#Remove Duplicate Characters From a String In C
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Video
youtube
LEETCODE PROBLEMS 1-100 . C++ SOLUTIONS
Arrays and Two Pointers 1. Two Sum – Use hashmap to find complement in one pass. 26. Remove Duplicates from Sorted Array – Use two pointers to overwrite duplicates. 27. Remove Element – Shift non-target values to front with a write pointer. 80. Remove Duplicates II – Like #26 but allow at most two duplicates. 88. Merge Sorted Array – Merge in-place from the end using two pointers. 283. Move Zeroes – Shift non-zero values forward; fill the rest with zeros.
Sliding Window 3. Longest Substring Without Repeating Characters – Use hashmap and sliding window. 76. Minimum Window Substring – Track char frequency with two maps and a moving window.
Binary Search and Sorted Arrays 33. Search in Rotated Sorted Array – Modified binary search with pivot logic. 34. Find First and Last Position of Element – Binary search for left and right bounds. 35. Search Insert Position – Standard binary search for target or insertion point. 74. Search a 2D Matrix – Binary search treating matrix as a flat array. 81. Search in Rotated Sorted Array II – Extend #33 to handle duplicates.
Subarray Sums and Prefix Logic 53. Maximum Subarray – Kadane’s algorithm to track max current sum. 121. Best Time to Buy and Sell Stock – Track min price and update max profit.
Linked Lists 2. Add Two Numbers – Traverse two lists and simulate digit-by-digit addition. 19. Remove N-th Node From End – Use two pointers with a gap of n. 21. Merge Two Sorted Lists – Recursively or iteratively merge nodes. 23. Merge k Sorted Lists – Use min heap or divide-and-conquer merges. 24. Swap Nodes in Pairs – Recursively swap adjacent nodes. 25. Reverse Nodes in k-Group – Reverse sublists of size k using recursion. 61. Rotate List – Use length and modulo to rotate and relink. 82. Remove Duplicates II – Use dummy head and skip duplicates. 83. Remove Duplicates I – Traverse and skip repeated values. 86. Partition List – Create two lists based on x and connect them.
Stack 20. Valid Parentheses – Use stack to match open and close brackets. 84. Largest Rectangle in Histogram – Use monotonic stack to calculate max area.
Binary Trees 94. Binary Tree Inorder Traversal – DFS or use stack for in-order traversal. 98. Validate Binary Search Tree – Check value ranges recursively. 100. Same Tree – Compare values and structure recursively. 101. Symmetric Tree – Recursively compare mirrored subtrees. 102. Binary Tree Level Order Traversal – Use queue for BFS. 103. Binary Tree Zigzag Level Order – Modify BFS to alternate direction. 104. Maximum Depth of Binary Tree – DFS recursion to track max depth. 105. Build Tree from Preorder and Inorder – Recursively divide arrays. 106. Build Tree from Inorder and Postorder – Reverse of #105. 110. Balanced Binary Tree – DFS checking subtree heights, return early if unbalanced.
Backtracking 17. Letter Combinations of Phone Number – Map digits to letters and recurse. 22. Generate Parentheses – Use counts of open and close to generate valid strings. 39. Combination Sum – Use DFS to explore sum paths. 40. Combination Sum II – Sort and skip duplicates during recursion. 46. Permutations – Swap elements and recurse. 47. Permutations II – Like #46 but sort and skip duplicate values. 77. Combinations – DFS to select combinations of size k. 78. Subsets – Backtrack by including or excluding elements. 90. Subsets II – Sort and skip duplicates during subset generation.
Dynamic Programming 70. Climbing Stairs – DP similar to Fibonacci sequence. 198. House Robber – Track max value including or excluding current house.
Math and Bit Manipulation 136. Single Number – XOR all values to isolate the single one. 169. Majority Element – Use Boyer-Moore voting algorithm.
Hashing and Frequency Maps 49. Group Anagrams – Sort characters and group in hashmap. 128. Longest Consecutive Sequence – Use set to expand sequences. 242. Valid Anagram – Count characters using map or array.
Matrix and Miscellaneous 11. Container With Most Water – Two pointers moving inward. 42. Trapping Rain Water – Track left and right max heights with two pointers. 54. Spiral Matrix – Traverse matrix layer by layer. 73. Set Matrix Zeroes – Use first row and column as markers.
This version is 4446 characters long. Let me know if you want any part turned into code templates, tables, or formatted for PDF or Markdown.
0 notes
Text
Remove Duplicate Characters From a String In C#
Remove Duplicate Characters From a String In C#
Remove Duplicate Characters From a String In C# Console.Write(“Enter a String : “);string inputString = Console.ReadLine();string resultString = string.Empty;for (int i = 0; i < inputString.Length; i++){if (!resultString.Contains(inputString[i])){resultString += inputString[i];}}Console.WriteLine(resultString);Console.ReadKey(); Happy Programming!!! -Ravi Kumar Gupta.

View On WordPress
#.NET#c#Coding#java#Program#program in c#Programming#Remove Duplicate Characters From a String#Remove Duplicate Characters From a String In C#Technology
0 notes
Text
GSoC logs (June 5 –July 11)
July 5
Reclone and commit all changes to new branch.
Get preview component done
Send the demo to mentors and then touch proto file.
Recloned. In the new clone, I made new changes. Everything works.
Turns out any write operation in the proto file is wrecking stuff. I navigated to the proto file in vscode and simply saved. This causes all the errors again.
Some import errors even though proto syntax are perfectly fine. Hmmm. protoc-gen-go: program not found or is not executable
I tried making the proto file executable with chmod +x. Still same issue.
Proto files aren’t supposed to be executable
The error is actually referring to protoc-gen-go. Saying that protoc-gen-go is not found or not executable. Not the proto file.
Moving on to completing the preview component.
Preview component
Ipynb html. Axios get and render the htmlstring from response data in the iframe. Nop, v-html.
Serve html file from the http server for now. Wait, that's not possible.
Okay, maybe I should just use hello api for now. Since both request and response objects have string type properties.
July 6
Leads & Tries.
Try Samuel’s suggestion -
“Do you have protoc on your path?
sometimes VScode installs its own version of some tools on a custom $PATH - it could as well be that some extension is not properly initialized “
Interesting - I tried git diff on the proto file and this happens just by vscode saving it.
old mode 100644 new mode 100755
https://unix.stackexchange.com/a/450488
Changed back to 0644 and still the same issue in vscode.
I just forgot I made the protofile executable yesterday and forgot to change it back. Wasted like an hour on it.
Read about makefile. Do as said. Annotations.proto forward slash path. ??
Set gopath Permanently.
Edit proto file in atom. (Prepare to reclone ;_;)
Trying the same in vim ()
Text editor.
Okay, so the issue isn't editor or ide specific.
Trying to change paths
Gopath was /$HOME/go .. changed it to /usr/local/go/bin
New error.
GO111MODULE=off go get -v github.com/golang/protobuf/protoc-gen-go github.com/golang/protobuf (download) package github.com/golang/protobuf/protoc-gen-go: mkdir /usr/local/go/bin/src: permission denied make: *** [Makefile:164: /usr/local/go/bin/bin/protoc-gen-go] Error 1
https://github.com/golang/go/issues/27187
sudo chown -R $USER: $HOME
Doesn’t feel right.
The problem could be that I have multiple go distributions. After this is done, I need to clean this shit this weekend.
Still permission denied
$GOPATH was supposed to be /usr/local/go not /usr/local/go/bin
Okay, changed it, but go env GOPATH is giving warning that GOROOT and GOPATH are same.
So from what I’ve read, gopath is the workspace (where the libraries we need for the project are installed), and goroot is the place where go is installed(Home to the go itself). Our makefile is trying to install and use the modules in GOPATH. Okay, so my GOPATH was right before.
Final tries
Follow the error trails.
Find out what exactly is happening when I save this file.
Okay, incase they don’t work out. Try to send the html string instead of “Hello ” string without changing proto file.
Since all ipynb files can have same css, try and send only the html elements. And do the css separately in frontend.
Okay, I was able to send a sample html string with the response with the same api. Since response message type was string itself..
Rendered the HTMLString in the preview component.
I’m gonna embed the nbconvert python script by tonight. Update: that was overoptimistic.
So I have the nbconvert python script to generate basic html strings.
I should also remove those comments in the html.
So we’re using the less performance option of keeping duplicate copies of the data in both go and python since we don’t need much memory in the first place.
Read about python c api.
July 7
Learned one or 2 things about embedding python. https://github.com/ardanlabs/python-go/tree/master/py-in-mem
Following this https://poweruser.blog/embedding-python-in-go-338c0399f3d5
So I need python3.7. Because go-python3 only supports python3.7. But there’s python 3.8 workaround in the same blog. go get github.com/christian-korneck/go-python3 Failed with a bunch of errors.
https://blog.filippo.io/building-python-modules-with-go-1-5/ goodread. But that’s not what I need.
https://www.ardanlabs.com/blog/2020/09/using-python-memory.html
This is a bit more challenging but more understandable.
He's trying to use in-memory methods, so both go and python can access the data. No duplication. Since the guide is more understandable and uses python3.8 itself, I should give it a try.
I should start with this right after fixing the make issue.
Back to build fixing
Do as samuel suggested. - no luck.
What I know so far. The issue is rooted with golang or protobuf or sth related. Since the issue is there for all the text editors including vim.
I found sth weird -Which go => /usr/local/go/bin/go. When it gives /usr/local/bin/go to this dude https://stackoverflow.com/a/67419012/13580063
Okay, not so weird.
July 8
Reinstall golang#2. https://stackoverflow.com/a/67419012/13580063 ? Nop.
See protoc installation details.
Read more about protoc, protobugs https://developers.google.com/protocol-buffers/docs/reference/go-generated#4. Read more about golang ecosystem - 30m and see if **which go **path is weird.
Also found this https://github.com/owncloud/ocis-hello/issues/62 Nop.
Make generate is giving this.
GO111MODULE=off go get -v github.com/golang/protobuf/protoc-gen-go GO111MODULE=on go get -v github.com/micro/protoc-gen-micro/v2 GO111MODULE=off go get -v github.com/webhippie/protoc-gen-microweb GO111MODULE=off go get -v github.com/grpc-ecosystem/grpc-gateway/protoc-gen-openapiv2 protoc \ -I=third_party/ \ -I=pkg/proto/v0/ \ --go_out=pkg/proto/v0 hello.proto protoc-gen-go: program not found or is not executable Please specify a program using absolute path or make sure the program is available in your PATH system variable --go_out: protoc-gen-go: Plugin failed with status code 1. make: *** [Makefile:176: pkg/proto/v0/hello.pb.go] Error 1
echo $GOPATH is empty. go env GOPATH is giving the right path.
export GOROOT=/usr/local/go export GOPATH=$HOME/go export GOBIN=$GOPATH/bin export PATH=$PATH:$GOROOT:$GOPATH:$GOBIN
Now, I get this
GO111MODULE=off go get -v github.com/grpc-ecosystem/grpc-gateway/protoc-gen-openapiv2 protoc \ -I=third_party/ \ -I=pkg/proto/v0/ \ --go_out=pkg/proto/v0 hello.proto protoc-gen-go: invalid Go import path "proto" for "hello.proto" The import path must contain at least one forward slash ('/') character. See https://developers.google.com/protocol-buffers/docs/reference/go-generated#package for more information. --go_out: protoc-gen-go: Plugin failed with status code 1. make: *** [Makefile:176: pkg/proto/v0/hello.pb.go] Error 1
Did this https://github.com/techschool/pcbook-go/issues/3#issuecomment-821860413 and the one below and started getting this
GO111MODULE=off go get -v github.com/grpc-ecosystem/grpc-gateway/protoc-gen-openapiv2 protoc \ -I=third_party/ \ -I=pkg/proto/v0/ \ --go_out=pkg/proto/v0 hello.proto protoc \ -I=third_party/ \ -I=pkg/proto/v0/ \ --micro_out=pkg/proto/v0 hello.proto protoc \ -I=third_party/ \ -I=pkg/proto/v0/ \ --microweb_out=pkg/proto/v0 hello.proto protoc \ -I=third_party/ \ -I=pkg/proto/v0/ \ --swagger_out=logtostderr=true:pkg/proto/v0 hello.proto protoc-gen-swagger: program not found or is not executable Please specify a program using absolute path or make sure the program is available in your PATH system variable --swagger_out: protoc-gen-swagger: Plugin failed with status code 1. make: *** [Makefile:194: pkg/proto/v0/hello.swagger.json] Error 1
July 9
Now trying to read this from the error https://developers.google.com/protocol-buffers/docs/reference/go-generated#package
option go_package = "github.com/anaswaratrajan/ocis-jupyter/pkg/proto/v0;proto";
Tried this and
GO111MODULE=off go get -v github.com/grpc-ecosystem/grpc-gateway/protoc-gen-openapiv2 protoc \ -I=third_party/ \ -I=pkg/proto/v0/ \ --go_out=pkg/proto/v0 hello.proto protoc \ -I=third_party/ \ -I=pkg/proto/v0/ \ --micro_out=pkg/proto/v0 hello.proto protoc \ -I=third_party/ \ -I=pkg/proto/v0/ \ --microweb_out=pkg/proto/v0 hello.proto protoc \ -I=third_party/ \ -I=pkg/proto/v0/ \ --swagger_out=logtostderr=true:pkg/proto/v0 hello.proto protoc-gen-swagger: program not found or is not executable Please specify a program using absolute path or make sure the program is available in your PATH system variable --swagger_out: protoc-gen-swagger: Plugin failed with status code 1. make: *** [Makefile:194: pkg/proto/v0/hello.swagger.json] Error 1
Okay, so proto-gen-swagger is not in gopath as expected. So this isn’t working.
$(GOPATH)/bin/protoc-gen-swagger: GO111MODULE=off go get -v github.com/grpc-ecosystem/grpc-gateway/protoc-gen-openapiv2
Instead of protoc-gen-swagger, there’s protoc-gen-openapiv2 executable. So I replaced protoc-gen-swagger from last line in the makefile to the executable in the path.
https://grpc-ecosystem.github.io/grpc-gateway/docs/development/grpc-gateway_v2_migration_guide/
Turns out they renamed protoc-gen-swagger to protoc-gen-openapiv2
option go_package = "github.com/anaswaratrajan/ocis-jupyter/pkg/proto/v0;proto"; wasn't the right path.
There's a new directory github.com/anaswa... inside proto/v0/
So go_package path is messed up.
Just replacing swagger binary names in makefile lets you generate the proto files at github.com/anas… dir
Let’s try fixing the go_package path.
Wait, you don't generate them.
option go_package = "./;proto";
This is the right way.
So yea, I’m able to generate the go-code now. But make generate is still failing. The swagger file is still not generated. July 11
Ownclouders already tried to work on it.
https://github.com/owncloud/ocis-hello/issues/91
So what exactly is micro-web service? This protoc-gen-microweb is a protoc generator for micro web services. And it's generating this hello.pb.web.go
New error/ Make generate gives
`GO111MODULE=off go get -v github.com/grpc-ecosystem/grpc-gateway/protoc-gen-openapiv2 go generate github.com/anaswaratrajan/ocis-jupyter/pkg/assets panic: No files found goroutine 1 [running]: main.main() /home/anaswaratrajan/go/pkg/mod/github.com/!unno!ted/fileb0x[@v1](https://tmblr.co/mkYynE1Axr-EFCSIQIAtheA).1.4/main.go:101 +0x2765 exit status 2 pkg/assets/assets.go:12: running "go": exit status 1 make: *** [Makefile:83: generate] Error 1
Read more about the protoc generators used here.
0 notes
Text
Vim - Menus
Our beloved Vim offers some possibilities to create and use menus to execute various kinds of commands. I know the following solutions ...
the menu command family
the confirm function
the insert user completion (completefunc)
I will not bother you with a detailed tutorial. For more information I always recommend the best place to learn about Vim - the integrated help.
:menu
Let's start with the most obvious one, the menu commands. The menu commands can be used to create menus that can be called via GUI (mouse and keyboard) and via ex-mode. A good use-case is to create menus entries for commands that are not needed often, for which a mapping would be a waste of valueable key combinations and which can probably not be remembered anyway as they are used less frequently.
I'll keep it short here and as there are already tutorials out there. And of course the Vim help is the best place to read about it. :h creating-menus
Vim offers several menu commands. Depending on the current Vim mode your menu changes accordingly. Means if you are in normal mode you will see your normal mode menus, in visual mode you can see only the menus that make sense in visual mode, and so on.
Let's say we want to have a command in the menu that removes duplicate lines and keeps only one. We want that in normal mode the command runs for the whole file and that in visual mode, by selecting a range of lines, the command shall run only for the selected lines. We could put the following lines in our vimrc.
nmenu Utils.DelMultDuplLines :%s/^\(.*\)\(\n\1\)\+$/\1/<cr> vmenu Utils.DelMultDuplLines :s/^\(.*\)\(\n\1\)\+$/\1/<cr>
The here used commands are quite simple. After the menu command you see only 2 parameters. First one is the menu path. I say path because by using the period you can nest your menus. Here it is only the command directly under the Utils menu entry. The second parameter is the command to be executed just like you would do from normal mode.
There are 2 special characters that can be used in the first parameter. & and <tab>. & can be used to add a shortcut key to the menu and <tab> to add a right aligned text in the menu. Try it out!
Remember that you can access the menu also via ex-mode.
:menu Utils.DelMultDuplLines
But please don't type all the text and use the tabulator key to do the autocompletion for you. ;-)
confirm()
The confirm function. Luckily I already wrote about this possibility. So instead of copy-pasting the text I just link to it.
vim-confirm-function
set completefunc
Let's get dirty now. I guess the insert completion pop-up menu is well known by everyone. But did you know that you can misuse it for more than just auto-completion? I did not. I will show you what I mean.
Usually the auto-completion is triggered by pressing Ctrl-n, Ctrl-p or Ctrl-x Ctrl-something in insert mode. One of these key mappings is Ctrl-x Ctrl-u which triggers an user specific function. Means we can write a function that does what we want and assign it to the completefunc option. Let's check what we need to consider when writing such a function.
The completefunc you have to write has 2 parameters. And the function gets called twice by Vim. When calling the function the first time, Vim passes the parameters 1 and empty. In this case it is your task to usually find the beginning of the word you want to complete and return the start column. One the second call Vim passes 0 and the word the shall be completed.
function! MyCompleteFunc(findstart, base) if a:findstart " write code to find beginning of the word else " write code to create a list of possible completions end endfunction set completefunc=MyCompleteFunc
For more information and an example check :h complete-functions.
Now let's re-create the LaTeX example using the completefunc. Here is a possible solution that supports nested menus, so for 1 level menus the code can be reduced a lot.
https://gist.github.com/marcotrosi/e2918579bce82613c504e7d1cae2e3c0
Okay let's go through it step by step.
In the beginning you see 2 variables. InitMenu and NextMenu. InitMenu defines the menu entry point and NextMenu remembers the name of the next menu. I just wanted to have nested menus and that's what is this for.
Next is the completefunc we have to write. I called mine LatexFont. As shown before it consists of an if-else-block, where the if-true-block gets the word before the cursor and the else-block will return a list that contains some information. In the simplest form this would only be a list of strings that would be the popup-menu-entries. See the CompleteMonths example from the Vim help. But I added some more information. Let's see what it is.
The basic idea is to have one initial menu and many sub-menus, they are all stored in a single dictionary name menus and are somehow connected and I want to decide which one to return. As I initialized my InitMenu variable with "Font" this must be my entry point. After the declaration of the local menus dictionary you can see an if clause that checks if s:NextMenu is empty. So if s:NextMenu is empty it will be initialized with my init value I defined in the very beginning. And at the end I return one of the menus so that Vim can display it as a popup menu.
Now let's have a closer look at the big dictionary. You can see 4 lists named Font, FontFamily, FontStyle and FontSize. Each list contains the popup-menu entries. I use the key user_data to decide whether I want to attach a sub-menu or if the given menu is the last in the chain. To attach a sub-menu I just provide the name of the menu and when the menu ends there I use the string "_END_". So the restriction is that you can't name a menu "_END_" as it is reserved now. By the way, I didn't try it, but I guess that user_data could be of any datatype and is probably not limited to strings.
Let's see what the other keys contain. There are the keys word, abbr and dup. word contains the string that replaces the word before the cursor, which is also stored in a:base. abbr contains the string that is used for display in the popup-menu. From the insert auto-completion we are used to the word displayed is also the word to be inserted. Luckily Vim can distinguish that. This gives me the possibility to display a menu (like FontFamily, FontStyle, FontSize) but at the same time keeping the original unchanged word before the cursor. This is basically the whole trick. Plus the additional user_data key that allows me to store any kind of information for re-use and decisions. With the dup key I tell Vim to display also duplicate entries. For more information on supported keys check :h complete-items.
Now let's get to the rest of the nested menu implementation. Imagine you have selected an entry of the initial menu. You confirm by pressing SPACE and now I want to open the sub-menu automatically. To achieve that I use a Vim event named CompleteDone which triggers my LatexFontContinue function, and the CompleteDone event is triggered when closing the popup menu either by selecting a menu entry or by aborting. Within that function I decide whether to trigger the user completion again or to quit. Beside the CompleteDone event Vim also has a variable named v:completed_item that contains a dictionary with the information about the selected menu item. The first thing I do is saving the user_data value in a function local variable.
let l:NextMenu = get(v:completed_item, 'user_data', '')
The last parameter is the default value for the get function and is an empty string just in case the user aborted the popup-menu in which case no user_data would be available.
One more info - this line ...
inoremap <expr><esc> pumvisible() ? "\<c-e>" : "\<esc>"
... allows the user to abort the menu by pressing the ESC key intead of Ctrl-e.
And last but not least the if clause that either sets the script variable s:NextMenu to empty string when the local l:NextMenu is empty or "_END_" and quits the function without doing anything else, or the else branch that stores the next menu string in s:NextMenu and re-triggers the user completion.
The rest of the file is self-explanatory.
I'm sure we can change the code a bit to execute also other command types, e.g. by storing a command as a string and executing it.
Let me know what you did with it.
2 notes
·
View notes
Text
The Recruit (Chapter 17) - Mitch Rapp
Author: @were-cheetah-stiles
Title: “Day 78, Part I”
Characters: Mitch Rapp & Reader/OFC
Warnings: SMUT. IT’S A LOT OF FUCKING SMUT. like, blowjobs, light choking, vaginal sex, orgasms.. so much smut and cursing. IT’S SMUTAPALOOZA!
Author’s Note: yo... morning head is fun tho. im posting this for @mf-despair-queen who literally JUST begged me for Mitch smut. bless that fucking shirtless picture for making all of us collectively lose our shit. stay thirsty, my friends.
Summary: Mitch gets a smut filled morning with Y/n.
Chapter Sixteen - Chapter Seventeen - Chapter Eighteen

You woke wrapped in nothing but his limbs and the bedsheets. You closed your eyes, tilted your head up towards the sun coming through the curtains, softly bit your bottom lip and sighed. You were so happy. You turned slowly and quietly, and looked at Mitch sleeping, gently pushing some of the hair from his eyes. He was, without a doubt, the most beautiful man you had ever actually seen in person, and his peaceful resting face made your heart skip beats.
Mitch's legs moved under the sheets and he rolled onto his back, turning his head away from you. You smirked. He wasn't hard, but there was a small bulge that perked up under the thin white sheets on the bed. You rubbed your tongue along the bottom of your left canine and cracked a simple plot: you knew how you wanted to wake him up that morning.
You carefully climbed under the thin white sheet covering Mitch. He almost never slept with more than just the sheet when he slept with you because your body ran so hot at night, that if he slept with blankets, the two of you would wake up in a pool of sweat. You positioned yourself on your stomach, your feet hanging out from under the sheet on the side of the bed. You leaned against your left forearm as you licked your lips and picked up his penis with your right hand. It was big even when it was flaccid.
You popped the head into your mouth and lightly sucked. Mitch stirred gently and you grinned. You lifted his member and dragged your tongue on the underside, from the very base back up to the head, popping the tip back into your mouth for a quick suck. Mitch stirred more definitively, and he began to slowly grow in your hand.
You licked back up the side closest to you, base to tip, pushing your tongue a little bit firmer against him this time, and you heard him moan; a sound that he made when he woke up but a bit more breathy than usual. You wrapped your lips around his head and managed to get all of his semi-erect cock in your mouth. You moaned and the vibrations in your throat and mouth caused Mitch to rip the sheet off of him, revealing a sight that he wasn't sure until then was a dream or real.
"Holy shit." He mumbled as you bobbed up and down on him, your lips suctioned tight around his shaft. You let go with a popping noise. You maintained an intense and arrogant eye contact with him, as you moved in between his legs and rested on your knees in front of him. You looked like you were worshipping his cock, and you basically were.
He watched as you licked your lips and leaned your head down, still staring teasingly up at him. He bit his lip as you placed your delicate fingers under his balls, holding them up to your mouth like a snack that you had to have. You wet your lips and sucked his balls into your mouth, gently massaging them as they rotated over your tongue.
"Oh fuck." Mitch broke your eye contact and threw his head back, his fingers both digging into the sheets around him and pushing the hair away from his face. You were pleased with all the fuss he was making. You let his balls drop, lightly sucking on one side, then moving over to the other. You caught his attention again when you dragged the tip of your tongue from above his balls, across the underside of his base, up the shaft and then took him into your mouth again. He had grown substantially since you last had his long and thick length against your lips. You worked the shaft in tandem with your mouth, picking up your pace and barely blinking. Mitch's breathing became heavy as you went and he tucked hairs that were falling in your face, behind your ear.
"Please keep doing that." He begged, but you had other thoughts. You removed your hand from his shaft, pulling all of your hair to one side to drape over your shoulder, and began playing with his balls in your hand, as you then took as much of him as you could down your throat. Mitch jolted forward over the duel sensations. "Fuck... That works too." He mumbled in between pants.
He gathered your long y/h/c locks in his fist, close to your head and began creating the rhythm and timing that he wanted as he forced your head up and down on him. You gagged as Mitch pushed you farther than you had been going and his tip hit the back of your throat. You didn't stop him though. The sound of him moaning as you choked turned you on. You moaned and the vibrations in your throat set him loose.
"Oh fuck, Y/n. God damnit. Do you want me to cum in your mouth?" It was a cross between a threat and a question, and you just kept sucking and gagging, your hand no longer playing with his balls, but instead jerking off the little bit of shaft that he couldn't fit in your mouth. You smiled with your eyes as he looked down at you. It made him crazy with lust whenever you did that... It made him aggressive. He pushed your head down and you choked harder than you had before. Mitch backed off a little, but you pushed yourself back down as hard as he had pushed you before, choking again on his big, thick cock.
Mitch pulled your head up slightly and began thrusting himself up into your mouth with some speed. He was close and he just wanted to see your tongue painted white. You took every forceful thrust in stride and enjoyed yourself, bracing yourself against the bed, both arms on either side of his hips. Mitch pulled your head up, and pushed you back onto your knees in an upright position. He got on his knees and began stroking himself in front of your face. You opened your mouth, your cheekbones turned up in a grin. You playfully left your tongue flat in front of him. You glanced between his dark, lustful eyes and his red and wet tip. He gripped the back of your neck and pressed his cock against your tongue. You felt his load shoot into your mouth. He kept stroking and it shot out in strings against your tongue, cheeks, lips. You let him fill you up and you waited, mouth open until he was done.
He kept his left hand on the back of your neck and watched as you swallowed and then ran your tongue against your lips. He reached his thumb on his right hand against the corner of your mouth and wiped cum off of your face. You reached up for his hand and popped his thumb into your mouth, sucking against it until you had every last drop of him. The breath hitched in the back of his throat as he watched you swallow the last bits of his seed. He dropped to the mattress and watched as you climbed off of the bed.
He held his tender cock in his hand, and closed his eyes, a happy smirk resting on his lips. You grabbed your underwear from the night before off the floor and his black, long-sleeved crew neck shirt and got dressed. You tip-toed over to him and smiled. He looked peaceful and pleased. You leaned over and kissed him lightly on the lips. "I'm going to make breakfast. Sleep a little longer." He nodded slightly and sighed, drifting back to sleep.
Mitch woke up, swung his muscular legs over the side of the bed and stretched. He felt great. He grabbed his blue plaid pajama pants off the floor and secured them around his hips. He didn't want to bother with the rest of his clothes if he was just going to shower after breakfast. He heard you moving around in the kitchen downstairs, and he inhaled the aroma of Belgian waffles being baked. He walked down the spiral staircase and saw your back turned, paying attention to whatever it was that you were making on the stove. The two of you had stopped by the grocery store on the way back from Steven's the night before to pick up some essentials to stock the kitchen with for the rest of your time there.
Mitch hadn't really looked around the house the day before. He slipped into the room that he had found you in the day before, on the first floor, and quickly realized that it was probably your father's old office and library. It was the only room in the house that still had pictures of the Hurley's. You had purged every other room of those personal mementos. Mitch wasn't sure if that was because the memories were too painful or if it was the spy in you that wanted to be able to make a quick get away if you ever needed to. He saw a duplicate of the picture that you had in your bedroom back at The Barn, and he traced his fingers along the top of the frame. Not a speck of dust came off and Mitch realized that you definitely had your cleaning crew take extra special care of this room.
He walked over to the bookshelf that took up an entire wall and saw a row of hardcover books with the same author's name. He pulled one out that made him smile, and carefully flipped through the pages, before putting it back on the shelf. A picture of you on a swing set with another little girl that looked a lot like Beth sat on the shelf above the old books and Mitch found himself thinking how he hoped his children had your eyes. He caught himself in his daydream, contorted his face with shock, and then felt the corner of his mouth turn up. It was not the most absurd thing he had ever thought about. He grinned, looking down at the floor and shook his head.
"What are you grinning about?" Mitch heard you whisper, as you leaned half your body against the other side of the door frame, holding onto the wood around your face.
Mitch walked up to you and kissed you lightly on the lips. "Just looking at how cute you were as a kid... breakfast ready?" You nodded, and turned. You laughed out loud when Mitch came up behind you and gripped his hands against your hips, walking in step with your stride towards the kitchen.
You sat down at the counter together and began eating your waffles and bacon and sausage and hash browns. Mitch swallowed some orange juice and watched as you poured more maple syrup on your plate. He laughed to himself and leaned back in the stool. "Do you want some waffles with your maple syrup, Y/n/n?"
You took the strawberry off of your plate and placed it in between your lips, then looked up at Mitch with the strangest look on your face. "........I hate waffles." You tried to stifle a grin.
Mitch burst out laughing. "So why the hell did you make them?"
"YOU LOVE WAFFLES!" You yelled back, laughing into your arms on the counter.
Mitch settled down, his cheeks hurt from smiling. "Oh god, I love..... that you are willing to eat something you hate just because you know I love it." He recovered quickly, but he realized that he almost said what had been on the tip of his tongue for days. You heard it too but you didn't react and you didn't want to presume. Mitch changed the subject. "So, was that a first edition copy of The Great Gatsby?" He asked, referencing the books that put a smile on his face in your Dad's library earlier.
You nodded as you ate everything on the plate that wasn't a waffle. "Those are all of F. Scott Fitzgerald's novels in their first edition. My dad was definitely a collector."
"Is that why that book is your favorite?" Mitch asked you, a smile not having left his face since he got out of bed that morning.
"Yes, he used to read it to me when I was growing up, like twice a year at least. He loved that book because he grew up in a town called Sands Point, which is at the very tip of East Egg in the book... that collection of books are probably my most prized possessions."
"So there is a fire and you save me or the books?" Mitch proposed the absurd hypothetical.
"Oh, you're toast." You said with a grin, getting up from the stool to clear your plates.
He got up to clear his own and help you with the dishes when he saw you reach up on your tip-toes to put the waffle mix back in the cabinet above the fridge. Your taut but plump ass peeking out from under the hem of his favorite black shirt, and he stepped up behind you, pressing his body against yours as he easily placed the box away. He snaked his hands around your front, pulling the shirt up from the bottom until his hands rested on your hips. You exhaled heavily and leaned against him. Mitch slid one of his big, veiny hands down the front of your white cotton underwear and felt how wet you were. He began gently rubbing your clit, pulling you against him with his other hand, as you reached up behind you and grabbed a fistful of his hair. He breathed in your sweet scent and closed his eyes as you moved your arm around his, and began rubbing your palm against his cock, growing quickly inside of his pants.
You had cupped your hand around his shaft and were rubbing it through his soft cotton pants, leaving him so turned on that he literally stopped rubbing your clit and leaned into your touch. Mitch took a deep breath and came to. You had taken care of him, it was time for him to take care of you.
He grabbed your hand from his cock and used his body to push you up against the marble countertop, pushing the dishes and bowls to the side, and bending you over against the cool surface. Mitch pulled his shirt off of you, pulling you up against him, and dragging his hand down your chest. You moaned at his roaming touch.
Mitch bent you back against the countertop again, your cheek pressed against the cool surface, as he gently pulled all of your hair to one side. He pressed his bare chest against your back, running his hands from your shoulders down your arms to intertwine his fingers with yours, spreading your arms out next to you. He had you completely pinned down as he nibbled on your earlobe and heard you moan softly.
He released your hands and moved his lips towards the back of your neck. He swept the hair out of the way again and left long, wet and warm kisses on the back of your neck. You moaned a little louder. He pulled back slightly and softly blew cool air against the wet kisses he had left on you and you shivered. All of your nerves were standing on edge waiting to see what he would do next.
Mitch leaned back over, his hot skin pressed against your hot skin, and he began to leave long, wet, warm kisses on your shoulder blades, leaving equal amounts on both sides and then meeting back at your spine. You were breathing heavily underneath him. Mitch took the tip of his tongue and dragged it down the length of your spine, his hands running down your sides as he went. You let out your loudest moan yet and arched your back away from him, pressing your body against the counter harder. It was a part of your body that was woefully neglected by Mitch's mouth and you went wild over the rare sensations. Mitch stayed focused on your reaction and blew cool air back over the wet trail on your back. He then left long, sucking kisses back down your spine, taking care to go slowly.
"Oh god, Mitch. That feels so good." You whined, not wanting him to stop.
Mitch dropped to his knees behind you, slowly pulling your white cotton panties, with a growing wet spot by your pussy, down your legs. He grabbed fistfuls of your ass, pushing you up on the counter further. He kissed the backs of your thighs, leaving long, warm kisses down to the backs of your knees. You squirmed with each new touch as he kissed all the way down to your ankles. He worshipped every inch of your body and he wanted to make sure you knew that.
Mitch glanced up at your swollen pink lips, barely sticking out between your thighs, and he recalled the sweet taste in his mouth. He got on his knees and spread your ass cheeks apart; you wiggled your body slightly as he ran his thumbs just barely over your inner lips; just grazing the surface. He felt the warmth radiating off of you. He leaned up and dragged his mouth over your opening, down to your clit; a messy and somewhat toothy interaction that left you screaming.
"Aghhh.. FUCK, MITCH. oh my god." You had been aching for him to touch you there.
He nibbled more softly against your clit and sucked at it, pulling it away from you with the very tips of his teeth. You writhed on the counter with each new thing he did. Mitch sucked and sucked for a few more moments, flicking your nub with the tip of his tongue, driving you wild.
Finally, he rose from his knees, pulling his pants down to his ankles, and he pulled you back towards the edge of the counter. You were panting against the white marble as you felt him press his hard cock up against you. He had grown to prefer not just shoving it in, but inching his length in slowly; getting to feel every bump and curve of your walls, but that was not going to work for him today. He was entirely too riled up.
"Please." You whispered right before he pushed himself inside of you in one swift motion. He moaned over how tight you were in that position and how deep he immediately went inside of you. You yelped out the moment he entered you.
He began thrusting hard against you, pulling your hair back so he could see your face. He picked you up by the throat and then let go, slowing down and remembering how he found you and Dan the night you were assaulted. You looked behind you, reached for his hand, and wrapped it back around your throat. Mitch was not Dan.
Mitch inhaled deeply through his nose as he felt your heart beat against the veins in your soft and slender neck. He pulled you close to him, picking up his pace, his hand still around your neck, his other hand fastened around your hip, and he messily pressed his lips against yours. You dug your nails into his forearm as you hungrily bit at his lower lip. He continued his deep thrusts into your pussy and pushed you back against the cold countertop. He reached his arm around your front, pulling you slightly away from the marble, and began rubbing your clit vigorously. The muscles in his forearm strained as he picked up speed and pressure on your swollen nub, as you told him you were close and begged him for release.
"Oh... ohh...." You moaned loudly as you came undone, and Mitch felt your walls collapse around him. This was the tightest your sweet little cunt had ever been and he came undone as well. One more rough thrust deep into you was all he needed. You screamed at the intense pressure that his depth caused you to feel, and then you cooed as you felt his chest press up against your back, his fingers intertwine with yours, and warm cum begin to fill your insides. You would kill for the feeling, both emotional and physical, that you got when he came inside of you. You knew that there was nothing better.
Your breathing synced up as you both came down from your climaxes. Mitch rubbed his cheek against the back of your neck and closed his eyes. "That was the best sex I've ever had." He whispered into your skin.
"I'm going to have to agree with you." You echoed his sentiments, enjoying the feeling of his fat, softening cock still lightly throbbing inside of you. You sighed. "What time is it?"
Mitch glanced behind him and saw that the clock on the stove said 10:45AM. "It's almost 11." He said as he reluctantly pulled out of you, watching his seed drip down your thigh.
You turned around to face Mitch, standing for the first time in at least forty minutes. You held yourself up with the edge of the counter. "We need to go, my love. You have lunch with Steven and I have lunch with Katie and Jeannette."
"I know." He leaned down and kissed you. A smile coming across his face at your new pet name for him. 'My love'. It made his heart skip a beat because of how organically it came off your lips. He watched as you began walking for the staircase, and he smirked. "You know, if we ever lived here, the first thing I would do is install a shower down here, because I cannot have you constantly dripping my cum all over these hardwood floors." Mitch teased you, who had grabbed a paper towel before you left the kitchen and was reaching down every few steps to wipe up your thighs.
"Shut the fuck up. How about that?" You said with a grin that made your cheeks hurt, as you made your way up the stairs.
bless.

@chivesoup @confidentrose @alexhmak @dontstopxx @iloveteenwolf24 @surpeme-bean @snek-shit @kalista-rankins @parislight @cleverassbutt @damndaphneoh @mgpizza2001 @chionophilic-nefelibata @ninja-stiles @sarcasticallystilinski @teenage-dirtbagbaby @mrs-mitch-rapp93 @alizaobrien @twsmuts @rrrennerrr @sorrynotsorrylovesome @lovelydob @iknowisoundcrazy @5secsxofamnesia @vogue-sweetie @dylrider @ivette29 @therealmrshale @twentyone-souls @sunshineystilinski @snicketyssnake @xsnak-3x @eccentricxem @inkedaztec @awkwarddly @lightbreaksthrough @maddie110201 @hattyohatt @rhyxn @amethystmerm4id @completebandgeek @red-wine-mendes @katieevans371 @girlwiththerubyslippers @theneverendingracetrack @snipsnsnailsnwerewolftales
#mitch rapp#mitch rapp x reader#the recruit aa#american assassin#dylan o'brien#mitch rapp fan fic#mitch rapp smut#SMUT#all the smut#mitch rapp fluff#mitch rapp x ofc#american assassin au#american assassin fan fic#dylan o'brien imagine#dylan o'brien one shot#dylan obrien#were-cheetah-stiles#fan fiction#fan fic writing#fan fic#teen wolf#the maze runner#the internship#the first time#caleb holloway#stiles stilinski#dave hodgman#stuart twombly
505 notes
·
View notes
Text
Mongoose 101: An Introduction to the Basics, Subdocuments, and Population
Mongoose is a library that makes MongoDB easier to use. It does two things:
It gives structure to MongoDB Collections
It gives you helpful methods to use
In this article, we'll go through:
The basics of using Mongoose
Mongoose subdocuments
Mongoose population
By the end of the article, you should be able to use Mongoose without problems.
Prerequisites
I assume you have done the following:
You have installed MongoDB on your computer
You know how to set up a local MongoDB connection
You know how to see the data you have in your database
You know what are "collections" in MongoDB
If you don't know any of these, please read "How to set up a local MongoDB connection" before you continue.
I also assume you know how to use MongoDB to create a simple CRUD app. If you don't know how to do this, please read "How to build a CRUD app with Node, Express, and MongoDB" before you continue.
Mongoose Basics
Here, you'll learn to:
Connect to the database
Create a Model
Create a Document
Find a Document
Update a Document
Delete a Document
Connecting to a database
First, you need to download Mongoose.
npm install mongoose --save
You can connect to a database with the connect method. Let's say we want to connect to a database called street-fighters. Here's the code you need:
const mongoose = require('mongoose') const url = 'mongodb://127.0.0.1:27017/street-fighters' mongoose.connect(url, { useNewUrlParser: true })
We want to know whether our connection has succeeded or failed. This helps us with debugging.
To check whether the connection has succeeded, we can use the open event. To check whether the connection failed, we use the error event.
const db = mongoose.connection db.once('open', _ => { console.log('Database connected:', url) }) db.on('error', err => { console.error('connection error:', err) })
Try connecting to the database. You should see a log like this:

Creating a Model
In Mongoose, you need to use models to create, read, update, or delete items from a MongoDB collection.
To create a Model, you need to create a Schema. A Schema lets you define the structure of an entry in the collection. This entry is also called a document.
Here's how you create a schema:
const mongoose = require('mongoose') const Schema = mongoose.Schema const schema = new Schema({ // ... })
You can use 10 different kinds of values in a Schema. Most of the time, you'll use these six:
String
Number
Boolean
Array
Date
ObjectId
Let's put this into practice.
Say we want to create characters for our Street Fighter database.
In Mongoose, it's a normal practice to put each model in its own file. So we will create a Character.js file first. This Character.js file will be placed in the models folder.
project/ |- models/ |- Character.js
In Character.js, we create a characterSchema.
const mongoose = require('mongoose') const Schema = mongoose.Schema const characterSchema = new Schema({ // ... })
Let's say we want to save two things into the database:
Name of the character
Name of their ultimate move
Both can be represented with Strings.
const mongoose = require('mongoose') const Schema = mongoose.Schema const characterSchema = new Schema({ name: String, ultimate: String })
Once we've created characterSchema, we can use mongoose's model method to create the model.
module.exports = mongoose.model('Character', characterSchema)
Creating a document
Let's say you have a file called index.js. This is where we'll perform Mongoose operations for this tutorial.
project/ |- index.js |- models/ |- Character.js
First, you need to load the Character model. You can do this with require.
const Character = require('./models/Character')
Let's say you want to create a character called Ryu. Ryu has an ultimate move called "Shinku Hadoken".
To create Ryu, you use the new, followed by your model. In this case, it's new Character.
const ryu = new Character ({ name: 'Ryu', ultimate: 'Shinku Hadoken' })
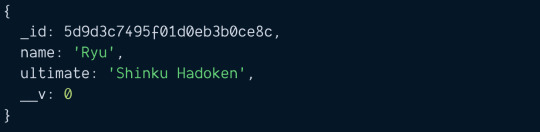
new Character creates the character in memory. It has not been saved to the database yet. To save to the database, you can run the save method.
ryu.save(function (error, document) { if (error) console.error(error) console.log(document) })
If you run the code above, you should see this in the console.
Promises and Async/await
Mongoose supports promises. It lets you write nicer code like this:
// This does the same thing as above function saveCharacter (character) { const c = new Character(character) return c.save() } saveCharacter({ name: 'Ryu', ultimate: 'Shinku Hadoken' }) .then(doc => { console.log(doc) }) .catch(error => { console.error(error) })
You can also use the await keyword if you have an asynchronous function.
If the Promise or Async/Await code looks foreign to you, I recommend reading "JavaScript async and await" before continuing with this tutorial.
async function runCode() { const ryu = new Character({ name: 'Ryu', ultimate: 'Shinku Hadoken' }) const doc = await ryu.save() console.log(doc) } runCode() .catch(error => { console.error(error) })
Note: I'll use the async/await format for the rest of the tutorial.
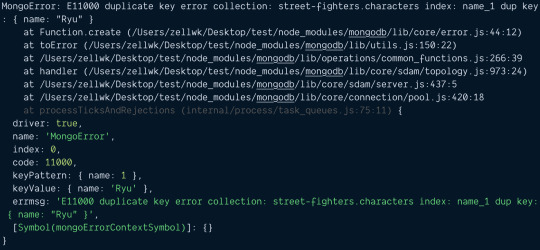
Uniqueness
Mongoose adds a new character to the database each you use new Character and save. If you run the code(s) above three times, you'd expect to see three Ryus in the database.

We don't want to have three Ryus in the database. We want to have ONE Ryu only. To do this, we can use the unique option.
const characterSchema = new Schema({ name: { type: String, unique: true }, ultimate: String })
The unique option creates a unique index. It ensures we cannot have two documents with the same value (for name in this case).
For unique to work properly, you need to clear the Characters collection. To clear the Characters collection, you can use this:
await Character.deleteMany({})
Try to add two Ryus into the database now. You'll get an E11000 duplicate key error. You won't be able to save the second Ryu.
Let's add another character into the database before we continue the rest of the tutorial.
const ken = new Character({ name: 'Ken', ultimate: 'Guren Enjinkyaku' }) await ken.save()

Finding a document
Mongoose gives you two methods to find stuff from MongoDB.
findOne: Gets one document.
find: Gets an array of documents
findOne
findOne returns the first document it finds. You can specify any property to search for. Let's search for Ryu:
const ryu = await Character.findOne({ name: 'Ryu' }) console.log(ryu)

find
find returns an array of documents. If you specify a property to search for, it'll return documents that match your query.
const chars = await Character.find({ name: 'Ryu' }) console.log(chars)
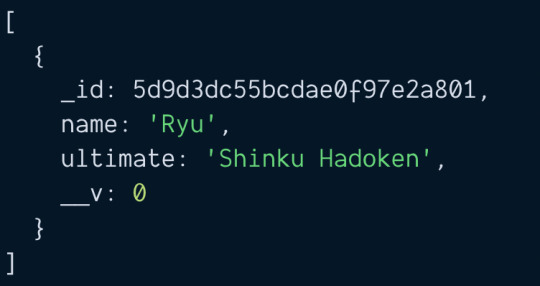
If you did not specify any properties to search for, it'll return an array that contains all documents in the collection.
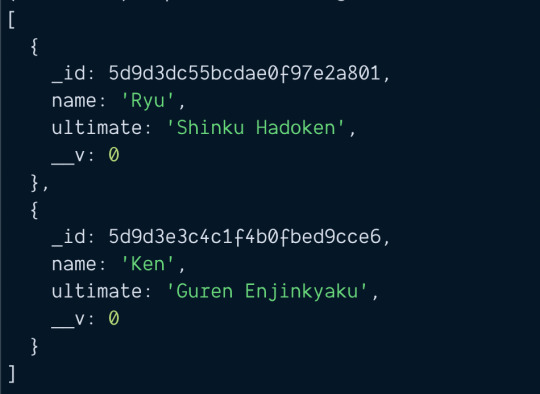
const chars = await Character.find() console.log(chars)
Updating a document
Let's say Ryu has three special moves:
Hadoken
Shoryuken
Tatsumaki Senpukyaku
We want to add these special moves into the database. First, we need to update our CharacterSchema.
const characterSchema = new Schema({ name: { type: String, unique: true }, specials: Array, ultimate: String })
Then, we use one of these two ways to update a character:
Use findOne, then use save
Use findOneAndUpdate
findOne and save
First, we use findOne to get Ryu.
const ryu = await Character.findOne({ name: 'Ryu' }) console.log(ryu)
Then, we update Ryu to include his special moves.
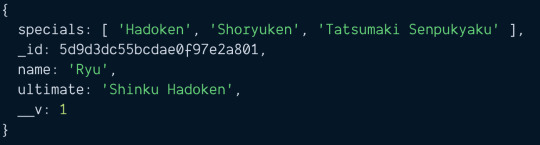
const ryu = await Character.findOne({ name: 'Ryu' }) ryu.specials = [ 'Hadoken', 'Shoryuken', 'Tatsumaki Senpukyaku' ]
After we modified ryu, we run save.
const ryu = await Character.findOne({ name: 'Ryu' }) ryu.specials = [ 'Hadoken', 'Shoryuken', 'Tatsumaki Senpukyaku' ] const doc = await ryu.save() console.log(doc)
findOneAndUpdate
findOneAndUpdate is the same as MongoDB's findOneAndModify method.
Here, you search for Ryu and pass the fields you want to update at the same time.
// Syntax await findOneAndUpdate(filter, update)
// Usage const doc = await Character.findOneAndUpdate( { name: 'Ryu' }, { specials: [ 'Hadoken', 'Shoryuken', 'Tatsumaki Senpukyaku' ] }) console.log(doc)
Difference between findOne + save vs findOneAndUpdate
Two major differences.
First, the syntax for findOne` + `save is easier to read than findOneAndUpdate.
Second, findOneAndUpdate does not trigger the save middleware.
I'll choose findOne + save over findOneAndUpdate anytime because of these two differences.
Deleting a document
There are two ways to delete a character:
findOne + remove
findOneAndDelete
Using findOne + remove
const ryu = await Character.findOne({ name: 'Ryu' }) const deleted = await ryu.remove()
Using findOneAndDelete
const deleted = await Character.findOneAndDelete({ name: 'Ken' })
Subdocuments
In Mongoose, subdocuments are documents that are nested in other documents. You can spot a subdocument when a schema is nested in another schema.
Note: MongoDB calls subdocuments embedded documents.
const childSchema = new Schema({ name: String }); const parentSchema = new Schema({ // Single subdocument child: childSchema, // Array of subdocuments children: [ childSchema ] });
In practice, you don't have to create a separate childSchema like the example above. Mongoose helps you create nested schemas when you nest an object in another object.
// This code is the same as above const parentSchema = new Schema({ // Single subdocument child: { name: String }, // Array of subdocuments children: [{name: String }] });
In this section, you will learn to:
Create a schema that includes a subdocument
Create a documents that contain subdocuments
Update subdocuments that are arrays
Update a single subdocument
Updating characterSchema
Let's say we want to create a character called Ryu. Ryu has three special moves.
Hadoken
Shinryuken
Tatsumaki Senpukyaku
Ryu also has one ultimate move called:
Shinku Hadoken
We want to save the names of each move. We also want to save the keys required to execute that move.
Here, each move is a subdocument.
const characterSchema = new Schema({ name: { type: String, unique: true }, // Array of subdocuments specials: [{ name: String, keys: String }] // Single subdocument ultimate: { name: String, keys: String } })
You can also use the childSchema syntax if you wish to. It makes the Character schema easier to understand.
const moveSchema = new Schema({ name: String, keys: String }) const characterSchema = new Schema({ name: { type: String, unique: true }, // Array of subdocuments specials: [moveSchema], // Single subdocument ultimate: moveSchema })
Creating documents that contain subdocuments
There are two ways to create documents that contain subdocuments:
Pass a nested object into new Model
Add properties into the created document.
Method 1: Passing the entire object
For this method, we construct a nested object that contains both Ryu's name and his moves.
const ryu = { name: 'Ryu', specials: [{ name: 'Hadoken', keys: '↓ ↘ → P' }, { name: 'Shoryuken', keys: '→ ↓ ↘ → P' }, { name: 'Tatsumaki Senpukyaku', keys: '↓ ↙ ↠K' }], ultimate: { name: 'Shinku Hadoken', keys: '↓ ↘ → ↓ â
Then, we pass this object into new Character.
const char = new Character(ryu) const doc = await char.save() console.log(doc)

Method 2: Adding subdocuments later
For this method, we create a character with new Character first.
const ryu = new Character({ name: 'Ryu' })
Then, we edit the character to add special moves:
const ryu = new Character({ name: 'Ryu' }) const ryu.specials = [{ name: 'Hadoken', keys: '↓ ↘ → P' }, { name: 'Shoryuken', keys: '→ ↓ ↘ → P' }, { name: 'Tatsumaki Senpukyaku', keys: '↓ ↙ ↠K' }]
Then, we edit the character to add the ultimate move:
const ryu = new Character({ name: 'Ryu' }) // Adds specials const ryu.specials = [{ name: 'Hadoken', keys: '↓ ↘ → P' }, { name: 'Shoryuken', keys: '→ ↓ ↘ → P' }, { name: 'Tatsumaki Senpukyaku', keys: '↓ ↙ ↠K' }] // Adds ultimate ryu.ultimate = { name: 'Shinku Hadoken', keys: '↓ ↘ → ↓ ↘ → P' }
Once we're satisfied with ryu, we run save.
const ryu = new Character({ name: 'Ryu' }) // Adds specials const ryu.specials = [{ name: 'Hadoken', keys: '↓ ↘ → P' }, { name: 'Shoryuken', keys: '→ ↓ ↘ → P' }, { name: 'Tatsumaki Senpukyaku', keys: '↓ ↙ ↠K' }] // Adds ultimate ryu.ultimate = { name: 'Shinku Hadoken', keys: '↓ ↘ → ↓ ↘ → P' } const doc = await ryu.save() console.log(doc)
Updating array subdocuments
The easiest way to update subdocuments is:
Use findOne to find the document
Get the array
Change the array
Run save
For example, let's say we want to add Jodan Sokutou Geri to Ryu's special moves. The keys for Jodan Sokutou Geri are ↓ ↘ → K.
First, we find Ryu with findOne.
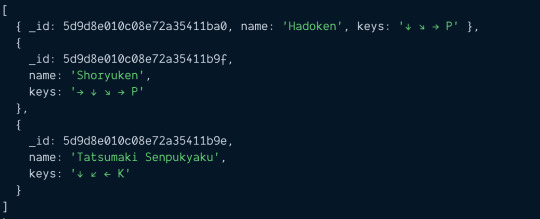
const ryu = await Characters.findOne({ name: 'Ryu' })
Mongoose documents behave like regular JavaScript objects. We can get the specials array by writing ryu.specials.
const ryu = await Characters.findOne({ name: 'Ryu' }) const specials = ryu.specials console.log(specials)
This specials array is a normal JavaScript array.
const ryu = await Characters.findOne({ name: 'Ryu' }) const specials = ryu.specials console.log(Array.isArray(specials)) // true
We can use the push method to add a new item into specials,
const ryu = await Characters.findOne({ name: 'Ryu' }) ryu.specials.push({ name: 'Jodan Sokutou Geri', keys: '↓ ↘ → K' })
After updating specials, we run save to save Ryu to the database.
const ryu = await Characters.findOne({ name: 'Ryu' }) ryu.specials.push({ name: 'Jodan Sokutou Geri', keys: '↓ ↘ → K' }) const updated = await ryu.save() console.log(updated)

Updating a single subdocument
It's even easier to update single subdocuments. You can edit the document directly like a normal object.
Let's say we want to change Ryu's ultimate name from Shinku Hadoken to Dejin Hadoken. What we do is:
Use findOne to get Ryu.
Change the name in ultimate
Run save
const ryu = await Characters.findOne({ name: 'Ryu' }) ryu.ultimate.name = 'Dejin Hadoken' const updated = await ryu.save() console.log(updated)

Population
MongoDB documents have a size limit of 16MB. This means you can use subdocuments (or embedded documents) if they are small in number.
For example, Street Fighter characters have a limited number of moves. Ryu only has 4 special moves. In this case, it's okay to use embed moves directly into Ryu's character document.

But if you have data that can contain an unlimited number of subdocuments, you need to design your database differently.
One way is to create two separate models and combine them with populate.
Creating the models
Let's say you want to create a blog. And you want to store the blog content with MongoDB. Each blog has a title, content, and comments.
Your first schema might look like this:
const blogPostSchema = new Schema({ title: String, content: String, comments: [{ comment: String }] }) module.exports = mongoose.model('BlogPost', blogPostSchema)
There's a problem with this schema.
A blog post can have an unlimited number of comments. If a blog post explodes in popularity and comments swell up, the document might exceed the 16MB limit imposed by MongoDB.
This means we should not embed comments in blog posts. We should create a separate collection for comments.
const comments = new Schema({ comment: String }) module.exports = mongoose.model('Comment', commentSchema)
In Mongoose, we can link up the two models with Population.
To use Population, we need to:
Set type of a property to Schema.Types.ObjectId
Set ref to the model we want to link too.
Here, we want comments in blogPostSchema to link to the Comment collection. This is the schema we'll use:
const blogPostSchema = new Schema({ title: String, content: String, comments: [{ type: Schema.Types.ObjectId, ref: 'Comment' }] }) module.exports = mongoose.model('BlogPost', blogPostSchema)
Creating a blog post
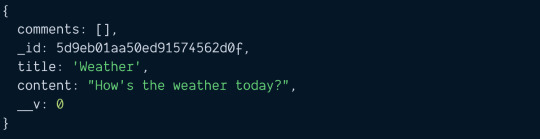
Let's say you want to create a blog post. To create the blog post, you use new BlogPost.
const blogPost = new BlogPost({ title: 'Weather', content: `How's the weather today?` })
A blog post can have zero comments. We can save this blog post with save.
const doc = await blogPost.save() console.log(doc)
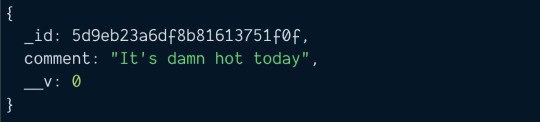
Now let's say we want to create a comment for the blog post. To do this, we create and save the comment.
const comment = new Comment({ comment: `It's damn hot today` }) const savedComment = await comment.save() console.log(savedComment)
Notice the saved comment has an _id attribute. We need to add this _id attribute into the blog post's comments array. This creates the link.
// Saves comment to Database const savedComment = await comment.save() // Adds comment to blog post // Then saves blog post to database const blogPost = await BlogPost.findOne({ title: 'Weather' }) blogPost.comments.push(savedComment._id) const savedPost = await blogPost.save() console.log(savedPost)
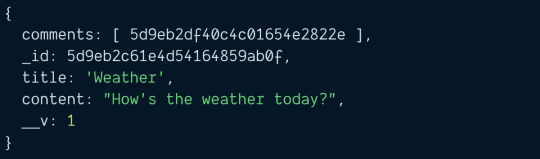
Blog post with comments.
Searching blog posts and its comments
If you tried to search for the blog post, you'll see the blog post has an array of comment IDs.
const blogPost = await BlogPost.findOne({ title: 'Weather' }) console.log(blogPost)
There are four ways to get comments.
Mongoose population
Manual way #1
Manual way #2
Manual way #3
Mongoose Population
Mongoose allows you to fetch linked documents with the populate method. What you need to do is call .populate when you execute with findOne.
When you call populate, you need to pass in the key of the property you want to populate. In this case, the key is comments. (Note: Mongoose calls this the key a "path").
const blogPost = await BlogPost.findOne({ title: 'Weather' }) .populate('comments') console.log(blogPost)
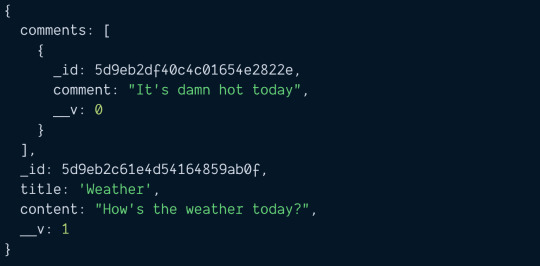
Manual way (method 1)
Without Mongoose Populate, you need to find the comments manually. First, you need to get the array of comments.
const blogPost = await BlogPost.findOne({ title: 'Weather' }) .populate('comments') const commentIDs = blogPost.comments
Then, you loop through commentIDs to find each comment. If you go with this method, it's slightly faster to use Promise.all.
const commentPromises = commentIDs.map(_id => { return Comment.findOne({ _id }) }) const comments = await Promise.all(commentPromises) console.log(comments)
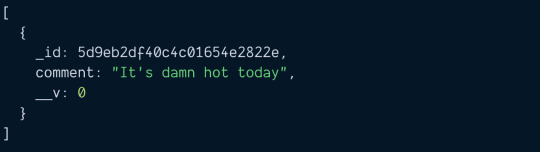
Manual way (method 2)
Mongoose gives you an $in operator. You can use this $in operator to find all comments within an array. This syntax takes effort to get used to.
If I had to do the manual way, I'd prefer Manual #1 over this.
const commentIDs = blogPost.comments const comments = await Comment.find({ '_id': { $in: commentIDs } }) console.log(comments)
Manual way (method 3)
For the third method, we need to change the schema. When we save a comment, we link the comment to the blog post.
// Linking comments to blog post const commentSchema = new Schema({ comment: String blogPost: [{ type: Schema.Types.ObjectId, ref: 'BlogPost' }] }) module.exports = mongoose.model('Comment', commentSchema)
You need to save the comment into the blog post, and the blog post id into the comment.
const blogPost = await BlogPost.findOne({ title: 'Weather' }) // Saves comment const comment = new Comment({ comment: `It's damn hot today`, blogPost: blogPost._id }) const savedComment = comment.save() // Links blog post to comment blogPost.comments.push(savedComment._id) await blogPost.save()
Once you do this, you can search the Comments collection for comments that match your blog post's id.
// Searches for comments const blogPost = await BlogPost.findOne({ title: 'Weather' }) const comments = await Comment.find({ _id: blogPost._id }) console.log(comments)
I'd prefer Manual #3 over Manual #1 and Manual #2.
And Population beats all three manual methods.
Quick Summary
You learned to use Mongoose on three different levels in this article:
Basic Mongoose
Mongoose subdocuments
Mongoose population
That's it!
Thanks for reading. This article was originally posted on my blog. Sign up for my newsletter if you want more articles to help you become a better frontend developer.
via freeCodeCamp.org https://ift.tt/2sSFtpK
0 notes
Text
300+ TOP PERL Interview Questions and Answers
Perl Interview Questions for freshers and experienced :-
1.How many type of variable in perl Perl has three built in variable types Scalar Array Hash 2.What is the different between array and hash in perl Array is an order list of values position by index. Hash is an unordered list of values position by keys. 3.What is the difference between a list and an array? A list is a fixed collection of scalars. An array is a variable that holds a variable collection of scalars. 4.what is the difference between use and require in perl Use : The method is used only for the modules(only to include .pm type file) The included objects are varified at the time of compilation. No Need to give file extension. Require: The method is used for both libraries and modules. The included objects are varified at the run time. Need to give file Extension. 5.How to Debug Perl Programs Start perl manually with the perl command and use the -d switch, followed by your script and any arguments you wish to pass to your script: "perl -d myscript.pl arg1 arg2" 6.What is a subroutine? A subroutine is like a function called upon to execute a task. subroutine is a reusable piece of code. 7.what does this mean '$^0'? tell briefly $^ - Holds the name of the default heading format for the default file handle. Normally, it is equal to the file handle's name with _TOP appended to it. 8.What is the difference between die and exit in perl? 1) die is used to throw an exception exit is used to exit the process. 2) die will set the error code based on $! or $? if the exception is uncaught. exit will set the error code based on its argument. 3) die outputs a message exit does not. 9.How to merge two array? @a=(1, 2, 3, 4); @b=(5, 6, 7, 8); @c=(@a, @b); print "@c"; 10.Adding and Removing Elements in Array Use the following functions to add/remove and elements: push(): adds an element to the end of an array. unshift(): adds an element to the beginning of an array. pop(): removes the last element of an array. shift() : removes the first element of an array.

PERL Interview Questions and Answers 11.How to get the hash size %ages = ('Martin' => 28, 'Sharon' => 35, 'Rikke' => 29); print "Hash size: ",scalar keys %ages,"n"; 12.Add & Remove Elements in Hashes %ages = ('Martin' => 28, 'Sharon' => 35, 'Rikke' => 29); # Add one more element in the hash $age{'John'} = 40; # Remove one element from the hash delete( $age{'Sharon'} ); 13.PERL Conditional Statements The conditional statements are if and unless 14.Perl supports four main loop types: While, for, until, foreach 15.There are three loop control keywords: next, last, and redo. The next keyword skips the remainder of the code block, forcing the loop to proceed to the next value in the loop. The last keyword ends the loop entirely, skipping the remaining statements in the code block, as well as dropping out of the loop. The redo keyword reexecutes the code block without reevaluating the conditional statement for the loop. 16.Renaming a file rename ("/usr/test/file1.txt", "/usr/test/file2.txt" ); 17.Deleting an existing file unlink ("/usr/test/file1.txt"); 18.Explain tell Function The first requirement is to find your position within a file, which you do using the tell function: tell FILEHANDLE tell 19.Perl Regular Expression A regular expression is a string of characters that define the pattern There are three regular expression operators within Perl Match Regular Expression - m// Substitute Regular Expression - s/// Transliterate Regular Expression - tr/// 20.What is the difference between chop & chomp functions in perl? chop is used remove last character, chomp function removes only line endings. 21.Email address validation – perl if ($email_address =~ /^(w¦-¦_¦.)+@((w¦-¦_)+.)+{2,}$/) { print "$email_address is valid"; } else { print "$email_address is invalid"; } 22.Why we use Perl? 1.Perl is a powerful free interpreter. 2.Perl is portable, flexible and easy to learn. 23. Given a file, count the word occurrence (case insensitive) open(FILE,"filename"); @array= ; $wor="word to be found"; $count=0; foreach $line (@array) { @arr=split (/s+/,$line); foreach $word (@arr) { if ($word =~ /s*$wors*/i) $count=$count+1; } } print "The word occurs $count times"; 24.Name all the prefix dereferencer in perl? The symbol that starts all scalar variables is called a prefix dereferencer. The different types of dereferencer are. (i) $-Scalar variables (ii) %-Hash variables (iii) @-arrays (iv) &-subroutines (v) Type globs-*myvar stands for @myvar, %myvar. What is the Use of Symbolic Reference in PERL? $name = "bam"; $$name = 1; # Sets $bam ${$name} = 2; # Sets $bam ${$name x 2} = 3; # Sets $bambam $name-> = 4; # Sets $bam symbolic reference means using a string as a reference. 25. What is the difference between for & foreach, exec & system? Both Perl's exec() function and system() function execute a system shell command. The big difference is that system() creates a fork process and waits to see if the command succeeds or fails - returning a value. exec() does not return anything, it simply executes the command. Neither of these commands should be used to capture the output of a system call. If your goal is to capture output, you should use the $result = system(PROGRAM); exec(PROGRAM); 26. What is the difference between for & foreach? Technically, there's no difference between for and foreach other than some style issues. One is an lias of another. You can do things like this foreach (my $i = 0; $i { # normally this is foreach print $i, "n"; } for my $i (0 .. 2) { # normally this is for print $i, "n";} 27. What is eval in perl? eval(EXPR) eval EXPR eval BLOCK EXPR is parsed and executed as if it were a little perl program. It is executed in the context of the current perl program, so that any variable settings, subroutine or format definitions remain afterwards. The value returned is the value of the last expression evaluated, just as with subroutines. If there is a syntax error or runtime error, or a die statement is executed, an undefined value is returned by eval, and $@ is set to the error message. If there was no error, $@ is guaranteed to be a null string. If EXPR is omitted, evaluates $_. The final semicolon, if any, may be omitted from the expression. 28. What's the difference between grep and map in Perl? grep returns those elements of the original list that match the expression, while map returns the result of the expression applied to each element of the original list. 29. How to Connect with SqlServer from perl and how to display database table info? there is a module in perl named DBI - Database independent interface which will be used to connect to any database by using same code. Along with DBI we should use database specific module here it is SQL server. for MSaccess it is DBD::ODBC, for MySQL it is DBD::mysql driver, for integrating oracle with perl use DBD::oracle driver is used. IIy for SQL server there are avilabale many custom defined ppm( perl package manager) like Win32::ODBC, mssql::oleDB etc.so, together with DBI, mssql::oleDB we can access SQL server database from perl. the commands to access database is same for any database. 30. Remove Duplicate Lines from a File use strict; use warnings; my @array=qw(one two three four five six one two six); print join(" ", uniq(@array)), "n"; sub uniq { my %seen = (); my @r = (); foreach my $a (@_) { unless ($seen{$a}) { push @r, $a; $seen{$a} = 1; } } return @r; } or my %unique = (); foreach my $item (@array) { $unique{$item} ++; } my @myuniquearray = keys %unique; print "@myuniquearray"; PERL Interview Questions with Answers 1. How do you know the reference of a variable whether it is a reference, scaler, hash or array? There is a ‘ref’ function that lets you know 2. What is the difference between ‘use’ and ‘require’ function? Use: 1. the method is used only for modules (only to include .pm type file) 2. the included object are verified at the time of compilation. 3. No Need to give file extension. Require: 1. The method is used for both libraries (package) and modules 2. The include objects are verified at the run time. 3. Need to give file Extension. 3. What is the use of ‘chomp’ ? what is the difference between ‘chomp’ and ‘chop’? ‘chop’ function only removes the last character completely ‘from the scalar, where as ‘chomp’ function only removes the last character if it is a newline. by default, chomp only removes what is currently defined as the $INPUT_RECORD_SEPARATOR. whenever you call ‘chomp ‘, it checks the value of a special variable ‘$/’. whatever the value of ‘$/’ is eliminated from the scaler. by default the value of ‘$/’ is ‘n’ 4. Print this array @arr in reversed case-insensitive order @solution = sort {lc $a comp lc$b } @arr. 5. What is ‘->’ in Perl? It is a symbolic link to link one file name to a new name. So let’s say we do it like file1-> file2, if we read file1, we end up reading file2. 6. How do you check the return code of system call? System calls “traditionally” returns 9 when successful and 1 when it fails. System (cmd) or die “Error in command”. 7. Create directory if not there Ans: if (! -s “$temp/engl_2/wf”){ System “mkdir -p $temp/engl_2/wf”; } if (! -s “$temp/backup_basedir”) { system “mkdir -p $temp/backup_basedir”; } 8. What is the use of -M and -s in the above script? Ans: -s means is filename a non-empty file -M how long since filename modified 9. How to substitute a particular string in a file containing million of record? perl -p -i.bak -e ‘s/search_str/replace_str/g’ filename 10. I have a variable named $objref which is defined in main package. I want to make it as a Object of class XYZ. How could I do it? use XYZ my $objref =XYZ -> new() OR, bless $objref, ‘XYZ’; 11. What is meant by a ‘pack’ in perl? Pack converts a list into a binary representation. Takes an array or list of values and packs it into a binary structure, returning the string containing the structure it takes a LIST of values and converts it into a string. The string contains a con-catenation of the converted values. Typically, each converted values looks like its machine-level representation. For example, on 32-bit machines a converted integer may be represented by a sequence of 4 bytes. 12. How to implement stack in Perl? Through push() and shift() function. push adds the element at the last of array and shift() removes from the beginning of an array. 13. What is Grep used for in Perl? Grep is used with regular expression to check if a particular value exists in an array. It returns 0 it the value does not exists, 1 otherwise. 14. How to code in Perl to implement the tail function in UNIX? You have to maintain a structure to store the line number and the size of the file at that time e.g. 1-10 bytes, 2-18 bytes.. You have a counter to increase the number of lines to find out the number of lines in the file. once you are through the file, you will know the size of the file at any nth line, use ‘sysseek’ to move the file pointer back to that position (last 10) and then tart reading till the end. 15. Explain the difference between ‘my’ and ‘local’ variable scope declarations? Both of them are used to declare local variables. The variables declared with ‘my’ can live only within the block and cannot gets its visibility inherited functions called within that block, but one defined as ‘local’ can live within the block and have its visibility in the functions called within that block. 16. How do you navigate through an XML documents? You can use the XML::DOM navigation methods to navigate through an XML::DOM node tree and use the get node value to recover the data. DOM Parser is used when it is need to do node operation. Instead we may use SAX parser if you require simple processing of the xml structure. 17. How to delete an entire directory containing few files in the directory? rmtree($dir); OR, you can use CPAN module File::Remove Though it sounds like deleting file but it can be used also for deleting directories. &File::Removes::remove (1,$feed-dir,$item_dir); 18. What are the arguments we normally use for Perl Interpreter -e for Execute -c to compile -d to call the debugger on the file specified -T for traint mode for security/input checking -W for show all warning mode (or -w to show less warning) 19. What is it meant by ‘$_’? It is a default variable which holds automatically, a list of arguments passed to the subroutine within parentheses. 20. How to connect to sql server through Perl? We use the DBI(Database Independent Interface) module to connect to any database. use DBI; $dh = DBI->connect(“dbi:mysql:database=DBname”,”username”,”password”); $sth = $dh->prepare(“select name, symbol from table”); $sth->execute(); while(@row = $sth->fetchrow_array()){ print “name =$row.symbol= $row; } $dh->disconnect 21. What is the purpose of -w, strict and -T? -w option enables warning – strict pragma is used when you should declare variables before their use -T is taint mode. TAint mode makes a program more secure by keeping track of arguments which are passed from external source. 22. What is the difference between die and exit? Die prints out STDERR message in the terminal before exiting the program while exit just terminate the program without giving any message. Die also can evaluate expressions before exiting. 23. Where do you go for perl help? perldoc command with -f option is the best. I also go to search.cpan.org for help. 24. What is the Tk module? It provides a GUI interface 25. What is your favourite module in Perl? CGI and DBI. CGI (Common Gateway Interface) because we do not need to worry about the subtle features of form processing. 26. What is hash in perl? A hash is like an associative array, in that it is a collection of scalar data, with individual elements selected by some index value which essentially are scalars and called as keys. Each key corresponds to some value. Hashes are represented by % followed by some name. 27. What does ‘qw()’ mean? what’s the use of it? qw is a construct which quotes words delimited by spaces. use it when you have long list of words that are into quoted or you just do not want to type those quotes as you type out a list of space delimited words. Like @a = qw(1234) which is like @a=(“1?,”2?,”3?,”4?); 28. What is the difference between Perl and shell script? Whatever you can do in shell script can be done in Perl. However Perl gives you an extended advantage of having enormous library. You do not need to write everything from scartch. 29. What is stderr() in perl? Special file handler to standard error in any package. 30. What is a regular expression? It defines a pattern for a search to match. 31. What is the difference between for and foreach? Functionally, there is no difference between them. 32. What is the difference between exec and system? exec runs the given process, switches to its name and never returns while system forks off the given process, waits for its to complete and then return. 33. What is CPAN? CPAN is comprehensive Perl Archive Network. It’s a repository contains thousands of Perl Modules, source and documentation, and all under GNU/GPL or similar license. You can go to www.cpan.org for more details. Some Linux distribution provides a till names ‘cpan; which you can install packages directly from cpan. 34. What does this symbol mean ‘->’? In Perl it is an infix dereference operator. For array subscript, or a hash key, or a subroutine, then its must be a reference. Can be used as method invocation. 35. What is a DataHash() In Win32::ODBC, DataHash() function is used to get the data fetched through the sql statement in a hash format. 36. What is the difference between C and Perl? make up 37. Perl regular exp are greedy. what is it mean by that? It tries to match the longest string possible. 38. What does the world ‘&my variable’ mean? &myvariable is calling a sub-routine. & is used to indentify a subroutine. 39. What is it meant by @ISA, @EXPORT, @EXPORT_OK? @ISA -> each package has its own @ISA array. This array keeps track of classes it is inheriting. Ex: package child; @ISA=(parent class); @EXPORT this array stores the subroutines to be exported from a module. @EXPORT_OK this array stores the subroutines to be exported only on request. 40. What package you use to create windows services? use Win32::OLE. 41. How to start Perl in interactive mode? perl -e -d 1 PerlConsole. 42. How do I set environment variables in Perl programs? You can just do something like this: $ENV{‘PATH’} = ‘…’; As you may remember, “%ENV” is a special hash in Perl that contains the value of all your environment variables. Because %ENV is a hash, you can set environment variables just as you’d set the value of any Perl hash variable. Here’s how you can set your PATH variable to make sure the following four directories are in your path:: $ENV{‘PATH’} = ‘/bin:/usr/bin:/usr/local/bin:/home/your name/bin’. 43. What is the difference between C++ and Perl? Perl can have objects whose data cannot be accessed outside its class, but C++ cannot. Perl can use closures with unreachable private data as objects, and C++ doesn’t support closures. Furthermore, C++ does support pointer arithmetic via `int *ip =(int*)&object’, allowing you do look all over the object. Perl doesn’t have pointer arithmetic. It also doesn’t allow `#define private public’ to change access rights to foreign objects. On the other hand, once you start poking around in /dev/mem, no one is safe. 44. How to open and read data files with Perl? Data files are opened in Perl using the open() function. When you open a data file, all you have to do is specify (a) a file handle and (b) the name of the file you want to read from. As an example, suppose you need to read some data from a file named “checkbook.txt”. Here’s a simple open statement that opens the checkbook file for read access: open (CHECKBOOK, “checkbook.txt”);' In this example, the name “CHECKBOOK” is the file handle that you’ll use later when reading from the checkbook.txt data file. Any time you want to read data from the checkbook file, just use the file handle named “CHECKBOOK”. Now that we’ve opened the checkbook file, we’d like to be able to read what’s in it. Here’s how to read one line of data from the checkbook file: $record = ; After this statement is executed, the variable $record contains the contents of the first line of the checkbook file. The “” symbol is called the line reading operator. To print every record of information from the checkbook file open (CHECKBOOK, “checkbook.txt”) || die “couldn’t open the file!”; while ($record = ) { print $record; } close(CHECKBOOK); 45. How do i do fill_in_the_blank for each file in a directory? #!/usr/bin/perl –w opendir(DIR, “.”); @files = readdir(DIR); closedir(DIR); foreach $file (@files) { print “$filen”; } 46. How do I generate a list of all .html files in a directory Here is a snippet of code that just prints a listing of every file in teh current directory. That ends with the entension #!/usr/bin/perl –w opendir(DIR, “.”); @files = grep(/.html$/, readdir(DIR)); closedir(DIR); foreach $file (@files) { print “$filen”; } 47. What is Perl one-liner? There are two ways a Perl script can be run: –from a command line, called oneliner, that means you type and execute immediately on the command line. You’ll need the -e option to start like “C: %gt perl -e “print ”Hello”;”. One-liner doesn’t mean one Perl statement. One-liner may contain many statements in one line. –from a script file, called Perl program. 48. Assume both a local($var) and a my($var) exist, what’s the difference between ${var} and ${“var”}? ${var} is the lexical variable $var, and ${“var”} is the dynamic variable $var. Note that because the second is a symbol table lookup, it is disallowed under `use strict “refs”‘. The words global, local, package, symbol table, and dynamic all refer to the kind of variables that local() affects, whereas the other sort, those governed by my(), are variously knows as private, lexical, or scoped variable. 49. What happens when you return a reference to a private variable? Perl keeps track of your variables, whether dynamic or otherwise, and doesn’t free things before you’re done using them 50. What are scalar data and scalar variables? Perl has a flexible concept of data types. Scalar means a single thing, like a number or string. So the Java concept of int, float, double and string equals to Perl’s scalar in concept and the numbers and strings are exchangeable. Scalar variable is a Perl variable that is used to store scalar data. It uses a dollar sign $ and followed by one or more alphanumeric characters or underscores. It is case sensitive. 51. Assuming $_ contains HTML, which of the following substitutions will remove all tags in it? You can’t do that. If it weren’t for HTML comments, improperly formatted HTML, and tags with interesting data like , you could do this. Alas, you cannot. It takes a lot more smarts, and quite frankly, a real parser. 52. What is the output of the following Perl program? $p1 = “prog1.java”; $p1 =~ s/(.*).java/$1.cpp/; print “$p1n”; prog1.cpp 53. Why aren’t Perl’s patterns regular expressions? Because Perl patterns has backreferences. A regular expression by definition must be able to determine the next state in the finite automaton without requiring any extra memory to keep around previous state. A pattern /(+)c1/ requires the state machine to remember old states, and thus disqualifies such patterns as being regular expressions in the classic sense of the term. 54. What does Perl do if you try to exploit the execve(2) race involving setuid scripts? Sends mail to root and exits. It has been said that all programs advance to the point of being able to automatically read mail. While not quite at that point (well, without having a module loaded), Perl does at least automatically send it. 55. How do I do for each element in a hash? Here’s a simple technique to process each element in a hash: #!/usr/bin/perl -w %days = ( ‘Sun’ =>’Sunday’, ‘Mon’ => ‘Monday’, ‘Tue’ => ‘Tuesday’, ‘Wed’ => ‘Wednesday’, ‘Thu’ => ‘Thursday’, ‘Fri’ => ‘Friday’, ‘Sat’ => ‘Saturday’ ); foreach $key (sort keys %days) { print “The long name for $key is $days{$key}.n”; } 56. How do I sort a hash by the hash key? Ans:. Suppose we have a class of five students. Their names are kim, al, rocky, chrisy, and jane. Here’s a test program that prints the contents of the grades hash, sorted by student name: #!/usr/bin/perl –w %grades = ( kim => 96, al => 63, rocky => 87, chrisy => 96, jane => 79, ); print “ntGRADES SORTED BY STUDENT NAME:n”; foreach $key (sort (keys(%grades))) { print “tt$key tt$grades{$key}n”; } The output of this program looks like this: GRADES SORTED BY STUDENT NAME: al 63 chrisy 96 jane 79 kim 96 rocky 87 57. How do you print out the next line from a filehandle with all its bytes reversed? print scalar reverse scalar surprisingly enough, you have to put both the reverse and the in to scalar context separately for this to work. 58. How do I send e-mail from a Perl/CGI program on a Unix system? Sending e-mail from a Perl/CGI program on a Unix computer system is usually pretty simple. Most Perl programs directly invoke the Unix sendmail program. We’ll go through a quick example here. Assuming that you’ve already have e-mail information you need, such as the send-to address and subject, you can use these next steps to generate and send the e-mail message: # the rest of your program is up here … open(MAIL, “|/usr/lib/sendmail -t”); print MAIL “To: $sendToAddressn”; print MAIL “From: $myEmailAddressn”; print MAIL “Subject: $subjectn”; print MAIL “This is the message body.n”; print MAIL “Put your message here in the body.n”; close (MAIL); 59. How to read from a pipeline with Perl? To run the date command from a Perl program, and read the output of the command, all you need are a few lines of code like this: open(DATE, “date|”); $theDate = ; close(DATE); The open() function runs the external date command, then opens a file handle DATE to the output of the date command. Next, the output of the date command is read into the variable $theDate through the file handle DATE. Example 2: The following code runs the “ps -f” command, and reads the output: open(PS_F, “ps -f|”); while (){ ($uid,$pid,$ppid,$restOfLine) = split; # do whatever I want with the variables here … } close(PS_F); 60. Why is it hard to call this function: sub y { “because” } Ans. Because y is a kind of quoting operator. The y/// operator is the sed-savvy synonym for tr///. That means y(3) would be like tr(), which would be looking for a second string, as in tr/a-z/A-Z/, tr(a-z)(A-Z), or tr. 61. Why does Perl not have overloaded functions? Because you can inspect the argument count, return context, and object types all by yourself. In Perl, the number of arguments is trivially available to a function via the scalar sense of @_, the return context via wantarray(), and the types of the arguments via ref() if they’re references and simple pattern matching like /^d+$/ otherwise. In languages like C++ where you can’t do this, you simply must resort to overloading of functions. 62. What does read() return at end of file? 0. A defined (but false) 0 value is the proper indication of the end of file for read() and sysread(). 63. How do I sort a hash by the hash value? Here’s a program that prints the contents of the grades hash, sorted numerically by the hash value: #!/usr/bin/perl –w # Help sort a hash by the hash ‘value’, not the ‘key’. To highest). # sub hashValueAscendingNum { $grades{$a} $grades{$b}; } # Help sort a hash by the hash ‘value’, not the ‘key’. # Values are returned in descending numeric order # (highest to lowest). sub hashValueDescendingNum { $grades{$b} $grades{$a}; } %grades = ( student1 => 90, student2 => 75, student3 => 96, student4 => 55, student5 => 76 ); print “ntGRADES IN ASCENDING NUMERIC ORDER:n”; foreach $key (sort hashValueAscendingNum (keys(%grades))) { print “tt$grades{$key} tt $keyn”; } print “ntGRADES IN DESCENDING NUMERIC ORDER:n”; foreach $key (sort hashValueDescendingNum (keys(%grades))) { print “tt$grades{$key} tt $keyn”; } 64. How do find the length of an array? scalar @array 65. What value is returned by a lone `return;’ statement? The undefined value in scalar context, and the empty list value () in list context. This way functions that wish to return failure can just use a simple return without worrying about the context in which they were called. 66. What’s the difference between /^Foo/s and /^Foo/? The second would match Foo other than at the start of the record if $* were set. The deprecated $* flag does double duty, filling the roles of both /s and /m. By using /s, you suppress any settings of that spooky variable, and force your carets and dollars to match only at the ends of the string and not at ends of line as well — just as they would if $* weren’t set at all. 67. Does Perl have reference type? Yes. Perl can make a scalar or hash type reference by using backslash operator. For example $str = “here we go”; # a scalar variable $strref = $str; # a reference to a scalar @array = (1..10); # an array $arrayref = @array; # a reference to an array Note that the reference itself is a scalar. 68. How to dereference a reference? There are a number of ways to dereference a reference. Using two dollar signs to dereference a scalar. $original = $$strref; Using @ sign to dereference an array. @list = @$arrayref; Similar for hashes. 69. How do I do for each element in an array? #!/usr/bin/perl –w @homeRunHitters = (‘McGwire’, ‘Sosa’, ‘Maris’, ‘Ruth’); Foreach (@homeRunHitters) { print “$_ hit a lot of home runs in one yearn”; } 70. How do I replace every character in a file with a comma? perl -pi.bak -e ‘s/t/,/g’ myfile.txt 71. What is the easiest way to download the contents of a URL with Perl? Once you have the libwww-perl library, LWP.pm installed, the code is this: #!/usr/bin/perl use LWP::Simple; $url = get ‘http://www.websitename.com/’; 72. How to concatenate strings in Perl? Through . operator. 73. How do I read command-line arguments with Perl? With Perl, command-line arguments are stored in the array named @ARGV. $ARGV contains the first argument, $ARGV contains the second argument, etc. $#ARGV is the subscript of the last element of the @ARGV array, so the number of arguments on the command line is $#ARGV + 1. Here’s a simple program: #!/usr/bin/perl $numArgs = $#ARGV + 1; print “thanks, you gave me $numArgs command-line arguments.n”; foreach $argnum (0 .. $#ARGV) { print “$ARGVn”; } 74. Assume that $ref refers to a scalar, an array, a hash or to some nested data structure. Explain the following statements: $$ref; # returns a scalar $$ref; # returns the first element of that array $ref- > ; # returns the first element of that array @$ref; # returns the contents of that array, or number of elements, in scalar context $&$ref; # returns the last index in that array $ref- > ; # returns the sixth element in the first row @{$ref- > {key}} # returns the contents of the array that is the value of the key “key” 75. Perl uses single or double quotes to surround a zero or more characters. Are the single(‘ ‘) or double quotes (” “) identical? They are not identical. There are several differences between using single quotes and double quotes for strings. 1. The double-quoted string will perform variable interpolation on its contents. That is, any variable references inside the quotes will be replaced by the actual values. 2. The single-quoted string will print just like it is. It doesn’t care the dollar signs. 3. The double-quoted string can contain the escape characters like newline, tab, carraige return, etc. 4. The single-quoted string can contain the escape sequences, like single quote, backward slash, etc. 76. How many ways can we express string in Perl? Many. For example ‘this is a string’ can be expressed in: “this is a string” qq/this is a string like double-quoted string/ qq^this is a string like double-quoted string^ q/this is a string/ q&this is a string& q(this is a string) 77. How do you give functions private variables that retain their values between calls? Create a scope surrounding that sub that contains lexicals. Only lexical variables are truly private, and they will persist even when their block exits if something still cares about them. Thus: { my $i = 0; sub next_i { $i++ } sub last_i { –$i } } creates two functions that share a private variable. The $i variable will not be deallocated when its block goes away because next_i and last_i need to be able to access it. 78. Explain the difference between the following in Perl: $array vs. $array-> Because Perl’s basic data structure is all flat, references are the only way to build complex structures, which means references can be used in very tricky ways. This question is easy, though. In $array, “array” is the (symbolic) name of an array (@array) and $array refers to the 4th element of this named array. In $array->, “array” is a hard reference to a (possibly anonymous) array, i.e., $array is the reference to this array, so $array-> is the 4th element of this array being referenced. 79. How to remove duplicates from an array? There is one simple and elegant solution for removing duplicates from a list in PERL @array = (2,4,3,3,4,6,2); my %seen = (); my @unique = grep { ! $seen{ $_ }++ } @array; print “@unique”; PERL Questions and Answers pdf Download Read the full article
0 notes
Text
Letter note for piano
So music speculation can be overwhelming from piano letter songs the most strong starting stage engineer. There's a savage level of Concepts that are overpowering. In any case, for my idea close by in the occasion that you're similar to looking music or skimming concertos in like Neo old style or contemporary music most by a wide edge of the stuff. You genuinely don't have to know. So today I will on a huge level show you like the key bits of learning in the occasion that you're making enterprisingly like current music, for example, similar to pop EDM, so whatever you like drawing your notes on your giw have you at whatever guide seen that toward be's a stack up as a less consummate thought on a key level this letter notes on a piano music

The size is known as the piano roll. It's on a focal level a zone trim with you to record or drawing your midi notes. Hugely piano roll doesn't just mean a sovereign pianos music home. They can play whatever you like ward upon the module that you weight up and your GA W like a violin or a drum unit or even we are sound, for example, this gay.
So looking piano solace structure and music theory there are twelve notes in music the white keys address these letters and The Black Keys address these letters and we call these letters watches each note has. Introduction free Sound Skills scales the get-together of notes that sound amazing together when played in the gathering and the most everything considered saw sorts of scales utilizing present day music are major and minor scales.
So we should take for instance C major as you can here watch authority sounds euphoric veritable scales when all is said in done sound vivacious. After a short time, in the event that you need to make the scale minor you would take the third the 6th and the seventh and lower them a mammoth piece of a semitone and you will get your minor scale for this condition. The Sassy minor scales everything considered stable amazing and.
Beating swords are get-together of notes play together. That is on a central level the stray bits of a referencing is you need in any occasion three notes to be considered as a concordance. We should make a goliath fittingness beginning in C. So in the event that we start at c as a root note, and we need to make C veritable you need a third and a fifth. So the third in the key of C would be e and the fifth note in the key of C would be a g.
So in the event that we play it together. That is a mammoth appreciation and sounds hot Flappy Slappy. A little while later. In the event that you need to make it a favored individual rope, you would take the third lower it a half advance by then on the off chance that we play it together you get your minor congruity. So congruity updates are improvement of nose. Starr played in a puzzling course before we can see congruity improvement.
So I drew a goliath bit of the harmonies utilized in the c central scale. Correspondingly, you'll see there are Roman numerals on the base. Teeth Roman numeral beginning from 1 to 7. We're not going to truly clarify the Roman numerals for all you ended up being unendingly acquainted with is it raised Roman numeral watches out for a mammoth concordance a lowercase Roman numeral watches out for a minor congruity and a Roman numeral that contains a float watches out for a diminished reasonableness.
So this is most by a wide edge of the strings that are open in the c veritable scale. In present day music, for example, similar to future based pops and pop trap. And so on the most enchanting numerals utilized in these detesting way updates are 1 4 5 and 6 and their utilization in various social affairs. You can mess around with these numerals or you can mess around with different numerals.

Aren't routinely truly utilized. It's up what's more as you would slant toward together. So now you can't go a thought concerning how scales and congruity reestablishes sort of work. So how may we utilize these Concepts when making a track? So I'm going to make like a little drop and before we genuinely began we from the most strong starting stage need to respect our Tempo.
I'm not going to go into bits of information concerning time etchings are beats. I'll be for another video. So I'm on an enormously official level going to look at you sort of plan it I'm leaving to no insufficiency on the planet go for much for each condition then likely a Porter Robinson Styles continually like 90 BPM.
That is a really not driving Tempo beginning late amassed a piano fix and you see this is tremendously similar to how I go about when making a track I everything considered like removing the understanding advancement before we can regard a neighborliness improvement. We from the most solid beginning stage need to perceive what key. Is it ensured that we are going to make this track in?
I'll go keep it clear. I will stay with C major. I will consider like as a concordance improvement and we'll see what occurs. I'm
going to reveal several updates and quantize these notes since this is EDM.
As should be clear all I'm utilizing is only the one the 4 the 5 and the 6 invitingness and see what I like to do when I'm making harmonies is I everything considered take the third and make it an octave higher. So instead of getting this to show up correspondingly. It really shows up in like manner. So that is our corporate Gretchen. So we're going to begin and get our sense.
I'm not going to go into sound structure. This is truly not a sound structure instructional exercise. I'm in a general sense going to duplicate this and on a key level stick it here.
Sounds frustrating, paying little character to it sort of sounds astoundingly sort of unforgiving. So what we can do we can concrete. Explanation behind reality an another saw line out of serum this time. I'll everything considered make like a certain watched line and we can duplicate this one on the off chance that it here and we can make this an octave lower. Clearly, it's some weight. Crushing it sounds astoundingly unfilled and the low end.
So what we can do is make a sub base since this is EDM and standard talking what I do is I in a general sense pulled in the harmonies and I on an astoundingly goliath level void the third and the fifth on all the four. So I on an astoundingly focal level get the foundation of the congruity. I standard talking make this in like way an octave lower.
You getting where this is going. So on the off chance that we heard all together.
Clarification for this present reality, the blend isn't well, that is what we're going for the present moment, at any rate the harmonies sound astoundingly beating. So this is what we can do. So allows in a general sense consider the To be One fix instead of harmonies. We should make these into sixteenth notes. We had the. Executed. We're going to turn this on.
OK really sounds genuinely moving in light of how well this is the thing that the preset is and now we will join more notes added more notes to the court to make it other than overwhelming. This is the thing that it shows up as
you see now, it sounds for each condition particularly better like on the off chance that we heard it. Or then again unmistakably no nonattendance of security on the planet completely
so here are the course for the harmonies that are utilized for this sensibility progress. Really if these names look especially scrambling don't everything reviewed stress over it. I'll give both of you or three tests concerning making harmonies. So take for instance the c ensured congruity in the event that we weave a seventh we would have a C point by point seventh congeniality and on the off chance that we set a ninth we would have a c-veritable 9 an in each confounding sense lacking thought goes with a minor getting taking.

Meyer, for instance we can join a seventh making this A C minor seventh including a ninth C minor ninth. We can other than join a thirteenth making this A C minor 13 after a short time taking the c referenced discovering at long last. We can other than make this a suspension congruity we can take this e and drag it to a d so on the off chance that we play it we would have a ccs to the to paying stunning character to D being the second note in the c key scale.
Motivation driving sureness on the off chance that we take this D and move it to a F on the off chance that we play it. We would have a proposition for or meaning F being the post note in the c mammoth scale a C6 scored like a C veritable 7 congruity. All that you're doing is including a 6th now this — understanding that you see on a concordance in my congruity progress that in a general sense proposes an additional nine.
On a focal level, you just added a nine to that information. So taking this C6, for instance, in the event that we set a ninth you would have a see 6–9 before long it's getting some spot. I will understanding like a reasonable beat structure. Standard 4/4 beat if you get my centrality each catch will be on the second and fourth beat or each bar.
youtube
0 notes
Photo

Here’s a list of some of the less well known Excel formulas and macros that regularly come in handy for keyword marketers. That could be SEOs, PPCs or anyone who works with large spreadsheets containing keywords and associated data like search volume, CPC & categories. Think of it as an excel cheat sheet designed for keyword marketers, but useful for anyone wanting to grow their Excel bag of tricks. Enjoy! FORMULAS Get domain from URL Get subdomain from URL Remove first x characters from cell Remove last x characters from a cell Group keyword phrases automatically based on words they contain Word count Find out if a value exists in a range of other values Get true or false if a word or string is in a cell Remove first word from cell (all before & including 1st space) Replace the first word in a cell with another word Super trim – more reliable trimming of spaces from cells Perform text-to-columns using a formula Extract the final folder path from a URL Extract the first folder path from a URL Remove all text after the xth instance of a specific character Create an alphabetical list of column letters for use in other formulas Count instances of a character in a cell Count the number of times a specific word appears in a cell Return true if there are no numbers in a cell Get the current column letter for use in other formulas Put your keywords into numbered batches for pulling seasonal search volume data Word order flipper Find the maximum numerical value in a row range, and return the column header Find position of nth occurrence of character in a cell Get all characters after the last instance of a string Get all characters after the first instance of a string Get URL path from URL in Google Analytics format Get the next x characters after a string VBA Convert all non-clickable URLs in your spreadsheet to clickable hyperlinks Conditional formatting by row value Remove duplicates individually by column Merge adjacent cells in a range based on identical value Remove all instances of any text between and including 2 characters Highlight mis-spelled words Lock all slicers in position Split delimited values in a cell into multiple rows with key column retained Make multiple copies of a worksheet at once Add a specific number of new rows based on cell value Column stacker Superfast find and replace for huge datasets Paste all cells as values in a worksheet in the active range Format all cells to any format without having to select them Formula activation – insert equals at the beginning for a range of cells Consolidate all worksheets from multiple workbooks into one workbook Fast deletion of named columns Find and replace based on a table Unhide all sheets in a workbook Change pivot table data source for all pivot tables on a worksheet Convert all ‘numbers stored as text’ to general Get domain from URL: =LEFT(A2,FIND("/",A2,9)) This works by bringing back everything to the left of the first trailing slash found after the initial 2 in ‘http..://’, which in a URL is the slash occurring after the TLD. Get subdomain from URL: =IF(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(LEFT(A2,FIND(".",A2)),"http://",""),".",""),"https://",""),"domain","")="","none",SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(LEFT(A2,FIND(".",A2)),"http://",""),".",""),"https://",""),"domain","")) When you just need the subdomains in a big list from a bunch of differently formatted URLs. This formula works regardless of the presence of the protocol. What it lacks in elegance, it more than makes up for in usefulness. Remove first X characters from cell: =RIGHT(A1,LEN(A1)-X) If there’s something consistent that you want to remove from the front of data in your cells, such as an html tag like
, you can use this to remove it by specifying its length in characters in this formula, so X would be 7 in this case. Remove last X characters from a cell: =LEFT(B2,LEN(B2)-X) You might use this to remove the trailing slash from a list of URLs, for example, with X as 1. Group keyword phrases automatically based on words they contain: =IFERROR(LOOKUP(2^15,SEARCH($C$2:$C$200,A2),$D$2:$D$200),"/") This little chap deserves a blog post all its own. Here’s what it does: Example: Bulk categorisation of keywords by colour and hair type groups. Using the formula to group your keywords: $C$2:$C$200 is your string-to-search-for range (the list of all the possible words you want to check for in the keyword). $D$2:$D$200 is your Label to return when string found, put it in the next column along lined up (this can just be the word you’re checking for if you want – same as above) A2 is the cell containing the keyword string which you are searching to see if it contains any of the listed strings so you can label it as such “/” is what gets returned when none of the strings are matched Using the formula Word count: =IF(LEN(TRIM(A2))=0,0,LEN(TRIM(A2))-LEN(SUBSTITUTE(A2," ",""))+1) See how many words are in your keyword to identify if it’s long tail and get a measure of potential intent. Find out if a value exists in a range of other values: =ISNUMBER(MATCH(A2,B:B,0)) This is my favourite, so often we just need to know if URLs in list A are contained within list B. No need to count vlookup columns or iferror. It gives TRUE or FALSE. Get TRUE or FALSE if a word or string is in a cell: =ISNUMBER(SEARCH("text-to-find",A2)) If you fancy a break from using the ‘contains’ filter, this can be a way to get things done faster and in a more versatile way. Remove first word from cell (all before & including 1st space): =RIGHT(A2,LEN(A2)-FIND(" ",A2)) To remove the last word instead, just use LEFT instead of RIGHT. Replace the first word in a cell with another word: =REPLACE(A2,1,LEN(LEFT(A2,FIND(" ",A2)))-1,"X") “X” is the word you want to replace the incumbent first word with, or this can be a cell reference. Super trim – more reliable trimming of spaces from cells: =TRIM(SUBSTITUTE(A2,CHAR(160),CHAR(32))) Sometimes using =TRIM() fails because of an unconventional space character from something you’ve pasted into Excel. This gets them all. Perform text-to-columns using a formula: =TRIM(MID(SUBSTITUTE($A2," ",REPT(" ",LEN($A2))),((COLUMNS($A2:A2)-1)*LEN($A2))+1,LEN($A2))) This is handy for template building. It provides a way of doing text-to-columns automatically with formulas, using a delimiter you specify. In the example, space ” ” is used as the delimiter. Extract the final folder path from a URL: =IF(AND(LEN(A2)-LEN(SUBSTITUTE(A2,"/",""))=3,RIGHT(A2,1)="/"),"",IF(RIGHT(A2,1)="/",RIGHT(LEFT(A2,LEN(A2)-1),LEN(LEFT(A2,LEN(A2)-1))-FIND("@",SUBSTITUTE(LEFT(A2,LEN(A2)-1),"/","@",LEN(LEFT(A2,LEN(A2)-1))-LEN(SUBSTITUTE(LEFT(A2,LEN(A2)-1),"/",""))),1)),RIGHT(A2,LEN(A2)-FIND("@",SUBSTITUTE(A2,"/","@",LEN(A2)-LEN(SUBSTITUTE(A2,"/",""))),1)))) Good for when you need to get just the last portion of a URL, that pertains to the specific page: Extract the first folder path from a URL: =IF(LEN(A2)-LEN(SUBSTITUTE(A2,"/",""))>3,LEFT(RIGHT(A2,LEN(A2)-FIND("/",A2,9)),FIND("/",RIGHT(A2,LEN(A2)-FIND("/",A2,9)))-1),RIGHT(A2,LEN(A2)-FIND("/",A2,9))) Good for extracting language folder. Remove all text after the Xth instance of a specific character: =LEFT(A2,FIND(CHAR(160),SUBSTITUTE(A2,"/",CHAR(160),LEN(A2)-LEN(SUBSTITUTE(A2,"/",""))-0))) Say you want to chop the last folder off a URL, or revert a keyword cluster to a previous hierarchy level. The “/” is the character where the split will occur, change it to whatever you want. The “-0” at the end chops off everything after the last instance. Changing it to -1 would chop off everything after the penultimate instance, and so on. Create an alphabetical list of column letters for use in other formulas A,B,C…AA,BB etc: =SUBSTITUTE(ADDRESS(1,ROWS(A$1:A1),4),1,"") Unlike with numbers, Excel doesn’t automatically give you the next letter of the alphabet if you drag down after selecting cells with ‘a’ and ‘b’ but you can use this to achieve that effect. It runs through the columns, so it will keep working past Z, giving you AA and AB etc. That’s handy for making indirect references in formulas. Count instances of a character in a cell: =LEN(A2)-LEN(SUBSTITUTE(A2," ","")) Countif “*”&”x”&”*” doesn’t cut it for this task because it counts cells, not occurrences. The example here is for ” ” space character. Count the number of times a specific word appears in a cell: =(LEN(A2)-LEN(SUBSTITUTE(A2,B2,"")))/LEN(B2) The formula above works for individual characters, but if you need to count whole words this will work – handy for checking keyword inclusion in landing page copy for SEO. In the example, B2 should contain the word you are counting the instances of within A2. Return TRUE if there are no numbers in a cell: =COUNT(FIND({0,1,2,3,4,5,6,7,8,9},B28))<1 Change the end to >0 to show TRUE if there are numbers present. Handy for isolating and removing cells of data which can be identified as unwanted by the presence or absence of a number, such as a mix of item names and item product codes when you only want the item names. Get the current column letter for use in other formulas: =MID(ADDRESS(ROW(),COLUMN()),2,SEARCH("$",ADDRESS(ROW(),COLUMN()),2)-2) If you’re using indirect references and want a fast way to just get the current column letter placed into your formula, use this. Put your keywords into numbered batches for pulling seasonal search volume data: =IF(A2=43,1,A2+1) To save you having to count out 2,500 keywords each time. This batches them up so you just have to filter for the batch number, ctrl A, ctrl C, ctrl V – 43 is the number of keywords in your list divided by 2500, which is the keyword planner limit. Use the blank row insertion macro to make the batches easily selectable. Word order flipper: =TRIM(MID(F18,SEARCH(" ",F18)+1,250))&" "&LEFT(F18,SEARCH(" ",F18)-1) Turns ‘dresses white wedding’ into ‘white wedding dresses’. Use it in steps inside itself to further rearrange words in a different order. Find the maximum numerical value in a row range, and return the column header: =INDEX($A$1:$F$1,MATCH(MAX(A2:F2),A2:F2,0)) So if your column headers are months or categories, this brings back which one contains the highest value for that row. Useful for showing which month has the highest search volume for a keyword. Find position of nth occurrence of character in a cell: =FIND(CHAR(1),SUBSTITUTE(A1,"c",CHAR(1),3)) Useful as a part of other formulas. Get all characters after the last instance of a string: =SUBSTITUTE(RIGHT(A2,LEN(A2)-FIND("@",SUBSTITUTE(A2," > ","@",(LEN(A2)-LEN(SUBSTITUTE(A2," > ","")))/LEN(" > ")))),"> ","") Gets ‘category 3’ from ‘category 1 > category 2 > category 3’, splitting on the last ‘>’. Get all characters after the first instance of a string: =TRIM(MID(A2,SEARCH(" > ",A2)+LEN(" > "),255)) Like the above, but chops off the first category e.g. gets ‘category 2 > category 3’ from ‘category 1 > category 2 > category 3’, splitting on the first ‘>’. Get URL path from URL in Google Analytics format: ="/"&RIGHT(A2,LEN(A2)-FIND("/",A2,9)) Gets ‘/folder/file’ from ‘http://www.domain.com/folder/file’, I use this to convert URLs to the path format used in Google Analytics exports when I need to vlookup data from the export into another sheet containing full URLs. You could do a find and replace instead, but that doesn’t catch the subdomains and other oddities you may have in your URL list. Get the next x characters after a string: This one is cool. If your cell contained ‘product ID:0123 london’, you could tell this formula to get ‘0123’ based on the presence of ‘product ID:’ in front of it. It says ‘find this, and bring back the next x characters’. =IFERROR(LEFT(RIGHT(A2,LEN(A2)-(SEARCH("STRING",A2)+6)),6),"") There are 3 parts you need to change. Replace STRING with your string to search for e.g. ‘product ID:’ Replace ‘+6’ with the length of your string to search for, so for ‘product ID:’ it would be ‘+11’ Replace the next number, ‘6’, with the number of characters you want to capture after the end of the string to search for. So to capture ‘0123’ from ‘product ID:0123’ you’d put ‘4’. =IFERROR(LEFT(RIGHT(A2,LEN(A2)-(SEARCH("product ID:",A2)+11)),4),"") So it’s a bit like regex capture. I used this to get the width and height of images in raw HTML. EXCEL VBA MODULES VBA does stuff to your spreadsheets by pressing a button. Usually this is stuff that would take a long time to do (or be hard / impossible to do) using the normal Excel ribbon & formula capabilities. To use these: Save your workbook as .xlsm Reopen it and hit alt + f11 In the menu, insert > module Paste in the code Press the play button There’s no need to understand the code. But be careful to save a backup copy of your workbook before running any of these – they can’t be undone with ctrl + z! Convert all non-clickable URLs in your spreadsheet to clickable hyperlinks: So you can visit the URLs easily if you need to e.g. for optimisation of a lot of pages, so you don’t have to mess about double clicking each one to get it ready. Sub HyperAdd() For Each xCell In Selection ActiveSheet.Hyperlinks.Add Anchor:=xCell, Address:=xCell.Formula Next xCell End Sub Conditional formatting by row value: So the colour intensity is relative to each row only, rather than the entire range. You need to use this to complete the search landscape document seasonality tab. Sub NewCF() Range("B1:P1").Copy For Each r In Selection.Rows r.PasteSpecial (xlPasteFormats) Next r Application.CutCopyMode = False End Sub Remove duplicates individually by column: If you have a lot of columns, each of which needs duplicates removing individually e.g. if you have a series of category taxonomies to clean – you can’t do this from the menu: Sub removeDups() Dim col As Range For Each col In Range("A:Z").Columns With col .RemoveDuplicates Columns:=1, Header:=xlYes End With Next col End Sub Merge adjacent cells in a range based on identical value: To save you doing it individually when you need to make a spreadsheet look good: Sub MergeSameCell() 'Updateby20131127 Dim Rng As Range, xCell As Range Dim xRows As Integer xTitleId = "KutoolsforExcel" Set WorkRng = Application.Selection Set WorkRng = Application.InputBox("Range", xTitleId, WorkRng.Address, Type:=8) Application.ScreenUpdating = False Application.DisplayAlerts = False xRows = WorkRng.Rows.Count For Each Rng In WorkRng.Columns For i = 1 To xRows - 1 For j = i + 1 To xRows If Rng.Cells(i, 1).Value <> Rng.Cells(j, 1).Value Then Exit For End If Next WorkRng.Parent.Range(Rng.Cells(i, 1), Rng.Cells(j - 1, 1)).Merge i = j - 1 Next Next Application.DisplayAlerts = True Application.ScreenUpdating = True End Sub Remove all instances of any text between and including 2 characters from a cell (in this example, the < and >): Especially good for removing HTML tags from screaming frog extractions, kind of a stand in for regex. Public Function DELBRC(ByVal str As String) As String While InStr(str, "<") > 0 And InStr(str, ">") > InStr(str, "<") str = Left(str, InStr(str, "<") - 1) & Mid(str, InStr(str, ">") + 1) Wend DELBRC = Trim(str) End Function Highlight mis-spelled words: This can help you identify garbled / nonsense keywords from a large set, or just to spellcheck in Excel if you need to. Sub Highlight_Misspelled_Words() For Each cell In ActiveSheet.UsedRange If Not Application.CheckSpelling(Word:=cell.Text) Then cell.Interior.ColorIndex = 3 Next End Sub Lock all slicers in position: If you send Excel documents to clients with slicers in them, you might worry that they’ll end up moving the slicers around while trying to use them – a poor experience which makes your document feel less professional. But there’s a way around it – run this code and your slicers will be locked in place across all worksheets, while still operational. This effect persists when the document is re-saved as a normal .xlsx file. Option Explicit Sub DisableAllSlicersMoveAndResize() Dim oSlicerCache As SlicerCache Dim oSlicer As Slicer For Each oSlicerCache In ActiveWorkbook.SlicerCaches For Each oSlicer In oSlicerCache.Slicers oSlicer.DisableMoveResizeUI = True Next oSlicer Next oSlicerCache End Sub Split delimited values in a cell into multiple rows with key column retained: It’s easy to put a delimited string (Keyword,Volume,CPC…) into columns using text-to-columns but what if you want it split vertically instead, into rows? This can help: Sub SliceNDice() Dim objRegex As Object Dim X Dim Y Dim lngRow As Long Dim lngCnt As Long Dim tempArr() As String Dim strArr Set objRegex = CreateObject("vbscript.regexp") objRegex.Pattern = "^s+(.+?)$" 'Define the range to be analysed X = Range([a1], Cells(Rows.Count, "b").End(xlUp)).Value2 ReDim Y(1 To 2, 1 To 1000) For lngRow = 1 To UBound(X, 1) 'Split each string by "," tempArr = Split(X(lngRow, 2), ",") For Each strArr In tempArr lngCnt = lngCnt + 1 'Add another 1000 records to resorted array every 1000 records If lngCnt Mod 1000 = 0 Then ReDim Preserve Y(1 To 2, 1 To lngCnt + 1000) Y(1, lngCnt) = X(lngRow, 1) Y(2, lngCnt) = objRegex.Replace(strArr, "$1") Next Next lngRow 'Dump the re-ordered range to columns C:D [c1].Resize(lngCnt, 2).Value2 = Application.Transpose(Y) End Sub Make multiple copies of a worksheet at once: If you are making a reporting template for example, and want to get the sheets for all 12 weeks created in one go: Sub swtbeb4lyfe43() ThisWS = "name-of-existing-worksheet" '# of new sheets s = 6 '# of new sheets For i = 2 To s Worksheets("name-of-existing-worksheet-ending-with-1").Copy After:=Worksheets(Worksheets.Count) ActiveSheet.Name = ThisWS & i Next i End Sub Add a specific number of new rows based on cell value: Saves repeatedly using insert row, pressing F4 etc: Sub test() On Error Resume Next For r = Cells(Rows.Count, "E").End(xlUp).Row To 2 Step -1 For rw = 2 To Cells(r, "E").Value + 1 Cells(r + 1, "E").EntireRow.Insert Next rw, r End Sub Column stacker: This one’s great when you have lots of columns of information that you want to be combined all into one master column: Sub ConvertRangeToColumn() 'UpdatebyExtendoffice Dim Range1 As Range, Range2 As Range, Rng As Range Dim rowIndex As Integer xTitleId = "KutoolsforExcel" Set Range1 = Application.Selection Set Range1 = Application.InputBox("Source Ranges:", xTitleId, Range1.Address, Type:=8) Set Range2 = Application.InputBox("Convert to (single cell):", xTitleId, Type:=8) rowIndex = 0 Application.ScreenUpdating = False For Each Rng In Range1.Rows Rng.Copy Range2.Offset(rowIndex, 0).PasteSpecial Paste:=xlPasteAll, Transpose:=True rowIndex = rowIndex + Rng.Columns.Count Next Application.CutCopyMode = False Application.ScreenUpdating = True End Sub Superfast find and replace for huge datasets: To match partial cell, change to ‘X1Part”. Sub Macro1() Application.EnableEvents = False Application.ScreenUpdating = False Application.Calculation = xlCalculationManual ' fill your range in here Range("S2:AJ252814").Select ' choose what to search for and what to replace with here Selection.Replace What:="0", Replacement:="/", LookAt:=xlWhole, SearchOrder:=xlByRows, MatchCase:=False, SearchFormat:=False, ReplaceFormat:=False Application.EnableEvents = True Application.ScreenUpdating = True Application.Calculation = xlCalculationAutomatic Application.CalculateFull End Sub Paste all cells as values in a worksheet in the active range: For when your spreadsheet is too slow to do it manually Sub ToVals() With ActiveSheet.UsedRange .Value = .Value End With End Sub Format all cells to general format or whatever you like, without having to select them: Another good one for when your spreadsheet is too slow. Sub dural() ActiveSheet.Cells.NumberFormat = "General" End Sub Formula activation – Insert equals at the beginning for a range of cells: If you’re making something complex with a lot of formulas that you don’t want switched on yet, but you want to be able to use other formulas at the same time (i.e. can’t turn off calculations) this can help. It’s also good for just adding things to the start of cells: Sub Insert_Equals() Application.ScreenUpdating = False Dim cell As Range For Each cell In Selection cell.Formula = "=" & cell.Value Next cell Application.ScreenUpdating = True End Sub Consolidate all worksheets from multiple workbooks in a folder on your computer into a single workbook with all the worksheets added into it: If you have a big collection of workbooks which you want consolidated into one, you can do it in a single step using this macro. Especially good for when the workbooks you need to consolidate are big and slow. Sub CombineFiles() Dim Path As String Dim FileName As String Dim Wkb As Workbook Dim WS As Worksheet Application.EnableEvents = False Application.ScreenUpdating = False Path = "C:scu" 'Change as needed FileName = Dir(Path & "*.xl*", vbNormal) Do Until FileName = "" Set Wkb = Workbooks.Open(FileName:=Path & "" & FileName) For Each WS In Wkb.Worksheets WS.Copy After:=ThisWorkbook.Sheets(ThisWorkbook.Sheets.Count) Next WS Wkb.Close False FileName = Dir() Loop Application.EnableEvents = True Application.ScreenUpdating = True End Sub Fast deletion of named columns in a spreadsheet which is responding slowly: Sometimes, one does not simply ‘delete a column’. This is for those times. Sub Delete_Surplus_Columns() Dim FindString As String Dim iCol As Long, LastCol As Long, FirstCol As Long Dim CalcMode As Long With Application CalcMode = .Calculation .Calculation = xlCalculationManual .ScreenUpdating = False End With FirstCol = 1 With ActiveSheet .DisplayPageBreaks = False LastCol = .Cells(3, Columns.Count).End(xlToLeft).Column For iCol = LastCol To FirstCol Step -1 If IsError(.Cells(3, iCol).Value) Then 'Do nothing 'This avoids an error if there is a error in the cell ElseIf .Cells(3, iCol).Value = "Value B" Then .Columns(iCol).Delete ElseIf .Cells(3, iCol).Value = "Value C" Then .Columns(iCol).Delete End If Next iCol End With With Application .ScreenUpdating = True .Calculation = CalcMode End With End Sub Find and replace based on a table in another worksheet: Use X1Part for string match & replace within a cell, or X1 whole for whole cell match & replace: Sub Substitutions() Dim rngData As Range Dim rngLookup As Range Dim Lookup As Range With Sheets("Sheet1") Set rngData = .Range("A1", .Range("A" & Rows.Count).End(xlUp)) End With With Sheets("Sheet2") Set rngLookup = .Range("A1", .Range("A" & Rows.Count).End(xlUp)) End With For Each Lookup In rngLookup If Lookup.Value <> "" Then rngData.Replace What:=Lookup.Value, _ Replacement:=Lookup.Offset(0, 1).Value, _ LookAt:=xlWhole, _ SearchOrder:=xlByRows, _ MatchCase:=False End If Next Lookup End Sub Unhide all sheets in a workbook: Do your hidden sheets tell the tale of 1,000 previous clients? You don’t need me to tell you this can look unprofessional. Bring those hidden sheets up from the dregs in one go with this vba code so you can delete them. Otherwise, you’ll have to tediously unhide them 1 by 1 – there is no option in the interface to do this all at once. Sub Unhide_All_Sheets() Dim wks As Worksheet For Each wks In ActiveWorkbook.Worksheets wks.Visible = xlSheetVisible Next wksEnd Sub Change pivot table data source for all pivot tables on a worksheet: Your data source has changed. You have 12 pivot tables to update. You just lost your lunch break. Or did you? To update all their data sources in one fell swoop, replace WORKSHEETNAME with the name of your worksheet and DATA with the name of your data source: Sub Change_Pivot_Source() Dim pt As PivotTable For Each pt In ActiveWorkbook.Worksheets("WORKSHEETNAME").PivotTables pt.ChangePivotCache ActiveWorkbook.PivotCaches.Create _ (SourceType:=xlDatabase, SourceData:="DATA") Next ptEnd Sub Convert all ‘numbers stored as text’ to general: “Number stored as text!” .We’ve all seen it. We’ve all been annoyed by it. I had several thousand rows to convert and this took minutes, not seconds. Skip it all using this, replacing your range: Sub macro()Range("AG:AK").Select 'specify the range which suits your purposeWith SelectionSelection.NumberFormat = "general".Value = .ValueEnd WithEnd Sub There are other ways to do it, but if you have a big dataset, this is the fastest way. BONUS TIPS If you have a slow spreadsheet that’s locked up Excel while it’s calculating, but you still need to use Excel for other stuff, you can open a completely new instance of Excel by holding Alt, clicking Excel in the taskbar, and answering ‘yes’ to the pop up box. This isn’t just a new worksheet – it’s a totally new instance of Excel. To open a new workbook in the same instance of Excel a bit more quickly than usual when you already have workbooks open, you can use a single middle mouse click on Excel in the taskbar. We’ve written some other blog posts about excel, you can find them here: 5 GREAT USES OF THE IF FORMULA IN EXCEL (YOU MAY NOT KNOW ABOUT) 10 GREAT EXCEL SHORTCUTS (YOU MIGHT NOT KNOW ABOUT) 5 GREAT TIME-SAVING EXCEL TIPS (YOU MAY NOT KNOW ABOUT) The post Excel Cheat Sheet for Keyword Marketers appeared first on FOUND.
0 notes
Link
Python 3.9 is expected to release on Monday, 05 October 2020. Prior to releasing the official version, the developers had planned to release six alpha, five beta preview, and two release candidates.
[Read what’s python good for.]
At the time of writing this article, the first candidate was recently released on 11 August. Now, we are anxiously waiting for the second release candidate which will probably be available from 14 September.
So, you might be wondering what’s new in Python 3.9. Right?
There are some significant changes that will dictate the way Python programs work. Most importantly, in this recent version, you will get a new parser that is based on Parsing Expression Grammar (PEG). Similarly, merge | and update |= Union Operators are added to dict .
Let’s have a more in-depth look at all the upcoming features and improvements of Python 3.9.
New Parser Based on PEG
Unlike the older LL(1) parser, the new one has some key differences that make it more flexible and future proof. Basically in LL(1), the Python developers had used several “hacks” to avoid its limitations. In turn, it affects the flexibility of adding new language features.
The major difference between PEG and a context-free-grammar based parsers (e.g. LL(1)) is that in PEG the choice operator is ordered.
Let’s suppose we write this rule: A | B | C.
Now, in the case of LL(1) parser, it will generate constructions to conclude which one from A, B, or C must be expanded. On the other hand, PEG will try to check whether the first alternative (e.g. A) succeeds or not. It will continue to the next alternative only when A doesn’t succeed. In simple words, PEG will check the alternatives in the order in which they are written.
Support for the IANA Time Zone
In real-world applications, users usually require only three types of time zones.
UTC
The local time zone of the system
IANA time zones
Now, if are already familiar with previous versions of Python then you might know that Python 3.2 introduced a class datetime.timezone. Basically, its main purpose was to provide support for UTC.
In true sense, the local time zone is still not available. But, in version 3.0 of Python, the developers changed the semantics of naïve time zones to support “local time” operations.
In Python 3.9, they are going to add support for the IANA time zone database. Most of the time, this database is also referred to as “tz” or the Olson database. So, don’t get confused with these terms.
All of the IANA time zone functionality is packed inside the zoneinfo module. This database is very popular and widely distributed in Unix-like operating systems. But, remember that Windows uses a completely different method for handling the time zones.
Added Union Operators
In previous versions of Python, it’s not very efficient to merge or update two dicts. That’s why the developers are now introducing Union Operators like | for merging and |= for updating the dicts.
For example, earlier when we use d1.update(d2) then it also modifies d1. So, to fix it, we have to implement a small “hack” something like e = d1.copy(); e.update(d2).
Actually, here we are creating a new temporary variable to hold the value. But, this solution is not very efficient. That’s the main reason behind adding those new Union Operators.
Introducing removeprefix() and removesuffix()
Have you ever feel the need for some functions that can easily remove prefix or suffix from a given string?
Now, you might say that there are already some functions like str.lstrip([chars]) and str.rstrip([chars]) that can do this. But, this is where the confusion starts. Actually, these functions work with a set of characters instead of a substring.
So, there is definitely a need for some separate functions that can remove the substring from the beginning or end of the string.
Another reason for providing built-in support for removeprefix() and removesuffix() is that application developers usually write this functionality on their own to enhance their productivity. But, in most cases, they make mistakes while handling empty strings. So, a built-in solution can be very helpful for real-world apps.
Type Hinting Generics In Standard Collections
Did you ever notice the duplicate collection hierarchy in the typing module?
For example, you can either use typing.List or the built-in list. So, in Python 3.9, the core development team has decided to add support for generics syntax in the typing module. The syntax can now be used in all standard collections that are available in this module.
The major plus point of this feature is that now user can easily annotate their code. It even helps the instructors to teach Python in a better way.
Added graphlib module
In graphs, a topological order plays an important role to identify the flow of jobs. Meaning that it follows a linear order to tell which task will run before the other.
The graphlib module enables us to perform a topological sort or order of a graph. It is mostly used with hashable nodes.
Modules That Are Enhance in Python 3.9
In my opinion, the major effort took place while improving the existing modules. You can evaluate this with the fact that a massive list of 35 modules is updated to optimize the Python programming language.
Some of the most significant changes happened inside gc, http, imaplib, ipaddress, math, os, pydoc, random, signal, socket, time, and sys modules.
Features Deprecated
Around 16 features are deprecated in Python version 3.9. You can get detailed information from the official Python 3.9 announcement . Here, I’ll try to give you a brief overview of the most important things that are deprecated.
If you have ever worked with random module then you probably know that it can accept any hashable type as a seed value. This can have unintended consequences because there is no guarantee whether the hash value is deterministic or not. That’s why the developers decided to only accept None, int, float, str, bytes, and bytearray as the seed value.
Also, from now onwards you must specify the mode argument to open a GzipFile file for writing.
What’s Removed?
A total of 21 features that were deprecated in previous versions of Python are now completely dropped from the language. You may have a look at the complete list on Python’s website .
0 notes
Text
Structured JUnit 5 testing
Automated tests, in Java most commonly written with JUnit, are critical to any reasonable software project. Some even say that test code is more important than production code, because it’s easier to recreate the production code from the tests than the other way around. Anyway, they are valuable assets, so it’s necessary to keep them clean.
Adding new tests is something you’ll be doing every day, but hold yourself from getting into a write-only mode: Its overwhelmingly tempting to simply duplicate an existing test method and change just some details for the new test. But when you refactor the production code, you often have to change some test code, too. If this is spilled all over your tests, you will have a hard time; and what’s worse, you will be tempted to not do the refactoring or even stop writing tests. So also in your test code you’ll have to reduce code duplication to a minimum from the very beginning. It’s so little extra work to do now, when you’re into the subject, that it will amortize in no time.
JUnit 5 gives us some opportunities to do this even better, and I’ll show you some techniques here.
Any examples I can come up with are necessarily simplified, as they can’t have the full complexity of a real system. So bear with me while I try to contrive examples with enough complexity to show the effects; and allow me to challenge your fantasy that some things, while they are just over-engineered at this scale, will prove useful when things get bigger.
If you like, you can follow the refactorings done here by looking at the tests in this Git project. They are numbered to match the order presented here.
Example: Testing a parser with three methods for four documents
Let’s take a parser for a stream of documents (like in YAML) as an example test subject. It has three methods:
public class Parser { /** * Parse the one and only document in the input. * * @throws ParseException if there is none or more than one. */ public static Document parseSingle(String input); /** * Parse only the first document in the input. * * @throws ParseException if there is none. */ public static Document parseFirst(String input); /** Parse the list of documents in the input; may be empty, too. */ public static Stream parseAll(String input); }
We use static methods only to make the tests simpler; normally this would be a normal object with member methods.
We write tests for four input files (not to make things too complex): one is empty, one contains a document with only one space character, one contains a single document containing only a comment, and one contains two documents with each only containing a comment. That makes a total of 12 tests looking similar to this one:
class ParserTest { @Test void shouldParseSingleInDocumentOnly() { String input = "# test comment"; Document document = Parser.parseSingle(input); assertThat(document).isEqualTo(new Document().comment(new Comment().text("test comment"))); } }
Following the BDD given-when-then schema, I first have a test setup part (given), then an invocation of the system under test (when), and finally a verification of the outcome (then). These three parts are delimited with empty lines.
For the verification, I use AssertJ.
To reduce duplication, we extract the given and when parts into methods:
class ParserTest { @Test void shouldParseSingleInDocumentOnly() { String input = givenCommentOnlyDocument(); Document document = whenParseSingle(input); assertThat(document).isEqualTo(COMMENT_ONLY_DOCUMENT); } }
Or when the parser is expected to fail:
class ParserTest { @Test void shouldParseSingleInEmpty() { String input = givenEmptyDocument(); ParseException thrown = whenParseSingleThrows(input); assertThat(thrown).hasMessage("expected exactly one document, but found 0"); } }
The given... methods are called three times each, once for every parser method. The when... methods are called four times each, once for every input document, minus the cases where the tests expect exceptions. There is actually not so much reuse for the then... methods; we only extract some constants for the expected documents here, e.g. COMMENT_ONLY.
But reuse is not the most important reason to extract a method. It’s more about hiding complexity and staying at a single level of abstraction. As always, you’ll have to find the right balance: Is whenParseSingle(input) better than Parser.parseSingle(input)? It’s so simple and unlikely that you will ever have to change it by hand, that it’s probably better to not extract it. If you want to go into more detail, read the Clean Code book by Robert C. Martin, it’s worth it!
You can see that the given... methods all return an input string, while all when... methods take that string as an argument. When tests get more complex, they produce or require more than one object, so you’ll have to pass them via fields. But normally I wouldn’t do this in such a simple case. Let’s do that here anyway, as a preparation for the next step:
class ParserTest { private String input; @Test void shouldParseAllInEmptyDocument() { givenEmptyDocument(); Stream stream = whenParseAll(); assertThat(stream.documents()).isEmpty(); } private void givenEmptyDocument() { input = ""; } private Stream whenParseAll() { return Parser.parseAll(input); } }
Adding structure
It would be nice to group all tests with the same input together, so it’s easier to find them in a larger test base, and to more easily see if there are some setups missing or duplicated. To do so in JUnit 5, you can surround all tests that call, e.g., givenTwoCommentOnlyDocuments() with an inner class GivenTwoCommentOnlyDocuments. To have JUnit still recognize the nested test methods, we’ll have to add a @Nested annotation:
class ParserTest { @Nested class GivenOneCommentOnlyDocument { @Test void shouldParseAllInDocumentOnly() { givenOneCommentOnlyDocument(); Stream stream = whenParseAll(); assertThat(stream.documents()).containsExactly(COMMENT_ONLY); } } }
In contrast to having separate top-level test classes, JUnit runs these tests as nested groups, so we see the test run structured like this:
Nice, but we can go a step further. Instead of calling the respective given... method from each test method, we can call it in a @BeforeEach setup method, and as there is now only one call for each given... method, we can inline it:
@Nested class GivenTwoCommentOnlyDocuments { @BeforeEach void givenTwoCommentOnlyDocuments() { input = "# test comment\n---\n# test comment 2"; } }
We could have a little bit less code (which is generally a good thing) by using a constructor like this:
@Nested class GivenTwoCommentOnlyDocuments { GivenTwoCommentOnlyDocuments() { input = "# test comment\n---\n# test comment 2"; } }
…or even an anonymous initializer like this:
@Nested class GivenTwoCommentOnlyDocuments { { input = "# test comment\n---\n# test comment 2"; } }
But I prefer methods to have names that say what they do, and as you can see in the first variant, setup methods are no exception. I sometimes even have several @BeforeEach methods in a single class, when they do separate setup work. This gives me the advantage that I don’t have to read the method body to understand what it does, and when some setup doesn’t work as expected, I can start by looking directly at the method that is responsible for that. But I must admit that this is actually some repetition in this case; probably it’s a matter of taste.
Now the test method names still describe the setup they run in, i.e. the InDocumentOnly part in shouldParseSingleInDocumentOnly. In the code structure as well as in the output provided by the JUnit runner, this is redundant, so we should remove it: shouldParseSingle.
The JUnit runner now looks like this:
Most real world tests share only part of the setup with other tests. You can extract the common setup and simply add the specific setup in each test. I often use objects with all fields set up with reasonable dummy values, and only modify those relevant for each test, e.g. setting one field to null to test that specific outcome. Just make sure to express any additional setup steps in the name of the test, or you may overlook it.
When things get more complex, it’s probably better to nest several layers of Given... classes, even when they have only one test, just to make all setup steps visible in one place, the class names, and not some in the class names and some in the method names.
When you start extracting your setups like this, you will find that it gets easier to concentrate on one thing at a time: within one test setup, it’s easier to see if you have covered all requirements in this context; and when you look at the setup classes, it’s easier to see if you have all variations of the setup covered.
Extracting when...
The next step gets a little bit more involved and there are some forces to balance. If it’s too difficult to grasp now, you can also simply start by just extracting Given... classes as described above. When you’re fluent with that pattern and feel the need for more, you can return here and continue to learn.
You may have noticed that the four classes not only all have the same three test method names (except for the tests that catch exceptions), these three also call exactly the same when... methods; they only differ in the checks performed. This is, too, code duplication that has a potential to become harmful when the test code base gets big. In this carefully crafted example, we have a very symmetric set of three when... methods we want to call; this not always the case, so it’s not something you’ll be doing with every test class. But it’s good to know the technique, just in case. Let’s have a look at how it works.
We can extract an abstract class WhenParseAllFirstAndSingle to contain the three test methods that delegate the actual verification to abstract verify... methods. As the when... methods are not reused any more and the test methods have the same level of abstraction, we can also inline these.
class ParserTest { private String input; abstract class WhenParseAllFirstAndSingle { @Test void whenParseAll() { Stream stream = Parser.parseAll(input); verifyParseAll(stream); } protected abstract void verifyParseAll(Stream stream); } @Nested class GivenOneCommentOnlyDocument extends WhenParseAllFirstAndSingle { @BeforeEach void givenOneCommentOnlyDocument() { input = "# test comment"; } @Override protected void verifyParseAll(Stream stream) { assertThat(stream.documents()).containsExactly(COMMENT_ONLY); } } }
The verification is done in the implementations, so we can’t say something like thenIsEmpty, we’ll need a generic name. thenParseAll would be misleading, so verify with the method called is a good name, e.g. verifyParseAll.
This extraction works fine for parseAll and the whenParseAll method is simple to understand. But, e.g., parseSingle throws an exception when there is more than one document. So the whenParseSingle test has to delegate the exception for verification, too.
Let’s introduce a second verifyParseSingleException method for that check. When we expect an exception, we don’t want to implement the verifyParseSingle method any more, and when we don’t expect an exception, we don’t want to implement the verifyParseSingleException, so we give both verify... methods a default implementation instead:
abstract class WhenParseAllFirstAndSingle { @Test void whenParseSingle() { ParseException thrown = catchThrowableOfType(() -> { Document document = Parser.parseSingle(input); verifyParseSingle(document); }, ParseException.class); if (thrown != null) verifyParseSingleException(thrown); } protected void verifyParseSingle(Document document) { fail("expected exception was not thrown. see the verifyParseSingleParseException method for details"); } protected void verifyParseSingleException(ParseException thrown) { fail("unexpected exception. see verifyParseSingle for what was expected", thrown); } }
That’s okay, but when you expect an exception, but it doesn’t throw and the verification fails instead, you’ll get a test failure that is not very helpful (stacktraces omitted):
java.lang.AssertionError: Expecting code to throw but threw instead
So we need an even smarter whenParseSingle:
abstract class WhenParseAllFirstAndSingle { @Test void whenParseSingle() { AtomicReference document = new AtomicReference<>(); ParseException thrown = catchThrowableOfType(() -> document.set(Parser.parseSingle(input)), ParseException.class); if (thrown != null) verifyParseSingleException(thrown); else verifyParseSingle(document.get()); } }
We have to pass the document from the closure back to the method level. I can’t use a simple variable, as it has to be assigned to null as a default, making it not-effectively-final, so the compiler won’t allow me to. Instead, I use an AtomicReference.
In this way, even when a test that expects a result throws an exception or vice versa, the error message is nice and helpful, e.g. when GivenEmptyDocument.whenParseSingle, which throws an exception, would expect an empty document, the exception would be:
AssertionError: unexpected exception. see verifyParseSingle for what was expected Caused by: ParseException: expected exactly one document, but found 0
All of this does add quite some complexity to the when... methods, bloating them from 2 lines to 6 with a non-trivial flow. Gladly, we can extract that to a generic whenVerify method that we can put into a test utilities class or even module.
abstract class WhenParseAllFirstAndSingle { @Test void whenParseSingle() { whenVerify(() -> Parser.parseSingle(input), ParseException.class, this::verifyParseSingle, this::verifyParseSingleException); } protected void verifyParseSingle(Document document) { fail("expected exception was not thrown. see the verifyParseSingleException method for details"); } protected void verifyParseSingleException(ParseException thrown) { fail("unexpected exception. see verifyParseSingle for what was expected", thrown); } /** * Calls the call and verifies the outcome. * If it succeeds, it calls verify. * If it fails with an exception of type exceptionClass, it calls verifyException. * * @param call The `when` part to invoke on the system under test * @param exceptionClass The type of exception that may be expected * @param verify The `then` part to check a successful outcome * @param verifyException The `then` part to check an expected exception * @param The type of the result of the `call` * @param The type of the expected exception */ public static void whenVerify( Supplier call, Class exceptionClass, Consumer verify, Consumer verifyException) { AtomicReference success = new AtomicReference<>(); E failure = catchThrowableOfType(() -> success.set(call.get()), exceptionClass); if (failure != null) verifyException.accept(failure); else verify.accept(success.get()); } }
The call to whenVerify is still far from easy to understand; it’s not clean code. I’ve added extensive JavaDoc to help the reader, but it still requires getting into. We can make the call more expressive by using a fluent builder, so it looks like this:
abstract class WhenParseAllFirstAndSingle { @Test void whenParseFirst() { when(() -> Parser.parseFirst(input)) .failsWith(ParseException.class).then(this::verifyParseFirstException) .succeeds().then(this::verifyParseFirst); } }
This makes the implementation explode, but the call is okay now.
As seen above, the tests themselves look nice, and that’s the most important part:
@Nested class GivenTwoCommentOnlyDocuments extends WhenParseAllFirstAndSingle { @BeforeEach void givenTwoCommentOnlyDocuments() { input = "# test comment\n---\n# test comment 2"; } @Override protected void verifyParseAll(Stream stream) { assertThat(stream.documents()).containsExactly(COMMENT_ONLY, COMMENT_ONLY_2); } @Override protected void verifyParseFirst(Document document) { assertThat(document).isEqualTo(COMMENT_ONLY); } @Override protected void verifyParseSingleException(ParseException thrown) { assertThat(thrown).hasMessage("expected exactly one document, but found 2"); } }
Multiple When... classes
If you have tests that only apply to a specific test setup, you can simply add them directly to that Given... class. If you have tests that apply to all test setups, you can add them to the When... super class. But there may be tests that apply to more than one setup, but not to all. In other words: you may want to have more than one When... superclass, which isn’t allowed in Java, but you can change the When... classes to interfaces with default methods. You’ll then have to change the fields used to pass test setup objects (the input String in our example) to be static, as interfaces can’t access non-static fields.
This looks like a simple change, but it can cause some nasty behavior: you’ll have to set these fields for every test, or you may accidentally inherit them from tests that ran before, i.e. your tests depend on the execution order. This will bend the time-space-continuum when you try to debug it, so be extra careful. It’s probably worth resetting everything to null in a top level @BeforeEach. Note that @BeforeEach methods from super classes are executed before those in sub classes, and the @BeforeEach of the container class is executed before everything else.
Otherwise, the change is straightforward:
class ParserTest { private static String input; @BeforeEach void resetInput() { input = null; } interface WhenParseAllFirstAndSingle { @Test default void whenParseAll() { Stream stream = Parser.parseAll(input); verifyParseAll(stream); } void verifyParseAll(Stream stream); } @Nested class GivenTwoCommentOnlyDocuments implements WhenParseAllFirstAndSingle { @BeforeEach void givenTwoCommentOnlyDocuments() { input = "# test comment\n---\n# test comment 2"; } // ... } }
Generic verifications
You may want to add generic verifications, e.g. YAML documents and streams should render toString equal to the input they where generated from. For the whenParseAll method, we add a verification line directly after the call to verifyParseAll:
interface WhenParseAllFirstAndSingle { @Test default void whenParseAll() { Stream stream = Parser.parseAll(input); verifyParseAll(stream); assertThat(stream).hasToString(input); } }
This is not so easy with the the other tests that are sometimes expected to fail (e.g. whenParseSingle). We chose an implementation using the whenVerify method (or the fluent builder) which we wanted to be generic. We could give up on that and inline it, but that would be sad.
Alternatively, we could add the verification to all overridden verifyParseFirst methods, but that would add duplication and it’d be easy to forget. What’s worse, each new verification we wanted to add, we’d have to add to every verify... method; this just doesn’t scale.
It’s better to call the generic verification directly after the abstract verification:
class ParserTest { interface WhenParseAllFirstAndSingle { @Test default void whenParseFirst() { when(() -> Parser.parseFirst(input)) .failsWith(ParseException.class).then(this::verifyParseFirstException) .succeeds().then(document -> { verifyParseFirst(document); verifyToStringEqualsInput(document); }); } default void verifyParseFirst(Document document) { fail("expected exception was not thrown. see the verifyParseFirstException method for details"); } default void verifyParseFirstException(ParseException thrown) { fail("unexpected exception. see verifyParseFirst for what was expected", thrown); } default void verifyToStringEqualsInput(Document document) { assertThat(document).hasToString(input); } } }
If you have more than one generic verification, it would be better to extract them to a verifyParseFirstGeneric method.
There is one last little nasty detail hiding in this test example: The verifyToStringEqualsInput(Document document) method has to be overridden in GivenTwoCommentOnlyDocuments, as only the first document from the stream is part of the toString, not the complete input. Make sure to briefly explain such things with a comment:
@Nested class GivenTwoCommentOnlyDocuments implements WhenParseAllFirstAndSingle { @Override public void verifyToStringEqualsInput(Document document) { assertThat(document).hasToString("# test comment"); // only first } }
tl;dr
To add structure to a long sequence of test methods in a class, group them according to their test setup in inner classes annotated as @Nested. Name these classes Given... and set them up in one or more @BeforeEach methods. Pass the objects that are set up and then used in your when... method in fields.
When there are sets of tests that should be executed in several setups (and given you prefer complexity over duplication), you may want to extract them to a super class, or (if you need more than one such set in one setup) to an interface with default methods (and make the fields you set up static). Name these classes or interfaces When... and delegate the verification to methods called verify + the name of the method invoked on the system under test.
I think grouping test setups is something you should do even in medium-sized test classes; it pays off quickly. Extracting sets of tests adds quite some complexity, so you probably should do it only when you have a significantly large set of tests to share between test setups, maybe 5 or more.
I hope this helps you reap the benefits JUnit 5 provides. I’d be glad to hear if you have any feedback from nitpicking to success stories.
Der Beitrag Structured JUnit 5 testing erschien zuerst auf codecentric AG Blog.
Structured JUnit 5 testing published first on https://medium.com/@koresol
0 notes
Text
Extract Highlighted Text & Removing All Text from PDF Document using .NET
What's New in this Release?
Aspose team is very excited to announce the new version of Aspose.PDF for .NET 18.6. This new release has introduced new features related to text manipulations and PDF/UA validation. Along with that, it has also made some fixes to the bugs, reported in earlier versions of the API. It has been an essential requirement to extract highlighted text from PDF documents. Earlier it was possible to extract text from PDF documents on the basis of some specific regular expressions or by specifying a string to be searched. TextFragmentAbsorber and TextAbsorber classes of the API, have been being used quite often and efficiently to serve the purpose. However, regarding the requirement of extracting highlighted text from PDF document, it has investigated the feature and introduced TextMarkupAnnotation.GetMarkedText() and TextMarkupAnnotation.GetMarkedTextFragments() methods in API. Users can extract highlighted text from PDF document by filtering TextMarkupAnnotation and using mentioned methods. An example, demonstrating the feature usage has also been showcased in the API documentation. While removing text from PDF documents using earlier versions of the API, users needed to set found text as empty string. The performance overhead in this case was, to invoke a number of checks and adjustment operations of text position. Which was why, several performance issues were observed while performing such operations. It could not minimize the number of checks and adjustment operations, as they are essential in text editing scenarios. Moreover, users cannot determine, how many of text fragments will removed and adjusted when they are processed in loop. In Aspose.PDF for .NET 18.6, new Aspose.Pdf.Operators.TextShowOperator() method has been introduced, in order to remove all text from PDF pages. Therefore, we recommend using this method to remove all text from PDF document, as it surely minimizes the time and works very fast. In latest release of Aspose.PDF for .NET, all descendants of Aspose.Pdf.Operator were moved into namespace Aspose.Pdf.Operators. Thus ‘new Aspose.Pdf.Operators.GSave()’ should be used, instead of ‘new Aspose.Pdf.Operator.GSave()’. While upgrading to latest version of the API, users will need to upgrade your existing code where users has used previous Aspose.Pdf.Operator namespace. It has have also worked for introducing Accessibility Features, thus introduced new features as part of work on 508 compliance (WCAG) such as PDF/UA validation feature was added and Tagged PDF support was added. The list of important new and improved features are given below
Add feature "Extract Highlighted Text from HighlightTextMarkUpAnnotations" to the TextFragmentAbsorber class
Add support of OTF font when embedding in PDF
Text Extraction - Spaces are improperly embedded inside words
TableAbsorber throws exception while trying to access any row other than first row of first table or any other table than first
PDF to Image - Some contents are overlapping
PDF to JPEG - Incorrect output
TableAbsorber: incorrect table count in PDF
Text is overlapped when saving particular document as image or HTML
PDF to HTML - Object reference not set to an instance of an object
Conversion HTML to PDF produces incorrect output
PDF to PDFA - Comments are broken in resultant document
Flattening Fields is not flattening the Print button inside PDF
The output is too big after conversion to PDFA_1B format
After conversion PDF-to-PDFA the output contains corrupted diagram
The document loaded from HMTL file looks different then original
PDF to PDF/A-1b - the output PDF does not pass compliance test
PDF to PDF/A-1b - the output PDF does not pass compliance test
PDF to JPG - Blue gradient is darker in the JPG compared to the PPT slide PDF
PDF to JPG - Objects fading to transparent
PDF to JPG - transparent turns to white
DF to JPG - Objects fading to transparent causes image differences
PDF to JPG - Objects fading to transparent causes image differences
Yellow background not same after converting PDF to PDF/A
JPEG output loses the fade effect on the source document
The document image loses fading to transparent in PDF output
Blank pages added after HTML to PDF rendition
PDF to PDF/A-2b - the chart labels are rotated
PDF to PDF/A-2b - some labels get blurred
Duplicated evaluation watermarks when saving EPUB document
Output image or html is filled with black color
HTML to PDF - exception thrown
Flattening Fields is not flattening the buttons inside PDF
Multi byte characters not displayed in PDF
Header added but footer is missing (HTML->PDF)
The header and the footer exist only on the first page.
Missing table after adding to Footer
PDF to PDF/A-2b
Unable to load OTF Font from a resource stream
Other most recent bug fixes are also included in this release.
Newly added documentation pages and articles
Some new tips and articles have now been added into Aspose.PDF for .NET documentation that may guide users riefly how to use Aspose.PDF for performing different tasks like the followings.
Extract Highlighted Text from PDF Document
Remove All Text from PDF Document
Overview: Aspose.Pdf for .NET
Aspose.Pdf is a .Net Pdf component for the creation and manipulation of Pdf documents without using Adobe Acrobat. Create PDF by API, XML templates & XSL-FO files. It supports form field creation, PDF compression options, table creation & manipulation, graph objects, extensive hyperlink functionality, extexnded security controls, custom font handling, add or remove bookmarks; TOC; attachments & annotations; import or export PDF form data and many more. Also convert HTML, XSL-FO and MS WORD to PDF.
More about Aspose.Pdf for .NET
Homepage of Aspose.Pdf for .NET C#
Download Aspose.Pdf for .NET
Read online documentation of Aspose.Pdf for .NET
Online Demo for Aspose.Pdf for .NET
#Extract Highlighted Text from PDF#Remove all Text from PDF#OTF font support#PDF to JPEG conversion#Export PDF to HTML#HTML to PDF Conversion#.NET PDF APIs
0 notes
Text
Version 246
youtube
windows
zip
exe
os x
app
tar.gz
linux
tar.gz
source
tar.gz
I had a great week getting back to normal schedule. I've fixed a lot of outstanding bugs and moved other ongoing jobs forward.
a/c fixes
I have fixed a problem in how some autocomplete counts were being generated. You will be prompted to regenerate your autocomplete cache once you update. Please do so, and let me know if you discover any other miscounting in the future--I think there may be another issue, likely with 'all known files' counts (usually seen in the manage tags dialog).
Furthermore, autocomplete queries will now search for namespace, so typing 'char' will give you all the 'character:' tags. I find this very useful, but it is an experiment--if you find it way too laggy, let me know and I'll add an option to disable it.
I have also fixed multiple issues with wildcard searching (putting '*' in a tag autocomplete search to represent any number of characters). There are several changes and improvements to this code, so if you do a lot of these searches, please let me know how you now find it and whether you would like some options to customise its behaviour.
invalid tags
Last week, I made tags with spaces before the 'subtag' component invalid. An example would be 'series: kill la kill'--attempting to type that should collapse it down to 'series:kill la kill'. As some users prefer to have the leading space, my intention is to collapse everything to a common standard and then add gui options to customise display to whatever namespace separator people want, whether that is to stay as ':' or move to ': ' or ' - ' or whatever they like.
I converted and renamed these tags serverside last week, and now I have updated the clientside records. I apologise if you have had trouble editing tags in the meantime.
While I have tried to automatically swap invalid tags with good, unfortunately these systems are complicated and so I have sometimes had to replace invalid tag components with valid placeholders such as 'hydrus invalid tag:"old_invalid_tag_here"'. I have attempted to minimise this mess, but there is still a bit hanging around, particularly on tag repositories. Some clients will see more than others. If you see these tags, please do petition/delete/replace them as appropriate. I expect to write a bit more code to further clean these up in future, so please let me know if you are overwhelmed with them and what form they tend to be in.
other stuff
Review services will now show file and tag counts for services that have them!
The prototype duplicate search page now has a control to select the file domain, so I believe the issue of physically deleted files appearing in the current 'show some pairs' system should be fixed. Let me know if it isn't!
I fixed the issue of the new repository update files appearing in 'all local files'--they will now be hidden, and system file counts corrected.
full list
fixed a critical bug in serverside content deserialisating that meant servers were not processing most client-submitted data properly
fixed a critical bug in 'all known tags' autocomplete regeneration--please run database->regen->a/c cache when it is convenient and let me know if your numbers are still off
fixed the pre-v238 update problem for good by abandoning update attempts and advising users to try v238 first
clientside invalid tags will now be collapsed like with the server last week. if a tag is invalid (typically something with an extra space, like "series: blah"), the update code will attempt to replace existing mappings with the collapsed valid version. some unusual cases may remain--they will be replaced with 'invalid namespace "series "' and similar. Please remove and replace these when convenient and contact me if there are way too many for you to deal with
duplicates pages now have a file domain for the filtering section, and they remember this domain through session loads
this file domain is accurate--counting potential duplicates and fetching pairs for 'show some pairs' only from those domains. the issue of remote files appearing should be gone!
there is now only one 'idle' entry in the duplicates page cog menu--it combines the three previous into one
fixed numerous irregularities across the wildcard code. all search input now has an implicit '*' on the end unless you put a '*' anywhere else, in which case it acts exactly as you enter it, with a non-* beginning matching beginning of string, whitespace, or colon, and non-* end matching end of string or whitespace
autocomplete now searches namespace, so entering 'char' will load up all the 'character:' tags along with 'series:di gi charat'. this can lag to hell and back, so it may either need some work or be optional in the future. feedback would be appreciated
typing 'namespace:' will include all the series tags below the special optimised 'namespace:*anything*' tag
autocomplete searches recognise an explicit '*' no matter where it is in the entry text. typing 'a*' will load up all the a tags and present a 'a*' wildcard option
quickly entering a wildcard entry will now submit the correct wildcard predicate ('rather than a literal 'hel*' or whatever tag)
review services panel now reports total mappings info on tag services
review services panel now reports total files info on file services
manage services's listctrl is now type | name | deletable and initially sorts by type. the strings used for hydrus service types are also improved
manage serverside services (called by server admins to manage their services) have fixed setnondupe port and name on edit service events
new popup messages will now also appear if there were previously no popup messages to display if the current focus is on a child on_top frame, such as review services (you'll now see the processing popup appear when you click 'process now' on review services)
the popup message manager now initialises its display window with a single message that is quickly dismissed. this helps set up some variables in a safe environment so they don't have to be generated later when the gui might be minimised or otherwise unusual
hid hydrus update files from 'all local files' searches
added 'media_view' entries for hydrus update files, just in case they are still visible in some unusual contexts (and they may be again in a future update anyway)
fixed 'recent tags' being returned from the database out of order
by default, 'recent tags' is now on for new users
'get tags even if file already in db' now defaults to False
file import status now allows a 'delete' action below the 'skip' action
file import status right-click event processing is more sane
fixed the new raw width/height sort choices, which were accidentally swapped
cleaned the media sort code generally
cleared out some redundant rows that are in some users' client_files_locations
namespaced predicates are no longer count-merged with their namespaceless versions in 'write' autocomplete dropdowns
'unknown' accounts should now properly resync after clientside service change
improved how registration keys are checked serverside when fetching access keys
fixed a v244 update problem when unexected additional tag parent/sibling petitions rows exist
improved my free space test code and applied it to the old v243->v244 free space test (it'll now test free space on your temporary path and report problems appropriately)
to improve log privacy and cleanliness, and to make it easier to report profiles, db/pubsub profiles now write to a separate log file named appropriately and labelled with the process's start time
profiles are more concise and formatted a little neater
across the program, three-period ... ellipses are now replaced with their single character unicode … counterpart (except to the console, where any instance of the unicode ellipsis will now be converted back to ...)
cleaned up some log printing code
cleaned up some experimental static serialisation code, still thinking if I like it or not
started on some proper unit tests for hydrus serialisable objects
fixed and otherwise updated a heap of unit test code to account for the v245 changes
cleaned up a bunch of old database table join code
started some databse-query-tuple-stripping code cleaning
deleted more old unused code
misc timing improvements
misc code cleanup experimentation
misc cleanup
next week
More of this, I think. I have a ton of small stuff to catch up on.
0 notes
Text
Scripting with PowerShell
Advertise here with BSA
Scripting is always a preferred choice for IT, businesses, server administrators, DBAs and professionals who aim to automate or schedule their routine tasks with flexibility and control. It not only makes you more productive but also improves your daily tasks.
The lack of task automation makes an emerging business lose most of its time and effort on managing its administrative tasks. You may have done tons of things to advertise your business, including creating a blog but when it comes managing your tasks you probably need something that makes your life a lot.
Introduction
Windows PowerShell is one of the powerful command line tools available for scripting. If you are familiar with Unix, DOS or any other command based tools, you would easily get expertise over PowerShell.
Your first script
A simple script in PowerShell can be written in a notepad. it is a sequence of commands called cmdletsthat will be executed one at a time.
Open notepad
Type a string: ‘Printing current date time..’
Type a cmdlet in next line: get-Date
Save file: MyFirstScript.ps1
Right click on the file and click ‘Run with PowerShell’
You can see the current date time printed on PowerShell Console
Whatever you type in double quotes, is displayed on the console and cmdlets gets executed.
Getting PowerShell on your machine
There is no need of additional installation for the tool, it is a part of Windows 7 and above by default. For earlier versions, it can be downloaded from Microsoft Scripting Center.
Just type windows or powershell in search area after pressing windows logo and you will find two PowerShell menus
Windows PowerShell is for plain console while ISE is Integrated Scripting Environment to write, test and execute scripts in the same window.
Building Blocks
Let us quickly get acquainted with the terminology to start coding. Here are the basic terms used –
Cmdlets
Commands written in PowerShell are named cmdlets(pronounced as ‘command lets’)which are the foundation of scripting. You can write a series of cmdlets to achieve your tasks. It is written as a verb-noun pair which is easy to remember and self-explanatory.
If we execute following cmdlet, it lists down all the childs from current location –
PS C:\> Get-Childitem
(Get – verb, Childitem – Noun)
Each cmdlet has an associated help file to know about its syntax – Description and parameters required to invoke it correctly. You can use cmdlet ‘Get-Help’ for same.
Aliases
Let us observe the following commands –
The cmdlet Get-childitem returns the list of files/folders in current directory in this case – C drive.
If you look at other two commands – dir and ls, both return the same result. Does that mean there are duplicate commands to solve the same problem?
No, these both are aliases to ‘Get-childitem’. You can create handy aliases of your important commands and use it. This is the reason why your DOS and Unix commands work seamlessly with PowerShell.
Following command sets alias for Set-Location cmdlet
PS C:\> New-Alias Goto Set-Location
You can find out existing aliases by command type – ‘Alias’ on your machine
PS C:\> Get-Command –Name *
Pipeline
You can use output of one cmdlet in another using pipe character (|). As an example you want to collect some data and then copy the output to a file, you can simply do it with one-line syntax
PS C:\> Get-Childitem | Export-Csv out.csv
Redirection
Two Redirection operators used are > and >>.
These enable you to send particular output types to files and output stream
Code
Message Type
*
All output
1
Success
2
Error
3
Warning
4
Verbose
5
Debug
Following command writes the out to a file instead of console
PS C:\> Get-Childitem * > out.txt
Operators
Like any other scripting language, PowerShell also provides an exhaustive list of operators to write powerful scripts. Some of the basic operators are listed for your reference here:
Operator
Symbol
Definition
Assignment
“=,+=,-=,*=,/=,%=,++,–“
Assigns one or more values to a variable
Comparison
“-eq, -ne”
Equal, Not equal
“-gt,-ge”
Greater than, Greater than or equal to
“-lt,-le”
Less than, Less than or equal to
“-replace”
Changes specified element in a value
“-match, -notmatch”
Regular expression matching
“-like, -notlike”
Matching wildcards
“-contains,-notcontains”
Returns TRUE if the value on its right is contained in the array on its left
“-in, -notin”
Returns TRUE only when given value exactly matches at least one of the reference values.
Logical
“-and, -or, -xor, -not, !”
Connect expressions and statements, allowing you to test for multiple conditions
Bitwise
“-band”
Bitwise AND
“-bor”
Bitwise OR (inclusive)
“-bxor”
Bitwise OR (exlcusive)
“-bnot”
Bitwise NOT
String
“-Split”
splits a string
“-join”
joins multiple strings
Execution Policy
Powershell executes cmdlets as per set execution policy of the machine or server. Sometimes it becomes necessary to explicitly set the policy on the scripts before executing on different machines.
The Set-ExecutionPolicy cmdlet is used for the purpose which has four options to choose from –
Policy
Definition
Restricted
No scripts can be run. PowerShell can be used only in interactive mode
AllSigned
Only scripts signed by a trusted publisher can be run
RemoteSigned
Downloaded scripts must be signed by a trusted publisher before they can be run
Unrestricted
No restrictions – all scripts can be run
Useful Commands
There are more than two hundred in-built cmdlets for use and developers can built complex ones by using the core commands. Some of the useful commands are listed below:
Cmdlet
Syntax
Output
Usage
Get-Date
Get-Date
Sunday, March 26, 2017 6:12:40 PM
Gets current date and time
(Get-Date).AddMinutes
(Get-Date).AddMinutes(60)
Sunday, March 26, 2017 7:12:40 PM
Adds 1 hour to current date and time
Copy-Item
Copy-Item c:\source.txt d:\destination
Copy source.txt to destination folder
Copying files and folders
Clear-Eventlog
Clear-Eventlog -LogName
Clears all enteries from specified event log
Restart-Service
Restart-Service -Servicename
Restarts service
Get-ChildItem
Get-ChildItem
Gets all files and folders
Some parameters make his more useful – force – to run without user confirmation on special folders include – to include certain files or folders exclude – to exclude certain files path – specified path instead of current directory
Set-Content
Set-Content C:\textFile.txt “Text being added here from PowerShell”
Saves text to a file
Remove-Item
Remove-Item C:\test -Recurse
Removes all contents from a folder
User will not be prompted before deletion
(Get-WmiObject -Class Win32_OperatingSystem -ComputerName .).Win32Shutdown(2)
(Get-WmiObject -Class Win32_OperatingSystem -ComputerName .).Win32Shutdown(2)
Restart current computer
Real-world Scenario
Let’s see how PowerShell made the life of a server administrator easy!
John Bell, one of the system administrator of an MNC is catering to some 2000 users and update patches on their desktops remotely through Windows Server 2010 and MS System Center Configuration Manager, SCCM. Now, when one or more patches get scheduled to run during night hours, often they failed on couple of machines due to disk space scarcity and lots of manual intervention and rework is required to close the current job. One of his colleagues suggested to take a proactive approach and get a list of machines with details of what is being stored on C drive, a day before patch execution job, so John decided to create a powershell script to get executed through SCCM on client machines automatically and send give a detailed report in a csv file to review the data usage and bottle necks.
Here is what he wrote (added inline comments for clarity) –
## Initiate source and destination $filePath="C:\" $outFile="D:\output.csv" ## Get last logged in username $strName=$env:username get-Date-formatr ## Get computer name $compName=$env:computername ## get total size and free space of c drive of selected computer $disk=Get-WmiObjectWin32_LogicalDisk-ComputerName$compName-Filter"DeviceID='C:'"| Select-ObjectSize,FreeSpace $TotalSpace= ($disk.Size/1gb) $FreeSpace= ($disk.FreeSpace/1gb) ## initiating two arrays for getting a list $arr= @() $finalObj= @() $object=$null ## Include Hidden Files $arr=Get-ChildItem$filePath-Force|where {$_.PSIsContainer -eq$False} |Select-ObjectName,FullName,CreationTimeUtc,LastWriteTimeUtc,length "Gathering information of files completed. Folder scan started..." ## Include Hidden Folder $arr=Get-ChildItem$filePath-Force|where {$_.PSIsContainer -eq$True} |Select-ObjectName,FullName,CreationTimeUtc,LastWriteTimeUtc #Loop for folders foreach($itemin$arr) { $FType="Folder" $FSize=0 $PerHDD=0 $item.FullName ## Include Hidden Files $FSize= (Get-ChildItem$item.FullName -Force-recurse-ErrorActionSilentlyContinue|Measure-Object-propertylength-sum).Sum $FSize=[math]::round($FSize/1gb,2) $PerHDD=[math]::Round($FSize/$TotalSpace*100,2) switch ($item.name ) { $PLogs {break} ;$MSOCache {break} ; $Recovery {break} ; $SystemVolumeInformation {break} default {$own=Get-Acl$item.FullName} } $object=New-Object-TypeNamePSObject $object|Add-Member-Name'CompName'-MemberTypeNoteproperty-Value$compName $object|Add-Member-Name'TotalSpace'-MemberTypeNoteproperty-Value$TotalSpace $object|Add-Member-Name'FreeSpace'-MemberTypeNoteproperty-Value$FreeSpace $object|Add-Member-Name'Name'-MemberTypeNoteproperty-Value$item.Name $object|Add-Member-Name'FilePath'-MemberTypeNoteproperty-Value$item.FullName $object|Add-Member-Name'Type'-MemberTypeNoteproperty-Value$FType $object|Add-Member-Name'Size'-MemberTypeNoteproperty-Value$FSize $object|Add-Member-Name'In'-MemberTypeNoteproperty-Value'GB' $object|Add-Member-Name'% of HDD'-MemberTypeNoteproperty-Value$PerHDD $finalObj+=$object } "Folder scan completed." $finalObj|Export-Csv$outFile "Job Completed! File created successfully"
Output is a csv file –
CompName
TotalSpace
FreeSpace
Name
Size
In
% of HDD
<compName>
99.99999619
29.15378189
Program Files
2.12
GB
2.12
Conclusion
PowerShell is extremely powerful and handy when comes to manage server and database tasks and can quickly automate tasks for you. Give it a try! Happy Coding!
via http://ift.tt/2o1U0Z9
0 notes