#SQL Server Destination
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Choosing Between SQL Server Destination and OLE DB Destination in SSIS: Performance & Flexibility
When working with SQL Server Integration Services (SSIS) to perform data integration and ETL (Extract, Transform, Load) tasks, you might encounter various destination components that allow you to write data to SQL Server. Two common components are the SQL Server Destination and the OLE DB Destination. Understanding the differences between these two can help you choose the appropriate component…
View On WordPress
0 notes
Text
Oracle Golden Gate - Replicat Process
Replicat Process Replicat process run on the destination or target server which reads the trail file, get the DML or DDL, and applies them to target database. It acts as a SQL apply. In Oracle GoldenGate, the Replicat process is a key component responsible for applying the data changes captured from the source database to the target database. Illustration of the GoldenGate Extract and Replicate…

View On WordPress
0 notes
Text
Python Full Stack Training in Kochi: Build Your Future with Code
In the rapidly evolving tech world, being a specialist is good—but being a full stack developer is even better. And when it comes to learning full stack development with Python, Kochi is becoming one of the most sought-after hubs in South India. If you're looking for comprehensive Python full stack training in Kochi, you're already on the right path toward a high-demand, future-proof career.
🧠 What is Python Full Stack Development?
Python full stack development combines front-end technologies like HTML, CSS, and JavaScript with back-end programming using Python frameworks such as Django or Flask. It’s not just about learning a language—it’s about understanding the full architecture of modern web applications.
A full stack Python developer can:
Build user interfaces (UI) with responsive design.
Handle server-side logic using Python.
Manage databases like MySQL or MongoDB.
Deploy applications using tools like Docker and Git.
Work with APIs and cloud-based technologies.
This makes Python full stack developers some of the most flexible and employable professionals in the IT industry.
🌴 Why Choose Kochi for Python Full Stack Training?
Kochi, known as the commercial capital of Kerala, has become a booming tech and startup destination. With the presence of IT parks like Infopark, affordable living, and strong educational infrastructure, it’s an ideal place to learn and grow.
Top reasons to study in Kochi:
A growing tech ecosystem with job opportunities.
Access to skilled trainers and mentors.
Affordable courses compared to metro cities.
A vibrant student community and internship options.
📘 What Will You Learn in a Python Full Stack Course?
A quality Python full stack course in Kochi should include:
Front-End Development
HTML5, CSS3, Bootstrap
JavaScript, React or Angular
Back-End Development with Python
Core Python programming
Django/Flask frameworks
REST API development
Database Management
SQL & NoSQL (MySQL, MongoDB)
Version Control and Deployment
Git, GitHub, Docker, Cloud basics
Live Projects & Internships
Real-world application building
Portfolio and resume support
👨💻 Who Can Join?
Whether you're a student, fresher, working professional, or someone switching careers, Python full stack training in Kochi is open to anyone eager to learn coding and development. No advanced coding knowledge is required to start—just a passion for learning and problem-solving.
💼 Career Opportunities After Training
Upon completing a Python full stack course, you can apply for roles like:
Full Stack Developer
Python Developer
Back-End Developer
Web Application Developer
Software Engineer
With startups and tech companies always on the lookout for dynamic developers, full stack expertise gives you a competitive edge.
🔍 Looking for the Best Python Full Stack Training in Kochi?
When choosing a training institute, look for one that offers hands-on projects, industry-aligned curriculum, experienced mentors, and placement support. One such name making waves in Kochi is Zoople Technologies.
✅ Why Zoople Technologies?
Zoople Technologies stands out for its practical, project-based approach to teaching. Their Python full stack training in Kochi is designed for real-world development—from beginner level to deployment-ready applications. With experienced trainers, small batch sizes, internship support, and direct industry links, Zoople makes sure you're not just learning—you’re building a future.
📍 If you're serious about mastering full stack development with Python, Zoople Technologies in Kochi is the launchpad you've been looking for.
Ready to take your first step? Start your Python full stack training in Kochi with Zoople Technologies and transform your passion into a profession.
0 notes
Text
Cross-Mapping Tableau Prep Workflows into Power Query: A Developer’s Blueprint
When migrating from Tableau to Power BI, one of the most technically nuanced challenges is translating Tableau Prep workflows into Power Query in Power BI. Both tools are built for data shaping and preparation, but they differ significantly in structure, functionality, and logic execution. For developers and BI engineers, mastering this cross-mapping process is essential to preserve the integrity of ETL pipelines during the migration. This blog offers a developer-centric blueprint to help you navigate this transition with clarity and precision.
Understanding the Core Differences
At a foundational level, Tableau Prep focuses on a flow-based, visual paradigm where data steps are connected in a linear or branching path. Power Query, meanwhile, operates in a functional, stepwise M code environment. While both support similar operations—joins, filters, aggregations, data type conversions—the implementation logic varies.
In Tableau Prep:
Actions are visual and sequential (Clean, Join, Output).
Operations are visually displayed in a flow pane.
Users rely heavily on drag-and-drop transformations.
In Power Query:
Transformations are recorded as a series of applied steps using the M language.
Logic is encapsulated within functional scripts.
The interface supports formula-based flexibility.
Step-by-Step Mapping Blueprint
Here’s how developers can strategically cross-map common Tableau Prep components into Power Query steps:
1. Data Input Sources
Tableau Prep: Uses connectors or extracts to pull from databases, Excel, or flat files.
Power Query Equivalent: Use “Get Data” with the appropriate connector (SQL Server, Excel, Web, etc.) and configure using the Navigator pane.
✅ Developer Tip: Ensure all parameters and credentials are migrated securely to avoid broken connections during refresh.
2. Cleaning and Shaping Data
Tableau Prep Actions: Rename fields, remove nulls, change types, etc.
Power Query Steps: Use commands like Table.RenameColumns, Table.SelectRows, and Table.TransformColumnTypes.
✅ Example: Tableau Prep’s “Change Data Type” ↪ Power Query:
mCopy
Edit
Table.TransformColumnTypes(Source,{{"Date", type date}})
3. Joins and Unions
Tableau Prep: Visual Join nodes with configurations (Inner, Left, Right).
Power Query: Use Table.Join or the Merge Queries feature.
✅ Equivalent Code Snippet:
mCopy
Edit
Table.NestedJoin(TableA, {"ID"}, TableB, {"ID"}, "NewColumn", JoinKind.Inner)
4. Calculated Fields / Derived Columns
Tableau Prep: Create Calculated Fields using simple functions or logic.
Power Query: Use “Add Column” > “Custom Column” and M code logic.
✅ Tableau Formula Example: IF [Sales] > 100 THEN "High" ELSE "Low" ↪ Power Query:
mCopy
Edit
if [Sales] > 100 then "High" else "Low"
5. Output to Destination
Tableau Prep: Output to .hyper, Tableau Server, or file.
Power BI: Load to Power BI Data Model or export via Power Query Editor to Excel or CSV.
✅ Developer Note: In Power BI, outputs are loaded to the model; no need for manual exports unless specified.
Best Practices for Developers
Modularize: Break complex Prep flows into multiple Power Query queries to enhance maintainability.
Comment Your Code: Use // to annotate M code for easier debugging and team collaboration.
Use Parameters: Replace hardcoded values with Power BI parameters to improve reusability.
Optimize for Performance: Apply filters early in Power Query to reduce data volume.
Final Thoughts
Migrating from Tableau Prep to Power Query isn’t just a copy-paste process—it requires thoughtful mapping and a clear understanding of both platforms’ paradigms. With this blueprint, developers can preserve logic, reduce data preparation errors, and ensure consistency across systems. Embrace this cross-mapping journey as an opportunity to streamline and modernize your BI workflows.
For more hands-on migration strategies, tools, and support, explore our insights at https://tableautopowerbimigration.com – powered by OfficeSolution.
0 notes
Text
Data Engineering vs Data Science: Which Course Should You Take Abroad?
The rapid growth of data-driven industries has brought about two prominent and in-demand career paths: Data Engineering and Data Science. For international students dreaming of a global tech career, these two fields offer promising opportunities, high salaries, and exciting work environments. But which course should you take abroad? What are the key differences, career paths, skills needed, and best study destinations?
In this blog, we’ll break down the key distinctions between Data Engineering and Data Science, explore which path suits you best, and highlight the best countries and universities abroad to pursue these courses.
What is Data Engineering?
Data Engineering focuses on designing, building, and maintaining data pipelines, systems, and architecture. Data Engineers prepare data so that Data Scientists can analyze it. They work with large-scale data processing systems and ensure that data flows smoothly between servers, applications, and databases.
Key Responsibilities of a Data Engineer:
Developing, testing, and maintaining data pipelines
Building data architectures (e.g., databases, warehouses)
Managing ETL (Extract, Transform, Load) processes
Working with tools like Apache Spark, Hadoop, SQL, Python, and AWS
Ensuring data quality and integrity
What is Data Science?
analysis, machine learning, and data visualization. Data Scientists use data to drive business decisions, create predictive models, and uncover trends.
Key Responsibilities of a Data Scientist:
Cleaning and analyzing large datasets
Building machine learning and AI models
Creating visualizations to communicate findings
Using tools like Python, R, SQL, TensorFlow, and Tableau
Applying statistical and mathematical techniques to solve problems
Which Course Should You Take Abroad?
Choosing between Data Engineering and Data Science depends on your interests, academic background, and long-term career goals. Here’s a quick guide to help you decide:
Take Data Engineering if:
You love building systems and solving technical challenges.
You have a background in software engineering, computer science, or IT.
You prefer backend development, architecture design, and working with infrastructure.
You enjoy automating data workflows and handling massive datasets.
Take Data Science if:
You’re passionate about data analysis, problem-solving, and storytelling with data.
You have a background in statistics, mathematics, computer science, or economics.
You’re interested in machine learning, predictive modeling, and data visualization.
You want to work on solving real-world problems using data.
Top Countries to Study Data Engineering and Data Science
Studying abroad can enhance your exposure, improve career prospects, and provide access to global job markets. Here are some of the best countries to study both courses:
1. Germany
Why? Affordable education, strong focus on engineering and analytics.
Top Universities:
Technical University of Munich
RWTH Aachen University
University of Mannheim
2. United Kingdom
Why? Globally recognized degrees, data-focused programs.
Top Universities:
University of Oxford
Imperial College London
4. Sweden
Why? Innovation-driven, excellent data education programs.
Top Universities:
KTH Royal Institute of Technology
Lund University
Chalmers University of Technology
Course Structure Abroad
Whether you choose Data Engineering or Data Science, most universities abroad offer:
Bachelor’s Degrees (3-4 years):
Focus on foundational subjects like programming, databases, statistics, algorithms, and software engineering.
Recommended for students starting out or looking to build from scratch.
Master’s Degrees (1-2 years):
Ideal for those with a bachelor’s in CS, IT, math, or engineering.
Specializations in Data Engineering or Data Science.
Often include hands-on projects, capstone assignments, and internship opportunities.
Certifications & Short-Term Diplomas:
Offered by top institutions and platforms (e.g., MITx, Coursera, edX).
Helpful for career-switchers or those seeking to upgrade their skills.
Career Prospects and Salaries
Both fields are highly rewarding and offer excellent career growth.
Career Paths in Data Engineering:
Data Engineer
Data Architect
Big Data Engineer
ETL Developer
Cloud Data Engineer
Average Salary (Globally):
Entry-Level: $70,000 - $90,000
Mid-Level: $90,000 - $120,000
Senior-Level: $120,000 - $150,000+
Career Paths in Data Science:
Data Scientist
Machine Learning Engineer
Business Intelligence Analyst
Research Scientist
AI Engineer
Average Salary (Globally):
Entry-Level: $75,000 - $100,000
Mid-Level: $100,000 - $130,000
Senior-Level: $130,000 - $160,000+
Industry Demand
The demand for both data engineers and data scientists is growing rapidly across sectors like:
E-commerce
Healthcare
Finance and Banking
Transportation and Logistics
Media and Entertainment
Government and Public Policy
Artificial Intelligence and Machine Learning Startups
According to LinkedIn and Glassdoor reports, Data Engineer roles have surged by over 50% in recent years, while Data Scientist roles remain in the top 10 most in-demand jobs globally.
Skills You’ll Learn Abroad
Whether you choose Data Engineering or Data Science, here are some skills typically covered in top university programs:
For Data Engineering:
Advanced SQL
Data Warehouse Design
Apache Spark, Kafka
Data Lake Architecture
Python/Scala Programming
Cloud Platforms: AWS, Azure, GCP
For Data Science:
Machine Learning Algorithms
Data Mining and Visualization
Statistics and Probability
Python, R, MATLAB
Tools: Jupyter, Tableau, Power BI
Deep Learning, AI Basics
Internship & Job Opportunities Abroad
Studying abroad often opens doors to internships, which can convert into full-time job roles.
Countries like Germany, Canada, Australia, and the UK allow international students to work part-time during studies and offer post-study work visas. This means you can gain industry experience after graduation.
Additionally, global tech giants like Google, Amazon, IBM, Microsoft, and Facebook frequently hire data professionals across both disciplines.
Final Thoughts: Data Engineering vs Data Science – Which One Should You Choose?
There’s no one-size-fits-all answer, but here’s a quick recap:
Choose Data Engineering if you’re technically inclined, love working on infrastructure, and enjoy building systems from scratch.
Choose Data Science if you enjoy exploring data, making predictions, and translating data into business insights.
Both fields are highly lucrative, future-proof, and in high demand globally. What matters most is your interest, learning style, and career aspirations.
If you're still unsure, consider starting with a general data science or computer science program abroad that allows you to specialize in your second year. This way, you get the best of both worlds before narrowing down your focus.
Need Help Deciding Your Path?
At Cliftons Study Abroad, we guide students in selecting the right course and country tailored to their goals. Whether it’s Data Engineering in Germany or Data Science in Canada, we help you navigate admissions, visa applications, scholarships, and more.
Contact us today to take your first step towards a successful international data career!
0 notes
Text
👩🏻💻 𝙰𝚛𝚌𝚑𝚒𝚟𝚒𝚘 𝚍𝚒 𝚜𝚝𝚛𝚞𝚖𝚎𝚗𝚝𝚒 𝚙𝚎𝚛 𝚌𝚢𝚋𝚎𝚛𝚜𝚎𝚌𝚞𝚛𝚒𝚝𝚢 𝚌𝚑𝚎 𝚖𝚒 𝚟𝚎𝚗𝚐𝚘𝚗𝚘 𝚌𝚘𝚗𝚜𝚒𝚐𝚕𝚒𝚊𝚝𝚒 𝚘 𝚌𝚒𝚝𝚊𝚝𝚒 𝚗𝚎𝚕 𝚝𝚎𝚖𝚙𝚘
AnyRun: cloud-based malware analysis service (sandbox).
Burp Suite: a proprietary software tool for security assessment and penetration testing of web applications. La community edition, gratis, contiene Burp Proxy and Interceptor (intercetta le richieste effettuate dal browser, consente modifiche on-the-fly e di modificare le risposte; utile per testare applicazioni basate su javascript), Burp Site Map, Burp Logger and HTTP History, Burp Repeater (consente di replicare e modificare le richieste effettuate, aggiungere parametri, rimuoverli, ecc), Burp Decoder, Burp Sequencer, Burp Comparer, Burp Extender (estensioni delle funzionalità di burpsuite, plugin specializzati per individuare bug specifici, automatizzare parte delle attività, ecc) e Burp Intruder (consente di iterare richieste con payload differenti e automatizzare attività di injection).
CyberChef: is a simple, intuitive web app for carrying out all manner of "cyber" operations within a web browser. These operations include simple encoding like XOR and Base64, more complex encryption like AES, DES and Blowfish, creating binary and hexdumps, compression and decompression of data, calculating hashes and checksums, IPv6 and X.509 parsing, changing character encodings, and much more.
DorkSearch: an AI-powered Google Dorking tool that helps create effective search queries to uncover sensitive information on the internet.
FFUF: fast web fuzzer written in Go.
GrayHatWarfare: is a search engine that indexes publicly accessible Amazon S3 buckets. It helps users identify exposed cloud storage and potential security risks.
JoeSandbox: detects and analyzes potential malicious files and URLs on Windows, Mac OS, and Linux for suspicious activities. It performs deep malware analysis and generates comprehensive and detailed analysis reports.
Nikto: is a free software command-line vulnerability scanner that scans web servers for dangerous files or CGIs, outdated server software and other problems.
Nuclei: is a fast, customizable vulnerability scanner powered by the global security community and built on a simple YAML-based DSL, enabling collaboration to tackle trending vulnerabilities on the internet. It helps you find vulnerabilities in your applications, APIs, networks, DNS, and cloud configurations.
Owasp Zap: Zed Attack Proxy (ZAP) by Checkmarx is a free, open-source penetration testing tool. ZAP is designed specifically for testing web applications and is both flexible and extensible. At its core, ZAP is what is known as a “manipulator-in-the-middle proxy.” It stands between the tester’s browser and the web application so that it can intercept and inspect messages sent between browser and web application, modify the contents if needed, and then forward those packets on to the destination. It can be used as a stand-alone application, and as a daemon process.
PIA: aims to help data controllers build and demonstrate compliance to the GDPR. It facilitates carrying out a data protection impact assessment.
SecLists: is the security tester's companion. It's a collection of multiple types of lists used during security assessments, collected in one place. List types include usernames, passwords, URLs, sensitive data patterns, fuzzing payloads, web shells, and many more.
SQLMAP: is an open source penetration testing tool that automates the process of detecting and exploiting SQL injection flaws and taking over of database servers. It comes with a powerful detection engine, many niche features for the ultimate penetration tester and a broad range of switches lasting from database fingerprinting, over data fetching from the database, to accessing the underlying file system and executing commands on the operating system via out-of-band connections.
Subfinder: fast passive subdomain enumeration tool.
Triage: cloud-based sandbox analysis service to help cybersecurity professionals to analyse malicious files and prioritise incident alerts and accelerate alert triage. It allows for dynamic analysis of files (Windows, Linux, Mac, Android) in a secure environment, offering detailed reports on malware behavior, including malicious scoring. This service integrates with various cybersecurity tools and platforms, making it a valuable tool for incident response and threat hunting.
VirusTotal: analyse suspicious files, domains, IPs and URLs to detect malware and other breaches, automatically share them with the security community.
Wayback Machine: is a digital archive of the World Wide Web founded by Internet Archive. The service allows users to go "back in time" to see how websites looked in the past.
Wapiti: allows you to audit the security of your websites or web applications. It performs "black-box" scans of the web application by crawling the webpages of the deployed webapp, looking for scripts and forms where it can inject data. Once it gets the list of URLs, forms and their inputs, Wapiti acts like a fuzzer, injecting payloads to see if a script is vulnerable.
WPScan: written for security professionals and blog maintainers to test the security of their WordPress websites.
✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖
👩🏻💻𝚂𝚒𝚝𝚒-𝚕𝚊𝚋𝚘𝚛𝚊𝚝𝚘𝚛𝚒
flAWS: through a series of levels you'll learn about common mistakes and gotchas when using Amazon Web Services (AWS).
flAWS2: this game/tutorial teaches you AWS (Amazon Web Services) security concepts. The challenges are focused on AWS specific issues. You can be an attacker or a defender.
✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖✖
👩🏻💻𝙱𝚛𝚎𝚟𝚎 𝚕𝚒𝚜𝚝𝚊 𝚍𝚒 𝚜𝚒𝚝𝚒 𝚊𝚙𝚙𝚘𝚜𝚒𝚝𝚊𝚖𝚎𝚗𝚝𝚎 𝚟𝚞𝚕𝚗𝚎𝚛𝚊𝚋𝚒𝚕𝚒 𝚜𝚞 𝚌𝚞𝚒 𝚏𝚊𝚛𝚎 𝚎𝚜𝚎𝚛𝚌𝚒𝚣𝚒𝚘
http://testphp.vulnweb.com
0 notes
Text
Understanding Data Movement in Azure Data Factory: Key Concepts and Best Practices
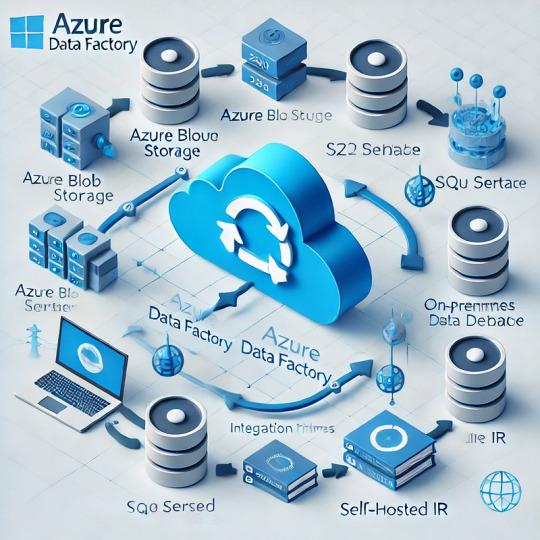
Introduction
Azure Data Factory (ADF) is a fully managed, cloud-based data integration service that enables organizations to move and transform data efficiently. Understanding how data movement works in ADF is crucial for building optimized, secure, and cost-effective data pipelines.
In this blog, we will explore: ✔ Core concepts of data movement in ADF ✔ Data flow types (ETL vs. ELT, batch vs. real-time) ✔ Best practices for performance, security, and cost efficiency ✔ Common pitfalls and how to avoid them
1. Key Concepts of Data Movement in Azure Data Factory
1.1 Data Movement Overview
ADF moves data between various sources and destinations, such as on-premises databases, cloud storage, SaaS applications, and big data platforms. The service relies on integration runtimes (IRs) to facilitate this movement.
1.2 Integration Runtimes (IRs) in Data Movement
ADF supports three types of integration runtimes:
Azure Integration Runtime (for cloud-based data movement)
Self-hosted Integration Runtime (for on-premises and hybrid data movement)
SSIS Integration Runtime (for lifting and shifting SSIS packages to Azure)
Choosing the right IR is critical for performance, security, and connectivity.
1.3 Data Transfer Mechanisms
ADF primarily uses Copy Activity for data movement, leveraging different connectors and optimizations:
Binary Copy (for direct file transfers)
Delimited Text & JSON (for structured data)
Table-based Movement (for databases like SQL Server, Snowflake, etc.)
2. Data Flow Types in ADF
2.1 ETL vs. ELT Approach
ETL (Extract, Transform, Load): Data is extracted, transformed in a staging area, then loaded into the target system.
ELT (Extract, Load, Transform): Data is extracted, loaded into the target system first, then transformed in-place.
ADF supports both ETL and ELT, but ELT is more scalable for large datasets when combined with services like Azure Synapse Analytics.
2.2 Batch vs. Real-Time Data Movement
Batch Processing: Scheduled or triggered executions of data movement (e.g., nightly ETL jobs).
Real-Time Streaming: Continuous data movement (e.g., IoT, event-driven architectures).
ADF primarily supports batch processing, but for real-time processing, it integrates with Azure Stream Analytics or Event Hub.
3. Best Practices for Data Movement in ADF
3.1 Performance Optimization
✅ Optimize Data Partitioning — Use parallelism and partitioning in Copy Activity to speed up large transfers. ✅ Choose the Right Integration Runtime — Use self-hosted IR for on-prem data and Azure IR for cloud-native sources. ✅ Enable Compression — Compress data during transfer to reduce latency and costs. ✅ Use Staging for Large Data — Store intermediate results in Azure Blob or ADLS Gen2 for faster processing.
3.2 Security Best Practices
🔒 Use Managed Identities & Service Principals — Avoid using credentials in linked services. 🔒 Encrypt Data in Transit & at Rest — Use TLS for transfers and Azure Key Vault for secrets. 🔒 Restrict Network Access — Use Private Endpoints and VNet Integration to prevent data exposure.
3.3 Cost Optimization
💰 Monitor & Optimize Data Transfers — Use Azure Monitor to track pipeline costs and adjust accordingly. 💰 Leverage Data Flow Debugging — Reduce unnecessary runs by debugging pipelines before full execution. 💰 Use Incremental Data Loads — Avoid full data reloads by moving only changed records.
4. Common Pitfalls & How to Avoid Them
❌ Overusing Copy Activity without Parallelism — Always enable parallel copy for large datasets. ❌ Ignoring Data Skew in Partitioning — Ensure even data distribution when using partitioned copy. ❌ Not Handling Failures with Retry Logic — Use error handling mechanisms in ADF for automatic retries. ❌ Lack of Logging & Monitoring — Enable Activity Runs, Alerts, and Diagnostics Logs to track performance.
Conclusion
Data movement in Azure Data Factory is a key component of modern data engineering, enabling seamless integration between cloud, on-premises, and hybrid environments. By understanding the core concepts, data flow types, and best practices, you can design efficient, secure, and cost-effective pipelines.
Want to dive deeper into advanced ADF techniques? Stay tuned for upcoming blogs on metadata-driven pipelines, ADF REST APIs, and integrating ADF with Azure Synapse Analytics!
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
How Oracle GoldenGate works
Oracle GoldenGate operates by capturing changes directly from the transaction logs of source databases. It supports both homogeneous and heterogeneous environments, enabling real-time data replication across different types of databases, such as Oracle, MySQL, SQL Server, PostgreSQL, and more. Oracle GoldenGate Data Flow Explanation Target DatabaseThis is the destination where the replicated…
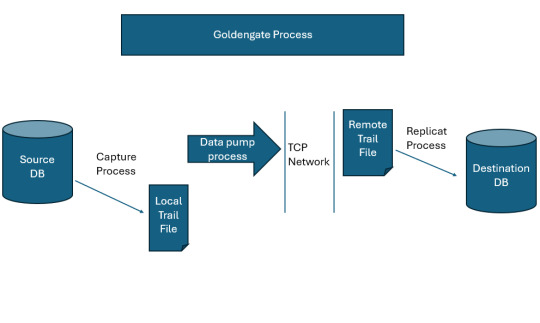
View On WordPress
0 notes
Text
VPC Flow Analyzer: Your Key to Network Traffic Intelligence

Overview of the Flow Analyzer
Without writing intricate SQL queries to analyze VPC Flow Logs, you can quickly and effectively comprehend your VPC traffic flows with Flow Analyzer. With a 5-tuple granularity (source IP, destination IP, source port, destination port, and protocol), Flow Analyzer enables you to conduct opinionated network traffic analysis.
Flow Analyzer, created with Log Analytics and driven by BigQuery, allows you to examine your virtual machine instances’ inbound and outgoing traffic in great detail. It enables you to keep an eye on, troubleshoot, and optimize your networking configuration for improved security and performance, which helps to guarantee compliance and reduce expenses.
Data from VPC Flow Logs that are kept in a log bucket (record format) are examined by Flow Analyzer. You must choose a project with a log bucket containing VPC Flow Logs in order to use Flow Analyzer. Network monitoring, forensics, real-time security analysis, and cost optimization are all possible with VPC Flow Logs.
The fields contained in VPC Flow Logs are subjected to searches by Flow Analyzer.
The following tasks can be completed with Flow Analyzer:
Create and execute a basic VPC Flow Logs query.
Create a SQL filter for the VPC Flow Logs query (using a WHERE statement).
Sort the query results based on aggregate packets and total traffic, then arrange the results using the chosen attributes.
Examine the traffic at specific intervals.
See a graphical representation of the top five traffic flows over time in relation to the overall traffic.
See a tabular representation of the resources with the most traffic combined over the chosen period.
View the query results to see the specifics of the traffic between a given source and destination pair.
Utilizing the remaining fields in the VPC Flow Logs, drill down the query results.
How it operates
A sample of network flows sent from and received by VPC resources, including Google Kubernetes Engine nodes and virtual machine instances, are recorded in VPC Flow Logs.
The flow logs can be exported to any location supported by Logging export and examined in Cloud Logging. Log analytics can be used to perform queries that examine log data, and the results of those queries can subsequently be shown as tables and charts.
By using Log Analytics, Flow Analyzer enables you to execute queries on VPC Flow Logs and obtain additional information about the traffic flows. This includes a table that offers details about every data flow and a graphic that shows the largest data flows.
Components of a query
You must execute a query on VPC Flow Logs in order to examine and comprehend your traffic flows. In order to view and track your traffic flows, Flow Analyzer assists you in creating the query, adjusting the display settings, and drilling down.
Traffic Aggregation
You must choose an aggregation strategy to filter the flows between the resources in order to examine VPC traffic flows. The following is how Flow Analyzer arranges the flow logs for aggregation:
Source and destination: this option makes use of the VPC Flow Logs’ SRC and DEST data. The traffic is aggregated from source to destination in this view.
Client and server: this setting looks for the person who started the connection. The server is a resource that has a lower port number. Because services don’t make requests, it also views the resources with the gke_service specification as servers. Both directions of traffic are combined in this shot.
Time-range selector
The time-range picker allows you to center the time range on a certain timestamp, choose from preset time options, or define a custom start and finish time. By default, the time range is one hour. For instance, choose Last 1 week from the time-range selector if you wish to display the data for the previous week.
Additionally, you can use the time-range slider to set your preferred time zone.
Basic filters
By arranging the flows in both directions based on the resources, you may construct the question.
Choose the fields from the list and enter values for them to use the filters.
Filter flows that match the chosen key-value combinations can have more than one filter expression added to them. An OR operator is used if you choose numerous filters for the same field. An AND operator is used when selecting filters for distinct fields.
For instance, the following filter logic is applied to the query if you choose two IP address values (1.2.3.4 and 10.20.10.30) and two country values (US and France):
(Country=US OR Country=France) AND (IP=1.2.3.4 OR IP=10.20.10.30)
The outcomes may differ if you attempt to alter the traffic choices or endpoint filters. To see the revised results, you have to execute the query one more.
SQL filters
SQL filters can be used to create sophisticated queries. You can carry out operations like the following by using sophisticated queries:
Comparing the values of the fields
Using AND/OR and layered OR operations to construct intricate boolean logic
Utilizing BigQuery capabilities to carry out intricate operations on IP addresses
BigQuery SQL syntax is used in the SQL filter queries.
Query result
The following elements are included in the query results:
The highest data flows chart shows the remaining traffic as well as the top five largest traffic flows throughout time. This graphic can be used to identify trends, such as increases in traffic.
The top traffic flows up to 10,000 rows averaged during the chosen period are displayed in the All Data Flows table. The fields chosen to organize the flows while defining the query’s filters are shown in this table.
Read more on Govindhtech.com
#FlowAnalyzer#SQL#BigQuery#virtualmachine#GoogleKubernetesEngine#SQLsyntax#News#Technews#Technology#Technologynwes#Technologytrends#govindhtech
0 notes
Text
Best Full Stack Developer Course in Pune: Learn and Get Placed with SyntaxLevelUp
Pune, often referred to as the "Oxford of the East," has become a top destination for students and professionals looking to upgrade their skills. Among the most in-demand skill sets in today’s tech-driven world is Full Stack Development. If you're seeking the best full stack training in Pune, you've come to the right place. With plenty of options, it's essential to choose a program that provides a comprehensive learning experience and offers placement support.

Let’s dive into what you should look for in a full stack developer course in Pune and why SyntaxLevelUp stands out as a prime choice for aspiring developers.
Why Pursue a Full Stack Developer Course in Pune?
A full stack developer is someone proficient in both front-end and back-end development, ensuring seamless user experiences while managing server-side logic. As businesses increasingly move online, the demand for full stack developers has skyrocketed. Pursuing a full stack developer course in Pune with placement can open doors to countless opportunities in the tech world, both locally and globally.
Pune’s tech landscape has grown tremendously, and companies are actively seeking skilled full stack developers who can build robust applications. A full stack course in Pune will give you the expertise to work with various technologies, including HTML, CSS, JavaScript, React, Angular, Node.js, MongoDB, SQL, and more.
Full Stack Developer Classes in Pune
When choosing full stack developer classes in Pune, it's essential to find one that offers practical, hands-on training. SyntaxLevelUp provides just that, with industry-driven projects and experienced mentors to guide you through your learning journey. Whether you're looking to specialize in full stack web development or become a full stack Java developer, SyntaxLevelUp offers flexible and comprehensive courses that cater to your needs.
What to Expect from a Full Stack Web Development Course in Pune
A full stack web development course in Pune focuses on both client-side (front-end) and server-side (back-end) programming. Here’s what you can expect to learn:
Front-End Development: Master HTML, CSS, JavaScript, and modern frameworks like React or Angular to build dynamic, responsive websites.
Back-End Development: Get hands-on with databases, server management, and programming languages like Java, Python, or Node.js to handle the server logic and database integration.
Database Management: Learn how to use both SQL and NoSQL databases like MySQL and MongoDB to store and retrieve data efficiently.
Version Control & Deployment: Gain skills in Git, GitHub, and cloud deployment strategies to ensure your applications are properly maintained and accessible.
Placement Assistance
One of the key factors when selecting a full stack developer course in Pune with placement is the institution’s job assistance. SyntaxLevelUp provides robust placement support with connections to top companies, ensuring that graduates are job-ready.
Why Choose SyntaxLevelUp for Full Stack Developer Courses?
Among the many full stack developer courses in Pune, SyntaxLevelUp is considered one of the best full stack developer courses in Pune for a reason:
Expert Instructors: Learn from experienced professionals who have worked with leading tech firms.
Real-World Projects: Work on live projects that simulate industry scenarios.
Flexible Learning Options: Choose between in-person and online classes, making it easier to fit learning into your schedule.
Career Guidance: SyntaxLevelUp offers personalized career support, including resume building, mock interviews, and direct placements with partner companies.
Specialized Full Stack Java Developer Course in Pune
For those specifically interested in Java, SyntaxLevelUp offers a dedicated full stack Java developer course in Pune. Java remains one of the most popular languages for building scalable and secure applications. This course covers everything from core Java programming to advanced web development using Java frameworks like Spring Boot and Hibernate.
Conclusion
If you're looking to kickstart or enhance your tech career, enrolling in a full stack developer course in Pune is a smart move. Whether you choose a full stack Java developer course in Pune or a general full stack web development course, SyntaxLevelUp provides top-tier education and placement opportunities to help you succeed in the competitive tech landscape.
Don’t wait—take the first step towards becoming a full stack developer and enroll in the best full stack classes in Pune with SyntaxLevelUp today! #FullStackTrainingPune #FullStackDeveloperPune #FullStackCoursePune #LearnFullStackInPune#SyntaxLevelUp #FullStackWithPlacement #BestFullStackCoursePune #FullStackWebDevelopment #JavaFullStackPune #PuneTechCourses
#fullstack training in pune#full stack developer course in pune#full stack developer course in pune with placement#full stack java developer course in pune#full stack developer classes in pune#full stack course in pune#best full stack developer course in pune#full stack classes in pune#full stack web development course in pune
0 notes
Text
SQL Server Integration Services (SSIS)
SQL Server Integration Services (SSIS) is a powerful data integration and workflow tool from Microsoft, designed to solve complex business challenges by efficiently managing data movement and transformation. Part of the Microsoft SQL Server suite, SSIS is widely used for data migration, data warehousing, ETL (Extract, Transform, Load) processes, and automating workflows between disparate systems.
With SSIS, users can:
Extract data from various sources like databases, Excel, and flat files.
Transform it by applying business logic, data cleansing, and validation.
Load the refined data into databases, data warehouses, or other destinations.
Its user-friendly graphical interface, native support for Microsoft ecosystems, and scalability make SSIS a preferred choice for both small businesses and enterprise-level operations. Whether you're building data pipelines, automating workflows, or migrating large datasets, SSIS provides a robust, customizable platform to streamline operations.
For more information on SSIS (Complete Tutorial) >> https://www.tutorialgateway.org/ssis/
0 notes
Text
Why Full Stack Training in Pune at SyntaxLevelUp is the Key to Your Success
Are you ready to dive into the world of technology and unlock endless career opportunities? If so, enrolling in a Full Stack Developer Course in Pune could be your ticket to a promising future in web development. Pune, often hailed as the IT hub of India, offers a wealth of opportunities for aspiring developers. In this blog, we’ll explore why pursuing full stack training in Pune is a smart choice and how SyntaxLevelUp is shaping up to be the go-to destination for such training.

Why Choose Full Stack Development?
The demand for full stack developers is at an all-time high. These professionals possess a unique skill set that spans both front-end and back-end development. This makes them invaluable to companies looking to build dynamic and responsive websites or applications. Mastering full stack development means you’ll have the ability to manage entire web development projects, from user interface design to database management.
Here are some of the key reasons why enrolling in a full stack course in Pune can be a game-changer for your career:
Comprehensive Skill SetFull stack developers are like the Swiss Army knives of the tech world. By mastering both front-end technologies like HTML, CSS, and JavaScript, and back-end languages such as Python, Java, or Node.js, you'll be able to handle every aspect of web development.
High Demand in the Job MarketCompanies are constantly on the lookout for versatile developers who can handle both client and server-side programming. With full stack expertise, you can expect lucrative job offers from leading tech companies and startups in Pune and beyond.
Career Growth and OpportunitiesPune is one of India’s leading IT hubs, hosting top-tier companies like Infosys, Wipro, and TCS. This creates a high demand for skilled full stack developers. Completing a full stack training in Pune can open doors to career opportunities at some of the most innovative firms in the region.
Why Pune is Ideal for Full Stack Training
Pune is not just a city of IT companies; it’s also home to a growing community of tech enthusiasts, startups, and world-class educational institutions. Whether you’re a beginner or an experienced professional, Pune provides an ideal ecosystem for full stack development courses.
Strategic Location: Pune is close to Mumbai and has a strong connection with the IT industry, providing excellent job placement opportunities for students.
Thriving Tech Culture: Pune's tech-savvy environment encourages continuous learning and development, making it a prime location for tech-related courses.
SyntaxLevelUp: The Best Full Stack Developer Course in Pune
When it comes to choosing a training provider for full stack development, SyntaxLevelUp stands out for several reasons:
Industry-Focused CurriculumSyntaxLevelUp offers a comprehensive full stack developer course in Pune that’s designed to meet the needs of the modern tech industry. Their curriculum covers everything from front-end development (HTML, CSS, JavaScript) to back-end frameworks (Node.js, Express) and database management (MongoDB, SQL).
Hands-On ProjectsOne of the biggest advantages of enrolling in a full stack course in Pune with SyntaxLevelUp is their project-based learning approach. You’ll get the chance to work on real-world projects that mimic the challenges you’ll face in the industry.
Experienced InstructorsThe instructors at SyntaxLevelUp are industry professionals with years of experience. They bring real-world insights and practical knowledge to the classroom, ensuring you receive up-to-date training.
Flexible Learning OptionsWhether you're a working professional or a student, SyntaxLevelUp offers flexible learning schedules. They provide both part-time and full-time courses, making it easier for you to learn at your own pace.
Job Placement AssistanceWith strong connections to local tech companies, SyntaxLevelUp also offers job placement assistance to help students land jobs as full stack developers upon course completion.
Enroll in the Full Stack Developer Course at SyntaxLevelUp Today!
If you’re looking to start or accelerate your career in web development, enrolling in a full stack developer course in Pune with SyntaxLevelUp is a smart move. The combination of Pune’s thriving tech environment and SyntaxLevelUp's industry-focused training provides the perfect blend for learning and growth.
So, why wait? Sign up for full stack training in Pune today and take your first step towards becoming a full stack developer!
#often hailed as the IT hub of India#Comprehensive Skill Set#CSS#and JavaScript#and back-end languages such as Python#Java#or Node.js#Career Growth and Opportunities#Pune is one of India’s leading IT hubs#Wipro#Why Pune is Ideal for Full Stack Training#startups#Industry-Focused Curriculum#SQL).#Hands-On Projects#Job Placement Assistance#So#full stack course in pune#full stack classes in pune
0 notes
Text
Understanding SQL Server Integration Services (SSIS)
In today’s fast-paced business environment, data integration is crucial for effective decision-making and business operations. As organizations collect data from multiple sources—ranging from on-premises databases to cloud-based services—integrating and transforming this data into usable information becomes challenging. This is where SQL Server Integration Services (SSIS) comes into play.
SQL Server Integration Services (SSIS) is a powerful data integration tool included with Microsoft SQL Server that allows businesses to extract, transform, and load (ETL) data from various sources into a centralized location for analysis and reporting. In this article, we’ll dive deep into SSIS, exploring its core functionalities, benefits, and its importance in modern data-driven environments. We will also highlight how SSIS-816 improves data integration efficiency in the conclusion.
What is SQL Server Integration Services (SSIS)?
SSIS is a component of Microsoft's SQL Server database software that can be used to perform a wide range of data migration tasks. It is a scalable, high-performance ETL platform that simplifies data management, whether it’s importing large datasets, cleansing data, or executing complex data transformations.
SSIS provides a user-friendly graphical interface within SQL Server Data Tools (SSDT) to create packages that manage data integration tasks. These packages can be scheduled to run automatically, allowing businesses to automate their data flow between systems.
Key Features of SSIS
1. Data Extraction, Transformation, and Loading (ETL)
SSIS is primarily used for ETL tasks. It can connect to various data sources such as SQL databases, Excel spreadsheets, flat files, and web services to extract raw data. This data is then transformed using SSIS tools to cleanse, filter, and manipulate it before loading it into the target destination.
2. Data Integration
SSIS allows for the seamless integration of data from multiple sources, enabling businesses to merge data into a single, coherent system. This is especially useful for organizations with complex infrastructures that include various data types and storage systems.
3. Data Cleansing
Poor data quality can severely impact business decisions. SSIS provides advanced data cleansing capabilities, including de-duplication, validation, and formatting. This ensures that businesses work with accurate, consistent, and high-quality data.
4. Workflow Automation
One of the most powerful features of SSIS is its ability to automate workflows. Businesses can set up SSIS packages to run automatically at scheduled intervals or trigger them based on specific events. This means that repetitive tasks such as data loading, transformations, and reporting can be fully automated, reducing manual intervention and saving time.
5. Error Handling and Logging
SSIS provides robust error-handling features, allowing users to identify and resolve issues during data integration. It logs errors and failures in the process, ensuring transparency and enabling efficient troubleshooting. This reduces downtime and helps maintain data accuracy.
6. Data Transformation Tools
SSIS offers a range of transformations such as sorting, aggregating, merging, and converting data. These transformations allow businesses to manipulate data according to their needs, ensuring it is in the proper format before loading it into a destination database.
Conclusion:
In conclusion, SQL Server Integration Services (SSIS) is a powerful solution for businesses looking to integrate and manage their data efficiently. With advanced ETL capabilities, automation, and error handling, SSIS can transform the way companies handle data, providing a robust foundation for analytics and business intelligence. Tools like SSIS-816 further enhance these capabilities, making data integration more streamlined, accurate, and reliable for modern enterprises.
0 notes
Text
MSBI Tutorial Guide For Beginners
In the rapidly evolving world of data analytics & business intelligence, MSBI stands out as a powerful tool for transforming raw data into actionable insights. If you are new to the field or looking to enhance your skills, this MSBI Tutorial Guide For Beginners will provide a comprehensive overview of what MSBI is & how it can benefit your career. We will also touch on available resources, such as MSBI online training & certification courses, to help you get started.
What is MSBI?
MSBI, or Microsoft Business Intelligence, is a suite of tools provided by Microsoft designed to help businesses analyze & visualize their data effectively. The primary components of MSBI include SQL Server Integration Services (SSIS), SQL Server Analysis Services (SSAS), & SQL Server Reporting Services (SSRS). These tools work together to provide a complete solution for data extraction, analysis, & reporting.
SQL Server Integration Services (SSIS)
SSIS is responsible for data integration & transformation. It allows users to extract data from various sources, transform it into a format suitable for analysis, & load it into a destination database or data warehouse. For instance, you might use SSIS to pull data from multiple sources, clean & format it, & then load it into a SQL Server database for further analysis.
SQL Server Analysis Services (SSAS)
SSAS is used for data analysis & building OLAP (Online Analytical Processing) cubes. These cubes enable complex calculations, trend analysis, & data summarization, making it easier to generate business insights. SSAS helps in creating multidimensional structures that provide fast query performance & in depth analysis.
SQL Server Reporting Services (SSRS)
SSRS is the reporting component of MSBI. It allows users to create, manage, & deliver interactive & printed reports. With SSRS, you can design reports using a variety of formats & data sources, schedule report generation, & even integrate reports into web applications.
MSBI Tutorial Guide For Beginners
If you are just starting out with MSBI, it can be overwhelming to navigate through its components. This MSBI Tutorial Guide For Beginners aims to break down the basics & offer a step by step approach to mastering each component.
Getting Started with MSBI
To learn MSBI software, one should follow a systematic approach. Described below is best suitable way to master this platform -
Understand the Basics: Before diving into technical details, familiarize yourself with the core concepts of MSBI. Learn about data warehousing, ETL (Extract, Transform, Load) processes, & reporting.
Set Up Your Environment: Install SQL Server & the associated tools (SSIS, SSAS, SSRS). Microsoft provides comprehensive documentation & tutorials to help you get started with installation & configuration.
Learn SQL Basics: Since MSBI relies heavily on SQL, having a good grasp of SQL basics is crucial. Focus on writing queries, understanding joins, & working with stored procedures.
Diving Deeper into SSIS: SSIS is the foundation for data integration & ETL. Begin by learning how to create & manage SSIS packages, which are used to perform data extraction, transformation, & loading tasks. Explore data flow tasks, control flow tasks, & various transformations provided by SSIS.
Exploring SSAS: For SSAS, start with creating & deploying OLAP cubes. Learn how to design dimensions & measures, & understand the basics of MDX (Multidimensional Expressions) queries. Dive into data mining & create data models that help in generating insightful reports.
Mastering SSRS: SSRS is all about creating reports. Begin by designing basic reports using the Report Designer tool. Learn how to use datasets, data sources, & report parameters. Experiment with different types of reports, such as tabular, matrix, & chart reports.
MSBI Online Training & Certification
To gain a deeper understanding of MSBI & enhance your skills, consider enrolling in MSBI online training programs. These courses offer structured learning paths, practical exercises, & real world examples to help you grasp the intricacies of MSBI components.
Choosing the Right MSBI Certification Course
An MSBI Certification Course can significantly boost your credentials. Look for courses that cover all aspects of MSBI, including SSIS, SSAS, & SSRS. Certification can validate your skills & make you a more competitive candidate in the job market.
Benefits of MSBI Certification
Obtaining an msbi training certificate demonstrates your expertise in business intelligence tools & techniques. It can open doors to advanced roles in data analysis, reporting, & business intelligence. Many organizations value certified professionals who can deliver actionable insights & drive business decisions based on data.
Final Comment
In summary, MSBI is a robust suite of tools that empowers businesses to turn data into valuable insights. For beginners, this MSBI Tutorial Guide For Beginners provides a foundational understanding of what MSBI is & how to get started. By exploring each component—SSIS, SSAS, & SSRS—you can build a comprehensive skill set in business intelligence.
Investing in MSBI online training & obtaining an MSBI Certification Course can further enhance your skills & career prospects. Whether you are aiming to analyze data more effectively, create insightful reports, or manage complex data transformations, mastering MSBI tools can be a significant step towards achieving your professional goals.
People Also Read : What is UiPath? UiPath Tutorial For Beginners
0 notes
Text
Step-by-Step Guide to Connecting On-Premises Data Sources with Azure Data Factory
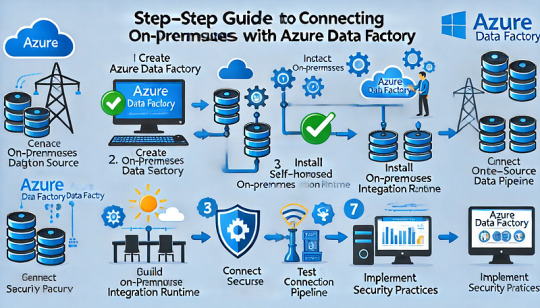
Step-by-Step Guide to Connecting On-Premises Data Sources with Azure Data Factory
Connecting on-premises data sources with Azure Data Factory (ADF) allows organizations to securely transfer and integrate data across hybrid environments. This step-by-step guide outlines the process for establishing a secure connection between your on-premises data sources and Azure Data Factory using a Self-Hosted Integration Runtime (IR).
Step 1: Prerequisites
Before proceeding, ensure you have the following:
✅ An Azure Data Factory instance. ✅ An on-premises machine (Windows) with internet access. ✅ Appropriate permissions for creating pipelines in Azure Data Factory. ✅ Installed Self-Hosted Integration Runtime (covered in Step 3).
Step 2: Create an Azure Data Factory Instance
Sign in to the Azure portal.
Go to Create a Resource and select Data Factory.
Fill in the required details:
Subscription: Choose your Azure subscription.
Resource Group: Select or create a new one.
Region: Select the region closest to your on-premises data source.
Name: Provide a meaningful name for your Data Factory.
Click Review + Create, then Create.
Step 3: Install and Configure the Self-Hosted Integration Runtime
To enable secure data movement between your on-premises system and Azure Data Factory, you must install the Self-Hosted IR.
In the Azure portal, go to your Data Factory instance.
Navigate to Manage → Integration Runtimes.
Click + New → Select Self-Hosted → Click Continue.
Enter a name for your Self-Hosted IR and click Create.
Download the Integration Runtime installer by clicking Download and Install Integration Runtime.
Install the downloaded file on your on-premises machine.
During installation, you’ll be prompted to enter a Registration Key (available from the Azure portal). Paste the key when requested.
Verify the status shows Running in Azure Data Factory.
Step 4: Connect On-Premises Data Source
In Azure Data Factory, go to the Author tab.
Click the + (Add) button and select Dataset.
Choose the appropriate data store type (e.g., SQL Server, Oracle, or File System).
Provide the connection details:
Linked Service Name
Connection String (for databases)
Username and Password (for authentication)
Under the Connect via Integration Runtime section, select your Self-Hosted IR.
Click Test Connection to validate connectivity.
Once verified, click Create.
Step 5: Build and Configure a Pipeline
In the Author tab, click the + (Add) button and select Pipeline.
Add a Copy Data activity to the pipeline.
Configure the following:
Source: Choose the dataset linked to your on-premises data source.
Sink (Destination): Choose the Azure data store where you want the data to land (e.g., Azure SQL Database, Blob Storage).
Click Validate to check for errors.
Click Publish All to save your changes.
Step 6: Trigger and Monitor the Pipeline
Click Add Trigger → Trigger Now to execute the pipeline.
Navigate to the Monitor tab to track pipeline execution status.
In case of errors, review the detailed logs for troubleshooting.
Step 7: Best Practices for Secure Data Integration
Use firewall rules to restrict data access.
Ensure SSL/TLS encryption is enabled for secure data transfer.
Regularly update your Self-Hosted Integration Runtime for performance and security improvements.
Implement role-based access control (RBAC) to manage permissions effectively.
Conclusion
By following these steps, you can successfully connect your on-premises data sources to Azure Data Factory. The Self-Hosted Integration Runtime ensures secure and reliable data movement, enabling seamless integration for hybrid data environments.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
Top Full Stack Developer Courses in Pune: Your Gateway to a Successful Tech Career
In today's tech-driven world, the demand for skilled full stack developers is at an all-time high. If you're looking to kickstart or elevate your career in software development, enrolling in a Full Stack Developer Course in Pune is a smart move. Pune, a bustling hub for IT and education, offers a myriad of opportunities for aspiring developers. Here's why you should consider joining a Full Stack Developer Course in Pune with Placement.

Why Choose Full Stack Developer Training in Pune?
Pune has emerged as a leading destination for quality education, especially in technology. With numerous Full Stack Developer Classes in Pune, you can gain comprehensive knowledge and hands-on experience in both front-end and back-end development. Whether you're interested in learning Java or exploring other technologies, there's a Full Stack Course in Pune tailored to your needs.
What is Full Stack Development?
Full stack development refers to the ability to work on both the front-end and back-end of a web application. A Full Stack Web Development Course in Pune will equip you with the skills needed to build, deploy, and maintain complex web applications. You'll learn how to work with databases, server-side languages, and client-side technologies to create fully functional web applications.
Course Highlights
When you enroll in the Best Full Stack Developer Course in Pune, you can expect to cover a wide range of topics, including:
Front-End Development: Learn HTML, CSS, JavaScript, and popular frameworks like Angular or React.
Back-End Development: Master server-side programming with languages like Java, Node.js, and Python.
Database Management: Gain expertise in managing databases using SQL, MongoDB, and more.
Deployment & DevOps: Understand the deployment process and learn tools like Docker and Jenkins.
Full Stack Java Developer Course in Pune
If you have a particular interest in Java, there are specialized courses available. The Full Stack Java Developer Course in Pune focuses on building robust web applications using Java technologies. This course is ideal for those who want to dive deep into one of the most widely used programming languages in the world.
Placement Assistance
One of the key advantages of enrolling in a Full Stack Developer Course in Pune with Placement is the career support you'll receive. Many institutes offer dedicated placement cells that help students secure jobs in top companies. The comprehensive training, combined with real-world projects, ensures that you are job-ready by the time you complete the course.
Why Pune?
Pune's IT industry is booming, with numerous startups and established companies looking for skilled developers. The city's vibrant tech community and numerous networking events make it an ideal place to start your career. By enrolling in Full Stack Developer Classes in Pune, you're setting yourself up for success in a city that's known for its innovation and growth.
Final Thoughts
Choosing the right training program is crucial for your career growth. A Full Stack Developer Course in Pune offers the perfect blend of theoretical knowledge and practical experience, ensuring you're well-equipped to handle the demands of the industry. Whether you're a beginner or looking to upskill, Pune's training institutes have something to offer everyone.
So, why wait? Enroll in a Full Stack Course in Pune today and take the first step towards a fulfilling career in software development.
#fullstack training in pune#full stack developer course in pune#full stack developer course in pune with placement#full stack java developer course in pune#full stack developer classes in pune#full stack course in pune#best full stack developer course in pune#full stack classes in pune#full stack web development course in pune
0 notes