#Web scraping precios
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
Crawler y Scraper: Diferencias, Qué Son y Cómo Funcionan | #Crawler #Scraper #Scraping #SeguridadWeb #Web
0 notes
Text
Perspectiva de Datos: 54 Industrias que Usan Web Scraping
¿Qué es el web scraping?
Web Scraping (también llamado Web Crawling, Data Extraction, Screen Scraping) es el proceso de extraer datos de múltiples sitios web y guardarlos Excel, txt, CSV y JSON en formatos de databases locales. Con los abrumadores datos disponibles en Internet, el web scraping se convierte en un enfoque esencial para agregar Big Data.
¿Quién está usando web scraping?
Vamos a abordar esta pregunta analizando las diferentes industrias y trabajos que requieren habilidades de web scraping. Para hacer esto, hemos compilado y analizado información de trabajo extraída de sitios de trabajo, incluidos Indeed, Glassdoor y LinkedIn.
Para ver exactamente qué trabajos están usando habilidades de web scraping, tomamos un gigante tecnológico (Google) como ejemplo en esta investigación. Raspamos y analizamos las ofertas de trabajo de Google, para descubrir cuáles y cuántos trabajos requieren habilidades de web scraping.
Nuestros hallazgos se muestran a continuación. Después de leerlos, puede que estés tan sorprendido como nosotros. Si está interesado en el proceso de scraping, puede consultar los GitHub Repositories para descargar los rastreadores (que se ejecutan en una herramienta de web scraping gratuita Octoparse) para obtener los datos que desea.
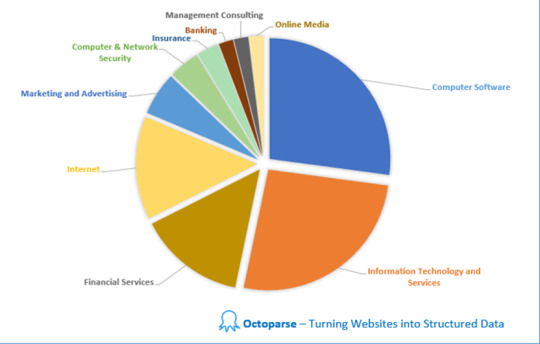
Encontrar 1: 54 Industrias Requieren habilidades de Web Scraping
Raspamos y analizamos las ofertas de trabajo en diferentes industrias que requieren web scraping skills en LinkedIn. En total, hay trabajos en 54 industrias que requieren habilidades de web scraping. Las 10 principales industrias con la mayor demanda de habilidades de web scraping son Software de Computadora (22%), Tecnología de la Información y Servicios (21%), Servicios Financieros (12%), Internet (11%), Marketing y Publicidad (5%) Computadora&Seguridad de red (3%), Seguros (2%), Banca (2%), Consultoría de Gestión (2%) y Medios en línea (2%).
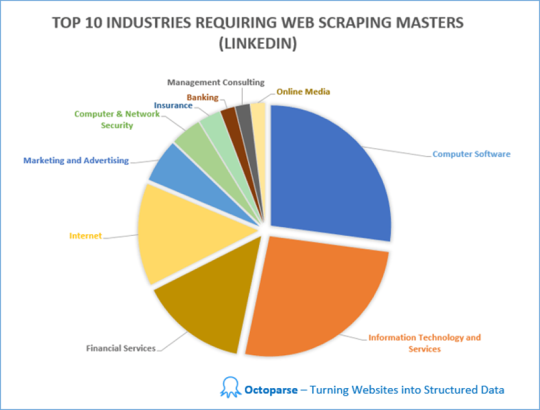
Otras industrias incluyen Petróleo & Energía, Construcción, Bienes de Consumo, Defensa y Espacio, Personal y Reclutamiento, Atención Hospitalaria & de Salud, Gestión Educativa, Gestión de Organizaciones sin fines de lucro, Productos Farmacéuticos, Publicaciones, Investigación, Fabricación Eléctrica/Electrónica, Administración Gubernamental ... etc.
Hallazgo 2: Los trabajos no tecnológicos requieren Web Scraping Skills
También en base a la información extraída de LinkedIn, descubrimos que los trabajos no tecnológicos también incluyen el web scraping en sus requisitos de trabajo.
La sabiduría tradicional dice que la mayoría de los trabajos que requieren web scraping son relevantes para la tecnología, como la tecnología de la información y la ingeniería. Sin embargo, sorprendentemente, hay muchos otros tipos de trabajos que requieren habilidades de web scraping, como ventas, desarrollo de negocios, marketing, recursos humanos, redacción/edición y consultoría.

Específicamente, exploramos de web scraping jobs in Google, para descubrir cuántos trabajos requieren habilidades de web scraping y qué otros requisitos hay además del web scraping.
Hallazgo 3: Habilidades de Web Scraping en Tech Company (Google como ejemplo) Dado que es bastante obvio que las compañías de software y tecnología de la información tienen la mayor demanda de expertos en web scraping, decidimos profundizar en las ofertas de trabajo de Google. Las categorías de trabajo que más necesitan habilidades de web scraping son Ingeniería de Software, Ventas y Gestión de Cuentas y Gestión de Programas, seguidas de Soluciones Técnicas y Marketing & Comunicaciones.
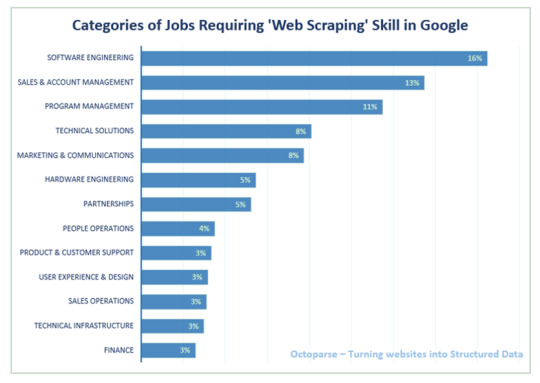
Para aquellos que tienen curiosidad sobre otros requisitos de habilidades para el ingeniero de software y ventas y administración de cuentas en Google, convertimos los requisitos del trabajo en nubes de palabras para darle una mejor idea.
Requisitos sobre Ingeniería de Software en Google

Requisitos sobre Ventas & Gestión de Cuentas en Google

Además de analizar las ofertas de trabajo que requieren habilidades de web scraping, también logramos ver una imagen más amplia de todos los trabajos disponibles en todas las industrias. Aquí hay información adicional que obtuvimos.
Hallazgo 4: Los 10 mejores trabajos mejor pagados
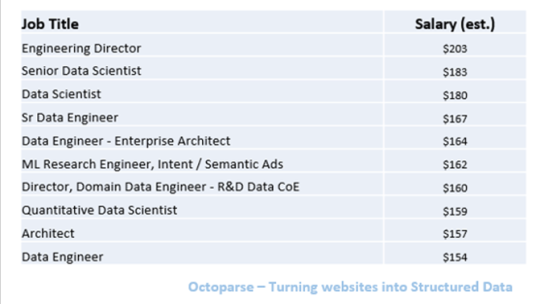
Según la información agregada de Glassdoor, existen grandes diferencias en los salarios para diferentes trabajos, que van desde $25K a $203K. Entre todos, los ingenieros de datos superiores y los científicos de datos son los trabajos mejor pagados.
Los datos anteriores se basan en la estimación de Glassdoor de los salarios base de los trabajos, que no necesariamente es respaldada por los empleadores. )
Entre toda la información sobre el trabajo que recopilamos, los trabajos que pagan menos son Político Reportero y Reclutador Junior, a partir de $25K y $29K.
Hallazgo 5: Las 10 Mejores Industrias de Pago
También exploramos el salario promedio en diferentes industrias, en base al mismo conjunto de datos extraído de Glassdoor. Las industrias con los salarios más altos son los servicios de petróleo y gas, biotecnología y productos farmacéuticos, y mercadería general y supermercado. Para nuestra sorpresa, Information Technology solo ocupa el número 5 en la lista.

Conclusión
Es seguro decir que el web scraping se ha convertido en una habilidad esencial para adquirir en el mundo digital actual, no solo para empresas tecnológicas y puestos tecnológicos, sino también para trabajos no tecnológicos. La capacidad de compilar grandes conjuntos de datos es fundamental para el análisis de Big Data, el aprendizaje automático y la inteligencia artificial.
Afortunadamente, Big Data es cada vez más fácil de acceder que nunca. Con Los 30 Mejores Software Gratuitos de Web Scraping en 2020 que se vuelven más inteligentes y populares, incluso las personas sin experiencia en programación pueden aplicar fácilmente el web scraping para agregar todo tipo de datos, trabajar con los conocimientos de Big Data para potenciar su negocio.
Dicho esto, si desea aprender sobre el web scraping pero no quiere lidiar con Python u otros lenguajes de programación, una herramienta de web scraping es una gran opción. He perfilado una lista de herramientas de web scraping a continuación para su referencia. Entre todas las opciones en el mercado, Octoparse se destaca como el mejor web scraper automático GRATUITO como una solución para la extracción de datos a escala.
#Web scraping precios#scraping y crawling scraping y crawling#web scraping extracción de datos#web scraping import io#web scraper chrome#scraper parsers#excel importar datos web contraseña#buscar personas por ccorreo electrónico#crawly web scraper#web scraping extracción de datos en la web
0 notes
Text
Cómo conseguir generación de leads con web scraping
La tecnología está cambiando el rostro del mundo empresarial y haciendo que las tácticas de marketing críticas y la información empresarial sean de fácil acceso. Una de esas tácticas que ha estado circulando por la generación de leads de calidad es el web scraping.
El web scraping no es más que recopilar información valiosa de páginas web y reunirlas todas para el uso futuro. Si alguna vez has copiado contenido de palabras de un sitio web y luego lo has utilizado para tu propósito, tú, también has utilizado el proceso de raspado web, aunque a un nivel minúsculo. Este artículo habla en detalle sobre el proceso de web scraping y su impacto en la generación de leads de calidad de alto-valor.
Tabla de contenido
1. Introducción al web scraping
Conceptos básicos del web scraping
Procesos de web scraping
Industrias beneficiadas por el web scraping
2. Cómo generar leads con Web Scraping
3. Otros beneficios de Web Scraping
4. Conclusiones
Introducción al web scraping
Conceptos básicos del web scraping
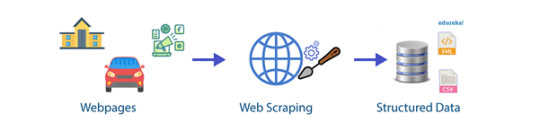
El flujo básico de los procesos de web scraping
¿Qué es?
Web scraping, también conocido como Recolección en la Web y Extracción de datos web, es el proceso de extraer o copiar datos específicos o información valiosa de sitios web y depositarlos en una base de datos central u hoja de cálculo para investigación, análisis o generación de prospectos más adelante. Si bien el web scraping también se puede realizar manualmente, las empresas utilizan cada vez más bots o rastreadores web para implementar un proceso automatizado.
#Tip: Yellow Pages es uno de los directorios de empresas más grandes de la web, especialmente en los EE. UU. Es la mejor vía para scrapear contactos como nombres, direcciones, números de teléfono y correos electrónicos para la generación de clientes potenciales.
Procesos de web scraping
Web Scraping es un proceso extremadamente simple e involucra solo dos componentes- un web crawler(rastreador web) y un web scraper(raspador web). Y gracias a la tecnología ninja, estos los realizan por bots de IA con una intervención manual mínima o nula. Mientras que el crawler, generalmente llamado un "spider(araña)", explora varias páginas web para indexar y buscar contenido siguiendo los enlaces, el scraper extrae rápidamente la información exacta.
El proceso comienza cuando el crawler accede a la World Wide Web directamente a través de un navegador y recupera las páginas descargándolas. El segundo proceso incluye la extracción en la que el web scraper copia los datos en una hoja de cálculo y los formatea en segmentos que no se pueden procesar para su posterior procesamiento.
El diseño y el uso de los raspadores web varían ampliamente, depende del proyecto y su propósito.
Industrias beneficiadas por el web scraping
Reclutamiento
Comercio electrónico
Industria minorista
Entretenimiento
Belleza y estilo de vida
Bienes raíces
Ciencia de los datos
Finanzas
Los minoristas de moda informan a los diseñadores sobre las próximas tendencias basándose en información extraída, los inversores cronometran sus posiciones en acciones y los equipos de marketing abruman a la competencia con información detallada. Un ejemplo generalizado de web scraping es extraer nombres, números de teléfono, ubicaciones e ID de correo electrónico de los sitios de publicación de trabajos por parte de los reclutadores de recursos humanos.
#Tip: Después de COVID 19, la generación de datos en el sector de la salud se ha multiplicado exponencialmente, debido a que el web scraping en la industria de la salud y farmacéutica relacionada ha aumentado en un 57%. Las empresas están analizando datos para diseñar nuevas políticas, desarrollar vacunas, ofrecer mejores soluciones de salud pública, etc. para transformar las oportunidades comerciales.
Web Scraping y Generación de Leads
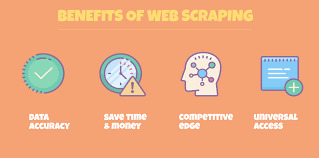
Beneficios de Web Scraping para la generación de leads
#Realidad: 79% de los especialistas en marketing ven el web scraping como una fuente muy beneficiosa de generación de leads.
Los analistas de datos y los expertos en negocios coinciden unánimemente en el hecho de que utilizar Web Scraping mediante la aplicación de proxies residenciales (los proxies residenciales le permiten elegir una ubicación específica y navegar por la web como un usuario real en esa área) es una de las formas más beneficiosas de generar clientes potenciales calificados de ventas para tu negocio. Diseñar un raspador de clientes potenciales único para generar clientes potenciales puede ser mucho más rentable y rentable para generar rápidamente clientes potenciales de calidad.
El web scraping juega un papel importante en la generación de leads mediante dos pasos:
Identificar fuentes
El primer paso para todas las empresas en la generación de leads es agilizar el proceso. ¿Qué fuentes vas a utilizar? ¿Quién es tu público objetivo? ¿A qué ubicación geográfica vas a apuntar? ¿Cuál es tu presupuesto de marketing? ¿Cuáles son los objetivos de tu marca? ¿Qué imagen quieres establecer a través de tu marca? ¿Qué tipo de marketing quieres seguir? ¿Quiénes son tus competidores?
Decodificar la respuesta a estas preguntas fundamentales y diseñar un bot raspador específicamente para cumplir con tus requisitos te llevará a extraer y acceder a información relativa de alta-calidad.
Tip: Si la información de los clientes de tus competidores está disponible públicamente, puedes raspar sus sitios web para su demografía. Esto te daría una buena visualización de quiénes son tus clientes potenciales y qué ofrecen actualmente.
Extraer datos
Después de descubrir las preguntas fundamentales para administrar un negocio exitoso, el siguiente paso es extraer los datos más relevantes, en tiempo real, procesables y de alto rendimiento para diseñar campañas de estratégicas de marketing para obtener el máximo beneficio. Sin embargo, hay dos formas posibles de hacerlo-
A) Optar por una herramienta de generación de leads
Uno de los proveedores de datos B2B más comunes, DataCaptive, ofrece un servicio de generación de lead y otras soluciones de marketing para brindar un soporte incomparable a tu negocio y aumentar el ROI por 4.
B) Usar herramientas de scraping
Octoparse es uno de los proveedores de herramientas de scraping más destacados que te proporciona información valiosa para maximizar el proceso de generación de clientes potenciales. Nuestra flexibilidad y escalabilidad de web scraping aseguran cumplir con los parámetros de tu proyecto con facilidad.
Nuestro proceso de raspado web de tres pasos incluye-
En el primer paso, personalizamos los raspadores que son únicos y complementan los requisitos de tu proyecto para identificar y extraer datos exactos que darán los resultados más beneficiosos. También puedes registrar el sitio web o las páginas web que deseas raspar específicamente.
Los raspadores recuperan los datos en formato HTML. A continuación, eliminamos lo que rodea a los datos y los analizamos para extraer los datos que desees. Los datos pueden ser simples o complejos, según el proyecto y su demanda.
En el tercer y último proceso, los datos se formatean según la demanda exacta del proyecto y se almacenan en consecuencia.
Otros beneficios de Web Scraping
Comparación de precios
Tener acceso al precio actual y en tiempo real de los servicios relacionados ofrecidos por tus competidores puede revolucionar tus procedimientos comerciales diarios y aumentar la visibilidad de tu marca. El web scraping es la solución de un solo paso para determinar soluciones de precios automáticas y analizar perspectivas rentables.
Analizar sentimiento / psicología del comprador
El análisis de sentimientos o persona del comprador ayuda a las marcas a comprender a su clientela mediante el análisis de su comportamiento de compra, historial de navegación y participación en línea. Los datos extraídos de la Web desempeñan un papel clave en la erradicación de interpretaciones sesgadas mediante la recopilación y el análisis de datos de compradores relevantes y perspicaces.
Marketing- contenido, redes sociales y otros medios digitales
El raspado web es la solución definitiva para monitorear, agregar y analizar las historias más críticas de tu industria y generar contenido a tu alrededor para obtener respuestas más impactantes.
Inversión de las empresas
Datos web diseñados explícitamente para que los inversores estimen los fundamentos de la empresa y el gobierno y analicen las perspectivas de las presentaciones ante la SEC y comprendan los escenarios del mercado para tomar decisiones de inversión sólidas.
Investigación de mercado
El web scraping está haciendo que el proceso de investigación de mercado e inteligencia empresarial sea aún más crítico en todo el mundo al proporcionar datos de alta calidad, gran volumen y muy perspicaz de todas las formas y tamaños.
Conclusiones
Web scraping es el proceso de seleccionar páginas web en busca de contenido relevante y descargarlas en una hoja de cálculo para el uso posterior con un rastreador web y un raspador web.
Las industrias más destacadas para practicar el web scraping para generar lead e impulsar las ventas son la ciencia de datos, bienes raíces, el marketing digital, el entretenimiento, la educación, el comercio minorista, reclutamiento y la belleza y estilo de vida, entre muchas otras.
Después de la pandemia de COVD 19, la industria farmacéutica y de la salud ha sido testigo de un aumento significativo en su porcentaje de raspado web debido a su aumento continuo y exponencial en la generación de datos.
Además de la generación de leads, el web scraping también es beneficioso para la investigación de mercado, la creación de contenido, la planificación de inversiones, el análisis de la competencia, etc.
Algunas de las mejores y más utilizadas herramientas de raspado web o proveedores de herramientas son Octoparse, ScraperAPI, ScrapeSimple, Parsehub, Scrappy, Diffbot y Cheerio.
1 note
·
View note
Text
Comfortable and steady. Adorable shoe for everyday. I got the marley size 8. Consistent with size, aside from the one versatile tie at tge top appears to be a bit cozy for me. Im sure after some time I can extend it. In any case an extremely charming shoe for consistently wear.

My underlying request landed with the flexible on the left shoe cut totally through (you can see it a little in the photograph). I have no clue why this occurred, my conjecture is that a crate shaper may have found a good pace postage.
Nonetheless, I do truly like this shoe. It has a cozy, slender impact point however a wide metatarsal territory (toe box), so it accommodates my foot type pleasantly. I am an artist and I walk a ton, so I need shoes that permit me to explain my foot totally. The toe box on these are wide enough that I can walk level or on the bundles of my feet with no tightening. I love this, since I will in general walk/remain around on demi pointe (artist propensity). I additionally love the delightful way the impact point cup is cozy, since it doesn't sneak off my foot when strolling (something that typically occurs with other wide shoes). It is the best of the two universes!
I used to wear Converse hurls strictly, however I figure these Blowfish tennis shoes will be my new go-to easygoing shoe! I can hardly wait for the substitution pair to show up. I'm certain I'll wear them consistently!
They are extremely decent looking, high caliber, slick and exactly what I needed in looks. The fit is extremely odd. I requested my typical size 8 and they are excessively limited in the toe region. The toe length is fine, just excessively thin. I have never worn wide size shoes so not certain what to think about the issue. The length is fine and the width is ordinary in all parts with the exception of that one territory. I should bring them back. I wore them for one minute and my feet despite everything hurt from them.
Extraordinary pair of shoes - I purchased the steel dark which looks progressively like a washed beige to me - simply like it looked on the web. I wear them with "no show" socks and love them! I've gotten a few commendations. I normally wear 8 and 8.5 shoes and purchased a 8.5 right now. Fits flawless with the dainty "no show" socks. My solitary slight negative is that the base of the shoe is that fluffy stuff that covers the elastic so it makes it a little elusive when strolling on waxed floors. Nothing where I've slipped, yet I wouldn't go running in these in Target! Obviously that wears off after some time and I've been scraping them on cement to accelerate that procedure. In general - I'm exceptionally satisfied with this buy!
Love, love, love these shoes! I didn't have any issue with the fit, possibly; I wear a 8, and it fit splendidly. Indeed, they're a smidgen heavier than an ordinary running/broadly educating shoe, yet they are as yet agreeable for getting things done and slipping on rapidly. I purchased the camo print and have gotten a few commendations. Several audits referenced not having the option to slip directly on without the tongue stalling out. For hell's sake! Plunk down, slip the shoe on, and clutch the tongue so it doesn't get bundled up. It isn't so large of an arrangement. Furthermore, indeed, it's somewhat smooth on the base from the start; simply scrape up the bottoms on your walkway or garage. I'm going to arrange another pair in the dim! Love them!
I purchased these in April of 2017, it's currently December 2018 and I am getting another pair. In any case, considering I wore these to Disneyland 20+ occasions ( avg visitor strolls 7+ miles in Disneyland) ,2 excursions to Vegas , and I wore these practically consistently the previous summer! I'd state these got their utilization! They are the comfiest shoes I possess! Furthermore, they go with all the fixings! They're anything but difficult to clean as well! I spilled brew on them and turned them dark colored for seven days however once I got some sanitizer on a toothbrush and scoured a bit. The stain came directly out. going to get them again since the pair I possess as nearly been worn through.
youtube
I love Blowfish. Preceding an outing to Costa Rica, I stumbled over a lovable pair of shoes and it was love. Since I love the shoes so a lot, I chose to attempt the sneakers. I requested Steel Gray. Here is the thing that I found with these shoes. They are difficult to jump on in light of the fact that the tongue on the shoes descends when putting them on and it is hard to haul it out. These were additionally excessively little for my foot. I am returning them and requesting an alternate style. I gave 4 stars since they are extremely adorable shoes and, while I would not retry any with versatile over the top, I do anticipate another enjoyment style.
Extremely adorable shoes. I have numerous Blowfish shoes and shoes. I love this brand. They look simply like the image. The main negative thing is they are somewhat hardened and level on the ground. In case you're utilized to the springy wanting to walk shoes, these don't have that. They're not awkward, only somewhat firm. The "bands" are flexible so there's a decent stretch there. I will get some gel supplements to place in them.
I truly like these. I'd been searching for a couple that I could slip on and use for easygoing occasions, and I like how these stay on my feet. I additionally acknowledge how thick the sole is. Different styles watch out for just last one summer yet these ones will last a couple of years, which is extraordinary. I sprayed them to make them simpler to think about.
Estos tennis llegaron risks del tiempo estimado, child muuuuy cómodos, la talla es exacta y el shading tal cual se ve en la imagen, lastima que no feed muchos colores que entren en la categoría PRIME y con otros proveedores se eleva muchisimo el precio.
I truly like this shoe from the start. It fits impeccably, it's agreeable and it's lovely. I got the white pair so it coordinates most outfits. Be that as it may, when it gets contact with mud, it's a torment to clean and the stains remain there :( I've had white shoes previously and afterward I would Jason Markk shoe cleaner and they're spotless once more. In any case, for this one, the stains sink into canvas material.
I would prescribe this shoe however get the dim hued ones.
1 note
·
View note
Text
OtterBox | Defender Series | Carcasa para Samsung Galaxy S9 (prot

Proveedor: OtterBox Tipo: Estuches Precio: 41.35
Este articulo se consigue en diferentes colores Pregunte por la disponibilidad de su preferencia antes de efectuar su compra
EstiloCaso | ColorNegro | Empaque del productoStandard Packaging Worry less while youre working| adventuring and living when you defend your device against drops| dirt and scrapes The new Screenless Edition Defender Series is specifically designed for the Galaxy S9 touchscreen Combining a solid internal shell with a resilient outer slipcover| Defender Series deflects the action and accidents that come your way every day Plus| the included holster doubles as a kickstand for handsfree viewing Materials Polycarbonate shell| Synthetic rubber slipcover
Compatible con Midas Robusto| funda protectora| de 3 capas con un protector de visualizacion integrado| resiste aranazos| caidas y golpes Incluye clip de cinturon que tambien sirve como soporte para una visualizacion con manos libres puerto cubre mantener fuera el polvo y los escombros Incluye 1 estuche Otterbox ver pagina web para mas detalles y 100 autentico
Otras caracteristicas
Modelos de telefono compatibles Samsung Galaxy S9
Marca OtterBox
Color Negro
Material Polycarbonate shell Synthetic rubber slipcover
Factor de forma Belt Clip
source https://www.electroika.com/products/otterbox-defender-series-carcasa-para-samsung-galaxy-s9-prot
0 notes
Text
Plugin Para Wordpress | Comparación de precios de Scrape - Afiliados Complemento de WooCommerce y Wordpress
Plugin Para Wordpress | Comparación de precios de Scrape – Afiliados Complemento de WooCommerce y Wordpress
[ad_1]
LIVE PREVIEWBUY FOR $46
Scrape Price Comparison es un plugin de WordPress que puede obtener en miles de tiendas en línea usando el plugin WooCommerce para crear una comparación de precios de productos o agregar precios con un shortcode en cualquier publicación, página o widget de texto, de forma rápida y sencilla en solo unos minutos. Busca precios en vivo desde otros sitios web / tiendas…
View On WordPress
#añadir scripts en wordpress#aplicaciones para wordpress#app para wordpress#plugins wordpress profesionales#software para wordpress
0 notes
Text
Análisis del Mercado de Valores Utilizando Raspado Web
Las empresas de inversión hoy en día están en la carrera de desarrollar algoritmos sofisticados para el comercio de acciones. Ya sea que se trate de la predicción del precio de las acciones, el análisis del sentimiento del mercado de valores o la investigación de acciones, necesitan un gran volumen de datos precisos. Es frecuente que tengan el capital para contratar una tropa de desarrolladores. Para que los investigadores independientes puedan predecir el mercado de valores, existe un método asequible para obtener los datos a escala sin esfuerzo.
En este tutorial, le mostraré cómo extraer datos de stock actualizados para acciones adicionales.
Prerrequisitos:
Este método no requiere codificación. Puede extraer información valiosa de sitios web sin experiencia en tecnología para extraer información valiosa.
Necesitamos usar una herramienta de web scraping tool, sería mejor si tienes instalado Octoparse en tu computadora. Mira este video si eres nuevo en la herramienta.
youtube
Vamos a sumergirnos en eso.
¡Extraeremos Balance general de las acciones de Bank of America de Yahoo! Las finanzas como ejemplo. Con el Balance general, puede construir una base de datos junto con el precio histórico de las acciones. Con estos datos, podría desarrollar algoritmos/aprendizaje automático que correlacionen los números con los precios de acciónes. Cuando escala el número de existencias, tiene una tubería más grande para entrenar el modelo de su IA.
La URL que vamos a necesitar es https://finance.yahoo.com/quote/BAC/balance-sheet?p=BAC
1) Crear un nuevo proyecto:
Haga clic en "+ Tarea" en Modo avanzado. Ingrese la URL en el cuadro y haga clic en "Guardar URL"
Esto traerá al mercado de valores del Banco de América con el navegador incorporado Octoparse.
Los datos se presentan en forma de celdas de tabla. Como resultado, el bot necesita raspar por filas de la tabla. Para aclarar lo que quiero decir, podemos abrir las herramientas para desarrolladores de Chrome e inspeccionar la fuente del sitio web. Toda la tabla está construida con <tr>, y <tr> consiste en múltiples <td> s que representan los datos de una fila. Los datos que vamos a extraer se almacenan dentro de cada <td>. Tiene sentido que el bot siga la lógica del código fuente y extraiga la información por filas.

2) A continuación, tenemos que decirle al bot qué información queremos obtener. Haga clic en cualquier número de la celda de la tabla. El bot descubre otros números de la misma columna. Como mencioné anteriormente, debemos seguir la lógica del código fuente y extraer por filas. En este caso, haga clic en "TR" en la parte inferior del Panel de acciones. Ahora Octoparse encuentra la primera fila. ¡Esto es genial! Elija "Seleccionar todo el subelemento", luego elija "Seleccionar todo" para continuar.

3) Ahora todos los elementos han sido seleccionados con éxito. Elija el comando "Extraer datos en el bucle" para continuar.
4) Ahora terminamos de construir el rastreador! Haga clic en "Iniciar extracción" y elija "Extracción local" para ejecutar la tarea. Tenga en cuenta que "Extracción local" es ejecutar el rastreador en su propia computadora. A diferencia de Cloud Extraction que tiene múltiples extracciones paralelas distribuidas en diferentes servidores, Local Extraction solo grava el recurso local y la velocidad se ve afectada por Internet y el hardware. Es probable que se sobrecargue si tiene tareas simultáneas en ejecución. Por lo tanto, Cloud Extraction es una opción óptima para extracciones a gran escala.
5) Los datos que raspó deberían ser así. Puede elegir un formato preferido para exportar los datos.

Ahora tenemos Balance General de las acciones de Bank of America de 2015 a 2018, pero ¿cómo puede usarlo en un análisis de mercado?
No soy un experto en inversiones financieras, y este blog no proporciona asesoramiento financiero. Con suerte, puede darte una idea para buscar empresas dignas de inventar.
1 note
·
View note
Text
Simple Scraping con Google Sheets (2020 actualizado)
Este herramienta de web scraping puede automatizar el proceso de copia y pegado repetitivos. En realidad, las hojas de Google pueden considerarse un web scraping básico. Puede usar una fórmula especial para extraer datos de una página web, importar los datos directamente a las hojas de Google y compartirlos con sus amigos.
En este artículo, primero le mostraré cómo construir un web scraping simple con Hojas de cálculo de Google. Luego lo compararé con Octoparse web scraping automático. Después de leerlo, tendrá una idea clara sobre qué método funcionaría mejor para sus necesidades específicas de web scraping.
Opción#1: Cree un web scraping sencillo con ImportXML en Google Spreadsheets
Paso 1: Abre una nueva hoja de Google.
Paso 2: Abra un sitio web de destino con Chrome. En este caso, elegimos ’Games sales’. Haga clic derecho en la página web y aparecerá un menú desplegable. Luego seleccione "inspeccionar". Presione una combinación de tres teclas: "Ctrl” + "Shift" + "C" para activar "Selector". Esto permitiría al panel de inspección obtener la información del elemento seleccionado dentro de la página web.
Paso 3: Copie y pegue la URL del sitio web en la hoja.
Opción#2: Intentemos obtener datos de precios con una fórmula simple: ImportXML
Paso 1: Copie el Xpath del elemento. Seleccione el elemento de precio y haga clic con el botón derecho para que aparezca el menú desplegable. Luego seleccione "Copiar", elija "Copiar XPath".
Paso 2: Escriba la fórmula en la hoja de cálculo.
=IMPORTXML(“URL”, “XPATH expression”)
Tenga en cuenta que la "expresión Xpath" es la que acabamos de copiar de Chrome. Reemplace la comilla doble "" dentro de la expresión Xpath con una comilla simple ''.
Opción#3: Hay otra fórmula que podemos usar:
=IMPORTHTML(“URL”, “QUERY”, Index)
Con esta fórmula, extraes toda la tabla.
Ahora, veamos cómo se puede lograr la misma tarea de raspado con un rastreador web, Octoparse.
Paso 1: Abra Octoparse, cree una nueva tarea seleccionando "+ Tarea" en el "Modo avanzado"
Paso 2: Elija su grupo de tareas preferido. Luego ingrese la URL del sitio web de destino y haga clic en "Guardar URL". En este caso: sitio web de Game Sale http://steamspy.com/
Paso 3: Aviso El sitio web de Game Sale se muestra en la sección de vista interactiva de Octoparse. Necesitamos crear una lista de bucles para que Octoparse revise los listados.
1. Haga clic en una fila de la tabla (podría ser cualquier archivo dentro de la tabla). Octoparse detectará elementos similares y los resaltará en rojo.
2. Necesitamos extraer por filas, así que elija "TR" (Fila de Tabla) desde el panel de control.
3. Después de seleccionar una fila, elija el comando "Seleccionar todos los subelementos" en el panel Consejos de acción. Elija el comando "Seleccionar todo" para seleccionar todas las filas de la tabla.
Paso 4: Elija "Extraer datos en el bucle" para extraer los datos.
Puede exportar los datos a Excel, CSV, TXT u otros formatos deseados. Las hojas de cálculo requieren que se copie y pegue, pero Octoparse automatiza el proceso. Además, Octoparse tiene más control sobre sitios web dinámicos con AJAX o reCaptcha.
Más recursos:
Create your first scraper with Octoparse [Video]
Los 20 mejores programas gratuitos de web scraping
Comparacion de las 5 mejores herramientas de web scraping
#Web scraping precios#scraping mensaje#como hacer web scraping con python#web scraping legal#web scraping javascript#scraper idealista#extraer datos de una web#correos electrónicos buscar#buscar personas por ccorreo electrónico#scrab in linkedin#Búsqueda de correos electrónicos#chrome scrab in
0 notes
Link
¿Cómo puede descargar imágenes de enlaces de forma gratuita en lote?
Para descargar la imagen del enlace, es posible que desee buscar en "Descargadores de imágenes a granel". Inspirado por las consultas recibidas, decidí hacer una lista de "los 5 mejores descargadores de imágenes masivas" para usted. Asegúrese de consultar este artículo Si desea descargar imágenes del enlace sin costo. (Si no está seguro de cómo extraer las URL de las imágenes, consulte esto: Cómo construir un rastreador de imágenes sin codificación)
#Web scraping precios#scraping mensaje#como hacer web scraping con python#web scraping legal#web scraping javascript#scraper idealista#extraer datos de una web#correos electrónicos buscar#buscar personas por ccorreo electrónico#scrab in linkedin#Búsqueda de correos electrónicos#chrome scrab in#web scraping software#crawly web scraper
0 notes
Text
Los 30 Mejores Software de Web Scraping Gratis en 2020
El Web scraping (también denominado extracción de datos web, web crawler, captura de pantalla o recolección web) es una técnica web para extraer datos de los sitios web. Convierte datos no estructurados en datos estructurados que pueden almacenarse en su computadora local o en una base de datos.
Puede ser difícil crear un web scraping para personas que no saben nada sobre codificación. Afortunadamente, hay herramientas disponibles tanto para personas que tienen o no habilidades de programación. Aquí está nuestra lista de las 30 herramientas de web scraping más populares, desde bibliotecas de código abierto hasta extensiones de navegador y software de escritorio.
1. Beautiful Soup
¿Para quién es esto?: desarrolladores que dominan la programación para crear un web scraping/web crawler para rastrear los sitios web.
Por qué deberías usarlo:Beautiful Soup es una biblioteca de Python de código abierto diseñada para scrape archivos HTML y XML. Son los principales analizadores de Python que se han utilizado ampliamente. Si tiene habilidades de programación, funciona mejor cuando combina esta biblioteca con Python.
2. Octoparse
¿Cómo hacer web scraping?: Las empresas o las personas tienen la necesidad de extraer datos de la web: comercio electrónico, inversión, criptomoneda, marketing, bienes raíces, etc. Este software no requiere habilidades de programación y codificación.
Por qué debería usarlo: Octoparse es una plataforma de datos web SaaS gratuita de por vida. Puede usar para raspar datos web y convertir datos no estructurados o semiestructurados de sitios web en un conjunto de datos estructurados sin codificación. También proporciona task templates para usar, como eBay, Twitter, BestBuy y muchas otras. Octoparse también proporciona servicio de datos web. Puede personalizar el tarea scraper según sus necesidades de raspado.
3. Import.io
Para quién es esto: Empresa que busca una solución de integración en datos web.
Por qué debería usarlo: Import.io es una plataforma de datos web SaaS. Proporciona un software de web scraping que le permite raspar datos de sitios web y organizarlos en conjuntos de datos. Pueden integrar los datos web en herramientas analíticas para ventas y marketing para obtener información.
4. Mozenda
Para quién es esto: Empresas y negocios hay necesidades de fluctuantes de datos/datos en tiempo real.
Por qué debería usarlo: Mozenda proporciona una herramienta de extracción de datos que facilita la captura de contenido de la web. También proporcionan servicios de visualización de datos. Elimina la necesidad de contratar a un analista de datos.
5. Parsehub
Para quién es esto: analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: ParseHub es un software visual de web scrapinng que puede usar para obtener datos de la web. Puede extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar su dirección IP cuando se encuentre con sitios web agresivos con una técnica anti-raspado.
6. Crawlmonster
Para quién es esto: SEO y especialistas en marketing
Por qué deberías usarlo: CrawlMonster es un software gratuito de web scraping. Le permite escanear sitios web y analizar el contenido de su sitio web, el código fuente, el estado de la página y muchos otros.
7. Connotate
Para quién es esto: Empresa que busca una solución de integración en datos web.
Por qué debería usarlo: Connotate ha estado trabajando junto con Import.IO, que proporciona una solución para automatizar el scraping de datos web. Proporciona un servicio de datos web que puede ayudarlo a raspar, recopilar y manejar los datos.
8. Common Crawl
Para quién es esto: Investigador, estudiantes y profesores.
Por qué deberías usarlo: Common Crawl se basa en la idea del código abierto en la era digital. Proporciona conjuntos de datos abiertos de sitios web rastreados. Contiene datos sin procesar de la página web, metadatos extraídos y extracciones de texto.
9. Crawly
Para quién es esto: Personas con requisitos de datos básicos sin hababilidad de codificación.
Por qué debería usarlo: Crawly proporciona un servicio automático que raspa un sitio web y lo convierte en datos estructurados en forma de JSON o CSV. Pueden extraer elementos limitados en segundos, lo que incluye: Texto del título. HTML, comentarios, etiquetas de fecha y entidad, autor, URL de imágenes, videos, editor y país.
10. Content Grabber
Para quién es esto: Desarrolladores de Python que son expertos en programación.
Por qué debería usarlo: Content Grabber es un software de web scraping dirigido a empresas. Puede crear sus propios agentes de web scraping con sus herramientas integradas de terceros. Es muy flexible en el manejo de sitios web complejos y extracción de datos.
11. Diffbot
Para quién es esto: Desarrolladores y empresas.
Por qué debería usarlo: Diffbot es una herramienta de web scraping que utiliza aprendizaje automático y algoritmos y API públicas para extraer datos de páginas web (web scraping). Puede usar Diffbot para el análisis de la competencia, el monitoreo de precios, analizar el comportamiento del consumidor y muchos más.
12. Dexi.io
Para quién es esto: Personas con habilidades de programación y cotificación.
Por qué deberías usarlo: Dexi.io es un rastreador web basado en navegador. Proporciona tres tipos de robots: extractor, rastreador y tuberías. PIPES tiene una función de robot maestro donde 1 robot puede controlar múltiples tareas. Admite muchos servicios de terceros (solucionadores de captcha, almacenamiento en la nube, etc.) que puede integrar fácilmente en sus robots.
13. DataScraping.co
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Data Scraping Studio es un software gratuito de raspado web para recolectar datos de páginas web, HTML, XML y pdf. Actualmente, el cliente de escritorio solo está disponible para Windows.
14. Easy Web Extract
Para quién es esto: Negocios con necesidades limitadas de datos, especialistas en marketing e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Easy Web Extract es un software visual de raspado web para fines comerciales. Puede extraer el contenido (texto, URL, imagen, archivos) de las páginas web y transformar los resultados en múltiples formatos.
15. FMiner
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: FMiner es un software de web scraping con un diseñador de diagramas visuales, y le permite construir un proyecto con una grabadora de macros sin codificación. La característica avanzada le permite raspar desde sitios web dinámicos usando Ajax y Javascript.
16. Scrapy
Para quién es esto: Desarrollador de Python con habilidades de programación y scraping
Por qué deberías usarlo: Scrapy se usa para desarrollar y construir una araña web. Lo bueno de este producto es que tiene una biblioteca de red asincrónica que le permitirá avanzar en la siguiente tarea antes de que finalice.
17. Helium Scrape
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Helium Scraper es un software visual de scraping de datos web que funciona bastante bien, especialmente eficaz para elementos pequeños en el sitio web. Tiene una interfaz fácil de apuntar y hacer clic, lo que facilita su uso.
18. Scrape.it
Para quién es esto: Personas que necesitan datos escalables sin codificación.
Por qué deberías usarlo: Permite que los datos raspados se almacenen en tu disco local que autorizas. Puede crear un Scraper utilizando su lenguaje de web scraping (WSL), que tiene una curva de aprendizaje baja y no tiene que estudiar codificación. Es una buena opción y vale la pena intentarlo si está buscando una herramienta de web scraping segura.
19. ScraperWiki
Para quién es esto: Un entorno de análisis de datos Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
Por qué deberías usarlo: Tiene dos partes dentro de la empresa. Uno es QuickCode, que está diseñado para economistas, estadísticos y administradores de datos con conocimiento del lenguaje Python y R. La segunda parte es The Sensible Code Company, que proporciona un servicio de datos web para convertir información desordenada en datos estructurados.
20. Scrapinghub
¿Para quién es esto?: Python/Desarrolladores de web scraping
Por qué debería usarlo: Scraping Hub es una plataforma web basada en la nube. Tiene cuatro tipos diferentes de herramientas: Scrapy Cloud, Portia, Crawlera y Splash. Es genial que Scrapinghub ofrezca una colección de direcciones IP cubiertas en más de 50 países, que es una solución para los problemas de prohibición de IP.
21. Screen-Scraper
Para quién es esto: Para los negocios se relaciona con la industria automotriz, médica, financiera y de comercio electrónico.
Por qué debería usarlo: Screen Scraper puede proporcionar servicios de datos web para las industrias automotriz, médica, financiera y de comercio electrónico. Es más conveniente y básico en comparación con otras herramientas de web scraping como Octoparse. También tiene un ciclo de aprendizaje corto para las personas que no tienen experiencia en el web scraping.
22. Salestools.io
Para quién es esto: Comercializador y ventas.
Por qué debería usarlo: Salestools.io proporciona un software de web scraping que ayuda a los vendedores a recopilar datos en redes profesionales como LinkedIn, Angellist, Viadeo.
23. ScrapeHero
¿Quién es este: Para inversores, Hedge Funds, Market Analyst es muy útil.
Por qué debería usarlo: ScrapeHero como proveedor de API le permite convertir sitios web en datos. Proporciona servicios de datos web personalizados para empresas y empresas.
24. UniPath
Para quién es esto: Negocios con todos los tamaños
Por qué debería usarlo: UiPath es un software de automatización de procesos robótico para el web scraping gratuito. Permite a los usuarios crear, implementar y administrar la automatización en los procesos comerciales. Es una gran opción para los usuarios de negocios, ya que te hace crear reglas para la gestión de datos.
25. Web Content Extractor
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Web Content Extractor es un software de web scraping fácil de usar para fines privados o empresariales. Es muy fácil de aprender y dominar. Tiene una prueba gratuita de 14 días
26. Webharvy
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: WebHarvy es un software de web scraping de apuntar y hacer clic. Está diseñado para no programadores. El extractor no le permite programar. Tienen tutoriales de web scraping que son muy útiles para la mayoría de los usuarios principiantes.
27. Web Scraper.io
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Web Scraper es una extensión de navegador Chrome creada para extraer datos de sitios web. Es un software gratuito de web scraping para raspar páginas web dinámicas.
28. Web Sundew
Para quién es esto: Empresas, comercializadores e investigadores.
Por qué debería usarlo: WebSundew es una herramienta de raspado visual que funciona para el raspado estructurado de datos web. La edición Enterprise le permite ejecutar el scraping en un servidor remoto y publicar los datos recopilados a través de FTP.
29. Winautomation
Para quién es esto: Desarrolladores, líderes de operaciones comerciales, profesionales de IT
Por qué debería usarlo: Winautomation es una herramienta de web scraping de Windows que le permite automatizar tareas de escritorio y basadas en la web.
30. Web Robots
Para quién es esto: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué debería usarlo: Web Robots es una plataforma de web scraping basada en la nube para raspar sitios web dinámicos con mucho Javascript. Tiene una extensión de navegador web, así como un software de escritorio que es fácil para las personas para extraer datos de los sitios web.
#web scraping precios#cómo hhacer web scraping python#scraping mensaje#web scraping legal#web scraping javascript#scraper idealista#extraer datos de una web#scrab in linkedin
0 notes
Text
Cómo obtener datos a gran escala (guía 2020)
A medida que su negocio se amplía, es necesario llevar el proceso de extracción de datos al siguiente nivel y raspar los datos a gran escala. Sin embargo, la ampliación no es una tarea fácil. Es posible que encuentre algunos desafíos que le impidan obtener una cantidad significativa de datos de varias fuentes automáticamente.
Tabla de contenidos:
4 desafíos de extracción a gran escala
Combate con estos desafíos
Obstáculos mientras se somete a web spider a escala:
De The Lazy Artist Gallery
1. Estructura dinámica del sitio web: Es fácil scrape páginas web HTML. Sin embargo, muchos sitios web ahora dependen en gran medida de las técnicas de Javascript/Ajax para la carga dinámica de contenido. Ambos requieren todo tipo de bibliotecas complejas que estas bases de datos hacen que la scraping de datos en la red sea complejas
2. Tecnologías anti-scraping: Tales como Captcha y antecedentes después de iniciar sesión sirven como vigilancia para detener el correo no deseado. Sin embargo, también representan un gran desafío para que se pasado un web scraper básico. Como tales tecnologías anti-scraping aplican algoritmos de codificación complejos, se necesita mucho esfuerzo para encontrar una solución técnica para solucionarlo. Algunos incluso pueden necesitar un middleware como 2Captcha para resolver.
3. Velocidad de carga lenta: Cuantas más páginas web necesite un raspador (scraper), más tardará en completarse. Es obvio que el scraping a gran escala requerirá muchos recursos en una máquina local. Una carga de trabajo más pesada en la máquina local puede provocar una falla.
4. Almacenamiento de datos: Una extracción a gran escala genera un gran volumen de datos. Esto requiere una infraestructura sólida en el almacenamiento de datos para poder almacenar los datos de forma segura. Se necesitará mucho dinero y tiempo para mantener dicha base de datos.
Aunque estos son algunos de los desafíos comunes de la scraping a gran escala, Octoparse ya ayudó a muchas empresas a superar estos problemas. La tecnología de extracción de datos en la nube de Octoparse está diseñada para la extracción a gran escala.
La extracción en la nube optimiza el raspado a escala
La extracción en la nube le permite extraer datos de sus sitios web de destino 24/7 y transmitirlos a su base de datos, todo de forma automática. ¿La única ventaja obvia? No necesita sentarse junto a su computadora y esperar a que se complete la tarea.
Pero ... en realidad, hay cosas más importantes que puede lograr con la extracción en la nube. Déjame desglosarlos en detalles:
1. Rapidez
En Octoparse, llamamos a un proyecto de scraping una "tarea". Con la extracción en la nube, puede scrape hasta 6 a 20 veces más rápido que una ejecución local.
Así es como funciona la extracción en la nube. Cuando se crea una tarea y se configura para ejecutarse en la nube, Octoparse envía la tarea a varios servidores de la nube que luego realizan las tareas de raspado simultáneamente. Por ejemplo, si está tratando de raspar la información del producto para 10 almohadas diferentes en Amazon, en lugar de extraer las 10 almohadas una por una, Octoparse inicia la tarea y la envía a 10 servidores en la nube, cada uno extrae datos para uno de los diez almohadas Al final, obtendría 10 datos de almohadas extraídos en 1/10 del tiempo si extrajera los datos localmente.
Aparentemente, esta es una explicaciób demasiado simplificada del algoritmo Octoparse, pero se entiende la idea.
2. Scrape más sitios web simultáneamente
Cloud extracción también permite scrape hasta 20 sitios web simultáneamente. Siguiendo la misma idea, cada sitio web se raspa en un único servidor en la nube que luego envía los extraídos a su cuenta.
Puede configurar diferentes tareas con varias prioridades para asegurarse de que los sitios web se scraped en el orden preferido.
3. Almacenamiento ilimitado en la nube
Durante una extracción en la nube, Octoparse elimina los datos duplicados y almacena los datos limpios en la nube para que pueda acceder fácilmente a los datos en cualquier momento, en cualquier lugar y no hay límite para la cantidad de datos que puede almacenar. Para una experiencia de raspado aún más fluida, integre Octoparse con su propio programa o base de datos a través de API para administrar sus tareas y datos.
4. Programe ejecuciones para la extracción regular de datos Si va a necesitar feeds de datos regulares de cualquier sitio web, esta es la característica para usted. Con Octoparse, puede configurar fácilmente sus tareas para que se ejecuten según lo programado, diariamente, semanalmente, mensualmente o incluso en cualquier momento específico de cada día. Una vez que termine de programar, haga clic en "Guardar y comenzar". La tarea se ejecutará según lo programado.
5. Menos bloqueo
La extracción en la nube reduce la posibilidad de ser incluido en la lista negra/bloqueado. Puede usar proxies IP, cambiar agentes de usuario, borrar cookies, ajustar la velocidad de raspado, etc.
El seguimiento de datos web en un gran volumen, como redes sociales, noticias y sitios web de comercio electrónico, elevará el rendimiento de su negocio con prácticas basadas en datos. Es hora de deshacerse de la navegación web antigua y usar la tecnología de raspado web para obtener una ventaja competitiva ahora.
#herramienta de scraping#web scraping gratis#extraer datos de la web#extraer datos a excel#web scraping tutorial#web scraping precios#que es web scraping#web scraping python#web scraping amazon
0 notes
Text
9 herramientas de Web Scraping Gratuitas que No Te Puedes Perder en 2021
¿Cuánto sabes sobre web scraping? No te preocupe, este artículo te informará sobre los conceptos básicos del web scraping, cómo acceder a una herramienta de web scraping para obtener una herramienta que se adapte perfectamente a tus necesidades y por último, pero no por ello menos importante, te presentará una lista de herramientas de web scraping para tu referencia.
Web Scraping Y Como Se Usa
El web scraping es una forma de recopilar datos de páginas web con un bot de scraping, por lo que todo el proceso se realiza de forma automatizada. La técnica permite a las personas obtener datos web a gran escala rápidamente. Mientras tanto, instrumentos como Regex (Expresión Regular) permiten la limpieza de datos durante el proceso de raspado, lo que significa que las personas pueden obtener datos limpios bien estructurados en un solo lugar.
¿Cómo funciona el web scraping?
En primer lugar, un robot de raspado web simula el acto de navegación humana por el sitio web. Con la URL de destino ingresada, envía una solicitud al servidor y obtiene información en el archivo HTML.
A continuación, con el código fuente HTML a mano, el bot puede llegar al nodo donde se encuentran los datos de destino y analizar los datos como se ordena en el código de raspado.
Por último, (según cómo esté configurado el bot de raspado) el grupo de datos raspados se limpiará, se colocará en una estructura y estará listo para descargar o transferir a tu base de datos.
Cómo Elegir Una Herramienta De Web Scraping
Hay formas de acceder a los datos web. A pesar de que lo has reducido a una herramienta de raspado web, las herramientas que aparecieron en los resultados de búsqueda con todas las características confusas aún pueden hacer que una decisión sea difícil de alcanzar.
Hay algunas dimensiones que puedes tener en cuenta antes de elegir una herramienta de raspado web:
Dispositivo: si eres un usuario de Mac o Linux, debes asegurarte de que la herramienta sea compatible con tu sistema.
Servicio en la nube: el servicio en la nube es importante si deseas acceder a tus datos en todos los dispositivos en cualquier momento.
Integración: ¿cómo utilizarías los datos más adelante? Las opciones de integración permiten una mejor automatización de todo el proceso de manejo de datos.
Formación: si no sobresales en la programación, es mejor asegurarte de que haya guías y soporte para ayudarte a lo largo del viaje de recolección de datos.
Precio: sí, el costo de una herramienta siempre se debe tener en cuenta y varía mucho entre los diferentes proveedores.
Ahora es posible que desees saber qué herramientas de raspado web puedes elegir:
Tres Tipos De Herramientas De Raspado Web
Cliente Web Scraper
Complementos / Extensión de Web Scraping
Aplicación de raspado basada en web
Hay muchas herramientas gratuitas de raspado web. Sin embargo, no todo el software de web scraping es para no programadores. Las siguientes listas son las mejores herramientas de raspado web sin habilidades de codificación a un bajo costo. El software gratuito que se enumera a continuación es fácil de adquirir y satisfaría la mayoría de las necesidades de raspado con una cantidad razonable de requisitos de datos.
Software de Web Scraping de Cliente
1. Octoparse
Octoparse es una herramienta robusta de web scraping que también proporciona un servicio de web scraping para empresarios y empresas.
Dispositivo: como se puede instalar tanto en Windows como en Mac OS, los usuarios pueden extraer datos con dispositivos Apple.
Datos: extracción de datos web para redes sociales, comercio electrónico, marketing, listados de bienes raíces, etc.
Función:
- manejar sitios web estáticos y dinámicos con AJAX, JavaScript, cookies, etc.
- extraer datos de un sitio web complejo que requiere inicio de sesión y paginación.
- tratar la información que no se muestra en los sitios web analizando el código fuente.
Casos de uso: como resultado, puedes lograr un seguimiento automático de inventarios, monitoreo de precios y generación de leads al alcance de tu mano.
Octoparse ofrece diferentes opciones para usuarios con diferentes niveles de habilidades de codificación.
El Modo de Plantilla de Tareas Un usuario con habilidades básicas de datos scraping puede usar esta nueva característica que convirte páginas web en algunos datos estructurados al instante. El modo de plantilla de tareas solo toma alrededor de 6.5 segundos para desplegar los datos detrás de una página y te permite descargar los datos a Excel.
El modo avanzado tiene más flexibilidad comparando los otros dos modos. Esto permite a los usuarios configurar y editar el flujo de trabajo con más opciones. El modo avanzado se usa para scrape sitios web más complejos con una gran cantidad de datos.
La nueva función de detección automática te permite crear un rastreador con un solo clic. Si no estás satisfecho con los campos de datos generados automáticamente, siempre puedes personalizar la tarea de raspado para permitirte raspar los datos por ti.
Los servicios en la nube permiten una gran extracción de datos en un corto período de tiempo, ya que varios servidores en la nube se ejecutan simultáneamente para una tarea. Además de eso, el servicio en la nube te permitirá almacenar y recuperar los datos en cualquier momento.
2.
ParseHub
Parsehub es un raspador web que recopila datos de sitios web que utilizan tecnologías AJAX, JavaScript, cookies, etc. Parsehub aprovecha la tecnología de aprendizaje automático que puede leer, analizar y transformar documentos web en datos relevantes.
Dispositivo: la aplicación de escritorio de Parsehub es compatible con sistemas como Windows, Mac OS X y Linux, o puedes usar la extensión del navegador para lograr un raspado instantáneo.
Precio: no es completamente gratuito, pero aún puedes configurar hasta cinco tareas de raspado de forma gratuita. El plan de suscripción paga te permite configurar al menos 20 proyectos privados.
Tutorial: hay muchos tutoriales en Parsehub y puedes obtener más información en la página de inicio.
3.
Import.io
Import.io es un software de integración de datos web SaaS. Proporciona un entorno visual para que los usuarios finales diseñen y personalicen los flujos de trabajo para recopilar datos. Cubre todo el ciclo de vida de la extracción web, desde la extracción de datos hasta el análisis dentro de una plataforma. Y también puedes integrarte fácilmente en otros sistemas.
Función: raspado de datos a gran escala, captura de fotos y archivos PDF en un formato factible
Integración: integración con herramientas de análisis de datos
Precios: el precio del servicio solo se presenta mediante consulta caso por caso
Complementos / Extensión de Web Scraping1.
Data Scraper (Chrome)
Data Scraper puede extraer datos de tablas y datos de tipo de listado de una sola página web. Su plan gratuito debería satisfacer el scraping más simple con una pequeña cantidad de datos. El plan pagado tiene más funciones, como API y muchos servidores proxy IP anónimos. Puede recuperar un gran volumen de datos en tiempo real más rápido. Puede scrapear hasta 500 páginas por mes, si necesitas scrapear más páginas, necesitas actualizar a un plan pago.
2.
Web scraper
El raspador web tiene una extensión de Chrome y una extensión de nube.
Para la versión de extensión de Chrome, puedes crear un mapa del sitio (plan) sobre cómo se debe navegar por un sitio web y qué datos deben rasparse.
La extensión de la nube puede raspar un gran volumen de datos y ejecutar múltiples tareas de raspado al mismo tiempo. Puedes exportar los datos en CSV o almacenarlos en Couch DB.
3.
Scraper (Chrome)
El Scraper es otro raspador web de pantalla fácil de usar que puede extraer fácilmente datos de una tabla en línea y subir el resultado a Google Docs.
Simplemente selecciona un texto en una tabla o lista, haz clic con el botón derecho en el texto seleccionado y elige "Scrape similar" en el menú del navegador. Luego obtendrás los datos y extraerás otro contenido agregando nuevas columnas usando XPath o JQuery. Esta herramienta está destinada a usuarios de nivel intermedio a avanzado que saben cómo escribir XPath.
4.
Outwit hub(Firefox)
Outwit hub es una extensión de Firefox y se puede descargar fácilmente desde la tienda de complementos de Firefox. Una vez instalado y activado, puedes extraer el contenido de los sitios web al instante.
Función: tiene características sobresalientes de "Raspado rápido", que rápidamente extrae datos de una lista de URL que ingresas. La extracción de datos de sitios que usan Outwit Hub no requiere habilidades de programación.
Formación: El proceso de raspado es bastante fácil de aprender. Los usuarios pueden consultar sus guías para comenzar con el web scraping con la herramienta.
Outwit Hub also offers services of tailor-making scrapers.Outwit Hub también ofrece servicios de raspadores a medida.
Aplicación de raspado basada en web1.
Dexi.io (anteriormente conocido como raspado de nubes)
Dexi.io está destinado a usuarios avanzados que tienen habilidades de programación competentes. Tiene tres tipos de robots para que puedas crear una tarea de raspado - Extractor, Crawler, y Pipes. Proporciona varias herramientas que te permiten extraer los datos con mayor precisión. Con su característica moderna, podrás abordar los detalles en cualquier sitio web. Sin conocimientos de programación, es posible que debas tomarte un tiempo para acostumbrarte antes de crear un robot de raspado web. Consulta su página de inicio para obtener más información sobre la base de conocimientos.
El software gratuito proporciona servidores proxy web anónimos para raspar la web. Los datos extraídos se alojarán en los servidores de Dexi.io durante dos semanas antes de ser archivados, o puedes exportar directamente los datos extraídos a archivos JSON o CSV. Ofrece servicios de pago para satisfacer tus necesidades de obtención de datos en tiempo real.
2.
Webhose.io
Webhose.io te permite obtener datos en tiempo real de raspar fuentes en línea de todo el mundo en varios formatos limpios. Incluso puedes recopilar información en sitios web que no aparecen en los motores de búsqueda. Este raspador web te permite raspar datos en muchos idiomas diferentes utilizando múltiples filtros y exportar datos raspados en formatos XML, JSON y RSS.
El software gratuito ofrece un plan de suscripción gratuito para que puedas realizar 1000 solicitudes HTTP por mes y planes de suscripción pagados para realizar más solicitudes HTTP por mes para satisfacer tus necesidades de raspado web.
0 notes
Text
¿Para qué se usa el screen scraping y cómo construir uno?
Screen Scraping
Por lo general, se refiere a analizar el HTML en el contenido web generado con programas diseñados para extraer patrones específicos de contenido.
El raspado de pantalla es el método de recopilar datos de visualización de pantalla de una aplicación y traducirlos para que otra aplicación pueda mostrarlos. Normalmente, esto se hace para capturar datos de una aplicación heredada con el fin de mostrarlos utilizando una interfaz de usuario más moderna.
A veces se confunde con el raspado de contenido, que es el uso de medios manuales o automáticos para extraer contenido de un sitio web sin la aprobación del propietario del sitio web. Muy a menudo, el raspado de pantalla se refiere a un cliente web que analiza las páginas HTML del sitio web de destino para extraer datos formateados.
Screen Scrapers
Un raspador de pantalla es un programa de computadora que utiliza una técnica de raspado de pantalla para traducir entre programas de aplicación heredados (escritos para comunicarse con dispositivos de entrada / salida e interfaces de usuario ahora generalmente obsoletos) y nuevas interfaces de usuario para que la lógica y los datos asociados con los programas heredados puede seguir utilizándose.

En los primeros días de las PC, los raspadores de pantalla emulaban un terminal (por ejemplo, IBM 3270) y pretendían ser un usuario para extraer y actualizar información de forma interactiva en el mainframe. En tiempos más recientes, el concepto se aplica a cualquier aplicación que proporcione una interfaz a través de páginas web.
¿Para qué se usa Screen Scrapers?
Los raspadores de pantalla se han aplicado en una amplia cantidad de campos para una variedad de casos de uso. Algunos usos potenciales incluyen:
aplicaciones bancarias y transacciones financieras
guardar datos significativos para su uso posterior
para realizar acciones que un usuario haría en un sitio web
para traducir datos de una aplicación heredada a una aplicación moderna
para agregadores de datos, como sitios web de comparación de precios
para rastrear perfiles de usuario para ver actividades en línea; y
para obtener datos
Top 10 industrias que utilizan screen scraping
Uno de los casos de uso más importantes ha sido el de la banca. Es posible que los prestamistas deseen utilizar el raspado de pantalla para recopilar los datos financieros de un cliente. Las aplicaciones basadas en finanzas pueden usar el rastreo de pantalla para acceder a múltiples cuentas de un usuario, agregando toda la información en un solo lugar. Sin embargo, los usuarios deberían confiar explícitamente en la aplicación, ya que confían en esa organización con sus cuentas, datos de clientes y contraseñas. El raspado de pantalla también se puede utilizar para aplicaciones de proveedores de hipotecas.
Es posible que una organización también desee utilizar el raspado de pantalla para traducir entre programas de aplicaciones heredados y nuevas interfaces de usuario (UI) para que la lógica y los datos asociados con los programas heredados puedan seguir utilizándose. Esta opción rara vez se usa y solo se ve como una opción cuando otros métodos no son prácticos.
Raspado de datos sin codificación

Si deseas probar la extracción, Octoparse te permite trabajar con datos dinámicos no estructurados con solo hacer clic en puntos de datos individuales y generará automáticamente un código eficiente para extraer datos. No se requiere codificación en este proceso. Además, te permite exportar datos a formatos de tu elección como Excel, JSON, CSV, TXT, HTML, incluso directamente a tu base de datos a través de API.
0 notes
Text
Los 30 Mejores Software Gratuitos de Web Scraping en 2021
El Web scraping (también denominado extracción datos de una web, web crawler, web scraper o web spider) es una web scraping técnica para extraer datos de una página web . Convierte datos no estructurados en datos estructurados que pueden almacenarse en su computadora local o en database.
Puede ser difícil crear un web scraping para personas que no saben nada sobre codificación. Afortunadamente, hay herramientas disponibles tanto para personas que tienen o no habilidades de programación. Aquí está nuestra lista de las 30 herramientas de web scraping más populares, desde bibliotecas de código abierto hasta extensiones de navegador y software de escritorio.
Tabla de Contenido
Beautiful Soup
Octoparse
Import.io
Mozenda
Parsehub
Crawlmonster
Connotate
Common Crawl
Crawly
Content Grabber
Diffbot
Dexi.io
DataScraping.co
Easy Web Extract
FMiner
Scrapy
Helium Scraper
Scrape.it
Scrapinghub
Screen-Scraper
Salestools.io
ScrapeHero
UniPath
Web Content Extractor
WebHarvy
Web Scraper.io
Web Sundew
Winautomation
Web Robots
1. Beautiful Soup
Para quién sirve: desarrolladores que dominan la programación para crear un web spider/web crawler.
Por qué deberías usarlo:Beautiful Soup es una biblioteca de Python de código abierto diseñada para scrape archivos HTML y XML. Son los principales analizadores de Python que se han utilizado ampliamente. Si tienes habilidades de programación, funciona mejor cuando combina esta biblioteca con Python.
Esta tabla resume las ventajas y desventajas de cada parser:-
ParserUso estándarVentajasDesventajas
html.parser (puro)BeautifulSoup(markup, "html.parser")
Pilas incluidas
Velocidad decente
Leniente (Python 2.7.3 y 3.2.)
No es tan rápido como lxml, es menos permisivo que html5lib.
HTML (lxml)BeautifulSoup(markup, "lxml")
Muy rápido
Leniente
Dependencia externa de C
XML (lxml)
BeautifulSoup(markup, "lxml-xml") BeautifulSoup(markup, "xml")
Muy rápido
El único parser XML actualmente soportado
Dependencia externa de C
html5lib
BeautifulSoup(markup, "html5lib")
Extremadamente indulgente
Analizar las páginas de la misma manera que lo hace el navegador
Crear HTML5 válido
Demasiado lento
Dependencia externa de Python
2. Octoparse
Para quién sirve: Las empresas o las personas tienen la necesidad de captura estos sitios web: comercio electrónico, inversión, criptomoneda, marketing, bienes raíces, etc. Este software no requiere habilidades de programación y codificación.
Por qué deberías usarlo: Octoparse es una plataforma de datos web SaaS gratuita de por vida. Puedes usar para capturar datos web y convertir datos no estructurados o semiestructurados de sitios web en un conjunto de datos estructurados sin codificación. También proporciona task templates de los sitios web más populares de países hispanohablantes para usar, como Amazon.es, Idealista, Indeed.es, Mercadolibre y muchas otras. Octoparse también proporciona servicio de datos web. Puedes personalizar tu tarea de crawler según tus necesidades de scraping.
PROS
Interfaz limpia y fácil de usar con un panel de flujo de trabajo simple
Facilidad de uso, sin necesidad de conocimientos especiales
Capacidades variables para el trabajo de investigación
Plantillas de tareas abundantes
Extracción de nubes
Auto-detección
CONS
Se requiere algo de tiempo para configurar la herramienta y comenzar las primeras tareas
3. Import.io
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Import.io es una plataforma de datos web SaaS. Proporciona un software de web scraping que le permite extraer datos de una web y organizarlos en conjuntos de datos. Pueden integrar los datos web en herramientas analíticas para ventas y marketing para obtener información.
PROS
Colaboración con un equipo
Muy eficaz y preciso cuando se trata de extraer datos de grandes listas de URL
Rastrear páginas y raspar según los patrones que especificas a través de ejemplos
CONS
Es necesario reintroducir una aplicación de escritorio, ya que recientemente se basó en la nube
Los estudiantes tuvieron tiempo para comprender cómo usar la herramienta y luego dónde usarla.
4. Mozenda
Para quién sirve: Empresas y negocios hay necesidades de fluctuantes de datos/datos en tiempo real.
Por qué deberías usarlo: Mozenda proporciona una herramienta de extracción de datos que facilita la captura de contenido de la web. También proporcionan servicios de visualización de datos. Elimina la necesidad de contratar a un analista de datos.
PROS
Creación dinámica de agentes
Interfaz gráfica de usuario limpia para el diseño de agentes
Excelente soporte al cliente cuando sea necesario
CONS
La interfaz de usuario para la gestión de agentes se puede mejorar
Cuando los sitios web cambian, los agentes podrían mejorar en la actualización dinámica
Solo Windows
5. Parsehub
Para quién sirve: analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: ParseHub es un software visual de web scrapinng que puede usar para obtener datos de la web. Puede extraer los datos haciendo clic en cualquier campo del sitio web. También tiene una rotación de IP que ayudaría a cambiar su dirección IP cuando se encuentre con sitios web agresivos con una técnica anti-scraping.
PROS
Tener un excelente boaridng que te ayude a comprender el flujo de trabajo y los conceptos dentro de las herramientas
Plataforma cruzada, para Windows, Mac y Linux
No necesita conocimientos básicos de programación para comenzar
Soporte al usuario de muy alta calidad
CONS
No se puede importar / exportar la plantilla
Tener una integración limitada de javascript / regex solamente
6. Crawlmonster
Para quién sirve: SEO y especialistas en marketing
Por qué deberías usarlo: CrawlMonster es un software de web scraping gratis. Te permite escanear sitios web y analizar el contenido de tu sitio web, el código fuente, el estado de la página y muchos otros.
PROS
Facilidad de uso
Atención al cliente
Resumen y publicación de datos
Escanear el sitio web en busca de todo tipo de puntos de datos
CONS
Funcionalidades no son tan completas
7. Connotate
Para quién sirve: Empresa que busca una solución de integración en datos web.
Por qué deberías usarlo: Connotate ha estado trabajando junto con Import.io, que proporciona una solución para automatizar el scraping de datos web. Proporciona un servicio de datos web que puede ayudarlo a scrapear, recopilar y manejar los datos.
PROS
Fácil de usar, especialmente para no programadores
Los datos se reciben a diario y, por lo general, son bastante limpios y fáciles de procesar
Tiene el concepto de programación de trabajos, que ayuda a obtener datos en tiempos programados
CONS
Unos cuantos glitches con cada lanzamiento de una nueva versión provocan cierta frustración
Identificar las faltas y resolverlas puede llevar más tiempo del que nos gustaría
8. Common Crawl
Para quién sirve: Investigador, estudiantes y profesores.
Por qué deberías usarlo: Common Crawl se basa en la idea del código abierto en la era digital. Proporciona conjuntos de datos abiertos de sitios web rastreados. Contiene datos sin procesar de la página web, metadatos extraídos y extracciones de texto.
Common Crawl es una organización sin fines de lucro 501 (c) (3) que rastrea la web y proporciona libremente sus archivos y conjuntos de datos al público.
9. Crawly
Para quién sirve: Personas con requisitos de datos básicos sin hababilidad de codificación.
Por qué deberías usarlo: Crawly proporciona un servicio automático que scrape un sitio web y lo convierte en datos estructurados en forma de JSON o CSV. Pueden extraer elementos limitados en segundos, lo que incluye: Texto del título. HTML, comentarios, etiquetas de fecha y entidad, autor, URL de imágenes, videos, editor y país.
Características
Análisis de demanda
Investigación de fuentes de datos
Informe de resultados
Personalización del robot
Seguridad, LGPD y soporte
10. Content Grabber
Para quién sirve: Desarrolladores de Python que son expertos en programación.
Por qué deberías usarlo: Content Grabber es un software de web scraping dirigido a empresas. Puede crear sus propios agentes de web scraping con sus herramientas integradas de terceros. Es muy flexible en el manejo de sitios web complejos y extracción de datos.
PROS
Fácil de usar, no requiere habilidades especiales de programación
Capaz de raspar sitios web de datos específicos en minutos
Debugging avanzado
Ideal para raspados de bajo volumen de datos de sitios web
CONS
No se pueden realizar varios raspados al mismo tiempo
Falta de soporte
11. Diffbot
Para quién sirve: Desarrolladores y empresas.
Por qué deberías usarlo: Diffbot es una herramienta de web scraping que utiliza aprendizaje automático y algoritmos y API públicas para extraer datos de páginas web (web scraping). Puede usar Diffbot para el análisis de la competencia, el monitoreo de precios, analizar el comportamiento del consumidor y muchos más.
PROS
Información precisa actualizada
API confiable
Integración de Diffbot
CONS
La salida inicial fue en general bastante complicada, lo que requirió mucha limpieza antes de ser utilizable
12. Dexi.io
Para quién sirve: Personas con habilidades de programación y cotificación.
Por qué deberías usarlo: Dexi.io es un web spider basado en navegador. Proporciona tres tipos de robots: extractor, rastreador y tuberías. PIPES tiene una función de robot maestro donde 1 robot puede controlar múltiples tareas. Admite muchos servicios de terceros (solucionadores de captcha, almacenamiento en la nube, etc.) que puede integrar fácilmente en sus robots.
PROS
Fácil de empezar
El editor visual hace que la automatización web sea accesible para las personas que no están familiarizadas con la codificación
Integración con Amazon S3
CONS
La página de ayuda y soporte del sitio no cubre todo
Carece de alguna funcionalidad avanzada
13. DataScraping.co
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Data Scraping Studio es un software web scraping gratis para recolectar datos de páginas web, HTML, XML y pdf.
PROS
Una variedad de plataformas, incluidas en línea / basadas en la web, Windows, SaaS, Mac y Linux
14. Easy Web Extract
Para quién sirve: Negocios con necesidades limitadas de datos, especialistas en marketing e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Easy Web Extract es un software visual de scraping y crawling para fines comerciales. Puede extraer el contenido (texto, URL, imagen, archivos) de las páginas web y transformar los resultados en múltiples formatos.
Características
Agregación y publicación de datos
Extracción de direcciones de correo electrónico
Extracción de imágenes
Extracción de dirección IP
Extracción de número de teléfono
Extracción de datos web
15. FMiner
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: FMiner es un software de web scraping con un diseñador de diagramas visuales, y le permite construir un proyecto con una grabadora de macros sin codificación. La característica avanzada le permite scrapear desde sitios web dinámicos usando Ajax y Javascript.
PROS
Herramienta de diseño visual
No se requiere codificación
Características avanzadas
Múltiples opciones de navegación de rutas de rastreo
Listas de entrada de palabras clave
CONS
No ofrece formación
16. Scrapy
Para quién sirve: Desarrollador de Python con habilidades de programación y scraping
Por qué deberías usarlo: Scrapy se usa para desarrollar y construir una araña web. Lo bueno de este producto es que tiene una biblioteca de red asincrónica que le permitirá avanzar en la siguiente tarea antes de que finalice.
PROS
Construido sobre Twisted, un marco de trabajo de red asincrónico
Rápido, las arañas scrapy no tienen que esperar para hacer solicitudes una a la vez
CONS
Scrapy es solo para Python 2.7. +
La instalación es diferente para diferentes sistemas operativos
17. Helium Scrape
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Helium Scraper es un software visual de scraping de datos web que funciona bastante bien, especialmente eficaz para elementos pequeños en el sitio web. Tiene una interfaz fácil de apuntar y hacer clic, lo que facilita su uso.
Características:
Extracción rápida. Realizado por varios navegadores web Chromium fuera de la pantalla
Capturar datos complejos
Extracción rápida
Capturar datos complejos
Extracción rápida
Flujo de trabajo simple
Capturar datos complejos
18. Scrape.it
Para quién sirve: Personas que necesitan datos escalables sin codificación.
Por qué deberías usarlo: Permite que los datos raspados se almacenen en tu disco local que autorizas. Puede crear un Scraper utilizando su lenguaje de web scraping (WSL), que tiene una curva de aprendizaje baja y no tiene que estudiar codificación. Es una buena opción y vale la pena intentarlo si está buscando una herramienta de web scraping segura.
PROS
Soporte móvil
Agregación y publicación de datos
Automatizará todo el sitio web para ti
CONS
El precio es un poco alto
19. ScraperWiki
Para quién sirve: Un entorno de análisis de datos Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
Por qué deberías usarlo: ScraperWiki tiene dos nombres
QuickCode: es el nuevo nombre del producto ScraperWiki original. Le cambian el nombre, ya que ya no es un wiki o simplemente para rasparlo. Es un entorno de análisis de datos de Python y R, ideal para economistas, estadísticos y administradores de datos que son nuevos en la codificación.
The Sensible Code Company: es el nuevo nombre de su empresa. Diseñan y venden productos que convierten la información desordenada en datos valiosos.
20. Zyte (anteriormente Scrapinghub)
Para quién sirve: Python/Desarrolladores de web scraping
Por qué deberías usarlo: Zyte es una plataforma web basada en la nube. Tiene cuatro tipos diferentes de herramientas: Scrapy Cloud, Portia, Crawlera y Splash. Es genial que Zyte ofrezca una colección de direcciones IP cubiertas en más de 50 países, que es una solución para los problemas de prohibición de IP.
PROS
La integración (scrapy + scrapinghub) es realmente buena, desde una simple implementación a través de una biblioteca o un docker lo hace adecuado para cualquier necesidad
El panel de trabajo es fácil de entender
La efectividad
CONS
No hay una interfaz de usuario en tiempo real que pueda ver lo que está sucediendo dentro de Splash
No hay una solución simple para el rastreo distribuido / de gran volumen
Falta de monitoreo y alerta.
21. Screen-Scraper
Para quién sirve: Para los negocios se relaciona con la industria automotriz, médica, financiera y de comercio electrónico.
Por qué deberías usarlo: Screen Scraper puede proporcionar servicios de datos web para las industrias automotriz, médica, financiera y de comercio electrónico. Es más conveniente y básico en comparación con otras herramientas de web scraping como Octoparse. También tiene un ciclo de aprendizaje corto para las personas que no tienen experiencia en el web scraping.
PROS
Sencillo de ejecutar - se puede recopilar una gran cantidad de información hecha una vez
Económico - el raspado brinda un servicio básico que requiere poco o ningún esfuerzo
Precisión - los servicios de raspado no solo son rápidos, también son exactos
CONS
Difícil de analizar - el proceso de raspado es confuso para obtenerlo si no eres un experto
Tiempo - dado que el software tiene una curva de aprendizaje
Políticas de velocidad y protección - una de las principales desventajas del rastreo de pantalla es que no solo funciona más lento que las llamadas a la API, pero también se ha prohibido su uso en muchos sitios web
22. Salestools.io
Para quién sirve: Comercializador y ventas.
Por qué deberías usarlo: Salestools.io proporciona un software de web scraping que ayuda a los vendedores a recopilar datos en redes profesionales como LinkedIn, Angellist, Viadeo.
PROS
Crear procesos de seguimiento automático en Pipedrive basados en los acuerdos creados
Ser capaz de agregar prospectos a lo largo del camino al crear acuerdos en el CRM
Ser capaz de integrarse de manera eficiente con CRM Pipedrive
CONS
La herramienta requiere cierto conocimiento de las estrategias de salida y no es fácil para todos la primera vez
El servicio necesita bastantes interacciones para obtener el valor total
23. ScrapeHero
Para quién sirve: Para inversores, Hedge Funds, Market Analyst es muy útil.
Por qué deberías usarlo: ScrapeHero como proveedor de API le permite convertir sitios web en datos. Proporciona servicios de datos web personalizados para empresas y empresas.
PROS
La calidad y consistencia del contenido entregado es excelente
Buena capacidad de respuesta y atención al cliente
Tiene buenos analizadores disponibles para la conversión de documentos a texto
CONS
Limited functionality in terms of what it can do with RPA, it is difficult to implement in use cases that are non traditional
Los datos solo vienen como un archivo CSV
24. UniPath
Para quién sirve: Negocios con todos los tamaños
Por qué deberías usarlo: UiPath es un software de automatización de procesos robótico para el web scraping gratuito. Permite a los usuarios crear, implementar y administrar la automatización en los procesos comerciales. Es una gran opción para los usuarios de negocios, ya que te hace crear reglas para la gestión de datos.
Características:
Conversión del valor FPKM de expresión génica en valor P
Combinación de valores P
Ajuste de valores P
ATAC-seq de celda única
Puntuaciones de accesibilidad global
Conversión de perfiles scATAC-seq en puntuaciones de enriquecimiento de la vía
25. Web Content Extractor
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Content Extractor es un software de web scraping fácil de usar para fines privados o empresariales. Es muy fácil de aprender y dominar. Tiene una prueba gratuita de 14 días.
PROS
Fácil de usar para la mayoría de los casos que puede encontrar en web scraping
Raspar un sitio web con un simple clic y obtendrá tus resultados de inmediato
Su soporte responderá a tus preguntas relacionadas con el software
CONS
El tutorial de youtube fue limitado
26. Webharvy
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: WebHarvy es un web scraping software de apuntar y hacer clic. Está diseñado para no programadores. El extractor no le permite programar. Tienen tutoriales de web scraping que son muy útiles para la mayoría de los usuarios principiantes.
PROS
Webharvey es realmente útil y eficaz. Viene con una excelente atención al cliente
Perfecto para raspar correos electrónicos y clientes potenciales
La configuración se realiza mediante una GUI que facilita la instalación inicialmente, pero las opciones hacen que la herramienta sea aún más poderosa
CONS
A menudo no es obvio cómo funciona una función
Tienes que invertir mucho esfuerzo en aprender a usar el producto correctamente
27. Web Scraper.io
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Scraper es una extensión de navegador Chrome creada para extraer datos en la web. Es un software gratuito de web scraping para descargar páginas web dinámicas.
PROS
Los datos que se raspan se almacenan en el almacenamiento local y, por lo tanto, son fácilmente accesibles
Funciona con una interfaz limpia y sencilla
El sistema de consultas es fácil de usar y es coherente con todos los proveedores de datos
CONS
Tiene alguna curva de aprendizaje
No para organizaciones
28. Web Sundew
Para quién sirve: Empresas, comercializadores e investigadores.
Por qué deberías usarlo: WebSundew es una herramienta de crawly web scraper visual que funciona para el raspado estructurado de datos web. La edición Enterprise le permite ejecutar el scraping en un servidor remoto y publicar los datos recopilados a través de FTP.
Caraterísticas:
Interfaz fácil de apuntar y hacer clic
Extraer cualquier dato web sin una línea de codificación
Desarrollado por Modern Web Engine
Software de plataforma agnóstico
29. Winautomation
Para quién sirve: Desarrolladores, líderes de operaciones comerciales, profesionales de IT
Por qué deberías usarlo: Winautomation es una herramienta de web scraper parsers de Windows que le permite automatizar tareas de escritorio y basadas en la web.
PROS
Automatizar tareas repetitivas
Fácil de configurar
Flexible para permitir una automatización más complicada
Se notifica cuando un proceso ha fallado
CONS
Podría vigilar y descartar actualizaciones de software estándar o avisos de mantenimiento
La funcionalidad FTP es útil pero complicada
Ocasionalmente pierde la pista de las ventanas de la aplicación
30. Web Robots
Para quién sirve: Analista de datos, comercializadores e investigadores que carecen de habilidades de programación.
Por qué deberías usarlo: Web Robots es una plataforma de web scraping basada en la nube para scrape sitios web dinámicos con mucho Javascript. Tiene una extensión de navegador web, así como un software de escritorio que es fácil para las personas para extraer datos de los sitios web.
PROS
Ejecutarse en tu navegador Chrome o Edge como extensión
Localizar y extraer automáticamente datos de páginas web
SLA garantizado y excelente servicio al cliente
Puedes ver datos, código fuente, estadísticas e informes en el portal del cliente
CONS
Solo en la nube, SaaS, basado en web
Falta de tutoriales, no tiene videos
1 note
·
View note
Text
¿Cómo pueden los dropshippers aprender del negocio D2C?
Con el aumento del número de compradores en línea, los clientes se adaptan gradualmente al modelo de comercio electrónico y se vuelven más exigentes. El cambio en el comportamiento de compra ciertamente crea más oportunidades pero desafíos para los transportistas directos. Para la mayoría de los propietarios de negocios de envío directo, ahora la pregunta es, ¿cómo subir de nivel tu negocio para destacarse de la competencia y obtener continuamente más clientes?
Probablemente olfatees la nueva tendencia: D2C (Direct-to-customers). Aunque el término ha estado flotando durante un par de años, pocas personas prestaron atención hasta que ocurrió la pandemia de COVID-19. Con la creciente demanda de comercio electrónico que elimina la barrera entre los vendedores y los consumidores, ahora D2C es el nuevo negro.

Ciertamente, hay algunas cosas que podemos tomar prestadas del modelo de negocio D2C y usarlo en el negocio de dropship.
“Según el análisis de eMarketer en febrero de 2021, las ventas de comercio electrónico de D2C en los EE. UU. Han crecido un 45,5% en 2020, generando alrededor de $ 111,54 mil millones y representando el 14% de las ventas totales de comercio electrónico minorista. Se espera que D2C mantenga un crecimiento relativamente constante cada año hasta 2023, momento en el que las ventas de comercio electrónico de D2C podrían haber alcanzado los $ 174,98 mil millones ".
Tabla de contenidos
¿Qué es D2C y qué lo hace tan popular?
La diferencia entre D2C y dropshipping
Estrategia 1 de Drop-ship: comenzar con los proveedores adecuados
Estrategia 2 de Drop-ship: muestra tu marca con un escaparate en línea
Estrategia 3 de Drop-ship: subir de nivel los servicios
¿Qué es D2C y qué lo hace tan popular?
Bajo un modelo D2C o Direct-to-Customer, los propietarios de marcas pueden vender productos directamente a sus clientes en los sitios web oficiales de sus marcas, en lugar de depender de tiendas físicas, mercados de comercio electrónico o cualquier otra plataforma de intermediarios.
Esto ha trascendido el modelo de negocio tradicional B2C de muchas formas. Los propietarios de negocios que apliquen una estrategia D2C obtendrán más control sobre sus marcas sin que un minorista se interponga en el medio. Como resultado, pueden construir relaciones más estrechas con los clientes finales y ser más interactivos con la demanda del mercado.
¿En qué se diferencia D2C de Dropshipping?
No mezcla estos dos conceptos. Los dropshippers manejan los pedidos de los clientes directamente y luego envían los productos utilizando un proveedor externo. Como ya has notado, el costo del almacenamiento físico constituye el margen de oportunidad. Los dropshippers no tienen ninguna inversión inicial para mantener el inventario, PERO no es sostenible a largo plazo. Considerando que, D2C no suena como un enfoque esbelto, ya que no solo debes pagar por el almacenamiento, sino también por todo lo relacionado con la operación. Sin embargo, los partidarios del modelo D2C saben que aquellos que se acercan a los clientes pueden mantenerse firmes hasta el final de la competencia.
Si deseas construir un negocio de Dropshipping sostenible como el modelo D2C, no es difícil darte cuenta de que solo necesitas algunas cosas para salir adelante: proveedores confiables, conocer a tus clientes y una solución de cumplimiento de pedidos nivelada. Así es como se ve una estrategia de envío directo en un nivel alto:
Comenzando con los proveedores adecuados:
Un proveedor confiable que vende productos que se ajustan al nicho de marketing podría ganarte más probabilidades en el juego. Cuando pensamos en proveedores, pensamos en Aliexpress u otras empresas locales que pueden ofrecer productos de calidad a un costo menor.
Con tantas ideas de productos para mirar y tanta información disponible en línea, buscar una buena opción puede ser más desafiante a través de la investigación de mercados. Así es como el web scraping viene a tu rescate.
El wep scraping es la mejor práctica para recuperar datos web dispersos en un formato utilizable. Puede recoger información de productos de múltiples fuentes en un formato organizado y estructurado. Eventualmente, los datos se pueden sincronizar con tu tienda en línea a través de una integración de API, que conecta tus tiendas y proveedores en línea sin problemas. Puede proporcionarte información básica del producto que incluye: precios, nombre del producto, SKU, inventario y URL de imágenes.
A continuación, recopila datos para comprender verdaderamente a tus clientes.
Cada acción del cliente ofrece información valiosa sobre el comportamiento del cliente. Para determinar cómo reaccionan los clientes ante tus productos o tus competidores, puedes monitorear los productos en todos los mercados. Esto te brinda más información sobre tu posición en el mercado. Herramientas como Octoparse pueden recopilar información como reseñas, revisores, calificaciones, niveles de existencias, etc.
Muestra tu marca con un escaparate en línea:
En lugar de depender de un mercado como Amazon, que tiene un millón de variedades de productos que compiten entre sí en cada línea de productos, tener una tienda en línea independiente te permite mostrar tus productos únicos. La mejor parte es que tienes control total sobre el tráfico y los clientes finales con los que puedes entablar relaciones y compartir una experiencia de marca personalizada.
El gigante de las maquinillas de afeitar Harry's optó por la estrategia de marketing exacta que lo ayudó a ganar más de $ 1 millón en ventas en el primer mes y rápidamente subió a $ 100 millones en 2 años. Andy Katz-Mayfield, cofundador de Harry's, se dio cuenta del hecho de que lo que los consumidores necesitan son productos simples pero efectivos que se sientan bien de usar. Este es un gran avance para iniciar su propio negocio de maquinillas de afeitar, que ofrece un modelo de venta simple: una gran maquinilla de afeitar entregada directamente a tu puerta.
¿Encuentra la diferencia? Harry's intenta ofrecer un viaje de compra simplificado pero personalizado, además de una historia de marca genuina que resuene entre los clientes. Esto hace que los clientes se sientan más conectados con la marca y alivia fácilmente sus preocupaciones sobre un nuevo negocio.
Por último, subir de nivel los servicios de cumplimiento de pedidos y, por lo tanto, la experiencia del cliente.
Como dropshipper, probablemente te acostumbres a que los proveedores se ocupen de todo el proceso de cumplimiento del pedido y no le presten mucha atención. Pero si este trabajo de "última milla" se vuelve problemático, todo tu esfuerzo anterior para mejorar la experiencia del cliente se arruinará. Estado de pedido transparente, productos de calidad según lo prometido en los listados, paquetes con visibilidad de marca constante, servicio postventa receptivo ... Hay muchos aspectos que debes considerar para mejorar las soluciones de cumplimiento de pedidos.
En lugar de dedicar tiempo a pensar en hacer mandados, un proveedor confiable de soluciones de envío directo como BuckyDrop puede ser muy útil. Proporcionan servicios que incluyen cumplimiento de pedidos, abastecimiento de productos, gestión de suministros, servicio postventa y marca de la tienda. BuckyDrop es el único socio privado, agente, experto e inversor que necesitarás para ganar dropshipping. Tienen una solución de dropshipping integral de clase mundial que está abierta a cualquier emprendedor de dropshipping que aspire a construir una marca y tener éxito.
Es muy probable que crees la próxima marca en auge con la solución adecuada que te respalde. ¡Estamos aquí para ayudar!
0 notes
Text
¿Qué es el Big Data en el turismo?
De acuerdo con Viajes National Geographic, dentro de los 25 desinos más populares del mundo según los viajeros en 2019, los de países hispanohablantes ocupan 4 posiciones. La industria del turismo estaba superando a la economía global hasta 2019, y luego cayó en picada en 2020. Sí, ya sabes la razón. Pero la buena noticia es que los viajes y el turismo están recuperando terreno. Y la industria del turismo está aprovechando la tecnología para acelerar las cosas. Una tecnología tan impactante y transformadora para el sector de viajes y turismo es Big Data. Esta información pretende ser tu guía sobre "Big Data en el turismo". Después de leer esta información, vas a conocer:

Tabla de contenido
Parte 1 ¿Qué es el big data en el turismo?
Parte 2 ¿Cómo se puede aprovechar / extraer big data usando web scraping?
Parte 3 Casos de uso empresarial de big data en el turismo
Parte 4 Desafíos de Big Data en viajes & turismo
Conclusión
¿Qué es el big data en el turismo?
¿Qué es Big Data? Big data es un enfoque para extraer, procesar y visualizar sistemáticamente grandes conjuntos de datos. ¿Qué significa eso? Suponga que tienes datos personales, es decir, nombre, edad, sexo, país, etcétera, de 1000 clientes que visitaron Francia en 2020. ¿Se trata de big data? Realmente no. Pero si tienes datos sobre un millón de personas que llegaron a diferentes rincones del mundo, el hotel en el que se hospedaron, la comida que pidieron, los lugares que visitaron, los eventos que tuvieron lugar en diferentes geografías, los diferentes recursos en línea / fuera de línea que utilizaron, etc., entonces, idealmente, debería considerarse Big Data. En términos sencillos,
El big data suele tener un tamaño superior a varios terabytes (TB) y petabytes (PB) de datos..
Es alto en volumen, variedad y velocidad.
Para extraer, analizar y visualizar big data, los métodos tradicionales son ineficientes.
Entonces, usas
Técnicas modernas de extracción de datos como web scraping para extraer datos de la web.
Herramientas sofisticadas como Hadoop, KNIME, NodeXL, QlikView, FusionCharts, Watson analytics etc para realizar análisis de big data y visualizar las tendencias y patrones.
¿Qué tipo de big data se puede capturar en la industria del turismo?
Información de destino- Lugares para Visitar, Reglas & Regulaciones, etc.,
Datos de Hoteles & Restaurantes - Rating & Reseñas de Clientes, Precios, Detalles del Servicio, etc.
Datos de Transporte - Billetes de Avión, Mapas de Ruta, Datos de Tráfico
Datos de Eventos - Deportes, Festivales, Cumbres, etc.
Datos de Esquemas Gubernamentales
Datos Turísticos - Entrada & Salida de Turistas, Lugar de Origen, Edad, Idiomas Hablados, etc.
Datos Sociales - Publicaciones de los viajeros en las RRSS con geoetiquetas, Etiquetas de marca, Hashtags relacionados con viajes, etc.
Noticias de viajes & Hostelería
Datos Diversos: Búsqueda en la web, Visitas al sitio web, Aplicaciones solicitadas de pasaporte & Visa, Educación internacional y Empleo, etc.
¿Cómo extraer big data de viajes & turismo?
Para extraer big data de viajes & turismo, puedes preferir:
1. Web-scraping
El web scraping de turismo es un enfoque para extraer datos de manera programática de sitios web enfocados en viajes & turismo. Puedes utilizar herramientas de raspado web o escribir tus scripts para extraer datos de estos sitios web. Por ejemplo, supongamos que necesitas datos de hoteles & restaurantes, es decir, precios, reseñas, servicios prestados, ubicación, etc., de "Booking.com". Puedes extraer fácilmente cientos y miles de datos de hoteles & restaurantes de Booking.com en unos pocos minutos.
Utiliza herramientas de raspado web si lo necesitas
Para extraer rápidamente big data de turismo
Una solución asequible, escalable, robusta y segura
2. Recursos internos & externos
También puedes obtener los datos dentro de la empresa. Buscar datos valiosos en tu software de gestión de reservas, servicios & libros de cuentas, etc.
También podrías solicitar a las juntas de turismo y a los proveedores de datos de terceros que te proporcionen los datos. Pero la veracidad de los datos es mucho mayor si extraes mediante web scraping.
¿Cuáles son los casos de uso de Big Data en la industria turística?
La clave para revivir el turismo & otros sectores emparentados es aprovechar el poder de la cultura y la creatividad, optimizar las operaciones de viajes, personalizar las ofertas, brindar experiencias perfectas, y desbloquear nuevos canales de crecimiento. Big data puede ser de ayuda aquí:
1. Investigación de Mercado Turístico
En la última década, la penetración de los dispositivos móviles ha catalizado positivamente la cantidad de datos producidos por diferentes fuentes. En el sector del turismo, los datos se dividen en tres categorías:
Datos generados por el usuario: datos textuales en línea como blogs, publicaciones en RRSS, comentarios, reseñas, geo-etiquetado comida, restaurante, datos de imágenes de destino.
Datos del dispositivo: cámaras CCTV en lugares turísticos, hoteles, restaurantes, datos de GPS móviles & vehículos, datos de itinerancia móvil, datos de Bluetooth, datos meteorológicos, etc .;
Datos de transacciones: datos de motores de búsqueda, datos de visitas a páginas web, datos de reservas online, etc.
Todos estos datos pueden ser un buen alimento para que los investigadores lleven a cabo investigaciones relacionadas con el turismo. ¿Qué tipo de investigación? Se pueden analizar las tendencias turísticas, los hábitos y comportamientos turísticos, el impacto de ciertos esquemas / campañas en la afluencia de turistas, etc.
2. Asignación racional de recursos de tráfico
La identificación y predicción del estado del flujo de tráfico en tiempo real podría ser la respuesta para aliviar la congestión del tráfico en los puntos de atracción turística y en las rutas turísticas:
Correlación Temporal: Los detectores de flujo de tráfico fijos y móviles pueden ayudar a recopilar y analizar datos de tráfico.
Correlación Espacial: El flujo de tráfico en uno o más cruces impacta el flujo en los cruces vecinos.
Correlación Histórica: Los datos de tráfico en torno al flujo, la velocidad y la ocupación tienen características similares basadas en el tiempo en determinados días de la semana o fines de semana.
Los modelos de agrupación de tráfico, los modelos de fusión de datos, los modelos correlacionales y los modelos de optimización son los enfoques analíticos más comunes para explotar de manera eficiente el big data relacionado con el tráfico y manejar el tráfico de manera inteligente.
3. Gestión operativa de atractivos turísticos mediante el análisis de comportamientos turísticos
El análisis del comportamiento de los turistas podría ser útil para diferentes partes interesadas.
Estacionalidad de la demanda en viajes, turismo y hostelería para operaciones flexibles. El big data puede ser crucial para gestionar de forma rentable los aspectos operativos de las atracciones turísticas.
Además de las agencias de gestión de operaciones de destino, puede ser útil para cadenas minoristas, cadenas de hoteles y restaurantes, etcétera.
Los turistas tienen un alto potencial de gasto. Cuando los turistas visitan tu localidad, a menudo van de compras, exploran restaurantes y participan en festivales o eventos locales. El análisis de datos en torno a todos estos puntos ayuda a los ejecutivos en la toma de decisiones estratégicas.
Por ejemplo, basándose en las tendencias históricas y actuales, los actores del turismo pueden pronosticar la afluencia de turistas en una atracción turística en particular. En consecuencia, pueden hacer arreglos para el viaje, el alojamiento, la comida y otros recursos.
4. Estimación de la demanda de viajes
Las demandas de viajes tienen sus raíces en el concepto económico de "demanda". La demanda turística generalmente significa llegadas y gasto de turistas. Puedes recopilar y analizar datos de llegada de turistas o datos de gasto en función de tu objetivo, ya sea maximizar las pisadas de turistas o maximizar el gasto. Por ejemplo, los planificadores de paquetes turísticos pueden personalizar sus planes para adaptarse a los bolsillos de los turistas de un país de origen en particular. Digamos que si el gasto promedio de los turistas del país XYZ es mayor, entonces tal vez las juntas nacionales de turismo puedan planificar promover agresivamente el turismo en los EE. UU. E incluso planificar con los proveedores de servicios y los planificadores de paquetes turísticos para reducir los precios. Esto puede catalizar positivamente la afluencia de turistas.
5. Gestión de ingresos
Los hoteles y restaurantes pueden tener información sobre tasas de ocupación, reservas actuales, precios, etcétera, y combinarla con datos externos como condiciones climáticas, vacaciones escolares, eventos locales, información de vuelos, etcétera para pronosticar eficazmente las demandas y elaborar estrategias para maximizar los ingresos. Por ejemplo, subir sensiblemente los precios.
6. Gestión de marca, seguimiento de la competencia & experiencia del cliente
El 91% de los clientes jóvenes confía en las reseñas en línea. Hoy en día, las RRSS son tan poderosas que un tweet negativo de un influencer puede reducir drásticamente los ingresos de una empresa. Es importante monitorear la imagen de tu marca manteniendo un toque en las RRSS, blogs y plataformas de reseñas en línea. En una nota positiva, también puedeS monitorear lo que a los clientes les gusta de tu servicio y resaltarlo en tus campañas de marketing, mejorarlo aún más, etcétera. No solo pueded analizar los sentimientos de los clientes sobre tu marca, sino también
Monitorea a tus competidores
Analiza las estrategias de precios de los competidores y pon el precio que deseas a tus servicios inteligentemente.
7. Marketing personalizado
La diversidad, el ocio, los viajes de negocios, las reuniones con familiares, etcétera, son los principales factores que influyen en las personas para viajar. Si conoces la intención detrás de los viajes, puedes personalizar tus estrategias de marketing para obtener más ventas. Cuantos más datos calificados tengas, mejor podrás ejecutar un marketing personalizado dirigido.
8. Bots de viaje inteligentes
El uso de big data para PNL es un caso de uso independiente de la industria. El big data textual de las RRSS se pueden utilizar bien para alimentar algoritmos de aprendizaje automático. Dado que estas publicaciones en las RRSS relacionadas con el turismo son en su mayoría de turistas, es fácil desarrollar bots inteligentes orientados al cliente para abordar sus preguntas en un idioma que los turistas entiendan.
Desafíos de Big Data en la industria del turismo
Ciberseguridad & Privacidad de datos:
Las herramientas de web scraping han facilitado muchísimo la extracción de macrodatos turísticos de la web. Pero el big data también tiene sus desafíos. Con una mayor dependencia de los macrodatos turísticos, los riesgos de violaciones de datos son igualmente altos. Con cada violación, la confianza y las marcas se ponen en riesgo. La gobernanza y la ética de los datos es otra gran preocupación relacionada con el big data turístico.
Analizar datos no estructurados
Aunque es fácil raspar y recopilar datos utilizando herramientas de raspado web, la web está llena de datos erróneos y no estructurados que son difíciles de analizar. La eficiencia de los algoritmos ML sigue siendo un desafío.
Conclusión
La OMT ha pronosticado 1.800 millones de llegadas de turistas internacionales para 2030. Aprovechar con éxito el big data y otras tecnologías de transformación digital será clave para desbloquear y aprovechar nuevos canales de crecimiento en la industria del turismo. En esta información, te brindamos una perspectiva en profundidad de "Big Data en el turismo", cómo extraer datos de viajes y turismo, casos de uso de big data en el turismo, desafíos, etcétera. Con los avances tecnológicos, estamos viendo un flujo sin precedentes en el comportamiento de los clientes, las operaciones comerciales y la forma en que las personas viven y se comunican. Un tweet puede afectar a las empresas de formas impredecibles. Es importante tomar decisiones comerciales calculadas, validadas y basadas en pruebas.
0 notes