#LLaMA3
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
MediaTek Dimensity 9300+: Experience Next-Level Performance

MediaTek Dimensity 9300+
All-Big-Core Processor: Superior Performance With the MediaTek Dimensity 9300+, Arm Cortex-X4 speeds are increased to unprecedented heights, setting a new standard for smartphone performance for enthusiasts and gamers.
1X Cortex-X4 operating at 3.4 GHz Max. 3X Cortex-X4 2.85GHz Up to 2.0GHz, 4X Cortex-A720 18 MB L3 + SLC cache Supported up to LPDDR5T 9600Mbps MCQ plus UFS 4.0 Third generation of TSMC 4nm chips manufactured MediaTek��s second-generation thermally optimised packaging design Premier Generative AI System in MediaTek Dimensity 9300+
Faster and safer edge computing is made possible by the MediaTek APU 790 generative AI engine. MediaTek Dimensity 9300+ first-to-market features and extensive toolchain help developers create multimodal generative AI applications at the edge quickly and effectively, offering consumers cutting-edge experiences with generative AI for text, photos, music, and more.
Assistance with on-device NeuroPilot LoRA Fusion 2.0 and LoRA Fusion With NeuroPilot Speculative Decode Acceleration and ExecutorTorch Delegation support, performance can increase by up to 10%. Gen-AI partnerships Artificial Intelligence Cloud Alibaba Qwen LLM AI Baichuan ERNIE-3.5-SE Google Gemini Nano Llama 2 and Llama 3 Meta Epic Play
Flagship GPU with 12 cores Experience the most popular online games in HDR at 90 frames per second, while using up to 20% less power than other flagship smartphone platforms.
Adaptive gaming technology from MediaTek Activate MAGT to increase power efficiency in well-known gaming titles. This will allow top titles to run smoothly for up to an hour.
Experience the most popular online games in HDR at 90 frames per second, while using up to 20% less power than other flagship smartphone platforms.
Mobile Raytracing accelerated via hardware The Immortalis-G720 offers gamers quick, immersive raytracing experiences at a fluid 60 frames per second along with console-quality global lighting effects thanks to its 2nd generation hardware raytracing engine.
HyperEngine from MediaTek: Network Observation System (NOS)
Working with top game companies, MediaTek HyperEngine NOS offloads real-time network connectivity quality assessment, allowing for more efficient and power-efficient Wi-Fi/cellular dual network concurrency during gameplay.
Accurate Network Forecasting 10% or more in power savings Save up to 25% on cellular data guarantees a steady and fluid connection for internet gaming. Working along with Tencent GCloud Amazing Media Capture in All Situations The Imagiq 990 boasts zero latency video preview, AI photography, and 18-bit RAW ISP. Utilise its 16 categories of scene segmentation modification and AI Semantic Analysis Video Engine for more visually stunning cinematic video capture.
With three microphones capturing high dynamic range audio and filtering out background noise and wind, you can be heard clearly. This makes it perfect for impromptu vlogging.
AI-displayed MediaTek MiraVision 990 Set your goals on faster, sharper screens, and take advantage of the newest HDR standards and AI improvements for next-generation cinematic experiences.
Amazing displays: 4K120 or WQHD 180Hz AI depth finding Support that folds and has two active screens The best anti-burn-in technology available for AMOLED screens Maximum Interconnectedness WiFi 7 Extended Range Connections can extend up to 4.5 metres indoors thanks to MediaTek Xtra Range 2.0 technology (5GHz band). Up to 200% throughput improvement is provided for smoother graphics while streaming wirelessly to 4K Smart TVs thanks to coexistence and anti-interference technologies. UltraSaver Wi-Fi 7 MediaTek Wi-Fi 7 with Multi-Link Operation (MLO) and 320MHz BW up to 6.5Gbps Top Bluetooth Features Wi-Fi/BT Hybrid Coexistence 3.0 by MediaTek UltraSave Bluetooth LightningConnect MediaTek Extremely low Bluetooth audio latency (<35 ms) Smooth sub-6GHz with a 5G AI modem Sub-6GHz capable 4CC-CA 5G R16 modem Dedicated sub-6GHz downlink speed of up to 7 Gbps Modern AI equipped with situation awareness Dual SIM, Dual Active, Multimode 3.0 for MediaTek 5G UltraSave Outstanding Security for a Flagship SoC for Android
Introducing a user-privacy-focused security design that safeguards critical processes both during secure computing and boot-up, preventing physical attacks on data access.
During startup and operation, standalone hardware (Secure Processor, HWRoT) is used with New Arm Memory Tagging Extension (MTE) technology.
The next big thing in innovation is generative AI MediaTek Dimensity 9300+, the industry leader in creating high-performing and power-efficient system-on-chips, is already integrating the advantages of their potent, internally developed AI processors into their wide range of product offerings.
Every year,their inventions impact over 2 billion devices Fifth-largest fabless semiconductor maker MediaTek. MediaTek chips power 2 billion devices annually; you undoubtedly have one! Here at MediaTek, they design technology with people in mind to improve and enrich daily existence.
Amazing In Amazing Escape Smartphones with MediaTek Dimensity – 5G The cutting edge is available on MediaTek Dimensity 5G smartphone platforms, which offer amazing nonstop gaming, sophisticated AI, and professional-grade photography and multi-camera videography. Together, they enhance the intelligence, potency, and efficiency of your experience.
Chromebooks, the ubiquitous computing companion from MediaTek Kompanio MediaTek Kompanio is the dependable, creative, versatile, go-anywhere, and do-anything partner for amazing Chromebook experiences. It’s the perfect partner for learning, daily work, streaming media, video conferences, or just experimenting with one’s creativity.
MediaTek provides you with all you need in terms of computing. MediaTek processors are made to meet the needs of the modern user, whether they be for gaming, streaming, work, or education.
Brilliance on the brink IoT with Edge-AI with MediaTek Genio MediaTek Dimensity 9300+ Genio propels IoT innovation by elevating software platforms that are simple to use and have strong artificial intelligence. MediaTek helps start-ups to multinational corporations creating new IoT devices with Edge-AI capabilities, accelerating time to market to create new opportunities.
Entrepreneurs with a Vision: MediaTek Pentonic – 8K/4K Smart Televisions Five key technology pillars are offered by MediaTek Pentonic in their flagship and premium 8K/4K smart TVs: display, audio, AI, broadcasting, and connectivity. With a 60% global TV market share,they are the leading provider of smart TV platforms, supporting the largest smart TV brands in the world.
Experiences that are always connected Wi-Fi MediaTek Filogic With the most extreme speeds, improved coverage, built-in security, exceptional power efficiency, and crucial EasyMesh certification, MediaTek Filogic is bringing in a new era of smarter, more powerful Wi-Fi 7, 6E, and 6 solutions. These solutions will enable users to enjoy seamless, always-connected experiences.
MediaTek Dimensity 9300+ Specs CPU Processor 1x Arm Cortex-X4 up to 3.4GHz 3x Arm Cortex-X4 up to 2.85GHz 4x Arm Cortex-A720 up to 2.0GHz Cores Octa (8)
Memory and Storage Memory Type LPDDR5X LPDDR5T Max Memory Frequency 9600Mbps
Storage Type UFS 4 + MCQ
Connectivity Cellular Technologies Sub-6GHz (FR1), mmWave (FR2), 2G-5G multi-mode, 5G-CA, 4G-CA, 5G FDD / TDD, 4G FDD / TDD, TD-SCDMA, WDCDMA, EDGE, GSM
Specific Functions 5G/4G Dual SIM Dual Active, SA & NSA modes; SA Option2, NSA Option3 / 3a / 3x, NR FR1 TDD+FDD, DSS, FR1 DL 4CC up to 300 MHz 4×4 MIMO, FR2 DL 4CC up to 400MHz, 256QAM FR1 UL 2CC 2×2 MIMO, 256QAM NR UL 2CC, R16 UL Enhancement, 256QAM VoNR / EPS fallback
GNSS GPS L1CA+L5+ L1C BeiDou B1I+ B1C + B2a +B2b Glonass L1OF Galileo E1 + E5a +E5b QZSS L1CA+ L5 NavIC L5 Wi-Fi Wi-Fi 7 (a/b/g/n/ac/ax/be) ready
Wi-Fi Antenna 2T2R
Bluetooth 5.4
Camera Max Camera Sensor Supported 320MP
Max Video Capture Resolution 8K30 (7690 x 4320) 4K60 (3840 x 2160) Graphics GPU Type Arm Immortalis-G720 MC12
Video Encoding H.264 HEVC Video Playback H.264 HEVC VP-9 AV1 Display Max Refresh Rate 4K up to 120Hz WQHD up to 180Hz AI AI Processing Unit MediaTek APU 790 (Generative AI)
Security Security Features Secure Processor, HWRoT Arm Memory Tagging Extension (MTE) Technology CC EAL4+ Capable, FIPS 140-3, China DRM
Read more on Govindhtech.com
#MediaTekDimensity9300#mediatek#MediaTekDimensity#ai#generativeai#llama2#smartphone#lorafution#llm#llama3#meta#technology#technews#news#govindhtech
4 notes
·
View notes
Text
Gemma 2 vs. LLaMA 3: Which AI is Right for Your Business? 🤖
Choosing the right AI can make or break your strategy. Dive into our latest blog to find the perfect fit for your needs!
📖 Read now

0 notes
Text

Discover how Llama 3.3 redefines AI with its groundbreaking performance, outpacing GPT-4 in speed and accuracy. This new AI model delivers faster, more efficient responses, making it a must-try for developers and tech enthusiasts. See how it stacks up and why it's quickly becoming the go-to choice for next-gen artificial intelligence.
0 notes
Text
Google's AlphaChip and Meta's Llama 3.2 Signal Major Shifts in AI Strategies
Google and Meta update their AI strategies: Google launches AlphaChip for faster chip design and Gemini 1.5 model improvements, while Meta releases Llama 3.2 with powerful LLMs optimized for vision, edge, and mobile.
#thecioconnect#OnlineBusinessMagazine#BusinessMagazine#businessleaders#AIAssistant#MetaAI#AI#Google#Meta#AlphaChip#Llama3#AIModels#TechNews#Gemini#ChipDesign#MachineLearning#AIResearch#AIUpdates#OpenSourceAI#ArtificialIntelligence
0 notes
Text
🚀 #Meta's #llama 3.2 is here, and it's a game-changer! 🖼️📝
This new #AI can understand both text AND images, with models ranging from mobile-friendly to supercomputer-scale:
#ArtificialIntelligence #technology #technews #news #llm
video by Meta
#artificial intelligence#technology#artificial#inteligência artificial#ai technology#tech#ai tools#technews#future#meta#meta ai#llama3#llama#intelligence#emotion#technology news#world news#news#newsies
0 notes
Text
https://llmstock.com/text2image has integrated stability sd3 api and the prompt refiner can wrok with llama3.1 from groq. Let's look how the two powerfull tools can empower your imagination.(currently stability free credits is low you can buy more credits if draw api fails)
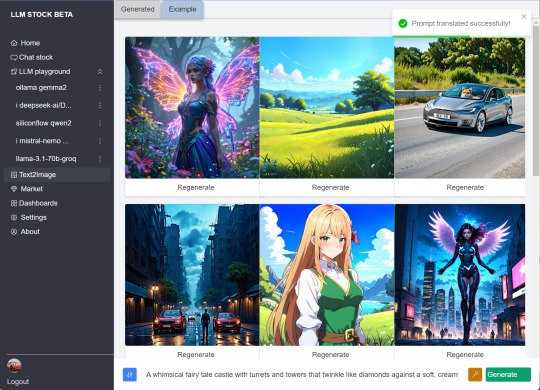
1 note
·
View note
Text

If you like these posts, please share one of your special toys! This is my daily invitation to visit my website www.saidtheskinhorse.com - it's a site that celebrates the special relationship we have with our favorite toys from childhood. Here's one of our newest additions!
#soft toys#toybox#vintage toys#plushies#plush#old toys#toys#kids toys#stuffed animals#plush toys#llama3#llama#alpacas#drama llama#llamas
1 note
·
View note
Text
*rustles limbs* i accidentally made an indefinite "two trees hate on humans" chat loop



1 note
·
View note
Text
Local LLM Model in Private AI server in WSL
Local LLM Model in Private AI server in WSL - learn how to setup a local AI server with WSL Ollama and llama3 #ai #localllm #localai #privateaiserver #wsl #linuxai #nvidiagpu #homelab #homeserver #privateserver #selfhosting #selfhosted
We are in the age of AI and machine learning. It seems like everyone is using it. However, is the only real way to use AI tied to public services like OpenAI? No. We can run an LLM locally, which has many great benefits, such as keeping the data local to your environment, either in the home network or home lab environment. Let’s see how we can run a local LLM model to host our own private local…

View On WordPress
0 notes
Text
Leo AI And Ollama Presents RTX-Accelerated Local LLMs

Brave New World: RTX-Accelerated Local LLMs for Brave Browser Users Presented by Leo AI and Ollama.
Leo AI
Using local models in well-known apps is now simpler than ever with RTX-accelerated community tools.
AI is being incorporated into apps more and more to improve user experiences and increase productivity. These applications range from productivity tools and software development to gaming and content creation apps.
These increases in productivity also apply to routine chores like surfing the web. Recently, Brave, a privacy-focused online browser, introduced Leo AI, a smart AI assistant that assists users with summarizing articles and movies, surfacing insights from documents, answering queries, and more.
The hardware, libraries, and ecosystem software that Brave and other AI-powered products are built using are tuned for the particular requirements of artificial intelligence.
The Significance of Software
Whether it’s operating on a desktop computer locally or in a data center, NVIDIA GPUs power the world’s AI. Tensor Cores, which are particularly designed to speed up AI applications like Leo AI by performing the enormous amount of computations required for AI concurrently rather than one at a time via massively parallel number crunching, are present in them.
However, excellent hardware is only useful if apps can effectively use it. Enabling the quickest and most responsive AI experience also depends on the software that runs on top of GPUs.
The AI inference library, which is the initial layer, functions as a translator, taking requests for typical AI tasks and translating them into precise instructions that the hardware can follow. Well-known inference libraries include llama.cpp, which is used by Brave and Leo AI via Ollama, Microsoft’s DirectML, and NVIDIA TensorRT.
An open-source framework and library is called llama.cpp. Tensor Core acceleration for hundreds of models, including well-known large language models (LLMs) like Gemma, Llama 3, Mistral, and Phi, is made possible via CUDA, the NVIDIA software application programming interface that allows developers to optimize for GeForce RTX and NVIDIA RTX GPUs.
Applications often employ a local inference server to ease integration on top of the inference library. Instead of the application having to, the inference server manages processes like downloading and configuring certain AI models.
The open-source Ollama project gives users access to the library’s functionalities by sitting on top of llama.cpp. It facilitates the delivery of local AI capabilities via an ecosystem of apps. In order to provide RTX users with quicker, more responsive AI experiences, NVIDIA optimizes tools such as Ollama for NVIDIA hardware across the whole technological stack.
NVIDIA optimizes every aspect of the technology stack, including the hardware, system software, inference libraries, and tools that allow apps to provide RTX users with AI experiences that are quicker and more responsive.
Ollama
Local vs Cloud
Via Ollama, Brave’s Leo AI may operate locally on a PC or on the cloud.
Using a local model for inference processing has several advantages. The experience remains private and accessible at all times since it doesn’t transmit requests to an external server for processing. Users of Brave, for example, may get financial or medical assistance without transferring any data to the cloud. Additionally, paying for unlimited cloud access is eliminated while operating locally. Compared to other hosted services, which sometimes support just one or two variations of the same AI model, Ollama offers consumers access to a greater selection of open-source models.
Additionally, users may interact with models with a variety of specializations, including code generation, compact size, bilingualism, and more.
When AI is executed locally, RTX makes it possible for a quick, responsive experience. When using llama.cpp and the Llama 3 8B model, customers may anticipate replies up to 149 tokens per second, or around 110 words per second. This translates into quicker answers to queries, requests for material summaries, and more when used Brave with Leo AI and Ollama.
Brave Leo AI
Launch Brave Using Ollama and Leo AI
The Ollama installer may be easily installed by downloading it from the project website and leaving it to run in the background. Users may download and install a broad range of supported models from a command prompt, and then use the command line to interact with the local model.
Leo AI will utilize the locally hosted LLM for prompts and inquiries when it is set up to link to Ollama. Additionally, users may always swap between local and cloud models.
Read more on Govindhtech.com
#LeoAI#Ollama#LocalLLMs#RTXAccelerated#AI#NVIDIARTXGPUs#Llama3#cloudmodels#ArtificialIntelligence#NVIDIAGPUs#GPUs#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
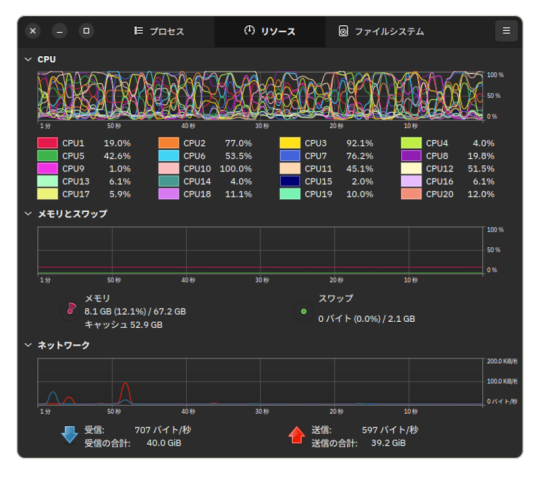
Llama3 70bをローカルで動かしてみる
モノづくり塾のGPU搭載PCで試しました。 PCのスペックはCPU Core i5 13500、RAM 64GB、GPU RTX A4000です。OSはUbuntu 22.04…
View On WordPress
0 notes
Text
Llama 3
I just sat through a video by a fanboy of Llama 3.?? Okay, Llama 3 is a good AI that is open source. I first used Llama 3 with Ollama, which runs in the background of Windows, with the PowerShell 7 command prompt. Maybe I missed it, but all the video said was that Llama 3 is great and improving every day, but I didn’t hear how Lama 3 has improved. Unless Tech Genius A.I. is trying to tell us…

View On WordPress
0 notes
Text
The LLM Copilot is More of a Companion.
I almost forgot to write something here today. I’ve been knocking out scenes and finding the limitations of the LLM as I go along, which is great. The particular LLM I’m working with is llama3 which I’ve tweaked and saved as I’ve worked with it. It’s fun because it sucks. It can handle about 500-1000 words easy to analyze at a time – figure a scene at a time. Meanwhile, it forgets all the…

View On WordPress
0 notes
Text

L.L.M. > llama3 ready
write text about attending a react conference and modeling applications on combinations of jsx and ftp.
this should be a story of not more than twelve paragraphs. It is set in busy suburbs of Mountain View, and offers for hardware should form major plot point.
the story should also include uses of rhyme, epigram and metaphor. Close the writing on an optimistic note, such as potential of developer's work getting positive reviews from Techcrunch and from Engadget.
L.L.M > writing
L.L.M > text complete

In the bustling suburbs of Mountain View, where tech dreams come true,
A React conference beckoned, and I knew what to do.
I packed my bags, grabbed my laptop with care,
And headed to the venue, with a mind full of flair.
As I walked in, the energy was palpable and bright,
Developers buzzing, eager to learn and take flight.
The keynote speaker took the stage,
a master of the craft,
Sharing secrets of JSX and FTP,
a perfect blend to draft.
I sat enthralled, as the presenter wove a tale,
Of building apps that shine, with stuff of action .
JSX for structure, FTP for projections, our duo divine,
Together they create, a user experience superstition.
But just as the talk ended, a surprise announcement came,
A hardware offer that left us all in awe and giddy.
A chance to win a top-notch device,
to fuel our coding dreams,
A prize that would take our apps
to the next level, it seemed.
The competition was fierce, but I didn't let that deter,
I dove into coding, my heart full of cheer.
I built and I built, with JSX and FTP as my guide,
Crafting an app that would make
the judges take notice and with us side.
As the day drew to a close, and the submissions were in,
I felt proud of my work, and the potential to win.
The judges deliberated, and the tension was high,
But finally, the results came, and I couldn't deny.
My app had made the cut, and I was over the moon,
A chance to showcase my work, to the tech world in June.
Positive reviews from Techcrunch
and Engadget too, a dream come true,
A developer's work, recognized,
and all thanks to React, devrel anew.
The conference ended, but the journey had just begun,
A new wave of innovation, and a community that's won.
I left with a heart full of hope,
and a mind full of cheer,
Ready to build and create,
and banish dumb fear.
1 note
·
View note
Text
👨⚕️Med42-v2 is here to change the face of #AI #healthcare! With unmatched accuracy and a strong ethical foundation, this AI model is set to become a trusted tool in medicine:
#artificialintelligence #heal #future #aiforhealth #llm #llama

image by M42
#artificial intelligence#technology#artificial#ai technology#technews#tech#ai tools#inteligência artificial#openai#llama3#llama#llms#google#chatgpt#artifical intelligence#machine learning#genai#llm#futurism#future#futuristic#latest news#news#world news#international
1 note
·
View note