#XPath
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
XML и XPath?
XML - это формат файлов для хранения и передачи данных.
В пример возьмём данные о каком-то кинотеатре, в прокате которого есть три фильма и запишем их в xml формате:
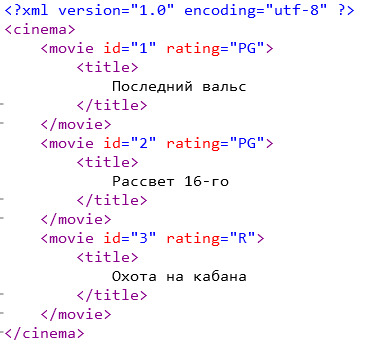
Первая строчка - это пролог или xml декларация, в которой указывается версия и кодировка файла.
Далее идут xml элементы (узлы): cinema - корневой элемент, содержащий три элемента movie, в каждом из которых есть title. На реальных примерах такая вложенность может продолжаться до бесконечности, из-за чего ориентироваться в файле становиться трудно, но данные надо как-то доставать. Поэтому придумали XPath.
XPath - язык запросов для поиска нужных xml-элементов.
Пример:
/cinema/movie
Таким образом будут найдены все элементы movie в корневом элементе cinema.
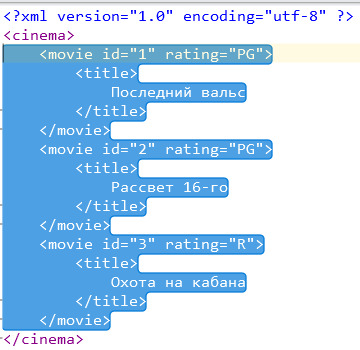
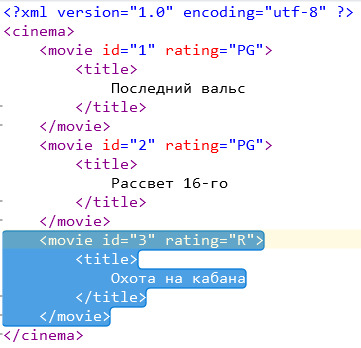
А следующей строчкой будут найдены все movie, у которых атрибут rating имеет значение R.
/cinema/movie[@ rating="R"] (пробела после "@" не должно быть, это сделано чтобы на тамблере никого не тегнуть)
Основы синтаксиса XPath
/ - выбор от корневого элемента (абсолютный путь);
// - выбор от любого элемента (относительный путь);
. - текущий элемент;
.. - родитель элемента;
@ - атрибут;
То есть
/movie - не найдёт ничего, потому что нет такого корневого элемента "movie";
//movie - найдёт все элементы movie, и не важно где и как они вложены;
//movie/.. - найдёт всех родителей элементов movie;
//@ rating - найдёт все атрибуты rating.
Подробнее про синтаксис и прочие возможности XPath написано здесь.
#студент бормочет#xml#xpath#обычно я не люблю просто оставлять ссылки на учебники#но иначе это будет чистое ctrl c ctrl v
2 notes
·
View notes
Text

What is XPath?
0 notes
Text
XML - XPath - Exemplu
Următoarele documente XML, scheme XSD și exemple de foi de stil XSL vă ajută să puneți împreună tot ce ați învățat în acest capitol folosind date din viața reală. Pe măsură ce studiați acest exemplu, veți observa cum XPath poate fi folosit în foaia de stil pentru a apela și modifica ieșirea unor informații specifice din document. Mai jos este un document XML (Expunerea 9.4) <?xml version="1.0"…
0 notes
Text
Mastering XPath in Selenium: A Complete Guide for Efficient Web Element Identification
🚀 Mastering XPath in Selenium is a game-changer for any automation tester! 🛠️ Whether you’re navigating through complex HTML structures or dealing with dynamic web elements, XPath provides the precision and flexibility needed to locate elements with ease. By integrating XPath into your Selenium tests, you can ensure more robust and reliable automation scripts, leading to higher quality web applications.
0 notes
Text
What are the types of XPath?
XPath is a query language used for navigating and querying XML documents. XPath provides a way to navigate through elements and attributes in an XML document.

There are two main types of XPath expressions: absolute and relative.
Absolute XPath:
Absolute XPath starts from the root of the document and includes the complete path to the element.
It begins with a single forward slash ("/") representing the root node and includes all the elements along the path to the target element.
For example: /html/body/div[1]/p[2]/a
Relative XPath:
Relative XPath is more flexible and doesn't start from the root. Instead, it starts from any node in the document.
It uses a double forward slash ("//") to select nodes at any level in the document.
For example: //div[@class='example']//a[contains(@href, 'example')]
XPath can also be categorized based on the types of expressions used:
Node Selection:
XPath can be used to select nodes based on their type, such as element nodes, attribute nodes, text nodes, etc.
Example: /bookstore/book selects all <book> elements that are children of the <bookstore> element.
Path Expression:
Path expressions in XPath describe a path to navigate through elements and attributes in an XML document.
Example: /bookstore/book/title selects all <title> elements that are children of the <book> elements that are children of the <bookstore> element.
Predicate:
Predicates are used to filter nodes based on certain conditions.
Example: /bookstore/book[price>35] selects all <book> elements that have a <price> element with a value greater than 35.
Function:
XPath provides a variety of functions for string manipulation, mathematical operations, and more.
Example: //div[contains(@class, 'example')] selects all <div> elements with a class attribute containing the word 'example'.
These types and expressions can be combined and customized to create powerful XPath queries for different XML structures. XPath is commonly used in web scraping, XML document processing, and in conjunction with tools like Selenium for web automation.
#xpath#selenium#automation testing#xpath types#software testing#future trends#software development#software engineer
0 notes
Text
writing code and I get to a variable for an xpath predicate and I write
xpath_pred = '{SOME COMPLEX CODE HERE}'
now I have to make an xpath_prey or all the furries into vore will get mad at me
148 notes
·
View notes
Text
Меня искренне забавляет то, как импульсивно туда сюда скачет моя нагрузка изо дня в день. С утра пораньше Куратор написал, что за��ание я сделала немного не так, его нужно было посчитать не в ручную, а с помощью xpath.
Что такое xpath я узнала сегодня утром пять минут назад и через пол часа на нем нужно будет пробовать писать запросы.
А как ваши приколы поживают?
#работа#русский tumblr#русский тамблер#личный блог#русский блог#мой блог#мой tumblr#ситуация#турумбочка
8 notes
·
View notes
Text
Tumblr Fixer 2.0
I'm making this the first post of my sideblog - I'm the same user as madamepestilence, and you can message me on my other blog if you'd like to confirm that.
I'm not affiliated with Tumblr whatsoever, but I'm sick of their changes. This list will provide exclusively the uBlock Origin changes, which alter their site to a much more bearable condition.
This list of changes will alter your page to look this clean:
What you need to add to your uBlock Origin dashboard is as follows:
www.tumblr.com##[href="#managed-icon__shop"]:xpath(../../../../../../..) www.tumblr.com##.I6Lwl ||assets.tumblr.com/pop/src/components/one-piece/assets/toggle-dff697e4.png$image www.tumblr.com##div.MNkkC:nth-of-type(2) www.tumblr.com##.RAEnv ||64.media.tumblr.com/eb3cc57ecea1ea4f54214a39526675ff/ea6c161a5fdfdce8-25/s512x512u_c1/0b98d9d20de62cdcb6798fd0c54a72ad8ebc7f01.pnj$image ||64.media.tumblr.com/eb3cc57ecea1ea4f54214a39526675ff/ea6c161a5fdfdce8-25/s512x512u_c1/0b98d9d20de62cdcb6798fd0c54a72ad8ebc7f01.pnj$image www.tumblr.com##div._f1es.rZlUD:nth-of-type(2) www.tumblr.com##div._f1es.rZlUD:nth-of-type(41) www.tumblr.com##div._f1es.rZlUD:nth-of-type(50) www.tumblr.com##div._f1es.rZlUD:nth-of-type(89) www.tumblr.com##.Gav7q www.tumblr.com##li.g8SYn.IYrO9:nth-of-type(4) www.tumblr.com##.oNZY7 > .FtjPK ||assets.tumblr.com/pop/src/components/one-piece/assets/toggle-6d176646.png$image www.tumblr.com##li.g8SYn.IYrO9:nth-of-type(8) www.tumblr.com##li.g8SYn.IYrO9:nth-of-type(9) www.tumblr.com##li.g8SYn.IYrO9:nth-of-type(3) www.tumblr.com##div.MNkkC:nth-of-type(3) www.tumblr.com##.ZyGTE.I_SFh www.tumblr.com##div.FZkjV:nth-of-type(4) www.tumblr.com##div.FZkjV:nth-of-type(3)
Enjoy!
#tumblr fix#tumblr fixing#tumblr fixer#tumblr fixes#dashboard unfucker#dashboard fixer#dashboard fix#dashboard fixes#pirate#i hate these changes so much
13 notes
·
View notes
Text
Zillow Scraping Mastery: Advanced Techniques Revealed

In the ever-evolving landscape of data acquisition, Zillow stands tall as a treasure trove of valuable real estate information. From property prices to market trends, Zillow's extensive database holds a wealth of insights for investors, analysts, and researchers alike. However, accessing this data at scale requires more than just a basic understanding of web scraping techniques. It demands mastery of advanced methods tailored specifically for Zillow's unique structure and policies. In this comprehensive guide, we delve into the intricacies of Zillow scraping, unveiling advanced techniques to empower data enthusiasts in their quest for valuable insights.
Understanding the Zillow Scraper Landscape
Before diving into advanced techniques, it's crucial to grasp the landscape of zillow scraper. As a leading real estate marketplace, Zillow is equipped with robust anti-scraping measures to protect its data and ensure fair usage. These measures include rate limiting, CAPTCHA challenges, and dynamic page rendering, making traditional scraping approaches ineffective. To navigate this landscape successfully, aspiring scrapers must employ sophisticated strategies tailored to bypass these obstacles seamlessly.
Advanced Techniques Unveiled
User-Agent Rotation: One of the most effective ways to evade detection is by rotating User-Agent strings. Zillow's anti-scraping mechanisms often target commonly used User-Agent identifiers associated with popular scraping libraries. By rotating through a diverse pool of User-Agent strings mimicking legitimate browser traffic, scrapers can significantly reduce the risk of detection and maintain uninterrupted data access.
IP Rotation and Proxies: Zillow closely monitors IP addresses to identify and block suspicious scraping activities. To counter this, employing a robust proxy rotation system becomes indispensable. By routing requests through a pool of diverse IP addresses, scrapers can distribute traffic evenly and mitigate the risk of IP bans. Additionally, utilizing residential proxies offers the added advantage of mimicking genuine user behavior, further enhancing scraping stealth.
Session Persistence: Zillow employs session-based authentication to track user interactions and identify potential scrapers. Implementing session persistence techniques, such as maintaining persistent cookies and managing session tokens, allows scrapers to simulate continuous user engagement. By emulating authentic browsing patterns, scrapers can evade detection more effectively and ensure prolonged data access.
JavaScript Rendering: Zillow's dynamic web pages rely heavily on client-side JavaScript to render content dynamically. Traditional scraping approaches often fail to capture dynamically generated data, leading to incomplete or inaccurate results. Leveraging headless browser automation frameworks, such as Selenium or Puppeteer, enables scrapers to execute JavaScript code dynamically and extract fully rendered content accurately. This advanced technique ensures comprehensive data coverage across Zillow's dynamic pages, empowering scrapers with unparalleled insights.
Data Parsing and Extraction: Once data is retrieved from Zillow's servers, efficient parsing and extraction techniques are essential to transform raw HTML content into structured data formats. Utilizing robust parsing libraries, such as BeautifulSoup or Scrapy, facilitates seamless extraction of relevant information from complex web page structures. Advanced XPath or CSS selectors further streamline the extraction process, enabling scrapers to target specific elements with precision and extract valuable insights efficiently.
Ethical Considerations and Compliance
While advanced scraping techniques offer unparalleled access to valuable data, it's essential to uphold ethical standards and comply with Zillow's terms of service. Scrapers must exercise restraint and avoid overloading Zillow's servers with excessive requests, as this may disrupt service for genuine users and violate platform policies. Additionally, respecting robots.txt directives and adhering to rate limits demonstrates integrity and fosters a sustainable scraping ecosystem beneficial to all stakeholders.
Conclusion
In the realm of data acquisition, mastering advanced scraping techniques is paramount for unlocking the full potential of platforms like Zillow. By employing sophisticated strategies tailored to bypass anti-scraping measures seamlessly, data enthusiasts can harness the wealth of insights hidden within Zillow's vast repository of real estate data. However, it's imperative to approach scraping ethically and responsibly, ensuring compliance with platform policies and fostering a mutually beneficial scraping ecosystem. With these advanced techniques at their disposal, aspiring scrapers can embark on a journey of exploration and discovery, unraveling valuable insights to inform strategic decisions and drive innovation in the real estate industry.
2 notes
·
View notes
Text

What is XSLT ?
0 notes
Text
XML - XPath: căi de locație, axe, predicate și funcții
Patru tipuri de căi de locație XPath Există două distincții diferite pentru a separa diferite căi de locație: neabreviat vs. abreviat și relativ vs. absolut. Combinarea acestor două concepte ar putea fi utilă atunci când vorbim despre căile de locație XPath. Ca să nu mai vorbim că te-ar putea face să pari foarte inteligent în fața prietenilor tăi când spui lucruri precum: Căi de locație relativă…
0 notes
Text
Maximizing Test Effectiveness: Unraveling the Advantages of Selenium in Web Testing
Introduction: Selenium, a prominent automation testing framework, has redefined the landscape of web application testing. Renowned for its versatility, user-friendliness, and robust capabilities, Selenium is an indispensable asset for professionals engaged in software testing. In this discourse, we explore the manifold advantages of utilizing Selenium for web testing and elucidate how it empowers testers to achieve optimal outcomes.

1. Precision and Dependability: Selenium provides precise and dependable element identification, enabling testers to accurately pinpoint and interact with web elements on a page. Leveraging unique attributes such as IDs, classes, or XPath expressions, Selenium ensures tests execute consistently and yield reliable results across various browsers and environments.
2. Enhanced Test Stability: Selenium bolsters test stability by mitigating the impact of changes in the application under test. Selenium locators are adept at withstanding alterations in page layout or structure, ensuring tests remain stable and impervious to minor UI modifications. This stability is pivotal for upholding the integrity of test suites and ensuring accurate validation of application functionality.
3. Improved Test Efficiency: Leveraging Selenium for web testing enhances efficiency and productivity by automating repetitive testing tasks. By automating routine test cases, testers can allocate their time and effort toward more intricate scenarios and exploratory testing, thereby expediting the overall testing process and reducing time-to-market for web applications.
4. Cross-Browser Compatibility: A standout feature of Selenium is its cross-browser compatibility, facilitating test execution across diverse web browsers with minimal effort. Selenium WebDriver seamlessly supports popular browsers like Chrome, Firefox, Safari, and Edge, ensuring consistent test execution and compatibility across varied browser environments.

5. Seamless Integration with Testing Frameworks: Selenium seamlessly integrates with a myriad of testing frameworks, enabling testers to harness their preferred tools and methodologies. Whether utilizing TestNG, JUnit, or NUnit, Selenium can be effortlessly integrated into existing testing workflows, affording flexibility and customization options tailored to the needs of individual testing teams.
6. Scalability and Reusability: Selenium advocates scalability and reusability through its modular test design and component-based architecture. Test scripts and components can be modularized and repurposed across multiple test cases, curbing duplication of effort and maintenance overhead. This modular approach fosters test maintainability and facilitates the creation of robust, scalable test suites.
7. Cost-Effectiveness: By automating web testing tasks, Selenium aids organizations in trimming manual testing efforts and associated costs. Automated tests can be executed repeatedly sans additional expenses, resulting in long-term cost savings and heightened return on investment. Additionally, Selenium's open-source nature obviates licensing fees, rendering it a cost-effective choice for organizations of all sizes.
8. Comprehensive Test Coverage: Selenium empowers testers to attain comprehensive test coverage by supporting a gamut of testing scenarios and workflows. From functional and regression testing to performance and compatibility testing, Selenium caters to diverse testing requirements, ensuring thorough validation of web applications across various dimensions.
In summation, Selenium offers a plethora of advantages for web testing, encompassing precision and reliability, enhanced test stability, improved efficiency, cross-browser compatibility, seamless integration, scalability, cost-effectiveness, and comprehensive test coverage. By harnessing the power of Selenium, testers can streamline their testing endeavors, augment test coverage, and deliver high-quality web applications that align with the expectations of end-users and stakeholders alike.
2 notes
·
View notes
Text
Unveiling Selenium's Testing Terrain: Overcoming Limitations
In the dynamic field of web application testing, Selenium has emerged as a robust ally, offering testers a suite of powerful features. However, as with any technology, Selenium is not without its limitations. This blog post aims to explore these drawbacks, providing insights into potential challenges and offering strategies to navigate them effectively.

1. Constraints in Non-Web Application Testing: While Selenium excels in web application testing, its scope is limited when dealing with non-web applications. Recognizing this constraint is crucial for projects that involve a diverse array of application types. Supplementing Selenium with specialized tools for non-web applications ensures a holistic testing approach.
2. Learning Curve Dynamics: Selenium's feature-rich environment may pose a steep learning curve, especially for those new to the tool. However, this initial challenge transforms into a valuable skill set over time. The extensive features demand dedicated learning efforts, but the resulting proficiency allows testers to harness Selenium's capabilities effectively.
3. Reporting Dependencies on External Tools: Selenium lacks built-in reporting features, necessitating the use of third-party tools or plugins for comprehensive reporting. While considered a drawback, this flexibility enables testers to choose reporting tools that align with their specific needs, enhancing the depth and insightfulness of test reports.
4. Challenges with Dynamic Element Identification: Dynamic web pages with frequently changing elements present challenges for Selenium. Stable identification of these elements requires advanced strategies to ensure the reliability of test scripts. Testers need to employ dynamic element identification techniques, such as using relative XPath or implementing effective waiting strategies.

5. Image-Based Testing Limitations: Selenium's primary focus on HTML elements limits its support for image-based testing scenarios. Projects heavily reliant on visual validation may find Selenium's capabilities in this area lacking. To address this limitation, testers may explore additional tools specifically designed for image-based testing, seamlessly integrating them into their testing toolkit.
In summary, while Selenium stands as a strong contender for web application testing, understanding its limitations is paramount for a successful testing strategy. The outlined drawbacks serve as guideposts, indicating areas where Selenium may not be the singular solution. Testers can strategically supplement Selenium with specialized tools based on project requirements, ensuring a comprehensive and effective testing process. The dynamic nature of testing calls for a nuanced approach, leveraging the strengths of each tool judiciously to deliver high-quality web applications seamlessly. By navigating Selenium's limitations thoughtfully, testers can optimize their testing processes and contribute to a robust quality assurance framework.
2 notes
·
View notes
Text
XPath in Selenium is a powerful tool for locating elements on a webpage using XML path expressions. It enables precise navigation and identification of HTML elements, making it a crucial feature for automated web testing. Developers use XPath to create robust and reliable test scripts, ensuring accurate interaction with web elements.
0 notes
Text
www.tumblr.com##[aria-label^="Scroll carousel left"]:xpath(..):xpath(..):xpath(..):xpath(..)
Put that in "My Filters" in uBlock Origin to hide the Tumblr Live row at the top of your dash.
2 notes
·
View notes
Text
Why I Love Get By Text
I have a confession: I've been writing browser tests lately, and my preferred approach to locators is becoming get by text or get by label.
I am aware that some of you might want to throw some full wine bottles at me now. But I stand by it.
Over the course of my career as a test automation specialist, I've worked with a bunch of web applications for which I automated browser tests. One of the most critical aspects of writing browser tests is finding good locators to hook into in order to drive the application. Naturally, since there are plenty of options there are also plenty of opinions on what kind of locator strategies to use. Typically these follow some kind pattern like this;
Use id attributes that are permanent, if you can. If you can't, then
Use data-testid or other custom attributes specifically for automation if you can. If this isn't an option then
Use class attributes, which tend to be stable. If you can't do this, then
Use CSS properties to specify elements. And if all the above aren't options, then
Use text or xpath locators or something and hope for the best.
Generally patterns like this are a good heuristic for identifying locators. However, the nature of front-end web applications has gradually changed over the past decade. Most front-ends are now generated through frameworks and not through hand-written HTML, CSS and JS. A result of such frameworks is that elements aren't always able to be directly manipulated by developers, and you need to rely on the capabilities of the framework. Browsers (and computers more generally) have gotten faster and more efficient. And lastly, tooling has evolved greatly for browser automation. Selenium WebDriver is a web standard now, and there's lots of other tools that can be used.
Based on all this progress, one would imagine that there's been progress on how to choose or use locators well with modern and maybe less-modern web apps and pages. One would be, I think, disappointed to find out there hasn't been much progress here. Finding and maintaining locators is pretty similar to how things looked many years ago. Front-end developers still hesitate to add custom attributes for testing sometimes. Newer web frameworks dynamically create elements, so id attributes are either not present or not reliable enough for automation. No one understands CSS, still.
What to do based on this state of affairs? I've been using Playwright lately for browser automation, and Playwright provides a getByText() method for finding elements. I started using it out of convenience at first and, well, I'm convinced it's a good approach. Why? Because - frankly - it works well.
The thing about text in web applications, whether that be labels next to inputs or placeholder text, is that it's actually fairly stable. Most buttons with the text Submit will continue to have the text Submit for a long time. And if the text does change on an element it is straightforward and obvious to update your tests. Plus, text doesn't tend to go away: moving from Angular to React to Vue to Svelte still means your Name field has a label of "Name" that end users will see.
One big objection to using text is localization internationalization, which can be a valid point. However, if your web app has five options for language, does that mean the logic and workflows change as well? They might, but if they don't, you can likely test one language and still feel confident in the test results. If you can't use text-based locators, then you'll have to evalutate your strategy anyway.
I am a big fan of the adage "What's the simplest thing that could possibly work". When it comes to finding elements by text, this advice seems to hold true.
0 notes