#Lidar Annotation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s website traffic is steadily declining.
Text
Challenges in Point Cloud Annotation & Strategies for Better Accuracy
Point cloud annotation from Infosearch is a labeling process regarding 3D data collected from various devices (such as LiDAR or depth cameras) and is relevant to autonomous car driving; robotics, and AR/VR. Annotation of point clouds is a difficult task because of the inherent complexities, i.e., sparse data, unstructured format, and vast volume of information, of 3D.
Infosearch is a key provider of LiDAR annotation and point cloud annotation services for machine learning.
We provide the main challenges and the proposed techniques to increase the accuracy of point cloud labeling below.
The Critical Hindrances to Achieving Point Cloud Annotation.
1. Sparsity and Occlusion
• Distant objects are commonly described by few points in LiDAR data.
• Obscuration and partial visibility—such as behind cars or trees—happen often in 3D data.
Result: Knowing where one object ends and the other begins is not exactly simple.
2. Unstructured Data Format
• Point clouds frustrate the image-like structure due to their scattered points in a 3D space.
• Spatially dispersed points in a 3D scene prevent effective use of its 2D counterparts or natural human cognition.
Result: Higher cognitive load for annotators.
3. Class Ambiguity
• It is difficult to distinguish similar-looking objects, such as pedestrians and aides.
• Heterogeneity in datasets or labeling practices between practitioners can damage model performance.
Result: Class confusion and poor generalization.
4. Time-Consuming and Labor-Intensive
• Annotation tasks such as 3D bounding box or segmentation masks generation are laborious, as long as scenes are not simple.
Result: Costly human resource and slow progress on iterations.
5. Multi-Sensor Alignment Errors
• It is common for LiDAR, radar and RGB camera data to misalign, thereby causing wrong annotations.
Result: Perception models are trained with flawed annotation using incorrect datasets.
Strategies to Improve Annotation Accuracy
1. Use Advanced Annotation Platforms
• Leverage tools that offer:
o 3D visualization and manipulation
o Integration of views of camera and LiDAR for more accurate labeling.
o Smart snapping and interpolation
Tools: Scale AI, Supervisely, CVAT-3D, Segments.ai
2. Employ Semi-Automated Annotation
• Utilize automated labelers, pre-labelers with object detection models, to simplify workflows.
• Combine with human-in-the-loop verification.
Benefit: Helps to reduce direct labor inputs and still achieve more annotation consistency.
3. Establish Clear Annotation Protocols
• Output specifications for labeling should include minimum sized objects and occlusion considerations.
• The common instances should be illustrated, with tips given for rare cases.
Benefit: Minimises errors in human work and differences in annotators.
4. 3D-Aware QA Processes
• Perform post-annotation validation:
o Check for missing labels
o Validate object dimensions and orientation
o Review alignment with camera views
Benefit: Increases the confidence in annotations and elevates model results.
5. Utilize Synthetic & Augmented Data
• Replicate or augment point cloud datasets in orders of simulation, like CARLA and AirSim, to facilitate real world cases.
Benefit: Improves the completeness of datasets.
6. Train and Specialize Annotators
• Provide 3D-specific training to labeling teams.
• Enforce a narrow classification methodology (pedestrians, traffic signs), among labeling crews, for optimal yields.
Benefit: Affects the duration to a large extent and reduces the chances of mistaking within annotation procedures.
Summary Table
Challenge Strategy to Mitigate
Sparsity & Occlusion Use multi-sensor views; AI-assisted tools
Unstructured Format 3D-native annotation platforms
Class absence of ambiguity To establish exact parameters for labelling, use rigorous QA controls.
Time-Intensive Labeling Pre-labeling + human verification
Misalignment Sensor calibration + multi-modal QA
Final Thoughts
The process of annotating point clouds is critical as far as establishing reliable 3D perception technologies are concerned. Team productivity is improved by the merging of sophisticated tools, systematic procedures and automation, facilitating delivery of quality data that fuels real-world autonomy and intelligence.
Contact Infosearch for your data annotation services.
0 notes
Text
ADVANTAGES OF DATA ANNOTATION
Data annotation is essential for training AI models effectively. Precise labeling ensures accurate predictions, while scalability handles large datasets efficiently. Contextual understanding enhances model comprehension, and adaptability caters to diverse needs. Quality assurance processes maintain data integrity, while collaboration fosters synergy among annotators, driving innovation in AI technologies.
#Data Annotation Company#Data Labeling Company#Computer Vision Companies in India#Data Labeling Companies in India#Image Annotation Services#Data labeling & annotation services#AI Data Solutions#Lidar Annotation
0 notes
Text
LiDAR data Annotation

Centillion Networks is a leading Geospatial & LiDAR, Engineering and Software Development company, specialized in Telecom and Utility domains. Our proven ability to deliver innovative and cutting-edge solutions is backed by the domain experts. Centillion Application Development division offers its clients a great capability to manage their existing and new applications, aimed at productivity and profitability. Centillion Networks IT Professional Services follow a well-defined and matured Development process that ensures a guaranteed Quality product to the Client. Visit - https://centillionnetworks.com/exploring-applications-of-lidar-drone-surveys-and-lidar-data-annotation/
0 notes
Text
Lidar Annotation Services
Elevate your Lidar data precision with SBL's specialized Lidar Annotation Services. Our detailed 3D point cloud annotations drive superior accuracy in object detection and localization for autonomous systems and robotics. Partner with us to advance your AI initiatives seamlessly. Read more at https://www.sblcorp.ai/services/data-annotation-services/lidar-annotation-services/
0 notes
Text
The Future is Lidar: Unlocking Possibilities with Precise Labeling

Lidar (which stands for Light Detection and Ranging) is a type of 3D sensing technology that uses laser light to measure distances and create detailed 3D maps of objects and environments. Lidar has a wide range of applications, including self-driving cars, robotics, virtual reality, and geospatial mapping.
Lidar works by emitting laser light pulses and measuring the time it takes for the light to bounce back after hitting an object or surface. This data is then used to create a precise 3D map of the surrounding environment, with detailed information about the size, shape, and distance of objects within the map. Lidar sensors can vary in their range and resolution, with some sensors able to measure distances up to several hundred meters, and others able to detect fine details as small as a few centimeters.
One of the primary applications of lidar is in autonomous vehicles, where lidar sensors can be used to create a detailed 3D map of the surrounding environment, allowing the vehicle to detect and avoid obstacles in real-time. Lidar is also used in robotics for navigation and obstacle avoidance, and in virtual reality for creating immersive, 3D environments. https://www.youtube.com/embed/BVRMh9NO9Cs
In addition, lidar is used in geospatial mapping and surveying, where it can be used to create highly accurate 3D maps of terrain and buildings for a variety of applications, including urban planning, disaster response, and natural resource management.
Overall, lidar is a powerful and versatile technology that is driving advances in a wide range of fields, from autonomous vehicles to robotics to geospatial mapping.
Choosing your labeling modality
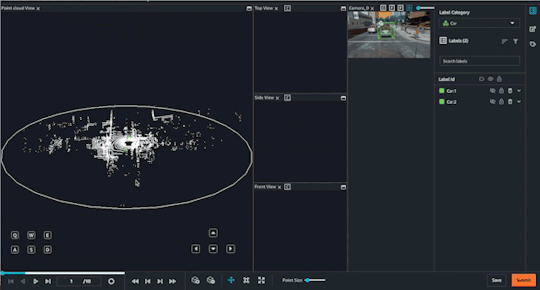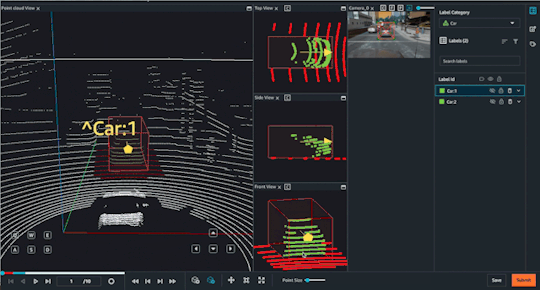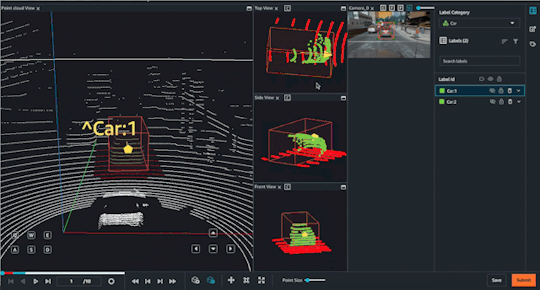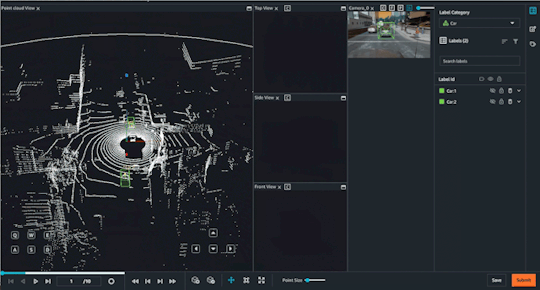
Object Tracking
Computer vision techniques are often used in combination with lidar 3D point cloud data to extract information and insights from the data. Here are some of the different computer vision techniques that can be used with lidar 3D point cloud data:
Object detection and recognition:-This involves using computer vision algorithms to detect and identify objects within the point cloud data, such as cars, buildings, and trees. Object detection and recognition can be useful for a wide range of applications, from urban planning to autonomous driving.
Object tracking:-This involves tracking the movement and trajectory of objects within the point cloud data over time. Object tracking can be used for applications such as crowd monitoring or autonomous vehicle navigation.
Segmentation:-This involves dividing the point cloud data into different segments based on the properties of the points, such as color or reflectivity. Segmentation can be used to identify regions of interest within the data, such as road surfaces or building facades.
Overall, these computer vision techniques can help to extract valuable information and insights from lidar 3D point cloud data and enable a wide range of applications and use cases. By combining lidar data with computer vision techniques, it is possible to create highly accurate and detailed 3D models of objects and environments, with a wide range of potential applications.
Why High-Quality labeling is important
High-quality lidar 3D point cloud labels are important for creating accurate and reliable 3D models of objects and environments. Here are some reasons why high-quality lidar 3D point cloud labels matter for a high-quality model:
Accuracy:-High-quality lidar 3D point cloud labels ensure that objects are accurately and consistently identified and labeled within the data. This is important for applications such as autonomous vehicles or robotics, where accurate and reliable information about objects in the environment is critical.
Consistency:-High-quality lidar 3D point cloud labels ensure that objects are labeled consistently across the data, with no variations in naming or identification. This is important for applications such as object detection or segmentation, where consistent labels are necessary for accurate and reliable results.
Completeness:-High-quality lidar 3D point cloud labels ensure that all objects within the data are identified and labeled, with no missing or incomplete information. This is important for applications such as geospatial mapping or urban planning, where complete and comprehensive information about objects in the environment is necessary.
Cost-effectiveness:-While high-quality lidar 3D point cloud labels may be more expensive to acquire or process initially, they can actually be more cost-effective in the long run, as they may require fewer resources to process or analyze and may be more suitable for a wider range of applications.
Overall, high-quality lidar 3D point cloud labels are critical for creating accurate and reliable 3D models of objects and environments, with a wide range of potential applications and benefits. By investing in high-quality labeling and processing, it is possible to create more accurate, detailed, and valuable 3D models that can be used in a wide range of applications, from autonomous vehicles to urban planning to robotics.
Best Practices to Manage Large Scale Lidar 3D Point Cloud Labeling Projects
Planning your lidar 3D point cloud labeling project is an important step in ensuring that the project is completed on time, on budget, and with the desired level of quality. Here are some key considerations to keep in mind when planning your lidar 3D point cloud labeling project:
Project scope:-Define the scope of the project, including the size of the dataset, the types of objects to be labeled, and the level of detail required. This will help to ensure that the project is focused and well-defined.
Labeling requirements:-Define the labeling requirements for the project, including the labeling schema, the labeling accuracy, and the level of detail required. This will help to ensure that the labeling process is consistent and produces high-quality results.
Labeling team:-Define the size and composition of the labeling team, including the number of labelers, their expertise, and their availability. Objectways can provide 1000s of trained Lidar labeling experts to match the throughput demand.
Tools and resources:-Identify the tools and resources required for the labeling project, including software, hardware, and data storage. This will help to ensure that the labeling process is efficient and that the results are consistent and of high quality.
Timeline and budget:-Define the timeline and budget for the labeling project, including the estimated time required for labeling, the cost of resources, and the expected deliverables. This will help to ensure that the project is completed on time and within budget.
Use Pre-labeling or downsampling to Save Cost:-There are many SOTA models available for pre-labeling that can provide starting point for labeling to save human labeling cost. Other approach in object tracking is to downsample frames at lower rate to reduce labeling effort
Overall, careful planning is key to the success of any lidar 3D point cloud labeling project. By taking the time to define the scope, requirements, team, tools, timeline, and budget for the project, it is possible to ensure that the project is completed with the desired level of quality and within the allotted resources.
At Objectways, we have worked on 100s of Lidar 3D point Cloud labeling projects across Autonomous Vehicles, Robotics, Agriculture and Geospatial domains. Contact Objectways for planning your next Lidar 3D point cloud labeling project
Lidar 3D Object Detection
Computer Vision
Autonomous Vehicle
Self Driving Cars
Tesla
#artificial intelligence#data annotation#data labeling#data science#machine learning#objectways#Lidar#Lidar 3d#Cloud Lableing#Cloud Labeling
0 notes
Text
Accelerating Autonomous Driving with High-Quality Data Annotation
Autonomous driving systems depend on accurately labeled data from cameras, LiDAR, and radar to navigate safely. Expert data annotation services provide the detailed, scalable input needed to train these models. By ensuring precision and consistency, these services enable vehicles to recognize environments, make decisions, and operate autonomously with confidence.
0 notes
Text
3d Point Cloud Annotation Services | Aipersonic
Accurate 3D Point Cloud Annotation Services by Aipersonic for AI training, LiDAR data labeling, and object detection.
0 notes
Text
Automated Data Annotation: Making the Automotive Industry Smarter

Automated data annotation is redefining how the automotive industry advances toward intelligent, AI-driven solutions. As AI integration deepens, the demand for precise, high-volume data labeling grows exponentially. According to G2, "The market for AI-based automated data labeling tools is estimated to grow at a CAGR of over 30% by 2025." This surge is propelled by the industry's need to power autonomous driving and smart vehicle systems efficiently through advanced auto annotation technologies.
Accurate data annotation forms the backbone of safe and responsive AI in vehicles. Poor-quality annotations can hinder model performance, while structured, automated labeling enhances precision and reduces training time. Industry insights reveal that 80% of large companies will seek external expertise to handle complex and large-scale data annotation demands.
These trends reflect a broader transformation: as automotive innovation accelerates, companies are embracing automated data annotation to achieve faster development cycles, reduce operational costs, and enable safer on-road experiences. In this blog, we’ll explore how automation is becoming an indispensable engine for smart mobility.
Understanding Data Annotation
At its core, data annotation involves tagging and labeling raw data, such as images, video, or sensor inputs, so that AI systems can learn from it. In the automotive sector, this means identifying road signs, lanes, pedestrians, vehicles, and environmental conditions in datasets that help train machine learning models. Traditional annotation methods can be time-consuming and prone to human error, especially as the scale of data expands. This is where automated data annotation comes into play.
Automated Data Labeling leverages AI and machine learning algorithms to label massive volumes of data faster and with higher accuracy. Unlike manual methods, automated systems continuously learn and improve from new datasets, reducing the reliance on human annotators. For automotive companies, using data annotation services enables them to process millions of data points collected from sensors and cameras in record time. This facilitates real-time decision-making and enhances the training of autonomous driving models, making them more robust and effective.
By annotating data efficiently and accurately, automotive innovators can ensure their AI models are equipped with high-quality, labeled datasets, significantly improving the performance and safety of autonomous vehicles.
How to Automate Data Annotation for Autonomous Vehicles
Training perception systems for autonomous vehicles requires massive amounts of high-quality labeled data from sources like cameras, LIDAR, and radar. However, manual data labeling is a major bottleneck. For automotive AI teams, it’s not just about labeling—it’s about doing so accurately, at scale, and fast enough to keep up with development cycles.
Research and industry benchmarks suggest that data preparation consumes up to 80% of the total effort in AI projects, with labeling being one of the most time- and resource-intensive components. For the automotive sector—where safety, real-time decision-making, and high-volume sensor data are critical—manual labeling simply doesn’t scale.
That’s where AI data labeling comes into play—automating the annotation process to boost efficiency and meet the demands of advanced automotive systems.
Why Automate Data Annotation in Automotive AI?
Autonomous vehicles rely on AI models that must interpret complex road environments, detect and classify objects, and make split-second decisions. Automating the labeling of visual and sensor data helps teams:
Reduce human errors in identifying objects like road signs, vehicles, pedestrians, and lane boundaries
Accelerate training cycles by labeling thousands of frames per hour
Ensure consistency across large-scale datasets from diverse driving environments
Cut costs by minimizing manual annotation labor
Enable continuous learning as vehicle systems evolve
Key Approaches to Automate Data Annotation
Here are the most effective techniques for automating annotation in the autonomous driving domain:
1. Pre-trained Models and Transfer Learning
AI models trained on existing datasets (e.g., for object detection or segmentation) can auto-label new data, significantly reducing manual workload. These are often adapted to recognize automotive-specific objects like traffic lights, road markings, and cyclists.
2. Sensor Fusion-Based Labeling
Combining camera, LIDAR, and radar inputs helps create more accurate labels—especially for 3D perception tasks. Automation tools use fused data to label object depth, orientation, and movement.
3. Human-in-the-Loop (HITL)
While AI handles the bulk of labeling, human reviewers validate and correct complex or ambiguous labels—ensuring safety-critical precision without the inefficiency of full manual annotation.
4. Programmatic Labeling
Rule-based logic and scripts can be used to label recurring patterns, like lane lines or turn signals, across large datasets. This is especially useful for repetitive or static elements in driving scenes.
5. Active Learning and Semi-Supervised Learning
Models suggest labels for the most uncertain or critical samples, which are then verified by experts. These feedback loops help improve labeling models while reducing the need for human intervention.
Build or Buy? Choosing the Right Automation Solution
For automotive teams, choosing the right annotation tool depends on multiple factors: the complexity of the sensor data, integration with existing ML pipelines, compliance requirements, and time-to-market pressures.
Some opt to build in-house platforms tailored to their unique sensor stack, while others use off-the-shelf solutions that support automotive-specific annotation formats, dashboards, and collaborative workflows.
Top Automated Data Annotation Techniques in the Automotive Industry
Automated data annotation is transforming the way training data is prepared for automotive AI systems by increasing efficiency, consistency, and scalability. Different automotive use cases require distinct automated annotation techniques. Below are some of the most commonly employed methods:
Bounding Box Annotation
In this technique, AI-powered tools for AI labeling automatically generate rectangular boxes around objects like vehicles, pedestrians, traffic lights, and animals. Automated bounding boxes speed up the labeling process and ensure consistent object detection for real-time perception systems. This method is especially useful for training models that require large volumes of annotated video or image data.
Semantic Segmentation
Here, automation tools classify every pixel in an image into categories such as road, vehicle, pedestrian, or traffic sign. Advanced models powered by deep learning can perform this pixel-level annotation with high precision, enabling more detailed scene understanding for autonomous navigation and path planning.
Polyline Annotation
Machine learning algorithms detect and annotate lane markings, road edges, and boundaries by drawing polylines. AI annotation through polylines is critical for systems like lane departure warning, autonomous lane changes, and maintaining accurate road topology in dynamic driving environments.
3D Cuboid Annotation
AI systems generate 3D boxes around objects using camera or LIDAR data to capture volume, orientation, and spatial positioning. Automated cuboid annotation is crucial for depth estimation and environmental awareness in self-driving vehicles, helping models understand how far and how big an object is in 3D space.
Keypoint Annotation
Using AI models, systems can automatically mark specific points on objects, such as joints on pedestrians or facial landmarks on drivers. This form of annotation supports behavioral analysis, including gaze tracking, gesture recognition, and posture monitoring, all of which enhance in-cabin safety and external interaction with road users.
Impact of Automated Data Annotation on Automotive
Automated data annotation is revolutionizing the automotive industry by enabling faster, more accurate AI model training. From enhancing safety to optimizing manufacturing, it’s key to accelerating the future of autonomous mobility.
Enhancing Safety in Autonomous Driving
Automated data annotation plays a critical role in training AI models to detect and respond accurately to road elements, such as pedestrians, vehicles, traffic signs, and road conditions. By automating the process of annotating data, systems like ADAS (Advanced Driver Assistance Systems) can make real-time decisions that prevent accidents, ensuring both passenger and pedestrian safety.
Accelerating the Development of Self-Driving Cars
Automated data labeling enables the rapid creation of high-quality datasets, drastically reducing the time needed to train machine learning models. This accelerates prototyping and brings self-driving technologies to market more quickly, allowing automotive companies to stay ahead of the competition and meet evolving demands.
Reducing Costs Through Virtual Testing
Automated annotation makes it easier to create synthetic test environments for autonomous vehicles. By providing large volumes of annotated data, AI models can be tested in virtual environments, simulating complex driving scenarios. This eliminates the need for extensive physical testing, saving both time and operational costs.
Customizing Vehicles for Global Markets
Different regions have distinct traffic laws, road infrastructures, and driving behaviors. Automated data annotation allows AI systems to be trained on country-specific road signs, symbols, and cultural driving habits, enabling manufacturers to create regionally optimized autonomous driving systems. This ensures compliance with local regulations and enhances safety across markets.
Improving Driver Monitoring Systems
AI-powered data labeling of internal camera feeds helps detect critical driver behaviors, such as fatigue, distraction, or drowsiness. Automated systems can analyze these labeled data points and trigger alerts or system interventions to prevent accidents. As these technologies are increasingly mandated, especially in commercial fleets and ride-hailing services, automated annotation ensures effective monitoring.
Advancing Manufacturing and Quality Control
In the automotive manufacturing sector, automated data annotation helps AI systems identify defects and anomalies during production. By labeling data from vision systems in real-time, manufacturers can streamline quality control processes, reduce production errors, and improve overall efficiency. This leads to higher-quality vehicles and fewer recalls.
Supporting Predictive Maintenance
Automated data annotation aids in predictive maintenance by labeling sensor and diagnostic data. These labeled datasets help machine learning models recognize patterns in vehicle components, predicting potential failures before they occur. This capability reduces downtime, minimizes costly repairs, and enhances the longevity of automotive assets.
Enabling Smart Infotainment and HMI Systems
As human-machine interaction (HMI) evolves, automated data annotation plays a pivotal role in improving voice and gesture recognition in vehicles. By training systems with AI training data across various modalities, automotive manufacturers can enhance the responsiveness, accuracy, and personalization of smart infotainment systems, providing a better user experience.
Enhancing Road Infrastructure Interaction
For autonomous vehicles to navigate complex environments, such as toll booths, parking gates, and traffic management systems, high-quality annotated data is required. Automated data annotation allows vehicles to learn how to interact seamlessly with road infrastructure, improving safety and efficiency when handling real-world scenarios.
Optimizing Data Processing Pipelines
Integrating automated annotation tools into the automotive AI data pipeline enhances efficiency by reducing manual intervention. These tools automatically label sensor data, validate label accuracy, and flag edge cases for human review. This process streamlines dataset development, improves model precision, and speeds up the deployment of AI-driven features.
Conclusion
As the automotive industry moves toward a future of intelligent mobility, the impact of automated data annotation becomes more evident. It is no longer just about processing raw data; it’s about transforming that data into actionable insights that enhance vehicle autonomy, safety, and performance. From autonomous driving to predictive maintenance, automated data annotation fuels the evolution of AI systems that make intelligent, real-time decisions.
The demand for precision, speed, and scalability is only growing, and manual annotation can no longer keep pace with the volume of data generated by modern vehicles. Data annotation companies now offer the automotive sector a powerful solution to reduce operational costs, accelerate development cycles, and ensure the safety and reliability of AI systems through scalable auto-annotation tools.
In an industry where every decision can have life-or-death consequences, embracing automated data annotation is not just a technological advancement—it’s a strategic necessity. Automotive manufacturers and innovators who adopt these technologies will be better positioned to lead the charge toward safer, smarter, and more efficient vehicles, shaping the future of mobility worldwide.
Looking for scalable, high-quality annotation solutions for your automotive AI needs? TagX offers advanced automated data annotation services that accelerate the development of intelligent automotive systems.
Original Source, https://www.tagxdata.com/automated-data-annotation-making-the-automotive-industry-smarter
0 notes
Text
Best Image Annotation Companies Compared: Features, Pricing, and Accuracy

Introduction
As applications powered by artificial intelligence, such as self-driving cars, healthcare diagnostics, and online retail, expand, image annotation has emerged as a crucial component in developing effective machine learning models. However, with numerous providers offering annotation services, how can one select the most suitable Image Annotation Companies for their requirements? In this article, we evaluate several leading image annotation companies in 2025, considering their features, pricing, and accuracy, to assist you in identifying the best match for your project.
1. GTS.AI – Enterprise-Grade Accuracy with Custom Workflows
GTS.AI is renowned for its flexible annotation pipelines, stringent enterprise security standards, and its ability to cater to various sectors such as the automotive, healthcare, and retail industries.
Key Features:
Supports various annotation types including bounding boxes, polygons, keypoints, segmentation, and video annotation.
Offers a scalable workforce that includes human validation.
Integrates seamlessly with major machine learning tools.
Adheres to ISO-compliant data security protocols.
Pricing:
Custom pricing is determined based on the volume of data, type of annotation, and required turnaround time.
Offers competitive rates for datasets requiring high accuracy.
Accuracy:
Achieves over 98% annotation accuracy through a multi-stage quality control process.
Provides annotator training programs and conducts regular audits.
Best for: Companies in need of scalable, highly accurate annotation services across various industries.
2. Labelbox – Platform Flexibility and AI-Assisted Tools
Labelbox provides a robust platform for teams seeking to manage their annotation processes effectively, featuring capabilities that cater to both internal teams and external outsourcing.
Key Features
Include a powerful data labeling user interface and software development kits,
Automation through model-assisted labeling,
Seamless integration with cloud storage and machine learning workflows.
Pricing
Options consist of a freemium tier,
Custom pricing for enterprises,
Pay-per-usage model for annotations.
Accuracy
May vary based on whether annotators are in-house or outsourced, with strong quality
Control tools that necessitate internal supervision.
This platform is ideal for machine learning teams in need of versatile labeling tools and integration possibilities.
3. Scale AI – Enterprise-Level Services for Complex Use Cases
Scale AI is a leading provider in the market for extensive and complex annotation tasks, such as 3D perception, LiDAR, and autonomous vehicle data.
Key Features:
Offers a wide range of annotation types, including 3D sensor data.
Utilizes an API-first platform that integrates with machine learning.
Provides dedicated project managers for large clients.
Pricing
Premium pricing, particularly for high-complexity data.
Offers project-based quotes.
Accuracy:
Renowned for top-tier annotation accuracy.
Implements multi-layered quality checks and human review.
Best for: Projects in autonomous driving, defense, and robotics that require precision and scale.
4. CloudFactory – Human-Centric Approach with Ethical Sourcing
CloudFactory offers a unique blend of skilled human annotators and ethical AI practices, positioning itself as an excellent choice for companies prioritizing fair labor practices and high data quality.
Key Features:
The workforce is trained according to industry-specific guidelines.
It supports annotation for images, videos, audio, and documents.
There's a strong focus on data ethics and the welfare of the workforce.
Pricing
Pricing is based on volume and is moderately priced compared to other providers.
Contracts are transparent.
Accuracy
There are multiple stages of human review.
Continuous training and feedback loops are implemented.
Best for: Companies looking for socially responsible and high-quality annotation services.
5. Appen – Global Crowd with AI Integration

Appen boasts one of the largest international crowds for data annotation, offering extensive support for various AI training data types, such as natural language processing and computer vision.
Key Features
Include a diverse global crowd with multilingual capabilities,
Automated workflows, and data validation tools,
As well as high data throughput suitable for large-scale projects.
Pricing
Appen provides competitive rates for bulk annotation tasks,
With options for pay-as-you-go and contract models.
Accuracy
The quality of data can fluctuate based on project management,
Although the workflows are robust, necessitating a quality control setup.
Best for: This service is ideal for global brands and research teams that need support across multiple languages and domains.
Conclusion: Choosing the Right Partner
The ideal image annotation company for your project is contingent upon your specific requirements:
If you require enterprise-level quality with adaptable services, Globose Technology Solution.AI is recommended.
For those seeking comprehensive control over labeling processes, Labelbox is an excellent choice.
If your project involves intricate 3D or autonomous data, Scale AI is specifically designed for such tasks.
If ethical sourcing and transparency are priorities, CloudFactory should be considered.
For multilingual and scalable teams, Appen may be the right fit.
Prior to selecting a vendor, it is essential to assess your project's scale, data type, necessary accuracy, and compliance requirements. A strategic partner will not only assist in labeling your data but also enhance your entire AI development pipeline.
0 notes
Text
LiDAR Data: A Guide to Annotation and AI Integration
This article covers an introduction to LiDAR technology, the essentials of LiDAR data annotation, an overview of LiDAR data collection to its applications in AI models. Read to know how Cogito Tech can help with LiDAR data annotation.

0 notes
Text
Video Data Collection Services: Powering the Advancement of AI and Machine Learning

Introduction:
In the contemporary data-centric landscape, video data has become an invaluable asset for the training of artificial intelligence (AI) and machine learning (ML) models. The increasing prevalence of technologies such as computer vision, facial recognition, autonomous vehicles, and real-time surveillance systems has heightened the demand for high-quality video data. This is where video data collection services are essential, as they facilitate the acquisition, curation, and organization of video data to support advanced AI and ML applications.
What Are Video Data Collection Services?
Video Data Collection Services encompass the systematic gathering and structuring of video footage to develop organized datasets for AI and ML models. These services are tailored to collect a diverse range of video data types, including:
Indoor and outdoor settings
Human interactions and activities
Vehicle and traffic patterns
Facial expressions and gestures
Object detection and tracking
Natural scenes and landscapes
The gathered data is subsequently annotated and labeled, rendering it suitable for training AI models in various tasks such as object recognition, behavior analysis, and autonomous navigation, among others.
The Significance of Video Data Collection
1. Training Artificial Intelligence Models
Artificial intelligence models necessitate extensive volumes of high-quality data to enhance their accuracy and performance. Video data provides a wealth of information, encompassing motion, color, depth, and texture, which aids AI in comprehending intricate real-world situations more effectively.
2. Advancing Computer Vision
Computer vision models significantly depend on annotated video data to identify objects, monitor movements, and interpret human actions. The collection of video data is crucial for creating comprehensive datasets for these applications.
3. Developing Autonomous Systems
Autonomous vehicles, drones, and robotic systems rely on real-time video feeds to make instantaneous decisions. High-quality video datasets are vital for training these systems to accurately respond to their surroundings.
4. Enhancing Facial and Gesture Recognition
AI models focused on facial recognition and emotion detection that utilize video require varied datasets that encompass different lighting conditions, angles, and expressions.
Types of Video Data Collection Services
1.Crowdsourced Data Collection
Organizations utilize crowdsourcing platforms to obtain video data from a wide array of individuals and settings. This approach fosters the development of a more comprehensive and impartial dataset.
2.Controlled Environment Collection
Data is gathered in a studio or regulated environment where variables such as lighting, background, and participant actions can be managed effectively.
3.Real-World Data Collection
This method involves recording video data from actual situations, including traffic intersections, retail establishments, or outdoor settings, to train AI models for real-world applications.
4.Sensor-Based Data Collection
This technique employs specialized cameras (such as thermal and night vision) and LiDAR technology to capture intricate video data for sophisticated AI applications.
Key Benefits of Video Data Collection Services
Scalability: Enables the rapid and efficient collection of large quantities of video data.
Diversity: Ensures a well-rounded dataset by incorporating data from various locations, demographics, and environments.
Customization: Allows for data collection to be adapted to meet specific project requirements.
Annotation and Labeling: The collected video data is frequently pre-processed with annotations, rendering it ready for AI use.
Improved Model Accuracy: Enhanced data quality contributes to superior AI performance and decision-making capabilities.
Applications of Video Data Collection

Autonomous Vehicles – Training AI systems to recognize pedestrians, vehicles, and traffic signs.
Security and Surveillance – Facilitating real-time threat detection and activity monitoring.
Healthcare – Observing patient behavior and diagnosing conditions based on physical movements.
Retail – Analyzing customer behavior and optimizing store layouts.
Sports and Fitness – Monitoring athlete performance and conducting motion analysis.
Challenges in Video Data Collection
Privacy Issues – The recording of human activities presents ethical and legal challenges concerning data privacy.
Data Integrity – Factors such as inadequate lighting, low resolution, and ambient noise can compromise data quality.
Storage and Processing Requirements – The substantial size of video files necessitates considerable storage capacity and computational resources for effective processing.
Bias and Representation – A lack of diversity within the dataset may result in biased outcomes in AI applications.
Future of Video Data Collection
With the ongoing advancements in artificial intelligence and machine learning, the need for video data collection services is expected to increase significantly. Innovations such as 5G technology, edge computing, and high-definition cameras will further improve the efficiency and quality of video data acquisition. Additionally, the incorporation of synthetic data and augmented reality will create new avenues for producing intricate video datasets for AI training purposes.
Conclusion
As artificial intelligence progresses, the importance of video data collection services becomes increasingly significant in developing more intelligent and efficient models. Whether applied in autonomous driving, intelligent surveillance, or healthcare advancements, high-quality video datasets serve as the cornerstone of AI progress. Collaborating with a reputable data provider such as Globose Technology Solutions guarantees access to dependable, diverse, and superior video data for innovative AI applications.
0 notes
Text
IEEE Transactions on Artificial Intelligence, Volume 6, Issue 3, March 2025
1) Fair Machine Learning in Healthcare: A Survey
Author(s): Qizhang Feng, Mengnan Du, Na Zou, Xia Hu
Pages: 493 - 507
2) Regret and Belief Complexity Tradeoff in Gaussian Process Bandits via Information Thresholding
Author(s): Amrit Singh Bedi, Dheeraj Peddireddy, Vaneet Aggarwal, Brian M. Sadler, Alec Koppel
Pages: 508 - 517
3) An Evolutionary Multitasking Algorithm for Efficient Multiobjective Recommendations
Author(s): Ye Tian, Luke Ji, Yiwei Hu, Haiping Ma, Le Wu, Xingyi Zhang
Pages: 518 - 532
4) Deep-Learning-Based Uncertainty-Estimation Approach for Unknown Traffic Identification
Author(s): Siqi Le, Yingxu Lai, Yipeng Wang, Huijie He
Pages: 533 - 548
5) ReLAQA: Reinforcement Learning-Based Autonomous Quantum Agent for Quantum Applications
Author(s): Ahmad Alomari, Sathish A. P. Kumar
Pages: 549 - 558
6) Traffexplainer: A Framework Toward GNN-Based Interpretable Traffic Prediction
Author(s): Lingbai Kong, Hanchen Yang, Wengen Li, Yichao Zhang, Jihong Guan, Shuigeng Zhou
Pages: 559 - 573
7) Personalized Learning Path Problem Variations: Computational Complexity and AI Approaches
Author(s): Sean A. Mochocki, Mark G. Reith, Brett J. Borghetti, Gilbert L. Peterson, John D. Jasper, Laurence D. Merkle
Pages: 574 - 588
8) Prompt Learning for Few-Shot Question Answering via Self-Context Data Augmentation
Author(s): Jian-Qiang Qiu, Chun-Yang Zhang, C. L. Philip Chen
Pages: 589 - 603
9) MDA-GAN: Multiscale and Dual Attention Generative Adversarial Network for Bone Suppression in Chest X-Rays
Author(s): Anushikha Singh, Rukhshanda Hussain, Rajarshi Bhattacharya, Brejesh Lall, B.K. Panigrahi, Anjali Agrawal, Anurag Agrawal, Balamugesh Thangakunam, D.J. Christopher
Pages: 604 - 613
10) Image Tampering Detection With Frequency-Aware Attention and Multiview Fusion
Author(s): Xu Xu, Junxin Chen, Wenrui Lv, Wei Wang, Yushu Zhang
Pages: 614 - 625
11) NICASU: Neurotransmitter Inspired Cognitive AI Architecture for Surveillance Underwater
Author(s): Mehvish Nissar, Badri Narayan Subudhi, Amit Kumar Mishra, Vinit Jakhetiya
Pages: 626 - 638
12) Att2CPC: Attention-Guided Lossy Attribute Compression of Point Clouds
Author(s): Kai Liu, Kang You, Pan Gao, Manoranjan Paul
Pages: 639 - 650
13) Neural Network-Based Ensemble Learning Model to Identify Antigenic Fragments of SARS-CoV-2
Author(s): Syed Nisar Hussain Bukhari, Kingsley A. Ogudo
Pages: 651 - 660
14) Bridging the Climate Gap: Multimodel Framework With Explainable Decision-Making for IOD and ENSO Forecasting
Author(s): Harshit Tiwari, Prashant Kumar, Ramakant Prasad, Kamlesh Kumar Saha, Anurag Singh, Hocine Cherifi, Rajni
Pages: 661 - 675
15) Model-Heterogeneous Federated Graph Learning With Prototype Propagation
Author(s): Zhi Liu, Hanlin Zhou, Xiaohua He, Haopeng Yuan, Jiaxin Du, Mengmeng Wang, Guojiang Shen, Xiangjie Kong, Feng Xia
Pages: 676 - 689
16) Semisupervised Breast MRI Density Segmentation Integrating Fine and Rough Annotations
Author(s): Tianyu Xie, Yue Sun, Hongxu Yang, Shuo Li, Jinhong Song, Qimin Yang, Hao Chen, Mingxiang Wu, Tao Tan
Pages: 690 - 699
17) NL-CoWNet: A Deep Convolutional Encoder–Decoder Architecture for OCT Speckle Elimination Using Nonlocal and Subband Modulated DT-CWT Blocks
Author(s): P. S. Arun, Bibin Francis, Varun P. Gopi
Pages: 700 - 709
18) Multiattribute Deep CNN-Based Approach for Detecting Medicinal Plants and Their Use for Skin Diseases
Author(s): Prachi Dalvi, Dhananjay R. Kalbande, Surendra Singh Rathod, Harshal Dalvi, Amey Agarwal
Pages: 710 - 724
19) Deep Feature Unsupervised Domain Adaptation for Time-Series Classification
Author(s): Nannan Lu, Tong Yan, Song Zhu, Jiansheng Qian, Min Han
Pages: 725 - 737
20) Enhanced LiDAR-Based Localization via Multiresolution Iterative Closest Point Algorithms and Feature Extraction
Author(s): Yecheng Lyu, Xinkai Zhang, Feng Tao
Pages: 738 - 746
21) Swin-MGNet: Swin Transformer Based Multiview Grouping Network for 3-D Object Recognition
Author(s): Xin Ning, Limin Jiang, Weijun Li, Zaiyang Yu, Jinlong Xie, Lusi Li, Prayag Tiwari, Fernando Alonso-Fernandez
Pages: 747 - 758
22) A Two-Level Neural-RL-Based Approach for Hierarchical Multiplayer Systems Under Mismatched Uncertainties
Author(s): Xiangnan Zhong, Zhen Ni
Pages: 759 - 772
23) Adaptive Neural Network Finite-Time Event Triggered Intelligent Control for Stochastic Nonlinear Systems With Time-Varying Constraints
Author(s): Jia Liu, Jiapeng Liu, Qing-Guo Wang, Jinpeng Yu
Pages: 773 - 779
24) DDM-Lag: A Diffusion-Based Decision-Making Model for Autonomous Vehicles With Lagrangian Safety Enhancement
Author(s): Jiaqi Liu, Peng Hang, Xiaocong Zhao, Jianqiang Wang, Jian Sun
Pages: 780 - 791
0 notes
Text
Data Collection Through Images: Techniques and Tools

Introduction
In the contemporary landscape driven by data, the Data Collection Images -based data has emerged as a fundamental element across numerous sectors, including artificial intelligence (AI), healthcare, retail, and security. The evolution of computer vision and deep learning technologies has made the gathering and processing of image data increasingly essential. This article delves into the primary methodologies and tools employed in image data collection, as well as their significance in current applications.
The Importance of Image Data Collection
Image data is crucial for:
Training AI Models: Applications in computer vision, such as facial recognition, object detection, and medical imaging, are heavily reliant on extensive datasets.
Automation & Robotics: Technologies like self-driving vehicles, drones, and industrial automation systems require high-quality image datasets to inform their decision-making processes.
Retail & Marketing: Analyzing customer behavior and enabling visual product recognition utilize image data for enhanced personalization and analytics.
Healthcare & Biometric Security: Image-based datasets are essential for accurate medical diagnoses and identity verification.
Methods for Image Data Collection
1. Web Scraping & APIs
Web scraping is a prevalent technique for collecting image data, involving the use of scripts to extract images from various websites. Additionally, APIs from services such as Google Vision, Flickr, and OpenCV offer access to extensive image datasets.
2. Manual Image Annotation
The process of manually annotating images is a critical method for training machine learning models. This includes techniques such as bounding boxes, segmentation, and keypoint annotations.
3. Crowdsourcing
Services such as Amazon Mechanical Turk and Figure Eight facilitate the gathering and annotation of extensive image datasets through human input.
4. Synthetic Data Generation
In situations where real-world data is limited, images generated by artificial intelligence can be utilized to produce synthetic datasets for training models.
5. Sensor & Camera-Based Collection
Sectors such as autonomous driving and surveillance utilize high-resolution cameras and LiDAR sensors to gather image data in real-time.
Tools for Image Data Collection
1. Labeling
A widely utilized open-source tool for bounding box annotation, particularly effective for object detection models.
2. Roboflow
A robust platform designed for the management, annotation, and preprocessing of image datasets.
3. OpenCV
A well-known computer vision library that facilitates the processing and collection of image data in real-time applications.
4. Super Annotate
A collaborative annotation platform tailored for AI teams engaged in image and video dataset projects.
5. ImageNet & COCO Dataset
Established large-scale datasets that offer a variety of image collections for training artificial intelligence models.
Where to Obtain High-Quality Image Datasets
For those in search of a dataset for face detection, consider utilizing the Face Detection Dataset. This resource is specifically crafted to improve AI models focused on facial recognition and object detection.
How GTS.ai Facilitates Image Data Collection for Your Initiative
GTS.ai offers premium datasets and tools that streamline the process of image data collection, enabling businesses and researchers to train AI models with accuracy. The following are ways in which it can enhance your initiative:
Pre-Annotated Datasets – Gain access to a variety of pre-labeled image datasets, including the Face Detection Dataset for facial recognition purposes.
Tailored Data Collection – Gather images customized for particular AI applications, such as those in healthcare, security, and retail sectors.
Automated Annotation – Employ AI-driven tools to efficiently and accurately label and categorize images.
Data Quality Assurance – Maintain high levels of accuracy through integrated validation processes and human oversight.
Scalability and Integration – Effortlessly incorporate datasets into machine learning workflows via APIs and cloud-based solutions.
By utilizing GTS.ai, your initiative can expedite AI training, enhance model precision, and optimize image data collection methods.
Conclusion
The collection of image-based data is an essential aspect of advancements in Globose Technology Solutions AI and computer vision. By employing appropriate techniques and tools, businesses and researchers can develop robust models for a wide range of applications. As technology progresses, the future of image data collection is poised to become increasingly automated, ethical, and efficient.
0 notes
Text
The Future of Autonomous Vehicle Datasets with GTS.AI

The autonomous vehicle Dataset represents a commendable step in the advancement of transportation technology, ensuring safety, efficiency, and ease of use. The high-quality datasets at the heart of these self-driving systems are crucial. These datasets are essential in training and refining the machine learning models necessary for autonomous vehicles to navigate complex locations.
Generating and Providing the Datasets for Autonomous Driving
For an autonomous vehicle to drive safely, it must have real-time diverse and reliable knowledge of the driving environment, make sound decisions, and perform movements accordingly. This process is known as the perception-decision-action cycle, which threatens data. Good datasets become the basis of information that different types of machine learning algorithms use to recognize objects, estimate motions, and plan trajectories.
Some datasets are complex, comprising:
Visual Data: Images and videos collected by cameras mounted on the vehicle to form a visual map of the environment.
LiDAR Data: Light Detection and Ranging data primarily representing 3D point clouds through which the vehicle calculates distances and recognizes obstacles. Radar Data: Used to determine the velocity and position of objects, ideal in adverse weather conditions. GPS and IMU Data: These provide detailed information on the position and movement of the vehicle.
In order for AV systems to process, the diverse data sets should be properly synchronized and labeled. Annotations could include labeling objects (pedestrians and traffic signs), segmenting drivable surfaces, or marking lane boundaries.
The Fourfold Challenges of Collecting Quality Datasets
Collecting and curating datasets for autonomous cars entails several challenges.
Diversity of Scenarios: AVs must be outfitted to deal with a wide variety of traffic conditions, ranging from various weather conditions, lighting changes, and various traffic situations. Such variability can only be accomplished through thorough data collection efforts. Volume of Data: The amount of data that is gathered by sensors is tremendous. Thus, the sheer volume of data makes it imperative to store, manage, and process the data effectively. Annotation Complexity: This is laborious; only through an arduous process of painstaking checking will a dataset provide reliable training data for machine-learning models. Privacy Concerns: The collection of data in public spaces raises some pressing privacy concerns, which needs to be dealt with by mechanisms that ensure the anonymization of sensitive information.
GTS.ai: Pioneering High-Quality Data Collection
To overcome these challenges, an expert with extensive experience in data collection and annotation must be called. Globose Technology Solutions, or GTS.ai, stands at the forefront of this domain by offering high-caliber data collection services that emphasize the human touch. With over 25 years of this practice under the belt, GTS.ai specializes in the delivery of highly customized datasets for machine learning applications.
GTS.ai's Services
Collection of Image and Video Data-Creation of specialized datasets, including traffic videos and urban scenes, that train perception systems in AVs. Annotation Services-The application of various annotation techniques to ensure image and video identification and thus improve the accuracy of the generated data by machine learning models. Collection of Speech and Text Data - Collection and annotation of audio and text data supporting natural language processing applications regarding the automotive industry.
Using the expertise of GTS.ai, organizations will now source datasets that are sound and carefully tailored to meet the different needs posed by autonomous driving systems.
Case Study: Case Study in Autonomous Vehicle Driving Dataset
The first case study showcasing GTS.ai capacities is about KITTI Vision Benchmark Suite, an already well-known dataset in the AV research community. The particular collection is rich in terms of high-resolution pictures and 3D cloud points from various driving scenarios for worth resources in AV training or evaluation.
gts.ai
GTS.ai founded this dataset and labeled it so that it can suit the rigors of machine learning applications in autonomous vehicles. This particular activity emphasizes the purpose of GTS.ai in good quality data solutions to help improve the AV technology.
A Look at Future Autonomous Vehicle Datasets
With both autonomous driving technology and the dataset being worked on and improved, the pressure for more sophisticated and broad-ranging datasets is only going to grow. Future datasets must cover a wider variety of situations, including infrequent and edge cases, to allow the AVs to successfully handle situations that may occur in the real world. Combine that with the rise of approaches for fusing simulation data with real-world data. Simulated data would therefore afford additional scenarios that remain hard to achieve or dangerous to collect in real life.
In this dynamic landscape, companies like GTS.ai play a crucial role. With their expertise in the collection and annotation of this data, AV developers get the data rich in quality that drives evolution and makes sure safe and reliable autonomous vehicles are on our roads. In closing, the journey to fully autonomous vehicles is data-driven. Solid datasets lay the foundations for AV systems themselves to perceive, decide, and act within complicated environments. With organizations such as GTS.ai making a concerted effort, that future is looking increasingly intelligent and autonomous.
0 notes
Text
Data Collection For Machine Learning: Fueling the Next Generation of AI

In the text of artificial intelligence, data is that which gives breath to innovation and transformation. In other words, the heart of any model of machine learning is the dataset. The process of data gathering in machine learning is what builds the intelligent systems that allow algorithms to learn, adapt, and make decisions. Irrespective of their sophistication, advanced AI would fail without good quality, well-organized data.
This article discusses the importance of data collection for machine learning, its role in AI development, the different methodologies, challenges, and how it is shaping the future of intelligent systems.
Significance of Data Collection in Machine Learning
Data is the lifeblood of machine learning models. These models analyze examples to derive patterns, ascertain relationships, and develop a prediction based on them. The amount and quality of data given to the machine learning model will directly affect the model's accuracy, reliability, and generalization.
The Role of Data Collection in AI Success
Statistical Training and Testing of Algorithms: Machine learning algorithms are trainable with data. A spectrum of datasets allows models to train on alternate scenarios, which would enable accurate predictions during everyday applications of models. Validation datasets check for model effectiveness and help in reducing overfitting.
Facilitating Personalization: An intelligent system could tailor a richer experience based on personal information typically gathered from social interactions with high-quality data. In some instances, that might include recommendations on streaming services or targeted marketing campaigns.
Driving Advancement: The autonomous car, medical diagnosis, etc. would be nothing without big datasets for performing some of those advanced tasks like object detection, or sentiment analysis, or even what we call disease prediction.
Data Collection Process for Machine Learning
Collecting data for machine learning, therefore, is an exhaustive process wherein some steps need to be followed to ensure the data is to be used from a quality perspective.
Identification of Data Requirements: Prior to gathering the data, it is mandatory to identify the data type that is to be collected. It depends on the problem that one may want the AI system to address.
Sources of Data: Sources from which data can be derived include, public datasets, web scraping, sensor and IoT devices.
Data Annotation and Labelling: Raw data has to be annotated, that is labelled in order to be useful for machine learning. This can consist of images labelled by objects or feature. Text can be tagged with sentiment or intent. Audio files can be transcribed into text, or can be classified by sound type.
Data Cleaning and Preprocessing: The collected data is often found imperfect. Thus, cleaning removes errors, duplicates, and irrelevant information. Preprocessing helps to ensure that data is presented in a fashion or normalized data to be input into machine learning models.
Diverse Data: For the models to achieve maximum approximating generalization, the data must represent varied scenarios, demographics, and conditions. A lack of diversity in data may lead to biased predictions. This would undermine the reliability of the system.
Applications of Collected Data in AI Systems
Datasets collected empower AI systems across different sectors enabling them to attain remarkable results:
Healthcare: In medical AI, datasets collected from imaging, electronic health records, and genetic data are used to, diagnose diseases, predict patient outcomes, personalize treatment plans.
Autonomous Systems: Self-driving cars require massive amounts of data--acquired from road cameras, LiDAR, and GPS--to understand how to navigate safely and efficiently.
Retail and E-Commerce: Customer behavior, purchase history, and product review data allow AI models to recommend products, anticipate trends, and improve upon customer experience.
Natural Language Processing: From chatbots to translation tools, speech and text datasets enable machines to understand and generate human-like language.
Smart Cities: Data collected from urban infrastructure, sensors, and traffic systems is used to plan for cities, reducing congestion and improving public safety.
Challenges of Data Collection for Machine Learning
While data collection is extremely important, there are a few issues to be addressed as they pose challenges to successful AI development:
Data privacy and security: Collection of sensitive data from people's personal information or medical records provides numerous ethical hurdles. Security of sensitive data and abiding by privacy regulations such as GDPR are important.
Bias in Data: Bias in collected data can make AI models unfair. For example, facial recognition systems trained on non-diverse datasets might not recognize some people from underrepresented populations.
Scalability: As the AI system advances in complexity, so does the volume of data needed. The collection, storage, and management of such vast amounts can heavily utilize resources.
Cost and resources: Data collection, annotation, and preprocessing require considerable time, effort, and monetary input.
The Future of Data Collection in AI
With these technological advances, data collection is set to become more efficient and effective. The emerging trends include:
Synthetic Data Generation: AI-driven tools create artificial datasets that reduce reliance on real-world data and ease issues around privacy.
Real-time Data Streaming: Data is retrieved by IoT devices and edge computing for live AI processing.
Decentralized Data Collection: The use of Blockchain ensures secure and transparent exchange of information among different organizations and individuals.
Conclusion
Data-driven collection for machine learning is central to AI, the enabling force behind systems transforming industries and enhancing lives across the world. Every effort-from data sourcing and annotation to the resolution of ethical challenges-adds leaps in the development of ever-more intelligent and trustworthy AI models.
As technology enhances, tools and forms of data collection appear to be improving and, consequently, paving the way for smart systems that are of better accuracy, inclusion, and impact. Investing now in quality data collection sets the stage for a future where AI systems can sap their full potentials for meaningful change across the globe.
Visit Globose Technology Solutions to see how the team can speed up your data collection for machine learning projects.
0 notes
Text
The Future of Image Data Annotation in Deep Learning

Introduction
In the swiftly advancing realm of artificial intelligence (AI) and deep learning, the annotation of image data is essential for the development of high-performing models. As computer vision, autonomous systems, and AI applications continue to progress, the future of Image Data Annotation is poised to become increasingly innovative, efficient, and automated.
The Progression of Image Data Annotation
Historically, the process of image annotation involved significant manual effort, with annotators tasked with labeling images through methods such as bounding boxes, polygons, or segmentation masks. However, the increasing demand for high-quality annotated datasets has led to the development of innovative technologies and methodologies that enhance the scalability and accuracy of this process.
Significant Trends Influencing the Future of Image Annotation
1. AI-Enhanced Annotation: The integration of artificial intelligence and machine learning is transforming the annotation landscape by automating substantial portions of the labeling process. Pre-annotation models facilitate quicker labeling by identifying objects and proposing annotations, thereby minimizing manual labor while ensuring precision.
2. Synthetic Data and Augmentation: The adoption of synthetic data is on the rise as a means to complement real-world datasets. By creating artificially annotated images, deep learning models can be trained with a broader range of examples, thereby lessening the reliance on extensive manual annotation.
3.Self-Supervised and Weakly Supervised Learning: Emerging self-supervised learning techniques enable models to discern patterns with limited human input, moving away from the dependence on fully labeled datasets. Additionally, weakly supervised learning further diminishes annotation expenses by utilizing partially labeled or noisy datasets.
4. Crowdsourcing and Distributed Labeling: Platforms designed for crowdsourced annotation enable extensive image labeling by numerous contributors from around the globe. This decentralized method accelerates the labeling process while ensuring quality through established validation mechanisms.
5. 3D and Multi-Sensor Annotation: As augmented reality (AR), virtual reality (VR), and autonomous vehicles become more prevalent, the demand for 3D annotation is increasing. Future annotation tools are expected to incorporate LiDAR, depth sensing, and multi-sensor fusion to improve object recognition capabilities.
6. Blockchain for Annotation Quality Control: The potential of blockchain technology is being investigated for the purpose of verifying the authenticity and precision of annotations. Decentralized verification approaches can provide transparency and foster trust in labeled datasets utilized for AI training.
The Importance of Sophisticated Annotation Tools
In response to the increasing requirements of AI applications, sophisticated annotation tools and platforms are undergoing constant enhancement. Organizations such as GTS AI provide state-of-the-art image and video annotation services, guaranteeing that AI models are developed using high-quality labeled datasets.
Conclusion
As deep learning continues to expand the horizons of artificial intelligence, the future of image data annotation will be influenced by automation, efficiency, and innovative methodologies. By utilizing AI-assisted annotation, synthetic data, and self-supervised learning, the sector is progressing towards more scalable and intelligent solutions. Investing in advanced annotation methods today will be essential for constructing the AI models of the future.
0 notes