Now you can turn on Monitors, and Databricks start computing metrics. Any Data Drift or Model Drift can be root caused to upstream ETL tables or source code. Imagine that you love other tools in the market for monitoring, then just have them crawl these tables and get your own insights.

Looks like Databricks want to take it up the notch by extending Expectations framework in DLT to extend to any Delta Table. Imagine the ability to set up column level constraints and instructing jobs to fail, rollback or default. So, it means problems can be pre-empted before they happen. Can't wait to see this evolution in the next few months.

To summarize, I came up with the following comparison between SageMaker and Databricks Model Monitoring.CapabilityWinnerSageMakerDatabricksRoot cause AnalysisDatabricksConstraint and violations due to concept and model driftExtends RCA to upstream ETL pipelines as lineage is maintainedBuilt-in statisticsSageMakerUses Deque Spark library and SageMaker Clarify for Bias driftUnderlying metrics library is not exposed but most likely Spark libraryDashboardingDatabricksAvailable using SageMaker Studio so it is a mustRedash dashboards are built and can be customized or use your favorite BI tool.AlertingDatabricksNeeds additional configuration using Event BridgeBuilt in alertingCustomizabilityBothUses Processing jobs so customization of your own metricsMost metrics are built-in, but dashboards can be customizedUse case coverageSageMakerCoverage for Tabular and NLP use casesCoverage for tabular use casesEase of UseDatabricksOne-click enablementOne-click enablement but bonus for monitoring upstream ETL tables
Hope you enjoyed the quick read. Hope you can engage Propensity Labs for your next Machine Learning project no matter how hard the problem is, we have a solution. Keep monitoring.
0 notes
Text
Unlocking Full Potential: The Compelling Reasons to Migrate to Databricks Unity Catalog
In a world overwhelmed by data complexities and AI advancements, Databricks Unity Catalog emerges as a game-changer. This blog delves into how Unity Catalog revolutionizes data and AI governance, offering a unified, agile solution .
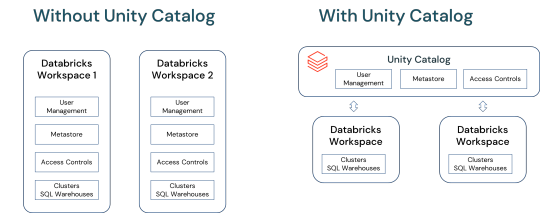
View On WordPress
#Access Control in Data Platforms#Advanced User Management#AI and ML Data Governance#AI Data Management#Big Data Solutions#Centralized Metadata Management#Cloud Data Management#Data Collaboration Tools#Data Ecosystem Integration#Data Governance Solutions#Data Lakehouse Architecture#Data Platform Modernization#Data Security and Compliance#Databricks for Data Scientists#Databricks Unity catalog#Enterprise Data Strategy#Migrating to Unity Catalog#Scalable Data Architecture#Unity Catalog Features
0 notes
Text
Your Complete Guide to Azure Data Engineering: Skills, Certification & Training

Introduction
Why Azure Data Engineering Matters
Today, as we live in the big data and cloud computing era, Azure Data Engineering is considered one of the most sought-after skills around the world. If you want to get a high-paying job in technology or enhance your data toolbox, learning Azure data services can put you ahead of the competition in today's IT world. This guide will provide you with an insight into what Azure Data Engineering is, why certification is important, and how good training can kick off your data career.
What is Azure Data Engineering?
Azure Data Engineering is focused on designing, building, and maintaining elastic data pipelines and data storage arrangements using Microsoft Azure. It involves:
Building data solutions with tools like Azure Data Factory and Azure Synapse Analytics
Building ETL (Extract, Transform, Load) data workflows for big data processing
Synchronizing cloud data infrastructure efficiently
Enabling data analytics and business intelligence using tools like Power BI
An Azure Data Engineer certification helps businesses transform raw data into useful insights.
Benefits of Obtaining Azure Data Engineer Certification
Becoming an Azure Data Engineer certified isn't just a credential — it's a career enhancer. Here's why:
Confirms your technical know-how in real Azure environments
Enhances your hiring prospects with businesses and consumers
Opens up global opportunities and enhanced salary offers
Keep yourself updated with Microsoft Azure's evolving ecosystem
Starting with Azure Data Engineer Training
To become a successful Azure Data Engineer, proper training is required. Seek an Azure Data Engineer training program that offers:
• In-depth modules on Azure Data Factory, Azure Synapse, Azure Databricks
• Hands-on labs and live data pipeline projects
• Integration with Power BI for end-to-end data flow
• Mock exams, doubt-clearing sessions, and job interview preparation
By the time you finish your course, you should be prepared to take the Azure Data Engineer certification exam.
Azure Data Engineering Trends
The world is evolving quickly. Some of the top trends in 2025 include:
Massive shift to cloud-native data platforms across industries
Integration of AI and ML models within Azure pipelines
Increased demand for automation and data orchestration skills
Heightened need for certified professionals who can offer insights at scale
Why Global Teq for Azure Data Engineer Training?
In your pursuit of a career in Azure Data Engineering, Global Teq is your partner in learning. Here's why:
Expert Trainers – Get trained by actual Azure industry experts
Industry-Ready Curriculum – Theory, practice, and project experience
Flexible Learning Modes – Online learning at your own pace
Career Support – Resume guidance, mock interviews & placement assistance
Low Cost – Affordable quality training
Thousands of students have built their careers with Global Teq. Join the crowd and unlock your potential as a certified Azure Data Engineer!
Leap into a Data-Driven Career
As an Azure Data Engineer certified, it's not only a career shift—it's an investment in your future. With the right training and certification, you can enjoy top jobs in cloud computing, data architecture, and analytics. Whether you're new to industry or upskilling, Global Teq gives you the edge you require.
Start your Azure Data Engineering profession today with Global Teq. Sign up now and become a cloud data leader!
#Azure#azure data engineer course online#Azure data engineer certification#Azure data engineer course#Azure data engineer training#Azure certification data engineer
0 notes
Text
microsoft azure ai engineer associate certification

Top Career Opportunities After Earning Azure AI Engineer Associate Certification
In today’s ever-evolving tech world, Artificial Intelligence (AI) is no longer just a buzzword — it’s a full-blown career path. With organizations embracing AI to improve operations, customer service, and innovation, professionals are rushing to upskill themselves. Among the top choices, the Microsoft Azure AI Engineer Associate Certification is gaining significant attention.
If you’re serious about making a mark in AI, then the Microsoft Azure AI certification pathway can be your golden ticket. This article dives deep into the top career opportunities after earning Azure AI Engineer Associate Certification, how this certification boosts your job prospects, and the roles you can aim for.
Why Choose the Azure AI Engineer Associate Certification?
The Azure AI Engineer Associate Certification is offered by Microsoft, a global leader in cloud computing and AI. It verifies your ability to use Azure Cognitive Services, Azure Machine Learning, and conversational AI to build and deploy AI solutions.
Professionals holding this certification demonstrate hands-on skills and are preferred by companies that want ready-to-deploy AI talent.
Benefits of the Azure AI Engineer Associate Certification
Let’s understand why more professionals are choosing this certification to strengthen their careers:
1. Industry Recognition
Companies worldwide trust Microsoft technologies. Getting certified adds credibility to your resume.
2. Cloud-Centric Skillset
The demand for cloud-based AI solutions is skyrocketing. This certification proves your expertise in building such systems.
3. Competitive Salary Packages
Certified professionals are often offered higher salaries due to their validated skills.
4. Global Opportunities
Whether you're in India, the USA, or Europe, Azure AI certification opens doors globally.
Top Career Opportunities After Earning Azure AI Engineer Associate Certification
The top career opportunities after earning Azure AI Engineer Associate Certification span across various industries, from healthcare and finance to retail and logistics. Below are the most promising roles you can pursue:
AI Engineer
As an AI Engineer, you’ll build, test, and deploy AI models. You'll work with machine learning algorithms and integrate Azure Cognitive Services. This is one of the most common and direct roles after certification.
Machine Learning Engineer
You’ll design and implement machine learning models in real-world applications. You'll be responsible for model training, evaluation, and fine-tuning on Azure ML Studio or Azure Databricks.
Data Scientist
This role involves data analysis, visualization, and model building. Azure tools like Machine Learning Designer make your job easier. Data scientists with Azure skills are in massive demand across all sectors.
AI Solutions Architect
Here, you’ll lead the design of AI solutions for enterprise applications. You need to combine business understanding with deep technical expertise in AI and Azure services.
Cloud AI Consultant
Companies hire consultants to guide their AI strategy. Your Azure certification gives you the tools to advise clients on how to build scalable AI systems using cloud services.
Business Intelligence Developer
BI developers use AI to gain insights from business data. With Azure’s AI tools, you can automate reporting, forecast trends, and build smart dashboards.
AI Product Manager
This role is perfect if you love tech and strategy. As a product manager, you’ll plan the AI product roadmap and ensure Azure services align with customer needs.
Chatbot Developer
With expertise in Azure Bot Services and Language Understanding (LUIS), you’ll create conversational AI that enhances customer experiences across websites, apps, and support systems.
Automation Engineer
You’ll design intelligent automation workflows using Azure AI and RPA tools. From customer onboarding to document processing, AI is the key.
Azure Developer with AI Focus
A developer well-versed in .NET or Python and now skilled in Azure AI can build powerful applications that utilize computer vision, NLP, and predictive models.
Industries Hiring Azure AI Certified Professionals
The top career opportunities after earning Azure AI Engineer Associate Certification are not limited to IT companies. Here’s where you’re likely to be hired:
Healthcare: AI-driven diagnostics and patient care
Finance: Fraud detection and predictive analytics
Retail: Customer behavior analysis and chatbots
Logistics: Smart inventory and route optimization
Education: Personalized learning platforms
Demand Outlook and Salary Trends
Let’s take a look at what the future holds:
AI Engineer: ₹10–25 LPA in India / $120K+ in the US
ML Engineer: ₹12–30 LPA in India / $130K+ in the US
Data Scientist: ₹8–22 LPA in India / $110K+ in the US
Companies like Microsoft, Accenture, Infosys, Deloitte, and IBM are actively hiring Azure AI-certified professionals. Job listings on platforms like LinkedIn and Indeed reflect growing demand.
Skills Gained from the Certification
The Azure AI Engineer Associate Certification equips you with:
Knowledge of Azure Cognitive Services
Skills in NLP, speech, vision, and language understanding
Proficiency in Azure Bot Services
Hands-on with Machine Learning pipelines
Use of Azure ML Studio and Notebooks
You don’t just become a certificate holder—you become a problem solver.
Career Growth After the Certification
As you progress in your AI journey, the certification lays the foundation for:
Mid-level roles after 2–3 years: Lead AI Engineer, AI Consultant
Senior roles after 5+ years: AI Architect, Director of AI Solutions
Leadership after 10+ years: Chief Data Officer, Head of AI
Real-World Projects That Get You Hired
Employers love practical knowledge. The certification encourages project-based learning, such as:
Sentiment analysis using Azure Cognitive Services
Building chatbots for e-commerce
Predictive analytics models for healthcare
Language translation tools
Automated document processing using Azure Form Recognizer
Completing and showcasing such projects makes your portfolio job-ready.
Middle of the Article Keyword Usage
If you're aiming to future-proof your tech career, then exploring the top career opportunities after earning Azure AI Engineer Associate Certification is one of the smartest moves you can make. It not only adds to your credentials but directly connects you to real-world AI roles.
Who Should Pursue This Certification?
This certification is ideal for:
Freshers with Python/AI interest
Software developers entering AI
Data professionals upskilling
Cloud engineers expanding into AI
Technical leads managing AI projects
How to Prepare for the Certification
Tips to ace the exam:
Take official Microsoft learning paths
Join instructor-led training programs
Practice with Azure sandbox labs
Study real-world use cases
Attempt mock exams
Final Thoughts
The top career opportunities after earning Azure AI Engineer Associate Certification are not only growing—they’re evolving. This certification doesn’t just give you knowledge; it opens doors to meaningful, high-paying, and future-ready roles. Whether you aim to be an AI engineer, a consultant, or a product manager, this certification lays the perfect foundation for your next big move in the AI industry.
FAQs
What are the prerequisites for taking the Azure AI certification exam?
You should have a basic understanding of Python, machine learning concepts, and experience with Microsoft Azure.
Is it necessary to have prior AI experience?
No, but having foundational knowledge in AI and cloud computing will make the learning curve easier.
How long does it take to prepare for the exam?
On average, candidates spend 4–6 weeks preparing with structured study plans and hands-on practice.
Is this certification useful for non-developers?
Yes! Even business analysts and managers with tech interest can benefit, especially in AI product management and consulting roles.
Can I get a job immediately after certification?
It depends on your background, but certification significantly boosts your chances of landing interviews and roles.
Does this certification expire?
Yes, typically after one year. Microsoft provides updates and renewal paths to keep your skills current.
What tools should I master for this certification?
Azure Machine Learning, Azure Cognitive Services, Azure Bot Service, and Python are key tools to learn.
What is the exam format like?
It usually consists of 40–60 questions including MCQs, case studies, and practical scenarios.
Can I do this certification online?
Yes, you can take the exam online with proctoring or at an authorized test center.
How is it different from other cloud certifications?
This certification focuses specifically on AI implementation using Azure, unlike general cloud certifications that cover infrastructure and DevOps.
1 note
·
View note
Text

Accelerate your data career with Accentfuture’s Databricks Online Training. Gain real-time experience in Spark, data pipelines, and ML workflows. Learn from industry experts with flexible schedules, live sessions, and practical project-based learning
0 notes
Text
Unlocking the Power of Data: Why Kadel Labs Offers the Best Databricks Services and Consultants
In today’s rapidly evolving digital landscape, data is not just a byproduct of business operations—it is the foundation for strategic decision-making, innovation, and competitive advantage. Companies across the globe are leveraging advanced data platforms to transform raw data into actionable insights. One of the most powerful platforms enabling this transformation is Databricks, a cloud-based data engineering and analytics platform built on Apache Spark. However, to harness its full potential, organizations often require expert guidance and execution. This is where Kadel Labs steps in, offering the best Databricks consultants and top-tier Databricks services tailored to meet diverse business needs.
Understanding Databricks and Its Importance
Before diving into why Kadel Labs stands out, it’s important to understand what makes Databricks so valuable. Databricks combines the best of data engineering, machine learning, and data science into a unified analytics platform. It simplifies the process of building, training, and deploying AI and ML models, while also ensuring high scalability and performance.
The platform enables:
Seamless integration with multiple cloud providers (Azure, AWS, GCP)
Collaboration across data teams using notebooks and shared workspaces
Accelerated ETL processes through automated workflows
Real-time data analytics and business intelligence
Yet, while Databricks is powerful, unlocking its full value requires more than just a subscription—it demands expertise, vision, and customization. That’s where Kadel Labs truly shines.
Who Is Kadel Labs?
Kadel Labs is a technology consulting and solutions company specializing in data analytics, AI/ML, and digital transformation. With a strong commitment to innovation and a client-first philosophy, Kadel Labs has emerged as a trusted partner for businesses looking to leverage data as a strategic asset.
What sets Kadel Labs apart is its ability to deliver the best Databricks services, ensuring clients maximize ROI from their data infrastructure investments. From initial implementation to complex machine learning pipelines, Kadel Labs helps companies at every step of the data journey.
Why Kadel Labs Offers the Best Databricks Consultants
When it comes to data platform adoption and optimization, the right consultant can make or break a project. Kadel Labs boasts a team of highly skilled, certified, and experienced Databricks professionals who have worked across multiple industries—including finance, healthcare, e-commerce, and manufacturing.
1. Certified Expertise
Kadel Labs’ consultants hold various certifications directly from Databricks and other cloud providers. This ensures that they not only understand the technical nuances of the platform but also remain updated on the latest features, capabilities, and best practices.
2. Industry Experience
Experience matters. The consultants at Kadel Labs have hands-on experience with deploying large-scale Databricks environments for enterprise clients. This includes setting up data lakes, implementing Delta Lake, building ML workflows, and optimizing performance across various data pipelines.
3. Tailored Solutions
Rather than offering a one-size-fits-all approach, Kadel Labs customizes its Databricks services to align with each client’s specific business goals, data maturity, and regulatory requirements.
4. End-to-End Services
From assessment and strategy formulation to implementation and ongoing support, Kadel Labs offers comprehensive Databricks consulting services. This full lifecycle engagement ensures that clients get consistent value and minimal disruption.
Kadel Labs’ Core Databricks Services
Here’s an overview of why businesses consider Kadel Labs as the go-to provider for the best Databricks services:
1. Databricks Platform Implementation
Kadel Labs assists clients in setting up and configuring their Databricks environments across cloud platforms like Azure, AWS, and GCP. This includes provisioning clusters, configuring security roles, and ensuring seamless data integration.
2. Data Lake Architecture with Delta Lake
Modern data lakes need to be fast, reliable, and scalable. Kadel Labs leverages Delta Lake—Databricks’ open-source storage layer—to build high-performance data lakes that support ACID transactions and schema enforcement.
3. ETL and Data Engineering
ETL (Extract, Transform, Load) processes are at the heart of data analytics. Kadel Labs builds robust and scalable ETL pipelines using Apache Spark, streamlining data flow from various sources into Databricks.
4. Machine Learning & AI Integration
With an in-house team of data scientists and ML engineers, Kadel Labs helps clients build, train, and deploy machine learning models directly on the Databricks platform. The use of MLflow and AutoML accelerates time-to-value and model accuracy.
5. Real-time Analytics and BI Dashboards
Kadel Labs integrates Databricks with visualization tools like Power BI, Tableau, and Looker to create real-time dashboards that support faster and more informed business decisions.
6. Databricks Optimization and Support
Once the platform is operational, ongoing support and optimization are critical. Kadel Labs offers performance tuning, cost management, and troubleshooting to ensure that Databricks runs at peak efficiency.
Real-World Impact: Case Studies
Financial Services Firm Reduces Reporting Time by 70%
A leading financial services client partnered with Kadel Labs to modernize their data infrastructure using Databricks. By implementing a Delta Lake architecture and optimizing ETL workflows, the client reduced their report generation time from 10 hours to just under 3 hours.
Healthcare Provider Implements Predictive Analytics
Kadel Labs worked with a large healthcare organization to deploy a predictive analytics model using Databricks. The solution helped identify at-risk patients in real-time, improving early intervention strategies and patient outcomes.
The Kadel Labs Advantage
So what makes Kadel Labs the best Databricks consultants in the industry? It comes down to a few key differentiators:
Agile Methodology: Kadel Labs employs agile project management to ensure iterative progress, constant feedback, and faster results.
Cross-functional Teams: Their teams include not just data engineers, but also cloud architects, DevOps specialists, and domain experts.
Client-Centric Approach: Every engagement is structured around the client’s goals, timelines, and KPIs.
Scalability: Whether you're a startup or a Fortune 500 company, Kadel Labs scales its services to meet your data needs.
The Future of Data is Collaborative, Scalable, and Intelligent
As data becomes increasingly central to business strategy, the need for platforms like Databricks—and the consultants who can leverage them—will only grow. With emerging trends such as real-time analytics, generative AI, and data sharing across ecosystems, companies will need partners who can keep them ahead of the curve.
Kadel Labs is not just a service provider—it’s a strategic partner helping organizations turn data into a growth engine.
Final Thoughts
In a world where data is the new oil, harnessing it effectively requires not only the right tools but also the right people. Kadel Labs stands out by offering the best Databricks consultants and the best Databricks services, making it a trusted partner for organizations across industries. Whether you’re just beginning your data journey or looking to elevate your existing infrastructure, Kadel Labs provides the expertise, technology, and dedication to help you succeed.
If you’re ready to accelerate your data transformation, Kadel Labs is the partner you need to move forward with confidence.
0 notes
Text
Master the Future: Become a Databricks Certified Generative AI Engineer

What if we told you that one certification could position you at the crossroads of AI innovation, high-paying job opportunities, and technical leadership?
That’s exactly what the Databricks Certified Generative AI Engineer certification does. As generative AI explodes across industries, skilled professionals who can bridge the gap between AI theory and real-world data solutions are in high demand. Databricks, a company at the forefront of data and AI, now offers a credential designed for those who want to lead the next wave of innovation.
If you're someone looking to validate your AI engineering skills with an in-demand, globally respected certification, keep reading. This blog will guide you through what the certification is, why it’s valuable, how to prepare effectively, and how it can launch or elevate your tech career.
Why the Databricks Certified Generative AI Engineer Certification Matters
Let’s start with the basics: why should you care about this certification?
Databricks has become synonymous with large-scale data processing, AI model deployment, and seamless ML integration across platforms. As AI continues to evolve into Generative AI, the need for professionals who can implement real-world solutions—using tools like Databricks Unity Catalog, MLflow, Apache Spark, and Lakehouse architecture—is only going to grow.
This certification tells employers that:
You can design and implement generative AI models.
You understand the complexities of data management in modern AI systems.
You know how to use Databricks tools to scale and deploy these models effectively.
For tech professionals, data scientists, ML engineers, and cloud developers, this isn't just a badge—it's a career accelerator.
Who Should Pursue This Certification?
The Databricks Certified Generative AI Engineer path is for:
Data Scientists & Machine Learning Engineers who want to shift into more cutting-edge roles.
Cloud Developers working with AI pipelines in enterprise environments.
AI Enthusiasts and Researchers ready to demonstrate their applied knowledge.
Professionals preparing for AI roles at companies using Databricks, Azure, AWS, or Google Cloud.
If you’re familiar with Python, machine learning fundamentals, and basic model deployment workflows, you’re ready to get started.
What You'll Learn: Core Skills Covered
The exam and its preparation cover a broad but practical set of topics:
🧠 1. Foundation of Generative AI
What is generative AI?
How do models like GPT, DALL·E, and Stable Diffusion actually work?
Introduction to transformer architectures and tokenization.
📊 2. Databricks Ecosystem
Using Databricks notebooks and workflows
Unity Catalog for data governance and model security
Integrating MLflow for reproducibility and experiment tracking
🔁 3. Model Training & Tuning
Fine-tuning foundation models on your data
Optimizing training with distributed computing
Managing costs and resource allocation
⚙️ 4. Deployment & Monitoring
Creating real-time endpoints
Model versioning and rollback strategies
Using MLflow’s model registry for lifecycle tracking
🔐 5. Responsible AI & Ethics
Bias detection and mitigation
Privacy-preserving machine learning
Explainability and fairness
Each of these topics is deeply embedded in the exam and reflects current best practices in the industry.
Why Databricks Is Leading the AI Charge
Databricks isn’t just a platform—it’s a movement. With its Lakehouse architecture, the company bridges the gap between data warehouses and data lakes, providing a unified platform to manage and deploy AI solutions.
Databricks is already trusted by organizations like:
Comcast
Shell
HSBC
Regeneron Pharmaceuticals
So, when you add a Databricks Certified Generative AI Engineer credential to your profile, you’re aligning yourself with the tools and platforms that Fortune 500 companies rely on.
What’s the Exam Format?
Here’s what to expect:
Multiple choice and scenario-based questions
90 minutes total
Around 60 questions
Online proctored format
You’ll be tested on:
Generative AI fundamentals
Databricks-specific tools
Model development, deployment, and monitoring
Data handling in an AI lifecycle
How to Prepare: Your Study Blueprint
Passing this certification isn’t about memorizing definitions. It’s about understanding workflows, being able to apply best practices, and showing proficiency in a Databricks-native AI environment.
Step 1: Enroll in a Solid Practice Course
The most effective way to prepare is to take mock tests and get hands-on experience. We recommend enrolling in the Databricks Certified Generative AI Engineer practice test course, which gives you access to realistic exam-style questions, explanations, and performance feedback.
Step 2: Set Up a Databricks Workspace
If you don’t already have one, create a free Databricks Community Edition workspace. Explore notebooks, work with data in Delta Lake, and train a simple model using MLflow.
Step 3: Focus on the Databricks Stack
Make sure you’re confident using:
Databricks Notebooks
MLflow
Unity Catalog
Model Serving
Feature Store
Step 4: Review Key AI Concepts
Brush up on:
Transformer models and attention mechanisms
Fine-tuning vs. prompt engineering
Transfer learning
Generative model evaluation metrics (BLEU, ROUGE, etc.)
What Makes This Certification Unique?
Unlike many AI certifications that stay theoretical, this one is deeply practical. You’ll not only learn what generative AI is but also how to build and manage it in production.
Here are three reasons this stands out:
✅ 1. Real-world Integration
You’ll learn deployment, version control, and monitoring—which is what companies care about most.
✅ 2. Based on Industry-Proven Tools
Everything is built on top of Databricks, Apache Spark, and MLflow, used by data teams globally.
✅ 3. Focus on Modern AI Workflows
This certification keeps pace with the rapid evolution of AI—especially around LLMs (Large Language Models), prompt engineering, and GenAI use cases.
How It Benefits Your Career
Once certified, you’ll be well-positioned to:
Land roles like AI Engineer, ML Engineer, or Data Scientist in leading tech firms.
Negotiate a higher salary thanks to your verified skills.
Work on cutting-edge projects in AI, including enterprise chatbots, text summarization, image generation, and more.
Stand out in competitive job markets with a Databricks-backed credential on your LinkedIn.
According to recent industry trends, professionals with AI certifications earn an average of 20-30% more than those without.
Use Cases You’ll Be Ready to Tackle
After completing the course and passing the exam, you’ll be able to confidently work on:
Enterprise chatbots using foundation models
Real-time content moderation
AI-driven customer service agents
Medical imaging enhancement
Financial fraud detection using pattern generation
The scope is broad—and the possibilities are endless.
Don’t Just Study—Practice
It’s tempting to dive into study guides or YouTube videos, but what really works is practice. The Databricks Certified Generative AI Engineer practice course offers exam-style challenges that simulate the pressure and format of the real exam.
You’ll learn by doing—and that makes all the difference.
Final Thoughts: The Time to Act Is Now
Generative AI isn’t the future anymore—it’s the present. Companies across every sector are racing to integrate it. The question is:
Will you be ready to lead that charge?
If your goal is to become an in-demand AI expert with practical, validated skills, earning the Databricks Certified Generative AI Engineer credential is the move to make.
Start today. Equip yourself with the skills the industry is hungry for. Stand out. Level up.
👉 Enroll in the Databricks Certified Generative AI Engineer practice course now and take control of your AI journey.
🔍 Keyword Optimiz
0 notes
Text
Master the Machines: Learn Machine Learning with Ascendient Learning
Why Machine Learning Skills Are in High Demand
Machine learning is at the core of nearly every innovation in technology today. From personalized product recommendations and fraud detection to predictive maintenance and self-driving cars, businesses rely on machine learning to gain insights, optimize performance, and make smarter decisions. As organizations generate more data than ever before, the demand for professionals who can design, train, and deploy machine learning models is rising rapidly across industries.
Ascendient Learning: The Smartest Path to ML Expertise
Ascendient Learning is a trusted provider of machine learning training, offering courses developed in partnership with top vendors like AWS, IBM, Microsoft, Google Cloud, NVIDIA, and Databricks. With access to official courseware, experienced instructors, and flexible learning formats, Ascendient equips individuals and teams with the skills needed to turn data into action.
Courses are available in live virtual classrooms, in-person sessions, and self-paced formats. Learners benefit from hands-on labs, real-world case studies, and post-class support that reinforces what they’ve learned. Whether you’re a data scientist, software engineer, analyst, or IT manager, Ascendient has a training path that fits your role and future goals.
Training That Matches Real-World Applications
Ascendient Learning’s machine learning curriculum spans from foundational concepts to advanced implementation techniques. Beginners can start with introductory courses like Machine Learning on Google Cloud, Introduction to AI and ML, or Practical Data Science and Machine Learning with Python. These courses provide a strong base in algorithms, supervised and unsupervised learning, and model evaluation.
For more advanced learners, courses such as Advanced Machine Learning, Generative AI Engineering with Databricks, and Machine Learning with Apache Spark offer in-depth training on building scalable ML solutions and integrating them into cloud environments. Students can explore technologies like TensorFlow, Scikit-learn, PyTorch, and tools such as Amazon SageMaker and IBM Watson Studio.
Gain Skills That Translate into Real Impact
Machine learning isn’t just a buzzword. It's transforming the way organizations work. With the right training, professionals can improve business forecasting, automate time-consuming processes, and uncover patterns that would be impossible to detect manually.
In sectors like healthcare, ML helps identify treatment risks and recommend care paths. In retail, it powers dynamic pricing and customer segmentation. In manufacturing, it predicts equipment failure before it happens. Professionals who can harness machine learning contribute directly to innovation, efficiency, and growth.
Certification Paths That Build Career Momentum
Ascendient Learning’s machine learning training is also aligned with certification goals from AWS, IBM, Google Cloud, and Microsoft. Certifications such as AWS Certified Machine Learning – Specialty, Microsoft Azure AI Engineer Associate, and Google Cloud Certified – Professional ML Engineer validate your skills and demonstrate your readiness to lead AI initiatives.
Certified professionals often enjoy increased job opportunities, higher salaries, and greater credibility within their organizations. Ascendient supports this journey by offering prep materials, expert guidance, and access to labs even after the course ends.
Machine Learning with Ascendient
Machine learning is shaping the future of work, and those with the skills to understand and apply it will lead the change. Ascendient Learning offers a clear, flexible, and expert-led path to help you develop those skills, earn certifications, and make an impact in your career and organization.
Explore Ascendient Learning’s machine learning course catalog today. Discover the training that can turn your curiosity into capability and your ideas into innovation.
For more information visit: https://www.ascendientlearning.com/it-training/topics/ai-and-machine-learning
0 notes
Text
Empowering Businesses with Advanced Data Engineering Solutions in Toronto – C Data Insights
In a rapidly digitizing world, companies are swimming in data—but only a few truly know how to harness it. At C Data Insights, we bridge that gap by delivering top-tier data engineering solutions in Toronto designed to transform your raw data into actionable insights. From building robust data pipelines to enabling intelligent machine learning applications, we are your trusted partner in the Greater Toronto Area (GTA).
What Is Data Engineering and Why Is It Critical?
Data engineering involves the design, construction, and maintenance of scalable systems for collecting, storing, and analyzing data. In the modern business landscape, it forms the backbone of decision-making, automation, and strategic planning.
Without a solid data infrastructure, businesses struggle with:
Inconsistent or missing data
Delayed analytics reports
Poor data quality impacting AI/ML performance
Increased operational costs
That’s where our data engineering service in GTA helps. We create a seamless flow of clean, usable, and timely data—so you can focus on growth.
Key Features of Our Data Engineering Solutions
As a leading provider of data engineering solutions in Toronto, C Data Insights offers a full suite of services tailored to your business goals:
1. Data Pipeline Development
We build automated, resilient pipelines that efficiently extract, transform, and load (ETL) data from multiple sources—be it APIs, cloud platforms, or on-premise databases.
2. Cloud-Based Architecture
Need scalable infrastructure? We design data systems on AWS, Azure, and Google Cloud, ensuring flexibility, security, and real-time access.
3. Data Warehousing & Lakehouses
Store structured and unstructured data efficiently with modern data warehousing technologies like Snowflake, BigQuery, and Databricks.
4. Batch & Streaming Data Processing
Process large volumes of data in real-time or at scheduled intervals with tools like Apache Kafka, Spark, and Airflow.
Data Engineering and Machine Learning – A Powerful Duo
Data engineering lays the groundwork, and machine learning unlocks its full potential. Our solutions enable you to go beyond dashboards and reports by integrating data engineering and machine learning into your workflow.
We help you:
Build feature stores for ML models
Automate model training with clean data
Deploy models for real-time predictions
Monitor model accuracy and performance
Whether you want to optimize your marketing spend or forecast inventory needs, we ensure your data infrastructure supports accurate, AI-powered decisions.
Serving the Greater Toronto Area with Local Expertise
As a trusted data engineering service in GTA, we take pride in supporting businesses across:
Toronto
Mississauga
Brampton
Markham
Vaughan
Richmond Hill
Scarborough
Our local presence allows us to offer faster response times, better collaboration, and solutions tailored to local business dynamics.
Why Businesses Choose C Data Insights
✔ End-to-End Support: From strategy to execution, we’re with you every step of the way ✔ Industry Experience: Proven success across retail, healthcare, finance, and logistics ✔ Scalable Systems: Our solutions grow with your business needs ✔ Innovation-Focused: We use the latest tools and best practices to keep you ahead of the curve
Take Control of Your Data Today
Don’t let disorganized or inaccessible data hold your business back. Partner with C Data Insights to unlock the full potential of your data. Whether you need help with cloud migration, real-time analytics, or data engineering and machine learning, we’re here to guide you.
📍 Proudly offering data engineering solutions in Toronto and expert data engineering service in GTA.
📞 Contact us today for a free consultation 🌐 https://cdatainsights.com
C Data Insights – Engineering Data for Smart, Scalable, and Successful Businesses
#data engineering solutions in Toronto#data engineering and machine learning#data engineering service in Gta
0 notes
Text
Data Science Tutorial for 2025: Tools, Trends, and Techniques
Data science continues to be one of the most dynamic and high-impact fields in technology, with new tools and methodologies evolving rapidly. As we enter 2025, data science is more than just crunching numbers—it's about building intelligent systems, automating decision-making, and unlocking insights from complex data at scale.
Whether you're a beginner or a working professional looking to sharpen your skills, this tutorial will guide you through the essential tools, the latest trends, and the most effective techniques shaping data science in 2025.
What is Data Science?
At its core, data science is the interdisciplinary field that combines statistics, computer science, and domain expertise to extract meaningful insights from structured and unstructured data. It involves collecting data, cleaning and processing it, analyzing patterns, and building predictive or explanatory models.
Data scientists are problem-solvers, storytellers, and innovators. Their work influences business strategies, public policy, healthcare solutions, and even climate models.

Essential Tools for Data Science in 2025
The data science toolkit has matured significantly, with tools becoming more powerful, user-friendly, and integrated with AI. Here are the must-know tools for 2025:
1. Python 3.12+
Python remains the most widely used language in data science due to its simplicity and vast ecosystem. In 2025, the latest Python versions offer faster performance and better support for concurrency—making large-scale data operations smoother.
Popular Libraries:
Pandas: For data manipulation
NumPy: For numerical computing
Matplotlib / Seaborn / Plotly: For data visualization
Scikit-learn: For traditional machine learning
XGBoost / LightGBM: For gradient boosting models
2. JupyterLab
The evolution of the classic Jupyter Notebook, JupyterLab, is now the default environment for exploratory data analysis, allowing a modular, tabbed interface with support for terminals, text editors, and rich output.
3. Apache Spark with PySpark
Handling massive datasets? PySpark—Python’s interface to Apache Spark—is ideal for distributed data processing across clusters, now deeply integrated with cloud platforms like Databricks and Snowflake.
4. Cloud Platforms (AWS, Azure, Google Cloud)
In 2025, most data science workloads run on the cloud. Services like Amazon SageMaker, Azure Machine Learning, and Google Vertex AI simplify model training, deployment, and monitoring.
5. AutoML & No-Code Tools
Tools like DataRobot, Google AutoML, and H2O.ai now offer drag-and-drop model building and optimization. These are powerful for non-coders and help accelerate workflows for pros.
Top Data Science Trends in 2025
1. Generative AI for Data Science
With the rise of large language models (LLMs), generative AI now assists data scientists in code generation, data exploration, and feature engineering. Tools like OpenAI's ChatGPT for Code and GitHub Copilot help automate repetitive tasks.
2. Data-Centric AI
Rather than obsessing over model architecture, 2025’s best practices focus on improving the quality of data—through labeling, augmentation, and domain understanding. Clean data beats complex models.
3. MLOps Maturity
MLOps—machine learning operations—is no longer optional. In 2025, companies treat ML models like software, with versioning, monitoring, CI/CD pipelines, and reproducibility built-in from the start.
4. Explainable AI (XAI)
As AI impacts sensitive areas like finance and healthcare, transparency is crucial. Tools like SHAP, LIME, and InterpretML help data scientists explain model predictions to stakeholders and regulators.
5. Edge Data Science
With IoT devices and on-device AI becoming the norm, edge computing allows models to run in real-time on smartphones, sensors, and drones—opening new use cases from agriculture to autonomous vehicles.
Core Techniques Every Data Scientist Should Know in 2025
Whether you’re starting out or upskilling, mastering these foundational techniques is critical:
1. Data Wrangling
Before any analysis begins, data must be cleaned and reshaped. Techniques include:
Handling missing values
Normalization and standardization
Encoding categorical variables
Time series transformation
2. Exploratory Data Analysis (EDA)
EDA is about understanding your dataset through visualization and summary statistics. Use histograms, scatter plots, correlation heatmaps, and boxplots to uncover trends and outliers.
3. Machine Learning Basics
Classification (e.g., predicting if a customer will churn)
Regression (e.g., predicting house prices)
Clustering (e.g., customer segmentation)
Dimensionality Reduction (e.g., PCA, t-SNE for visualization)
4. Deep Learning (Optional but Useful)
If you're working with images, text, or audio, deep learning with TensorFlow, PyTorch, or Keras can be invaluable. Hugging Face’s transformers make it easier than ever to work with large models.
5. Model Evaluation
Learn how to assess model performance with:
Accuracy, Precision, Recall, F1 Score
ROC-AUC Curve
Cross-validation
Confusion Matrix
Final Thoughts
As we move deeper into 2025, data science tutorial continues to be an exciting blend of math, coding, and real-world impact. Whether you're analyzing customer behavior, improving healthcare diagnostics, or predicting financial markets, your toolkit and mindset will be your most valuable assets.
Start by learning the fundamentals, keep experimenting with new tools, and stay updated with emerging trends. The best data scientists aren’t just great with code—they’re lifelong learners who turn data into decisions.
0 notes
Text
Semantic Knowledge Graphing Market Size, Share, Analysis, Forecast, and Growth Trends to 2032: Transforming Data into Knowledge at Scale
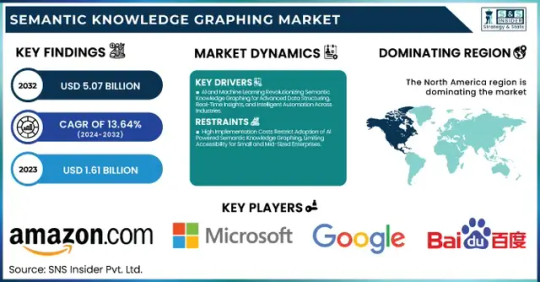
The Semantic Knowledge Graphing Market was valued at USD 1.61 billion in 2023 and is expected to reach USD 5.07 billion by 2032, growing at a CAGR of 13.64% from 2024-2032.
The Semantic Knowledge Graphing Market is rapidly evolving as organizations increasingly seek intelligent data integration and real-time insights. With the growing need to link structured and unstructured data for better decision-making, semantic technologies are becoming essential tools across sectors like healthcare, finance, e-commerce, and IT. This market is seeing a surge in demand driven by the rise of AI, machine learning, and big data analytics, as enterprises aim for context-aware computing and smarter data architectures.
Semantic Knowledge Graphing Market Poised for Strategic Transformation this evolving landscape is being shaped by an urgent need to solve complex data challenges with semantic understanding. Companies are leveraging semantic graphs to build context-rich models, enhance search capabilities, and create more intuitive AI experiences. As the digital economy thrives, semantic graphing offers a foundation for scalable, intelligent data ecosystems, allowing seamless connections between disparate data sources.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/6040
Market Keyplayers:
Amazon.com Inc. (Amazon Neptune, AWS Graph Database)
Baidu, Inc. (Baidu Knowledge Graph, PaddlePaddle)
Facebook Inc. (Facebook Graph API, DeepText)
Google LLC (Google Knowledge Graph, Google Cloud Dataproc)
Microsoft Corporation (Azure Cosmos DB, Microsoft Graph)
Mitsubishi Electric Corporation (Maisart AI, MELFA Smart Plus)
NELL (Never-Ending Language Learner, NELL Knowledge Graph)
Semantic Web Company (PoolParty Semantic Suite, Semantic Middleware)
YAGO (YAGO Knowledge Base, YAGO Ontology)
Yandex (Yandex Knowledge Graph, Yandex Cloud ML)
IBM Corporation (IBM Watson Discovery, IBM Graph)
Oracle Corporation (Oracle Spatial and Graph, Oracle Cloud AI)
SAP SE (SAP HANA Graph, SAP Data Intelligence)
Neo4j Inc. (Neo4j Graph Database, Neo4j Bloom)
Databricks Inc. (Databricks GraphFrames, Databricks Delta Lake)
Stardog Union (Stardog Knowledge Graph, Stardog Studio)
OpenAI (GPT-based Knowledge Graphs, OpenAI Embeddings)
Franz Inc. (AllegroGraph, Allegro CL)
Ontotext AD (GraphDB, Ontotext Platform)
Glean (Glean Knowledge Graph, Glean AI Search)
Market Analysis
The Semantic Knowledge Graphing Market is transitioning from a niche segment to a critical component of enterprise IT strategy. Integration with AI/ML models has shifted semantic graphs from backend enablers to core strategic assets. With open data initiatives, industry-standard ontologies, and a push for explainable AI, enterprises are aggressively adopting semantic solutions to uncover hidden patterns, support predictive analytics, and enhance data interoperability. Vendors are focusing on APIs, graph visualization tools, and cloud-native deployments to streamline adoption and scalability.
Market Trends
AI-Powered Semantics: Use of NLP and machine learning in semantic graphing is automating knowledge extraction and relationship mapping.
Graph-Based Search Evolution: Businesses are prioritizing semantic search engines to offer context-aware, precise results.
Industry-Specific Graphs: Tailored graphs are emerging in healthcare (clinical data mapping), finance (fraud detection), and e-commerce (product recommendation).
Integration with LLMs: Semantic graphs are increasingly being used to ground large language models with factual, structured data.
Open Source Momentum: Tools like RDF4J, Neo4j, and GraphDB are gaining traction for community-led innovation.
Real-Time Applications: Event-driven semantic graphs are now enabling real-time analytics in domains like cybersecurity and logistics.
Cross-Platform Compatibility: Vendors are prioritizing seamless integration with existing data lakes, APIs, and enterprise knowledge bases.
Market Scope
Semantic knowledge graphing holds vast potential across industries:
Healthcare: Improves patient data mapping, drug discovery, and clinical decision support.
Finance: Enhances fraud detection, compliance tracking, and investment analysis.
Retail & E-Commerce: Powers hyper-personalized recommendations and dynamic customer journeys.
Manufacturing: Enables digital twins and intelligent supply chain management.
Government & Public Sector: Supports policy modeling, public data transparency, and inter-agency collaboration.
These use cases represent only the surface of a deeper transformation, where data is no longer isolated but intelligently interconnected.
Market Forecast
As AI continues to integrate deeper into enterprise functions, semantic knowledge graphs will play a central role in enabling contextual AI systems. Rather than just storing relationships, future graphing solutions will actively drive insight generation, data governance, and operational automation. Strategic investments by leading tech firms, coupled with the rise of vertical-specific graphing platforms, suggest that semantic knowledge graphing will become a staple of digital infrastructure. Market maturity is expected to rise rapidly, with early adopters gaining a significant edge in predictive capability, data agility, and innovation speed.
Access Complete Report: https://www.snsinsider.com/reports/semantic-knowledge-graphing-market-6040
Conclusion
The Semantic Knowledge Graphing Market is no longer just a futuristic concept—it's the connective tissue of modern data ecosystems. As industries grapple with increasingly complex information landscapes, the ability to harness semantic relationships is emerging as a decisive factor in digital competitiveness.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#Semantic Knowledge Graphing Market#Semantic Knowledge Graphing Market Share#Semantic Knowledge Graphing Market Scope#Semantic Knowledge Graphing Market Trends
1 note
·
View note
Text
0 notes
Text
The top Data Engineering trends to look for in 2025

Data engineering is the unsung hero of our data-driven world. It's the critical discipline that builds and maintains the robust infrastructure enabling organizations to collect, store, process, and analyze vast amounts of data. As we navigate mid-2025, this foundational field is evolving at an unprecedented pace, driven by the exponential growth of data, the insatiable demand for real-time insights, and the transformative power of AI.
Staying ahead of these shifts is no longer optional; it's essential for data engineers and the organizations they support. Let's dive into the key data engineering trends that are defining the landscape in 2025.
1. The Dominance of the Data Lakehouse
What it is: The data lakehouse architecture continues its strong upward trajectory, aiming to unify the best features of data lakes (flexible, low-cost storage for raw, diverse data types) and data warehouses (structured data management, ACID transactions, and robust governance). Why it's significant: It offers a single platform for various analytics workloads, from BI and reporting to AI and machine learning, reducing data silos, complexity, and redundancy. Open table formats like Apache Iceberg, Delta Lake, and Hudi are pivotal in enabling lakehouse capabilities. Impact: Greater data accessibility, improved data quality and reliability for analytics, simplified data architecture, and cost efficiencies. Key Technologies: Databricks, Snowflake, Amazon S3, Azure Data Lake Storage, Apache Spark, and open table formats.
2. AI-Powered Data Engineering (Including Generative AI)
What it is: Artificial intelligence, and increasingly Generative AI, are becoming integral to data engineering itself. This involves using AI/ML to automate and optimize various data engineering tasks. Why it's significant: AI can significantly boost efficiency, reduce manual effort, improve data quality, and even help generate code for data pipelines or transformations. Impact: * Automated Data Integration & Transformation: AI tools can now automate aspects of data mapping, cleansing, and pipeline optimization. * Intelligent Data Quality & Anomaly Detection: ML algorithms can proactively identify and flag data quality issues or anomalies in pipelines. * Optimized Pipeline Performance: AI can help in tuning and optimizing the performance of data workflows. * Generative AI for Code & Documentation: LLMs are being used to assist in writing SQL queries, Python scripts for ETL, and auto-generating documentation. Key Technologies: AI-driven ETL/ELT tools, MLOps frameworks integrated with DataOps, platforms with built-in AI capabilities (e.g., Databricks AI Functions, AWS DMS with GenAI).
3. Real-Time Data Processing & Streaming Analytics as the Norm
What it is: The demand for immediate insights and actions based on live data streams continues to grow. Batch processing is no longer sufficient for many use cases. Why it's significant: Businesses across industries like e-commerce, finance, IoT, and logistics require real-time capabilities for fraud detection, personalized recommendations, operational monitoring, and instant decision-making. Impact: A shift towards streaming architectures, event-driven data pipelines, and tools that can handle high-throughput, low-latency data. Key Technologies: Apache Kafka, Apache Flink, Apache Spark Streaming, Apache Pulsar, cloud-native streaming services (e.g., Amazon Kinesis, Google Cloud Dataflow, Azure Stream Analytics), and real-time analytical databases.
4. The Rise of Data Mesh & Data Fabric Architectures
What it is: * Data Mesh: A decentralized sociotechnical approach that emphasizes domain-oriented data ownership, treating data as a product, self-serve data infrastructure, and federated computational governance. * Data Fabric: An architectural approach that automates data integration and delivery across disparate data sources, often using metadata and AI to provide a unified view and access to data regardless of where it resides. Why it's significant: Traditional centralized data architectures struggle with the scale and complexity of modern data. These approaches offer greater agility, scalability, and empower domain teams. Impact: Improved data accessibility and discoverability, faster time-to-insight for domain teams, reduced bottlenecks for central data teams, and better alignment of data with business domains. Key Technologies: Data catalogs, data virtualization tools, API-based data access, and platforms supporting decentralized data management.
5. Enhanced Focus on Data Observability & Governance
What it is: * Data Observability: Going beyond traditional monitoring to provide deep visibility into the health and state of data and data pipelines. It involves tracking data lineage, quality, freshness, schema changes, and distribution. * Data Governance by Design: Integrating robust data governance, security, and compliance practices directly into the data lifecycle and infrastructure from the outset, rather than as an afterthought. Why it's significant: As data volumes and complexity grow, ensuring data quality, reliability, and compliance (e.g., GDPR, CCPA) becomes paramount for building trust and making sound decisions. Regulatory landscapes, like the EU AI Act, are also making strong governance non-negotiable. Impact: Improved data trust and reliability, faster incident resolution, better compliance, and more secure data handling. Key Technologies: AI-powered data observability platforms, data cataloging tools with governance features, automated data quality frameworks, and tools supporting data lineage.
6. Maturation of DataOps and MLOps Practices
What it is: * DataOps: Applying Agile and DevOps principles (automation, collaboration, continuous integration/continuous delivery - CI/CD) to the entire data analytics lifecycle, from data ingestion to insight delivery. * MLOps: Extending DevOps principles specifically to the machine learning lifecycle, focusing on streamlining model development, deployment, monitoring, and retraining. Why it's significant: These practices are crucial for improving the speed, quality, reliability, and efficiency of data and machine learning pipelines. Impact: Faster delivery of data products and ML models, improved data quality, enhanced collaboration between data engineers, data scientists, and IT operations, and more reliable production systems. Key Technologies: Workflow orchestration tools (e.g., Apache Airflow, Kestra), CI/CD tools (e.g., Jenkins, GitLab CI), version control systems (Git), containerization (Docker, Kubernetes), and MLOps platforms (e.g., MLflow, Kubeflow, SageMaker, Azure ML).
The Cross-Cutting Theme: Cloud-Native and Cost Optimization
Underpinning many of these trends is the continued dominance of cloud-native data engineering. Cloud platforms (AWS, Azure, GCP) provide the scalable, flexible, and managed services that are essential for modern data infrastructure. Coupled with this is an increasing focus on cloud cost optimization (FinOps for data), as organizations strive to manage and reduce the expenses associated with large-scale data processing and storage in the cloud.
The Evolving Role of the Data Engineer
These trends are reshaping the role of the data engineer. Beyond building pipelines, data engineers in 2025 are increasingly becoming architects of more intelligent, automated, and governed data systems. Skills in AI/ML, cloud platforms, real-time processing, and distributed architectures are becoming even more crucial.
Global Relevance, Local Impact
These global data engineering trends are particularly critical for rapidly developing digital economies. In countries like India, where the data explosion is immense and the drive for digital transformation is strong, adopting these advanced data engineering practices is key to harnessing data for innovation, improving operational efficiency, and building competitive advantages on a global scale.
Conclusion: Building the Future, One Pipeline at a Time
The field of data engineering is more dynamic and critical than ever. The trends of 2025 point towards more automated, real-time, governed, and AI-augmented data infrastructures. For data engineering professionals and the organizations they serve, embracing these changes means not just keeping pace, but actively shaping the future of how data powers our world.
1 note
·
View note
Text
🧮🛠📊✒️🗝📇
DataCon Sofia 10.04.2025!
#SchwarzIT #DataCon #databricks #stackit #Europe #Bulgaria
AI, Gen AI, ML, Super Brain, Agents, Lakehouses, Backbones, Workflows...
It is all about the data:
Where? What? When? Why? Who? How?
Thank you for having us at the event!
0 notes
Text
Unlocking the Power of Delta Live Tables in Data bricks with Kadel Labs
Introduction
In the rapidly evolving landscape of big data and analytics, businesses are constantly seeking ways to streamline data processing, ensure data reliability, and improve real-time analytics. One of the most powerful solutions available today is Delta Live Tables (DLT) in Databricks. This cutting-edge feature simplifies data engineering and ensures efficiency in data pipelines.
Kadel Labs, a leader in digital transformation and data engineering solutions, leverages Delta Live Tables to optimize data workflows, ensuring businesses can harness the full potential of their data. In this article, we will explore what Delta Live Tables are, how they function in Databricks, and how Kadel Labs integrates this technology to drive innovation.
Understanding Delta Live Tables
What Are Delta Live Tables?
Delta Live Tables (DLT) is an advanced framework within Databricks that simplifies the process of building and maintaining reliable ETL (Extract, Transform, Load) pipelines. With DLT, data engineers can define incremental data processing pipelines using SQL or Python, ensuring efficient data ingestion, transformation, and management.
Key Features of Delta Live Tables
Automated Pipeline Management
DLT automatically tracks changes in source data, eliminating the need for manual intervention.
Data Reliability and Quality
Built-in data quality enforcement ensures data consistency and correctness.
Incremental Processing
Instead of processing entire datasets, DLT processes only new data, improving efficiency.
Integration with Delta Lake
DLT is built on Delta Lake, ensuring ACID transactions and versioned data storage.
Monitoring and Observability
With automatic lineage tracking, businesses gain better insights into data transformations.
How Delta Live Tables Work in Databricks
Databricks, a unified data analytics platform, integrates Delta Live Tables to streamline data lake house architectures. Using DLT, businesses can create declarative ETL pipelines that are easy to maintain and highly scalable.
The DLT Workflow
Define a Table and Pipeline
Data engineers specify data sources, transformation logic, and the target Delta table.
Data Ingestion and Transformation
DLT automatically ingests raw data and applies transformation logic in real-time.
Validation and Quality Checks
DLT enforces data quality rules, ensuring only clean and accurate data is processed.
Automatic Processing and Scaling
Databricks dynamically scales resources to handle varying data loads efficiently.
Continuous or Triggered Execution
DLT pipelines can run continuously or be triggered on-demand based on business needs.
Kadel Labs: Enhancing Data Pipelines with Delta Live Tables
As a digital transformation company, Kadel Labs specializes in deploying cutting-edge data engineering solutions that drive business intelligence and operational efficiency. The integration of Delta Live Tables in Databricks is a game-changer for organizations looking to automate, optimize, and scale their data operations.
How Kadel Labs Uses Delta Live Tables
Real-Time Data Streaming
Kadel Labs implements DLT-powered streaming pipelines for real-time analytics and decision-making.
Data Governance and Compliance
By leveraging DLT’s built-in monitoring and validation, Kadel Labs ensures regulatory compliance.
Optimized Data Warehousing
DLT enables businesses to build cost-effective data warehouses with improved data integrity.
Seamless Cloud Integration
Kadel Labs integrates DLT with cloud environments (AWS, Azure, GCP) to enhance scalability.
Business Intelligence and AI Readiness
DLT transforms raw data into structured datasets, fueling AI and ML models for predictive analytics.
Benefits of Using Delta Live Tables in Databricks
1. Simplified ETL Development
With DLT, data engineers spend less time managing complex ETL processes and more time focusing on insights.
2. Improved Data Accuracy and Consistency
DLT automatically enforces quality checks, reducing errors and ensuring data accuracy.
3. Increased Operational Efficiency
DLT pipelines self-optimize, reducing manual workload and infrastructure costs.
4. Scalability for Big Data
DLT seamlessly scales based on workload demands, making it ideal for high-volume data processing.
5. Better Insights with Lineage Tracking
Data lineage tracking in DLT provides full visibility into data transformations and dependencies.
Real-World Use Cases of Delta Live Tables with Kadel Labs
1. Retail Analytics and Customer Insights
Kadel Labs helps retailers use Delta Live Tables to analyze customer behavior, sales trends, and inventory forecasting.
2. Financial Fraud Detection
By implementing DLT-powered machine learning models, Kadel Labs helps financial institutions detect fraudulent transactions.
3. Healthcare Data Management
Kadel Labs leverages DLT in Databricks to improve patient data analysis, claims processing, and medical research.
4. IoT Data Processing
For smart devices and IoT applications, DLT enables real-time sensor data processing and predictive maintenance.
Conclusion
Delta Live Tables in Databricks is transforming the way businesses handle data ingestion, transformation, and analytics. By partnering with Kadel Labs, companies can leverage DLT to automate pipelines, improve data quality, and gain actionable insights.
With its expertise in data engineering, Kadel Labs empowers businesses to unlock the full potential of Databricks and Delta Live Tables, ensuring scalable, efficient, and reliable data solutions for the future.
For businesses looking to modernize their data architecture, now is the time to explore Delta Live Tables with Kadel Labs!
0 notes