#PHP const class
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
PHP Constants Explained: Learn How to Use Constants in PHP
Master PHP constants with this detailed guide. Learn how to define constants using define() and const, understand use cases, and explore best practices. 🌟 Ultimate Guide to PHP Constants PHP Constants are essential for creating immutable values in your scripts — values that never change once defined. This tutorial covers everything you need to know about PHP Constants, including how to define,…
#const in PHP#define()#global constants PHP#PHP const class#PHP constant vs variable#PHP Constants#PHP magic constants
0 notes
Text
Super Simple OpenAI PHP Class
I’ve been playing around with hooking up ChatGPT/Dall-E to WordPress and WP-CLI. To do this, I whipped up a super simple class to make this easier: <?php class OpenAI_API { public const API_KEY = 'hunter2'; // Get your own darn key! /** * Generates an image based on the provided prompt using the OpenAI API. * * @param string $prompt The text prompt to generate the image from. Default is an…
0 notes
Text
Configure default datetime format of Symfony Serializer DateTimeNormalizer
I know that’s a mouthful of a title but it has just taken me forever to find out how to do this and hopefully this title will help some people to not run down the same rabbit holes.
By default the Symfony Serializer Component uses the built in DateTimeNormalizer. That will take a DateTime object (or anything that implements the interface, such as datetimeimmutable) and normalize it into a string. The default is given as DateTimeInterface::RFC3339 which produces output like 2005-08-15T15:52:01+00:00 for the normalized value. That is fine for most people but I needed a bit extra. Although the official RFC3339 supports milliseconds at least, in PHP it’s hidden behind the DateTimeInterface::RFC3339_EXTENDED constant, which then produces 2005-08-15T15:52:01.000+00:00 as an output. What if you want that or even go down to microseconds (6 decimals)? A lot of nothing is to be found everywhere on that topic. So I came up with my own.
Simply put, you just overwrite the default normalizers service definition with your own. This is from a Symfony 5.0.1 application and it’s in the root directory services.yaml file on the config folder. Order of loading things matters, so if it doesn’t work for you, you might need to check when it’s getting loaded.
services: serializer.normalizer.datetime: class: 'Symfony\Component\Serializer\Normalizer\DateTimeNormalizer arguments - !php/const Symfony\Component\Serializer\Normalizer\DateTimeNormalizer::FORMAT_KEY: 'Y-m-d\TH:i:s.uP' tags: - { name: serializer.normalizer, priority: -910 }
And that’s it. The ‘Y-m-d\TH:i:s.uP’ part is what you need to replace with your own pattern to have what you need. This will operate on every single date time though now, so if you need a more finegrained control on a per property basis, this will probably not be for you.
6 notes
·
View notes
Text
Facebook webdrive php assert

#FACEBOOK WEBDRIVE PHP ASSERT DRIVER#
#FACEBOOK WEBDRIVE PHP ASSERT MAC#
These commands allow you to select components off the React VirtualDOM and return either a single WebdriverIO Element or an array of elements (depending on which function is used). To do this, you have a choice of two commands: react$ and react$$. WebdriverIO provides a way to select React components based on the component name. You can fix this by updating the Appium Server settings, see the Appium docsįor the settings and this comment on a detailed explanation. The provided image selector might have been taken from the original screenshot. This will result in not finding a match because
#FACEBOOK WEBDRIVE PHP ASSERT MAC#
On iPhones but also on Mac machines with a Retina display because the DPR is bigger than 1). To verify if the element can be found in that (app)screenshot.īe aware of the fact that Appium might resize the taken (app)screenshot to make it match the CSS-size of your (app)screen (this will happen Note: The way how Appium works with this selector is that it will internally make a (app)screenshot and use the provided image selector In Appium you send the Java code, as a string, to the server, which executes it in the application’s environment, returning the element or elements.Ĭonst elem = await $ ( './file/path/of/image/test.jpg' ) You can use the UI Automator API, in particular the UiSelector class to locate elements. Android UiAutomator Īndroid’s UI Automator framework provides a number of ways to find elements. This is especially useful when a test needs some fine-grained control over finding elements. Only then can the methods mentioned above can be used.įor native mobile testing, there is no switching between contexts, as you have to use mobile strategies and use the underlying device automation technology directly.
#FACEBOOK WEBDRIVE PHP ASSERT DRIVER#
But to select elements from the DOM, the driver will need to be set to the platform's webview context. For automating gestures, the driver ideally should be set to native context. getText ( ) ) // outputs: "Open downloads folder"įor hybrid mobile testing, it's important that the automation server is in the correct context before executing commands. Const button = await $ ( '>.dropdown-item:not()' )Ĭonsole.
0 notes
Text
CommandBus na sterydach w praktyce
Najpierw zacznijmy od teorii. Command Bus o którym będzie tu mowa to połączenie wzorca polecenie (Command pattern) z warstwą usługi (service layer).
Wzorzec warstw usług to wzorzec polegający na grupowaniu usług na warstwy funkcjonalne. Powoduje to, że zmiany dokonywane są na mniejszych fragmentach kodu które dotyczą konkretnego zagadnienia. Zmniejsza to ilość zależności w ramach konkretnego działania.Usługi powinny być zaprojektowane w taki sposób, aby umożliwiać ich ponowne wykorzystanie. A ograniczenie ich odpowiedzialności do konkretnego zadania upraszcze ich budowę i logikę.
Wzorzec Polecenie (Command pattern) polega na zdefiniowaniu klasy która przechowuje niezbędne informacje do wykonania polecenia. Oraz oczywiście samego kodu wykonującego to polecenie. Implementacji tego wzorca widziałem wiele. Są źródła które zamykają wszystko w jednej klasie, ale są też takie które rozbiają te zależności na osobne byty. Nie chciałbym się skupiać tu na szczegółach a oprzeć się na implementacji którą oferuje league/tactician i osadzić ją w Symfony dzięki gotowemu już thephpleague/tactician-bundle.
Zacznijmy od zainstalowania biblioteki.
$ composer require league/tactician-bundle
Teraz dodajemy nowego Bundle do naszego AppKernel:
<?php // ... class AppKernel extends Kernel { public function registerBundles() { $bundles = array( // ... new League\Tactician\Bundle\TacticianBundle(), ); // ... } // ... }
Dodajmy teraz konfigurację:
tactician: commandbus: default: middleware: - tactician.middleware.locking - tactician.middleware.command_handler
Aby nie definiować wszystkich handlerów ręcznie, dodajmy taki wpis do naszego pliku services.yml
CommandBus\Command\: resource: "%kernel.project_dir%/src/CommandBus/Command/**/*Handler.php" tags: [{name: tactician.handler, typehints: true}]
W końcu możemy przejść do rzeczy. No więc jak działa Command Bus? Zasada jest dość prosta. Potrzebujemy prostą klasę polecenia (Command) która przyjmie konkretne dane wymagane do wykonania. Powinny być to dane proste. Nie całe encje a np. identyfikator który pozwoli tą encję wybrać z bazy. Szczegółowa implementacja może wyglądać tak jak to ustali zespół który zamierza z tego korzystać. Może być to prosty klasa z publicznymi właściwościami. Może być to klasa z samymi "geterami". Dobrze aby wymuszała ona istnieje wszystkich niezbędnych parametrów. Przykład takiej klasy:
<?php declare(strict_types=1); namespace CommandBus\Command\User\AddFriend; class AddFriendCommand { /** * @var int */ private $userId; /** * @var int */ private $firndId; public function __construct(int $userId, int $firndId) { $this->userId = $userId; $this->firndId = $firndId; } public function getUserId(): int { return $this->userId; } public function getFirndId(): int { return $this->firndId; } }
Teraz potrzebowalibyśmy czegoś co nam wykona takiego commanda. Klasy tekie niech będą miały surfix Handler zamiast Command pozwoli to na łatwe odnalezienie takiej klasy która zdefiniuje nam właśnie serwis który wykona oczekiwaną operację. Przykład takiej klasy:
<?php declare(strict_types=1); namespace CommandBus\Command\User\AddFriend; use CommandBus\Command\User\AddFriend\AddFriendCommand; use UserBundle\Entity\UserRepository; class AddFriendHandler { /** * @var UserRepository */ private $userRepository; public function __construct(UserRepository $userRepository) { $this->userRepository = $userRepository; } public function execute(AddFriendCommand $command) { $user = $this->userRepository->find($command->getUserId()); $friend = $this->userRepository->find($command->getFirndId()); $user->addFriend($friend); } }
I teraz jak wygląda wywołanie takiego polecenia. Nalezy przekazać Command do naszego CommandBus reszte załatwi zainstalowana biblioteka. Czyli:
<?php declare(strict_types=1); use League\Tactician\CommandBus; use Symfony\Component\HttpFoundation\Request; use CommandBus\Command\User\AddFriend\AddFriendCommand; class UserController { private $commandBus; public function __construct(CommandBus $commandBus) { $this->commandBus = $commandBus; } public function addFriend(Request $request) { $command = new AddFriendCommand( $request->request->get('userId'), $request->request->get('friendId') ); $this->commandBus->handle($command); return $this->json([]); } }
Domyślnie command zostanie wykonany natychmiastowo. Czyli poniżej moglibyśmy pobrać listę znajomych i powinna ona być wzbogacona o dodanego w nim nowego znajomego. Więc jeżeli ktoś potrzebuje zwrócić od razu rezultat to może. Ale nic nie stoi na przeszkodzie by zdefiniować sobie drugi własny command bus który będzie odkładał polecenie na kolejkę. (Przykładu takiego serwisu) Do tego dodać konsumera który takie zadania będzie z kolejki ściągać i wykonywać. A przerzucenie zadania które wykonuje się za długo w kontrollerze na kolejkę sprowadzać się będzie tylko do użycia innego command busa.
I to jest podstawowe użycie i działanie. Nie jest źle ale szału nie ma. Command Bus od tactician pozwala nam na dodawanie pośredników (middleware). Co pozwala sprawić, że narzędzie to staje się jeszcze bardziej użyteczne. Obecnie proces wykonania polecenia wygląda następująco:
Dobrze jest rozdzielić warstwę kodu który wykonuje daną odperację od walidacji jego danych. Walidacja czasem jest prosta a czasem bardziej skomplikowana ale raczej zawsze jakaś jest. Dlatego spróbujmy stworzyć middleware który uruchomi walidator commanda by zweryfkować czy Command w ogóle powinien się wykonać.
Aby odróżnić błędne wywołania które zakończą się jakiś wyjątkiem. Lepiej tak zaprojektować middleware by błędy były po prostu zwracane. Może być to true/false może być to po prostu string, ale jeżeli zamierzamy mieć różne wersje językowe serwisu to lepiej niech to będzie obiekt do którego będzie można przekazać klucz tłumaczenia i predykaty. Ja na razię przekazuje po prostu treść błędu ale tu każdy powinien przemyśleć to co będzie odpowiednie do jego rojektu.
<?php declare(strict_types=1); namespace CommandBus\Middleware; use League\Tactician\Middleware; abstract class AbstractMiddleware implements Middleware { const COMMAND_SUFFIX = 'Command'; public function createServiceName(string $commandClassName, string $suffix): string { $commandSuffixLength = \strlen(self::COMMAND_SUFFIX); if (substr($commandClassName, -$commandSuffixLength) !== self::COMMAND_SUFFIX) { throw new \Exception(sprintf('Class %s is no command class', $commandClassName)); } return substr($commandClassName, 0, -$commandSuffixLength) . $suffix; } }
<?php declare(strict_types=1); namespace CommandBus\Middleware; use Symfony\Component\DependencyInjection\ContainerInterface; class ValidateMiddleware extends AbstractMiddleware { const VALIDATOR_SUFFIX = 'Validator'; /** * @var ContainerInterface */ private $container; public function __construct(ContainerInterface $container) { $this->container = $container; } /** * @return mixed * @throws \Exception */ public function execute($command, callable $next) { $validatorName = $this->createServiceName(get_class($command), self::VALIDATOR_SUFFIX); if (!$this->container->has($validatorName)) { throw new \Exception('Validator service can not be found'); } $validator = $this->container->get($validatorName); $error = $validator->validate($command); if ($error) { return $error; } return $next($command); } }
Dodajmy middleware do konfiguracji:
tactician: commandbus: default: middleware: - tactician.middleware.locking - CommandBus\Middleware\ValidateMiddleware - tactician.middleware.command_handler
Dopiszmy teraz klasę walidacji do naszego Command-a.
<?php declare(strict_types=1); namespace CommandBus\Command\User\AddFriend; use UsersBundle\Repository\UserRepository; class AddFriendValidator { public function __construct(UserRepository $userRepository) { $this->userRepository = $userRepository; } public function validate(AddFriendCommand $command): ?ValidationFailed { $user = $this->userRepository->find($command->getUserId()); if (!$user) { return new ValidationFailed('User does not exists'); } if ($user->isBanned()) { return new ValidationFailed('User is banned'); } $friend = $this->userRepository->find($command->getFirndId()); if (!$friend) { return new ValidationFailed('Friend does not exists'); } if ($user->hasFriend($friend)) { return new ValidationFailed('Users are already friends'); } } }
Proces działania naszych poleceń wygląda teraz tak:
Fajnie by było aby wszystkie Polecenia były zamknięte w transakcje. Jeżeli programista nie będzie musiał o tym pamiętać to jest szansa, że ochroni to nas przed kilkoma, czasem przykrymi w skutkach problemami. Zobaczmy jak taki middleware dodający transakcje mógłby wyglądać:
<?php declare(strict_types=1); namespace CommandBus\Middleware; use Doctrine\DBAL\Connection; use Doctrine\ORM\EntityManager; class TransactionMiddleware extends AbstractMiddleware { /** * @var EntityManager */ private $entityManager; public function __construct(EntityManager $entityManager) { $this->entityManager = $entityManager; } /** * @throws \Doctrine\Common\Persistence\Mapping\MappingException * @throws \Exception */ public function execute($command, callable $next) { $this->entityManager->getConnection()->setTransactionIsolation(Connection::TRANSACTION_READ_COMMITTED); $this->entityManager->beginTransaction(); try{ $error = $next($command); if ($error) { $this->entityManager->clear(); $this->entityManager->rollback(); return $error; } $this->entityManager->flush(); $this->entityManager->commit(); } catch (\Exception $exception) { $this->entityManager->clear(); $this->entityManager->rollback(); throw $exception; } } }
Dodajemy go do konfiguracji:
tactician: commandbus: default: middleware: - tactician.middleware.locking - CommandBus\Middleware\TransactionMiddleware - CommandBus\Middleware\ValidateMiddleware - tactician.middleware.command_handler
Teraz proces działania naszych poleceń wygląda tak:
Gdy mamy operacje zamknięte w transakcje może wystąpić problem, że w trakcie trwania naszej transakcji encja zmieni stan na taki który już by nie przeszedł walidacji. Lub inne zadanie zablokuje rekordy w innej kolejności co spowoduje zablokowanie się zadań nawzajem. Zminimalizować wystąpienie tego problemu można blokując samemu rekordy wykonująć zapytanie SELECT FOR UPDATE. Jako, że mieszanie technikali z logiką biznesową nie jest najlepszym pomysłem zróbmy middleware który wywoła serwis w razie potrzeby i zablokuje sobie na czas transakcji odpowiednie rekordy. Przykład takiego middleware mógłby wyglądać tak:
<?php declare(strict_types=1); namespace CommandBus\Middleware; use Symfony\Component\DependencyInjection\ContainerInterface; class LockingStrategyMiddleware extends AbstractMiddleware { const LOCKER_SUFFIX = 'Locker'; /** * @var ContainerInterface */ private $container; public function __construct(ContainerInterface $container) { $this->container = $container; } /** * @return mixed * @throws \Exception */ public function execute($command, callable $next) { $lockerName = $this->createServiceName(get_class($command), self::LOCKER_SUFFIX); if ($this->container->has($lockerName)) { $lockingStrategyService = $this->container->get($lockerName); $lockingStrategyService->lock($command); } return $next($command); } }
Dodajemy middleware do konfiguracji:
tactician: commandbus: default: middleware: - tactician.middleware.locking - CommandBus\Middleware\TransactionMiddleware - CommandBus\Middleware\LockingStrategyMiddleware - CommandBus\Middleware\ValidateMiddleware - tactician.middleware.command_handler
No i dodajmy klasę blokującą nasze rekordy.
<?php declare(strict_types=1); namespace CommandBus\Command\User\AddFriend; use Doctrine\ORM\EntityManager; class AddFriendLocker { /** * @var EntityManager */ private $entityManager; public function __construct(EntityManager $entityManager) { $this->entityManager = $entityManager; } public function validate(AddFriendCommand $command): void { $this->entityManager->find('UserBundle\Entity\User', $command->getUserId(), LockMode::PESSIMISTIC_WRITE); $this->entityManager->find('UserBundle\Entity\User', $command->getFirndId(), LockMode::PESSIMISTIC_WRITE); } }
Proces działania naszych poleceń wygląda teraz tak:
Możemy stworzyć dodatkowo middleware który będzie logował wywołanie każdego Command-a oraz ewentualne błedy. Wtedy bez problemu będziemy w stanie ponowić takie commandy gdy poprawimy działanie naszego kodu.
<?php declare(strict_types=1); namespace CommandBus\Middleware; use CommandBus\Command\LoggableInterface; use Psr\Log\LoggerInterface; class LoggingMiddleware extends AbstractMiddleware { /** * @var LoggerInterface */ private $logger; public function __construct(LoggerInterface $logger) { $this->logger = $logger; } /** * @param object $command * @param callable $next * * @return mixed */ public function execute($command, callable $next) { $commandInfo = [ 'class' => get_class($command), ]; try { $this->logger->info('Execute command', $commandInfo); $error = $next($command); if ($error) { $this->logger->warning( 'Command not pass validate', [ 'command' => $commandInfo, 'error' => $error, ] ); } else { $this->logger->info('Command executed', $commandInfo); } return $error; } catch (\Exception $exception) { $this->logger->error( 'Command failed', [ 'command' => $commandInfo, 'error' => $exception->getMessage(), 'stacktrace' => $exception->getTraceAsString(), ] ); throw $exception; } } }
Dodajemy middleware do konfiguracji:
tactician: commandbus: default: middleware: - tactician.middleware.locking - CommandBus\Middleware\LoggingMiddleware - CommandBus\Middleware\TransactionMiddleware - CommandBus\Middleware\LockingStrategyMiddleware - CommandBus\Middleware\ValidateMiddleware - tactician.middleware.command_handler
Teraz uzyskaliśmy taką architektórę naszego CommandBus:
Zastanówmy się teraz jaki uzyskaliśmy rezultat.
Mamy proste wejście do każdej operacji zapisu w naszej aplikacji. Bez problemu więc możemy napisać command Symfonowy który wywoła dowolny command w naszej aplikacji.
Mamy ładny obraz tego co nasz system robi. Nawet nowa osoba w zespole widząc taką listę commandów szybciej zrozumie co się dzieje w systemie niż grzebiąc i szukając po kontrolerach co gdzie jak. A tworząc kod analogicznie jest większa szansa, że będzie on spójny z resztą. W natłoku serwisów często zadarza się tak, że każdy pisze kod trochę inaczej.
Dodaliśmy transakcje do każdej opercji zapisu - nie trzeba już o tym pamiętać
Rozdzieliliśmy logikę blokowania rekordów do zapisu, walidacji oraz wykonania.
Logujemy wykonanie i niepowodzenie każdej operacji zapisu w naszym systemie.
Łatwo możemy wydelegować dowolne zadanie na kolejkę. Jaśli raz stworzymy taką wersję command bus-a. Wystarczy zmienić commandBus do którego przekażemy Command.
Dzięki ładnemu podziałowi odpowiedzialności na rózne klasy nasz kod stał się bardziej SOLID.
Będąc uczciwym trzeba powiedzieć kilka słów o wadach tego rozwiązania. Jeżeli oddzielnie pobieramy encje Lock oddzielnie w Validate i na koniec w Handler to zwiększya się ilość zapytań bazodanowych. W większości przypadków to nie będzie problem. W większości pozostałych przypadków przeniesienie zadań na kolejkę rozwiąże problem. A dla pozostałych przypadków można postarać się o modyfikacje middleware-ów i przekazywanie pobranych encji między tymi warstwami. Osobiście pracując nawet przy projektach gdzie wykonywanych było naprawdę dużo zapisów w jednym czasie. To o ile zapytania wykorzystywały indeksy to nie powodowało to większych problemów.
Drugim minusem to na pewno większa liczba klass do napisania. Jeżeli kogoś bardzo drażni tworzenie tylu klas to ten problem można rozwiązać tworząc command w cli. Przekażemy do niego nazwę commanda a on nam wygeneruje wszystkie pliki w odpowiednim katalogu.
Kiedy więc takie rozwiązanie nam się nie sprawdzi. W małych aplikacjach, czyli takich które da się ogarnąć jedną myślą w kilka minut. W aplikacjach które są czystym CRUDem. Wtedy zapewne lepszym pomysłem będzie użycie jakiejś biblioteki lub frameworka który zapewne proste zapisy i odczyty załatwi za nas. W takich przypadkach byłby to przerost formy nad treścią. W każdym innym przypadku zapewne szybko docenimy wyżej wymienione zalety. Oczywiście należy pamiętać, że to nie jedyny sposób rozwiązania omawianych tu problemów. Zawsze wprowadzając jakieś nowe rozwiązanie/wzorzec do projektu trzeba rozważyć wady i zalety.
W rozbudowywaniu procesu naszego Command Bus-a o nowe middleware ogranicza nas tylko wyobraźnia. Ale co najważniejsze robimy to raz dla wszystkich commandów i zapominamy. W naszej gestii zostanie tylko pisanie nowych Command i ich wywoływanie. Czyli dokładnie to czego dotyczą zadania. Kwestie transakcji, kolejkowania, czy logowania tego co się dzieje w systemie mamy już rozwiązane. Ciekaw jestem czy ktoś ma jakieś pomysły na inne middleware które mogłyby w czymś pomóc?
1 note
·
View note
Text
[Laravel][Testing] Display clearly array not equals error messages
Problem
When assertEqual asserting was failed, I can’t not known where the path of properies is not match.
Example: Assume I have many configs(contains inputs and expected result) With bellow test, I will receive the bellow message.
private const CONFIGS = [ [ 'params' => [ 'level' => JlptRank::N4, 'parts_score' => [ JlptCategoryConstant::JLPT_VOCABULARY__VALUE => 50, JlptCategoryConstant::JLPT_READING__VALUE => 50, JlptCategoryConstant::JLPT_LISTENING__VALUE => 50, ] ], 'expect_return_value' => JlptRank::RANK_A ], // ... ];
Test code:
/** @test */ public function it_returns_expect_results() { foreach (self::CONFIGS as $config) { $this->assertEquals( $config['expect_return_value'], JlptRank::calculate_Jlpt_rank(...array_values($config['params'])) ); } }
Test result:
Failed asserting that two strings are equal. Expected :'C' Actual :'D'
It is hard to find where is the *config that happen don’t match.*
Solution
Merge inputs and expected results in to array, and comparsion it.
/** @test */ public function it_returns_expect_results() { foreach (self::CONFIGS as $config) { $this->assertEquals( json_encode($config), json_encode(array_merge($config, ['expect_return_value' => JlptRank::calculate_Jlpt_rank(...array_values($config['params']))])) ); } }
Test result will be:
Failed asserting that two strings are equal. Expected :'{"params":{"level":4,"parts_score":{"91":10,"93":60,"94":10}},"expect_return_value":"C"}' Actual :'{"params":{"level":4,"parts_score":{"91":10,"93":60,"94":10}},"expect_return_value":"D"}'
Now you can easily see which properties don’t match.
0 notes
Text
Tumblr Tag Cloud Tutorial
I wanted a tag cloud for my personal Tumblr but couldn’t find a good one. There seem to be three main options: Heather Rivers’ which didn’t load for me, drunkonschadenfreude’s which doesn’t link to your tag pages, and Pearl Trees’, but you have to join them to use it. The tutorials I found mostly revolve around using jQuery or require you to host your own Tumblr blog and use PHP or whatever, so I ended up writing my own little script.
I was so happy with it I made a tag cloud generator you can use. The generator is pretty self explanatory. I figured the easiest way to use it would be to stick your blog name and API Key in a form, and there’s some basic customisation for sorting, the minimum tag frequency you want to include in your tag cloud, etc. You essentially copy and paste the code for the generated tag cloud into your page. I’ve put mine in the sidebar.
However it might not be quite perfect for everyone, so I decided to write a little tutorial so you could stick the code in your own blog and customise it for your own use.
The code is simple and pretty self explanatory, and you can really just copy it and replace the capitalised text with the correct values for you.
What annoyed me about many of the guides/tutorials on the internet that tell you how to make a Tumblr tag cloud is that they tend to use jQuery.. Here I use fetch to fetch your blog posts, which is really easy and straightforward.
fetch('https://api.tumblr.com/v2/blog/YOURTUMBLRNAME.tumblr.com/posts?api_key=YOURTUMBLRAPIKEY').then(response =>{

...and now you can probably also see why I’ve made it so you copy and paste the generated HTML on the Tag Cloud Generator instead of the javascript itself - your Tumblr API Key is exposed. I assume that you don’t host your own Tumblr blog and just want to casually stick some code in it. What you can do if you don’t want to keep going to the Tag Cloud Generator is set up a basic HTML file like this on your laptop or phone or whatever and just run it whenever you need to update your tag cloud. Also remember that Tumblr’s imposed a rate limit, so you probably don’t want to just stick the javascript on your page anyway.
Anyway.
After it fetches your blog posts and all is good...
not good
if (response.status != 200) { console.log('error', response.status) return }
good
response.json().then(function(data) { const {posts} = data.response
...it goes through all your posts and pushes all of your tags into a giant array allTags...
const allTags = [] posts.forEach(function (post, index) { allTags.push(...post.tags) })
...and then counts all the unique tags.
const tagCount = allTags.reduce((acc, tag) => { acc[tag] = (acc[tag] || 0)+1 return acc }, {})
Then it sorts your tags, in this case in descending order, but at this point you can sort it in other ways too: in ascending order, randomly, alphabetically, etc.
const sortedTags = Object.keys(tagCount) .map((key) => [key, tagCount[key]]) .sort((a,b) => b[1]-a[1])
This point is probably where you’ll want to customise the most. The tag list is filtered to show only the tags above a minimum number of posts (replace MINIMUMENTRIES with the number you want), but you can also filter it to exclude tags with certain values (eg. if all your text-based posts are tagged as ‘text’ and that isn’t a useful tag for your readers, you can filter out value[0] == ‘text’).
let fontsize const tagList = sortedTags .filter(value => value[1] > MINIMUMENTRIES)
A common feature of tag clouds is that tags that recur more are often in a bigger, bolder font. I’ve split my own tags into three groups and applied different classes on each: a default ‘middle’ group with an average font size, infrequent tags in a small font and the most used tags in the largest font. Replace UPPERLIMIT and LOWERLIMIT with the values you want, or split the tags into more groups. Then style the classes with css.
.map(value => { if (value[1] > UPPERLIMIT) { fontsize = 'font3' } else if (value[1] < LOWERLIMIT) { fontsize = 'font1' } else { fontsize = 'font2' }
The tag list is then returned as a list, which you can style. I’ve gone for a cluster of tags without line breaks in between each list item.
return '<li><a href=http://YOURTUMBLRNAME.tumblr.com/tagged/'+value[0]+' class='+fontsize+'>'+value[0]+' ['+value[1]+']</a></li>' })
Last of all, the tag cloud is wrapped up in an unordered list in a div with the ID tagcloud, and gets written into a div (’#generatedTags’ in this example), but obviously you can write it into whatever div you want, and you could have an ordered list too.
document.getElementById('generatedTags').innerHTML = <div id=tagcloud><ul>"+tagList.join(' ')+"</ul></div>" }) }) }
Don’t forget to call the script!
As you can see in this tutorial the Tumblr API is pretty easy to use. If you have a look at the Tumblr API docs, you’ll see it’s pretty easy to branch off this tag cloud generator example and pimp your blog in other ways with data from the Tumblr API.
Have fun! Feel free to ask me any questions you might have.
View full code here:
10 notes
·
View notes
Text
JavaScript Closures
Closures are really common in JavaScript, but their definition can seem to be a little dark. Let's take a look at them!
Introduction
MDN web docs defines closures like so:
"A closure is the combination of a function and the lexical environment within which that function was declared."
What does that really mean? We can view closures as objects that contain a function and a reference to the environment in which the function was created. They allow to implement such things as callbacks or event handlers. They give us access to an outer function's scope from an inner function.
Basically, we can use a closure by defining a function inside another function. We then have to expose it by returning it or passing it to another function.
In JavaScript, closures are used to enable data privacy because the enclosed variables are only in scope within the parent function.
A few definitions
First, let's take a look at some definitions.
Scope
In JavaScript, a scope refers to the "place" where variables and functions are accessible and in what context it is being executed. When something is accessible from anywhere in our code, it is in the global scope. Local scope refers to something that is only accessible in a certain part of our code.
When we create a function, it has access to variables created inside and outside the function. Variables created inside a function are locally defined and can only be accessed inside this function.
First-Class Functions
Basically, functions are considered as First-Class Citizens when they are "being able to do what everyone else can do". So, they can be assigned to a variable, passed as an argument or returned from a function.
Inner Functions
Also called Nested Functions, they are defined inside of another function (outer function). Every time this outer function is called, an instance of the inner function is created.
Basic example
Knowing what we know, let's make a simple example using a closure.
function say() { let x = 'Hello World!'; function hello() { console.log(x); } return hello; } let sayHello = say(); sayHello();
Here, our function say() returns the inner function hello() from the outer function before being executed. The hello() function is only available within the body of the say() function and has no local variables. Nevertheless, because inner functions have access to the variables of outer functions, hello() can access the variable x declared in the parent function.
Once say() has finished executing, we might expect that the x variable would no longer be accessible, but it is not the case. sayHello() is a reference to the instance of the function hello() that is created when say() function is run and so a reference is kept to the lexical environment of hello() where the variable x exists. This is why this last variable remains available when sayHello() is invoked.
A factory of functions
Let's imagine the following code:
function sentenceFactory(x) { return function(y) { return String(x) + String(y); }; } let sentence1 = sentenceFactory('Hello '); let sentence2 = sentenceFactory('Hey '); console.log(sentence1('John')); console.log(sentence2('Paul'));
Here, we create some kind of factory, sentenceFactory(x), that takes a single argument and returns a new function that also takes one argument. Our functions sentence1 and sentence2 are closures and they share the same function body definition, but they store different lexical environments.
Controlling side effects
Closures can be helpful to control side effects, such as Ajax request or timeout.
function sayHello(name) { setTimeout(function() { console.log('Hello ' + name); }, 1000); }
The previous code would print out our message immediately after one second. Maybe we don't want that and print our message later. We can do that with a closure:
function sayHello(name) { return function() { setTimeout(function() { console.log('Hello ' + name); }, 1000); } } const sayHelloLater = sayHello('Ringo'); sayHelloLater();
Emulating private methods
JavaScript does not support private data and does not provide a native way of doing this. However, we can emulate private methods using closures. Private methods are useful for restricting access to code and provide a way of managing our global namespace.
function Person(name) { let _name = name; function takeInstrument() { return 'guitar'; } return { sayHello: function() { console.log('Hello ' + _name); }, getName: function() { console.log(_name); }, play: function() { console.log(_name + ' is playing the ' + takeInstrument()); } } } const person1 = Person('George'); person1.sayHello(); person1.getName(); person1.play();
In this example, name and takeInstrument() are private because they cannot be accessed directly from outside the Person(name) function. They are accessed by three public functions that are returned.
Loop problem
It can be very tempting to create closures in a loop. Let's first imagine the following example:
function generateLinks() { var info = [ {'name': 'John', 'instrument': 'Guitar'}, {'name': 'Paul', 'instrument': 'Bass'}, {'name': 'George', 'instrument': 'Guitar'}, {'name': 'Ringo', 'instrument': 'Drum'} ]; for (var i = 0, link; i < info.length; i++) { var item = info[i]; var link = document.createElement("a"); link.innerHTML = item.name; link.onclick = function() { alert(item.instrument); }; document.body.appendChild(link); } } window.onload = generateLinks;
This code doesn't work as expected: our alert always shows the same message. But why? Four closures have been created by the loop, but each one shares the same single lexical environment. The item.instrument value is determined when the onclick callbacks are fired. It means that the loop continues until the end and so the item variable is left pointing to the last entry when generateLinks() exits.
We could fix it like so:
function createAlert(info) { return function() { alert(info); }; } function generateLinks() { var info = [ {'name': 'John', 'instrument': 'Guitar'}, {'name': 'Paul', 'instrument': 'Bass'}, {'name': 'George', 'instrument': 'Guitar'}, {'name': 'Ringo', 'instrument': 'Drum'} ]; for (var i = 0, link; i < info.length; i++) { var item = info[i]; var link = document.createElement("a"); link.innerHTML = item.name; link.onclick = createAlert(item.instrument); document.body.appendChild(link); } } window.onload = generateLinks;
We could also fix our code by using let instead of var.
In other programming languages
Closures are not available just in JavaScript. We can use them in other programming languages.
With PHP:
function adder($n) { return function($v) use($n) { return $v + $n; }; } $adder10 = adder(10); $adder10(1);
With Python:
def adder(nombre): return lambda v: v + n adder10 = adder(10) adder10(1)
With Swift:
func adder(_ n: Int) -> (Int) -> Int { return { n + $0 } } let adder10 = adder(10) print(adder10(5))
And so on!
Conclusion
Through this article, we took a look at closures in JavaScript and saw how they work. We saw that a closure is formed when an outer function exposes an inner function and it contains a function and a reference to the environment in which it was created. Closures can be used to deal with callback functions and to emulate private data.
One last word
If you like this article, you can consider supporting and helping me on Patreon! It would be awesome! Otherwise, you can find my other posts on Medium and Tumblr. You will also know more about myself on my personal website. Until next time, happy headache!
17 notes
·
View notes
Text
Should The NFL Be Able To Suspend Or Fine Players Who Are Charged With A Crime But Found Innocent?
By Nicholas Bellino, Binghamton University Class of 2023
September 10, 2020

On May 16th, 2020, Ed Oliver, a Buffalo Bills defensive tackle, was arrested and charged with a DUI and a class-A misdemeanor "Unlawful Carry of Weapon". He was stopped because a concerned citizen reported him for swerving all over the road and breaking the speed limit. They suspected that he was under the influence. The police officers reported that when they approached the vehicle, there was a smell of alcohol and there was an open bottle of beer in the front of the car[1]. The police officer also reported seeing a firearm in the car. Eventually, the case got dropped because there was not enough evidence due to the fact that the blood test that Ed Oliver was required to take, came back negative for drugs and/or alcohol(Wilson,1). The weapons charge was also dropped because in Montgomery, Alabama people are allowed to carry guns if they are not drunk. This case ended but the question still remains, will the NFL suspend Ed Oliver even though he was innocent
Some may think that this is a very clear cut case. The charges against Ed Oliver were dropped so he is innocent of those charges. But, the NFL Personal Conduct Policy may say otherwise. This document directly states "It is not enough simply to avoid being found guilty of a crime. We are all held to a higher standard
and must conduct ourselves in a way that is responsible, promotes the values of the NFL, and is lawful"(NFL). So, it is possible that the NFL could take action against players who are found not guilty in a court of law. They list the offenses that would require league action and one of them simply states that an action that undermines the NFL could be enough to either fine or suspend a player. All the other offenses are much more specific and actually represent serious crimes. If a player is rumored to have broken one of these rules, the NFL should be able to investigate the issue. This last rule does not specifically state a certain crime that would warrant investigation. This creates a problem because NFL players do not really know what not to do. Should something this vague really be a reason to suspend or fine a player if they were found not guilty or if they were not even charged with a crime?
One of the biggest issues with this personal conduct policy is the vagueness of the last rule listed. The reason that this is a problem is that NFL players do not really know what they are agreeing to when signing their NFL contract. They are young players, fresh out of college. They are not going to look too much into their contract. Because of the many interpretations of this last rule, the contract is an ambiguous document which should be looked into, either in a court of law or by the NFL Players Association. That last rule can incorporate anything that the NFL rules is undermining them. They never actually list things that would be considered undermining in the personal conduct policy. If an NFL player ever finds in issue with this ambiguity, they would have to discuss it with their lawyers and the NFL lawyers. There is also another issue with this contract in terms of whether or not it is right to punish the innocent.
Legally, the NFL has the right to do this because every player signs a contract and agrees to this policy in order to play in the NFL. But in terms of justice, the problem with this contract is the ability to punish the innocent. In the U.S. Constitution, there is an amendment that protects citizens from being tried for the same crime twice(U.S Const. Amend V). This is called double jeopardy. The NFL does not have the ability to try a case, therefore they are not going against this amendment in any way. What they do have the ability to do is investigate and punish players even if they have already been proven innocent. This goes against what the 5th amendment is supposed to protect U.S. citizens from. If somebody is accused of something that they did not do, they should not have to prove their innocence more than once. And in this situation Ed Oliver would have to prove that he did not undermine the NFL, in the event that the NFL actually takes any sort of action. Although, it is unlikely that the NFL will actually take some sort of action. Legally, they could with no repercussions due to the vagueness of their personal conduct policy. If players were to find an issue with this policy, the NFL Players Association would need to renegotiate the terms of the policy in order to keep the NFL from exploiting the wording of the policy. In most cases, the NFL would not suspend or fine a player for this type of offense, but they do have the power to punish the innocent which goes against the ideas that this nation was founded on.
________________________________________________________________
[1] Wilson, Aaron. “Bills DT Ed Oliver's DWI, Gun Charges Dismissed.” ExpressNews.com, Houston Chronicle, 22 July 2020, www.expressnews.com/texas-sports-nation/texans/article/Bills-Ed-Oliver-DWI-gun-charges-dismissed-Houston-15426652.php.
[2] NFL Personal Conduct Policy
[3] United States Constitution Amendment V
0 notes
Link
JavaScript is one of the most popular programming languages in the world. I believe it's a great language to be your first programming language ever. We mainly use JavaScript to create websites web applications server-side applications using Node.js but JavaScript is not limited to these things, and it can also be used to create mobile applications using tools like React Native create programs for microcontrollers and the internet of things create smartwatch applications It can basically do anything. It's so popular that everything new that shows up is going to have some kind of JavaScript integration at some point. JavaScript is a programming language that is: high level: it provides abstractions that allow you to ignore the details of the machine where it's running on. It manages memory automatically with a garbage collector, so you can focus on the code instead of managing memory like other languages like C would need, and provides many constructs which allow you to deal with highly powerful variables and objects. dynamic: opposed to static programming languages, a dynamic language executes at runtime many of the things that a static language does at compile time. This has pros and cons, and it gives us powerful features like dynamic typing, late binding, reflection, functional programming, object runtime alteration, closures and much more. Don't worry if those things are unknown to you - you'll know all of those at the end of the course. dynamically typed: a variable does not enforce a type. You can reassign any type to a variable, for example, assigning an integer to a variable that holds a string. loosely typed: as opposed to strong typing, loosely (or weakly) typed languages do not enforce the type of an object, allowing more flexibility but denying us type safety and type checking (something that TypeScript - which builds on top of JavaScript - provides) interpreted: it's commonly known as an interpreted language, which means that it does not need a compilation stage before a program can run, as opposed to C, Java or Go for example. In practice, browsers do compile JavaScript before executing it, for performance reasons, but this is transparent to you: there is no additional step involved. multi-paradigm: the language does not enforce any particular programming paradigm, unlike Java for example, which forces the use of object-oriented programming, or C that forces imperative programming. You can write JavaScript using an object-oriented paradigm, using prototypes and the new (as of ES6) classes syntax. You can write JavaScript in a functional programming style, with its first-class functions, or even in an imperative style (C-like). In case you're wondering, JavaScript has nothing to do with Java, it's a poor name choice but we have to live with it. Update: You can now get a PDF and ePub version of this JavaScript Beginner's Handbook.A little bit of history Created 20 years ago, JavaScript has gone a very long way since its humble beginnings. It was the first scripting language that was supported natively by web browsers, and thanks to this it gained a competitive advantage over any other language and today it's still the only scripting language that we can use to build Web Applications. Other languages exist, but all must compile to JavaScript - or more recently to WebAssembly, but this is another story. In the beginnings, JavaScript was not nearly powerful as it is today, and it was mainly used for fancy animations and the marvel known at the time as Dynamic HTML. With the growing needs that the web platform demanded (and continues to demand), JavaScript had the responsibility to grow as well, to accommodate the needs of one of the most widely used ecosystems of the world. JavaScript is now widely used also outside of the browser. The rise of Node.js in the last few years unlocked backend development, once the domain of Java, Ruby, Python, PHP and more traditional server-side languages. JavaScript is now also the language powering databases and many more applications, and it's even possible to develop embedded applications, mobile apps, TV sets apps and much more. What started as a tiny language inside the browser is now the most popular language in the world. Just JavaScript Sometimes it's hard to separate JavaScript from the features of the environment it is used in. For example, the console.log() line you can find in many code examples is not JavaScript. Instead, it's part of the vast library of APIs provided to us in the browser. In the same way, on the server it can be sometimes hard to separate the JavaScript language features from the APIs provided by Node.js. Is a particular feature provided by React or Vue? Or is it "plain JavaScript", or "vanilla JavaScript" as often called? In this book I talk about JavaScript, the language. Without complicating your learning process with things that are outside of it, and provided by external ecosystems. A brief intro to the syntax of JavaScript In this little introduction I want to tell you about 5 concepts: white space case sensitivity literals identifiers White space JavaScript does not consider white space meaningful. Spaces and line breaks can be added in any fashion you might like, even though this is in theory. In practice, you will most likely keep a well defined style and adhere to what people commonly use, and enforce this using a linter or a style tool such as Prettier. For example, I like to always 2 characters to indent. Case sensitive JavaScript is case sensitive. A variable named something is different from Something. The same goes for any identifier. Literals We define as literal a value that is written in the source code, for example, a number, a string, a boolean or also more advanced constructs, like Object Literals or Array Literals: 5 'Test' true ['a', 'b'] {color: 'red', shape: 'Rectangle'} Identifiers An identifier is a sequence of characters that can be used to identify a variable, a function, an object. It can start with a letter, the dollar sign $ or an underscore _, and it can contain digits. Using Unicode, a letter can be any allowed char, for example, an emoji 😄. Test test TEST _test Test1 $test The dollar sign is commonly used to reference DOM elements. Some names are reserved for JavaScript internal use, and we can't use them as identifiers. Comments are one of the most important part of any program. In any programming language. They are important because they let us annotate the code and add important information that otherwise would not be available to other people (or ourselves) reading the code. In JavaScript, we can write a comment on a single line using //. Everything after // is not considered as code by the JavaScript interpreter. Like this: // a comment true //another comment Another type of comment is a multi-line comment. It starts with /* and ends with */. Everything in between is not considered as code: /* some kind of comment */ Semicolons Every line in a JavaScript program is optionally terminated using semicolons. I said optionally, because the JavaScript interpreter is smart enough to introduce semicolons for you. In most cases, you can omit semicolons altogether from your programs, without even thinking about it. This fact is very controversial. Some developers will always use semicolons, some others will never use semicolons, and you'll always find code that uses semicolons and code that does not. My personal preference is to avoid semicolons, so my examples in the book will not include them. Values A hello string is a value. A number like 12 is a value. hello and 12 are values. string and number are the types of those values. The type is the kind of value, its category. We have many different types in JavaScript, and we'll talk about them in detail later on. Each type has its own characteristics. When we need to have a reference to a value, we assign it to a variable. The variable can have a name, and the value is what's stored in a variable, so we can later access that value through the variable name. Variables A variable is a value assigned to an identifier, so you can reference and use it later in the program. This is because JavaScript is loosely typed, a concept you'll frequently hear about. A variable must be declared before you can use it. We have 2 main ways to declare variables. The first is to use const: const a = 0 The second way is to use let: let a = 0 What's the difference? const defines a constant reference to a value. This means the reference cannot be changed. You cannot reassign a new value to it. Using let you can assign a new value to it. For example, you cannot do this: const a = 0 a = 1 Because you'll get an error: TypeError: Assignment to constant variable.. On the other hand, you can do it using let: let a = 0 a = 1 const does not mean "constant" in the way some other languages like C mean. In particular, it does not mean the value cannot change - it means it cannot be reassigned. If the variable points to an object or an array (we'll see more about objects and arrays later) the content of the object or the array can freely change. Const variables must be initialized at the declaration time: const a = 0 but let values can be initialized later: let a a = 0 You can declare multiple variables at once in the same statement: const a = 1, b = 2 let c = 1, d = 2 But you cannot redeclare the same variable more than one time: let a = 1 let a = 2 or you'd get a "duplicate declaration" error. My advice is to always use const and only use let when you know you'll need to reassign a value to that variable. Why? Because the less power our code has, the better. If we know a value cannot be reassigned, it's one less source for bugs. Now that we saw how to work with const and let, I want to mention var. Until 2015, var was the only way we could declare a variable in JavaScript. Today, a modern codebase will most likely just use const and let. There are some fundamental differences which I detail in this post but if you're just starting out, you might not care about. Just use const and let. Types Variables in JavaScript do not have any type attached. They are untyped. Once you assign a value with some type to a variable, you can later reassign the variable to host a value of any other type, without any issue. In JavaScript we have 2 main kinds of types: primitive types and object types. Primitive types Primitive types are numbers strings booleans symbols And two special types: null and undefined. Object types Any value that's not of a primitive type (a string, a number, a boolean, null or undefined) is an object. Object types have properties and also have methods that can act on those properties. We'll talk more about objects later on. Expressions An expression is a single unit of JavaScript code that the JavaScript engine can evaluate, and return a value. Expressions can vary in complexity. We start from the very simple ones, called primary expressions: 2 0.02 'something' true false this //the current scope undefined i //where i is a variable or a constant Arithmetic expressions are expressions that take a variable and an operator (more on operators soon), and result into a number: 1 / 2 i++ i -= 2 i * 2 String expressions are expressions that result into a string: 'A ' + 'string' Logical expressions make use of logical operators and resolve to a boolean value: a && b a || b !a More advanced expressions involve objects, functions, and arrays, and I'll introduce them later. Operators Operators allow you to get two simple expressions and combine them to form a more complex expression. We can classify operators based on the operands they work with. Some operators work with 1 operand. Most with 2 operands. Just one operator works with 3 operands. In this first introduction to operators, we'll introduce the operators you are most likely familar with: operators with 2 operands. I already introduced one when talking about variables: the assignment operator =. You use = to assign a value to a variable: let b = 2 Let's now introduce another set of binary operators that you already familiar with, from basic math. The addition operator (+) const three = 1 + 2 const four = three + 1 The + operator also serves as string concatenation if you use strings, so pay attention: const three = 1 + 2 three + 1 // 4 'three' + 1 // three1 The subtraction operator (-) const two = 4 - 2 The division operator (/) Returns the quotient of the first operator and the second: const result = 20 / 5 //result === 4 const result = 20 / 7 //result === 2.857142857142857 If you divide by zero, JavaScript does not raise any error but returns the Infinity value (or -Infinity if the value is negative). 1 / 0 //Infinity -1 / 0 //-Infinity The remainder operator (%) The remainder is a very useful calculation in many use cases: const result = 20 % 5 //result === 0 const result = 20 % 7 //result === 6 A reminder by zero is always NaN, a special value that means "Not a Number": 1 % 0 //NaN -1 % 0 //NaN The multiplication operator (*) Multiply two numbers 1 * 2 //2 -1 * 2 //-2 The exponentiation operator (**) Raise the first operand to the power second operand 1 ** 2 //1 2 ** 1 //2 2 ** 2 //4 2 ** 8 //256 8 ** 2 //64 Precedence rules Every complex statement with multiple operators in the same line will introduce precedence problems. Take this example: let a = 1 * 2 + 5 / 2 % 2 The result is 2.5, but why? What operations are executed first, and which need to wait? Some operations have more precedence than the others. The precedence rules are listed in this table: Operator Description * / % multiplication/dividision + - addition/subtraction = assignment Operations on the same level (like + and -) are executed in the order they are found, from left to right. Following these rules, the operation above can be solved in this way: let a = 1 * 2 + 5 / 2 % 2 let a = 2 + 5 / 2 % 2 let a = 2 + 2.5 % 2 let a = 2 + 0.5 let a = 2.5 Comparison operators After assignment and math operators, the third set of operators I want to introduce is conditional operators. You can use the following operators to compare two numbers, or two strings. Comparison operators always returns a boolean, a value that's true or false). Those are disequality comparison operators: < means "less than" <= means "minus than, or equal to" means "greater than" = means "greater than, or equal to" Example: = 1 //true In addition to those, we have 4 equality operators. They accept two values, and return a boolean: === checks for equality !== checks for inequality Note that we also have == and != in JavaScript, but I highly suggest to only use === and !== because they can prevent some subtle problems. Conditionals With the comparison operators in place, we can talk about conditionals. An if statement is used to make the program take a route, or another, depending on the result of an expression evaluation. This is the simplest example, which always executes: if (true) { //do something } on the contrary, this is never executed: if (false) { //do something (? never ?) } The conditional checks the expression you pass to it for true or false value. If you pass a number, that always evaluates to true unless it's 0. If you pass a string, it always evaluates to true unless it's an empty string. Those are general rules of casting types to a boolean. Did you notice the curly braces? That is called a block, and it is used to group a list of different statements. A block can be put wherever you can have a single statement. And if you have a single statement to execute after the conditionals, you can omit the block, and just write the statement: if (true) doSomething() But I always like to use curly braces to be more clear. You can provide a second part to the if statement: else. You attach a statement that is going to be executed if the if condition is false: if (true) { //do something } else { //do something else } Since else accepts a statement, you can nest another if/else statement inside it: if (a === true) { //do something } else if (b === true) { //do something else } else { //fallback } Arrays An array is a collection of elements. Arrays in JavaScript are not a type on their own. Arrays are objects. We can initialize an empty array in these 2 different ways: const a = [] const a = Array() The first is using the array literal syntax. The second uses the Array built-in function. You can pre-fill the array using this syntax: const a = [1, 2, 3] const a = Array.of(1, 2, 3) An array can hold any value, even value of different types: const a = [1, 'Flavio', ['a', 'b']] Since we can add an array into an array, we can create multi-dimensional arrays, which have very useful applications (e.g. a matrix): const matrix = [ [1, 2, 3], [4, 5, 6], [7, 8, 9] ] matrix[0][0] //1 matrix[2][0] //7 You can access any element of the array by referencing its index, which starts from zero: a[0] //1 a[1] //2 a[2] //3 You can initialize a new array with a set of values using this syntax, which first initializes an array of 12 elements, and fills each element with the 0 number: Array(12).fill(0) You can get the number of elements in the array by checking its length property: const a = [1, 2, 3] a.length //3 Note that you can set the length of the array. If you assign a bigger number than the arrays current capacity, nothing happens. If you assign a smaller number, the array is cut at that position: const a = [1, 2, 3] a //[ 1, 2, 3 ] a.length = 2 a //[ 1, 2 ] How to add an item to an array We can add an element at the end of an array using the push() method: a.push(4) We can add an element at the beginning of an array using the unshift() method: a.unshift(0) a.unshift(-2, -1) How to remove an item from an array We can remove an item from the end of an array using the pop() method: a.pop() We can remove an item from the beginning of an array using the shift() method: a.shift() How to join two or more arrays You can join multiple arrays by using concat(): const a = [1, 2] const b = [3, 4] const c = a.concat(b) //[1,2,3,4] a //[1,2] b //[3,4] You can also use the spread operator (...) in this way: const a = [1, 2] const b = [3, 4] const c = [...a, ...b] c //[1,2,3,4] How to find a specific item in the array You can use the find() method of an array: { //return true or false }) Returns the first item that returns true. Returns undefined if the element is not found. A commonly used syntax is: x.id === my_id) The above line will return the first element in the array that has id === my_id. findIndex() works similarly to find(), but returns the index of the first item that returns true, and if not found, it returns undefined: { //return true or false }) Another method is includes(): a.includes(value) Returns true if a contains value. a.includes(value, i) Returns true if a contains value after the position i. Strings A string is a sequence of characters. It can be also defined as a string literal, which is enclosed in quotes or double quotes: 'A string' "Another string" I personally prefer single quotes all the time, and use double quotes only in HTML to define attributes. You assign a string value to a variable like this: const name = 'Flavio' You can determine the length of a string using the length property of it: 'Flavio'.length //6 const name = 'Flavio' name.length //6 This is an empty string: ''. Its length property is 0: ''.length //0 Two strings can be joined using the + operator: "A " + "string" You can use the + operator to interpolate variables: const name = 'Flavio' "My name is " + name //My name is Flavio Another way to define strings is to use template literals, defined inside backticks. They are especially useful to make multiline strings much simpler. With single or double quotes you can't define a multiline string easily: you'd need to use escaping characters. Once a template literal is opened with the backtick, you just press enter to create a new line, with no special characters, and it's rendered as-is: const string = `Hey this string is awesome!` Template literals are also great because they provide an easy way to interpolate variables and expressions into strings. You do so by using the ${...} syntax: const var = 'test' const string = `something ${var}` //something test inside the ${} you can add anything, even expressions: const string = `something ${1 + 2 + 3}` const string2 = `something ${foo() ? 'x' : 'y'}` Loops Loops are one of the main control structures of JavaScript. With a loop we can automate and repeat indefinitely a block of code, for how many times we want it to run. JavaScript provides many way to iterate through loops. I want to focus on 3 ways: while loops for loops for..of loops while The while loop is the simplest looping structure that JavaScript provides us. We add a condition after the while keyword, and we provide a block that is run until the condition evaluates to true. Example: const list = ['a', 'b', 'c'] let i = 0 while (i < list.length) { console.log(list[i]) //value console.log(i) //index i = i + 1 } You can interrupt a while loop using the break keyword, like this: while (true) { if (somethingIsTrue) break } and if you decide that in the middle of a loop you want to skip the current iteration, you can jump to the next iteration using continue: while (true) { if (somethingIsTrue) continue //do something else } Very similar to while, we have do..while loops. It's basically the same as while, except the condition is evaluated after the code block is executed. This means the block is always executed at least once. Example: const list = ['a', 'b', 'c'] let i = 0 do { console.log(list[i]) //value console.log(i) //index i = i + 1 } while (i < list.length) for The second very important looping structure in JavaScript is the for loop. We use the for keyword and we pass a set of 3 instructions: the initialization, the condition, and the increment part. Example: const list = ['a', 'b', 'c'] for (let i = 0; i < list.length; i++) { console.log(list[i]) //value console.log(i) //index } Just like with while loops, you can interrupt a for loop using break and you can fast forward to the next iteration of a for loop using continue. for...of This loop is relatively recent (introduced in 2015) and it's a simplified version of the for loop: const list = ['a', 'b', 'c'] for (const value of list) { console.log(value) //value } Functions In any moderately complex JavaScript program, everything happens inside functions. Functions are a core, essential part of JavaScript. What is a function? A function is a block of code, self contained. Here's a function declaration: function getData() { // do something } A function can be run any times you want by invoking it, like this: getData() A function can have one or more argument: function getData() { //do something } function getData(color) { //do something } function getData(color, age) { //do something } When we can pass an argument, we invoke the function passing parameters: function getData(color, age) { //do something } getData('green', 24) getData('black') Note that in the second invokation I passed the black string parameter as the color argument, but no age. In this case, age inside the function is undefined. We can check if a value is not undefined using this conditional: function getData(color, age) { //do something if (typeof age !== 'undefined') { //... } } typeof is a unary operator that allows us to check the type of a variable. You can also check in this way: function getData(color, age) { //do something if (age) { //... } } although the conditional will also be true if age is null, 0 or an empty string. You can have default values for parameters, in case they are not passed: function getData(color = 'black', age = 25) { //do something } You can pass any value as a parameter: numbers, strings, booleans, arrays, objects, and also functions. A function has a return value. By default a function returns undefined, unless you add a return keyword with a value: function getData() { // do something return 'hi!' } We can assign this return value to a variable when we invoke the function: function getData() { // do something return 'hi!' } let result = getData() result now holds a string with the the hi! value. You can only return one value. To return multiple values, you can return an object, or an array, like this: function getData() { return ['Flavio', 37] } let [name, age] = getData() Functions can be defined inside other functions: {} dosomething() return 'test' } The nested function cannot be called from the outside of the enclosing function. You can return a function from a function, too. Arrow functions Arrow functions are a recent introduction to JavaScript. They are very often used instead of "regular" functions, the one I described in the previous chapter. You'll find both forms used everywhere. Visually, they allows you to write functions with a shorter syntax, from: function getData() { //... } to { //... } But.. notice that we don't have a name here. Arrow functions are anonymous. We must assign them to a variable. We can assign a regular function to a variable, like this: let getData = function getData() { //... } When we do so, we can remove the name from the function: let getData = function() { //... } and invoke the function using the variable name: let getData = function() { //... } getData() That's the same thing we do with arrow functions: { //... } getData() If the function body contains just a single statement, you can omit the parentheses and write all on a single line: console.log('hi!') Parameters are passed in the parentheses: console.log(param1, param2) If you have one (and just one) parameter, you could omit the parentheses completely: console.log(param) Arrow functions allow you to have an implicit return: values are returned without having to use the return keyword. It works when there is a on-line statement in the function body: 'test' getData() //'test' Like with regular functions, we can have default parameters: You can have default values for parameters, in case they are not passed: { //do something } and we can only return one value. Arrow functions can contain other arrow function, or also regular functions. The are very similar, so you might ask why they were introduced? The big difference with regular functions is when they are used as object methods. This is something we'll soon look into. Objects Any value that's not of a primitive type (a string, a number, a boolean, a symbol, null, or undefined) is an object. Here's how we define an object: const car = { } This is the object literal syntax, which is one of the nicest things in JavaScript. You can also use the new Object syntax: const car = new Object() Another syntax is to use Object.create(): const car = Object.create() You can also initialize an object using the new keyword before a function with a capital letter. This function serves as a constructor for that object. In there, we can initialize the arguments we receive as parameters, to setup the initial state of the object: function Car(brand, model) { this.brand = brand this.model = model } We initialize a new object using const myCar = new Car('Ford', 'Fiesta') myCar.brand //'Ford' myCar.model //'Fiesta' Objects are always passed by reference. If you assign a variable the same value of another, if it's a primitive type like a number or a string, they are passed by value: Take this example: let age = 36 let myAge = age myAge = 37 age //36 const car = { color: 'blue' } const anotherCar = car anotherCar.color = 'yellow' car.color //'yellow' Even arrays or functions are, under the hoods, objects, so it's very important to understand how they work. Object Properties Objects have properties, which are composed by a label associated with a value. The value of a property can be of any type, which means that it can be an array, a function, and it can even be an object, as objects can nest other objects. This is the object literal syntax we saw in the previous chapter: const car = { } We can define a color property in this way: const car = { color: 'blue' } here we have a car object with a property named color, with value blue. Labels can be any string, but beware special characters: if I wanted to include a character not valid as a variable name in the property name, I would have had to use quotes around it: const car = { color: 'blue', 'the color': 'blue' } Invalid variable name characters include spaces, hyphens, and other special characters. As you see, when we have multiple properties, we separate each property with a comma. We can retrieve the value of a property using 2 different syntaxes. The first is dot notation: car.color //'blue' The second (which is the only one we can use for properties with invalid names), is to use square brackets: car['the color'] //'blue' If you access an unexisting property, you'll get the undefined value: car.brand //undefined As said, objects can have nested objects as properties: const car = { brand: { name: 'Ford' }, color: 'blue' } In this example, you can access the brand name using car.brand.name or car['brand']['name'] You can set the value of a property when you define the object. But you can always update it later on: const car = { color: 'blue' } car.color = 'yellow' car['color'] = 'red' And you can also add new properties to an object: car.model = 'Fiesta' car.model //'Fiesta' Given the object const car = { color: 'blue', brand: 'Ford' } you can delete a property from this object using delete car.brand Object Methods I talked about functions in a previous chapter. Functions can be assigned to a function property, and in this case they are called methods. In this example, the start property has a function assigned, and we can invoke it by using the dot syntax we used for properties, with the parentheses at the end: const car = { brand: 'Ford', model: 'Fiesta', start: function() { console.log('Started') } } car.start() Inside a method defined using a function() {} syntax we have access to the object instance by referencing this. In the following example, we have access to the brand and model properties values using this.brand and this.model: const car = { brand: 'Ford', model: 'Fiesta', start: function() { console.log(`Started ${this.brand} ${this.model}`) } } car.start() It's important to note this distinction between regular functions and arrow functions: we don't have access to this if we use an arrow function: { console.log(`Started ${this.brand} ${this.model}`) //not going to work } } car.start() This is because arrow functions are not bound to the object. This is the reason why regular functions are often used as object methods. Methods can accept parameters, like regular functions: const car = { brand: 'Ford', model: 'Fiesta', goTo: function(destination) { console.log(`Going to ${destination}`) } } car.goTo('Rome') Classes We talked about objects, which are one of the most interesting parts of JavaScript. In this chapter we'll go up one level, introducing classes. What are classes? They are a way to define a common pattern for multiple objects. Let's take a person object: const person = { name: 'Flavio' } We can create a class named Person (note the capital P, a convention when using classes), that has a name property: class Person { name } Now from this class, we initialize a flavio object like this: const flavio = new Person() flavio is called an instance of the Person class. We can set the value of the name property: flavio.name = 'Flavio' and we can access it using flavio.name like we do for object properties. Classes can hold properties, like name, and methods. Methods are defined in this way: class Person { hello() { return 'Hello, I am Flavio' } } and we can invoke methods on an instance of the class: class Person { hello() { return 'Hello, I am Flavio' } } const flavio = new Person() flavio.hello() There is a special method called called constructor() that we can use to initialize the class properties when we create a new object instance. It works like this: class Person { constructor(name) { this.name = name } hello() { return 'Hello, I am ' + this.name + '.' } } Note how we use this to access the object instance. Now we can instantiate a new object from the class, passing a string, and when we call hello, we'll get a personalized message: const flavio = new Person('flavio') flavio.hello() //'Hello, I am flavio.' When the object is initialized, the constructor method is called, with any parameters passed. Normally methods are defined on the object instance, not on the class. You can define a method as static to allow it to be executed on the class instead: class Person { static genericHello() { return 'Hello' } } Person.genericHello() //Hello This is very useful, at times. Inheritance A class can extend another class, and objects initialized using that class inherit all the methods of both classes. Suppose we have a class Person: class Person { hello() { return 'Hello, I am a Person' } } We can define a new class Programmer that extends Person: class Programmer extends Person { } Now if we instantiate a new object with class Programmer, it has access to the hello() method: const flavio = new Programmer() flavio.hello() //'Hello, I am a Person' Inside a child class, you can reference the parent class calling super(): class Programmer extends Person { hello() { return super.hello() + '. I am also a programmer.' } } const flavio = new Programmer() flavio.hello() The above program prints Hello, I am a Person. I am also a programmer.. Asynchonous Programming and Callbacks Most of the time, JavaScript code is ran synchronously. This means that a line of code is executed, then the next one is executed, and so on. Everything is as you expect, and how it works in most programming languages. However there are times when you cannot just wait for a line of code to execute. You can't just wait 2 seconds for a big file to load, and halt the program completely. You can't just wait for a network resource to be downloaded, before doing something else. JavaScript solves this problem using callbacks. One of the simplest examples of how to use callbacks is timers. Timers are not part of JavaScript, but they are provided by the browser, and Node.js. Let me talk about one of the timers we have: setTimeout(). The setTimeout() function accepts 2 arguments: a function, and a number. The number is the milliseconds that must pass before the function is ran. Example: { // runs after 2 seconds console.log('inside the function') }, 2000) The function containing the console.log('inside the function') line will be executed after 2 seconds. If you add a console.log('before') prior to the function, and console.log('after') after it: { // runs after 2 seconds console.log('inside the function') }, 2000) console.log('after') You will see this happening in your console: before after inside the function The callback function is executed asynchronously. This is a very common pattern when working with the file system, the network, events, or the DOM in the browser. All of the things I mentioned are not "core" JavaScript, so they are not explained in this handbook, but you'll find lots of examples in my other handbooks available at https://flaviocopes.com. Here's how we can implement callbacks in our code. We define a function that accepts a callback parameter, which is a function. When the code is ready to invoke the callback, we invoke it passing the result: { //do things //do things const result = /* .. */ callback(result) } Code using this function would use it like this: { console.log(result) }) Promises Promises are an alternative way to deal with asynchronous code. As we saw in the previous chapter, with callbacks we'd be passing a function to another function call, that would be called when the function has finished processing. Like this: { console.log(result) }) When the doSomething() code ends, it calls the function received as a a parameter: { //do things //do things const result = /* .. */ callback(result) } The main problems with this approach is that the callback is executed asynchronously, so we don't have a way to do something, and then simply go on with our function. All our code must be nested inside the callback, and if we have to do 2-3 callbacks we enter in what is usually defined "callback hell" with many levels of functions indented into other functions: { console.log(result) }) }) }) Promises are one way to deal with this. Instead of doing: { console.log(result) }) We call a promise-based function in this way: { console.log(result) }) We first call the function, then we have a then() method that is called when the function ends. The indentation does not matter, but you'll often use this style for clarity. It's common to detect errors using a catch() method: { console.log(error) }) Now, to be able to use this syntax, the doSomething() function implementation must be a little bit special. It must use the Promises API. Instead of declaring it as a normal function: { } We declare it as a promise object: const doSomething = new Promise() and we pass a function in the Promise constructor: { }) This function receives 2 parameters. The first is a function we call to resolve the promise, the second a function we call to reject the promise. { }) Resolving a promise means complete it successfully (which results in calling the then() method in who uses it). Rejecting a promise means ending it with an error (which results in calling the catch() method in who uses it). Here's how: { //some code const success = /* ... */ if (success) { resolve('ok') } else { reject('this error occurred') } } ) We can pass a parameter to the resolve and reject functions, of any type we want. Async and Await Async functions are a higher level abstraction over promises. An async function returns a promise, like in this example: resolve('some data'), 2000) }) } Any code that want to use this function will use the async keyword right before the function: const data = await getData() and doing so, any data returned by the promise is going to be assigned to the data variable. In our case, the data is the "some data" string. With one particular caveat: whenever we use the await keyword, we must do so inside a function defined as async. Like this: { const data = await getData() console.log(data) } The Async/await duo allows us to have a cleaner code and a simple mental model to work with asynchronous code. As you can see in the example above, our code looks very simple. Compare it to code using promises, or callback functions. And this is a very simple example, the major benefits will arise when the code is much more complex. As an example, here's how you would get a JSON resource using the Fetch API, and parse it, using promises: response.json()) } getFirstUserData() And here is the same functionality provided using await/async: { // get users list const response = await fetch('/users.json') // parse JSON const users = await response.json() // pick first user const user = users[0] // get user data const userResponse = await fetch(`/users/${user.name}`) // parse JSON const userData = await user.json() return userData } getFirstUserData() Variables scope When I introduced variables, I talked about using const, let, and var. Scope is the set of variables that's visible to a part of the program. In JavaScript we have a global scope, block scope and function scope. If a variable is defined outside of a function or block, it's attached to the global object and it has a global scope, which mean it's available in every part of a program. There is a very important difference between var, let and const declarations. A variable defined as var inside a function is only visible inside that function. Similarly to a function arguments: A variable defined as const or let on the other hand is only visible inside the block where it is defined. A block is a set of instructions grouped into a pair of curly braces, like the ones we can find inside an if statement or a for loop. And a function, too. It's important to understand that a block does not define a new scope for var, but it does for let and const. This has very practical implications. Suppose you define a var variable inside an if conditional in a function function getData() { if (true) { var data = 'some data' console.log(data) } } If you call this function, you'll get some data printed to the console. If you try to move console.log(data) after the if, it still works: function getData() { if (true) { var data = 'some data' } console.log(data) } But if you switch var data to let data: function getData() { if (true) { let data = 'some data' } console.log(data) } You'll get an error: ReferenceError: data is not defined. This is because var is function scoped, and there's a special thing happening here, called hoisting. In short, the var declaration is moved to the top of the closest function by JavaScript, before it runs the code. More or less this is what the function looks like to JS, internally: function getData() { var data if (true) { data = 'some data' } console.log(data) } This is why you can also console.log(data) at the top of a function, even before it's declared, and you'll get undefined as a value for that variable: function getData() { console.log(data) if (true) { var data = 'some data' } } but if you switch to let, you'll get an error ReferenceError: data is not defined, because hoisting does not happen to let declarations. const follows the same rules as let: it's block scoped. It can be tricky at first, but once you realize this difference, then you'll see why var is considered a bad practice nowadays compared to let: they do have less moving parts, and their scope is limited to the block, which also makes them very good as loop variables, because they cease to exist after a loop has ended: function doLoop() { for (var i = 0; i < 10; i++) { console.log(i) } console.log(i) } doLoop() When you exit the loop, i will be a valid variable with value 10. If you switch to let, if you try to console.log(i) will result in an error ReferenceError: i is not defined. Conclusion Thanks a lot for reading this book. I hope it will inspire you to know more about JavaScript. For more on JavaScript, check out my blog flaviocopes.com. Note: You can get a PDF and ePub version of this JavaScript Beginner's Handbook
0 notes
Text
How We Tagged Google Fonts and Created goofonts.com
GooFonts is a side project signed by a developer-wife and a designer-husband, both of them big fans of typography. We’ve been tagging Google Fonts and built a website that makes searching through and finding the right font easier.
GooFonts uses WordPress in the back end and NuxtJS (a Vue.js framework) on the front end. I’d love to tell you the story behind goofonts.com and share a few technical details regarding the technologies we’ve chosen and how we adapted and used them for this project.
Why we built GooFonts
At the moment of writing this article, there are 977 typefaces offered by Google Fonts. You can check the exact number at any moment using the Google Fonts Developer API. You can retrieve the dynamic list of all fonts, including a list of the available styles and scripts for each family.
The Google Fonts website provides a beautiful interface where you can preview all fonts, sorting them by trending, popularity, date, or name.
But what about the search functionality?
You can include and exclude fonts by five categories: serif, sans-serif, display, handwriting, and monospace.
You can search within scripts (like Latin Extended, Cyrillic, or Devanagari (they are called subsets in Google Fonts). But you cannot search within multiple subsets at once.

You can search by four properties: thickness, slant, width, and "number of styles." A style, also called variant, refers both to the style (italic or regular) and weights (100, 200, up to 900). Often, the body font requires three variants: regular, bold, and italic. The “number of styles” property sorts out fonts with many variants, but it does not allow to select fonts that come in the “regular, bold, italic” combo.
There is also a custom search field where you can type your query. Unfortunately, the search is performed exclusively over the names of the fonts. Thus, the results often include font families uniquely from services other than Google Fonts.

Let's take the "cartoon" query as an example. It results in "Cartoon Script" from an external foundry Linotype.
I can remember working on a project that demanded two highly stylized typefaces — one evoking the old Wild West, the other mimicking a screenplay. That was the moment when I decided to tag Google Fonts. :)
GooFonts in action
Let me show you how GooFonts works. The dark sidebar on the right is your “search” area. You can type your keywords in the search field — this will perform an “AND” search. For example, you can look for fonts that are at once cartoon and slab.
We handpicked a bunch of keywords — click any of them! If your project requires some specific subsets, check them in the subsets sections. You can also check all the variants that you need for your font.
If you like a font, click its heart icon, and it will be stored in your browser’s localStorage. You can find your bookmarked fonts on the goofonts.com/bookmarks page. Together with the code, you might need to embed them.

How we built it: the WordPress part
To start, we needed some kind of interface where we could preview and tag each font. We also needed a database to store those tags.
I had some experience with WordPress. Moreover, WordPress comes with its REST API, which opens multiple possibilities for dealing with the data on the front end. That choice was made quickly.
I went for the most straightforward possible initial setup. Each font is a post, and we use post tags for keywords. A custom post type could have worked as well, but since we are using WordPress only for the data, the default content type works perfectly well.
Clearly, we needed to add all the fonts programmatically. We also needed to be able to programmatically update the fonts, including adding new ones or adding new available variants and subsets.
The approach described below can be useful with any other data available via an external API. In a custom WordPress plugin, we register a menu page from which we can check for updates from the API. For simplicity, the page will display a title, a button to activate the update and a progress bar for some visual feedback.
/** * Register a custom menu page. */ function register_custom_menu_page() { add_menu_page( 'Google Fonts to WordPress', 'WP GooFonts', 'manage_options', 'wp-goofonts-menu', function() { ?> <h1>Google Fonts API</h1> <button type="button" id="wp-goofonts-button">Run</button> <p id="info"></p> <progress id="progress" max="100" value="0"></progress> <?php } ); } add_action( 'admin_menu', 'register_custom_menu_page' );
Let's start by writing the JavaScript part. While most of the examples of using Ajax with WordPress implements jQuery and the jQuery.ajax method, the same can be obtained without jQuery, using axios and a small helper Qs.js for data serialization.
We want to load our custom script in the footer, after loading axios and qs:
add_action( 'admin_enqueue_scripts' function() { wp__script( 'axios', 'https://unpkg.com/axios/dist/axios.min.js' ); wp_enqueue_script( 'qs', 'https://unpkg.com/qs/dist/qs.js' ); wp_enqueue_script( 'wp-goofonts-admin-script', plugin_dir_url( __FILE__ ) . 'js/wp-goofonts.js', array( 'axios', 'qs' ), '1.0.0', true ); });
Let’s look how the JavaScript could look like:
const BUTTON = document.getElementById('wp-goofonts-button') const INFO = document.getElementById('info') const PROGRESS = document.getElementById('progress') const updater = { totalCount: 0, totalChecked: 0, updated: [], init: async function() { try { const allFonts = await axios.get('https://www.googleapis.com/webfonts/v1/webfonts?key=API_KEY&sort=date') this.totalCount = allFonts.data.items.length INFO.textContent = `Fetched ${this.totalCount} fonts.` this.updatePost(allFonts.data.items, 0) } catch (e) { console.error(e) } }, updatePost: async function(els, index) { if (index === this.totalCount) { return } const data = { action: 'goofonts_update_post', font: els[index], } try { const apiRequest = await axios.post(ajaxurl, Qs.stringify(data)) this.totalChecked++ PROGRESS.setAttribute('value', Math.round(100*this.totalChecked/this.totalCount)) this.updatePost(els, index+1) } catch (e) { console.error(e) } } } BUTTON.addEventListener('click', () => { updater.init() })
The init method makes a request to the Google Fonts API. Once the data from the API is available, we call the recursive asynchronous updatePost method that sends an individual font in the POST request to the WordPress server.
Now, it’s important to remember that WordPress implements Ajax in its specific way. First of all, each request must be sent to wp-admin/admin-ajax.php. This URL is available in the administration area as a global JavaScript variable ajaxurl.
Second, all WordPress Ajax requests must include an action argument in the data. The value of the action determines which hook tag will be used on the server-side.
In our case, the action value is goofonts_update_post. That means what happens on the server-side is determined by the wp_ajax_goofonts_update_post hook.
add_action( 'wp_ajax_goofonts_update_post', function() { if ( isset( $_POST['font'] ) ) { /* the post tile is the name of the font */ $title = wp_strip_all_tags( $_POST['font']['family'] ); $variants = $_POST['font']['variants']; $subsets = $_POST['font']['subsets']; $category = $_POST['font']['category']; /* check if the post already exists */ $object = get_page_by_title( $title, 'OBJECT', 'post' ); if ( NULL === $object ) { /* create a new post and set category, variants and subsets as tags */ goofonts_new_post( $title, $category, $variants, $subsets ); } else { /* check if $variants or $subsets changed */ goofonts_update_post( $object, $variants, $subsets ); } } }); function goofonts_new_post( $title, $category, $variants, $subsets ) { $post_id = wp_insert_post( array( 'post_author' => 1, 'post_name' => sanitize_title( $title ), 'post_title' => $title, 'post_type' => 'post', 'post_status' => 'draft', ) ); if ( $post_id > 0 ) { /* the easy part of tagging ;) append the font category, variants and subsets (these three come from the Google Fonts API) as tags */ wp_set_object_terms( $post_id, $category, 'post_tag', true ); wp_set_object_terms( $post_id, $variants, 'post_tag', true ); wp_set_object_terms( $post_id, $subsets, 'post_tag', true ); } }
This way, in less than a minute, we end up with almost one thousand post drafts in the dashboard — all of them with a few tags already in place. And that’s the moment when the crucial, most time-consuming part of the project begins. We need to start manually add tags for each font one by one. The default WordPress editor does not make much sense in this case. What we needed is a preview of the font. A link to the font’s page on fonts.google.com also comes in handy.
A custom meta box does the job very well. In most cases, you will use meta boxes for custom form elements to save some custom data related to the post. In fact, the content of a meta box can be practically any HTML.
function display_font_preview( $post ) { /* font name, for example Abril Fatface */ $font = $post->post_title; /* font as in url, for example Abril+Fatface */ $font_url_part = implode( '+', explode( ' ', $font )); ?> <div class="font-preview"> <link href="<?php echo 'https://fonts.googleapis.com/css?family=' . $font_url_part . '&display=swap'; ?>" rel="stylesheet"> <header> <h2><?php echo $font; ?></h2> <a href="<?php echo 'https://fonts.google.com/specimen/' . $font_url_part; ?>" target="_blank" rel="noopener">Specimen on Google Fonts</a> </header> <div contenteditable="true" style="font-family: <?php echo $font; ?>"> <p>The quick brown fox jumps over a lazy dog.</p> <p style="text-transform: uppercase;">The quick brown fox jumps over a lazy dog.</p> <p>1 2 3 4 5 6 7 8 9 0</p> <p>& ! ; ? {}[]</p> </div> </div> <?php } add_action( 'add_meta_boxes', function() { add_meta_box( 'font_preview', /* metabox id */ 'Font Preview', /* metabox title */ 'display_font_preview', /* content callback */ 'post' /* where to display */ ); });

Tagging fonts is a long-term task with a lot of repetition. It also requires a big dose of consistency. That’s why we started by defining a set of tag “presets.” That could be, for example:
{ /* ... */ comic: { tags: 'comic, casual, informal, cartoon' }, cursive: { tags: 'cursive, calligraphy, script, manuscript, signature' }, /* ... */ }
Next with some custom CSS and JavaScript, we “hacked” the WordPress editor and tags form by enriching it with the set of preset buttons.
How we built it: The front end part (using NuxtJS)
The goofonts.com interface was designed by Sylvain Guizard, a french graphic and web designer (who also happens to be my husband). We wanted something simple with a distinguished “search” area. Sylvain deliberately went for colors that are not too far from the Google Fonts identity. We were looking for a balance between building something unique and original while avoiding user confusion.
While I did not hesitate choosing WordPress for the back-end, I didn’t want to use it on front end. We were aiming for an app-like experience and I, personally, wanted to code in JavaScript, using Vue.js in particular.
I came across an example of a website using NuxtJS with WordPress and decided to give it a try. The choice was made immediately. NuxtJS is a very popular Vue.js framework, and I really enjoy its simplicity and flexibility. I’ve been playing around with different NuxtJS settings to end up with a 100% static website. The fully static solution felt the most performant; the overall experience seemed the most fluid.That also means that my WordPress site is only used during the build process. Thus, it can run on my localhost. This is not negligible since it eliminates the hosting costs and most of all, lets me skip the security-related WordPress configuration and relieves me of the security-related stress. ;)
If you are familiar with NuxtJS, you probably know that the full static generation is not (yet) a part of NuxtJS. The prerendered pages try to fetch the data again when you are navigating.
That’s why we have to somehow “hack” the 100% static generation. In this case, we are saving the useful parts of the fetched data to a JSON file before each build process. This is possible, thanks to Nuxt hooks, in particular, its builder hooks.
Hooks are typically used in Nuxt modules:
/* modules/beforebuild.js */ const fs = require('fs') const axios = require('axios') const sourcePath = 'http://wpgoofonts.local/wp-json/wp/v2/' const path = 'static/allfonts.json' module.exports = () => { /* write data to the file, replacing the file if it already exists */ const storeData = (data, path) => { try { fs.writeFileSync(path, JSON.stringify(data)) } catch (err) { console.error(err) } } async function getData() { const fetchedTags = await axios.get(`${sourcePath}tags?per_page=500`) .catch(e => { console.log(e); return false }) /* build an object of tag_id: tag_slug */ const tags = fetchedTags.data.reduce((acc, cur) => { acc[cur.id] = cur.slug return acc }, {}) /* we want to know the total number or pages */ const mhead = await axios.head(`${sourcePath}posts?per_page=100`) .catch(e => { console.log(e); return false }) const totalPages = mhead.headers['x-wp-totalpages'] /* let's fetch all fonts */ let fonts = [] let i = 0 while (i < totalPages) { i++ const response = await axios.get(`${sourcePath}posts?per_page=100&page=${i}`) fonts.push.apply(fonts, response.data) } /* and reduce them to an object with entries like: {roboto: {name: Roboto, tags: ["clean","contemporary", ...]}} */ fonts = (fonts).reduce((acc, el) => { acc[el.slug] = { name: el.title.rendered, tags: el.tags.map(i => tags[i]), } return acc }, {}) /* save the fonts object to a .json file */ storeData(fonts, path) } /* make sure this happens before each build */ this.nuxt.hook('build:before', getData) }
/* nuxt.config.js */ module.exports = { // ... buildModules: [ ['~modules/beforebuild'] ], // ... }
As you can see, we only request a list of tags and a list posts. That means we only use default WordPress REST API endpoints, and no configuration is required.
Final thoughts
Working on GooFonts was a long-term adventure. It is also this kind of projects that needs to be actively maintained. We regularly keep checking Google Fonts for the new typefaces, subsets, or variants. We tag new items and update our database. Recently, I was genuinely excited to discover that Bebas Neue has joint the family. We also have our personal favs among the much lesser-known specimens.
As a trainer that gives regular workshops, I can observe real users playing with GooFonts. At this stage of the project, we want to get as much feedback as possible. We would love GooFonts to be a useful, handy and intuitive tool for web designers. One of the to-do features is searching a font by its name. We would also love to add a possibility to share the bookmarked sets and create multiple "collections" of fonts.
As a developer, I truly enjoyed the multi-disciplinary aspect of this project. It was the first time I worked with the WordPress REST API, it was my first big project in Vue.js, and I learned so much about typography.
Would we do anything differently if we could? Absolutely. It was a learning process. On the other hand, I don't think we would change the main tools. The flexibility of both WordPress and Nuxt.js proved to be the right choice. Starting over today, I would definitely took time to explore GraphQL, and I will probably implement it in the future.
I hope that you find some of the discussed methods useful. As I said before, your feedback is very precious. If you have any questions or remarks, please let me know in the comments!
The post How We Tagged Google Fonts and Created goofonts.com appeared first on CSS-Tricks.
How We Tagged Google Fonts and Created goofonts.com published first on https://deskbysnafu.tumblr.com/
0 notes
Text
Adding Dynamic And Async Functionality To JAMstack Sites
Adding Dynamic And Async Functionality To JAMstack Sites
Jason Lengstorf
2019-12-18T11:30:00+00:002019-12-18T12:07:17+00:00
It’s increasingly common to see websites built using the JAMstack — that is, websites that can be served as static HTML files built from JavaScript, Markup, and APIs. Companies love the JAMstack because it reduces infrastructure costs, speeds up delivery, and lowers the barriers for performance and security improvements because shipping static assets removes the need for scaling servers or keeping databases highly available (which also means there are no servers or databases that can be hacked). Developers like the JAMstack because it cuts down on the complexity of getting a website live on the internet: there are no servers to manage or deploy; we can write front-end code and it just goes live, like magic.
(“Magic” in this case is automated static deployments, which are available for free from a number of companies, including Netlify, where I work.)
But if you spend a lot of time talking to developers about the JAMstack, the question of whether or not the JAMstack can handle Serious Web Applications™ will come up. After all, JAMstack sites are static sites, right? And aren’t static sites super limited in what they can do?
This is a really common misconception, and in this article we’re going to dive into where the misconception comes from, look at the capabilities of the JAMstack, and walk through several examples of using the JAMstack to build Serious Web Applications™.
JAMstack Fundamentals
Phil Hawksworth explains what JAMStack actually means and when it makes sense to use it in your projects, as well as how it affects tooling and front-end architecture. Read article →
What Makes A JAMstack Site “Static”?
Web browsers today load HTML, CSS, and JavaScript files, just like they did back in the 90s.
A JAMstack site, at its core, is a folder full of HTML, CSS, and JavaScript files.
These are “static assets”, meaning we don’t need an intermediate step to generate them (for example, PHP projects like WordPress need a server to generate the HTML on every request).
That’s the true power of the JAMstack: it doesn’t require any specialized infrastructure to work. You can run a JAMstack site on your local computer, by putting it on your preferred content delivery network (CDN), hosting it with services like GitHub Pages — you can even drag-and-drop the folder into your favorite FTP client to upload it to shared hosting.
Static Assets Don’t Necessarily Mean Static Experiences
Because JAMstack sites are made of static files, it’s easy to assume that the experience on those sites is, y’know, static. But that’s not the case!
JavaScript is capable of doing a whole lot of dynamic stuff. After all, modern JavaScript frameworks are static files after we get through the build step — and there are hundreds of examples of incredibly dynamic website experiences powered by them.
There is a common misconception that “static” means inflexible or fixed. But all that “static” really means in the context of “static sites” is that browsers don’t need any help delivering their content — they’re able to use them natively without a server handling a processing step first.
Or, put in another way:
“Static assets” does not mean static apps; it means no server required.
“
Can The JAMstack Do That?
If someone asks about building a new app, it’s common to see suggestions for JAMstack approaches such as Gatsby, Eleventy, Nuxt, and other similar tools. It’s equally common to see objections arise: “static site generators can’t do _______”, where _______ is something dynamic.
But — as we touched on in the previous section — JAMstack sites can handle dynamic content and interactions!
Here’s an incomplete list of things that I’ve repeatedly heard people claim the JAMstack can’t handle that it definitely can:
Load data asynchronously
Handle processing files, such as manipulating images
Read from and write to a database
Handle user authentication and protect content behind a login
In the following sections, we’ll look at how to implement each of these workflows on a JAMstack site.
If you can’t wait to see the dynamic JAMstack in action, you can check out the demos first, then come back and learn how they work.
A note about the demos: These demos are written without any frameworks. They are only HTML, CSS, and standard JavaScript. They were built with modern browsers (e.g. Chrome, Firefox, Safari, Edge) in mind and take advantage of newer features like JavaScript modules, HTML templates, and the Fetch API. No polyfills were added, so if you’re using an unsupported browser, the demos will probably fail.
Load Data From A Third-Party API Asynchronously
“What if I need to get new data after my static files are built?”
In the JAMstack, we can take advantage of numerous asynchronous request libraries, including the built-in Fetch API, to load data using JavaScript at any point.
Demo: Search A Third-Party API From A JAMstack Site
A common scenario that requires asynchronous loading is when the content we need depends on user input. For example, if we build a search page for the Rick & Morty API, we don’t know what content to display until someone has entered a search term.
To handle that, we need to:
Create a form where people can type in their search term,
Listen for a form submission,
Get the search term from the form submission,
Send an asynchronous request to the Rick & Morty API using the search term,
Display the request results on the page.
First, we need to create a form and an empty element that will contain our search results, which looks like this:
<form> <label for="name">Find characters by name</label> <input type="text" id="name" name="name" required /> <button type="submit">Search</button> </form> <ul id="search-results"></ul>
Next, we need to write a function that handles form submissions. This function will:
Prevent the default form submission behavior
Get the search term from the form input
Use the Fetch API to send a request to the Rick & Morty API using the search term
Call a helper function that displays the search results on the page
We also need to add an event listener on the form for the submit event that calls our handler function.
Here’s what that code looks like altogether:
<script type="module"> import showResults from './show-results.js'; const form = document.querySelector('form'); const handleSubmit = async event => { event.preventDefault(); // get the search term from the form input const name = form.elements['name'].value; // send a request to the Rick & Morty API based on the user input const characters = await fetch( `https://rickandmortyapi.com/api/character/?name=${name}`, ) .then(response => response.json()) .catch(error => console.error(error)); // add the search results to the DOM showResults(characters.results); }; form.addEventListener('submit', handleSubmit); </script>
Note: to stay focused on dynamic JAMstack behaviors, we will not be discussing how utility functions like showResults are written. The code is thoroughly commented, though, so check out the source to learn how it works!
With this code in place, we can load our site in a browser and we’ll see the empty form with no results showing:

The empty search form (Large preview)
If we enter a character name (e.g. “rick”) and click “search”, we see a list of characters whose names contain “rick” displayed:

We see search results after the form is filled out. (Large preview)
Hey! Did that static site just dynamically load data? Holy buckets!
You can try this out for yourself on the live demo, or check out the full source code for more details.
Handle Expensive Computing Tasks Off the User’s Device
In many apps, we need to do things that are pretty resource-intensive, such as processing an image. While some of these kinds of operations are possible using client-side JavaScript only, it’s not necessarily a great idea to make your users’ devices do all that work. If they’re on a low-powered device or trying to stretch out their last 5% of battery life, making their device do a bunch of work is probably going to be a frustrating experience for them.
So does that mean that JAMstack apps are out of luck? Not at all!
The “A” in JAMstack stands for APIs. This means we can send off that work to an API and avoid spinning our users’ computer fans up to the “hover” setting.
“But wait,” you might say. “If our app needs to do custom work, and that work requires an API, doesn’t that just mean we’re building a server?”
Thanks to the power of serverless functions, we don’t have to!
Serverless functions (also called “lambda functions”) are a sort of API without any server boilerplate required. We get to write a plain old JavaScript function, and all of the work of deploying, scaling, routing, and so on is offloaded to our serverless provider of choice.
Using serverless functions doesn’t mean there’s not a server; it just means that we don’t need to think about a server.
“
Serverless functions are the peanut butter to our JAMstack: they unlock a whole world of high-powered, dynamic functionality without ever asking us to deal with server code or devops.
Demo: Convert An Image To Grayscale
Let’s assume we have an app that needs to:
Download an image from a URL
Convert that image to grayscale
Upload the converted image to a GitHub repo
As far as I know, there’s no way to do image conversions like that entirely in the browser — and even if there was, it’s a fairly resource-intensive thing to do, so we probably don’t want to put that load on our users’ devices.
Instead, we can submit the URL to be converted to a serverless function, which will do the heavy lifting for us and send back a URL to a converted image.
For our serverless function, we’ll be using Netlify Functions. In our site’s code, we add a folder at the root level called “functions” and create a new file called “convert-image.js” inside. Then we write what’s called a handler, which is what receives and — as you may have guessed — handles requests to our serverless function.
To convert an image, it looks like this:
exports.handler = async event => { // only try to handle POST requests if (event.httpMethod !== 'POST') { return { statusCode: 404, body: '404 Not Found' }; } try { // get the image URL from the POST submission const { imageURL } = JSON.parse(event.body); // use a temporary directory to avoid intermediate file cruft // see https://www.npmjs.com/package/tmp const tmpDir = tmp.dirSync(); const convertedPath = await convertToGrayscale(imageURL, tmpDir); // upload the processed image to GitHub const response = await uploadToGitHub(convertedPath, tmpDir.name); return { statusCode: 200, body: JSON.stringify({ url: response.data.content.download_url, }), }; } catch (error) { return { statusCode: 500, body: JSON.stringify(error.message), }; } };
This function does the following:
Checks to make sure the request was sent using the HTTP POST method
Grabs the image URL from the POST body
Creates a temporary directory for storing files that will be cleaned up once the function is done executing
Calls a helper function that converts the image to grayscale
Calls a helper function that uploads the converted image to GitHub
Returns a response object with an HTTP 200 status code and the newly uploaded image’s URL
Note: We won’t go over how the helper functions for image conversion or uploading to GitHub work, but the source code is well commented so you can see how it works.
Next, we need to add a form that will be used to submit URLs for processing and a place to show the before and after:
<form id="image-form" action="/.netlify/functions/convert-image" method="POST" > <label for="imageURL">URL of an image to convert</label> <input type="url" name="imageURL" required /> <button type="submit">Convert</button> </form> <div id="converted"></div>
Finally, we need to add an event listener to the form so we can send off the URLs to our serverless function for processing:
<script type="module"> import showResults from './show-results.js'; const form = document.querySelector('form'); form.addEventListener('submit', event => { event.preventDefault(); // get the image URL from the form const imageURL = form.elements['imageURL'].value; // send the image off for processing const promise = fetch('/.netlify/functions/convert-image', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ imageURL }), }) .then(result => result.json()) .catch(error => console.error(error)); // do the work to show the result on the page showResults(imageURL, promise); }); </script>
After deploying the site (along with its new “functions” folder) to Netlify and/or starting up Netlify Dev in our CLI, we can see the form in our browser:

An empty form that accepts an image URL (Large preview)
If we add an image URL to the form and click “convert”, we’ll see “processing…” for a moment while the conversion is happening, then we’ll see the original image and its newly created grayscale counterpart:
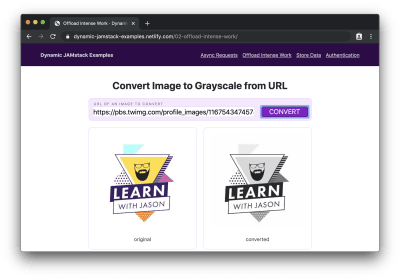
The image is converted from full color to grayscale. (Large preview)
Oh dang! Our JAMstack site just handled some pretty serious business and we didn’t have to think about servers once or drain our users’ batteries!
Use A Database To Store And Retrieve Entries
In many apps, we’re inevitably going to need the ability to save user input. And that means we need a database.
You may be thinking, “So that’s it, right? The jig is up? Surely a JAMstack site — which you’ve told us is just a collection of files in a folder — can’t be connected to a database!”
Au contraire.
As we saw in the previous section, serverless functions give us the ability to do all sorts of powerful things without needing to create our own servers.
Similarly, we can use database-as-a-service (DBaaS) tools, such as Fauna and Amplify DataStore, to read and write to a database without having to set one up or host it ourselves.
DBaaS tools massively simplify the process of setting up databases for websites: creating a new database is as straightforward as defining the types of data we want to store. The tools automatically generate all of the code to manage create, read, update, and delete (CRUD) operations and make it available for us to use via API, so we don’t have to actually manage a database; we just get to use it.
Demo: Create a Petition Page
If we want to create a small app to collect digital signatures for a petition, we need to set up a database to store those signatures and allow the page to read them out for display.
For this demo we’ll use Fauna as our DBaaS provider. We won’t go deep into how Fauna works, but in the interest of demonstrating the small amount of effort required to set up a database, let’s list each step and click to get a ready-to-use database:
Create a Fauna account at https://fauna.com
Click “create a new database”
Give the database a name (e.g. “dynamic-jamstack-demos”)
Click “create”
Click “security” in the left-hand menu on the next page
Click “new key”
Change the role dropdown to “Server”
Add a name for the key (e.g. “Dynamic JAMstack Demos”)
Store the key somewhere secure for use with the app
Click “save”
Click “GraphQL” in the left-hand menu
Click “import schema”
Upload a file called db-schema.gql that contains the following code:
type Signature { name: String! } type Query { signatures: [Signature!]! }
Once we upload the schema, our database is ready to use. (Seriously.)
Thirteen steps is a lot, but with those thirteen steps, we just got a database, a GraphQL API, automatic management of capacity, scaling, deployment, security, and more — all handled by database experts. For free. What a time to be alive!
To try it out, the “GraphQL” option in the left-hand menu gives us a GraphQL explorer with documentation on the available queries and mutations that allow us to perform CRUD operations.
Note: We won’t go into details about GraphQL queries and mutations in this post, but Eve Porcello wrote an excellent intro to sending GraphQL queries and mutations if you want a primer on how it works.
With the database ready to go, we can create a serverless function that stores new signatures in the database:
const qs = require('querystring'); const graphql = require('./util/graphql'); exports.handler = async event => { try { // get the signature from the POST data const { signature } = qs.parse(event.body); const ADD_SIGNATURE = ` mutation($signature: String!) { createSignature(data: { name: $signature }) { _id } } `; // store the signature in the database await graphql(ADD_SIGNATURE, { signature }); // send people back to the petition page return { statusCode: 302, headers: { Location: '/03-store-data/', }, // body is unused in 3xx codes, but required in all function responses body: 'redirecting...', }; } catch (error) { return { statusCode: 500, body: JSON.stringify(error.message), }; } };
This function does the following:
Grabs the signature value from the form POST data
Calls a helper function that stores the signature in the database
Defines a GraphQL mutation to write to the database
Sends off the mutation using a GraphQL helper function
Redirects back to the page that submitted the data
Next, we need a serverless function to read out all of the signatures from the database so we can show how many people support our petition:
const graphql = require('./util/graphql'); exports.handler = async () => { const { signatures } = await graphql(` query { signatures { data { name } } } `); return { statusCode: 200, body: JSON.stringify(signatures.data), }; };
This function sends off a query and returns it.
An important note about sensitive keys and JAMstack apps: One thing to note about this app is that we’re using serverless functions to make these calls because we need to pass a private server key to Fauna that proves we have read and write access to this database. We cannot put this key into client-side code, because that would mean anyone could find it in the source code and use it to perform CRUD operations against our database. Serverless functions are critical for keeping private keys private in JAMstack apps.
Once we have our serverless functions set up, we can add a form that submits to the function for adding a signature, an element to show existing signatures, and a little bit of JS to call the function to get signatures and put them into our display element:
<form action="/.netlify/functions/add-signature" method="POST"> <label for="signature">Your name</label> <input type="text" name="signature" required /> <button type="submit">Sign</button> </form> <ul class="signatures"></ul> <script> fetch('/.netlify/functions/get-signatures') .then(res => res.json()) .then(names => { const signatures = document.querySelector('.signatures'); names.forEach(({ name }) => { const li = document.createElement('li'); li.innerText = name; signatures.appendChild(li); }); }); </script>
If we load this in the browser, we’ll see our petition form with signatures below it:
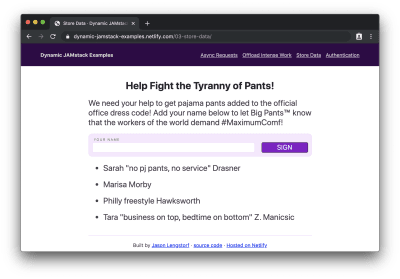
An empty form that accepts a digital signature (Large preview)
Then, if we add our signature…

The petition form with a name filled in (Large preview)
…and submit it, we’ll see our name appended to the bottom of the list:

The petition form clears and the new signature is added to the bottom of the list. (Large preview)
Hot diggity dog! We just wrote a full-on database-powered JAMstack app with about 75 lines of code and 7 lines of database schema!
Protect Content With User Authentication
“Okay, you’re for sure stuck this time,” you may be thinking. “There is no way a JAMstack site can handle user authentication. How the heck would that work, even?!”
I’ll tell you how it works, my friend: with our trusty serverless functions and OAuth.
OAuth is a widely-adopted standard for allowing people to give apps limited access to their account info rather than sharing their passwords. If you’ve ever logged into a service using another service (for example, “sign in with your Google account”), you’ve used OAuth before.
Note: We won’t go deep into how OAuth works, but Aaron Parecki wrote a solid overview of OAuth that covers the details and workflow.
In JAMstack apps, we can take advantage of OAuth, and the JSON Web Tokens (JWTs) that it provides us with for identifying users, to protect content and only allow logged-in users to view it.
Demo: Require Login to View Protected Content
If we need to build a site that only shows content to logged-in users, we need a few things:
An identity provider that manages users and the sign-in flow
UI elements to manage logging in and logging out
A serverless function that checks for a logged-in user using JWTs and returns protected content if one is provided
For this example, we’ll use Netlify Identity, which gives us a really pleasant developer experience for adding authentication and provides a drop-in widget for managing login and logout actions.
To enable it:
Visit your Netlify dashboard
Choose the site that needs auth from your sites list
Click “identity” in the top nav
Click the “Enable Identity” button
We can add Netlify Identity to our site by adding markup that shows logged out content and adds an element to show protected content after logging in:
<div class="content logged-out"> <h1>Super Secret Stuff!</h1> <p>🔐 only my bestest friends can see this content</p> <button class="login">log in / sign up to be my best friend</button> </div> <div class="content logged-in"> <div class="secret-stuff"></div> <button class="logout">log out</button> </div>
This markup relies on CSS to show content based on whether the user is logged in or not. However, we can’t rely on that to actually protect the content — anyone could view the source code and steal our secrets!
Instead, we created an empty div that will contain our protected content, but we’ll need to make a request to a serverless function to actually get that content. We’ll dig into how that works shortly.
Next, we need to add code to make our login button work, load the protected content, and show it on screen:
<script src="https://identity.netlify.com/v1/netlify-identity-widget.js"></script> <script> const login = document.querySelector('.login'); login.addEventListener('click', () => { netlifyIdentity.open(); }); const logout = document.querySelector('.logout'); logout.addEventListener('click', () => { netlifyIdentity.logout(); }); netlifyIdentity.on('logout', () => { document.querySelector('body').classList.remove('authenticated'); }); netlifyIdentity.on('login', async () => { document.querySelector('body').classList.add('authenticated'); const token = await netlifyIdentity.currentUser().jwt(); const response = await fetch('/.netlify/functions/get-secret-content', { headers: { Authorization: `Bearer ${token}`, }, }).then(res => res.text()); document.querySelector('.secret-stuff').innerHTML = response; }); </script>
Here’s what this code does:
Loads the Netlify Identity widget, which is a helper library that creates a login modal, handles the OAuth workflow with Netlify Identity, and gives our app access to the logged-in user’s info
Adds an event listener to the login button that triggers the Netlify Identity login modal to open
Adds an event listener to the logout button that calls the Netlify Identity logout method
Adds an event handler for logging out to remove the authenticated class on logout, which hides the logged-in content and shows the logged-out content
Adds an event handler for logging in that:
Adds the authenticated class to show the logged-in content and hide the logged-out content
Grabs the logged-in user’s JWT
Calls a serverless function to load protected content, sending the JWT in the Authorization header
Puts the secret content in the secret-stuff div so logged-in users can see it
Right now the serverless function we’re calling in that code doesn’t exist. Let’s create it with the following code:
exports.handler = async (_event, context) => { try { const { user } = context.clientContext; if (!user) throw new Error('Not Authorized'); return { statusCode: 200, headers: { 'Content-Type': 'text/html', }, body: `
You're Invited, ${user.user_metadata.full_name}!
If you can read this it means we're best friends.
Here are the secret details for my birthday party: jason.af/party
`, }; } catch (error) { return { statusCode: 401, body: 'Not Authorized', }; } };
This function does the following:
Checks for a user in the serverless function’s context argument
Throws an error if no user is found
Returns secret content after ensuring that a logged-in user requested it
Netlify Functions will detect Netlify Identity JWTs in Authorization headers and automatically put that information into context — this means we can check for a valid JWTs without needing to write code to validate JWTs!
When we load this page in our browser, we’ll see the logged out page first:
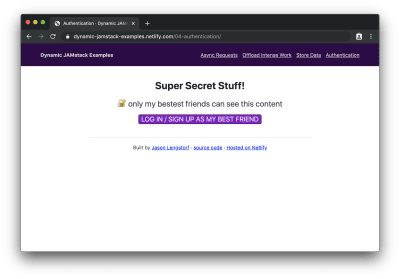
When logged out, we can only see information about logging in. (Large preview)
If we click the button to log in, we’ll see the Netlify Identity widget:

The Netlify Identity Widget provides the whole login/sign up experience. (Large preview)
After logging in (or signing up), we can see the protected content:
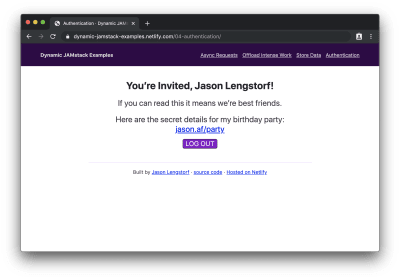
After logging in, we can see protected content. (Large preview)
Wowee! We just added user login and protected content to a JAMstack app!
What To Do Next
The JAMstack is much more than “just static sites” — we can respond to user interactions, store data, handle user authentication, and just about anything else we want to do on a modern website. And all without the need to provision, configure, or deploy a server!
What do you want to build with the JAMstack? Is there anything you’re still not convinced the JAMstack can handle? I’d love to hear about it — hit me up on Twitter or in the comments!

(dm, il)
0 notes
Text
PHP 7: Cool & Exciting Features

Php community is very happy with the new release of latest release PHP 7. It doesn’t mean that PHP’s old version has not been working properly. On the contrary, some little bit changes in the next version brought many changes to its features. These new changes are about the support of Object-Oriented programming and many features associated with that. PHP 7 beta version was released on November 12, 2015. It has been making technical decisions since then. PHP 7 has taken huge improvement in matters related to speed and performance.
The blog is all about the clearing doubts you may have about what all changes and updates you can expect from PHP 7.
The Zend Engine-
To increase the performance of PHP applications, PHP 7 uses the latest Zend Engine having code-name as PHPNG(PHP Next-Gen). It doubles the performance of PHP.
PHP 7 twice as fast as PHP 5.6 –
PHP 7 runs applications faster in performance as compared to those running on PHP 5.6. This is because of the new PHPNG engine. According to PHP founder Rasmus Lerdorf, the upgrade means using less number of servers, while still serving the same number of users. The Just-in-time compilation (JIT) is another speed catalyst, which allows run time compilation before execution.
Dependable 64-bit support-
As it provides dependable 64-bit support means no more slow data operations. Due to this, arrays and variables are more ably handled. Applications that require large data arrays will get benefit of it. For eg., Scientific applications, data management, digital media related and CAD-like functionality programs. Performance is increased and this is because of the 64-bit.
New Features of PHP 7-
1. Anonymous Classes-
Anonymous function is for creating the scope to create anonymous class objects, especially in creating one-off objects. Support for this feature has been added in PHP 7. By using efficiently, they can execute and code quickly.
//Pre-PHP 7 code-
Class Logger
{
public function log($msg)
{
echo $msg;
}
}
$util->setLogger(new Logger());
//PHP 7+ code
$util->setLogger(new class
{
public function log($msg)
{
echo $msg;
}
};
2. Return Type Declarations-
This is another one developer-friendly add-on. Most of the developers prefer declaring the function’s return type. Any type, including objects and arrays can be returned. As a result, the execution works faster and passing control to the line from where it is called.
function arraysSum(array…$arrays): array
{
return array_map(function(array $array): int
{
return array_sum($array);
}, $arrays);
}
print_r(arraysSum([1,2,3], [4,5,6], [7,8,9]));
/* Output
Array
(
[0] => 6
[1] => 15
[2] => 24
)
*/
3. Group Use Declarations-
This new feature is for those developers who want to use the same namespace to import several classes. Code is relatively neat and it also saves the typing time. Debugging of the code get easier because of the group use declarations. This helps to identify imports that are part of the same module. Example is as follows:
// Pre PHP 7 code
use some\namespace\ClassA;
use some\namespace\ClassB;
use some\namespace\ClassC as C;
use function some\namespace\fn_a;
use function some\namespace\fn_b;
use function some\namespace\fn_c;
use const some\namespace\ConstA;
use const some\namespace\ConstB;
use const some\namespace\ConstC;
// PHP 7+ code
use some\namespace\{ClassA, ClassB, ClassC as C};
use function some\namespace\{fn_a, fn_b, fn_c};
use const some\namespace\{ConstA, ConstB, ConstC};
Read More at- https://solaceinfotech.com/blog/php-7-exciting-features/
0 notes
Photo

Master Modern JavaScript with This Curated Reading List
Are you daunted by the complexity of the JavaScript ecosystem? Are you still writing ES5, but looking for an opportunity to embrace modern standards? Or, are you confused by the explosion of frameworks and build tools, and unsure what to learn first? Fear not, here are my handpicked selection of books from SitePoint Premium, intended to help you well on your way to mastering modern JavaScript.
JavaScript: Novice to Ninja, Second Edition
I've placed this book at the top of my list, as it has something for almost everybody. It starts by covering the fundamentals (and thus serves well as a desk reference), then moves on to tackle more advanced topics, such as testing and functional programming.
The second edition has been updated to cover ECMAScript 6 and does a great job of introducing you to its more common features. You also get to put your newly acquired knowledge into practice at the end of each chapter, as you build out a quiz app, adding features as you move through the book. I really like this project-based approach to learning and think it is one of the better ways to advance your programming skills.
For those who just want to dip, I'd recommend reading the Modern JavaScript Development chapter. This will bring you up-to-date with many of the recent developments, such as working with modules, and the hows and the whys of transpiling your code.
➤ Read the book
Practical ES6
This anthology picks up where Novice to Ninja left off and allows you to dive deeper into many of the newer additions to the JavaScript language. It covers much of the basic syntax (e.g. const, let, arrow functions, etc...), and offers a great way to get up to speed in a particular area.
There are also more in-depth articles on topics such as ES6 classes and ES6 modules, as well as a look at what came down the pipeline in ES2017 and ES2018. And if you're starting to get confused about what all these version numbers mean, we've got you covered. The anthology packs a chapter on JavaScript versioning and the process of deciding what gets added to the language.
➤ Read the book
A Beginner's Guide to npm - the Node Package Manager
npm is a package manager for JavaScript, similar to PHP's composer, or Perl's CPAN. It allows you to search an online database of packages (a.k.a. the registry) and install them on your machine. The npm registry is vast — containing over 600,000 packages — and I think it is fair to say that it has revolutionized the way JavaScript developers collaborate with each other.
This short book from our Developer Essentials series has made the list because npm is something you cannot ignore if you are serious about writing JavaScript in 2019. The guide walks you through getting npm installed and configured (which can sometimes be a tad tricky) and using it effectively in your day-to-day work. If you're going to learn just one JavaScript tool in 2019, make it npm. You'll encounter it in tutorials everywhere and it is the standard delivery mechanism for almost any modern JavaScript library out there.
➤ Read the book
JavaScript: Best Practice
Now that we've had a look at the basics, it's time to kick it up a notch with some JavaScript best practices. This anthology is full of tips and tricks to help you write modern JavaScript that is performant, maintainable, and reusable. It's hard to pick favorites from so many great titles, but there are two articles that stand out.
The Anatomy of a Modern JavaScript Application takes a good look at how to build a JavaScript application in 2019. It covers everything from application architecture to deployment and will help you to order many of the concepts and buzzwords you may have heard floating about.
Flow Control in Modern JavaScript introduces you to a variety of strategies for dealing with asynchronous JavaScript in a modern code base. It looks at one of my favorite additions to the language — async await — and dispels the myth that writing a JavaScript web app will automatically land you in callback hell.
➤ Read the book
Node.js Web Development, Fourth Edition
No journey through modern JavaScript would be complete without a look at how to run it on the server. And this book gives you an excellent starting point, bringing you straight to the heart of developing web applications with Node.js.
As you follow along you'll build and iterate on a note taking app. This will form the basis for learning all about real-time applications, data storage, user authentication, deployment with Docker and much more. And even if server-side development isn't your thing, I'd still recommend reading the first couple of chapters. These will give you a good idea where Node fits in to today's JavaScript landscape.
➤ Read the book
The Versioning Guide to Modern JavaScript
To finish we have The Versioning Guide to Modern JavaScript, which is really a large collection of links taken from the much-missed Versioning newsletter. I've included this, as there's so much going on in the world of modern JavaScript development, that I've barely been able to scratch the surface here. I'm confident that this guide will offer you a wealth of ideas and inspiration on what to dig into next.
➤ Read the book
And that's a wrap. I hope this curated list goes some way to helping you navigate the choppy waters of modern JavaScript development.
The post Master Modern JavaScript with This Curated Reading List appeared first on SitePoint.
by James Hibbard via SitePoint https://ift.tt/2YiLRVB
0 notes
Text
[Laravel] Write better code
After reviewing the code for the new team members, I found long/wrong codes. I write it down here.
Content
1. Use default params when getting value from request
2. Use Eloquent when function
3. Use Eloquent updateOrCreate
4. Use map instead of bundle if/else
5. Use collection when you can
6. Stop calling query in loop
7. Stop printing raw user inputted values in blade.
8. Be careful when running javascript with user input.
9. Stop abusing Morph
1. Use default params when getting value from request
The original code
$search_type = SearchTypeConstant::TITLE; if($request->has('search_type')){ $search_type = $request->get('search_type'); }
It is verbose
Refactoring
$search_type = $request->get('search_type', SearchTypeConstant::TITLE);
2. Use Eloquent when function
The original code
$query = User::active(); if($first_name = $request->get('first_name')){ $query = $query->where('first_name', $first_name); } $users = $query->get();
We can remove temp $query variable
Refactoring
$users = User::active()->when($first_name = $request->get('first_name'), function($first_name){ return $q->where('first_name', $first_name); })->get();
3. Use Eloquent updateOrCreate
The original code
if($user->profile){ $user->profile->update($request->get('profile')->only('phone', 'address')); } else { $user->profile()->create($request->get('profile')->only('phone', 'address')); }
It is verbose
Refactoring
$user->profile()->updateOrCreate([], $request->get('profile')->only('phone', 'address'));
4. Use map instead of bundle if/else
The original code
function get_status_i18n($status){ if($status == STATUS::COMING){ return 'coming'; } if($status == STATUS::PUBLISH){ return 'publish'; } return 'draft'; }
It is long
Refactoring
private const MAP_STATUS_I18N = [ STATUS::COMING => 'coming', STATUS::PUBLISH => 'publish' ]; function get_status_i18n($status){ return self::MAP_STATUS_I18N[$status] ?? 'draft'; }
5. Use collection when you can
The original code
function get_car_equipment_names($car){ $names = []; foreach($car->equipments as $equipment){ if($equipment->name){ $names[] = $equipment->name; } } return $names; }
It is long
Refactoring
function get_car_equipment_names($car){ return $car->equipments()->pluck('name')->filter(); }
6. Stop calling query in loop
Ex1:
The original code
$books = Book::all(); // *1 query* foreach ($books as $book) { echo $book->author->name; // Make one query like *select \* from authors where id = ${book.author_id}* every time it is called }
N + 1 queries problem
Refactoring
$books = Book::with('author')->get(); // Only two queries will be called. // select * from books // select * from authors where id in (1, 2, 3, 4, 5, ...) foreach ($books as $book) { echo $book->author->name; }
Simple implementation of $books = Book::with('author')->get() code as the bellow.
$books = Book::all(); //*1 query* $books_authors = Author::whereIn('id', $books->pluck('author_id'))->get()->keyBy('author_id'); // *1 query* foreach($books as $book){ $books->author = $books_authors[$book->author_id] ?? null; }
Ex2;
The original code
$books = Book::all(); // *1 query* foreach($books as $book){ echo $book->comments()->count(); // Make one query like *select count(1) from comments where book_id = ${book.id}* every time it is called }
N + 1 queries problem
Refactoring
=>
$books = Book::withCount('comments')->get(); // Only two queries will be called. foreach($books as $book){ echo $book->comments_count; }
Simple implementation of $books = Book::withCount('comments')->get() code as the bellow.
$books = Book::all(); // *1 query* $books_counts= Comment::whereIn('book_id', $books->pluck('id'))->groupBy('book_id')->select(['count(1) as cnt', 'book_id'] )->pluck('book_id', cnt); // *1 query* foreach($books as $book){ $book->comments_count = $likes[$book->id] ?? 0; }
Total: 2 queries
Note: Read more about eager-loading In some frameworks, like phoenix, lazy-load is disabled by default to stop incorrect usage.
7. Stop printing raw user inputted values in blade.
The original code
<div>{!! nl2br($post->comment) !!}</div>
There is a XSS security issue
Refactoring
<div>{{ $post->comment }}</div>
Note: if you want to keep new line in div, you can use white-space: pre-wrap Rules: Don't use printing raw({!! !}}) with user input values.
8. Be careful when running javascript with user input.
The original code
function linkify(string){ return string.replace(/((http|https)?:\/\/[^\s]+)/g, "<a href="%241">$1</a>") } const $post_content = $("#content_post"); $post_content.html(linkify($post_content.text()));
There is a XSS security issue. Easy hack with input is http:deptrai.com<a href="javascript:alert('hacked!');">stackoverflow.com</a> or http:deptrai.com<img src="1" alt="image">
Refactoring
function linkify(string){ return string.replace(/((http|https)?:\/\/[^\s]+)/g, "<a href="%241">$1</a>") } const post = $("#content_post").get(0); post.innerHTML = linkify(post.innerHTML)
Bonus: simple sanitize function Note: Don't use unescaped user input to innerHTML. Almost javascript frameworks will sanitize input before print it into Dom by default. So, be careful when using some functions like react.dangerouslySetInnerHTML or jquery.append() for user inputted values.
In my test results, WAF(Using our provider's default rules) can prevent server-side XSS quite well, but not good with Dom-Base XSS.
Rules: Be careful when exec scripts that contains user input values.
9. Stop abusing Morph
When using morph, we cannot use foreign key relationship and when the table is grow big we will face performance issues.
The original code
posts id - integer name - string videos id - integer name - string tags id - integer name - string taggables tag_id - integer taggable_id - integer taggable_type - string
Refactoring
posts id - integer name - string videos id - integer name - string tags id - integer name - string posts_tags tag_id - integer post_id - integer videos_tags tag_id - integer video_id - integer
0 notes
Text
Learn How to Master in Using Magento 2 Admin Grid In 5 Minutes
Magento 2 admin grid tutorial is such a good document that can provide for you a clear vision about Magento 2 admin grid. For example, you can record all orders in a table so that you can take control of all of them easily.
Sometimes, you even desire to change the appearance of your page according to your preference. You have tried many ways to carry out such things but failed!
Fortunately, we will give you all the information to do it.
Get started!
What Is Magento 2 Admin Grid?
>>>Have a look at How to Optimize Magento 2 Order Management!
Magento 2 admin grid, so-called admin workspace, is a kind of table that lists the items in your database table and provides access to all tools, data, and content that you need to run your store.
Many Admin pages have a grid that lists the data for the section, with a set of tools to search, sort, filter, select, and apply actions.
The default start-up page can be set in the configuration and by default, the dashboard is a startup page for admin.
However, you can choose any other page to appear as the startup page when you log in. If you want to return the Admin startup page, just tap the Magento logo in the Admin sidebar.
>>>Pay a visit for All about Mage Guides to Improve your Business!
Magento 2 Admin Grid Tutorials for Beginners
In this section, we will give you detailed instructions about using the admin workspace effectively and quickly.
Change the admin startup page
On the admin sidebar, go to Stores => Settings => Configuration
In the left side panel under Advanced, choose Admin
Expand the Startup Page section
Set the startup page you want to appear first when you log in the Admin
When complete, click Save Configuration
Grid controls
Admin pages that manage data display a collection of records in a grid.
Furthermore, the controls at the top of each column can be used to sort the data.
The current sort order is indicated by an ascending or descending arrow in the column header.
Moreover, you can specify which columns appear in the grid, and drag them into different positions and also save different column arrangements as views that can be used later.
The Action column lists operations that can be applied to an individual record.
In addition, the date from the current view of most grids can be exported to a CSV or XML file.
>>>Don’t miss this: Learn All About Magento 2 Shopping Cart Here!!
Stort the list
Click any column header and then the arrow indicates the current order as either ascending or descending.
Use the pagination controls to view additional pages in the collection.
Paginate list
Set the Pagination control to the number of records that you want to view per page.
Click Next and Previous to page through the list, or enter a specific Page Number.
Filter the list
>>>Here Is Magento 2 Layout Tutorial To Customise Your Frontend Store. Interested?!
Click filters.
Complete as many filters as necessary to describe the record you want to look for.
Click Apply filters.
Export data
>>>Also read: Magento Sample Data: Install, Update, Remove Guide [Updated 2020]!
Select the records that you want to export.
2. In the Export menu in the up-right corner, choose one of the following file formats: one is CVS and the other is Excel XML.
Click export
Look for the downloaded file of exported data at the location used for downloads by your browser.
Grid layout
You can change the selection of columns and their order in the grid simply and easily according to your preference and then save as a view.
Keep in mind that only nine of twenty available columns are visible in the grid.
With the Magento 2 admin grid tutorial below, you can adjust the grid quickly without difficulty.
Change the selection of columns
In the upper right corner, click the Columns control.
Change the column selections:
Select the checkbox of any column you want to add to the grid.
Clear the checkbox of any column you want to remove from the grid.
Make sure to scroll down to see all available columns.
Move a column
Click the header of the column and hold.
Drag the column to the new position and release.
Save a grid view
Click the view control
Click Save Current View
Enter a name for the view
Click the arrow to save all changes
The name of the view now appears as the current view.
Change the grid view
Click the view control
Do of the following:
To use a different view, click the name of the view.
To change the name of a view, click the Edit () icon and update the name.
Actions control
This part of the Magento 2 admin grid tutorial you should not miss because when working with a collection of records in the grid, you can use the Actions control to apply an operation to one or more records.
The Actions control lists each operation that is available for the specific type of data.
For example, you can use the Actions control to update the attributes of selected products, to change the status from Disabled to Enabled, or to delete records from the database.
Apart from that, you can make as many changes as necessary, and then update the records in a single step. It is much more efficient than changing the settings individually for each product.
Applying edits to a batch of records is an asynchronous operation, which executes in the background so that you can continue working in the Admin without waiting for the operation to finish. The system displays a message when the task is complete.
The selection of available actions varies by list, and additional options might appear, depending on the action selected. For example, when changing the status of a group of records, a Status box appears next to the Actions control with additional options.
There are two steps in this part to complete the actions control process.
Step 1: Select records
The checkbox in the first column of the list identifies each record that is a target for the action.
The filter controls can be used to narrow the list to the records you want to target for the action.
Select the checkbox of each record that is a target for the action. Or, you can use one of the following Actions to select a group of records:
Select all / unselect all
Select all on this page / Deselect all on this page
If you want to include any records, set the filters at the top of each column to show only ones.
Step 2: Apply an action to selected records
Set the Actions control to the operation that you want to apply
For example, update attributes
In the list, select the checkbox of each record to be updated.
Set the Actions control to Update Attributes and click Submit.
The Update Attributes page lists all the available attributes, organized by the group in the panel on the left.
Select the Change checkbox next to each attribute and make the necessary changes.
Click Save to update the attributes for the group of selected records.
When complete, click Submit.
This is all Magento 2 admin grid tutorials for beginners. If these instructions above are too easy to your level, keep reading the next section as we will show you how to create the Admin grid in Magento 2.
A Guide on How to Create Magento 2 Admin Grid Programmatically
In the next part of the Magento 2 admin grid tutorial, we will show you how to create an admin grid effectively and shortly so that you can do it by yourself without difficulty.
Thanks, MageDirect for this useful piece of code that we will mention below.
Create ACL
When you create an ACL ( Access control list rules) file to control access to our faq grid
You can use this code below to carry out it:
<?<!-- app/code/[VendorName]/[ModuleName]/etc/acl.xml --> <?xml version="1.0"?> <config xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:framework:Acl/etc/acl.xsd"> <acl> <resources> <resource id="Magento_Backend::admin"> <resource id="Magento_Backend::content"> <resource id="Magento_Backend::content_elements"> <resource id="MageDirect_Faq::faq" title="Faqs" translate="title" sortOrder="100"/> </resource> </resource> </resource> </resources> </acl> </config>
Add new menu item
Add new menu item by editing etc/adminhtml/menu.xml inside the module. In this case, we will add an item under Content > Elements:
<?<!-- app/code/[VendorName]/[ModuleName]/etc/adminhtml/menu.xml --> <?xml version="1.0"?> <configxmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:module:Magento_Backend:etc/menu.xsd"> <menu> <add id="MageDirect_Faq::faqs" title="Faqs" translate="title" module="MageDirect_Faq" sortOrder="100 parent="Magento_Backend::content_elements"action="faq/faq" resource="MageDirect_Faq::faq"/> </menu> </config>
“Add” directive has next attributes:
the id attribute is the unique name in format VendorName_ModuleName::menu_name;
the title attribute will be visible in the menu bar;
the module attribute specifies the module which this menu item belongs to;
the action attribute contains the url of the page on which our admin grid will be shown;
the resource attribute is used to define the ACL rule which the admin user must have in order to access this menu item;
the parent attribute defines parent menu item;
the sortOrder attribute defines menu item position inside menu bar.
Add routes.xml
To etc/adminhtml folder add routes.xml file with the next content:
<?<!-- app/code/[VendorName]/[ModuleName]/etc/adminhtml/routes.xml --> <?xml version="1.0"?> <configxmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:framework:App/etc/routes.xsd"> <router id="admin"> <route id="faq" frontName="faq"> <module name="MageDirect_Faq" /> </route> </router> </config>
Create admin controller class
<?<?php // app/code/[VendorName]/[ModuleName]/Controller/Adminhtml/Faq/Index.php namespace Magedirect\Faq\Controller\Adminhtml\Faq; use Magento\Backend\App\Action\Context; use Magento\Framework\View\Result\PageFactory; class Index extends \Magento\Backend\App\Action { /** * Authorization level of a basic admin session * * @see _isAllowed() */ const ADMIN_RESOURCE = 'MageDirect_Faq::faq'; /** * @var PageFactory */ protected $resultPageFactory; /** * @param Context $context * @param PageFactory $resultPageFactory */ public function __construct(Context $context, PageFactory $resultPageFactory) { $this->resultPageFactory = $resultPageFactory; parent::__construct($context); } /** * @return \Magento\Framework\Controller\ResultInterface */ public function execute() { /** @var \Magento\Backend\Model\View\Result\Page $resultPage */ $resultPage = $this->resultPageFactory->create(); $resultPage->setActiveMenu('MageDirect_Faq::faqs') ->getConfig()->getTitle()->prepend(__('Faqs')); return $resultPage; } }
Clean cache
Clean cache and we will see the new empty page in the admin panel:
<?<span style="font-weight: 400;">php bin/magento cache:clean</span>
Now we can add a simple grid to this page by using UI Component. Let’s do it
Create layout files
<?<!-- app/code/[VendorName]/[ModuleName]/view/adminhtml/layout/faq_faq_index.xml --> <?xml version="1.0"?> <pagexmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="urn:magento:framework:View/Layout/etc/page_configuration.xsd"> <body> <referenceContainer name="content"> <uiComponent name="faq_listing"/> </referenceContainer> </body> </page>
Final Thoughts
This is the end of Magento 2 admin grid tutorial, we hope that you have more knowledge after reading this.
If you have any questions or trouble, feel free to contact us.
We will give you full support and solve your problem.
The post Learn How to Master in Using Magento 2 Admin Grid In 5 Minutes appeared first on Mageguides.
from Mageguides https://ift.tt/2YGMp6B via IFTTT
0 notes