#Amazon Web Data Extraction
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
Which are The Best Scraping Tools For Amazon Web Data Extraction?

In the vast expanse of e-commerce, Amazon stands as a colossus, offering an extensive array of products and services to millions of customers worldwide. For businesses and researchers, extracting data from Amazon's platform can unlock valuable insights into market trends, competitor analysis, pricing strategies, and more. However, manual data collection is time-consuming and inefficient. Enter web scraping tools, which automate the process, allowing users to extract large volumes of data quickly and efficiently. In this article, we'll explore some of the best scraping tools tailored for Amazon web data extraction.
Scrapy: Scrapy is a powerful and flexible web crawling framework written in Python. It provides a robust set of tools for extracting data from websites, including Amazon. With its high-level architecture and built-in support for handling dynamic content, Scrapy makes it relatively straightforward to scrape product listings, reviews, prices, and other relevant information from Amazon's pages. Its extensibility and scalability make it an excellent choice for both small-scale and large-scale data extraction projects.
Octoparse: Octoparse is a user-friendly web scraping tool that offers a point-and-click interface, making it accessible to users with limited programming knowledge. It allows you to create custom scraping workflows by visually selecting the elements you want to extract from Amazon's website. Octoparse also provides advanced features such as automatic IP rotation, CAPTCHA solving, and cloud extraction, making it suitable for handling complex scraping tasks with ease.
ParseHub: ParseHub is another intuitive web scraping tool that excels at extracting data from dynamic websites like Amazon. Its visual point-and-click interface allows users to build scraping agents without writing a single line of code. ParseHub's advanced features include support for AJAX, infinite scrolling, and pagination, ensuring comprehensive data extraction from Amazon's product listings, reviews, and more. It also offers scheduling and API integration capabilities, making it a versatile solution for data-driven businesses.
Apify: Apify is a cloud-based web scraping and automation platform that provides a range of tools for extracting data from Amazon and other websites. Its actor-based architecture allows users to create custom scraping scripts using JavaScript or TypeScript, leveraging the power of headless browsers like Puppeteer and Playwright. Apify offers pre-built actors for scraping Amazon product listings, reviews, and seller information, enabling rapid development and deployment of scraping workflows without the need for infrastructure management.
Beautiful Soup: Beautiful Soup is a Python library for parsing HTML and XML documents, often used in conjunction with web scraping frameworks like Scrapy or Selenium. While it lacks the built-in web crawling capabilities of Scrapy, Beautiful Soup excels at extracting data from static web pages, including Amazon product listings and reviews. Its simplicity and ease of use make it a popular choice for beginners and Python enthusiasts looking to perform basic scraping tasks without a steep learning curve.
Selenium: Selenium is a powerful browser automation tool that can be used for web scraping Amazon and other dynamic websites. It allows you to simulate user interactions, such as clicking buttons, filling out forms, and scrolling through pages, making it ideal for scraping JavaScript-heavy sites like Amazon. Selenium's Python bindings provide a convenient interface for writing scraping scripts, enabling you to extract data from Amazon's product pages with ease.
In conclusion, the best scraping tool for Amazon web data extraction depends on your specific requirements, technical expertise, and budget. Whether you prefer a user-friendly point-and-click interface or a more hands-on approach using Python scripting, there are plenty of options available to suit your needs. By leveraging the power of web scraping tools, you can unlock valuable insights from Amazon's vast trove of data, empowering your business or research endeavors with actionable intelligence.
0 notes
Text
How to Extract Amazon Product Prices Data with Python 3
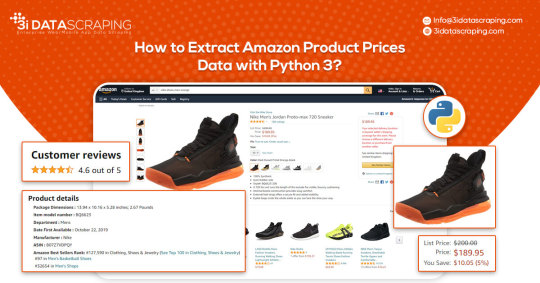
Web data scraping assists in automating web scraping from websites. In this blog, we will create an Amazon product data scraper for scraping product prices and details. We will create this easy web extractor using SelectorLib and Python and run that in the console.
#webscraping#data extraction#web scraping api#Amazon Data Scraping#Amazon Product Pricing#ecommerce data scraping#Data EXtraction Services
3 notes
·
View notes
Text
By Sesona Mdlokovana
Understanding Data Colonialism
Data colonialism is the unregulated extraction, commodification and monopolisation of data from developing countries by multinational corporations that are primarily based in the West. Companies like Meta (outlawed in Russia - InfoBRICS), Google, Microsoft, Amazon and Apple dominate digital infrastructures across the globe, offering low-cost or free services in exchange for vast amounts of governmental, personal and commercial data. In countries across Latin America, Africa and South Asia, these tech conglomerates use their technological and financial dominance to enforce unequal digital dependencies. For example:
- The dominance of Google in cloud and search services means that millions of government institutions and businesses across the Global South store highly sensitive data on Western-owned servers, often located outside of their jurisdictions.
- Meta controlling social media platforms such as WhatsApp, Facebook and Instagram has led to content moderation policies that disproportionately have serious impacts on non-Western voices, while simultaneously profiting from local user-generated content.
- Amazon Web Services (AWS) hosts an immense amount of cloud storage and creates a scenario where governments and local startups in BRICS nations have to rely on foreign digital infrastructure.
- AI models and fintech systems rely on data from Global South users, yet these countries see little economic benefit from its monetisation.
The BRICS bloc response: Strengthening Digital Sovereignty In order to counter data colonialism, BRICS countries have to prioritise strategies and policies that assert digital sovereignty while facilitating indigenous technological growth. There are several approaches in which this could be achieved:
2 notes
·
View notes
Text
The Future of AWS: Innovations, Challenges, and Opportunities
As we stand on the top of an increasingly digital and interconnected world, the role of cloud computing has never been more vital. At the forefront of this technological revolution stands Amazon Web Services (AWS), a A leader and an innovator in the field of cloud computing. AWS has not only transformed the way businesses operate but has also ignited a global shift towards cloud-centric solutions. Now, as we gaze into the horizon, it's time to dive into the future of AWS—a future marked by innovations, challenges, and boundless opportunities.

In this exploration, we will navigate through the evolving landscape of AWS, where every day brings new advancements, complex challenges, and a multitude of avenues for growth and success. This journey is a testament to the enduring spirit of innovation that propels AWS forward, the challenges it must overcome to maintain its leadership, and the vast array of opportunities it presents to businesses, developers, and tech enthusiasts alike.
Join us as we embark on a voyage into the future of AWS, where the cloud continues to shape our digital world, and where AWS stands as a beacon guiding us through this transformative era.
Constant Innovation: The AWS Edge
One of AWS's defining characteristics is its unwavering commitment to innovation. AWS has a history of introducing groundbreaking services and features that cater to the evolving needs of businesses. In the future, we can expect this commitment to innovation to reach new heights. AWS will likely continue to push the boundaries of cloud technology, delivering cutting-edge solutions to its users.
This dedication to innovation is particularly evident in AWS's investments in machine learning (ML) and artificial intelligence (AI). With services like Amazon SageMaker and AWS Deep Learning, AWS has democratized ML and AI, making these advanced technologies accessible to developers and businesses of all sizes. In the future, we can anticipate even more sophisticated ML and AI capabilities, empowering businesses to extract valuable insights and create intelligent applications.
Global Reach: Expanding the AWS Footprint
AWS's global infrastructure, comprising data centers in numerous regions worldwide, has been key in providing low-latency access and backup to customers globally. As the demand for cloud services continues to surge, AWS's expansion efforts are expected to persist. This means an even broader global presence, ensuring that AWS remains a reliable partner for organizations seeking to operate on a global scale.
Industry-Specific Solutions: Tailored for Success
Every industry has its unique challenges and requirements. AWS recognizes this and has been increasingly tailoring its services to cater to specific industries, including healthcare, finance, manufacturing, and more. This trend is likely to intensify in the future, with AWS offering industry-specific solutions and compliance certifications. This ensures that organizations in regulated sectors can leverage the power of the cloud while adhering to strict industry standards.
Edge Computing: A Thriving Frontier
The rise of the Internet of Things (IoT) and the growing importance of edge computing are reshaping the technology landscape. AWS is positioned to capitalize on this trend by investing in edge services. Edge computing enables real-time data processing and analysis at the edge of the network, a capability that's becoming increasingly critical in scenarios like autonomous vehicles, smart cities, and industrial automation.
Sustainability Initiatives: A Greener Cloud
Sustainability is a primary concern in today's mindful world. AWS has already committed to sustainability with initiatives like the "AWS Sustainability Accelerator." In the future, we can expect more green data centers, eco-friendly practices, and a continued focus on reducing the harmful effects of cloud services. AWS's dedication to sustainability aligns with the broader industry trend towards environmentally responsible computing.
Security and Compliance: Paramount Concerns
The ever-growing importance of data privacy and security cannot be overstated. AWS has been proactive in enhancing its security services and compliance offerings. This trend will likely continue, with AWS introducing advanced security measures and compliance certifications to meet the evolving threat landscape and regulatory requirements.
Serverless Computing: A Paradigm Shift
Serverless computing, characterized by services like AWS Lambda and AWS Fargate, is gaining rapid adoption due to its simplicity and cost-effectiveness. In the future, we can expect serverless architecture to become even more mainstream. AWS will continue to refine and expand its serverless offerings, simplifying application deployment and management for developers and organizations.
Hybrid and Multi-Cloud Solutions: Bridging the Gap
AWS recognizes the significance of hybrid and multi-cloud environments, where organizations blend on-premises and cloud resources. Future developments will likely focus on effortless integration between these environments, enabling businesses to leverage the advantages of both on-premises and cloud-based infrastructure.
Training and Certification: Nurturing Talent
AWS professionals with advanced skills are in more demand. Platforms like ACTE Technologies have stepped up to offer comprehensive AWS training and certification programs. These programs equip individuals with the skills needed to excel in the world of AWS and cloud computing. As the cloud becomes increasingly integral to business operations, certified AWS professionals will continue to be in high demand.
In conclusion, the future of AWS shines brightly with promise. As a expert in cloud computing, AWS remains committed to continuous innovation, global expansion, industry-specific solutions, sustainability, security, and empowering businesses with advanced technologies. For those looking to embark on a career or excel further in the realm of AWS, platforms like ACTE Technologies offer industry-aligned training and certification programs.
As businesses increasingly rely on cloud services to drive their digital transformation, AWS will continue to play a key role in reshaping industries and empowering innovation. Whether you are an aspiring cloud professional or a seasoned expert, staying ahead of AWS's evolving landscape is most important. The future of AWS is not just about technology; it's about the limitless possibilities it offers to organizations and individuals willing to embrace the cloud's transformative power.
8 notes
·
View notes
Text
Navigating the Cloud: Unleashing Amazon Web Services' (AWS) Impact on Digital Transformation
In the ever-evolving realm of technology, cloud computing stands as a transformative force, offering unparalleled flexibility, scalability, and cost-effectiveness. At the forefront of this paradigm shift is Amazon Web Services (AWS), a comprehensive cloud computing platform provided by Amazon.com. For those eager to elevate their proficiency in AWS, specialized training initiatives like AWS Training in Pune offer invaluable insights into maximizing the potential of AWS services.

Exploring AWS: A Catalyst for Digital Transformation
As we traverse the dynamic landscape of cloud computing, AWS emerges as a pivotal player, empowering businesses, individuals, and organizations to fully embrace the capabilities of the cloud. Let's delve into the multifaceted ways in which AWS is reshaping the digital landscape and providing a robust foundation for innovation.
Decoding the Heart of AWS
AWS in a Nutshell: Amazon Web Services serves as a robust cloud computing platform, delivering a diverse range of scalable and cost-effective services. Tailored to meet the needs of individual users and large enterprises alike, AWS acts as a gateway, unlocking the potential of the cloud for various applications.
Core Function of AWS: At its essence, AWS is designed to offer on-demand computing resources over the internet. This revolutionary approach eliminates the need for substantial upfront investments in hardware and infrastructure, providing users with seamless access to a myriad of services.
AWS Toolkit: Key Services Redefined
Empowering Scalable Computing: Through Elastic Compute Cloud (EC2) instances, AWS furnishes virtual servers, enabling users to dynamically scale computing resources based on demand. This adaptability is paramount for handling fluctuating workloads without the constraints of physical hardware.
Versatile Storage Solutions: AWS presents a spectrum of storage options, such as Amazon Simple Storage Service (S3) for object storage, Amazon Elastic Block Store (EBS) for block storage, and Amazon Glacier for long-term archival. These services deliver robust and scalable solutions to address diverse data storage needs.
Streamlining Database Services: Managed database services like Amazon Relational Database Service (RDS) and Amazon DynamoDB (NoSQL database) streamline efficient data storage and retrieval. AWS simplifies the intricacies of database management, ensuring both reliability and performance.
AI and Machine Learning Prowess: AWS empowers users with machine learning services, exemplified by Amazon SageMaker. This facilitates the seamless development, training, and deployment of machine learning models, opening new avenues for businesses integrating artificial intelligence into their applications. To master AWS intricacies, individuals can leverage the Best AWS Online Training for comprehensive insights.
In-Depth Analytics: Amazon Redshift and Amazon Athena play pivotal roles in analyzing vast datasets and extracting valuable insights. These services empower businesses to make informed, data-driven decisions, fostering innovation and sustainable growth.
Networking and Content Delivery Excellence: AWS services, such as Amazon Virtual Private Cloud (VPC) for network isolation and Amazon CloudFront for content delivery, ensure low-latency access to resources. These features enhance the overall user experience in the digital realm.
Commitment to Security and Compliance: With an unwavering emphasis on security, AWS provides a comprehensive suite of services and features to fortify the protection of applications and data. Furthermore, AWS aligns with various industry standards and certifications, instilling confidence in users regarding data protection.
Championing the Internet of Things (IoT): AWS IoT services empower users to seamlessly connect and manage IoT devices, collect and analyze data, and implement IoT applications. This aligns seamlessly with the burgeoning trend of interconnected devices and the escalating importance of IoT across various industries.
Closing Thoughts: AWS, the Catalyst for Transformation
In conclusion, Amazon Web Services stands as a pioneering force, reshaping how businesses and individuals harness the power of the cloud. By providing a dynamic, scalable, and cost-effective infrastructure, AWS empowers users to redirect their focus towards innovation, unburdened by the complexities of managing hardware and infrastructure. As technology advances, AWS remains a stalwart, propelling diverse industries into a future brimming with endless possibilities. The journey into the cloud with AWS signifies more than just migration; it's a profound transformation, unlocking novel potentials and propelling organizations toward an era of perpetual innovation.
2 notes
·
View notes
Text
Use Amazon Review Scraping Services To Boost The Pricing Strategies
Use data extraction services to gather detailed insights from customer reviews. Our advanced web scraping services provide a comprehensive analysis of product feedback, ratings, and comments. Make informed decisions, understand market trends, and refine your business strategies with precision. Stay ahead of the competition by utilizing Amazon review scraping services, ensuring your brand remains attuned to customer sentiments and preferences for strategic growth.
2 notes
·
View notes
Link
0 notes
Text
Scraping Grocery Apps for Nutritional and Ingredient Data

Introduction
With health trends becoming more rampant, consumers are focusing heavily on nutrition and accurate ingredient and nutritional information. Grocery applications provide an elaborate study of food products, but manual collection and comparison of this data can take up an inordinate amount of time. Therefore, scraping grocery applications for nutritional and ingredient data would provide an automated and fast means for obtaining that information from any of the stakeholders be it customers, businesses, or researchers.
This blog shall discuss the importance of scraping nutritional data from grocery applications, its technical workings, major challenges, and best practices to extract reliable information. Be it for tracking diets, regulatory purposes, or customized shopping, nutritional data scraping is extremely valuable.
Why Scrape Nutritional and Ingredient Data from Grocery Apps?
1. Health and Dietary Awareness
Consumers rely on nutritional and ingredient data scraping to monitor calorie intake, macronutrients, and allergen warnings.
2. Product Comparison and Selection
Web scraping nutritional and ingredient data helps to compare similar products and make informed decisions according to dietary needs.
3. Regulatory & Compliance Requirements
Companies require nutritional and ingredient data extraction to be compliant with food labeling regulations and ensure a fair marketing approach.
4. E-commerce & Grocery Retail Optimization
Web scraping nutritional and ingredient data is used by retailers for better filtering, recommendations, and comparative analysis of similar products.
5. Scientific Research and Analytics
Nutritionists and health professionals invoke the scraping of nutritional data for research in diet planning, practical food safety, and trends in consumer behavior.
How Web Scraping Works for Nutritional and Ingredient Data
1. Identifying Target Grocery Apps
Popular grocery apps with extensive product details include:
Instacart
Amazon Fresh
Walmart Grocery
Kroger
Target Grocery
Whole Foods Market
2. Extracting Product and Nutritional Information
Scraping grocery apps involves making HTTP requests to retrieve HTML data containing nutritional facts and ingredient lists.
3. Parsing and Structuring Data
Using Python tools like BeautifulSoup, Scrapy, or Selenium, structured data is extracted and categorized.
4. Storing and Analyzing Data
The cleaned data is stored in JSON, CSV, or databases for easy access and analysis.
5. Displaying Information for End Users
Extracted nutritional and ingredient data can be displayed in dashboards, diet tracking apps, or regulatory compliance tools.
Essential Data Fields for Nutritional Data Scraping
1. Product Details
Product Name
Brand
Category (e.g., dairy, beverages, snacks)
Packaging Information
2. Nutritional Information
Calories
Macronutrients (Carbs, Proteins, Fats)
Sugar and Sodium Content
Fiber and Vitamins
3. Ingredient Data
Full Ingredient List
Organic/Non-Organic Label
Preservatives and Additives
Allergen Warnings
4. Additional Attributes
Expiry Date
Certifications (Non-GMO, Gluten-Free, Vegan)
Serving Size and Portions
Cooking Instructions
Challenges in Scraping Nutritional and Ingredient Data
1. Anti-Scraping Measures
Many grocery apps implement CAPTCHAs, IP bans, and bot detection mechanisms to prevent automated data extraction.
2. Dynamic Webpage Content
JavaScript-based content loading complicates extraction without using tools like Selenium or Puppeteer.
3. Data Inconsistency and Formatting Issues
Different brands and retailers display nutritional information in varied formats, requiring extensive data normalization.
4. Legal and Ethical Considerations
Ensuring compliance with data privacy regulations and robots.txt policies is essential to avoid legal risks.
Best Practices for Scraping Grocery Apps for Nutritional Data
1. Use Rotating Proxies and Headers
Changing IP addresses and user-agent strings prevents detection and blocking.
2. Implement Headless Browsing for Dynamic Content
Selenium or Puppeteer ensures seamless interaction with JavaScript-rendered nutritional data.
3. Schedule Automated Scraping Jobs
Frequent scraping ensures updated and accurate nutritional information for comparisons.
4. Clean and Standardize Data
Using data cleaning and NLP techniques helps resolve inconsistencies in ingredient naming and formatting.
5. Comply with Ethical Web Scraping Standards
Respecting robots.txt directives and seeking permission where necessary ensures responsible data extraction.
Building a Nutritional Data Extractor Using Web Scraping APIs
1. Choosing the Right Tech Stack
Programming Language: Python or JavaScript
Scraping Libraries: Scrapy, BeautifulSoup, Selenium
Storage Solutions: PostgreSQL, MongoDB, Google Sheets
APIs for Automation: CrawlXpert, Apify, Scrapy Cloud
2. Developing the Web Scraper
A Python-based scraper using Scrapy or Selenium can fetch and structure nutritional and ingredient data effectively.
3. Creating a Dashboard for Data Visualization
A user-friendly web interface built with React.js or Flask can display comparative nutritional data.
4. Implementing API-Based Data Retrieval
Using APIs ensures real-time access to structured and up-to-date ingredient and nutritional data.
Future of Nutritional Data Scraping with AI and Automation
1. AI-Enhanced Data Normalization
Machine learning models can standardize nutritional data for accurate comparisons and predictions.
2. Blockchain for Data Transparency
Decentralized food data storage could improve trust and traceability in ingredient sourcing.
3. Integration with Wearable Health Devices
Future innovations may allow direct nutritional tracking from grocery apps to smart health monitors.
4. Customized Nutrition Recommendations
With the help of AI, grocery applications will be able to establish personalized meal planning based on the nutritional and ingredient data culled from the net.
Conclusion
Automated web scraping of grocery applications for nutritional and ingredient data provides consumers, businesses, and researchers with accurate dietary information. Not just a tool for price-checking, web scraping touches all aspects of modern-day nutritional analytics.
If you are looking for an advanced nutritional data scraping solution, CrawlXpert is your trusted partner. We provide web scraping services that scrape, process, and analyze grocery nutritional data. Work with CrawlXpert today and let web scraping drive your nutritional and ingredient data for better decisions and business insights!
Know More : https://www.crawlxpert.com/blog/scraping-grocery-apps-for-nutritional-and-ingredient-data
#scrapingnutritionaldatafromgrocery#ScrapeNutritionalDatafromGroceryApps#NutritionalDataScraping#NutritionalDataScrapingwithAI
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
Various web scraping tools will help you to extract Amazon data to the spreadsheet. It is a reliable solution for scraping Amazon data and fetching valuable and important information.
For More Information:-
0 notes
Text
How To Extract Amazon Product Prices Data With Python 3?

How To Extract Amazon Product Data From Amazon Product Pages?
Markup all data fields to be extracted using Selectorlib
Then copy as well as run the given code
Setting Up Your Computer For Amazon Scraping
We will utilize Python 3 for the Amazon Data Scraper. This code won’t run in case, you use Python 2.7. You require a computer having Python 3 as well as PIP installed.
Follow the guide given to setup the computer as well as install packages in case, you are using Windows.
Packages For Installing Amazon Data Scraping
Python Requests for making requests as well as download HTML content from Amazon’s product pages
SelectorLib python packages to scrape data using a YAML file that we have created from webpages that we download
Using pip3,
pip3 install requests selectorlib
Extract Product Data From Amazon Product Pages
An Amazon product pages extractor will extract the following data from product pages.
Product Name
Pricing
Short Description
Complete Product Description
Ratings
Images URLs
Total Reviews
Optional ASINs
Link to Review Pages
Sales Ranking
Markup Data Fields With Selectorlib
As we have marked up all the data already, you can skip the step in case you wish to have rights of the data.
Let’s save it as the file named selectors.yml in same directory with our code
For More Information : https://www.3idatascraping.com/how-to-extract-amazon-prices-and-product-data-with-python-3/
#Extract Amazon Product Price#Amazon Data Scraper#Scrape Amazon Data#amazon scraper#Amazon Data Extraction#web scraping amazon using python#amazon scraping#amazon scraper python#scrape amazon prices
1 note
·
View note
Text
🧠 Build What Customers Actually Want – Powered by Web Data! 🚀

Struggling to align product features with market demand? RealDataAPI’s Product Development Web Scraping Services, you can tap into real-time consumer trends, competitor products, pricing, and feedback—all from public web sources.
📌 Why It Matters for Product Teams & Innovators:
✅ Extract user reviews, feature requests & complaints
✅ Track competing products across platforms (Amazon, Flipkart, etc.)
✅ Identify trending keywords, top features & pain points
✅ Analyze product specs, pricing history, and customer sentiment
✅ Integrate directly into your roadmap, R&D or market research workflow
💡 “Product success isn’t luck—it’s data-informed execution.”
📩 Contact us: [email protected]
0 notes
Text
Unlocking Data Science's Potential: Transforming Data into Perceptive Meaning
Data is created on a regular basis in our digitally connected environment, from social media likes to financial transactions and detection labour. However, without the ability to extract valuable insights from this enormous amount of data, it is not very useful. Data insight can help you win in that situation. Online Course in Data Science It is a multidisciplinary field that combines computer knowledge, statistics, and subject-specific expertise to evaluate data and provide useful perception. This essay will explore the definition of data knowledge, its essential components, its significance, and its global transubstantiation diligence.

Understanding Data Science: To find patterns and shape opinions, data wisdom essentially entails collecting, purifying, testing, and analysing large, complicated datasets. It combines a number of fields.
Statistics: To establish predictive models and derive conclusions.
Computer intelligence: For algorithm enforcement, robotization, and coding.
Sphere moxie: To place perceptivity in a particular field of study, such as healthcare or finance.
It is the responsibility of a data scientist to pose pertinent queries, handle massive amounts of data effectively, and produce findings that have an impact on operations and strategy.
The Significance of Data Science
1. Informed Decision Making: To improve the stoner experience, streamline procedures, and identify emerging trends, associations rely on data-driven perception.
2. Increased Effectiveness: Businesses can decrease manual labour by automating operations like spotting fraudulent transactions or managing AI-powered customer support.
3. Acclimatised Gests: Websites like Netflix and Amazon analyse user data to provide suggestions for products and verified content.
4. Improvements in Medicine: Data knowledge helps with early problem diagnosis, treatment development, and bodying medical actions.
Essential Data Science Foundations:

1. Data Acquisition & Preparation: Databases, web scraping, APIs, and detectors are some sources of data. Before analysis starts, it is crucial to draw the data, correct offences, eliminate duplicates, and handle missing values.
2. Exploratory Data Analysis (EDA): EDA identifies patterns in data, describes anomalies, and comprehends the relationships between variables by using visualisation tools such as Seaborn or Matplotlib.
3. Modelling & Machine Learning: By using techniques like
Retrogression: For predicting numerical patterns.
Bracket: Used for data sorting (e.g., spam discovery).
For group segmentation (such as client profiling), clustering is used.
Data scientists create models that automate procedures and predict problems. Enrol in a reputable software training institution's Data Science course.
4. Visualisation & Liar: For stakeholders who are not technical, visual tools such as Tableau and Power BI assist in distilling complex data into understandable, captivating dashboards and reports.
Data Science Activities Across Diligence:
1. Online shopping
personalised recommendations for products.
Demand-driven real-time pricing schemes.
2. Finance & Banking
identifying deceptive conditioning.
trading that is automated and powered by predictive analytics.
3. Medical Care
tracking the spread of complaints and formulating therapeutic suggestions.
using AI to improve medical imaging.
4. Social Media
assessing public opinion and stoner sentiment.
curation of feeds and optimisation of content.
Typical Data Science Challenges:
Despite its potential, data wisdom has drawbacks.
Ethics & Sequestration: Preserving stoner data and preventing algorithmic prejudice.
Data Integrity: Inaccurate perception results from low-quality data.
Scalability: Pall computing and other high-performance structures are necessary for managing large datasets.
The Road Ahead:
As artificial intelligence advances, data wisdom will remain a crucial motorist of invention. unborn trends include :
AutoML – Making machine literacy accessible to non-specialists.
Responsible AI – icing fairness and translucency in automated systems.
Edge Computing – Bringing data recycling near to the source for real- time perceptivity.
Conclusion:
Data wisdom is reconsidering how businesses, governments, and healthcare providers make opinions by converting raw data into strategic sapience. Its impact spans innumerous sectors and continues to grow. With rising demand for professed professionals, now is an ideal time to explore this dynamic field.
0 notes
Link
#AIethics#Antitrust#digitalmarkets#enshittification#interoperability#platformcapitalism#platformdecay#techregulation
0 notes
Text
Big Data Market 2032: Will Enterprises Unlock the Real Power Behind the Numbers
The Big Data Market was valued at USD 325.4 Billion in 2023 and is expected to reach USD 1035.2 Billion by 2032, growing at a CAGR of 13.74% from 2024-2032.
Big Data Market is witnessing a significant surge as organizations increasingly harness data to drive decision-making, optimize operations, and deliver personalized customer experiences. Across sectors like finance, healthcare, manufacturing, and retail, big data is revolutionizing how insights are generated and applied. Advancements in AI, cloud storage, and analytics tools are further accelerating adoption.
U.S. leads global adoption with strong investment in big data infrastructure and innovation
Big Data Market continues to expand as enterprises shift from traditional databases to scalable, intelligent data platforms. With growing data volumes and demand for real-time processing, companies are integrating big data technologies to enhance agility and remain competitive in a data-centric economy.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/2817
Market Keyplayers:
IBM
Microsoft
Oracle
SAP
Amazon Web Services (AWS)
Google
Cloudera
Teradata
Hadoop
Splunk
SAS
Snowflake
Market Analysis
The Big Data Market is shaped by exponential data growth and the rising complexity of digital ecosystems. Businesses are seeking solutions that not only store massive datasets but also extract actionable intelligence. Big data tools, combined with machine learning, are enabling predictive analytics, anomaly detection, and smarter automation. The U.S. market is at the forefront, with Europe close behind, driven by regulatory compliance and advanced analytics adoption.
Market Trends
Rapid integration of AI and machine learning with data platforms
Growth in cloud-native data lakes and hybrid storage models
Surge in real-time analytics and streaming data processing
Increased demand for data governance and compliance tools
Rising use of big data in fraud detection and risk management
Data-as-a-Service (DaaS) models gaining traction
Industry-specific analytics solutions becoming more prevalent
Market Scope
Big data’s footprint spans nearly every industry, with expanding use cases that enhance efficiency and innovation. The scope continues to grow with digital transformation and IoT connectivity.
Healthcare: Patient analytics, disease tracking, and personalized care
Finance: Risk modeling, compliance, and trading analytics
Retail: Consumer behavior prediction and inventory optimization
Manufacturing: Predictive maintenance and process automation
Government: Smart city planning and public service optimization
Marketing: Customer segmentation and campaign effectiveness
Forecast Outlook
The Big Data Market is on a strong growth trajectory as data becomes a core enterprise asset. Future success hinges on scalable infrastructure, robust security frameworks, and the ability to translate raw data into strategic value. Organizations investing in modern data architectures and AI integration are best positioned to lead in this evolving landscape.
Access Complete Report: https://www.snsinsider.com/reports/big-data-market-2817
Conclusion
In an increasingly digital world, the Big Data Market is not just a technology trend—it’s a critical engine of innovation. From New York to Berlin, enterprises are transforming raw data into competitive advantage. As the market matures, the focus shifts from volume to value, rewarding those who can extract insights with speed, precision, and responsibility.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Related Reports:
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
Mail us: [email protected]
0 notes
Link
[ad_1] In this tutorial, we walk you through building an enhanced web scraping tool that leverages BrightData’s powerful proxy network alongside Google’s Gemini API for intelligent data extraction. You’ll see how to structure your Python project, install and import the necessary libraries, and encapsulate scraping logic within a clean, reusable BrightDataScraper class. Whether you’re targeting Amazon product pages, bestseller listings, or LinkedIn profiles, the scraper’s modular methods demonstrate how to configure scraping parameters, handle errors gracefully, and return structured JSON results. An optional React-style AI agent integration also shows you how to combine LLM-driven reasoning with real-time scraping, empowering you to pose natural language queries for on-the-fly data analysis. !pip install langchain-brightdata langchain-google-genai langgraph langchain-core google-generativeai We install all of the key libraries needed for the tutorial in one step: langchain-brightdata for BrightData web scraping, langchain-google-genai and google-generativeai for Google Gemini integration, langgraph for agent orchestration, and langchain-core for the core LangChain framework. import os import json from typing import Dict, Any, Optional from langchain_brightdata import BrightDataWebScraperAPI from langchain_google_genai import ChatGoogleGenerativeAI from langgraph.prebuilt import create_react_agent These imports prepare your environment and core functionality: os and json handle system operations and data serialization, while typing provides structured type hints. You then bring in BrightDataWebScraperAPI for BrightData scraping, ChatGoogleGenerativeAI to interface with Google’s Gemini LLM, and create_react_agent to orchestrate these components in a React-style agent. class BrightDataScraper: """Enhanced web scraper using BrightData API""" def __init__(self, api_key: str, google_api_key: Optional[str] = None): """Initialize scraper with API keys""" self.api_key = api_key self.scraper = BrightDataWebScraperAPI(bright_data_api_key=api_key) if google_api_key: self.llm = ChatGoogleGenerativeAI( model="gemini-2.0-flash", google_api_key=google_api_key ) self.agent = create_react_agent(self.llm, [self.scraper]) def scrape_amazon_product(self, url: str, zipcode: str = "10001") -> Dict[str, Any]: """Scrape Amazon product data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product", "zipcode": zipcode ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_amazon_bestsellers(self, region: str = "in") -> Dict[str, Any]: """Scrape Amazon bestsellers""" try: url = f" results = self.scraper.invoke( "url": url, "dataset_type": "amazon_product" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def scrape_linkedin_profile(self, url: str) -> Dict[str, Any]: """Scrape LinkedIn profile data""" try: results = self.scraper.invoke( "url": url, "dataset_type": "linkedin_person_profile" ) return "success": True, "data": results except Exception as e: return "success": False, "error": str(e) def run_agent_query(self, query: str) -> None: """Run AI agent with natural language query""" if not hasattr(self, 'agent'): print("Error: Google API key required for agent functionality") return try: for step in self.agent.stream( "messages": query, stream_mode="values" ): step["messages"][-1].pretty_print() except Exception as e: print(f"Agent error: e") def print_results(self, results: Dict[str, Any], title: str = "Results") -> None: """Pretty print results""" print(f"\n'='*50") print(f"title") print(f"'='*50") if results["success"]: print(json.dumps(results["data"], indent=2, ensure_ascii=False)) else: print(f"Error: results['error']") print() The BrightDataScraper class encapsulates all BrightData web-scraping logic and optional Gemini-powered intelligence under a single, reusable interface. Its methods enable you to easily fetch Amazon product details, bestseller lists, and LinkedIn profiles, handling API calls, error handling, and JSON formatting, and even stream natural-language “agent” queries when a Google API key is provided. A convenient print_results helper ensures your output is always cleanly formatted for inspection. def main(): """Main execution function""" BRIGHT_DATA_API_KEY = "Use Your Own API Key" GOOGLE_API_KEY = "Use Your Own API Key" scraper = BrightDataScraper(BRIGHT_DATA_API_KEY, GOOGLE_API_KEY) print("🛍️ Scraping Amazon India Bestsellers...") bestsellers = scraper.scrape_amazon_bestsellers("in") scraper.print_results(bestsellers, "Amazon India Bestsellers") print("📦 Scraping Amazon Product...") product_url = " product_data = scraper.scrape_amazon_product(product_url, "10001") scraper.print_results(product_data, "Amazon Product Data") print("👤 Scraping LinkedIn Profile...") linkedin_url = " linkedin_data = scraper.scrape_linkedin_profile(linkedin_url) scraper.print_results(linkedin_data, "LinkedIn Profile Data") print("🤖 Running AI Agent Query...") agent_query = """ Scrape Amazon product data for in New York (zipcode 10001) and summarize the key product details. """ scraper.run_agent_query(agent_query) The main() function ties everything together by setting your BrightData and Google API keys, instantiating the BrightDataScraper, and then demonstrating each feature: it scrapes Amazon India’s bestsellers, fetches details for a specific product, retrieves a LinkedIn profile, and finally runs a natural-language agent query, printing neatly formatted results after each step. if __name__ == "__main__": print("Installing required packages...") os.system("pip install -q langchain-brightdata langchain-google-genai langgraph") os.environ["BRIGHT_DATA_API_KEY"] = "Use Your Own API Key" main() Finally, this entry-point block ensures that, when run as a standalone script, the required scraping libraries are quietly installed, and the BrightData API key is set in the environment. Then the main function is executed to initiate all scraping and agent workflows. In conclusion, by the end of this tutorial, you’ll have a ready-to-use Python script that automates tedious data collection tasks, abstracts away low-level API details, and optionally taps into generative AI for advanced query handling. You can extend this foundation by adding support for other dataset types, integrating additional LLMs, or deploying the scraper as part of a larger data pipeline or web service. With these building blocks in place, you’re now equipped to gather, analyze, and present web data more efficiently, whether for market research, competitive intelligence, or custom AI-driven applications. Check out the Notebook. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes