#Java session timeout
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs




Fun Fact
Tumblr’s website traffic is steadily declining.
Text
How do you handle session management in Java for web applications?

1. Intro to Java Session Management
So, how do you manage sessions in Java for web apps? This is a key question for developers who want to create safe and scalable applications. Session management is all about keeping track of a user's activity on a web app over time. Java has built-in tools for this using HttpSession, cookies, and URL rewriting. Learning how to handle sessions well is an important skill, and taking a Java course in Coimbatore can provide you with hands-on experience. Whether you're just starting out or looking to be a full-stack developer, getting the hang of session concepts is essential for building secure and efficient apps.
2. Understanding HttpSession in Java
So, what about HttpSession? It’s the go-to API for managing sessions in Java. It keeps track of a user's info across several HTTP requests, created by the servlet container. You can access it using request.getSession(). With it, you can store user-specific data like login details or shopping cart items. If you enroll in Java training in Coimbatore, you will learn to create and manage sessions the right way. HttpSession also has methods to end sessions and track them, making it a key part of Java web development.
3. Session Tracking Techniques
When it comes to tracking sessions, there are some common methods: cookies, URL rewriting, and hidden form fields. Cookies are small bits of data saved on the client side, while URL rewriting adds session IDs to URLs. Hidden fields are less used but are still an option. These methods are thoroughly covered in a Java Full Stack Developer Course in Coimbatore. Knowing these options helps you pick the right one for your project. Each method has its benefits based on your app's security and scalability needs.
4. Importance of Session Timeout
Managing session timeout is super important for security and user experience. You can set up timeouts in the web.xml file or by using session.setMaxInactiveInterval(). This helps avoid unused sessions from taking up server resources and lowers the risk of hijacking. Sessions automatically end after a certain time without activity. In a Java course in Coimbatore, you’ll learn how to set timeout values that fit your app's needs. Proper timeout handling is part of building secure Java applications.
5. Secure Session Management Practices
How do you ensure session management is secure in your Java web applications? Always use HTTPS, create new session IDs when a user logs in, and end sessions when they log out. Avoid keeping sensitive info in sessions. Developers taking Java training in Coimbatore learn to apply these practices in real-life projects. Good session management isn't just about saving data; it's about protecting it, which helps safeguard against threats like session fixation.
6. Storing Complex Data in Sessions
When it comes to more complex data, Java sessions can handle that too. You can store objects using session.setAttribute(), which is great for keeping user profiles and cart items. Just remember that the objects need to be serializable and avoid making the session too big. Practical lessons in a Java Full Stack Developer Course in Coimbatore often touch on these points. Good data storage practices can improve performance and keep your code clean.
7. Session Persistence and Scalability
In cases where applications are spread across multiple servers, you have to think about sharing sessions. This can be done with persistent sessions or clustering. Tools like Redis and Memcached help manage state across servers. These ideas are often covered in advanced modules of Java courses in Coimbatore. Learning about session replication and load balancing is key to scaling your app while keeping the state intact.
8. Invalidating and Cleaning Sessions
Another important part of session management is cleaning up. Properly ending sessions is crucial. You can use session.invalidate() when a user logs out to terminate a session. Also, make sure to remove unnecessary attributes to save memory. Good session cleanup is important to prevent memory leaks and keep your app running smoothly. These topics are usually explained in Java training in Coimbatore, teaching students how to manage sessions responsibly.
9. Real-world Applications of Session Management
Understanding the theory is just one part. How does session management play out in the real world? Examples include e-commerce carts, user logins, and personalized dashboards. Sessions are essential for adding a personal touch. The Java Full Stack Developer Course in Coimbatore includes practical projects where session management is used in real web apps. Learning through practical examples helps solidify the concept and prepares developers for actual job roles.
10. Conclusion with Career Opportunities
Getting a handle on session management in Java can really open up job opportunities in backend or full-stack roles. With a solid grasp of HttpSession, tracking methods, and security measures, you'll be able to build secure applications. Whether you’re taking a Java course in Coimbatore or pursuing a full-stack course, this is a key topic you shouldn't overlook. At Xplore IT Corp, we focus on making sure our students are ready for the industry with practical session handling skills and more.
FAQs
1. What’s a session in Java web applications?
A session tracks a single user's activity with a web app over multiple requests and keeps user-specific info.
2. How do I create a session in Java?
You can create one using request.getSession() in servlet-based apps.
3. How do I expire a session in Java?
Use session.invalidate() to end it or set a timeout with setMaxInactiveInterval().
4. What are the options other than HttpSession?
You can use cookies, URL rewriting, hidden fields, or client-side storage depending on what you need.
5. Why is secure session management important?
To protect against threats like session hijacking and to keep user data safe.
#ava servlet session#Java web security#Java session timeout#Session tracking in Java#Cookies in Java#URL rewriting in Java#HttpSession methods#Java EE sessions#Serializable Java object#Java backend development
0 notes
Text
Price: [price_with_discount] (as of [price_update_date] - Details) [ad_1] 1.Java Networking Network Basics and Socket overview, TCP/IP client sockets, URL, TCP/IP server sockets, Datagrams, java.net package Socket, ServerSocket, InetAddress, URL, URLConnection. (Chapter - 1) 2.JDBC Programming The JDBC Connectivity Model, Database Programming : Connecting to the Database, Creating a SQL Query, Getting the Results, Updating Database Data, Error Checking and the SQLException Class, The SQLWarning Class, The Statement Interface, PreparedStatement, CallableStatement The ResultSet Interface, Updatable Result Sets, JDBC Types, Executing SQL Queries, ResultSetMetaData, Executing SQL Updates, Transaction Management. (Chapter - 2) 3.Servlet API and Overview Servlet Model : Overview of Servlet, Servlet Life Cycle, HTTP Methods Structure and Deployment descriptor ServletContext and ServletConfig interface, Attributes in Servlet, Request Dispacher interface. The Filter API: Filter, FilterChain, Filter Config Cookies and Session Management : Understanding state and session, Understanding Session Timeout and Session Tracking, URL Rewriting. (Chapter - 3) 4.Java Server Pages JSP Overview: The Problem with Servlets, Life Cycle of JSP Page, JSP Processing, JSP Application Design with MVC, Setting Up the JSP Environment, JSP Directives, JSP Action, JSP Implicit Objects JSP Form Processing, JSP Session and Cookies Handling, JSP Session Tracking JSP Database Access, JSP Standard Tag Libraries, JSP Custom Tag, JSP Expression Language, JSP Exception Handling, JSP XML Processing. (Chapter - 4) 5.Java Server Faces 2.0 Introduction to JSF, JSF request processing Life cycle, JSF Expression Language, JSF Standard Component, JSF Facelets Tag, JSF Convertor Tag, JSF Validation Tag, JSF Event Handling and Database Access, JSF Libraries : PrimeFaces. (Chapter - 5) 6.Hibernate 4.0 Overview of Hibernate, Hibernate Architecture, Hibernate Mapping Types, Hibernate O/R Mapping, Hibernate Annotation, Hibernate Query Language. (Chapter - 6) 7.Java Web Frameworks . Publisher : Technical Publications; First Edition (1 January 2021) Language : English Paperback : 392 pages ISBN-10 : 9333221638 ISBN-13 : 978-9333221634 Item Weight : 520 g Dimensions : 24 x 18.3 x 1.5 cm Country of Origin : India Generic Name : Books [ad_2]
0 notes
Text
Top 10 Selenium interview questions
Top 10 Selenium Interview Questions
Selenium is a widely used open-source automation testing framework that has become an essential tool for software quality assurance professionals. If you're preparing for a job interview in the field of test automation or software testing, you're likely to encounter questions related to Selenium. To help you succeed in your interview, we've compiled a list of the top 10 Selenium interview questions along with detailed answers.
Question 1: What is Selenium?
Answer: Selenium is an open-source tool primarily used for automating web applications for testing purposes. It provides a platform-independent framework for automating web browsers like Chrome, Firefox, Safari, Edge, and more. Selenium supports various programming languages like Java, Python, C#, and others, making it versatile and widely adopted in the industry.
Question 2: Explain the components of Selenium.
Answer: Selenium consists of four main components:
Selenium WebDriver: WebDriver is the core component that provides APIs for interacting with web browsers programmatically. It allows testers to automate user interactions with web elements like clicking buttons, filling forms, and navigating between web pages.
Selenium IDE: Selenium Integrated Development Environment (IDE) is a browser extension that records and plays back user interactions with a web application. It's primarily used for creating test cases quickly, making it suitable for beginners.
Selenium Grid: Selenium Grid is used for parallel test execution on multiple machines and browsers simultaneously. It allows you to distribute test cases across different environments, reducing test execution time.
Selenium RC (Remote Control): Selenium RC is an outdated component that has been replaced by WebDriver. It allowed users to write tests in various programming languages, but it had limitations that WebDriver addressed.
Question 3: What is the difference between findElement() and findElements() in Selenium WebDriver?
Answer:
findElement(): This method is used to locate and return the first web element that matches the specified criteria (e.g., by ID, name, XPath, etc.). If no matching element is found, it throws a NoSuchElementException.
findElements(): This method is used to locate and return a list of all web elements that match the specified criteria. If no matching elements are found, it returns an empty list. It does not throw an exception.
Question 4: Explain the difference between implicit wait and explicit wait in Selenium.
Answer:
Implicit Wait: Implicit wait is a global wait applied throughout the WebDriver session. It instructs the WebDriver to wait for a specified amount of time before throwing an exception if an element is not immediately available. It is set using the driver.manage().timeouts().implicitlyWait() method.
Explicit Wait: Explicit wait is a more precise and flexible wait mechanism. It allows you to wait for a specific condition to be met before proceeding with the execution. You can use conditions like element visibility, element clickability, or custom conditions with explicit waits. It is implemented using the WebDriverWait class and ExpectedConditions in Selenium.
Question 5: What is Selenium Grid, and how does it work?
Answer: Selenium Grid is a tool used for parallel test execution across multiple machines and browsers. It consists of a hub and multiple nodes. The hub acts as a central control point, while the nodes are the machines where the tests are executed. Here's how it works:
The test scripts are written to interact with the hub.
The hub routes the test scripts to the appropriate node based on the desired browser and platform configurations.
The tests are executed concurrently on multiple nodes, improving test execution speed.
Test results are collected and reported back to the hub, which can then be analyzed.
Selenium Grid is beneficial for cross-browser testing and speeding up test execution in a distributed environment.
Question 6: What is the Page Object Model (POM), and why is it used in Selenium?
Answer: The Page Object Model (POM) is a design pattern used in Selenium to enhance test maintainability and reusability. In POM:
Each web page is represented as a separate class.
Web elements on a page are defined as variables in the corresponding class.
Actions and interactions with these elements are encapsulated as methods within the class.
Test scripts interact with the web page through these methods rather than directly interacting with the web elements.
POM helps in separating test code from page-specific code, making the codebase cleaner and easier to maintain. It also promotes code reusability since changes to a page's structure or functionality only require updates in the corresponding page class.
Question 7: How do you handle dynamic elements in Selenium?
Answer: Dynamic elements are elements on a web page that change their attributes or properties after page load or based on user interactions. To handle dynamic elements:
Explicit Waits: Use explicit waits with conditions like element visibility or element presence to wait for the element to become stable before interacting with it.
Unique Attributes: Identify elements using attributes that are less likely to change, such as CSS classes, data attributes, or unique combinations of attributes.
XPath and CSS Selectors: Use dynamic XPath or CSS selectors that can adapt to changing attributes. For example, you can use contains(), starts-with(), or ends-with() functions in XPath.
Javascript Execution: In some cases, you can use JavaScript to interact with dynamic elements by executing JavaScript code that manipulates the element.
Handling dynamic elements requires a combination of these techniques, depending on the specific scenario.
Question 8: What are the advantages of using TestNG with Selenium?
Answer: TestNG (Test Next Generation) is a popular testing framework in the Java ecosystem often used in conjunction with Selenium. Some advantages of using TestNG with Selenium include:
Parallel Test Execution: TestNG allows you to execute tests in parallel across multiple threads and browsers, significantly reducing test execution time.
Test Dependencies: You can define dependencies between test methods, ensuring that tests run in a specific order.
Annotations: TestNG provides annotations like @BeforeTest, @AfterTest, @BeforeMethod, and @AfterMethod that simplify test setup and teardown.
Parameterization: TestNG supports parameterization of test methods, enabling you to run the same test with different sets of data.
Reporting: It generates detailed HTML reports with test results and logs, making it easier to analyze test execution.
Question 9: How do you handle pop-up windows and alerts in Selenium?
Answer: Handling pop-up windows and alerts in Selenium can be done using the Alert interface and the SwitchTo class. Here are the basic steps:
Alerts: To handle JavaScript alerts, confirmations, and prompts, you can use the Alert interface. You can switch to an alert using driver.switchTo().alert(), and then you can accept, dismiss, or enter text into the alert.
Pop-Up Windows: For handling pop-up windows, you can switch the WebDriver focus to the new window using driver.switchTo().window(windowHandle), where windowHandle is the handle of the new window. You can obtain window handles using driver.getWindowHandles().
Frames: To work with frames or iframes within a web page, you can use driver.switchTo().frame(frameLocator) to switch the focus
to the desired frame. You can switch back to the default content using driver.switchTo().defaultContent().
Here's a code example for handling an alert:
javaCopy code
// Switch to the alert Alert alert = driver.switchTo().alert(); // Get the alert text String alertText = alert.getText(); // Accept the alert alert.accept();
And here's an example for switching to a new window:
javaCopy code
// Get the current window handle String currentWindowHandle = driver.getWindowHandle(); // Perform an action that opens a new window // Switch to the new window for (String windowHandle : driver.getWindowHandles()) { if (!windowHandle.equals(currentWindowHandle)) { driver.switchTo().window(windowHandle); break; } } // Perform actions in the new window // Close the new window and switch back to the original window driver.close(); driver.switchTo().window(currentWindowHandle);
Question 10: What are the common challenges in Selenium automation testing?
Answer: Selenium automation testing comes with several challenges, including:
Browser Compatibility: Ensuring that your tests work consistently across different web browsers and versions can be challenging due to browser-specific behaviors and inconsistencies.
Dynamic Elements: Handling dynamic elements that change their attributes or positions on the web page can be complex and requires effective strategies.
Performance Testing: Selenium is primarily used for functional testing, and conducting performance testing (e.g., load testing) might require additional tools or frameworks.
Test Data Management: Managing test data, especially in automated testing, can be a significant challenge. Test data should be well-organized, and the environment should be maintained consistently.
Test Maintenance: As the application evolves, test scripts may need frequent updates. Ensuring that automation scripts remain up-to-date and relevant can be a continuous effort.
Test Execution Speed: Selenium tests can be time-consuming, especially when running a large number of test cases. Parallel execution and distributed testing with Selenium Grid can address this issue.
Reporting and Analysis: Creating meaningful test reports and analyzing test results can be complex, especially when dealing with a large number of test cases and data sets.
Test Framework Selection: Choosing the right test framework, programming language, and tools for test automation can be critical to the success of your automation efforts.
In conclusion, Selenium is a powerful tool for automating web applications, and mastering it can open doors to exciting career opportunities in software testing and quality assurance. Preparing for Selenium interviews involves not only answering technical questions but also demonstrating your practical knowledge and problem-solving skills. By studying these top 10 Selenium interview questions and their answers, you'll be better equipped to impress potential employers and secure your dream job in the world of automation testing. Good luck with your interview preparations!
0 notes
Text
“Selenium Automation Framework: Streamlining Web Testing Efforts”
Certainly, I’m excited to explore the world of Selenium with you. My knowledge and expertise in this field have grown significantly over time. Selenium is a widely recognized and extensively used practice across various industries.

A Selenium automation framework serves as an organized set of principles, best practices, and reusable components designed for test automation using Selenium, an open-source web automation tool. This framework simplifies the process of creating, developing, and maintaining automated tests, making it more efficient and manageable.
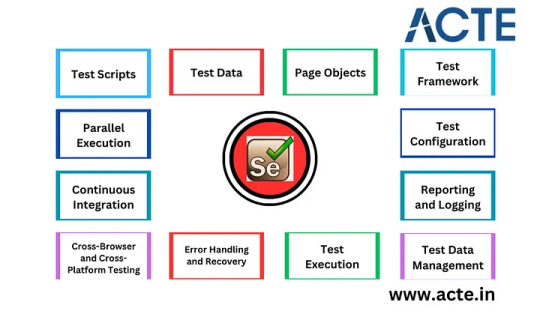
It typically comprises the following fundamental elements:
1. Test Scripts: These are the actual test cases scripted in programming languages like Java, C#, Python, or Ruby, utilizing Selenium’s API. These scripts define the interactions with web elements to simulate user actions and validate expected behaviors.
2. Test Data: This includes the input data necessary for test cases, encompassing valid and invalid datasets. It’s often stored separately from the test scripts for easy modification and reuse.
3. Page Objects: Following the design pattern, page objects separate the web page structure and elements from the test logic. They represent web pages and encapsulate interactions with elements, enhancing maintainability and reusability.
4. Test Framework: The underlying structure that manages test cases, reporting, and execution control. Common test frameworks employed with Selenium include TestNG, JUnit, or other custom frameworks.
5. Test Configuration: This element comprises parameters and settings used to configure test runs, such as browser type, URL, timeouts, and environment-specific details. Configuration details are often stored in property or configuration files.
6. Reporting and Logging: Frameworks often include tools for generating detailed reports of test execution results, aiding testers and stakeholders in understanding test outcomes and identifying issues. Logging is essential for recording additional information for debugging purposes.
7. Test Data Management: This component encompasses tools and mechanisms for managing test data, which can include data generation, data-driven testing, or connecting to databases and external data sources.
8. Test Execution: The framework manages test execution, including initiating and closing browser sessions, configuring the test environment, and executing test cases in parallel when necessary.
9. Error Handling and Recovery: A well-structured framework includes mechanisms for handling unexpected exceptions during test execution and offers strategies for recovering from failures.
10. Cross-Browser and Cross-Platform Testing: The framework should support running tests on multiple web browsers (e.g., Chrome, Firefox, Edge) and platforms (e.g., Windows, macOS, Linux).
11. Continuous Integration Integration: Integration with CI/CD (Continuous Integration/Continuous Delivery) systems such as Jenkins, Travis CI, or CircleCI ensures automated test execution as part of the development pipeline.
12. Parallel Execution: The framework should be capable of running tests concurrently, reducing test execution time and enhancing efficiency.
Various types of Selenium frameworks are available, including data-driven, keyword-driven, behavior-driven (using tools like Cucumber), and hybrid frameworks that combine elements of multiple approaches. The choice of framework depends on the project’s requirements and the team’s preferences.
In summary, a Selenium automation framework is a vital component of Selenium test automation that streamlines test design, maintenance, and execution. It ensures that automated tests are well-structured, maintainable, and scalable, thereby contributing to efficient software testing processes.
If you’re eager to explore the world of the Selenium Course, I highly recommend considering ACTE Technologies. They provide certification programs and job placement opportunities, guided by experienced instructors to enrich your learning journey. These resources are available both online and in person. If this aligns with your interests, taking a step-by-step approach and considering enrollment in a course could be a beneficial decision.
I believe this response effectively addresses your inquiry. If you have additional questions or need further clarification, please don’t hesitate to ask in the comments section.
If you’ve found this response valuable, I kindly invite you to follow me on this platform and give it an upvote to encourage further discussions and insights about Selenium. Your time and engagement are genuinely appreciated, and I extend my best wishes for a wonderful day ahead.
0 notes
Text
Apache Httpclient Ssl

Apache Httpclient Download
Apache Httpclient Ssl File
Apache Httpclient Ssl Verification
Apache Httpclient Example
In fact Java has had its own built-in HTTP client: HttpURLConnection since JDK1.1 (even the super-class, URLConnection is already exists since JDK1.0). But I believed most of us will use HttpComponents Client from Apache, which I also used in below example.
HttpClient does not come with support for SSL/TLS because it doesn't have to. Both security protocols are for the transport layer, while the HTTP protocol operates on top of the transport layer. You can mix and match HttpClient with any independent SSL/TLS implementation. Our SSL/TLS guide explains how to do this.
Apache httpclient ssl certificate authentication Apache HTTP Client: Client-Side SSL Certificate, It's not a surprise that client-side SSL certificates (also known as two-way SSL or mutual SSL authentication) is doable, but of course, being Unlimited Servers No Extra Cost. Award Winning - Quick & Easy Setup.
Basic Configuration Example. Your SSL configuration will need to contain, at minimum, the following directives. LoadModule sslmodule modules/modssl.so Listen 443 ServerName www.example.com SSLEngine on SSLCertificateFile '/path/to/www.example.com.cert' SSLCertificateKeyFile '/path/to/www.example.com.key'.
Apache Httpclient Download
The Hyper-Text Transfer Protocol (HTTP) is perhaps the most significant protocol used on the Internet today. Web services, network-enabled appliances and the growth of network computing continue to expand the role of the HTTP protocol beyond user-driven web browsers, while increasing the number of applications that require HTTP support.
Although the java.net package provides basic functionality for accessing resources via HTTP, it doesn’t provide the full flexibility or functionality needed by many applications. HttpClient seeks to fill this void by providing an efficient, up-to-date, and feature-rich package implementing the client side of the most recent HTTP standards and recommendations.
Designed for extension while providing robust support for the base HTTP protocol, HttpClient may be of interest to anyone building HTTP-aware client applications such as web browsers, web service clients, or systems that leverage or extend the HTTP protocol for distributed communication.
Documentation
Quick Start - contains a simple, complete example of an HTTP GET and POST with parameters.
HttpClient Tutorial (PDF)
HttpClient Examples - a set of examples demonstrating some of the more complex use scenarios.
HttpClient Primer - explains the scope of HttpClient. Note that HttpClient is not a browser. It lacks the UI, HTML renderer and a JavaScript engine that a browser will possess.
Javadocs
API compatibility reports
Apache Httpclient Ssl File
Features
Apache Httpclient Ssl Verification
Standards based, pure Java, implementation of HTTP versions 1.0 and 1.1
Full implementation of all HTTP methods (GET, POST, PUT, DELETE, HEAD, OPTIONS, and TRACE) in an extensible OO framework.
Supports encryption with HTTPS (HTTP over SSL) protocol.
Transparent connections through HTTP proxies.
Tunneled HTTPS connections through HTTP proxies, via the CONNECT method.
Basic, Digest, NTLMv1, NTLMv2, NTLM2 Session, SNPNEGO, Kerberos authentication schemes.
Plug-in mechanism for custom authentication schemes.
Pluggable secure socket factories, making it easier to use third party solutions
Connection management support for use in multi-threaded applications. Supports setting the maximum total connections as well as the maximum connections per host. Detects and closes stale connections.
Automatic Cookie handling for reading Set-Cookie: headers from the server and sending them back out in a Cookie header when appropriate.
Plug-in mechanism for custom cookie policies.
Request output streams to avoid buffering any content body by streaming directly to the socket to the server.
Response input streams to efficiently read the response body by streaming directly from the socket to the server.
Persistent connections using KeepAlive in HTTP/1.0 and persistance in HTTP/1.1
Direct access to the response code and headers sent by the server.
The ability to set connection timeouts.
Support for HTTP/1.1 response caching.
Source code is freely available under the Apache License.
Standards Compliance
Apache Httpclient Example
HttpClient strives to conform to the following specifications endorsed by the Internet Engineering Task Force (IETF) and the internet at large:
RFC 1945 - Hypertext Transfer Protocol – HTTP/1.0
RFC 2616 - Hypertext Transfer Protocol – HTTP/1.1
RFC 2617 - HTTP Authentication: Basic and Digest Access Authentication
RFC 2396 - Uniform Resource Identifiers (URI): Generic Syntax
RFC 6265 - HTTP State Management Mechanism (Cookies)
1 note
·
View note
Text
Leading 10 Internet Scraping Devices For Reliable Data Extraction In 2023
It likewise provides fantastic support help through conversation, e-mail as well as also over a telephone call. Prospects.io provides 2 kinds of prices plans, one is for Beginners and the other is for experts. The strategies can be paid either monthly or yearly however for the expert plan, you require to ask for a demo.
DASSAULT SYSTÈMES PRIVACY POLICY - discover.3ds.com
DASSAULT SYSTÈMES PRIVACY POLICY.
Posted: Wed, 26 Oct 2022 07:00:00 GMT [source]
You can export your information in JSON or CSV styles and also effortlessly incorporate it with NodeJS, Cheerio, Python Selenium, as well as Python Scrapy Combination. Shifter.io is a leading supplier of on-line proxy solutions with among the biggest residential proxy networks available. Additionally, the website offers a banner at the top of the https://public.sitejot.com/gjwhana987.html page that makes it possible for clients to pick in which language they 'd like to view the web site. Even the firm's Products navigation food selection consists of how the item can "Get Your Business Online" and "Market Your Company". Providing a lot valuable, fascinating content free of charge is a superb instance of reliable B2B advertising, which should constantly supply worth prior to it attempts to remove it. Adobe is successful on the application due to the fact that it creates engaging content specifically provided for TikTok's audience.
youtube
Extracting Details From Tables
You can likewise set up crawls or cause them via API, as well as connect to significant storage space platforms. It sustains shows languages such as Node.js, Java, C#, Python, VB, PHP, Ruby, and Perl. Furthermore, it provides customized search specifications, geolocation, time range, safe setting, and other features. The device additionally provides geotargeting with as much as 195 places, rotating proxies, and advanced abilities for avoiding captcha, fingerprinting, and also IP blocking. With easy modification of headers, sticky sessions, and also timeout limitations, it's easy to customize your scraping to your details requirements. Whether you're a beginner or an experienced information expert, our detailed guide will aid you find the very best web scraping tool for your demands.
Increased competitors amongst marketing professionals has actually made it required for services to keep an eye on rival's rates approaches. Customers are continuously trying to find the best services or product at the most affordable rate. All these variables motivate organizations to perform item prices contrast consisting of sales and discount costs, rate history, and also many more. Since manually locating such vast data can be an overwhelming task, executing internet scrapers can automate marketing research to extract accurate information in genuine time. The Byteline no-code internet scraper saves even more time by quickly automating processes across your cloud services.
Select Your Marketing Mix (or The 4 Ps Of Advertising)
You can accomplish this by manually including the addresses to your list or by utilizing a tool that will certainly do it for you. Essence the leads from any type of LinkedIn or Sales Navigator search and also send them directly to possibility listing. The list of Instagram e-mail scrapers is Hunter, Skyrapp.io, SalesQL.com, Kendo, Getprospect.io, and also a lot more. The checklist of e-mail extractors from internet sites is Zoominfo, Skyrapp.io, Octoparse, Hunter.io, Rocket reach, and much more. Sales Navigator is the best technique to fulfill the demands of the modern-day sales associates these days. Whether it is performing sales prospecting or shutting deals with this application both the processes have actually taken one action in the direction of providing a reliable outcome.
Just how do I gather e-mails for associate advertising and marketing?
So, this is definitely an outstanding opportunity to gain some added funds. You can get your repayment after 45 days by means of PayPal after every successful referral conversion. Zyte is result-driven, and also its proxy server is among the most made use of and also reliable web servers when compared across various ranges of API systems. It has a fast, automated, and straightforward data junking and also web combination, which or else verifies to be very pricey as well as ineffective as a result of manual work as well as scaling problems. Closing is an integral part of the email where you can once again link to your target market. An effective closing urges individuals to ask inquiries as well as enter contact.
The Utmost Overview To B2b Advertising In 2023 [+ Brand-new Information] What Is B2b Marketing?
Some websites have them as they are, while others may have them named arbitrarily, in the footer, or behind a picture. We present our CRM monitoring method to increase your efficiency and remain organized. Two various other plans to improve 5,000 leads or 20,000 leads/month are likewise offered at EUR49 and also EUR99/month specifically. Evaboot permits you to discover the contacts of your target straight from LinkedIn and after that import the data received in csv straight right into your Sales Automation options. Lemlist makes it SEO scraping for improved search engine rankings very easy to create HYPER-customized multi-channel Cold Email as well as LinkedIn sequences many thanks to the Liquid language and personalized picture options. Below are the guidelines that would extract general info and all blog post details from ScrapingBee's blog.
Your recipient demands to really feel vital, so ensure your e-mail is custom-tailored to the target market you are especially sending the email to. Fire a message to simply link you to the relevant person, and also they will enjoy to do so. Just make sure that your e-mail trademark states your objective of connecting or you may be disregarded.
Spend more time connecting with your followers with our time-saving collection of social tools.
The video clip asked its audience, Who is a creative TikToker we should know about?
10.1% increase in associate marketing spending in the United States each year; by 2020, that number will certainly get to $6.8 billion.
Import.io is an user-friendly internet scratching tool that simplifies information extraction from any kind of web page as well as exports it to CSV for easy combination right into applications using APIs as well as webhooks.
Several business utilize web scraping to develop substantial databases and also remove industry-specific understandings from them.
There are lots of ways internet scraping services can benefit your advertising initiatives; however, in this specific article, we will certainly speak about what an excellent device information scraping is for associate advertising and marketing. A lot more particularly, we'll check into methods you can make use of e-mail advertising and marketing for affiliate https://www.eater.com/users/ofeithbknd advertising and marketing by leveraging the power of internet scratching. While information removal is an essential process, it can be complicated and also untidy, commonly calling for a considerable quantity of time as well as effort to accomplish. This is where web scrapers can be found in useful, as they can remove structured information and also web content from a web site by examining the underlying HTML code and also information stored in a data source. To help you select the ideal internet scraping tool, we have actually assembled a checklist of the leading 10 ideal web scuffing devices based on their attributes, pricing, as well as ease-of-use. Our listing covers a broad variety of internet scratching devices, from straightforward browser expansions to effective enterprise-level services, so you can pick the one that best suits your requirements.
0 notes
Text
The Platform To Power up Synchronized Digital Experiences In Real-Time With Socket io

Our everyday digital experiences are in the midst of a real-time revolution. Whether attending an event in a virtual venue, or receiving real-time financial information, or monitoring live car performance data – consumers simply expect realtime digital experience as standard.
What Socket.IO is Socket.IO is a library that enables low-latency, bi-directional and event-based communication between a client and a server.
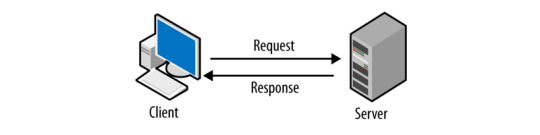
It is built on top of the WebSocket protocol and provides additional guarantees, like fallback to HTTP and HTTPS long-polling or automatic reconnection. WebSocket is a communication protocol which provides a full-duplex and low-latency channel between the server and the browser.
There are several Socket.IO server implementations available:
JavaScript (which can be run either on the browser, in Node.js or in React Native)
Java: https://github.com/socketio/socket.io-client-java
C++: https://github.com/socketio/socket.io-client-cpp
Swift: https://github.com/socketio/socket.io-client-swift
Dart: https://github.com/rikulo/socket.io-client-dart
Python: https://github.com/miguelgrinberg/python-socketio
.Net: https://github.com/doghappy/socket.io-client-csharp
Rust: https://github.com/1c3t3a/rust-socketio
Kotlin: https://github.com/icerockdev/moko-socket-io
Installation steps
API
Source code
App Development Tips From Our Experienced Developer. Also, check some of the tips shared by our developers who have experience working with top developing tools to create mobile applications with Socket.IO. Being the best mobile app development company.
What Socket.IO is not
Although Socket.IO indeed uses WebSocket for transport when possible, it adds additional metadata to each packet. That is why a WebSocket client will not be able to successfully connect to a Socket.IO server, and a Socket.IO client will not be able to connect to a plain WebSocket server either.
Reliability
Connections are established even in the presence of:
proxies and load balancers.
personal firewall and antivirus software.
For this purpose, it relies on Engine.IO, which first establishes a long-polling connection, then tries to upgrade to better transports that are “tested” on the side, like WebSocket. Please see the Goals section for more information.
Auto-reconnection support Unless instructed, otherwise a disconnected client will try to reconnect forever, until the server is available again. Please see the available reconnection options here.
Disconnection detection A heartbeat mechanism is implemented at the Engine.IO level, allowing both the server and the client to know when the other one is not responding anymore.
That functionality is achieved with timers set on both the server and the client, with timeout values (the pingInterval and pingTimeout parameters) shared during the connection handshake. Those timers require any subsequent client calls to be directed to the same server, hence the sticky-session requirement when using multiple nodes.
Binary support
Any serializable data structures can be emitted, including:
ArrayBuffer and Blob in the browser
ArrayBuffer and Buffer in Node.js
Let’s conclude This module provides an easy and reliable way to set up a WebRTC connection between peers, and communicates using events (the socket.io-protocol). Socket.IO is used to transport signaling data; and as a fallback for clients where WebRTC PeerConnection is not supported.
Well, that’s how to integrate socket IO on many platforms . The package made it all easy. Thank you for reading, give it a clap or buy me a coffee!
Source:
#Soket IO#mobile app development company#create mobile applications#Expert App Development#iOS App Development#Hire App Developer#Hire mobile app developer#mobile app development services#9series
0 notes
Text
The Platform To Power up Synchronized Digital Experiences In Real-Time With Socket io

Our everyday digital experiences are in the midst of a real-time revolution. Whether attending an event in a virtual venue, or receiving real-time financial information, or monitoring live car performance data – consumers simply expect realtime digital experience as standard.
What Socket.IO is Socket.IO is a library that enables low-latency, bi-directional and event-based communication between a client and a server.
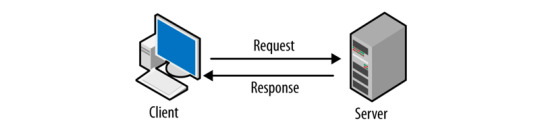
It is built on top of the WebSocket protocol and provides additional guarantees, like fallback to HTTP and HTTPS long-polling or automatic reconnection. WebSocket is a communication protocol which provides a full-duplex and low-latency channel between the server and the browser.
There are several Socket.IO server implementations available:
JavaScript (which can be run either on the browser, in Node.js or in React Native)
Installation steps
API
Source code
Java: https://github.com/socketio/socket.io-client-java
C++: https://github.com/socketio/socket.io-client-cpp
Swift: https://github.com/socketio/socket.io-client-swift
Dart: https://github.com/rikulo/socket.io-client-dart
Python: https://github.com/miguelgrinberg/python-socketio
.Net: https://github.com/doghappy/socket.io-client-csharp
Rust: https://github.com/1c3t3a/rust-socketio
Kotlin: https://github.com/icerockdev/moko-socket-io
App Development Tips From Our Experienced Developer. Also, check some of the tips shared by our developers who have experience working with top developing tools to create mobile applications with Socket.IO. Being the best mobile app development company.
What Socket.IO is not
Although Socket.IO indeed uses WebSocket for transport when possible, it adds additional metadata to each packet. That is why a WebSocket client will not be able to successfully connect to a Socket.IO server, and a Socket.IO client will not be able to connect to a plain WebSocket server either.
Reliability
Connections are established even in the presence of:
proxies and load balancers.
personal firewall and antivirus software.
For this purpose, it relies on Engine.IO, which first establishes a long-polling connection, then tries to upgrade to better transports that are “tested” on the side, like WebSocket. Please see the Goals section for more information.
Auto-reconnection support Unless instructed, otherwise a disconnected client will try to reconnect forever, until the server is available again. Please see the available reconnection options here.
Disconnection detection A heartbeat mechanism is implemented at the Engine.IO level, allowing both the server and the client to know when the other one is not responding anymore.
That functionality is achieved with timers set on both the server and the client, with timeout values (the pingInterval and pingTimeout parameters) shared during the connection handshake. Those timers require any subsequent client calls to be directed to the same server, hence the sticky-session requirement when using multiple nodes.
Binary support
Any serializable data structures can be emitted, including:
ArrayBuffer and Blob in the browser
ArrayBuffer and Buffer in Node.js
Let’s conclude This module provides an easy and reliable way to set up a WebRTC connection between peers, and communicates using events (the socket.io-protocol). Socket.IO is used to transport signaling data; and as a fallback for clients where WebRTC PeerConnection is not supported.
Well, that’s how to integrate socket IO on many platforms . The package made it all easy. Thank you for reading, give it a clap or buy me a coffee!
Feel free to get in touch with us.
Source: 9series
#Socket IO#create mobile applications#mobile app development#Expert App Development#create apps with Soketio#hire app developer#hire mobile app developer#iOS#Android#Developer#9series
0 notes
Text
Top 10 Selenium interview questions
Top 10 Selenium Interview Questions
Selenium is a widely used open-source automation testing framework that has become an essential tool for software quality assurance professionals. If you're preparing for a job interview in the field of test automation or software testing, you're likely to encounter questions related to Selenium. To help you succeed in your interview, we've compiled a list of the top 10 Selenium interview questions along with detailed answers.
Question 1: What is Selenium?
Answer: Selenium is an open-source tool primarily used for automating web applications for testing purposes. It provides a platform-independent framework for automating web browsers like Chrome, Firefox, Safari, Edge, and more. Selenium supports various programming languages like Java, Python, C#, and others, making it versatile and widely adopted in the industry.
Question 2: Explain the components of Selenium.
Answer: Selenium consists of four main components:
Selenium WebDriver: WebDriver is the core component that provides APIs for interacting with web browsers programmatically. It allows testers to automate user interactions with web elements like clicking buttons, filling forms, and navigating between web pages.
Selenium IDE: Selenium Integrated Development Environment (IDE) is a browser extension that records and plays back user interactions with a web application. It's primarily used for creating test cases quickly, making it suitable for beginners.
Selenium Grid: Selenium Grid is used for parallel test execution on multiple machines and browsers simultaneously. It allows you to distribute test cases across different environments, reducing test execution time.
Selenium RC (Remote Control): Selenium RC is an outdated component that has been replaced by WebDriver. It allowed users to write tests in various programming languages, but it had limitations that WebDriver addressed.
Question 3: What is the difference between findElement() and findElements() in Selenium WebDriver?
Answer:
findElement(): This method is used to locate and return the first web element that matches the specified criteria (e.g., by ID, name, XPath, etc.). If no matching element is found, it throws a NoSuchElementException.
findElements(): This method is used to locate and return a list of all web elements that match the specified criteria. If no matching elements are found, it returns an empty list. It does not throw an exception.
Question 4: Explain the difference between implicit wait and explicit wait in Selenium.
Answer:
Implicit Wait: Implicit wait is a global wait applied throughout the WebDriver session. It instructs the WebDriver to wait for a specified amount of time before throwing an exception if an element is not immediately available. It is set using the driver.manage().timeouts().implicitlyWait() method.
Explicit Wait: Explicit wait is a more precise and flexible wait mechanism. It allows you to wait for a specific condition to be met before proceeding with the execution. You can use conditions like element visibility, element clickability, or custom conditions with explicit waits. It is implemented using the WebDriverWait class and ExpectedConditions in Selenium.
Question 5: What is Selenium Grid, and how does it work?
Answer: Selenium Grid is a tool used for parallel test execution across multiple machines and browsers. It consists of a hub and multiple nodes. The hub acts as a central control point, while the nodes are the machines where the tests are executed. Here's how it works:
The test scripts are written to interact with the hub.
The hub routes the test scripts to the appropriate node based on the desired browser and platform configurations.
The tests are executed concurrently on multiple nodes, improving test execution speed.
Test results are collected and reported back to the hub, which can then be analyzed.
Selenium Grid is beneficial for cross-browser testing and speeding up test execution in a distributed environment.
Question 6: What is the Page Object Model (POM), and why is it used in Selenium?
Answer: The Page Object Model (POM) is a design pattern used in Selenium to enhance test maintainability and reusability. In POM:
Each web page is represented as a separate class.
Web elements on a page are defined as variables in the corresponding class.
Actions and interactions with these elements are encapsulated as methods within the class.
Test scripts interact with the web page through these methods rather than directly interacting with the web elements.
POM helps in separating test code from page-specific code, making the codebase cleaner and easier to maintain. It also promotes code reusability since changes to a page's structure or functionality only require updates in the corresponding page class.
Question 7: How do you handle dynamic elements in Selenium?
Answer: Dynamic elements are elements on a web page that change their attributes or properties after page load or based on user interactions. To handle dynamic elements:
Explicit Waits: Use explicit waits with conditions like element visibility or element presence to wait for the element to become stable before interacting with it.
Unique Attributes: Identify elements using attributes that are less likely to change, such as CSS classes, data attributes, or unique combinations of attributes.
XPath and CSS Selectors: Use dynamic XPath or CSS selectors that can adapt to changing attributes. For example, you can use contains(), starts-with(), or ends-with() functions in XPath.
Javascript Execution: In some cases, you can use JavaScript to interact with dynamic elements by executing JavaScript code that manipulates the element.
Handling dynamic elements requires a combination of these techniques, depending on the specific scenario.
Question 8: What are the advantages of using TestNG with Selenium?
Answer: TestNG (Test Next Generation) is a popular testing framework in the Java ecosystem often used in conjunction with Selenium. Some advantages of using TestNG with Selenium include:
Parallel Test Execution: TestNG allows you to execute tests in parallel across multiple threads and browsers, significantly reducing test execution time.
Test Dependencies: You can define dependencies between test methods, ensuring that tests run in a specific order.
Annotations: TestNG provides annotations like @BeforeTest, @AfterTest, @BeforeMethod, and @AfterMethod that simplify test setup and teardown.
Parameterization: TestNG supports parameterization of test methods, enabling you to run the same test with different sets of data.
Reporting: It generates detailed HTML reports with test results and logs, making it easier to analyze test execution.
Question 9: How do you handle pop-up windows and alerts in Selenium?
Answer: Handling pop-up windows and alerts in Selenium can be done using the Alert interface and the SwitchTo class. Here are the basic steps:
Alerts: To handle JavaScript alerts, confirmations, and prompts, you can use the Alert interface. You can switch to an alert using driver.switchTo().alert(), and then you can accept, dismiss, or enter text into the alert.
Pop-Up Windows: For handling pop-up windows, you can switch the WebDriver focus to the new window using driver.switchTo().window(windowHandle), where windowHandle is the handle of the new window. You can obtain window handles using driver.getWindowHandles().
Frames: To work with frames or iframes within a web page, you can use driver.switchTo().frame(frameLocator) to switch the focus
to the desired frame. You can switch back to the default content using driver.switchTo().defaultContent().
Here's a code example for handling an alert:
javaCopy code
// Switch to the alert Alert alert = driver.switchTo().alert(); // Get the alert text String alertText = alert.getText(); // Accept the alert alert.accept();
And here's an example for switching to a new window:
javaCopy code
// Get the current window handle String currentWindowHandle = driver.getWindowHandle(); // Perform an action that opens a new window // Switch to the new window for (String windowHandle : driver.getWindowHandles()) { if (!windowHandle.equals(currentWindowHandle)) { driver.switchTo().window(windowHandle); break; } } // Perform actions in the new window // Close the new window and switch back to the original window driver.close(); driver.switchTo().window(currentWindowHandle);
Question 10: What are the common challenges in Selenium automation testing?
Answer: Selenium automation testing comes with several challenges, including:
Browser Compatibility: Ensuring that your tests work consistently across different web browsers and versions can be challenging due to browser-specific behaviors and inconsistencies.
Dynamic Elements: Handling dynamic elements that change their attributes or positions on the web page can be complex and requires effective strategies.
Performance Testing: Selenium is primarily used for functional testing, and conducting performance testing (e.g., load testing) might require additional tools or frameworks.
Test Data Management: Managing test data, especially in automated testing, can be a significant challenge. Test data should be well-organized, and the environment should be maintained consistently.
Test Maintenance: As the application evolves, test scripts may need frequent updates. Ensuring that automation scripts remain up-to-date and relevant can be a continuous effort.
Test Execution Speed: Selenium tests can be time-consuming, especially when running a large number of test cases. Parallel execution and distributed testing with Selenium Grid can address this issue.
Reporting and Analysis: Creating meaningful test reports and analyzing test results can be complex, especially when dealing with a large number of test cases and data sets.
Test Framework Selection: Choosing the right test framework, programming language, and tools for test automation can be critical to the success of your automation efforts.
In conclusion, Selenium is a powerful tool for automating web applications, and mastering it can open doors to exciting career opportunities in software testing and quality assurance. Preparing for Selenium interviews involves not only answering technical questions but also demonstrating your practical knowledge and problem-solving skills. By studying these top 10 Selenium interview questions and their answers, you'll be better equipped to impress potential employers and secure your dream job in the world of automation testing. Good luck with your interview preparations!
0 notes
Text
Apache Tomcat 403

Apache Tomcat 403 Forbidden
Apache Tomcat Http Status 403
Apache Tomcat 9 403 Access Denied
It was really very helpful for me. I was using version 8.5.32 and worked fine.thnaks. What is Apache Tomcat? Answer: Apache Tomcat is basically a Web Server and Servlet system. Because of the bug CVE-2020-1938 we want to use the latest Tomcat 7.0.100. See also CVE-2020-1938 We also use an Apache server in version 2.4, which connects to the Tomcat via AJP.
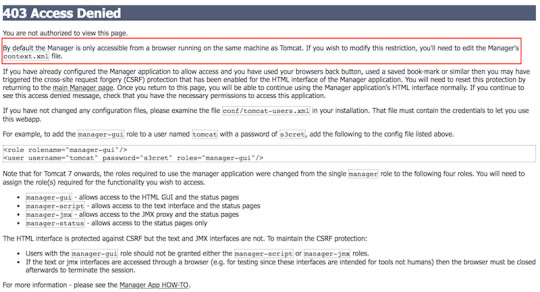
After you installed the Apache Tomcat server and successfully launched the <host>:8080 web page, you click on the Manager App button, and you get a 403 Access Denied message.
The Apache Tomcat Project is proud to announce the release of version 7.0.109 of Apache Tomcat. This release implements specifications that are part of the Java EE 6 platform. This release contains a number of bug fixes and improvements compared to version 7.0.108.
Hi, we have a strange symptom after an upgrade from Tomcat 8 to Tomcat 9, because we get a 403 for a call that works flawlessly with the previous version. Let's describe the scenario: We have a customer with a Wordpress application hosted on an Apache server. Some pages perform XMLHttpRequests to load and embed HTML snippets from other sources.
To fix it 1. Open the $CATALINA_BASE/conf/tomcat-users.xml file and add the following to the <tomcat-users> section.
<user username='admin' password='goanywhere' roles='admin-gui,manager-gui' />
2. If you are accessing the Tomcat server from a remote computer, open or create the file: $CATALINA_BASE/conf/Catalina/localhost/manager.xml, and add the below to the file.
<Context privileged='true' antiResourceLocking='false'
<Valve className='org.apache.catalina.valves.RemoteAddrValve' allow='^.*$' />
3. Restart the tomcat server: sudo systemctl restart tomcat.service
----------------------------------------------------------------------------------------------------------------- Watch the blessing and loving online channel: SupremeMasterTV live
If you have ever asked yourself these questions, this is the book for you. What is the meaning of life? Why do people suffer? What is in control of my life? Why is life the way it is? How can I stop suffering and be happy? How can I have a successful life? How can I have a life I like to have? How can I be the person I like to be? How can I be wiser and smarter? How can I have good and harmonious relations with others? Why do people meditate to achieve enlightenment? What is the true meaning of spiritual practice? Why all beings are one? Read the book for free here.
The AJP Connector
Table of Contents
Attributes
Special Features
Introduction
The AJP Connector element represents a Connector component that communicates with a web connector via the AJP protocol. This is used for cases where you wish to invisibly integrate Tomcat into an existing (or new) Apache installation, and you want Apache to handle the static content contained in the web application, and/or utilize Apache's SSL processing.
Use of the AJP protocol requires additional security considerations because it allows greater direct manipulation of Tomcat's internal data structures than the HTTP connectors. Particular attention should be paid to the values used for the address, secret, secretRequired and allowedRequestAttributesPattern attributes.
This connector supports load balancing when used in conjunction with the jvmRoute attribute of the Engine.
The native connectors supported with this Tomcat release are:
JK 1.2.x with any of the supported servers. See the JK docs for details.
mod_proxy on Apache httpd 2.x (included by default in Apache HTTP Server 2.2), with AJP enabled: see the httpd docs for details.
Other native connectors supporting AJP may work, but are no longer supported.
Attributes
Common Attributes
Apache Tomcat 403 Forbidden
All implementations of Connector support the following attributes:
Attribute Description ajpFlush
A boolean value which can be used to enable or disable sending AJP flush messages to the fronting proxy whenever an explicit flush happens. The default value is true. An AJP flush message is a SEND_BODY_CHUNK packet with no body content. Proxy implementations like mod_jk or mod_proxy_ajp will flush the data buffered in the web server to the client when they receive such a packet. Setting this to false can reduce AJP packet traffic but might delay sending packets to the client. At the end of the response, AJP does always flush to the client.
allowTrace
A boolean value which can be used to enable or disable the TRACE HTTP method. If not specified, this attribute is set to false.
asyncTimeout
The default timeout for asynchronous requests in milliseconds. If not specified, this attribute is set to the Servlet specification default of 30000 (30 seconds).
enableLookups
Set to true if you want calls to request.getRemoteHost() to perform DNS lookups in order to return the actual host name of the remote client. Set to false to skip the DNS lookup and return the IP address in String form instead (thereby improving performance). By default, DNS lookups are disabled.
encodedSolidusHandling
When set to reject request paths containing a %2f sequence will be rejected with a 400 response. When set to decode request paths containing a %2f sequence will have that sequence decoded to / at the same time other %nn sequences are decoded. When set to passthrough request paths containing a %2f sequence will be processed with the %2f sequence unchanged. If not specified the default value is reject. This default may be modified if the deprecated system propertyorg.apache.tomcat.util.buf.UDecoder.ALLOW_ENCODED_SLASH is set.
maxHeaderCount
The maximum number of headers in a request that are allowed by the container. A request that contains more headers than the specified limit will be rejected. A value of less than 0 means no limit. If not specified, a default of 100 is used.
maxParameterCount
The maximum number of parameter and value pairs (GET plus POST) which will be automatically parsed by the container. Parameter and value pairs beyond this limit will be ignored. A value of less than 0 means no limit. If not specified, a default of 10000 is used. Note that FailedRequestFilterfilter can be used to reject requests that hit the limit.
maxPostSize
The maximum size in bytes of the POST which will be handled by the container FORM URL parameter parsing. The limit can be disabled by setting this attribute to a value less than zero. If not specified, this attribute is set to 2097152 (2 megabytes). Note that the FailedRequestFilter can be used to reject requests that exceed this limit.
maxSavePostSize
The maximum size in bytes of the POST which will be saved/buffered by the container during FORM or CLIENT-CERT authentication. For both types of authentication, the POST will be saved/buffered before the user is authenticated. For CLIENT-CERT authentication, the POST is buffered for the duration of the SSL handshake and the buffer emptied when the request is processed. For FORM authentication the POST is saved whilst the user is re-directed to the login form and is retained until the user successfully authenticates or the session associated with the authentication request expires. The limit can be disabled by setting this attribute to -1. Setting the attribute to zero will disable the saving of POST data during authentication. If not specified, this attribute is set to 4096 (4 kilobytes).
parseBodyMethods
A comma-separated list of HTTP methods for which request bodies using application/x-www-form-urlencoded will be parsed for request parameters identically to POST. This is useful in RESTful applications that want to support POST-style semantics for PUT requests. Note that any setting other than POST causes Tomcat to behave in a way that goes against the intent of the servlet specification. The HTTP method TRACE is specifically forbidden here in accordance with the HTTP specification. The default is POST
port
The TCP port number on which this Connector will create a server socket and await incoming connections. Your operating system will allow only one server application to listen to a particular port number on a particular IP address. If the special value of 0 (zero) is used, then Tomcat will select a free port at random to use for this connector. This is typically only useful in embedded and testing applications.
protocol
Sets the protocol to handle incoming traffic. To configure an AJP connector this must be specified. If no value for protocol is provided, an HTTP connector rather than an AJP connector will be configured. The standard protocol value for an AJP connector is AJP/1.3 which uses an auto-switching mechanism to select either a Java NIO based connector or an APR/native based connector. If the PATH (Windows) or LD_LIBRARY_PATH (on most unix systems) environment variables contain the Tomcat native library, the native/APR connector will be used. If the native library cannot be found, the Java NIO based connector will be used. To use an explicit protocol rather than rely on the auto-switching mechanism described above, the following values may be used: org.apache.coyote.ajp.AjpNioProtocol - non blocking Java NIO connector. org.apache.coyote.ajp.AjpNio2Protocol - non blocking Java NIO2 connector. org.apache.coyote.ajp.AjpAprProtocol - the APR/native connector. Custom implementations may also be used. Take a look at our Connector Comparison chart.
proxyName
If this Connector is being used in a proxy configuration, configure this attribute to specify the server name to be returned for calls to request.getServerName(). See Proxy Support for more information.
proxyPort
If this Connector is being used in a proxy configuration, configure this attribute to specify the server port to be returned for calls to request.getServerPort(). See Proxy Support for more information.
redirectPort
If this Connector is supporting non-SSL requests, and a request is received for which a matching <security-constraint> requires SSL transport, Catalina will automatically redirect the request to the port number specified here.
scheme
Set this attribute to the name of the protocol you wish to have returned by calls to request.getScheme(). For example, you would set this attribute to 'https' for an SSL Connector. The default value is 'http'.
secure
Set this attribute to true if you wish to have calls to request.isSecure() to return true for requests received by this Connector. You would want this on an SSL Connector or a non SSL connector that is receiving data from a SSL accelerator, like a crypto card, an SSL appliance or even a webserver. The default value is false.
sendReasonPhrase
Set this attribute to true if you wish to have a reason phrase in the response. The default value is false.
Note: This option is deprecated and will be removed in Tomcat 9. The reason phrase will not be sent.
URIEncoding
This specifies the character encoding used to decode the URI bytes, after %xx decoding the URL. If not specified, UTF-8 will be used unless the org.apache.catalina.STRICT_SERVLET_COMPLIANCEsystem property is set to true in which case ISO-8859-1 will be used.
useBodyEncodingForURI
This specifies if the encoding specified in contentType should be used for URI query parameters, instead of using the URIEncoding. This setting is present for compatibility with Tomcat 4.1.x, where the encoding specified in the contentType, or explicitly set using Request.setCharacterEncoding method was also used for the parameters from the URL. The default value is false.
Notes: See notes on this attribute in HTTP Connector documentation.
useIPVHosts
Set this attribute to true to cause Tomcat to use the IP address passed by the native web server to determine the Host to send the request to. The default value is false.
xpoweredBy
Set this attribute to true to cause Tomcat to advertise support for the Servlet specification using the header recommended in the specification. The default value is false.
Standard Implementations
To use AJP, you must specify the protocol attribute (see above).
The standard AJP connectors (NIO, NIO2 and APR/native) all support the following attributes in addition to the common Connector attributes listed above.
Attribute Description acceptCount
The maximum queue length for incoming connection requests when all possible request processing threads are in use. Any requests received when the queue is full will be refused. The default value is 100.
acceptorThreadCount
The number of threads to be used to accept connections. Increase this value on a multi CPU machine, although you would never really need more than 2. Also, with a lot of non keep alive connections, you might want to increase this value as well. Default value is 1.
acceptorThreadPriority
The priority of the acceptor threads. The threads used to accept new connections. The default value is 5 (the value of the java.lang.Thread.NORM_PRIORITY constant). See the JavaDoc for the java.lang.Thread class for more details on what this priority means.
address
For servers with more than one IP address, this attribute specifies which address will be used for listening on the specified port. By default, the connector will listen on the loopback address. Unless the JVM is configured otherwise using system properties, the Java based connectors (NIO, NIO2) will listen on both IPv4 and IPv6 addresses when configured with either 0.0.0.0 or ::. The APR/native connector will only listen on IPv4 addresses if configured with 0.0.0.0 and will listen on IPv6 addresses (and optionally IPv4 addresses depending on the setting of ipv6v6only) if configured with ::.
allowedRequestAttributesPattern
The AJP protocol passes some information from the reverse proxy to the AJP connector using request attributes. These attributes are:
javax.servlet.request.cipher_suite
javax.servlet.request.key_size
javax.servlet.request.ssl_session
javax.servlet.request.X509Certificate
AJP_LOCAL_ADDR
AJP_REMOTE_PORT
AJP_SSL_PROTOCOL
JK_LB_ACTIVATION
CERT_ISSUER (IIS only)
CERT_SUBJECT (IIS only)
CERT_COOKIE (IIS only)
HTTPS_SERVER_SUBJECT (IIS only)
CERT_FLAGS (IIS only)
HTTPS_SECRETKEYSIZE (IIS only)
CERT_SERIALNUMBER (IIS only)
HTTPS_SERVER_ISSUER (IIS only)
HTTPS_KEYSIZE (IIS only)
The AJP protocol supports the passing of arbitrary request attributes. Requests containing arbitrary request attributes will be rejected with a 403 response unless the entire attribute name matches this regular expression. If not specified, the default value is null.
bindOnInit
Controls when the socket used by the connector is bound. By default it is bound when the connector is initiated and unbound when the connector is destroyed. If set to false, the socket will be bound when the connector is started and unbound when it is stopped.
clientCertProvider
When client certificate information is presented in a form other than instances of java.security.cert.X509Certificate it needs to be converted before it can be used and this property controls which JSSE provider is used to perform the conversion. For example it is used with the AJP connectors, the HTTP APR connector and with the org.apache.catalina.valves.SSLValve.If not specified, the default provider will be used.
connectionLinger
The number of seconds during which the sockets used by this Connector will linger when they are closed. The default value is -1 which disables socket linger.
connectionTimeout
The number of milliseconds this Connector will wait, after accepting a connection, for the request URI line to be presented. The default value for AJP protocol connectors is -1 (i.e. infinite).
executor
A reference to the name in an Executor element. If this attribute is set, and the named executor exists, the connector will use the executor, and all the other thread attributes will be ignored. Note that if a shared executor is not specified for a connector then the connector will use a private, internal executor to provide the thread pool.
executorTerminationTimeoutMillis
The time that the private internal executor will wait for request processing threads to terminate before continuing with the process of stopping the connector. If not set, the default is 5000 (5 seconds).
keepAliveTimeout
The number of milliseconds this Connector will wait for another AJP request before closing the connection. The default value is to use the value that has been set for the connectionTimeout attribute.
maxConnections
The maximum number of connections that the server will accept and process at any given time. When this number has been reached, the server will accept, but not process, one further connection. This additional connection be blocked until the number of connections being processed falls below maxConnections at which point the server will start accepting and processing new connections again. Note that once the limit has been reached, the operating system may still accept connections based on the acceptCount setting. The default value varies by connector type. For NIO and NIO2 the default is 10000. For APR/native, the default is 8192.
For NIO/NIO2 only, setting the value to -1, will disable the maxConnections feature and connections will not be counted.
maxCookieCount
The maximum number of cookies that are permitted for a request. A value of less than zero means no limit. If not specified, a default value of 200 will be used.
maxThreads
The maximum number of request processing threads to be created by this Connector, which therefore determines the maximum number of simultaneous requests that can be handled. If not specified, this attribute is set to 200. If an executor is associated with this connector, this attribute is ignored as the connector will execute tasks using the executor rather than an internal thread pool. Note that if an executor is configured any value set for this attribute will be recorded correctly but it will be reported (e.g. via JMX) as -1 to make clear that it is not used.
minSpareThreads
The minimum number of threads always kept running. This includes both active and idle threads. If not specified, the default of 10 is used. If an executor is associated with this connector, this attribute is ignored as the connector will execute tasks using the executor rather than an internal thread pool. Note that if an executor is configured any value set for this attribute will be recorded correctly but it will be reported (e.g. via JMX) as -1 to make clear that it is not used.
packetSize
This attribute sets the maximum AJP packet size in Bytes. The maximum value is 65536. It should be the same as the max_packet_size directive configured for mod_jk. Normally it is not necessary to change the maximum packet size. Problems with the default value have been reported when sending certificates or certificate chains. The default value is 8192. If set to less than 8192 then the setting will ignored and the default value of 8192 used.
processorCache
The protocol handler caches Processor objects to speed up performance. This setting dictates how many of these objects get cached. -1 means unlimited, default is 200. If not using Servlet 3.0 asynchronous processing, a good default is to use the same as the maxThreads setting. If using Servlet 3.0 asynchronous processing, a good default is to use the larger of maxThreads and the maximum number of expected concurrent requests (synchronous and asynchronous).
secret
Only requests from workers with this secret keyword will be accepted. The default value is null. This attribute must be specified with a non-null, non-zero length value unless secretRequired is explicitly configured to be false. If this attribute is configured with a non-null, non-zero length value then the workers must provide a matching value else the request will be rejected irrespective of the setting of secretRequired.
secretRequired
If this attribute is true, the AJP Connector will only start if the secret attribute is configured with a non-null, non-zero length value. This attribute only controls whether the secret attribute is required to be specified for the AJP Connector to start. It does not control whether workers are required to provide the secret. The default value is true. This attribute should only be set to false when the Connector is used on a trusted network.
tcpNoDelay
If set to true, the TCP_NO_DELAY option will be set on the server socket, which improves performance under most circumstances. This is set to true by default.
threadPriority
The priority of the request processing threads within the JVM. The default value is 5 (the value of the java.lang.Thread.NORM_PRIORITY constant). See the JavaDoc for the java.lang.Thread class for more details on what this priority means.If an executor is associated with this connector, this attribute is ignored as the connector will execute tasks using the executor rather than an internal thread pool. Note that if an executor is configured any value set for this attribute will be recorded correctly but it will be reported (e.g. via JMX) as -1 to make clear that it is not used.
tomcatAuthentication
If set to true, the authentication will be done in Tomcat. Otherwise, the authenticated principal will be propagated from the native webserver and used for authorization in Tomcat.
The web server must send the user principal (username) as a request attribute named REMOTE_USER.
Note that this principal will have no roles associated with it.
The default value is true. If tomcatAuthorization is set to true this attribute has no effect.
tomcatAuthorization
If set to true, the authenticated principal will be propagated from the native webserver and considered already authenticated in Tomcat. If the web application has one or more security constraints, authorization will then be performed by Tomcat and roles assigned to the authenticated principal. If the appropriate Tomcat Realm for the request does not recognise the provided user name, a Principal will be still be created but it will have no roles. The default value is false.
Java TCP socket attributes
The NIO and NIO2 implementation support the following Java TCP socket attributes in addition to the common Connector and HTTP attributes listed above.
Attribute Description socket.rxBufSize
(int)The socket receive buffer (SO_RCVBUF) size in bytes. JVM default used if not set.
socket.txBufSize
(int)The socket send buffer (SO_SNDBUF) size in bytes. JVM default used if not set. Care should be taken if explicitly setting this value. Very poor performance has been observed on some JVMs with values less than ~8k.
socket.tcpNoDelay
(bool)This is equivalent to standard attribute tcpNoDelay.
socket.soKeepAlive
(bool)Boolean value for the socket's keep alive setting (SO_KEEPALIVE). JVM default used if not set.
socket.ooBInline
(bool)Boolean value for the socket OOBINLINE setting. JVM default used if not set.
socket.soReuseAddress
(bool)Boolean value for the sockets reuse address option (SO_REUSEADDR). JVM default used if not set.
socket.soLingerOn
(bool)Boolean value for the sockets so linger option (SO_LINGER). A value for the standard attribute connectionLinger that is >=0 is equivalent to setting this to true. A value for the standard attribute connectionLinger that is <0 is equivalent to setting this to false. Both this attribute and soLingerTime must be set else the JVM defaults will be used for both.
socket.soLingerTime
(int)Value in seconds for the sockets so linger option (SO_LINGER). This is equivalent to standard attribute connectionLinger. Both this attribute and soLingerOn must be set else the JVM defaults will be used for both.
socket.soTimeout
This is equivalent to standard attribute connectionTimeout.
socket.performanceConnectionTime
(int)The first value for the performance settings. See Socket Performance Options All three performance attributes must be set else the JVM defaults will be used for all three.
socket.performanceLatency
(int)The second value for the performance settings. See Socket Performance Options All three performance attributes must be set else the JVM defaults will be used for all three.
socket.performanceBandwidth
(int)The third value for the performance settings. See Socket Performance Options All three performance attributes must be set else the JVM defaults will be used for all three.
socket.unlockTimeout
(int) The timeout for a socket unlock. When a connector is stopped, it will try to release the acceptor thread by opening a connector to itself. The default value is 250 and the value is in milliseconds
NIO specific configuration
The following attributes are specific to the NIO connector.
Attribute Description socket.directBuffer
(bool)Boolean value, whether to use direct ByteBuffers or java mapped ByteBuffers. Default is false. When you are using direct buffers, make sure you allocate the appropriate amount of memory for the direct memory space. On Sun's JDK that would be something like -XX:MaxDirectMemorySize=256m.
socket.appReadBufSize
(int)Each connection that is opened up in Tomcat get associated with a read ByteBuffer. This attribute controls the size of this buffer. By default this read buffer is sized at 8192 bytes. For lower concurrency, you can increase this to buffer more data. For an extreme amount of keep alive connections, decrease this number or increase your heap size.
socket.appWriteBufSize
(int)Each connection that is opened up in Tomcat get associated with a write ByteBuffer. This attribute controls the size of this buffer. By default this write buffer is sized at 8192 bytes. For low concurrency you can increase this to buffer more response data. For an extreme amount of keep alive connections, decrease this number or increase your heap size. The default value here is pretty low, you should up it if you are not dealing with tens of thousands concurrent connections.
socket.bufferPool
(int)The NIO connector uses a class called NioChannel that holds elements linked to a socket. To reduce garbage collection, the NIO connector caches these channel objects. This value specifies the size of this cache. The default value is 500, and represents that the cache will hold 500 NioChannel objects. Other values are -1 for unlimited cache and 0 for no cache.
socket.bufferPoolSize
(int)The NioChannel pool can also be size based, not used object based. The size is calculated as follows: NioChannel buffer size = read buffer size + write buffer size SecureNioChannel buffer size = application read buffer size + application write buffer size + network read buffer size + network write buffer size The value is in bytes, the default value is 1024*1024*100 (100MB).
socket.processorCache
(int)Tomcat will cache SocketProcessor objects to reduce garbage collection. The integer value specifies how many objects to keep in the cache at most. The default is 500. Other values are -1 for unlimited cache and 0 Body outline drawing. for no cache.
socket.keyCache
(int)Tomcat will cache KeyAttachment objects to reduce garbage collection. The integer value specifies how many objects to keep in the cache at most. The default is 500. Other values are -1 for unlimited cache and 0 for no cache.
socket.eventCache
(int)Tomcat will cache PollerEvent objects to reduce garbage collection. The integer value specifies how many objects to keep in the cache at most. The default is 500. Other values are -1 for unlimited cache and 0 for no cache.
selectorPool.maxSelectors
(int)The max selectors to be used in the pool, to reduce selector contention. Use this option when the command line org.apache.tomcat.util.net.NioSelectorShared value is set to false. Default value is 200.
selectorPool.maxSpareSelectors
(int)The max spare selectors to be used in the pool, to reduce selector contention. When a selector is returned to the pool, the system can decide to keep it or let it be GC'd. Use this option when the command line org.apache.tomcat.util.net.NioSelectorShared value is set to false. Default value is -1 (unlimited).
command-line-options
The following command line options are available for the NIO connector: -Dorg.apache.tomcat.util.net.NioSelectorShared=true|false - default is true. Set this value to false if you wish to use a selector for each thread. When you set it to false, you can control the size of the pool of selectors by using the selectorPool.maxSelectors attribute.
NIO2 specific configuration
The following attributes are specific to the NIO2 connector.
Attribute Description useCaches
(bool)Use this attribute to enable or disable object caching to reduce the amount of GC objects produced. The default value is false.
socket.directBuffer
(bool)Boolean value, whether to use direct ByteBuffers or java mapped ByteBuffers. Default is false. When you are using direct buffers, make sure you allocate the appropriate amount of memory for the direct memory space. On Sun's JDK that would be something like -XX:MaxDirectMemorySize=256m.
socket.appReadBufSize
(int)Each connection that is opened up in Tomcat get associated with a read ByteBuffer. This attribute controls the size of this buffer. By default this read buffer is sized at 8192 bytes. For lower concurrency, you can increase this to buffer more data. For an extreme amount of keep alive connections, decrease this number or increase your heap size.
We are an experienced Drupal development company with decade-long proven track record offering best-in-class customization, module, migration and Drupal development services worldwide. Drupal web services. Drupal is a powerful CMS widely used to develop variety of web solutions; ranging from a single page website to complex eCommerce stores. There are large numbers of web development companies in tech world that claim to provide excellent Drupal development services.
socket.appWriteBufSize
(int)Each connection that is opened up in Tomcat get associated with a write ByteBuffer. This attribute controls the size of this buffer. By default this write buffer is sized at 8192 bytes. For low concurrency you can increase this to buffer more response data. For an extreme amount of keep alive connections, decrease this number or increase your heap size. The default value here is pretty low, you should up it if you are not dealing with tens of thousands concurrent connections.
socket.bufferPoolSize
(int)The NIO2 connector uses a class called Nio2Channel that holds elements linked to a socket. To reduce garbage collection, the NIO connector caches these channel objects. This value specifies the size of this cache. The default value is 500, and represents that the cache will hold 500 Nio2Channel objects. Other values are -1 for unlimited cache and 0 for no cache.
socket.processorCache
(int)Tomcat will cache SocketProcessor objects to reduce garbage collection. The integer value specifies how many objects to keep in the cache at most. The default is 500. Other values are -1 for unlimited cache and 0 for no cache.
APR/native specific configuration
The APR/native implementation supports the following attributes in addition to the common Connector and AJP attributes listed above.
Attribute Description ipv6v6only
If listening on an IPv6 address on a dual stack system, should the connector only listen on the IPv6 address? If not specified the default is false and the connector will listen on the IPv6 address and the equivalent IPv4 address if present.
pollTime
Duration of a poll call in microseconds. Lowering this value will slightly decrease latency of connections being kept alive in some cases , but will use more CPU as more poll calls are being made. The default value is 2000 (2ms).
Nested Components
Special Features
Proxy Support
The proxyName and proxyPort attributes can be used when Tomcat is run behind a proxy server. These attributes modify the values returned to web applications that call the request.getServerName() and request.getServerPort() methods, which are often used to construct absolute URLs for redirects. Without configuring these attributes, the values returned would reflect the server name and port on which the connection from the proxy server was received, rather than the server name and port to whom the client directed the original request.
For more information, see the Proxy Support How-To.
Connector Comparison
Apache Tomcat Http Status 403

Below is a small chart that shows how the connectors differ.
Apache Tomcat 9 403 Access Denied
Java Nio Connector NIOJava Nio2 Connector NIO2APR/native Connector APRClassnameAjpNioProtocolAjpNio2ProtocolAjpAprProtocolTomcat Version7.x onwards8.x onwards5.5.x onwardsSupport PollingYESYESYESPolling SizemaxConnectionsmaxConnectionsmaxConnectionsRead Request HeadersBlockingBlockingBlockingRead Request BodyBlockingBlockingBlockingWrite Response Headers and BodyBlockingBlockingBlockingWait for next RequestNon BlockingNon BlockingNon BlockingMax ConnectionsmaxConnectionsmaxConnectionsmaxConnections
0 notes
Text
MySQL Connector/J 8.0.24 has been released
Dear MySQL users, MySQL Connector/J 8.0.24 is the latest General Availability release of the MySQL Connector/J 8.0 series. It is suitable for use with MySQL Server versions 8.0 and 5.7. It supports the Java Database Connectivity (JDBC) 4.2 API, and implements the X DevAPI. This release includes the following new features and changes, also described in more detail on https://dev.mysql.com/doc/relnotes/connector-j/8.0/en/news-8-0-24.htmlAs always, we recommend that you check the “CHANGES” file in the download archive to be aware of changes in behavior that might affect your application. To download MySQL Connector/J 8.0.24 GA, see the “General Availability (GA) Releases” tab at http://dev.mysql.com/downloads/connector/j/Enjoy! Changes in MySQL Connector/J 8.0.24 (2021-04-20, General Availability) * Functionality Added or Changed * Bugs Fixed Functionality Added or Changed * X DevAPI: For X Protocol connections, the Server now provides three new kinds of notifications for disconnections: + Server shutdown: This is due to a server shutdown. It causes Connector/J to terminate all active and idle sessions connected to the server in the connection pool with the error message “Server shutdown in progress”. + Connection idle: This is due to the connection idling for longer than the relevant timeout settings. It causes Connector/J to close the current connection with the error message “IO Read error: read_timeout exceeded”. + Connection killed: This is due to the connection being killed by another client session. It causes Connector/J to close the connection in the current session with the error message “Session was killed”. * A new connection property, scrollTolerantForwardOnly, has been introduced, which preserved the legacy behavior of Connector/J 8.0.17 and earlier by tolerating backward and absolute cursor movements on result sets of type ResultSet.TYPE_FORWARD_ONLY. This is for maintaining compatibility with legacy code that took advantage of the old behavior. See the description for scrollTolerantForwardOnly for details. (Bug #31747910) References: See also: Bug #30474158. * Connector/J now supports “userless” authentication for JDBC connections: When the user for the connection is unspecified, Connector/J uses the name of the OS user who runs the application for authentication with the MySQL server. See Connector/J: Obtaining a connection from the DriverManager (https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-usagenotes-connect-drivermanager.html#connector-j-examples-connection-drivermanager) for more details. * Starting from this release, whenever an authentication plugin is explicitly set for the connection property defaultAuthenticationPlugin (https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-connp-props-connection.html#cj-conn-prop_defaultAuthenticationPlugin), the specified plugin takes precedence over the server’s default when Connector/J negotiates a plugin with the server. There is no behavioral change for Connector/J if no value is explicitly set for the property, in which case the server’s choice of default plugin takes precedence over the implicit default of mysql_native_password for Connector/J. See the description of defaultAuthenticationPlugin (https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-connp-props-connection.html#cj-conn-prop_defaultAuthenticationPlugin) for details. * In the past, for JDBC connections, when the server closed a session because a client was idling beyond the period specified by the server’s wait_timeout system variable, Connector/J returned a generic IO error. Connector/J now relays a clearer error message from the server. Bugs Fixed * X DevAPI: Concurrently getting and closing multiple sessions from the same X DevAPI Client object might result in a ConcurrentModificationException thrown by Connector/J at the closing of a session. (Bug #31699993) * X DevAPI: Under some specific conditions, when using Deflate as the algorithm for compression of X Protocol connections, Connector/J threw an AssertionFailedException (ASSERTION FAILED: Unknown message type: 57). It was because when a compressed packet was just a few bytes longer than the size of some internal buffer used by a Java InflaterInputStream, the leftover bytes from the inflate procedure were being discarded by Connector/J, causing inflation of subsequent packets to fail. With this fix, no data bytes are discarded, and the inflation works as expected. (Bug #31510398, Bug #99708) * When a SecurityManager was in place, connections to a MySQL Server could not be established unless the client had been properly configured to use SASL-based LDAP authentication. It was because the AuthenticationLdapSaslClientPlugin in Connector/J requires a special permission to load the provider MySQLScramShaSasl when a SecurityManager is in place; but since the provider was loaded by a static initializer during initialization for the plugin, the lack of the permission was causing an error and then failures for all connections, even if the plugin was never used or enabled. This fix changes how the provider is loaded: the loading now happens only at the plugin instance’s initialization and the initialization was deferred to the time when the plugin is actually needed, so that connections that do not use SASL-based LDAP authentication are unaffected by security settings regarding the plugin. (Bug #32526663, Bug #102188) * When using Connector/J 8.0.23, ResultSetMetaData.getColumnClassName() did not return the correct class name corresponding to DATETIME columns. (Bug #32405590, Bug #102321) * Creation of an UpdatableResultSet failed with a NullPointerException when it was generated by querying a view with a derived value. (Bug #32338451, Bug #102131) * Using getLong() on the CHAR_OCTET_LENGTH column of the ResultSet for DatabaseMetaData.getProcedureColumns() (or getFunctionColumns()) resulted in a NumberOutOfRange exception when the column’s value exceeded 2^32 − 1. With this patch, the value of 2^32 − 1 is returned in the situation. (Bug #32329915, Bug #102076) * Connections to a server could not be established when the user supplied an implementation of the ConnectionPropertiesTransform interface using the connection property propertiesTransform. This was because Connector/J called PropertyKey.PORT.getKeyName() instead of PropertyKey.HOST.getKeyName() for getting the host name, and that has been corrected by this fix. (Bug #32151143, Bug #101596) * A NullPointerException was returned when a statement that could not be used as a ServerPreparedStatement was executed and the connection property useUsageAdvisor (https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-connp-props-debugging-profiling.html#cj-conn-prop_useUsageAdvisor) was set to true. With this fix, a SQLException is returned instead. (Bug #32141210, Bug #101558) * Using the setSessionMaxRows() method on a closed connection resulted in a NullPointerException. With this fix, a SQLNonTransientConnectionException is thrown instead, with the error message “No operations allowed after connection closed.” (Bug #22508715) * Using the setObject() method for a target type of Types.TIME resulted in a SQLException when the value to be set had a fractional part, or when the value did not fit any pattern described in Date and Time Literals (https://dev.mysql.com/doc/refman/8.0/en/date-and-time-literals.html). This patch introduced a new logic that can handle fractional parts; also, it performs the conversion according to the patterns of the literals and, when needed, the target data type. (Bug #20391832) Enjoy and thanks for the support! On Behalf of the MySQL Engineering Team, Nawaz Nazeer Ahamed https://insidemysql.com/mysql-connector-j-8-0-24/
0 notes
Photo

Macで HTTP Proxy 経由のSSH http://bit.ly/2GbgDpo
macOS からWindows を経由して SSH する機会があったため、調査した内容を残しておきます。 Web上で色々情報が見つかったのですが、現在では古い情報も混ざっているため自分用に整理した内容です。

要件
結果 — Linuxでのncコマンド — Macでのncコマンド
調査 — HTTP Proxy 経由のSSH — netcat(nc)色々 —– Ncat(Nmap付属) —– Open BSD netcat —– Amazon Linux の例 —– Ubuntu の例 —– Netcat Darwin Port —– GNU netcat
要件
macOS -> win_proxy(Windows) -> web(Linux)
上記のように直接接続が許可されていない、win_proxy(WindowsのProxyサーバ)の背後のweb(Linuxサーバ)に対し、 macOSからSSH接続を行います。
HTTP tunnel – Wikipedia
HTTP CONNECT メソッドで接続を確立し���ンネルすることで SSH での接続が可能になります。 環境は以下の通りです。
接続元
macOS Sierra version 10.12.6
Proxy
Windows Server 2016
Squid for Windows 3.5.28
結果
Nmap付属のncatを使用すると最も環境に依存せずに実現可能と思います。
Download the Free Nmap Security Scanner for Linux/Mac/Windows --proxy-type オプションで “http” を指定します。
Specify proxy type (“http” or “socks4” or “socks5”)
$ ssh -o ProxyCommand='ncat --proxy-type http --proxy win_proxy:3128 %h %p' -i ~/.ssh/id_rsa ubuntu@web # ssh config Host web Hostname web User ubuntu IdentityFile ~/.ssh/id_rsa ProxyCommand ncat --proxy-type http --proxy win_proxy:3128 %h %p ServerAliveInterval 10
Linuxでのncコマンド
-X オプションで “connect” を指定します。
Supported protocols are “4” (SOCKS v.4), “5” (SOCKS v.5) and “connect” (HTTPS proxy). If the protocol is not specified, SOCKS version 5 is used.
ssh ProxyCommand='nc -X connect -x win_proxy:3128 %h %p' -i ~/.ssh/id_rsa ubuntu@web # ssh config Host web Hostname web User ubuntu IdentityFile ~/.ssh/id_rsa ProxyCommand nc -X connect -x win_proxy:3128 %h %p ServerAliveInterval 10
Macでのncコマンド
macOS 標準搭載のncコマンドでは接続エラーを解消できずでした。
nc: Proxy error: "HTTP/1.1 200 Connection established" ssh_exchange_identification: Connection closed by remote host
間にLinux等を挟む事で無理やり繋ぐ事は可能です。
macOS -> bastion_linux -> win_proxy -> web(Linux)
ssh ProxyCommand='ssh bastion_linux nc --proxy-type http --proxy win_proxy:3128 %h %p' -i ~/.ssh/id_rsa ubuntu@web # ssh_config Host bastion_linux Hostname bastion_linux User hoge Host web Hostname web User ubuntu IdentityFile ~/.ssh/id_rsa ProxyCommand ssh bastion_linux nc --proxy-type http --proxy win_proxy:3128 %h %p ServerAliveInterval 10
調査
以下メモレベルですが、上記Nmap付属のncat使用に至った経緯です。 無駄に長いので折り畳みます。
HTTP Proxy 経由のSSH
OpenSSH で利用するには以下のいずれかが必要になります。
connect コマンド (connect.c)
要コンパイル
公式? connect / wiki / Home — Bitbucket
netcat(nc) コマンド
Macは標準導入されている。派生コマンドが多数(後述)
-W オプション
OpenSSH 5.4 以降 で利用可能な模様
connect-proxy
Debian/Ubuntu であれば apt で導入可能な模様
Redhat系は RPMForge から connect を入れる事例が多い(しかし、既に RPMForge/RepoForge は無い物と考えた方が良い)
netcat(nc)色々
nc コマンドは色々な派生バージョンがあり、どれを指しているのかは環境・オプションにより異なっているようです。
派生・互換ツール(Wiki引用)
Netcat – Wikipedia
- Ncat(Nmap付属) - Nmapの一部として開発された。GPLライセンス。 - OpenBSD netcat - 0から書き直されたnetcat互換ツールでIPv6に対応しているnetcat。BSDライセンス。 - GNU netcat - 0から書き直されたnetcat互換ツール。GPLライセンス。 - Netcat Darwin Port - Mac OS Xで使用可能なnetcatである。 - Windows版netcat - Windows上で使用可能なnetcatである。 - Jetcat - netcatの一部の機能をJavaで実現したものである。
Ncat(Nmap付属)
環境依存が最も少ないのではないかと思われる物です。
公式 Nmap: the Network Mapper – Free Security Scanner
Mac OS X 用のバイナリもあります。 今回使用した端末は諸事情によりソフトウェアのインストールが行えなかったため実際には未確認です。 Linux上での接続は確認できました。オプション等は同じようなので、同様に接続可能と思われます。 proxy-type オプションに http 指定して接続します。
Proxying | Ncat Users’ Guide
# インストール $ sudo rpm -vhU https://nmap.org/dist/ncat-7.70-1.x86_64.rpm Retrieving https://nmap.org/dist/ncat-7.70-1.x86_64.rpm Preparing... ################################# [100%] Updating / installing... 1:ncat-2:7.70-1 ################################# [100%] $ which ncat /usr/bin/ncat
# ヘルプ $ ncat --help Ncat 7.70 ( https://nmap.org/ncat ) Usage: ncat [options] [hostname] [port] Options taking a time assume seconds. Append 'ms' for milliseconds, 's' for seconds, 'm' for minutes, or 'h' for hours (e.g. 500ms). -4 Use IPv4 only -6 Use IPv6 only -U, --unixsock Use Unix domain sockets only -C, --crlf Use CRLF for EOL sequence -c, --sh-exec <command> Executes the given command via /bin/sh -e, --exec <command> Executes the given command --lua-exec <filename> Executes the given Lua script -g hop1[,hop2,...] Loose source routing hop points (8 max) -G <n> Loose source routing hop pointer (4, 8, 12, ...) -m, --max-conns <n> Maximum <n> simultaneous connections -h, --help Display this help screen -d, --delay <time> Wait between read/writes -o, --output <filename> Dump session data to a file -x, --hex-dump <filename> Dump session data as hex to a file -i, --idle-timeout <time> Idle read/write timeout -p, --source-port port Specify source port to use -s, --source addr Specify source address to use (doesn't affect -l) -l, --listen Bind and listen for incoming connections -k, --keep-open Accept multiple connections in listen mode -n, --nodns Do not resolve hostnames via DNS -t, --telnet Answer Telnet negotiations -u, --udp Use UDP instead of default TCP --sctp Use SCTP instead of default TCP -v, --verbose Set verbosity level (can be used several times) -w, --wait <time> Connect timeout -z Zero-I/O mode, report connection status only --append-output Append rather than clobber specified output files --send-only Only send data, ignoring received; quit on EOF --recv-only Only receive data, never send anything --allow Allow only given hosts to connect to Ncat --allowfile A file of hosts allowed to connect to Ncat --deny Deny given hosts from connecting to Ncat --denyfile A file of hosts denied from connecting to Ncat --broker Enable Ncat's connection brokering mode --chat Start a simple Ncat chat server --proxy <addr[:port]> Specify address of host to proxy through --proxy-type <type> Specify proxy type ("http" or "socks4" or "socks5") --proxy-auth <auth> Authenticate with HTTP or SOCKS proxy server --ssl Connect or listen with SSL --ssl-cert Specify SSL certificate file (PEM) for listening --ssl-key Specify SSL private key (PEM) for listening --ssl-verify Verify trust and domain name of certificates --ssl-trustfile PEM file containing trusted SSL certificates --ssl-ciphers Cipherlist containing SSL ciphers to use --ssl-alpn ALPN protocol list to use. --version Display Ncat's version information and exit See the ncat(1) manpage for full options, descriptions and usage examples
OpenBSD netcat
Linux に標準導入されているコマンドを指している物と思われます。
Amazon Linux の例
Amazon Linux AMI 2018.03
$ yum list installed nc nc.x86_64 1.84-24.8.amzn1 installed [ec2-user@ip-172-30-2-241 ~]$ $ which nc /usr/bin/nc
# help 抜粋 $ nc -h usage: nc [-46DdhklnrStUuvzC] [-i interval] [-p source_port] [-s source_ip_address] [-T ToS] [-w timeout] [-X proxy_version] [-x proxy_address[:port]] [hostname] [port[s]] # man 抜粋 NC(1) BSD General Commands Manual NC(1) NAME nc — arbitrary TCP and UDP connections and listens SYNOPSIS nc [-46DdhklnrStUuvzC] [-i interval] [-p source_port] [-s source_ip_address] [-T ToS] [-w timeout] [-X proxy_protocol] [-x proxy_address[:port]] [hostname] [port[s]] DESCRIPTION The nc (or netcat) utility is used for just about anything under the sun involving TCP or UDP. It can open TCP connections, send UDP packets, listen on arbitrary TCP and UDP ports, do port scanning, and deal with both IPv4 and IPv6. Unlike telnet(1), nc scripts nicely, and separates error messages onto standard error instead of sending them to standard output, as telnet(1) does with some. ・・・ SEE ALSO cat(1), ssh(1) AUTHORS Original implementation by *Hobbit* ⟨[email protected]⟩. Rewritten with IPv6 support by Eric Jackson <[email protected]>. CAVEATS UDP port scans will always succeed (i.e. report the port as open), rendering the -uz combination of flags relatively useless. BSD August 22, 2006 BSD
Ubuntu の例
Ubuntu 16.04.5 LTS
$ dpkg -l | grep netcat ii netcat-openbsd 1.105-7ubuntu1 amd64 TCP/IP swiss army knife $ which nc /bin/nc $ ls -l /bin/nc lrwxrwxrwx 1 root root 20 Sep 12 13:39 /bin/nc -> /etc/alternatives/nc $ ls -l /etc/alternatives/nc lrwxrwxrwx 1 root root 15 Sep 12 13:39 /etc/alternatives/nc -> /bin/nc.openbsd $ ls -l /bin/nc.openbsd -rwxr-xr-x 1 root root 31248 Dec 4 2012 /bin/nc.openbsd
# help $ nc This is nc from the netcat-openbsd package. An alternative nc is available in the netcat-traditional package. usage: nc [-46bCDdhjklnrStUuvZz] [-I length] [-i interval] [-O length] [-P proxy_username] [-p source_port] [-q seconds] [-s source] [-T toskeyword] [-V rtable] [-w timeout] [-X proxy_protocol] [-x proxy_address[:port]] [destination] [port] # man(抜粋) $ man nc |cat NC(1) BSD General Commands Manual NC(1) NAME nc — arbitrary TCP and UDP connections and listens SYNOPSIS nc [-46bCDdhklnrStUuvZz] [-I length] [-i interval] [-O length] [-P proxy_username] [-p source_port] [-q seconds] [-s source] [-T toskeyword] [-V rtable] [-w timeout] [-X proxy_protocol] [-x proxy_address[:port]] [destination] [port] DESCRIPTION The nc (or netcat) utility is used for just about anything under the sun involving TCP, UDP, or UNIX-domain sockets. It can open TCP connec‐ tions, send UDP packets, listen on arbitrary TCP and UDP ports, do port scanning, and deal with both IPv4 and IPv6. Unlike telnet(1), nc scripts nicely, and separates error messages onto standard error instead of sending them to standard output, as telnet(1) does with some. ・・・ SEE ALSO cat(1), ssh(1) AUTHORS Original implementation by *Hobbit* ⟨[email protected]⟩. Rewritten with IPv6 support by Eric Jackson <[email protected]>. Modified for Debian port by Aron Xu ⟨[email protected]⟩. CAVEATS UDP port scans using the -uz combination of flags will always report success irrespective of the target machine's state. However, in con‐ junction with a traffic sniffer either on the target machine or an intermediary device, the -uz combination could be useful for communica‐ tions diagnostics. Note that the amount of UDP traffic generated may be limited either due to hardware resources and/or configuration settings. BSD February 7, 2012 BSD
Netcat Darwin Port
Macで標準導入されているncコマンドを指すと思われます。
$ which nc /usr/bin/nc
# help(stringsからの)抜粋 ・・・ This help text %s%s -i secs Delay interval for lines sent, ports scanned Keep inbound sockets open for multiple connects Listen mode, for inbound connects %s%s Suppress name/port resolutions %s%s%s -p port Specify local port for remote connects (cannot use with -l) Randomize remote ports -s addr Local source address Answer TELNET negotiation Use UNIX domain socket UDP mode Verbose -w secs Timeout for connects and final net reads -X proto Proxy protocol: "4", "5" (SOCKS) or "connect" -x addr[:port] Specify proxy address and port Zero-I/O mode [used for scanning] %s%s Port numbers can be individual or ranges: lo-hi [inclusive] Set SO_RECV_ANYIF on socket Set SO_AWDL_UNRESTRICTED on socket -b ifbound Bind socket to interface Don't use cellular connection Don't use expensive interfaces Do not use flow advisory (flow adv enabled by default) -G conntimo Connection timeout in seconds -H keepidle Initial idle timeout in seconds -I keepintvl Interval for repeating idle timeouts in seconds -J keepcnt Number of times to repeat idle timeout -K tclass Specify traffic class -L num_probes Number of probes to send before generating a read timeout event Set SO_INTCOPROC_ALLOW on socket Use MULTIPATH domain socket -N num_probes Number of probes to send before generating a write timeout event Use old-style connect instead of connectx Issue socket options after connect/bind --apple-delegate-pid pid Set socket as delegate using pid --apple-delegate-uuid uuid Set socket as delegate using uuid --apple-ext-bk-idle Extended background idle time --apple-ecn Set the ECN mode --apple-sockev Receive and print socket events --apple-notify-ack Receive events when data gets acknowledged --apple-tos Set the IP_TOS or IPV6_TCLASS option --apple-netsvctype Set the network service type usage: nc [-46AacCDdEFhklMnOortUuvz] [-K tc] [-b boundif] [-i interval] [-p source_port] [--apple-delegate-pid pid] [--apple-delegate-uuid uuid] [-s source_ip_address] [-w timeout] [-X proxy_version] [-x proxy_address[:port]] [hostname] [port[s]] ・・・ @(#)PROGRAM:nc PROJECT:netcat-41
今回、この標準コマンドで繋ぐことができれば話が早かったのですが、 弊端末からは接続できない(以下エラーが解消できない)状態でした。 同様のNW構成としたLinux端末からは接続可能、また、接続可能な事例もいくつか見られましたので、環境・バージョンの問題かと思われます。
nc: Proxy error: "HTTP/1.1 200 Connection established" ssh_exchange_identification: Connection closed by remote host
参考URL
Connect with SSH through a proxy – Stack Overflow
OS X では SOCKS5 でしか繋げないような回答
Squid – Users – squid upgrade issue and tunnelled ssh connections
Squid 3.4.2 にアップデート後、ssh接続が利用不可となった事例
GNU netcat
brew でインストール可能です。 proxy_version のオプションが無く、http_proxyの指定ができないようでした。
$ brew install netcat $ brew list netcat /usr/local/Cellar/netcat/0.7.1/bin/nc /usr/local/Cellar/netcat/0.7.1/bin/netcat /usr/local/Cellar/netcat/0.7.1/share/info/netcat.info /usr/local/Cellar/netcat/0.7.1/share/man/ (2 files) $ which netcat /usr/local/bin/netcat $ ls /usr/local/Cellar/netcat/0.7.1/bin/ nc@ netcat*
# help $ netcat --help GNU netcat 0.7.1, a rewrite of the famous networking tool. Basic usages: connect to somewhere: netcat [options] hostname port [port] ... listen for inbound: netcat -l -p port [options] [hostname] [port] ... tunnel to somewhere: netcat -L hostname:port -p port [options] Mandatory arguments to long options are mandatory for short options too. Options: -c, --close close connection on EOF from stdin -e, --exec=PROGRAM program to exec after connect -g, --gateway=LIST source-routing hop point[s], up to 8 -G, --pointer=NUM source-routing pointer: 4, 8, 12, ... -h, --help display this help and exit -i, --interval=SECS delay interval for lines sent, ports scanned -l, --listen listen mode, for inbound connects -L, --tunnel=ADDRESS:PORT forward local port to remote address -n, --dont-resolve numeric-only IP addresses, no DNS -o, --output=FILE output hexdump traffic to FILE (implies -x) -p, --local-port=NUM local port number -r, --randomize randomize local and remote ports -s, --source=ADDRESS local source address (ip or hostname) -t, --tcp TCP mode (default) -T, --telnet answer using TELNET negotiation -u, --udp UDP mode -v, --verbose verbose (use twice to be more verbose) -V, --version output version information and exit -x, --hexdump hexdump incoming and outgoing traffic -w, --wait=SECS timeout for connects and final net reads -z, --zero zero-I/O mode (used for scanning) Remote port number can also be specified as range. Example: '1-1024'
元記事はこちら
「Macで HTTP Proxy 経由のSSH」
January 30, 2019 at 12:00PM
0 notes
Text
Selenium Training New Batch Will Start in Bangalore
New Batch Will Start September 20th, October 6th & 11th , 2018, Call or whatsapp: +91-9686770604
Selenium Course Details:
Duration : 45 Hours (Selenium+Core Java)
Demo and First 3 classes free
All session video access
Real Time training with hands on Project
Assignment and Case Studies
Week Day & Week End Batches (Class Room +Online Virtual Classes)

SELENIUM WEB DRIVER – TESTING TOOL:
PACKAGES & ACCESS MODIFIERS
Relevance of Packages
Creating Packages
Accessing modifiers – Public, Private, Default, Protected
Accessing Classes Across Packages
Collection API
Introduction to Collections API
Array List Class
Vector Class
Linked List Class
Hash Set Class
Linked Hash Set Class
Tree Set Class
Hash Table Class
Hash Map Class
Tree Map Class
Iterating through the content of Array List, Vector, Set, Hash Map
Array List vs Vector
Hash Table vs Hash Map
Selenium WEBDRIVER :
Why Web Driver?
Downloading and configuring web driver in eclipse
Web Driver Interface Drivers for Firefox, IE, chrome
First Selenium Web Driver Code
Working with multiple browsers
Close and Quit methods in Web driver
HTML language tags
Handling Links with Web Driver
Extracting Xpaths and relevence of Xpaths
Identifying WebElements using id, name, linkname, class, xpath, tagname etc
Handling Input Box/Buttons
Handling WebList
Handling CheckBoxes
Making your own xpaths without firebug Dynamic objects
Extracting links and other webelements
Capturing screenshots with WebDriver
Window handlesUnderstanding Xpath functions
Mouse movement with selenium
Handling Autosuggests
Absolute wait, Implicit wait, Explicit wait, page load timeout
Handling Frames
READ MORE
MORE TAGS:
Selenium Online Training in Bangalore | Selenium Institutes in Bangalore | Selenium Training Institutes in Bangalore | Best Selenium Institute in Bangalore | Selenium Certification Course in Bangalore | Selenium Classes in Bangalore | Selenium Coaching in Bangalore | Testing Institutes in Bangalore
AND MORE: SAP FICO Training in Bangalore | SAP FICO Course in Bangalore | SAP FICO Certification Course in Bangalore | SAP Finance Training in Bangalore | SAP FICO Training Institutes Bangalore | Best SAP FICO Training Bangalore
PL SQL Training Institutes in Bangalore | Oracle PL SQL Training in Bangalore | PL SQL Training in Bangalore | sql training institutes in bangalore | oracle sql training in bangalore | SQL training in bangalore | best pl sql training institutes in bangalore
python training in bangalore | python classes in bangalore | best python training institute in bangalore | best python training in bangalore | python training institute in bangalore | python training in koramangala | python training in hsr | best python training institutes in bangalore
0 notes
Text
DPoP with Spring Boot and Spring Security
Solid is an exciting project that I first heard about back in January. Its goal is to help “re-decentralize” the Web by empowering users to control access to their own data. Users set up “pods” to store their data, which applications can securely interact with using the Solid protocol. Furthermore, Solid documents are stored as linked data, which allows applications to interoperate more easily, hopefully leading to less of the platform lock-in that exists with today’s Web.
I’ve been itching to play with this for months, and finally got some free time over the past few weekends to try building a Solid app. Solid's authentication protocol, Solid OIDC, is built on top of regular OIDC with a mechanism called DPoP, or "Demonstration of Proof of Possession". While Spring Security makes it fairly easy to configure OIDC providers and clients, it doesn't yet have out-of-the-box support for DPoP. This post is a rough guide on adding DPoP to a Spring Boot app using Spring Security 5, which gets a lot of the way towards implementing the Solid OIDC flow. The full working example can be found here.
DPoP vs. Bearer Tokens
What's the point of DPoP? I will admit it's taken me a fair amount of reading and re-reading over the past several weeks to feel like I can grasp what DPoP is about. My understanding thus far: If a regular bearer token is stolen, it can potentially be used by a malicious client to impersonate the client that it was intended for. Adding audience information into the token mitigates some of the danger, but also constrains where the token can be used in a way that might be too restrictive. DPoP is instead an example of a "sender-constrained" token pattern, where the access token contains a reference to an ephemeral public key, and every request where it's used must be additionally accompanied by a request-specific token that's signed by the corresponding private key. This proves that the client using the access token also possesses the private key for the token, which at least allows the token to be used with multiple resource servers with less risk of it being misused.
So, the DPoP auth flow differs from Spring's default OAuth2 flow in two ways: the initial token request contains more information than the usual token request; and, each request made by the app needs to create and sign a JWT that will accompany the request in addition to the access token. Let's take a look at how to implement both of these steps.
Overriding the Token Request
In the authorization code grant flow for requesting access tokens, the authorization process is kicked off by the client sending an initial request to the auth server's authorization endpoint. The auth server then responds with a code, which the client includes in a final request to the auth server's token endpoint to obtain its tokens. Solid OIDC recommends using a more secure variation on this exchange called PKCE ("Proof Key for Code Exchange"), which adds a code verifier into the mix; the client generates a code verifier and sends its hash along with the authorization request, and when it makes its token request, it must also include the original code verifier so that the auth server can confirm that it originated the authorization request.
Spring autoconfigures classes that implement both the authorization code grant flow and the PKCE variation, which we can reuse for the first half of our DPoP flow. What we need to customize is the second half -- the token request itself.
To do this we implement the OAuth2AccessTokenResponseClient interface, parameterized with OAuth2AuthorizationCodeGrantRequest since DPoP uses the authorization code grant flow. (For reference, the default implementation provided by Spring can be found in the DefaultAuthorizationCodeTokenResponseClient class.) In the tokenRequest method of our class, we do the following:
retrieve the code verifier generated during the authorization request
retrieve the code received in response to the authorization request
generate an ephemeral key pair, and save it somewhere the app can access it during the lifetime of the session
construct a JWT with request-specific info, and sign it using our generated private key
make a request to the token endpoint using the above data, and return the result as an OAuth2AccessTokenResponse.
Here's the concrete implementation of all of that. We get the various data that we need from the OAuth2AuthorizationCodeGrantRequest object passed to our method. We then call on RequestContextHolder to get the current session ID and use that to save the session keys we generate to a map in the DPoPUtils bean. We create and sign a JWT which goes into the DPoP header, make the token request, and finally convert the response to an OAuth2AccessTokenResponse.
Using the DPoP Access Token
Now, to make authenticated requests to a Solid pod our app will need access to both an Authentication object (provided automatically by Spring) containing the DPoP access token obtained from the above, as well as DPoPUtils for the key pair needed to use the token.
On each request, the application must generate a fresh JWT and place it in a DPoP header as demonstrated by the authHeaders method below:
private fun authHeaders( authToken: String, sessionId: String, method: String, requestURI: String ): HttpHeaders { val headers = HttpHeaders() headers.add("Authorization", "DPoP $authToken") dpopUtils.sessionKey(sessionId)?.let { key -> headers.add("DPoP", dpopUtils.dpopJWT(method, requestURI, key)) } return headers }
The body of the JWT created by DPoPUtils#dpopJWT contains claims that identify the HTTP method and the target URI of the request:
private fun payload(method: String, targetURI: String) : JWTClaimsSet = JWTClaimsSet.Builder() .jwtID(UUID.randomUUID().toString()) .issueTime(Date.from(Instant.now())) .claim("htm", method) .claim("htu", targetURI) .build()
A GET request, for example, would then look something like this:
val headers = authHeaders( authToken, sessionId, "GET", requestURI ) val httpEntity = HttpEntity(headers) val response = restTemplate.exchange( requestURI, HttpMethod.GET, httpEntity, String::class.java )
A couple of last things to note: First, the session ID passed to the above methods is not retrieved from RequestContextHolder as before, but from the Authentication object provided by Spring:
val sessionId = ((authentication as OAuth2AuthenticationToken) .details as WebAuthenticationDetails).sessionId
And second, we want the ephemeral keys we generate during the token request to be removed from DPoPUtils when the session they were created for is destroyed. To accomplish this, we create an HttpSessionListener and override its sessionDestroyed method:
@Component class KeyRemovalSessionListener( private val dPoPUtils: DPoPUtils ) : HttpSessionListener { override fun sessionDestroyed(se: HttpSessionEvent) { val securityContext = se.session .getAttribute("SPRING_SECURITY_CONTEXT") as SecurityContextImpl val webAuthDetails = securityContext.authentication.details as WebAuthenticationDetails val sessionId = webAuthDetails.sessionId dPoPUtils.removeSessionKey(sessionId) } }
This method will be invoked on user logout as well as on session timeout.
0 notes
Text
300+ TOP RPA Interview Questions and Answers
RPA Interview Questions for freshers experienced :-
1. What is RPA? Robotic Process Automation(RPA) allows organizations to automate a task, just like an employee of your organization doing them across application and systems. 2. What are the different applications of RPA? Some popular applications of RPA are Barcode Scanning Enter PO to receive invoices Match PO and Invoice Complete Invoice Processing. 3. Give three advantages of RPA tool Here are three benefits of using RPA tools. RPA offers real time visibility into bug/defect discovery RPA allows regular compliance process, with error-free auditing. It allows you to automate a large number of processes. 4. What are the things you should remember in the process of RPA Implementation? Define and focus on the desired ROI You should target to automate important and highly impactful processes Combine attended and unattended RPA 5. Which RPA offers an open platform for automation? UiPath is open-source RPA tool that allows you to design, deploy any robotic workforce upon their organization. 6. Explain important characteristics of RPA Three most important characteristics of RPA are: Code-free User-Friendly Non-Disruptive 7. What are Popular RPA tools? Describe each one in detail There are mainly three popular RPA tools. Blue Prism: Blue Prism software offers business operations to be agile and cost-effective by automating rule-based, repetitive back-office processes. Automation Anywhere: Automation Anywhere offers powerful and User- friendly Robotic Process Automation tools to automate tasks of any complexity. UiPath: UiPath is a Windows desktop software used for automation for various types of web and desktop-based applications. 8. What are the steps you should follow to implement Robotic Process Automation? Six steps to be followed for a successful RPA implementation are: Identify the Automation Opportunities Optimize the Identified Processes Build a Business Case Select the RPA Vendor of your choice Model RPA Development Start Continue Building Expertise RPA bots 9. Can you audit the RPA process? What are the benefits of same? Yes, it is possible to audit the RPA process. Auditing brings several new strategies that can easily be adopted. 10. State the different between between Thin Client & Thick Client? Thick Client : The thick client is the application that reuires certain attribute features using RPA tools, e.g., computer, calculator, Internet Explorer. Thin Client : The thin client is the application that never acuires the specific properties while using RPA tools. 11. How long does a robot automation project take? Generally, any projects are measured in weeks. However, the complex project might take more time depending on the level of object re-use available. 12. Does Blue Prism need Coding? No, the Blue prism is a code-free and can automate and software. This digital workforce should be applied to automate the process in any department where clerical or administrative work is performed across an organization. 13. What is the main difference between Blue Prism And UiPath? Blue Prism uses C# for coding and UiPath uses Visual Basic for coding. 14. What is the future scope of RPA? The future of Robotic Process Automation is very bright as there are plenty of human actions that can be automated, handling RPA tools and technology. 15. Does handling RPA operations need special skills? RPA is an approach that doesn't reuire programming skills. Anyone can become an RPA certified professional with some basic knowledge or training, which is also a short duration. Everything can be managed easily using the flowchart or in a stepwise manner. 16. Name two scripting standards which you will consider during automation testing? Two scripting stands that you need to consider during automation testing are Adeuate indentation Uniform naming convention 17. What are the key metrics which you should consider to map the success of automation testing? Two key metrics to measure the success of automation testing are: Reduction in cost of various modules Defect Detection Ratio 18. Explain the use of PGP PGP allows you to encrypt and decrypt a file by assigning a passphrase. 19. What is meant by Bot? A bot is a set of the command used to automate the task. 20. Name different types of bots Different types of Bots used in RPA process are: TaskBot MetaBot I Bot Chatbot 21. Explain the term dynamic selectors If the selector information changes freuently, then it is called dynamic selectors 22. What is the primary goal of the RPA process? The main object behind the development of the RPA process helps you to replace the repetitive and tedious tasks performed by humans, with the help of a virtual workforce. 23. How to create RPA Bot? To create RPA bot, you need to follow these steps: Record a task Completed the bot implementation Test the bot Upload the bot the perform the automation. 24. How can you do screen scraping in RPA? Screen scraping is an important component of RPA toolkit. It allows you to capture bitmap data from the screen and crosses verified it with stored details in your computer. 25. What are the benefits of screen scraping? Here, are some major benefits of screen scraping: Works on the application which are not accessible even using UI frameworks Offers test digitization through Optical character Easy to implement & mostly accurate 26. Name the framework used in software automation testing Four most crucial framework used in software automation are: Hybrid automation framework Keyword-driven framework Modular automation framework Data-driven framework 27. What the difference between TaskBot and IBot Taskbot manages repetitive and rule-based tasks, while IBot helps you to manage fuzzy rules. 28. Give an example of TaskBot HR administration and Payment procedure are examples of TaskBot. 29. Explain the term workflow Designer It is a graphical representation way of coding, where condition decision-based task is added for whole process reuirement. 30. What is the default time out limit in timeout property? The default timeout limit is 3000 milliseconds. 31. What the major difference between RPA and Macros? Robots Macros Allows you to learn and enhance itself from the repetitive process. Never learn anything for the repetitive process. It can act Autonomously. It cannot work autonomously. It responds to external stimuli and reprograms itself. It doesn't respond to external stimuli. It offers Highly secured automation. Security is not a high priority. 32. Name different types of Default Logs Six types of Default logs are: Execution start Execution end Transaction start Transaction end Error log Debugging log 33. Name two email automation commands Important automation commands are: Email Automation and Send mail. 34. How many types of variables are there in AA? There are two types of applications in Automation Anywhere: System Variable Local Variable 35. In the process of RPA, when you will automate a test? You should try to automate all the repetitive task of organization with the help of the RPA process. 36. What kind of support do you need to handle operation or a process which is based on RPA? It depends on the type of expertise and skill needed for a specific task, project, or process. However, it is not always necessary that all the tasks are completed using similar RPA skills. 37. Explain the term element mask Element mask is the future in application modeler, which allows you to copy the attribute selection of one element and apply it with others. 38. How is Chabot different from RPA? A chatbot is a bot programmed to chat with a user like a human being while RPA is a bot programmed to automate a manual business process of executing a task or an activity within a business function. 39. How much time for the developed automated process? The intimal three days training course provides the based knowledge needed to begin to create a simple automated process. 40. For an Agile method, when you will not use automation testing? If your reuirements are freuently changing or your documentation becomes massive, then it is better to avoid automation testing method. 41. What is dynamic selectors ? if the part of the selector information keeps on changing the it is called dynamic selectors 42. Is it possible to capture selectors in citrix environment ? No 43. What are the activites supported in citrix environment ? Send hot keys, and image click activites 44. How Blue Prism interacts with an SAP control to extend the functionality ? We can use XML files.The XML files are SAPElements.XML Actions.XML 45. Who will be created PDD ? Client SME and/or Blue Prism analyst 46. How can you read the image ? Use Read stage with Read Text with OCR action. 47. What is copy and paste element mask ? When you have decided upon the best attributes to leave ticked for an element, it is likely that this will be the same for most elements within the application. To save time ticking the correct attributes for other new elements you can use the Copy Element Mask and Paste Element Mask options within Application Modeller to copy the attribute ticks from one element to others. 48. What is Application Navigator ? Application Modeller contains a feature called Application Navigator which provides a treeview of all the Accessibility Elements available within the application so that they can be easily found and selected. 49. Can you launch the application via process name ? Yes . We can 50. Can you run a session to multiple times? No 51. What type of Scripts you can Run? JAVA SCRIPT VB SCRIPT 52. Which command will you use to run script? Run script command will available in commands. 53. What are the types of recorders? 3Types In version 10.3 names have changed Screen recorder Smart recorder Web recorder 54. What are email automation commands? Email Automation Send Email We have to configure with SMTP server setting 55. when we are using token in blue prism? in the environment locking 56. How many types variables are there in AA? There are two types:- System Variable Local variable or User defined variable. 57. Explain the different types of variable available in the Task Editor? There are 4 types of variables available in Automation Anywhere are:- List Random Value Array 58. Expalin the different types of variable available in the MetaBot? There are 3 types of variables available in Megabit are:- Value Array password 59. Can you use environment variable to change the value between session ? No 60. Can you run the process by login agent runtime resource ? No 61. what are the languages use to build objects ? VB , C# , J# 62. How many times can run one session ? only one time 63. How can you set the sequence of priority to item ? 0 is first priority and 1 is second link 2, 3….. 64. Can you change work queue internal business object ? No 65. How to configure scheduler settings to retry if resource is offline? Go to system tab and under system click scheduler . We have Resilience section there If a resource is offline , retry after ‘n’ seconds. 66. when scheduler configure change will effect ? After application server restart. 67. what is invisible elements? It is sometimes possible to manipulate HTML elements that aren’t on the visible screen. 68. what is element mask ? Element mask is future in application modeller that enable you to copy the attribute selection of one element and apply it to another. 69. What is thin client & thick client in RPA? Thin client : Does not run on local machine, runs on virtual client/server architecture. Eg.vmvare, virtualbox Thick client : Directly installed in local machine itself. Eg. Any apps like notepad, browser etc.. 70. Shall I run more than one process at same resource ? Yes . By changing run mode options 71. Which tool has recordeding future ? UI path 72. which tool is best for virtual automation ? UI path Robotic Process Automation Questions and Answers Pdf Download Read the full article
0 notes
Text
The Most Common Techniques Employed By Cyber-Thieves To Compromise The Website

The Internet continues to grow at an incredible pace, with more archives of valuable information are being placed online than ever before. A significant amount of those archives distributed online is extremely valuable, including credit card details, crypto-currency, intellectual property, personal details, and trade secrets.
Businesses, governments, and consumers are also more reliant on the Internet for their daily activities. The transactions performed online are worth billions of dollars and trillions of archives of information is exchanged online every day.
The lucrative nature of the Internet has led to a significant increase in the number of Cyber-Attack from Cyber-Thieves. These Cyber-Thieves may employ various tools and techniques to gain access to the sensitive information that is found online. They often compromise the websites and network resources in an effort to extort money or steal assets from organizations.
To protect yourself and your business against Cyber-Thieves, it is important to be aware of how website compromising technique works. This guide will share the most common Cyber-Attack, to help you prepare for most types of malicious threats.
SQL Injection Cyber-Attack
SQL Injection Cyber-Attack is the most common website compromising technique. Most websites employ Structured Query Language (SQL) to interact with archives. SQL allows the website to create, retrieve, update, and delete records from the archives. It is normally employed for everything from logging the authorized client into the website to storing details of an e-commerce transaction.
An SQL injection Cyber-Attack places SQL into a web form in an attempt to get the application to run it. For example, instead of typing plain text into the field of login credentials, a Cyber-Thief may type in ‘ OR 1=1.
If the application appends this string directly to an SQL command that is designed to check if the authorized client exists in the archives, it will always return true. This can allow these Cyber-Thieves to gain access to a restricted section of a website. Other SQL injection Cyber-Attack can be employed to delete information from the archives or document new information.
Cyber-Thieves sometimes employ automated tools to perform SQL injections on remote websites. They will scan thousands of websites, testing many types of injection Cyber-Attack until they are successful.
SQL injection Cyber-Attack can be prevented by correctly filtering input from the authorized client. Most programming languages have special functions to safely handle the input or requests sent by the authorized client.
Cross Site Scripting (XSS)
Cross-Site Scripting is a major vulnerability that is often exploited by Cyber-Thieves to compromise a website. It is one of the more difficult vulnerabilities to deal with because of the way it works. Some of the largest websites in the world have dealt with successful XSS Cyber-Attack including Microsoft and Google.
Most XSS website compromising cyber-attacks employ malicious Java-script, those scripts are embedded in hyperlinks. When the authorized client clicks the link, it might steal personal information, hijack a web session, take over client’s account, or change the advertisements that are being displayed on a page.
Cyber-Thieves will often insert these malicious links into web forums, social media websites, and other prominent locations where authorized clients will click them. To avoid XSS Cyber-Attack, website owners must filter input received by authorized clients to remove any malicious code.
Denial of Service (DoS/DDoS)
The denial of service is the latest technique used by Cyber-Thieves, in which they overwhelm a website with an immense amount of fake Internet traffic created employing several bots and this ultimately causes the servers to become overloaded with a huge amount of requests, which results in a server crash. Most DDoS Cyber-Attack are carried out using Digital-Systems that have been compromised with malware. The owners of the infected Digital-System may not even be aware that their machine is sending requests to access the archives of their website.
Denial of service Cyber-Attack can be prevented by:
Rate limiting your web server’s router
Adding filters to your router to drop packets from dubious sources
Dropping spoofed or malformed packets
Setting more aggressive timeouts on connections
Using firewalls with DDoS protection
Using third-party DDoS mitigation program from Akamai, Cloudflare, VeriSign, Arbor Networks or another provider
Cross-Site Request Forgery (CSRF or XSRF)
Cross-site request forgery is a very common technique employed by Cyber-Thieves to exploit vulnerabilities of websites. It occurs when unauthorized commands are transmitted from a client that a web application trusts. The client is usually logged into the website, so they have a higher level of privileges, allowing the Cyber-Thief to transfer funds, obtain account information or gain access to sensitive information.
There are many ways for Cyber-Thieves to transmit forged commands including hidden forms, AJAX, and image tags. The authorized client is not aware that the command has been sent and the website believes that the command has come from an authorized client. The main difference between an XSS and CSRF Cyber-Attack is that the client should be logged in and trusted by a website for a CSRF website compromising Cyber-Attack to work. Website owners can prevent CSRF Cyber-Attack by checking HTTP headers to verify where the request is coming from and check CSRF tokens in web forms. This type of diagnosis will make sure that the request has come from the internal page of a web application and not from an unknown external source.
DNS Spoofing (DNS Cache Poisoning)
This attacking technique injects a corrupt domain system archive into a DNS resolver’s cache to redirect where a website’s traffic is sent. It often employs the way of sending traffic from legitimate websites to malicious websites that contain malware. DNS spoofing can also be employed to gather information about the traffic being diverted. The best technique for preventing DNS spoofing is to set short TTL times and regularly clear the DNS caches of local machines.
Social Engineering Techniques
In some cases, the greatest weakness in a website’s security system is the people that operate it. Social engineering seeks to exploit this weakness. The Cyber-Thieves will convince a website administrator to divulge some important information that helps them exploit the website. There are many forms of social engineered Cyber-Attacks, including:
Phishing
The authorized clients of a website are sent fraudulent emails that look like they have come from the website, then the client is asked to divulge some information, such as their login details or personal information. Cyber-Thieves can employ this information to compromises the website.
Baiting
This is a classic social engineering technique was first employed in the 1970s. The Cyber-Thief will leave a device near your place of business, perhaps marked with a label like “employee salaries”. One of your employees might pick it up and insert it into their Digital-System out of curiosity. The USB stick will contain malware that infects your Digital-System’s network and compromises your website.
Pretexting
The Cyber-Thief will contact you, one of your customers or an employee and pretend to be someone else. They will demand sensitive information, which they employ to compromise your website. The best way to eliminate social engineered Cyber-Attack is to educate your employees and customers about these kinds of threats.
Non-targeted website Attacking
In many cases, Cyber-Thieves won’t specifically target your website. Instead of your website, they will be more focused on exploring vulnerabilities present in your plugin, content management system or templates.
For example, they may have developed an attacking technique that targets a vulnerability in a particular version of Word-Press, Joomla, or another content management system. They will employ automated bots to find websites using this version of the content management system in question before launching a Cyber-Attack. They might employ the vulnerability to delete stored archives from your website, steal sensitive information, or to insert malicious program onto your server.
The best way to avoid website compromising Cyber-Attacks to ensure your content management system, plugins, and templates are all up-to-date.
#cybersecurity#security#Secure#technology#web development#web developing company#technologies#Webmaster#blog
0 notes