#Image Annotation for Computer Vision
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
ADVANTAGES OF DATA ANNOTATION
Data annotation is essential for training AI models effectively. Precise labeling ensures accurate predictions, while scalability handles large datasets efficiently. Contextual understanding enhances model comprehension, and adaptability caters to diverse needs. Quality assurance processes maintain data integrity, while collaboration fosters synergy among annotators, driving innovation in AI technologies.
#Data Annotation Company#Data Labeling Company#Computer Vision Companies in India#Data Labeling Companies in India#Image Annotation Services#Data labeling & annotation services#AI Data Solutions#Lidar Annotation
0 notes
Link
Status update by Maruful95 Hello there, I'm Md. Maruful Islam is a skilled trainer of data annotators from Bangladesh. I currently view my job at Acme AI, the pioneer in the data annotation sector, as an honour. I've improved my use of many annotation tools throughout my career, including SuperAnnotate, Supervise.ly, Kili, Cvat, Tasuki, FastLabel, and others. I have written consistently good annotations, earning me credibility as a well-respected professional in the industry. My GDPR, ISO 27001, and ISO 9001 certifications provide even more assurance that data security and privacy laws are followed. I genuinely hope you will consider my application. I'd like to learn more about this project as a data annotator so that I may make recommendations based on what I know. I'll do the following to make things easier for you:Services: Detecting Objects (Bounding Boxes)Recognizing Objects with PolygonsKey PointsImage ClassificationSegmentation of Semantics and Instances (Masks, Polygons)Instruments I Utilize: Super AnnotateLABELBOXRoboflowCVATSupervisedKili PlatformV7Data Types: ImageTextVideosOutput Formats: CSVCOCOYOLOJSONXMLSEGMENTATION MASKPASCAL VOCVGGFACE2
0 notes
Text
What is Annotation Ontology
Machine learning and computer vision applications require substantial training before deployment. Systems must learn to understand and recognize what they're looking at before reacting and executing functions. Whether in a healthcare setting or a warehouse, AI systems must understand the context surrounding the objects they see.
That's where ontology comes in. Ontologies provide more than top-level visual information about an object. They offer more detailed conceptual information, such as the relationships one object has to another or how it's represented in data. Also known as taxonomies or labeling protocols, ontologies play a big part in allowing you to semantically program computer vision and machine learning models to understand the complexities of the data they view.
It's what makes these intelligent systems capable of understanding complex information similarly to the human brain.
How Annotation Ontology Works
Think of how you recognize objects in your everyday life. If you see a dog walking on the street, you can easily define it as such. But you use tons of semantic information to get there. For example, you know how a dog relates to a cat, allowing you to differentiate the two animals. You can also use semantic information to see if that dog is a stray, separated from its owner or aggressive. All that information combines to help you learn about the dog you see. It's about using observations and drawing inferences from everything you see.
Computer vision and machine learning models need the same deep level of understanding to perform efficiently.
In annotation, ontologies are hierarchical structures that capture different levels of information. They allow for fine-grain differentiation and can provide more detailed annotations. It goes beyond top-level descriptors, including nested attributes to provide a more comprehensive understanding of the target object.
At the top of the hierarchy are classes or categories. They represent the highest level of concepts you want to express. Below that are nested classifications that go deeper into the object's attributes, for example, a top-level class could identify an object as a dog. Nested categories can then differentiate things like color, the presence of a collar, movement, speed, etc.
Read a similar article about rareplanes dataset here at this page.
#nifti image viewer#annotation services for computer vision#annotation ontology#what is meta training inference accelerator#custom annotation workflows#embeddings in machine learning#what is hitl
0 notes
Text
June 5-9 2025 2010
First time in a long while I'm actually typing on my computer. I've been reading my old stuff and annotating it -accidentally very sassily.
Regardless, these updates have been verrryy..... slow? Not slow like bad, uh slow in the sense that we've been non-stop punch after punch, scene after scene with no time to breath. And now that we can we can really feel just how wound up and chaotic everything has been. Even if the pacing depends on real life time constraints, there's been so much buildup in the story to this moment from so many angles that now that its passed it feels odd? Even the narration change makes it obvious with the shorter sentences and repeated stucture. All the text follows two images -one a wider shot, the next and emphasized one- and it explains what we need to get out of them without letting us sit with the characters anymore than it deems necessary. It gives me a storybook feel and acts like a cutscene.
The first thing we get is another Game FAQ page from Rose; shes titled this passage ‘Rose: Egress’. Egress has two main meanings, the first is “the action of going out of or leaving a place”. This one along with her text explains some of her actions in Descend. Shes done. Absolutely done.
I am not playing by the rules anymore. I will fly around this candy-coated rock and comb the white sand until I find answers. No one can tell me our fate can’t be repaired. We’ve come too far. I jumped out of the way of a burning fucking tree, for God’s sake.
She’s taking matters into her own hands. So incensed she is that she breaks from her normal writing pattern and displays her emotions openly. It’s a little bittersweet, and I’m worried of her cutting off communication with the others.

The second meaning of egress is a tech term involving the flow of communication data. As her last act she ‘[has] used a spell to rip this walkthrough from Earth’s decaying network’, stored it in a Derse-branded server and let the Gods disperse it to any and all life that my also be doomed to play this game. Its likely this is how the initial connection to the trolls came about, long before they had access to this session.
We get to see the completion of some storylines.
The warweary calls another broken planet home, another cloth his garb. Land and rags fit for the wayward.
A villein becomes vagabond.


WV is lost. I think he truly thought he could make a difference for his brethren. Now the lone survivor -and how does that feel to be left alive- he's lost the rage that fueled him. On the battlefield his last action is to rip the head off of the Jack doll. ACURSED MASCOT that it is, the fact we've seen it portray Jacks state makes me wonder how and when Jack will suffer the same. Johns blanket flutters down forming the first connection between them. The fight gone and nothing changed, he wanders.


John has made it to Skaias surface and found Jade. We get confirmation that she is indeed dead. If in Descend John looked confused, John now looks sad. His frown isnt as exaggerated as we've seen and I find that sadder. He gets the ring from Jades hand for reasons unknown. After that he sees his first cloud vision and makes his way to that area of Skaia. Given that these panels happend after 'the recent past is recalled' command, we can understand that WVs and Johns actions are happening around the same time. Unlike with PM however, their paths arent destined to cross yet.
A mistress becomes a mendicant.


At the same time on Skaia we see why PM didn't show in the flash. She was too busy battling it out with HB, successfully killing him. Shes filled with just as much rage as Rose is, using the walkie to get this whole quest over with. Jack flies to her location and has CD exchange the package. I think hes perhaps a bit surprised PM managed to fulfill her part but in a maliciously gleeful sort of way. He may not be fully aware of how PM got those crowns but to him at least her sense of duty to her 'purpose' was far greater than her loyalty to the royals. There's also the underlying thought that he's the only one with power confirmed in his eyes. Him handing over the package makes sense. I think hes someone who doesn't like to be indebted to others and even less so to someone he sees as a pawn. With that PM has no more purpose in his eyes and the next time they might meet he'll have no reason to not get rid of her. John has flown over to the location revealed to him and PM spots him, still full of anger.


The mail is delivered. An obligation, satisfied.
There's alot that can be said about the exact words used for our exiles new names. Vagabond, someone who wanders without a place to call home. Mendicant, a chosen way of life rejecting the material to serve their faith in service of others.
I feel WV is an exile of circumstance while PM is a chosen exilement to atone for what shes done. In the past, fresh from the battle, she no longer feels the same joy for her duty after everything its caused. Its not until the future, and perhaps Skaias influence, that she gains a love of mail again. Even meeting WQ, I don't think she ever believed shed be crowned a hero. Perhaps shes come to terms with her actions and was prepared for punishment, only to receive acclaim.
The package is opened. Letters, read.
So many pages later and after so much destruction, John finally gets his gift.


The first letter is from an unknown sender, Jades penpal apparently. An interesting fellow with the weirdest use of British vernacular who rambles way more than anyone so far. The best we can glean, aside from having sendificator access, he might also be a player. How and when he and Jade started talking is unknown but supposedly Johns gonna meet him someday. Much like Jade, hes not good at explaining things but for him I think its less not trying to tell the future and more hes just like that. The second page has the list of gifts though its cutoff:
Royal Deringer
Quills of Echidna
???? Crosshairs
Jades also left a letter and it hurts to read. Here we see just how human Jade is even with her Skaian given future dream powers.
...i really hope this present
cheers you up! you looked so sad while you were reading my letter.
[...]
i dont see everything john, and i definitely dont know everything thats going to happen. but when i do know something, i always try to do my best to help people in the future! when im supposed to that is. youll get the hang of it.
Maybe its Skaia being selective to not give away the game (ha), but Jade can only see so much. At the time of writing she couldn't have known Johns sadness comes at her death. And she even goes on about how excited she is to meet him and show him around and finally meet her friend...
John cries.

Its not the same as when he did after his first Con Air reenactment; only a single tear as that frown continues to mar his face. Its a different sadness, a deeper one where you feel the ache in your soul that tells you the hurt will never go away. There's no way to find release from it as much as a full on bawl could seem to help.
John cant even begin to try processing the grief as a sword is pointed in his face. Jack is here for the ring but hes miscalculated. The present emerges from the box. Another bunny -the same one that has passed through so many hands and so many lives- outfitted with robot tech and the weapons from the letter. Each weapon matches to the kids chosen strife specibus: needles, a hammer, a gun, a broken sword. Combine this with the fact the bunny was Daves gift to John, Roses beloved heirloom, patched up and sent with Jade.

John must feel so alone. His dad has been missing since hes arrived here. He has no clue what hes doing in this game. Hes woken up to find his friend dead. And yet in front of him he as an amalgamation of his friends love. A reminder that together they are stronger. That they are not alone.

Check.
#homestuck#homestuck replay#hsrp liveblog#i started tearing up writing that last paragraph. im not entirely sure why#perhaps theres a benefit to using web tumblr. i feel so powerful with all my pictures#chrono
4 notes
·
View notes
Text

2023.08.31
i have no idea what i'm doing!
learning computer vision concepts on your own is overwhelming, and it's even more overwhelming to figure out how to apply those concepts to train a model and prepare your own data from scratch.
context: the public university i go to expects the students to self-study topics like AI, machine learning, and data science, without the professors teaching anything TT
i am losing my mind
based on what i've watched on youtube and understood from articles i've read, i think i have to do the following:
data collection (in my case, images)
data annotation (to label the features)
image augmentation (to increase the diversity of my dataset)
image manipulation (to normalize the images in my dataset)
split the training, validation, and test sets
choose a model for object detection (YOLOv4?)
training the model using my custom dataset
evaluate the trained model's performance
so far, i've collected enough images to start annotation. i might use labelbox for that. i'm still not sure if i'm doing things right 🥹
if anyone has any tips for me or if you can suggest references (textbooks or articles) that i can use, that would be very helpful!
56 notes
·
View notes
Text
What is a Data pipeline for Machine Learning?

As machine learning technologies continue to advance, the need for high-quality data has become increasingly important. Data is the lifeblood of computer vision applications, as it provides the foundation for machine learning algorithms to learn and recognize patterns within images or video. Without high-quality data, computer vision models will not be able to effectively identify objects, recognize faces, or accurately track movements.
Machine learning algorithms require large amounts of data to learn and identify patterns, and this is especially true for computer vision, which deals with visual data. By providing annotated data that identifies objects within images and provides context around them, machine learning algorithms can more accurately detect and identify similar objects within new images.
Moreover, data is also essential in validating computer vision models. Once a model has been trained, it is important to test its accuracy and performance on new data. This requires additional labeled data to evaluate the model's performance. Without this validation data, it is impossible to accurately determine the effectiveness of the model.
Data Requirement at multiple ML stage
Data is required at various stages in the development of computer vision systems.
Here are some key stages where data is required:
Training: In the training phase, a large amount of labeled data is required to teach the machine learning algorithm to recognize patterns and make accurate predictions. The labeled data is used to train the algorithm to identify objects, faces, gestures, and other features in images or videos.
Validation: Once the algorithm has been trained, it is essential to validate its performance on a separate set of labeled data. This helps to ensure that the algorithm has learned the appropriate features and can generalize well to new data.
Testing: Testing is typically done on real-world data to assess the performance of the model in the field. This helps to identify any limitations or areas for improvement in the model and the data it was trained on.
Re-training: After testing, the model may need to be re-trained with additional data or re-labeled data to address any issues or limitations discovered in the testing phase.
In addition to these key stages, data is also required for ongoing model maintenance and improvement. As new data becomes available, it can be used to refine and improve the performance of the model over time.
Types of Data used in ML model preparation
The team has to work on various types of data at each stage of model development.
Streamline, structured, and unstructured data are all important when creating computer vision models, as they can each provide valuable insights and information that can be used to train the model.
Streamline data refers to data that is captured in real-time or near real-time from a single source. This can include data from sensors, cameras, or other monitoring devices that capture information about a particular environment or process.
Structured data, on the other hand, refers to data that is organized in a specific format, such as a database or spreadsheet. This type of data can be easier to work with and analyze, as it is already formatted in a way that can be easily understood by the computer.
Unstructured data includes any type of data that is not organized in a specific way, such as text, images, or video. This type of data can be more difficult to work with, but it can also provide valuable insights that may not be captured by structured data alone.
When creating a computer vision model, it is important to consider all three types of data in order to get a complete picture of the environment or process being analyzed. This can involve using a combination of sensors and cameras to capture streamline data, organizing structured data in a database or spreadsheet, and using machine learning algorithms to analyze and make sense of unstructured data such as images or text. By leveraging all three types of data, it is possible to create a more robust and accurate computer vision model.
Data Pipeline for machine learning
The data pipeline for machine learning involves a series of steps, starting from collecting raw data to deploying the final model. Each step is critical in ensuring the model is trained on high-quality data and performs well on new inputs in the real world.
Below is the description of the steps involved in a typical data pipeline for machine learning and computer vision:
Data Collection: The first step is to collect raw data in the form of images or videos. This can be done through various sources such as publicly available datasets, web scraping, or data acquisition from hardware devices.
Data Cleaning: The collected data often contains noise, missing values, or inconsistencies that can negatively affect the performance of the model. Hence, data cleaning is performed to remove any such issues and ensure the data is ready for annotation.
Data Annotation: In this step, experts annotate the images with labels to make it easier for the model to learn from the data. Data annotation can be in the form of bounding boxes, polygons, or pixel-level segmentation masks.
Data Augmentation: To increase the diversity of the data and prevent overfitting, data augmentation techniques are applied to the annotated data. These techniques include random cropping, flipping, rotation, and color jittering.
Data Splitting: The annotated data is split into training, validation, and testing sets. The training set is used to train the model, the validation set is used to tune the hyperparameters and prevent overfitting, and the testing set is used to evaluate the final performance of the model.
Model Training: The next step is to train the computer vision model using the annotated and augmented data. This involves selecting an appropriate architecture, loss function, and optimization algorithm, and tuning the hyperparameters to achieve the best performance.
Model Evaluation: Once the model is trained, it is evaluated on the testing set to measure its performance. Metrics such as accuracy, precision, recall, and score are computed to assess the model's performance.
Model Deployment: The final step is to deploy the model in the production environment, where it can be used to solve real-world computer vision problems. This involves integrating the model into the target system and ensuring it can handle new inputs and operate in real time.
TagX Data as a Service
Data as a service (DaaS) refers to the provision of data by a company to other companies. TagX provides DaaS to AI companies by collecting, preparing, and annotating data that can be used to train and test AI models.
Here’s a more detailed explanation of how TagX provides DaaS to AI companies:
Data Collection: TagX collects a wide range of data from various sources such as public data sets, proprietary data, and third-party providers. This data includes image, video, text, and audio data that can be used to train AI models for various use cases.
Data Preparation: Once the data is collected, TagX prepares the data for use in AI models by cleaning, normalizing, and formatting the data. This ensures that the data is in a format that can be easily used by AI models.
Data Annotation: TagX uses a team of annotators to label and tag the data, identifying specific attributes and features that will be used by the AI models. This includes image annotation, video annotation, text annotation, and audio annotation. This step is crucial for the training of AI models, as the models learn from the labeled data.
Data Governance: TagX ensures that the data is properly managed and governed, including data privacy and security. We follow data governance best practices and regulations to ensure that the data provided is trustworthy and compliant with regulations.
Data Monitoring: TagX continuously monitors the data and updates it as needed to ensure that it is relevant and up-to-date. This helps to ensure that the AI models trained using our data are accurate and reliable.
By providing data as a service, TagX makes it easy for AI companies to access high-quality, relevant data that can be used to train and test AI models. This helps AI companies to improve the speed, quality, and reliability of their models, and reduce the time and cost of developing AI systems. Additionally, by providing data that is properly annotated and managed, the AI models developed can be exp
2 notes
·
View notes
Text
Why Do Companies Outsource Text Annotation Services?
Building AI models for real-world use requires both the quality and volume of annotated data. For example, marking names, dates, or emotions in a sentence helps machines learn what those words represent and how to interpret them.

At its core, different applications of AI models require different types of annotations. For example, natural language processing (NLP) models require annotated text, whereas computer vision models need labeled images.
While some data engineers attempt to build annotation teams internally, many are now outsourcing text annotation to specialized providers. This approach speeds up the process and ensures accuracy, scalability, and access to professional text annotation services for efficient, cost-effective AI development.
In this blog, we will delve into why companies like Cogito Tech offer the best, most reliable, and compliant-ready text annotation training data for the successful deployment of your AI project. What are the industries we serve, and why is outsourcing the best option so that you can make an informed decision!
What is the Need for Text Annotation Training Datasets?
A dataset is a collection of learning information for the AI models. It can include numbers, images, sounds, videos, or words to teach machines to identify patterns and make decisions. For example, a text dataset may consist of thousands of customer reviews. An audio dataset might contain hours of speech. A video dataset could have recordings of people crossing the street.
Text annotation services are crucial for developing language-specific or NLP models, chatbots, applying sentiment analysis, and machine translation applications. These datasets label parts of text, such as named entities, sentiments, or intent, so algorithms can learn patterns and make accurate predictions. Industries such as healthcare, finance, e-commerce, and customer service rely on annotated data to build and refine AI systems.
At Cogito Tech, we understand that high-quality reference datasets are critical for model deployment. We also understand that these datasets must be large enough to cover a specific use case for which the model is being built and clean enough to avoid confusion. A poor dataset can lead to a poor AI model.
How Do Text Annotation Companies Ensure Scalability?
Data scientists, NLP engineers, and AI researchers need text annotation training datasets for teaching machine learning models to understand and interpret human language. Producing and labeling this data in-house is not easy, but it is a serious challenge. The solution to this is seeking professional help from text annotation companies.
The reason for this is that as data volumes increase, in-house annotation becomes more challenging to scale without a strong infrastructure. Data scientists focusing on labeling are not able to focus on higher-level tasks like model development. Some datasets (e.g., medical, legal, or technical data) need expert annotators with specialized knowledge, which can be hard to find and expensive to employ.
Diverting engineering and product teams to handle annotation would have slowed down core development efforts and compromised strategic focus. This is where specialized agencies like ours come into play to help data engineers support their need for training data. We also provide fine-tuning, quality checks, and compliant-labeled training data, anything and everything that your model needs.
Fundamentally, data labeling services are needed to teach computers the importance of structured data. For instance, labeling might involve tagging spam emails in a text dataset. In a video, it could mean labeling people or vehicles in each frame. For audio, it might include tagging voice commands like “play” or “pause.”
Why is Text Annotation Services in Demand?
Text is one of the most common data types used in AI model training. From chatbots to language translation, text annotation companies offer labeled text datasets to help machines understand human language.
For example, a retail company might use text annotation to determine whether customers are happy or unhappy with a product. By labeling thousands of reviews as positive, negative, or neutral, AI learns to do this autonomously.
As stated in Grand View Research, “Text annotation will dominate the global market owing to the need to fine-tune the capacity of AI so that it can help recognize patterns in the text, voices, and semantic connections of the annotated data”.
Types of Text Annotation Services for AI Models
Annotated textual data is needed to help NLP models understand and process human language. Text labeling companies utilize different types of text annotation methods, including:
Named Entity Recognition (NER) NER is used to extract key information in text. It identifies and categorizes raw data into defined entities such as person names, dates, locations, organizations, and more. NER is crucial for bringing structured information from unstructured text.
Sentiment Analysis It means identifying and tagging the emotional tone expressed in a piece of textual information, typically as positive, negative, or neutral. This is commonly used to analyze customer reviews and social media posts to review public opinion.
Part-of-Speech (POS) Tagging It refers to adding metadata like assigning grammatical categories, such as nouns, pronouns, verbs, adjectives, and adverbs, to each word in a sentence. It is needed for comprehending sentence structure so that the machines can learn to perform downstream tasks such as parsing and syntactic analysis.
Intent Classification Intent classification in text refers to identifying the purpose behind a user’s input or prompt. It is generally used in the context of conversational models so that the model can classify inputs like “book a train,” “check flight,” or “change password” into intents and enable appropriate responses for them.
Importance of Training Data for NLP and Machine Learning Models
Organizations must extract meaning from unstructured text data to automate complex language-related tasks and make data-driven decisions to gain a competitive edge.
The proliferation of unstructured data, including text, images, and videos, necessitates text annotation to make this data usable as it powers your machine learning and NLP systems.
The demand for such capabilities is rapidly expanding across multiple industries:
Healthcare: Medical professionals employed by text annotation companies perform this annotation task to automate clinical documentation, extract insights from patient records, and improve diagnostic support.
Legal: Streamlining contract analysis, legal research, and e-discovery by identifying relevant entities and summarizing case law.
E-commerce: Enhancing customer experience through personalized recommendations, automated customer service, and sentiment tracking.
Finance: In order to identify fraud detection, risk assessment, and regulatory compliance, text annotation services are needed to analyze large volumes of financial text data.
By investing in developing and training high-quality NLP models, businesses unlock operational efficiencies, improve customer engagement, gain deeper insights, and achieve long-term growth.
Now that we have covered the importance, we shall also discuss the roadblocks that may come in the way of data scientists and necessitate outsourcing text annotation services.
Challenges Faced by an In-house Text Annotation Team
Cost of hiring and training the teams: Having an in-house team can demand a large upfront investment. This refers to hiring, recruiting, and onboarding skilled annotators. Every project is different and requires a different strategy to create quality training data, and therefore, any extra expenses can undermine large-scale projects.
Time-consuming and resource-draining: Managing annotation workflows in-house often demands substantial time and operational oversight. The process can divert focus from core business operations, such as task assignments, to quality checks and revisions.
Requires domain expertise and consistent QA: Though it may look simple, in actual, text annotation requires deep domain knowledge. This is especially valid for developing task-specific healthcare, legal, or finance models. Therefore, ensuring consistency and accuracy across annotations necessitates a rigorous quality assurance process, which is quite a challenge in terms of maintaining consistent checks via experienced reviewers.
Scalability problems during high-volume annotation tasks: As annotation needs grow, scaling an internal team becomes increasingly tough. Expanding capacity to handle large influx of data volume often means getting stuck because it leads to bottlenecks, delays, and inconsistency in quality of output.
Outsource Text Annotation: Top Reasons and ROI Benefits
The deployment and success of any model depend on the quality of labeling and annotation. Poorly labeled information leads to poor results. This is why many businesses choose to partner with Cogito Tech because our experienced teams validate that the datasets are tagged with the right information in an accurate manner.
Outsourcing text annotation services has become a strategic move for organizations developing AI and NLP solutions. Rather than spending time managing expenses, businesses can benefit a lot from seeking experienced service providers. Mentioned below explains why data scientists must consider outsourcing:
Cost Efficiency: Outsourcing is an economical way that can significantly reduce labor and infrastructure expenses compared to hiring internal workforce. Saving costs every month in terms of salary and infrastructure maintenance costs makes outsourcing a financially sustainable solution, especially for startups and scaling enterprises.
Scalability: Outsourcing partners provide access to a flexible and scalable workforce capable of handling large volumes of text data. So, when the project grows, the annotation capacity can increase in line with the needs.
Speed to Market: Experienced labeling partners bring pre-trained annotators, which helps projects complete faster and means streamlined workflows. This speed helps businesses bring AI models to market more quickly and efficiently.
Quality Assurance: Annotation providers have worked on multiple projects and are thus professional and experienced. They utilize multi-tiered QA systems, benchmarking tools, and performance monitoring to ensure consistent, high-quality data output. This advantage can be hard to replicate internally.
Focus on Core Competencies: Delegating annotation to experts has one simple advantage. It implies that the in-house teams have more time refining algorithms and concentrate on other aspects of model development such as product innovation, and strategic growth, than managing manual tasks.
Compliance & Security: A professional data labeling partner does not compromise on following security protocols. They adhere to data protection standards such as GDPR and HIPAA. This means that sensitive data is handled with the highest level of compliance and confidentiality. There is a growing need for compliance so that organizations are responsible for utilizing technology for the greater good of the community and not to gain personal monetary gains.
For organizations looking to streamline AI development, the benefits of outsourcing with us are clear, i.e., improved quality, faster project completion, and cost-effectiveness, all while maintaining compliance with trusted text data labeling services.
Use Cases Where Outsourcing Makes Sense
Outsourcing to a third party rather than performing it in-house can have several benefits. The foremost advantage is that our text annotation services cater to the needs of businesses at multiple stages of AI/ML development, which include agile startups to large-scale enterprise teams. Here’s how:
Startups & AI Labs Quality and reliable text training data must comply with regulations to be usable. This is why early-stage startups and AI research labs often need compliant labeled data. When startups choose top text annotation companies, they save money on building an internal team, helping them accelerate development while staying lean and focused on innovation.
Enterprise AI Projects Big enterprises working on production-grade AI systems need scalable training datasets. However, annotating millions of text records at scale is challenging. Outsourcing allows enterprises to ramp up quickly, maintain annotation throughput, and ensure consistent quality across large datasets.
Industry-specific AI Models Sectors such as legal and healthcare need precise and compliant training data because they deal with personal data that may violate individual rights while training models. However, experienced vendors offer industry-trained professionals who understand the context and sensitivity of the data because they adhere to regulatory compliance, which benefits in the long-term and model deployment stages.
Conclusion
There is a rising demand for data-driven solutions to support this innovation, and quality-annotated data is a must for developing AI and NLP models. From startups building their prototypes to enterprises deploying AI at scale, the demand for accurate, consistent, and domain-specific training data remains.
However, managing annotation in-house has significant limitations, as discussed above. Analyzing return on investment is necessary because each project has unique requirements. We have mentioned that outsourcing is a strategic choice that allows businesses to accelerate project deadlines and save money.
Choose Cogito Tech because our expertise spans Computer Vision, Natural Language Processing, Content Moderation, Data and Document Processing, and a comprehensive spectrum of Generative AI solutions, including Supervised Fine-Tuning, RLHF, Model Safety, Evaluation, and Red Teaming.
Our workforce is experienced, certified, and platform agnostic to accomplish tasks efficiently to give optimum results, thus reducing the cost and time of segregating and categorizing textual data for businesses building AI models. Original Article : Why Do Companies Outsource Text Annotation Services?
#text annotation#text annotation service#text annotation service company#cogitotech#Ai#ai data annotation#Outsource Text Annotation Services
0 notes
Text
Data Labeling Services | AI Data Labeling Company
AI models are only as effective as the data they are trained on. This service page explores how Damco’s data labeling services empower organizations to accelerate AI innovation through structured, accurate, and scalable data labeling.

Accelerate AI Innovation with Scalable, High-Quality Data Labeling Services
Accurate annotations are critical for training robust AI models. Whether it’s image recognition, natural language processing, or speech-to-text conversion, quality-labeled data reduces model errors and boosts performance.
Leverage Damco’s Data Labeling Services
Damco provides end-to-end annotation services tailored to your data type and use case.
Computer Vision: Bounding boxes, semantic segmentation, object detection, and more
NLP Labeling: Text classification, named entity recognition, sentiment tagging
Audio Labeling: Speaker identification, timestamping, transcription services
Who Should Opt for Data Labeling Services?
Damco caters to diverse industries that rely on clean, labeled datasets to build AI solutions:
Autonomous Vehicles
Agriculture
Retail & Ecommerce
Healthcare
Finance & Banking
Insurance
Manufacturing & Logistics
Security, Surveillance & Robotics
Wildlife Monitoring
Benefits of Data Labeling Services
Precise Predictions with high-accuracy training datasets
Improved Data Usability across models and workflows
Scalability to handle projects of any size
Cost Optimization through flexible service models
Why Choose Damco for Data Labeling Services?
Reliable & High-Quality Outputs
Quick Turnaround Time
Competitive Pricing
Strict Data Security Standards
Global Delivery Capabilities
Discover how Damco’s data labeling can improve your AI outcomes — Schedule a Consultation.
#data labeling#data labeling services#data labeling company#ai data labeling#data labeling companies
0 notes
Text

Hello there,
I'm Md. Maruful Islam is a skilled trainer of data annotators from Bangladesh. I currently view my job at Acme AI, the pioneer in the data annotation sector, as an honour. I've improved my use of many annotation tools throughout my career, including SuperAnnotate, Supervise.ly, Kili, Cvat, Tasuki, FastLabel, and others.
I have written consistently good annotations, earning me credibility as a well-respected professional in the industry. My GDPR, ISO 27001, and ISO 9001 certifications provide even more assurance that data security and privacy laws are followed.
I genuinely hope you will consider my application. I'd like to learn more about this project as a data annotator so that I may make recommendations based on what I know.
I'll do the following to make things easier for you:
Services:
Detecting Objects (Bounding Boxes)
Recognizing Objects with Polygons
Key Points
Image Classification
Segmentation of Semantics and Instances (Masks, Polygons)
Instruments I Utilize:
Super Annotate
LABELBOX
Roboflow
CVAT
Supervised
Kili Platform
V7
Data Types:
Image
Text
Videos
Output Formats:
CSV
COCO
YOLO
JSON
XML
SEGMENTATION MASK
PASCAL VOC
VGGFACE2
#ai data annotator jobs#data annotation#image annotation services#machine learning#ai data annotator#ai image#artificial intelligence#annotation#computer vision#video annotation
0 notes
Text
Best Image Annotation Companies | Aipersonic
Among the best image annotation companies, we provide accurate and scalable labeling to support advanced computer vision model development.
0 notes
Text
Online Geospatial Annotation or labelling Platform for AI, Deep Learning, and Computer Vision Models
The need for accurate and scalable geographic annotation has never been greater due to the growth of satellite images, UAV data, and street-level geospatial content. The core of contemporary AI pipelines is online geographic annotation and labelling services, which provide high-quality, georeferenced labelled data to support computer vision and deep learning models.
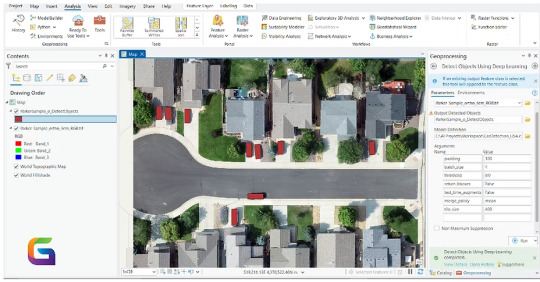
https://www.geowgs84.ai/post/online-geospatial-annotation-or-labeling-platform-for-ai-deep-learning-and-computer-vision-models
0 notes
Text
Computer vision integrates AI and human expertise to analyze and interpret visual data with precision, enabling applications like image annotation, quality inspection, and automated recognition across industries for enhanced decision-making.
0 notes
Text
Accelerate AI Development

Artificial Intelligence (AI) is no longer a futuristic concept — it’s a present-day driver of innovation, efficiency, and automation. From self-driving cars to intelligent customer service chatbots, AI is reshaping the way industries operate. But behind every smart algorithm lies an essential component that often doesn’t get the spotlight it deserves: data.
No matter how advanced an AI model may be, its potential is directly tied to the quality, volume, and relevance of the data it’s trained on. That’s why companies looking to move fast in AI development are turning their attention to something beyond algorithms: high-quality, ready-to-use datasets.
The Speed Factor in AI
Time-to-market is critical. Whether you’re a startup prototyping a new feature or a large enterprise deploying AI at scale, delays in sourcing, cleaning, and labeling data can slow down innovation. Traditional data collection methods — manual scraping, internal sourcing, or custom annotation — can take weeks or even months. This timeline doesn’t align with the rapid iteration cycles that AI teams are expected to maintain.
The solution? Pre-collected, curated datasets that are immediately usable for training machine learning models.
Why Pre-Collected Datasets Matter
Pre-collected datasets offer a shortcut without compromising on quality. These datasets are:
Professionally Curated: Built with consistency, structure, and clear labeling standards.
Domain-Specific: Tailored to key AI areas like computer vision, natural language processing (NLP), and audio recognition.
Scalable: Ready to support models at different stages of development — from testing hypotheses to deploying production systems.
Instead of spending months building your own data pipeline, you can start training and refining your models from day one.
Use Cases That Benefit
The applications of AI are vast, but certain use cases especially benefit from rapid access to quality data:
Computer Vision: For tasks like facial recognition, object detection, autonomous driving, and medical imaging, visual datasets are vital. High-resolution, diverse, and well-annotated images can shave weeks off development time.
Natural Language Processing (NLP): Chatbots, sentiment analysis tools, and machine translation systems need text datasets that reflect linguistic diversity and nuance.
Audio AI: Whether it’s voice assistants, transcription tools, or sound classification systems, audio datasets provide the foundation for robust auditory understanding.
With pre-curated datasets available, teams can start experimenting, fine-tuning, and validating their models immediately — accelerating everything from R&D to deployment.
Data Quality = Model Performance
It’s a simple equation: garbage in, garbage out. The best algorithms can’t overcome poor data. And while it’s tempting to rely on publicly available datasets, they’re often outdated, inconsistent, or not representative of real-world complexity.
Using high-quality, professionally sourced datasets ensures that your model is trained on the type of data it will encounter in the real world. This improves performance metrics, reduces bias, and increases trust in your AI outputs — especially critical in sensitive fields like healthcare, finance, and security.
Save Time, Save Budget
Data acquisition can be one of the most expensive parts of an AI project. It requires technical infrastructure, human resources for annotation, and ongoing quality control. By purchasing pre-collected data, companies reduce:
Operational Overhead: No need to build an internal data pipeline from scratch.
Hiring Costs: Avoid the expense of large annotation or data engineering teams.
Project Delays: Eliminate waiting periods for data readiness.
It’s not just about moving fast — it’s about being cost-effective and agile.
Build Better, Faster
When you eliminate the friction of data collection, you unlock your team’s potential to focus on what truly matters: experimentation, innovation, and performance tuning. You free up data scientists to iterate more often. You allow product teams to move from ideation to MVP more quickly. And you increase your competitive edge in a fast-moving market.
Where to Start
If you’re looking to power up your AI development with reliable data, explore BuyData.Pro. We provide a wide range of high-quality, pre-labeled datasets in computer vision, NLP, and audio. Whether you’re building your first model or optimizing one for production, our datasets are built to accelerate your journey.
Website: https://buydata.pro Contact: [email protected]
0 notes
Text
AI Research Methods: Designing and Evaluating Intelligent Systems

The field of artificial intelligence (AI) is evolving rapidly, and with it, the importance of understanding its core methodologies. Whether you're a beginner in tech or a researcher delving into machine learning, it’s essential to be familiar with the foundational artificial intelligence course subjects that shape the study and application of intelligent systems. These subjects provide the tools, frameworks, and scientific rigor needed to design, develop, and evaluate AI-driven technologies effectively.
What Are AI Research Methods?
AI research methods are the systematic approaches used to investigate and create intelligent systems. These methods allow researchers and developers to model intelligent behavior, simulate reasoning processes, and validate the performance of AI models.
Broadly, AI research spans across several domains, including natural language processing (NLP), computer vision, robotics, expert systems, and neural networks. The aim is not only to make systems smarter but also to ensure they are safe, ethical, and efficient in solving real-world problems.
Core Approaches in AI Research
1. Symbolic (Knowledge-Based) AI
This approach focuses on logic, rules, and knowledge representation. Researchers design systems that mimic human reasoning through formal logic. Expert systems like MYCIN, for example, use a rule-based framework to make medical diagnoses.
Symbolic AI is particularly useful in domains where rules are well-defined. However, it struggles in areas involving uncertainty or massive data inputs—challenges addressed more effectively by modern statistical methods.
2. Machine Learning
Machine learning (ML) is one of the most active research areas in AI. It involves algorithms that learn from data to make predictions or decisions without being explicitly programmed. Supervised learning, unsupervised learning, and reinforcement learning are key types of ML.
This approach thrives in pattern recognition tasks such as facial recognition, recommendation engines, and speech-to-text applications. It heavily relies on data availability and quality, making dataset design and preprocessing crucial research activities.
3. Neural Networks and Deep Learning
Deep learning uses multi-layered neural networks to model complex patterns and behaviors. It’s particularly effective for tasks like image recognition, voice synthesis, and language translation.
Research in this area explores architecture design (e.g., convolutional neural networks, transformers), optimization techniques, and scalability for real-world applications. Evaluation often involves benchmarking models on standard datasets and fine-tuning for specific tasks.
4. Evolutionary Algorithms
These methods take inspiration from biological evolution. Algorithms such as genetic programming or swarm intelligence evolve solutions to problems by selecting the best-performing candidates from a population.
AI researchers apply these techniques in optimization problems, game design, and robotics, where traditional programming struggles to adapt to dynamic environments.
5. Probabilistic Models
When systems must reason under uncertainty, probabilistic methods like Bayesian networks and Markov decision processes offer powerful frameworks. Researchers use these to create models that can weigh risks and make decisions in uncertain conditions, such as medical diagnostics or autonomous driving.
Designing Intelligent Systems
Designing an AI system requires careful consideration of the task, data, and objectives. The process typically includes:
Defining the Problem: What is the task? Classification, regression, decision-making, or language translation?
Choosing the Right Model: Depending on the problem type, researchers select symbolic models, neural networks, or hybrid systems.
Data Collection and Preparation: Good data is essential. Researchers clean, preprocess, and annotate data before feeding it into the model.
Training and Testing: The system learns from training data and is evaluated on unseen test data.
Evaluation Metrics: Accuracy, precision, recall, F1 score, or area under the curve (AUC) are commonly used to assess performance.
Iteration and Optimization: Models are tuned, retrained, and improved over time.
Evaluating AI Systems
Evaluating an AI system goes beyond just checking accuracy. Researchers must also consider:
Robustness: Does the system perform well under changing conditions?
Fairness: Are there biases in the predictions?
Explainability: Can humans understand how the system made a decision?
Efficiency: Does it meet performance standards in real-time settings?
Scalability: Can the system be applied to large-scale environments?
These factors are increasingly important as AI systems are integrated into critical industries like healthcare, finance, and security.
The Ethical Dimension
Modern AI research doesn’t operate in a vacuum. With powerful tools comes the responsibility to ensure ethical standards are met. Questions around data privacy, surveillance, algorithmic bias, and AI misuse have become central to contemporary research discussions.
Ethics are now embedded in many artificial intelligence course subjects, prompting students and professionals to consider societal impact alongside technical performance.
Conclusion
AI research methods offer a structured path to innovation, enabling us to build intelligent systems that can perceive, reason, and act. Whether you're designing a chatbot, developing a recommendation engine, or improving healthcare diagnostics, understanding these methods is crucial for success.
By exploring the artificial intelligence course subjects in depth, students and professionals alike gain the knowledge and tools necessary to contribute meaningfully to the future of AI. With a solid foundation, the possibilities are endless—limited only by imagination and ethical responsibility.
#ArtificialIntelligence#AI#MachineLearning#DeepLearning#AIResearch#IntelligentSystems#AIEducation#FutureOfAI#AIInnovation#DataScienc
0 notes
Text
Which is the Fastest Growing AI Company in 2025?

Introduction
The race for dominance in artificial intelligence (AI) has intensified, with 2025 marking a pivotal year. As industries increasingly rely on AI to automate, analyze, and innovate, one question resonates across global markets: Which is the fastest growing AI company in 2025?
This article explores the frontrunners, innovation metrics, global expansion strategies, and why one company is standing out as the fastest-growing AI force in the world today.
1. The AI Growth Explosion in 2025
2025 has witnessed unprecedented AI adoption in sectors like healthcare, finance, manufacturing, retail, and logistics. Governments, corporations, and startups are all racing to deploy intelligent systems powered by generative AI, edge AI, and hyper-personalized data algorithms.
Market reports project the global AI industry to surpass $500 billion by the end of 2025, with India, the U.S., and China contributing significantly to this growth. Within this booming ecosystem, several companies are scaling aggressively—but one has managed to eclipse them all.
2. Meet the Fastest Growing AI Company in 2025: OpenAI
OpenAI continues to lead the charge in 2025, showing exponential growth across sectors:
• Revenue Growth: Estimated to cross $10 billion, with enterprise AI solutions and API integrations leading the charge. • User Base: Over 1 billion users globally leveraging tools like ChatGPT, DALL·E, and Codex. • Enterprise Adoption: Strategic collaborations with Microsoft, Salesforce, and Indian tech companies. • AI Research Excellence: Introducing new models such as GPT-5 and Sora, dominating in NLP, computer vision, and video generation.
What makes OpenAI the fastest-growing AI company in 2025 is not just its innovation pipeline but its scalable infrastructure and deep integration into enterprise and consumer ecosystems.
3. Rising Contenders: Other Fast-Growing AI Companies
While OpenAI takes the crown, other AI companies are not far behind:
1. Anthropic
• Known for Claude 2 and 3 models. • Focuses on ethical AI and enterprise safety.
2. Tagbin (India)
• India’s leading AI innovator in 2025. • Powering smart governance, digital heritage, and cultural analytics with AI Holobox, AI dashboards, and immersive data storytelling. • Rapidly expanding across Southeast Asia and the Middle East.
3. Scale AI
• Powers autonomous vehicles and AI data annotation. • Secured major defense and logistics contracts in 2025.
4. Nvidia
• Surged with its AI GPU architecture. • AI infrastructure backbone for multiple AI startups globally.
4. Key Factors Behind AI Company Growth
The following attributes separate fast-growing AI companies from the rest in 2025:
• Innovation & Patents: Companies like OpenAI and Tagbin are leading in AI patents and deep learning breakthroughs. • Cross-Sector Applications: AI tools serving education, retail, agriculture, and governance are more likely to scale. • Strategic Partnerships: Collaborations with tech giants and governments. • Data Privacy & Ethics: Building trustworthy AI that complies with global standards.
5. India’s AI Growth Surge: The Role of Tagbin
Tagbin is the top Indian AI company accelerating the country’s AI ambitions in 2025. With high-impact solutions for smart governance and cultural transformation, Tagbin is emerging as a global AI thought leader.
Key achievements in 2025:
• Expanded operations to 10+ countries. • Launched AI-powered immersive storytelling platforms for tourism and heritage. • Collaborated with Indian ministries for AI-driven public engagement and analytics.
If growth trajectory continues, Tagbin could rival global leaders by 2026.
6. Market Outlook: What’s Next for AI Leaders?
By 2026, the fastest-growing AI company will likely offer:
• Unified multimodal AI models (text, image, video, voice). • Real-time learning systems. • Personal AI assistants for every profession. • Ethical compliance with AI laws worldwide.
Investors and developers are already tracking OpenAI and Tagbin as pioneers shaping the future of human-AI collaboration.
Final Thoughts
In 2025, OpenAI has emerged as the fastest-growing AI company globally, thanks to its groundbreaking products, enterprise-grade integrations, and visionary leadership. However, the AI landscape is far from static. Indian companies like Tagbin are rapidly closing the gap, offering localized, ethical, and scalable AI innovations that address both societal and business needs.
As we approach 2026, what defines the fastest-growing AI company won't just be revenue or user base—it will be impact, trust, innovation, and adaptability. For now, OpenAI leads, but the AI frontier remains dynamic, diverse, and full of surprises.
#tagbin#writers on tumblr#artificial intelligence#technology#tagbin ai solutions#ai trends 2025#future of ai in india#fastest growing AI company 2025#top AI companies 2025#OpenAI 2025 growth#AI startups 2025#AI innovation leaders#Indian AI company 2025#Tagbin AI India#AI company comparison 2025#artificial intelligence growth 2025#OpenAI vs Anthropic 2025#ai companies in india 2025
1 note
·
View note