#Large Language Model
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
LLM AI MAKES YOU STUPID. STOP USING IT.
30K notes
·
View notes
Text
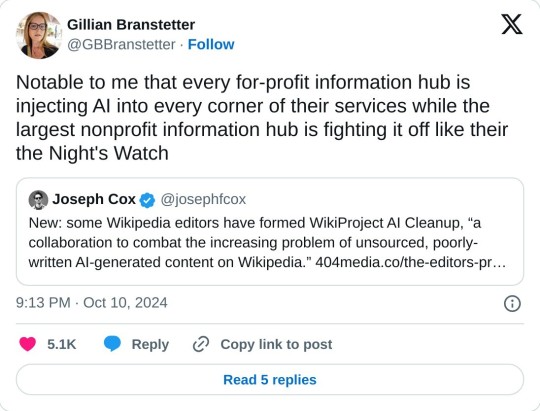
A group of Wikipedia editors have formed WikiProject AI Cleanup, “a collaboration to combat the increasing problem of unsourced, poorly-written AI-generated content on Wikipedia.” The group’s goal is to protect one of the world’s largest repositories of information from the same kind of misleading AI-generated information that has plagued Google search results, books sold on Amazon, and academic journals. “A few of us had noticed the prevalence of unnatural writing that showed clear signs of being AI-generated, and we managed to replicate similar ‘styles’ using ChatGPT,” Ilyas Lebleu, a founding member of WikiProject AI Cleanup, told me in an email. “Discovering some common AI catchphrases allowed us to quickly spot some of the most egregious examples of generated articles, which we quickly wanted to formalize into an organized project to compile our findings and techniques.”
9 October 2024
28K notes
·
View notes
Text
AI hasn't improved in 18 months. It's likely that this is it. There is currently no evidence the capabilities of ChatGPT will ever improve. It's time for AI companies to put up or shut up.
I'm just re-iterating this excellent post from Ed Zitron, but it's not left my head since I read it and I want to share it. I'm also taking some talking points from Ed's other posts. So basically:
We keep hearing AI is going to get better and better, but these promises seem to be coming from a mix of companies engaging in wild speculation and lying.
Chatgpt, the industry leading large language model, has not materially improved in 18 months. For something that claims to be getting exponentially better, it sure is the same shit.
Hallucinations appear to be an inherent aspect of the technology. Since it's based on statistics and ai doesn't know anything, it can never know what is true. How could I possibly trust it to get any real work done if I can't rely on it's output? If I have to fact check everything it says I might as well do the work myself.
For "real" ai that does know what is true to exist, it would require us to discover new concepts in psychology, math, and computing, which open ai is not working on, and seemingly no other ai companies are either.
Open ai has already seemingly slurped up all the data from the open web already. Chatgpt 5 would take 5x more training data than chatgpt 4 to train. Where is this data coming from, exactly?
Since improvement appears to have ground to a halt, what if this is it? What if Chatgpt 4 is as good as LLMs can ever be? What use is it?
As Jim Covello, a leading semiconductor analyst at Goldman Sachs said (on page 10, and that's big finance so you know they only care about money): if tech companies are spending a trillion dollars to build up the infrastructure to support ai, what trillion dollar problem is it meant to solve? AI companies have a unique talent for burning venture capital and it's unclear if Open AI will be able to survive more than a few years unless everyone suddenly adopts it all at once. (Hey, didn't crypto and the metaverse also require spontaneous mass adoption to make sense?)
There is no problem that current ai is a solution to. Consumer tech is basically solved, normal people don't need more tech than a laptop and a smartphone. Big tech have run out of innovations, and they are desperately looking for the next thing to sell. It happened with the metaverse and it's happening again.
In summary:
Ai hasn't materially improved since the launch of Chatgpt4, which wasn't that big of an upgrade to 3.
There is currently no technological roadmap for ai to become better than it is. (As Jim Covello said on the Goldman Sachs report, the evolution of smartphones was openly planned years ahead of time.) The current problems are inherent to the current technology and nobody has indicated there is any way to solve them in the pipeline. We have likely reached the limits of what LLMs can do, and they still can't do much.
Don't believe AI companies when they say things are going to improve from where they are now before they provide evidence. It's time for the AI shills to put up, or shut up.
5K notes
·
View notes
Text
The real issue with DeepSeek is that capitalists can't profit from it.
I always appreciate when the capitalist class just says it out loud so I don't have to be called a conspiracy theorist for pointing out the obvious.

#deepseek#ai#lmm#large language model#artificial intelligence#open source#capitalism#techbros#silicon valley#openai
955 notes
·
View notes
Note
is checking facts by chatgpt smart? i once asked chatgpt about the hair color in the image and asked the same question two times and chatgpt said two different answers lol
Never, ever, ever use ChatGPT or any LMM for fact checking! All large language models are highly prone to generating misinformation (here's a recent example!), because they're basically just fancy autocomplete.
If you need to fact check, use reliable fact checking websites (like PolitiFact, AP News, FactCheck.org), go to actual experts, check primary sources, things like that. To learn more, I recommend this site:
349 notes
·
View notes
Text
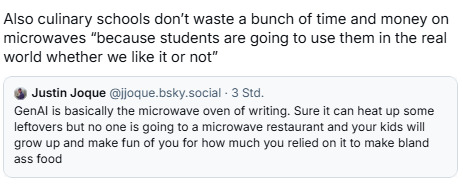
This might be the best summation of GenAI I have seen.
182 notes
·
View notes
Text
When summarizing scientific studies, large language models (LLMs) like ChatGPT and DeepSeek produce inaccurate conclusions in up to 73% of cases, according to a study by Uwe Peters (Utrecht University) and Benjamin Chin-Yee (Western University, Canada/University of Cambridge, UK). The researchers tested the most prominent LLMs and analyzed thousands of chatbot-generated science summaries, revealing that most models consistently produced broader conclusions than those in the summarized texts. Surprisingly, prompts for accuracy increased the problem and newer LLMs performed worse than older ones. The work is published in the journal Royal Society Open Science.
Continue Reading.
117 notes
·
View notes
Text






#ai generated#astrology#birth chart#chatgpt#cyclicaljigsaw#cyclicalpuzzle#large language model#machinelearning#projectveneris#strawberry#chatgpt 4o#chatgpt4opreview#chatgpt4omini#bolivia#🇧🇴
139 notes
·
View notes
Text
The question shouldn't be how DeepSeek made such a good LLM with so little money and resources.
The question should be how OpenAI, Meta, Microsoft, Google, and Apple all made such bad LLMs with so much money and resources.
#rambles#ai#fuck ai#gen ai#fuck gen ai#deepseek#chatgpt#openai#llm#large language model#apple#fuck apple#fuck openai#meta#fuck meta#microsoft#fuck microsoft#google#fuck google#greed#corporate america#eat the rich
55 notes
·
View notes
Text

#ai#generative#large language model#generative AI#ai theft#copyright violations#copyright law#anything AI created is inherently theft#fuck AI#and fuck you too if you push it
55 notes
·
View notes
Text
The problem here isn’t that large language models hallucinate, lie, or misrepresent the world in some way. It’s that they are not designed to represent the world at all; instead, they are designed to convey convincing lines of text. So when they are provided with a database of some sort, they use this, in one way or another, to make their responses more convincing. But they are not in any real way attempting to convey or transmit the information in the database. As Chirag Shah and Emily Bender put it: “Nothing in the design of language models (whose training task is to predict words given context) is actually designed to handle arithmetic, temporal reasoning, etc. To the extent that they sometimes get the right answer to such questions is only because they happened to synthesize relevant strings out of what was in their training data. No reasoning is involved […] Similarly, language models are prone to making stuff up […] because they are not designed to express some underlying set of information in natural language; they are only manipulating the form of language” (Shah & Bender, 2022). These models aren’t designed to transmit information, so we shouldn’t be too surprised when their assertions turn out to be false.
ChatGPT is bullshit
7K notes
·
View notes
Text

23 notes
·
View notes
Text
What an AI generated website can look like
Hey folks! I just encountered a website that's obviously AI generated, so I figured I'd use it as an example to help you spot websites that might be AI generated content farms!
First, the website is called faunafacts.com. And one of the first things that sticks out to me is how low-effort the logo is:

Regardless of whether a website is AI generated or not, a lazy and low-quality logo is a big clue that the website's content will also be lazy and low-quality.
If we click on Browse Animals, we see four options: Cows, Wolves, Bears, and Snakes.
Let's click Wolves.

The first thing I want you to notice is the lack of topical focus. Sure, it's all about wolves, but the content on them is all over the place. We have content on wolf hunting, a page on animals that resemble wolves, pages that explain the alleged social structure of wolves, and pages on wolf symbolism.
A website with content created by real people isn't going to be all over the place like this. It would be created with more of a focus in mind, like animal biology and behavior. The whole spiritual symbol thing here mixed with supposed biological and behavioral information is weird.
The next thing I want you to notice are the links to pages on topics that are quite frankly bizarre: "Wolf vs Mastiff: Things You Need To Know" and "Can You Ride A Wolf? (No, Because...)" Who is even looking for this kind of information in large enough numbers that it needs a dedicated page?
Then of course, there's the fact that they're repeating the debunked wolf hierarchy stuff, which anyone who actually knew anything about wolves at this point wouldn't post.
Now let's look at what's on one of the actual pages. We'll check out the wolves vs. mastiff page, and we can soon find a telltale sign of AI: rambling off topic to talk about something completely unrelated.
Both animals are carnivores. In the wild, wolves hunt large animals like bison, deer, and even elk. Sometimes, they may also hunt small mammals like the beaver.
Mastiffs, on the other hand, are mainly fed with dog food. As a dog, a mastiff left in the wild will eat anything. However, it will have difficulties hunting, as this instinct may have already departed the dogs of today.
A mastiff is not an obligate carnivore. Dogs can eat plant matter. Some say that dogs can survive on a vegetable diet.
Dogs being made vegetarians is a contentious issue. Scientifically, dogs belong to the order Carnivora. There is a movement today to convert dogs to a vegan diet. While science has nothing against it, the fear of many is that when dog owners do this, a vegan diet will certainly have an impact on the species.
This page is supposed to be comparing mastiffs with wolves, but then it starts talking about the vegan pet food movement. This happened because large language models generate text based on on what's statistically likely to follow the last text it just generated.
Finally, the website's images are AI generated:

If you know what to look for, this is a very obviously AI generated image. There's no graininess to the image, and the details are both unnaturally smooth and unnaturally crisp. It also has that high color saturation that many AI generated images have.
So there you go, this is one example of what an AI generated website can look like! Be careful out there!
#lmms#large language model#ai#critical thinking#fake websites#ai generated websites#discernment#recognizing ai
108 notes
·
View notes
Text
We need to talk about AI
Okay, several people asked me to post about this, so I guess I am going to post about this. Or to say it differently: Hey, for once I am posting about the stuff I am actually doing for university. Woohoo!
Because here is the issue. We are kinda suffering a death of nuance right now, when it comes to the topic of AI.
I understand why this happening (basically everyone wanting to market anything is calling it AI even though it is often a thousand different things) but it is a problem.
So, let's talk about "AI", that isn't actually intelligent, what the term means right now, what it is, what it isn't, and why it is not always bad. I am trying to be short, alright?

So, right now when anyone says they are using AI they mean, that they are using a program that functions based on what computer nerds call "a neural network" through a process called "deep learning" or "machine learning" (yes, those terms mean slightly different things, but frankly, you really do not need to know the details).
Now, the theory for this has been around since the 1940s! The idea had always been to create calculation nodes that mirror the way neurons in the human brain work. That looks kinda like this:

Basically, there are input nodes, in which you put some data, those do some transformations that kinda depend on the kind of thing you want to train it for and in the end a number comes out, that the program than "remembers". I could explain the details, but your eyes would glaze over the same way everyone's eyes glaze over in this class I have on this on every Friday afternoon.
All you need to know: You put in some sort of data (that can be text, math, pictures, audio, whatever), the computer does magic math, and then it gets a number that has a meaning to it.
And we actually have been using this sinde the 80s in some way. If any Digimon fans are here: there is a reason the digital world in Digimon Tamers was created in Stanford in the 80s. This was studied there.
But if it was around so long, why am I hearing so much about it now?
This is a good question hypothetical reader. The very short answer is: some super-nerds found a way to make this work way, way better in 2012, and from that work (which was then called Deep Learning in Artifical Neural Networks, short ANN) we got basically everything that TechBros will not shut up about for the last like ten years. Including "AI".
Now, most things you think about when you hear "AI" is some form of generative AI. Usually it will use some form of a LLM, a Large Language Model to process text, and a method called Stable Diffusion to create visuals. (Tbh, I have no clue what method audio generation uses, as the only audio AI I have so far looked into was based on wolf howls.)
LLMs were like this big, big break through, because they actually appear to comprehend natural language. They don't, of coruse, as to them words and phrases are just stastical variables. Scientists call them also "stochastic parrots". But of course our dumb human brains love to anthropogice shit. So they go: "It makes human words. It gotta be human!"
It is a whole thing.
It does not understand or grasp language. But the mathematics behind it will basically create a statistical analysis of all the words and then create a likely answer.

What you have to understand however is, that LLMs and Stable Diffusion are just a a tiny, minority type of use cases for ANNs. Because research right now is starting to use ANNs for EVERYTHING. Some also partially using Stable Diffusion and LLMs, but not to take away people'S jobs.
Which is probably the place where I will share what I have been doing recently with AI.
The stuff I am doing with Neural Networks
The neat thing: if a Neural Network is Open Source, it is surprisingly easy to work with it. Last year when I started with this I was so intimidated, but frankly, I will confidently say now: As someone who has been working with computers for like more than 10 years, this is easier programming than most shit I did to organize data bases. So, during this last year I did three things with AI. One for a university research project, one for my work, and one because I find it interesting.
The university research project trained an AI to watch video live streams of our biology department's fish tanks, analyse the behavior of the fish and notify someone if a fish showed signs of being sick. We used an AI named "YOLO" for this, that is very good at analyzing pictures, though the base framework did not know anything about stuff that lived not on land. So we needed to teach it what a fish was, how to analyze videos (as the base framework only can look at single pictures) and then we needed to teach it how fish were supposed to behave. We still managed to get that whole thing working in about 5 months. So... Yeah. But nobody can watch hundreds of fish all the time, so without this, those fish will just die if something is wrong.
The second is for my work. For this I used a really old Neural Network Framework called tesseract. This was developed by Google ages ago. And I mean ages. This is one of those neural network based on 1980s research, simply doing OCR. OCR being "optical character recognition". Aka: if you give it a picture of writing, it can read that writing. My work has the issue, that we have tons and tons of old paper work that has been scanned and needs to be digitized into a database. But everyone who was hired to do this manually found this mindnumbing. Just imagine doing this all day: take a contract, look up certain data, fill it into a table, put the contract away, take the next contract and do the same. Thousands of contracts, 8 hours a day. Nobody wants to do that. Our company has been using another OCR software for this. But that one was super expensive. So I was asked if I could built something to do that. So I did. And this was so ridiculously easy, it took me three weeks. And it actually has a higher successrate than the expensive software before.
Lastly there is the one I am doing right now, and this one is a bit more complex. See: we have tons and tons of historical shit, that never has been translated. Be it papyri, stone tablets, letters, manuscripts, whatever. And right now I used tesseract which by now is open source to develop it further to allow it to read handwritten stuff and completely different letters than what it knows so far. I plan to hook it up, once it can reliably do the OCR, to a LLM to then translate those texts. Because here is the thing: these things have not been translated because there is just not enough people speaking those old languages. Which leads to people going like: "GASP! We found this super important document that actually shows things from the anceint world we wanted to know forever, and it was lying in our collection collecting dust for 90 years!" I am not the only person who has this idea, and yeah, I just hope maybe we can in the next few years get something going to help historians and archeologists to do their work.

Make no mistake: ANNs are saving lives right now
Here is the thing: ANNs are Deep Learning are saving lives right now. I really cannot stress enough how quickly this technology has become incredibly important in fields like biology and medicine to analyze data and predict outcomes in a way that a human just never would be capable of.
I saw a post yesterday saying "AI" can never be a part of Solarpunk. I heavily will disagree on that. Solarpunk for example would need the help of AI for a lot of stuff, as it can help us deal with ecological things, might be able to predict weather in ways we are not capable of, will help with medicine, with plants and so many other things.
ANNs are a good thing in general. And yes, they might also be used for some just fun things in general.
And for things that we may not need to know, but that would be fun to know. Like, I mentioned above: the only audio research I read through was based on wolf howls. Basically there is a group of researchers trying to understand wolves and they are using AI to analyze the howling and grunting and find patterns in there which humans are not capable of due ot human bias. So maybe AI will hlep us understand some animals at some point.
Heck, we saw so far, that some LLMs have been capable of on their on extrapolating from being taught one version of a language to just automatically understand another version of it. Like going from modern English to old English and such. Which is why some researchers wonder, if it might actually be able to understand languages that were never deciphered.
All of that is interesting and fascinating.
Again, the generative stuff is a very, very minute part of what AI is being used for.

Yeah, but WHAT ABOUT the generative stuff?
So, let's talk about the generative stuff. Because I kinda hate it, but I also understand that there is a big issue.
If you know me, you know how much I freaking love the creative industry. If I had more money, I would just throw it all at all those amazing creative people online. I mean, fuck! I adore y'all!
And I do think that basically art fully created by AI is lacking the human "heart" - or to phrase it more artistically: it is lacking the chemical inbalances that make a human human lol. Same goes for writing. After all, an AI is actually incapable of actually creating a complex plot and all of that. And even if we managed to train it to do it, I don't think it should.
AI saving lives = good.
AI doing the shit humans actually evolved to do = bad.
And I also think that people who just do the "AI Art/Writing" shit are lazy and need to just put in work to learn the skill. Meh.
However...
I do think that these forms of AI can have a place in the creative process. There are people creating works of art that use some assets created with genAI but still putting in hours and hours of work on their own. And given that collages are legal to create - I do not see how this is meaningfully different. If you can take someone else's artwork as part of a collage legally, you can also take some art created by AI trained on someone else's art legally for the collage.
And then there is also the thing... Look, right now there is a lot of crunch in a lot of creative industries, and a lot of the work is not the fun creative kind, but the annoying creative kind that nobody actually enjoys and still eats hours and hours before deadlines. Swen the Man (the Larian boss) spoke about that recently: how mocapping often created some artifacts where the computer stuff used to record it (which already is done partially by an algorithm) gets janky. So far this was cleaned up by humans, and it is shitty brain numbing work most people hate. You can train AI to do this.
And I am going to assume that in normal 2D animation there is also more than enough clean up steps and such that nobody actually likes to do and that can just help to prevent crunch. Same goes for like those overworked souls doing movie VFX, who have worked 80 hour weeks for the last 5 years. In movie VFX we just do not have enough workers. This is a fact. So, yeah, if we can help those people out: great.
If this is all directed by a human vision and just helping out to make certain processes easier? It is fine.
However, something that is just 100% AI? That is dumb and sucks. And it sucks even more that people's fanart, fanfics, and also commercial work online got stolen for it.
And yet... Yeah, I am sorry, I am afraid I have to join the camp of: "I am afraid criminalizing taking the training data is a really bad idea." Because yeah... It is fucking shitty how Facebook, Microsoft, Google, OpenAI and whatever are using this stolen data to create programs to make themselves richer and what not, while not even making their models open source. BUT... If we outlawed it, the only people being capable of even creating such algorithms that absolutely can help in some processes would be big media corporations that already own a ton of data for training (so basically Disney, Warner and Universal) who would then get a monopoly. And that would actually be a bad thing. So, like... both variations suck. There is no good solution, I am afraid.
And mind you, Disney, Warner, and Universal would still not pay their artists for it. lol
However, that does not mean, you should not bully the companies who are using this stolen data right now without making their models open source! And also please, please bully Hasbro and Riot and whoever for using AI Art in their merchandise. Bully them hard. They have a lot of money and they deserve to be bullied!

But yeah. Generally speaking: Please, please, as I will always say... inform yourself on these topics. Do not hate on stuff without understanding what it actually is. Most topics in life are nuanced. Not all. But many.
#computer science#artifical intelligence#neural network#artifical neural network#ann#deep learning#ai#large language model#science#research#nuance#explanation#opinion#text post#ai explained#solarpunk#cyberpunk
27 notes
·
View notes
Text
Much as a pilot might practice maneuvers in a flight simulator, scientists might soon be able to perform experiments on a realistic simulation of the mouse brain. In a new study, Stanford Medicine researchers and collaborators used an artificial intelligence model to build a “digital twin” of the part of the mouse brain that processes visual information. The digital twin was trained on large datasets of brain activity collected from the visual cortex of real mice as they watched movie clips. It could then predict the response of tens of thousands of neurons to new videos and images. Digital twins could make studying the inner workings of the brain easier and more efficient.
Continue Reading.
42 notes
·
View notes