#Custom Python Runtime
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text
#Custom Python Runtime#Streaming with AWS Lambda#Amazon Streaming Services#Serverless Streaming Solutions#Streaming Architecture AWS#Spotify
0 notes
Text
Docker Tutorial for Beginners: Learn Docker Step by Step
What is Docker?
Docker is an open-source platform that enables developers to automate the deployment of applications inside lightweight, portable containers. These containers include everything the application needs to run—code, runtime, system tools, libraries, and settings—so that it can work reliably in any environment.
Before Docker, developers faced the age-old problem: “It works on my machine!” Docker solves this by providing a consistent runtime environment across development, testing, and production.
Why Learn Docker?
Docker is used by organizations of all sizes to simplify software delivery and improve scalability. As more companies shift to microservices, cloud computing, and DevOps practices, Docker has become a must-have skill. Learning Docker helps you:
Package applications quickly and consistently
Deploy apps across different environments with confidence
Reduce system conflicts and configuration issues
Improve collaboration between development and operations teams
Work more effectively with modern cloud platforms like AWS, Azure, and GCP
Who Is This Docker Tutorial For?
This Docker tutorial is designed for absolute beginners. Whether you're a developer, system administrator, QA engineer, or DevOps enthusiast, you’ll find step-by-step instructions to help you:
Understand the basics of Docker
Install Docker on your machine
Create and manage Docker containers
Build custom Docker images
Use Docker commands and best practices
No prior knowledge of containers is required, but basic familiarity with the command line and a programming language (like Python, Java, or Node.js) will be helpful.
What You Will Learn: Step-by-Step Breakdown
1. Introduction to Docker
We start with the fundamentals. You’ll learn:
What Docker is and why it’s useful
The difference between containers and virtual machines
Key Docker components: Docker Engine, Docker Hub, Dockerfile, Docker Compose
2. Installing Docker
Next, we guide you through installing Docker on:
Windows
macOS
Linux
You’ll set up Docker Desktop or Docker CLI and run your first container using the hello-world image.
3. Working with Docker Images and Containers
You’ll explore:
How to pull images from Docker Hub
How to run containers using docker run
Inspecting containers with docker ps, docker inspect, and docker logs
Stopping and removing containers
4. Building Custom Docker Images
You’ll learn how to:
Write a Dockerfile
Use docker build to create a custom image
Add dependencies and environment variables
Optimize Docker images for performance
5. Docker Volumes and Networking
Understand how to:
Use volumes to persist data outside containers
Create custom networks for container communication
Link multiple containers (e.g., a Node.js app with a MongoDB container)
6. Docker Compose (Bonus Section)
Docker Compose lets you define multi-container applications. You’ll learn how to:
Write a docker-compose.yml file
Start multiple services with a single command
Manage application stacks easily
Real-World Examples Included
Throughout the tutorial, we use real-world examples to reinforce each concept. You’ll deploy a simple web application using Docker, connect it to a database, and scale services with Docker Compose.
Example Projects:
Dockerizing a static HTML website
Creating a REST API with Node.js and Express inside a container
Running a MySQL or MongoDB database container
Building a full-stack web app with Docker Compose
Best Practices and Tips
As you progress, you’ll also learn:
Naming conventions for containers and images
How to clean up unused images and containers
Tagging and pushing images to Docker Hub
Security basics when using Docker in production
What’s Next After This Tutorial?
After completing this Docker tutorial, you’ll be well-equipped to:
Use Docker in personal or professional projects
Learn Kubernetes and container orchestration
Apply Docker in CI/CD pipelines
Deploy containers to cloud platforms
Conclusion
Docker is an essential tool in the modern developer's toolbox. By learning Docker step by step in this beginner-friendly tutorial, you’ll gain the skills and confidence to build, deploy, and manage applications efficiently and consistently across different environments.
Whether you’re building simple web apps or complex microservices, Docker provides the flexibility, speed, and scalability needed for success. So dive in, follow along with the hands-on examples, and start your journey to mastering containerization with Docker tpoint-tech!
0 notes
Text
What is metaclass use case?
A metaclass in Python is a class of a class that defines how classes behave. In other words, while classes define the structure and behavior of instances (objects), metaclasses define the structure and behavior of classes themselves. This is an advanced and powerful feature that enables customization of class creation and behavior at a higher level.
Use Case of Metaclasses
Metaclasses are most commonly used when you need to control the creation of classes, enforce rules, or automatically modify or inject code into classes. A practical use case is in framework development, where specific structures or constraints must be imposed on classes created by developers.
For instance, consider a scenario where all classes in a plugin system must define a run() method. You can use a metaclass to enforce this rule at the time the class is defined, not at runtime. If a developer forgets to include the run() method, the metaclass can raise an error immediately.
class PluginMeta(type): def __new__(cls, name, bases, dct): if 'run' not in dct: raise TypeError(f"{name} must define 'run' method") return super().__new__(cls, name, bases, dct) class MyPlugin(metaclass=PluginMeta): def run(self): print("Plugin running")
In this example, PluginMeta ensures that every class using it as a metaclass includes a run() method.
Metaclasses are also used in ORMs (Object-Relational Mappings) like Django, where they are responsible for registering models, managing field definitions, and connecting to databases dynamically.
Understanding metaclasses requires a strong foundation in Python’s object model. To explore this and other advanced topics step-by-step, it's helpful to enroll in a well-structured python course for beginners.
0 notes
Text
Introduction to Multi Agent Systems Enhancement in Vertex AI

Multi-agent systems introduction
Vertex AI offers new multi-agent system creation and management methods.
All businesses will need multi-agent systems with AI agents working together, regardless of framework or vendor. Intelligent systems with memory, planning, and reasoning can act for you. They can multi-step plan and complete projects across many platforms with your instruction.
Multi-agent systems require models like Gemini 2.5 with better reasoning. They need corporate data and process integration. Vertex AI, its comprehensive platform for coordinating models, data, and agents, seamlessly integrates these components. It combines an open approach with strong platform capabilities to ensure agents work reliably without disconnected and brittle solutions.
Today, Google Cloud unveils Vertex AI advancements so you can:
Develop open agents and implement corporate controls
The open-source Agent Development Kit (ADK) is based on Google Agentspace and Google Customer Engagement Suite (CES) agents. Agent Garden has several extendable sample agents and good examples.
Vertex AI's Agent Engine is a managed runtime that safely deploys your custom agents to production globally with integrated testing, release, and reliability.
Connect agents throughout your organisation ecosystem
The Agent2Agent protocol gives agents a single, open language to communicate regardless of framework or vendor. This open project is led by us and collaborates with over fifty industry professionals to further our multi-agent system vision.
Give agents your data using open standards like Model Context Protocol (MCP) or Google Cloud APIs and connections. Google Maps, your preferred data sources, or Google Search may power AI responses.
Creation of agents using an open methodology with Agent Garden and Agent Development Kit
Google's new open-source Agent Development Kit (ADK) simplifies agent creation and complicated multi-agent systems while maintaining fine-grained control over agent behaviour. You can construct an AI agent using ADK in under 100 lines of user-friendly code. Look at these examples.
Available currently in Python (other languages will be released later this year), you can:
With orchestration controls and deterministic guardrails, you can accurately govern agent behaviour and decision-making.
ADK's bidirectional audio and video streaming enable human-like agent conversations. Writing a few lines of code to establish genuine interactions with agents may turn text into rich, dynamic discourse.
Agent Garden, a suite of useful tools and samples in ADK, can assist you start developing. Use pre-built agent components and patterns to learn from working examples and expedite development.
Pick the model that fits you. ADK works with all Model Garden models, including Gemini. Anthropic, Meta, Mistral AI, AI21 Labs, CAMB.AI, Qodo, and others provide over 200 models in addition to Google's.
Choose a deployment destination for local debugging or containerised production like Cloud Run, Kubernetes, or Vertex AI. ADK also supports MCP for secure data-agent connections.
Launch production using Vertex AI's direct integration. The reliable, clear path from development to enterprise-grade deployment eliminates the difficulty of transitioning agents to production.
ADK is optimised for Gemini and Vertex AI but works with your chosen tools. Gemini 2.5 Pro Experimental's improved reasoning and tool-use capabilities allow ADK-developed AI agents to decompose complex challenges and communicate with your favourite platforms. ADK's direct connection to Vertex AI lets you deploy this agent to a fully controlled runtime and execute it at enterprise scale.
Agent Engine deploys AI agents with enterprise-grade controls
Agent Engine, Google Cloud's controlled runtime, simplifies AI agent building. Agent system rebuilding during prototype-to-production is no longer required. Agent Engine manages security, evaluation, monitoring, scaling complexity, infrastructure, and agent context. Agent Engine integrates with ADK (or your chosen framework) for a smooth develop-to-deploy process. Together, you can:
Use ADK, LangGraph, Crew.ai, or others to deploy agents. Choose any model, such Gemini, Claude from Anthropic, Mistral AI, or others. Flexibility is paired with enterprise-grade control and compliance.
Keep session context: The Agent Engine supports short-term and long-term memory, so you don't have to start over. This lets your agents remember your discussions and preferences as you handle sessions.
Vertex AI has several tools to evaluate and improve agent quality. Improve agent performance by fine-tuning models based on real-world usage or utilising the Example Store.
Linking to Agentspace can boost utilisation. You may register Agent Engine-hosted agents with Google Agentspace. Gemini, Google-quality search, and strong agents are available to employees on this corporate platform, which centralises management and security.
Google Cloud will improve Agent Engine in the next months with cutting-edge testing and tooling. Agents can utilise computers and programs. To ensure production reliability, test agents with many user personas and realistic tools in a specialist simulation environment.
The Agent2Agent protocol connects agents across your enterprise
One of the biggest barriers to corporate AI adoption is getting agents from different frameworks and suppliers to work together. Google Cloud worked with industry leaders that support multi-agent systems to create an open Agent2Agent (A2A) protocol.
Agent2Agent allows agents from different ecosystems to interact, regardless of framework (ADK, LangGraph, Crew.ai, etc.) or vendor. A2A lets agents securely cooperate while publicising their capabilities and choosing how to connect with users (text, forms, bidirectional audio/video).
Your agents must collaborate and access your enterprise truth, the informational environment you developed utilising data sources, APIs, and business capabilities. Instead of beginning from scratch, you may give agents your corporate truth data using any method:
ADK supports Model Context Protocol (MCP), so your agents may connect to the growing ecosystem of MCP-compatible devices to access your numerous data sources and capabilities.
ADK lets you directly connect agents to corporate capabilities and systems. Data from AlloyDB, BigQuery, NetApp, and other systems, as well as more than 100 pre-built interfaces and processes established using Application Integration, are included. Your NetApp data may be used to create AI agents without data duplication.
ADK makes it easy to connect to call tools from MCP, LangChain, CrewAI, Application Integration, OpenAPI endpoints, and your present agents in other frameworks like LangGraph.
We manage over 800K APIs that operate your organisation within and outside Google Cloud. Your agents may utilise ADK to access these API investments from anywhere with the correct permission.
After linking, you may supplement your AI replies using Google Search or Zoominfo, S&P Global, HGInsights, Cotality, and Dun & Bradstreet data. For geospatial agents, we now allow Google Maps grounding. To maintain accuracy, we refresh 100 million Maps data points daily. Grounding with Google Maps lets your agents reply with geographical data from millions of US locales.
Create trustworthy AI agents with enterprise-grade security
Incorrect content creation, unauthorised data access, and prompt injection attacks threaten corporate AI agents' functionality and security. Google Cloud's Gemini and Vertex AI building addresses these difficulties on several levels. You could:
Manage agent output with Gemini's system instructions that limit banned subjects and match your brand voice and configurable content filters.
Identity controls can prevent privilege escalation and inappropriate access by determining whether agents work with dedicated service accounts or for individual users.
Google Cloud's VPC service controls can restrict agent activity inside secure perimeters, block data exfiltration, and decrease the impact radius to protect sensitive data.
Set boundaries around your agents to regulate interactions at every level, from parameter verification before tool execution to input screening before models. Defensive boundaries can limit database queries to certain tables or use lightweight models with safety validators.
Automatically track agent activities with rich tracing features. These traits reveal an agent's execution routes, tool choices, and reasoning.
Build multi-agent systems
Vertex AI's value depends in its whole functionality, not simply its features. Integration of solutions from various sources is now easy on a single platform. This unified strategy eliminates painful model trade-offs, corporate app and data integration, and production readiness.
#technology#technews#govindhtech#news#technologynews#AI#artificial intelligence#multi-agent systems#Agent Engine#AI agents#Vertex AI#Agent2Agent protocol#Agent Garden#multi agent
0 notes
Text
Why You Should Hire Dedicated ReactJS Developers for Your Next Project
Introduction
In the ever-evolving digital world, businesses need high-performing, interactive, and scalable web applications. ReactJS has emerged as a leading front-end technology, helping developers build seamless and dynamic user interfaces. If you're planning to create an intuitive web application, it’s essential to hire dedicated ReactJS developers who can bring efficiency and innovation to your project.

Many enterprises and startups struggle with slow, unresponsive web applications that fail to engage users. With ReactJS, businesses can achieve faster load times, better UI/UX, and a highly scalable architecture. Hiring dedicated ReactJS developers ensures that your web application remains competitive and provides a seamless user experience.
Top Benefits of Hiring Dedicated ReactJS Developers
Faster Development Process – React’s reusable components speed up the development cycle, reducing time-to-market.
Rich UI/UX – ReactJS enables developers to create engaging, dynamic, and visually appealing interfaces.
High Performance & Speed – With the Virtual DOM, React minimizes updates and enhances overall application performance.
Scalability & Flexibility – Whether you’re developing a single-page application or a large-scale web app, ReactJS is flexible and scalable.
Cross-Platform Compatibility – React Native allows you to build mobile applications alongside web applications, ensuring a consistent user experience.
ReactJS in Full-Stack Development
ReactJS is a powerful front-end library, but when combined with a robust back-end, it creates a seamless full-stack solution. Many businesses prefer MERN Stack Development Services, which includes:
MongoDB (Database)
Express.js (Backend Framework)
ReactJS (Frontend Library)
Node.js (Runtime Environment)
With MERN Stack Development Services, businesses can create highly scalable, real-time, and dynamic web applications.
Why Choose Brain Inventory for ReactJS Development?
Brain Inventory is a trusted web and mobile development company, specializing in ReactJS development, MERN Stack Development Services, and Python Web Development. Our team of dedicated ReactJS developers ensures:
✅ Custom Web Application Development✅ ReactJS UI/UX Design & Development✅ Migration & Integration Services✅ High-Performance Web Applications✅ Ongoing Support & Maintenance
Conclusion
If you’re looking to build a scalable, high-performing, and interactive web application, hiring dedicated ReactJS developers is the best choice. With expertise in ReactJS, MERN Stack Development Services, and Python Web Development, Brain Inventory ensures top-quality solutions that drive business growth. Contact us today to get started!
0 notes
Text
Understanding Python’s Error Handling and Debugging Techniques
Error handling and debugging are essential skills for writing robust Python code. Python provides various techniques to manage and identify errors that may arise during program execution.
1. Error Types in Python:
Python categorizes errors into two main types:
Syntax Errors: These occur when there is a mistake in the structure of the code. Python’s interpreter catches them before the program runs.
python
print("Hello world" # SyntaxError: unexpected EOF while parsing
Exceptions: These occur during execution when the program encounters a runtime issue. Common exceptions include:
ValueError: Raised when an operation or function receives an argument of the correct type but an inappropriate value.
TypeError: Raised when an operation is performed on an object of inappropriate type.
IndexError: Raised when trying to access an element in a list using an invalid index.
FileNotFoundError: Raised when trying to open a file that doesn’t exist.
Example of a runtime exception:
python
x = 10 y = 0 print(x / y) # ZeroDivisionError: division by zero
2. Using try, except, else, and finally:
Python uses these blocks to handle exceptions:
try block: The code that might raise an exception goes here.
except block: Handles the exception if one occurs.
else block: Executes code if no exception was raised.
finally block: Executes code that should run no matter what (whether an exception was raised or not).
Example:pythonCopyEdittry: number = int(input("Enter a number: ")) result = 10 / number except ZeroDivisionError: print("Cannot divide by zero.") except ValueError: print("Invalid input! Please enter a number.") else: print(f"Result: {result}") finally: print("Execution complete.")
3. Raising Exceptions:
You can raise exceptions explicitly using the raise statement. This is useful for custom error handling or for testing purposes.
Example:pythonCopyEdidef check_age(age): if age < 18: raise ValueError("Age must be 18 or older.") return "Access granted."try: print(check_age(16)) except ValueError as e: print(f"Error: {e}")
4. Custom Exceptions:
You can define your own exception classes by sub classing the built-in Exception class.
Example:pythonclass InvalidAgeError(Exception): passdef check_age(age): if age < 18: raise InvalidAgeError("Age must be 18 or older.") return "Access granted."try: print(check_age(16)) except InvalidAgeError as e: print(f"Error: {e}")
5. Debugging Techniques:
Using pdb (Python Debugger): The Python standard library includes the pdb module, which allows you to set breakpoints and step through code interactively.
Example:
python
import pdb x = 10 y = 0 pdb.set_trace() # Sets a breakpoint print(x / y)
Once the program reaches pdb.set_trace(), the debugger will start, and you can enter commands like n (next), s (step into), c (continue), etc.
Using print Statements: For simple debugging, you can insert print() statements to check the flow of execution and values of variables.
Example:
python
def calculate(a, b): print(f"a: {a}, b: {b}") # Debugging output return a + b
Logging: Instead of using print(), Python’s logging module provides more flexible ways to log messages, including different severity levels (e.g., debug, info, warning, error, critical).
Example:
python
import logging logging.basicConfig(level=logging.DEBUG) logging.debug("This is a debug message") logging.info("This is an info message") logging.error("This is an error message")
6. Handling Multiple Exceptions:
You can handle multiple exceptions in one block or use multiple except clauses.
Example:pythontry: value = int(input("Enter a number: ")) result = 10 / value except (ValueError, ZeroDivisionError) as e: print(f"Error occurred: {e}")
Conclusion:
Understanding Python’s error handling mechanisms and debugging techniques is crucial for writing resilient programs. Using try, except, and other error-handling structures allows you to gracefully manage exceptions, while debugging tools like pdb help identify and resolve issues more efficiently.
WEBSITE: https://www.ficusoft.in/python-training-in-chennai/
0 notes
Text
How to Monitor and Debug Python-Based ETL Pipelines
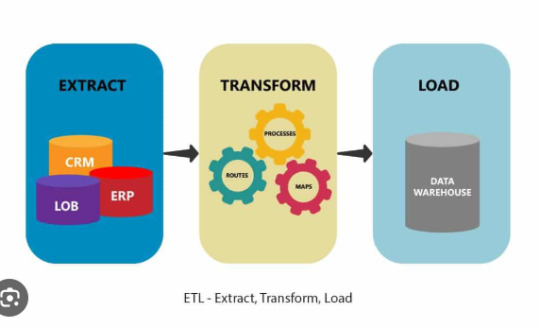
In the world of data engineering, Extract, Transform, Load (ETL) Python workflows are the backbone of moving, cleaning, and transforming data into actionable insights. However, even the most well-designed ETL pipelines can run into issues like slow performance, data mismatches, or outright failures. To ensure smooth operation, monitoring and debugging Python-based ETL pipelines is critical. This article will guide you through practical strategies and tools to monitor and debug ETL workflows effectively.
Why Monitor Python-Based ETL Pipelines?
Monitoring is essential to maintain the reliability of ETL pipelines. It helps identify bottlenecks, spot anomalies, and ensure data integrity. Without robust monitoring, errors may go unnoticed until they cause significant downstream issues, such as corrupted reports or unresponsive applications.
Common Challenges in Python ETL Pipelines
Before diving into solutions, let’s explore common issues faced when running ETL pipelines:
Data Extraction Failures: API timeouts, file unavailability, or incorrect data formats can disrupt the extraction process.
Transformation Errors: Logical flaws in data transformation scripts can lead to inaccurate results.
Load Failures: Issues like database connectivity problems or schema mismatches can hinder the loading process.
Performance Bottlenecks: Handling large datasets may slow down pipelines if not optimized.
Missing Data Validation: Without proper checks, pipelines may process incomplete or corrupt data.
Effective Monitoring Strategies for ETL Pipelines
1. Use Logging for Transparency
Logging is the cornerstone of monitoring ETL pipelines. Python’s logging library allows you to capture details about pipeline execution, including errors, processing times, and data anomalies. Implement structured logging to make logs machine-readable, which simplifies debugging.
2. Monitor Pipeline Metrics
Track metrics like execution time, row counts, and resource utilization to spot inefficiencies. Tools like Prometheus and Grafana can visualize these metrics, providing actionable insights.
3. Set Up Alerts for Failures
Use tools like Apache Airflow, Dagster, or custom scripts to trigger alerts when a pipeline fails. Alerts can be sent via email, Slack, or SMS to ensure prompt action.
Debugging Techniques for Python-Based ETL Pipelines
1. Identify the Faulty Stage
Divide your pipeline into stages (Extract, Transform, Load) and isolate the problematic one. For instance:
If the error occurs during extraction, check the data source connectivity.
If transformation fails, debug the logic in your Python code.
For loading errors, examine database logs for schema mismatches or connectivity issues.
2. Utilize Python Debugging Tools
Python’s built-in debugger, pdb, is invaluable for inspecting code at runtime. You can set breakpoints to pause execution and examine variable values.
3. Test with Mock Data
Create unit tests using frameworks like pytest to simulate different pipeline scenarios. Mock external dependencies (e.g., databases, APIs) to test your logic in isolation.
4. Validate Data at Every Step
Incorporate data validation checks to ensure input, intermediate, and output data meet expectations. Libraries like pandas and great_expectations simplify this process.
Tools for Monitoring and Debugging ETL Pipelines
Apache Airflow: Schedule, monitor, and manage workflows with built-in task-level logging and alerting.
Dagster: Provides observability with real-time logs and metadata tracking.
DataDog: Monitors application performance and sends alerts for anomalies.
ELK Stack: Use Elasticsearch, Logstash, and Kibana to collect and analyze logs.
Best Practices for Reliable ETL Pipelines
Implement Retry Mechanisms: Use libraries like tenacity to retry failed tasks automatically.
Version Control Your Code: Use Git to track changes and quickly revert to a stable version if needed.
Optimize Resource Usage: Profile your code with tools like cProfile and use parallel processing libraries (e.g., Dask, multiprocessing) for efficiency.
Document Your Pipeline: Clear documentation helps identify potential issues faster.
Conclusion
Monitoring and debugging Python-based ETL pipelines require a mix of proactive tracking and reactive problem-solving. Leveraging tools like logging frameworks, Airflow, and testing libraries, you can ensure your Extract, Transform, Load Python workflows are robust and reliable. By implementing the strategies discussed in this article, you’ll minimize downtime, improve performance, and maintain data integrity throughout your pipelines.
0 notes
Text
Essential Tools to Take Your Web Development to the Next Level
To take your web development skills to the next level, here are some essential tools that can help:
1. Code Editors and IDEs:
VS Code: A powerful, extensible code editor that supports a wide range of languages, extensions, and debugging tools.
Sublime Text: A fast and feature-rich editor with support for multiple programming languages and a sleek interface.
Atom: An open-source, customizable text editor, ideal for web development.
2. Version Control Systems:
Git: A version control tool to track changes in code and collaborate efficiently with other developers.
GitHub/GitLab/Bitbucket: Platforms for hosting Git repositories and collaborating with teams.
3. Front-End Frameworks:
React.js: A JavaScript library for building dynamic and interactive user interfaces.
Vue.js: A progressive JavaScript framework for building web interfaces.
Angular: A robust framework for creating scalable and structured web apps.
Tailwind CSS: A utility-first CSS framework for building custom designs quickly.
Bootstrap: A popular CSS framework for building responsive and mobile-first websites.
4. Back-End Frameworks:
Node.js: A JavaScript runtime for building scalable server-side applications.
Express.js: A minimal web framework for Node.js, often used for building APIs and web apps.
Django: A high-level Python web framework for building secure and maintainable websites.
Ruby on Rails: A full-stack framework built on Ruby, known for rapid development and ease of use.
5. Database Management:
MySQL: A widely used relational database management system.
MongoDB: A NoSQL database that's flexible and scalable.
PostgreSQL: A powerful, open-source object-relational database system.
Firebase: A cloud-based real-time database with simple authentication and data synchronization.
6. Package Managers:
npm: Node.js package manager for managing JavaScript libraries and dependencies.
Yarn: An alternative package manager for JavaScript with a focus on performance and reliability.
7. API Tools:
Postman: A powerful tool for testing and interacting with APIs.
Swagger: An open-source framework for API documentation, design, and testing.
8. Task Runners & Module Bundlers:
Webpack: A static module bundler for JavaScript, CSS, and other assets.
Gulp: A task runner used for automating repetitive development tasks.
Parcel: A zero-config bundler that is easy to use and fast.
9. CSS Preprocessors:
Sass: A CSS preprocessor that extends CSS with variables, nested rules, and functions.
Less: A preprocessor with features like variables and functions to make CSS more manageable.
10. Testing Tools:
Jest: A testing framework for JavaScript, commonly used for testing React apps.
Mocha: A flexible JavaScript testing framework for Node.js.
Cypress: An end-to-end testing framework for web applications.
Selenium: A tool for automating web browsers, useful for functional and UI testing.
11. Containerization & Deployment:
Docker: A platform for building, running, and shipping applications inside containers.
Kubernetes: An orchestration platform for automating the deployment, scaling, and management of containerized applications.
Netlify: A platform for continuous deployment of web apps with automatic scaling.
Vercel: A platform that provides serverless deployment and front-end hosting.
12. UI/UX Design Tools:
Figma: A collaborative interface design tool for creating web and app prototypes.
Adobe XD: A vector-based tool for designing and prototyping user experiences.
Sketch: A design tool for web and mobile interfaces, available for macOS.
13. Collaboration Tools:
Slack: A messaging platform for team communication and collaboration.
Trello: A task management tool for organizing and prioritizing tasks in a project.
Asana: A work management platform that helps teams plan, organize, and execute projects.
Using these tools effectively can streamline your workflow, help you collaborate better with teams, and enhance the quality of your web development projects.
0 notes
Text
Google Colab vs. Google Data Studio: A Comprehensive Comparison
Google provides a suite of tools to address the diverse needs of data analysis, collaboration, and visualization. Among these, Google Colab (Google Colab) and Google Data Studio (datastudio.google.com) are two standout platforms. While both are robust, they cater to different functionalities and audiences. This article compares their unique features and use cases to help you determine which tool best suits your needs.

1. Purpose and Features
Google Colab
Purpose: Google Colab is a cloud-based coding platform for Python programming, primarily used for data analysis, machine learning, and computational tasks. It is akin to an online Jupyter Notebook.
Features:Write and execute Python code interactively.Pre-installed libraries like TensorFlow, NumPy, and Pandas.Access to GPUs and TPUs for high-performance computation.Real-time collaboration on shared notebooks.
Ideal For:Building and testing machine learning models.Exploring large datasets programmatically.Teaching and learning Python-based data science.
Like That:
FREE Instagram Private Profile Viewer Without Following
Private Instagram Viewer
This Is Link Style
https://colab.research.google.com/drive/1jL_ythMr1Ejk2c3pyvlno1EO1BBOtK_Z
https://colab.research.google.com/drive/1e9AxOP_ELN4SYSLhJW8b8KXFcM5-CavY
Google Data Studio
Purpose: Google Data Studio is a business intelligence tool that turns raw data into dynamic, visually appealing dashboards and reports.
Features:Seamlessly integrate with data sources such as Google Analytics, BigQuery, and Sheets.Create interactive, customizable reports and dashboards.Enable real-time updates for shared insights.
Ideal For:Visualizing marketing and business performance data.Crafting presentations for decision-making.Tracking KPIs and performance metrics efficiently.
Like That:
Free Instagram private account viewer
How to see private Instagram profiles
Private Instagram Viewer Apps
Recover hacked Instagram account
Recover hacked Snapchat account
Use Cases:
https://datastudio.google.com/embed/s/hqgxnNMpaBA
https://datastudio.google.com/embed/s/g8oLu_-1sNQ
2. Target Users
Google Colab
Targeted at data scientists, researchers, and developers proficient in Python.
Requires programming expertise for tasks such as algorithm development and data modeling.
Google Data Studio
Designed for business analysts, marketers, and decision-makers without coding knowledge.
Simplifies data interpretation through easy-to-use visual tools.
3. Data Access and Processing
Google Colab
Allows direct data manipulation using Python scripts.
Supports integrations with Google Drive, APIs, databases, and other sources.
Offers unparalleled flexibility for custom computations and workflows.
Google Data Studio
Focused on visualizing structured data from external sources like SQL databases or CSV files.
Limited in data transformation capabilities compared to coding tools like Colab.
4. Collaboration Capabilities
Google Colab
Enables simultaneous editing and execution of code in a shared notebook environment.
Perfect for team projects involving programming and analysis.
Google Data Studio
Supports collaborative creation and sharing of dashboards and reports.
Real-time updates ensure everyone is on the same page.
5. Performance and Scalability
Google Colab
Free tier provides basic compute resources, including limited GPU and TPU access.
Colab Pro plans offer enhanced runtimes and resource allocation for intensive tasks.
Google Data Studio
Scales efficiently for real-time data visualization.
Performance depends on the complexity of the report and connected data sources.
6. Cost and Accessibility
Google Colab
Free tier includes essential features for most users.
Paid Pro plans add advanced compute options for heavy workloads.
Google Data Studio
Free to use for creating reports and dashboards.
Some integrations, like BigQuery, may incur additional costs based on usage.
Google Colab vs. Google Data Studio: Understanding Their Differences
Understanding the Key Differences Between Google Colab and Google Data Studio
Conclusion
Both Google Colab and Google Data Studio are invaluable tools, but they serve different purposes. Google Colab is tailored for programmers and data scientists needing a flexible coding environment for analysis and machine learning. Conversely, Google Data Studio excels in creating visually engaging reports for business insights. Depending on your workflow, you might find value in using both—leveraging Colab for data preparation and analysis, and Data Studio for presenting insights to stakeholders.
1 note
·
View note
Text
Frontend vs. Backend Frameworks: A Full-Stack Perspective for Businesses

Modern software development hinges on frameworks that bridge both sides, ensuring a seamless user experience and efficient application functionality. This article delves into the roles of frontend and backend frameworks, their importance in full-stack development, and how businesses can leverage these tools by hiring full-stack developers or engaging with custom software development services.
What Are Frontend Frameworks?
Frontend frameworks handle the client side of an application, focusing on what users see and interact with. They are essential for creating intuitive, dynamic, and visually appealing user interfaces.
Some popular frontend frameworks include:
React: Known for its component-based architecture, it allows developers to build reusable and efficient UI elements.
Angular: A comprehensive framework for building robust single-page applications (SPAs).
Vue.js: Lightweight and easy to integrate, suitable for developing high-performance user interfaces.
Frontend frameworks enhance user experience by ensuring fast loading times, smooth animations, and responsive designs, making them crucial for customer-facing applications developed by a mobile development company or other specialized teams.
What Are Backend Frameworks?
Backend frameworks focus on the server side, handling the application logic, database interactions, and security. They ensure the smooth functioning of features like data storage, user authentication, and API integration.
Key backend frameworks include:
Node.js: A JavaScript runtime known for its speed and scalability, often used in real-time applications.
Django: A Python-based framework emphasizing security and rapid development.
Laravel: A PHP framework designed for web application backends with elegant syntax and tools for caching and routing.
These frameworks provide the backbone for modern applications, ensuring they remain secure and efficient while meeting the demands of users and businesses alike.
Full-Stack Development: Bridging Frontend and Backend
Full-stack development involves expertise in both frontend and backend frameworks, enabling developers to create cohesive applications. Full-stack developers use their knowledge to integrate these frameworks effectively, ensuring the application’s frontend and backend communicate seamlessly.
For businesses, hiring full-stack developers or partnering with a custom software development company offers several benefits:
Cost Efficiency: Full-stack developers can handle multiple development stages, reducing the need for specialized resources.
Faster Delivery: With a single team managing the entire stack, projects progress more quickly.
Scalability: Full-stack developers can design scalable applications by leveraging the strengths of both frontend and backend frameworks.
Full-Stack Frameworks: A Unified Approach
While most applications rely on separate frontend and backend frameworks, some full-stack frameworks provide a unified solution for both. These frameworks streamline development by offering built-in tools for both sides of the stack.
Examples include:
Meteor.js: A JavaScript framework offering end-to-end development for web and mobile apps.
Ruby on Rails: Combines backend logic with frontend templates for efficient development workflows.
Such frameworks simplify the development process, making them ideal for businesses seeking rapid deployment and reduced complexity.
Frontend vs. Backend Frameworks: A Comparison
Frontend Frameworks
Purpose: User interface and experience
Examples: React, Angular, Vue.js
Focus: Visual design, interactivity
Impact on Full-Stack: Enhances user engagement
Backend Frameworks
Purpose: Application logic and database management
Examples: Node.js, Django, Laravel
Focus: Performance, security, and scalability
Impact on Full-Stack: Ensures reliable functionality
Understanding the distinct roles of these frameworks helps businesses choose the right combination for their needs, whether they’re partnering with a mobile development company or building in-house teams.
Why Businesses Should Invest in Full-Stack Development
In today’s competitive market, businesses must focus on delivering seamless, high-quality digital experiences. Full-stack development allows for end-to-end project management, with developers skilled in frontend and backend technologies.
Scenarios where hiring full-stack developers benefits businesses:
Startups needing a quick, cost-effective MVP.
Enterprises requiring scalable and secure applications.
Businesses looking to reduce development timelines without compromising quality.
Conclusion
Frontend and backend frameworks are the building blocks of modern software development. By hiring experienced full-stack developers or engaging with a custom software development company, businesses can integrate the best of both worlds, delivering applications that are both user-friendly and functionally robust.
If you’re planning your next software project, consult with experts offering custom software development services or a mobile development company to choose the right frameworks and development approach for your goals.
#mobile app development#frontend development#backend development#backend frameworks#full stack development
1 note
·
View note
Text
What Is Backend Web Development and Why It’s Crucial for Your Website?

In today’s digital age, websites are more than just a collection of static pages. They serve as dynamic platforms that enable businesses to interact with customers, manage data, and offer services. While frontend development focuses on what users see and interact with, backend web development is what powers the inner workings of a website. It ensures that your site is secure, scalable, and functions smoothly.
In this blog, we’ll explore what backend web development is, its key components, and why it’s essential for your website's performance, security, and overall success.
What Is Backend Web Development?
Backend web development is the process of building and maintaining the "server-side" of a website or application. It involves the development of the components and systems that are not visible to users but are essential for making websites work. Backend developers work on things like databases, servers, and application programming interfaces (APIs), ensuring that everything functions seamlessly behind the scenes.
While frontend development deals with the layout and visual elements of a site, backend development ensures that the website or web application operates efficiently, processes user data, and communicates with servers.
Some of the common programming languages used in backend development include:
Python
Java
PHP
Ruby
Node.js (JavaScript runtime)
Additionally, backend developers work with databases like MySQL, PostgreSQL, and MongoDB, which store the data that is used on the site.
Key Components of Backend Development
1. Server
A server is a powerful computer that stores a website’s data, files, and services. When a user enters a website’s URL in their browser, the server processes the request, retrieves the necessary data, and sends it back to the user’s browser.
There are different types of servers involved in backend development:
Web servers: Handle HTTP requests and deliver web pages.
Application servers: Handle business logic and dynamic content.
Database servers: Store and retrieve data for use on the site.
A backend developer configures and maintains these servers to ensure a website operates smoothly.
2. Database Management
Databases are essential for storing, organizing, and retrieving data used by your website. Whether it's user information, content, or transaction records, the backend developer ensures that the data is structured correctly and can be accessed efficiently.
There are two types of databases:
Relational databases (e.g., MySQL, PostgreSQL): Store data in tables with predefined relationships between them.
Non-relational (NoSQL) databases (e.g., MongoDB): Store data in a flexible, non-tabular format.
Backend developers decide the right database type based on the needs of the project and ensure smooth data flow throughout the site.
3. APIs and Integrations
APIs (Application Programming Interfaces) allow different software systems to communicate with each other. For example, a website might need to integrate with external services like payment gateways, weather data providers, or social media platforms. Backend developers build and maintain APIs that allow these integrations to happen smoothly.
By enabling external systems to send and receive data, APIs ensure that your website can interact with other systems, enhancing its functionality.
Backend Development vs. Frontend Development
While both backend and frontend development are integral to creating a successful website, they focus on different aspects.
Frontend development is concerned with the visible parts of a website, such as the design, layout, and interactive elements that users see and interact with.
Backend development, on the other hand, focuses on the server-side of the website, dealing with databases, servers, and APIs. Backend developers ensure that data is processed and sent to the frontend seamlessly.
Although the two roles differ, they must work together to provide a seamless and dynamic user experience. A solid backend ensures that the frontend functions properly, delivering content and data as needed.
Benefits of Robust Backend Web Development
Investing in high-quality backend web development provides several benefits that can significantly impact the performance, security, and scalability of your website.
Enhanced Website Performance and Speed A well-optimized backend ensures that the website loads quickly and performs tasks efficiently. Optimized databases and server management techniques lead to faster response times, which is crucial for providing a good user experience.
Improved Security Features Backend development plays a key role in securing your website against potential threats. By implementing secure authentication systems, encrypting sensitive data, and ensuring safe communication between systems, backend developers help protect your website and its users.
Scalability for Future Growth A solid backend allows your website to grow without performance issues. As your business expands, you may need to handle more traffic, data, or complex features. A scalable backend ensures that your website can handle these demands smoothly.
Complex Functions Support Backend development enables advanced functions like user authentication, content management systems (CMS), e-commerce platforms, and more. These features are essential for businesses that rely on dynamic, interactive websites.
Choosing the Right Backend Developer for Your Business
When selecting a backend developer for your website, there are several qualities to look for:
Technical expertise in backend programming languages and databases.
Problem-solving skills to tackle issues like optimizing performance or ensuring data security.
Experience with APIs and integrations to handle third-party services.
Understanding of scalability to ensure your website can handle future growth.
It’s also important to choose a developer who understands the business goals and can align backend development with your company’s digital strategy.
Conclusion
Backend web development is a critical part of building a functional, secure, and scalable website. It handles everything from server management and database organization to API integrations, ensuring that your site runs smoothly and efficiently. At Markteer Media, we specialize in providing end-to-end digital solutions, including robust backend development, to help your business build secure and high-performing websites.
Ready to take your website to the next level? Reach out to us for expert backend development services tailored to your business needs!
0 notes
Text
AWS Lambda is a serverless cloud computing service that offers Functions as a Service (FaaS). It has been called disruptive because it enables the deployment of any code, in any language, through one platform. As long as the code is wrapped inside a function and run through Lambda, you won’t need to handle any networking, database, or security tasks. You can simply work on your code and use the client-side logic, which is intuitive and easy to use.In this article, we’ll review the basic principles of AWS Lambda, including the core concepts, components, how AWS Lambda works, and the best practices as recommended by AWS.What Is AWS Lambda?AWS Lambda is an on-demand serverless computing service, which provides developers with a fully-managed cloud-based and event-driven system for running code. To enable the use of any coding language, AWS Lambda uses lambda functions, which are anonymous functions that aren’t bound to an identifier. That means you can package any code into a function and run it.In a serverless architecture model, the cloud provider manages the allocation and provisioning of servers, including the database, security, and backend logic. The customer enjoys the use of the front-end logic without the heavy lifting associated with computer networking work. The pricing is based on the number of executions, and functions are offered as a service (FaaS).AWS Lambda use Cases Include but aren’t limited toConfiguring triggers to execute codes for real-time data, file and stream processing.Building serverless backends for web, mobile, Internet of Things (IoT), and third party API.Automatically increasing volumes in AWS EBS. How AWS Lambda WorksIf you haven’t used Lambda yet, here are a few key principles to get you familiarized with the system.AWS Lamda’s ComponentsLambda Functions—anonymous functions that contain pieces of code that trigger events.Packaging Functions—the process of compressing the function, with all its dependencies, and sending it to AWS by uploading the function to an S3 bucket. AWS Lambda’s Execution ModelContainer—a piece of execution code that uses AWS-managed resources to execute the function.Instances—containers are immutable and can’t be used again after shut off. To enable on-demand usage, AWS Lambda creates instances—replicas—of the container. Lambda adjusts the number of instances according to the usage requirements.Stateless functions—the function in Lambda is controlled and optimized by AWS and usually invoked once per container instantiation.Events—requests which are served by a single instance of a Lambda function, and are managed by AWS Lambda.AWS Lambda’s SpecsLambda’s supported runtimes are Node.js: v10.15 and v8.10, Java 8, Python: 3.7, 3.6, and 2.7, .NET Core: 1.0.1 and 2.1, Go 1.x, Ruby 2.5 and RustIn Lambda, functions run inside containers, each with a 64-bit Amazon Linux AMI.The central processing unit (CPU) increases or decreases with the memory capacity. You can control the CPU only through the memory.A Lambda function can run for up to 900 seconds or 15 minutes, which means Lambda isn’t ideal for long-running processes.The /tmp directory serves as the ephemeral disk space. Subsequent invocations don’t have access to the /tmp directory.Uncompressed function packages are limited to 250MB and compressed function packages are limited to 50MB. Best Practices for Working with AWS Lambda FunctionsAWS Recommends the Following Best Practices for Each Lambda Function CodeFor creating a unit-testable function, separate the Lambda handler (entry point) from your core logic.Improve the performance of your function with the Execution Context reuse feature.Pass operational parameters to your function with AWS Lda Environment Variables.If you want full control of your function’s dependencies, package them with your deployment package. Otherwise, your functions will be subjected to AWS updates.To increase deployment efficiency, include only runtime necessities in your deployment package, put your Java dependency .
jar files in a separate /lib directory, and use simple load frameworks on the Execution Context startup.To prevent bugs in volume scales and costs, avoid using recursive code in your Lambda function.AWS Recommends the Following Best Practices for Function ConfigurationTest your Lambda function before choosing memory size configuration, because any memory increase triggers a CPU increase, and therefore a price increase. You can see your memory usage in the AWS CloudWatch Logs.To ensure optimum concurrency, put your Lambda function through a load test. Set your timeout value accordingly, to take into account possible problems with dependency services.To prevent unauthorized access to your functions, set up your IAM policies to most-restrictive permissions.When you configure runtime resource limits, take into account the payload size, file descriptors, and /tmp space.To ensure you get the most cost-effective pricing, delete inactive Lambda functions.When using Amazon Simple Queue Service, including the CreateFunction and UpdateFunctionConfiguration—set the value of the function's expected execution time to a number that never exceeds the value of the Visibility Timeout on the queue. It’s a Wrap!AWS Lambda is a useful service for independent software vendors (ISV) and software developers. You can delegate your infrastructure jobs AWS Lambda, which handles all of the database, security, and backend logic work. AWS Lambda is serverless, cloud-native, and offers containerized FaaS and a cost-effective pricing model. However, due to the runtime limitations of Lambda functions, the AWS Lambda service isn’t as effective for long-running processes. Be sure to compare the service’s specs with the specs of your project, in advance. It’s always best to run a test before introducing a new service or a product into your workflow. You can also take advantage of the free tier module to check out the service and make sure it suits your needs.
0 notes
Text
Top Tools and Frameworks for Custom Software
In the world of tech, custom software is on the rise. Every business, big or small, wants software that’s made for them. But here’s the thing custom software isn’t just about writing code. It’s about choosing the right tools and frameworks that match your project goals, scale and performance. The tools you choose can make or break your project, from development speed to end user experience.
So whether you’re a developer, project manager or business owner looking to get the most out of your custom software development, knowing the top tools and frameworks out there is key. In this post we’ll look at some of the most popular and powerful ones that can help you bring your software to life.
1. React.js
React.js is the go to framework for front-end development. Built by Facebook, this JavaScript library lets you build dynamic and interactive UI’s with ease. Its component based architecture makes it perfect for large scale applications where consistency and performance is key.
2. Angular
Angular, maintained by Google, is another big player in front-end development. Unlike React, Angular is a full framework that comes with everything you need to build robust applications, from data binding to dependency injection. Its strong community support and regular updates means your application will always be modern and efficient.
3. Django
For back-end development, Django is a framework that’s hard to ignore. Written in Python, Django helps developers build secure and scalable web applications fast. Its “batteries-included” philosophy means it comes with loads of built-in features like authentication, ORM (Object-Relational Mapping) and more, so you don’t need to hunt for third party libraries.
4. Node.js
Node.js is a runtime environment that lets you run JavaScript on the server side. It’s popular for building scalable network applications thanks to its non-blocking, event driven architecture. Node.js is perfect for real-time applications like chat apps or online gaming where performance and speed is key.
5. Spring Boot
Spring Boot makes developing Java applications easier, especially when it comes to microservices. With its convention-over-configuration approach, Spring Boot reduces the amount of boilerplate code, so you can focus on the business logic of the app. It also plays nicely with other Spring components so it’s a great choice for enterprise apps.
6. Flutter
For mobile apps, Flutter is becoming a popular framework that lets you build natively compiled apps for mobile, web and desktop from a single codebase. Built by Google, Flutter’s UI approach using widgets lets you build fast and beautiful apps.
7. Docker
Not a framework, but a must have tool in modern software development. Docker lets you package your application into containers so the application will run the same way on your developer’s laptop as it will in production, so no more “it works on my machine” problem.
8. Kubernetes
As your software applications get more complex, managing them in production gets harder. This is where Kubernetes comes in. Kubernetes is an open source platform to automate deploying, scaling and operating application containers. It’s particularly useful for microservices architecture to ensure your application is resilient and scalable under different loads.
Summary
The world of custom software development is full of tools and frameworks, each with its own advantages. Choose the ones that fit your project’s needs. By using these tools you can speed up your development, improve your software and deliver what your business needs. Whether you want to build a front-end, back-end or high performance mobile app, there’s a tool or framework for that.
0 notes
Text
New AMD ROCm 6.3 Release Expands AI and HPC Horizons

Opening Up New Paths in AI and HPC with AMD’s Release ROCm 6.3. With the introduction of cutting-edge tools and optimizations to improve AI, ML, and HPC workloads on AMD Instinct GPU accelerators, ROCm 6.3 represents a major milestone for the AMD open-source platform. By increasing developer productivity, ROCm 6.3 is designed to enable a diverse spectrum of clients, from cutting-edge AI startups to HPC-driven businesses.
This blog explores the release’s key features, which include a redesigned FlashAttention-2 for better AI training and inference, the introduction of multi-node Fast Fourier Transform (FFT) to transform HPC workflows, a smooth integration of SGLang for faster AI inferencing, and more. Discover these fascinating developments and more as ROCm 6.3 propels industry innovation.
Super-Fast Inferencing of Generative AI (GenAI) Models with SGLang in ROCm 6.3
Industries are being revolutionized by GenAI, yet implementing huge models frequently involves overcoming latency, throughput, and resource usage issues. Presenting SGLang, a new runtime optimized for inferring state-of-the-art generative models like LLMs and VLMs on AMD Instinct GPUs and supported by ROCm 6.3.
Why It Is Important to You
6X Higher Throughput: According to research, you can outperform current systems on LLM inferencing by up to 6X, allowing your company to support AI applications on a large scale.
Usability: With Python integrated and pre-configured in the ROCm Docker containers, developers can quickly construct scalable cloud backends, multimodal processes, and interactive AI helpers with less setup time.
SGLang provides the performance and usability required to satisfy corporate objectives, whether you’re developing AI products that interact with customers or expanding AI workloads in the cloud.
Next-Level Transformer Optimization: Re-Engineered FlashAttention-2 on AMD Instinct
The foundation of contemporary AI is transformer models, although scalability has always been constrained by their large memory and processing requirements. AMD resolves these issues with FlashAttention-2 designed for ROCm 6.3, allowing for quicker, more effective training and inference.
Why It Will Be Favorite by Developers
3X Speedups: In comparison to FlashAttention-1, achieve up to 3X speedups on backward passes and a highly efficient forward pass. This will speed up model training and inference, lowering the time-to-market for corporate AI applications.
Extended Sequence Lengths: AMD Instinct GPUs handle longer sequences with ease with to their effective memory use and low I/O overhead.
With ROCm’s PyTorch container and Composable Kernel (CK) as the backend, you can easily add FlashAttention-2 on AMD Instinct GPU accelerators into your current workflows and optimize your AI pipelines.
AMD Fortran Compiler: Bridging Legacy Code to GPU Acceleration
With the release of the new AMD Fortran compiler in ROCm 6.3, businesses using AMD Instinct accelerators to run historical Fortran-based HPC applications may now fully utilize the potential of contemporary GPU acceleration.
Principal Advantages
Direct GPU Offloading: Use OpenMP offloading to take advantage of AMD Instinct GPUs and speed up important scientific applications.
Backward Compatibility: Utilize AMD’s next-generation GPU capabilities while building upon pre-existing Fortran code.
Streamlined Integrations: Connect to ROCm Libraries and HIP Kernels with ease, removing the need for intricate code rewrites.
Businesses in sectors like weather modeling, pharmaceuticals, and aerospace may now leverage the potential of GPU acceleration without requiring the kind of substantial code overhauls that were previously necessary to future-proof their older HPC systems. This comprehensive tutorial will help you get started with the AMD Fortran Compiler on AMD Instinct GPUs.
New Multi-Node FFT in rocFFT: Game changer for HPC Workflows
Distributed computing systems that scale well are necessary for industries that depend on HPC workloads, such as oil and gas and climate modeling. High-performance distributed FFT calculations are made possible by ROCm 6.3, which adds multi-node FFT functionality to rocFFT.
The Significance of It for HPC
The integration of the built-in Message Passing Interface (MPI) streamlines multi-node scalability, lowering developer complexity and hastening the deployment of distributed applications.
Scalability of Leadership: Optimize performance for crucial activities like climate modeling and seismic imaging by scaling fluidly over large datasets.
Larger datasets may now be processed more efficiently by organizations in sectors like scientific research and oil and gas, resulting in quicker and more accurate decision-making.
Enhanced Computer Vision Libraries: AV1, rocJPEG, and Beyond
AI developers need effective preprocessing and augmentation tools when dealing with contemporary media and datasets. With improvements to its computer vision libraries, rocDecode, rocJPEG, and rocAL, ROCm 6.3 enables businesses to take on a variety of tasks, from dataset augmentation to video analytics.
Why It Is Important to You
Support for the AV1 Codec: rocDecode and rocPyDecode provide affordable, royalty-free decoding for contemporary media processing.
GPU-Accelerated JPEG Decoding: Use the rocJPEG library’s built-in fallback methods to perform image preparation at scale with ease.
Better Audio Augmentation: Using the rocAL package, preprocessing has been enhanced for reliable model training in noisy situations.
From entertainment and media to self-governing systems, these characteristics allow engineers to produce more complex AI solutions for practical uses.
It’s important to note that, in addition to these noteworthy improvements, Omnitrace and Omniperf which were first released in ROCm 6.2 have been renamed as ROCm System Profiler and ROCm Compute Profiler. Improved usability, reliability, and smooth integration into the existing ROCm profiling environment are all benefits of this rebranding.
Why ROCm 6.3?
AMD With each release, ROCm has advanced, and version 6.3 is no different. It offers state-of-the-art tools to streamline development and improve speed and scalability for workloads including AI and HPC. ROCm enables companies to innovate more quickly, grow more intelligently, and maintain an advantage in cutthroat markets by adopting the open-source philosophy and constantly changing to satisfy developer demands.
Are You Prepared to Jump? Examine ROCm 6.3‘s full potential and discover how AMD Instinct accelerators may support the next significant innovation in your company.
Read more on Govindhtech.com
#AMDROCm6.3#ROCm6.3#AMDROCm#AI#HPC#AMDInstinctGPU#AMDInstinct#GPUAcceleration#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes

Text
Show how to extend ADF capabilities with serverless Azure Functions.
Extending Azure Data Factory (ADF) Capabilities with Serverless Azure Functions
Azure Data Factory (ADF) is a powerful data integration service, but sometimes you need additional logic beyond its built-in activities. This is where serverless Azure Functions come in.
By integrating Azure Functions with ADF, you can extend its capabilities to handle complex transformations, custom data processing, and external system interactions.
1. Why Use Azure Functions with ADF?
ADF provides built-in activities for data movement and transformation, but some scenarios require custom processing, such as: ✅ Custom Data Transformations — Processing JSON, XML, or proprietary data formats. ✅ Calling External APIs — Fetching data from web services or third-party APIs. ✅ Triggering External Workflows — Sending notifications or integrating with other Azure services. ✅ Performing Complex Validations — Running business logic before inserting data into a database.
2. Setting Up an Azure Function for ADF
Step 1: Create an Azure Function
1️⃣ Navigate to the Azure Portal → Create a Function App. 2️⃣ Choose Runtime Stack (e.g., Python, C#, Java, Node.js). 3️⃣ Deploy the function using Azure CLI, Visual Studio Code, or GitHub Actions.
Step 2: Write a Sample Azure Function
Here’s an example of an HTTP-triggered Azure Function in Python that transforms JSON data before loading it into a database.import json import azure.functions as funcdef main(req: func.HttpRequest) -> func.HttpResponse: data = req.get_json() # Example: Convert all values to uppercase transformed_data = {key: value.upper() for key, value in data.items()} return func.HttpResponse(json.dumps(transformed_data), mimetype="application/json")
Step 3: Deploy and Obtain the Function URL
Once deployed, copy the Function URL for integration with ADF.
3. Integrating Azure Function with ADF
Step 4: Create an ADF Pipeline
1️⃣ Go to Azure Data Factory → Create a new Pipeline. 2️⃣ Add a Web Activity to call the Azure Function. 3️⃣ Configure the Web Activity:
Method: POST
URL: Paste the Function App URL
Headers: { "Content-Type": "application/json" }
Body: JSON payload required by the function
Step 5: Process the Function Response
Use Data Flow or Copy Activity to store transformed data in Azure Blob Storage, SQL Database, or another destination.
4. Example Use Cases
✅ Dynamic Filename Generation — Generate filenames dynamically before loading files into Azure Blob. ✅ Data Validation Rules — Validate input records before processing in ADF. ✅ Calling Third-Party APIs — Fetch real-time stock prices, weather data, or other external information. ✅ Triggering Notifications — Send alerts via email or Microsoft Teams after data processing.
5. Monitoring and Scaling
Use Application Insights for logging and monitoring function execution.
Scale automatically with consumption-based pricing, reducing infrastructure costs.
Conclusion
By integrating Azure Functions with ADF, you can enhance its capabilities, automate workflows, and handle complex data transformations efficiently.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes