#Dateisysteme
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
ZFS vs. Btrfs: Welches Dateisystem ist besser und wo liegen die Unterschiede?
Zwischen den modernen Dateisystemen ZFS und Btrfs kommt bei vielen die Frage auf, welches dieser beiden Dateisysteme die bessere Wahl für das eigene System in Bezug auf die Leistung und die Zuverlässigkeit ist. Dabei gibt es, wie so oft, einige Gemeinsamkeiten...[Weiterlesen]
1 note
·
View note
Text
Western Digital externe SSD My Passport 2000 GB

Western Digital externe SSD My Passport 2000 GB Gold Stromversorgung: USB Speicherkapazität total: 2000 GB Speicherverschlüsselung: 256-Bit-AES Detailfarbe: Gold Dateisystem: exFAT (Windows & Mac OS) Schnittstellen: Type-C USB 3.0 (3.1 / 3.2 Gen. 1) Type-A USB 3.1 (3.1 / 3.2 Gen. 2) https://shop.compsupport.ch/de/products/1817361 https://compsupport.ch/2025/04/16/western-digital-externe-ssd-my-passport-2000-gb/?fsp_sid=7184 #Compsupport #ComputingundSoftware #externeSSD #externerSpeicher #Peripherie #WesternDigitalexterneSSDMyPassport2000GB
0 notes
Text
MicroPython mit ESP32: Lesen und Schreiben von Dateien

Mit dem ESP32 kannst du nicht nur Programme speichern, sondern auch Dateien lesen und schreiben. So lassen sich Messdaten oder Konfigurationen direkt auf dem Mikrocontroller ablegen. In diesem Beitrag zeige ich dir, wie du mit MicroPython eine Datei auf dem ESP32 erstellst und Daten darin speicherst. https://youtu.be/Edkn7l4ocm0
Ein kleines Beispiel - Lesen einer Datei auf dem Mikrocontroller via MicroPython
Starten wir zunächst damit und legen eine Datei auf dem Mikrocontroller ab und lesen diese ein. Die Datei, welche ich ablege, enthält lediglich zwei Zeilen: Hallo Welt! zweite Zeile Nachfolgender Code durchläuft die Textdatei mit lesendem Zugriff, Zeile für Zeile: # Der Dateiname welcher gelesen werden soll. filename = 'text.txt' # öffnen der Datei in lesendem Zugriff # mit dem Namen file with open(filename, 'r') as file: # alle Zeilen einlesen in eine Liste zeilen = file.readlines() # die Liste mit den Zeilen durchlaufen for zeile in zeilen: # ausgeben der Zeile auf der Kommandozeile # die Funktion strip - bewirkt das # Zeilenumbrüche und Einrückungen entfernt werden print(zeile.strip()) Auf der Kommandozeile werden dann die Daten aus der Textdatei untereinander angezeigt. Die Zeilenumbrüche und Einrückungen werden zusätzlich entfernt! >>> %Run -c $EDITOR_CONTENT MPY: soft reboot Hallo Welt! zweite Zeile >>>
Modi zum Erstellen, Speichern und Lesen von Dateien auf dem ESP32
Du kannst eine Datei in nachfolgende Modi öffnen und behandeln: - r - lesend (read), - w - schreibend (write), - a - anfügen (append) Wichtig: Wenn die Datei besteht und du nutzt den Modus 'w' dann werden die vorhandenen Daten überschrieben!
Lesen der ablegten Dateien und Verzeichnisse
Das Auslesen aller Dateien und Verzeichnisse auf dem ESP32 bietet mehrere Vorteile: - Dynamische Datenverwaltung: Du bist nicht auf feste Dateinamen angewiesen und kannst flexibel auf Änderungen im Dateisystem reagieren. - Überblick über gespeicherte Daten: Einfach feststellen, welche Daten bereits gespeichert sind und ob neue Daten hinzugefügt wurden. - Erleichtertes Debuggen und Wartung: Du erhältst einen Überblick über alle gespeicherten Dateien und deren Inhalte. - Automatisierte Reaktionen: Nützlich, um automatisch auf bestimmte Dateitypen oder -namen zu reagieren, ohne diese im Voraus zu kennen. - Effiziente Datenverwaltung: Erlaubt eine organisierte und effiziente Handhabung von Dateien und Verzeichnissen. # Modul zum Zugriff auf das Dateisystem import os # Des Verzeichnisses welches ausgelesen werden soll. directory = 'data' print("root:") # Ausgeben aller Dateien und Verzeichnisse aus dem # root Verzeichniss. print(os.listdir()) print() print(directory + ":") # Ausgeben aller Dateien und Verzeichnisse aus dem # Verzeichniss 'data' auf der Kommandozeile. print(os.listdir(directory)) Auf dem Mikrocontroller befinden sich diverse Python Dateien sowie ein Verzeichnis data mit einer Textdatei sowie CSV-Datei.

Thonny - Dateien auf dem Dateisystem des ESP32
Auslesen von CSV-Dateien mit MicroPython auf dem ESP32
Im Verzeichnis data habe ich eine kleine CSV-Datei abgelegt, in welcher 4 Zeilen mit Daten abgelegt wurden. 12.06.2024 12:45:12;12;34 12.06.2024 12:45:15;11;34 12.06.2024 12:45:18;13;37 12.06.2024 12:45:21;14;39 Im Feld dateiname wird der Pfad auf dem Dateisystem zur CSV-Datei abgelegt, den Trenner habe ich im Feld trenner abgelegt und somit ist dieser Code etwas universeller zu verwenden. Die Datei wird dann einmalig ausgelesen und die Zeilen werden mit dem Zeichen aus dem Feld trenner in ein Array gesplittet, aus welchem wir die Daten mit einem Index auslesen können. dateiname = 'data/data2.csv' trenner = ';' with open(dateiname,'r') as file: zeilen = file.readlines() for zeile in zeilen: daten = zeile.strip().split(trenner) print("Datum:", daten) print("Temperatur:", daten,"°C") print("rel. Luftfeuchtigkeit:", daten, "%") print() Auf der Kommandozeile werden die Daten aus der CSV-Datei nacheinander angezeigt. Im nächsten Schritt könnten wir diese auch auf einer Webseite tabellarisch präsentieren. MPY: soft reboot Datum: 12.06.2024 12:45:12 Temperatur: 12 °C rel. Luftfeuchtigkeit: 34 % Datum: 12.06.2024 12:45:15 Temperatur: 11 °C rel. Luftfeuchtigkeit: 34 % Datum: 12.06.2024 12:45:18 Temperatur: 13 °C rel. Luftfeuchtigkeit: 37 % Datum: 12.06.2024 12:45:21 Temperatur: 14 °C rel. Luftfeuchtigkeit: 39 % Read the full article
0 notes
Text
Einheit 2: Technische Grundlagen Teil 2
In dieser Einheit arbeiten wir direkt mit einer Shell auf Git Hub. Ich schätze die praktische Seite dieser Übung. In einem ersten Schritt sind wir unabhängig, indem wir dem folgenden Tutorial folgen: https://librarycarpentry.org/lc-shell/02-navigating-the-filesystem.html
Textanalyse mit der Shell
Diese Übung entspricht Kapitel 5 der Library Carpentry Lesson "The Unix Shell". Auch hier handelt es sich größtenteils um eine Wiederholung für mich. Die Verwendung von Pipes ist sehr befriedigend. Da ich jedoch wenig Übung darin habe, ziehe ich es vor, jeden Prompt einzeln zu testen und dann mit Pipes zu kombinieren. Auf diese Weise ist es einfacher, Fehler zu finden und zu verstehen, wie Bash funktioniert. Ich stelle mir vor, dass ich diese Schritte nicht mehr machen muss, wenn ich mit der Bash-Sprache vertrauter bin. Allerdings kritisiere ich die Erklärung des "Regular Expressions". Dieser Begriff taucht plötzlich gegen Ende des Kapitels auf, ohne dass wirklich viel erklärt wird. Außerdem wird nicht erklärt, warum man bei der Verwendung von Regular Expression mit grep das Flag -E verwenden muss. Ein eigenes Kapitel zu diesem Thema wäre sinnvoll, bevor man dieses Konzept mit grep oder einem anderen Befehl kombiniert. So musste ich selbst im Internet nachschauen, worum es geht. Das ist kein Problem, aber es ist frustrierend, wenn man sich auf ein Tutorial verlässt, das einen dann plötzlich verrät, indem es Begriffe einführt, die mehr Aufmerksamkeit verdienen.
Ein weiteres Problem, das ich hatte, war, dass in dem vom Dozent bereitgestellten Skript nur auf die Kapitel 2, 3 und 5 hingewiesen wurde. Daraus hatte ich geschlossen, dass es nicht notwendig sei, die Kapitel 1 und 4 zu machen. Ich war also ziemlich überrascht, als die Loops am Ende von Kapitel 5 auftauchten. Glücklicherweise hatte ich Python in einem anderen Modul geübt und konnte so leicht herausfinden, dass mir etwas fehlte und vor allem, was. Daraus habe ich abgeleitet, dass ich auch Kapitel 4 lesen muss, bevor ich zum Ende von Kapitel 5 zurückkehren und es richtig beenden kann. Ich muss zugeben, dass dies sehr frustrierend ist, da ich das Gefühl habe, meine Zeit zu verschwenden und ein Kapitel nicht beenden kann, bevor ich mit einem anderen beginne. Das führt zu weiteren "Stand-by"-Aktivitäten und gibt einem das Gefühl, mit der Arbeit nicht voranzukommen. Die Arbeitslast verdoppelt sich auch auf einen Schlag, wenn ich dachte, ich wäre am Ende des Kapitels angelangt…
Ich kritisiere auch die Erklärung der Loops, die für mich in dem Tutorial nicht sehr klar ist. Meine Erfahrung mit Python war hier sehr hilfreich. Ohne diese wäre ich wohl extrem verloren gewesen, um das Konzept zu verstehen und es richtig anzuwenden.
Dateisystem
Die erste Übung konzentrierte sich auf die Library Carpentry Lesson (Kapitel 1 bis 3) zur Unix Shell. Da ich bereits in anderen Modulen mit Bash-Befehlen unter Linux gearbeitet hatte, war das Tutorial leicht zu verstehen. Da ich sie aber nicht täglich benutze, war es trotzdem notwendig, sie noch einmal durchzugehen, als würde ich sie zum ersten Mal lernen. Ich habe Git Bash ohne Probleme auf meinem eigenen Windows-Computer installiert. Der Grund, warum ich diese Software einer anderen (wie z.B. dem Code Space von GitHhub) vorgezogen habe, ist, dass ich es gerne selbst ausprobiere. Das Ausprobieren mit meinen eigenen Dateien und Ordnern, mit denen ich bekannt bin, ist einfacher als das Ausprobieren in einem Codespace, mit dem ich nicht bekannt bin. Ich plane, diese Befehle regelmäßig zu verwenden, um zu sehen, ob sie mir wirklich Zeit sparen. Das einzige Problem, das ich habe und über das ich keine Angabe im Internet gefunden habe, ist, dass es nicht möglich ist, eine Datei mit einem anderen Programm zu öffnen. Dafür gibt es nur "cat"/"head"/"tail". Das ist sehr ärgerlich, wenn man mit PDFs oder Bildern arbeitet.
Wie gehe ich vor
Ich nehme jeden Befehl aus den Lessons einzeln und probiere ihn in meinem eigenen Terminal aus. Wenn ich Schwierigkeiten habe, oder manchmal auch nur aus Neugier, suche ich im Internet weiter. Zum Beispiel habe ich nachgeschaut, was "pwd" (Print work directory) bedeutet, damit ich es mir leichter merken kann.
Den Befehl "explorer" kannte ich noch nicht. Ich fand ihn sehr nützlich, weil es manchmal schwierig ist, sich genau zu merken, wo man sich in seinen Dateien befindet, vor allem, wenn man nicht daran gewöhnt ist. Allerdings war ich von diesem Befehl verwirrt, da er den Datei-Explorer im Hintergrund öffnet und nicht vor dem Terminal. Ich dachte fünf Minuten lang, dass der Befehl nicht funktionieren würde, konnte aber keinen Grund dafür finden. Ich war auch verwirrt über den Befehl "man", der bei mir --help ist. Leider hatte ich die Lesson viel zu schnell gelesen und nicht gesehen, dass sie sich ein paar Zeilen weiter unten darauf bezog. Am Ende habe ich vielleicht etwas zu viel Zeit in diese Übung investiert, vor allem weil es mir Spaß macht, Bash-Code zu benutzen.
0 notes
Text
Wie Cyberkriminelle Führungskräfte ins Visier nehmen und Malware als Köder nutzen

In einer Welt, in der digitale Verbindungen so tiefgreifend sind wie nie zuvor, haben Cyberkriminelle innovative Wege gefunden, um ihre Opfer zu erreichen. Eine besonders hinterhältige Methode, die derzeit im Umlauf ist, zielt direkt auf Führungskräfte ab, die sich oft in einflussreichen Positionen und mit sensiblen Informationen befinden. Doch wie genau gehen diese Kriminellen vor, um hochrangige Geschäftsleute ins Visier zu nehmen und sie mit Malware zu infizieren?Die Taktik der CybergaunerCyberkriminelle haben erkannt, dass soziale Netzwerke wie Facebook ein fruchtbarer Boden für potenzielle Opfer sind. Mit gefälschten Jobinseraten für Führungspositionen locken sie arglose Nutzer an. Die Anzeigen versprechen hochrangige Positionen in renommierten Unternehmen und locken die Aufmerksamkeit von Personen, die sich beruflich weiterentwickeln möchten.Doch der Teufel steckt im Detail. Die eigentliche Malware verbirgt sich nicht in den Anzeigen selbst, sondern in einem Link, der zu einer scheinbar harmlosen PDF-Datei auf Onedrive führt. Die Datei verspricht Informationen über die ausgeschriebene Stelle, lockt aber stattdessen die Opfer auf die Community-Plattform Discord. Dort angekommen, wird ein bösartiges Script heruntergeladen, das von der Windows-Powershell ausgeführt wird. Dieses Script lädt dann die Schadsoftware von Github herunter, die unter dem Namen Ov3r_Stealer bekannt ist.Die Funktionsweise der MalwareOv3r_Stealer ist eine gefährliche Form von Malware, die darauf abzielt, eine Fülle von sensiblen Informationen von den infizierten Systemen zu stehlen. Einmal aktiviert, durchsucht sie die Systeme nach Daten wie Kryptowährungs-Wallets, Webbrowser-Verlauf, Discord-Nachrichten, Filezilla-Zugangsdaten und vieles mehr. Sie analysiert auch die konfigurierten Systemdienste, möglicherweise auf der Suche nach Schwachstellen, die ausgenutzt werden können. Zusätzlich durchforstet sie das Dateisystem nach Dokumenten, die weitere Einblicke oder sensible Informationen liefern könnten.Was diese Malware besonders hinterhältig macht, ist ihre regelmäßige Kommunikation mit einem Bot auf dem Messenger Telegram. Alle 90 Minuten sendet sie ihre gesammelten Daten an diesen Bot, der sie dann möglicherweise an die Drahtzieher der Kriminellen weiterleitet.Die Warnung der ExpertenExperten warnen davor, die Bedrohung, die von dieser Taktik ausgeht, zu unterschätzen. Obwohl gefälschte Jobangebote an sich nichts Neues sind, stellt die gezielte Ausrichtung auf Führungskräfte eine alarmierende Entwicklung dar. Angesichts der weit verbreiteten Nutzung von Plattformen wie Facebook ist die potenzielle Opfergruppe groß und attraktiv für Cyberkriminelle.Es ist auch wichtig zu betonen, dass diese Art von Angriff nicht auf Facebook beschränkt ist. Ähnliche Methoden wurden bereits in anderen sozialen Medien und Messenger-Diensten beobachtet. Die Kriminellen gehen sogar so weit, ihre Opfer dazu zu bringen, tatsächliche Arbeiten auszuführen, die jedoch dazu dienen, die Opfer finanziell zu schädigen.
Fazit
Die Taktik, Führungskräfte mit gefälschten Jobinseraten anzulocken und dann Malware einzusetzen, ist ein beunruhigender Trend in der Welt der Cyberkriminalität. Es ist von entscheidender Bedeutung, dass Unternehmen und Einzelpersonen sich der Risiken bewusst sind und proaktiv Maßnahmen ergreifen, um sich zu schützen. Dies umfasst die Schulung von Mitarbeitern über die Gefahren von Phishing-Angriffen, die Verwendung von Antiviren- und Malware-Schutzsoftware und die Implementierung von Sicherheitsprotokollen, um verdächtige Aktivitäten zu erkennen und darauf zu reagieren.Indem wir uns der Methoden und Taktiken bewusst sind, die von Cyberkriminellen eingesetzt werden, können wir besser darauf vorbereitet sein, uns selbst und unsere Organisationen vor potenziellen Angriffen zu schützen.
Diese Fragen stellen andere
Wie können sich Führungskräfte vor dieser Art von Cyberangriffen schützen? Führungskräfte stehen heutzutage vor einer Vielzahl von Bedrohungen aus dem Cyberspace, und die Vermeidung von Angriffen erfordert ein proaktives Herangehen an die Sicherheit. Hier sind einige wichtige Schritte, die Führungskräfte ergreifen können, um sich vor dieser speziellen Art von Cyberangriffen zu schützen:- Sensibilisierung und Schulung: Eine der effektivsten Maßnahmen ist die regelmäßige Sensibilisierung und Schulung der Führungskräfte sowie aller Mitarbeiter in Bezug auf die neuesten Bedrohungen und die Erkennung von Phishing-Angriffen. Schulungen sollten praktische Beispiele und Simulationen von Angriffsszenarien enthalten, um die Wachsamkeit zu schärfen und das Bewusstsein für die Risiken zu stärken. - Überprüfung von Jobangeboten: Führungskräfte sollten besonders skeptisch sein, wenn sie unerwartete Jobangebote über soziale Medien oder andere Plattformen erhalten, insbesondere wenn sie von unbekannten Quellen stammen. Es ist wichtig, verdächtige Anzeigen und Nachrichten gründlich zu überprüfen, bevor man auf Links klickt oder persönliche Informationen preisgibt. Im Zweifelsfall sollten die Führungskräfte den Absender kontaktieren, um die Echtheit des Angebots zu bestätigen. - Implementierung von Sicherheitslösungen: Unternehmen sollten robuste Sicherheitslösungen implementieren, die dazu beitragen, Malware und andere bösartige Aktivitäten zu erkennen und zu blockieren. Dazu gehören Antivirenprogramme, Firewalls, Intrusion Detection Systems (IDS) und Endpoint-Schutzlösungen. Diese sollten regelmäßig aktualisiert und überwacht werden, um sicherzustellen, dass sie mit den neuesten Bedrohungen Schritt halten können. - Einsatz von Multi-Faktor-Authentifizierung: Um die Sicherheit von Konten und Systemen weiter zu verbessern, sollten Führungskräfte die Multi-Faktor-Authentifizierung (MFA) aktivieren, wo immer dies möglich ist. Durch die Kombination von Passwörtern mit zusätzlichen Authentifizierungsmethoden wie Fingerabdruck-Scans oder Einmalpasswörtern wird die Wahrscheinlichkeit verringert, dass Hacker Zugang zu sensiblen Informationen erhalten. - Regelmäßige Sicherheitsüberprüfungen: Unternehmen sollten regelmäßige Sicherheitsüberprüfungen durchführen, um potenzielle Schwachstellen in ihren Systemen und Netzwerken zu identifizieren und zu beheben. Dies kann Penetrationstests, Sicherheitsaudits und Vulnerability Scans umfassen, um sicherzustellen, dass alle Sicherheitsmaßnahmen wirksam sind und den aktuellen Bedrohungen standhalten können.Indem Führungskräfte diese Maßnahmen ergreifen und die Sicherheit zu einer Priorität machen, können sie das Risiko von Cyberangriffen verringern und ihre Organisationen besser schützen. Welche Rolle spielt die Zusammenarbeit zwischen Unternehmen und Behörden im Kampf gegen Cyberkriminalität? Die Zusammenarbeit zwischen Unternehmen und Behörden spielt eine entscheidende Rolle im Kampf gegen Cyberkriminalität und ist von entscheidender Bedeutung, um die Herausforderungen im Cyberspace effektiv anzugehen. Hier sind einige Schlüsselaspekte dieser Zusammenarbeit:- Informationsaustausch: Unternehmen und Behörden sollten aktiv Informationen über die neuesten Bedrohungen und Angriffsmuster austauschen. Dies ermöglicht es Unternehmen, sich besser auf potenzielle Angriffe vorzubereiten und proaktiv Sicherheitsmaßnahmen zu ergreifen. Auf der anderen Seite können Behörden von den Kenntnissen und Einblicken der Unternehmen in aktuelle Cyberbedrohungen profitieren, um ihre Ermittlungen zu unterstützen und Strafverfolgungsmaßnahmen zu ergreifen. - Gemeinsame Übungen und Schulungen: Unternehmen und Behörden sollten gemeinsame Übungen und Schulungen durchführen, um ihre Mitarbeiter und Ermittler auf aktuelle Bedrohungen vorzubereiten und ihnen die Fähigkeiten zu vermitteln, diese zu bekämpfen. Diese Übungen können simulierten Angriffsszenarien und Reaktionen auf Cyberangriffe umfassen, um die Zusammenarbeit und Koordination zu verbessern. - Unterstützung bei Ermittlungen: Unternehmen sollten eng mit den Strafverfolgungsbehörden zusammenarbeiten, um bei der Untersuchung von Cyberangriffen zu unterstützen und Informationen bereitzustellen, die zur Identifizierung und Verfolgung von Angreifern erforderlich sind. Dies kann die Bereitstellung von Protokolldaten, forensischen Beweisen und anderen relevanten Informationen umfassen, um die Ermittlungen voranzutreiben und zur Verhaftung und Strafverfolgung von Tätern beizutragen. - Entwicklung gemeinsamer Richtlinien und Standards: Unternehmen und Behörden sollten gemeinsam an der Entwicklung von Richtlinien, Standards und Best Practices arbeiten, um die Cybersicherheit zu verbessern und die Resilienz gegenüber Cyberangriffen zu stärken. Dies kann die Entwicklung von Leitlinien für die Sicherung kritischer Infrastrukturen, die Standardisierung von Sicherheitsverfahren und die Förderung von Zusammenarbeit und Informationssicherheit auf internationaler Ebene umfassen.Indem Unternehmen und Behörden zusammenarbeiten und ihr Fachwissen und ihre Ressourcen bündeln, können sie effektiver auf die wachsende Bedrohung durch Cyberkriminalität reagieren und gemeinsam eine sicherere und widerstandsfähigere Cybersicherheitslandschaft schaffen. Wie können Unternehmen die Sicherheitskultur innerhalb ihrer Organisation fördern? Die Förderung einer starken Sicherheitskultur innerhalb eines Unternehmens ist entscheidend, um Mitarbeiter zu sensibilisieren und zu befähigen, eine proaktive Rolle bei der Sicherung von Daten und Systemen zu spielen. Hier sind einige Schritte, die Unternehmen unternehmen können, um eine Sicherheitskultur zu fördern:- Führung von oben: Eine starke Sicherheitskultur muss von der Unternehmensführung unterstützt und gefördert werden. Führungskräfte sollten das Beispiel geben und die Bedeutung von Cybersicherheit betonen, indem sie Sicherheitsrichtlinien und -verfahren aktiv unterstützen und sich selbst an bewusstem und sicheren Verhalten beteiligen. - Sensibilisierung und Schulung: Unternehmen sollten regelmäßige Schulungen und Schulungen zur Cybersicherheit für alle Mitarbeiter durchführen. Diese Schulungen sollten praxisorientiert sein und auf aktuelle Bedrohungen und Best Practices eingehen, um die Mitarbeiter für potenzielle Risiken zu sensibilisieren und ihnen die Fähigkeiten zu vermitteln, sich selbst und das Unternehmen zu schützen. - Klare Richtlinien und Verfahren: Unternehmen sollten klare Richtlinien und Verfahren zur Gewährleistung der Informationssicherheit entwickeln und implementieren. Diese Richtlinien sollten die Nutzung von Unternehmensressourcen regeln, den Umgang mit sensiblen Informationen definieren und klare Anweisungen für den Umgang mit Sicherheitsvorfällen enthalten. - Belohnung und Anerkennung: Unternehmen sollten Mitarbeiter belohnen und anerkennen, die sich aktiv an der Sicherheitskultur beteiligen und dazu beitragen, das Sicherheitsniveau des Unternehmens zu verbessern. Dies kann durch Prämien, Auszeichnungen oder andere Anreize erfolgen, um ein positives Sicherheitsverhalten zu fördern und zu verstärken. - Regelmäßige Überprüfung und Anpassung: Eine starke Sicherheitskultur erfordert kontinuierliche Überprüfung und Anpassung. Unternehmen sollten regelmäßig ihre Sicherheitspraktiken überprüfen, um sicherzustellen, dass sie mit den aktuellen Bedrohungen Schritt halten, und ihre Schulungs- und Sensibilisierungsprogramme entsprechend anpassen.Indem Unternehmen diese Maßnahmen ergreifen und eine Kultur der Sicherheit und des Bewusstseins schaffen, können sie das Risiko von Sicherheitsvorfällen verringern und die Widerstandsfähigkeit ihrer Organisation gegenüber Cyberangriffen stärken. Read the full article
#Cybersicherheit#Datenschutz#Malware#SecurityAwarenessSchulung#Sicherheitsbewusstsein#SicherheitsrisikenamArbeitsplatz#Unternehmen
0 notes
Text
App-Programmierung für Anfänger: Eine Schritt-für-Schritt-Anleitung
Das Erlernen der App-Programmierung ist eine aufregende Reise, die Türen zu einer Welt voller Kreativität, Problemlösung und Innovation öffnen kann. Unabhängig davon, ob Sie mobile Apps für iOS oder Android erstellen möchten, hilft Ihnen diese Schritt-für-Schritt-Anleitung beim Einstieg in Ihre Programmierreise.
Wählen Sie eine Plattform und Sprache:
Entscheiden Sie, ob Sie Apps für iOS oder Android entwickeln möchten. Für iOS verwenden Sie hauptsächlich Swift oder Objective-C, während die Android-Entwicklung auf Java oder Kotlin setzt. Recherchieren Sie jede Plattform und Sprache, um ihre Stärken und Schwächen zu verstehen.
Richten Sie Ihre Entwicklungsumgebung ein:
Installieren Sie die erforderlichen Tools und Software. Für die iOS-Entwicklung benötigen Sie Xcode- (nur macOS) und Swift/Objective-C-Kenntnisse. Für Android verwenden Sie Android Studio, das auf mehreren Plattformen verfügbar ist, zusammen mit Java/Kotlin.
Lernen Sie die Grundlagen des Programmierens:
Bevor Sie sich mit der App-Entwicklung befassen, sollten Sie sich mit den Grundlagen der Programmierung vertraut machen. Verstehen Sie Konzepte wie Variablen, Datentypen, Kontrollstrukturen (IF-Anweisungen, Schleifen) und Funktionen. Machen Sie sich mit der Syntax der von Ihnen gewählten Programmiersprache vertraut.
Erkunden Sie Benutzeroberflächen:
Bei Apps dreht sich alles um Benutzeroberflächen (UI). Erfahren Sie, wie Sie benutzerfreundliche Schnittstellen entwerfen, indem Sie Layouts, Ansichten und Widgets für Android oder Ansichten und Ansichtscontroller für iOS verstehen. Machen Sie sich mit Designprinzipien zur Erstellung ansprechender und intuitiver Benutzeroberflächen vertraut.
Datenverarbeitung und -speicherung:
Da Apps oft mit Daten arbeiten, ist es wichtig zu lernen, wie man Daten verwaltet. Verstehen Sie, wie Sie Daten aus dem lokalen Speicher (Dateisystem, Datenbanken) lesen und schreiben und wie Sie Netzwerkanfragen stellen, um Daten von Remote-Quellen abzurufen.
Anwendungslogik:
Beherrschen Sie die Logik, die die Funktionalität Ihrer App steuert. Dazu gehört das Schreiben von Code, der auf Benutzerinteraktionen reagiert, Daten verarbeitet und Aktionen ausführt. Erfahren Sie, wie Sie Ihren Code effizient strukturieren.
Debuggen und Testen:
Erfahren Sie, wie Sie Ihren Code debuggen, um Fehler zu identifizieren und zu beheben. Entdecken Sie Testtechniken, um sicherzustellen, dass Ihre App wie vorgesehen funktioniert. Machen Sie sich mit den Tools und Techniken zum Testen und Debuggen auf der von Ihnen gewählten Plattform vertraut.
Bauprojekte und Praxis:
Um ein kompetenter App-Programmierer zu werden, ist praktische Erfahrung unerlässlich. Beginnen Sie mit kleinen Projekten und arbeiten Sie sich nach und nach zu komplexeren Apps vor. Diese praktische Erfahrung wird Ihr Lernen verstärken.
Kontinuierlich studieren und lernen:
Die Tech-Welt entwickelt sich ständig weiter. Bleiben Sie auf dem Laufenden, indem Sie Bücher und Blogs lesen und an Online-Kursen oder Foren teilnehmen. Bleiben Sie mit der Programmier-Community in Verbindung, um von anderen zu lernen und über Best Practices auf dem Laufenden zu bleiben.
Veröffentlichen und teilen Sie Ihre Apps:
Wenn Sie Vertrauen gewonnen und ein Projekt abgeschlossen haben, sollten Sie darüber nachdenken, Ihre App bei Google Play (Android) oder im app entwickeln (iOS) zu veröffentlichen. Ihre Arbeit mit der Welt zu teilen ist eine lohnende Möglichkeit, Ihre Fähigkeiten zu präsentieren und Feedback zu erhalten.
Bitten Sie um Feedback und Zusammenarbeit:
Zögern Sie nicht, Feedback von erfahrenen Entwicklern und Ihren potenziellen Benutzern einzuholen. Arbeiten Sie mit anderen an Open-Source-Projekten oder App-Entwicklungsteams zusammen, um praktische Erfahrungen zu sammeln.
Zusammenfassend lässt sich sagen, dass die App-Programmierung für Anfänger eine spannende und lohnende Reise sein kann. Indem Sie dieser Schritt-für-Schritt-Anleitung folgen und eine konsistente Lernmentalität beibehalten, können Sie den Grundstein für eine erfolgreiche Karriere als App-Entwickler legen. Nehmen Sie die Herausforderungen an, feiern Sie Ihre Erfolge und bleiben Sie neugierig, um das volle Potenzial der App-Programmierung auszuschöpfen.
0 notes
Text
Vorlesung 1 - Technische Grundlagen
Kurze Info: Leider war es mir bisher aufgrund meiner Krankheit noch nicht möglich, die gesamte Vorlesung des 15.2.2023 nachzuholen. Daher wird dies noch in den nächsten Tagen folgen.
Generelle Inhalte der 1. Vorlesung:
Einführung in die Lernumgebung inkl. HedgeDoc, Github
Markdown
Einführung in die Grundlagen von UnixShell
Übung zum Dateisystem mit UnixShell
Versionskontrolle mit Git
Beitreten und Beenden von Code Spaces
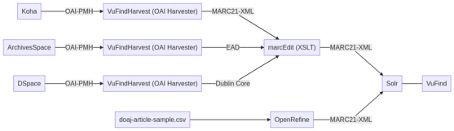
Zunächst einmal wurde das Schaubild, welches durch diesen Kurs führen soll erklärt. Hier werden die wichtigsten technischen Zusammenhänge dargestellt und erklärt.
Wir haben somit drei Katalogisierungssysteme. Durch eine Schnittstelle (OAI-PMH) wird es dem Harvester möglich gemacht Datensätze aus den Systemen herunterzuladen. Wenn die Daten heruntergeladen werden, können sie über diverse Programme (Open Refine und marcEdit) konvertiert werden. Diese Daten wiederum können über Suchsysteme wie Solr durchsucht werden und über eine Suchmaske bzw. Oberfläche gesucht werden (VuFind).
Der Unterricht wurde gemeinsam in einem Dokument durchgeführt, was eine neue Art des Unterrichts für mich war, mir aber gut gefallen hat.
Übung zu der Auszeichnungssprache Markdown
Markdown war etwas, von dem ich zwar schon viel gehört hatte, mich aber nie wirklich auseinandersetzt habe. Das Tutorial, welches verlinkt war, war eine sehr hilfreiche Übung. Durch den langsamen Aufbau der Schwierigkeit und das repetitieren eine klare und verständliche Einführung war.
Markdown
Die Idee hinter Marktdown ist, so schnell lesbar und schreibbar zu sein wie möglich. Die Quelle dafür ist die Formatierung von Nur-Text-Emails und bietet daher nur wenige formatierungs Möglichkeiten an. Diese Formatierungen sind HTML-Tags. Es ist im Unterschied zu HTML, was ein Publikations-Format ist, ein Schreibformat.
Von Bedeutung sind:
Überschriften: werden mit # dargestellt, je mehr Rauten, desto kleiner die Überschrift
Zitate: können über > gemacht werden. Wie bei den Überschriften gilt hier - je mehr, desto verschachtelter.
Listen: können über mehrere Zeichen erstellt werden: - , + und * (oder über Nummerierungen)
Fusszeilen: bzw. Quellenangaben gehen über [^1] erstellt werden. An einer anderen Stelle muss dann: [^1] (Quellenangabe) stehen.
Kursiv: *in Sternchen*
Fett: _mit Unterstrich_
Weitere Infos unter: Markdown
Die Unix Shell
Die Shell wurde bereits in einigen Vorlesungen wie beispielsweise Wirtschaftsinformatik und ARIS eingeführt und verwendet. Dennoch fällt mir der Umgang mit der Shell zugegebenermaßen immer noch nicht leicht. Daher war es ganz gut, dass diese nochmals besprochen wurde.
Was ist die Shell?
Sie ist der Mittler zwischen dem Benutzer und dem Betriebssystemkern. Ihr Ziel ist es, Kommandos entgegenzunehmen und das Betriebssystem um die Ausführung dieser zu bitten. Diese Kommandos sind festgelegt und laufen nach einem bestimmten Schema ab. Es gibt zwei Arten von Kommandos:
Kommandos in der Shell
Kommandos die im Dateisystem gesucht und gestartet werden.
Wichtige Kommandos: cat, -b, -n, -s, ln (link), cp (Copy), mv (move/verschieben), rm (remove /löschen), cd (wechseln des aktuellen Arbeitsverzeichnisses), pwd (Print Working Directory - Name des aktuellen Verzeichnisses).
Weitere Kommandos
Links: https://de.wikipedia.org/wiki/Unix-Shell
0 notes
Photo

Die Leute geben Millionen für NFTs aus. Was? Warum? https://teknoleft.de/die-leute-geben-millionen-fur-nfts-aus-was-warum/
#dateisystem raw#raw in ntfs umwandeln ohne datenverlust#festplatte raw format in ntfs umwandeln#raw zu ntfs umwandeln ohne formatierung#computer
0 notes
Text
JPEG oder Wert?
Krypto und Web3 im Blog. Alarm!
Naja, so dramatisch wird es nicht werden. Das Thema finde ich aktuell einfach faszinierend. Ich bemerke da bei mir eine Aufbruchstimmung, teilweise sogar Euphorie, kindliche Freude, dass sich das Netz weiterentwickelt und Menschen wieder Tools, Anwendungen und Seiten zu einem neuen Ökosystem zusammenbauen. Es fühlt sich ein wenig wie die Anfangstage des Web 2.0 an.
Da die Entwicklung m.E. immer noch in einem frühen Stadium steckt, wird wahrscheinlich vieles in zwei, fünf, zehn Jahren anders aussehen. Dienste, Anwendungen und Webseiten wird es nicht mehr geben und viele Leute werden vermutlich viel Geld verloren haben.
Ich möchte im Blog in unregelmäßigen Abständen ein paar Themen und Meldungen zu Web3/Krypto behandeln. Ihr könnt mir dabei etwas beim Lernen und Entdecken zusehen, wenn ihr mögt. 😉
Eines der heißesten Themen zur Zeit in diesem Themenkomplex sind NFTs, die non-fungible tokens. Meist lesen wir von NFTs, wenn es sich um digitale Bilder handelt. Doch sind die Bilder wirklich das, was Käufer*innen erwerben? Eher nicht. Vielmehr repräsentieren NFTs Einträge in einer Blockchain. Die Einträge vermerken, welche (Wallet-)Adresse zu welchem Zeitpunkt Rechte an etwas erworben hat. Zusätzlich gibt es einen Pointer zu dem Gegenstand der erworbenen Rechte.
Schauen wir uns das einmal an einem Beispiel an. Ausgangspunkt ist dieser Artikel in der ZEIT über die NFTs des WWF Deutschland (die Seite des WWF zu den NFTs).
Der WWF hat die Polygon-Blockchain verwendet, die Ressourcen schonender und günstiger arbeitet als die oft bei NFTs verwendete Ethereum-Blockchain (Unterschiede der Blockchains vielleicht zu einem späteren Zeitpunkt, wenn ich etwas zum Thema gelernt habe). Die Abbildung aus der ZEIT und die zugehörigen Daten findet man auf der Plattform OpenSea.
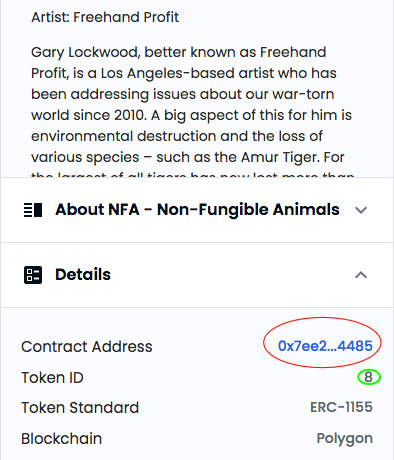
Klappt man die Details aus, wird die Adresse des Smart Contracts sichtbar (rotes Oval, das grüne Oval, die Token ID, wird gleich noch wichtig):
Exkurs Smart Contracts: Nur so viel: Manche Blockchains sind programmierbar und man kann sogenannte Smart Contracts hinterlegen. Ethereum und Polygon, das an Ethereum andockt, sind zwei solcher Blockchains.
Die Contract Adresse verweist auf Polygonscan, wo man alle Daten und Abwicklungen auf der Polygon-Blockchain findet und nachvollziehen kann:
https://polygonscan.com/address/0x7ee2c4a5cab5b0d6fdf4c55177b0a8bf99054485

Den Inhalt des Smart Contract kann man unter - wer hätte das gedacht - Read Contract einsehen. Die URI, also der Pointer, lässt sich unter Punkt 17 abfragen. Dazu benötigen wir die Token ID von oben, die 8:

Ein Klick auf Query offenbart uns diese Adresse: https://gateway.ipfs.io/ipfs/QmQRJXgPtfB6DAz9RYnSPJyncPjwyQCEpnAQNDjA4RGDE9
Gibt man die Adresse im Browser ein, ist erst einmal nur Text zu sehen. In diesem Beispiel gibt es Hinweise auf den Künstler, auf den WWF, die Hintergründe zu den NFTs und schließlich noch zwei URLs:
https://gateway.ipfs.io/ipfs/QmdPYeQ63YPWzXaTeWA1EfK3yYY6WN4mQQkRHABDwXqhcb -> Hier verbirgt sich das Bild.
Wie wir in der Übersicht auf OpenSea bereits gesehen haben, gibt es zu diesem NFT auch noch eine Animation. Die findet sich hinter dieser URL: https://gateway.ipfs.io/ipfs/QmdKqZEDshn38TYtXAxXat2g2nDYLWeyuUZ2YQQtUVBwnB
Exkurs IPFS: Was zum Henker ist IPFS? Das ist das InterPlanetary File System. Aus der Wikipedia:
InterPlanetary File System (IPFS) ist ein Protokoll und namensgebendes Netzwerk, entworfen um eine inhaltsadressierbare, Peer-to-Peer-Methode des Speicherns und Teilens von Hypermedien in einem verteilten Dateisystem zu schaffen.
Kurz: Man kann mit IPFS Webseiten und Dateien dezentral spiegeln.
Wie ekennbar ist, könnte der Pointer im Vertrag aber auch zu einer völlig normalen URL zeigen (das WordPress Blog oder - wenn mich nicht alles täuscht - auch die URL zur freigegebenen Datei auf Dropbox). Diese Seiten sind allerdings anfällig gegenüber Angriffen oder noch profaneren Dingen wie die vergessene Verlängerung der Domainregistrierung. Sie bestehen also ggf. nicht für alle Ewigkeiten. IPFS ist hier ein kleiner Rettungsanker. Wie anfällig und ausfallsicher IPFS ist, weiß ich nicht. Das Protokoll ist mir tatsächlich erstmalig im Zusammenhang mit NFTs begegenet, obwohl es das schon seit einiger Zeit gibt (s. obigen Artikel der Wikipedia).
Für Käufer*innen von NFTs bietet es sich also zumindest an, die URLs ausfindig zu machen und die Dateien zu sichern. Besitzt man aber überhaupt noch Rechte an z.B. einem Bild, wenn die Adresse des Pointers aus dem Vertrag nicht mehr vorhanden ist? Oder hat man nur noch ein JPEG (GIF,...) ohne Rechte?
Mit diesem Wissen lässt es sich trefflich darüber streiten, ob NFTs überhaupt einen Wert haben können, wenn die Beständigkeit des zugrundeliegenden Gutes nicht gewährleistet ist. Ich nehme zugunsten von NFTs an, dass es Entwicklungen geben wird, die da eine größere Sicherheit garantieren werden. Aber wer weiß...
2 notes
·
View notes
Text
April bis Dezember 2016
Podcasts erstmal nur noch mit Gummi
Immer noch (so wie seit 2008 und vor zwei Jahren dokumentiert) höre ich auf extrem umständliche Weise mit einem iPod Shuffle der zweiten Generation Podcasts, und zwar durchweg mit demselben Gerät. Daß der Akku immer schwächer wird, ist gerade so zu verkraften. Recherchen nach Austauschakkus verlaufen erfolglos: Möglich, aber fast so teuer wie ein neues Gerät und dank Apples Klebemontage viel zu kompliziert. Gelegentlich recherchiere ich nach alternativen MP3-Playern, aber mit wachsender Unlust. Das acht Jahre alte Gerät ist nach wie vor schöner als das meiste aktuelle, aus den Nachfolgeversionen läßt sich iTunes nicht raushacken, und aus irrationalen Gründen hänge ich an meinem absurd komplizierten Verfahren, Dateien halb automatisiert herunterzuladen und von Hand aufzukopieren.
Nun aber kommt es genau da zu Alterserscheinungen, wo ich sie als letztes erwartet hätte: Die Klammer zum Befestigen an der Kleidung klammert nicht mehr, von einem Tag auf den anderen. Ich probiere verschiedene Workarounds aus, von der Aufbewahrung in der Hemdtasche bis zum Einmachgummi, das die unreparierbare Feder ersetzt. Das Einmachgummi erzielt die besten Ergebnisse, auch wenn es etwas fitzelig ist: Das Gummi darf nicht so weit vorne sein, daß man nichts mehr klammern kann, aber auch nicht so weit hinten, daß es Knöpfe drückt.

Dieses Provisorium halte ich über ein halbes Jahr lang durch, bis der summierte Ärger von Akku und Klammer mich zu einem radikalen Schritt bringt: Nach acht Jahren, acht Monaten und drei Wochen mustere ich den iPod aus und ersetze ihn durch mein ohnehin immer dabeies Smartphone.
Damit es weiterhin schön kompliziert bleibt, nehme ich dafür natürlich keine dezidierte Podcast-App. Stattdessen teste ich ca. alle Audioplayer in Googles Appstore, die versprechen, ganze Ordner im Dateisystem abspielen zu können, bis ich bei der App »Folder Player« lande. Dieses Provisorium sollte wieder ein paar Jahre halten.
(Felix Neumann)
2 notes
·
View notes
Text
Neuer Blogpost: Wie man die aktuelle Ausgabe der c’t als Hörbuch konsumiert
Wer mit öffentlichen Verkehrsmitteln zur Arbeit pendelt und dabei die Computerzeitschrift c’t lesen möchte, hat mit der passenden App eine gute Möglichkeit, diese am Handy oder Tablet zu konsumieren. Sitzt man aber am Steuer des eigenen PKWs, sollte es schon eine gesprochene Fassung sein; eine solche gibt es aber bislang nicht. Mit etwas Handarbeit und „Text to Speech“-Vorlesefunktion (TTS) funktioniert dies mit einem Android-Handy sogar ohne permanente Internetverbindung recht gut. — Nachfolgend findet sich meine Lösung zum Nachmachen.
Der Start: Das Digital-Abo der c’t
Den Start bildet ein Digital-Abo der c’t. Um herauszufinden, ob man so etwas hat, schaut am besten unter shop.heise.de unter „Abo“ nach. Lässt sich die aktuelle c’t dort als PDF-Datei (mit persönlichem Watermark) herunterladen, hat man das passende Abo. — Nebenbei bemerkt: Ich gehe davon aus, dass die nachfolgende Vorgehensweise auch mit den Schwester-Zeitschriften der c’t des Heise-Verlags funktioniert, also iX, Mac & i, Technology Review und Make.
Die heruntergeladene PDF-Datei ist eigentlich bereits eine gute Basis für die Vorlesefunktion. Die Erfahrung zeigt aber, dass beim mehrspaltigen PDF-Print-Layout mitunter unpassende Vorlese-Reihenfolgen entstehen, und dass sporadisch mal Kopf- oder Fußzeilen mitten im Text erneut zu Gehör gebracht werden – das ist natürlich unschön.
Idealer Einstieg: Heise Select
Den besseren Einstieg bietet die Online-Ausgabe der c’t unter „Heise Select“. Hier lassen sich alle redaktionellen Bestandteile der aktuellen Ausgabe in sauber formatierter HML-Fassung direkt im Browser lesen. — Obacht: Bitte stichprobenartig überprüfen, ob man hier tatsächlich tatsächlich angemeldet ist und die Volltexte sehen kann, siehe Screenshots.
Ist das tatsächlich der Fall, sind alle Vorbedingungen erfüllt, um den redaktionellen Teil in Form einzelner HTML-Dateien pro Artikel auf den eigenen Computer herunterzuladen, die für die Vorleser-App deutlich besser zu verdauen sind als die im Print-Layout formatierte, monolithische PDF-Datei. Allerdings wird man schwerlich jeden einzelnen Artikel mit der rechten Maustaste anklicken und so deren HTML-Fassungen einzeln auf die Festplatte speichern wollen.
Kekse für wget
Daher geht es nun in die Kommandozeile – das ist ein bisschen nerdig, aber hey, wir reden hier ja von der c’t und nicht von einer Modezeitschrift. Also: Ein bisschen Einsatz bitte!
Gefragt ist das kostenlos verfügbare Open Source-Kommandozeilen-Tool „wget“, das alle HTML-Dateien in einem Rutsch ohne fehlerträchtige Handarbeit bequem auf den eigen Computer herunterlädt. Ist wget auf dem jeweiligen Computer noch nicht vorhanden, lässt es sich unter Linux meist recht einfach per Paketmanager nachrüsten, am Mac empfehle ich dem geneigten Nerd den Weg über Homebrew. Für Windows findet man wget z.B. unter diesem Link.
wget stellt einen „Browser ohne Fenster“ dar, lädt die besuchten HTML-Dateien herunter und folgt den darin enthaltenen Links, um sicher zu gehen, keine Datei zu vergessen. Korrekt konfiguriert kann man auf diese Weise einen entsprechenden Teil des WWW auf den eigenen Computer kopieren, auch „mirrorn“ genannt.
Würde man wget nun allerdings ohne Vorbereitung auf Heise Select loslassen, würde man nur die gekürzten Ausgaben („Sie wollen wissen, wie es weitergeht?“, s.o.) mit dem Login-Hinweis herunterladen. Das ist nur allzu verständlich, schließlich verfügt wget nicht über die Anmelde-Cookies, mit denen der Heise-Webserver dem Desktop-Browser den Zugriff auf die Volltexte gewährt.
Folglich müssen wir das Cookie-Jar des Desktop-Browsers nach wget transplantieren. Dabei hilft den Nutzern von Google Chrome die Browser-Erweiterung „cookies.txt“.
Sie dient exakt dazu, das komplette, zum aktuellen Download-Pfad gehörige Cookie-Jar in einer .txt-Datei zu speichern, die wget verdauen kann. Anschließend erhält wget dieselben Download-Befugnisse wie das ursprüngliche Browserfenster.
wget – übernehmen Sie!
Meine eigenen Cookies von heise.de habe ich in einer Datei namens „cookies-gero.txt“ gespeichert, die Namensgebung ist natürlich vollkommen beliebig. Derart gewappnet geht’s nun endlich an den Download. Meine Kommandozeile lautet am Beispiel der am 29. Februar 2020 erschienen Ausgabe 06/2020 (in einer Zeile!):
wget -r -l 1 -k -E -p -np -R jpg,jpeg,png,gif,pdf,css,js,svg --cut-dirs=2 --load-cookies cookies-gero.txt https://www.heise.de/select/ct/2020/6/
Im Klartext (vgl. Manpage zu wget): Wir laden rekursiv, folgen also den Links; wir bleiben aber bei einer Link-Tiefe von 1; wir konvertieren Links, wir passen die Endungen an; wir laden Inline-Bilder herunter; wir verbieten das Parent-Directory; wir interessieren uns aber nicht für Bilder und andere Downloads; die ersten beiden Dateinamens-Ebenen der URL sollen beim Speichern aus dem Dateipfad abgeschnitten werden, damit es auf der heimischen Festplatte etwas übersichtlicher bleibt; dann wird noch das aus Chrome heruntergeladene Cookie-Jar eingebunden. Und endlich geht es ab dafür – mit der zur aktuellen Ausgabe passenden URL.
Bei mir dauert der komplette Download der 70-80 Einzeldateien meist ca. 3 Minuten – wobei sicher nicht der Breitband-Anschluss den Flaschenhals darstellt, sondern das Herumsuchen und der Einzel-Download verschiedenen Dateien. Das Resultat ist lediglich ca. 4 MB klein und ist im nachfolgenden Bild dargestellt.
Man wird sporadisch überprüfen wollen, ob die Downloads tatsächlich den vollständigen Text enthalten: Die Anmelde-Cookies haben eine Verfallsdatum, anschließend grast wget das Heise Select-Portal wieder ohne gültige Benutzeranmeldung ab. In diesem Fall muss man sich erneut im Chrome auf der Webseite anmelden und die cookies.txt-Datei erneuern, damit es wieder klappt.
Dateitransfer aufs Handy
Nun transferiert man den Stapel HTML-Dateien an eine geeignet erscheinende Stelle aufs Android-Handy. Jeder mag hier die eigene präferierte Methode verwenden: Per USB-Kabel, per Google Drive Cloud, per Mail an sich selbst mit einer ZIP-Datei des Ordners und anschließendem Herunterladen und Auspacken des Attachments im „Download“-Ordner … oder wie auch immer – jeder Jeck ist anders.
Ich persönlich empfehle hierfür den kostenlosen, werbefreien Total Commander – Dateimanager für Android mitsamt des passenden WiFi/WLAN-Plugin für Totalcmd.
Mit Hilfe dieses Plugins kann man ganze Ordner des Android-Dateisystems im heimischen (W)LAN freigeben und von Finder, Explorer & Co. per WebDAV darauf zugreifen.
Hierzu muss man natürlich die etwas sperrige Freigabe-URL eintippen; alternativ sucht man sich einen QR-Code-Scanner für die Laptop-Webcam (unter macOS etwa das kostenlose „QR Journal“) und ist fein raus.
Anschließend kann man die Dateien einfach per Drag & Drop vom Desktop aufs Handy ziehen. So sieht das Resultat dann (wiederum im Total Commander) am Handy aus:
Text-to-Speech Sprachmodule
Nun zur eigentlichen Vorlesefunktion, auf englisch „Text-to-Speech“ oder kurz „TTS“ genannt. Grundsätzlich beherrschen moderne Android-Handys diese Funktion mit Bordmitteln, entsprechende APIs existieren im Dienste der Barrierefreiheit im Betriebssystem. Maschinelle Vorleser mit verschiedenen Stimmen und unterschiedlich gut gelungener Sprachsynthese, die sich anschließend wahlweise nutzen lassen, gibt es im Google Play-Store herunterzuladen – kostenlos wie kostenpflichtig.
Man findet im Internet verschiedene Vergleichstests darüber, welche Stimme für welchen Zweck besser oder schlechter geeignet ist. Schlussendlich entscheidet aber auch noch der eigene Geschmack. Die mit meinem in Ehre ergrauten Samsung Galaxy S7 mitgelieferte Samsung-Stimme gefällt mir persönlich nicht so sehr, sie klingt arg künstlich.
Aktuell verwende ich stattdessen Googles kostenlos verfügbare Sprachsynthese „Google Sprachausgabe“, die sowohl mit männlicher als auch weiblicher Stimme verschiedenste Sprachen unterstützt, die man sich jeweils in-app dazu laden kann. — Wie gesagt, Geschmäcker sind verschieden.
Vorlesen – there’s an app for that
Das eigentliche Vorlesen von Texten geht natürlich über die reine Handy-Bedienung für Personen mit eingeschränktem Sehvermögen hinaus. Für diesen Zweck muss man mit einer spezialisierten App nachhelfen. Auch derer gibt es mehrere verschiedene im Google Play Store.
Ich persönlich verwende @Voice Aloud Reader, ich habe mir sogar die @Voice Premium Lizenz für aktuell 9,50 EUR gegönnt (mehr dazu weiter unten). @Voice merkt man an, dass er über viele Jahre hinweg entstanden ist und nach und nach immer mehr Features und Einstellmöglichkeiten hinzu gekommen ist. Man kann sich leicht darin verirren, und einiges ist wenig offensichtlich und erfordert anfänglich etwas Herumprobieren.
Man beginnt idealerweise damit, oben links das (schmale) „Burger-Menü“ aufzurufen. Auf der nun erscheinenden, anfangs leeren Seite tippt man unten links auf das „+“, um Dateien hinzuzufügen. Nun kann man sich nun in das gewünschte Verzeichnis durchhangeln, in das man oben die heruntergeladenen .html-Dateien kopiert hatte. — Liegen diese auf der eingelegten SD-Karte, fordert die App typischerweise zur Freigabe von Zugriffsrechten auf.
Dort finden sich alle zum Vorlesen geeigneten Dateien des gewählten Verzeichnisses, und sie lassen sich zum Vorlesen an- oder abwählen – gerne auch alle auf einmal mit dem entsprechenden Symbol oben rechts in der Leiste. Freundlicherweise wird hier „natürlich“ sortiert, d.h. 1…9 kommt vor 10…11…99 kommt vor 100… usw. — Auf „index.html“, das das Inhaltsverzeichnis repräsentiert, kann man getrost verzichten.
Nach „Fertig“ gelangt man zurück auf die zuvor leere Seite, die nun die soeben angewählten Dateien enthält, die man bei Bedarf umsortieren kann. Tippt man nun etwa die oberste an (typischerweise das c’t-Editorial auf „seite-3.html“) und tippt unten rechts auf das „Play“-Symbol, gelangt man zurück zum Hauptbildschirm – und „schon“ geht’s los. Ein Tipp auf den „Pfeil nach oben“ ganz unten rechts klappt das abgebildete Menü aus, auf dem sich die grundlegenden Spracheinstellungen konfigurieren lassen.
Detailliertere Einstellungen, insbesondere die Wahl der Stimme und entsprechende Feineinstellungen, finden sich im Wust der Programmeinstellungen oben rechts hinter dem Zahnrad-Symbol. Als ungemein wichtig empfinde ich vor allem die erst in der Vollversion freigeschaltete Möglichkeit, Sprachersetzungen zu konfigurieren.
Mitunter wird man nämlich beim Zuhören über Begriffe wie etwa „Liezen-Zart“ stolpern und nach kurzem Nachdenken amüsiert feststellen, dass damit wohl „Lizenz-Art“ gemeint war. Jegliche derartigen Abstrusitäten wird man wohl kaum vorab finden, aber sträflichen Aussprachefehlern wie die meiner Google-Stimme, die dazu neigt, „iOS“ als „Ieh-Oss“ und „macOS“ als „Mah-Koss“ auszusprechen, kann man damit wirksam entgegentreten.
Die merkwürdigen Sonderzeichen vor „iOS“ und „macOS“ rühren übrigens daher, dass diese als „Nur als ganzes Wort“ markiert sind – damit aus „grandios“ nicht etwa also „grand-Ei-Oh-Ess“ ausgesprochen wird.
Wiedergabe und Steuerung per Medientasten am Autoradio
Nachdem man seine persönliche Lieblingsstimme und die optimale Vorlesegeschwindigkeit gefunden hat, gestaltet sich das Vorlesen als überaus angenehm. Richtig nett wird das alles natürlich erst, wenn das Handy per Bluetooth mit dem Autoradio gekoppelt ist und das Playback folglich nicht über den quäkenden Handy-Lautsprecher, sondern über das Auto-Audiosystem erfolgt.
Natürlich wird man zur Navigation im Text nicht das Handy in die Hand nehmen wollen (bzw. auch gar nicht dürfen). Stattdessen unterstützt @Voice zumindest die drei Medientasten Pause, Prev und Next, die das entsprechend ausgestattete Autoradio per Bluetooth ans Handy zurück schickt, und die @Voice entsprechend auswertet.
Dabei gilt: Während des laufenden Playbacks springt ein Druck auf Next/Prev satzweise vor bzw. zurück. Das hilft, wenn man den letzten Satz noch einmal hören möchte, oder wenn man beispielsweise über ein kryptisches Code-Beispiel hinweg skippen möchte, das ungelenk vorgelesen wird.
Der deutlich wichtigere Anwendungsfall ist aber sicher, einen weniger interessanten Artikel abzubrechen und unverzüglich zum nächsten Artikel zu wechseln. Etwas versteckt findet sich in der Anleitung zu @Voice der rettenden Hinweis: Man unterbricht zuerst die Wiedergabe durch Druck auf die Pause-Taste – und drückt erst dann die Next-Taste. Damit springt @Voice tatsächlich in die nächste Datei und damit zum nächsten Artikel.
All das möchte man vielleicht einmal vor Fahrtantritt noch auf dem Parkplatz stehend mit eingeschaltetem Handydisplay ausprobieren, bevor man das Gerät in den Standby schickt und in die Mittelkonsole legt. Man gewöhnt sich aber schnell daran und will es bald nicht mehr missen.
Share
von GZB – Gero Zahns Blog – ger.oza.hn https://ift.tt/39duF5c
2 notes
·
View notes
Photo


Anleitung: PC - Amiga Transfer mit CrossDos
CrossDos ist ein Dateisystem für den Amiga, das das Lesen und Beschreiben von PC-DOS Disketten im FAT-Format ermöglicht. Dies ist eine der einfachsten Methoden, kleinere Daten-Mengen zwischen den PC und Amiga auszutauschen.
Zum Eintrag
9 notes
·
View notes
Text
Avi Und Mp3 Zusammenfьgen
MP3Tag ist ein Software zum komfortablen Bearbeiten von Tags, den Informationen zu Interpret, Album, Titel, usw. Danke für die Blumen, ich hoffe das Tutorial hilft weiter. Du sprichst da etwas an, dass mich auch schon seit längerem beschäftigt. Ich habe dies der Einfachheit halber aus dem Tutorial bewusst rausgelassen. Ich habe aber inzwischen einen neuen Submit geschrieben, der genau dieses Problem angeht. Bei der Recherche bin ich außerdem noch auf ein anderes Freeware Programm gestoßen, dass dir auch gefallen dürfte. Bitte berichte, was für dich am Besten funktioniert.
Dateien, die Sie codieren möchten, fügen Sie dem Warteschlangenfenster hinzu. Sie können Quellvideo- oder Audiodateien, MP3s zusammenfügen Adobe Premiere Pro-Sequenzen oder Adobe After Effects-Kompositionen zur Warteschlange der zu codierenden Objekte hinzufügen. Sie können die Dateien per Drag-and-Drop in die Wartschlange ziehen oder auf Quelle hinzufügen klicken und dann die zu codierenden Quelldateien auswählen. Timbre prides auf Sein der kompletteste Audioherausgeber und Provideodie herausgeber-APP, die überhaupt gebildet werden. Die populärsten Eigenschaften von Timbre sind der Scherblock MP3 Cutter u. mp4. Aber es tut viel mehr, Liede mp3 als einfach schneiden oder schneidenvideos, es auch die Funktionalität Ringtone Maker und MP3 des Bildschirmes Converter hat. Der Clou bei Lame ist nun, dass dieses Downside umgangen wird, indem die samplegenaue Länge des Stückes in den Header der MP3-Dateien geschrieben wird. foobar2000 kann diese Data auslesen, und spielt auch nur die gefüllten Samples ab. So kann man mit foobar2000 auch lückenlose AudioCDs brennen, oder die einzelnen Tracks per Converter lückenlos, dafür natürlich aber mit Qualitätsverlust durch erneute Umwandlung, zusammenfügen. Nun mit "File -> Add file(s)" das MP3 im mp3val öffnen. Es wird nun in der Liste angezeigt. Rechtsklick auf die Datei, "Scan chosen files for errors" anklicken. Je nach Größe derDatei kann die Überprüfung auch einige Minuten dauern! Das Programm ist fertig, wenn rechts neben der Datei entweder "OK" oder "Drawback" angezeigt werden. Wenn "Problem" angezeigt wird, so klickt man nochmals auf die Datei (und sieht auch in der unteren Fensterhälfte, was genau das Problem ist) und wählt "Repair selected file" aus. Auch das kann je nach Dateigröße und Tempo des PCs einige Minuten dauern. Bei OK passt alles - weiter zum nächsten Schritt. Für die Bearbeitung von Songs, die nicht länger als sieben Minuten sind, bietet sich dieses kostenlose MP3 Schnittprogramm an, die ebenfalls darauf verzichtet, die MP3s ins Wave-Format zu konvertieren. Die Software program eignet sich besonders, um am Anfang und am Ende des Songs ein wenig zu schneiden. Damit der Schnitt dann auch nicht zu abrupt wirkt, gibt es die Möglichkeit durch Fade-in und Fade-out Anfang und Ende des Tracks abzurunden. Das Free Studio ist ein Multimedia-Baukasten mit Werkzeugen für viele Zwecke, einige davon speziell für On-line-Movies von YouTube oder Dailymotion. Zu dem Programm gehören mehr als 20 Module, mit denen Sie zum Beispiel YouTube-Videos herunterladen oder dort veröffentlichen können, den Ton von Musikvideos als MP3-Datei sichern, Aufnahmen für bestimmte Ausgabegeräte konvertieren oder Clips schneiden. Dazu kommen Brenner und ein 3D-Picture-Maker. Wenn Sie über ein YouTube Benutzerkonto verfügen, MP3s zusammenfügen können Sie Ihre fertigen Werke direkt bei YouTube veröffentlichen. Zusätzlich wird Batch-Konvertierung unterstützt, was Zeit spart. Sie können mehrere Video- und Audiodateien in MP3 Audio, OGG Vorbis Audio, WAVE Audio, AAC Audio, MPEG-four Audio, http://www.mergemp3.com/de/ WMA Audio und Free Lossless Audio Codec gleichzeitig umwandeln.In Ihrem täglichem Leben brauchen Sie manchmal Lieder zusammenzuzufügen. Oder Sie möchten manche wertvolle Audiodateien zusammenfügen. Folgender MP3 Merger hilft Ihnen, alle MP3 nach Wunsch auf Ihr Laptop computer zusammenzufügen. Kostenlos downloaden Sie den MP3 Merger und folgen Sie die Schritte darunter. Wenn Sie MP3 auf Mac zusammenfügen möchten, können Sie eine Mac-Verison MP3 Merger downloaden. Die Methode der Benutzung ist gleich wie House windows.Speichere zunächst alle Dateien auf dem USB-Stick ab. Wichtig: Damit die PS4 das Gerät erkennt, muss es mit dem Dateisystem FAT32 oder ExFAT formatiert sein − bei NTFS geht es nicht. Um das zu überprüfen, klickst Du mit der rechten Maustaste auf den am Laptop-Bildschirm angezeigten USB-Stick. Anschließend wählst Du „Eigenschaften aus und suchst den Punkt „Dateisystem. Dort sollte die Data stehen, welches Dateisystem der USB-Stick hat.
1 note
·
View note
Text
MicroPython mit ESP32: Grundlagen der Programmierung

In diesem Beitrag möchte ich dir die Grundlagen zur Programmierung in MicroPython anhand des ESP32 D1 R32 näher bringen. Du kannst dieses jedoch auch sehr einfach auf andere Mikrocontroller anwenden, welche ebenso mit MicroPython arbeiten. https://youtu.be/ua_qigAk6s0 Im letzten Beitrag MicroPython mit ESP32: Einführung in den ESP32 D1 R32 habe ich dir bereits den Mikrocontroller ESP32 D1 R32 vorgestellt und aufgezeigt wie dieser für MicroPython geflasht wird.
MicroPython vs. Python
MicroPython ist eine vollständige Implementierung der Programmiersprache Python 3, die direkt auf eingebetteter Hardware wie dem ESP32 D1 R32 oder dem Raspberry Pi Pico läuft. Während beide Sprachen auf der gleichen Grundlage basieren, gibt es einige wesentliche Unterschiede und Anpassungen, die MicroPython besonders für den Einsatz in Mikrocontrollern geeignet machen: - Interaktive Eingabeaufforderung (REPL): MicroPython bietet eine interaktive Eingabeaufforderung (REPL - Read-Eval-Print Loop), die es ermöglicht, Befehle sofort über USB-Serial auszuführen. Dies ist besonders nützlich für schnelles Testen und Debuggen von Code auf der Hardware. - Eingebautes Dateisystem: MicroPython beinhaltet ein eingebautes Dateisystem, das auf dem Flash-Speicher des Mikrocontrollers gespeichert wird. Dies ermöglicht das Speichern und Verwalten von Skripten und Daten direkt auf dem Gerät. - Modulspezifischer Zugriff auf Hardware: Der ESP32-Port von MicroPython umfasst spezielle Module, die den Zugriff auf hardware-spezifische Funktionen des Chips ermöglichen. Dazu gehören beispielsweise GPIO-Steuerung, PWM, I2C, SPI und andere Peripheriegeräte. - Ressourceneffizienz: MicroPython ist so konzipiert, dass es auf ressourcenbeschränkten Geräten läuft. Es verwendet weniger Speicher und Rechenleistung im Vergleich zu einer vollständigen Python-Implementierung auf einem Desktop-Computer. - Bibliotheken und Module: MicroPython enthält eine Auswahl an Standardbibliotheken und modulspezifischen Bibliotheken, die für die Entwicklung von Embedded-Anwendungen nützlich sind. Während einige Bibliotheken aus der Standard-Python-Bibliothek fehlen, gibt es spezielle Bibliotheken, die für die Arbeit mit Mikrocontrollern optimiert sind. Diese Unterschiede machen MicroPython zu einer idealen Wahl für die Programmierung von Mikrocontrollern wie dem ESP32 D1 R32, da es die Leistungsfähigkeit und Einfachheit von Python mit der Effizienz und Funktionalität für Embedded-Systeme kombiniert.
Aufbau des Quellcodes in MicroPython
In MicroPython gibt es keine Klammern für das Zusammenfassen von Codeblöcken, du musst hier mit Einrückungen arbeiten. Du kannst hier wählen zwischen Leerschritte und Tabulatoren. Jedoch wenn du dich einmal auf eine Art festgelegt hast, dann musst du diese weiterverwenden! Solltest du also nachfolgende Fehlermeldung erhalten, so prüfe zuerst die Anzahl der Leerschritte / Tabs vor deinen Codeblöcken. Traceback (most recent call last): File "", line 1 IndentationError: unexpected indent
Kommentare
Mit Kommentaren kannst du Text in deinen Quellcode einfügen, welcher keinen Einfluss auf das Verhalten des Codes hat. Kommentare werden meist verwendet, um komplizierten Code zu beschreiben oder für andere Entwickler einen leichteren Einstieg in den Quellcode zu schaffen. Auch kannst du Code auskommentieren, um die Funktion / den Codeblock zu überspringen. Du kannst einzelne Zeilen mit einem "#" Symbol auskommentieren und wenn du einen mehrzeiligen Kommentar erstellen möchtest, dann leitest du diesen mit drei doppelte Anführungszeichen ein und beendest dieses auch damit. # Hier steht ein einzeiliger Kommentar """ Hier können mehrere Zeilen gleichzeig auskommentiert werden """ Wenn du eine Entwicklungsumgebung verwendest, dann werden Kommentare immer speziell angezeigt, sodass diese sich vom eigentlichen Quellcode abheben.
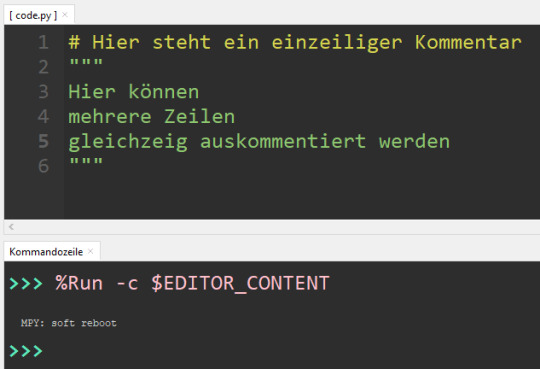
MicroPython - Kommentare Du kannst auch hinter dem Quellcode Kommentare setzen und so platzsparend Informationen hinterlassen.

MicroPython - Kommentar und Code in einer Zeile
Ausgaben auf der Kommandozeile
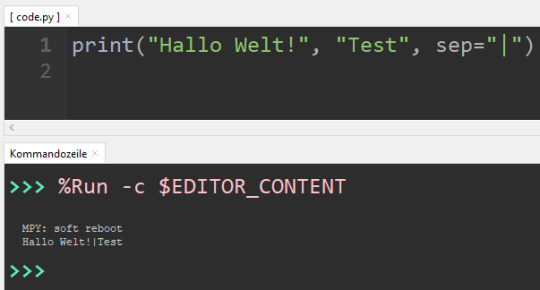
Zur Fehlersuche und für die Ausgabe von Sensordaten können wir den einfachen aber trotzdem mächtigen Befehl "print" nutzen. Diesem Befehl können wir einfach einen Text übergeben, welcher dann auf der Kommandozeile ausgegeben wird. print("Hallo Welt!") print("Test") In der Kommandozeile siehst du die Ausgabe der beiden Texte, welche jeweils durch einen Zeilenumbruch getrennt sind.
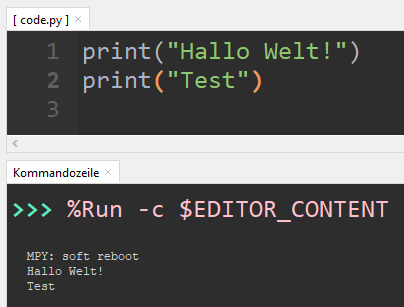
MicroPython - Befehl print Du kannst diesem Befehl jedoch auch mehrere Werte übergeben, dazu trennst du diese mit einem Komma. print("Hallo Welt!", "Test") Die Werte werden mit einem Komma getrennt und auf der Kommandozeile hintereinander (getrennt durch ein Leerzeichen) ausgegeben.

MicroPython - Befehl "print", mehrere Werte Wenn du statt einem Leerzeichen ein anderes verwenden möchtest, dann kannst du diesen Separator mithilfe des optionalen Parameters "sep=" benennen. print("Hallo Welt!", "Test", sep="|") In diesem Fall verwende ich zum Trennen der Werte einen geraden Strich. Du kannst auch beliebig andere Symbole, Buchstaben oder Zahlen verwenden.
Erzeugen von Variablen
In MicroPython bzw. Python gibt es keine Datentypen. Das heißt für uns, wir legen neue Variablen an, indem wir einfach einen Namen für unsere neue Variable schreiben, gefolgt von einem Wert. Dabei kannst du diesen Wert auch jederzeit mit einem anderen Wert / Datentyp beliebig überschreiben.

MicroPython - Variablen

Du kannst mit den bereits bekannten mathematischen Operatoren Zahlen Addieren, Subtrahieren usw. und natürlich mit dem Befehl print diesen Wert ausgeben. Verketten von Texten Wenn du Texte verketten / verbinden möchtest, dann verwendest du das + Symbol. Das funktioniert für Texte sehr einfach. text1 = "Text1" text2 = "Text2" print(text1+text2) Die beiden Texte werden einfach zusammengefügt und auf der Kommandozeile ausgegeben.

Wenn wir jedoch einen Text und eine Zahl verbinden möchten, dann können wir dieses nicht so einfach machen. text1 = "Text1" zahl1 = 2 print(text1+zahl1) Der Code erzeugt die nebenstehende Fehlermeldung. Diese besagt, dass String & Int nicht mit der Funktion add zusammengefügt werden können. Traceback (most recent call last): File "", line 3, in TypeError: unsupported types for add: 'str', 'int' Wir müssen also zunächst die Zahl in einen String umwandeln. Um die Zahl 1 umzuwandeln, können wir nun einfach jeweils ein doppeltes Anführungszeichen am Anfang und Ende hinzufügen, oder wir nutzen die Funktion "str". text1 = "Text1" zahl1 = 2 print(text1+str(zahl1)) Die Funktion str erwartet einen Zahlenwert (Ganzzahl oder Gleitkommazahl) und wandelt diese in einen Text um und gibt diesen zurück. Das kannst du zum Beispiel verwenden, wenn du einen Sensorwert auf einem Display mit dem zugehörigen Symbol dahinter anzeigen möchtest.

Schleifen
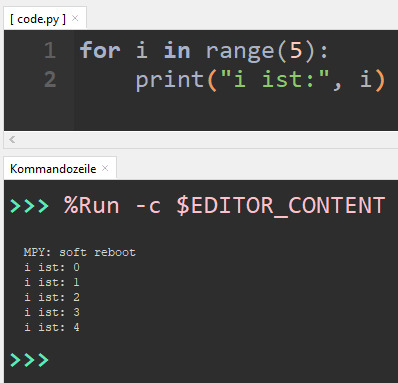
Wenn du Codeblöcke in einer bestimmten Anzahl wiederholen möchtest, oder dauerhaft wiederholen möchtest, dann benötigst du eine Schleife. For-Schleifen Um einen Block 5-mal zu wiederholen, können wir eine For-Schleife verwenden. for i in range(5): print("i ist:", i) Du kannst den Index i innerhalb der For-Schleife verwenden und auf diesen reagieren. Die Funktion range liefert dir eine Liste von Zahlen, von 0 bis 4 (insgesamt 5). Wenn du die Zahlenfolge 1 bis 6 möchtest, kannst du dieser Funktion wie folgt anpassen. for i in range(1, 6): print("i ist:", i)
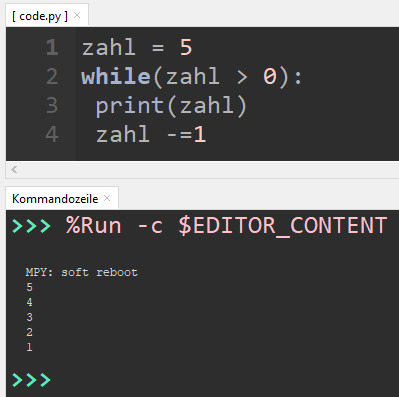
While-Schleife Eine While-Schleife wird verwendet, um einen Ausdruck zu prüfen, um diese innerhalb der Schleife abzubrechen. zahl = 5 while(zahl > 0): print(zahl) zahl -=1 Innerhalb der While-Schleife wird die Variable zahl um 1 verringert und im Kopf der Schleife wird geprüft, ob dieser Wert größer 0 ist. Sobald der Wert der Variable zahl den Wert 0 erreicht, wird die Schleife abgebrochen.
Endlosschleife Mit der While-Schleife kannst du eine Endlosschleife starten, dazu übergibst du dieser lediglich ein True. while True: print("Hallo Welt!") Dieser kleine Code bewirkt nun, dass auf der Kommandozeile der Text "Hallo Welt!" fortlaufend ausgegeben wird. Abbrechen einer Schleife Wenn du innerhalb der Schleife diese abbrechen möchtest, dann verwendest du den Befehl break. Mit diesem Aufruf wird dann sofort die Schleife verlassen und der nachfolgende Code ausgeführt (soweit vorhanden). while True: print("Hallo Welt!") break In diesem Beispiel startet die Endlosschleife, gibt den Text "Hallo Welt!" aus und sofort danach wird diese abgebrochen. Natürlich ergibt dieser Code wenig Sinn, jedoch mit einem später vorgestellten If-Statement wird etwas mehr Funktion geschaffen.

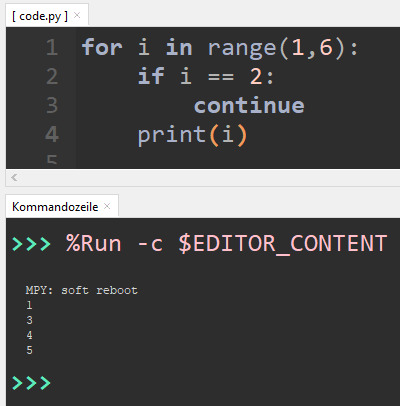
Überspringen einer Ausführung innerhalb einer Schleife Wenn du die Schleife nicht abbrechen möchtest, sondern nur die Ausführung der Schleife überspringen möchtest, dann verwendest du den Befehl continue. Damit wird wieder zum Kopf gesprungen und von vorne gestartet. for i in range(1,6): if i == 2: continue print(i) In der Ausgabe siehst du das die Zahl 2 übersprungen wurde, das liegt daran das wir im Code prüfen ob der aktuelle Index gleich 2 ist und wenn dieses so ist, soll die Ausführung an dieser Stelle abgebrochen werden. Anders als bei break wird die Schleife jedoch fortgeführt.
If-Statements
Mit If-Statements kannst du innerhalb deines Quellcodes bedingten Code erzeugen. Du prüfst innerhalb des Statements einen Ausdruck welcher einen Wahrheitswert hat True/False 1/0. test = True if test: print("Der Wert von test ist Wahr!") Man muss bei boolschen Werten nicht unbedingt mit einem doppelten Gleichheitszeichen prüfen, hier reicht es aus den Wert hineinzuschreiben. if test == True: #oder if test: Genaus kann man auch prüfen ob ein Wert Falsch ist. if test == False: #oder if !test:

Zahlenwerte kannst du mit den nachfolgenden Symbolen prüfen: - prüfen ob ein Wert größer ist > - prüfen ob ein Wert größer gleich ist >= - prüfen ob ein Wert kleiner ist < - prüfen ob ein Wert kleiner gleich ist - prüfen ob ein Wert ungleich ist != - prüfen ob ein Wert gleich ist == 0: print("Der Wert von test ist größer 0") else: print("Der Wert von test ist kleiner 1") Im rechten Beispiel wird die Variable test geprüft ob die größer 0 ist. Wenn dieses nicht so ist (also der Wert ist kleiner 1) dann wird der Text "Der Wert von test ist kleiner 1" ausgegeben.

weitere Prüfungen mit elif Wenn du weitere Prüfungen hinzufügen möchtest dann kannst du dieses mit elif machen, jedoch musst du bedenken das wenn einmal ein Statement zu einer Ausführung geführt hat die anderen Prüfungen nicht ausgeführt / geprüft werden! test = 17 if test > 0 and test < 10: print("Der Wert von test ist zwischen 1 und 9.") elif test >= 10 and test < 20: print("Der Wert von test ist zwischen 10 und 19.") elif test >= 20: print("Der Wert von test ist größer gleich 20.") In diesem Beispiel wird geprüft ob sich der Wert der Variable test zwischen bestimmten Werten befindet oder größer gleich 20 ist.
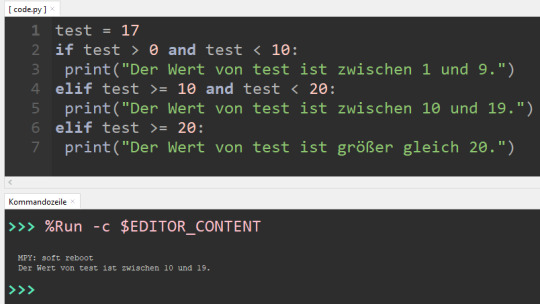
Ausblick
Mit diesem Beitrag habe ich dir nun einen Überblick über die Programmiersprache MicroPython anhand von Beispielen gegeben. Jedoch ist dieses nur der "normale" Funktionsumfang, bei Mikrocontroller wird es schon etwas spezieller denn hier können wir Schnittstellen, GPIO Pins etc. ansteuern und somit Sensoren / Aktoren bedienen. Wie du die GPIOs ansteuern kannst zeige ich dir im nächsten Beitrag anhand von einfachen LEDs, Taster usw. Read the full article
0 notes
Text
NAS-Datenrettung: Tipps und Lösungen für Unternehmen
NAS (Network Attached Storage) ist eine beliebte Speicherlösung für Unternehmen und Selbstständige im SoHo-Bereich. NAS-Systeme bieten eine bequeme Möglichkeit, Daten zu speichern, zu teilen und zu sichern. Sie sind in der Regel 24/7 im Betrieb und bieten eine hohe Verfügbarkeit und Zuverlässigkeit. NAS-Systeme können in Rechenzentren oder als Rackmount-Systeme montiert werden und bieten in der Regel eine Warn-LED, die auf Fehler hinweist.
Ein häufiges Problem Network Attached Storage ist das Initialisieren des RAID-Arrays, bei dem eine inkorrekte Konfiguration zu Datenverlusten führen kann. In solchen Fällen ist es wichtig, einen erfahrenen Data Recovery Spezialisten zu konsultieren, der über das notwendige technische Wissen und Erfahrung verfügt, um eine erfolgreiche NAS Datenwiederherstellung durchzuführen.

Häufigste Fehlerursachen bei NAS-Systemen
Eine erfolgreiche NAS-Datenrettung erfordert umfassendes technisches Wissen und Erfahrung. Die Ursachen für einen Verlust von NAS Daten sind vielfältig:
Firmware-Probleme: Fehlerhafte Firmware-Updates oder beschädigte Firmware können dazu führen, dass das NAS-System nicht mehr erkannt wird oder die Datenbank beschädigt wird.
Hardware-Fehler: Defekte Festplatten, Stromausfälle oder Überhitzung können zu Datenverlusten führen.
Software-Probleme: Viren, Malware oder beschädigte Dateisysteme können zu Datenverlusten führen.
Menschliches Versagen: Versehentliches Löschen von Dateien, fehlerhafte Bedienung oder unsachgemäße Handhabung von NAS-Systemen können zu Datenverlusten führen.
Datenrettung bei NAS-Systemen
Ein häufiges Problem bei NAS-Festplatten ist, dass sie aufgrund von Firmware-Problemen oder anderen Fehlern nicht mehr erkannt werden. In solchen Fällen ist es wichtig, einen Data Recovery Spezialisten zu konsultieren, der über umfassendes technisches Wissen und Erfahrung verfügt.
youtube
Es gibt verschiedene Modelle von NAS-Systemen, die unterschiedliche RAID-Konfigurationen unterstützen. Die RAID-Konfigurationen spielen eine wichtige Rolle bei der Datenrettung von NAS-Systemen. Die Initialisierung des RAID-Systems und der Datenbank ist ein kritischer Schritt bei der Datenwiederherstellung. Der RAID Datenrettungsspezialist muss die RAID-Level und die Datei-Systeme wie RAID 5, EXT3, EXT4, XFS und BTRFS verstehen, um eine erfolgreiche Datenwiederherstellung durchzuführen.
Firmware-Updates bei NAS-Systemen
Firmware-Updates können ebenfalls ein Problem verursachen. Ein fehlerhaftes Firmware-Update kann zu Datenverlust führen, wenn das NAS-System nicht mehr erkannt wird oder die Datenbank beschädigt ist. In solchen Fällen ist es wichtig, einen erfahrenen Data Recovery Spezialisten zu kontaktieren, der in der Lage ist, die Firmware-Updates rückgängig zu machen und die Daten zu retten.
Linux-basierte NAS-Systeme
Linux-basierte NAS-Systeme sind besonders anfällig für Datenverluste. Dies liegt daran, dass Linux-basierte Systeme eine komplexe Struktur aufweisen und häufig benutzerdefinierte Einstellungenerfordern. Ein erfahrener Data Recovery Spezialist, der mit Linux und NAS-Systemen vertraut ist, kann jedoch häufig eine erfolgreiche Datenwiederherstellung durchführen.

Linux RAID md (Multiple Devices) ist eine häufig genutzte Technologie für die Datenhaltung auf NAS-Systemen. Diese Technologie wird von vielen NAS-Systemen verwendet, um einen hohen Grad an Datensicherheit und -integrität zu gewährleisten. MD (Multiple Devices) ist ein Kernel-Modul für das Linux-Betriebssystem, das es ermöglicht, mehrere Festplatten als ein logisches Gerät zu verwenden und die Zuverlässigkeit durch die Kombination der Festplatten zu erhöhen.
MD bietet verschiedene RAID-Level wie RAID 0, RAID 1, RAID 5, RAID 6, RAID 10, RAID 50 und RAID 60, die unterschiedliche Eigenschaften und Vorteile bieten.
MD bietet auch eine Möglichkeit zur Erweiterung des RAID-Systems durch Hinzufügen weiterer Festplatten oder zum Austausch defekter Festplatten. Die Verwaltung des RAID-Systems erfolgt über das mdadm-Tool, das verschiedene Konfigurationen und Verwaltungsoptionen bietet.
Da die meisten NAS-Systeme auf dem Linux-Betriebssystem basieren, nutzen sie häufig die MD-Technologie zur Datenspeicherung. Dies ermöglicht eine höhere Datensicherheit und -integrität durch die Kombination mehrerer Festplatten zu einem logischen Gerät.
Vorbeugung von Datenverlust bei NAS-Systemen
Um Datenverlust bei NAS-Systemen zu vermeiden, ist es wichtig, regelmäßige Datensicherungen durchzuführen und die Firmware-Updates regelmäßig zu überprüfen. Ein zuverlässiges Backup-System ist eine kritische Komponente bei der Vorbeugung von Datenverlusten. Ein weiterer wichtiger Schritt ist die Überwachung von Warn-LEDs und der Hardware-Leistung, um mögliche Probleme frühzeitig zu erkennen.
Datenrettungsfirma für NAS
NAS-Systeme bieten eine bequeme Möglichkeit, Daten zu speichern, zu teilen und zu sichern. Eine erfolgreiche Datenrettung erfordert jedoch umfassendes technisches Wissen und Erfahrung. Bei Datenverlust ist es wichtig, schnell zu handeln und eine erfahrene Datenrettungsfirma zu kontaktieren. Durch die Vorbeugung von Datenverlusten und regelmäßige Wartung können Unternehmen und Selbstständige den Wert und die Zuverlässigkeit ihrer NAS-Systeme maximieren.
1 note
·
View note
Link
Ubuntu-Unterbau mit Gnome-Desktop klingt erstmal nicht aufregend, aber abseits davon wandelt die Linux-Distribution Vanilla OS auf unbekannten Pfaden. Wichtige Bausteine wie einen universellen Paketmanager, unveränderliche Systempartitionen und transaktionale Updates gibt es zwar so oder so ähnlich schon länger in der Linux-Welt, Vanilla OS schnürt sie aber zu einem wartungsarmen und einsteigerfreundlichen Gesamtpaket.
0 notes