
collection of text/stats analyses on the dbh ao3 fandom || also on github pages
Don't wanna be here? Send us removal request.
Statistics
We looked inside some of the posts by program-800 and here's what we found interesting.
Average Info
Notes Per Post
279
Likes Per Post
207
Reblog Per Post
66
Reply Per Post
6
Time Between Posts
3 months
Number of Posts By Type
Text
9
Photo
8
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
/where have i been/the future
I've been gone a long while because I decided in some possessed state of mind in summer 2022 that I wanted to try for a PhD. I rolled the dice for the first time in December 2023 and (to my shock) landed an offer. I wrote about analysing fanfiction in my SOP and I really hope now to realise that as part of my formal research agenda.
The path to preparing for applications, finding information, etc. took me by surprise in terms of how much self-reflection it generated and the subsequent pain that followed. I consider myself very much an outsider to these things based on my personal and academic background.
To be honest, I'm still reeling in doubt from the offer. I am excited but also so very afraid. I've always been very candid that I learned to code by myself and am not from CS (I'm from the social sciences) - this Tumblr is entirely structured off self-learning - and I guess I'll always carry that fear of being unqualified in computational work because of that.
This is all perhaps very irrational but I think at the end of the day, I'll find a way to gather up the courage and give this offer my best shot. For anyone who's ever read this blog, I thank you for your interest. It has in no small part helped develop a dream which pushed me to consider a PhD. I hope I'll be able to write about such analyses again in the near future - maybe here, or maybe (if I dare to dream further; but it's clouded by nerves now) even a paper.
1 note
·
View note
Photo

A preliminary WIP dialogue analysis of Connor in D:BH fics
I’ve been going on for ages about wanting to get into ‘deeper’ analyses of the fic text and this is one of my first attempts at it. With the help of the very cool BookNLP library, I tried to extract dialogue spoken by Connor in my collection of 16,211 D:BH AO3 fics.
I was curious about questions like (1) whether certain words in Connor's fanfic dialogue/his fanfic utterances possibly separable by rating, and (2) how similar his fanfic utterances are to his canon utterances.
The result was (1) a really humbling experience about the difficulties of proper dialogue extraction and attribution and (2) a reminder that dialogue and people don’t happen in a vacuum, context is really important. The full write-up of the process, analyses, and my thoughts is on my Github page. With the lessons learned here from my really naïve handling of the data and questions, I hope to improve on this (especially wrt context-handling).
14 notes
·
View notes
Photo

/ a very drarry special ||| pt.2 of ? DRARRY ON AO3: ASSOCIATING FREEFORM TAGS WITH FIC RATINGS
It’s been a while, but I’ve been attempting to work on some analyses for my Detroit: Become Human dataset still. Recently it hit a block and I was looking around for methods. That search brought me to correspondence analysis (which looks like it’s been used a fair bit by computational humanities/lit scholars - very cool!).
I decided to try it out on the AO3 dump dataset first, specifically on 47,244 Drarry fics. Basically this analysis hopes to address the question: are certain freeform tags associated with certain ratings?
Clearly, we can guess already what the freeform tags of the more ‘polarised’ ratings (explicit/general audiences) fics might look like, but I was also very keen to look into freeform tags associated with the teen/mature ratings (spoiler: Hanahaki disease appears to have an association with the Teen rating - at least for Drarry?).
The interactive plot shown in the gif and the full analysis write-up can be found on my Github page. This was very fun to do! I really enjoyed combing through the nice plots provided by the analysis.
4 notes
·
View notes
Photo





/ a very drarry special ||| pt.1 of ? DRARRY ON AO3: TROPES THROUGH TAGS
I think many of us have heard of AO3′s data dump by now! I was really excited like everyone else to be able to play with that dataset - especially because it's an entry point into analysing my first and still most-loved ship: Drarry.
Drarry - like many other ships in many other fandoms - has its unique set of tropes. After getting into a new ship and reading it for a while, we kind of intuitively know about its common tropes. Within Harry Potter, there are so many that have accumulated across the history of the fandom – Veela blood inheritance, Hogwarts 8th year, Harry in Slytherin AUs, etc. And we know that when we see certain tags – e.g., creature inheritance – we can expect to see certain other tags (e.g. veela Draco Malfoy, magical bonds/soulmates).
That brings us to the question: are we able to capture some of these tropes or ideas automatically given a huge dataset of tags? That’s what I attempted (attempted is a huge keyword here) to do, looking at each rating (Gen/Teen/Mature/Explicit) separately.
The networks shown are samples of some groups of tags which were pulled out with the help of some preprocessing and a community detection algorithm. You can view these interactive plots and the whole write-up here on my Github page.
//
As with my work on using tags to characterise characters in the D:BH fandom, I want to reiterate that this work is very coarse, with tags capturing only a small part of the picture. This is not an attempt to replace close qualitative reading and understanding of fic text. Feedback, etc is always welcome too, always looking to improve my handling of data!
5 notes
·
View notes
Text
(An attempt at) visualising AO3 D:BH fics based on verb usage

WIP. x Interactive visualisation on my Github page (link in description/Tumblr heading).
I’ve been terribly busy (at work, but also mostly in my own head). This is something I’ve been working on for a couple weekends, but I can’t get cleaner results so this write-up’s going up first while I slowly figure out improvements.
The idea was simple: can I cluster fics based on the actions that occurred within them? Obviously there’s going to be a couple clusters for smut, but how about fics which focus around character introspection, fics which focus on fluff dates, etc?
That’s what I tried here - and as is clear from the gif (tsne visualisation), the clustering didn’t work out fantastically. Details of process under the cut. Dataset is 16,211 D:BH fics published on AO3 between May 2018 to June 2020.
1. Clean up the fics. I didn’t do any stopword removal here because of step 2. Just removal of funny symbols, etc.
2. Pull out and clean the verbs. I used Spacy’s part of speech tagger for this. I also lemmatised all verbs pulled (so you may see some odd-looking words if you do explore the visualisation). Of course, sometimes the tagger misidentifies words as verbs, so you may see what should be nouns, etc. I’ve tried to remove character names at least by relying on the long list of names I created from running topic modeling on this corpus some time back.
3. TF-IDF weight the words. Basically, count how many times a verb appears in a fic, and then multiply it by the inverse count of how many fics the verb appears in. Words which are more ‘important’ or ‘representative’ of the fic in question should be weighted higher.
4. Perform non-negative matrix factorisation for dimensionality reduction. At this point, I could have possibly gone straight to tsne for visualisation with the tf-idf weights, but the results were even worse (if I recall). So I performed NMF. Like other topic modeling methods like LDA, the number of dimensions/topics to go for is user-prescribed.
I ran NMF from 10 to 60. At each point, I calculated the mean cosine similarity between all topics (we’d want something that’s lower, topics that are too similar to each other aren’t great). I picked 40 topics in the end, since that’s where the mean cosine similarity seems to level off. This is definitely a subjective call, but since I’m just really doing NMF for faster tsne visualisation, I was ok just eyeballing the graph and rolling with this.
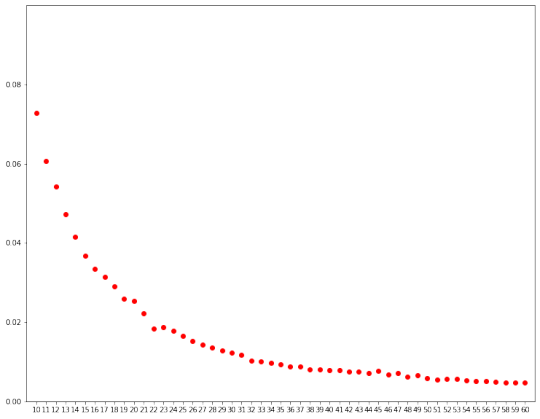
(The top 15 keywords for each topic can also be viewed on my Github page.)
5. Run tsne. I used sklearn’s implementation. I also normalised my NMF weights before submitting it for the run. I’m terribly new to tsne, so I’m pretty sure the parameters I selected weren’t great.
I went with a perplexity of 350, PCA initialisation, a learning rate of 100, a max number of 30,000 iterations with stopping if there is no improvement after 500 iterations. tl;dr, the output of tsne is heavily dependent on the parameters you set (there’s a great Distill article out there on this), and with my lack of experience I may have bungled this.
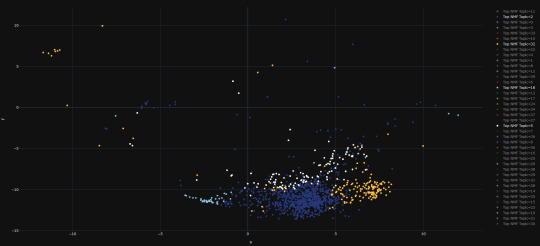
6. Visualise tsne. I used plotly’s scatterplot for this. Each dot is one fic. If you hover over the dot, you can see the top-5 tf-idf weighted verbs for it (the most ‘important’ verbs to that fic, according to the tf-idf metric).
Overall, the visualisation is more or less just a hairball, but to my amusement/chagrin, there appears to be what is a little nest of smutty-seeming fics lurking at the bottom:
8 notes
·
View notes
Text
A continued look at kudos on AO3 D:BH fics
So more than a month ago I started looking at the kudos information I scraped from AO3 D:BH fics, very basic descriptive stuff.
Assuming (1) choosing to write a fic about a certain ship(s), and/or (2) choosing to read a fic with a certain ship(s) and leaving a kudos on it can be taken to be some proxy measure of interest in a ship, I decided to make a simple plot summarising the amount of interested users that each ship has and that each ship shares with another ship in the fandom.
Resulting plot:

x Interactive version of the plot can be found on my Github (link in description/Tumblr heading). My Github page also has links to tables with the raw counts shown when hovering over the nodes/links, for easier reference.
Again, note that this scrape was done in June 2020. I removed any fics that were non-English, were crossovers, or had less than 10 words. 16211 fics remain for analysis.
Details of the process under the cut.
1. Preprocessing relationship tags Ship tags can get pretty unstandardised! I took only tags that had a ‘/’ between the characters (e.g. Connor/RK900). I then split each tag at the ‘/’ character and standardised the resulting two (or more) names. For example, Connor (one-sided), RK 800, Connie, Connor - they all fall under ‘Connor’.
As ships may involve more than two characters, for the sake of visualisation, I converted those into a list of every possible permutation of pairs within the listed ship; so Connor/RK900/Hank into [Connor/RK900, Connor/Hank, RK900/Hank].
2. Extracting user interest in ship(s) Again, I took user interest in a ship to be signalled by: (1) being an author of a fic with the ship tagged, or (2) leaving a kudos on a fic with the ship tagged (1) was extracted very simply given that each fic has an author(s) tied to it. (2) was taken from the kudos list shown at the end of every fic. Given that there’s no way to disambiguate guests and tie them across different fics on my end, I discarded that information and focused only on registered site users.
At the end of this process, I had a long list of user-ship interest pairs. 354382 entries, to be exact.
3. Preparing the plot Given the information I have (user-ship interest pairs), I started with a bipartite plot. All that means is that there’s one set of nodes that’s all users, and another set of nodes that’s all the D:BH ships ever written about on AO3. Between these two sets of nodes are links that connect a user to a particular ship if they’ve expressed interest in it. The set of user nodes has no links within it, same for the set of ship nodes.
The bipartite graph can then be flattened/projected into a regular graph with just one type of nodes (in this case, ships, since I’m interested to see how many interested users each pair of ships shares). So we keep only the ship nodes, and a link exists between two ship nodes now if they share at least one common interested user. We can weight the links by the number of common interested users they share.
This graph has 311 ship nodes and 34429 links. It’s not huge, but it’s very unwieldy to visualise. Likely, many nodes also share very weak links (e.g. just a couple of common users). Since my end-goal is really just visualisation, I decided to prune the graph.
4. Filtering the graph I reuse the same filter from Serrano et al., (2009) that I applied on my character co-occurence graph. I set it at a relatively strict level of α=.001. This filtered the graph down to 185 ship nodes and 1251 links.
5. Visualising the graph I made this one less springy than the previous ones, since I realised how annoying it was to explore when the nodes keep bouncing back to place when you tug them out.
Ship node size is determined by number of users that have indicated interest in the ship (bigger=more). Link size is determined by the number of common interested users the pair of ships shares (thicker=more).
I also realised it’s still a little tough to really pick apart the links to get a good look, so I’ve uploaded the tables with the raw counts on my Github page. Unfortunately I cannot add a search bar since I don’t think I can deploy Dash on Github pages, so it may be a bit tedious looking through the link table.
7 notes
·
View notes
Text
An initial look at kudos on AO3 D:BH fics
In my June 2020 rescrape of the AO3 D:BH collection, I added a few more things that weren’t available in my old Oct 2019 dataset (all my previous analyses are listed here). The list of who left kudos is one of them.
Though this is still very rudimentary (I am hoping to build on this information on kudos for a few analyses), right now I’m just mad relieved that I’ve gotten the preprocessing out of the way. I hope I got all the numbers correct - if I find any errors later, I will highlight them in this post and update accordingly.
Again, I removed any fics that were non-English, were crossovers, or had less than 10 words. 16211 fics remain for analysis. x Interactive versions of the plots below can be found on my Github (link in description/Tumblr heading).
1. Overall number of kudos Overall, I extracted 3144226 kudos. There is a slight discrepancy against the count I get from summing the kudos count field that AO3 provides (that one sums to 3144430). That makes a discrepancy of 204 kudos. Thankfully, this is a really, really small discrepancy. I also checked the fics where the kudos I extracted did not match the count provided by AO3. They largely differed by a count of 1, and only 2 fics differed by a count of 2. Perhaps readers were leaving kudos when I was scraping and this wasn’t reflected yet in the kudo list? In any case, given the small difference, I decided my kudos extraction was sound enough to work with.
2. Breakdown of kudos-givers (user vs guest)

3. Breakdown of kudos-givers (user vs guest), by rating

4. Distribution of proportion of kudos-givers who are guests, by rating For each fic, I divided the number of guests kudos-givers against the total number of kudos it received. I was wondering, for example, if explicit fics might skew more to a higher guest kudos-giver proportion, etc?

Based on this simple boxplot, no. Across the 5 ratings, fics typically are very well-balanced between guest/registered user kudos-givers proportions.
Extra info: preprocessing I extracted the kudos list for each story as a long string (not sure if I could’ve done this better). For example, ‘Connor, Markus, Kara, and 2 more users Hank and Sumo, as well as 5 guests left kudos on this work!’ The number of guests and the names of the users were extracted using very flimsy regex.
2 notes
·
View notes
Text
AO3 D:BH fanfic publishing frequencies (June 2020)
Part 12 of a series on AO3 D:BH fics. I’ve finally updated my D:BH AO3 dataset with a June 2020 scrape!
As usual, I removed any fics that were non-English, were crossovers, or had less than 10 words. 16211 fics remain for analysis.
Before I move on to other analyses, I wanted to have a quick look at how the D:BH fandom has progressed since my original scrape in Oct 2019. My other analyses on the older dataset are listed here. x Interactive versions of the plots below can be found on my Github (link in description/Tumblr heading). Please click the images to expand because Tumblr formatting is ugh.
1. New fics published per month

Numbers seem to have stabilised around 400~ per month. There was a slight dip in Nov/Dec 2019, but perhaps the PC release in Dec 2019 helped boost the numbers back in Jan 2020.
2. Ratings breakdown at time of scrape

Breakdown percentages are still more or less the same as back in Oct 2019.
3. New fics published per month, by rating

Overall, the ratings seem to follow a similar publishing rate across months (but I see you, the little bumps in Explicit for Kinktobers).
4 notes
·
View notes
Text
/update
Slight delay/inactivity because I’ve been in a really bad headspace for the past few months, but I’ve finally updated my fic dataset and will be pushing out new analyses! I’m also finalising code which should pull most comments.
The new fic dataset consists of 16,211 D:BH AO3 fics (only English, no cross-overs, word count of at least 10).
2 notes
·
View notes
Text
Exploring D:BH Fics (Part 11)

(A partial attempt at) AUTOMATICALLY FINDING SIMILAR SUMMARIES (D:BH AO3 FICS)
Disclaimer: this is more of a ‘I wanted to give this tool a try’ post than anything really revealing about fandom itself. I’m not very pleased with the outcome (probably need a lot more refining/better preprocessing), but I’m putting it up here as another WIP.
Basically, given a set of a few thousand summaries, how can I find the ones which are more similar to each other automatically? There are more than a couple of ways to tackle that, but I recently came across Word Mover’s Distance (which nicely taps onto word2vec, which I trained a few months ago!) - so, why not. View my Github page for the summary network in the GIF.
Record of process under the cut.
First off, credit for a lot of code goes to Gensim’s tutorial.
A traditional way to assess similarity between two writings is to look at their common words (bag-of-words). We run into a problem if the writings don’t use the same words even though we know they’re kind of alike/have some degree of similarity though - e.g. ‘Connor really likes dogs.’ and ‘Connor loves puppies’.
Word Mover’s Distance (WMD) improves on this by tapping on word2vec embeddings (tl;dr, words that are semantically similar/used in similar contexts, like dogs and puppies, should have more similar embeddings than those which are not, e.g. dogs and fruit). WMD calculates the distance needed to get from the embeddings of the words in one document to another. In other words, the shorter the distance needed to travel, the more similar the two documents should be. (Obviously the implication here is that the word2vec model doesn’t suck completely as well, and hm, well, not completely sure about the strength of my D:BH one.)
With that out of the way, on to the methodology:
1. Load a pre-trained word2vec model. As I mentioned, I’ve already trained one on my collection of D:BH fics.
2. Clean all the summaries. For this exploration, I dropped all not rated fics (leaving me with 12,647 fics). I removed all names and stopwords (really common words like ‘the’, ‘a’) from the summaries. Stopwords were removed because they don’t contribute much to understanding how similar two summaries are in this case.
I dropped any summary that had a length of 0 after cleaning. The mean length of a cleaned summary was 21.3, median was 16, and standard deviation was 17.5. Boxplots for cleaned summary length broken down by ratings, for the curious:

3. Run WMD (partially). I used Gensim’s implementation of WMD. Looping over each summary, I calculated the WMD between it and every other summary, recording only those that shared a .55 or above similarity with it (note: arbitrary decision on my part for that figure). Each query takes quite a bit though, anywhere from 25 seconds to over 200 seconds - so I stopped at about ~1000 summaries (out of the total 12,647), since I just wanted to get a gauge of how this was working on my fic dataset.
4. Plot out network for marginally easier exploration. It got a bit tiring trying to scroll through the printed results, so I decided to put whatever I have into an interactive network so I can more quickly get a sense of the results. Again, I used pyvis.
Nothing fancy here, nodes are summaries (I cut them off at 150 characters, otherwise some would run on for too long) and they’re linked if they have at least .55 similarity with each other. You can hover over nodes to glimpse at the summaries, but I didn’t add any other story details/numbers, because the network would take too long to load otherwise.
I did label the nodes by rating, however, so - red nodes are Explicit, orange nodes are Mature, pink nodes are Teen & Up, and white nodes are for General Audiences.
Do I like the results? They kind of make sense, I guess, but I’m far from satisfied. The results maybe can be improved if I augmented the summary with other stuff that we see in the story blurb (author-provided tags, story title, characters involved, etc) - so, another thing to work on!
2 notes
·
View notes
Text
Exploring D:BH Fics (Part 10)

A NETWORK OF D:BH CHARACTER CO-OCCURRENCE ACROSS AO3 FICS
I built an interactive network of D:BH characters based on the character tags of 13k+ AO3 fics published between May 2018 to mid-Oct 2019. To access the network, please visit my Github page.
The network has quite a bit of information; it summarises the following: For individual character nodes: 1) The most common rating the character typically appears in 2) How many unique characters the character has appeared with 3) The top 5 characters that appear with the character 4) How often the character is shipped whenever they appear 5) The most common rating of the character’s shipfics For links between a pair of characters: 1) How many fics they have appeared in together 2) The most common rating the pair typically appears in together 3) How often the two are shipped together whenever they appear 4) The most common rating of the pair’s shipfics
I’ve also created a ship network earlier last year, if you haven’t seen it.
Happy exploring! If you’d like to know more about how the network was created, read more under the cut.
This is more a descriptive summary of a dataset than an actual analysis, so this is really just a collation of very basic steps.
1. Standardising character tags AO3 has a ‘character tag’ category, so I tapped on that. However, the tags aren’t very standardised (there are at least more than 100 ways writers have tagged Connor alone), so I manually sorted all these 60k+ tags. There were also tags that were more of the writer’s commentary than anything (e.g. ‘possibly more in the future’) - I put those under an ‘Other’ category and did not include them in the network.
At the end of this process, I had a list of 118 unique characters. I then relied on this manually sorted list to automatically relabel the character tags of every fic.
2. Retrieving basic character and character-character information Okay, so now we have standardised character tags on every fic. With that we can already the most basic question about each character, i.e. which fic rating do they usually pop up in?
We can also go a bit further and start looking at character-character pairs. This is easy to do - just create every possible pair permutation from a fic’s character tags. For example, a fic tags RK900, Hank, Connor - we can create a set of pairs, [(Hank, RK900), (Connor, Hank), (Connor, RK900)]. So now we can also start thinking about questions relating to the relationships between characters e.g. what is the most common rating Connor and RK900 typically appear together in?
Specifically, at this stage, I derived the following info to dump into the network: 1) The most common rating the character typically appears in 2) How many unique characters the character has appeared with 3) The top 5 characters that appear with the character 4) How many fics a character pair has appeared in together 5) The most common rating a character pair typically appears in together
3. Adding ship information This network focuses on character occurrence, but I also wanted to add some info on ships for easier comparison (just because two characters co-occur a lot together =/= there are a lot of shipfics of them; think Connor and Sumo).
For this I relied on the ‘relationships’ category for tags and a lot of the work that I did earlier for the ship network. As before, I looked at only tags with the ‘/’ between characters (i.e., don’t count tags written in the style of Markus & Simon as ships). Again, the tags are unstandardised, but a lot of the cleaning work has been done for the earlier network so I tapped on that.
With standardised ship information now available alongside the standardised character appearance information, we can start doing other simple comparisons. For example, of all the fics the character has appeared in, what percentage actually has them in a ship? Note that this is just a rough number; three characters (unspecified humans, Reader, AP700) have percentages that exceed 100% (i.e., they appear in more ship tags than character tags).
We can also create permutations as we did for character pairs for polyships (e.g. Connor/Hank/RK900 into [(Hank, RK900), (Connor, Hank), (Connor, RK900)]) that can help answer questions like: of all the fics the character pair has appeared in, what percentage actually ship them? Again, this is just a rough number; 7 pairs (RK900/unspecified humans, Ralph/Reader, Traci/Traci, Connor/SWAT, AP700/Connor, Connor/Reader, Reader/unspecified humans) have more ship tags than tagged appearances.
At this stage, I added the following info: 1) How often the character is shipped whenever they appear 2) The most common rating of the character’s shipfics 3) How often a pair of characters are shipped together whenever they appear 4) The most common rating of a pair’s shipfics
4. Creating the network As before, I relied on the library pyvis to create this interactive visualisation. The characters are nodes and they’re linked if they’ve appeared on a fic together at least once.
Node qualities: x Node size: The larger a character node, the more unique characters the character has appeared with. x Node shape: Star-shaped nodes indicate characters that are shipped in 50% or more fics that they appear in. Diamond-shaped nodes indicate characters that are shipped in 25% to 50% of the fics they appear in. Regular circle-shaped nodes are characters that are shipped in below 25% of the fics they appear in. x Node colour: Node colour is determined by the fic rating the character typically appears in. Colour reference: grey = Not Rated, green = Gen, blue = Teen, orange = Mature, red = Explicit.
Link qualities: x Link thickness: The thicker the link, the more often that pair of characters has appeared together. x Link colour: Link colour is determined by the fic rating the character pair typically appears in. The colour scheme follows that of the character nodes.
Hovering over nodes and links also provides more information (for specific numbers, ship information for comparison, etc). For the specific percentages (e.g. 28.97% of fics shipping Connor are Explicit; 83.33% of fics that ship Kamski and ST200 are Explicit) - these are given for the majority category; in other words the top rating for Connor shipfics is Explicit, the top rating for Kamski/ST200 fics is Explicit.
But wait! If you look at the final network in the gif/Github, it’s obvious that there aren’t the 2000+ links I mentioned and it doesn’t even look like there are over 100 nodes. What I did at this final stage was run the network through a disparity filter.
The original network looked like this:

Practically unreadable. The issue is that many links between many characters are likely to be spurious (i.e., really only a small handful of fics had them appearing together). The disparity filter I used is from Serrano et al., (2009) and basically tests the links of every node for significance (your usual p<=.05 stuff).
This keeps only the links between characters that likely did not occur to mere chance alone, resulting in the final network you see in the gif/Github. So while the network stats were built off all the details collected from 13k+ fic, for clarity I visualise only a condensed backboned version of it.
And that’s it for now! Will update this space if any edits are made.
1 note
·
View note
Photo

/just an update on things
I’ve finally graduated from my masters and am starting my first ‘real’ job! Making a blog like this has been one of my big to-do wishes for a long while and I'm really happy to have fulfilled that personal goal.
For anyone who’s stumbled across this Tumblr and enjoyed it, I still intend to continue running it for as long as I can. I’m also still contactable via chat/ask, even if the blog doesn’t seem as active. I just might be a lot slower with posting. Plans, though:
1) I initially thought of moving to analyse other fandoms, but I probably would just end up repeating a lot of analyses I’ve done here. I think it would be more meaningful if I stayed with the D:BH fandom and continued trying out and learning new analyses. So - this blog is staying a D:BH blog.
2) Rescraping and updating the AO3 dataset. I did it in mid Oct 2019; since then, D:BH has come out for the PC and I’m sure many have updated their fics. I am currently updating the code to include comment details and am targeting a May 2020 rescrape (2nd anniversary of D:BH’s release!).
3) Hopefully, more diverse analyses (i.e., more work with the actual text, more work with networks).
It’s all a little vague right now because I’m really uncertain (and nervous about the job, which I feel quite underqualified for), but I really want to thank everyone who has taken the time to read this blog. I noticed too (from here and my art blog) that the character wordclouds turned out to be pretty amusing viewing material - I’m happy for that! ( ゚▽゚)/
3 notes
·
View notes
Text
Exploring D:BH Fics (Part 9)

D:BH CHARACTER PROMINENCE IN THE ACTUAL GAME VS AO3 FICS
Which characters are relatively more prominent in canon and are they the same ones prominent in the fandom? I tried my hand at answering that question (quantitatively) and the graph above is the result.
I sorted the graph by prominence in fandom (i.e., percent of character tags received). The graph is meant to act as a rough gauge to identify characters that may have gotten (or lost) prominence when moving from canon to fandom material. The specific percentage numbers between the two sources (canon/fandom) are not directly comparable since prominence had to be operationalised differently between the two sources (all details under the cut). x Interactive versions of all graphs presented (so you can see the numbers clearly, etc) available on my Github page (link in description/tumblr heading!).
Usually I split the methods write-up from the results, but this time I’ll keep them together, again, because the process and assumptions made are especially important for this analysis (for starters, how was prominence even operationalised in canon/fandom material?).
Other work: I - II - III - IV - V - VI - VII - VIII
Before I go into the methods, two questions to think about:
1) There are a lot of ways to talk about the prominence of a character - how many times did they appear (and what counts as an appearance; just walking across the street, or actually being the focus of action)? How much screen-time did they get? How many lines did they say? How many times their name appeared or they were referred to? Maybe even how much influence they had over events?
2) If we’ve settled on an answer for (1), how do we compare that between different mediums? D:BH is a game and fics are, well, mainly text.
These were questions I thought a lot about before proceeding. In the end, I settled for rather simplistic operationalisations. For the actual game, I relied on the dialogue transcriptions from the Detroit: Become Text project. For fics, I relied on the character tags provided by the AO3 authors.
1. D:BH ACTUAL GAME DIALOGUE Dataset: Some people have done wonderful work transcribing most of the dialogue in the actual D:BH game (please see Detroit: Become Text on Github!). I worked with all the material they had - 4728 lines of dialogue.
1.1 Preprocessing Everything was in HTML so it was a simple task of writing some code to pull out the character names and counting the number of dialogue lines each individual had. x Assumption 1: Share of dialogue is indicative of character prominence in the game. I decided on this mainly because I was limited by the information I had (D:BT almost fully transcribes dialogue only) and also because D:BH is a very conversation-heavy game. x Assumption 2: Sometimes characters might be interchangeable for certain lines, e.g. Josh or Simon can tell Markus, “Be careful, Markus. Our people need you.” I chose to drop these lines and not assign them to any character’s count since there were only 15 of them in the whole transcription. x Assumption 3: The game has multiple scenarios based on your choices. I chose not to distinguish between them, taking the whole transcription as a long text document. My justification is that if the writers decided a character was important enough to have/be in several variants of the scenario (think Connor’s multiple endings versus, maybe, the android Markus picked up paint from), I should not discount that.
Following this, I selected 40 named characters (i.e., no random policeman/passer-bys) for visualisation and comparison. These 40 characters together had 3745 transcribed lines.
1.2 Results
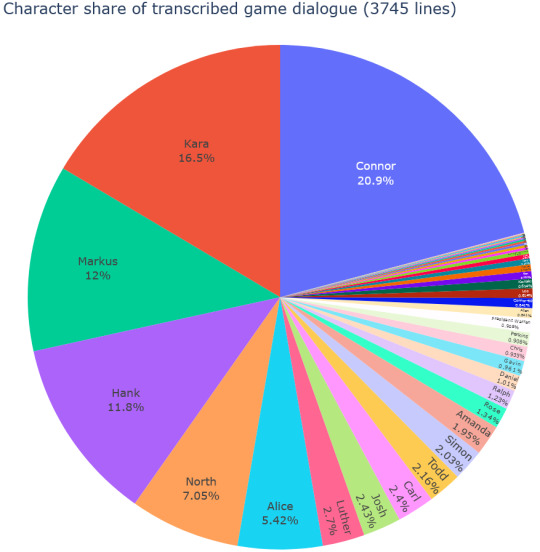
Note the percentage is calculated from the lines of these 40 characters only (i.e., does not cover dialogue counts of unnamed policemen, unnamed deviants, etc).
Connor, Kara, and Markus take up almost 50% together. I think Markus has slightly less lines than Connor and Kara since it’s possible for North to take his place. Fan favourites like Gavin hold only a tiny sliver of the pie. Note that according to this operationalisation of prominence, RK900 is at 0% (since he doesn’t say anything in-game).
2. CHARACTER TAGS FROM D:BH AO3 FICS Dataset: 13,933 English-language fics scraped from AO3, spanning May 2018 to mid Oct- 2019.
2.1 Preprocessing I collated all the tags that fell under the AO3 character class (61333 tags). I did a fair bit of manual cleaning as usual (for misspellings, different ways to tag a character, etc). x (Long) assumption: Picking out dialogue lines from fic and attributing it correctly to characters is an extremely difficult task (I think I've seen machine learning papers on it). So, I chose to go with tags - I assumed that characters that are important or at the very least more than a one-liner would receive a tag. At the same time, I assumed that characters that are really just one-liner appearances (like “He saw Nines walk across the room.” with zero mention of Nines in the rest of the fic) would not get tagged.
Clearly this is not foolproof since everyone has different ideas of what constitutes a character that should be tagged, but it’s what I worked with (otherwise I would have to read and check every fic). Stuff to note:
1) Ambiguous tags like “everyone” were not assigned to any character. 2) Tags that mentioned multiple characters (e.g “mentioned North and Josh”) or ships were also not assigned to any character. 3) Tags that were in the style of “Connor (mentioned)” were still added to their respective characters. Again, I think most writers have varying ideas of what a “mention” actually means, so I decided to be less stringent and more inclusive here. 4) Tags for ‘Jericho’ and ‘Jericrew’, etc - I added 0.25 to the counts of Markus, North, Simon, and Josh each time such a tag appeared. Whether I did that or not probably wouldn’t have drastically changed the results though, since there were only 87~ Jericho-related character tags.
I picked out the same 40 named characters I looked at from the actual game dialogue. These 40 characters together had received 53274 tags.
2.2 Results

Again, note the percentage is calculated from the total number of times these 40 characters were tagged (e.g., does not include tag counts for OCs - which were tagged quite a bit as well).
We see Connor still holding on to his share and huge jumps from Gavin and RK900. DPD members in general also seem to have slightly bigger slices of the pie in fandom.
3. Ending notes It’s pretty difficult to see some of the information from the two pie charts, so I put the information from both into the bar chart that I introduced this whole post with:
I can’t emphasise enough that the exact percentage numbers between canon/fandom are not directly comparable since prominence had to be operationalised differently. Nonetheless, I think the chart does capture a trend that reflects my reading experience. Now I just need more spare time/need to kidnap some data minions so I can work on a more rigorous and direct comparison.
119 notes
·
View notes
Photo

WHAT IS FANON GAVIN LIKE? Gavin Reed as described by tags aggregated from a dataset of over 13,000 AO3 D:BH fics.
Top 3 words in the wordcloud: asshole, android, trans.
x View Connor | RK900 | Hank Methodology covered here.
#gavin reed#dbh gavin#detroit become human#dbh#fandom stats#ao3#text analysis#last one of this series
21 notes
·
View notes
Photo

WHAT IS FANON HANK LIKE? Hank Anderson as described by tags aggregated from a dataset of over 13,000 AO3 D:BH fics.
Top 3 words in the wordcloud: good parent, parent, protective.
x View Connor | RK900 Methodology covered here.
#dbh hank#hank anderson#detroit become human#dbh#fandom stats#ao3#text analysis#probably gonna pick just one more character before moving on
41 notes
·
View notes
Photo

WHAT IS FANON RK900 LIKE? RK900 as described by tags aggregated from a dataset of over 13,000 AO3 D:BH fics.
Much less dense than Connor's wordcloud since there were much fewer tags to work with. Top 3 words in the wordcloud: top, protective, soft.
For clarity, descriptions of RK900 as ‘deviant’, ‘machine’, and ‘human’ were separated from the wordcloud. The breakdown is here:

x View Connor here. Methodology covered here.
#rk900#dbh#detroit become human#fandom stats#ao3#text analysis#is there actually a canon rk900 if he really only appears for a couple seconds in a specific route to check out i mean evaluate connor
15 notes
·
View notes
Photo

WHAT IS FANON CONNOR LIKE? Connor as described by tags aggregated from a dataset of over 13,000 AO3 D:BH fics.
Top 3 words in the wordcloud: bottom, adorable, trans.
For clarity, descriptions of Connor as ‘deviant’, ‘machine’, and ‘human’ were separated from the wordcloud. The breakdown is here:

Methodology covered here.
30 notes
·
View notes