#SQL Server concatenation
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
Concatenating Row Values into a Single String in SQL Server
Concatenating text from multiple rows into a single text string in SQL Server can be achieved using different methods, depending on the version of SQL Server you are using. The most common approaches involve using the FOR XML PATH method for older versions, and the STRING_AGG function, which was introduced in SQL Server 2017. I’ll explain both methods. Using STRING_AGG (SQL Server 2017 and…
View On WordPress
#FOR XML PATH method#merging SQL rows#SQL Server concatenation#SQL Server text aggregation#STRING_AGG function
0 notes
Text
How to Prevent

Preventing injection requires keeping data separate from commands and queries:
The preferred option is to use a safe API, which avoids using the interpreter entirely, provides a parameterized interface, or migrates to Object Relational Mapping Tools (ORMs). Note: Even when parameterized, stored procedures can still introduce SQL injection if PL/SQL or T-SQL concatenates queries and data or executes hostile data with EXECUTE IMMEDIATE or exec().
Use positive server-side input validation. This is not a complete defense as many applications require special characters, such as text areas or APIs for mobile applications.
For any residual dynamic queries, escape special characters using the specific escape syntax for that interpreter. (escaping technique) Note: SQL structures such as table names, column names, and so on cannot be escaped, and thus user-supplied structure names are dangerous. This is a common issue in report-writing software.
Use LIMIT and other SQL controls within queries to prevent mass disclosure of records in case of SQL injection.
bonus question: think about how query on the image above should look like? answer will be in the comment section
4 notes
·
View notes
Text
The Importance of Security in .NET Applications: Best Practices

When it comes to developing secure applications, there is no room for error. As cyberattacks become increasingly sophisticated, ensuring the security of your .NET applications is more important than ever. With a rapidly growing reliance on web services, APIs, and cloud integrations, .NET developers must stay vigilant about safeguarding their software from vulnerabilities. In this blog, we will explore the importance of security in .NET applications and provide best practices that every developer should follow to protect their applications from potential threats. If you're involved in Dot Net Development, it's crucial to understand how to implement these practices to ensure a secure environment for both users and developers.
Why Security Matters in .NET Applications
.NET is a powerful framework used to build a wide range of applications, from web and mobile apps to enterprise-level solutions. While the framework itself offers many built-in features for developers, such as managed code and type safety, security must still be a priority. Vulnerabilities in your .NET applications can lead to catastrophic results, such as data breaches, unauthorized access, or even financial losses. As a result, focusing on security from the early stages of development can mitigate these risks and provide long-term protection.
Best Practices for Securing .NET Applications
Securing .NET applications doesn't need to be complicated if the right practices are followed. Below, we discuss several key strategies for ensuring the security of your applications:
1. Use Secure Coding Practices
The foundation of secure .NET application development starts with using secure coding practices. This includes:
Input Validation: Always validate user input to avoid SQL injection, cross-site scripting (XSS), and other injection attacks. Use techniques like whitelisting and regular expressions to ensure that data is clean and safe.
Error Handling: Avoid exposing stack traces or any sensitive information in error messages. Instead, log detailed errors server-side and show users a generic message to prevent attackers from gaining insights into your system.
Use Parameterized Queries: Never concatenate user input directly into SQL queries. Use parameterized queries or stored procedures to ensure safe interactions with databases.
2. Implement Authentication and Authorization Properly
In .NET applications, authentication and authorization are vital to securing sensitive data. These two concepts should never be compromised.
Authentication: Use trusted authentication mechanisms such as OAuth or OpenID Connect. ASP.NET Identity is a useful library to implement user authentication and management. Always prefer multi-factor authentication (MFA) when possible to add an extra layer of security.
Authorization: Ensure that users only have access to the resources they are authorized to view. Leverage role-based access control (RBAC) and fine-grained permissions to enforce this principle. This will ensure that even if an attacker gains access to one part of your system, they can't exploit other areas without the proper credentials.
3. Encryption and Data Protection
Encryption is one of the most effective ways to protect sensitive data. When working with .NET applications, always implement encryption both for data at rest (stored data) and data in transit (data being transferred between systems).
Use HTTPS: Always ensure that data transmitted over the network is encrypted by using HTTPS. This can be done easily by enabling SSL/TLS certificates on your server.
Encrypt Sensitive Data: Store passwords and other sensitive data like payment information in an encrypted format. The .NET framework provides the System.Security.Cryptography namespace for secure encryption and decryption. Use strong encryption algorithms like AES (Advanced Encryption Standard).
4. Regularly Update Libraries and Dependencies
In many cases, vulnerabilities are introduced through third-party libraries and dependencies. Using outdated libraries can expose your application to various security risks. To mitigate this, always:
Regularly update all libraries and dependencies used in your .NET application to their latest secure versions.
Use tools like NuGet to check for outdated packages and apply necessary updates.
Consider using a vulnerability scanner to automatically identify any known vulnerabilities in your dependencies.
5. Implement Logging and Monitoring
Security isn't just about preventing attacks; it's also about detecting them when they occur. Implement proper logging and monitoring to track suspicious activities and respond quickly to potential breaches.
Logging: Log every critical event, including login attempts, access control changes, and sensitive data access. Use structured logging to make it easier to analyze logs.
Monitoring: Set up real-time alerts to notify you about abnormal activities or patterns that might indicate an attempted attack.
The Role of Security in Mobile Apps
As more businesses extend their services to mobile platforms, the importance of securing mobile applications has risen significantly. While the underlying principles of securing .NET applications remain the same, mobile apps come with additional complexities. For instance, developers should take extra care in managing API security, preventing reverse engineering, and handling sensitive user data on mobile devices.
To understand the potential costs of developing secure mobile applications, you might want to use a mobile app cost calculator. This tool can help you assess the cost of integrating security measures such as encryption, user authentication, and secure storage for mobile apps. If you're interested in exploring the benefits of Dot net development services for your business, we encourage you to book an appointment with our team of experts.
Book an Appointment
Conclusion
Security is paramount in the development of any .NET application. By implementing secure coding practices, robust authentication and authorization mechanisms, encryption, and regular updates, you can protect your application from the ever-growing threat of cyberattacks. Additionally, leveraging proper logging, monitoring, and auditing techniques ensures that even if a breach does occur, you can identify and mitigate the damage swiftly.
If you're working with .NET technology and need help building secure applications, consider partnering with a Dot Net Development Company. Their expertise will help you implement the best security practices and ensure your applications remain safe and resilient against future threats.
0 notes
Text
MySQL Naming Conventions

What is MySQL?
MySQL is a freely available open source Relational Database Management System (RDBMS) that uses Structured Query Language (SQL). SQL is the most popular language for adding, accessing and managing content in a database. It is most noted for its quick processing, proven reliability, ease and flexibility of use.
What is a naming convention?
In computer programming, a naming convention is a set of rules for choosing the character sequence to be used for identifiers that denote variables, types, functions, and other entities in source code and documentation.
General rules — Naming conventions
Using lowercase will help speed typing, avoid mistakes as MYSQL is case sensitive.
Space replaced with Underscore — Using space between words is not advised.
Numbers are not for names — While naming, it is essential that it contains only Alpha English alphabets.
Valid Names — Names should be descriptive of the elements. i.e. — Self-explanatory and not more than 64 characters.
No prefixes allowed.
Database name convention
Name can be singular or plural but as the database represents a single database it should be singular.
Avoid prefix if possible.
MySQL table name
Lowercase table name
MySQL is usually hosted in a Linux server which is case-sensitive hence to stay on the safe side use lowercase. Many PHP or similar programming frameworks, auto-detect or auto-generate class-based table names and most of them expect lowercase names.
Table name in singular
The table is made up of fields and rows filled with various forms of data, similarly the table name could be plural but the table itself is a single entity hence it is odd and confusing. Hence use names like User, Comment.
Prefixed table name
The table usually has the database or project name. sometimes some tables may exist under the same name in the database to avoid replacing this, you can use prefixes. Essentially, names should be meaningful and self-explanatory. If you can’t avoid prefix you can fix it using php class.
Field names
Use all above cases which include lowercase, no space, no numbers, and avoid prefix.
Choose short names no-longer than two words.
Field names should be easy and understandable
Primary key can be id or table name_id or it can be a self-explanatory name.
Avoid using reserve words as field name. i.e. — Pre-defined words or Keywords. You can add prefix to these names to make it understandable like user_name, signup_date.
Avoid using column with same name as table name. This can cause confusion while writing query.
Avoid abbreviated, concatenated, or acronym-based names.
Do define a foreign key on database schema.
Foreign key column must have a table name with their primary key.
e.g. blog_id represents foreign key id from table blog.
Avoid semantically — meaningful primary key names. A classic design mistake is creating a table with primary key that has actual meaning like ‘name’ as primary key. In this case if someone changes their name then the relationship with the other tables will be affected and the name can be repetitive losing its uniqueness.
Conclusion
Make your table and database names simple yet understandable by both database designers and programmers. It should things that might cause confusion, issues with linking tables to one another. And finally, it should be readable for programming language or the framework that is implemented.
#MySQL#DatabaseManagement#SQL#NamingConventions#RelationalDatabase#DatabaseDesign#CodingStandards#TableNaming#FieldNaming#DatabaseSchema#ProgrammingTips#DataManagement#CaseSensitivity#PrimaryKey#ForeignKey#DatabaseBestPractices#OpenSource#DatabaseOptimization#MySQLTips#DataStructure
0 notes
Text
Improving Data Clarity with the SSRS Split Function

One useful feature in SQL Server Reporting Services for improving data clarity is the SSRS Split Function. This function makes it possible to divide concatenated strings into independent components according to a given delimiter, making reports easier to read and manage. If you work with lists of names, categories, or any other type of delimited data, the SSRS Split Function can help you break up complex data into manageable chunks. It is imperative for report developers to use this function since it enhances data presentation and facilitates efficient analysis and decision-making.
0 notes
Text
Securing ASP.NET Applications: Best Practices
With the increase in cyberattacks and vulnerabilities, securing web applications is more critical than ever, and ASP.NET is no exception. ASP.NET, a popular web application framework by Microsoft, requires diligent security measures to safeguard sensitive data and protect against common threats. In this article, we outline best practices for securing ASP NET applications, helping developers defend against attacks and ensure data integrity.

1. Enable HTTPS Everywhere
One of the most essential steps in securing any web application is enforcing HTTPS to ensure that all data exchanged between the client and server is encrypted. HTTPS protects against man-in-the-middle attacks and ensures data confidentiality.
2. Use Strong Authentication and Authorization
Proper authentication and authorization are critical to preventing unauthorized access to your application. ASP.NET provides tools like ASP.NET Identity for managing user authentication and role-based authorization.
Tips for Strong Authentication:
Use Multi-Factor Authentication (MFA) to add an extra layer of security, requiring methods such as SMS codes or authenticator apps.
Implement strong password policies (length, complexity, expiration).
Consider using OAuth or OpenID Connect for secure, third-party login options (Google, Microsoft, etc.).
3. Protect Against Cross-Site Scripting (XSS)
XSS attacks happen when malicious scripts are injected into web pages that are viewed by other users. To prevent XSS in ASP.NET, all user input should be validated and properly encoded.
Tips to Prevent XSS:
Use the AntiXSS library built into ASP.NET for safe encoding.
Validate and sanitize all user input—never trust incoming data.
Use a Content Security Policy (CSP) to restrict which types of content (e.g., scripts) can be loaded.
4. Prevent SQL Injection Attacks
SQL injection occurs when attackers manipulate input data to execute malicious SQL queries. This can be prevented by avoiding direct SQL queries with user input.
How to Prevent SQL Injection:
Use parameterized queries or stored procedures instead of concatenating SQL queries.
Leverage ORM tools (e.g., Entity Framework), which handle query parameterization and prevent SQL injection.
5. Use Anti-Forgery Tokens to Prevent CSRF Attacks
Cross-Site Request Forgery (CSRF) tricks users into unknowingly submitting requests to a web application. ASP.NET provides anti-forgery tokens to validate incoming requests and prevent CSRF attacks.
6. Secure Sensitive Data with Encryption
Sensitive data, such as passwords and personal information, should always be encrypted both in transit and at rest.
How to Encrypt Data in ASP.NET:
Use the Data Protection API (DPAPI) to encrypt cookies, tokens, and user data.
Encrypt sensitive configuration data (e.g., connection strings) in the web.config file.
7. Regularly Patch and Update Dependencies
Outdated libraries and frameworks often contain vulnerabilities that attackers can exploit. Keeping your environment updated is crucial.
Best Practices for Updates:
Use package managers (e.g., NuGet) to keep your libraries up to date.
Use tools like OWASP Dependency-Check or Snyk to monitor vulnerabilities in your dependencies.
8. Implement Logging and Monitoring
Detailed logging is essential for tracking suspicious activities and troubleshooting security issues.
Best Practices for Logging:
Log all authentication attempts (successful and failed) to detect potential brute force attacks.
Use a centralized logging system like Serilog, ELK Stack, or Azure Monitor.
Monitor critical security events such as multiple failed login attempts, permission changes, and access to sensitive data.
9. Use Dependency Injection for Security
In ASP.NET Core, Dependency Injection (DI) allows for loosely coupled services that can be injected where needed. This helps manage security services such as authentication and encryption more effectively.
10. Use Content Security Headers
Security headers such as X-Content-Type-Options, X-Frame-Options, and X-XSS-Protection help prevent attacks like content-type sniffing, clickjacking, and XSS.
Conclusion
Securing ASP.NET applications is a continuous and evolving process that requires attention to detail. By implementing these best practices—from enforcing HTTPS to using security headers—you can reduce the attack surface of your application and protect it from common threats. Keeping up with modern security trends and integrating security at every development stage ensures a robust and secure ASP.NET application.
Security is not a one-time effort—it’s a continuous commitment
To know more: https://www.inestweb.com/best-practices-for-securing-asp-net-applications/
0 notes
Text
Analysing large data sets using AWS Athena
Handling large datasets can feel overwhelming, especially when you're faced with endless rows of data and complex information. At our company, we faced these challenges head-on until we discovered AWS Athena. Athena transformed the way we handle massive datasets by simplifying the querying process without the hassle of managing servers or dealing with complex infrastructure. In this article, I’ll Walk you through how AWS Athena has revolutionized our approach to data analysis. We’ll explore how it leverages SQL to make working with big data straightforward and efficient. If you’ve ever struggled with managing large datasets and are looking for a practical solution, you’re in the right place.
Efficient Data Storage and Querying
Through our experiences, we found that two key strategies significantly enhanced our performance with Athena: partitioning data and using columnar storage formats like Parquet. These methods have dramatically reduced our query times and improved our data analysis efficiency. Here’s a closer look at how we’ve implemented these strategies:
Data Organization for Partitioning and Parquet
Organize your data in S3 for efficient querying:
s3://your-bucket/your-data/
├── year=2023/
│ ├── month=01/
│ │ ├── day=01/
│ │ │ └── data-file
│ │ └── day=02/
│ └── month=02/
└── year=2024/
└── month=01/
└── day=01/
Preprocessing Data for Optimal Performance
Before importing datasets into AWS Glue and Athena, preprocessing is essential to ensure consistency and efficiency. This involves handling mixed data types, adding date columns for partitioning, and converting files to a format suitable for Athena.
Note: The following steps are optional based on the data and requirements. Use them according to your requirements.
1. Handling Mixed Data Types
To address columns with mixed data types, standardize them to the most common type using the following code snippet:def determine_majority_type(series): # get the types of all non-null values types = series.dropna().apply(type) # count the occurrences of each type type_counts = types.value_counts()
preprocess.py
2. Adding Date Columns for Partitioning
To facilitate partitioning, add additional columns for year, month, and day:def add_date_columns_to_csv(file_path): try: # read the CSV file df = pd.read_csv(file_path)
partitioning.py
3. Converting CSV to Parquet Format
For optimized storage and querying, convert CSV files to Parquet format:def detect_and_convert_mixed_types(df): for col in df.columns: # detect mixed types in the column if df[col].apply(type).nunique() > 1:
paraquet.py
4. Concatenating Multiple CSV Files
To consolidate multiple CSV files into one for Parquet conversion:def read_and_concatenate_csv_files(directory): all_dfs = [] # recursively search for CSV files in the directory
concatenate.py
Step-by-Step Guide to Managing Datasets with AWS Glue and Athena
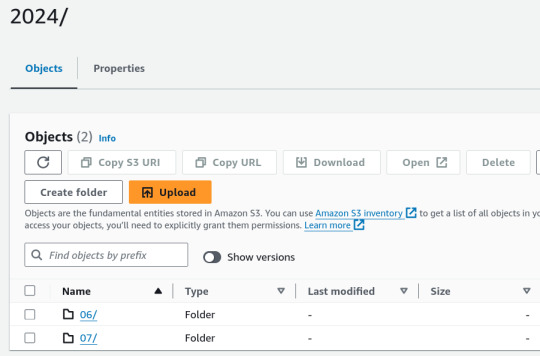
1. Place Your Source Dataset in S3
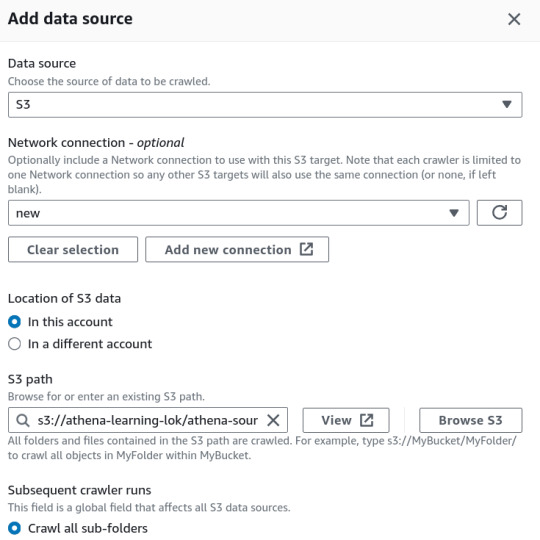
2. Create a Crawler in AWS Glue
In the AWS Glue console, create a new crawler to catalog your data and make it queryable with Athena.
Specify Your S3 Bucket: Set the S3 bucket path as the data source in the crawler configuration.
IAM Role: Assign an IAM role with the necessary permissions to access your S3 bucket and Glue Data Catalog.
3. Set Up the Glue Database
Create a new database in the AWS Glue Data Catalog where your CSV data will be stored. This database acts as a container for your tables.
Database Creation: Go to the AWS Glue Data Catalog section and create a new database.
Crawler Output Configuration: Specify this database for storing the table metadata and optionally provide a prefix for your table names.
4. Configure Crawler Schedule
Set the crawler schedule to keep your data catalog up to date:
Hourly
Daily
Weekly
Monthly
On-Demand
Scheduling the crawler ensures data will be updated to our table, if any updates to existing data or adding of new files etc.
5. Run the Crawler
Initiate the crawler by clicking the "Run Crawler" button in the Glue console. The crawler will analyze your data, determine optimal data types for each column, and create a table in the Glue Data Catalog.
6. Review and Edit the Table Schema
Post-crawler, review and modify the table schema:
Change Data Types: Adjust data types for any column as needed.
Create Partitions: Set up partitions to improve query performance and data organization.

7. Query Your Data with AWS Athena
In the Athena console:
Connect to Glue Database: Use the database created by the Glue Crawler.
Write SQL Queries: Leverage SQL for querying your data directly in Athena.
8. Performance Comparison
After the performance optimizations, we got the following results:
To illustrate it, I ran following queries on 1.6 GB data:
For Parquet data format without partitioning
SELECT * FROM "athena-learn"."parquet" WHERE transdate='2024-07-05';
For Partitioning with CSV

Query Runtime for Parquet Files: 8.748 seconds. Parquet’s columnar storage format and compression contribute to this efficiency.
Query Runtime for Partitioned CSV Files: 2.901 seconds. Partitioning helps reduce the data scanned, improving query speed.
Data Scanned for Paraquet Files: 60.44MB
Data Scanned for Partitioned CSV Files: 40.04MB
Key Insight: Partitioning CSV files improves query performance, but using Parquet files offers superior results due to their optimized storage and compression features.
9. AWS Athena Pricing and Optimization
AWS Athena pricing is straightforward: you pay $5.00 per terabyte (TB) of data scanned by your SQL queries. However, you can significantly reduce costs and enhance query performance by implementing several optimization strategies.
Conclusion
AWS Athena offers a powerful, serverless SQL interface for querying large datasets. By adopting best practices in data preprocessing, organization, and Athena usage, you can manage and analyze your data efficiently without the overhead of complex infrastructure.
0 notes
Text
Peak Performance: Crafting Clean and Efficient WordPress Plugins
Introduction:
WordPress has revolutionized the way websites are built and managed, empowering millions of users worldwide to create their online presence effortlessly. One of the key elements contributing to its flexibility and extensibility is the availability of plugins, which extend the functionality of WordPress sites. However, not all plugins are created equal. Clean and efficient code is crucial for plugin development to ensure smooth performance, compatibility, and maintainability. In this comprehensive guide, we'll delve into the best practices for writing clean and efficient WordPress plugin code, empowering developers to craft high-quality plugins that enhance the WordPress ecosystem.
1. Understanding WordPress Coding Standards:
- Familiarize yourself with the WordPress Coding Standards, which provide guidelines for consistent, readable, and maintainable code.
- Adhere to naming conventions, indentation standards, and coding style to ensure consistency across your plugin codebase.
- Utilize tools like PHP CodeSniffer and ESLint to automatically check your code against these standards and enforce best practices.
2. Modularization and Organization:
- Break down your plugin functionality into modular components, each responsible for a specific task or feature.
- Use classes, functions, and namespaces to organize your code logically, improving readability and maintainability.
- Adopt the MVC (Model-View-Controller) architecture or similar patterns to separate concerns and enhance code structure.
3. Proper Use of Hooks and Filters:
- Leverage WordPress' powerful hook system to integrate your plugin seamlessly into the WordPress ecosystem.
- Use action and filter hooks to extend WordPress core functionality without modifying core files, ensuring compatibility and upgradability.
- Document the hooks provided by your plugin, along with their parameters and usage, to facilitate customization by other developers.
4. Optimize Database Interactions:
- Minimize database queries by caching results, utilizing transients, and optimizing SQL queries.
- Follow WordPress best practices for database interactions, such as using the $wpdb class for direct database access and sanitizing user input to prevent SQL injection attacks.
- Consider the performance implications of database operations, especially on large-scale sites, and optimize queries accordingly.
5. Implement Caching Mechanisms:
- Integrate caching mechanisms to improve the performance of your plugin and reduce server load.
- Utilize WordPress' built-in caching functions like wp_cache_set() and wp_cache_get() or leverage third-party caching solutions.
- Cache expensive operations, such as database queries or remote API requests, to minimize response times and enhance scalability.
6. Prioritize Security:
- Follow WordPress security best practices to protect your plugin from vulnerabilities and malicious attacks.
- Sanitize and validate user input to prevent cross-site scripting (XSS), SQL injection, and other common security threats.
- Regularly update your plugin to patch security vulnerabilities and stay abreast of emerging security trends and best practices.
7. Optimize Asset Loading:
- Minimize page load times by optimizing the loading of CSS and JavaScript assets.
- Concatenate and minify CSS and JavaScript files to reduce file size and the number of HTTP requests.
- Load assets conditionally only when necessary, based on the page context or user interactions, to avoid unnecessary overhead.
8. Ensure Cross-Browser Compatibility:
- Test your plugin across different browsers and devices to ensure consistent behavior and appearance.
- Use feature detection techniques rather than browser detection to handle browser-specific quirks and inconsistencies.
- Stay informed about evolving web standards and best practices to ensure compatibility with modern browsers and technologies.
9. Document Your Code:
- Document your plugin code thoroughly using inline comments, PHPDoc blocks, and README files.
- Provide clear explanations of functions, classes, hooks, and filters, along with examples of usage.
- Document any dependencies, configuration options, and integration points to guide developers using your plugin.
10. Performance Monitoring and Optimization:
- Monitor your plugin's performance using tools like Query Monitor, New Relic, or Google PageSpeed Insights.
- Identify and address performance bottlenecks, such as slow database queries, excessive resource consumption, or inefficient code.
- Continuously optimize your plugin based on real-world usage patterns and performance metrics to ensure optimal performance under varying conditions.
Conclusion:
Developing custom WordPress plugins requires adherence to high coding standards and best practices. Mastering the art of writing clean and efficient WordPress plugin code is essential for building high-quality plugins that enhance the functionality and performance of WordPress sites. By following the best practices outlined in this guide, developers can ensure their plugins are secure, scalable, and maintainable, contributing positively to the WordPress ecosystem and providing value to users worldwide. Embrace these principles, strive for excellence, and elevate your WordPress plugin development to new heights.
0 notes
Text
This Week in Rust 480
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
Announcing Rust 1.67.0
Help test Cargo's new index protocol
Foundation
Rust Foundation Annual Report 2022
Newsletters
This Month in Rust GameDev #41 - December 2022
Project/Tooling Updates
Scaphandre 0.5.0, to measure energy consumption of IT servers and computers, is released : windows compatibility (experimental), multiple sensors support, and much more...
IntelliJ Rust Changelog #187
rust-analyzer changelog #166
argmin 0.8.0 and argmin-math 0.3.0 released
Fornjot (code-first CAD in Rust) - Weekly Release - The Usual Rabbit Hole
One step forward, an easier interoperability between Rust and Haskell
Managing complex communication over raw I/O streams using async-io-typed and async-io-converse
Autometrics - a macro that tracks metrics for any function & inserts links to Prometheus charts right into each function's doc comments
Observations/Thoughts
Ordering Numbers, How Hard Can It Be?
Next Rust Compiler
Forking Chrome to render in a terminal
40x Faster! We rewrote our project with Rust!
Moving and re-exporting a Rust type can be a major breaking change
What the HAL? The Quest for Finding a Suitable Embedded Rust HAL
Some Rust breaking changes don't require a major version
Crash! And now what?
Rust Walkthroughs
Handling Integer Overflow in Rust
Rust error handling with anyhow
Synchronizing state with Websockets and JSON Patch
Plugins for Rust
[series] Protohackers in Rust, Part 00: Dipping the toe in async and Tokio
Building gRPC APIs with Rust using Tonic
Miscellaneous
Rust's Ugly Syntax
[video] Rust's Witchcraft
[DE] CodeSandbox: Nun auch für die Rust-Entwicklung
Crate of the Week
This week's crate is symphonia, a collection of pure-Rust audio decoders for many common formats.
Thanks to Kornel for the suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
diesel - Generate matching SQL types for Mysql enums
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
377 pull requests were merged in the last week
move format_args!() into AST (and expand it during AST lowering)
implement Hash for proc_macro::LineColumn
add help message about function pointers
add hint for missing lifetime bound on trait object when type alias is used
add suggestion to remove if in let..else block
assume MIR types are fully normalized in ascribe_user_type
check for missing space between fat arrow and range pattern
compute generator saved locals on MIR
core: support variety of atomic widths in width-agnostic functions
correct suggestions for closure arguments that need a borrow
detect references to non-existant messages in Fluent resources
disable ConstGoto opt in cleanup blocks
don't merge vtables when full debuginfo is enabled
fix def-use dominance check
fix thin archive reading
impl DispatchFromDyn for Cell and UnsafeCell
implement simple CopyPropagation based on SSA analysis
improve proc macro attribute diagnostics
insert whitespace to avoid ident concatenation in suggestion
only compute mir_generator_witnesses query in drop_tracking_mir mode
preserve split DWARF files when building archives
recover from more const arguments that are not wrapped in curly braces
reimplement NormalizeArrayLen based on SsaLocals
remove overlapping parts of multipart suggestions
special-case deriving PartialOrd for enums with dataless variants
suggest coercion of Result using ?
suggest qualifying bare associated constants
suggest using a lock for *Cell: Sync bounds
teach parser to understand fake anonymous enum syntax
use can_eq to compare types for default assoc type error
use proper InferCtxt when probing for associated types in astconv
use stable metric for const eval limit instead of current terminator-based logic
remove optimistic spinning from mpsc::SyncSender
stabilize the const_socketaddr feature
codegen_gcc: fix/signed integer overflow
cargo: cargo add check [dependencies] order without considering the dotted item
cargo: avoid saving the same future_incompat warning multiple times
cargo: fix split-debuginfo support detection
cargo: make cargo aware of dwp files
cargo: mention current default value in publish.timeout docs
rustdoc: collect rustdoc-reachable items during early doc link resolution
rustdoc: prohibit scroll bar on source viewer in Safari
rustdoc: use smarter encoding for playground URL
rustdoc: add option to include private items in library docs
fix infinite loop in rustdoc get_all_import_attributes function
rustfmt: don't wrap comments that are part of a table
rustfmt: fix for handling empty code block in doc comment
clippy: invalid_regex: show full error when string value doesn't match source
clippy: multiple_unsafe_ops_per_block: don't lint in external macros
clippy: improve span for module_name_repetitions
clippy: missing config
clippy: prevents len_without_is_empty from triggering when len takes arguments besides &self
rust-analyzer: adding section for Visual Studio IDE Rust development support
rust-analyzer: don't fail workspace loading if sysroot can't be found
rust-analyzer: improve "match to let else" assist
rust-analyzer: show signature help when typing record literal
rust-analyzer: ide-assists: unwrap block when it parent is let stmt
rust-analyzer: fix config substitution failing extension activation
rust-analyzer: don't include lifetime or label apostrophe when renaming
rust-analyzer: fix "add missing impl members" assist for impls inside blocks
rust-analyzer: fix assoc item search finding unrelated definitions
rust-analyzer: fix process-changes not deduplicating changes correctly
rust-analyzer: handle boolean scrutinees in match <-> if let replacement assists better
rust-analyzer: substitute VSCode variables more generally
Rust Compiler Performance Triage
Overall a positive week, with relatively few regressions overall and a number of improvements.
Triage done by @simulacrum. Revision range: c8e6a9e..a64ef7d
Summary:
(instructions:u) mean range count Regressions ❌ (primary) 0.6% [0.6%, 0.6%] 1 Regressions ❌ (secondary) 0.3% [0.3%, 0.3%] 1 Improvements ✅ (primary) -0.8% [-2.0%, -0.2%] 27 Improvements ✅ (secondary) -0.9% [-1.9%, -0.5%] 11 All ❌✅ (primary) -0.8% [-2.0%, 0.6%] 28
2 Regressions, 4 Improvements, 6 Mixed; 2 of them in rollups 44 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Create an Operational Semantics Team
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Stabilize feature cstr_from_bytes_until_nul
[disposition: merge] Support true and false as boolean flag params
[disposition: merge] Implement AsFd and AsRawFd for Rc
[disposition: merge] rustdoc: compute maximum Levenshtein distance based on the query
New and Updated RFCs
[new] Permissions
[new] Add text for the CFG OS Version RFC
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
Feature: Help test Cargo's new index protocol
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-02-01 - 2023-03-01 🦀
Virtual
2023-02-01 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
New Year Virtual Social + Share
2023-02-01 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2023-02-01 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Reactor New York and Microsoft Reactor San Francisco
Primeros pasos con Rust: QA y horas de comunidad | New York Mirror | San Francisco Mirror
2023-02-01 | Virtual (Stuttgart, DE) | Rust Community Stuttgart
Rust-Meetup
2023-02-06 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Reactor New York and Microsoft Reactor San Francisco
Primeros pasos con Rust - Implementación de tipos y rasgos genéricos | New York Mirror | San Francisco Mirror
2023-02-07 | Virtual (Beijing, CN) | WebAssembly and Rust Meetup (Rustlang)
Monthly WasmEdge Community Meeting, a CNCF sandbox WebAssembly runtime
2023-02-07 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-02-07 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Reactor New York and Microsoft Reactor San Francisco
Primeros pasos con Rust - Módulos, paquetes y contenedores de terceros | New York Mirror | San Francisco Mirror
2023-02-08 | Virtual (Boulder, CO, US) | Boulder Elixir and Rust
Monthly Meetup
2023-02-08 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Rector New York and Microsoft Reactor San Francisco
Primeros pasos con Rust: QA y horas de comunidad | New York Mirror | San Francisco Mirror
2023-02-09 | Virtual (Nürnberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-02-11 | Virtual | Rust GameDev
Rust GameDev Monthly Meetup
2023-02-13 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Rector New York and Microsoft Reactor San Francisco
Primeros pasos con Rust - Escritura de pruebas automatizadas | New York Mirror | San Francisco Mirror
2023-02-14 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn
2023-02-14 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2023-02-14 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US) | Microsoft Reactor Redmond and Microsoft Rector New York and Microsoft Reactor San Francisco
Primeros pasos con Rust - Creamos un programa de ToDos en la línea de comandos | San Francisco Mirror | New York Mirror
2023-02-14 | Virtual (Saarbrücken, DE) | Rust-Saar
Meetup: 26u16
2023-02-15 | Virtual (Redmond, WA, US; New York, NY, US; San Francisco, CA, US; São Paulo, BR) | Microsoft Reactor Redmond and Microsoft Rector New York and Microsoft Reactor San Francisco and Microsoft Reactor São Paulo
Primeros pasos con Rust: QA y horas de comunidad | San Francisco Mirror | New York Mirror | São Paulo Mirror
2023-02-15 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-02-21 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
2023-02-23 | Virtual (Charlottesville, VA, US) | Charlottesville Rust Meetup
Tock, a Rust based Embedded Operating System
2023-02-23 | Virtual (Kassel, DE) | Java User Group Hessen
Eine Einführung in Rust (Stefan Baumgartner)
2023-02-28 | Virtual (Berlin, DE) | Open Tech School Berlin
Rust Hack and Learn
2023-02-28 | Virtual (Dallas, TX, US) | Dallas Rust
Last Tuesday
2023-03-01 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
Asia
2023-02-01 | Kyoto, JP | Kansai Rust
Rust talk: How to implement Iterator on tuples... kind of
2023-02-20 | Tel Aviv, IL | Rust TLV
February Edition - Redis and BioCatch talking Rust!
Europe
2023-02-02 | Berlin, DE | Prenzlauer Berg Software Engineers
PBerg engineers - inaugural meetup; Lukas: Serverless APIs using Rust and Azure functions (Fee)
2023-02-02 | Hamburg, DE | Rust Meetup Hamburg
Rust Hack & Learn February 2023
2023-02-02 | Lyon, FR | Rust Lyon
Rust Lyon meetup #01
2023-02-04 | Brussels, BE | FOSDEM
FOSDEM 2023 Conference: Rust devroom
2023-02-09 | Lille, FR | Rust Lille
Rust Lille #2
2023-02-15 | London, UK | Rust London User Group
Rust Nation Pre-Conference Reception with The Rust Foundation
2023-02-15 | Trondheim, NO | Rust Trondheim
Rust New Year's Resolution Bug Hunt
2023-02-16, 2023-02-17 | London, UK | Rust Nation UK
Rust Nation '23
2023-02-18 | London, UK | Rust London User Group
Post-Conference Rust in Enterprise Brunch Hosted at Red Badger
2023-02-21 | Zurich, CH | Rust Zurich
Practical Cryptography - February Meetup (Registration opens 7 Feb 2023)
2023-02-23 | Copenhagen, DK | Copenhagen Rust Community
Rust metup #33
North America
2023-02-09 | Mountain View, CA, US | Mountain View Rust Study Group
Rust Study Group at Hacker Dojo
2023-02-09 | New York, NY, US | Rust NYC
A Night of Interop: Rust in React Native & Rust in Golang (two talks)
2023-02-13 | Minneapolis, MN, US | Minneapolis Rust Meetup
Happy Hour and Beginner Embedded Rust Hacking Session (#3!)
2023-02-21 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2023-02-23 | Lehi, UT, US | Utah Rust
Upcoming Event
Oceania
2023-02-28 | Canberra, ACT, AU | Canberra Rust User Group
February Meetup
2023-03-01 | Sydney, NSW, AU | Rust Sydney
🦀 Lightning Talks - We are back!
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
Compilers are an error reporting tool with a code generation side-gig.
– Esteban Küber on Hacker News
Thanks to Stefan Majewsky for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
0 notes
Text
Everything you must know about the best PHP Crud Crud Generator?
If you’ve ever operated a database, you’ve probably worked with CRUD operations. CRUD operations are usually related to SQL. Since SQL is a pretty pre-eminent name in the development community, it’s essential for developers to know how CRUD operations run. So, this article is intended to draw you up to speed (if you’re not already) on CRUD operations and how to choose the best crud framework.
The Definition of CRUD
In the computer programming world, the acronym CRUD stands for create, read, update and delete. These are the four fundamental functions of resolute storage. Also, every letter in the acronym can refer to complete functions administered in relational database applications and planned to a standard HTTP method, DDS operation or SQL statement.
It can also define user-interface precepts that enable viewing, examining and altering information with the help of computer-based reports and forms. In essence, items are read, created, updated and deleted. Those same items can be revised by taking the data from a service and adjusting the setting fields before sending the data back to the service for an update. Plus, a PHP Crud is data-oriented and the regulated use of HTTP action verbs.
Most applications have some sort of CRUD functionality. In fact, each programmer has had to administer with CRUD at some point. Not to state, a CRUD application is one that employs forms to return and retrieve data from a database. Here’s a breakdown of the word CRUD:
CREATE methods: Performs the INSERT statement to create a new record.
READ methods: Reads the table records based on the primary keynoted within the input parameter.
UPDATE methods: Executes an UPDATE statement on the table based on the specified primary key for a record within the WHERE clause of the statement.
DELETE methods: Deletes a specified row in the WHERE clause.
Benefits of CRUD
Rather than using ad-hoc SQL statements, many programmers prefer to use CRUD because of its performance. When a stored procedure is first executed, the execution plan is stored in SQL Server’s procedure cache and reused for all applications of the stored procedure.
When a SQL statement is executed in SQL Server, the relational engine searches the procedure cache to ensure an existing execution plan for that particular SQL statement is available and uses the current plan to decrease the need for optimization, parsing and recompiling steps for the SQL statement.
If an execution plan is not available, then the SQL Server will create a new execution plan for the query. Moreover, when you remove SQL statements from the application code, all the SQL can be kept in the database while only stored procedure invocations are in the client application. When you use stored procedures, it helps to decrease database coupling.
Moreover, using CRUD operations helps to prevent SQL injection attacks. By utilizing stored procedures instead of string concatenation to build dynamic queries from user input data for all SQL Statements implies that everything placed into a parameter gets cited.
Choose the best Crud Builder
PDO Crud is an excellent PHP-based CRUD application. This PHP database framework supports MySQL, PostgreSQL, and SQLite databases. You can apply this PHP MySQL CRUD structure to create both the front-end and back-end of your application.
By writing just two to three lines of code, you can perform insert, update, delete, and select operations with an interactive table. You only need to generate objects and perform functions for items in the database; everything else will be generated automatically. Form fields will be created based on the data type. You can eliminate fields, change the type of fields, and do numerous types of customization too.
PDO Crud renders various shortcodes that can be used to perform the PDOCrud operations right from backend so that a non-technical person can also handle this application. Users can apply both shortcodes and core php code to perform CRUD operations. PDOCrud also provides various methods of customization By default, PDOCrud comes with the bootstrap framework but you can use any template you want. PDOCrud is very easy to use even for the non-programmers. Content management has become simple and flexible which saves a lot of time and it takes minutes to implement this application. You can easily change field types, add captcha, google map, hide/show the label, various settings using the config file.
1 note
·
View note
Text
Slow database? It might not be your fault
<rant>
Okay, it usually is your fault. If you logged the SQL your ORM was generating, or saw how you are doing joins in code, or realised what that indexed UUID does to your insert rate etc you’d probably admit it was all your fault. And the fault of your tooling, of course.
In my experience, most databases are tiny. Tiny tiny. Tables with a few thousand rows. If your web app is slow, its going to all be your fault. Stop building something webscale with microservices and just get things done right there in your database instead. Etc.
But, quite often, each company has one or two databases that have at least one or two large tables. Tables with tens of millions of rows. I work on databases with billions of rows. They exist. And that’s the kind of database where your database server is underserving you. There could well be a metric ton of actual performance improvements that your database is leaving on the table. Areas where your database server hasn’t kept up with recent (as in the past 20 years) of regular improvements in how programs can work with the kernel, for example.
Over the years I’ve read some really promising papers that have speeded up databases. But as far as I can tell, nothing ever happens. What is going on?
For example, your database might be slow just because its making a lot of syscalls. Back in 2010, experiments with syscall batching improved MySQL performance by 40% (and lots of other regular software by similar or better amounts!). That was long before spectre patches made the costs of syscalls even higher.
So where are our batched syscalls? I can’t see a downside to them. Why isn’t linux offering them and glib using them, and everyone benefiting from them? It’ll probably speed up your IDE and browser too.
Of course, your database might be slow just because you are using default settings. The historic defaults for MySQL were horrid. Pretty much the first thing any innodb user had to do was go increase the size of buffers and pools and various incantations they find by googling. I haven’t investigated, but I’d guess that a lot of the performance claims I’ve heard about innodb on MySQL 8 is probably just sensible modern defaults.
I would hold tokudb up as being much better at the defaults. That took over half your RAM, and deliberately left the other half to the operating system buffer cache.
That mention of the buffer cache brings me to another area your database could improve. Historically, databases did ��direct’ IO with the disks, bypassing the operating system. These days, that is a metric ton of complexity for very questionable benefit. Take tokudb again: that used normal buffered read writes to the file system and deliberately left the OS half the available RAM so the file system had somewhere to cache those pages. It didn’t try and reimplement and outsmart the kernel.
This paid off handsomely for tokudb because they combined it with absolutely great compression. It completely blows the two kinds of innodb compression right out of the water. Well, in my tests, tokudb completely blows innodb right out of the water, but then teams who adopted it had to live with its incomplete implementation e.g. minimal support for foreign keys. Things that have nothing to do with the storage, and only to do with how much integration boilerplate they wrote or didn’t write. (tokudb is being end-of-lifed by percona; don’t use it for a new project 😞)
However, even tokudb didn’t take the next step: they didn’t go to async IO. I’ve poked around with async IO, both for networking and the file system, and found it to be a major improvement. Think how quickly you could walk some tables by asking for pages breath-first and digging deeper as soon as the OS gets something back, rather than going through it depth-first and blocking, waiting for the next page to come back before you can proceed.
I’ve gone on enough about tokudb, which I admit I use extensively. Tokutek went the patent route (no, it didn’t pay off for them) and Google released leveldb and Facebook adapted leveldb to become the MySQL MyRocks engine. That’s all history now.
In the actual storage engines themselves there have been lots of advances. Fractal Trees came along, then there was a SSTable+LSM renaissance, and just this week I heard about a fascinating paper on B+ + LSM beating SSTable+LSM. A user called Jules commented, wondered about B-epsilon trees instead of B+, and that got my brain going too. There are lots of things you can imagine an LSM tree using instead of SSTable at each level.
But how invested is MyRocks in SSTable? And will MyRocks ever close the performance gap between it and tokudb on the kind of workloads they are both good at?
Of course, what about Postgres? TimescaleDB is a really interesting fork based on Postgres that has a ‘hypertable’ approach under the hood, with a table made from a collection of smaller, individually compressed tables. In so many ways it sounds like tokudb, but with some extra finesse like storing the min/max values for columns in a segment uncompressed so the engine can check some constraints and often skip uncompressing a segment.
Timescaledb is interesting because its kind of merging the classic OLAP column-store with the classic OLTP row-store. I want to know if TimescaleDB’s hypertable compression works for things that aren’t time-series too? I’m thinking ‘if we claim our invoice line items are time-series data…’
Compression in Postgres is a sore subject, as is out-of-tree storage engines generally. Saying the file system should do compression means nobody has big data in Postgres because which stable file system supports decent compression? Postgres really needs to have built-in compression and really needs to go embrace the storage engines approach rather than keeping all the cool new stuff as second class citizens.
Of course, I fight the query planner all the time. If, for example, you have a table partitioned by day and your query is for a time span that spans two or more partitions, then you probably get much faster results if you split that into n queries, each for a corresponding partition, and glue the results together client-side! There was even a proxy called ShardQuery that did that. Its crazy. When people are making proxies in PHP to rewrite queries like that, it means the database itself is leaving a massive amount of performance on the table.
And of course, the client library you use to access the database can come in for a lot of blame too. For example, when I profile my queries where I have lots of parameters, I find that the mysql jdbc drivers are generating a metric ton of garbage in their safe-string-split approach to prepared-query interpolation. It shouldn’t be that my insert rate doubles when I do my hand-rolled string concatenation approach. Oracle, stop generating garbage!
This doesn’t begin to touch on the fancy cloud service you are using to host your DB. You’ll probably find that your laptop outperforms your average cloud DB server. Between all the spectre patches (I really don’t want you to forget about the syscall-batching possibilities!) and how you have to mess around buying disk space to get IOPs and all kinds of nonsense, its likely that you really would be better off perforamnce-wise by leaving your dev laptop in a cabinet somewhere.
Crikey, what a lot of complaining! But if you hear about some promising progress in speeding up databases, remember it's not realistic to hope the databases you use will ever see any kind of benefit from it. The sad truth is, your database is still stuck in the 90s. Async IO? Huh no. Compression? Yeah right. Syscalls? Okay, that’s a Linux failing, but still!
Right now my hopes are on TimescaleDB. I want to see how it copes with billions of rows of something that aren’t technically time-series. That hybrid row and column approach just sounds so enticing.
Oh, and hopefully MyRocks2 might find something even better than SSTable for each tier?
But in the meantime, hopefully someone working on the Linux kernel will rediscover the batched syscalls idea…? ;)
2 notes
·
View notes
Text
Converting Table Data to JSON with UNPIVOT and FOR JSON PATH in SQL Server
Suppose we have a table called Customers with the following data:
I can provide you some sample script for creating Customers table like below
CREATE TABLE Customers (
CustomerID INT PRIMARY KEY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
City VARCHAR(50),
State VARCHAR(2),
ZipCode VARCHAR(10)
);
/* Insert statement */
INSERT INTO Customers (CustomerID, FirstName, LastName, City, State, ZipCode)
VALUES (1, ‘John’, ‘Doe’, ‘New York’, ‘NY’, ‘10001’),
(2, ‘Jane’, ‘Smith’, ‘Los Angeles’, ‘CA’, ‘90001’),
(3, ‘Bob’, ‘Johnson’, ‘Chicago’, ‘IL’, ‘60601’),
(4, ‘Alice’, ‘Williams’, ‘Houston’, ‘TX’, ‘77001’);
/* checking data/ Validate data*/

To convert this data to key-value pairs, you can use the following query:
SELECT CustomerId AS [CustomerId],
[FirstName] + ‘ ‘ + [LastName] as [CustomerName],
City AS [CustomerCity],
State AS [CustomerState],
ZipCode As [CustomerZipcode]
from Customers
For JSON Path, ROOT(‘CustomerData’)

Now i am going to explain you the query
This SQL query retrieves data from a table named Customers and formats the output as a JSON object with the key "CustomerData".
Specifically, the SELECT statement retrieves data from the Customers table, and applies the following transformations:
CustomerId AS [CustomerId] renames the CustomerId column to CustomerId in the output.
[FirstName] + ' ' + [LastName] as [CustomerName] concatenates the values of the FirstName and LastName columns with a space in between, and renames the resulting column to CustomerName in the output.
City AS [CustomerCity] renames the City column to CustomerCity in the output.
State AS [CustomerState] renames the State column to CustomerState in the output.
ZipCode As [CustomerZipcode] renames the ZipCode column to CustomerZipcode in the output.
Finally, the FOR JSON PATH, ROOT('CustomerData') clause formats the output as a JSON object with a key of "CustomerData".
This output contains an array of JSON objects, with each object representing a row from the Customers table and containing the renamed column values as key-value pairs.
Output of the above query would be like this
{ “CustomerData”: [ { “CustomerId”: 1, “CustomerName”: “John Doe”, “CustomerCity”: “New York”, “CustomerState”: “NY”, “CustomerZipcode”: “10001” }, { “CustomerId”: 2, “CustomerName”: “Jane Smith”, “CustomerCity”: “Los Angeles”, “CustomerState”: “CA”, “CustomerZipcode”: “90001” }, { “CustomerId”: 3, “CustomerName”: “Bob Johnson”, “CustomerCity”: “Chicago”, “CustomerState”: “IL”, “CustomerZipcode”: “60601” }, { “CustomerId”: 4, “CustomerName”: “Alice Williams”, “CustomerCity”: “Houston”, “CustomerState”: “TX”, “CustomerZipcode”: “77001” } ] }
1 note
·
View note
Text
sql injection cheat sheet trainer SOS&
💾 ►►► DOWNLOAD FILE 🔥🔥🔥🔥🔥 An SQL injection cheat sheet is a resource in which you can find detailed technical information about the many different variants of the SQL injection. MySQL SQL Injection Cheat Sheet ; Select Nth Char, SELECT substr('abcd', 3, 1); # returns c ; Bitwise AND, SELECT 6 & 2; # returns 2. SELECT 6 & 1; # returns 0. Use this SQL injection attack cheat sheet to learn about different variants of the SQL Injection vulnerability. But before we proceed, let us. MySQL-SQL-Injection-Cheatsheet. Tips for manually detect & exploit SQL injection Vulnerability : MySQL. Comment in MySQL. #; -- (After double dash put space). 9 This SQL injection cheat sheet contains examples of useful syntax that you can use to perform a variety of tasks that often arise when performing SQL injection attacks. You can extract part of a string, from a specified offset with a specified length. Note that the offset index is 1-based. Each of the following expressions will return the string ba. You can use comments to truncate a query and remove the portion of the original query that follows your input. You can query the database to determine its type and version. This information is useful when formulating more complicated attacks. You can list the tables that exist in the database, and the columns that those tables contain. You can test a single boolean condition and trigger a database error if the condition is true. You can use batched queries to execute multiple queries in succession. Note that while the subsequent queries are executed, the results are not returned to the application. Hence this technique is primarily of use in relation to blind vulnerabilities where you can use a second query to trigger a DNS lookup, conditional error, or time delay. You can cause a time delay in the database when the query is processed. The following will cause an unconditional time delay of 10 seconds. You can test a single boolean condition and trigger a time delay if the condition is true. You can cause the database to perform a DNS lookup to an external domain. To do this, you will need to use Burp Collaborator client to generate a unique Burp Collaborator subdomain that you will use in your attack, and then poll the Collaborator server to confirm that a DNS lookup occurred. You can cause the database to perform a DNS lookup to an external domain containing the results of an injected query. To do this, you will need to use Burp Collaborator client to generate a unique Burp Collaborator subdomain that you will use in your attack, and then poll the Collaborator server to retrieve details of any DNS interactions, including the exfiltrated data. Want to track your progress and have a more personalized learning experience? It's free! SQL injection cheat sheet This SQL injection cheat sheet contains examples of useful syntax that you can use to perform a variety of tasks that often arise when performing SQL injection attacks. String concatenation You can concatenate together multiple strings to make a single string. Oracle Does not support batched queries. Sign up Login. Patching times plummet for most critical vulnerabilities — report 30 August Log4Shell legacy? Patching times plummet for most critical vulnerabilities — report Introducing ODGen Graph-based JavaScript bug scanner discovers more than zero-day vulnerabilities in Node.
1 note
·
View note
Text
Klammer zuerst

The following example shows the incorrect and correct use of UNION in two SELECT statements in which a column is to be renamed in the output. The order of certain parameters used with the UNION clause is important. Using UNION of two SELECT statements with ORDER BY IF OBJECT_ID ('dbo.ProductResults', 'U') IS NOT NULLĬ. The Gloves table is created in the first SELECT statement. In the following example, the INTO clause in the second SELECT statement specifies that the table named ProductResults holds the final result set of the union of the selected columns of the ProductModel and Gloves tables. IF OBJECT_ID ('dbo.Gloves', 'U') IS NOT NULL In the following example, the result set includes the contents of the ProductModelID and Name columns of both the ProductModel and Gloves tables. If not specified, duplicate rows are removed. Incorporates all rows into the results, including duplicates. Specifies that multiple result sets are to be combined and returned as a single result set. If typed, they must be typed to the same XML schema collection. All columns must be either typed to an XML schema or untyped. For more information, see Precision, Scale, and Length (Transact-SQL).Ĭolumns of the xml data type must be equal. When the types are the same but differ in precision, scale, or length, the result is based on the same rules for combining expressions. When data types differ, the resulting data type is determined based on the rules for data type precedence. The definitions of the columns that are part of a UNION operation don't have to be the same, but they must be compatible through implicit conversion. Is a query specification or query expression that returns data to be combined with the data from another query specification or query expression. To view Transact-SQL syntax for SQL Server 2014 and earlier, see Previous versions documentation. The number and the order of the columns must be the same in all queries. The following are basic rules for combining the result sets of two queries by using UNION: A JOIN compares columns from two tables, to create result rows composed of columns from two tables.But a UNION does not create individual rows from columns gathered from two tables. A UNION concatenates result sets from two queries.You control whether the result set includes duplicate rows:Ī UNION operation is different from a JOIN: Concatenates the results of two queries into a single result set.
0 notes
Text
Compare two columns in excel and return differences

#Compare two columns in excel and return differences update
#Compare two columns in excel and return differences code
#Compare two columns in excel and return differences update
I am in the middle of taking it out and prepping it for deployment as it was bought as a spare, and a switch is failing calling for it to be replaced. I have configured it but I want to update the firmware. I have a HP Procurve 2920 Switch (Bought 2010). Will my HP Procurve Take Aruba firmware? Hardware.It is provided as an example and a starting point for your development.
#Compare two columns in excel and return differences code
This is Air Code - I have neither compiled nor tested it. Private Sub Worksheet_SelectionChange(ByVal Target As Range) Why did I write this as a separate procedure (rather than, for example, the Worksheet_Change event procedure on the worksheet)? Well, we want to call this procedure whenever something changes on either worksheet so we can share this procedure by coding each worksheet's Worksheet_Change event procedure like this: You can use the Worksheet.Change event to call this procedure. So, when should this procedure be called? I would suggest calling it every time any value on either of the two worksheets changes. ' the colors in case the row was marked asįirstSheet.Range(Cells(index1, 1), Cells(index1, 4)).Interior.Color = vbWhiteįirstSheet.Range(Cells(index1, 1), Cells(index1, 4)).Font.Color = vbBlackįirstSheet.Range(Cells(index1, 1), Cells(index1, 4)).Interior.Color = vbYellowįirstSheet.Range(Cells(index1, 1), Cells(index1, 4)).Font.Color = vbRed ' the two sheets change, so we need to RESET ' to be called repeatedly as the values on ' (We do this because we expect this procedure ' If we DIDN'T find a match, we want to mark ' We've found a row on the second sheet that & secondSheet.Cells(index2, SECONDCOLUMN2) SecondValue = secondSheet.Cells(index2, FIRSTCOLUMN2) _ ' Loop through the rows on the second sheet ' Keep track of whether we've found a match & firstSheet.Cells(index1, SECONDCOLUMN1) ' For each row, concatenate the values from the two cellsįirstValue = firstSheet.Cells(index1, FIRSTCOLUMN1) _ ' Loop through the rows on the first worksheet Set secondSheet = ActiveWorkbook.Sheets(secondSheetName) Set firstSheet = ActiveWorkbook.Sheets(firstSheetName) Public Sub CompareSheets(firstSheetName As String, secondSheetName As String) The procedure looks like this:Ĭonst FIRSTCOLUMN1 As Integer = 2 'Column BĬonst SECONDCOLUMN1 As Integer = 3 'Column CĬonst FIRSTCOLUMN2 As Integer = 1 'Column AĬonst SECONDCOLUMN2 As Integer = 3 'Column C Whenever a row on the first sheet fails to have a match somewhere on the second sheet, this procedure will change the colors of the row to make its error status visible. I've put together some code that will perform this process. The procedure (I prefer not to use the term "macro" because in Excel that can, and should, refer to an MS Excel 4.0 Macro, which is a completely different and much uglier beast) will need to have two nested loops: an outer loop to scan the rows on the first sheet, and an inner loop to scan the rows on the second sheet. You have correctly concluded that you will need to use VBA to fulfill your requirements. However, let's ignore that and try to come up with an answer to your question. As John has pointed out, this thread is in the wrong forum - it should be in the Visual Basic for Applications (VBA) forum ( http:/ / / groups/ technical-functional/ vb-vba-l) rather than the SQL Server forum ( http:/ / / groups/ technical-functional/ sql-server-l).
0 notes
Text
How to Create Custom Functions with the SSRS Split Function

Introduction
Delivering intelligent reports in SQL Server Reporting Services (SSRS) requires the ability to change and show data efficiently. The SSRS Split Function is a potent tool for accomplishing this. You can write your own custom functions to divide texts based on a delimiter even if SSRS does not come with a built-in split function as some computer languages do. You can use the SSRS Split Function to create and use custom functions by following the steps outlined in this article.
Comprehending the Split Function of SSRS
You can split a string into many sections using the SSRS Split Function by providing a delimiter. When working with data that has concatenated values, like lists of names, categories, or other delimited data, this is quite helpful. By dividing you can communicate these beliefs in a way that is more orderly and understandable.
A Comprehensive Guide for Developing Custom Functions
Step 1: access your SSRS report.
Open the SSRS report you already have open or create a new one using Report Builder or SQL Server Data Tools (SSDT).
Step 2: Open the Properties of the Report
Use the right-click menu to select the report body or any blank place inside the report design area.
From the context menu, choose Report Properties.
Step 3: Go to the Section with the Code
Pick the Code tab in the Report Properties box. You can create your own custom code functions here.
Write the Custom Split Function in Step Four.
For your custom split function, enter the following VB.NET code in the Code window:
vb Copy public function code DivideString(input_ByVal as String, delimiter_ByVal as String) as String()
If input is String.IsNullOrEmpty, then return New String() {}
Close If: Return input.Split(StringSplitOptions.None, New String() {delimiter})
Final Operation
The input string and the delimiter are the two parameters required by this function. If the supplied string is null or empty, it checks for it and returns an empty array. If not, it divides the string according to the designated delimiter.
Step 5: Utilizing Your Report's Custom Split Function
You can utilize the custom function in your report expressions now that you've developed it.
For instance, you can use the split method as follows if you have a field called FullNames with values like "John Doe, Jane Smith, Mark Johnson":
Include a fresh textbox in your report where you like to see the list's first name displayed.
Put this in the textbox expression:
vb
Copy the code (Code).SplitString(",")(0), Fields!FullNames.Value
The first name is obtained from the split string using this expression.
Step 6: Presenting Several Values
You can use the split function in conjunction with a List control to display all names in a list format. Here's how to do it:
In your report, drag a List control.
Choose your dataset as the List control's data source.
Include a textbox in the List control.
Set the textbox's expression to:
vb
Copy the code (Code).Fields!FullNames.Value, ",")(RowNumber(Nothing) - 1) SplitString
Based on the row number, each name in the list will be displayed as a result.
Top Techniques
Performance Considerations: Use caution while utilizing functions that manipulate strings particularly when working with big datasets. Optimizing the data via SQL preprocessing can improve performance.
Testing Make sure your custom function can handle a variety of instances, such empty strings or uncommon delimiters, by thoroughly testing it with a range of input conditions.
Documentation: If you intend to share the report with other developers or report users, be sure to include documentation about your custom functions in the report for future reference.
Summary
Using the SSRS Split Function to create custom functions is a great method to improve your reporting capabilities. Data can be presented more dynamically and clearly by dividing strings based on a delimiter. The quality and usability of your SSRS reports will be much enhanced by learning this technique, regardless of whether you are working with names, categories, or other concatenated data. Through exploration and practice, you may make the most of the SSRS Split Function to produce reports that are both informative and easy to use.
0 notes