#CleanData
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
130K people were victims of a chain letter scam that affected Tumblr in May 2011.
Text
Marketers are sending emails to the wrong people every day. TDZ Pro is here to fix that.
6 notes
·
View notes
Text


Bots do not scroll while they do crawl. 🕷️
Today’s #UncomplicateSeries is all about explaining what a web crawler is and why it matters.
👉 https://bit.ly/3FQ80BO
#WebScraping#DataQuality#CleanData#BigData#techforbusiness#ai#dataengineering#promptcloud#dataextraction#marketinsights#automation
0 notes
Text
The Role of Data Science in Healthcare and Diagnosis
Data science is changing many areas, and healthcare is one of the most important ones. Today, healthcare uses data science to help doctors find diseases early, make better decisions, and create treatments that fit each patient. Hospitals, clinics, and researchers have a lot of health data, like patient records, test results, and information from devices like fitness trackers. Data science helps to understand all this data and use it to improve health and save lives.
Why Healthcare Needs Data Science
Healthcare creates huge amounts of data every day. Each patient has a medical history, lab tests, prescriptions, and other information. But this data is often spread out and not easy to use. Data science helps by analyzing this data and finding useful patterns.
Using tools like machine learning and statistics, data scientists find important information that can help doctors and nurses make faster and better decisions. This means patients get the right care at the right time.
How Data Science Helps Healthcare
1. Finding Diseases Early
One of the biggest ways data science helps is by spotting diseases early. Doctors use data science models trained on thousands of medical images and patient data to find signs of diseases like cancer or heart problems before they become serious.
For example, some AI tools can look at breast cancer scans and find tiny changes that a doctor might miss. This helps catch cancer early when treatment is easier and more effective.
2. Predicting Health Problems
Data science can also predict which patients might get sick or need extra care. Hospitals use this to plan treatment and avoid emergencies.
For example, data models can predict if a patient might develop a serious infection like sepsis. If the model alerts the doctors early, they can start treatment sooner and save the patient’s life.
3. Making Treatment Personal
Every person is different, so one treatment might not work for everyone. Data science helps by studying a patient’s genes, lifestyle, and past treatments to suggest the best medicine or therapy for them.
In cancer treatment, for example, doctors use genetic data to choose the drugs that will work best for a patient’s specific type of cancer. This approach is called “precision medicine.”
4. Helping Doctors Read Medical Images
Reading X-rays, MRIs, or CT scans takes time and skill. Data science uses AI to help doctors by quickly analyzing these images and pointing out problems.
For example, AI can find small lung nodules on a chest X-ray, which could be early signs of lung cancer. This helps doctors make faster and more accurate diagnoses.
5. Finding New Medicines
Creating new drugs takes a long time and costs a lot of money. Data science can speed up this process by predicting which chemicals might work as medicines.
During the COVID-19 pandemic, data science helped researchers understand the virus and find possible treatments faster than ever before.
Tools Used in Healthcare Data Science
Healthcare data science uses many computer tools to do its work:
Python and R: These programming languages help analyze data and build models.
TensorFlow and PyTorch: These tools help create AI programs that learn from data.
Tableau and Power BI: These help make charts and graphs to show data clearly.
Cloud platforms like AWS and Azure: These provide places to store and process big amounts of data quickly.
Together, these tools help doctors and data scientists work as a team to improve health care.
Challenges of Using Data Science in Healthcare
Even though data science is very helpful, there are some challenges:
Privacy: Patient data is very private. It must be kept safe and only used in the right ways.
Data Quality: Sometimes data is incomplete or wrong, which can lead to mistakes.
Understanding AI: Doctors need to know how AI makes decisions to trust it, but sometimes AI is hard to understand.
Fairness: If data is biased, AI might make unfair decisions that hurt some patients.
Healthcare providers, data scientists, and regulators must work together to solve these problems carefully.
What the Future Looks Like
The future of healthcare will rely even more on data science. Some examples include:
AI assistants helping with mental health support.
Wearable devices that monitor health and alert doctors in emergencies.
Hospitals using data to manage patient care and resources better.
Digital models of patients that test treatments before trying them in real life.
As technology improves and more data becomes available, healthcare will become faster, safer, and more personal.
Conclusion
Data science is changing healthcare in many good ways. It helps find diseases early, predicts health risks, personalizes treatments, helps doctors read medical images, and speeds up drug discovery. These improvements come from using data and technology together.

#data#datascience#datastorytelling#machinelearning#bigdata#analytics#technology#informationtechnology#ai#datainsights#dataanalysis#datavisualization#predictiveanalytics#dataengineer#businessintelligence#deeplearning#dataanalytics#storytellingwithdata#pythonfordatascience#datajourney#mlmodels#cleandata#datascientistlife#datamakesdifference#dataisthenewoil#datasciencetools#techblog#futureofdata#insightsfromdata#datadriven
0 notes
Text
Accelerate AI Development

Artificial Intelligence (AI) is no longer a futuristic concept — it’s a present-day driver of innovation, efficiency, and automation. From self-driving cars to intelligent customer service chatbots, AI is reshaping the way industries operate. But behind every smart algorithm lies an essential component that often doesn’t get the spotlight it deserves: data.
No matter how advanced an AI model may be, its potential is directly tied to the quality, volume, and relevance of the data it’s trained on. That’s why companies looking to move fast in AI development are turning their attention to something beyond algorithms: high-quality, ready-to-use datasets.
The Speed Factor in AI
Time-to-market is critical. Whether you’re a startup prototyping a new feature or a large enterprise deploying AI at scale, delays in sourcing, cleaning, and labeling data can slow down innovation. Traditional data collection methods — manual scraping, internal sourcing, or custom annotation — can take weeks or even months. This timeline doesn’t align with the rapid iteration cycles that AI teams are expected to maintain.
The solution? Pre-collected, curated datasets that are immediately usable for training machine learning models.
Why Pre-Collected Datasets Matter
Pre-collected datasets offer a shortcut without compromising on quality. These datasets are:
Professionally Curated: Built with consistency, structure, and clear labeling standards.
Domain-Specific: Tailored to key AI areas like computer vision, natural language processing (NLP), and audio recognition.
Scalable: Ready to support models at different stages of development — from testing hypotheses to deploying production systems.
Instead of spending months building your own data pipeline, you can start training and refining your models from day one.
Use Cases That Benefit
The applications of AI are vast, but certain use cases especially benefit from rapid access to quality data:
Computer Vision: For tasks like facial recognition, object detection, autonomous driving, and medical imaging, visual datasets are vital. High-resolution, diverse, and well-annotated images can shave weeks off development time.
Natural Language Processing (NLP): Chatbots, sentiment analysis tools, and machine translation systems need text datasets that reflect linguistic diversity and nuance.
Audio AI: Whether it’s voice assistants, transcription tools, or sound classification systems, audio datasets provide the foundation for robust auditory understanding.
With pre-curated datasets available, teams can start experimenting, fine-tuning, and validating their models immediately — accelerating everything from R&D to deployment.
Data Quality = Model Performance
It’s a simple equation: garbage in, garbage out. The best algorithms can’t overcome poor data. And while it’s tempting to rely on publicly available datasets, they’re often outdated, inconsistent, or not representative of real-world complexity.
Using high-quality, professionally sourced datasets ensures that your model is trained on the type of data it will encounter in the real world. This improves performance metrics, reduces bias, and increases trust in your AI outputs — especially critical in sensitive fields like healthcare, finance, and security.
Save Time, Save Budget
Data acquisition can be one of the most expensive parts of an AI project. It requires technical infrastructure, human resources for annotation, and ongoing quality control. By purchasing pre-collected data, companies reduce:
Operational Overhead: No need to build an internal data pipeline from scratch.
Hiring Costs: Avoid the expense of large annotation or data engineering teams.
Project Delays: Eliminate waiting periods for data readiness.
It’s not just about moving fast — it’s about being cost-effective and agile.
Build Better, Faster
When you eliminate the friction of data collection, you unlock your team’s potential to focus on what truly matters: experimentation, innovation, and performance tuning. You free up data scientists to iterate more often. You allow product teams to move from ideation to MVP more quickly. And you increase your competitive edge in a fast-moving market.
Where to Start
If you’re looking to power up your AI development with reliable data, explore BuyData.Pro. We provide a wide range of high-quality, pre-labeled datasets in computer vision, NLP, and audio. Whether you’re building your first model or optimizing one for production, our datasets are built to accelerate your journey.
Website: https://buydata.pro Contact: [email protected]
0 notes
Text
How to Maintain Clean Data in Salesforce

Struggling with duplicate records, outdated contacts, or inconsistent data in Salesforce? Maintaining clean data is crucial for accurate reporting, effective automation, and confident decision-making. This guide explores best practices to keep your Salesforce CRM clean and reliable — from setting validation rules to using data hygiene tools and automation. Whether you’re a Salesforce Admin or user, learn how to keep your CRM organized, efficient, and ready to scale!
#SalesforceTips#DataCleaning#CleanData#SalesforceCRM#CRMManagement#SalesforceAdmin#DataQuality#SalesforceBestPractices#DataHygiene#CRMOptimization#SalesforceExperts#AutomationInSalesforce#DuplicateFree#AccurateData#SalesforceIndia
0 notes
Text
How to Maintain Clean Data in Salesforce

Struggling with duplicate records, outdated contacts, or inconsistent data in Salesforce? Maintaining clean data is crucial for accurate reporting, effective automation, and confident decision-making. This guide explores best practices to keep your Salesforce CRM clean and reliable — from setting validation rules to using data hygiene tools and automation. Whether you’re a Salesforce Admin or user, learn how to keep your CRM organized, efficient, and ready to scale!
#SalesforceTips#DataCleaning#CleanData#SalesforceCRM#CRMManagement#SalesforceAdmin#DataQuality#SalesforceBestPractices#DataHygiene#CRMOptimization#SalesforceExperts#AutomationInSalesforce#DuplicateFree#AccurateData#SalesforceIndia
0 notes
Text
How to Maintain Clean Data in Salesforce

Struggling with duplicate records, outdated contacts, or inconsistent data in Salesforce? Maintaining clean data is crucial for accurate reporting, effective automation, and confident decision-making. This guide explores best practices to keep your Salesforce CRM clean and reliable — from setting validation rules to using data hygiene tools and automation. Whether you’re a Salesforce Admin or user, learn how to keep your CRM organized, efficient, and ready to scale!
#SalesforceTips#DataCleaning#CleanData#SalesforceCRM#CRMManagement#SalesforceAdmin#DataQuality#SalesforceBestPractices#DataHygiene#CRMOptimization#SalesforceExperts#AutomationInSalesforce#DuplicateFree#AccurateData#SalesforceIndia
0 notes
Text

Common Data Quality Issues
✅ Missing Data – Info is blank or incomplete
✅ Duplicates – Same records showing up multiple times
✅ Outdated Info – Data that's no longer accurate
✅ Inaccurate Values – Data that doesn’t reflect real-world facts
✅ Why Choose Us?
✔️ 100% practical training
✔️ Real-time projects & case studies
✔️ Expert mentors with industry experience
✔️ Certification & job assistance
✔️ Easy-to-understand Telugu + English mix classes
🎯 Start your Data Analytics journey with us today!
📍 Institute Address:
3rd Floor, Dr. Atmaram Estates, Metro Pillar No. A690,
Beside Siri Pearls & Jewellery, near JNTU Metro Station,
Hyder Nagar, Vasantha Nagar, Hyderabad, Telangana – 500072
📞 Contact: +91 9948801222
📧 Email: [email protected]
🌐 Website: https://dataanalyticsmasters.in/
#DataAnalytics#DataQuality#DataCleaning#AnalyticsTips#LearnDataAnalytics#CleanData#DataScience#BigData#SQL#Python#BusinessAnalytics#InstaEducation#TechSkills#CareerInData
0 notes
Text
You don’t need more leads. You need verified ones. TDZ Pro delivers clean, up-to-date contact intelligence
1 note
·
View note
Text
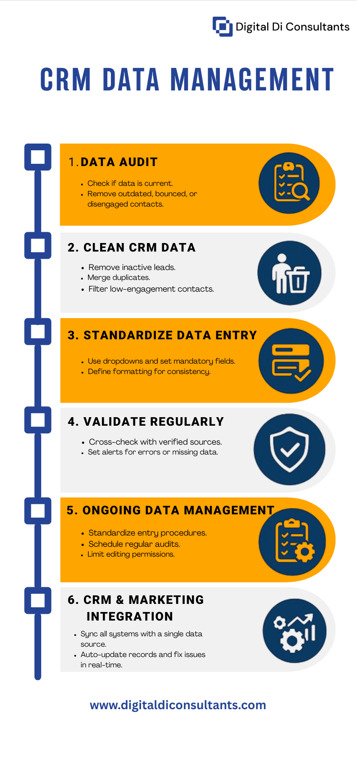
This infographic highlights the best practices for maintaining clean and accurate CRM data, including regular audits, de-duplication, and validation strategies that can improve marketing efforts, sales efficiency, and decision-making.
0 notes
Text
Data Preprocessing in Depth: Advanced Techniques for Data Scientists
The article “Data Preprocessing in Depth” explores advanced techniques data scientists use to clean, transform, and prepare raw data for analysis. It covers methods like feature scaling, outlier detection, handling missing values, and encoding categorical data—critical steps that enhance model accuracy and performance. These preprocessing techniques form the foundation of successful data science workflows Read More...

0 notes
Text
While others are still configuring proxies, PromptCloud delivers thousands of records across dozens of complex sites, every week.
We quietly power competitive intelligence, pricing analysis, product benchmarking, and market research for global teams.
⚡ That’s what winning looks like.
👉 Explore how we do it: https://bit.ly/4kWjHpg
#dataextraction#DataQuality#WebScraping#CleanData#BigData#techforbusiness#dataengineering#automation#promptcloud#marketinsights#ai
0 notes
Text
𝐄𝐧𝐡𝐚𝐧𝐜𝐞 𝐘𝐨𝐮𝐫 𝐃𝐚𝐭𝐚 𝐐𝐮𝐚𝐥𝐢𝐭𝐲 𝐰𝐢𝐭𝐡 𝐒𝐚𝐥𝐞𝐬𝐟𝐨𝐫𝐜𝐞 𝐃𝐚𝐭𝐚 𝐃𝐞𝐝𝐮𝐩𝐥𝐢𝐜𝐚𝐭𝐢𝐨𝐧!
Eliminate duplicate records, improve data accuracy, and streamline your CRM for better decision-making. Keep your Salesforce system clean and efficient with powerful deduplication tools. ✨
👉 𝐖𝐚𝐧𝐭 𝐭𝐨 𝐤𝐧𝐨𝐰 𝐦𝐨𝐫𝐞? 𝐂𝐥𝐢𝐜𝐤 𝐨𝐧 𝐭𝐡𝐞 𝐜𝐨𝐦𝐦𝐞𝐧𝐭𝐬 𝐛𝐞𝐥𝐨𝐰! 👇

#Salesforce#DataDeduplication#CRM#DataManagement#CleanData#TechSolutions#BusinessEfficiency#DataQuality#Automation
1 note
·
View note
Text

Is your data feeling a bit messy? 🧹✨ Let's clean it up and get it ready for action with some top-notch preprocessing magic!
1 note
·
View note
Text
Your campaign results are only as good as your data. TDZ Pro helps you clean up your leads and hit the right targets.
1 note
·
View note
Text
What techniques can be used to handle missing values in datasets effectively?
Handling missing values in datasets is an important step in data cleaning and preprocessing. Here are some commonly used techniques to handle missing values effectively:

Deletion: In some cases, if the missing values are relatively few or randomly distributed, you may choose to delete the rows or columns containing missing values. However, be cautious as this approach may lead to the loss of valuable information.
Mean/Median/Mode Imputation: For numerical variables, missing values can be replaced with the mean, median, or mode of the available data. This approach assumes that the missing values are similar to the observed values in the variable.
Regression Imputation: Regression imputation involves predicting missing values using regression models. A regression model is built using other variables as predictors, and the missing values are estimated based on the relationship with the predictors.
Multiple Imputation: Multiple imputations generates multiple plausible values for missing data based on the observed data and their relationships. This approach accounts for the uncertainty associated with missing values and allows for more robust statistical analysis.
Hot-Deck Imputation: Hot-deck imputation involves filling missing values with values from similar records or observations. This can be done by matching records based on some similarity criteria or using nearest neighbors.
K-Nearest Neighbors (KNN) Imputation: KNN imputation replaces missing values with values from the k-nearest neighbors in the dataset. The similarity between records is measured based on variables that have complete data.
Categorical Imputation: For categorical variables, missing values can be treated as a separate category or imputed using the mode (most frequent category) of the available data.
Time-Series Techniques: If dealing with time-series data, missing values can be imputed using techniques like interpolation or forward/backward filling, where missing values are replaced with values from adjacent time points.
Domain Knowledge Imputation: Depending on the context and domain knowledge, missing values can be imputed using expert judgment or external data sources. This approach requires careful consideration and validation.
Model-Based Imputation: Model-based imputation involves building a predictive model using variables with complete data and using that model to impute missing values. This can include techniques such as decision trees, random forests, or Bayesian methods.

When handling missing values, it's essential to understand the nature of the missingness, assess the potential impact on the analysis, and choose an appropriate technique that aligns with the characteristics of the data and the research objectives. Additionally, it's crucial to be aware of potential biases introduced by the imputation method and to document the imputation steps taken for transparency and reproducibility.
#DataCleaning#DataScrubbing#DataCleansing#DataQuality#DataPreparation#DataValidation#DataIntegrity#DataSanitization#DataStandardization#DataNormalization#DataHygiene#DataAccuracy#DataVerification#CleanData#TidyData
0 notes