#web scraping tutorial
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
I've recently learned how to scrape websites that require a login. This took a lot of work and seemed to have very little documentation online so I decided to go ahead and write my own tutorial on how to do it.
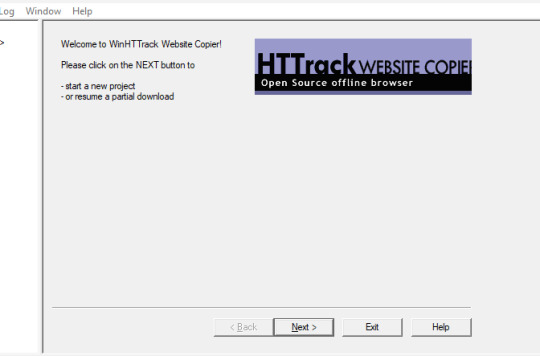
We're using HTTrack as I think that Cyotek does basically the same thing but it's just more complicated. Plus, I'm more familiar with HTTrack and I like the way it works.
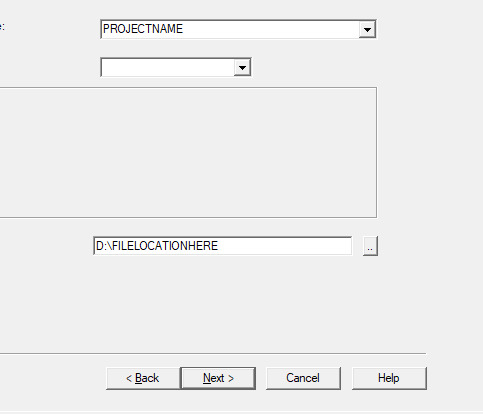
So first thing you'll do is give your project a name. This name is what the file that stores your scrape information will be called. If you need to come back to this later, you'll find that file.
Also, be sure to pick a good file-location for your scrape. It's a pain to have to restart a scrape (even if it's not from scratch) because you ran out of room on a drive. I have a secondary drive, so I'll put my scrape data there.
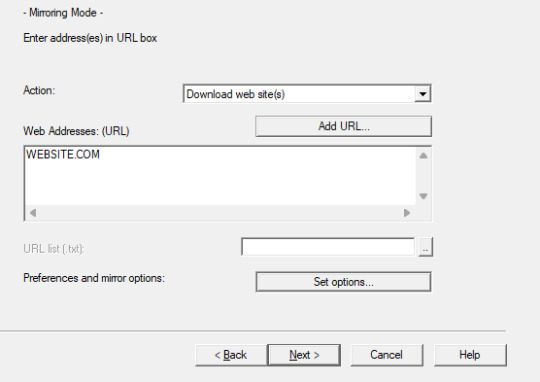
Next you'll put in your WEBSITE NAME and you'll hit "SET OPTIONS..."
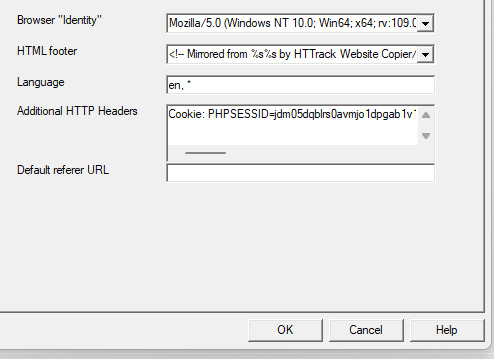
This is where things get a little bit complicated. So when the window pops up you'll hit 'browser ID' in the tabs menu up top. You'll see this screen.
What you're doing here is giving the program the cookies that you're using to log in. You'll need two things. You'll need your cookie and the ID of your browser. To do this you'll need to go to the website you plan to scrape and log in.
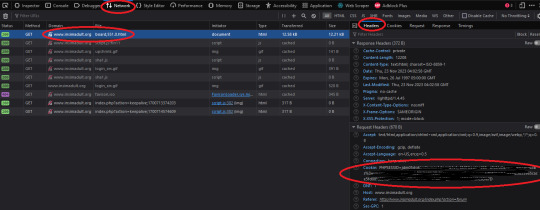
Once you're logged in press F12. You'll see a page pop up at the bottom of your screen on Firefox. I believe that for chrome it's on the side. I'll be using Firefox for this demonstration but everything is located in basically the same place so if you don't have Firefox don't worry.
So you'll need to click on some link within the website. You should see the area below be populated by items. Click on one and then click 'header' and then scroll down until you see cookies and browser id. Just copy those and put those into the corresponding text boxes in HTTrack! Be sure to add "Cookies: " before you paste your cookie text. Also make sure you have ONE space between the colon and the cookie.
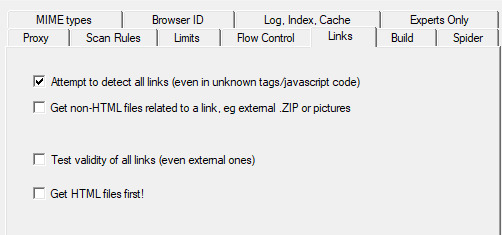
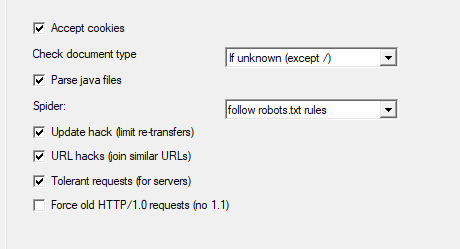
Next we're going to make two stops and make sure that we hit a few more smaller options before we add the rule set. First, we'll make a stop at LINKS and click GET NON-HTML LINKS and next we'll go and find the page where we turn on "TOLERANT REQUESTS", turn on "ACCEPT COOKIES" and select "DO NOT FOLLOW ROBOTS.TXT"
This will make sure that you're not overloading the servers, that you're getting everything from the scrape and NOT just pages, and that you're not following the websites indexing bot rules for Googlebots. Basically you want to get the pages that the website tells Google not to index!
Okay, last section. This part is a little difficult so be sure to read carefully!

So when I first started trying to do this, I kept having an issue where I kept getting logged out. I worked for hours until I realized that it's because the scraper was clicking "log out' to scrape the information and logging itself out! I tried to exclude the link by simply adding it to an exclude list but then I realized that wasn't enough.
So instead, I decided to only download certain files. So I'm going to show you how to do that. First I want to show you the two buttons over to the side. These will help you add rules. However, once you get good at this you'll be able to write your own by hand or copy and past a rule set that you like from a text file. That's what I did!

Here is my pre-written rule set. Basically this just tells the downloader that I want ALL images, I want any item that includes the following keyword, and the -* means that I want NOTHING ELSE. The 'attach' means that I'll get all .zip files and images that are attached since the website that I'm scraping has attachments with the word 'attach' in the URL.
It would probably be a good time to look at your website and find out what key words are important if you haven't already. You can base your rule set off of mine if you want!
WARNING: It is VERY important that you add -* at the END of the list or else it will basically ignore ALL of your rules. And anything added AFTER it will ALSO be ignored.

Good to go!
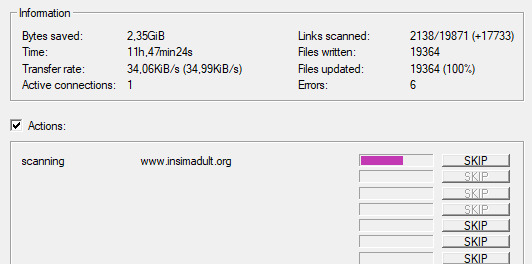
And you're scraping! I was using INSIMADULT as my test.
There are a few notes to keep in mind: This may take up to several days. You'll want to leave your computer on. Also, if you need to restart a scrape from a saved file, it still has to re-verify ALL of those links that it already downloaded. It's faster that starting from scratch but it still takes a while. It's better to just let it do it's thing all in one go.
Also, if you need to cancel a scrape but want all the data that is in the process of being added already then ONLY press cancel ONCE. If you press it twice it keeps all the temp files. Like I said, it's better to let it do its thing but if you need to stop it, only press cancel once. That way it can finish up the URLs already scanned before it closes.
40 notes
·
View notes
Text
Learn the art of web scraping with Python! This beginner-friendly guide covers the basics, ethics, legal considerations, and a step-by-step tutorial with code examples. Uncover valuable data and become a digital explorer.
#API#BeautifulSoup#Beginner’s Guide#Data Extraction#Data Science#Ethical Hacking#Pandas#Python#Python Programming#Requests#Tutorial#Web Crawler#web scraping
1 note
·
View note
Text
Saving Fic Epubs and Metadata Using Calibre
I FINALLY spent time learning how to set up Calibre with the FanFicFare plugin in order to easily keep track of fics that I've read. What's really awesome about it, though, is it does way more than just "keep track":
It saves epubs for future downloading (in case the fic is pulled from AO3)
It automatically "scrapes" metadata (title, tags, warnings, etc.) from the fic and includes it in Calibre's built-in spreadsheet
Allows you to create custom categories for things like notes and personal ratings, as well as categories for metadata not scraped by default (word count, for example).
Every bit of information scraped is SEARCHABLE and SORTABLE! Tags, authors, published date, etc.
However, the instructions for how to do all this are not clear-cut and are scattered on different sites and forums. So I've created a little guide based on what worked for me!
Here are my categories (if you know me the fic shown is not a surprise). I couldn't fit them into one long horizontal screenshot so I split them into two.


Most of these are default categories, but some (Thoughts, Words, Summary, Ratings, and Notes) are not. I've excluded default categories I didn't need, and created custom ones for the information I wanted to include.
Tutorial below the cut!
Download and install Calibre.
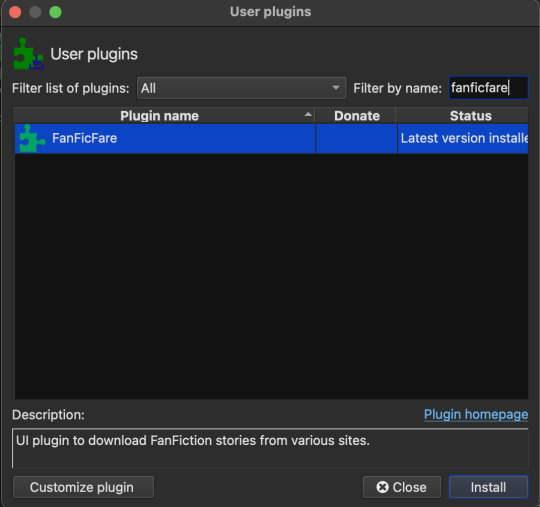
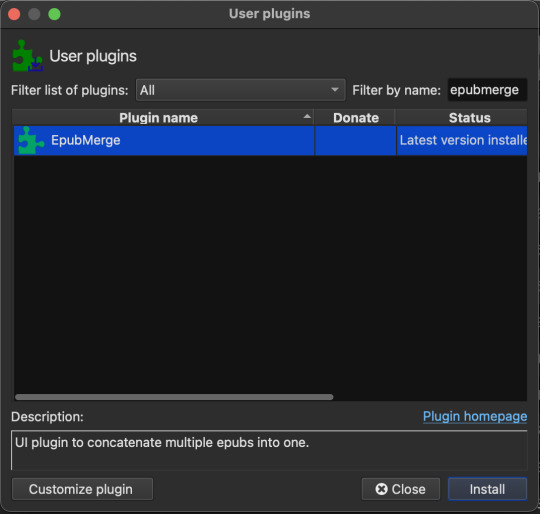
Once the program is open, click Preferences > Get plugins to enhance calibre Search for and install the FanFicFare and EpubMerge plugins (EpubMerge works in tandem with FFF and allows for downloading an entire fic series into one file).
_________________
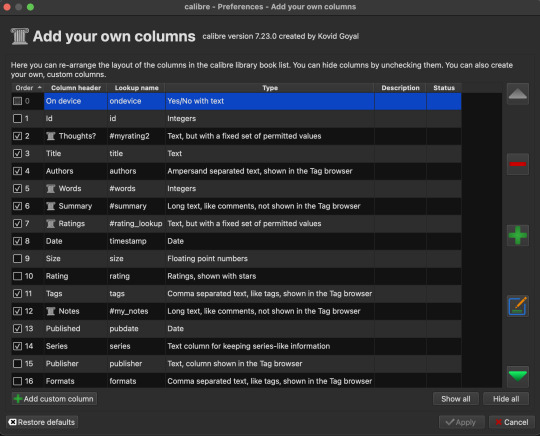
Custom Columns
Preferences > Preferences > Add your own columns The custom column screen is shown below. Anything unchecked is a category I didn't want to include in my list. Anything with a column icon next to it means its a custom column I created. To create a new column, click +Add custom column.
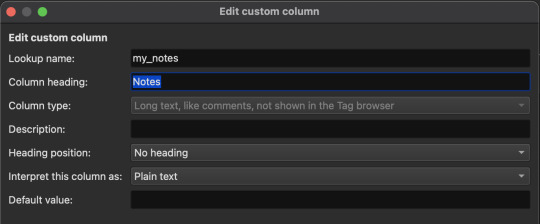
The settings I made for each of my custom categories are shown below. Take note of the "column type" for each category. You can make any kind of columns you'd like!
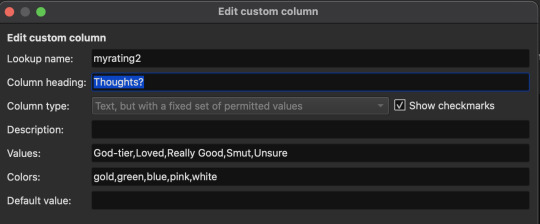
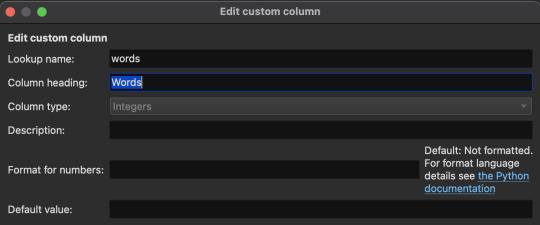
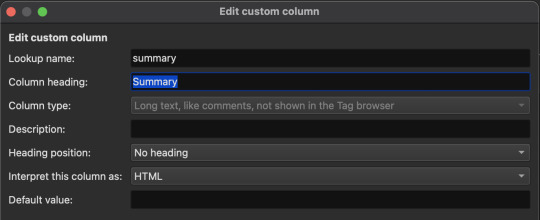
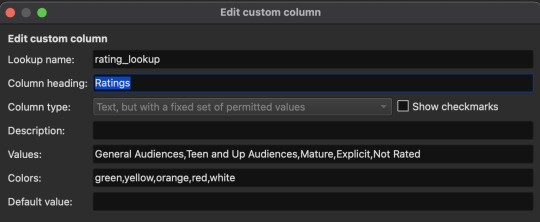
Once you've made your custom categories make sure to click Apply on the "Add your own columns" screen. Now we need to configure the FanFicFare plugin to assign data to some of the custom categories. Click the down arrow next to the FanFicFare plugin icon on the main Calibre screen, then click Configure FanFicFare. On the next screen click the Custom Columns tab.
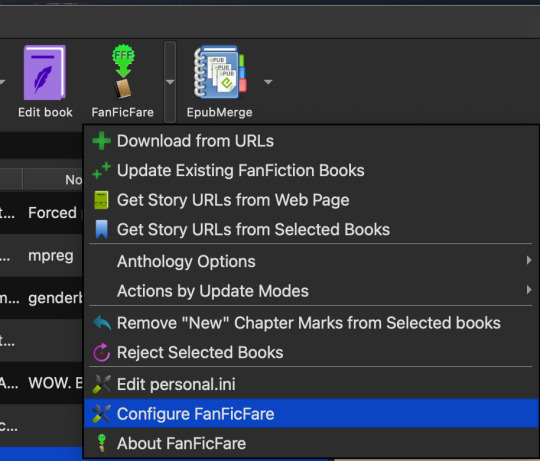
You will see a list of your custom columns with drop-down menus next to each. For columns you want the plugin to automatically fill, click the drop-down and select the matching data from AO3. There are many options to choose from, including pairing, language, warnings, etc. Note that I left the Notes and Thoughts columns blank. This is because I will input that information manually for each fic.

_________________
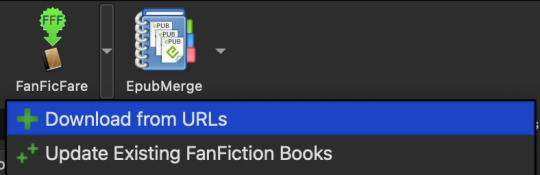
Downloading Individual Fics
Arrow next to FanFicFare > Download from URLs Paste in entire-work fic URLs into the black box. I personally found it tedious to copy/paste each link, so instead I found a Firefox extention called Copy All Tab URLs that does exactly what it says on the tin: copies all URLs from any open tabs. Much easier. Click OK. Then, WAIT. It takes a minute to fetch the data. If a fic is restricted, the plugin may show a pop-up asking you to log into AO3 so that it can access the fic.
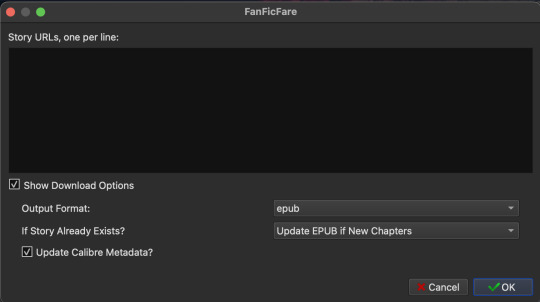
You're good to go when you see the following pop-up in the bottom-right corner. Click Yes.
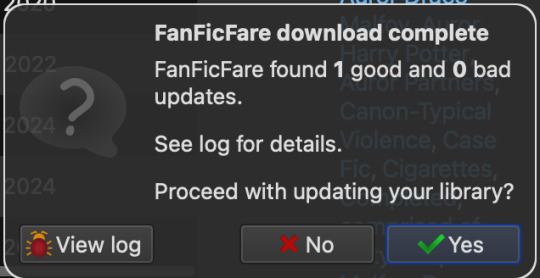
_________________
Downloading An Entire Series
FanFicFare combined with EpubMerge allows you to download an entire series into one epub file!
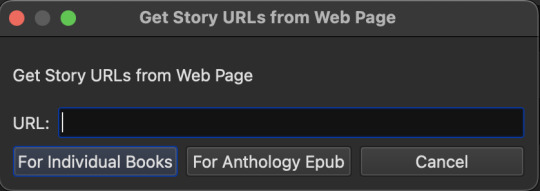
Arrow next to FanFicFare > Get Story URLs from Web Page
Paste in the link to the SERIES page.
Click For Anthology Epub to download everything in that series into a single epub.
The next screen lists all the links in that series. Nothing to do here but click OK.
27 notes
·
View notes
Note

Thank you very much for the fun surprise! I am growing more powerful.

As a total aside, I hope to find time this week to create a short tutorial explaining the web scraping R code. Capitalism Laura has a data science blog. XD
7 notes
·
View notes
Text
New Streaming Schedule (and New Update)

We're back with a Kickstarter update and a new streaming schedule! This December, we're going to git serious: we'll be streaming every week, twice a week (Monday and Thursday) for 2 hours at 3PM PST!
About the Streams
In addition to two new hangout editions of our “Let’s Build our Website” series where we'll finish all that we have pending and add more content to the website, we’ve added a couple new types of stream:
A tutorial write-along, where our project lead will explain how to use PayPal/Stripe links to easily add a tip jar on your Astro website (and compile that information in a blog post).
A learn-together session (possibly more than one), where you can follow an experienced software developer as she tries to learn the intricacies of accepting payments on the web, using the actual Stripe and PayPal APIs.
In addition to these, we’ll look at adding more characters into RobinBoob by scraping AO3 with AO3.js, and we’ll start a new series where we’ll rebuild the RobinBoob's functionality from scratch! After all, like many of our “April 1st projects”, RobinBoob was built in a feverish last-minute rush, and we cannot add some of the requested features without a serious rewrite!
Where to Find Them
We’ll see you this Monday, December 4th at 3PM (see converted time on the schedule) on Twitch, and all throughout December!
First Beta Feedback
And since Tumblr generously allows us to write as much as we want, here's a small sample of the feedback to the first draft of our first issue! You can read more about it under the cut, or get the full details on Kickstarter.
“Unlike other code guides, it's engaging and not dry. [I] wish some of the coding books i read in the past were like the fujoguide cause like. i would have been more into it”
“The guide was really easy to use for the most part, with cute examples and just... really fun!”
“I'm enjoying this, it's approachable and I really like the various ways information is presented; it looks like a legit textbook, like it seems like I could've picked this up from a shelf in Barnes & Noble.”
“I'm really happy at how many cool things are packed here. I have so many friends I will throw this guide at once complete!”
Looking forward to sharing our guide with you all!
30 notes
·
View notes
Note
I'm in IT already- cybersecurity - but I need to learn how to actually code.
But most of time I just lean some syntax that I don't know how to put together. I mostly need to code some scrapers.
Do you have any advice on how to overcome this?
Hiya! 💗
For learning how to code, I've answered a bunch of similar questions, so you can view the answers I gave here: LINK
For learning syntax, you might understand individual syntax or concepts but face problems in combining them effectively to create a functional program or achieve your desired outcome e.g. the scrapers you want. My advice for that is it would be helpful for you to focus on understanding the overall structure and flow of a scraper.
Aim to break down the scraping process into smaller, manageable steps and then gradually connect those steps together. If it is still not working, keep breaking it down and work your way up again.
By studying examples, tutorials, and documentation specifically related to web scraping, you can gain insights into how to assemble the different code components effectively.
Keep repeating. There's no other way to overcome it
Practising and working on small coding projects related to scraping will also be valuable. I'm an advocate of creating projects to learn best. theory is nice and all, but building something and making mistakes is better than reading theory.
I'm not too familiar with coding scrapers, that's more of my colleague's area, but I hope this helps! 💗🙌🏾
26 notes
·
View notes
Text
Long post. Press j to skip.
I AM SICK OF THE STUPID AI DEBATES, does it imagine, is it based on copyrightable material, are my patterns in there?
That's not the point.
I briefly got into website design freelancing (less than 3 months) before burn out.
The main reason was that automation had begun for generating stylesheets in somewhat tasteful palettes, for automatically making html/xml (they really haven't learned to simplify and tidy code though, they just load 50 divs instead of one), for batch colourising design elements to match and savvy designers weren't building graphics from scratch and to spec unless it was their day job.
Custom php and database design died with the free bundled CMS packages that come with your host with massive mostly empty unused values.
No-one has talked about the previous waves of people automated out of work by website design generators, code generators, the fiverr atomisation of what would have been a designers job into 1 logo and a swatch inserted into a CMS by an unpaid intern. Reviews, tutorials, explanations and articles are generated by stealing youtube video captions, scraping fan sites and putting them on a webpage. Digitally processing images got automated with scripts stolen from fan creators who shared. Screencaps went from curated processed images made by a person to machine produced once half a second and uploaded indiscriminately. Media recaps get run into google translate and back which is why they often read as a little odd when you look up the first results.
This was people's work, some of it done out of love, some done for pay. It's all automated and any paid work is immediately copied/co-opted for 20 different half baked articles on sites with more traffic now. Another area of expertise I'd cultivated was deep dive research, poring over scans of magazines and analysing papers, fact checking. I manually checked people's code for errors or simplifications, you can get generators to do that too, even for php. I used to be an english-french translator.
The generators got renamed AI and slightly better at picture making and writing but it's the same concept.
The artists that designed the web templates are obscured, paid a flat fee by the CMS developpers, the CMS coders are obscured, paid for their code often in flat fees by a company that owns all copyright over the code and all the design elements that go with. That would have been me if I hadn't had further health issues, hiding a layer in one of the graphics or a joke in the code that may or may not make it through to the final product. Or I could be a proof reader and fact checker for articles that get barely enough traffic while they run as "multi snippets" in other publications.
The problem isn't that the machines got smarter, it's that they now encroach on a new much larger area of workers. I'd like to ask why the text to speech folks got a flat fee for their work for example: it's mass usage it should be residual based. So many coders and artists and writers got screwed into flat fee gigs instead of jobs that pay a minimum and more if it gets mass use.
The people willing to pay an artist for a rendition of their pet in the artist's style are the same willing to pay for me to rewrite a machine translation to have the same nuances as the original text. The same people who want free are going to push forward so they keep free if a little less special cats and translations. They're the same people who make clocks that last 5 years instead of the ones my great uncle made that outlived him. The same computer chips my aunt assembled in the UK for a basic wage are made with a lot more damaged tossed chips in a factory far away that you live in with suicide nets on the stairs.
There is so much more to 'AI' than the narrow snake oil you are being sold: it is the classic and ancient automation of work by replacing a human with a limited machine. Robot from serf (forced work for a small living)
It's a large scale generator just like ye olde glitter text generators except that threw a few pennies at the coders who made the generator and glitter text only matters when a human with a spark of imagination knows when to deploy it to funny effect. The issue is that artists and writers are being forced to gig already. We have already toppled into precariousness. We are already half way down the slippery slope if you can get paid a flat fee of $300 for something that could make 300k for the company. The generators are the big threat keeping folks afraid and looking at the *wrong* thing.
We need art and companies can afford to pay you for art. Gig work for artists isn't a safe stable living. The fact that they want to make machines to take that pittance isn't the point. There is money, lots of money. It's not being sent to the people who make art. It's not supporting artists to mess around and create something new. It's not a fight between you and a machine, it's a fight to have artists and artisans valued as deserving a living wage not surviving between gigs.
#saf#Rantings#Yes but can the machine think#I don't care. I don't care. I really don't care if the machine is more precise than the artisan#What happens to all our artisans?#Long post#Press j to skip
4 notes
·
View notes
Text
Why CodingBrushup is the Ultimate Tool for Your Programming Skills Revamp
In today's fast-paced tech landscape, staying current with programming languages and frameworks is more important than ever. Whether you're a beginner looking to break into the world of development or a seasoned coder aiming to sharpen your skills, Coding Brushup is the perfect tool to help you revamp your programming knowledge. With its user-friendly features and comprehensive courses, Coding Brushup offers specialized resources to enhance your proficiency in languages like Java, Python, and frameworks such as React JS. In this blog, we’ll explore why Coding Brushup for Programming is the ultimate platform for improving your coding skills and boosting your career.

1. A Fresh Start with Java: Master the Fundamentals and Advanced Concepts
Java remains one of the most widely used programming languages in the world, especially for building large-scale applications, enterprise systems, and Android apps. However, it can be challenging to master Java’s syntax and complex libraries. This is where Coding Brushup shines.
For newcomers to Java or developers who have been away from the language for a while, CodingBrushup offers structured, in-depth tutorials that cover everything from basic syntax to advanced concepts like multithreading, file I/O, and networking. These interactive lessons help you brush up on core Java principles, making it easier to get back into coding without feeling overwhelmed.
The platform’s practice exercises and coding challenges further help reinforce the concepts you learn. You can start with simple exercises, such as writing a “Hello World” program, and gradually work your way up to more complicated tasks like creating a multi-threaded application. This step-by-step progression ensures that you gain confidence in your abilities as you go along.
Additionally, for those looking to prepare for Java certifications or technical interviews, CodingBrushup’s Java section is designed to simulate real-world interview questions and coding tests, giving you the tools you need to succeed in any professional setting.
2. Python: The Versatile Language for Every Developer
Python is another powerhouse in the programming world, known for its simplicity and versatility. From web development with Django and Flask to data science and machine learning with libraries like NumPy, Pandas, and TensorFlow, Python is a go-to language for a wide range of applications.
CodingBrushup offers an extensive Python course that is perfect for both beginners and experienced developers. Whether you're just starting with Python or need to brush up on more advanced topics, CodingBrushup’s interactive approach makes learning both efficient and fun.
One of the unique features of CodingBrushup is its ability to focus on real-world projects. You'll not only learn Python syntax but also build projects that involve web scraping, data visualization, and API integration. These hands-on projects allow you to apply your skills in real-world scenarios, preparing you for actual job roles such as a Python developer or data scientist.
For those looking to improve their problem-solving skills, CodingBrushup offers daily coding challenges that encourage you to think critically and efficiently, which is especially useful for coding interviews or competitive programming.
3. Level Up Your Front-End Development with React JS
In the world of front-end development, React JS has emerged as one of the most popular JavaScript libraries for building user interfaces. React is widely used by top companies like Facebook, Instagram, and Airbnb, making it an essential skill for modern web developers.
Learning React can sometimes be overwhelming due to its unique concepts such as JSX, state management, and component lifecycles. That’s where Coding Brushup excels, offering a structured React JS course designed to help you understand each concept in a digestible way.
Through CodingBrushup’s React JS tutorials, you'll learn how to:
Set up React applications using Create React App
Work with functional and class components
Manage state and props to pass data between components
Use React hooks like useState, useEffect, and useContext for cleaner code and better state management
Incorporate routing with React Router for multi-page applications
Optimize performance with React memoization techniques
The platform’s interactive coding environment lets you experiment with code directly, making learning React more hands-on. By building real-world projects like to-do apps, weather apps, or e-commerce platforms, you’ll learn not just the syntax but also how to structure complex web applications. This is especially useful for front-end developers looking to add React to their skillset.
4. Coding Brushup: The All-in-One Learning Platform
One of the best things about Coding Brushup is its all-in-one approach to learning. Instead of jumping between multiple platforms or textbooks, you can find everything you need in one place. CodingBrushup offers:
Interactive coding environments: Code directly in your browser with real-time feedback.
Comprehensive lessons: Detailed lessons that guide you from basic to advanced concepts in Java, Python, React JS, and other programming languages.
Project-based learning: Build projects that add to your portfolio, proving that you can apply your knowledge in practical settings.
Customizable difficulty levels: Choose courses and challenges that match your skill level, from beginner to advanced.
Code reviews: Get feedback on your code to improve quality and efficiency.
This structured learning approach allows developers to stay motivated, track progress, and continue to challenge themselves at their own pace. Whether you’re just getting started with programming or need to refresh your skills, Coding Brushup tailors its content to suit your needs.
5. Boost Your Career with Certifications
CodingBrushup isn’t just about learning code—it’s also about helping you land your dream job. After completing courses in Java, Python, or React JS, you can earn certifications that demonstrate your proficiency to potential employers.
Employers are constantly looking for developers who can quickly adapt to new languages and frameworks. By adding Coding Brushup certifications to your resume, you stand out in the competitive job market. Plus, the projects you build and the coding challenges you complete serve as tangible evidence of your skills.
6. Stay Current with Industry Trends
Technology is always evolving, and keeping up with the latest trends can be a challenge. Coding Brushup stays on top of these trends by regularly updating its content to include new libraries, frameworks, and best practices. For example, with the growing popularity of React Native for mobile app development or TensorFlow for machine learning, Coding Brushup ensures that developers have access to the latest resources and tools.
Additionally, Coding Brushup provides tutorials on new programming techniques and best practices, helping you stay at the forefront of the tech industry. Whether you’re learning about microservices, cloud computing, or containerization, CodingBrushup has you covered.
Conclusion
In the world of coding, continuous improvement is key to staying relevant and competitive. Coding Brushup offers the perfect solution for anyone looking to revamp their programming skills. With comprehensive courses on Java, Python, and React JS, interactive lessons, real-world projects, and career-boosting certifications, CodingBrushup is your one-stop shop for mastering the skills needed to succeed in today’s tech-driven world.
Whether you're preparing for a new job, transitioning to a different role, or just looking to challenge yourself, Coding Brushup has the tools you need to succeed.
0 notes
Text
Automate Web Scraping: Python & Scrapy Tutorial
Automating Web Scraping Tasks with Python and Scrapy 1. Introduction Web scraping is the process of extracting data from websites, web pages, and online documents. It is a crucial technique for data collection in various industries such as e-commerce, marketing, and data analysis. Automating web scraping tasks with tools like Python and Scrapy can save significant time and effort, allowing you…
0 notes
Text
Learn how to bypass restrictions and access blocked websites using Node Unblocker. A complete tutorial for web scraping enthusiasts and developers.
0 notes
Text
10 Key Benefits of Using Python Programming

It is interesting to note that today Python is among the most widely used programming languages globally. However, the language must be so because of one good reason: simplicity, versatility, and powerful features. It is useful from web development and data science all the way through artificial intelligence. Whether you have just started learning programming or you have been doing it for some time, Python provides some really good advantages, which make it a very popular programming language for programmers.
1. Very Easy to Read and Learn
Python is often recommended for beginners because of the higher level of readability and user-friendly syntax. Coding becomes very intuitive and keeps the learning curve short since it's plain English-like; even the most complex works can be done in far fewer lines of code than most other programming languages.
2. Open Source and Free
Python is totally free to use, distribute and modify. Since it's open-source, a big community of developers is involved in supporting the language; they are in the process of constantly improving and expanding its usefulness. This ensures that you obtain up-to-date versions of the language and are aware of latest trends and tools used across the globe.
3 Extensive Libraries and Frameworks
Libraries like NumPy, pandas, Matplotlib, TensorFlow, and Django are examples of Python's most significant assets-the rich ecosystem of libraries and frameworks. These libraries equip programmers with the ready-to-use tools for data analysis, machine learning, web development, and many others.
4. Independent of Platform
Being a cross-platform language, Python allows the code-written on one operating system to be run on another without any changes. Therefore, the time it takes to develop and deploy applications is lesser and easier to develop in multi-platform environments.
5. Highly Versatile
Python can be applied in a variety of almost any domain for development; including web development, desktop applications, automation, data analysis, artificial intelligence, and Internet of Things (IoT). Flexibility is the best asset of Python to possess where creating nearly anything using one language becomes practical.
6. Strong Community Support
The potential that Python provides exists with solid backing from a very large and active global community. If you have a problem or want guidance on a library, you'll always find available forums, tutorials, and documentation. Websites like Stack Overflow and GitHub have enough resources for Python.
7. Ideal for Automation
Such tasks as emailing, sorting files, and web scraping can very aptly be carried out using Python. The scripting capabilities are such that writing an automation script becomes very easy and efficient.
8. Excellent for Data Science and AI
Python is the best-performing language for data science, machine learning, and artificial intelligence applications. With up-to-date libraries like Scikit-learn, TensorFlow, and Keras, Python offers intelligent modeling and big data analysis tools.
9. Easy to Integrate with Other Languages
Python makes it very easy for one to integrate with other
such as C, C++, and Java. It, therefore, becomes perfect for projects where the intense optimization of performance must be handled or the integration of legacy systems needed.
10. Career Paths
The demand for python development has hit a high note. Companies, ranging from tech startups to multinational corporations, are running a search to find professionals who possess such skills. One of the emerging fields applications of python is found in artificial intelligence and data science, making it a skill for the future.
Conclusion
Python is more than just an easy programming language-it is a strong and powerful tool utilized in many ways across industries. Its simplicity, flexibility, and strong support by community make it one of the best choices for new learners and the most experienced developers alike. Whether you wish to automate tasks, build websites, or dive into data science, Python gives you the tools to succeed.
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
#computer classes near me#Programming Classes in Bopal Ahmedabad – TCCI#Python Training Course in Bopal Ahmedabad#Software Training Institute in Iskcon Ahmedabad#TCCI - Tririd Computer Coaching Institute
0 notes
Text
Manipulating Metadata with FanFicFare - Part 3
One of the many things I like about Ao3 is how it can so very easily group fics in a series. And one fic can even be in multiple series which is awesome for things like subseries or prompt challenges. But when you're downloading fanfics you probably noticed that for fics attached to multiple series, only the first series has it's information added to the downloaded fanfic's metadata. Or that if you download a series as both separate fics and as an anthology, the anthology isn't being marked as part of the series.
These are all fairly easy to fix, but lets start with the easiest to fix first. Which is the anthology issue.
Head into the FanFicFare menu and open the Configure FanFicFare model. Then choose the "Standard Columns" tab and take a look at the table of options for each standard column. Specifically the row of options for the 'Series' column. There should be three checkbox items: "New Only", "Set Calibre Series URL", and "Set 'Series [0]' for New Anthologies".

Make sure that last one is checked and the first one isn't. Then go to the OK button and click that, which will save and close the model.
Now go find either a new series to download as an anthology or one that's already downloaded (should have 'Anthology' in the title). For a new series use the "Get Story URLs from Web Page" option, choose the option for making an anthology, approve the URLs it finds, and let it download everything. For an existing anthology, select the fic in Calibre's book list and then use the FanFicFare option "Update Anthology Epub" in the FanFicFare menu (in the "Anthology Options" flyout) and walk through the update flow (basically the same as the add new anthology flow).
When it's done adding or updating the anthology, you should see it's added as "0 of <Series Name>".
Okay, that's the easy part. Now for adding some custom columns for those extra series listings.
First, lets take a look in the plugin-defaults.ini file. Well, I'm taking a look and pasting my findings here so you don't have to go digging, but it's pretty interesting to take a look through what's in the default settings for FanFicFare. (This file is found in the Configure FanFicFare modal in the "personal.ini" tab.)
Ao3 (and thus any supported Ao3 clones like SquidgeWorld) are going to have the following "extra_valid_entries:" options set in the plugin-defaults.ini file.
extra_valid_entries:fandoms, freeformtags, freefromtags, ao3categories, comments, chapterslashtotal, chapterstotal, kudos, hits, bookmarks, collections, byline, bookmarked, bookmarktags, bookmarksummary, bookmarkprivate, bookmarkrec, subscribed, markedforlater, restricted, series00, series01, series02, series03, series00Url, series01Url, series02Url, series03Url, series00HTML, series01HTML, series02HTML, series03HTML
That's a lot of metadata that FanFicFare scrapes. Some of it's transformed into standardized metadata information already. 'byline' presumably becomes 'author', 'fandoms' gets funneled into 'category', and so on. Of course, what we care about for the sake of this tutorial is the series data.
Specifically, lets take a look at series00, series01, series02, and series03.
Series00 is going to be the same information already being populated into the existing column for Series. Which means that extra series data for a fic in more than one series will be in the series01, series02, and series03 entries that aren't currently being saved anywhere.
Time to make some custom columns.
Head into the Calibre Preferences and then choose "Add your own columns". Click the button to "Add custom column" and fill out the following info:
Lookup name: series01 Column heading: Series 01 (Note: this can be whatever you want to name it) Column type: Text column for keeping series-like information

That should be all you really need. Hit OK and then add two more columns for series02 and series03.
It is important that the Lookup name matches the entry name for the metadata. For whatever reason, linking non matchy Lookup names to metadata entry names is a pain in the butt that I'm still working on figuring out. (It shouldn't be this hard and yet… sigh)
Once you've got your new columns added, hit Apply and restart Calibre. Now we can map the metadata entries to the new columns, we're officially halfway done. (It's all easy going again from here too.)
Time to go open up the FanFicFare personal.ini file to make a few minor changes. Under the "[archiveofourown.org]" section, before any metadata manipulation begins - so probably right beneath your username and password if you've set them - add the following four lines:
''' custom_columns_settings: series01=>#series01 series02=>#series02 series03=>#series03 '''
If you have a "[www.squidgeworld.org]" section you'll want to past those four lines there too.
Click the OK button to save and close the personal.ini file. Now go download a new fic associated with multiple series or find one you've already downloaded and update it's metadata only (unless you know it has new chapters). When the download/update process is done, you should see that the missing series data has been populated
Wait, however, there's one more thing you'll want to do. Because fic 1 in Series A might have Series A listed in the Series column but fic 2 might have it in the Series 01 column, searching just one column for all the fics in a series is no longer going to cut it. Searching 'series:"=Series A' won't return fic 2, but '#series01:"=Series A" will leave out fic 1. And if you want to combine the two search terms, it can be tedius to have to do that every single time.
The answer to this problem is to create a custom search term so that you can do 'allseries:"=Series A"' and have the search return Fic 1 and Fic 2. To do this, head back into Calibre's Preferences. In the top section labeled "Interface", the last option on the right should be "Searching" with a blue magnifying glass icon. Click that and then head to the "Grouped searches" tab.
In the Names input, type 'allseries'. Then head to the Value input. This one will offer auto-complete options as you type which is pretty useful - basically you want to type in the Lookup names for the columns you want the search to check and separate those Lookup names with commas. You'll want it to look like 'series, #series01, #series02, #series03,' when you're done filling it in. Note that the standard column series doesn't have a hashtag before it's Lookup name, but the custom columns do.

With the Names and Value inputs filled, the Save button should be available now. Click that to save the new search term and then click OK to close the modal. Exit from the Calibre Preferences and test out your new allseries search option.
You may need to go back and update metadata for a bunch of fics you've previously downloaded now, but it's definitely useful data to be able to keep track of.
0 notes
Text
Web Scraping 101: Everything You Need to Know in 2025

🕸️ What Is Web Scraping? An Introduction
Web scraping—also referred to as web data extraction—is the process of collecting structured information from websites using automated scripts or tools. Initially driven by simple scripts, it has now evolved into a core component of modern data strategies for competitive research, price monitoring, SEO, market intelligence, and more.
If you’re wondering “What is the introduction of web scraping?” — it’s this: the ability to turn unstructured web content into organized datasets businesses can use to make smarter, faster decisions.
💡 What Is Web Scraping Used For?
Businesses and developers alike use web scraping to:
Monitor competitors’ pricing and SEO rankings
Extract leads from directories or online marketplaces
Track product listings, reviews, and inventory
Aggregate news, blogs, and social content for trend analysis
Fuel AI models with large datasets from the open web
Whether it’s web scraping using Python, browser-based tools, or cloud APIs, the use cases are growing fast across marketing, research, and automation.
🔍 Examples of Web Scraping in Action
What is an example of web scraping?
A real estate firm scrapes listing data (price, location, features) from property websites to build a market dashboard.
An eCommerce brand scrapes competitor prices daily to adjust its own pricing in real time.
A SaaS company uses BeautifulSoup in Python to extract product reviews and social proof for sentiment analysis.
For many, web scraping is the first step in automating decision-making and building data pipelines for BI platforms.
⚖️ Is Web Scraping Legal?
Yes—if done ethically and responsibly. While scraping public data is legal in many jurisdictions, scraping private, gated, or copyrighted content can lead to violations.
To stay compliant:
Respect robots.txt rules
Avoid scraping personal or sensitive data
Prefer API access where possible
Follow website terms of service
If you’re wondering “Is web scraping legal?”—the answer lies in how you scrape and what you scrape.
🧠 Web Scraping with Python: Tools & Libraries
What is web scraping in Python? Python is the most popular language for scraping because of its ease of use and strong ecosystem.
Popular Python libraries for web scraping include:
BeautifulSoup – simple and effective for HTML parsing
Requests – handles HTTP requests
Selenium – ideal for dynamic JavaScript-heavy pages
Scrapy – robust framework for large-scale scraping projects
Puppeteer (via Node.js) – for advanced browser emulation
These tools are often used in tutorials like “Web scraping using Python BeautifulSoup” or “Python web scraping library for beginners.”
⚙️ DIY vs. Managed Web Scraping
You can choose between:
DIY scraping: Full control, requires dev resources
Managed scraping: Outsourced to experts, ideal for scale or non-technical teams
Use managed scraping services for large-scale needs, or build Python-based scrapers for targeted projects using frameworks and libraries mentioned above.
🚧 Challenges in Web Scraping (and How to Overcome Them)
Modern websites often include:
JavaScript rendering
CAPTCHA protection
Rate limiting and dynamic loading
To solve this:
Use rotating proxies
Implement headless browsers like Selenium
Leverage AI-powered scraping for content variation and structure detection
Deploy scrapers on cloud platforms using containers (e.g., Docker + AWS)
🔐 Ethical and Legal Best Practices
Scraping must balance business innovation with user privacy and legal integrity. Ethical scraping includes:
Minimal server load
Clear attribution
Honoring opt-out mechanisms
This ensures long-term scalability and compliance for enterprise-grade web scraping systems.
🔮 The Future of Web Scraping
As demand for real-time analytics and AI training data grows, scraping is becoming:
Smarter (AI-enhanced)
Faster (real-time extraction)
Scalable (cloud-native deployments)
From developers using BeautifulSoup or Scrapy, to businesses leveraging API-fed dashboards, web scraping is central to turning online information into strategic insights.
📘 Summary: Web Scraping 101 in 2025
Web scraping in 2025 is the automated collection of website data, widely used for SEO monitoring, price tracking, lead generation, and competitive research. It relies on powerful tools like BeautifulSoup, Selenium, and Scrapy, especially within Python environments. While scraping publicly available data is generally legal, it's crucial to follow website terms of service and ethical guidelines to avoid compliance issues. Despite challenges like dynamic content and anti-scraping defenses, the use of AI and cloud-based infrastructure is making web scraping smarter, faster, and more scalable than ever—transforming it into a cornerstone of modern data strategies.
🔗 Want to Build or Scale Your AI-Powered Scraping Strategy?
Whether you're exploring AI-driven tools, training models on web data, or integrating smart automation into your data workflows—AI is transforming how web scraping works at scale.
👉 Find AI Agencies specialized in intelligent web scraping on Catch Experts,
📲 Stay connected for the latest in AI, data automation, and scraping innovation:
💼 LinkedIn
🐦 Twitter
📸 Instagram
👍 Facebook
▶️ YouTube
#web scraping#what is web scraping#web scraping examples#AI-powered scraping#Python web scraping#web scraping tools#BeautifulSoup Python#web scraping using Python#ethical web scraping#web scraping 101#is web scraping legal#web scraping in 2025#web scraping libraries#data scraping for business#automated data extraction#AI and web scraping#cloud scraping solutions#scalable web scraping#managed scraping services#web scraping with AI
0 notes
Link
[ad_1] Web scraping and data extraction are crucial for transforming unstructured web content into actionable insights. Firecrawl Playground streamlines this process with a user-friendly interface, enabling developers and data practitioners to explore and preview API responses through various extraction methods easily. In this tutorial, we walk through the four primary features of Firecrawl Playground: Single URL (Scrape), Crawl, Map, and Extract, highlighting their unique functionalities. Single URL Scrape In the Single URL mode, users can extract structured content from individual web pages by providing a specific URL. The response preview within the Firecrawl Playground offers a concise JSON representation, including essential metadata such as page title, description, main content, images, and publication dates. The user can easily evaluate the structure and quality of data returned by this single-page scraping method. This feature is useful for cases where focused, precise data from individual pages, such as news articles, product pages, or blog posts, is required. The user accesses the Firecrawl Playground and enters the URL www.marktechpost.com under the Single URL (/scrape) tab. They select the FIRE-1 model and write the prompt: “Get me all the articles on the homepage.” This sets up Firecrawl’s agent to retrieve structured content from the MarkTechPost homepage using an LLM-powered extraction approach. The result of the single-page scrape is displayed in a Markdown view. It successfully extracts links to various sections, such as “Natural Language Processing,” “AI Agents,” “New Releases,” and more, from the homepage of MarkTechPost. Below these links, a sample article headline with introductory text is also displayed, indicating accurate content parsing. Crawl The Crawl mode significantly expands extraction capabilities by allowing automated traversal through multiple interconnected web pages starting from a given URL. Within the Playground’s preview, users can quickly examine responses from the initial crawl, observing JSON-formatted summaries of page content alongside URLs discovered during crawling. The Crawl feature effectively handles broader extraction tasks, including retrieving comprehensive content from entire websites, category pages, or multi-part articles. Users benefit from the ability to assess crawl depth, page limits, and response details through this preview functionality. In the Crawl (/crawl) tab, the same site ( www.marktechpost.com ) is used. The user sets a crawl limit of 10 pages and configures path filters to exclude pages such as “blog” or “about,” while including only URLs under the “/articles/” path. Page options are customized to extract only the main content, avoiding tags such as scripts, ads, and footers, thereby optimizing the crawl for relevant information. The platform shows results for 10 pages scraped from MarkTechPost. Each tile in the results grid presents content extracted from different sections, such as “Sponsored Content,” “SLD Dashboard,” and “Embed Link.” Each page has both Markdown and JSON response tabs, offering flexibility in how the extracted content is viewed or processed. Map The Map feature introduces an advanced extraction mechanism by applying user-defined mappings across crawled data. It enables users to specify custom schema structures, such as extracting particular text snippets, authors’ names, or detailed product descriptions from multiple pages simultaneously. The Playground preview clearly illustrates how mapping rules are applied, presenting extracted data in a neatly structured JSON format. Users can quickly confirm the accuracy of their mappings and ensure that the extracted content aligns precisely with their analytical requirements. This feature significantly streamlines complex data extraction workflows requiring consistency across multiple webpages. In the Map (/map) tab, the user again targets www.marktechpost.com but this time uses the Search (Beta) feature with the keyword “blog.” Additional options include enabling subdomain searches and respecting the site’s sitemap. This mode aims to retrieve a large number of relevant URLs that match the search pattern. The mapping operation returns a total of 5000 matched URLs from the MarkTechPost website. These include links to categories and articles under themes such as AI, machine learning, knowledge graphs, and others. The links are displayed in a structured list, with the option to view results as JSON or download them for further processing. Currently available in Beta, the Extract feature further refines Firecrawl’s capabilities by facilitating tailored data retrieval through advanced extraction schemas. With Extract, users design highly granular extraction patterns, such as isolating specific data points, including author metadata, detailed product specifications, pricing information, or publication timestamps. The Playground’s Extract preview displays real-time API responses that reflect user-defined schemas, providing immediate feedback on the accuracy and completeness of the extraction. As a result, users can iterate and fine-tune extraction rules seamlessly, ensuring data precision and relevance. Under the Extract (/extract) tab (Beta), the user enters the URL and defines a custom extraction schema. Two fields are specified: company_mission as a string and is_open_source as a boolean. The prompt guides the extraction to ignore details such as partners or integrations, focusing instead on the company’s mission and whether it is open-source. The final formatted JSON output shows that MarkTechPost is identified as an open-source platform, and its mission is accurately extracted: “To provide the latest news and insights in the field of Artificial Intelligence and technology, focusing on research, tutorials, and industry developments.” In conclusion, Firecrawl Playground provides a robust and user-friendly environment that significantly simplifies the complexities of web data extraction. Through intuitive previews of API responses across Single URL, Crawl, Map, and Extract modes, users can effortlessly validate and optimize their extraction strategies. Whether working with isolated web pages or executing intricate, multi-layered extraction schemas across entire sites, Firecrawl Playground empowers data professionals with powerful, versatile tools essential for effective and accurate web data retrieval. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. Don’t Forget to join our 90k+ ML SubReddit. 🔥 [Register Now] miniCON Virtual Conference on AGENTIC AI: FREE REGISTRATION + Certificate of Attendance + 4 Hour Short Event (May 21, 9 am- 1 pm PST) + Hands on Workshop Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences. [ad_2] Source link
0 notes
Text
The Advantages of Python: A Comprehensive Overview
Python has gained immense popularity in the programming world due to its simplicity, flexibility, and powerful capabilities. Considering the kind support of Python Course in Chennai Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

Whether you are a beginner stepping into coding or an experienced developer working on complex projects, Python offers numerous advantages that make it a preferred choice across various industries.
Easy to Learn and Use
Python is known for its clean and readable syntax, making it an excellent choice for beginners. Unlike other programming languages that require complex syntax, Python allows developers to write fewer lines of code while maintaining efficiency. Its simplicity ensures that even those without prior programming experience can quickly grasp the fundamentals and start coding.
Versatile Across Multiple Fields
One of Python’s biggest strengths is its versatility. It is used in web development, data science, artificial intelligence, machine learning, automation, game development, and even cybersecurity. This flexibility allows developers to transition between different domains without having to learn a new language.
Extensive Library and Framework Support
Python offers a vast collection of libraries and frameworks that simplify development tasks. Libraries like NumPy and Pandas are used for data analysis, TensorFlow and PyTorch for machine learning, Flask and Django for web development, and Selenium for automation. These libraries reduce the time and effort needed to build applications, allowing developers to focus on problem-solving.
Strong Community and Learning Resources
Python has a large and active global community that continuously contributes to its growth. Whether you need help debugging code, finding tutorials, or exploring best practices, numerous forums, documentation, and free learning platforms provide valuable support. This makes Python an ideal language for both self-learners and professionals. With the aid of Best Online Training & Placement Programs, which offer comprehensive training and job placement support to anyone looking to develop their talents, it’s easier to learn this tool and advance your career.

Cross-Platform Compatibility
Python is a cross-platform language, meaning it runs smoothly on Windows, macOS, and Linux without requiring major modifications. This feature enables developers to write code once and deploy it across different operating systems, saving time and effort.
Ideal for Automation and Scripting
Python is widely used for automating repetitive tasks, such as web scraping, file management, and system administration. Businesses leverage Python’s scripting capabilities to improve efficiency and reduce manual workloads. Many developers also use it to automate testing processes, making software development more streamlined.
High Demand in the Job Market
Python is one of the most sought-after programming languages in the job market. Companies across industries, including tech giants like Google, Amazon, and Microsoft, rely on Python for various applications. The demand for Python developers continues to grow, making it a valuable skill for those seeking career advancement.
Integration with Other Technologies
Python seamlessly integrates with other programming languages like C, C++, and Java, making it highly adaptable for different projects. This allows developers to enhance existing applications, optimize performance, and work efficiently with multiple technologies.
Conclusion
Python’s ease of use, versatility, and strong community support make it one of the best programming languages for both beginners and experienced developers. Whether you are interested in software development, data science, artificial intelligence, or automation, Python provides the tools and resources needed to succeed. With its continuous evolution and growing adoption, Python remains a powerful choice for modern programming needs.
#python course#python training#python#technology#tech#python online training#python programming#python online course#python online classes#python certification
0 notes