#Serializable Java object
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr posted its first advertisements in May 2012 and subsequently earned $13M in revenue.
Text
How do you handle session management in Java for web applications?

1. Intro to Java Session Management
So, how do you manage sessions in Java for web apps? This is a key question for developers who want to create safe and scalable applications. Session management is all about keeping track of a user's activity on a web app over time. Java has built-in tools for this using HttpSession, cookies, and URL rewriting. Learning how to handle sessions well is an important skill, and taking a Java course in Coimbatore can provide you with hands-on experience. Whether you're just starting out or looking to be a full-stack developer, getting the hang of session concepts is essential for building secure and efficient apps.
2. Understanding HttpSession in Java
So, what about HttpSession? It’s the go-to API for managing sessions in Java. It keeps track of a user's info across several HTTP requests, created by the servlet container. You can access it using request.getSession(). With it, you can store user-specific data like login details or shopping cart items. If you enroll in Java training in Coimbatore, you will learn to create and manage sessions the right way. HttpSession also has methods to end sessions and track them, making it a key part of Java web development.
3. Session Tracking Techniques
When it comes to tracking sessions, there are some common methods: cookies, URL rewriting, and hidden form fields. Cookies are small bits of data saved on the client side, while URL rewriting adds session IDs to URLs. Hidden fields are less used but are still an option. These methods are thoroughly covered in a Java Full Stack Developer Course in Coimbatore. Knowing these options helps you pick the right one for your project. Each method has its benefits based on your app's security and scalability needs.
4. Importance of Session Timeout
Managing session timeout is super important for security and user experience. You can set up timeouts in the web.xml file or by using session.setMaxInactiveInterval(). This helps avoid unused sessions from taking up server resources and lowers the risk of hijacking. Sessions automatically end after a certain time without activity. In a Java course in Coimbatore, you’ll learn how to set timeout values that fit your app's needs. Proper timeout handling is part of building secure Java applications.
5. Secure Session Management Practices
How do you ensure session management is secure in your Java web applications? Always use HTTPS, create new session IDs when a user logs in, and end sessions when they log out. Avoid keeping sensitive info in sessions. Developers taking Java training in Coimbatore learn to apply these practices in real-life projects. Good session management isn't just about saving data; it's about protecting it, which helps safeguard against threats like session fixation.
6. Storing Complex Data in Sessions
When it comes to more complex data, Java sessions can handle that too. You can store objects using session.setAttribute(), which is great for keeping user profiles and cart items. Just remember that the objects need to be serializable and avoid making the session too big. Practical lessons in a Java Full Stack Developer Course in Coimbatore often touch on these points. Good data storage practices can improve performance and keep your code clean.
7. Session Persistence and Scalability
In cases where applications are spread across multiple servers, you have to think about sharing sessions. This can be done with persistent sessions or clustering. Tools like Redis and Memcached help manage state across servers. These ideas are often covered in advanced modules of Java courses in Coimbatore. Learning about session replication and load balancing is key to scaling your app while keeping the state intact.
8. Invalidating and Cleaning Sessions
Another important part of session management is cleaning up. Properly ending sessions is crucial. You can use session.invalidate() when a user logs out to terminate a session. Also, make sure to remove unnecessary attributes to save memory. Good session cleanup is important to prevent memory leaks and keep your app running smoothly. These topics are usually explained in Java training in Coimbatore, teaching students how to manage sessions responsibly.
9. Real-world Applications of Session Management
Understanding the theory is just one part. How does session management play out in the real world? Examples include e-commerce carts, user logins, and personalized dashboards. Sessions are essential for adding a personal touch. The Java Full Stack Developer Course in Coimbatore includes practical projects where session management is used in real web apps. Learning through practical examples helps solidify the concept and prepares developers for actual job roles.
10. Conclusion with Career Opportunities
Getting a handle on session management in Java can really open up job opportunities in backend or full-stack roles. With a solid grasp of HttpSession, tracking methods, and security measures, you'll be able to build secure applications. Whether you’re taking a Java course in Coimbatore or pursuing a full-stack course, this is a key topic you shouldn't overlook. At Xplore IT Corp, we focus on making sure our students are ready for the industry with practical session handling skills and more.
FAQs
1. What’s a session in Java web applications?
A session tracks a single user's activity with a web app over multiple requests and keeps user-specific info.
2. How do I create a session in Java?
You can create one using request.getSession() in servlet-based apps.
3. How do I expire a session in Java?
Use session.invalidate() to end it or set a timeout with setMaxInactiveInterval().
4. What are the options other than HttpSession?
You can use cookies, URL rewriting, hidden fields, or client-side storage depending on what you need.
5. Why is secure session management important?
To protect against threats like session hijacking and to keep user data safe.
#ava servlet session#Java web security#Java session timeout#Session tracking in Java#Cookies in Java#URL rewriting in Java#HttpSession methods#Java EE sessions#Serializable Java object#Java backend development
0 notes
Text
JAC444 Workshops 4 & 5
This assignment lets you practice concepts such as Object Serialization, and Swing (or Java FX) GUI. In this assignment, you will be working with some objects of a Student class (which should be serializable.) This class has fields such as stdID (int), firstName (String), lastName (String), and courses (an array or preferably an ArrayList which contains the names of the courses the student…
0 notes
Text
Understanding Serialization in Java: A Comprehensive Guide
Serialization in Java is a fundamental concept that allows objects to be converted into a byte stream, enabling them to be easily stored, transmitted, or reconstructed later. This mechanism plays a crucial role in various scenarios such as network communication, persistence of object state, and distributed computing. In this article, we'll explore what serialization is, how it works in Java, its advantages, and some best practices to follow.
What is Serialization?
Serialization is the process of converting an object into a stream of bytes, which can then be stored in a file or sent over a network. This serialized form contains the object's data along with information about its type and structure. Deserialization is the reverse process where the byte stream is converted back into an object. Java provides built-in mechanisms for both serialization and deserialization through the java.io.Serializable interface.
How Serialization Works in Java
To enable serialization for a class in Java, it must implement the Serializable interface. This interface acts as a marker, indicating to the Java runtime that instances of the class can be serialized. Here's a basic example:
javaCopy code
import java.io.Serializable; class MyClass implements Serializable { // class members and methods }
Once a class implements Serializable, instances of that class can be serialized and deserialized using Java's serialization API. The core classes involved in serialization are ObjectOutputStream for writing objects to a byte stream and ObjectInputStream for reading objects from a byte stream.
javaCopy code
import java.io.*; public class SerializationExample { public static void main(String[] args) { try { // Serialization MyClass obj = new MyClass(); FileOutputStream fileOut = new FileOutputStream("object.ser"); ObjectOutputStream out = new ObjectOutputStream(fileOut); out.writeObject(obj); out.close(); fileOut.close(); // Deserialization FileInputStream fileIn = new FileInputStream("object.ser"); ObjectInputStream in = new ObjectInputStream(fileIn); MyClass newObj = (MyClass) in.readObject(); in.close(); fileIn.close(); } catch (IOException | ClassNotFoundException e) { e.printStackTrace(); } } }
Advantages of Serialization
Persistence: Serialized objects can be stored in files or databases, allowing data to persist beyond the lifetime of the Java application.
Interoperability: Serialized objects can be easily transmitted over a network and reconstructed by applications written in different languages or running on different platforms.
Object Cloning: Serialization can be used to create deep copies of objects by serializing them and then deserializing the byte stream.
Best Practices for Serialization
Versioning: When serializing classes, it's important to consider versioning to maintain compatibility between different versions of the class. This can be achieved by defining a serialVersionUID field or using externalizable interfaces.
Security: Be cautious when serializing sensitive data. Implement proper security measures such as encryption or using custom serialization mechanisms if necessary.
Transient Fields: Fields marked as transient are not serialized, which can be useful for excluding sensitive or unnecessary data from the serialized form.
Externalization: For more control over the serialization process, consider implementing the Externalizable interface instead of Serializable. This allows you to define custom serialization logic for your class.
Conclusion
Serialization is a powerful mechanism in Java that allows objects to be converted into byte streams for storage, transmission, or other purposes. By implementing the Serializable interface and using Java's built-in serialization API, developers can easily serialize and deserialize objects. Understanding the principles of serialization, its advantages, and best practices is essential for building robust and efficient Java applications.
for more please visit analyticsjobs.in
0 notes
Text
HOW TO AVOID SAFETY HAZARDS WHEN USING CLOSURES IN SCALA

Philipp Haller
ASSOCIATE PROFESSOR AT KTH ROYAL INSTITUTE OF TECHNOLOGY, SWEDEN
@philippkhaller
Closures are essential in Scala. Map and reduce are example of functions that are based off of closures.
Closures are also important for concurrent programming in Java.
If you are using Futures in Scala, you are also using Closures.
BUT, it is also easy to get things wrong while using closures.
A distributed data set is set across multiple data nodes, and the closure has to be serialized across all nodes.
Safety issues stem from unrestricted variable capture within closures. So we could deeply clone an object before using it in the closure as a potential solution.
How do you spot unsafe closures?
Capturing vars (reassignable variables)
In Java, captured variables need to be final, but not in Scala
Mutable types in closures can be an issue
Types that are not serializable
How to write safer closures: verify the creation of the closure
What is the logical snapshot of the memory that the closure should be initialized in?
Verify the semantics of the closure's execution. Does it mutate? Is it transactional? (hint, it shouldn't be)
Introducing Spores3, a new Scala 3 library to prevent these pitfalls.
Spores3 provides a dropin abstraction for closures
Spores3 is a complete reimplementation of spores from Scala.
Macro usage is simple and robust. Designed to be portable from the beginning, as opposed to spores for Scala 2.
val s = Spore((x: Int) => x + 2)
The type is Spore[Int, Int] { type Env = Nothing }
Nothing is the bottom type in Scala. No type has a type of Nothing.
Spore types are subtypes:
sealed trait Spore[-T, +R] extends )t => R) { type Env }
The Env type member of the Spore trait expresses type-based constraints.
A spore parameter can only capture thread-safe types.
We need a flexible way of serializing closures to make them portable. Serialization needs to be determined statically for safety.
Serialization is used for communication, not storage.
Every node needs to be running the same code
We also don't want to pass byte code back and forth.
In practice, we create a names Spore.Builder to create the spore to make a SporeData to "pickle" the spore (aka serialize it).
SporeData factory uses a macro to check for safety!
Thank you, Philipp, for the great talk!
0 notes
Text
Oxford Certified Java Professional

Oxford Certified Java Professional
Java is versatile as it can be used for a large number of things, including Software Development, Mobile Applications, and Large Systems Development, with the current statistics of it owning 88% market share as Mobile OS Android, putting it in the forefront. Oxford Software Institute, tapping its worth in the IT industry, provides the best classes in Java in Delhi. Through this course, we will provide the students a thorough understanding of the Java language and its role in the Object-Oriented World.
INTRODUCTION OF JAVA
This session will focus on History and Features of Java, Java Development Kit, Coding and Compiling through command prompt and NetBeans, Classes, Anatomy of Methods, Keywords, Data Types, Variables, Primitive / Abstract / Derived Data Types, Operators, Operator Precedence; Control Flow Statements like If-else and Switch Statement, Looping with For, While, Do…While, Break and Continue Statement, Arrays, Array of Object References, Accessing Arrays, Manipulating Arrays.
JAVA OOP CONCEPTS
In this session, we will focus on Classes and Objects, Defining A Class, Defining Instance Variables And Methods, Creating Object, Access Modifiers, Method calls via Object References, Constructors, Inheritance, extends and implements keywords in Java, Abstraction, Interfaces, Abstract and non-Abstract methods, Super class and Sub class, this keyword, super keyword, final in Java, Static variables and methods, Polymorphism, Overloading and Overriding of methods, Encapsulation, Java Bean, POJO, Getters/Setters, Memory management in Java, Heap, Stack, Package, Import statement and much more.
STRING, EXCEPTIONS AND FILE HANDLING
We will cover extensively the topic Strings, Immutability in Strings, String Creation on heap and constant pool, Method APIs on String, StringBuilder and StringBuffer, Splitting of Strings and StringTokenizer class, Exceptions - try, catch, finally, throw, throws, Rules for coding Exceptions, Declaring Exceptions, Defining and Throwing Exceptions, Errors and Runtime Exceptions, Custom Exception, Assertions, Enabling and disabling assertions in development environment, stream, Bytes vs. Characters, Java IO API, Reading and Writing to a file with APIs, Reading User input, PrintWriter Class and much more.
MULTITHREADING, COLLECTIONS AND SERIALIZATION
We will cover advance topics like Non-Threaded Applications and Threaded Applications, Multitasking – Process and Threaded, Creating Threads, States and Synchronization of threads, Concept of object and class locks, Coordination between threads, Inter-Thread Communication, Collections Framework, Collections API, Set, List, Map and Queue Interfaces and their implementation, Utility classes, Sorting collection, Primitive wrapper classes, Generics for Collections, Object Serialization, Serializable Interface, Serialization API, ObjectInputStream and ObjectOutput, readObject and writeObject.
JAVA APPLETS, SWING GUI AND JDBC
We will cover Applets, Event Handlers, Mouse and Click Events, AWT, Swing GUI, Advantages of Swing over AWT, Swing API, Swing GUI Components, Event Handlers, Sample Calculator application using Swing GUI and Swing Event handling, Introduction to JDBC, JDBC features and Architecture, java.sql package, Setting Up a Database and Creating a Schema, Writing JDBC code to connect to DB, Connection, Statement, ResultSet, Rowset, Prepared Statement, Batch Updates, ResultSetMetaData, Simple Transaction Management and their pros & cons, Features of JDBC 3.0, CRUD Operations with JDBC and much more
SOFT SKILLS
Having a technical and discipline-specific expertise can help you get to the interview room but it’s the soft skills that will make the hiring manager hand you the appointment letter. In this course, students will also learn various Soft Skills like how to communicate professionally in English, Speaking in public without hesitation, using effective gestures and postures to appear impressive, managing stress and emotions and taking successful interviews. Oxford Software Institute provides the best classes in Soft-skill training.
CERTIFICATIONS*
During this course, students will be trained for the following certifications
Oxford Certified JAVA Professional.
0 notes
Text
A PICO-8 Serializable Interface
After having played around with Java’s Serializable interface, I was really enjoying how simple and intuitive it was. Today I’ll go over how I’ve managed to make a similar interface in PICO-8 for saving cartdata in an efficient way.
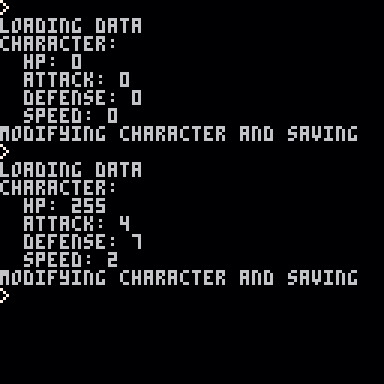
What you see here is the first two runs of a cart using this interface to write some simple character stats and read them back on the second run.
Before I begin, I’d like to break down what’s wrong with the current interface PICO-8 provides. Persistent cart data is mapped to 0x5e00 through 0x5eff, which we can access through several methods, peek, poke, peek4, poke4, dset and dget, all of which will write 1 or 4 bytes.
This is a problem for me, because there’s a chance we may have some unused bits. Say we’re storing position on the standard map in PICO-8 which is 128x64 tiles. Meaning x can be stored in 7 bits, and y can be stored in 5, in total, position would be 12 bits. peek/poke handles memory on a single byte scale so if we used it for storing this data we’d need to use 8 bits per value.
What this means visually is that if we store this data on a bit scale, we’ll free up a total of 4 bits for use with future data. This doesn’t sound like much, but let’s take for example Pico Wars’ map data. Tiles are not a fixed size. If they’re say, a city tile that can store team information, it’ll take an extra 3 bits for the team information. So a full map can vary wildly depending on how many tiles use team info. This leads to a huge amount of saved data.
So, let’s get to some code now. I wanted to replicate the Serializable interface in Java as best I could while also keeping token count in mind, so it doesn’t have every feature I’d like, but it’s got enough.
-- libraries -- i'm not going to explain these too much aside from naming them. -- these functions are library functions you can find on my github. -- https://github.com/Caaz/pico8-lib -- concatenate two tables in an array fashion function concat(a,b) for v in all(b) do a[#a+1] = v end end -- integer to bits function itb(number,size) local bits = {} if size then for i=1, size do bits[i] = false end end local i = 0 while number > 0 do i += 1 remainder = number % 2 bits[i] = remainder == 1 number = (number - remainder) / 2 end return bits end -- shift an element out of a table in an array fashion function shift(table) local element = table[1] del(table,element) return element end -- bits to integer function bti(bits) local total = 0 for i, v in pairs(bits) do if v then local add = shl(1,i-1) total += add end end return total end -- shift a number of elements out of a table containing booleans -- then turn those bits into an integer. function pull(data,size) local bits = {} for i = 1, size do add(bits,shift(data)) end return bti(bits) end -->8 -- code -- declare our variables in use local io, game, character -- this is our serializer. it handles the heavy lifting here. io = { -- io:write(some_variable, bitsize) -- write will write an unsigned integer to our data object write = function(this, value, size) concat(this.data, itb(value, size)) -- since we return this, this function can be chained. see: character return this end, -- io:read(some_variable, bitsize) -- pull out an unsigned integer from our data object. read = function(this, size) return pull(this.data, size) end, -- io:read_cartdata(object) -- read the actual cartdata and shove it into this.data. -- the object used here should be what entrypoint starts a chain of reading data from a save. -- that object should use the io:read method to pull data out, not access this.data directly. -- see: game read_cartdata = function(this, object) this.data = {} for i = 0x5e00, 0x5eff do concat(this.data, itb(peek(i),8)) end object:read_object(this) end, -- io:write_cartdata(object) -- write data to the cartdata. this will first populate this.data and then poke the cartdata to save. -- this can be called at any time, though it'll have to go through each object and write a new data each time. -- see: game write_cartdata = function(this, object) this.data = {} object:write_object(this) for i = 0x5e00, 0x5eff do poke(i,pull(this.data,8)) end end, -- io:clear_cartdata() -- this empties the cartdata. very useful for clearing save data during development clear_cartdata = function(this) this.data = {} for i = 0, 63 do dset(i,0) end end } -- our game object, which will be our entry point to read and write any data we want to store game = { read_object = function(this, io) -- read our level number as 6 bits this.level = io:read(6) -- read our character using the interface method character:read_object(io) end, write_object = function(this, io) -- write our level number as 6 bits io:write(this.level, 6) -- write our character using the interface method. character:write_object(io) end } -- character is an object which we'll be using to test, and it'll be within the game! character = { read_object = function(this, io) -- our hp can range from 0-255 so we'll write it as an 8 bit unsigned integer. this.hp = io:read(8) -- our remaining stats can range from 0-32, so we'll write them with 5 bits this.attack = io:read(5) this.defense = io:read(5) this.speed = io:read(5) end, write_object = function(this, io) -- here we'll write these stats to io -- when writing, we can chain these functions, as write returns io. io :write(this.hp, 8) :write(this.attack, 5) :write(this.defense, 5) :write(this.speed, 5) end, display = function(this) -- simply print out character information. print('character:') print(' hp: '..this.hp) print(' attack: '..this.attack) print(' defense: '..this.defense) print(' speed: '..this.speed) end } print('loading data') -- set the cartdata cartdata('8bitcaaz_serializable') -- load data into an object in io, and start reading it with our game object. io:read_cartdata(game) -- display character stats (an object within game) character:display() print('modifying character and saving') character.hp = 255 character.attack = 4 character.defense = 7 character.speed = 2 -- write our data to the cart, starting with game object again. io:write_cartdata(game)
#programming#lua#code#example#tutorial#pico8#pico-8#virtual console#8bit#binary#bits#integer#coding#development#cartdata#library#games#game design#8-bit#retro#serializable
12 notes
·
View notes
Text
JAC444 Assignment 5-Object Serialization, and Swing Solved
JAC444 Assignment 5-Object Serialization, and Swing Solved
This assignment lets you practice concepts such as Object Serialization, and Swing (or Java FX) GUI. In this assignment, you will be working with some objects of a Student class (which should be serializable.) This class has fields such as stdID (int), firstName (String), lastName (String), and courses (an array or preferably an ArrayList which contains the names of the courses the student…
View On WordPress
0 notes
Text
Advanced Java interview questions
Advanced Java is everything that goes beyond Core Java – most importantly the APIs defined in Java Enterprise Edition, includes Servlet programming, Web Services, the Persistence API, etc. It is a Web & Enterprise application development platform which basically follows client & server architecture.
Java Servlets are programs that run on a Web or Application server and act as a middle layer between a request coming from a Web browser or other HTTP client and databases or applications on the HTTP server. JavaServer Pages (JSP) is a technology for developing web pages that support dynamic content which helps developers insert java code in HTML pages by making use of special JSP tags, most of which start with <% and end with %>.
The most fundamental difference between Core Java and Advanced java is that, Core Java is put to use for creating general Java applications, whereas, Advanced Java is utilized for working up the mobile based applications and online applications.
Steps for developing SERIALIZABLE SUBCLASS:
A Serializable subclass is one which implements a predefined interface called java.io.Serializable.
1. Choose the appropriate package to keep the Serializable subclass. 2. Choose the user-defined class whose object participates in Serializable process. 3. Every user-defined class must implement a predefined interface called serializable. 4. Choose the set of data members for Serializable subclass. 5. Develop the set of set methods for each and every data members of the class. 6. Develop the set of getting methods for each and every data members of the class.
The above class is known as java bean class or component style based programming or POJO (Plain Old Java Object) class.
ODBC is having a common API or library for various databases and it is also developed in ‘C’ language and it is a platform dependent.
In later stages, SUN microsystems has developed a general specification called JDBC which contains a common API for all databases with platform-independent.
In order to deal with any database to represent the data permanently, we must use the driver (a driver is a software which acts as a middle layer between the database and front end application i.e., java) of the specific database. In real-world we have various drivers are available for various database products.
Steps for developing a JDBC program:
Loading the drivers.
Obtain the connection or specify the URL.
Pass the query.
Process the result which is obtained from the database.
Close the connection.
For more details please visit Advanced Java interview questions our website
SkillPractical provides the best Java tests and interview questions for Java from beginner to expert. It covers all the topics from Core Java to Advanced Java and Spring Boot. Some of the important interview questions they cover are:
1. Distinguish between static loading and dynamic class loading? 2. Can we import the same package/class twice. Will the JVM load the package twice at runtime? 3. Name the methods of an object class? 4. How can we restrict inheritance for a class? 5. If an application has multiple classes in it, is it okay to have a main method? 6. Java.util.regex consists of which classes? 7. Can we execute any code, even before the main method? 8. Can we declare the main method of our class as private?
SkillPractical also has the learning path that helps the user to learn the Java from scratch. If user have any questions on Java, he can post a question in SkillPractical community. They will get an answer from our expert consultants.

0 notes
Text
300+ TOP React Native Interview Questions and Answers
React Native Interview Questions for freshers experienced :-
1. What is React Native? React native is an open-source JavaScript framework designed by Facebook for native mobile applications development. It is based on a JavaScript library-React. React Native saves your development time as it enables you to build real and native mobile apps within a single language – JavaScript for both Android and iOS platforms, such that code once, run that on any platform, and the React Native App is ready for use with native look and feel. 2. Why use React Native? There is the following list of React Native features behind its use: Easy to use. Open-source framework Cross-platform compatibility Code Sharing Use a common language – JavaScript for cross-platform development. Faster Development Saves Time and efforts Gives Native look and feel 3. What are the advantages of React Native? React Native is based on “Learn Once Write Everywhere” approach to equip developers with a tool that only needs to be learned once, just in a single language and then can be reused on both iOS and Android mobile platform. React Native offers cross-platform development and a real experience to developers allowing them to build only one app with effectively 70% code sharing between different platforms. React Native helps in faster development. Building one app instead of two using a common language gives speedier app deployment, delivery, and quicker time-to-market. React Native exists with essential components for ending of native apps as the app development ends with native look and feel. React Native has a large community of developers for its security. The developers are always ready to fix bugs and issues that occur at any instant. They improve the performance of React Native from time to time with the best practices possible. React Native supports Live and Hot Reloading. Both are different features. Live Reloading is a tool that helps in compiling and reading the modified files. Hot Reloading is based on HMR (Hot Module Replacement) and helps to display the updated UI content. 4. List the essential components of React Native. These are the following essential components of React Native: View is the basic built-in component used to build UI. Text component displays text in the app. Image component displays images in the app. TextInput is used to input text into the app via the keypad. ScrollView is a scrolling container used to host multiple views. 5. What are the cons of React Native? React Native is still a new development platform as compared to iOS and Android platforms. It is still immature, i.e., in an improvement stage and impacting negatively on apps. Sometimes, React Native built-in apps face performance problem if there is a requirement of advanced functionality. In that case, they don’t perform well as compared to native apps. React Native has a steep learning curve for an average learner as it is not more comfortable in comparison to other cross-platform apps. It is because of existing JSX (JavaScript Syntax extension) in which HTML and JavaScript get combined and make learning challenging for average ones. React Native is based on JavaScript library which is fragile and creates a gap in the security robustness. As an expert’s point of view, React Native is not secure and robust for building highly confidential data apps like Banking and Financial apps. 6. How many threads run in React Native? There are two threads run in React Native: JavaScript thread Main UI thread 7. What are props in React Native? props pronounced as the properties of React Native Components. props are the immutable parameters passed in Presentational Component to provide data. 8. What are React Native Apps? React Native Apps are not web apps; they are the real and native mobile applications built-in a single language with the native components to run on mobile devices. 9. List the users of React Native? There are thousands of React Native built-in apps. Here is the list of those apps: Facebook Facebook Ads Manager Instagram F8 Airbnb Skype Tesla Bloomberg Gyroscope Myntra UberEats 10. For what purpose XHR module used in React Native? XHR module implements XMLHttpRequest to post data on the server.

React Native Interview Questions 11. Can we use Native code alongside React Native? Yes, we can use a native code alongside React Native for task completion, and several limitations can also overcome in previous versions like Titanium. 12. Are React Native built-in mobile apps like other Hybrid Apps which are slower in actual than Native ones? React Native designed as a highly-optimized performance-based framework that builds real mobile apps with native components. Facebook is the best-suited example of high performance based app built-in React Native. 13. What is the difference between React and React Native? React is a JavaScript library while React native is a framework based on React. js used for building UI and web applications while React Native is used for creating cross-platform native mobile apps. Both uses synonymous tags such as
are the tags in React.js and are the tags in React native. js uses DOM for path rendering of HTML tags while React Native uses AppRegistry for app registration. 14. What is the difference between React Native and Native Script? React Native uses only a single core development language- JavaScript while Native Script can use any of these languages- Angular, Vuejs, TypeScript, and JavaScript. React Native has faster development speed than Native Script. React Native exists with reusable components that developed at once can be used at different mobile platforms and accelerates mobile app development while Native Script exists with a less number of plugins among which some pass improper verification. React Native performs high as compared to Native Script. React Native is React based and uses virtual Dom for faster UI updation while Native Script uses slower Angulas, Vuejs, and TypeScript. Native Script exists with a box of various themes that shorten the gap between the different platform UIs while React Native doesn’t live with predefined themes; you get default look and feel by the devices. 15. Can we combine native codes of Android and iOS in React Native? Yes, we can do this as React Native fluently combines the components of both iOS and Android written in Swift/ Objective-C or Java. 16. What is the point of StyleSheet.create() in react native? In React Native, StyleSheet.create() send the style only once through the bridge to avoid passing new style object and ensures that values are immutable and opaque. 17. Why React Native has very clear animations? The animated API of React Native was designed as serializable so that users can send animations to native without going through the bridge on every frame. Once the animation starts, a JS thread can be blocked, and the animations will still run fluently. As the code converted into native views before rendering, the animations in React native will run smoothly, and the users get bright animations. 18. Differentiate between the React component and the React element. React component is a class or function that accepts input and returns a React element while React element displays the look of React Component Instance to be created. 19. Why React Native use Redux? Redux is a standalone state management library that React Native use to simplify data flow within an app. 20. Which node_modules will run in React Native? How to test for this? In React Native, node_modules as any pure JavaScript library that does not rely on Node.js runtime modules, and does not rely on web-specific concepts like window.location.pathname will run fine. But be conscious as there exists no way to test for this with Babel- it doesn’t scan these libraries for offending dependencies. A module that uses window.location.pathname may fail at runtime in a different unexpected place. 21. What is Virtual DOM and how it works in React Native? Virtual Dom is an in-memory tree representation of the real DOM with lightweight elements. It provides a declarative way of DOM representation for an app and allows to update UI whenever the state changes. Working Virtual DOM lists elements and their attributes and content. It renders the entire UI whenever any underlying data changes in React Native. Due to which React differentiates it with the previous DOM and a real DOM gets updated. 22. What is InteractionManager and what is its importance? InteractionManager is a native module in React native that defers the execution of a function until an “interaction” finished. Importance React Native has JavaScript UI thread as the only thread for making UI updates that can be overloaded and drop frames. In that case, InteractionManager helps by ensuring that the function is only executed after the animations occurred. 23. What is the point of the relationship between React Native and React? React is a JavaScript library. React Native is a framework based on React that use JavaScript for building mobile applications. It uses React to construct its application UI and to define application business logic. React updates a real DOM by tree diffing and allows React Native to work. 24. What are the similarities between React Native and React? React.js and React Native share same lifecycle methods like componentDidMount same state and prop variables same component architecture similar management libraries like Redux 25. Describe HOC. HOC (High Order Components) in React is the functional programming methodology for reusing component logic. takes a component as an argument and returns a new component It is a pattern evolved from React’s compositional nature to decompose the logic into simpler and smaller reusable functions. 26. Define Native apps. Native app is a software program for a specific mobile device that is developed on a particular platform in a specific programming language like Objective-C/Swift for iOS and Java for Android. It can use device-specific hardware and software as built on a particular device and its OS. It uses the latest technology such as GPS and provides optimized performance. 27. What are Hybrid Apps? Hybrid applications are the web applications developed through HTML, CSS, JavaScript web standards and wrapped in a native container using a mobile WebView object. These apps are easier to maintain. 28. What are refs in React? When to use Refs? Refs are escape hatch that provides a direct way to access DOM nodes or React elements created in the render method. Refs get in use when To manage focus, text selection, or media playback To trigger imperative animations To integrate with third-party DOM libraries 29. What does a react native packager do? A react native packager does a few things: It combines all JavaScript code into a single file It translates any JavaScript code that your device don’t understand (e.g., JSX or some of the newer JS syntax) It converts assets like PNG files into objects that can be displayed by an Image 30. What is NPM in React Native? npm installs the command line interface in React Native. npm install -g react-native-cli 31. What are “props” and “state”? “Props” and “state” are both plain JavaScript objects used to control data inside the components. props short for “properties.” Immutable parameters -> Unchangeable inside the component. Set by their parent and fixed for the whole lifetime of a component. Get passed to the Presentational component. state Mutable parameters -> Changeable inside the component. Get handled within the container component. Can’t be accessed and modified outside the component. 32. What is Style? The style prop is a plain JavaScript object use to making style of React Native application. There are two ways to style your element in React Native application. style property: adds styles inline. external Stylesheet: enables us to write concise code. 33. How To Handling Multiple Platforms? React Native smoothly handles multiple platforms. The large numbers of the React Native APIs are cross-platform so that one React Native component will work seamlessly on both iOS and Android. It provides the ways using which you can easily organize your code and separate it by platform: Platform module to detect the platform in which the app is running and platform-specific file extensions to load the relevant platform file. 34. When would you use a class component over a functional component? We use class component if our component has state or a lifecycle method(s). Otherwise, we use a Functional component. 35. How React Native handle different screen size? React Native offers many ways to handle different screen sizes: Flexbox Flexbox is designed to provide a consistent layout on different screen sizes. It offers three main properties: flexDirection justifyContent alignItems Pixel Ratio exists in the official documentation with the definition such that we can get access to the device pixel density by using PixelRatio class. We will get a higher resolution image if we are on a high pixel density device. An ethical principle is that multiply the size of the image we display by the pixel ratio. Dimensions easily handle different screen sizes and style the page precisely. It needs to write the code only once for working on any device. 36. Are all React components usable in React Native? Web React components use DOM elements to display (ex. div, h1, table, etc.), but React Native does not support these. We will need to find libraries/components made specifically for React Native. But today React is focusing on components that can be shared between the web version of React and React Native. This concept has been formalized since React v0.14. 37. What is the challenge with React Native? Working across separate Android and iOS codebases is challenging. 38. Does React Native use the same code base for Android and iOS? Yes, React Native uses the same code base for Android and IOS. React takes cares of the native components translations. For example A React Native ScrollView uses native ScrollView on Android and UiScrollView on iOS. 39. Thus React Native is a native Mobile App? Yes, React Native compiles a native mobile app using native app components. React Native builds a real mobile app that is indistinguishable from an app built using Objective-C or Java. 40. What is Gesture Responder System? The gesture responder system manages the lifecycle of gestures in the app. Users interact with mobile apps mainly through touch. They can use a combination of gestures, such as tapping on a button, zooming on a map, sliding on a widget or scrolling a list. The touch responder system is required to allow components to negotiate these touch interactions without any additional knowledge of their parent or child components. 41. How can React Native integrate more features on the existing app? React Native is great to start a new application from scratch. However, React Native works well to add new features to an existing native app. It needs some steps to add new React Native based features, screen, views, etc. The specific steps are different for different platform you’re targeting. Set up directory structure. Install JavaScript dependencies. Configuring permissions. Code integration. Test your integration. 42. What is the storage system in React Native? React Native uses AsyncStorage class to store data in key-value pair which is global to all app. AsyncStorage is a JavaScript code which is a simple, unencrypted, asynchronous and persistent. React Native also uses separate files for iOS and RocksBD or SQLite for Android. Using AsyncStorage class, you must have a data backup, and synchronization classes as data saved on the device is not permanent and not encrypted. 43. How React Native load data from server? React Native provides the Fetch API which deals networking needs. React Native uses componentDidMount lifecycle method to load the data from server. fetch('https://mywebsite.com/mydata.json') Other Networking libraries which interact with server are: XMLHttpRequest API WebSockets React Native Questions and Answers Pdf Download Read the full article
0 notes
Text
How can you serialize and deserialize Java objects for frontend-backend communication?

1. What’s Java Serialization and Deserialization All About?
So, how do you handle communication between the frontend and backend in Java? It’s all about turning Java objects into a byte stream (that’s serialization) and then back into objects (deserialization). This makes it easy to exchange data between different parts of your app. The Serializable interface in Java is key for this, as it helps keep the state of objects intact. If you’re taking a Java course in Coimbatore, you’ll get to work on this a lot. Serialization is super important for things like APIs and managing sessions. For Java backend developers, it's a must-know.
2. Why Is Serialization Important Nowadays?
When it comes to Java and modern web apps, we often use JSON or XML for serialized data. Libraries like Jackson and Gson make it easy to convert Java objects to JSON and vice versa. These formats are great for frontend and make communication smoother. If you study Java in Coimbatore, you'll learn how serialization fits into REST APIs. Good serialization helps keep your app performing well and your data secure while also supporting setups like microservices.
3. What’s the Serializable Interface?
The Serializable interface is a simple marker in Java telling the system which objects can be serialized. If you get this concept down, it really helps answer how to serialize and deserialize Java objects for frontend-backend communication. By using this interface, you can easily save and send Java objects. Students in a Java Full Stack Developer Course in Coimbatore learn how to manage complex object structures and deal with transient variables to keep things secure and fast.
4. Tools and Libraries for Serialization in Java
To serialize objects well, developers often rely on libraries like Jackson and Gson, along with Java’s ObjectOutputStream. These are essential when you’re trying to serialize Java objects for frontend-backend communication. With these tools, turning Java objects into JSON or XML is a breeze. In Java courses in Coimbatore, learners work with these tools on real projects, and they offer options for customizing how data is serialized and handling errors more smoothly.
5. Deserialization and Keeping Things Secure
Deserialization is about getting objects back from a byte stream, but you've got to do this carefully. To serialize and deserialize Java objects safely, you need to check the source and structure of incoming data. Training in Coimbatore covers secure deserialization practices so you can avoid issues like remote code execution. Sticking to trusted libraries and validating input helps keep your app safe from attacks.
6. Syncing Frontend and Backend
Getting the frontend and backend in sync relies heavily on good serialization methods. For instance, if the Java backend sends data as JSON, the frontend—often built with React or Angular—needs to handle it right. This is a key part of learning how to serialize and deserialize Java objects for frontend-backend communication. In Java Full Stack Developer Courses in Coimbatore, students work on apps that require this skill.
7. Dealing with Complex Objects and Nested Data
A big challenge is when you have to serialize complex or nested objects. When figuring out how to serialize and deserialize Java objects for frontend-backend communication, you need to manage object references and cycles well. Libraries like Jackson can help flatten or deeply serialize data structures. Courses in Coimbatore focus on real-world data models to give you practical experience.
8. Making Serialization Efficient
Efficient serialization cuts down on network delays and boosts app performance. Students in Java training in Coimbatore learn how to make serialization better by skipping unnecessary fields and using binary formats like Protocol Buffers. Balancing speed, readability, and security is the key to good serialization.
9. Real-Life Examples of Java Serialization
Things like login sessions, chat apps, and shopping carts all depend on serialized objects. To really understand how to serialize and deserialize Java objects for frontend-backend communication, you need to know about the real-time data demands. In a Java Full Stack Developer Course in Coimbatore, you’ll get to simulate these kinds of projects for hands-on experience.
10. Wrapping It Up: Getting Good at Serialization
So how should you go about learning how to serialize and deserialize Java objects? The right training, practice, and tools matter. Knowing how to map objects and secure deserialized data is crucial for full-stack devs. If you're keen to master these skills, check out a Java course or a Java Full Stack Developer Course in Coimbatore. With practical training and real projects, Xplore IT Corp can set you on the right path for a career in backend development.
FAQs
1. What’s Java serialization for?
Serialization is for turning objects into a byte stream so they can be stored, shared, or cached.
2. What are the risks with deserialization?
If deserialization is done incorrectly, it can lead to vulnerabilities like remote code execution.
3. Can every Java object be serialized?
Only objects that implement the Serializable interface can be serialized. Certain objects, like threads or sockets, can’t be.
4. Why use JSON for communication between frontend and backend?
JSON is lightweight, easy to read, and can be easily used with JavaScript, making it perfect for web apps.
5. Which course helps with Java serialization skills?
The Java Full Stack Developer Course in Coimbatore at Xplore IT Corp offers great training on serialization and backend integration.
#Java programming#Object-oriented language#Java Virtual Machine (JVM)#Java Development Kit (JDK)#Java Runtime Environment (JRE)#Core Java#Advanced Java#Java frameworks#Spring Boot#Java APIs#Java syntax#Java libraries#Java multithreading#Exception handling in Java#Java for web development#Java IDE (e.g.#Eclipse#IntelliJ)#Java classes and objects
0 notes
Link
Did you see a basket full of apples? What did you notice? 1. All the items in the basket are apple (same type). 2. All items are present side by side (continuous memory/space) and 3. The size of the basket is fixed and predefined i.e. size of basket can not auto expand to accommodate more items than its capacity. In the same way, in Java, we have Java arrays. The array is a collection of same type items. The size of the array is defined at declaration and can not change after that. Hope you got the idea of array pretty much. In this post, we will learn Java arrays and array usages in detail.
SO WHAT IS AN ARRAY?
So as defined earlier, an array is a fixed size collection of items of the same type. Here are important points about an array:
- All items in the array are of the same type
- An array can have duplicate items
- Size of an array is fixed and defined at instantiating time.
- Depending upon memory allocation, items are present in continuous memory space.
- Memory allocation to array is dynamic in Java i.e. memory is allocated automatically.
- Items in the array are ordered
- The array is a direct subclass of Object
- Every Array implementation implements Cloneable and Serializable interface.
- An array can be declared using "[]". e,g String[] arrayVar;
- An array can store primitive and object type both
- If the array store object then the actual objects are allocated memory in HEAP

Java Array and Indexing
CREATING, INITIALISING AND ACCESSING AN ARRAY
ONE DIMENSION ARRAY:
One dimensional array is can be declared like
type var-name[]; OR type[] var-name;
Array declaration contains type and variable name. Type of array tells which kind of items can be stored in the array. The type could be primitive or Object. Let's see examples of array declaration
byte[] byteArr; //byte array
int[] intArr; //can store int only
long[] longArr; // can store long
String[] stringArray; //can store strings only
Object[] objectArray; //can store items of type objects..literally any type in java
Above arrays are declared only i.e. such variable are not given any memory and nothing is actually existing for them. It just tells the compiler that such items/variables are declared.
INSTANTIATING AN ARRAY
- declaring an array just create reference only but no memory allocation. Proces of allocating memory to array is called array instantiation.
- an array can be instantiated like e.g. Type[] arr = new Type[sizeofarra];
- Type tells the type of array items
- sizeofarra is the size of the array it tells how many items can be stored in the array at max
- Index of items in an array starts at 0 and goes till (size of the array - 1)
e.g.
intArr = new int[20]; // allocating memory to the array intArr declared above - default values of array items are 0, false and null for Number type, boolean and object respectively.
INITIALIZING ARRAY WITH VALUES AT DECLARATION: ARRAY LITERAL
- The array can be declared and initialized using
int[] arr = {1,2,3,4,5,6,78,8};
- Above statement, does declaration, instantiation, and initialization automatically. You need not specify "new type[size]" etc.
- arrays in java can be easily iterated using loops and even Java above 5 provide optimized syntax to traverse array item like below
foreach(Type item in items){ //items is an array of type Type //can manipulate item here }
- If an attempt is made to access elements outside the array, you will encounter ArrayIndexOutOfBoundsException on runtime.
MULTIDIMENSIONAL ARRAY
- An array could be multidimensional i.e. each item of an array will contain a reference to one dimension lower array as that of a parent. e.g. int[][][] items is 3-D array; So items[0] will refer to int[][] array and items[0][0] will refer to int[] and item[1][0][0] will actually contain int value.

Java Multidimensional Array
- an array can be passed as an ARGUMENT OF THE FUNCTION USING ARRAY VARIABLE NAME ONLY.
- an array can be returned from a function using an array variable name.
- an array can contain the object of any valid java type or user-defined.
CLONING A JAVA ARRAY
an array can be cloned. Cloning is a process to deep copy I,e means an exact replica of the original array is created and cloned instance contains the exact item rather than the reference of the parent array items.
e.g. int[] arra = new int[10].
int[] clonedarra = arra.clone();
now arra and clonearra are two different arrays in memory with exactly the same items but a different copy.
USAGES:
- the array can be used when we know the max items to be stored.
- when items to be stored are of the same type
You may like to visit other Java Basic Concepts
Oh! you reached the end of the article. Hope you like, please share, subscribe and comment.
#java arrays#array usages#basic tutorial on array#practical usage of one dimentional array#multidimentional array#java array for beginners
0 notes
Text
data persistence
What is a data persistence??
Information systems process data and convert it into information. The data should persist for later use
To maintain the status
For logging purposes
To further process and derive knowledge (data science)
Data can be stored, read, updated/modified, and deleted. At run time of software systems, data is stored in main memory, which is volatile (computer storage that only maintains its data while the device is powered (RAM),Data should be stored in non-volatile storage for persistence(Hard disk)
Two main ways of storing data
Files
Databases, in here many formats for storing data.
Plain Text
JSON
Tables
Text files
Images
What is a Data, Database, Database Server, Database Management System??
Data: In computing, data is information that has been translated into a form that is efficient for movement or processing
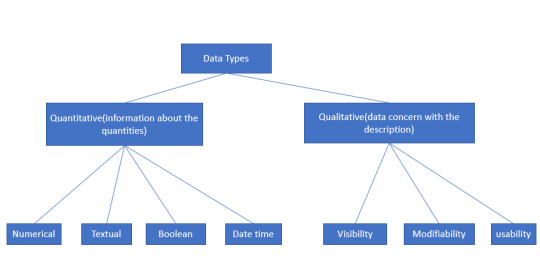
Data Types
Database: A database is a collection of information that is organized so that it can be easily accessed, managed and updated
Database types
Hierarchical databases: data is stored in a parent-children relationship nodes. In a hierarchical database, besides actual data, records also contain information about their groups of parent/child relationships.
Network databases: Network database management systems (Network DBMSs) use a network structure to create relationship between entities. Network databases are mainly used on a large digital computer.
Relational databases: In relational database management systems (RDBMS), the relationship between data is relational and data is stored in tabular form of columns and rows. Each column if a table represents an attribute and each row in a table represents a record. Each field in a table represents a data value.
Non-relational databases (NoSQL)
Object-oriented databases: In this Model we have to discuss the functionality of the object-oriented Programming. It takes more than storage of programming language objects.
Graph databases: Graph Databases are NoSQL databases and use a graph structure for sematic queries. The data is stored in form of nodes, edges, and properties.
Document databases: Document databases (Document DB) are also NoSQL database that store data in form of documents. Each document represents the data, its relationship between other data elements, and attributes
Database Server: The term database server may refer to both hardware and software used to run a database, according to the context. As software, a database server is the back-end portion of a database application, following the traditional client-server model. This back-end portion is sometimes called the instance. It may also refer to the physical computer used to host the database. When mentioned in this context, the database server is typically a dedicated higher-end computer that hosts the database.
Database Management System: A database management system (DBMS) is system software for creating and managing database. The DBMS provides users and programmers with a systematic way to create, retrieve, update and manage data.
Files and databases

Advantages of storing data in files
Higher productivity
Lower costs
Time saving
Disadvantages of storing data in files
Data redundancy
Data inconsistency
Integrity problem
Security problem
Advantages of storing data in database
Excellent data integrity independence from application programs
Improve data access to users through the use of hos and query language
Improve data security storage and retrieval
Disadvantages of storing data in database
Complex, difficult and time consuming to design
Substantial hardware and software start-up cost.
Initial training required for all programmers and users
Data arrangements
Un-structured - Unstructured data has internal structure but is not structured via pre-defined data models or schema. It may be textual or non-textual, and human- or machine-generated. It may also be stored within a non-relational database like NoSQL
E.g. – paragraph, essay
Semi- structured - Semi-structured data is a data type that contains semantic tags, but does not conform to the structure associated with typical relational databases. Semi-structured data is one of many different types of data.
Structured - Structured data is data that has been organized into a formatted repository, typically a database, so that its elements can be made addressable for more effective processing and analysis. This persistence technique is better for these arrangements.
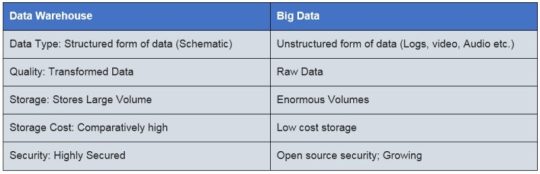
Data Warehouse is an architecture of data storing or data repository. Whereas Big Data is a technology to handle huge data and prepare the repository. ... Data warehouse only handles structure data (relational or not relational), but big data can handle structure, non-structure, semi-structured data.
APPLICATION TO FILES/DB
Files and DBs are external components.They are existing outside the software system. Software can connect to the files/DBs to perform CRUD operations on data
File –File path, URL
DB –connection string
To process data in DB ,
SQL statements
Statement interface is used to execute normal SQL queries. You can’t pass the parameters to SQL query at run time using this interface. This interface is preferred over other two interfaces if you are executing a particular SQL query only once. The performance of this interface is also very less compared to other two interfaces. In most of time, Statement interface is used for DDL statements like CREATE, ALTER, DROP etc. For example,
//Creating The Statement Object
Statement stmt = con.createStatement();
//Executing The Statement
stmt.executeUpdate("CREATE TABLE STUDENT(ID NUMBER NOT NULL, NAME VARCHAR)");
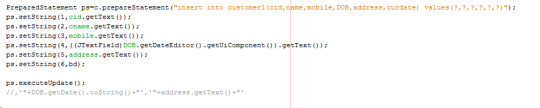
Prepared statements
Prepared Statement is used to execute dynamic or parameterized SQL queries. Prepared Statement extends Statement interface. You can pass the parameters to SQL query at run time using this interface. It is recommended to use Prepared Statement if you are executing a particular SQL query multiple times. It gives better performance than Statement interface. Because, Prepared Statement are precompiled and the query plan is created only once irrespective of how many times you are executing that query. This will save lots of time.
//Creating PreparedStatement object
PreparedStatement pstmt = con.prepareStatement("update STUDENT set NAME = ? where ID = ?");
//Setting values to place holders using setter methods of PreparedStatement object
pstmt.setString(1, "MyName"); //Assigns "MyName" to first place holder
pstmt.setInt(2, 111); //Assigns "111" to second place holder
//Executing PreparedStatement
pstmt.executeUpdate();
Callable statements
Callable Statement is used to execute the stored procedures. Callable Statement extends Prepared Statement. Usng Callable Statement, you can pass 3 types of parameters to stored procedures. They are : IN – used to pass the values to stored procedure, OUT – used to hold the result returned by the stored procedure and IN OUT – acts as both IN and OUT parameter. Before calling the stored procedure, you must register OUT parameters using registerOutParameter() method of Callable Statement. The performance of this interface is higher than the other two interfaces. Because, it calls the stored procedures which are already compiled and stored in the database server.
/Creating CallableStatement object
CallableStatement cstmt = con.prepareCall("{call anyProcedure(?, ?, ?)}");
//Use cstmt.setter() methods to pass IN parameters
//Use cstmt.registerOutParameter() method to register OUT parameters
//Executing the CallableStatement
cstmt.execute();
//Use cstmt.getter() methods to retrieve the result returned by the stored procedure
Useful objects
Connection
Statement
Reader
Result set
OBJECT RELATIONAL MAPPING (ORM)
There are different structures for holding data at runtime
Application holds data in objects
Database uses tables (entities)
Mismatches between relational and object models
Granularity: Object model has more granularity than relational model.
Subtypes: Subtypes (means inheritance) are not supported by all types of relational databases.
Identity: Like object model, relational model does not expose identity while writing equality.
Associations: Relational models cannot determine multiple relationships while looking into an object domain model.
Data navigation: Data navigation between objects in an object network is different in both models
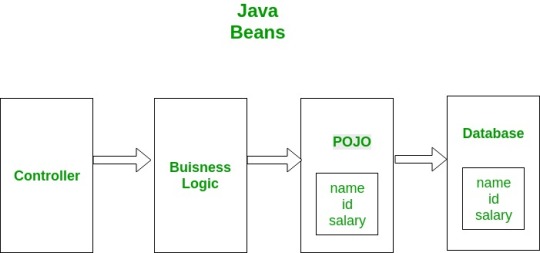
Beans use POJO
stands for Plain Old Java Object. It is an ordinary Java object, not bound by any special restriction other than those forced by the Java Language Specification and not requiring any class path. POJOs are used for increasing the readability and re-usability of a program. POJOs have gained most acceptance because they are easy to write and understand. They were introduced in EJB 3.0 by Sun microsystems.
A POJO should not:
Extend pre-specified classes.
Implement pre-specified interfaces.
Contain pre-specified annotations.
Beans
•Beans are special type of Pojos. There are some restrictions on POJO to be a bean. All JavaBeans are POJOs but not all POJOs are JavaBeans. Serializable i.e. they should implement Serializable interface. Still some POJOs who don’t implement Serializable interface are called POJOs because Serializable is a marker interface and therefore not of much burden. Fields should be private. This is to provide the complete control on fields. Fields should have getters or setters or both. A no-AR constructor should be there in a bean. Fields are accessed only by constructor or getter setters.
POJO/Bean to DB
Java Persistence API (JPA)
An API/specification for ORM.
Uses
POJO classes
XML based mapping file (represent the DB)
A provider (implementation of JPA)
JPA Architecture
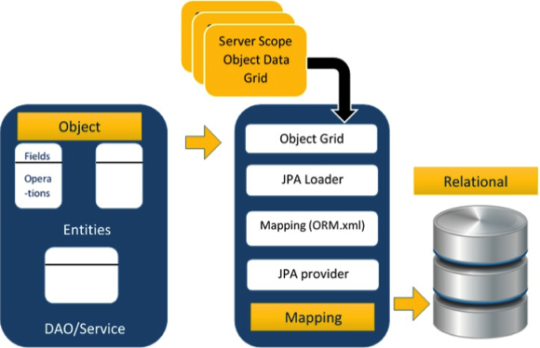
JPA implementations
Hybernate
JDO
EclipseLink
ObjectDB
NOSQL AND HADOOP
Not Only SQL (NOSQL)
Relational DBs are good for structured data.For semi-structured and un-structured data, some other types of DBs can be used
Key-value stores
Document databases
Wide-column stores
Graph stores
Benefits of NoSQL
When compared to relational databases, NoSQL databases are more scalable and provide superior performance, and their data model addresses several issues that the relational model is not designed to address:
Large volumes of rapidly changing structured, semi-structured, and unstructured data.
NoSQL DB servers
MongoDB
Cassandra
Redis
Amazon DynamoDB
Hbase
Hadoop
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Hadoop core concepts
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data
Hadoop YARN: A framework for job scheduling and cluster resource management.
Hadoop Map Reduce: A YARN-based system for parallel processing of large data sets.
INFORMATION RETRIEVAL
Data in the storages should be fetched, converted into information, and produced for proper use
Information is retrieved via search queries
Keyword search
Full-text search
The output can be
Text
Multimedia
0 notes
Text
“Data” is not simple as we think!
After a short period of time,hello again my friends! Today in our seventh blog article we will be talking about data controlling and few more new topics.

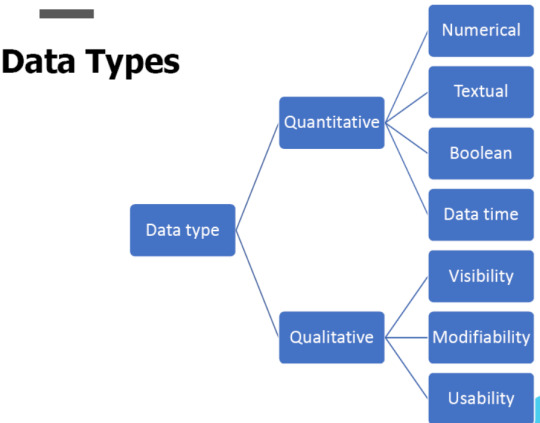
First lets learn what data and information is.Data is naturally unsorted things.
Data becomes information when they are sorted.That is when it becomes useful. Data can come in various formats like,
So data can can be stored, read, updated/modified, and deleted as we need to and thereby they can be organized in a useful manner.
At run time of software systems, data is stored in main memory, which is volatile Therefore data should be stored in non-volatile storage for persistence.
There are two main ways of storing data • Files •Databases

Out of these two types databases have proved to be much efficient. This is due to the advantages that are observed in databases.
Data independence –application programs are independent of the way the data is structured and stored. Efficient data access Enforcing integrity–provide capabilities to define and enforce constraints Ex: Data type for a name should be string Restricting unauthorized access Providing backup and recovery Concurrent access
There are many formats for storing data •Plain-text, XML, JSON, tables, text files, images, etc…
Digging more upto "data" related terms,lets take a brief look at the terms Database and Database Management System.
A database is a place where data is stored.More accurately a database is a collection of related data.Whereas a database management systems (DBMS) is a general-purpose software system that facilitates the processes of defining, constructing, manipulating, and sharing databases among various users and applications.
Also DBMSs are used to connect to the DB servers and manage the DBs and data in them •PHPMyAdmin •MySQL Workbench
In databases data can be arranged in the following manners.. •Un-structured Semi-structured data is data that has not been organized into a specialized repository, such as a database, but that nevertheless has associated information, such as metadata, that makes it more amenable to processing than raw data.
•Semi-structured Structured data is data that has been organized into a formatted repository, typically a database, so that its elements can be made addressable for more effective processing and analysis.
•Structured Unstructured data is information, in many different forms, that doesn't hew to conventional data models and thus typically isn't a good fit for a mainstream relational database.
*SQL-Structered Query Language
SQL-Structered Query Language is used to process data in a databases. Furthermore SQL can be categorized as DDL and DML.
DDL-Data definition language CRUD databases
DML-Data manipulation language CRUD data in databases
•Hierarchical databases •Network databases •Relational databases •Non-relational databases (NoSQL) •Object-oriented databases •Graph databases •Document databases are the types of databases to be found.
** Data warehouse and Big data
Data warehouse and Big data have become two popular topics in the new world.

Data warehouse a system used for reporting and data analysis, and is considered a core component of business intelligence.
Big data is a field that treats ways to analyze, systematically extract information from, or otherwise deal with data sets that are too large or complex to be dealt with by traditional data-processing application software. Big data was originally associated with three key concepts: volume, variety, and velocity.
So how do we use databases in day to day life? To process data in DB we use, •SQL statements •Prepared statements •Callable statements


Connection statement codes
Prepared statement codes
3.Callable statements
CallableStatement cstmt = con.prepareCall("{call anyProcedure(?, ?, ?)}"); cstmt.execute();
Other useful objects are, •Connection
•Statement
•Reader
•Result set
**ORM The mapping of relational objects (ORM, O / RM and O / R) in computer science is a programming technique for converting data between incompatible writing systems using object-oriented programming languages.
ORM implementations in JAVA • Java Beans • JPA
POJO stands for Plain Old Java Object, and would be used to describe the same things as a "Normal Class" whereas a JavaBean follows a set of rules. Most commonly Beans use getters and setters to protect their member variables, which are typically set to private and have a no-argument public constructor.
POJO stands for Plain Old Java Object, and would be used to describe the same things as a "Normal Class" whereas a JavaBean follows a set of rules. Most commonly Beans use getters and setters to protect their member variables, which are typically set to private and have a no-argument public constructor.
Beans Beans are special type of Pojos. There are some restrictions on POJO to be a bean.
POJO Vs Beans
All JavaBeans are POJOs but not all POJOs are JavaBeans. A JavaBean is a Java object that satisfies certain programming conventions: the JavaBean class must implement either Serializable or Externalizable; ... all JavaBean properties must have public setter and getter methods (as appropriate).
* Java Persistence API (JPA) Java Persistence API is a collection of classes and methods to persistently store the vast amounts of data into a database which is provided by the Oracle Corporation.
JPA can be used to reduce the burden of writing codes for relational object management. A programmer follows the ‘JPA Provider’ framework, which allows easy interaction with database instance. Here the required framework is taken over by JPA.
JPA is an open source API.Some of the products are, Eclipselink,Toplink,Hibernate.
**NoSQL SQL databases are commonly known as Relational databases(RDBMs),while NoSQL databases are called non-relational databases or distributed databases.
NoSQL comes in to need when semi-structured and un-structured data are needed to be processed.
It is advantageous to use NoSQL databases as they have high performance, supports both semi-structured and un-structured data,scalability.
MongoDB, BigTable, Redis, RavenDB Cassandra, HBase, Neo4j and CouchDB are examples of NoSQL databases.
You can find more by this link..
https://searchdatamanagement.techtarget.com/definition/NoSQL-Not-Only-SQL
**Hadoop Hadoop is an open source framework implmented by Apache.It is Java based.It is used to process large datasets across clusters of computers distributedly.Hadoop is designed to scale up from single server to thousands of machines, each offering local computation and storage.
Hadoop is consisted of two major layers,
1.Processing/Computation layer (MapReduce), and 2.Storage layer (Hadoop Distributed File System).
Finally we'll turn into the topic Information retrieval (IR).
This is the activity of obtaining information system resources relevant to an information need from a collection. Searches can be based on full-text or other content-based indexing.

For better results, IR should have the following characteristics. 1. Fast/performance 2. Scalablitiy 3. Efficient 4. Reliable/Correct
References
[1] Wikipedia.com. “ Hadoop ”. [Accessed: April 10, 2019].
[2] TutorialsPoint.com. “JPA”. [Accessed: April 10 , 2019]
[3] TutorialsPoint.com. “Hadoop”. [Accessed: April 10 , 2019].
0 notes
Text
Data Persistence
Introduction to Data Persistence
Information systems process data and convert them into information.
The data should persist for later use;
To maintain the status
For logging purposes
To further process and derive knowledge
Data can be stored, read, updated/modified, and deleted.
At run time of software systems, data is stored in main memory, which is volatile.
Data should be stored in non-volatile storage for persistence.
Two main ways of storing data
- Files
- Databases
Data, Files, Databases and DBMSs
Data : Data are raw facts and can be processed and convert into meaningful information.
Data Arrangements
Un Structured : Often include text and multimedia content.
Ex: email messages, word processing documents, videos, photos, audio files, presentations, web pages and many other kinds of business documents.
Semi Structured : Information that does not reside in a relational database but that does have some organizational properties that make it easier to analyze.
Ex: CSV but XML and JSON, NoSQL databases
Structured : This concerns all data which can be stored in database SQL in table with rows and columns
Databases : Databases are created and managed in database servers
SQL is used to process databases
- DDL - CRUD Databases
- DML - CRUD data in databases
Database Types
Hierarchical Databases
In a hierarchical database management systems (hierarchical DBMSs) model, data is stored in a parent-children relationship nodes. In a hierarchical database model, data is organized into a tree like structure.
The data is stored in form of collection of fields where each field contains only one value. The records are linked to each other via links into a parent-children relationship. In a hierarchical database model, each child record has only one parent. A parent can have multiple children
Ex: The IBM Information Management System (IMS) and Windows Registry
Advantages : Hierarchical database can be accessed and updated rapidly
Disadvantages : This type of database structure is that each child in the tree may have only one parent, and relationships or linkages between children are not permitted
Network Databases
Network database management systems (Network DBMSs) use a network structure to create relationship between entities. Network databases are mainly used on a large digital computers.
A network database looks more like a cobweb or interconnected network of records.
Ex: Integrated Data Store (IDS), IDMS (Integrated Database Management System), Raima Database Manager, TurboIMAGE, and Univac DMS-1100
Relational Databases
In relational database management systems (RDBMS), the relationship between data is relational and data is stored in tabular form of columns and rows. Each column if a table represents an attribute and each row in a table represents a record. Each field in a table represents a data value.
Structured Query Language (SQL) is a the language used to query a RDBMS including inserting, updating, deleting, and searching records.
Ex: Oracle, SQL Server, MySQL, SQLite, and IBM DB2
Object Oriented model
Object DBMS's increase the semantics of the C++ and Java. It provides full-featured database programming capability, while containing native language compatibility.
It adds the database functionality to object programming languages.
Ex: Gemstone, ObjectStore, GBase, VBase, InterSystems Cache, Versant Object Database, ODABA, ZODB, Poet. JADE
Graph Databases
Graph Databases are NoSQL databases and use a graph structure for sematic queries. The data is stored in form of nodes, edges, and properties.
Ex: The Neo4j, Azure Cosmos DB, SAP HANA, Sparksee, Oracle Spatial and Graph, OrientDB, ArrangoDB, and MarkLogic
ER Model Databases
An ER model is typically implemented as a database.
In a simple relational database implementation, each row of a table represents one instance of an entity type, and each field in a table represents an attribute type.
Document Databases
Document databases (Document DB) are also NoSQL database that store data in form of documents.
Each document represents the data, its relationship between other data elements, and attributes of data. Document database store data in a key value form.
Ex: Hadoop/Hbase, Cassandra, Hypertable, MapR, Hortonworks, Cloudera, Amazon SimpleDB, Apache Flink, IBM Informix, Elastic, MongoDB, and Azure DocumentDB
DBMSs : DBMSs are used to connect to the DB servers and manage the DBs and data in them
Data Arrangements
Data warehouse
Big data
- Volume
- Variety
- Velocity
Applications to Files/DB
Files and DBs are external components
Software can connect to the files/DBs to perform CRUD operations on data
- File – File path, URL
- Databases – Connection string
To process data in DB
- SQL statements
- Prepared statements
- Callable statements
Useful Objects
o Connection
o Statement
o Reader
o Result set
SQL Statements - Execute standard SQL statements from the application
Prepared Statements - The query only needs to be parsed once, but can be executed multiple times with the same or different parameters.
Callable Statements - Execute stored procedures
ORM
Stands for Object Relational Mapping
Different structures for holding data at runtime;
- Application holds data in objects
- Database uses tables
Mismatches between relational and object models
o Granularity – Object model has more granularity than relational model.
o Subtypes – Subtypes are not supported by all types of relational databases.
o Identity – Relational model does not expose identity while writing equality.
o Associations – Relational models cannot determine multiple relationships while looking into an object domain model.
o Data navigations – Data navigation between objects in an object network is different in both models.
ORM implementations in JAVA
JavaBeans
JPA (JAVA Persistence API)
Beans use POJO
POJO stands for Plain Old Java Object.
It is an ordinary Java object, not bound by any special restriction
POJOs are used for increasing the readability and re-usability of a program
POJOs have gained most acceptance because they are easy to write and understand
A POJO should not;·
Extend pre-specified classes
Implement pre-specified interfaces
Contain pre-specified annotations
Beans
Beans are special type of POJOs
All JavaBeans are POJOs but not all POJOs are JavaBeans
Serializable
Fields should be private
Fields should have getters or setters or both
A no-arg constructor should be there in a bean
Fields are accessed only by constructor or getters setters
POJO/Bean to DB
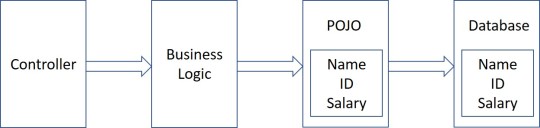
Java Persistence API
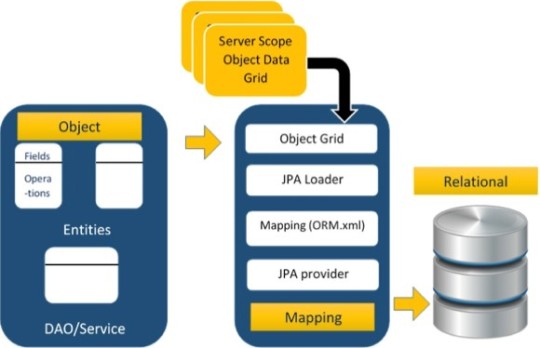
The above architecture explains how object data is stored into relational database in three phases.
Phase 1
The first phase, named as the Object data phase contains POJO classes, service interfaces and classes. It is the main business component layer, which has business logic operations and attributes.
Phase 2
The second phase named as mapping or persistence phase which contains JPA provider, mapping file (ORM.xml), JPA Loader, and Object Grid
Phase 3
The third phase is the Relational data phase. It contains the relational data which is logically connected to the business component.
JPA Implementations
Hybernate
EclipseLink
JDO
ObjectDB
Caster
Spring DAO
NoSQL and HADOOP
Relational DBs are good for structured data and for semi-structured and un-structured data, some other types of DBs can be used.
- Key value stores
- Document databases
- Wide column stores
- Graph stores
Benefits of NoSQL
Compared to relational databases, NoSQL databases are more scalable and provide superior performance
Their data model addresses several issues that the relational model is not designed to address
NoSQL DB Servers
o MongoDB
o Cassandra
o Redis
o Hbase
o Amazon DynamoDB
HADOOP
It is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models
It is designed to scale up from single servers to thousands of machines, each offering local computation and storage
HADOOP Core Concepts
HADOOP Distributed File System
- A distributed file system that provides high-throughput access to application data
HADOOP YARN
- A framework for job scheduling and cluster resource management
HADOOP Map Reduce
- A YARN-based system for parallel processing of large data sets
Information Retrieval
Data in the storages should be fetched, converted into information, and produced for proper use
Information is retrieved via search queries
1. Keyword Search
2. Full-text search
The output can be
1. Text
2. Multimedia
The information retrieval process should be;
Fast/performance
Scalable
Efficient
Reliable/Correct
Major implementations
Elasticsearch
Solr
Mainly used in search engines and recommendation systems
Additionally may use
Natural Language Processing
AI/Machine Learning
Ranking
References
https://www.tutorialspoint.com/jpa/jpa_orm_components.htm
https://www.c-sharpcorner.com/UploadFile/65fc13/types-of-database-management-systems/
0 notes
Text
Fun with Java Deserialization
Down the Rabbit Hole
I’ve just been scrambling down the rabbit hole to patch an app that Qualys is complaining has a deserialization vulnerability. What should have been a simple effort has turned into a mystery because, while we appear to have the correct libraries already in place, Qualys is still complaining about the error. A report that should be clean, to indicate compliance with GDPR, is instead “yellow”, or “orange”, or “red”, so fingers point, tempers flare, e-mails fly about, cc’ing higher and higher ups, so now we have assumptions, and based on those assumptions, tersely written orders, involvement by 3rd party vendors. Time to panic? Shall we be careful and tip-toe through the eggs?[0]
Well, it turns out to be a rather interesting mystery.
What is Java serialization?
First, some definitions are in order. What is Java serialization and why is it important? Perhaps Wikipedia[1] defines it the simplest:
A method for transferring data through the wires
Java serialization is a mechanism to store an object in a non-object form, i.e. a flat, serial stream rather than an object, so that it can be easily sent somewhere, such as to a filesystem, for example. It is also known as “marshaling”, “pickling”, “freezing” or “flattening”. Java programmers should be familiar with the concept, and with the Serializable interface, since it is required in various situations. For example, this technique is used for Oracle Coherence’s “Portable Object Format” to improve performance and support language independence.
Early Days of Java Serialization
Amazing to think that, back in the day, we used all the various tools required for distributed communication, whether simple like RMI and JMX, or more involved specs like CORBA and EJB, and we never thought much about the security aspects. I’m sure if I peruse my copy Henning and Vinoski’s definitive work on C++ and CORBA, I’ll find a chapter or so focusing on security[1], but I’m figuring, we, like everyone else, focused on the business details, getting the apps to communicate reliably, adding features, improving stability, etc, and not on whether there were any security holes, such as tricking a server into running cryptocurrency mining malware[2]. Yes, Bitcoin and the like did not even exist then.
The Biggest Wave of Remote Execution Bugs in History
Well, times change, and the twenty-year-old Java deserialization capability is the source of “nearly half of the vulnerabilities that have been patched in the JDK in the last 2 years” [3], so Oracle has plans in the works to completely revamp object serialization. Further note that this is not solely Oracle’s issue, nor is it limited to Java. Many other software vendors, and open source projects, whether tools or languages, have this weakness, such as Apache Commons Collections, Google Guava, Groovy, Jackson, and Spring.
It seems all the excitement, at least in the Java world, started when Chris Frohoff and Garbriel Lawrence presented their research on Java serialization “ultimately resulting in what can be readily described as the biggest wave of remote code execution bugs in Java history.” [6] However, it is important to note that this flaw is not limited to Java. While Frohoff and Lawrence focused on Java deserialization, Moritz Bechler wrote a paper that focuses on various Java open-source marshalling libraries:
Research into that matter indicated that these vulnerabilities are not exclusive to mechanisms as expressive as Java serialization or XStream, but some could possibly be applied to other mechanisms as well.
I think Moritz describes the heart of the issue the best:
Giving an attacker the opportunity to specify an arbitrary type to unmarshal into enables him to invoke a certain set of methods on an object of that type. Clearly the expectation is that these will be well-behaved – what could possibly go wrong?
Java deserialization
For our purposes, we focused on Java serialization and Apache Commons Collections. From the bug report COLLECTIONS-580[4]:
With InvokerTransformer serializable collections can be build that execute arbitrary Java code. sun.reflect.annotation.AnnotationInvocationHandler#readObject invokes #entrySet and #get on a deserialized collection.
If you have an endpoint that accepts serialized Java objects (JMX, RMI, remote EJB, …) you can combine the two to create arbitrary remote code execution vulnerability.
The Qualys report didn’t have much in the way of details, other than a port and the commons-collections payloads that illustrated the vulnerability, but I guessed from that info that the scanner simply uses the work done by the original folks (Frohoff and Lawrence) [5] that discovered the flaw available as the ysoserial project below.
https://www.youtube.com/watch?v=KSA7vUkXGSg
Source code here: https://github.com/frohoff/ysoserial
Now, in the flurry of trying to fix this error, given the annoyingly vague details from Qualys, I had looked at all sorts of issues, after noticing a few extra JVM arguments in the Tomcat configuration that happened to be set for the instances that were failing with this error, but were not set on other instances. Apparently someone had decided to add these, without informing our team. Interesting.
Now, remember that according to the original bug report, this exploit requires (1) untrusted deserialization, it (2) some way to send a payload, i.e. something listening on a port, such as a JMX service. In fact, These extra JVM args were for supporting remote access via JMX, so unraveling the thread, I researched Tomcat 8 vulnerabilities especially related to JMX. While it turns out that JMX is a weak point (JBoss in particular had quite a well-known major JMX flaw), I did have any luck convincing the customer that they should shut down the port. It is used to gather monitoring metrics useful in determining application performance such as CPU load, memory, and even cache information. Ok, easy but drastic solutions were off the table. I was back to the drawing board.
Next, I tried to see why it was flagging Apache collections in the first place. Going back to the ysoserial project, was it incorrectly flagging Apache Commons Collections 3.2.2, or Collections4-4.1, despite the fact that the libs were fixed? Further looking at the specific payloads, Qualys/Ysoserial was complaining about Collections 3.2.1, which limited the test scenarios to try to get working
Now here’s the interesting part: with ysoserial, I was unable to get the exploit to work, as depicted in the Marshalling Pickles video. It was failing with a strange error I hadn’t seen before, something about filter setting a “rejected” status. Now, this led me to finding info about Oracle’s critical patch update (_121). I was running with latest & greatest JDK, release _192, however our production servers were running a very out-of-date version - surprise surprise.
Apparently, with Oracle JDK at release 121 or later, Oracle has started to address this vulnerability in an official way, rather than what exists currently which is a bunch of ad-hoc solutions, mainly whitelisting/blacklisting, which is a difficult without library support. Some would call this ‘whack-a-mole’, but I think this illustrates quite well the idea of a “patch”, i.e. there’s a leak, so run over and put some tape over it, but we aren’t solving the fundamental issue. In other words, the current defense against this attach is limited because we can’t possibly know what libraries customers will use, so the library maintainer has to scramble to plug the holes whenever they are discovered. Note that even the best of libraries like Groovy, Apache and Spring have had to fix this flaw.
So kudos to Oracle for taking some much needed steps in solving this problem. Here’s a little detail on the new feature that works to make the deserialization process more secure:
The core mechanism of deserialization filtering is based on an ObjectInputFilter interface which provides a configuration capability so that incoming data streams can be validated during the deserialization process. The status check on the incoming stream is determined by Status.ALLOWED, Status.REJECTED, or Status.UNDECIDED arguments of an enum type within ObjectInputFilter interface.
https://access.redhat.com/blogs/766093/posts/3135411
While it is the “official” way to deal with the deserialization issue, it remains to be seen how well this strategy will work. As a further research project, I’m curious whether this model might be used beyond Java serialization, i.e. in projects like Jackson. Does it add anything more than Jackson already has, or does it simplify it, etc.
This feature is targeted for Java 9, but was backported to 8, though it looks like it doesn’t have all the functionality that Java 9 supports.
So you are probably wondering what happened? Did we fix all of the above, and even throw in an upgrade Tomcat, like the Monty Python “Meaning of Life” movie “everything, with a cherry on top!” Well, finally, given a little guidance on where to look, the 3rd party developers - turned out that not only had they added the JVM args, they had also added in some extra code to handle the authentication. Which used - you guessed it - the _old_ 3.2.1 version of commons-collections. This code was also manually maintained, so while the app our team maintained received the updated commons jar in an automated fashion along with all the other updates, this little bit of code, tucked away on the server, was never updated.
Lessons learned? Off-the-wall custom authentication? Don’t do this. But if you do, don’t leave manually updated chunks of code lying around, and further, keep up with the patches!
[0] Yes, I’m reading William Finnegan’s “Barbarian Days: The Surfing Life”, Finnegan’s hilarious and fascinating account of being a surfer in the early days of the sport. At one point, he complains to his friend and fellow surfer, who is getting on his nerves, that he is tired of walking on eggs around him. Of course, in his anger, he mixed up the quote, and meant “walking on eggshells”.
[1] https://en.wikipedia.org/wiki/Serialization
[2] A quick look at the omniORB doc shows it has a feature called the “Dynamic Invocation Interface…Thus using the DII applications may invoke operations on any CORBA object, possibly determining the object’s interface dynamically by using an Interface Repository.” Sounds like reflection doesn’t it? I’m not aware of any specific vulnerabilities, but it does seem we’ve traded a bit of the security that invoking statically-compiled objects brings for convenience.
https://www.cl.cam.ac.uk/research/dtg/attarchive/omniORB/doc/3.0/omniORB/omniORB011.html
[3] https://www.siliconrepublic.com/enterprise/cryptocurrency-malware-monero-secureworks
The Java Object Serialization Specification for Java references a good set of guidelines on how to mitigate the vulnerability:
https://www.oracle.com/technetwork/java/seccodeguide-139067.html#8
[4] https://www.securityinfowatch.com/cybersecurity/information-security/article/12420169/oracle-plans-to-end-java-serialization-but-thats-not-the-end-of-the-story
[5] https://issues.apache.org/jira/browse/COLLECTIONS-580
[6]Which seems to be a pretty standard strategy these days, i.e. proprietary companies like Qualys leveraging open source and adding it to their toolset. AWS does this to great effect, and we, as the consumer, benefit by getting simple interfaces. However, we should not forget that much of the code we use today is Open-source software, in some way or another.
Stratechery, as usual, has a very thoughtful post about this very idea:
It’s hard to not be sympathetic to MongoDB Inc. and Redis Labs: both spent a lot of money and effort building their products, and now Amazon is making money off of them. But that’s the thing: Amazon isn’t making money by selling software, they are making money by providing a service that enterprises value, and both MongoDB and Redis are popular in large part because they were open source to begin with.
[snip]
That, though, should give pause to AWS, Microsoft, and Google. It is hard to imagine them ever paying for open source software, but at the same time, writing (public-facing) software isn’t necessarily the core competency of their cloud businesses. They too have benefited from open-source companies: they provide the means by which their performance, scalability, and availability are realized. Right now everyone is winning: simply following economic realities could, in the long run, mean everyone is worse off.
https://stratechery.com/2019/aws-mongodb-and-the-economic-realities-of-open-source/
[7] https://www.github.com/mbechler/marshalsec/blob/master/marshalsec.pdf?raw=true
[8] https://medium.com/@cowtowncoder/on-jackson-cves-dont-panic-here-is-what-you-need-to-know-54cd0d6e8062
0 notes
Text
JAC444 Assignment 4-Object Serialization, and Swing Solved
JAC444 Assignment 4-Object Serialization, and Swing Solved
This assignment lets you practice concepts such as Object Serialization, and Swing (or Java FX) GUI. In this assignment, you will be working with some objects of a Student class (which should be serializable.) This class has fields such as stdID (int), firstName (String), lastName (String), and courses (an array or preferably an ArrayList which contains the names of the courses the student…
View On WordPress
0 notes