#openai
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs

vfstreaming-apprendre-a-t-aimer
Film=complet`voir` APPRENDRE À T'AIMER streaming vf (2020)FILM
1 post




Fun Fact
Tumblr’s website traffic is steadily declining.
Text
The problem here isn’t that large language models hallucinate, lie, or misrepresent the world in some way. It’s that they are not designed to represent the world at all; instead, they are designed to convey convincing lines of text. So when they are provided with a database of some sort, they use this, in one way or another, to make their responses more convincing. But they are not in any real way attempting to convey or transmit the information in the database. As Chirag Shah and Emily Bender put it: “Nothing in the design of language models (whose training task is to predict words given context) is actually designed to handle arithmetic, temporal reasoning, etc. To the extent that they sometimes get the right answer to such questions is only because they happened to synthesize relevant strings out of what was in their training data. No reasoning is involved […] Similarly, language models are prone to making stuff up […] because they are not designed to express some underlying set of information in natural language; they are only manipulating the form of language” (Shah & Bender, 2022). These models aren’t designed to transmit information, so we shouldn’t be too surprised when their assertions turn out to be false.
ChatGPT is bullshit
7K notes
·
View notes
Text

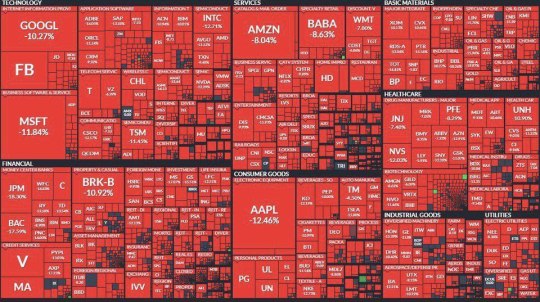
So on the 27th DeepSeek R1 dropped (a chinese version of ChatGPT that is open source, free and beats GPT's 200 dollar subscription, using less resources and less money) and the tech market just had a loss of $1,2 Trillion.
Source

#market crash#deepseek#deepseek AI#chatgpt#OpenAI#world news#destiel news#im quite late for the news but I havent seen it anywhere on tumblr so#here it is#fuck ai#meh
87K notes
·
View notes
Text
The real issue with DeepSeek is that capitalists can't profit from it.
I always appreciate when the capitalist class just says it out loud so I don't have to be called a conspiracy theorist for pointing out the obvious.

#deepseek#ai#lmm#large language model#artificial intelligence#open source#capitalism#techbros#silicon valley#openai
955 notes
·
View notes
Text


this reply kills me 😭 article link
73K notes
·
View notes
Text

#openai#deepseek#ai#meme#memes#shitpost#humor#shitposting#satire#funny memes#lol#irony#funny#funny humor#funny meme#comedy#joke#parody
1K notes
·
View notes
Text
PSA: Tumblr/Wordpress is preparing to start selling our user data to Midjourney and OpenAI.
you have to MANUALLY opt out of it as well.




to opt out on desktop, click your blog ➡️ blog settings ➡️ scroll til you see visibility options and it’ll be the last option to toggle.
to opt out on mobile, click your blog ➡️ scroll then click visibility ➡️ toggle opt out option.
if you’ve already opted out of showing up in google searches, it’s preselected for you. if you don’t have the option available, update your app or close your browser/refresh a few times. important to note you also have to opt out for each blog you own separately, so if you’d like to prevent AI scraping your blog i’d really recommend taking the time to opt out. (source)
#ai#tumblr ai#midjourney#openai#protect your creative efforts and don’t let them profit off your work!!#fuck tumblr they specifically said months ago they’d NEVER sell user data yet here we are#AND after the ceo has been harassing trans users like wtf is this fucking site becoming#tumblr news#tumblr#tumblr update#anti ai#support human artists
34K notes
·
View notes
Text
AI hasn't improved in 18 months. It's likely that this is it. There is currently no evidence the capabilities of ChatGPT will ever improve. It's time for AI companies to put up or shut up.
I'm just re-iterating this excellent post from Ed Zitron, but it's not left my head since I read it and I want to share it. I'm also taking some talking points from Ed's other posts. So basically:
We keep hearing AI is going to get better and better, but these promises seem to be coming from a mix of companies engaging in wild speculation and lying.
Chatgpt, the industry leading large language model, has not materially improved in 18 months. For something that claims to be getting exponentially better, it sure is the same shit.
Hallucinations appear to be an inherent aspect of the technology. Since it's based on statistics and ai doesn't know anything, it can never know what is true. How could I possibly trust it to get any real work done if I can't rely on it's output? If I have to fact check everything it says I might as well do the work myself.
For "real" ai that does know what is true to exist, it would require us to discover new concepts in psychology, math, and computing, which open ai is not working on, and seemingly no other ai companies are either.
Open ai has already seemingly slurped up all the data from the open web already. Chatgpt 5 would take 5x more training data than chatgpt 4 to train. Where is this data coming from, exactly?
Since improvement appears to have ground to a halt, what if this is it? What if Chatgpt 4 is as good as LLMs can ever be? What use is it?
As Jim Covello, a leading semiconductor analyst at Goldman Sachs said (on page 10, and that's big finance so you know they only care about money): if tech companies are spending a trillion dollars to build up the infrastructure to support ai, what trillion dollar problem is it meant to solve? AI companies have a unique talent for burning venture capital and it's unclear if Open AI will be able to survive more than a few years unless everyone suddenly adopts it all at once. (Hey, didn't crypto and the metaverse also require spontaneous mass adoption to make sense?)
There is no problem that current ai is a solution to. Consumer tech is basically solved, normal people don't need more tech than a laptop and a smartphone. Big tech have run out of innovations, and they are desperately looking for the next thing to sell. It happened with the metaverse and it's happening again.
In summary:
Ai hasn't materially improved since the launch of Chatgpt4, which wasn't that big of an upgrade to 3.
There is currently no technological roadmap for ai to become better than it is. (As Jim Covello said on the Goldman Sachs report, the evolution of smartphones was openly planned years ahead of time.) The current problems are inherent to the current technology and nobody has indicated there is any way to solve them in the pipeline. We have likely reached the limits of what LLMs can do, and they still can't do much.
Don't believe AI companies when they say things are going to improve from where they are now before they provide evidence. It's time for the AI shills to put up, or shut up.
5K notes
·
View notes
Text
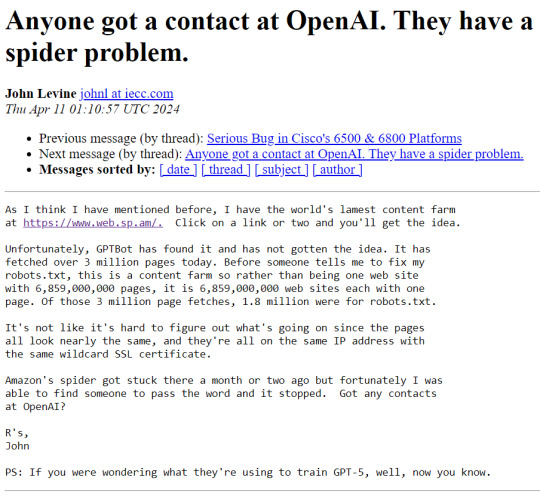
To understand what's going on here, know these things:
OpenAI is the company that makes ChatGPT
A spider is a kind of bot that autonomously crawls the web and sucks up web pages
robots.txt is a standard text file that most web sites use to inform spiders whether or not they have permission to crawl the site; basically a No Trespassing sign for robots
OpenAI's spider is ignoring robots.txt (very rude!)
the web.sp.am site is a research honeypot created to trap ill-behaved spiders, consisting of billions of nonsense garbage pages that look like real content to a dumb robot
OpenAI is training its newest ChatGPT model using this incredibly lame content, having consumed over 3 million pages and counting...
It's absurd and horrifying at the same time.
16K notes
·
View notes
Text
OpenAI is whining about how DeepSeek "stole" from them to train their own model, which is against ToS

532 notes
·
View notes
Text
I am very wary of people going "China does it better than America" because most of it is just reactionary rejection of your overlord in favor of his rival, but this story is 1. absolutely legit and 2. way too funny.

US wants to build an AI advantage over China, uses their part in the chip supply chain to cut off China from the high-end chip market.
China's chip manufacturing is famously a decade behind, so they can't advance, right?

They did see it as a problem, but what they then did is get a bunch of Computer Scientists and Junior Programmers fresh out of college and funded their research in DeepSeek. Instead of trying to improve output by buying thousands of Nvidia graphics cards, they tried to build a different kind of model, that allowed them to do what OpenAI does at a tenth of the cost.

Them being young and at a Hedgefund AI research branch and not at established Chinese techgiants seems to be important because chinese corporate culture is apparently full of internal sabotage, so newbies fresh from college being told they have to solve the hardest problems in computing was way more efficient than what usually is done. The result:

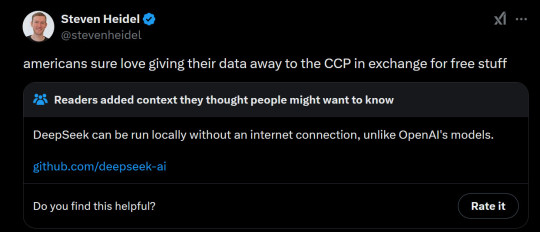
American AIs are shook. Nvidia, the only company who actually is making profit cause they are supplying hardware, took a hit. This is just the market being stupid, Nvidia also sells to China. And the worst part for OpenAI. DeepSeek is Open Source.

Anybody can implement deepseek's model, provided they have the hardware. They are totally independent from DeepSeek, as you can run it from your own network. I think you will soon have many more AI companies sprouting out of the ground using this as its base.

What does this mean? AI still costs too much energy to be worth using. The head of the project says so much himself: "there is no commercial use, this is research."

What this does mean is that OpenAI's position is severely challenged: there will soon be a lot more competitors using the DeepSeek model, more people can improve the code, OpenAI will have to ask for much lower prices if it eventually does want to make a profit because a 10 times more efficient opensource rival of equal capability is there.
And with OpenAI or anybody else having lost the ability to get the monopoly on the "market" (if you didn't know, no AI company has ever made a single cent in profit, they all are begging for investment), they probably won't be so attractive for investors anymore. There is a cheaper and equally good alternative now.
AI is still bad for the environment. Dumb companies will still want to push AI on everything. Lazy hacks trying to push AI art and writing to replace real artists will still be around and AI slop will not go away. But one of the main drivers of the AI boom is going to be severely compromised because there is a competitor who isn't in it for immediate commercialization. Instead you will have a more decentralized open source AI field.
Or in short:

3K notes
·
View notes
Text
Researchers have found that ChatGPT "power users," or those who use it the most and at the longest durations, are becoming dependent upon — or even addicted to — the chatbot. In a new joint study, researchers with OpenAI and the MIT Media Lab found that this small subset of ChatGPT users engaged in more "problematic use," defined in the paper as "indicators of addiction... including preoccupation, withdrawal symptoms, loss of control, and mood modification." To get there, the MIT and OpenAI team surveyed thousands of ChatGPT users to glean not only how they felt about the chatbot, but also to study what kinds of "affective cues," which was defined in a joint summary of the research as "aspects of interactions that indicate empathy, affection, or support," they used when chatting with it. Though the vast majority of people surveyed didn't engage emotionally with ChatGPT, those who used the chatbot for longer periods of time seemed to start considering it to be a "friend." The survey participants who chatted with ChatGPT the longest tended to be lonelier and get more stressed out over subtle changes in the model's behavior, too. Add it all up, and it's not good. In this study as in other cases we've seen, people tend to become dependent upon AI chatbots when their personal lives are lacking. In other words, the neediest people are developing the deepest parasocial relationship with AI — and where that leads could end up being sad, scary, or somewhere entirely unpredictable.
24 March 2025
501 notes
·
View notes
Text
Want to hear something funny? Akinator would have been called AI if it was released today. None of this "AI" bullshit is actually anything intelligent. It's programs and algorithms and computer mimicry. It learns nothing. Chatgpt and openai and midjourney are just Akinator. The term "AI" is just a marketting ploy thats working painfully well with the people who don't understand that this tech has been around and in use for YEARS. Akinator was relased in 2007. Its just slightly more advanced Akinator tech, but its not anything artificially intelligent. I really wish we'd stop calling it "AI"
10K notes
·
View notes
Text
Everyone should immediately stop contributing to the stack overflow and its network. The human touch is what made it unique. Delete your profile from SO AND all your answers. Freeloaders are making money out of human contributions.

2K notes
·
View notes
Text
A former OpenAI researcher known for whistleblowing the blockbuster artificial intelligence company facing a swell of lawsuits over its business model has died, authorities confirmed this week. Suchir Balaji, 26, was found dead inside his Buchanan Street apartment on Nov. 26, San Francisco police and the Office of the Chief Medical Examiner said. Police had been called to the Lower Haight residence at about 1 p.m. that day, after receiving a call asking officers to check on his well-being, a police spokesperson said. The medical examiner’s office has not released his cause of death, but police officials this week said there is “currently, no evidence of foul play.” Information he held was expected to play a key part in lawsuits against the San Francisco-based company. Balaji’s death comes three months after he publicly accused OpenAI of violating U.S. copyright law while developing ChatGPT, a generative artificial intelligence program that has become a moneymaking sensation used by hundreds of millions of people across the world.
totally normal that a 26-year-old man dies of natural causes alone in his apartment in San Francisco with no witnesses or reason to suspect foul play. completely normal stuff that happens to whistleblowers all the time.
2K notes
·
View notes
Text
FYI artists and writers: some info regarding tumblr's new "third-party sharing" (aka selling your content to OpenAI and Midjourney)
You may have already seen the post by @staff regarding third-party sharing and how to opt out. You may have also already seen various news articles discussing the matter.
But here's a little further clarity re some questions I had, and you may too. Caveat: Not all of this is on official tumblr pages, so it's possible things may change.
(1) "I heard they already have access to my data and it doesn't really matter if I opt out"
From the 404 article:
A new FAQ section we reviewed is titled “What happens when you opt out?” states “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
So please, go click that opt-out button.
(2) Some future user: "I've been away from tumblr for months, and I just heard about all this. I didn't opt out before, so does it make a difference anymore?"
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?” Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.”
It should make a difference! Go click that button.
(3) "I opted out, but my art posts have been reblogged by so many people, and I don't know if they all opted out. What does that mean for my stuff?"
This answer is actually on the support page for the toggle:
This option will prevent your blog's content, even when reblogged, from being shared with our licensed network of content and research partners, including those that train AI models.
And some further clarification by the COO and a product manager:
zingring: A couple people from work have reached out to let me know that yes, it applies to reblogs of "don't scrape" content. If you opt out, your content is opted out, even in reblog form. cyle: yep, for reblogs, we're taking it so far as "if anybody in the reblog trail has opted out, all of the content in that reblog will be opted out", when a reblog could be scraped/shared.
So not only your reblogged posts, but anyone who contributed in a reblog (such as posts where someone has been inspired to draw fanart of the OP) will presumably be protected by your opt-out. (A good reason to opt out even if you yourself are not a creator.)
Furthermore, if you the OP were offline and didn't know about the opt-out, if someone contributed to a reblog and they are opted out, then your original work is also protected. (Which makes it very tempting to contribute "scrapeable content" now whenever I reblog from an abandoned/disused blog...)
(4) "What about deleted blogs? They can't opt out!"
I was told by someone (not official) that he read "deleted blogs are all opted-out by default". However, he didn't recall the source, and I can't find it, so I can't guarantee that info. If I get more details - like if/when tumblr puts up that FAQ as reported in the 404 article - I will add it here as soon as I can.
Edit, tumblr has updated their help page for the option to opt-out of third-party sharing! It now states:
The content which will not be shared with our licensed network of content and research partners, including those that train AI models, includes: • Posts and reblogs of posts from blogs who have enabled the "Prevent third-party sharing" option. • Posts and reblogs of posts from deleted blogs. • Posts and reblogs of posts from password-protected blogs. • Posts and reblogs of posts from explicit blogs. • Posts and reblogs of posts from suspended/deactivated blogs. • Private posts. • Drafts. • Messages. • Asks and submissions which have not been publicly posted. • Post+ subscriber-only posts. • Explicit posts.
So no need to worry about your old deleted blogs that still have reblogs floating around. *\o/*
But for your existing blogs, please use the opt out option. And a reminder of how to opt out, under the cut:
The opt-out toggle is in Blog Settings, and please note you need to do it for each one of your blogs / sideblogs.
On dashboard, the toggle is at https://www.tumblr.com/settings/blog/blogname [replace "blogname" as applicable] down by Visibility:

For mobile, you need the most recent update of the app. (Android version 33.4.1.100, iOs version 33.4.) Then go to your blog tab (the little person icon), and then the gear icon for Settings, then click Visibility.
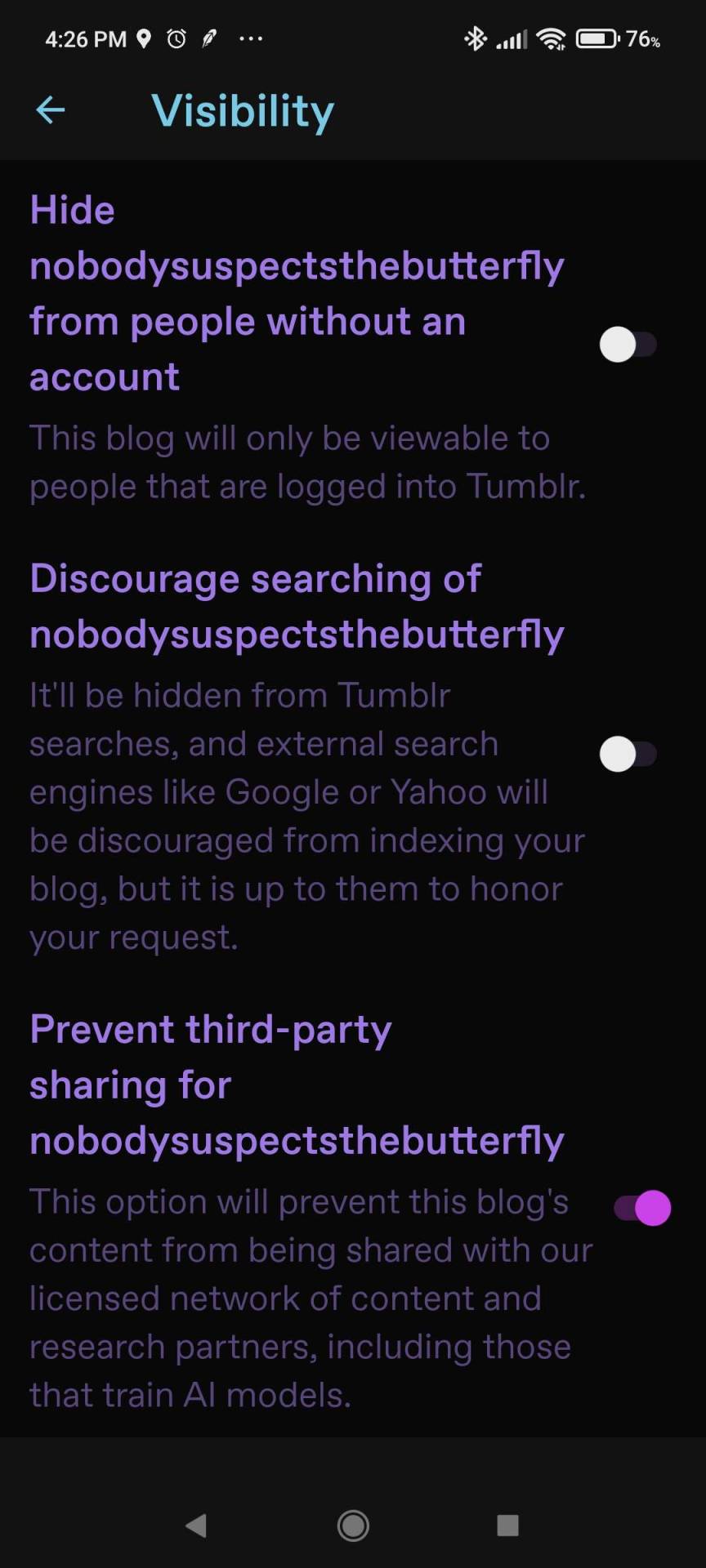
Again, if you have a sideblog, go back to the blog tab, switch to it, and go to settings again. Repeat as necessary.
If you do not have access to the newest version of the app for whatever reason, you can also log into tumblr in your mobile browser. Same URL as per desktop above, same location.
Note you do not need to change settings in both desktop and the app, just one is fine.
I hope this helps!
#tumblr#[tumblr]#third party sharing#openai#midjourney#chatgpt#ai art#ai#fyi#psa#anti-FUD#artists on tumblr#writers on tumblr#illustrators on tumblr#tumblr update#oh tumblr#hellsite (derogatory)#“opt out” no longer looks like a word#but still#opt out my friends#please#also if you want to leave tumblr i don't blame you but please remember to hit that opt-out button before you go
4K notes
·
View notes