#BigQuery
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Google Cloud’s BigQuery Autonomous Data To AI Platform

BigQuery automates data analysis, transformation, and insight generation using AI. AI and natural language interaction simplify difficult operations.
The fast-paced world needs data access and a real-time data activation flywheel. Artificial intelligence that integrates directly into the data environment and works with intelligent agents is emerging. These catalysts open doors and enable self-directed, rapid action, which is vital for success. This flywheel uses Google's Data & AI Cloud to activate data in real time. BigQuery has five times more organisations than the two leading cloud providers that just offer data science and data warehousing solutions due to this emphasis.
Examples of top companies:
With BigQuery, Radisson Hotel Group enhanced campaign productivity by 50% and revenue by over 20% by fine-tuning the Gemini model.
By connecting over 170 data sources with BigQuery, Gordon Food Service established a scalable, modern, AI-ready data architecture. This improved real-time response to critical business demands, enabled complete analytics, boosted client usage of their ordering systems, and offered staff rapid insights while cutting costs and boosting market share.
J.B. Hunt is revolutionising logistics for shippers and carriers by integrating Databricks into BigQuery.
General Mills saves over $100 million using BigQuery and Vertex AI to give workers secure access to LLMs for structured and unstructured data searches.
Google Cloud is unveiling many new features with its autonomous data to AI platform powered by BigQuery and Looker, a unified, trustworthy, and conversational BI platform:
New assistive and agentic experiences based on your trusted data and available through BigQuery and Looker will make data scientists, data engineers, analysts, and business users' jobs simpler and faster.
Advanced analytics and data science acceleration: Along with seamless integration with real-time and open-source technologies, BigQuery AI-assisted notebooks improve data science workflows and BigQuery AI Query Engine provides fresh insights.
Autonomous data foundation: BigQuery can collect, manage, and orchestrate any data with its new autonomous features, which include native support for unstructured data processing and open data formats like Iceberg.
Look at each change in detail.
User-specific agents
It believes everyone should have AI. BigQuery and Looker made AI-powered helpful experiences generally available, but Google Cloud now offers specialised agents for all data chores, such as:
Data engineering agents integrated with BigQuery pipelines help create data pipelines, convert and enhance data, discover anomalies, and automate metadata development. These agents provide trustworthy data and replace time-consuming and repetitive tasks, enhancing data team productivity. Data engineers traditionally spend hours cleaning, processing, and confirming data.
The data science agent in Google's Colab notebook enables model development at every step. Scalable training, intelligent model selection, automated feature engineering, and faster iteration are possible. This agent lets data science teams focus on complex methods rather than data and infrastructure.
Looker conversational analytics lets everyone utilise natural language with data. Expanded capabilities provided with DeepMind let all users understand the agent's actions and easily resolve misconceptions by undertaking advanced analysis and explaining its logic. Looker's semantic layer boosts accuracy by two-thirds. The agent understands business language like “revenue” and “segments” and can compute metrics in real time, ensuring trustworthy, accurate, and relevant results. An API for conversational analytics is also being introduced to help developers integrate it into processes and apps.
In the BigQuery autonomous data to AI platform, Google Cloud introduced the BigQuery knowledge engine to power assistive and agentic experiences. It models data associations, suggests business vocabulary words, and creates metadata instantaneously using Gemini's table descriptions, query histories, and schema connections. This knowledge engine grounds AI and agents in business context, enabling semantic search across BigQuery and AI-powered data insights.
All customers may access Gemini-powered agentic and assistive experiences in BigQuery and Looker without add-ons in the existing price model tiers!
Accelerating data science and advanced analytics
BigQuery autonomous data to AI platform is revolutionising data science and analytics by enabling new AI-driven data science experiences and engines to manage complex data and provide real-time analytics.
First, AI improves BigQuery notebooks. It adds intelligent SQL cells to your notebook that can merge data sources, comprehend data context, and make code-writing suggestions. It also uses native exploratory analysis and visualisation capabilities for data exploration and peer collaboration. Data scientists can also schedule analyses and update insights. Google Cloud also lets you construct laptop-driven, dynamic, user-friendly, interactive data apps to share insights across the organisation.
This enhanced notebook experience is complemented by the BigQuery AI query engine for AI-driven analytics. This engine lets data scientists easily manage organised and unstructured data and add real-world context—not simply retrieve it. BigQuery AI co-processes SQL and Gemini, adding runtime verbal comprehension, reasoning skills, and real-world knowledge. Their new engine processes unstructured photographs and matches them to your product catalogue. This engine supports several use cases, including model enhancement, sophisticated segmentation, and new insights.
Additionally, it provides users with the most cloud-optimized open-source environment. Google Cloud for Apache Kafka enables real-time data pipelines for event sourcing, model scoring, communications, and analytics in BigQuery for serverless Apache Spark execution. Customers have almost doubled their serverless Spark use in the last year, and Google Cloud has upgraded this engine to handle data 2.7 times faster.
BigQuery lets data scientists utilise SQL, Spark, or foundation models on Google's serverless and scalable architecture to innovate faster without the challenges of traditional infrastructure.
An independent data foundation throughout data lifetime
An independent data foundation created for modern data complexity supports its advanced analytics engines and specialised agents. BigQuery is transforming the environment by making unstructured data first-class citizens. New platform features, such as orchestration for a variety of data workloads, autonomous and invisible governance, and open formats for flexibility, ensure that your data is always ready for data science or artificial intelligence issues. It does this while giving the best cost and decreasing operational overhead.
For many companies, unstructured data is their biggest untapped potential. Even while structured data provides analytical avenues, unique ideas in text, audio, video, and photographs are often underutilised and discovered in siloed systems. BigQuery instantly tackles this issue by making unstructured data a first-class citizen using multimodal tables (preview), which integrate structured data with rich, complex data types for unified querying and storage.
Google Cloud's expanded BigQuery governance enables data stewards and professionals a single perspective to manage discovery, classification, curation, quality, usage, and sharing, including automatic cataloguing and metadata production, to efficiently manage this large data estate. BigQuery continuous queries use SQL to analyse and act on streaming data regardless of format, ensuring timely insights from all your data streams.
Customers utilise Google's AI models in BigQuery for multimodal analysis 16 times more than last year, driven by advanced support for structured and unstructured multimodal data. BigQuery with Vertex AI are 8–16 times cheaper than independent data warehouse and AI solutions.
Google Cloud maintains open ecology. BigQuery tables for Apache Iceberg combine BigQuery's performance and integrated capabilities with the flexibility of an open data lakehouse to link Iceberg data to SQL, Spark, AI, and third-party engines in an open and interoperable fashion. This service provides adaptive and autonomous table management, high-performance streaming, auto-AI-generated insights, practically infinite serverless scalability, and improved governance. Cloud storage enables fail-safe features and centralised fine-grained access control management in their managed solution.
Finaly, AI platform autonomous data optimises. Scaling resources, managing workloads, and ensuring cost-effectiveness are its competencies. The new BigQuery spend commit unifies spending throughout BigQuery platform and allows flexibility in shifting spend across streaming, governance, data processing engines, and more, making purchase easier.
Start your data and AI adventure with BigQuery data migration. Google Cloud wants to know how you innovate with data.
#technology#technews#govindhtech#news#technologynews#BigQuery autonomous data to AI platform#BigQuery#autonomous data to AI platform#BigQuery platform#autonomous data#BigQuery AI Query Engine
2 notes
·
View notes
Text
Soham Mazumdar, Co-Founder & CEO of WisdomAI – Interview Series
New Post has been published on https://thedigitalinsider.com/soham-mazumdar-co-founder-ceo-of-wisdomai-interview-series/
Soham Mazumdar, Co-Founder & CEO of WisdomAI – Interview Series

Soham Mazumdar is the Co-Founder and CEO of WisdomAI, a company at the forefront of AI-driven solutions. Prior to founding WisdomAI in 2023, he was Co-Founder and Chief Architect at Rubrik, where he played a key role in scaling the company over a 9-year period. Soham previously held engineering leadership roles at Facebook and Google, where he contributed to core search infrastructure and was recognized with the Google Founder’s Award. He also co-founded Tagtile, a mobile loyalty platform acquired by Facebook. With two decades of experience in software architecture and AI innovation, Soham is a seasoned entrepreneur and technologist based in the San Francisco Bay Area.
WisdomAI is an AI-native business intelligence platform that helps enterprises access real-time, accurate insights by integrating structured and unstructured data through its proprietary “Knowledge Fabric.” The platform powers specialized AI agents that curate data context, answer business questions in natural language, and proactively surface trends or risks—without generating hallucinated content. Unlike traditional BI tools, WisdomAI uses generative AI strictly for query generation, ensuring high accuracy and reliability. It integrates with existing data ecosystems and supports enterprise-grade security, with early adoption by major firms like Cisco and ConocoPhillips.
You co-founded Rubrik and helped scale it into a major enterprise success. What inspired you to leave in 2023 and build WisdomAI—and was there a particular moment that clarified this new direction?
The enterprise data inefficiency problem was staring me right in the face. During my time at Rubrik, I witnessed firsthand how Fortune 500 companies were drowning in data but starving for insights. Even with all the infrastructure we built, less than 20% of enterprise users actually had the right access and know-how to use data effectively in their daily work. It was a massive, systemic problem that no one was really solving.
I’m also a builder by nature – you can see it in my path from Google to Tagtile to Rubrik and now WisdomAI. I get energized by taking on fundamental challenges and building solutions from the ground up. After helping scale Rubrik to enterprise success, I felt that entrepreneurial pull again to tackle something equally ambitious.
Last but not least, the AI opportunity was impossible to ignore. By 2023, it became clear that AI could finally bridge that gap between data availability and data usability. The timing felt perfect to build something that could democratize data insights for every enterprise user, not just the technical few.
The moment of clarity came when I realized we could combine everything I’d learned about enterprise data infrastructure at Rubrik with the transformative potential of AI to solve this fundamental inefficiency problem.
WisdomAI introduces a “Knowledge Fabric” and a suite of AI agents. Can you break down how this system works together to move beyond traditional BI dashboards?
We’ve built an agentic data insights platform that works with data where it is – structured, unstructured, and even “dirty” data. Rather than asking analytics teams to run reports, business managers can directly ask questions and drill into details. Our platform can be trained on any data warehousing system by analyzing query logs.
We’re compatible with major cloud data services like Snowflake, Microsoft Fabric, Google’s BigQuery, Amazon’s Redshift, Databricks, and Postgres and also just document formats like excel, PDF, powerpoint etc.
Unlike conventional tools designed primarily for analysts, our conversational interface empowers business users to get answers directly, while our multi-agent architecture enables complex queries across diverse data systems.
You’ve emphasized that WisdomAI avoids hallucinations by separating GenAI from answer generation. Can you explain how your system uses GenAI differently—and why that matters for enterprise trust?
Our AI-Ready Context Model trains on the organization’s data to create a universal context understanding that answers questions with high semantic accuracy while maintaining data privacy and governance. Furthermore, we use generative AI to formulate well-scoped queries that allow us to extract data from the different systems, as opposed to feeding raw data into the LLMs. This is crucial for addressing hallucination and safety concerns with LLMs.
You coined the term “Agentic Data Insights Platform.” How is agentic intelligence different from traditional analytics tools or even standard LLM-based assistants?
Traditional BI stacks slow decision-making because every question has to fight its way through disconnected data silos and a relay team of specialists. When a chief revenue officer needs to know how to close the quarter, the answer typically passes through half a dozen hands—analysts wrangling CRM extracts, data engineers stitching files together, and dashboard builders refreshing reports—turning a simple query into a multi-day project.
Our platform breaks down those silos and puts the full depth of data one keystroke away, so the CRO can drill from headline metrics all the way to row-level detail in seconds.
No waiting in the analyst queue, no predefined dashboards that can’t keep up with new questions—just true self-service insights delivered at the speed the business moves.
How do you ensure WisdomAI adapts to the unique data vocabulary and structure of each enterprise? What role does human input play in refining the Knowledge Fabric?
Working with data where and how it is – that’s essentially the holy grail for enterprise business intelligence. Traditional systems aren’t built to handle unstructured data or “dirty” data with typos and errors. When information exists across varied sources – databases, documents, telemetry data – organizations struggle to integrate this information cohesively.
Without capabilities to handle these diverse data types, valuable context remains isolated in separate systems. Our platform can be trained on any data warehousing system by analyzing query logs, allowing it to adapt to each organization’s unique data vocabulary and structure.
You’ve described WisdomAI’s development process as ‘vibe coding’—building product experiences directly in code first, then iterating through real-world use. What advantages has this approach given you compared to traditional product design?
“Vibe coding” is a significant shift in how software is built where developers leverage the power of AI tools to generate code simply by describing the desired functionality in natural language. It’s like an intelligent assistant that does what you want the software to do, and it writes the code for you. This dramatically reduces the manual effort and time traditionally required for coding.
For years, the creation of digital products has largely followed a familiar script: meticulously plan the product and UX design, then execute the development, and iterate based on feedback. The logic was clear because investing in design upfront minimizes costly rework during the more expensive and time-consuming development phase. But what happens when the cost and time to execute that development drastically shrinks? This capability flips the traditional development sequence on its head. Suddenly, developers can start building functional software based on a high-level understanding of the requirements, even before detailed product and UX designs are finalized.
With the speed of AI code generation, the effort involved in creating exhaustive upfront designs can, in certain contexts, become relatively more time-consuming than getting a basic, functional version of the software up and running. The new paradigm in the world of vibe coding becomes: execute (code with AI), then adapt (design and refine).
This approach allows for incredibly early user validation of the core concepts. Imagine getting feedback on the actual functionality of a feature before investing heavily in detailed visual designs. This can lead to more user-centric designs, as the design process is directly informed by how users interact with a tangible product.
At WisdomAI, we actively embrace AI code generation. We’ve found that by embracing rapid initial development, we can quickly test core functionalities and gather invaluable user feedback early in the process, live on the product. This allows our design team to then focus on refining the user experience and visual design based on real-world usage, leading to more effective and user-loved products, faster.
From sales and marketing to manufacturing and customer success, WisdomAI targets a wide spectrum of business use cases. Which verticals have seen the fastest adoption—and what use cases have surprised you in their impact?
We’ve seen transformative results with multiple customers. For F500 oil and gas company, ConocoPhillips, drilling engineers and operators now use our platform to query complex well data directly in natural language. Before WisdomAI, these engineers needed technical help for even basic operational questions about well status or job performance. Now they can instantly access this information while simultaneously comparing against best practices in their drilling manuals—all through the same conversational interface. They evaluated numerous AI vendors in a six-month process, and our solution delivered a 50% accuracy improvement over the closest competitor.
At a hyper growth Cyber Security company Descope, WisdomAI is used as a virtual data analyst for Sales and Finance. We reduced report creation time from 2-3 days to just 2-3 hours—a 90% decrease. This transformed their weekly sales meetings from data-gathering exercises to strategy sessions focused on actionable insights. As their CRO notes, “Wisdom AI brings data to my fingertips. It really democratizes the data, bringing me the power to go answer questions and move on with my day, rather than define your question, wait for somebody to build that answer, and then get it in 5 days.” This ability to make data-driven decisions with unprecedented speed has been particularly crucial for a fast-growing company in the competitive identity management market.
A practical example: A chief revenue officer asks, “How am I going to close my quarter?” Our platform immediately offers a list of pending deals to focus on, along with information on what’s delaying each one – such as specific questions customers are waiting to have answered. This happens with five keystrokes instead of five specialists and days of delay.
Many companies today are overloaded with dashboards, reports, and siloed tools. What are the most common misconceptions enterprises have about business intelligence today?
Organizations sit on troves of information yet struggle to leverage this data for quick decision-making. The challenge isn’t just about having data, but working with it in its natural state – which often includes “dirty” data not cleaned of typos or errors. Companies invest heavily in infrastructure but face bottlenecks with rigid dashboards, poor data hygiene, and siloed information. Most enterprises need specialized teams to run reports, creating significant delays when business leaders need answers quickly. The interface where people consume data remains outdated despite advancements in cloud data engines and data science.
Do you view WisdomAI as augmenting or eventually replacing existing BI tools like Tableau or Looker? How do you fit into the broader enterprise data stack?
We’re compatible with major cloud data services like Snowflake, Microsoft Fabric, Google’s BigQuery, Amazon’s Redshift, Databricks, and Postgres and also just document formats like excel, PDF, powerpoint etc. Our approach transforms the interface where people consume data, which has remained outdated despite advancements in cloud data engines and data science.
Looking ahead, where do you see WisdomAI in five years—and how do you see the concept of “agentic intelligence” evolving across the enterprise landscape?
The future of analytics is moving from specialist-driven reports to self-service intelligence accessible to everyone. BI tools have been around for 20+ years, but adoption hasn’t even reached 20% of company employees. Meanwhile, in just twelve months, 60% of workplace users adopted ChatGPT, many using it for data analysis. This dramatic difference shows the potential for conversational interfaces to increase adoption.
We’re seeing a fundamental shift where all employees can directly interrogate data without technical skills. The future will combine the computational power of AI with natural human interaction, allowing insights to find users proactively rather than requiring them to hunt through dashboards.
Thank you for the great interview, readers who wish to learn more should visit WisdomAI.
#2023#adoption#agent#agents#ai#AI AGENTS#ai code generation#AI innovation#ai tools#Amazon#Analysis#Analytics#approach#architecture#assistants#bi#bi tools#bigquery#bridge#Building#Business#Business Intelligence#CEO#challenge#chatGPT#Cisco#Cloud#cloud data#code#code generation
0 notes
Text
BigQuery: Definition, Meaning, Uses, Examples, History, and More
Explore a comprehensive dictionary-style guide to BigQuery—its definition, pronunciation, synonyms, history, examples, grammar, FAQs, and real-world applications in cloud computing and data analytics. BigQuery Pronunciation: /ˈbɪɡˌkwɪəri/Syllables: Big·Que·ryPart of Speech: NounPlural: BigQueriesCapitalization: Always capitalized (Proper noun)Field of Usage: Computing, Data Science, Cloud…
#BigQuery#BigQuery antonyms#BigQuery article#BigQuery data warehouse#BigQuery definition#BigQuery etymology#BigQuery examples#BigQuery FAQ#BigQuery for beginners#BigQuery Google Cloud#BigQuery grammar#BigQuery in sentences#BigQuery kids definition#BigQuery machine learning#BigQuery meaning#BigQuery medical definition#BigQuery pricing#BigQuery pronunciation#BigQuery rhymes#BigQuery SQL#BigQuery synonyms#BigQuery usage#BigQuery use cases#Google BigQuery#history of BigQuery#what is BigQuery
0 notes
Text

#QuizTime Which DB offers best support for analytics?
A) PostgreSQL 📊 B) MySQL 📘 C) Snowflake ❄️ D) BigQuery 📈
Comments your answer below👇
💻 Explore insights on the latest in #technology on our Blog Page 👉 https://simplelogic-it.com/blogs/
🚀 Ready for your next career move? Check out our #careers page for exciting opportunities 👉 https://simplelogic-it.com/careers/
#quiztime#testyourknowledge#brainteasers#triviachallenge#thinkfast#quizmaster#analytics#postgresql#mysql#snowflake#bigquery#knowledgeIspower#mindgames#funfacts#makeitsimple#simplelogicit#simplelogic#makingitsimple#itservices#itconsulting
0 notes
Text
youtube
Why you should try Bigquery in 6 minutes
0 notes
Text
Snowflake vs Redshift vs BigQuery vs Databricks: A Detailed Comparison
In the world of cloud-based data warehousing and analytics, organizations are increasingly relying on advanced platforms to manage their massive datasets. Four of the most popular options available today are Snowflake, Amazon Redshift, Google BigQuery, and Databricks. Each offers unique features, benefits, and challenges for different types of organizations, depending on their size, industry, and data needs. In this article, we will explore these platforms in detail, comparing their performance, scalability, ease of use, and specific use cases to help you make an informed decision.
What Are Snowflake, Redshift, BigQuery, and Databricks?
Snowflake: A cloud-based data warehousing platform known for its unique architecture that separates storage from compute. It’s designed for high performance and ease of use, offering scalability without complex infrastructure management.
Amazon Redshift: Amazon’s managed data warehouse service that allows users to run complex queries on massive datasets. Redshift integrates tightly with AWS services and is optimized for speed and efficiency in the AWS ecosystem.
Google BigQuery: A fully managed and serverless data warehouse provided by Google Cloud. BigQuery is known for its scalable performance and cost-effectiveness, especially for large, analytic workloads that require SQL-based queries.
Databricks: More than just a data warehouse, Databricks is a unified data analytics platform built on Apache Spark. It focuses on big data processing and machine learning workflows, providing an environment for collaborative data science and engineering teams.
Snowflake Overview
Snowflake is built for cloud environments and uses a hybrid architecture that separates compute, storage, and services. This unique architecture allows for efficient scaling and the ability to run independent workloads simultaneously, making it an excellent choice for enterprises that need flexibility and high performance without managing infrastructure.
Key Features:
Data Sharing: Snowflake’s data sharing capabilities allow users to share data across different organizations without the need for data movement or transformation.
Zero Management: Snowflake handles most administrative tasks, such as scaling, optimization, and tuning, so teams can focus on analyzing data.
Multi-Cloud Support: Snowflake runs on AWS, Google Cloud, and Azure, giving users flexibility in choosing their cloud provider.
Real-World Use Case:
A global retail company uses Snowflake to aggregate sales data from various regions, optimizing its supply chain and inventory management processes. By leveraging Snowflake’s data sharing capabilities, the company shares real-time sales data with external partners, improving forecasting accuracy.
Amazon Redshift Overview
Amazon Redshift is a fully managed, petabyte-scale data warehouse solution in the cloud. It is optimized for high-performance querying and is closely integrated with other AWS services, such as S3, making it a top choice for organizations that already use the AWS ecosystem.
Key Features:
Columnar Storage: Redshift stores data in a columnar format, which makes querying large datasets more efficient by minimizing disk I/O.
Integration with AWS: Redshift works seamlessly with other AWS services, such as Amazon S3, Amazon EMR, and AWS Glue, to provide a comprehensive solution for data management.
Concurrency Scaling: Redshift automatically adds additional resources when needed to handle large numbers of concurrent queries.
Real-World Use Case:
A financial services company leverages Redshift for data analysis and reporting, analyzing millions of transactions daily. By integrating Redshift with AWS Glue, the company has built an automated ETL pipeline that loads new transaction data from Amazon S3 for analysis in near-real-time.
Google BigQuery Overview
BigQuery is a fully managed, serverless data warehouse that excels in handling large-scale, complex data analysis workloads. It allows users to run SQL queries on massive datasets without worrying about the underlying infrastructure. BigQuery is particularly known for its cost efficiency, as it charges based on the amount of data processed rather than the resources used.
Key Features:
Serverless Architecture: BigQuery automatically handles all infrastructure management, allowing users to focus purely on querying and analyzing data.
Real-Time Analytics: It supports real-time analytics, enabling businesses to make data-driven decisions quickly.
Cost Efficiency: With its pay-per-query model, BigQuery is highly cost-effective, especially for organizations with varying data processing needs.
Real-World Use Case:
A digital marketing agency uses BigQuery to analyze massive amounts of user behavior data from its advertising campaigns. By integrating BigQuery with Google Analytics and Google Ads, the agency is able to optimize its ad spend and refine targeting strategies.
Databricks Overview
Databricks is a unified analytics platform built on Apache Spark, making it ideal for data engineering, data science, and machine learning workflows. Unlike traditional data warehouses, Databricks combines data lakes, warehouses, and machine learning into a single platform, making it suitable for advanced analytics.
Key Features:
Unified Analytics Platform: Databricks combines data engineering, data science, and machine learning workflows into a single platform.
Built on Apache Spark: Databricks provides a fast, scalable environment for big data processing using Spark’s distributed computing capabilities.
Collaboration: Databricks provides collaborative notebooks that allow data scientists, analysts, and engineers to work together on the same project.
Real-World Use Case:
A healthcare provider uses Databricks to process patient data in real-time and apply machine learning models to predict patient outcomes. The platform enables collaboration between data scientists and engineers, allowing the team to deploy predictive models that improve patient care.

People Also Ask
1. Which is better for data warehousing: Snowflake or Redshift?
Both Snowflake and Redshift are excellent for data warehousing, but the best option depends on your existing ecosystem. Snowflake’s multi-cloud support and unique architecture make it a better choice for enterprises that need flexibility and easy scaling. Redshift, however, is ideal for organizations already using AWS, as it integrates seamlessly with AWS services.
2. Can BigQuery handle real-time data?
Yes, BigQuery is capable of handling real-time data through its streaming API. This makes it an excellent choice for organizations that need to analyze data as it’s generated, such as in IoT or e-commerce environments where real-time decision-making is critical.
3. What is the primary difference between Databricks and Snowflake?
Databricks is a unified platform for data engineering, data science, and machine learning, focusing on big data processing using Apache Spark. Snowflake, on the other hand, is a cloud data warehouse optimized for SQL-based analytics. If your organization requires machine learning workflows and big data processing, Databricks may be the better option.
Conclusion
When choosing between Snowflake, Redshift, BigQuery, and Databricks, it's essential to consider the specific needs of your organization. Snowflake is a flexible, high-performance cloud data warehouse, making it ideal for enterprises that need a multi-cloud solution. Redshift, best suited for those already invested in the AWS ecosystem, offers strong performance for large datasets. BigQuery excels in cost-effective, serverless analytics, particularly in the Google Cloud environment. Databricks shines for companies focused on big data processing, machine learning, and collaborative data science workflows.
The future of data analytics and warehousing will likely see further integration of AI and machine learning capabilities, with platforms like Databricks leading the way in this area. However, the best choice for your organization depends on your existing infrastructure, budget, and long-term data strategy.
1 note
·
View note
Text
With the growing demand for cloud-native solutions, Teradata to BigQuery migration is becoming a popular choice for organizations seeking scalable and cost-efficient data platforms. BigQuery’s serverless architecture and real-time analytics capabilities make it an ideal solution for modern data analytics needs.
By migrating from traditional on-premises systems like Teradata or Netezza, businesses can reduce infrastructure costs, scale automatically with data growth, and leverage BigQuery's advanced querying features for faster insights. Unlike legacy systems that require significant investments in physical hardware, BigQuery operates on a flexible pay-per-use pricing model, offering significant cost savings and operational efficiency.
The migration process from Teradata to BigQuery involves careful planning, data transformation, and ensuring compatibility with BigQuery’s cloud architecture. For businesses transitioning from Netezza to BigQuery migration, similar steps apply, ensuring a smooth transition to a more agile, cloud-based solution.
Overall, BigQuery’s integration with Google Cloud services, its scalability, and cost-effectiveness make it a powerful tool for businesses looking to modernize their data infrastructure. Moving to BigQuery enables real-time analytics and enhances decision-making, helping companies stay competitive in a data-driven world.
#TeradataToBigQuery#CloudMigration#BigQuery#DataAnalytics#DataMigration#CloudDataSolutions#NetezzaToBigQuery#RealTimeAnalytics#DataInfrastructure#GoogleCloud#BigData#DataTransformation
0 notes
Text
Completed with the tutorial videos of the module on Data Warehousing with BigQuery in #dezoomcamp @DataTalksClub . Now one to assignments. Very little time to deadline; got to hurry!!
0 notes
Text
0 notes
Text
Greetings from Ashra Technologies
we are hiring.....
#ashra#ashratechnologies#ashrajobs#jobsearch#jobs#hiring#recruiting#recruitingpost#flex#dataengineer#gcp#bigquery#sql#Dataproc#postgresql#linkedinhelp#linkedinlive#linkedingrowth#linkedingroups#linkedinconnections#linkedinnews#linkedinnewsindia
0 notes
Text
Aible And Google Cloud: Gen AI Models Sets Business Security
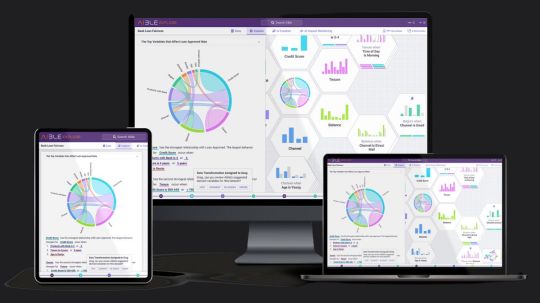
Enterprise controls and generative AI for business users in real time.
Aible
With solutions for customer acquisition, churn avoidance, demand prediction, preventive maintenance, and more, Aible is a pioneer in producing business impact from AI in less than 30 days. Teams can use AI to extract company value from raw enterprise data. Previously using BigQuery’s serverless architecture to save analytics costs, Aible is now working with Google Cloud to provide users the confidence and security to create, train, and implement generative AI models on their own data.
The following important factors have surfaced as market awareness of generative AI’s potential grows:
Enabling enterprise-grade control
Businesses want to utilize their corporate data to allow new AI experiences, but they also want to make sure they have control over their data to prevent unintentional usage of it to train AI models.
Reducing and preventing hallucinations
The possibility that models may produce illogical or non-factual information is another particular danger associated with general artificial intelligence.
Empowering business users
Enabling and empowering business people to utilize gen AI models with the least amount of hassle is one of the most beneficial use cases, even if gen AI supports many enterprise use cases.
Scaling use cases for gen AI
Businesses need a method for gathering and implementing their most promising use cases at scale, as well as for establishing standardized best practices and controls.
Regarding data privacy, policy, and regulatory compliance, the majority of enterprises have a low risk tolerance. However, given its potential to drive change, they do not see postponing the deployment of Gen AI as a feasible solution to market and competitive challenges. As a consequence, Aible sought an AI strategy that would protect client data while enabling a broad range of corporate users to swiftly adapt to a fast changing environment.
In order to provide clients complete control over how their data is used and accessed while creating, training, or optimizing AI models, Aible chose to utilize Vertex AI, Google Cloud’s AI platform.
Enabling enterprise-grade controls
Because of Google Cloud’s design methodology, users don’t need to take any more steps to ensure that their data is safe from day one. Google Cloud tenant projects immediately benefit from security and privacy thanks to Google AI products and services. For example, protected customer data in Cloud Storage may be accessed and used by Vertex AI Agent Builder, Enterprise Search, and Conversation AI. Customer-managed encryption keys (CMEK) can be used to further safeguard this data.
With Aible‘s Infrastructure as Code methodology, you can quickly incorporate all of Google Cloud’s advantages into your own applications. Whether you choose open models like LLama or Gemma, third-party models like Anthropic and Cohere, or Google gen AI models like Gemini, the whole experience is fully protected in the Vertex AI Model Garden.
In order to create a system that may activate third-party gen AI models without disclosing private data outside of Google Cloud, Aible additionally collaborated with its client advisory council, which consists of Fortune 100 organizations. Aible merely transmits high-level statistics on clusters which may be hidden if necessary instead of raw data to an external model. For instance, rather of transmitting raw sales data, it may communicate counts and averages depending on product or area.
This makes use of k-anonymity, a privacy approach that protects data privacy by never disclosing information about groups of people smaller than k. You may alter the default value of k; the more private the information transmission, the higher the k value. Aible makes the data transmission even more secure by changing the names of variables like “Country” to “Variable A” and values like “Italy” to “Value X” when masking is used.
Mitigating hallucination risk
It’s crucial to use grounding, retrieval augmented generation (RAG), and other strategies to lessen and lower the likelihood of hallucinations while employing gen AI. Aible, a partner of Built with Google Cloud AI, offers automated analysis to support human-in-the-loop review procedures, giving human specialists the right tools that can outperform manual labor.
Using its auto-generated Information Model (IM), an explainable AI that verifies facts based on the context contained in your structured corporate data at scale and double checks gen AI replies to avoid making incorrect conclusions, is one of the main ways Aible helps eliminate hallucinations.
Hallucinations are addressed in two ways by Aible’s Information Model:
It has been shown that the IM helps lessen hallucinations by grounding gen AI models on a relevant subset of data.
To verify each fact, Aible parses through the outputs of Gen AI and compares them to millions of responses that the Information Model already knows.
This is comparable to Google Cloud’s Vertex AI grounding features, which let you link models to dependable information sources, like as your company’s papers or the Internet, to base replies in certain data sources. A fact that has been automatically verified is shown in blue with the words “If it’s blue, it’s true.” Additionally, you may examine a matching chart created only by the Information Model and verify a certain pattern or variable.
The graphic below illustrates how Aible and Google Cloud collaborate to provide an end-to-end serverless environment that prioritizes artificial intelligence. Aible can analyze datasets of any size since it leverages BigQuery to efficiently analyze and conduct serverless queries across millions of variable combinations. One Fortune 500 client of Aible and Google Cloud, for instance, was able to automatically analyze over 75 datasets, which included 150 million questions and answers with 100 million rows of data. That assessment only cost $80 in total.
Aible may also access Model Garden, which contains Gemini and other top open-source and third-party models, by using Vertex AI. This implies that Aible may use AI models that are not Google-generated while yet enjoying the advantages of extra security measures like masking and k-anonymity.
All of your feedback, reinforcement learning, and Low-Rank Adaptation (LoRA) data are safely stored in your Google Cloud project and are never accessed by Aible.
Read more on Govindhtech.com
#Aible#GenAI#GenAIModels#BusinessSecurity#AI#BigQuery#AImodels#VertexAI#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
0 notes
Text
Replication of SAP Applications to Google BigQuery
In this post, we will go into the various facets of replicating applications from SAP to BigQuery through SAP Data Services.
Presently, users can integrate data such as Google BigQuery with business data that exists in the SAP Data Warehouse Cloud of the SAP Business Technology Platform. This is done with the help of hyper-scaler storage. What is important here is that data is queried through virtual tables directly with specific tools.

It is also possible to replicate data from SAP to BigQuery and assess all SAP data in one place.
To start the process of replicating data from SAP to BigQuery, ensure that the database is on SAP HANA or any other platform supported by SAP. This SAP to BigQuery activity is typically used to merge data in SAP systems with that of BigQuery.
After the replication process is completed, this data is used for getting deep business insights from Machine Learning (ML) for petabyte scale analytics. The SAP to BigQuery replication process is not complex and SAP system administrators with knowledge of configuring SAP Basis, SAP DS, and the Google Cloud can easily do it.
Here is the replication process of SAP to BigQuery.
Update all data in the source system SAP applications
The SAP LT Replication Server replicates all changes made to the data. These are then stored in the Operational Data Queue.
A subscriber of the Operational Delta Queue, SAP DS, continually tracks changes to the data at pre-determined intervals.
The data from the delta queue is extracted by SAP DS and then processed and formatted to match the structure that is supported by BigQuery.
Finally, data is loaded from SAP to BigQuery.
0 notes
Text
not enough bigquery or sql memes on tumblr
0 notes
Text
man i dont know how to access the """""bigquery table""""" from the """"""databricks catalog"""""". you want me to kill myself
2 notes
·
View notes
Text
Why Tableau is Essential in Data Science: Transforming Raw Data into Insights

Data science is all about turning raw data into valuable insights. But numbers and statistics alone don’t tell the full story—they need to be visualized to make sense. That’s where Tableau comes in.
Tableau is a powerful tool that helps data scientists, analysts, and businesses see and understand data better. It simplifies complex datasets, making them interactive and easy to interpret. But with so many tools available, why is Tableau a must-have for data science? Let’s explore.
1. The Importance of Data Visualization in Data Science
Imagine you’re working with millions of data points from customer purchases, social media interactions, or financial transactions. Analyzing raw numbers manually would be overwhelming.
That’s why visualization is crucial in data science:
Identifies trends and patterns – Instead of sifting through spreadsheets, you can quickly spot trends in a visual format.
Makes complex data understandable – Graphs, heatmaps, and dashboards simplify the interpretation of large datasets.
Enhances decision-making – Stakeholders can easily grasp insights and make data-driven decisions faster.
Saves time and effort – Instead of writing lengthy reports, an interactive dashboard tells the story in seconds.
Without tools like Tableau, data science would be limited to experts who can code and run statistical models. With Tableau, insights become accessible to everyone—from data scientists to business executives.
2. Why Tableau Stands Out in Data Science
A. User-Friendly and Requires No Coding
One of the biggest advantages of Tableau is its drag-and-drop interface. Unlike Python or R, which require programming skills, Tableau allows users to create visualizations without writing a single line of code.
Even if you’re a beginner, you can:
✅ Upload data from multiple sources
✅ Create interactive dashboards in minutes
✅ Share insights with teams easily
This no-code approach makes Tableau ideal for both technical and non-technical professionals in data science.
B. Handles Large Datasets Efficiently
Data scientists often work with massive datasets—whether it’s financial transactions, customer behavior, or healthcare records. Traditional tools like Excel struggle with large volumes of data.
Tableau, on the other hand:
Can process millions of rows without slowing down
Optimizes performance using advanced data engine technology
Supports real-time data streaming for up-to-date analysis
This makes it a go-to tool for businesses that need fast, data-driven insights.
C. Connects with Multiple Data Sources
A major challenge in data science is bringing together data from different platforms. Tableau seamlessly integrates with a variety of sources, including:
Databases: MySQL, PostgreSQL, Microsoft SQL Server
Cloud platforms: AWS, Google BigQuery, Snowflake
Spreadsheets and APIs: Excel, Google Sheets, web-based data sources
This flexibility allows data scientists to combine datasets from multiple sources without needing complex SQL queries or scripts.
D. Real-Time Data Analysis
Industries like finance, healthcare, and e-commerce rely on real-time data to make quick decisions. Tableau’s live data connection allows users to:
Track stock market trends as they happen
Monitor website traffic and customer interactions in real time
Detect fraudulent transactions instantly
Instead of waiting for reports to be generated manually, Tableau delivers insights as events unfold.
E. Advanced Analytics Without Complexity
While Tableau is known for its visualizations, it also supports advanced analytics. You can:
Forecast trends based on historical data
Perform clustering and segmentation to identify patterns
Integrate with Python and R for machine learning and predictive modeling
This means data scientists can combine deep analytics with intuitive visualization, making Tableau a versatile tool.
3. How Tableau Helps Data Scientists in Real Life
Tableau has been adopted by the majority of industries to make data science more impactful and accessible. This is applied in the following real-life scenarios:
A. Analytics for Health Care
Tableau is deployed by hospitals and research institutions for the following purposes:
Monitor patient recovery rates and predict outbreaks of diseases
Analyze hospital occupancy and resource allocation
Identify trends in patient demographics and treatment results
B. Finance and Banking
Banks and investment firms rely on Tableau for the following purposes:
✅ Detect fraud by analyzing transaction patterns
✅ Track stock market fluctuations and make informed investment decisions
✅ Assess credit risk and loan performance
C. Marketing and Customer Insights
Companies use Tableau to:
✅ Track customer buying behavior and personalize recommendations
✅ Analyze social media engagement and campaign effectiveness
✅ Optimize ad spend by identifying high-performing channels
D. Retail and Supply Chain Management
Retailers leverage Tableau to:
✅ Forecast product demand and adjust inventory levels
✅ Identify regional sales trends and adjust marketing strategies
✅ Optimize supply chain logistics and reduce delivery delays
These applications show why Tableau is a must-have for data-driven decision-making.
4. Tableau vs. Other Data Visualization Tools
There are many visualization tools available, but Tableau consistently ranks as one of the best. Here’s why:
Tableau vs. Excel – Excel struggles with big data and lacks interactivity; Tableau handles large datasets effortlessly.
Tableau vs. Power BI – Power BI is great for Microsoft users, but Tableau offers more flexibility across different data sources.
Tableau vs. Python (Matplotlib, Seaborn) – Python libraries require coding skills, while Tableau simplifies visualization for all users.
This makes Tableau the go-to tool for both beginners and experienced professionals in data science.
5. Conclusion
Tableau has become an essential tool in data science because it simplifies data visualization, handles large datasets, and integrates seamlessly with various data sources. It enables professionals to analyze, interpret, and present data interactively, making insights accessible to everyone—from data scientists to business leaders.
If you’re looking to build a strong foundation in data science, learning Tableau is a smart career move. Many data science courses now include Tableau as a key skill, as companies increasingly demand professionals who can transform raw data into meaningful insights.
In a world where data is the driving force behind decision-making, Tableau ensures that the insights you uncover are not just accurate—but also clear, impactful, and easy to act upon.
#data science course#top data science course online#top data science institute online#artificial intelligence course#deepseek#tableau
3 notes
·
View notes