#Adsbot
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
50 şirketimiz kalkınma ajansları desteği ile CES 2024'e çıkarma yapılacak
50 şirketimiz kalkınma ajansları desteği ile CES 2024'e çıkarma yapılacak
150’nin üzerinde ülkeden 1.200’den fazla teknoloji şirketinin katılacağı fuarda, Türk girişimciler; görme engelli çocuklar için akıllı baston girişiminden, kahve atıklarını biyo-ham maddeye dönüştüren yerli girişime; elektrikli araç performans yönetimi platformundan, giyilebilir teknolojilere kadar inovatif ürünlerini ilk kez sergileyecek. ABD’nin Las Vegas şehrinde 9-12 Ocak 2024 tarihleri…

View On WordPress
#Adsbot#Archi&039;s Academy (Tech Career)#Arkerobox#artlabs#Arya-AI#Boatmate#CES 2024#Co-one#Cormind#Efilli#FanSupport (FS Teknoloji)#From Your Eyes#Genoride#Gokido#Homster#Integva#istanbul kalkınma ajansı#Kidu#Kodgem#KuartisMED#Link Robotics#LOOP 3D (Teknodizayn Makina)#manset#MediTechLabs#Mimiq#MIOTE#miselium.io (Printive 3D)#Mocky AI (Ron Dijital)#Mostas Tecnology#myBudizzz (Bartka Inovasyon) Navlungo
1 note
·
View note
Text
Adsbot Lifetime Deal 🔥 on Appsumo only $39 🔥Optimize Google Ads and start saving on ad spend using automated insights and alerts
youtube
🔥 Limited Time Offer! Get the Adsbot Lifetime Deal on Appsumo for just $39! 🔥 Are you tired of spending endless hours and heaps of money on Google Ads without seeing the results you desire? Say hello to Adsbot, your ultimate solution to optimizing Google Ads and saving big on ad spend! 🎯 Supercharge Your Google Ads Performance 🎯 Adsbot is a powerful, automated tool designed to revolutionize the way you handle your Google Ads campaigns. Whether you're a seasoned marketer or just starting out, this game-changing platform will help you skyrocket your ROI and reach your business goals faster.
0 notes
Photo

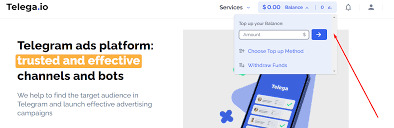
Telega.io
Telegram ads platform:
Trusted and effective channels and bots
We help to find the target audience in Telegram and launch effective advertising campaigns.
Why is Telega.io convenient?
Find the list of desired channels (Google, Catalogs)
Check channels for fake subscribers
Write to channel owners to find out the publication cost
Make separate payments to each owner
Create advertising posts
Send ad post to each owner
Control the publication of an advertising post on each channel
Hot Deals with realdiscounts from 25%!
How It Works?
Sign up to Telega.io
Select suitable channel in the catalog
Top up your balance any convenient way
Create ad campaign: you place in the system post with link and image or video
Channel owner publishes ad post and you get a link to check
You can download an ad report.
Lear more HERE
#telegram#telegrambot#bot#ads#telegramads#ads platform#adsbot#telegram channel#earn money with ads#telegram ads#telegram bot
3 notes
·
View notes
Text
Google Updates User Agent For AdsBot Mobile Web Crawler
Google Updates User Agent For AdsBot Mobile Web Crawler
Google has updated the user agent string for the AdsBot Mobile Web crawler. Google said if you hard-coded the old user agent string, you will want to make sure to update that in your code. This was updated in the Google crawler documentation. The new user agent string for Google AdsBot Mobile Web is: Mozilla/5.0 (iPhone; CPU iPhone OS 14_7_1 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko)…

View On WordPress
0 notes
Text
What is Google Algorithm for SEO used by the Digital Marketing Agencies?
Google updates often pressurize fear into the hearts of each seo and marketing crew across the globe. The latest update in July 2021 has rocked everyone globally, but the focal point remains on the user experience. There are numerous guidelines and suggestions to ensure your seo is on top; however, seo still relies on how nicely a user receives the site. According to the Best Digital Marketing Agency in Kolkata Clunky, boring, and difficult-to-use web pages will not do properly, regardless of how well they score in seo, because people will stop visiting your website.
All websites worldwide are crawled through Googlebot, that's liable for analyzing them to establish a relevant ranking inside the search results. We will see here Googlebot's unique actions, its expectancies, and the tricks used by it.
GoogleBot
Googlebot is a virtual robot evolved via engineers at the massive's Mountain View offices. This little "Wall-E of the net" quickly visits websites before indexing a few of their pages. This machine program searches for and reads websites' content and modifies its index according to the information that it reveals. The index, wherein search results are saved, is a type of Google's brain. This is where all its data is stored.
Google uses lots of small devices to send its crawlers to each corner of the web to discover pages, to look at what's on them. There are numerous unique robots, each with a well-defined motive. For instance, AdSense and AdsBot are liable for checking paid advertisements' relevance, while Android mobile Apps tests Android apps. There may also be pictures, Googlebot, news, and so on.
CSS stands for Cascading Style Sheets. This document describes how HTML elements ought to be displayed on the screen. It saves much time; that is why the style sheets practice all through the website. It could even manipulate several websites' formats at the same time. Googlebot does not just examine textual content; and it also downloads CSS files to recognize a page's overall content better.
Come across feasible manipulation attempts via websites to mislead robots and higher position themselves (the most well-known: cloaking and white police on a white background).
download a few pics (logo, pictograms, and so on.)
study the tips for responsive layout that are essential to reveal that a website is appropriate for mobile browsing.
Google would not explain an entire lot about how those work; however, it has presented what determines search results, consisting of:
The that means and motive of a query
How relevant a specific webpage is to that query
The quality and reliability of the content on the stated webpage
The usability of the web page
The context and settings associated with the character carrying out the search consist of location, previous searches, and any settings on the Google account.
How Does Google Calculate search rankings?
SERPs exist to satisfy a specific need: connecting people to data. While a user searches for a product or a service, Google strives to scour the net to discover the most relevant and beneficial bits of content to be had.
In other words, Google is attempting to emulate us—the readers—in determining the quality, relevance, and benefit of a website's content and ranking it consequently.
The hassle of Calculating search rankings
Though, terms like quality and relevance are instinctive. There aren't any black-and-white approaches to filter out content by using these qualifiers, so Google has to depend upon heuristic metrics that offer a close (however no longer ideal) approximation of quality.
The most famous among them are keywords and backlinks. However, Google had found all possibilities in its analysis over time. According to the Best Digital Marketing Agency in Kolkata Google's first generation in 2000, each of these metrics had been used as stand-ins for content quality:
ALT and <H> tags
Content freshness
Content length
Keyword density
Backlink quality (determined by PageRank)
Backlink quantity
Meta descriptions
Anchor text
Bold and italic words
Internal links
Social shares
Do You Want to Improve SEO?
ASSEO is the Best SEO Company in Kolkata, providing high-level digital marketing and search engine optimization services for online businesses. They are the Best Digital marketing agency in Kolkata for affordable and high-quality search engine optimization, social media optimization, pay-per-click management, and search engine marketing services.
0 notes
Text
Do pages crawled by AdsBot-Google get processed for Google search index?
I see a lot more hits from AdsBot-Google than from Googlebot. I do use AdSense and Google Ads. But hits from AdsBot-Google outnumber hits from Googlebot and Mediapartners-Google by a factor of 10. And hits from AdsBot-Google are not just for my landing pages in Google Ads. Which is what AdsBot-Google is normally for. But AdsBot-Google crawls tens of thousands of URLs on my website. Does Google use data crawled with AdsBot-Google for search indexing? submitted by /u/uRh3f5BfFgjw74FGv3gf [link] [comments] https://www.reddit.com/r/SEO/comments/mprx4m/do_pages_crawled_by_adsbotgoogle_get_processed/
0 notes
Photo

Do pages crawled by AdsBot-Google get processed for Google search index? https://www.reddit.com/r/SEO/comments/mprx4m/do_pages_crawled_by_adsbotgoogle_get_processed/
I see a lot more hits from AdsBot-Google than from Googlebot.
I do use AdSense and Google Ads. But hits from AdsBot-Google outnumber hits from Googlebot and Mediapartners-Google by a factor of 10.
And hits from AdsBot-Google are not just for my landing pages in Google Ads. Which is what AdsBot-Google is normally for.
But AdsBot-Google crawls tens of thousands of URLs on my website.
Does Google use data crawled with AdsBot-Google for search indexing?
submitted by /u/uRh3f5BfFgjw74FGv3gf [link] [comments] April 13, 2021 at 06:43AM
0 notes
Link
Hi,
I am building a website for a personal project, nothing of wide interest or ever commercially relevant. As expected I am not getting many visitors, so be it.
However my logs show a large increase in traffic since last month, and it is all coming from Adsbot/3.1 from various IPs of hosted.static.webnx.com. This guy is scraping the full page several times per day, even though my content is completely static and I upload updates only every few weeks. The rest of my traffic is as expected, Bingbot and Googlebot have larger portions and the rest are random accesses from around the world.
I have already checked some of the bot databases, they all tell the same: Bot of unknown origin, hosted at webnx, ignores robots.txt and scrapes full site. My question really is: What possible motive can they have to scrape my site fully several times per day? My real fear is that as an inexperienced site owner I am falling victim for some kind of abuse that I am unaware of.
Submitted September 27, 2020 at 05:03AM by territrades https://www.reddit.com/r/webhosting/comments/j0pz7v/adsbot_causes_80_of_my_traffic_why/?utm_source=ifttt
from Blogger http://webdesignersolutions1.blogspot.com/2020/09/adsbot-causes-80-of-my-traffic-why.html via IFTTT
0 notes
Text
How to Create a robots.txt file in WordPress | Wordpress Robots txt
How to create Wordpress Robots txt File Step by step guide
How to create Robots.txt file for wordpress? A robots.txt file has an important role for the SEO of a WordPress blog. The robots.txt file decides how the search engine bots will crawl your blog / website. Today I am going to tell how to create robots.txt file is created and updated for wordpress. Because if you make even a small mistake while editing Robots.txt, then your blog will never be indexed in the search engine. So let's know what a Robots.txt file is and how to create a perfect robots.txt file for WordPress.

How to Create a robots.txt file in WordPress | Wordpress Robots txt
What is Robots.txt?
Whenever search engine bots come to your blog, they follow all the links on that page and crawl and index them. Only after this, your blog and post, pages show in search engine like Google, Bing, Yahoo, Yandex etc. As its name suggests, robots.txt is a text file that resides in the root directory of the website. Search engine bots follow the rules laid down in Robots.txt to crawl your blog. In a blog or website, apart from post, there are many other things like pages, category, tags, comments etc. But all these things are not useful for a search engine. Generally traffic comes from the search engine on a blog from its main url (https://ift.tt/3iT2kWl), posts, pages or images, apart from these things like archaive, pagination, wp-admin are not necessary for the search engine. Here robots.txt instructs search engine bots not to crawl such unnecessary pages. If you ever had a mail of index coverage on your Gmail, then you must have seen this kind of massage; New issue found: Submitted URL blocked by robots.txt Robots.txt is not allowed to crawl your URL here, that is why that url is blocked for search engine. That means, which web pages of your blog will show in Google or Bing and what not, it decides the robots.txt file. In this, any mistake can remove your entire blog from the search engine. So new bloggers are afraid to create it themselves. If you have not yet updated the robots.txt file in the blog, then firstly you understand some of its basic rules and create a perfect seo optimized robots.txt file for your blog.
How to Create WordPress Robots.txt file?
On any wordpress blog you get a default robots.txt file. But for better performace and seo of your blog, you have to customize this robots.txt according to yourself. Wordpress default robots.txt User-agent: * Disallow: / wp-admin / Allow: /wp-admin/admin-ajax.php Sitemap: [Blog URL] /sitemap.xml As you can see above some code / syntax is used for robots.txt. But most of you bloggers use these syntax in their blog without understanding it. First you understand the meaning of these syntax, after that you can create a proper robots.txt code for your blog by yourself. User-Agent: It is used to give instructions to Search Engines Crawlers / Bots. User-agent: * This means all search engine bots (Ex: googlebot, bingbot etc.) can crawl your site. User-agent: googlebot Only Google bot is allowed to crawl here. Allow: This tag allows search engine bots to crawl your web pages and folder. Disallow: This prevents syntax bots from crawl and indexing, so that no one else can access them. 1. If you want to index all the pages and directories of your site. You may have seen this syntax in the Blogger robots.txt file. User-agent: * Disallow: 2. But this code will block all the pages and directories of your site from being indexed. User-agent: * Disallow: / 3. If you use Adsense, then only use this code. This is for AdSense robots that manage ads. User-agent: Mediapartners-Google * Allow: / Example: If such a robots.txt file is there, let us know what is the meaning of the rules given in it; User-agent: * Allow: / wp-content / uploads / Disallow: / wp-content / plugins / Disallow: / wp- admin / Disallow: / archives / Disallow: / refer / Sitemap: https://ift.tt/1M7RHY8 Whatever files you upload images from within Wordpress are saved in / wp-content / uploads /. So this code allows the permision to index all i robots.txt file. It is not necessary that you also do the robots.txt code that I use. User-agent: * Disallow: / cgi-bin / Disallow: / wp-admin / Disallow: / archives / Disallow: / *? * Disallow: / comments / feed / Disallow: / refer / Disallow: /index.php Disallow: / wp-content / plugins / User-agent: Mediapartners-Google * Allow: / User-agent: Googlebot-Image Allow: / wp-content / uploads / User-agent: Adsbot-Google Allow: / User-agent: Googlebot-Mobile Allow: / Sitemap: https://ift.tt/1M7RHY8 Note: replace the sitemap of your blog under Sitemap here.
How to update robots.txt file in wordpress
You can manually update the robots.txt file by going to the root directory under wordpress hosting, or there are many plugins available through which you can add to the dashboard of wordpress. But today I will tell you the easiest way, how you can update robots.txt code in wordpress blog with the help of Yoast SEO plugin. Step 1: If you have a blog on wordpress, then you must be using Yoast SEO plugin to be seo. First go to Yoast SEO and click on Tools button. Here three tools will be open in front of you, you have to click on File Editor. Step 2: After clicking on the file editor, a page will open, click on the Create robots.txt file button under the Robots.txt section here. Step 3: In the box below Next Robots.txt, you remove the default code, paste the robots.txt code given above and click on Save Changes to Robot.txt. After updating the robots.txt file in WordPress, it is necessary to check whether there is any error in the Search Console through the robots.txt tester tool. This tool will automatically fetch your website's robots.txt file and will show it if there are errors and warnings. The main goal of your robots.txt file is to prevent the search engine from crawling pages that are not required to be made public. Hope this guide will help you to create a seo optimized robots.txt code. Conclusion:- So in this article i have complete guide you How to Create a robots.txt file in WordPress. Check this robots.txt by robots.txt checker. If you like this article then Help other bloggers by sharing this post as much as possible. Also Read This What is Instagram Reels how to use Instagram Reels? Best Chrome Extension 2020 | Top 10 to Install in 2020
How to Create a robots.txt file in WordPress | Wordpress Robots txt SEO Tips via exercisesfatburnig.blogspot.com https://ift.tt/2Ygv3fX
0 notes
Text
The ultimate guide to robots.txt
The robots.txt file is one of the main ways of telling a search engine where it can and can’t go on your website. All major search engines support the basic functionality it offers, but some of them respond to some extra rules which can be useful too. This guide covers all the ways to use robots.txt on your website, but, while it looks simple, any mistakes you make in your robots.txt can seriously harm your site, so make sure you read and understand the whole of this article before you dive in.
Want to learn all about technical SEO? Our Technical SEO bundle is on sale today: you���ll get a $40 discount if you get it now. This bundle combines our Technical SEO training and Structured data training. After completing this course, you’ll be able to detect and fix technical errors; optimize site speed and implement structured data. Don’t wait!
What is a robots.txt file?
What does the robots.txt file do?
Where should I put my robots.txt file?
Pros and cons of using robots.txt
Pro: managing crawl budget
Con: not removing a page from search results
Con: not spreading link value
robots.txt syntax
The User-agent directive
The most common user agents for search engine spiders
The Disallow directive
How to use wildcards/regular expressions
Non-standard robots.txt crawl directives
The Allow directive
The host directive
The crawl-delay directive
The sitemap directive for XML Sitemaps
Validate your robots.txt
What is a robots.txt file?
Crawl directives
The robots.txt file is one of a number of crawl directives. We have guides on all of them and you’ll find them here:
Crawl directives guides by Yoast »
A robots.txt file is a text file which is read by search engine spiders and follows a strict syntax. These spiders are also called robots – hence the name – and the syntax of the file is strict simply because it has to be computer readable. That means there’s no room for error here – something is either 1, or 0.
Also called the “Robots Exclusion Protocol”, the robots.txt file is the result of a consensus among early search engine spider developers. It’s not an official standard set by any standards organization, but all major search engines adhere to it.
What does the robots.txt file do?
humans.txt
Once upon a time, some developers sat down and decided that, since the web is supposed to be for humans, and since robots get a file on a website, the humans who built it should have one, too. So they created the humans.txt standard as a way of letting people know who worked on a website, amongst other things.
Search engines index the web by spidering pages, following links to go from site A to site B to site C and so on. Before a search engine spiders any page on a domain it hasn’t encountered before, it will open that domain’s robots.txt file, which tells the search engine which URLs on that site it’s allowed to index.
Search engines typically cache the contents of the robots.txt, but will usually refresh it several times a day, so changes will be reflected fairly quickly.
Where should I put my robots.txt file?
The robots.txt file should always be at the root of your domain. So if your domain is www.example.com, it should be found at https://www.example.com/robots.txt.
It’s also very important that your robots.txt file is actually called robots.txt. The name is case sensitive, so get that right or it just won’t work.
Pros and cons of using robots.txt
Pro: managing crawl budget
It’s generally understood that a search spider arrives at a website with a pre-determined “allowance” for how many pages it will crawl (or, how much resource/time it’ll spend, based on a site’s authority/size/reputation), and SEOs call this the crawl budget. This means that if you block sections of your site from the search engine spider, you can allow your crawl budget to be used for other sections.
It can sometimes be highly beneficial to block the search engines from crawling problematic sections of your site, especially on sites where a lot of SEO clean-up has to be done. Once you’ve tidied things up, the you can let them back in.
A note on blocking query parameters
One situation where crawl budget is particularly important is when your site uses a lot of query string parameters to filter and sort. Let’s say you have 10 different query parameters, each with different values that can be used in any combination. This leads to hundreds if not thousands of possible URLs. Blocking all query parameters from being crawled will help make sure the search engine only spiders your site’s main URLs and won’t go into the enormous trap that you’d otherwise create.
This line blocks all URLs on your site containing a query string:
Disallow: /*?*
Con: not removing a page from search results
Even though you can use the robots.txt file to tell a spider where it can’t go on your site, you can’t use it tell a search engine which URLs not to show in the search results – in other words, blocking it won’t stop it from being indexed. If the search engine finds enough links to that URL, it will include it, it will just not know what’s on that page. So your result will look like this:

If you want to reliably block a page from showing up in the search results, you need to use a meta robots noindex tag. That means that, in order to find the noindex tag, the search engine has to be able to access that page, so don’t block it with robots.txt.
Noindex directives
It remains an ongoing area of research and contention in SEO as to whether adding ‘noindex’ directives in your robots.txt file enables you to control indexing behaviour, and, to avoid these ‘fragments’ showing up in search engines. Test results vary, and, the search engines are unclear on what is and isn’t supported.
Con: not spreading link value
If a search engine can’t crawl a page, it can’t spread the link value across the links on that page. When a page is blocked with robots.txt, it’s a dead-end. Any link value which might have flowed to (and through) that page is lost.
robots.txt syntax
WordPress robots.txt
We have an entire article on how best to setup your robots.txt for WordPress. Don’t forget you can edit your site’s robots.txt file in the Yoast SEO Tools → File editor section.
A robots.txt file consists of one or more blocks of directives, each starting with a user-agent line. The “user-agent” is the name of the specific spider it addresses. You can either have one block for all search engines, using a wildcard for the user-agent, or specific blocks for specific search engines. A search engine spider will always pick the block that best matches its name.
These blocks look like this (don’t be scared, we’ll explain below):
User-agent: * Disallow: / User-agent: Googlebot Disallow: User-agent: bingbot Disallow: /not-for-bing/
Directives like Allow and Disallow should not be case sensitive, so it’s up to you whether you write them lowercase or capitalize them. The values are case sensitive however, /photo/ is not the same as /Photo/. We like to capitalize directives because it makes the file easier (for humans) to read.
The User-agent directive
The first bit of every block of directives is the user-agent, which identifies a specific spider. The user-agent field is matched against that specific spider’s (usually longer) user-agent, so for instance the most common spider from Google has the following user-agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
So if you want to tell this spider what to do, a relatively simple User-agent: Googlebot line will do the trick.
Most search engines have multiple spiders. They will use a specific spider for their normal index, for their ad programs, for images, for videos, etc.
Search engines will always choose the most specific block of directives they can find. Say you have 3 sets of directives: one for *, one for Googlebot and one for Googlebot-News. If a bot comes by whose user-agent is Googlebot-Video, it would follow the Googlebot restrictions. A bot with the user-agent Googlebot-News would use the more specific Googlebot-News directives.
The most common user agents for search engine spiders
Here’s a list of the user-agents you can use in your robots.txt file to match the most commonly used search engines:
Search engineFieldUser-agentBaiduGeneralbaiduspiderBaiduImagesbaiduspider-imageBaiduMobilebaiduspider-mobileBaiduNewsbaiduspider-newsBaiduVideobaiduspider-videoBingGeneralbingbotBingGeneralmsnbotBingImages & Videomsnbot-mediaBingAdsadidxbotGoogleGeneralGooglebotGoogleImagesGooglebot-ImageGoogleMobileGooglebot-MobileGoogleNewsGooglebot-NewsGoogleVideoGooglebot-VideoGoogleAdSenseMediapartners-GoogleGoogleAdWordsAdsBot-GoogleYahoo!GeneralslurpYandexGeneralyandex
The Disallow directive
The second line in any block of directives is the Disallow line. You can have one or more of these lines, specifying which parts of the site the specified spider can’t access. An empty Disallow line means you’re not disallowing anything, so basically it means that a spider can access all sections of your site.
The example below would block all search engines that “listen” to robots.txt from crawling your site.
User-agent: * Disallow: /
The example below would, with only one character less, allow all search engines to crawl your entire site.
User-agent: * Disallow:
The example below would block Google from crawling the Photo directory on your site – and everything in it.
User-agent: googlebot Disallow: /Photo
This means all the subdirectories of the /Photo directory would also not be spidered. It would not block Google from crawling the /photo directory, as these lines are case sensitive.
This would also block Google from accessing URLs containing /Photo, such as /Photography/.
How to use wildcards/regular expressions
“Officially”, the robots.txt standard doesn’t support regular expressions or wildcards, however, all major search engines do understand it. This means you can use lines like this to block groups of files:
Disallow: /*.php Disallow: /copyrighted-images/*.jpg
In the example above, * is expanded to whatever filename it matches. Note that the rest of the line is still case sensitive, so the second line above will not block a file called /copyrighted-images/example.JPG from being crawled.
Some search engines, like Google, allow for more complicated regular expressions, but be aware that some search engines might not understand this logic. The most useful feature this adds is the $, which indicates the end of a URL. In the following example you can see what this does:
Disallow: /*.php$
This means /index.php can’t be indexed, but /index.php?p=1 could be. Of course, this is only useful in very specific circumstances and also pretty dangerous: it’s easy to unblock things you didn’t actually want to unblock.
Non-standard robots.txt crawl directives
As well as the Disallow and User-agent directives there are a couple of other crawl directives you can use. These directives are not supported by all search engine crawlers so make sure you’re aware of their limitations.
The Allow directive
While not in the original “specification”, there was talk very early on of an allow directive. Most search engines seem to understand it, and it allows for simple, and very readable directives like this:
Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
The only other way of achieving the same result without an allow directive would have been to specifically disallow every single file in the wp-admin folder.
The host directive
Supported by Yandex (and not by Google, despite what some posts say), this directive lets you decide whether you want the search engine to show example.com or www.example.com. Simply specifying it like this does the trick:
host: example.com
But because only Yandex supports the host directive, we wouldn’t advise you to rely on it, especially as it doesn’t allow you to define a scheme (http or https) either. A better solution that works for all search engines would be to 301 redirect the hostnames that you don’t want in the index to the version that you do want. In our case, we redirect www.yoast.com to yoast.com.
The crawl-delay directive
Yahoo!, Bing and Yandex can sometimes be fairly crawl-hungry, but luckily they all respond to the crawl-delay directive, which slows them down. And while these search engines have slightly different ways of reading the directive, the end result is basically the same.
A line like the one below would instruct Yahoo! and Bing to wait 10 seconds after a crawl action, while Yandex would only access your site once in every 10 seconds. It’s a semantic difference, but still interesting to know. Here’s the example crawl-delay line:
crawl-delay: 10
Do take care when using the crawl-delay directive. By setting a crawl delay of 10 seconds you’re only allowing these search engines to access 8,640 pages a day. This might seem plenty for a small site, but on large sites it isn’t very many. On the other hand, if you get next to no traffic from these search engines, it’s a good way to save some bandwidth.
The sitemap directive for XML Sitemaps
Using the sitemap directive you can tell search engines – specifically Bing, Yandex and Google – where to find your XML sitemap. You can, of course, also submit your XML sitemaps to each search engine using their respective webmaster tools solutions, and we strongly recommend you do, because search engine webmaster tools programs will give you lots of valuable information about your site. If you don’t want to do that, adding a sitemap line to your robots.txt is a good quick alternative.
Validate your robots.txt
There are various tools out there that can help you validate your robots.txt, but when it comes to validating crawl directives, we always prefer to go to the source. Google has a robots.txt testing tool in its Google Search Console (under the ‘Old version’ menu) and we’d highly recommend using that:

Be sure to test your changes thoroughly before you put them live! You wouldn’t be the first to accidentally use robots.txt to block your entire site, and to slip into search engine oblivion!
Read more: WordPress SEO: The definitive guide to higher rankings for WordPress sites »
The post The ultimate guide to robots.txt appeared first on Yoast.
from Yoast • SEO for everyone https://yoast.com/ultimate-guide-robots-txt/
0 notes
Text
The ultimate guide to robots.txt
The robots.txt file is one of the main ways of telling a search engine where it can and can’t go on your website. All major search engines support the basic functionality it offers, but some of them respond to some extra rules which can be useful too. This guide covers all the ways to use robots.txt on your website, but, while it looks simple, any mistakes you make in your robots.txt can seriously harm your site, so make sure you read and understand the whole of this article before you dive in.
Want to learn all about technical SEO? Our Technical SEO bundle is on sale today: you’ll get a $40 discount if you get it now. This bundle combines our Technical SEO training and Structured data training. After completing this course, you’ll be able to detect and fix technical errors; optimize site speed and implement structured data. Don’t wait!
What is a robots.txt file?
What does the robots.txt file do?
Where should I put my robots.txt file?
Pros and cons of using robots.txt
Pro: managing crawl budget
Con: not removing a page from search results
Con: not spreading link value
robots.txt syntax
The User-agent directive
The most common user agents for search engine spiders
The Disallow directive
How to use wildcards/regular expressions
Non-standard robots.txt crawl directives
The Allow directive
The host directive
The crawl-delay directive
The sitemap directive for XML Sitemaps
Validate your robots.txt
What is a robots.txt file?
Crawl directives
The robots.txt file is one of a number of crawl directives. We have guides on all of them and you’ll find them here:
Crawl directives guides by Yoast »
A robots.txt file is a text file which is read by search engine spiders and follows a strict syntax. These spiders are also called robots – hence the name – and the syntax of the file is strict simply because it has to be computer readable. That means there’s no room for error here – something is either 1, or 0.
Also called the “Robots Exclusion Protocol”, the robots.txt file is the result of a consensus among early search engine spider developers. It’s not an official standard set by any standards organization, but all major search engines adhere to it.
What does the robots.txt file do?
humans.txt
Once upon a time, some developers sat down and decided that, since the web is supposed to be for humans, and since robots get a file on a website, the humans who built it should have one, too. So they created the humans.txt standard as a way of letting people know who worked on a website, amongst other things.
Search engines index the web by spidering pages, following links to go from site A to site B to site C and so on. Before a search engine spiders any page on a domain it hasn’t encountered before, it will open that domain’s robots.txt file, which tells the search engine which URLs on that site it’s allowed to index.
Search engines typically cache the contents of the robots.txt, but will usually refresh it several times a day, so changes will be reflected fairly quickly.
Where should I put my robots.txt file?
The robots.txt file should always be at the root of your domain. So if your domain is www.example.com, it should be found at https://www.example.com/robots.txt.
It’s also very important that your robots.txt file is actually called robots.txt. The name is case sensitive, so get that right or it just won’t work.
Pros and cons of using robots.txt
Pro: managing crawl budget
It’s generally understood that a search spider arrives at a website with a pre-determined “allowance” for how many pages it will crawl (or, how much resource/time it’ll spend, based on a site’s authority/size/reputation), and SEOs call this the crawl budget. This means that if you block sections of your site from the search engine spider, you can allow your crawl budget to be used for other sections.
It can sometimes be highly beneficial to block the search engines from crawling problematic sections of your site, especially on sites where a lot of SEO clean-up has to be done. Once you’ve tidied things up, the you can let them back in.
A note on blocking query parameters
One situation where crawl budget is particularly important is when your site uses a lot of query string parameters to filter and sort. Let’s say you have 10 different query parameters, each with different values that can be used in any combination. This leads to hundreds if not thousands of possible URLs. Blocking all query parameters from being crawled will help make sure the search engine only spiders your site’s main URLs and won’t go into the enormous trap that you’d otherwise create.
This line blocks all URLs on your site containing a query string:
Disallow: /*?*
Con: not removing a page from search results
Even though you can use the robots.txt file to tell a spider where it can’t go on your site, you can’t use it tell a search engine which URLs not to show in the search results – in other words, blocking it won’t stop it from being indexed. If the search engine finds enough links to that URL, it will include it, it will just not know what’s on that page. So your result will look like this:

If you want to reliably block a page from showing up in the search results, you need to use a meta robots noindex tag. That means that, in order to find the noindex tag, the search engine has to be able to access that page, so don’t block it with robots.txt.
Noindex directives
It remains an ongoing area of research and contention in SEO as to whether adding ‘noindex’ directives in your robots.txt file enables you to control indexing behaviour, and, to avoid these ‘fragments’ showing up in search engines. Test results vary, and, the search engines are unclear on what is and isn’t supported.
Con: not spreading link value
If a search engine can’t crawl a page, it can’t spread the link value across the links on that page. When a page is blocked with robots.txt, it’s a dead-end. Any link value which might have flowed to (and through) that page is lost.
robots.txt syntax
WordPress robots.txt
We have an entire article on how best to setup your robots.txt for WordPress. Don’t forget you can edit your site’s robots.txt file in the Yoast SEO Tools → File editor section.
A robots.txt file consists of one or more blocks of directives, each starting with a user-agent line. The “user-agent” is the name of the specific spider it addresses. You can either have one block for all search engines, using a wildcard for the user-agent, or specific blocks for specific search engines. A search engine spider will always pick the block that best matches its name.
These blocks look like this (don’t be scared, we’ll explain below):
User-agent: * Disallow: / User-agent: Googlebot Disallow: User-agent: bingbot Disallow: /not-for-bing/
Directives like Allow and Disallow should not be case sensitive, so it’s up to you whether you write them lowercase or capitalize them. The values are case sensitive however, /photo/ is not the same as /Photo/. We like to capitalize directives because it makes the file easier (for humans) to read.
The User-agent directive
The first bit of every block of directives is the user-agent, which identifies a specific spider. The user-agent field is matched against that specific spider’s (usually longer) user-agent, so for instance the most common spider from Google has the following user-agent:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
So if you want to tell this spider what to do, a relatively simple User-agent: Googlebot line will do the trick.
Most search engines have multiple spiders. They will use a specific spider for their normal index, for their ad programs, for images, for videos, etc.
Search engines will always choose the most specific block of directives they can find. Say you have 3 sets of directives: one for *, one for Googlebot and one for Googlebot-News. If a bot comes by whose user-agent is Googlebot-Video, it would follow the Googlebot restrictions. A bot with the user-agent Googlebot-News would use the more specific Googlebot-News directives.
The most common user agents for search engine spiders
Here’s a list of the user-agents you can use in your robots.txt file to match the most commonly used search engines:
Search engineFieldUser-agentBaiduGeneralbaiduspiderBaiduImagesbaiduspider-imageBaiduMobilebaiduspider-mobileBaiduNewsbaiduspider-newsBaiduVideobaiduspider-videoBingGeneralbingbotBingGeneralmsnbotBingImages & Videomsnbot-mediaBingAdsadidxbotGoogleGeneralGooglebotGoogleImagesGooglebot-ImageGoogleMobileGooglebot-MobileGoogleNewsGooglebot-NewsGoogleVideoGooglebot-VideoGoogleAdSenseMediapartners-GoogleGoogleAdWordsAdsBot-GoogleYahoo!GeneralslurpYandexGeneralyandex
The Disallow directive
The second line in any block of directives is the Disallow line. You can have one or more of these lines, specifying which parts of the site the specified spider can’t access. An empty Disallow line means you’re not disallowing anything, so basically it means that a spider can access all sections of your site.
The example below would block all search engines that “listen” to robots.txt from crawling your site.
User-agent: * Disallow: /
The example below would, with only one character less, allow all search engines to crawl your entire site.
User-agent: * Disallow:
The example below would block Google from crawling the Photo directory on your site – and everything in it.
User-agent: googlebot Disallow: /Photo
This means all the subdirectories of the /Photo directory would also not be spidered. It would not block Google from crawling the /photo directory, as these lines are case sensitive.
This would also block Google from accessing URLs containing /Photo, such as /Photography/.
How to use wildcards/regular expressions
“Officially”, the robots.txt standard doesn’t support regular expressions or wildcards, however, all major search engines do understand it. This means you can use lines like this to block groups of files:
Disallow: /*.php Disallow: /copyrighted-images/*.jpg
In the example above, * is expanded to whatever filename it matches. Note that the rest of the line is still case sensitive, so the second line above will not block a file called /copyrighted-images/example.JPG from being crawled.
Some search engines, like Google, allow for more complicated regular expressions, but be aware that some search engines might not understand this logic. The most useful feature this adds is the $, which indicates the end of a URL. In the following example you can see what this does:
Disallow: /*.php$
This means /index.php can’t be indexed, but /index.php?p=1 could be. Of course, this is only useful in very specific circumstances and also pretty dangerous: it’s easy to unblock things you didn’t actually want to unblock.
Non-standard robots.txt crawl directives
As well as the Disallow and User-agent directives there are a couple of other crawl directives you can use. These directives are not supported by all search engine crawlers so make sure you’re aware of their limitations.
The Allow directive
While not in the original “specification”, there was talk very early on of an allow directive. Most search engines seem to understand it, and it allows for simple, and very readable directives like this:
Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
The only other way of achieving the same result without an allow directive would have been to specifically disallow every single file in the wp-admin folder.
The host directive
Supported by Yandex (and not by Google, despite what some posts say), this directive lets you decide whether you want the search engine to show example.com or www.example.com. Simply specifying it like this does the trick:
host: example.com
But because only Yandex supports the host directive, we wouldn’t advise you to rely on it, especially as it doesn’t allow you to define a scheme (http or https) either. A better solution that works for all search engines would be to 301 redirect the hostnames that you don’t want in the index to the version that you do want. In our case, we redirect www.yoast.com to yoast.com.
The crawl-delay directive
Yahoo!, Bing and Yandex can sometimes be fairly crawl-hungry, but luckily they all respond to the crawl-delay directive, which slows them down. And while these search engines have slightly different ways of reading the directive, the end result is basically the same.
A line like the one below would instruct Yahoo! and Bing to wait 10 seconds after a crawl action, while Yandex would only access your site once in every 10 seconds. It’s a semantic difference, but still interesting to know. Here’s the example crawl-delay line:
crawl-delay: 10
Do take care when using the crawl-delay directive. By setting a crawl delay of 10 seconds you’re only allowing these search engines to access 8,640 pages a day. This might seem plenty for a small site, but on large sites it isn’t very many. On the other hand, if you get next to no traffic from these search engines, it’s a good way to save some bandwidth.
The sitemap directive for XML Sitemaps
Using the sitemap directive you can tell search engines – specifically Bing, Yandex and Google – where to find your XML sitemap. You can, of course, also submit your XML sitemaps to each search engine using their respective webmaster tools solutions, and we strongly recommend you do, because search engine webmaster tools programs will give you lots of valuable information about your site. If you don’t want to do that, adding a sitemap line to your robots.txt is a good quick alternative.
Validate your robots.txt
There are various tools out there that can help you validate your robots.txt, but when it comes to validating crawl directives, we always prefer to go to the source. Google has a robots.txt testing tool in its Google Search Console (under the ‘Old version’ menu) and we’d highly recommend using that:
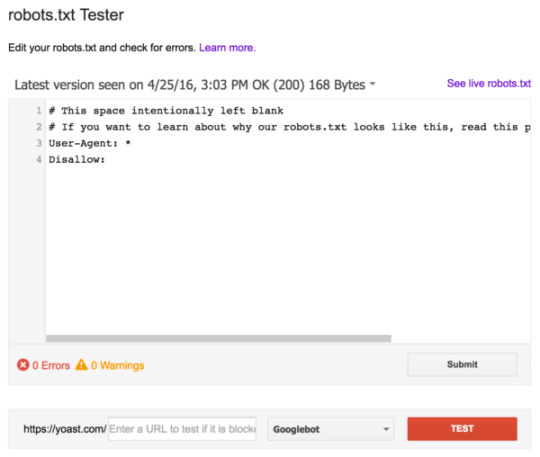
Be sure to test your changes thoroughly before you put them live! You wouldn’t be the first to accidentally use robots.txt to block your entire site, and to slip into search engine oblivion!
Read more: WordPress SEO: The definitive guide to higher rankings for WordPress sites »
The post The ultimate guide to robots.txt appeared first on Yoast.
from Yoast • SEO for everyone https://yoast.com/ultimate-guide-robots-txt/
0 notes
Text
Free web-based robots.txt parser based on Google’s open source C++ parser
The punchline: I’ve been playing around with a toy project recently and have deployed it as a free web-based tool for checking how Google will parse your robots.txt files, given that their own online tool does not replicate actual Googlebot behaviour. Check it out at realrobotstxt.com.
While preparing for my recent presentation at SearchLove London, I got mildly obsessed by the way that the deeper I dug into how robots.txt files work, the more surprising things I found, and the more places I found where there was conflicting information from different sources. Google’s open source robots.txt parser should have made everything easy by not only complying with their newly-published draft specification, but also by apparently being real production Google code.
Two challenges led me further down the rabbit hole that ultimately led to me building a web-based tool:
It’s a C++ project, so needs to be compiled, which requires at least some programming / code administration skills, so I didn’t feel like it was especially accessible to the wider search community
When I got it compiled and played with it, I discovered that it was missing crucial Google-specific functionality to enable us to see how Google crawlers like the images and video crawlers will interpret robots.txt files
Ways this tool differs from other resources
Apart from the benefit of being a web-based tool rather than requiring compilation to run locally, my realrobotstxt.com tool should be 100% compliant with the draft specification that Google released, as it is entirely powered by their open source tool except for two specific changes that I made to bring it in line with my understanding of how real Google crawlers work:
Googlebot-image, Googlebot-video and Googlebot-news(*) should all fall back on obeying Googlebot directives if there are no rulesets specifically targeting their own individual user agents - we have verified that this is at least how the images bot behaves in the real world
Google has a range of bots (AdsBot-Google, AdsBot-Google-Mobile, and the AdSense bot, Mediapartners-Google) which apparently ignore User-agent: * directives and only obey rulesets specifically targeting their own individual user agents
[(*) Note: unrelated to the tweaks I’ve made, but relevant because I mentioned Googlebot-news, it is very much not well-known that Googlebot-news is not a crawler and hasn’t been since 2011, apparently. If you didn’t know this, don’t worry - you’re not alone. I only learned it recently, and it’s pretty hard to discern from the documentation which regularly refers to it as a crawler. The only real official reference I can find is the blog post announcing its retirement. I mean, it makes sense to me, because having different crawlers for web and news search opens up dangerous cloaking opportunities, but why then refer to it as a crawler’s user agent throughout the docs? It seems, though I haven’t been able to test this in real life, as though rules directly targeting Googlebot-news function somewhat like a Google News-specific noindex. This is very confusing, because regular Googlebot blocking does not keep URLs out of the web index, but there you go.]
I expect to see the Search Console robots.txt checker retired soon
We have seen a gradual move to turn off old Search Console features and I expect that the robots.txt checker will be retired soon. Googlers have recently been referring recently to it being out of step with how their actual crawlers work - and we can see differences in our own testing:
These cases seem to be handled correctly by the open source parser - here’s my web-based tool on the exact same scenario:
This felt like all the more reason for me to release my web-based version, as the only official web-based tool we have is out of date and likely going away. Who knows whether Google will release an updated version based on their open source parser - but until they do, my tool might prove useful to some people.
I’d like to see the documentation updated
Unfortunately, while I can make a pull request against the open source code, I can’t do the same with Google documentation. Despite implications out of Google that the old Search Console checker isn’t in sync with real Googlebot, and hence shouldn’t be trusted as the authoritative answer about how Google will parse a robots.txt file, references to it remain widespread in the documentation:
Introduction to robots.txt
Avoid common mistakes
Create a robots.txt file
Test your robots.txt with the robots.txt Tester
Submit your updated robots.txt to Google
Debugging your pages
In addition, although it’s natural that old blog posts might not be updated with new information, these are still prominently ranking for some related searches:
New robots.txt feature and REP Meta Tags
Testing robots.txt files made easier
Who knows. Maybe they’ll update the docs with links to my tool ;)
Let me know if it’s useful to you
Anyway. I hope you find my tool useful - I enjoyed hacking around with a bit of C++ and Python to make it - it’s good to have a “maker” project on the go sometimes when your day job doesn’t involve shipping code. If you spot any weirdness, have questions, or just find it useful, please drop me a note to let me know. You can find me on Twitter.
0 notes
Text
Free web-based robots.txt parser based on Google’s open source C++ parser
The punchline: I’ve been playing around with a toy project recently and have deployed it as a free web-based tool for checking how Google will parse your robots.txt files, given that their own online tool does not replicate actual Googlebot behaviour. Check it out at realrobotstxt.com.
While preparing for my recent presentation at SearchLove London, I got mildly obsessed by the way that the deeper I dug into how robots.txt files work, the more surprising things I found, and the more places I found where there was conflicting information from different sources. Google’s open source robots.txt parser should have made everything easy by not only complying with their newly-published draft specification, but also by apparently being real production Google code.
Two challenges led me further down the rabbit hole that ultimately led to me building a web-based tool:
It’s a C++ project, so needs to be compiled, which requires at least some programming / code administration skills, so I didn’t feel like it was especially accessible to the wider search community
When I got it compiled and played with it, I discovered that it was missing crucial Google-specific functionality to enable us to see how Google crawlers like the images and video crawlers will interpret robots.txt files
Ways this tool differs from other resources
Apart from the benefit of being a web-based tool rather than requiring compilation to run locally, my realrobotstxt.com tool should be 100% compliant with the draft specification that Google released, as it is entirely powered by their open source tool except for two specific changes that I made to bring it in line with my understanding of how real Google crawlers work:
Googlebot-image, Googlebot-video and Googlebot-news(*) should all fall back on obeying Googlebot directives if there are no rulesets specifically targeting their own individual user agents - we have verified that this is at least how the images bot behaves in the real world
Google has a range of bots (AdsBot-Google, AdsBot-Google-Mobile, and the AdSense bot, Mediapartners-Google) which apparently ignore User-agent: * directives and only obey rulesets specifically targeting their own individual user agents
[(*) Note: unrelated to the tweaks I’ve made, but relevant because I mentioned Googlebot-news, it is very much not well-known that Googlebot-news is not a crawler and hasn’t been since 2011, apparently. If you didn’t know this, don’t worry - you’re not alone. I only learned it recently, and it’s pretty hard to discern from the documentation which regularly refers to it as a crawler. The only real official reference I can find is the blog post announcing its retirement. I mean, it makes sense to me, because having different crawlers for web and news search opens up dangerous cloaking opportunities, but why then refer to it as a crawler’s user agent throughout the docs? It seems, though I haven’t been able to test this in real life, as though rules directly targeting Googlebot-news function somewhat like a Google News-specific noindex. This is very confusing, because regular Googlebot blocking does not keep URLs out of the web index, but there you go.]
I expect to see the Search Console robots.txt checker retired soon
We have seen a gradual move to turn off old Search Console features and I expect that the robots.txt checker will be retired soon. Googlers have recently been referring recently to it being out of step with how their actual crawlers work - and we can see differences in our own testing:
These cases seem to be handled correctly by the open source parser - here’s my web-based tool on the exact same scenario:
This felt like all the more reason for me to release my web-based version, as the only official web-based tool we have is out of date and likely going away. Who knows whether Google will release an updated version based on their open source parser - but until they do, my tool might prove useful to some people.
I’d like to see the documentation updated
Unfortunately, while I can make a pull request against the open source code, I can’t do the same with Google documentation. Despite implications out of Google that the old Search Console checker isn’t in sync with real Googlebot, and hence shouldn’t be trusted as the authoritative answer about how Google will parse a robots.txt file, references to it remain widespread in the documentation:
Introduction to robots.txt
Avoid common mistakes
Create a robots.txt file
Test your robots.txt with the robots.txt Tester
Submit your updated robots.txt to Google
Debugging your pages
In addition, although it’s natural that old blog posts might not be updated with new information, these are still prominently ranking for some related searches:
New robots.txt feature and REP Meta Tags
Testing robots.txt files made easier
Who knows. Maybe they’ll update the docs with links to my tool ;)
Let me know if it’s useful to you
Anyway. I hope you find my tool useful - I enjoyed hacking around with a bit of C++ and Python to make it - it’s good to have a “maker” project on the go sometimes when your day job doesn’t involve shipping code. If you spot any weirdness, have questions, or just find it useful, please drop me a note to let me know. You can find me on Twitter.
from Digital Marketing https://www.distilled.net/resources/free-web-based-robotstxt-parser/ via http://www.rssmix.com/
0 notes
Text
Free web-based robots.txt parser based on Google’s open source C++ parser
The punchline: I’ve been playing around with a toy project recently and have deployed it as a free web-based tool for checking how Google will parse your robots.txt files, given that their own online tool does not replicate actual Googlebot behaviour. Check it out at realrobotstxt.com.
While preparing for my recent presentation at SearchLove London, I got mildly obsessed by the way that the deeper I dug into how robots.txt files work, the more surprising things I found, and the more places I found where there was conflicting information from different sources. Google’s open source robots.txt parser should have made everything easy by not only complying with their newly-published draft specification, but also by apparently being real production Google code.
Two challenges led me further down the rabbit hole that ultimately led to me building a web-based tool:
It’s a C++ project, so needs to be compiled, which requires at least some programming / code administration skills, so I didn’t feel like it was especially accessible to the wider search community
When I got it compiled and played with it, I discovered that it was missing crucial Google-specific functionality to enable us to see how Google crawlers like the images and video crawlers will interpret robots.txt files
Ways this tool differs from other resources
Apart from the benefit of being a web-based tool rather than requiring compilation to run locally, my realrobotstxt.com tool should be 100% compliant with the draft specification that Google released, as it is entirely powered by their open source tool except for two specific changes that I made to bring it in line with my understanding of how real Google crawlers work:
Googlebot-image, Googlebot-video and Googlebot-news(*) should all fall back on obeying Googlebot directives if there are no rulesets specifically targeting their own individual user agents - we have verified that this is at least how the images bot behaves in the real world
Google has a range of bots (AdsBot-Google, AdsBot-Google-Mobile, and the AdSense bot, Mediapartners-Google) which apparently ignore User-agent: * directives and only obey rulesets specifically targeting their own individual user agents
[(*) Note: unrelated to the tweaks I’ve made, but relevant because I mentioned Googlebot-news, it is very much not well-known that Googlebot-news is not a crawler and hasn’t been since 2011, apparently. If you didn’t know this, don’t worry - you’re not alone. I only learned it recently, and it’s pretty hard to discern from the documentation which regularly refers to it as a crawler. The only real official reference I can find is the blog post announcing its retirement. I mean, it makes sense to me, because having different crawlers for web and news search opens up dangerous cloaking opportunities, but why then refer to it as a crawler’s user agent throughout the docs? It seems, though I haven’t been able to test this in real life, as though rules directly targeting Googlebot-news function somewhat like a Google News-specific noindex. This is very confusing, because regular Googlebot blocking does not keep URLs out of the web index, but there you go.]
I expect to see the Search Console robots.txt checker retired soon
We have seen a gradual move to turn off old Search Console features and I expect that the robots.txt checker will be retired soon. Googlers have recently been referring recently to it being out of step with how their actual crawlers work - and we can see differences in our own testing:
These cases seem to be handled correctly by the open source parser - here’s my web-based tool on the exact same scenario:
This felt like all the more reason for me to release my web-based version, as the only official web-based tool we have is out of date and likely going away. Who knows whether Google will release an updated version based on their open source parser - but until they do, my tool might prove useful to some people.
I’d like to see the documentation updated
Unfortunately, while I can make a pull request against the open source code, I can’t do the same with Google documentation. Despite implications out of Google that the old Search Console checker isn’t in sync with real Googlebot, and hence shouldn’t be trusted as the authoritative answer about how Google will parse a robots.txt file, references to it remain widespread in the documentation:
Introduction to robots.txt
Avoid common mistakes
Create a robots.txt file
Test your robots.txt with the robots.txt Tester
Submit your updated robots.txt to Google
Debugging your pages
In addition, although it’s natural that old blog posts might not be updated with new information, these are still prominently ranking for some related searches:
New robots.txt feature and REP Meta Tags
Testing robots.txt files made easier
Who knows. Maybe they’ll update the docs with links to my tool ;)
Let me know if it’s useful to you
Anyway. I hope you find my tool useful - I enjoyed hacking around with a bit of C++ and Python to make it - it’s good to have a “maker” project on the go sometimes when your day job doesn’t involve shipping code. If you spot any weirdness, have questions, or just find it useful, please drop me a note to let me know. You can find me on Twitter.
Free web-based robots.txt parser based on Google’s open source C++ parser was originally posted by Video And Blog Marketing
0 notes
Text
Free web-based robots.txt parser based on Google’s open source C++ parser
The punchline: I’ve been playing around with a toy project recently and have deployed it as a free web-based tool for checking how Google will parse your robots.txt files, given that their own online tool does not replicate actual Googlebot behaviour. Check it out at realrobotstxt.com.
While preparing for my recent presentation at SearchLove London, I got mildly obsessed by the way that the deeper I dug into how robots.txt files work, the more surprising things I found, and the more places I found where there was conflicting information from different sources. Google’s open source robots.txt parser should have made everything easy by not only complying with their newly-published draft specification, but also by apparently being real production Google code.
Two challenges led me further down the rabbit hole that ultimately led to me building a web-based tool:
It’s a C++ project, so needs to be compiled, which requires at least some programming / code administration skills, so I didn’t feel like it was especially accessible to the wider search community
When I got it compiled and played with it, I discovered that it was missing crucial Google-specific functionality to enable us to see how Google crawlers like the images and video crawlers will interpret robots.txt files
Ways this tool differs from other resources
Apart from the benefit of being a web-based tool rather than requiring compilation to run locally, my realrobotstxt.com tool should be 100% compliant with the draft specification that Google released, as it is entirely powered by their open source tool except for two specific changes that I made to bring it in line with my understanding of how real Google crawlers work:
Googlebot-image, Googlebot-video and Googlebot-news(*) should all fall back on obeying Googlebot directives if there are no rulesets specifically targeting their own individual user agents - we have verified that this is at least how the images bot behaves in the real world
Google has a range of bots (AdsBot-Google, AdsBot-Google-Mobile, and the AdSense bot, Mediapartners-Google) which apparently ignore User-agent: * directives and only obey rulesets specifically targeting their own individual user agents
[(*) Note: unrelated to the tweaks I’ve made, but relevant because I mentioned Googlebot-news, it is very much not well-known that Googlebot-news is not a crawler and hasn’t been since 2011, apparently. If you didn’t know this, don’t worry - you’re not alone. I only learned it recently, and it’s pretty hard to discern from the documentation which regularly refers to it as a crawler. The only real official reference I can find is the blog post announcing its retirement. I mean, it makes sense to me, because having different crawlers for web and news search opens up dangerous cloaking opportunities, but why then refer to it as a crawler’s user agent throughout the docs? It seems, though I haven’t been able to test this in real life, as though rules directly targeting Googlebot-news function somewhat like a Google News-specific noindex. This is very confusing, because regular Googlebot blocking does not keep URLs out of the web index, but there you go.]
I expect to see the Search Console robots.txt checker retired soon
We have seen a gradual move to turn off old Search Console features and I expect that the robots.txt checker will be retired soon. Googlers have recently been referring recently to it being out of step with how their actual crawlers work - and we can see differences in our own testing:
These cases seem to be handled correctly by the open source parser - here’s my web-based tool on the exact same scenario:
This felt like all the more reason for me to release my web-based version, as the only official web-based tool we have is out of date and likely going away. Who knows whether Google will release an updated version based on their open source parser - but until they do, my tool might prove useful to some people.
I’d like to see the documentation updated
Unfortunately, while I can make a pull request against the open source code, I can’t do the same with Google documentation. Despite implications out of Google that the old Search Console checker isn’t in sync with real Googlebot, and hence shouldn’t be trusted as the authoritative answer about how Google will parse a robots.txt file, references to it remain widespread in the documentation:
Introduction to robots.txt
Avoid common mistakes
Create a robots.txt file
Test your robots.txt with the robots.txt Tester
Submit your updated robots.txt to Google
Debugging your pages
In addition, although it’s natural that old blog posts might not be updated with new information, these are still prominently ranking for some related searches:
New robots.txt feature and REP Meta Tags
Testing robots.txt files made easier
Who knows. Maybe they’ll update the docs with links to my tool ;)
Let me know if it’s useful to you
Anyway. I hope you find my tool useful - I enjoyed hacking around with a bit of C++ and Python to make it - it’s good to have a “maker” project on the go sometimes when your day job doesn’t involve shipping code. If you spot any weirdness, have questions, or just find it useful, please drop me a note to let me know. You can find me on Twitter.
from Digital https://www.distilled.net/resources/free-web-based-robotstxt-parser/ via http://www.rssmix.com/
0 notes