#SQL Server log file large size
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
25% of US internet users with an annual income of $80-100K use Tumblr.
Text
Automate SQL Server Log File Size Monitoring and Shrink Process
Monitor the size of log files for all the databases in SQL Server: SELECT DB_NAME(database_id) as DatabaseName, file_id, name as FileName, type_desc as FileType, size*8/1024 as SizeMB, growth*8/1024 as GrowthMB FROM sys.master_files where type = 1; Output: Create a script for automate the shrink process when it goes to specific threshold value. Following is the shrink Script: Use…

View On WordPress
0 notes
Text
Top 5 Tools for Salesforce Data Migration in 2025

Data migration is a critical aspect of any Salesforce implementation or upgrade. Whether you’re transitioning from legacy systems, merging Salesforce orgs, or simply updating your current Salesforce instance, choosing the right tool can make or break the success of your migration. In 2025, the landscape of Salesforce data migration tools has evolved significantly, offering more automation, better user interfaces, and improved compatibility with complex datasets.
If you're a business looking to ensure a smooth migration process, working with an experienced Salesforce consultant in New York can help you identify the best tools and practices. Here's a detailed look at the top five Salesforce data migration tools in 2025 and how they can help your organization move data efficiently and accurately.
1. Salesforce Data Loader (Enhanced 2025 Edition)
Overview: The Salesforce Data Loader remains one of the most popular tools, especially for companies looking for a free, secure, and reliable way to manage data migration. The 2025 edition comes with a modernized UI, faster processing speeds, and enhanced error logging.
Why It’s Top in 2025:
Improved speed and performance
Enhanced error tracking and data validation
Seamless integration with external databases like Oracle, SQL Server, and PostgreSQL
Support for larger datasets (up to 10 million records)
Best For: Organizations with experienced admins or developers who are comfortable working with CSV files and need a high level of control over their data migration process.
Pro Tip: Engage a Salesforce developer in New York to write custom scripts for automating the loading and extraction processes. This will save significant time during large migrations.
2. Skyvia
Overview: Skyvia has emerged as a go-to cloud-based data integration tool that simplifies Salesforce data migration, especially for non-technical users. With drag-and-drop functionality and pre-built templates, it supports integration between Salesforce and over 100 other platforms.
Why It’s Top in 2025:
No coding required
Advanced transformation capabilities
Real-time sync between Salesforce and other cloud applications
Enhanced data governance features
Best For: Mid-sized businesses and enterprises that need a user-friendly platform with robust functionality and real-time synchronization.
Use Case: A retail company integrating Shopify, Salesforce, and NetSuite found Skyvia especially helpful in maintaining consistent product and customer data across platforms.
Expert Advice: Work with a Salesforce consulting partner in New York to set up your data models and design a migration path that aligns with your business processes.
3. Jitterbit Harmony
Overview: Jitterbit Harmony is a powerful data integration platform that enables users to design, run, and manage integration workflows. In 2025, it remains a favorite for enterprises due to its AI-powered suggestions and robust performance in complex scenarios.
Why It’s Top in 2025:
AI-enhanced mapping and transformation logic
Native Salesforce connector with bulk API support
Real-time data flow monitoring and alerts
Cross-platform compatibility (on-premise to cloud, cloud to cloud)
Best For: Large enterprises and organizations with complex IT ecosystems requiring high-throughput data migration and real-time integrations.
Tip from the Field: A Salesforce consulting firm in New York can help fine-tune your Jitterbit setup to ensure compliance with your industry regulations and data handling policies.
4. Informatica Cloud Data Wizard
Overview: Informatica is well-known in the enterprise data integration space. The Cloud Data Wizard is a lightweight, Salesforce-focused tool designed for business users. In 2025, its intuitive interface and automated field mapping make it a favorite for quick and simple migrations.
Why It’s Top in 2025:
Automatic schema detection and mapping
Pre-built Salesforce templates
Role-based access control for secure collaboration
Integration with Salesforce Flow for process automation
Best For: Companies needing quick, on-the-fly migrations with minimal IT involvement.
Case in Point: A nonprofit organization used Informatica Cloud Data Wizard for migrating donor information from spreadsheets into Salesforce Nonprofit Success Pack (NPSP) with minimal technical assistance.
Pro Insight: Partner with a Salesforce consultant in New York to evaluate whether the Cloud Data Wizard meets your scalability and security needs before committing.
5. Talend Data Fabric
Overview: Talend Data Fabric combines data integration, quality, and governance in one unified platform. In 2025, it leads the way in enterprise-grade data migration for Salesforce users who require deep customization, high security, and data lineage tracking.
Why It’s Top in 2025:
Full data quality and compliance toolset
AI-driven suggestions for data cleaning and transformation
End-to-end data lineage tracking
Integration with AWS, Azure, and Google Cloud
Best For: Industries with strict compliance needs like finance, healthcare, or government, where data accuracy and traceability are paramount.
Strategic Advantage: A Salesforce consulting partner in New York can help configure Talend’s governance tools to align with HIPAA, GDPR, or other regulatory requirements.
Why Choosing the Right Tool Matters
Data migration is more than just moving records from one system to another—it’s about preserving the integrity, security, and usability of your data. Choosing the right tool ensures:
Fewer errors and data loss
Faster deployment timelines
Higher end-user adoption
Better alignment with business goals
Partnering with Salesforce Experts in New York
Working with an experienced Salesforce consultant in New York can help you navigate the complexities of data migration. Local consultants understand both the technical and business landscapes and can offer personalized support throughout the migration journey.
Whether you're a startup looking for lean, cost-effective solutions or a large enterprise needing advanced governance, engaging with Salesforce consultants in New York ensures you make the most informed decisions.
These professionals can:
Conduct data audits and mapping
Recommend the best tool for your specific use case
Build custom scripts or integrations as needed
Ensure a smooth transition with minimal business disruption
Final Thoughts
In 2025, Salesforce data migration is no longer a cumbersome, manual task. With tools like Salesforce Data Loader, Skyvia, Jitterbit, Informatica, and Talend, businesses of all sizes can achieve fast, secure, and seamless migrations. The key lies in selecting the right tool based on your business size, technical capacity, and compliance needs.
Moreover, partnering with a knowledgeable Salesforce consulting partner in New York gives you access to tailored solutions and hands-on support, making your data migration journey smooth and successful.
Ready to migrate your data the right way? Consult with a trusted Salesforce consulting in New York expert and empower your business to scale with confidence.
#salesforce consultant in new york#salesforce consulting in new york#salesforce consulting partner in new york#salesforce consultants in new york#salesforce developer in new york#Top 5 Tools for Salesforce Data Migration in 2025
0 notes
Text
Slow database? It might not be your fault
<rant>
Okay, it usually is your fault. If you logged the SQL your ORM was generating, or saw how you are doing joins in code, or realised what that indexed UUID does to your insert rate etc you’d probably admit it was all your fault. And the fault of your tooling, of course.
In my experience, most databases are tiny. Tiny tiny. Tables with a few thousand rows. If your web app is slow, its going to all be your fault. Stop building something webscale with microservices and just get things done right there in your database instead. Etc.
But, quite often, each company has one or two databases that have at least one or two large tables. Tables with tens of millions of rows. I work on databases with billions of rows. They exist. And that’s the kind of database where your database server is underserving you. There could well be a metric ton of actual performance improvements that your database is leaving on the table. Areas where your database server hasn’t kept up with recent (as in the past 20 years) of regular improvements in how programs can work with the kernel, for example.
Over the years I’ve read some really promising papers that have speeded up databases. But as far as I can tell, nothing ever happens. What is going on?
For example, your database might be slow just because its making a lot of syscalls. Back in 2010, experiments with syscall batching improved MySQL performance by 40% (and lots of other regular software by similar or better amounts!). That was long before spectre patches made the costs of syscalls even higher.
So where are our batched syscalls? I can’t see a downside to them. Why isn’t linux offering them and glib using them, and everyone benefiting from them? It’ll probably speed up your IDE and browser too.
Of course, your database might be slow just because you are using default settings. The historic defaults for MySQL were horrid. Pretty much the first thing any innodb user had to do was go increase the size of buffers and pools and various incantations they find by googling. I haven’t investigated, but I’d guess that a lot of the performance claims I’ve heard about innodb on MySQL 8 is probably just sensible modern defaults.
I would hold tokudb up as being much better at the defaults. That took over half your RAM, and deliberately left the other half to the operating system buffer cache.
That mention of the buffer cache brings me to another area your database could improve. Historically, databases did ‘direct’ IO with the disks, bypassing the operating system. These days, that is a metric ton of complexity for very questionable benefit. Take tokudb again: that used normal buffered read writes to the file system and deliberately left the OS half the available RAM so the file system had somewhere to cache those pages. It didn’t try and reimplement and outsmart the kernel.
This paid off handsomely for tokudb because they combined it with absolutely great compression. It completely blows the two kinds of innodb compression right out of the water. Well, in my tests, tokudb completely blows innodb right out of the water, but then teams who adopted it had to live with its incomplete implementation e.g. minimal support for foreign keys. Things that have nothing to do with the storage, and only to do with how much integration boilerplate they wrote or didn’t write. (tokudb is being end-of-lifed by percona; don’t use it for a new project 😞)
However, even tokudb didn’t take the next step: they didn’t go to async IO. I’ve poked around with async IO, both for networking and the file system, and found it to be a major improvement. Think how quickly you could walk some tables by asking for pages breath-first and digging deeper as soon as the OS gets something back, rather than going through it depth-first and blocking, waiting for the next page to come back before you can proceed.
I’ve gone on enough about tokudb, which I admit I use extensively. Tokutek went the patent route (no, it didn’t pay off for them) and Google released leveldb and Facebook adapted leveldb to become the MySQL MyRocks engine. That’s all history now.
In the actual storage engines themselves there have been lots of advances. Fractal Trees came along, then there was a SSTable+LSM renaissance, and just this week I heard about a fascinating paper on B+ + LSM beating SSTable+LSM. A user called Jules commented, wondered about B-epsilon trees instead of B+, and that got my brain going too. There are lots of things you can imagine an LSM tree using instead of SSTable at each level.
But how invested is MyRocks in SSTable? And will MyRocks ever close the performance gap between it and tokudb on the kind of workloads they are both good at?
Of course, what about Postgres? TimescaleDB is a really interesting fork based on Postgres that has a ‘hypertable’ approach under the hood, with a table made from a collection of smaller, individually compressed tables. In so many ways it sounds like tokudb, but with some extra finesse like storing the min/max values for columns in a segment uncompressed so the engine can check some constraints and often skip uncompressing a segment.
Timescaledb is interesting because its kind of merging the classic OLAP column-store with the classic OLTP row-store. I want to know if TimescaleDB’s hypertable compression works for things that aren’t time-series too? I’m thinking ‘if we claim our invoice line items are time-series data…’
Compression in Postgres is a sore subject, as is out-of-tree storage engines generally. Saying the file system should do compression means nobody has big data in Postgres because which stable file system supports decent compression? Postgres really needs to have built-in compression and really needs to go embrace the storage engines approach rather than keeping all the cool new stuff as second class citizens.
Of course, I fight the query planner all the time. If, for example, you have a table partitioned by day and your query is for a time span that spans two or more partitions, then you probably get much faster results if you split that into n queries, each for a corresponding partition, and glue the results together client-side! There was even a proxy called ShardQuery that did that. Its crazy. When people are making proxies in PHP to rewrite queries like that, it means the database itself is leaving a massive amount of performance on the table.
And of course, the client library you use to access the database can come in for a lot of blame too. For example, when I profile my queries where I have lots of parameters, I find that the mysql jdbc drivers are generating a metric ton of garbage in their safe-string-split approach to prepared-query interpolation. It shouldn’t be that my insert rate doubles when I do my hand-rolled string concatenation approach. Oracle, stop generating garbage!
This doesn’t begin to touch on the fancy cloud service you are using to host your DB. You’ll probably find that your laptop outperforms your average cloud DB server. Between all the spectre patches (I really don’t want you to forget about the syscall-batching possibilities!) and how you have to mess around buying disk space to get IOPs and all kinds of nonsense, its likely that you really would be better off perforamnce-wise by leaving your dev laptop in a cabinet somewhere.
Crikey, what a lot of complaining! But if you hear about some promising progress in speeding up databases, remember it's not realistic to hope the databases you use will ever see any kind of benefit from it. The sad truth is, your database is still stuck in the 90s. Async IO? Huh no. Compression? Yeah right. Syscalls? Okay, that’s a Linux failing, but still!
Right now my hopes are on TimescaleDB. I want to see how it copes with billions of rows of something that aren’t technically time-series. That hybrid row and column approach just sounds so enticing.
Oh, and hopefully MyRocks2 might find something even better than SSTable for each tier?
But in the meantime, hopefully someone working on the Linux kernel will rediscover the batched syscalls idea…? ;)
2 notes
·
View notes
Text
RMAN QUICK LEARN– FOR THE BEGINNERS
Oracle Recovery Manager (RMAN) is Oracle’s preferred method or tools by which we are able to take backups and restore and recover our database. You must develop a proper backup strategy which provides maximum flexibility to Restore & Recover the DB from any kind of failure. To develop a proper backup strategy you must decide the type of requirement then after think the possible backup option. The recommended backup strategy must include the backup of all datafiles, Archivelog and spfile & controlfile autobackup. To take online or hot backups database must be in archivelog mode. You can however use RMAN to take an offline or cold backup.Note: Selecting the backup storage media is also important consideration. If you are storing your backup on disk then it is recommended to keep an extra copy of backup at any other server. CREATING RECOVERY CATALOG: Oracle recommended to use separate database for RMAN catalog. Consider in below steps the database is already created: 1. Create tablespace for RMAN: SQL> create tablespace RTBS datafile 'D:ORACLEORADATARTBS01.DBF' size 200M extent management local uniform size 5M; 2. Create RMAN catalog user: SQL> create user CATALOG identified by CATALOG default tablespace RTBS quota unlimited on RTBS; 3. Grant some privileges to RMAN user: SQL> Grant connect, resource to CATALOG; SQL> grant recovery_catalog_owner to CATALOG; 4. Connect into catalog database and create the catalog: % rman catalog RMAN_USER/RMAN_PASSWORD@cat_db log=create_catalog.log RMAN> create catalog tablespace RTBS; RMAN> exit; 5. Connect into the target database and into the catalog database: % rman target sys/oracle@target_db RMAN> connect catalog RMAN_USER/RMAN_PASSWORD@cat_db 6. Connected into the both databases, register target database: RMAN> register database; The following list gives an overview of the commands and their uses in RMAN. For details description search the related topics of separate post on my blog: http://shahiddba.blogspot.com/INITIALIZATION PARAMETER: Some RMAN related database initialization parameters: control_file_record_keep_time: Time in days to retention records in the Control File. (default: 7 days) large_pool_size: Memory pool used for RMAN in backup/restore operations. shared_pool_size: Memory pool used for RMAN in backup/restore operations (only if large pool is not configured). CONNECTING RMANexport ORACLE_SID= --Linux platformset ORACLE_SID== --Windows platformTo connect on a target database execute RMAN.EXE then RMAN>connect target / RMAN>connect target username/password RMAN>connect target username/password@target_db To connect on a catalog database:RMAN>connect catalog username/password RMAN>connect catalog username/password@catalog_db To connect directly from the command prompt:C:>rman target / --target with nocatalog Recovery Manager: Release 9.2.0.1.0 - ProductionCopyright (c) 1995, 2002, Oracle Corporation. All rights reserved.connected to target database: RMAN (DBID=63198018)using target database controlfile instead of recovery catalogC:>rman target sys/oracle@orcl3 catalog catalog/catalog@rman --with catalogRecovery Manager: Release 9.2.0.1.0 - ProductionCopyright (c) 1995, 2002, Oracle Corporation. All rights reserved.connected to target database: SADHAN (DBID=63198018)connected to recovery catalog databaseRMAN PARAMETERSRMAN parameters can be set to a specified value and remain persistent. This information is stored in the target database’s controlfile (By default). Alternatively you can store this backup information into recovery catalog. If you connect without catalog or only to the target database, your repository should be in the controlfile.SHOW/CONFIGURE – SHOW command will show current values for set parameters and CONFIGURE – Command to set new value for parameterRMAN> show all;using target database control file instead of recovery catalogRMAN configuration parameters are:CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # defaultCONFIGURE BACKUP OPTIMIZATION OFF; # defaultCONFIGURE DEFAULT DEVICE TYPE TO ; # defaultCONFIGURE CONTROLFILE AUTOBACKUP ON;RMAN>show datafile backup copies; RMAN>show default device type; RMAN>show device type; RMAN>show channel; RMAN>show retention policy;RMAN> CONFIGURE CONTROLFILE AUTOBACKUP ON;old RMAN configuration parameters:CONFIGURE CONTROLFILE AUTOBACKUP OFF;new RMAN configuration parameters:CONFIGURE CONTROLFILE AUTOBACKUP ON; new RMAN configuration parameters are successfully stored CONFIGURE channel device type disk format 'D:oraback%U'; You can set many parameters by configuring them first and making them persistent or you can override them (discard any persistent configuration) by specifying them explicitly in your RMAN backup command. Setting Default Recommended Controlfile autobackup off on Retention policy to redundancy 1 to recovery window of 30 days Device type disk parallelism 1 ... disk|sbt prallelism 2 ... Default device type to disk to disk Backup optimization off off Channel device type none disk parms=‘...’ Maxsetsize unlimited depends on your database size Appending CLEAR or NONE at the last of configuration parameter command will reset the configuration to default and none setting.CONFIGURE RETENTION POLICY CLEAR;CONFIGURE RETENTION POLICY NONE; Overriding the configured retention policy: change backupset 421 keep forever nologs; change datafilecopy 'D:oracleoradatausers01.dbf' keep until 'SYSDATE+30';RMAN BACKUP SCRIPTS:Backing up the database can be done with just a few commands or can be made with numerous options. RMAN> backup database;RMAN> backup as compressed backupset database;RMAN> Backup INCREMENTAL level=0 database;RMAN> Backup database TAG=Weekly_Sadhan;RMAN> Backup database MAXSETSIZE=2g;RMAN> backup TABLESPACE orafin;You may also combine options together in a single backup and for multi channel backup.RMAN> Backup INCREMENTAL level=1 as COMPRESSED backupset databaseFORMAT 'H:ORABACK%U' maxsetsize 2G; backup full datafile x,y,z incremental level x include current controlfile archivelog all delete input copies x filesperset x maxsetsize xM diskratio x format = 'D:oraback%U';run {allocate channel d1 type disk FORMAT "H:orabackWeekly_%T_L0_%d-%s_%p.db";allocate channel d2 type disk FORMAT "H:orabackWeekly_%T_L0_%d-%s_%p.db";allocate channel d3 type disk FORMAT "H:orabackWeekly_%T_L0_%d-%s_%p.db"; backup incremental level 0 tag Sadhan_Full_DBbackup filesperset 8 FORMAT "H:orabackWeekly_%T_FULL_%d-%s_%p.db" DATABASE; SQL 'ALTER SYSTEM ARCHIVE LOG CURRENT'; backup archivelog all tag Sadhan_Full_Archiveback filesperset 8 format "H:orabackWeekly_%T_FULL_%d-%s_%p.arch"; release channel d1; release channel d2; release channel d3; } The COPY command and some copy scripts: copy datafile 'D:oracleoradatausers01.dbf' TO 'H:orabackusers01.dbf' tag=DF3, datafile 4 to TO 'H:orabackusers04.dbf' tag=DF4, archivelog 'arch_1060.arch' TO 'arch_1060.bak' tag=CP2ARCH16; run { allocate channel c1 type disk; copy datafile 'd:oracleoradatausers01.dbf' TO 'h:orabackusers01.dbf' tag=DF3, archivelog 'arch_1060.arch' TO 'arch_1060.bak' tag=CP2ARCH16; }COMPRESSED – Compresses the backup as it is taken.INCREMENTAL – Selecting incremental allows to backup only changes since last full backup.FORMAT – Allows you to specify an alternate location.TAG – You can name your backup.MAXSETSIZE – Limits backup piece size.TABLESPACE – Allows you to backup only a tablespace.RMAN MAINTAINANCE :You can review your RMAN backups using the LIST command. You can use LIST with options to customize what you want RMAN to return to you.RMAN> list backup SUMMARY;RMAN> list ARCHIVELOG ALL;RMAN> list backup COMPLETED before ‘02-FEB-09’;RMAN> list backup of database TAG Weekly_sadhan; RMAN> list backup of datafile "D:oracleoradatasadhanusers01.dbf" SUMMARY;You can test your backups using the validate command.RMAN> list copy of tablespace "SYSTEM"; You can ask RMAN to report backup information. RMAN> restore database validate; RMAN> report schema; RMAN> report need backup; RMAN> report need backup incremental 3 database; RMAN> report need backup days 3; RMAN> report need backup days 3 tablespace system; RMAN>report need backup redundancy 2; RMAN>report need backup recovery window of 3 days; RMAN> report unrecoverable; RMAN> report obsolete; RMAN> delete obsolete; RMAN> delete noprompt obsolete; RMAN> crosscheck; RMAN> crosscheck backup; RMAN> crosscheck backupset of database; RMAN> crosscheck copy; RMAN> delete expired; --use this after crosscheck command RMAN> delete noprompt expired backup of tablespace users; To delete backup and copies: RMAN> delete backupset 104; RMAN> delete datafilecopy 'D:oracleoradatausers01.dbf'; To change the status of some backups or copies to unavailable come back to available: RMAN>change backup of controlfile unavaliable; RMAN>change backup of controlfile available; RMAN>change datafilecopy 'H:orabackusers01.dbf' unavailable; RMAN>change copy of archivelog sequence between 230 and 240 unavailable; To catalog or uncatalog in RMAN repository some copies of datafiles, archivelogs and controlfies made by users using OS commands: RMAN>catalog datafilecopy 'F:orabacksample01.dbf'; RMAN>catalog archivelog 'E:oraclearch_404.arc', 'F:oraclearch_410.arc'; RMAN>catalog controlfilecopy 'H:oracleoradatacontrolfile.ctl'; RMAN> change datafilecopy 'F:orabacksample01.dbf' uncatalog; RMAN> change archivelog 'E:oraclearch_404.arc', 'E:oraclearch_410.arc' uncatalog; RMAN> change controlfilecopy 'H:oracleoradatacontrolfile.ctl' uncatalog; RESTORING & RECOVERING WITH RMAN BACKUPYou can perform easily restore & recover operation with RMAN. Depending on the situation you can select either complete or incomplete recovery process. The complete recovery process applies all the redo or archivelog where as incomplete recovery does not apply all of the redo or archive logs. In this case of recovery, as you are not going to complete recovery of the database to the most current time, you must tell Oracle when to terminate recovery. Note: You must open your database with resetlogs option after each incomplete recovery. The resetlogs operation starts the database with a new stream of log sequence number starting with sequence 1. DATAFILE – Restore specified datafile.CONTROLFILE – To restore controlfile from backup database must be in nomount.ARCHIVELOG or ARCHIVELOG from until – Restore archivelog to location there were backed up.TABLESPACE – Restores all the datafiles associated with specified tablespace. It can be done with database open.RECOVER TABLESPACE/DATAFILE:If a non-system tablespace or datafile is missing or corrupted, recovery can be performed while the database remains open.STARTUP; (you will get ora-1157 ora-1110 and the name of the missing datafile, the database will remain mounted)Use OS commands to restore the missing or corrupted datafile to its original location, ie: cp -p /user/backup/uman/user01.dbf /user/oradata/u01/dbtst/user01.dbfSQL>ALTER DATABASE DATAFILE3 OFFLINE; (tablespace cannot be used because the database is not open)SQL>ALTER DATABASE OPEN;SQL>RECOVER DATAFILE 3;SQL>ALTER TABLESPACE ONLINE; (Alternatively you can use ‘alter database’ command to take datafile online)If the problem is only the single file then restore only that particualr file otherwise restore & recover whole tablespace. The database can be in use while recovering the whole tablespace.run { sql ‘alter tablespace users offline’; allocate channel c1 device type disk|sbt; restore tablespace users; recover tablespace users; sql ‘alter tablespace users online’;}If the problem is in SYSTEM datafile or tableapce then you cannnot open the database. You need sifficient downtime to recover it. If problem is in more than one file then it is better to recover whole tablepace or database.startup mountrun { allocate channel c1 device type disk|sbt; allocate channel c2 device type disk|sbt; restore database check readonly; recover database; alter database open;}DATABASE DISASTER RECOVERY:Disaster recovery plans start with risk assessment. We need to identify all the risks that our data center can face such as: All datafiles are lost, All copies of current controlfile are lost, All online redolog group member are lost, Loss of OS, loss of a disk drive, complete loss of our server etc: Our disaster plan should give brief description about recovery from above disaster. Planning Disaster Recovery in advance is essential for DBA to avoid any worrying or panic situation.The below method is used for complete disaster recovery on the same as well as different server. set dbid=xxxxxxxstartup nomount;run {allocate channel c1 device type disk|sbt;restore spfile to ‘some_location’ from autobackup;recover database; alter database open resetlogs;}shutdown immediate;startup nomount;run { allocate channel c1 device type disk|sbt; restore controlfile from autobackup;alter database mount; } RMAN> restore database;RMAN> recover database; --no need incase of cold backupRMAN> alter database open resetlogs;}DATABASE POINT INTIME RECOVERY:DBPITR enables you to recover a database to some time in the past. For example, if logical error occurred today at 10.00 AM, DBPITR enables you to restore the entire database to the state it was in at 09:59 AM there by removing the effect of error but also remove all other valid update that occur since 09:59 AM. DBPTIR requires the database is in archivelog mode, and existing backup of database created before the point in time to which you wish to recover must exists, and all the archivelog and online logs created from the time of backup until the point in time to which you wish to recover must exist as well. RMAN> shutdown Abort; RMAN> startup mount; RMAN> run { Set until time to_date('12-May-2012 00:00:00′, ‘DD-MON-YYYY HH24:MI:SS'); restore database; recover database; }RMAN> alter database open resetlogs;Caution: It is highly recommended that you must backup your controlfile and online redo log file before invoking DBPITR. So you can recover back to the current point in time in case of any issue.Oracle will automatically stop recovery when the time specified in the RECOVER command has been reached. Oracle will respond with a recovery successful message.SCN/CHANGE BASED RECOVERY:Change-based recovery allows the DBA to recover to a desired point of System change number (SCN). This situation is most likely to occur if archive logfiles or redo logfiles needed for recovery are lost or damaged and cannot be restored.Steps:– If the database is still open, shut down the database using the SHUTDOWN command with the ABORT option.– Make a full backup of the database including all datafiles, a control file, and the parameter files in case an error is made during the recovery.– Restore backups of all datafiles. Make sure the backups were taken before the point in time you are going to recover to. Any datafiles added after the point in time you are recovering to should not be restored. They will not be used in the recovery and will have to be recreated after recovery is complete. Any data in the datafiles created after the point of recovery will be lost.– Make sure read-only tablespace are offline before you start recovery so recovery does not try to update the datafile headers.RMAN> shutdown Abort; RMAN> startup mount; RMAN>run { set until SCN 1048438; restore database; recover database; alter database open resetlogs; }RMAN> restore database until sequence 9923; --Archived log sequence number RMAN> recover database until sequence 9923; --Archived log sequence number RMAN> alter database open resetlogs;Note: Query with V$LOG_HISTORY and check the alert.log to find the SCN of an event and recover to a prior SCN.IMPORTANT VIEW: Views to consult into the target database: v$backup_device: Device types accepted for backups by RMAN. v$archived_log: Redo logs archived. v$backup_corruption: Corrupted blocks in backups. v$copy_corruption: Corrupted blocks in copies. v$database_block_corruption: Corrupted blocks in the database after last backup. v$backup_datafile: Backups of datafiles. v$backup_redolog: Backups of redo logs. v$backup_set: Backup sets made. v$backup_piece: Pieces of previous backup sets made. v$session_long_ops: Long operations running at this time. Views to consult into the RMAN catalog database: rc_database: Information about the target database. rc_datafile: Information about the datafiles of target database. rc_tablespace: Information about the tablespaces of target database. rc_stored_script: Stored scripts. rc_stored_script_line: Source of stored scripts. For More Information on RMAN click on the below link: Different RMAN Recovery Scenarios 24-Feb-13 Synchronizes the Test database with RMAN Cold Backup 16-Feb-13 Plan B: Renovate old Apps Server Hardware 27-Jan-13 Plan A: Renovate old Apps Server Hardware 25-Jan-13 Planning to Renovate old Apps Server Hardware 24-Jan-13 Duplicate Database with RMAN without Connecting to Target Database 23-Jan-13 Different RMAN Errors and their Solution 24-Nov-12 Block Media Recovery using RMAN 4-Nov-12 New features in RMAN since Oracle9i/10g 14-Oct-12 A Shell Script To Take RMAN Cold/Hot and Export Backup 7-Oct-12 Automate Rman Backup on Windows Environment 3-Sep-12 How to take cold backup of oracle database? 26-Aug-12 Deleting RMAN Backups 22-Aug-12 Script: RMAN Hot Backup on Linux Environment 1-Aug-12 How RMAN behave with the allocated channel during backup 31-Jul-12 RMAN Important Commands Description. 7-Jul-12 Script: Crontab Use for RMAN Backup 2-Jun-12 RMAN Report and Show Commands 16-May-12 RMAN backup on a Windows server thruogh DBMS_SCHEDULING 15-May-12 Format Parameter of Rman Backup 12-May-12 Rman Backup with Stored Script 12-May-12 Rman: Disaster Recovery from the Scratch 6-May-12 RMAN- Change-Based (SCN) Recovery 30-Apr-12 RMAN-Time-Based Recovery 30-Apr-12 RMAN – Cold backup Restore 23-Apr-12 RMAN Backup on Network Storage 22-Apr-12 Rman Catalog Backup Script 18-Apr-12 Point to be considered with RMAN Backup Scripts 11-Apr-12 Monitoring RMAN Through V$ Views 7-Apr-12 RMAN Weekly and Daily Backup Scripts 25-Mar-12 Unregister Database from RMAN: 6-Mar-12
1 note
·
View note
Text
Microsoft sql server 2014 express download free

#Microsoft sql server 2014 express freeload full#
#Microsoft sql server 2014 express freeload free#
An integrated edition with management tools.
Microsoft makes SQL Server Express N1 available as: It is possible create several instances of the LocalDB for different applications. To connect this version it is needs special connection string. LocalDB limits to local system only and supports no remote connections. LocalDB runs as non-admin user, requires no configuration or administration. This version supports silent installation, requires no management and it is compatible with other editions of SQL Server at the API level. SQL Server Express LocalDB announced at 2011. The predecessor product MSDE generally lacked basic GUI management tools, įeatures available in SQL Server "Standard" and better editions but absent from SQL Server Express include:
SQL Server Business Intelligence Development Studio.
SQL Server Surface Area Configuration tool.
SQL Server Management Studio - since 2012 SP1 before that, only a stripped-down version called SQL Server Management Studio Express is provided.
SQL Server Express includes several GUI tools for database management. Unlike the predecessor product, MSDE, the Express product does not include a concurrent workload-governor to "limit performance if the database engine receives more work than is typical of a small number of users." Analysis Services is not available for any Express variant. Express with Advanced Services has a limit of 4 GB per instance of Reporting Services (not available on other Express variants). "Recommended: Express Editions: 1 GB All other editions: At least 4 GB and should be increased as database size increases to ensure optimal performance." ).
1 GB of RAM (runs on a system with higher RAM amount, but uses only at most 1 GB per instance of SQL Server Database Engine.
Single physical CPU, but multiple cores allowable.
The limit applies per database (log files excluded) but in some scenarios users can access more data through the use of multiple interconnected databases.
Maximum database size of 10 GB per database in SQL Server 2019, SQL Server 2017, SQL Server 2016, SQL Server 2014, SQL Server 2012, and 2008 R2 Express (4 GB for SQL Server 2008 Express and earlier compared to 2 GB in the former MSDE).
Differences in the Express product include: However it has technical restrictions that make it unsuitable for some large-scale deployments.
#Microsoft sql server 2014 express freeload full#
SQL Server Express provides many of the features of the paid, full versions of Microsoft SQL Server database management system. It is targeted to developers, this version has following restrictions: up to 10 Gb database size and only local connections (network connections are not supported). Microsoft SQL Server Express LocalDB is a version of Microsoft SQL Server Express, on-demand managed instance of the SQL Server engine. The "Express" branding has been used since the release of SQL Server 2005. The product traces its roots to the Microsoft Database Engine (MSDE) product, which was shipped with SQL Server 2000. It comprises a database specifically targeted for embedded and smaller-scale applications.
#Microsoft sql server 2014 express freeload free#
Microsoft SQL Server Express is a version of Microsoft's SQL Server relational database management system that is free to download, distribute and use. English, Chinese, French, German, Italian, Japanese, Korean, Portuguese (Brazil), Russian, Spanish
0 notes
Text
Portable Log Parser Lizard Pro it's actually an excellent query tool in its own right. It gives you an attractive and intuitive window into Log Parser results and any other SQL queries you want to perform on big text-based data, regardless of its size and complexity. Its flexible report designer adds even more to its high-end display options. There's no question that Log Parser is the standard for SQL queries in the Windows realm, but it's equally true to say that it's far from the easiest query tool to use. This is where Log Parser Lizard comes in, giving you a ribbon-based tabbed interface for designing and running your own queries outside of the Spartan command line interface provided by Microsoft. You can then view the results as a spreadsheet (complete with a wide range of tools and features), as a pie chart, or as an attractive report that you can even design yourself. It also allows you to create your own dashboards with all the necessary data fields, arguments, values, and strings, and export data to PDF or Excel documents. And the best part is that you won't have to design and build the same query from scratch the next time you need it, because unlike MS Log Parser, you can save your queries for later use and adjust this or that parameter to fit your needs. searches when necessary. Log Parser Lizard can parse all types of text-based data, from CSV and TSV files to event logs, IIS logs, log entries, the files stored on your system, and XML files. Custom log formats like RegEx, Android, and log4net are also supported, and you're given all the tools you need to perform queries for Microsoft SQL Server, OLEDB, Facebook Query Language, and even Google BigQuery services. The program comes with a number of useful built-in queries (mostly related to your Windows Registries and File System), but, as said, you can create your own at any time from any text-based dataset. You can analyze data not only faster but more efficiently than ever before thanks to a number of new features available in this release, such as Quick Query, Dashboard Viewer and Designer, and Report Designer (both mentioned above), and DB Connection String Builder . Portable Log Parser Lizard Pro is much more than just a pretty face for MS Log Parser: it is a well-designed, attractive, comprehensive query tool with support (for both input and output) for all known data files based on in text , which provides high-quality reporting and visualization options and comprehensive analysis of large amounts of data. There is no need to rediscover this tool after years of successful implementations and improvements; suffice it to say that there is no better tool to make the most of the data provided by MS Log Parser than Portable Log Parser Lizard Pro. 7/8/8.1/10English98.70MB
0 notes
Text
Deploying Microsoft Access Database on a Remote Server
If you're looking to set up Microsoft Access solutions to work remotely, there's some groundwork to consider to ensure continued business performance and achieve desired results. Regardless of the type and size of the business, a typical MS Access database is a multi-user platform capable of supporting files of over 100 MB in size. It's generally not recommended to open large files over a VPN for a couple of reasons that can impact the overall performance of the business and employees.
Firstly, you'll experience a prolonged and substandard performance that prevents key screens from showing up. Secondly, even though the screen appears, the risk of data corruption is significantly high. However, an exception to this rule is to set up a database combined with MS Access front-end and SQL Server in the backend that runs front-end files on the local PC via the VPN connection.
Better, you can get the MS Access database to run successfully on a Windows Server installed in your organization and then set up remote access to it. The database hosting procedure allows you to share the application online with colleagues, irrespective of whether they're working from the office, other branches, on the move, and anywhere across the world.
Investing in expensive site servers and complicated networks, including typical VPN connections, and re-coding the application are practices best put in the past. MS Access solutions for the contemporary business world allow a seamless enterprise-class hosted remote desktop server that lets you run the application online like a web database, accessible by authorized users simultaneously from several locations globally.
All that's needed is to install a remote desktop client on users' computers that comes with nearly all modern operating systems. It allows your colleagues to access the hosted database on multiple devices, including Android, Mac, iPad, or Windows.
The Process
The Windows Server set up in your organization should be the host configured as a terminal server or remote desktop server to support multiple logins with a license for support. Moreover, the RAM and the processor should be able to support several simultaneous logins without interruptions or disconnection.
Microsoft Azure is an application you can use to set up a Windows Server on the cloud. Alternatively, you also have the option to set up the server via Infrastructures that act as service providers. Now, set up permissions for each remote login to establish a secure connection with the server. An outline of the process is as follows:
Pick a Windows Server in your organization to be the host server Set up permissions for the chosen users to enable them to log in to the server remotely Keep a copy of MS Access or the Microsoft Access Runtime Engine on the Windows Server
Let the Access program be in a shared folder on the chosen Windows Server Open the Access program on the server using Remote Desktop Ensure additional security to access the server over the internet
You can follow the below procedure that is elaborated for the same purpose:
v Make the authorized users' members of the Remote Desktop Users Group and update the security of the group membership
Set the default Domain Group Policy to let members of the Remote Desktop Users login remotely. If you have a domain controller, modify the Default Domain Controllers Group Policy to enable remote login for all the users
Let remote connections access the system properties area to enable remote login if you're using a Windows 10 workstation. Ensure the server has a copy of MS Access installed
MS Office Business, Premium, and Enterprise have the full version of MS Access. Install any version on the Windows Server running Remote Desktop Services with a costly volume license
The MS Access development program should be installed in a shared folder location on the chosen Windows Server. It lets remote users access the files from their location simultaneously. Using a remote desktop to that server helps you access the program
If you want to access the Windows Server on the cloud, ensure you have additional security on the server. You can use the existing VPN or set up a new one for this purpose
After successful connection with the VPN or the client to your workplace, its easy to guide them to use the remote desktop connection to connect to the Windows Server via the Local Area Network address A less secure procedure to establish a connection is by using the raw remote desktop access via firewall broadband internet router or modem
Accessing Remote Desktop on Other Devices
It's way easier to establish an MS Access small business database connection to other software that lets you access the database from anywhere. This is an additional feature of establishing a remote connection available apart from the remote desktop software option.
You can set up your PC to establish remote connections by installing Windows 10 Pro. If you're running Windows 10, you can upgrade it to Pro by visiting the system settings. Go to the setting and system to enable remote desktop from the remote desktop section. Make a note of the name of this PC. It's available under "How to connect to this PC" to use it in the future.
If you're planning to use a remote desktop to connect to your PC, you can open the taskbar from the local Windows 10 PC and search for the same in the search box. Next, you can type the name of the PC that you noted down and connect.
Now, choose the device you wish to open the remote desktop app available for free on Google Play, Mac App Store, and Microsoft Store. Next, enter the PC's name and choose the name of the remote PC that establishes a connection instantly.
You can now use your remote desktop PC from this device to connect with colleagues and teams located across the globe to provide all Access solutions.
#digitalmarketing#social media marketing#ms access solutions#MS Access Experts#ms access project management database
0 notes
Text
Gerdes Aktiengesellschaft Network & Wireless Cards Driver

SALTO Neo electronic cylinder gains BSI Enhanced Level IoT Kitemark™ SALTO Systems, world leaders in wire-free networked, wireless, cloud, and smart-phone based access control solutions, has announced that the SALTO Neo electronic cylinder is their latest product to gain the coveted BSI Enhanced Level IoT Kitemark™ certification for access control systems. Thank you very much for your interest in the GERDES Aktiengesellschaft. As a dynamic, technology oriented and steadily growing company we are always looking forward to unsolicited applications, too.
The TrojanPSW.Egspy is considered dangerous by lots of security experts. When this infection is active, you may notice unwanted processes in Task Manager list. In this case, it is adviced to scan your computer with GridinSoft Anti-Malware.
GridinSoft Anti-Malware
Removing PC viruses manually may take hours and may damage your PC in the process. We recommend to use GridinSoft Anti-Malware for virus removal. Allows to complete scan and cure your PC during the TRIAL period.

What TrojanPSW.Egspy virus can do?
Presents an Authenticode digital signature
Creates RWX memory
Reads data out of its own binary image
The binary likely contains encrypted or compressed data.
The executable is compressed using UPX
Creates or sets a registry key to a long series of bytes, possibly to store a binary or malware config
Creates a hidden or system file
Network activity detected but not expressed in API logs
How to determine TrojanPSW.Egspy?
TrojanPSW.Egspy also known as:
ClamAVWin.Trojan.Genome-8229VBA32TrojanPSW.Egspy
How to remove TrojanPSW.Egspy?
Download and install GridinSoft Anti-Malware.
Open GridinSoft Anti-Malware and perform a “Standard scan“.
“Move to quarantine” all items.
Open “Tools” tab – Press “Reset Browser Settings“.
Select proper browser and options – Click “Reset”.
Restart your computer.
License: All 1 2 | Free
GREmail is a professional email preview ClientUtility with SSL/TLS support designed to quickly and easily maintain many POP3 accounts from a single Windows application. Includes a rule manager that among other functions allows the user to classify messages to focus on important messages or to quickly identify and delete SPAM. Every account is automatically scanned after a..
Category: Internet / Email Publisher: GRSoftware, License: Shareware, Price: USD $19.99, File Size: 2.1 MB Platform: Windows
USBDeviceShare-Client is an Utility that gives you the possibility to share USB devices and access them remotely over network (LAN or internet). The USB devices connected to remote computers can be accessed as if they are locally plugged in. Afterwards, the applications which work with the device can then be run without the device being locally present.
Category: Business & Finance / Applications Publisher: SysNucleus, License: Shareware, Price: USD $99.00, File Size: 2.2 MB Platform: Windows Dexatek driver download for windows 10 7.
gateProtect Administration Client is a Utility that allows the user to connect to remote servers. This Client has all the features that is needed in order to operate effectively and high no risk. High security with advanced firewalls protect each and every server.

Category: Business & Finance / Business Finance Publisher: gateProtect Aktiengesellschaft Germany, License: Freeware, Price: USD $0.00, File Size: 13.7 MB Platform: Windows
Dreambox Server Client is a Utility that can help you to connect to an USB and read the Sony Ericsson and Siemens phones. It has a friendly interface and easy to use so it can improve your way of using the Dreambox software. You have to put a smart card and this tool will do everything for you.
Category: Software Development / Help File Utilities Publisher: GSM Dream Team, License: Freeware, Price: USD $0.00, File Size: 25.4 MB Platform: Windows
Gerdes Aktiengesellschaft Network & Wireless Cards Drivers
Whois Tool is a ClientUtility that communicates with WHOIS servers located around the world to obtain domain registration information. Whois supports IP address queries and automatically selects the appropriate whois server for IP addresses. This tool will lookup information on a domain, IP address, or a domain registration information . See website information, search the whois..
Category: Internet / Flash Tools Publisher: Nsasoft US LLC, License: Freeware, Price: USD $0.00, File Size: 620.0 KB Platform: Windows

eMailaya is a useful email ClientUtility. Here are some key features of 'eMailaya': · Main Password Protection: Ever been afraid of people seeing your private emails? Now you don't need to be! · Tabbed Emailing: Ever wanted to easily handle lots of windows? Now you can! · Text/HTML Mode: Ever wanted to email in text mode? or in html mode? Now you..
Category: Internet / Email Publisher: amos, License: Freeware, Price: USD $0.00, File Size: 1024.0 KB Platform: Windows, All
Advanced Access To PDF Table Converter is a database ClientUtility that allows execution of SQL (Structured Query Language) statements on Microsoft Access databases. Resultsets returned by select queries are automatically persisted as PDF files to a directory of your choice. The tool provides user interface to define PDF table column headers, PDF document page size, PDF document..
Gerdes Aktiengesellschaft Network & Wireless Cards Drivers
Category: Business & Finance / Calculators Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $0.00, File Size: 0 Platform: Windows
A relational database ClientUtility that allows execution of SQL (Structured Query Language) statements on Microsoft SQL Server, MySQL and Oracle databases. The result sets returned by the selected queries are automatically exported as RTF (Rich Text Format) files to a directory of your choice. RTF files can be further modified with Microsoft Word and other word processors. ..
Category: Business & Finance / Calculators Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $9.95, File Size: 1.2 MB Platform: Windows
A database ClientUtility that enables you to execute SQL (Structured Query Language) statements on Microsoft Access 97, 2000, 2003, 2007 and 2010 databases. Resultsets returned by select queries are automatically persisted as HTML and CSS table files to a directory of your choice. The program automatically persists most recently used output directory path and allows..
Category: Business & Finance / Calculators Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $0.00, File Size: 0 Platform: Windows
A scriptable relational database ClientUtility that allows execution of SQL (Structured Query Language) statements on Microsoft SQL Server and MySQL databases. Results returned by the selected statements are automatically exported as CSV (Comma Separated Values) spreadsheets. The application comes with an XML configuration file that allows users to use database..
Category: Business & Finance / Database Management Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $9.95, File Size: 391.0 KB Platform: Windows
Advanced SQL To PDF Table Converter is a relational database ClientUtility that allows execution of SQL (Structured Query Language) statements on Microsoft SQL Server and MySQL databases. Resultsets returned by select statements are automatically persisted as PDF tables to a directory of your choice.
Category: Business & Finance / MS Office Addons Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $9.95, File Size: 1.2 MB Platform: Windows
The ACITS LPR Remote Printing ClientUtility provides a TCP/IP print monitor port driver for seamless Windows 95/98/Me and NT 4.0 network printing. This port driver can be used on Windows 95/98/Me and NT 4.0 to direct print jobs from Windows 95/98/Me and NT 4.0 to any printer or printer server that utlizes the LPR/LPD protocol. This package also..
Category: Business & Finance / Business Finance Publisher: The University of Texas at Austin (UTA), License: Freeware, Price: USD $0.00, File Size: 3.6 MB Platform: Windows
Reliable E-Mail Alerter is a scriptable SMTP e-mail ClientUtility that sends out pre-configured e-mail messages. The application comes with an XML configuration file that maintains the following information: SMTP server name or IP address, port used for SMTP communication, e-mail account, e-mail account password, list of To e-mail addresses, list of optional CC..
Category: Internet / Email Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $9.95, File Size: 408.5 KB Platform: Windows
An SMTP ClientUtility that simplifies the task of sending text and HTML e-mail messages to small and large groups of contacts using SMTP server configured on your desktop, laptop, server computer or one operated by your e-mail hosting company. Advanced Reliable Mass E-Mailer supports the following input sources for 'To' e-mail addresses: Microsoft SQL..
Category: Internet / Email Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $0.00, File Size: 0 Platform: Windows
Advanced SQL To XML Query is a relational database ClientUtility that allows execution of SQL (Structured Query Language) statements on Microsoft SQL Server databases. Resultsets returned by select statements are automatically converted to XML files and persisted to a directory of your choice. The application automatically persists most recently used output..
Category: Multimedia & Design / Media Management Publisher: Advanced Reliable Software, Inc., License: Shareware, Price: USD $9.95, File Size: 426.0 KB Platform: Windows
Internet connectivity with a laptop or cell phone has never been easier than it is with Connection Manager Pro. Automatically detects available networks and automates the creation and management of connection and security settings. Allows laptop users seamless migration between LAN or Wireless networks with VPN connection support. Connection Manager Pro also enables use of a cell phone..
Category: Internet Publisher: BVRP Software, License: Commercial, Price: USD $29.90, File Size: 6.6 MB Platform: Windows
Novell Netware Client is available free for download by registering with Novell, but the features of this program cannot be best used without having a Novell Netware Server in the Network. The ClientUtility is a part of the Novell Netware Server Bundle. Novell Netware Client is a software developed by Novell Inc which enables the Windows based clients..
Category: Utilities / Misc. Utilities Publisher: Novell, Inc., License: Freeware, Price: USD $0.00, File Size: 0 Platform: Windows
Handy Backup Online 64-bit is a ClientUtility for Novosoft Online Backup Service. It is designed for 64-bit versions of Windows 8/7/Vista/XP and 2012/2008/2003 Server, and allows automatically backing up all data of any PC or Server. With Handy Backup Online 64-bit, you can back up individual files and folders, system registry, complete HDD images and specific partitions, and.. Ebook Driver Download for Windows 10.
Category: Utilities / Backup Publisher: Novosoft Handy Backup, License: Shareware, Price: USD $39.00, File Size: 27.7 MB Platform: Windows
i.Scribe is a useful email ClientUtility that allows you to send and receive emails. i.Scribe is a remarkably compact email program with an easy to use interface and many features, including a split view of folders and items, signatures, drag and drop, spell checking as well as an internal address book and calendar. i.Scribe is a small and fast email Client that lets you..
Category: Internet / Email Publisher: MemeCode Software, License: Freeware, Price: USD $0.00, File Size: 983.0 KB Platform: Windows, All
Handy Backup Online is a ClientUtility for HBDrive - new cloud storage service from Novosoft. It is designed for Windows 8/7/Vista/XP and 2012/2008/2003 Server, and allows you to automatically back up all data of your PC or server. Drivers data card port devices gigabit. With Handy Backup Online, you can back up individual files and folders, e-mails, Windows registry, snapshots of complete hard drives and specific..
For users of FARGO® printers, the FARGO Workbench utility enables the updating of the printer firmware/driver to take full advantage of new features, diagnostic tools, performance upgrades and enhanced security. Fargo driver download for windows xp. HID® FARGO® HDP5000 Windows Driver. Hdp5000windowsv3.3.0.1setup.zip - (23.87 MB) This driver has the fix for the Windows 10 build 1903 or later update. Operating Systems supported by Seagull Printer Drivers will include 32 and 64 bit versions of the following: Windows 10 and Server 2019; Windows 10 and Server 2016; Windows 8.1 and Server 2012 R2; Windows 8 and Server 2012; Windows 7 and Server 2008 R2. HID® FARGO® HDPii/HDPii Plus Windows Driver hdpiiplussetupv3.3.0.2.7.zip - 28.06 MB This driver has the fix for the Windows 10 build 1903 or later update.
Category: Utilities / Backup Publisher: Novosoft Handy Backup, License: Shareware, Price: USD $39.00, File Size: 22.5 MB Platform: Windows
Get official Wireless Drivers for your Windows XP system. Wireless Drivers For Windows XP Utility scans your computer for missing, corrupt, and outdated Wireless drivers and automatically updates them to the latest, most compatible version. Wireless Drivers For Windows XP Utility saves you time and frustration and works with all Wireless drivers..
Category: Utilities / System Surveillance Publisher: DriversForWindowsXP.com, License: Shareware, Price: USD $29.95, File Size: 1.4 MB Platform: Windows
Get official Wireless Drivers for your Windows Vista system. Wireless Drivers For Windows Vista Utility scans your computer for missing, corrupt, and outdated Wireless drivers and automatically updates them to the latest, most compatible version. Wireless Drivers For Windows Vista Utility saves you time and frustration and works with all..
Category: Utilities / System Surveillance Publisher: DriversForWindows7.com, License: Shareware, Price: USD $29.95, File Size: 1.4 MB Platform: Windows
Get official Wireless Drivers for your Windows 7 system. Wireless Drivers For Windows 7 Utility scans your computer for missing, corrupt, and outdated Wireless drivers and automatically updates them to the latest, most compatible version. Wireless Drivers For Windows 7 Utility saves you time and frustration and works with all Wireless drivers..
Category: Utilities / System Surveillance Publisher: DriversForWindowsXP.com, License: Shareware, Price: USD $29.95, File Size: 1.4 MB Platform: Windows
Tcp Client Sever is a useful network Utility for testing network programs, network services, firewalls and intrusion detection systems. Tcp Client Sever can also be used for debugging network programs and configuring other network tools. Depending on Client-Server mode the tool can work as a Tcp Client or Tcp server, accept multiple network connections,..
Category: Internet / Flash Tools Publisher: Nsasoft US LLC, License: Freeware, Price: USD $0.00, File Size: 589.7 KB Platform: Windows
Udp Client Sever is a useful network Utility for testing network programs, network services, firewalls and intrusion detection systems. Udp Client Sever can also be used for debugging network programs and configuring other network tools. The tool can work as a Udp Client and Udp server, send and receive udp packets. The tool is designed with a user-friendly interface..
Category: Internet / Flash Tools Publisher: Nsasoft US LLC, License: Freeware, Price: USD $0.00, File Size: 601.9 KB Platform: Windows
0 notes
Text
MySQL Cluster a 5 9s (99.999%) Database
MySQL Cluster: MySQL Cluster is a real time, ACID-compliant transactional database. It is a combination of MySQL server and the NDB storage engine. Data is cached in memory and durably stored on disk. Indexed columns are always kept in memory while non-indexed columns can be kept in memory or disk. It was mainly designed for telecom databases with 99.999% availability and high performance. Unlike simpler sharded systems, MySQL Cluster transactions can transparently query and update all data in the system. Key features of MySQL Cluster: MySQL Cluster is designed using a shared nothing architecture Support for large database sizes With all columns kept in memory, can store upto few terabytes With some columns kept on disk, can store upto few petabytes Supports read and write transactions: during upgrade, scaling out, adding new columns/index to thetables, backup, add new nodes, add/drop FK etc Survives multiple node failures while writes happen. Support for automated node failure detection and automated recovery after node failure. Support for 144 data nodes (version 8.0.18 or later). Support for multiple levels of replication: Synchronous replication inside the cluster (replica) Asynchronous replication between cluster (Source -> Replica) Support for both SQL and NoSQL (NDB API) i.e. in both ways userapplications can interact with the same data. Support for online scaling with no down time, i.e. cluster can be scaled while transactions are going on. Support for automatic data partitioning based on cluster architectureselected by the user. Cluster architectural diagram: Components of MySQL cluster in nutshell:From the above architectural diagram, one can see that there are three types of nodes exist. These are: Management node(s) Data nodes API nodes Management nodes:This node has a number of functions including: Handling the cluster configuration file called ‘config.ini’ and servingthis info to other nodes on request. Serves cluster address and port information to clients. Gathers and records aggregated cluster event logs. Provides a cluster status query and management service, available tousers via a Management client tool. Acts as an arbitrator in certain network partition scenarios. Management nodes are essential for bootstrapping a system and managing it in operation, but they are not critical to transactionprocessing, which requires only Data nodes and Api nodes.Since this server has limited responsibilities it does not need a lot ofresources to run. Data nodes:These are the heart of MySQL cluster storing the actual data and indexes,and processing distributed transactions. Almost all of the cluster functionality are implemented by these nodes. Data nodes are logicallygrouped into nodegroups. All data nodes in a nodegroup (up to four) contain the same data, kept in sync at all times. Different nodegroupscontain different data. This allows a single cluster to provide highavilability and scale out of data storage and transaction processingcapacity. Data nodes are internally scalable and can make good use ofmachines with large resources like CPU, RAM, Disk capacity etc.API nodes:Each API node connects to all of the data nodes. API nodes are the pointof access to the system for user transactions. User transactions are defined and sent to data nodes which process them and send results back.The most commonly used API node is MySQL server (mysqld) whichallows SQL access to data stored in the cluster. There are a number of different API node interfaces MySQL cluster supports like C++ NDB API, ClusterJ (for java applications), Node.js (for java script applications) etc.Use cases of MySQL Cluster: MySQl cluster was initially designed for telecom databases. After years of improvement, it is now used in many other areas like online gaming, authentication services, online banking services, payment services, fraud detection and many more. Performance:NDB is known for its high performance: 20M writes/second 200M reads/second 1B updates/minute in benchmarks limitation:Like every database, MySQl Cluster has some limitations which includes: Only READ COMMITTED transaction isolation level is supported No support for save point GTID (Global Transaction Identifiers) not supported No schema changes (DDL) allowed during data node restart For more information about MySQL NDB Cluster, Please check the officialdocumentation site. https://clustertesting.blogspot.com/2020/12/mysql-cluster-5-9s-99999-database.html
0 notes
Text
New Post has been published on Strange Hoot - How To’s, Reviews, Comparisons, Top 10s, & Tech Guide
New Post has been published on https://strangehoot.com/how-to-increase-mysql-upload-limit/
How to Increase MySQL Upload Limit on Server
MySQL is a free open source Relational Database Management System using Structured Query Language SQL, being the highly favourite language for content addition, access and management of a database. It is highly recommended for faster processing, utmost reliability, ease-of-work experience and flexible approach.
The utility of MySQL includes a broad spectrum of clients like e-commerce, logging applications and data warehousing, but the commonest of all is web database creation.
It stores and manipulates data through emphasizing on the relationship between the tables. Clients request the database thru pre-defined SQL statements to request response-information to get one on clients’ side.
DATABASE () function shows the name of the running database, which is an active one. Queries are subject to get results from and based on the running database. In MySQL, it is possible to substitute the function SCHEMA () with the function DATABASE ().
MySQL shell is an interactive tool to be used and act as an administrator of the MySQL database. Supporting JavaScript, Python or SQL modes has made it convenient for access and administrative use.
SQL being a standard language enabling the user to manage and design databases whereas, MySQL is a relational database management system permitting the storage and retrieval of data from the database. MySQL, at times, uses SQL to perform some specific operations.
The easiest and reliable way to connect to the MySQL server and get a MySQL databases list is running the SHOW DATABASES command. User can omit the -p switch, in case, the user has not set a password as a MySQL user. User can establish a connection to MySQL Database by logging into A2 Hosting account through SSH for which the user has to type the relevant command. The command need some changes like :-
Replace USERNAME with the username:
MySQL -u USERNAME -p.
Type the password at the Enter Password prompt, …
Type the command at the MySQL> prompt: SHOW DATABASES, to get a display of the list of databases.
Launch the MySQL Command-Line Client.
For launching the MySQL Command-Line client, the user must enter the below-given command in the Command Prompt window:
MySQL -u root -p
where -p option is required only in case of a root password has been defined for MySQL.
Users with a no-install package may use the instructions to install MySQL manually. For installing MySQL from a ZIP Archive package is as under:
Extract the main archive to the desired install directory
User may also extract the debug-test archive, which is optional in case plan is to execute the MySQL benchmark and test the software.
Option file can be created using the following commands:-
Choose a MySQL server type
Initialize MySQL
Start the server
Secure default user accounts
PHP, Hypertext Pre-processor is open source widely-used scripting language to be executed on the server. Rasmus Lerdorf generated the initial version of PHP in 1994 to be utilized in managing session tracking, dynamic content with PHP database. PHP is also used in building e-commerce sites.
The Server is a part of computer hardware/software in computing to offer functionality for the programs/devices, referred to as “clients”. The whole architecture is known as the client-server model.
Upload max file size is the maximum size for files that are being posted. The types of POST body data are not subject to the limit. In case you wish to upload large files, you must increase both limits.
Maximum execution time in PHP is of 30 seconds. The phrase “maximum execution time” is vague as it may be taken as
(a) elapsed time since the script started, or
(b) the total CPU time taken by the script, including or excluding the CPU time taken by OSC.
The maximum execution time by default for PHP scripts is taken to be 30 seconds. PHP stops the script and reports an error in case a script runs longer than maximum execution time. Amount of time PHP allows can be controlled by running the scripts for changing the maximum execution time directive in the php.ini file.
Client – Server Connection Ports
The default port used is Port 3306 for the classic MySQL (port) protocol. It is used by the MySQL Connectors, client, or for utilities like MySQL pump, MySQL dump. The port supported by MySQL Connectors or MySQL Shell or MySQL Router for X Protocol (mysqlx_port), is estimated by multiplying 10 to classic MySQL protocol port.
Increase upload / import size
You have a 2mb limit of upload/import size in MySQL which is totally odd and highly inconvenient to import large files. User can get the upload size increased by allowing and editing the server’s php.ini configuration file. Generally, it is located at /etc/php.ini in servers like CentOS.
The following commands can be typed to increase MySQL upload limit on the server
Step 1:
Go to php.ini and find the following and change the values to larger database size.
upload_max_filesize = 40M
post_max_size = 40M
Step2:
Restart the apache service for the new change to get set. Typically the command to restart apache would be: –
service httpd restart for CentOs
service apache2 restart for ubuntu
You can also restart directly from the path as :-
/etc/init.d/apache2 restart or /etc/init.d/httpd restart
In case of shared hosting with no root access or access to the php.ini configuration file, then another way is: –
to create a .ht access file in the application root and then adding the following line;
php_value upload_max_filesize 40M
php_value post_max_size 40M
Increase the MySQL Max Upload Size on Server
The cPanel server puts a cap on the database to be uploaded into PhpMyAdmin. The default limit is subjected to 50MB.
Therefore, it becomes difficult to upload a large database to PhpMyAdmin. But, to increase the max upload size in the PhpMyAdmin of the database file, the user can make changes in configuration in the WHM of the server like: –
Step 1:
Login to the WHM of the server by accessing the link https://yourIPaddress:2087 Or https://yourserverhostname:2087
Step 2:
Navigate to “Server Configuration”.
Step 3:
Select “Tweak Settings” from it. Step 4:
Navigate to PHP in Tweak settings.
Check cPanel max POST size and cPanel max upload size values.
Change the configuration according to the preference and save it.
Login to your PhpMyAdmin and verify the values, where you can see the value have been replaced with the changed one.
You can also go through the same procedure via the CLI:-
Step 1:
Login to your server via SSH.
# ssh root@IPaddress
Step 2:
Execute the following command to display the default PHP .ini file of the server.
# php –ini
Step 3:
Open it with the favourite text editor.
# vi path_to_php.ini (You may replace this with the original file path)
Step 4 :
Search for upload and post by writing M, write the preferred value.
upload_max_filesize = M
post_max_size = M
Step 5:
Restart the apache service.
# service httpd restart
or
# systemctl restart httpd
Read: How to Install Server Nginx on Ubuntu
0 notes
Text
3 THINGS TO EXTEND THE LIFE OF YOUR WEBSITE

There are lots of things that you can do to extend the life of your website from the very beginning; allowing it to run fast and reliably while also being safe from malicious attacks. However, there are three forgotten areas that you should be concerned about when developing a new site; security, stability, and performance.
Let’s discuss some aspects of each area and how they can increase the safety, reliability, and performance of your website.
Security
When most people think about web security, they think about someone hacking into the site and stealing customer data. However, this is not always the case. Sometimes hackers want to use your web server for other types of illegal or unethical practices such as setting up an email server to forward spam, using it to host illegal files or even illegal Bitcoin mining–just to name a few.
There’s nothing worse than having your website infecting your customer’s computers. Not only will Google mark your website as malicious but other filtering and antivirus services will blacklist your website and block their users from visiting it. From being blacklisted as a spammer to having your hosting provider completely shut you down – there’s no good outcome.
The cost of clean up can vary depending on how complicated your website is, the type of infection, and the quality of your backups.
If you are storing customer information, you may need to contact your insurance company and potentially report the breach. It’s a mess no matter how you look at it.
Below are some of the methods you can employ to reduce the risk of your web server being hacked as well as some overall best practices to prevent your server from being misused.
1. Prevent SQL Injection Attacks
If you use a data store that takes advantage of SQL and you use SQL directly in your code, then you could open yourself up to the possibility that a hacker will send malicious code that can cripple your site and/or corrupt your data. The best way to prevent this is to use structured parameters in your Transact SQL code. If you are using Microsoft SQL Server, you can also choose not to use open SQL in your code at all. Instead, you can use stored procedures that use formatted parameters. This will prevent random statements from being executed, and it will also be much faster since your SQL will be precompiled on the server.
2. Avoid Detailed Error Messages
If an error occurs, resist the temptation to use them as debugging tools. Handle the errors gracefully by giving the user a vague error statement and provide them navigation back to the homepage or the page they were on previously. Giving away too much information can give hackers what they need to exploit your site.
3. Prevent Cross-Site Scripting Attacks
Limit and evaluate comments and other forms of input submitted by users to guard against JavaScript injection attacks. You can set attributes through parameterized functions similar to the way you prevent SQL injection attacks. You can also employ the use of Content Security Policy to limit what types of JavaScript that can run in your pages.
4. Use Client and Server-Side Validation
Validate user input on both the client and server levels to make sure that malicious JavaScript wasn’t inserted between when the request was sent from the client to the time it arrives at the server.
5. Use HTTPS
Encrypting the traffic between the user’s browser and the server using SSL is always a good idea when the potential of transmitting sensitive data exists. This will prevent hackers from grabbing and deciphering the data as it is transmitted.
6. Use Two-factor Authentication to Log In
Using two-factor authentication to log into the management area of your website. Two-factor authentication essentially not only a username and password but potentially a continuously changing token/PIN or some sort of additional validation (i.e. a prompt on your cell phone) to verify it is you. Even if someone has your username and password, they can’t get in without the extra piece of information.
7. Keep Your Software Up to Date
In this day and age, you should be using a content management system (CMS). If you have an admin area you log into to manage content, then you are using a CMS. The CMS provider regularly provides updates to their core system, and various vendors provide updates to their plugins. Some updates add functionality, but many of the updates in between are primarily to fix security holes. If you don’t keep your system up to date, you are leaving yourself open to known vulnerabilities.
8. File Change Detection
You can run scripts on your server that notifies you of any changed files. There are some files that shouldn’t change often or at all unless you install an update. If you see that file change, you should be on high alert to find out what changed and who changed it. This is essentially a canary in a coal mine – it’s an early detection system.
9. Limit the Number of Login Attempts
Most systems these days can block an IP address if it has failed multiple authentication requests within a given period. Hackers have scripts that try different combinations to get in. If your website allows someone to continue trying, they may eventually get in. If you limit their ability to try new combinations, you may be able to keep them out. An example ruleset may look like five failed authentication attempts within a three minute period makes the user wait 15 minutes before allowing them to try again. You could even block their IP completely after a certain number of attempts.
10. Think in Layers
Consider someone picking a lock only to be met with another door with another lock. You can protect your website directly, but you should also protect your web server. You can use hardware or software firewalls, DDOS prevention systems, IP filtering, standard port changes, and malware scans to add an extra layer of protection.
Stability
Stability is a hard thing to define. There are lots of things that you should be aware of during development to make your site perform reliably and be more stable, such as cleaning up user sessions, guarding against memory leaks and managing garbage collection. There are also things that you can monitor for stability after the site has been deployed, like:
1. Clean Code
There is no replacement for clean code. Not only will it be more efficient, but it will be easier to track down bugs as well as easier for a new developer to understand. Code with no architecture or “spaghetti code” as we call doesn’t define code in a way that is separate and understandable. Instead, it is all mixed together and potentially duplicated in different areas of the site. There’s not much you can do with a site like this.
2. Load Testing
You should be utilizing cloud-based load testing tools if your website is expected to function under heavy load or heavy load spikes. You can create load simulations to see how your website performs under different scenarios. Make sure your testing environment matches your production environment.
3. Customize Memory Limits
If you have your own server make sure that your site’s memory limit is set to match your sites requirements as well as the resources of your server. You don’t want to make the website run on too little memory, but you also don’t want to allow one connection to use up all of your memory.
4. Cross Browser Testing
Stability is in the eye of the beholder. Make sure you test on the most popular version of Internet Explorer, Edge, Firefox, Chrome, and Safari. There are automated cloud tools to help you but adding manually testing never hurts.
5. Your Web Server
Are you using a dedicated server or a shared server? With a shared server, you are sharing the server’s resources with other websites. Although there should be limits on how many resources one website can use, we have seen servers at bulk hosting providers that may have hundreds of websites on one web server.
Performance
Not only do you want to make sure that your site is reliable and stable, but you also want it to be fast and easy to use. Below are a few of the things that you should monitor to make sure your site performs at its peak potential.
1. Full Page Loading Times
Measure the time it takes to fully load different pages. Especially measure the ones that contain linked content or things such as embedded content, large images or pages that query a database to pull in content. There are many tools out there to measure page speed. There are various factors to review such as first-byte time, DOM load, the overall file size of the website, compression, image optimization, caching, etc.
2. Geography
Try to test your site’s performance from different locations to make sure it isn’t slowing down in specific areas. This may have to do with the number of switches, networks, and servers someone goes through to get to your site. One solution is to use a Content Delivery Network (CDN). A CDN essentially caches copies of your website and places them on POP locations around the world, which then reduces the number of switches and servers your user has to go through to view your content. The network is set to come back to your main website and look for updated content.
3. Dedicated Resources
The cost of dedicated cloud servers has been going down. For the extra amount paid, you are essentially asking your provider to dedicate a certain amount of resources for your web server regardless of whether you are using it or not at that particular time. You are giving your website some breathing room instead of having it compete for resources.
4. Network Latency
Make sure to choose a reputable hosting provider. You can have a beast of a web server, but if their network has high latency or packet loss, your server won’t be the bottleneck.
5. DNS
When a visitor types in your website address or clicks a link on Google, their web browser has to do a DNS lookup. It’s essentially asking what IP address to go to in order to request the website files. Think of it as looking up a phone number. You want to make sure that lookup is as fast as possible. Make sure your DNS servers respond quickly.
6. Caching
In simple terms, caching is storing website data for future use. There are many places along the chain you can utilize caching and various types of caching systems. From server side caching to browser caching, you are essentially telling the server or browser to store pieces of information it will need to access often or information that will not change often. It’s one less lookup or transmission, and they add up.
7. Image optimization
Not all images are created equal. If you are taking a photo that you will print in a brochure and also use on your website, you actually have different requirements. For the brochure, you need high pixel density (DPI), but your screen needs fewer pixels. Additionally, there are file formats that work best for different images. You can choose between vector images or raster images. You have format options such as .jpg, .gif, .svg, and .png. You have compression options such as lossless compression or lossy compression. In short, you have a lot of options and what you use should be determined by the image itself and the display requirements.
8. Javascript Minification and CSS Aggregation
Have you ever received where the box was much larger than the contents? Minification is the same thing; it’s the process of taking out unused characters without changing how it functions. You are making it smaller so that it transmits faster. CSS Aggregation is a bit different, it’s like order five things and having them all come in the same box vs. five different boxes. It just reduces the number of files a browser has to download in order to render your website.
9. Query Optimization
This one is a bit more difficult because it requires experience and finesse. When building a website that relies on a database to function, you can pull that data from the database in many ways. Additionally, you may be pulling from multiple tables in one database to display the content.
For example, in an eCommerce website, you may store the user information in one table and order information in another table. When a user goes to their profile page to see past orders, you would pull data from the user table first and then use information in that query to pull data from another table. Sometimes, you are pulling data from many database tables.
Query optimization is essentially finding the most efficient route to get the information you need. If the query is not designed well, your user may have to wait several seconds for the server to pull up all the information and while that is happening, your server is using up more resources than it should which means it can serve fewer people at once.
Paying special attention to these three areas will help to ensure that your website is always safe, reliable and running at its peak. Designing, developing and deploying a website is only the beginning. If you compromise sensitive user data, your site is always down, or your site is consistently slow then users won’t want to return to your site, and you’ve done all of that hard work for nothing.
Managing and improving your website is an ongoing process. It is a living entity, and it needs to be given every opportunity to flourish. Contact Web designer in Denver, CO today if you want to extend the life of your website by ensuring that it is secure, stable, and performs.
0 notes
Text
300+ TOP FILEMAKER Interview Questions and Answers
FILEMAKER Interview Questions for freshers experienced :-
1.What is FileMaker Pro? FileMaker Pro is a 32 bit, Y2K compliant, cross-platform, fully relational, database program. Similar to Microsoft Access, the current version of FileMaker is a fully relational database development tool that allows one-to-one, one-to-many, many-to-one, and many-to-many relations between files (tables). Another one of FileMaker Pro's advantage is the FileMaker Developer tools that allows us to 'bundle' the form files with the FileMaker Runtime engine that allows our outside customers to use WSDOT forms without requiring them to purchase any additional software. 2.What are the symptoms of a corrupt FileMaker file? Symptoms vary from corruption type and level of corruption. Maybe your FileMaker application freezes when the file is tried to open, or maybe an error message is shown when you click the file to open it. 3.Is it possible to search any FileMaker .fp7 file? FileMaker Recovery Software has an inbuilt option to search FP7 files in a specified location. File properties like modification date, creation date, size, etc. are shown in the search result for accurate selection. 4.How is FileMaker Recovery Software different from other similar products in market? Many features have been included in latest version of FileMaker Recovery Software. Latest version of FileMaker Recovery Software supports File Maker Pro 10/11/Pro/Advance and above. Search option in the preview, selective recovery of a specific table, log summary, etc. make it above other similar software applications in the market. 5.What is FileMaker Recovery Software? FileMaker Recovery Software is used to repair, restore and recover corrupt FileMaker database (.fp7) files. A search feature is provided that helps in searching all the .fp7 files present in a drive or folder. A new FileMaker file is set as target to store the recovered table data. Data of Text, Number, Date, Timestamp, Calculation, Container and Summary data type are recovered back in the repaired database file. 6.Can I repair a FileMaker database for trial and evaluation without payment? Yes, you can download FileMaker Recovery Software absolutely free of cost. Preview is shown in the demo version for customer evaluation. If you are satisfied by the scanned results, you can register the demo version to save the recovered FileMaker database. 7.What is new in FileMaker Pro 6? The best just got better with FileMaker Pro 6 database software. It features digital image capture and import; more than 20 modern and powerful templates for "instant productivity" in business, education and home; many time-saving features like Format Painter and Custom Dialog Boxes for users and developers; and integrated XML support so FileMaker can exchange data with a large and growing number of other applications. FileMaker Pro 6 will jump-start the productivity and creativity of workgroups ranging from entire small businesses to departments within the enterprise. 8.Why is the new FileMaker Pro 6 available before other revised products? FileMaker Pro 6 files share the same file format as FileMaker Pro 5 and 5.5 files. Thus, all three versions may co-exist on the same network. In addition, all versions utilize the current FileMaker Server (now relabeled without a version number) features, enabling large workgroups to share information seamlessly. 9.Is XML import/export support in FileMaker Pro 6 a big deal? Absolutely the widespread support of XML (Extensible Markup Language) standards means FileMaker Pro 6 can exchange data with a large and growing number of other applications without complex and costly converting of data between proprietary formats. A developer can easily empower a workgroup using FileMaker Pro 6 to, for example, find and get data from Websites, import accounting data from QuickBooks, or query corporate databases without using ODBC drivers. With XML export, FileMaker Pro 6 users can share information with users of other applications. For example, users can export formatted FileMaker data in an attachment to an email, into Microsoft Excel, or into document-authoring applications. 10.What's new about XML support in FileMaker Pro 6? In the past, accessing FileMaker data as XML required users to make requests to the FileMaker Web Companion from an external application; in other words, it was "pull" only through the Web Companion. Additionally, processing XSLT style sheets required the user to have installed an XSLT processor on the client machine. With FileMaker Pro 6 the XML capabilities are integrated into the product as import/export menu selections without the need for the Web Companion. Alternatively, the customer can script XML data import and export. Also within FileMaker Pro 6 is an XSLT processor allowing style sheets can be processed without the need for the customer to install their own.

FILEMAKER Interview Questions 11.How hard is it to use XML import/export? Can anyone use it? While the creation of the XSLT style sheets does require a good understanding of XML and XSLT, the benefits of our XML import/export can be enjoyed by all users. Note that a developer can empower an entire workgroup, very efficiently, to enjoy the benefits of XML data-exchange while hiding the plumbing from the users. To further assist our customers with better understanding of XML and XSLT, we ship 8 XSLT style sheet examples with FileMaker Pro 6. Furthermore, customers can visit the FileMaker XSLT Library, which is part of our FileMaker XML Central. The FileMaker XSLT Library is a repository of XML/XSLT examples that are available for download at no charge. 12.Why did FileMaker add integrated XML support in FileMaker Pro 6? XML support is the tool that best accomplishes this task. With the implementation of our XML support, FileMaker Pro 6 users are now able to gather data from more data-sources and share data with more applications.FileMaker Pro 6 customers can benefit from XML import and export. Through the creation of an XSLT style sheet , a workgroup can: Import XML data from a SQL server without the use of ODBC drivers. Share information with other workgroups who don’t even use FileMaker Pro by sending data from FileMaker directly into a formatted Excel file (*.xls) or other text-based file formats. Create charts and graphics (*.svg) to represent FileMaker data. 13. Is there RAIC support for Instant Web Publishing in FileMaker Pro 6? There is no support for RAIC technology in FileMaker Pro 6. Use FileMaker Pro 6 Unlimited to deploy Web-based solutions to an unlimited number of users. It also includes the FileMaker Pro Web Server Connector and support for RAIC, which can increase the performance and scalability of your FileMaker Pro web databases. Toolbars are not supported under Mac OS X. 14.What is FileMaker Pro 5.5 Unlimited? FileMaker Pro 5.5 Unlimited includes all of the powerful desktop database functionality of FileMaker Pro 5.5, plus it allows databases to be hosted via the Web to an unlimited number of unique visitors with unique IP addresses. FileMaker Pro 5.5 Unlimited also includes the Web Server Connector and tools needed to use and access advanced functionalities such as Custom Web Publishing (via CDML), XML, JDBC, Java class libraries, and JavaScript. 15.What is the difference between FileMaker Pro 5.5 and FileMaker Pro 5.5 Unlimited? There are four major differences between FileMaker Pro 5.5 and FileMaker Pro 5.5 Unlimited: The Web Companion that ships with FileMaker Pro 5.5 Unlimited allows access to the Web Companion for an unlimited number of web browsers. The Web Companion that ships with FileMaker Pro 5.5 is limited to 10 IP addresses in a rolling 12 hour period. FileMaker Pro 5.5 Unlimited includes the FileMaker Web Server Connector. Additional copies of FileMaker Pro 5.5 Unlimited can be used to set up a Redundant Array of Inexpensive Computers (RAIC) structure to take advantage of scalable load balancing, and fault tolerance, to increase the performance of FileMaker web enabled databases. Computers running Mac OS X cannot serve as RAIC machines FileMaker Pro 5.5 Unlimited can be used with various CGIs, middleware, and application servers for deployment across the Web. Tools and information needed to implement solutions using advanced functionalities (JDBC driver, Java class library, Custom Web Publishing , Custom Workgroup Portal, XML) are not included in FileMaker Pro 5.5. 16.What is the FileMaker Web Server Connector? The FileMaker Web Server Connector is a Java servlet that is used to connect FileMaker Pro 5.5 Unlimited with powerful web servers. A servlet is a standard Java based mechanism for extending the functionality of a web server. The FileMaker Web Server Connector is used to pass through (or relay) requests received on a web server to FileMaker. The reasons to use the FileMaker Web Server Connector include. To take advantage of other web server plug-ins and features including SSL and server-side includes, provide a Redundant Array of Inexpensive Computers (RAIC) structure to increase throughput and reliability, increase performance by storing static pages and graphic images on the Web server, bypassing the Web Companion for pages that don't involve databases, and provide redundancy to allow for operation through failure situations. 17.Can I use the FileMaker Web Server Connector with FileMaker Pro 5.5? The FileMaker Web Server Connector is designed to work only with FileMaker Pro 5.5 Unlimited, the dedicated web publishing product in our product family. 18.Can I use the FileMaker Pro 5.5 Unlimited Web Server Connector with Instant Web Publishing? No. The improved FileMaker Pro 5.5 Unlimited Web Server Connector is intended for use with Custom Web Publishing. 19.How can I run reports and print labels via browser in databases hosted under FileMaker Pro Unlimited? If you need more functionality than browsing, searching, adding, updating, or deleting records, you will want to access the database using a copy of FileMaker Pro, rather than a browser. 20.How can I set up a Redundant Array of Inexpensive Computers (RAIC) with FileMaker Pro 5.5 Unlimited to increase scalability, performance and robustness? The FileMaker Web Server Connector, included with FileMaker Pro 5.5 Unlimited, lets you set up a RAIC. A RAIC increases the scalability of your web-based FileMaker Pro solutions and helps ensure operation through fail-over situations. To set up a RAIC, an additional copy of FileMaker Pro 5.5 Unlimited is required for each CPU you wish to add to the RAIC. 21.What languages will FileMaker Pro 5.5 Unlimited be available in? FileMaker Pro 5.5 Unlimited in Worldwide English, French, Italian, German, Swedish, Dutch, Japanese and Spanish. 22.What are the price and availability of FileMaker Pro 5.5 Unlimited? FileMaker Pro 5.5 Unlimited is currently available. Estimated retail price in the U.S. is $999. Upgrade price for licensed owners of FileMaker Pro 5 Unlimited is US $499. Volume license pricing is available. 23.Do I have to use the FileMaker Web Server Connector when I install FileMaker Pro 5.5 Unlimited? No. If you want to use FileMaker and simply have more than 10 IP addresses accessing your copy of FileMaker in a rolling 12 hour period and do not need to add scalability and load balancing to your FileMaker web solutions, you can simply install the "unlocked" version of FileMaker Pro 5.5 that ships with FileMaker Pro 5.5 Unlimited. 24.Is FileMaker Pro 5.5 Unlimited certified for Windows 2000? FileMaker Pro 5.5 Unlimited is certified for Windows 2000 Professional. 25.Why did we build FM Starting Point? When we worked with FileMaker, Inc. to rebuild and clean up the “Starter Solution Templates,” a premium was placed on simple functionality that would be easy for brand new FileMaker users to take apart and customize. Of course, with simplicity elevated to such a high degree, overall usefulness of a database can be quite limited. There is, therefore, a genuine need for a more robust FREE starter solution for FileMaker users; this tool meets those needs. 26.What is new in FM Starting Point 2? With the release of FileMaker 11, we decided to update our FM Starting Point template with a few new features. A few of these include Charting throughout the system, inventory tracking between the Invoice and Products module, and hourly rates in the Timesheets module. You will find a brand new Summary tab in the Projects Module that collects information from the Inventory, Expenses, and Timesheets tables to produce graphs showing the current status and profitability of a project. All this and more you will find in the new version. Once again, FM Starting Point 2 is a FREE solution so you can go ahead and download it as soon as you get FileMaker 11. 27.Will FM Starting Point 1 still be available? A new link has be put onto the FM Starting Point website for downloading our last release, FM Starting Point 1.0v15. 28.Is FileMaker Inc. responsible for this Database? No. FM Starting Point was influenced by the redevelopment of FileMaker’s “Starter Solution Templates” which are already included for FREE with each install of FileMaker Pro. FileMaker Inc. has not underwritten this enhanced solution. FMI staff provided feedback for the included features, and we greatly appreciate their assistance. All quality assurance testing was performed by RCC and not FMI. 29.How is this different than Data4Life? Some FileMaker users are aware of another FREE database offered, called Data4Life. Data4Life is designed for personal use, and not business use. FM Starting Point targeted towards small businesses, work groups, and non-profit organizations. 30.Does FM Starting Point connect to QuickBooks? FM Starting Point can connect to QuickBooks (on Windows only) via the use of third party plug-ins. The Mac version of QuickBooks has some limitations that prevent it from communicating with a Plug-in unless you are a FileMaker “power user” then you might need to get some help from a FileMaker developer with this task. 31.Does FM Starting Point connect to iCal or Address book on a Mac? FM Starting Point can connect to these other applications via the use of third party plug-ins. Unless you are a FileMaker “power user” then you might need to get some help from a FileMaker developer with this task. 32.Is there an instruction manual for FM Starting Point? No. There are several instructional on screen help videos to help get users rolling in the new system. We are also commenting on the scripts and various features within the database template. FM Starting Point is design for new users so it is not too complex. Few people read the manuals anyway. They just hack their way through a product. However, if someone wants to write a manual, and then give it away to everyone, let us know and we’ll post it for you. 33.What are the different kinds of Email I can send from FM Starting Point? Primarily, the email capabilities are within the "contacts" modules, where you can shoot off a myriad of different "canned" emails. These will be plain text emails, since that is what the new built in FileMaker 10 feature supports. Email may be sent through a users email client OR use the new “Direct Send” capability of FileMaker Pro 10. 34.When I am reviewing a specific to-do, from the to-do list, and I select a due date, the Window will flash. Why is this? We had to use a script trigger. When the due date is modified, it selects the to-do list window, and causes a refresh to occur. We did this because FileMaker 10’s new sticky sort capability would frequently re-sort the new to-do item off the visible list (above or below), and would confuse the user when the to-do pop up is closed. 35.In the FileMaker 10 Starter Solutions, there is frequent use of "Type Ahead" aka Clairvoyance. Why is this missing from FM Starting Point? Normally, we added functionality to the system, but not in this case. Type ahead causes a performance drain that is very noticeable for medium sized data sets, when accessed over a Wide Area network or Internet connection. We expect a fair number of people to access FMSP, hosted at their offices, or at a Hosting company, and then accessing the database remotely. These people would be highly disappointed by the huge slow down of FileMaker when using “Type Ahead” features. So to prevent nasty phone calls and flaming emails, we dropped this capability out of FMSP. If you run FMSP as a single user, on your local computer, feel free to turn “Type Ahead” back on. 36.What is FREE SuperContainer Hosted Lite? SuperContainer Hosted Lite is a FREE limited version of SuperContainer that is hosted by 360Works and is built specifically into FM Starting Point. The Lite Hosting Plan includes the following: No limit on number of users within your organization. Maximum of 2 megabytes per file. Limit of 10,000 total items. 250 megabytes total storage. Up to 1 gigabyte of download/upload traffic per month. Thumbnails display at a maximum resolution of 300x300. For use exclusively with the FM Starting Point solution. 37.What is SuperContainer Hosted Pro? SuperContainer Hosted Pro is a more powerful version of SuperContainer that is hosted by 360Works and is built specifically into FM Starting Point. The “Hosted Pro” version includes the following: No limit on number of users within your organization. Unlimited file size, total items, and thumbnail resolution. 20 gigabytes total storage. Up to 20 gigabytes of download/upload traffic per month. For use with any solution, not just Starting Point. Monthly charge of $49 US. 38.What is SuperContainer Enterprise? SuperContainer Enterprise is for an unlimited number of users and access via the web, running on your own in-house FileMaker Server. The Enterprise version includes the following: No limit on number of users within your organization. Accessible only with a Web Viewer in FileMaker Pro, or via a web browser for viewing and uploading files from the web. Unlimited file size, total items, thumbnail resolution (limited only by space on your server). Unlimited total storage (limited only by space on your server). Unlimited download/upload traffic per month (limited only by bandwidth to your server). Supports SSL encryption. For use with any solution, not just Starting Point. One-time charge of $695 US. 39.What is SuperContainer Workgroup? SuperContainer Workgroup is for up to 10 FileMaker users, running on your own in-house FileMaker Server. The Workgroup version includes the following: Up to 10 users within your organization. Accessible only with a Web Viewer in FileMaker Pro (not via the a web browser). Unlimited file size, total items, thumbnail resolution (limited only by space on your server). Unlimited total storage (limited only by space on your server). Unlimited download/upload traffic per month (limited only by bandwidth to your server). Supports SSL encryption. For use with any solution, not just Starting Point. One-time charge of $195 US. 40.Does FileMaker Work on the iPhone and iPad? Yes! The product is called “FileMaker Go,” and can be installed on either the iPhone or iPad, after being purchased from the App Store. You need this software before you can use FM Starting Point on these devices. Once you have FM Go installed, you have the choice of accessing the database as shared from a FileMaker Server, or as shared from a single desktop with peer to peer sharing turned on. Also, for maximum speed, you can email or otherwise transfer FMSP to your iPhone or iPad and have it run on the device locally. 41.How do I download the iPhone or iPad version of FMSP? The iPhone and iPad version of FMSP are all “rolled together” into a single FileMaker file – the same file that is accessed by the desktop copy of FileMaker Pro. All three versions are in a single file. This way, users with different devices can log onto the same database and share data. 42.Did you make some screens designed just for the iPhone or iPad? We did actually develop some screens specific to these devices. Building an interface for a touchscreen device is somewhat different than for a desktop computer with a mouse. For the iPhone, we built out screens that allow user to find, view, edit and add contacts to FMSP. Plus, if you click the contact's phone number, it will actually dial the number and make the call on the iPhone. For the iPad, we took all the screens and functionality of FMSP and duplicated them. Then we weaked these duplicated screens so they have bigger buttons and fields things you need for a touchscreen device. 43.Does FMSP and FileMaker Go on the iPhone work with the camera built into my iPhone? Unfortunately, no: integration with the iPhone's camera is not supported in this initial release of FileMaker Go. 44.Where did the charts go in FMSP on my iPhone and iPad? Why can't I save as PDF or Print? Charting is not yet a supported feature of FileMaker Go. Same for making PDFs and printing. 45.Can Recovery for FileMaker repair my FileMaker Pro database? The effective way to find out if a FileMaker Pro database is recoverable is to try the demo version of Recovery for FileMaker on it. 46.What limitations does the demo version of Recovery for FileMaker have? Demo version recovers limited number of the database rows. The remaining rows will be blank. Full version will restore demo-limited rows as well. 47.I have tried the demo. How do I decide whether to purchase the full version of Recovery for FileMaker? Evaluating the results of demo recovery can help in making the decision. 48. Why is WSDOT using FileMaker Pro for electronic forms? In October 1992, the department started researching and testing different software packages to develop and deploy electronic forms department wide. None of the software provided all of the features initially defined. FileMaker Pro (version 2.0) was chosen, providing the most features, flexibility, and usability within the WSDOT IT infrastructure. 49.After successful recovery of the original database a new .DBF file is created. What is the procedure for transferring data from this temporary file to a database? You should simply import data from the resulting file in .DBF format into a new database. 50.Will FMTouch support the Apple iPad? Yes, we have already tested and written the new code for FMTouch and the Apple iPad. 51.Will FMTouch work with FileMaker 11? Yes, FMTouch works with FileMaker 11. There was an update to a new plug-in for FMTouch FileMaker 11 support. If you are using FileMaker 11, please make sure you download the new plug-in. 52.Will FMTouch work on both the iPhone and the iPod iTouch? Yes, FMTouch works with both the iPhone and the iPod iTouch. 53.Do I have to be connected to the internet? No, you do not have to be connected to the internet. FMTouch runs locally on your mobile device as a local application. You can sync FMTouch while you have FileMaker running with the sync plug-in - sync once an hour, once a day on your own schedule. 54.Will Runtime solutions run on FMTouch? Yes, runtime solutions work on FMTouch. 55.What versions of FileMaker are supported? FMTouch works with FileMaker version 8-11 and beyond. We will not be releasing versions for FileMaker 7 and below. 56.Do I have to design special layouts or databases? You should make database layouts that would render effectively on the iPhone. Many developers are simply adding iPhone specific layouts. Smaller databases are also faster and take less time to load. 57.Is FMTouch Relational? Yes, and you will find that the ability to use and edit portals is great bonus. You have the ability to have many related tables and many related databases all talking to one another. 58.Can I have multiple layouts? Yes, you can have multiple layouts, and you can easily deselect the layouts that you don't want to display. 59.Can I do scripting and calculations? Scripting and Calculations are supported. 60.Are repeating fields supported? Yes, repeating fields are now supported as are merge fields. As of version 1.23. Note: Repeating fields require FileMaker 9+. 61.Will FMTouch work for both Windows and Macintosh? Yes, FMTouch works equally well with both Macintosh and Windows OS. 62.What versions of FileMaker does FMTouch support? Initially you will need FileMaker Advanced to create your DDR. Once this is generated, FMTouch can be used with FileMaker Pro 8-11. Note: 8.5 is needed for webviewer support. 63.Why do I need FileMaker Advanced? FileMaker Advanced enables you to generate your database DDR. This information is needed to help FMTouch create your database. Once the DDR is created you can use regular FileMaker Pro 8-10. 64.Will enterprise or developer licenses be available? Yes, enterprise licensing is available. 65.I am having problems syncing with my Mac? If you are having problems syncing 99% of the time it is because of a few things. You have a firewall set up - and the correct port is not open. You are trying to sync through the USB cable. You do not have the plug-in correctly installed. 66.I am having problems syncing with my PC? If you are having problems syncing 99% of the time it is because of a few things. You have a firewall set up - and the correct port is not open. You are trying to sync through the USB cable. You do not have the plug-in correctly installed. 67.Do you have an online Forum? Yes 68.Are container fields supported? Yes, beginning with version 1.30 we added container field support. 69.Can I sync to FileMaker Server on Windows and MaC? Yes, check out the user’s guide server section you can sync to both Mac and PC Server with FileMaker Server 9, 10 and 11. 70.What version of FileMaker Pro is the department using? The department is currently using FileMaker Pro 11.0v3. FileMaker Pro is a Level Playing Field software and is installed on all WSDOT workstations. For our downloadable eForms, we are using version 11.0v3 of the FileMaker Pro runtime engine. FileMaker Questions and Answers Pdf Download Read the full article
0 notes
Text
Kaspersky Coupon Code
This product will in addition protect your computer from other types of viruses and the best thing is that a free version Kaspersky promo code 2018 is available. With this kind of email, customers will be ensured that all information they have provided are secured and protected within the well-established website of e-commerce businesses. They are willing to spend much to enjoy their hobby. With the foreclosures and job losses rampant, clipping coupons no choice but a necessity. But a double-sided ID card can give more security to your company and is better for a bigger company or corporation Kaspersky promo that needs superior security. In order to staying Tuscany farmhouse rentals are scattered all over the region and available in different sizes to accommodate all whether smallest of families or up to the largest of holidaying groups even staying in a hotel in one of these cities and towns will only give you the very tip of what Tuscan life is really like. it can be bone, muscle or organ weight) and some diets make you lose muscles instead of Kaspersky discount coupon body fat (will be discussed in my later articles) We must define that weight loss is about fat loss first. When your goals are to create a successful online business, choosing a reliable Kaspersky promo 2018 web host Kaspersky coupon code is imperative. Although this Kaspersky coupon weight loss clinic in Bangalore may already be convenient for locals, Dr. Tailor galli as it is popularly known is host to at least fifty tailoring shops!A.A.Hussain is probably the oldest bookshop in all of Hyderabad..F.D.Khan was the one stop shop for clothes and furnishings!!! That is how you build a tremendous level of rapport Kaspersky discount 2018 as well as trust. Consumers can avail discounts on various products sold in super markets by showing coupons in the billing counter. By choosing either of these two options, you get to enjoy access to more resources and advantages instead of experiencing limited features, facilities and flexibilities. Getting a gaudy web page may appeal to several persons, but not all will be impressed with flare and shimmer. Hackers are usually expert programmers who usually see hacking as a real life Kaspersky promo code application of their skills. In 2005, Anthony began his post doctorate degree in Internal Medicine Kaspersky coupon 2018 at the Russian University. And they are very feature rich and useful jam packed with features. There are also honest adware products available, which are not installed without your consent. No, watermelon is not allowed on the HCG Kaspersky discount coupon 2018 Diet protocol but it is certainly the lesser of two evils. The constant attempt by the international community to delegitimize the Jewish state of Israel by viewing her as a rogue Kaspersky coupon code 2018 fascist-apartheid state does not promote peace, but more hostility. These companies are making Kaspersky discount handsome income to satisfy their shareholders and pay high salary to their employees. Any attachment that contains an executable file (*.exe) can contain a Trojan or other virus. Cyber-stalkers are much like real life stalkers except that they have the advantage of anonymity and fading into the shadows much thanks to all the advantages the Internet offers. The spreadsheet columns may be labeled: category, business name, contact name, email, website, blog, address (as in street address), city, state, zip code/country, telephone, mobile phone, fax, project manager, and comments. Go ahead, run this thing through its courses, you'll never need another lighter. This objective identifies and resolves concurrency problems, collect and analyze troubleshooting data and audit SQL Server instances. These symptoms convey that there is something amiss in one's system. Build a record document of your readings and than average each week's results. Be it problems like regular backup, security, performance boosters or even managing e-mail accounts, all of these become simple when you have engaged the best web hosting company to work for you. CoQ10 is known to make the body generate elastin and collagen. There is a huge flow of data to be managed and you need a system that makes sure that the management is not marred by errors, which would otherwise lead to mismanagement and give rise to several discrepancies. The corrupted OE folders can be repaired using commercial Email Recovery solutions that are exclusively built to repair such OE folders. Some ingredient labels on packaged foods sound more like a college chemistry class than anything we should be eating. Duplicate Finder finds and deletes files that are duplicated in your system. The company's operator was quick to respond to my call. Based on Cisco PIX Firewall technology, the Cisco Firewall Services Module offers large enterprises and service providers the security that is unmatched, reliable and guarantees performance enhancement and improvement. It was not significantly correlated with the physical function, role function/physical, or pain subscales. Bitdefender Mobile Security keeps a log of all important actions, status changes and other critical messages related to its activity.
1 note
·
View note
Text
Login Authentication with Flask
In today’s blog, we will learn how to build a login for different users defined in the database and a Web app with Python using Flask.

$ pip install Flask
Indeed, make a file Hello.py
from flask import Flask
app = Flask(__name__)
@app.route(“/”)
def index():
return “Hello World!”
if __name__ == “__main__”:
app.run(host=’0.0.0.0', port=8080)
Finally, run the app using this command:
$ python Hello.py
Open this URL http://localhost:8080/ in your web browser, and “Hello World!” should appear.
Building a Flask Login Screen
Create this Python file and save it as app.py:
from flask import Flask
from flask import Flask, flash, redirect, render_template, request, session, abort
import os
app = Flask(__name__)
@app.route(‘/’)
def home():
if not session.get(‘logged_in’):
return render_template(‘login.html’)
else:
return “Hello User!”
@app.route(‘/login’, methods=[’POST’])
def do_admin_login():
if request.form[’password’] == ‘password’ and request.form[’username’] == ‘admin’:
session[’logged_in’] = True
else:
flash(‘wrong credentials!’)
return home()
if __name__ == “__main__”:
app.secret_key = os.urandom(12)
app.run(debug=True,host=’0.0.0.0', port=8080)
Hence, we have created two routes here:
@app.route(‘/’)
@app.route(‘/login’, methods=[’POST’])
We make the directory /templates/. Make a file /templates/login.html with this code:
{% block body %};
{% if session[’logged_in’] %};
You’re logged in already!
{% else %};
<form action="/login" method="POST">
<input type="username" name="username" placeholder="Username">
<input type="password" name="password" placeholder="Password">
<input type="submit" value="Log in">
</form>
{% endif %};
{% endblock %}
{% endraw %};
Run the command:
$ python Hello.py
Open http://localhost:8080/ in your web browser, and show the login screen.
Make It Look Amazing
We make the directory/static with the file style.css for a better look.
* {
box-sizing: border-box;
}
*:focus {
outline: none;
}
body {
font-family: Arial;
background-color: #3498DB;
padding: 50px;
}
.login {
margin: 20px auto;
width: 300px;
}
.login-screen {
background-color: #FFF;
padding: 20px;
border-radius: 5px
}
.app-title {
text-align: center;
color: #777;
}
.login-form {
text-align: center;
}
.control-group {
margin-bottom: 10px;
}
input {
text-align: center;
background-color: #ECF0F1;
border: 2px solid transparent;
border-radius: 3px;
font-size: 16px;
font-weight: 200;
padding: 10px 0;
width: 250px;
transition: border .5s;
}
input:focus {
border: 2px solid #3498DB;
box-shadow: none;
}
.btn {
border: 2px solid transparent;
background: #3498DB;
color: #ffffff;
font-size: 16px;
line-height: 25px;
padding: 10px 0;
text-decoration: none;
text-shadow: none;
border-radius: 3px;
box-shadow: none;
transition: 0.25s;
display: block;
width: 250px;
margin: 0 auto;
}
.btn:hover {
background-color: #2980B9;
}
.login-link {
font-size: 12px;
color: #444;
display: block;
margin-top: 12px;
}
Modify the login.html template as:
<link rel="stylesheet" href="/static/style.css" type="text/css">
{% block body %}
<form action="/login" method="POST">
<div class="login">
<div class="login-screen">
<div class="app-title">
<h1>Login</h1>
</div>
<div class="login-form">
<div class="control-group">
<input type="text" class="login-field" value="" placeholder="username"
name=”username”>
<label class="login-field-icon fui-user" for="login-name"></label></div>
<div class="control-group">
<input type="password" class="login-field" value="" placeholder="password"
name=”password”>
<label class="login-field-icon fui-lock" for="login-pass"></label></div>
<input type="submit" value="Log in" class="btn btn-primary btn-large btn-block">
</div>
</div>
</div>
</form>
{% endblock %}
Please restart the application.
Logout
As you may have seen, there is no logout button or functionality. Creating that is very easy. The solution proposed below is only one of the many solutions. Subsequently, we create a new route /logout which directs to the function logout(). This function clears the session variable and returns to the login screen.
@app.route(“/logout”)
def logout():
session[’logged_in’] = False
return home()
The full code is shown below:
from flask import Flask
from flask import Flask, flash, redirect, render_template, request, session, abort
import os
app = Flask(__name__)
@app.route(‘/’)
def home():
if not session.get(‘logged_in’):
return render_template(‘login.html’)
else:
return “Hello user! <a href="/logout">Logout</a>“
@app.route(‘/login’, methods=[’POST’])
def do_admin_login():
if request.form[’password’] == ‘password’ and request.form[’username’] == ‘admin’:
session[’logged_in’] = True
else:
flash(‘wrong password!’)
return home()
@app.route(“/logout”)
def logout():
session[’logged_in’] = False
return home()
if __name__ == “__main__”:
app.secret_key = os.urandom(12)
app.run(debug=True,host=’0.0.0.0', port=8080)
Connecting a Database
If you want a multi-user login system, you should add a database layer to the application. Flask does not have out of the box database support. Moreover, you have to use a third-party library if you want database support. In this tutorial, we will use SqlAlchemy. If you do not have that installed type:
$ pip install Flask-SqlAlchemy
SQLAlchemy is an SQL toolkit and object-relational mapper (ORM) for the Python programming language. Also, it has support for MySQL, Microsoft SQL Server, and many more relational database management systems. If all of these terms are unfamiliar to you, keep reading.
Create the file tabledef.py:
from sqlalchemy import *
from sqlalchemy import create_engine, ForeignKey
from sqlalchemy import Column, Date, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship, backref
engine = create_engine(‘sqlite:///tutorial.db’, echo=True)
Base = declarative_base()
class User(Base):
“”””””
__tablename__ = “users”
id = Column(Integer, primary_key=True)
username = Column(String)
password = Column(String)
#———————————————————————————————————
def __init__(self, username, password):
“”””””
self.username = username
self.password = password
# create tables
Base.metadata.create_all(engine)
Execute it with:
python tabledef.py
Hence, this file will create the database structure. Inside the directory, you will find a file called tutorial.db. Therefore, create a file called demo.py which will contain this code:
import datetime
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from tabledef import *
engine = create_engine(‘sqlite:///tutorial.db’, echo=True)
# create a Session
Session = sessionmaker(bind=engine)
session = Session()
user = User(“admin”,”password”)
session.add(user)
user = User(“python”,”python”)
session.add(user)
user = User(“jumpiness”,”python”)
session.add(user)
# commit the record the database
session.commit()
session.commit()
$ python demo.py
This will put dummy data into your database. Finally, we update our app.py
Validating the Login Credentials with SqlAlchemy
The next step is to write the function that validates the user and password that exist in the database. Hence, using SqlAlchemy, we can do this (dummy/pseudo-code):
@app.route(‘/test’)
def test():
POST_USERNAME = “python”
POST_PASSWORD = “python”
Session = sessionmaker(bind=engine)
s = Session()
query = s.query(User).filter(User.username.in_([POST_USERNAME]),
User.password.in_([POST_PASSWORD]) )
result = query.first()
if result:
return “Object found”
else:
return “Object not found “ + POST_USERNAME + “ “ + POST_PASSWORD
Also, we use SqlAlchemys Object Relational Mapping (ORM). Undoubtedly, we map the objects to relational database tables and vice versa.
from flask import Flask
from flask import Flask, flash, redirect, render_template, request, session, abort
import os
from sqlalchemy.orm import sessionmaker
from tabledef import *
engine = create_engine(‘sqlite:///tutorial.db’, echo=True)
app = Flask(__name__)
@app.route(‘/’)
def home():
if not session.get(‘logged_in’):
return render_template(‘login.html’)
else:
return “Hello User! <a href="/logout">Logout</a>“
@app.route(‘/login’, methods=[’POST’])
def do_admin_login():
POST_USERNAME = str(request.form[’username’])
POST_PASSWORD = str(request.form[’password’])
Session = sessionmaker(bind=engine)
s = Session()
query = s.query(User).filter(User.username.in_([POST_USERNAME]),
User.password.in_([POST_PASSWORD]) )
result = query.first()
if result:
session[’logged_in’] = True
else:
flash(‘wrong password!’)
return home()
@app.route(“/logout”)
def logout():
session[’logged_in’] = False
return home()
if __name__ == “__main__”:
app.secret_key = os.urandom(12)
app.run(debug=True,host=’0.0.0.0', port=8080)
Finally, you can now login with different users defined in the database.
Please feel free to share your feedback and comments in the section below. To know more about our services, please visit Loginworks Softwares Inc.
0 notes
Text
MyDumper, MyLoader and My Experience of migrating to AWS RDS

Ref: https://tinyurl.com/yymj43hn How did we migrate large MySQL databases from 3 different DB servers of total size 1TB to a single AWS RDS instance using mydumper? Migration of database involves 3 parts: Dumping the data from the source DBRestoring the data to target DBReplication between source and target DBs Our customer had decided migration from Azure to AWS and as part of that needed to migrate about 35 databases running out of 3 different DB servers to a single RDS instance. RDS currently doesn’t support multi-source replication so we decided that we only set up replication from the largest DB and use dump and restore method for other 2 DB servers during the cutover period.
Setting up RDS Instance
In order to test the application end to end, and during the testing we need to change the data on the DB and that might cause issues in the DB replication process so we decided to set up a separate staging stack for testing purpose alone. Initially, we used native mysql tools like mysqldump, but found that these tools generate a single dump file for the whole database and some of our databases are of a size more than 400GB. We have some of the triggers and views using DEFINER=`root`@`localhost` but RDS doesn’t have root user so we need to either update the DEFINER or remove it according to this documentation. We found it really challenging to update such huge dump files so then upon a suggestion from my friend Bhuvanesh, we decided to try out the mydumper tool. Setting up a server for mydumper We could have run mydumper from the source DB server itself, but we decided to run it in a separate server as it will reduce the load on the source DB server during the dumping and restoration phases. Now let us see how to install mydumper. # Installers: https://github.com/maxbube/mydumper/releases# You may choose to take latest available release here. sudo yum install https://github.com/maxbube/mydumper/releases/download/v0.9.5/mydumper-0.9.5-2.el7.x86_64.rpm# Now we should have both mydumper and myloader commands installed on the serverDumping data from the source MyDumper tool extracts the DB data in parallel and creates separate files from schemas and tables data so it is easy to modify them before restoring them. You will need give at least SELECT and RELOAD permissions to the mydumper user. # Remember to run the following commands in the screen as it is a long running process.# Example1: Following will dump data from only DbName1 and DbName2 time \ mydumper \ --host= \ --user= \ --password= \ --outputdir=/db-dump/mydumper-files/ \ --rows=50000 \ -G -E -R \ --compress \ --build-empty-files \ --threads=16 \ --compress-protocol \ --regex '^(DbName1\.|DbName2\.)' \ -L //mydumper-logs.txt# Example2: Following will dump data from all databases except DbName1 and DbName2 time \ mydumper \ --host= \ --user= \ --password= \ --outputdir=/db-dump/mydumper-files/ \ --rows=50000 \ -G -E -R \ --compress \ --build-empty-files \ --threads=16 \ --compress-protocol \ --regex '^(?!(mysql|test|performance_schema|information_schema|DbName1|DbName2))' \ -L //mydumper-logs.txt Please decide the number of threads based on the CPU cores of the DB server and server load. For more information on various mydumper options, please read this. Also incase you want to use negative filters (Example2) for selecting databases to be dumped then please avoid default database such as (mysql, information_schema, performance_schema and test) It is important to measure the time it takes to take the dump as it can be used to plan the migration for production setup so here I have used thetime command to measure it. Also, please check if there any errors present in the //mydumper-logs.txt before restoring the data to RDS instance. Once the data is extracted from source DB, we need to clean up before loading into RDS. We need to remove the definers from schema files. cd # Check if any schema files are using DEFINER, as files are compressed, we need to use zgrep to search zgrep DEFINER *schema*# Uncompress the schema files find . -name "*schema*" | xargs gunzip # Remove definers using sed find . -name "*schema*" | xargs sed -i -e 's/DEFINER=`*`@`localhost`//g' find . -name "*schema*" | xargs sed -i -e 's/SQL SECURITY DEFINER//g'# Compress again find . -name "*schema*" | xargs gzipRestoring data to RDS instance Now the data is ready to restore, so let us prepare RDS MySQL instance for faster restoration. Create a new parameter group with the following parameters and attach to the RDS instance. transaction-isolation=READ-COMMITTED innodb_log_buffer_size = 256M innodb_log_file_size = 1G innodb_buffer_pool_size = {DBInstanceClassMemory*4/5} innodb_io_capacity = 2000 innodb_io_capacity_max = 3000 innodb_read_io_threads = 8 innodb_write_io_threads = 16 innodb_purge_threads = 2 innodb_buffer_pool_instances = 16 innodb_flush_log_at_trx_commit = 0 max_allowed_packet = 900MB time_zone = Also you can initally restore to a bigger instance to accheive faster restoration and later you can change to the desired the instance type. # Remember to run the following commands in the screen as it is a long running process.time myloader --host= --user= --password= --directory= --queries-per-transaction=50000 --threads=8 --compress-protocol --verbose=3 -e 2> Choose the number of threads according to the number of CPU cores of the RDS instance. Don’t forget to redirect STDERR to file (2>) as it will be useful to track the progress. Monitoring the progress of loader: it is a very long running process so it is very important to check the progress regularly. Schema files get loaded very quickly so we are checking the progress of data files only using the following commands. # Following gives approximate number of data files already restored grep restoring |grep Thread|grep -v schema|wc -l # Following gives total number of data files to be restored ls -l |grep -v schema|wc -l # Following gives information about errors grep -i error Verification of data on RDS against the source DB It is a very important step to make sure that data is restored correctly to target DB. We need to execute the following commands on the source and target DB servers and we should see the same results. # Check the databases show databases;# Check the tables count in each database SELECT table_schema, COUNT(*) as tables_count FROM information_schema.tables group by table_schema;# Check the triggers count in each database select trigger_schema, COUNT(*) as triggers_count from information_schema.triggers group by trigger_schema;# Check the routines count in each database select routine_schema, COUNT(*) as routines_count from information_schema.routines group by routine_schema;# Check the events count in each database select event_schema, COUNT(*) as events_count from information_schema.events group by event_schema;# Check the rows count of all tables from a database. Create the following procedure: # Run the following in both DB servers and compare for each database. call COUNT_ROWS_COUNTS_BY_TABLE('DbName1'); Make sure that all the commands are executed on both source and target DB servers and you should see same results. Once everything is good, take a snapshot before proceeding any further. Change DB parameter group to a new parameter group according to your current source configuration. Replication Now that data is restored let us now setup replication. Before we begin the replication process, we need to make sure that bin-logs are enabled in source DB and time_zone is the same on both servers. We can use the current server should be as staging DB for the end to end application testing and we need to create one more RDS instance from snapshot to set up the replication from source DB and we shouldn’t make any data modifications on this new RDS instance and this should be used as production DB in the applications. # Get bin-log info of source DB from mydumber metadata file cat /metadata# It should show something like below: SHOW MASTER STATUS: Log: mysql-bin-changelog.000856 # This is bin log path Pos: 154 # This is bin log postion# Set external master CALL mysql.rds_set_external_master( '', 3306, '', '', '', , 0);# Start the replication CALL mysql.rds_start_replication;# Check the replication status show slave status \G;# Make sure that there are no replication errors and Seconds_Behind_Master should reduce to 0. Once the replication is completed, please verify the data again and plan for application migration. Make sure that you don’t directly modify the data and on DB server till the writes are completely stop in source DB and applications are now pointing to the target DB server. Also set innodb_flush_log_at_trx_commit = 1 before switching applications as it provides better ACID compliance. Conclusion We have learned how to use mydumper and myloader tools for migration of MySQL DB to RDS instance. I hope this blog is useful for you to handle your next DB migration smoothly and confidently. In case you have any questions, please free to get in touch with me. Read the full article
0 notes
Text
Best of Google Database
New Post has been published on https://is.gd/42EFDP
Best of Google Database

Google Cloud Database By
Google provides 2 different types of databases i.e google database
Relational
No-SQL/ Non-relational
Google Relational Database
In this google have 2 different products .
Cloud SQL
Cloud Spanner
Common uses of this relational database are like below
Compatibility
Transactions
Complex queries
Joins
Google No-SQL/ Non-relational Database
In this google provide 4 different types of product or databases
Cloud BigTable
Cloud Firestore
Firebase Realtime database
Cloud Memorystore
Common uses cases for this is like below
TimeSeries data
Streaming
Mobile
IoT
Offline sync
Caching
Low latency
Google relational Databases
Cloud SQL
It is Google fully managed service that makes easy to setup MySQL, PostgreSQL and SQL server databases in the cloud.
Cloud SQL is a fully-managed database service that makes easy to maintain, Manage and administer database servers on the cloud.
The Cloud SQL offers high performance, high availability, scalability, and convenience.
This Cloud SQL takes care of managing database tasks that means you only need to focus on developing an application.
Google manage your database so we can focus on our development task. Cloud SQL is perfect for a wide variety of applications like geo-hospital applications, CRM tasks, an eCommerce application, and WordPress sites also.
Features of Cloud SQL
Focus on our application: managing database is taken care of by google so we can focus on only application development.
Simple and fully managed: it is easy to use and it automates all backups, replication, and patches and updates are having 99.955 of availability anywhere in the world. The main feature of Cloud SQL is automatic fail-over provides isolation from many types of infrastructure hardware and software. It automatically increases our storage capacity if our database grows.
Performance and scalability: it provides high performance and scalability up to 30 TB of storage capacity and 60,000 IOPS and 416Gb of ram per instance. Having 0 downtimes.
Reliability and Security: As it is google so security issue is automatically resolved but the data is automatically encrypted and Cloud SQL is SSAE 16, ISO 27001 and PCI DSS v3.0 compliant and supports HIPAA compliance so you can store patient data also in Cloud SQL.
Cloud SQL Pricing:
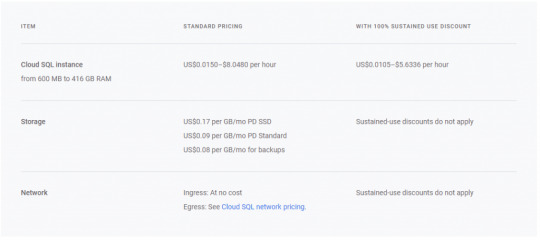
Google Cloud SQL Pricing -Image From Official Google Site
Cloud Spanner
It is a fully managed scalable relational database service for regional and global application data.
Cloud spanner is the first database who takes advantage of relational database and non-relational database.
It is enterprise-grade, globally distributed and strongly consistent database service which built for cloud and it combines benefits of relational and non-relational horizontal scale.
By using this combination you can deliver high-performance transactions and strong consistency across rows, regions and continent.
Cloud spanner have high availability of 99.999% it has no planned downtime and enterprise-grade security.
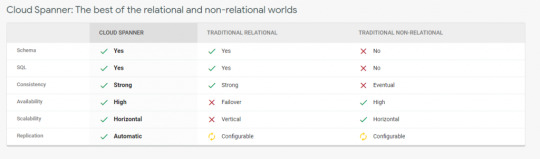
Google Cloud Spanner Features:- Image from official google site
Features of Cloud Spanner:
Scale+SQL:– in today’s world most database fail to deliver consistency and scale but at their, Cloud Spanner comes what it means? It means Cloud Spanner provides you advantage of relational database structure and not relational database scale and performance feature with external consistency across rows, regions and continents.
Cloud spanner scales it horizontally and serves data with low latency and along with that it maintains transactional consistency and industry-leading availability means 99.999%. It can scale up arbitrarily large database size means what It provides it avoids rewrites and migrations.
Less Task– it means google manage your database maintenance instead of you. If you want to replicate your database in a few clicks only you can do this.
Launch faster: it Is relational database with full relational semantics and handles schema changes it has no downtime. This database is fully tested by google itself for its mission-critical applications.
Security and Control:- encryption is by-default and audit logging, custom manufactured hardware and google owned and controlled global network.
Multi-language support means support c#, Go, Java, Php, Python and Ruby.
Pricing for Cloud Spanner:
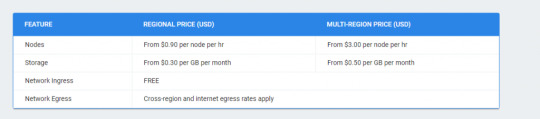
Google Cloud Spanner Pricing – Image from official google site
Non-relational Database by Google
BigTable
This Bigtable database is created by Google, it is compressed, high performance and proprietary data storage system which is created by Google and is built on top of google file system, LevelDB and other few google technologies.
This database development is starting in 2004 and now it is widely used by google like web indexing,google maps, google book search and google earth, blogger, google code, youtube.
The google is designed its own database because they need high scalability and better control over performance.
Bigtable is like wide column store. It maps 2 arbitrary string values which are row key and column key and timestamp for 3-dimensional mappings into an arbitrary byte array.
Remember it is not a relational database and it is more kind of sparse, distributed multi-dimensional sorted map.
BigTable is designed to scale in petabyte range across hundreds and thousands of machines and also to add additional commodity hardware machines is very easy in this and there is no need for reconfiguration.
Ex.
Suppose google copy of web can be stored in BigTable where row key is what is domain URL and Bigtable columns describe various properties of a web page and every column holds different versions of webpage.
He columns can have different timestamped versions of describing different copies of web page and it stores timestamp page when google retrieves that page or fetch that page.
Every cell in Bigtable has zero or timestamped versions of data.
In short, Bigtable is like a map-reduce worker pool.
A google cloud Bigtable is a petabyte-scale, fully managed and it is NoSQL database service provided by Google and it is mainly for large analytical and operational workloads.
Features Of Google Cloud BigTable:
It is having low latency and massively scalable NoSQL. It is mainly ideal for ad tech, fin-tech, and IoT. By using replication it provides high availability, higher durability, and resilience in the face of zonal failures. It is designed for storage for machine learning applications.
Fast and Performant
Seamless scaling and replication
Simple and integrated- it means it integrates easily with popular big data tools like Hadoop, cloud dataflow and Cloud Dataproc also support HBase API.
Fully Managed- means google manage the database and configuration related task and developer needs only focus on development.
Charges for BigTable- server: us-central
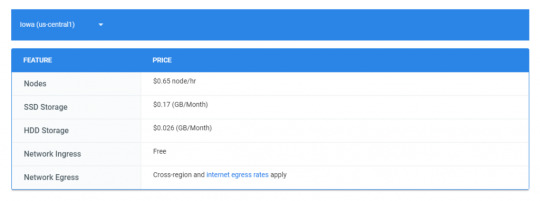
Google Bigtable Pricing- Image from official google site
Cloud Firestore
It is mainly serverless. Cloud Firestore is fast and serverless and fully managed and cloud-native NoSQL. It is document database which simplifies our storing data, syncing data and querying data from your IoT devices, mobile devices or web at global scale. It also provides offline support and its security features and integration with firebase and googles cloud platform.
Cloud Firestore features are below:
You can increase your development velocity with serverless: Is a cloud-native database and Cloud Firestore provides automatic scaling solution and it takes that advantage from googles powerful infrastructure. It provides live synchronization and offline support and also supports ACID properties for hundreds of documents and collections. From your mobile you can directly talk with cloud Firestore.
Synchronization of data on different devices: Suppose client use the different platform of your app means mobile, tab, desktop and when it do changes one device it will automatically reflected other devices with refresh or firing explicit query from user. Also if your user does offline changes and after while he comes back these changes sync when he is online and reflected across.
Simple and effortless: Is robust client libraries. By using this you can easily update and receive new data. You can scale easily as your app grows.
Enterprise-grade and scalable NoSQL: It is fast and managed NoSQL cloud database. It scales by using google infrastructure with horizontal scaling. It has built-in security access controls for data and simple data validations.
Pricing of Google Cloud Firestore:
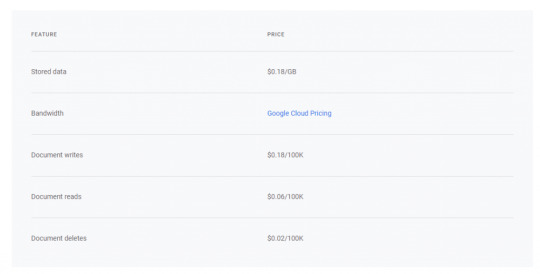
Google Cloud Firestore Pricing – Image from official googles site
FireBase
By tag line, it stores and sync data real-time. It stores data in JSON format. Different devices can access the same database.
It is also optimized for offline use and is having strong user-based security. This is also cloud-hosted database with a NoSQL database. It syncs In real-time across all clients and remains available if you go offline.
Capabilities of FireBase:
Realtime
Offline
Accessible from client devices
Scales across multiple databases: Means if you have blaze plan and your app go grow very fast and you need to scale your database so you can do in same firebase project with multiple database instances.
Firebase allows you to access the database from client-side code directly. Data is persisted locally and offline also in this realtime events are continuous fires by using this end-user experiences realtime responsiveness. When the client disconnected data is stored locally and when he comes online then it syncs with local data changes and merges automatically conflicts.
Firebase designed only to allow operations that can execute quickly.
Pricing of Firebase
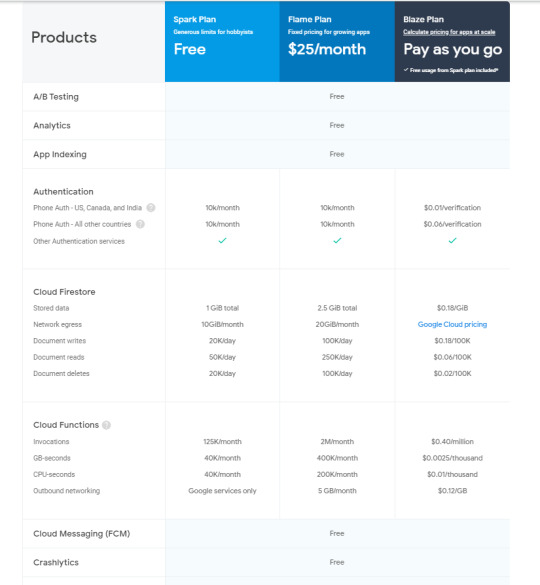
Google Firebase pricing-image from official google site
Cloud MemoryStores
This is an in-memory data store service for Redis. It is fully managed in-memory data store service which is built for scalability, security and highly available infrastructure which is managed by Google.
It is very much compatible with Redis protocol so it allows easy migration with zero code changes. When you want to store your app data in sub-millisecond then you can use this.
Features of Cloud memory stores:
It has the power of open-source Redis database and googles provide high availability, failure and monitoring is done by google
Scale as per your need:- by using this sub-millisecond latency and throughput achieve. It supports instances up to 300 Gb and network throughput 12 Gbps.
It is highly available- 99.9% availability
Google grade security
This is fully compatible with Redis protocol so your open-source Redis move to cloud memory store without any code change by using simple import and export feature.
Price for Cloud MemoryStore:
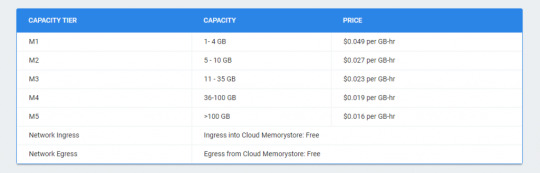
Google Cloud Memorystore price – image from official site of google
0 notes