#also if you DO have sources to send id be more than happy to view them i love being proved wrong
Text
Bringing this to Tumblr cuz I keep seeing people talk about it on Twitter but I'm not making a fucking thread right now.
Anyways, personally I just think it's a little weird how suddenly a bunch of the non English/poc qsmp members are under scrutiny for doing horrible things, to the point of people literally calling for their removal from the server, yet I have not seen a single person give any legit sources to prove these claims. Plus the accusations are never specific it's always "I think they maybe did [insert vague action] thing that's really bad" or "I've heard they did something horrible and they need to loose their platform.
Literally anytime I've seen someone ask what happened the replies have been VERBATIM, "several members have been found to be racist/homophobic/antisemitic/transphobic in the past." Like y'all can't even decide what you're even accusing them of might as well just chuck in every horrible label you know! I'm surprised misogyny isn't in there? Oh wait! That's right! These same people people are also calling for the only women on the server to be removed for things that are literally fucking harmless such as, attending the wedding of a person some people don't like, or, explaining their home country has flaws. So I guess accusing OTHER people of being sexist would be hypocritical of them.
Like no damn wonder Quackity hasn't addressed anything you guys cant even decide what needs to be addressed in the first place, just that everyone that's from a different culture than you (and sometimes even people from the same culture the way I've seen people talk about Bad and Jaiden is actually sickening) is somehow a horrific individual who is terribly bigoted. I've been watching this server almost every day for hours on end since it launched and I haven't seen anything from anyone that can't be quickly summed up to be a cultural difference or small misunderstanding that people are blowing out of the water. Like, if someone legit did something bad then it deff needs to be addressed, but that's if that thing happened less than a year ago, (especially not if it's from when they were A CHILD. Like people are trying to cancel Roier for shit he said when he was 13! 13! I'm the same age as him and I can promise that if you took shit I said from literally the same timeframe it wouldn't be pretty either!) If they haven't already apologized for it and moved on with their lives, or if it is something that is legitimately hurting people and not just something you find personally distasteful.
The qsmp is really fucking cool and it's clear that the creators involved have a lot of respect for each other so it's so disappointing that some of the fans don't have the same amount of respect. It's incredibly shameful and it makes me feel horrible just to be associated with some of these people. The whole point of this server is to break barriers and to make friends across cultures where there wouldn't have been an opportunity beforehand, and so many people are instead trying to sabotage that.
Especially from the English speaking community. We have the privilege of being an incredibly diverse and culturally complicated community (which isn't to say other communities aren't I think that ours just is especially here is the USA), and while the exposure of more cultures leads to more misunderstandings and unfortunately more straight up bigotry, we still have more exposure to diverse groups then other people do. If anyone should be understanding and welcoming it should be us! But some of you people are out here acting like fools. Once again, if someone legit did something bad, they do need to be held accountable for their actions. But way to many of you confuse being held accountable with having their entire lives upended. You also confuse "did a bad thing they need to take responsibility for." With, "they did this thing out of a lack of understanding and have since apologized, learned better, and moved on, but I'm still gonna bring it up again and hurt everyone involved because I think that making a mistake is grounds for being publicly ridiculed!" If there was something bad going on, and if people had legit proof that it IS INFACT happening because said person is a bigot and not just misguided, then I'll be behind it 100%, but after watching this dance over and over again I can't help but feel that instead of people actually being concerned that horrible people are in places of power, they're instead making up horrible accusations about normal people that are just trying to do their jobs. It really feels like there isn't an effort to actually understand where other people are coming from and instead to judge them and make them conform to your definition of socially appropriate, it's not fucking cool.
Us English speakers as a community should be holding ourselves to a higher standard because this type of behavior doesn't just make one person look bad, it paints a bad name for all of us. And please for the love of God dont immediately believe every fucking rumour you hear, and especially don't believe it if you can't find any evidence, and ESPECIALLY don't go and harass the person the rumors about! Like, I don't even know if some of the examples I used here are legit cuz I haven't seen sources/ cant find any for them, but even if they did have sources they would be total bullshit accusations anyways! Think for once instead of jumping on some hate train with all the other brainless idiots out there holy fuck.
#sorry for the rant im just so tired of this shit#qsmp#discourse#do better please#also if you DO have sources to send id be more than happy to view them i love being proved wrong#i just dont think I am wrong about this#and i hope that im not because im not a lunatic that wishes for creators to be bigots so i can have something to hate them for#quackity#mcyt#fandom discourse
66 notes
·
View notes
Text
Be My Garden of Eden Ch.5

When he came to, he was staring at the roof of a dilapidated building, mildewed and stained. A system scan informed him of a replacement joint in his shoulder, and new thirium lines in place of the damaged ones. His chest plate was switched out as well, the dents and tears completely gone. Other places that had 'scarred' were sautered closed and buffed out. With his synthetic skin on, they were no longer visible.
He's been at this address before, with a client. Where were you? How long has he been here? His injuries were repaired, so it must have been real, right? It wasn't another elaborate fantasy, was it? Was he getting so lost in his head that he could no longer tell dreams from reality? Was it so far-fetched to believe you cared about him?
That he could be free?
No, please, no. He can't go back, not anymore. Not to that repulsive club. To the horrendous people and that vicious owner. You were his owner now. He was gonna live with you and be whatever you wanted him to be. He was going to be happy.
His view of the roof became obscured, so he blinked, feeling something run down his face. He touched it, fingers coming away wet. Looking up again, he could see no fresh watermarks above him. Water kept filling his eyes though, and he kept having to blink it away. Was this… was he crying? Can androids cry? He rubbed at his eyes as a sob erupted from him. What if his client saw? He needed to stop, he needed to-
"-Piece of work, you know that?" Your voice rang, full of annoyance. The panic that had been threatening to suppress him released its grip almost immediately.
"I just calls it as I sees it. Though, gotta say, you picked yo'self out a fine slice." A male voice rang out, laughing. A program he had automatically ran the voice through some kind of database.
Eugene "TriXx" Wilhelms
Born: 10/11/2016
Criminal record: drug possession with intent to sell, possession of illegal substance, forgery, theft, identity theft, assault, assault with a deadly weapon, driving without a license.
He never understood why a sex bot needed this kind of program. It completely undid the point of discrepancy. He had learned many people's background this way, but he could do nothing about it. They were paying clients and he was their toy. This man, however, he had met before, in a similar building, selling meth to one of his clients. He had his own android with him, a PL600. Something about the android made his synthetic skin crawl, but he had no reason for it. He had never met him before, nor did he do anything of particular interest.
The real question was, why were you here, and with such a dangerous man? Sitting up, he found you heading toward him.
"Connor! How do you feel?" You looked him over, taking his face and looking him up and down. It was then that he realized he was dressed, wearing a grey sweater and a pair of dark blue jeans. They felt nice. Not as comfortable as the over-sized clothes you had lent him, but far better than his old clothes, or running around in only those horrible briefs. You had switched out of your black tights, wearing tight-fitting jeans instead, though you still wore the same boots. He could see the trace amounts of thirium still staining them.
"I'm okay, " Con answered. Your hands wiped at his tears, smile melancholic. "Where are we?"
You looked back at the man, hesitating, before turning back to Connor, removing your hands from his face. He already missed your touch and your actions filled him with dread. Why did you look so serious?
"Connor, I haven't been truthful with you." Your voice was a little shaky, so you cleared it in an attempt to steady it. He reached out, taking hold of your hand. He might not know what this was about, but he didn't like how uneasy you seemed. "Remember when I told you about that special group who believes androids are changing?" He nodded. "Well, as you might have guessed, I'm a member. Eugene," you gestured to the man behind you, "is also a member."
"It's TriXx."
"Shut it!" You quickly snapped at him before turning back to Connor, "because of Eugene's… chosen profession, he often sees androids that are being abused or suppressed. Most of the time, they're domestic androids. People can report them missing but without any human evidence, they have no way to trace them, so it just becomes another police report and another citizen for Canada." You sat down next to him.
"However, sometimes he sends me a curveball," you glared at the man currently tossing a dirty vase back and forth, "androids that are owned by clubs, even seedy ones, are far easier to track. They're more expensive, so the clubs are more willing to put in the effort of finding them, or at least, persecuting the ones who stole them. So-"
The vase shatters, making you jump. Connor only held your hand tighter.
"So?"
"…So, I have to purchase them. Eugene makes them fake IDs and passports and we send them on their way. We have members in Canada that will take them in until they can find a job and another place to live."
Connor was quiet for a few moments. Is that why you bought him? To send him away?
"What if they don't want to leave?" He looked into your eyes, a silent plea behind them, begging you to let him stay.
"If not, there is a place in Detroit, hidden away from the humans. Only an android can find it. It's called 'Jericho'. Paul has the key. Speaking of which, where is he?" You looked around.
"Went ta drop off medicine to one of our associates," Eugene kicked at some of the shards, crushing a large one under his boot, "He'll be back soon. I was gonna go, but he's rather fond of the ol' lady. She even insists he calls her 'Abuela'. Makes 'im tea every time he sees her, knowin' full well he can't drink it." She sounds like a nice woman, Connor thinks to himself.
"Well, as much as I enjoy your company," your voice was positively dripping with sarcasm, "I'm not waiting three hours in this musky, old house watching you sell drugs. Tell Paul thank you for fixing Connor and loaning him some clothes." You stood up. Connor stared, unsure if he was supposed to follow you or stay here with Eugene and go to Jericho. When your hand reached down, he was relieved, taking it and following you out.
"Catch ya later, Color Wheel!" Eugene called out to you.
"Color Wheel?"
"He's been calling me that since middle school when I would show up to class covered in paint."
"I see." While Connor found that to be interesting, he was only half paying attention. His current objective was finding a way to stay with you. He doesn't want to go to either Canada or Jericho. He doesn't want to leave you.
You both climbed into the automated taxi, and he quickly determined it was the same one as before. The blood looked to have been cleaned, but a program he didn't know he had kicked in, showing the large stain that had since evaporated. His systems told him that was five hours ago, and he was still wondering in what way this could ever be useful to a sexbot. If anything, it would be considered disturbing to know how long a stain was left somewhere.
It was dark by the time they reached your home. Using the flashlight on your phone, you walked up to the front porch, Connor following close behind. You managed to unlock the door, going inside. He was perplexed when you headed for the kitchen, still using your phone as your only light source. You came back with matches, lighting the candles scattered around your living room. Testing his theory, he flicked on a light switch. Nothing happened.
"Can't get nothing past you, can I?" You laughed, "electricity is off. I'm taking care of it tomorrow. We'll just have to find a way to entertain ourselves in the meantime."
The way the golden lights reflected off your skin, creating an almost ethereal glow over your face, it captivated him. He wanted to touch you, feel if you are real. Realizing what you said, he snapped himself out of it. These "free" thoughts were becoming more intrusive than before.
"Why was the electricity turned off?" You shrugged your shoulders.
"Couldn't afford it. It's fine, though." You tried to brush it off, but he knew he must have been a contributing factor, if not the main reason.
"I'm sorry." Eyes at his lap, he fiddled with the edge of the sweater.
"Don't be. I would do it again if I had the option. Plus, it's not like its winter yet, so I can handle a few days in the dark. It's already being taken care of, so don't worry about it." Hearing that this was not even the first day did not go over his head. How long have you been sitting in the dark? How could you paint under these conditions? The sun shines through your studio for a while, but not nearly long enough for you to finish any paintings, especially as the days get shorter.
You lit the candles over the mantle and Connor's heart stopped.
Carl's painting was gone.
"Where-"
"Pawned it." you cut him off, looking at the unnaturally vacant space, "his paintings are far more valuable than mine."
"Why? Wasn't it important to you?" How could you pawn such an expensive gift?
"It was my only viable option. Besides, I'm sure Carl would approve." He still looked upset. "If you don't believe me, you can ask him yourself. I've been meaning to pay him a visit anyway." He nodded. He would like to meet him.
"When do you think that will be?" He asked. You contemplated that for a moment.
"Probably not until the day after tomorrow. I'll have to call and see if he'll be home. Tomorrow, we're gonna see if we can't find you some more clothes."
"Clothes?"
"Yeah, you're gonna need a disguise to get across the border." Connor tried his best not to wince when you said that. At least now, he had an idea of how long he has to convince you. He set a timer, but pushed it out of his vision. Watching it tick down so quickly was making him anxious.
Chance of Success: 50%
After a few moments, you spoke again.
"I'm sorry." Connor stared at you, perplexed.
"For what?"
"For not helping sooner. I wanted to, I really did, but-" Connor took hold of your cheeks, feeling as they heated up.
"It doesn't matter. You saved me, and I can't thank you enough." He smiled softly, watching the way the lights of the candle flickered in your eyes. A thought occurred to him, or rather, an urge. He was drifting closer to you, almost like a magnetic pull. He kept looking down at your lips. They look soft, and he wonders how they would feel. He was so close, mere inches away when you turn your head. He pulled back, withdrawing his hands. What was he thinking? Of course you don't want him to touch you. You were only tolerating it until he was shipped off. You stood up suddenly.
vvChance of Success: 39%
"I-I'm gonna make a sandwich. I'll be right back!" You were nervous, unable to control the volume of your voice. Quickly, you scurried off to the kitchen. Connor sank further into the couch, a sense of gloom lingering over him. Why was he always screwing things up?
"Do you need some blue blood?" You shouted from the kitchen. His levels were only at 82%, but frankly, he didn't feel like drinking.
"No, thank you."
"Alright, they're in here if you want one." He just wanted to sit here. He wants his mind to stop pointing out the obvious. That he was a dirty, used sex machine and there was no way you would want him. Even if he wasn't, he was incompatible. You were human. You would want to be with another human, someone to start a family with.
These thoughts were so much worse after he broke the red walls. What did that even mean now? If he knew you were going to buy him, would he have been so eager to tear them down? They might have been oppressing, but at least he didn't know what 'this' felt like. A feeling akin to wanting to disappear, just, not existing anymore.
Connor was unusually quiet, and his LED flickering more yellow than blue, and you thought you saw some red mixed in. It had been half an hour since you came back with your food. You wished you had more in the ways of board games or card games, but all you had was a checkerboard and a jigsaw puzzle you bought on a whim years ago. You taught him how to play, and he quickly started kicking your ass at it, but it didn't so much as earn you a sincere smile. You moved to sit next to him, to which he didn't react.
"Hey, " you put your hand on his shoulder, prompting him to snap out of his thoughts and look at you, "You doing okay?"
"I'm alright, " he says, but his LED is still flickering. Your thumb started to stroke the junction between his shoulder and neck.
"If you don't want to talk about it, it's fine, but I'm here if you need me." There were so many things he wanted to ask you, so much he wanted to know, but he hesitated. If... If you didn't feel the same way towards him as he did you, he didn't want to know. If he didn't know, he could believe there is a chance he could sway you.
There was something else eating at him. Something you might have an answer for.
"When I was at the club, while the owner was..." He didn't want to say it, to think about it. Your hand squeezed his shoulder, encouraging him to continue, "Something strange happened. There were all these... Red walls, instructing me to follow the owner's instructions. If I had, he would have destroyed me. I... I was scared, and... Angry. I started tearing at the walls, and they crumbled so easily. Next thing I knew, I could do whatever I wanted. I could defend myself. I could leave the club. I could go-" Find you, he thought, but he halted his ramblings before he could dig himself deeper. You took his silence as him finishing what he had to say, trailing your hand down and taking his hand. He hid the shiver that was left in its wake by slowly exhaling. You were smiling wide, as if it was the best news you had ever heard.
"You broke through your code."
"What?" That's... That's not possible... Is it?
"You broke through your code. It means you don't have to listen to anyone if you don't want to. They call it "deviation"." He only seemed more confused, "just see for yourself. I'm listed as your new owner, right?"
"Yes."
"Well, I order you to cluck like a chicken while hopping on one leg."
A part of him wanted to do it simply because it was you who asked, but it seemed so... Ridiculous. His eyes widened when he realized he wasn't even making a move to stand, let alone impersonate a chicken. An idea even came to him, something he decided to take a chance on, just to gauge your reaction.
"Woof, " he said, smiling proudly. You laughed, shoving him playfully.
"Okay, wise guy, you get the point, " you giggled, "this is great! The last android wasn't a deviant and took two weeks to help her break her code. This will save so much time!"
His smile fell.
vvChance of Success: 12%
"What?" Your own cheerful demeanor dropped, replaced with concern.
He looked to you, eyes begging you. He was asking too much, but he can't do this. He can't.
"Why do I have to leave?" You seemed confused, not in the sense of misunderstanding, but more like it had never occurred to you.
"Do you... Do you not want to?"
He couldn't force the simple word out. He was being selfish, and he knew it. How could he ask this of you, when you risked so much for him already? You were sitting in the dark because of him! He should have kept his mouth shut.
"You know, I actually could use some help around the house. With me painting all the time, it's gone a little neglected. I could also use a model from time to time. Would you mind sticking around, just a little while longer?"
^^Chance of Success: 89%
"Yes. Yes, of course, " he spoke softly, in shock, before pulling you against him in a hug. Your sharp yelp, followed quickly with laughter soothed him. A little longer. It was a start.
#rk800 connor reader#connor fanfiction#detroit become human#rk800#gaming#dbh au#connor dbh#@witchjules#@michaels-endtime#Don't know if y'all still wanna be tagged
42 notes
·
View notes
Text
Want to f**k with your child’s life? You picked the wrong child.
This is not a hate post. This is about the revenge that we got on these bastards, pure and simple. If you want to go off all high and mighty about how awful <Topic> is since it was in this story, fuck off and do it somewhere else. This is about her revenge, not your opinion.
Anyways, let’s begin.
I’m going to retell the original story from the MC post because I left a lot out there. Sorry if you already read it.
About three years ago, I was in a multi-school academic support network, which had a summer camp. At this camp, I met K.
K was a closeted lesbian, and was very scared of us telling her parents due to their extreme political and narcissistic views. I had dealt with this situation a few times, but not on this extreme of a level. Her parents were so far off the end of the scale, I dared not say anything about politics or religion in fear of starting an inquisition. These people made Westboro look like moderates.
To give an example, they had complete control over her phone, emails, mail, and pretty much every other route of communication. So when they decided one of her friends was “too Jewish” (his last name sounded Jewish to them) they deleted him from her life. They called the program and rearranged her schedule so she would never see him. Later, we found out they filed false, anonymous complaints against him so he wouldn’t be invited back. Overnight, they removed him from her life.
And this was not the last kid they did this with.
K was terrified of her parents, but they owned her. There was no way to escape short of suddenly becoming an adult.
I was seriously worried about her, to the point where I bought her an emergency-only prepaid phone, which I told her to hide. This was, unequivocally, the best decision I’ve ever made.
Fast-forward to January. K is struggling with the stress of everything, and says something innocuous in group chat along the lines of “good thing I don’t have to worry about boys”.
We suddenly stop hearing responses from her. Her cell phone goes offline. The house phone kicks all of our numbers, but not pay phones or other lines. The parents pick up, but say that there’s no one with that name at this address, then hang up. Her classmate says she doesn’t show up for class that day. Alarm bells are going off for everyone.
And then I get the call from K. “Please, come pick me up. I was kicked out. It’s cold.”
I’m the closest, and I had a car, and I was driving in blowing, heavy snow in far below freezing weather. I won’t say that rage and panic fueled me, but I will say it got me there in one piece. I have never, ever, driven a car as recklessly, as hard, or as fast as I did that day.
When I got there she was huddled under a tarp, barefoot, in pajamas, at the foot of her house’s stairs. The parents saw my car and rush out to scream at me for “taking their child from the path of god” and “corrupting her with devil worshipping ideas” or some shit like that. I told them that if she listened to me, it was the first time she had ever done that.
And then the critical sentence (direct quote for once): “she’s not our child anymore! You godless heathen ruined her mind!” And then, “She’s no daughter of ours!”
Now, I’m going to pause this for a moment to preface everything that happens from this point on: this is not a pro-atheist or anti-Christian post. These whack jobs are the furthest thing from human I’ve ever seen. Do not use them as a generalization for <Religious Group> or a bandwagon to sell your ideals. I’m not dealing with that shit here.
K, freezing and scared, hides in my car. The parents start to get aggressive and hostile towards me, so I make two things very clear to them.
I am recording everything they say. I have a camera on my car and my phone, and I have a police officer waiting for me at the foot of the driveway (I called the cops before I arrived due to not feeling safe).
I am leaving and never coming back, as per their request. K will be coming with me, since she is not their daughter, per their screaming rant.
They start arguing with (aka screaming over) me about how she can be ‘cured’ by methods that range from dubious to straight up illegal. By this point, I’m done. I get back in my car while they’re screaming at me and head back down the driveway.
The cop and I have a short chat, and he recommends we be brought to the police station ASAP to prevent the parents from saying I kidnapped her. After a six-hour ER visit for her hypothermia and minor frostbite, escorted by police, we arrive. All of my video and audio recordings are entered into official records, and the officer’s dashcam footage, and K’s ER report are filed away.
I didn’t know it at the time, but all of that would prove to be essential in court later.
I sign her into a hotel in my town, and lawyer up. The lawyer I know specifically deals with cases like hers for free. He is very, very good at it.
There was a lot of legalese, and a long process and a lot of angry exchanges that I really didn’t understand or participate in, but two years later, she was emancipated. I got to be a witness, and that recording and the ER report cinched the case, proving neglect. The parents didn’t even try to argue against it, instead using some weird religious law argument.
K’s older half-brother learned what was happening during the first year and supported her financially while she was in school. He hated the parents far more than either of us did (K feared them more and I was just disgusted by them).
It wasn’t much of a fight. The parents represented themselves, and tried to drop the case on “religious grounds”, which isn’t a thing.
After this, the revenge started. And K did not hold back.
During proceedings, it was discovered that the parents had been using their children’s Social Security cards for loans, credit, bank accounts, and other sketchy stuff. They were already going to jail for that, but K took it to the next level.
Now, these were all the things K told me after the fact. I wasn’t involved in this part, and I didn’t write down all the details that well, but the following is approximately what happened from what I have been told or remember.
So, WARNING; fuzzy details.
One of the things that had been purchased in her name was the father’s truck. K reported it as missing, since she was technically an owner of the truck. They pulled the father over and confiscated the truck as stolen, because his name was not in the title, the wife’s was. When he tried to prove it was his by filling out the bill of sale on the back, he found that the title for the vehicle had been invalidated when K had ordered a new one and donated the vehicle to the fire department for Jaws-of-Life training. That same day.
The mother’s credit cards were the same, but K just cancelled all of them and declared ID theft. This froze some of the mother’s bank accounts, which were under K’s SSN.
The family was already in chaos but K cranked it to 11. Due to the SSN, K was listed as the main contact for the family’s cell phone and internet plans. She cancelled both. She killed the email accounts in her name that she could access and rerouted her mail to her new PO Box, where she may have “accidentally” forgotten to say they should only reroute her mail.
She also called in repossessions on everything that had been bought with her SSN on credit. The loans included renovations on the home, so the parents were forced to sell.
By the time K was done, the parents were happy to go to jail for fraud, identity theft, and their other, numerous crimes rather than live on the street.
All I do know is that they became social pariahs in town before that. Stores banned them for their increasingly violent attempts at converting people. People they knew for years turned on them. The father was fired for failing a performance review, and the mother lost her job selling <Stuff?> due to her increased radicalization.
In the end, K’s siblings went to live with her half-brother since he was the closest living relative. The parents lost all rights to visitation, as the state nullified their parental rights and gave guardianship to the half-brother, mostly due to the criminal charges.
But the real revenge might just be that as the sentencing was carried out, K flipped the parents off in front of the judge and the judge just laughed at the parent’s attempts to claim it was hate speech.
TL;DR: Narcissistic and awful parents attempt to ruin child’s life for being lesbian. Child sends them to jail.
(source) (story by CynicalAltruist)
2K notes
·
View notes
Text
Worshipers of the Old
Kylo Ren x OC / Kylo Ren x Reader
Read on AO3
Summary: He arrived at the archive during the late hours of the night, searching for answers regarding a long lost Force ability. When AR-210 is assigned to help him, she would never have anticipated the strange and terrifying series of events that were to follow... and what it all meant for her.
*Written in first person; main character has feminine qualities, but doesn’t have any defining characteristics.
Chapter 1: A Healing World
Warnings: None
Word Count: 3,018
A/N: hello! thank you for taking the time to read my story! this is the first star wars fic i’ve written, so i hope it’s good enough for this wonderful, amazing community.
this story does not follow the movies’ timeline and is heavily based on lore and Legends material. i put my own twist on things so it’s not important to read/look at any background info on any of it. however, if you want to read more, i suggest visiting Wookieepedia (also a great source for inspiration).
please enjoy!

『ID: AR-210
Passcode: ******
Keyword: Lower Level Overview Report』
I press the enter key on my datapad before setting it down on my desk, letting the entry load as I run out to the main lobby. Thirty minutes remain, and we aren’t even ready. Dozens of faculty members and students are rushing back and forth, each carrying some sort of device or package in their hands. I make a beeline for the Director’s office, but a voice calls out behind me before I can rush inside.
“Ahré!”
I whip my head around, seeing the Director himself running in my direction. His graying hair is a mess, and I can tell that his wrinkles are, well, even more wrinkly than before. I can practically feel the stress radiating off of him once he stops in front of me. “D-Director Malobry, I was just about to-“
“Reassure me that all the holobooks on the fifth floor in the east wing are all finally organized and shelved?” He storms past me and slams his office door open. I quickly follow. “It’s hell out there, and if that damn General sees that we’re behind schedule for the third consecutive month, he’ll have my head on a platter.”
“I-I’m sure that won’t be the case, Director-“
He holds a hand up. “Ahré, please.” He takes a breath, clearly trying to calm himself down. He lowers his voice. “Is the east wing done or not?”
I open my mouth but almost immediately clamp it shut. I don’t have any good news, and truth be told, none of those holobooks are shelved.
The Director waits for me to give him an answer, but after a moment, it seems like I don’t need to. Still, I hand my head and close my eyes, uttering a soft "no" under my breath.
There’s a pause. He collapses back into his chair and runs a hand through his hair. “Shit.”
Guilt forms in the pit of my stomach. The fear of witnessing the General’s wrath invades my mind, but perhaps the Director’s anger might be more concerning for the moment. I wasn’t even the archivist assigned to that wing, but I know who was: Jolson. The thought of him being reprimanded—or worse—for the third time this month... I can feel my head swim with fear.
“Go help Jolson with that floor,” the Director says quietly. He’s already accepted his fate. “Make sure you get every droid working on those shelves. We might still have a chance.”
I’m surprised, but I make a point not to show it. I bow my head and exit the office, merging with the traffic of people busying about. Several droids are attending to other minuscule chores in other rooms, so I call on them to go to the east wing before rounding up a few other archivists as well.
I glance at the time on one of the walls, but I don’t give myself the time to process the numbers. I immediately look away and make my way to the fifth floor.
Just focus, Ahré.
Once I arrive, there is a frenzy of excitement and eagerness flowing in the room as piles of holobooks and scrolls are being carried from one end to the other. Half of the staff inside is working on the main lower shelves, while the other is up on the mezzanine. It’s a slightly relieving sight, but I try not to let that get my hopes up. The majority of the shelves are still empty.
“Ahré! Over here!”
I turn to see Jolson on the other side of the room, wearing a fresh new uniform and a pair of shoes. His usually messy black hair swept up into a bun, and I can tell he put a little more effort into today’s occasion. Still, he looks a little tired. I watch him jog over with a stack of new flimsiplast, a big smile painted on his face. I do my best to return it with a disapproving frown.
He raises an eyebrow. “What?”
“We have less than half an hour until the General arrives. He’s already at Aurora looking at things over there. And the Director knows about your...” I gesture to the entirety of the room. “...lack of shelving.”
“Malobry can go die in the pits of Kaon for all I care,” he huffs, walking toward one of the supply shelves. “Hope to the Force one of the scranges get to him before anything else does.”
I trail behind him, suppressing an eye roll. “I know the both of you don’t... get along. But can you please, at least for today, keep your head on your shoulders? If the General sees one thing out of place, what’s to stop him from getting rid of Malobry?”
“Come on, Ahré. You know as well as I do Hux doesn’t have anyone else to look over these libraries. Not after all that’s happened.” He sets the packets of flimsiplast down on the floor before pulling out his datapad. “Besides, the Supreme Leader personally appointed Malobry. I doubt the General would want to oppose him.”
He does have a point... but there’s been talk about infighting among the First Order, especially between the both of them. After Kylo Ren got rid of the former Supreme Leader, things have become rather tense. There seems to be a stricter hold on First Order regions and institutions; not to mention the seemingly never-ending war with the Resistance. However, that only meant escape from the Yuuzhan Vong for Obroa-skai, so I can only complain so much.
Jolson snaps his fingers in front of my face, bringing me back to attention. “Obroa-skai to Ahré, helloooo?”
I swat his hand away. “Sorry, just... thinking,” I say dumbly.
He chuckles. “Sure. Now, stop worrying and help me with sections eight, nine, and ten, okay? We’ll get it done.” He looks down at me, his big blue eyes full of reassurance. A sincere smile graces his lips. He knows how to calm me down, and as much as I hate it, it works. Although he tends to lag behind most faculty and staff, he can always be counted on to do one thing: be a friend.
I guess that’s all I can really ask from him.
~
The General arrives at the archives precisely on time. He is accompanied by a few other officers with identical uniforms, some of whom seem to care less about the visit. At the entrance remain at least a dozen stormtroopers with blasters gripped in their hands, while a couple of others follow behind the group of men.
Odd.
All of our staff members are lined across the lobby, everyone standing in attention as General Hux and his entourage make their way up to the Director and I. He surveys the lines, eyeing each and every one of us with a scrutinizing glare. I have to stop myself from squirming in my spot and pray to the beings above I look presentable enough. I can already feel a chill running down my spine.
“Very well,” he finally says. He turns to Malobry. “I trust that work on Celebratus has ceased, Director.”
He nods. “Yes, General. We have been working tirelessly on the facility. The east and west wings are complete, as well as the lower levels.”
There’s a hum of approval. “Excellent. The Medical Director at Aurora has reported that there haven’t been any border attacks there as of late, so I believe the situation to be corresponding with this sector?”
“That would be correct,” Malobry confirms. I glance up at him, seeing a thin layer of sweat coating his forehead and neck. Poor guy.
General Hux turns back to the staff, giving them a final once-over before nodding. “You are all dismissed.”
They bow their heads quickly and head out in different directions of the archive. I catch a glimpse of Jolson, seeing him send me a playful wink my way. Warmth blooms in my chest at the small gesture.
“AR-210.”
I snap back into position. “Y-Yes, General?”
“The Supreme Leader is planning a visit later today. Seeing as you are the head clerk for the archive, I believe you could aid him with something he needs.”
My brows furrow together. Need? What in the galaxy would the leader of the First Order possibly need from here?
I manage a semi-nod, but it feels more like a confused tilt of the head instead. I’m sure I look oblivious, but I can’t help but feel like I am. Perhaps I’m missing something. “Of course. May I ask what he is looking for?”
The General scoffs. “He wouldn’t tell me,” he says, a hint of irritation laced in his words. “But I doubt it’s of much importance. Our own records and archives weren’t sufficient enough for his... research projects. He insisted on coming to Obroa-skai.”
My head is swimming with a thousand questions, none of them actually verbalized. Instead, I relax my features and bow my head. “I’d be happy to help, General.”
“Good. Now, Director, if you could show us around the facility, we will be on our way soon.”
I’ve never seen Malobry move faster. “Yes, yes, of course. Please, gentlemen, if you could follow me...”
Within ten seconds, they round a corner and disappear from view. I’m left standing in the lobby with the feeling of nothing but dread in the pit of my stomach. Now I’m the one sweating. There isn’t even a hint of comfort anywhere nearby, just a receptionist desk on the other side of the room. Stormtroopers still stand outside the entrance, perfectly still and ready at a moment’s notice. I decide to step away into my own office and wait there instead. It doesn’t help.
I grab my datapad and scroll through the entry I loaded up earlier. The words are a blur on the screen as I try to read, but it’s useless. Fear grips at my mind. Something about this doesn’t feel right. The Supreme Leader... in need of help with information he can’t already acquire? I sigh and sit down at my desk, letting my thoughts drown in stress.
~
Hours pass and no Kylo Ren. The General has already left, as well as half the stormtroopers that had initially arrived. The remaining still stand outside. My nerves have somewhat calmed down, but what remains is worry. Perhaps, to someone above, this may just be some sort of punishment for me. For what reason, I do not know, nor do I think it matters at this point.
A knock at my door nearly sends my heart over the point of no return. I get up, composing myself as I make my way to open it. The anxiety kicks back in, and for a moment I begin to feel nauseous. This could be it—the defining moment of whether or not I get to live another day. Would one slip-up ensure my demise? Would he really go that far? What if I can’t find what he’s looking for? I force my thoughts aside and slide the door open, relieved to see that it’s only Jolson. His eyes widen once they meet mine. “Ahré? Are you alright?”
“Jolson.” I let out a shaky breath. “Thank the stars. And no, no, I’m not alright,” I reply blatantly. He waits on me to elaborate, his worry turning into confusion.
“Well... what’s going on?”
I peek out into the corridor to make sure nobody else is present before pulling him into my office. “Sit,” I command, gesturing to the chair in the corner. He obliges, but the concerned expression he wears doesn’t waver for a second.
I slam the door shut. “The Supreme Leader is coming to the archive later,” I begin, walking behind my desk. “Apparently he needs help finding something.”
“Okay,” Jolson starts, hesitant. “What does he need from here?”
“That’s just it. I asked the General the same question, but even he didn’t know.” I fall back into my chair. “I also don’t know when he’s coming. He could be walking through the front doors right now. Maybe he is, and I’m just back here panicking. He’s going to think I’m terrified of him, which I’m sure he already knows, but it’s just going to—“
“Ahré,” Jolson interrupts, tone firm and deep. I shut my mouth immediately. “Why are you worrying so much? You shouldn’t be.”
I huff. “Why not? It’s the Supreme Leader-“
“Who is coming here specifically for help, Ahré.”
I pause, taken aback. He’s coming here... for help. For help.
Jolson’s features smooth out into a tired smile, no doubt exhausted after today’s near-disaster. I take a moment to look at him, really look at him, and see dark circles under his eyes. I suddenly forget about the Supreme Leader.
“Have you been taking care of yourself, Jolson?” I ask, my tone sounding perhaps a little more accusing than intended. “You look tired.”
He stands, chuckling as if amused, and extends an arm out towards me. I walk over. He wraps his arm around my shoulders, squeezing me gently. “I am,” he says. “But you’re anxiety over this whole thing might be tiring me out even more.”
I glare at him.
“I’m joking.”
We walk out into the main lobby. A few librarians and archivists are leaving for the night—no doubt heading out to the bar—while others are coming in for their shifts. Malobry is talking to Vess, one of our receptionists, with a bright smile I haven’t seen in months. The weight of today’s visit has been finally lifted off of our shoulders. We probably won’t have to worry about another inspection for a year or two. I only wish I could celebrate with the others.
Jolson stops for a moment, turning to face me. “You’re going to be fine,” he reassures once again. “Remember, he’s the one who needs your help. No need to get overwhelmed.”
His eyes bore into mine, and all I can do is nod.
He pats my arm softly before heading for the doors. I watch as he slaps Malobry’s back forcefully as he walks by, earning him a near disgusted look from the elder. He too heads out for the night a moment later.
The clock reads 25:00, and I decide whether to go back to my office and wait or just go home. General Hux did say that the Supreme Leader would be coming today... there’s still an hour left. I’ll wait until then.
I walk up the receptionist's desk, replaying Jolson’s words in my head. He’s right. There’s no need to get worked up about it. I know what I’m doing. This has been my job for the last five years, after all... I’m allowed to feel confident.
“Hey, Vess,” I greet with a warm smile. She looks up from the datapad in her hands, immediately returning my smile with her own.
“Ahré, oh my goodness! How are you? How was the inspection today? I heard that Jolson almost didn’t get his level of the east wing finished on time, and that the General asked you to help the Supreme Leader with something, and that Malobry almost passed out. Oh! Is it true that...” She speaks at a pace I can hardly keep up with, but I let her go on. Her golden curls bounce excitedly at the news of today’s events, and I almost feel bad that she has the late shift this month. It’s clear that she likes to stay in the loop.
“Everything is great,” I say once she’s done. “And yes, it was pretty busy today, but also kind of scary.”
“Oh, I’m sure! After all of that? I wish I could have seen it!” She leans back in her chair dramatically, bringing a hand up to her forehead with a swoon. “You are so lucky, Ahré.”
If only.
I giggle and shake my head. “Hey, I’m going to be in the fifth library study on the second floor until the Supreme Leader arrives. If you could direct him there when he comes, that would be great.”
She nods eagerly. “Of course! Absolutely no problem! Have fun!”
I thank her and go back to my office to grab my datapad before making my way up to the second floor. It’s quiet in this part of the building. No students, no faculty or staff... just the low hum of the heater and a couple of droids finishing up their work. It’s the perfect place to relax at this hour. I enter the study and climb up to the mezzanine. There’s an alcove in the back, a small armchair and lamp occupying the space. It looks so inviting, I have to stop myself from running over and laying down for a nap. Out of the couple thousand study rooms, this is by far my favorite.
I pass by a window that looks far out to the border, stopping for a second to watch the red blinking lights on the gate. On the other side lies a frozen wasteland, filled with nothing except what remains of the Yuuzhan Vong. Their arrival to Obroa-skai two years ago was anything but expected, and before we all knew it, they had destroyed much of the planet’s life within the span of a few months. It wasn’t until the First Order caught wind of the invasion did they come. They were able to wipe away a majority of the enemy rather quickly. Since then, we’ve all been trying our best to return to a sense of normalcy... but even now, that reality seems to be illusive as ever.
I tear my eyes away from the view and sit down in the armchair. The anxiety I’ve held back for the last few minutes settles in once again, and this time it just feels a little more real. I run my fingers across my datapad in an attempt to distract my nerves but to no avail. I turn it on and see the lower level report, still open and ready for me to read.
I skim through the subheadings: field reports in need of filing... more software malfunctions... registering new reference codes... Nothing out of the ordinary. Again. I sigh and begin to read from the top.
About a half-hour later, I hear the door open on the other side of the room.
#kylo ren x oc#kylo ren x reader#star wars#star wars legends#kylo ren fanfiction#star wars fanfiction#kylo ren fluff#reader insert#worshipers of the old#shanix writes#kylo ren
1 note
·
View note
Text
why are kids today less patriotic?
<h1 class="legacy">Why are kids today less patriotic?</h1>
<figure>
<img src="https://images.theconversation.com/files/305041/original/file-20191203-67011-6xrc7i.jpg?ixlib=rb-1.1.0&q=45&auto=format&w=754&fit=clip" />
<figcaption>
Young Americans today are more likely to say that they’re dissatisfied with the current state of affairs.
<span class="attribution"><a class="source" href="https://www.shutterstock.com/image-photo/group-happy-teen-students-holding-usa-1160956780?src=eaa2f6fe-2767-4b4f-bb4a-1ef4646c2f9d-2-21">LightField Studios/Shutterstock.com</a></span>
</figcaption>
</figure>
<span><a href="https://theconversation.com/profiles/jane-lo-880429">Jane Lo</a>, <em><a href="http://theconversation.com/institutions/florida-state-university-1372">Florida State University</a></em></span>
<figure class="align-left ">
<img alt="" src="https://images.theconversation.com/files/281719/original/file-20190628-76743-26slbc.png?ixlib=rb-1.1.0&q=45&auto=format&w=237&fit=clip" srcset="https://images.theconversation.com/files/281719/original/file-20190628-76743-26slbc.png?ixlib=rb-1.1.0&q=45&auto=format&w=600&h=293&fit=crop&dpr=1 600w, https://images.theconversation.com/files/281719/original/file-20190628-76743-26slbc.png?ixlib=rb-1.1.0&q=30&auto=format&w=600&h=293&fit=crop&dpr=2 1200w, https://images.theconversation.com/files/281719/original/file-20190628-76743-26slbc.png?ixlib=rb-1.1.0&q=15&auto=format&w=600&h=293&fit=crop&dpr=3 1800w, https://images.theconversation.com/files/281719/original/file-20190628-76743-26slbc.png?ixlib=rb-1.1.0&q=45&auto=format&w=754&h=368&fit=crop&dpr=1 754w, https://images.theconversation.com/files/281719/original/file-20190628-76743-26slbc.png?ixlib=rb-1.1.0&q=30&auto=format&w=754&h=368&fit=crop&dpr=2 1508w, https://images.theconversation.com/files/281719/original/file-20190628-76743-26slbc.png?ixlib=rb-1.1.0&q=15&auto=format&w=754&h=368&fit=crop&dpr=3 2262w" sizes="(min-width: 1466px) 754px, (max-width: 599px) 100vw, (min-width: 600px) 600px, 237px">
<figcaption>
<span class="caption"></span>
</figcaption>
</figure>
<p><em><a href="https://theconversation.com/us/topics/curious-kids-us-74795">Curious Kids</a> is a series for children of all ages. If you have a question you’d like an expert to answer, send it to <a href="mailto:[email protected]">[email protected]</a>.</em></p>
<hr>
<blockquote>
<p><strong>Why are younger people not really patriotic like me? Why do kids these days not realize why they stand for the flag or the Pledge of Allegiance or the national anthem? – Kim D., age 17, Goochland, Virginia</strong></p>
</blockquote>
<hr>
<p>The first bell of the day rings at a local school, and a voice blares over the intercom, asking students to rise from their seats and say the Pledge of Allegiance to the flag of the United States of America. </p>
<p>This is a familiar practice to students across the United States, since most states currently <a href="https://undergod.procon.org/view.additional-resource.php?resourceID=000074">require schools</a> to recite the pledge at the beginning of each day. And yet, some students opt out of the ritual, choosing instead to remain seated, or stand but stay silent. </p>
<p>Are these students less patriotic than those who stand willingly and proudly to recite the pledge? As <a href="https://scholar.google.com/citations?user=3KQghq8AAAAJ&hl=en&oi=ao">someone who studies</a> how young people engage with politics, I think the answer may be a bit more complex than you think.</p>
<p><a href="https://www.people-press.org/2011/11/03/section-4-views-of-the-nation/">Some studies</a> suggest that the answer is yes, that young people tend to view the country more negatively than older generations, or that younger generations tend to be less proud of the United States. </p>
<p>These studies often ask young people how satisfied they are with where the country is or where it is going. Younger generations – millennials, born between 1981 and 1996; and Generation Z, those born after 1996 – tend to be <a href="https://www.nytimes.com/2014/07/05/upshot/younger-americans-are-less-patriotic-at-least-in-some-ways.html">less satisfied</a> with the current state of affairs and less proud to be American.</p>
<p><iframe id="UzV9F" class="tc-infographic-datawrapper" src="https://datawrapper.dwcdn.net/UzV9F/1/" height="500px" width="100%" style="border: none" frameborder="0"></iframe></p>
<p>However, this dissatisfaction or lack of pride does not necessarily mean that young people are less patriotic; instead, it may point to <a href="https://www.wsj.com/articles/americans-have-shifted-dramatically-on-what-values-matter-most-11566738001">a shift in what matters</a> to young people and what they perceive as patriotism. </p>
<p>For example, a Market Research Foundation survey found that <a href="http://dailytorch.com/2019/08/no-generation-z-is-not-less-patriotic-or-religious/">younger generations still care</a> about the well-being of the United States and policies related to the country’s stability, even though they may not associate it with patriotism. </p>
<p>And a Center for Information and Research on Civic Learning and Engagement study shows that young voters are <a href="https://civicyouth.org/growing-voters-engaging-youth-before-they-reach-voting-age-to-strengthen-democracy/">showing up more for midterm elections</a>, which suggests that they care more about the future of the country than young generations of the past. </p>
<p>Furthermore, they seem to be <a href="https://civicyouth.org/circle-poll-youth-engagement-in-the-2018-election/">more engaged with politics</a> now than in the recent past, even if they are less committed to particular political parties.</p>
<p>When it comes to the flag as a symbol, a public opinion poll conducted by the Foundation for Liberty and American Greatness suggests that young people see the flag less as a symbol to be proud of and more as <a href="https://www.flagusa.org/wp-content/uploads/2018/11/FLAG-Patriotism-Report-11.13.2018.pdf">a symbol of what is wrong</a> with the country. If more students are associating the flag with flaws in the system, it would explain why some students opt out of standing for the pledge of allegiance or other celebratory acts. </p>
<p><a href="https://doi.org/10.1080/00933104.2016.1220877">My own work</a> on a project-based high school government course shows that school coursework can help students figure out how to engage with democracy in ways that make sense to them. This means that, even as students report feeling less patriotic about the current system, they are engaging with it in an effort to change it for the better.</p>
<figure class="align-center zoomable">
<a href="https://images.theconversation.com/files/305047/original/file-20191203-66986-1iluieq.jpg?ixlib=rb-1.1.0&q=45&auto=format&w=1000&fit=clip"><img alt="" src="https://images.theconversation.com/files/305047/original/file-20191203-66986-1iluieq.jpg?ixlib=rb-1.1.0&q=45&auto=format&w=754&fit=clip" srcset="https://images.theconversation.com/files/305047/original/file-20191203-66986-1iluieq.jpg?ixlib=rb-1.1.0&q=45&auto=format&w=600&h=400&fit=crop&dpr=1 600w, https://images.theconversation.com/files/305047/original/file-20191203-66986-1iluieq.jpg?ixlib=rb-1.1.0&q=30&auto=format&w=600&h=400&fit=crop&dpr=2 1200w, https://images.theconversation.com/files/305047/original/file-20191203-66986-1iluieq.jpg?ixlib=rb-1.1.0&q=15&auto=format&w=600&h=400&fit=crop&dpr=3 1800w, https://images.theconversation.com/files/305047/original/file-20191203-66986-1iluieq.jpg?ixlib=rb-1.1.0&q=45&auto=format&w=754&h=503&fit=crop&dpr=1 754w, https://images.theconversation.com/files/305047/original/file-20191203-66986-1iluieq.jpg?ixlib=rb-1.1.0&q=30&auto=format&w=754&h=503&fit=crop&dpr=2 1508w, https://images.theconversation.com/files/305047/original/file-20191203-66986-1iluieq.jpg?ixlib=rb-1.1.0&q=15&auto=format&w=754&h=503&fit=crop&dpr=3 2262w" sizes="(min-width: 1466px) 754px, (max-width: 599px) 100vw, (min-width: 600px) 600px, 237px"></a>
<figcaption>
<span class="caption">Climate activists participate in a student-led climate change march in Los Angeles on Nov. 1, 2019.</span>
<span class="attribution"><a class="source" href="http://www.apimages.com/metadata/Index/Greta-Thunberg-Youth-Protest/9d96b7216f2f4eff9e144fc0894cdc85/168/0">AP Photo/Ringo H.W. Chiu</a></span>
</figcaption>
</figure>
<p>In the end, it’s too simplistic to say that young people who are dissatisfied with the U.S. at present aren’t patriotic. It’s likely that the very students who are refusing to stand for the pledge are exhibiting their patriotism by demanding a better tomorrow, as was seen in the student <a href="https://www.tjsl.edu/sites/default/files/files/Student%20Protests,%20Then%20and%20Now%20-%20The%20Chronicle%20of%20Higher%20Education.pdf">protest movements of the 1960s</a> and other current <a href="http://neatoday.org/2019/09/19/the-greta-effect-student-activism-climate-change/">student-led protests</a>. </p>
<p>This might provide all Americans with some hope, since it means young people actually care about the future state of affairs. It may also signal it is time to work together to build a country that we can all celebrate. </p>
<hr>
<p><em>Hello, curious kids! Do you have a question you’d like an expert to answer? Ask an adult to send your question to <a href="mailto:[email protected]">[email protected]</a>. Please tell us your name, age and the city where you live.</em></p>
<p><em>And since curiosity has no age limit – adults, let us know what you’re wondering, too. We won’t be able to answer every question, but we will do our best.</em><!-- Below is The Conversation's page counter tag. Please DO NOT REMOVE. --><img src="https://counter.theconversation.com/content/126551/count.gif?distributor=republish-lightbox-basic" alt="The Conversation" width="1" height="1" style="border: none !important; box-shadow: none !important; margin: 0 !important; max-height: 1px !important; max-width: 1px !important; min-height: 1px !important; min-width: 1px !important; opacity: 0 !important; outline: none !important; padding: 0 !important; text-shadow: none !important" /><!-- End of code. If you don't see any code above, please get new code from the Advanced tab after you click the republish button. The page counter does not collect any personal data. More info: http://theconversation.com/republishing-guidelines --></p>
<p><span><a href="https://theconversation.com/profiles/jane-lo-880429">Jane Lo</a>, Assistant Professor of Education, <em><a href="http://theconversation.com/institutions/florida-state-university-1372">Florida State University</a></em></span></p>
<p>This article is republished from <a href="http://theconversation.com">The Conversation</a> under a Creative Commons license. Read the <a href="https://theconversation.com/why-are-kids-today-less-patriotic-126551">original article</a>.</p>
1 note
·
View note
Text
Apple’s Double Agent
For more than a year, an active member of a community that traded in illicitly obtained internal Apple documents and devices was also acting as an informant for the company.
On Twitter and in Discord channels for the loosely defined Apple "internal" community that trades leaked information and stolen prototypes, he advertised leaked apps, manuals, and stolen devices for sale. But unbeknownst to other members in the community, he shared with Apple personal information of people who sold stolen iPhone prototypes from China, Apple employees who leaked information online, journalists who had relationships with leakers and sellers, and anything that he thought the company would find interesting and worth investigating.
Andrey Shumeyko, also known as YRH04E and JVHResearch online, decided to share his story because he felt that Apple took advantage of him and should have compensated him for providing the company this information.
"Me coming forward is mostly me finally realizing that that relationship never took into consideration my side and me as a person," Shumeyko told Motherboard. Shumeyko shared several pieces of evidence to back up his claims, including texts and an email thread between him and an Apple email address for the company's Global Security team. Motherboard checked that the emails are legitimate by analyzing their headers, which show Shumeyko received a reply from servers owned by Apple, according to online records.
Shumeyko said he established a relationship with Apple's anti-leak team—officially called Global Security—after he alerted them of a potential phishing campaign against some Apple Store employees in 2017. Then, in mid-2020, he tried to help Apple investigate one of its worst leaks in recent memory, and became a "mole," as he put it.
Last year, months before the official release of Apple's mobile operating system iOS 14, iPhone hackers got their hands on a leaked early version.
At the time, people in the iPhone hacking community told Motherboard that the leaked iOS build came from a stolen prototype of an iPhone 11 that was purchased from gray-market vendors in China. Sensitive Apple software and hardware occasionally leaks out of China, and there is a thriving gray market of stolen iPhone prototypes that are marketed to security researchers and hackers interested in finding vulnerabilities and developing exploits for Apple's devices.
Apple is obviously not happy about any of this. But over the years, apart from the time it famously went after a Gizmodo journalist who found a prototype of an iPhone 4 in a San Francisco bar, the company has largely kept its response to leaks under wraps. In mid-June, Apple lawyers in China sent letters to a Chinese citizen who advertised and sold stolen devices, demanding they stop their activities and reveal their sources inside the company, as Motherboard reported last month.
“People trust me, and find me pretty likable, and so I’m capable of using that to my advantage”
The secretive Global Security reportedly employs former U.S. intelligence and FBI agents and is tasked with cracking down on leaks and leakers, but very little is known about the way it operates.
One of the ways the team tracks leaks and leakers is by cultivating relationships with people in the jailbreaking and internal community, such as Shumeyko. It's not the first time something like this has happened. As Motherboard reported in 2017, an Apple employee had infiltrated the early jailbreaking scene, acting as a double agent.
Shumeyko has never worked for Apple, but he assumed a similar role last year when he decided to give Apple information about the iOS 14 leak. He had obtained a copy of the leaked iOS 14 build himself, and said he also learned how the leak went down and wanted to share the information with Apple.
On May 15 of last year, Shumeyko reached out to Apple Global Security via email, according to an email chain he shared. He offered information about the person who allegedly purchased the iPhone 11 that contained the iOS 14 development build, the security researchers who got a leaked copy of the operating system, and a handful of people who apparently live in China and sell iPhone prototypes and other devices that appear to leak out of factories in Shenzhen.
"I think I found the mole who helped him orchestrate the thing," Shumeyko wrote to Apple, referring to the iOS 14 leak and the person who allegedly purchased the stolen prototype. "I've identified which one of the 3 Chinese hardware suppliers sent him the phone. I’ve received a package from that same guy in the past (still have the DHL tracking number), and I have his phone number. Would any of the above be of any aid?"
Do you work, or used to work for Apple? Do you research vulnerabilities on Apple's devices? We’d love to hear from you. You can contact Lorenzo Franceschi-Bicchierai securely on Signal at +1 917 257 1382, OTR chat at [email protected], or email [email protected]
At the end of the email chain, an Apple employee asked if Shhumeyko was free for a chat.
"What’s the number you use for Signal/Telegram? We will assign a member of the team to reach out," the employee wrote.
Shumeyko said he was willing to help as a way to redeem himself for being part of that community, and to get some money out of it, according to him and his online chats with an Apple Global Security employee.
"People trust me, and find me pretty likable, and so I’m capable of using that to my advantage," Shumeyko told the Apple employee during their monthslong online chats. "I regret my involvement in all that stuff and I’ll do whatever you need me to redeem my past actions."
"I know I’ve been naughty, but my actions so far landed the right connections which I can use to help further the company. Getting into this whole thing was a mistake on my side," Shumeyko told the Apple Global Security employee.
What he shared was interesting enough to prompt Apple employees to keep the communications channel with Shumeyko open for almost a year.
Two people who are part of the Apple jailbreaking and internal community confirmed that Shumeyko was dabbling in it by advertising leaked data on Twitter.
“He is widely trusted to be an original source of that information.”
"He’s tweeted a lot with internal materials from Apple," one of the people in the Apple jailbreaking and internal community told Motherboard in an online chat. "I think he is widely trusted to be an original source of that information."
Another person, who also asked to remain anonymous as he, too, is involved in the jailbreaking and internal communities and fears retaliation from Apple, told Motherboard that Shumeyko "was most definitely involved in that community and he most definitely had some level of access to things he shouldn’t have."
According to the person involved in the jailbreaking community, "the 'Apple Internal Community' is just a bunch of kids on Twitter who find, buy, sell, and trade firmware or other such things without realizing the repercussions such things carry." But other than kids, there are also serious sellers, mostly based in China, who sell prototype iPhones for thousands of dollars, as a Motherboard investigation showed in 2019.
And Apple has been trying to crack down on them recently by sending them legal letters, which revealed that the company knows their names and home addresses, despite the fact that they only use nicknames online.
Last year, Shumeyko sent Apple investigators a PDF titled "The List," essentially a dossier where he shared personal details such as phone numbers, WeChat IDs, and alleged locations of three people who advertised and sold devices on Twitter, as well as a U.S. citizen who collects iPhone prototypes. One of the people listed in the PDF is the one who received the legal letter from Apple, Motherboard has learned.
Apple declined to comment for this article.
None of the people Shumeyko mentioned to Apple, and whom Motherboard spoke to, had any idea that Shumeyko had become a mole for the company.
When he was acting as a mole, Shumeyko wanted to keep his relationship with Apple a secret, "fearing I might damage that fragile thing we had going on," he said, referring to the company. But at this point, now that he’s coming out, Shumeyko doesn't care what anyone will think of him.
"Them knowing what I am doesn’t really change my life for better or worse. And, well, I just wanted to be heard for once, and the story I tell to be truthful," Shumeyko said.

Three iPhone prototypes. (Image: Giulio Zompetti/Motherboard)
Months after he first reached out, Shumeyko explained more about why he wanted to help Apple.
"I was inspired by the rumor that the raid on the journalist’s house during the iPhone 4 Gizmodo incident was conducted by Apple’s own ‘police’ team," Shumeyko told a Global Security employee. "So I assumed prosecuting [an iPhone prototype collector who also traded leaked information and hardware] and the Chinese would be easy then, and that I’ll get to walk away with a reward generous enough to jumpstart my life entirely."
Shumeyko said he expected Apple to "do something" with the information he provided, but it's unclear what the company achieved with Shumeyko's information. Despite asking many times for details about how the company was acting on his information, the Apple employee he was corresponding with never gave him any answers. Shumeyko also repeatedly asked if it would be possible for him to be paid for his information, citing financial problems he needed to take care of. In this case, too, the Apple employee was noncommittal, according to the conversation's transcript.
"I know I'm very much a part of the problem that I'm trying to report, and I really hate to be the Karen of this story, but still, I'm determined to fully follow through with this and I'm sorry for being a huge inconvenience," Shumeyko told the Apple Global Security employee, according to the chats viewed by Motherboard. "I know you probably can't answer all of my previous questions, so could you kindly get someone who can talk to me over email or this app? Again: 1) How helpful were the materials provided? 2) Should I try to obtain more information? 3) Do I get any protection at all as a whistleblower?"
Still, his constant flow of tips on people in the jailbreaking and internals community, as well as tips on Apple employees who were active online and were leaking information, were well received by the Apple Global Security employee.
"We appreciate the information you provide. Please feel encouraged to keep sharing what you have," the nameless Apple Global Security employee said. The chats between Shumeyko and the employee spanned almost a year, and the Apple employee consistently thanked Shumeyko for the information and asked for more information about specific materials and people.
In the summer of 2020, Shumeyko told his Apple Global Security contact that he’d been in touch with an Apple employee in Germany who worked on Apple Maps. Shumeyko alleged that the employee was offering to sell access to an internal Apple account used by employees to log in to their corporate emails and intranet. Shumeyko said he always kept contact with the employee, who eventually told him that he’d gotten fired.
“Do the right things to protect Apple. Keep it that way, you will be proud of yourself, so will we.”
Shumeyko said he was hoping that by helping Apple, the company would help him in return. But that, he said, never happened. And he's now questioning whether he should have helped in the first place.
"Now it feels like I ruined someone for no good reason, really," Shumeyko told me, referring to the Apple employee in Germany.
Weeks later, out of frustration, Shumeyko said he leaked the information he gathered from the employee to the Apple-focused blog 9to5Mac, which wrote an article based on the leaked data. Shumeyko almost immediately regretted it, telling his Apple contact,"I know that looks bad. And I apologize for that."
"Going forward if you plan to publish anything, please consult us (if you want to do the right things for yourself)," Apple Global Security's employee told Shumeyko.
"Please understand that our goal is to protect Apple. All our actions are guided by the premise of what is best for the company, our employees, and our customers (of which you are one). Therefore your help—and insights—in understanding possible threats to us are very important," the Apple employee continued. "My personal advice is that you continue to do the right things so that you can build a positive image for yourself. Do the right things to protect Apple. Keep it that way, you will be proud of yourself, so will we."
During his conversations with the Apple Global Security employee, Shumeyko shared the contact information and social media profiles of three alleged sellers of stolen devices in China, a person who collects these type of devices and who was allegedly involved in the iOS 14 leak, and the personal details and names of connections of someone who allegedly used to be an Apple intern and then became part of the jailbreaking community.
A year after Shumeyko started talking to Global Security, his relationship with Apple is basically nonexistent. Shumeyko said he last heard from Global Security on July 15.
Shumeyko told Motherboard that he is still struggling financially. He is also still on Twitter trying to sell Apple data in an attempt to finally cash out on years of being involved in Apple leaks.

A screenshot of a recent tweet by Shumeyko (Image: Motherboard)
"Don't really enjoy doing this," Shumeyko said in a recent chat. "But I also do need the extra money. Unfortunately, I have more pressing issues to be worried about other than Apple."
Meanwhile, one of the people who knew of Shumeyko and is part of the jailbreaking and internal community said Shumeyko's story as an informant will make people suspicious and less open to talk about leaks.
"I think it goes to show that you can’t openly and safely experiment with leaked Apple internal materials," he said. "These sort of events sort of enhance the hostile vibe sometimes felt in the community."
Subscribe to our cybersecurity podcast CYBER, here.
Apple’s Double Agent syndicated from https://triviaqaweb.wordpress.com/feed/
0 notes
Text
Free Match Maker
1. CREATE PROFILE
How to play Matchmaker. Click two items to swap them, and make a line of 3 or more of the same to make the couple kiss. Kissing fills up the love meter! You can't combine any squares with the X icon. Combine the clock with any two identical icons for more time, and combine the lightning with any two identical icons to help fill up the love meter.

Create a free member account & verify to get full access.
2. FIND MATCHES
YOUR SINGLE LIFE JUST MET IT’S MATCH. Three years ago, Khadijah merged two talents, from a Maker of Films to a Maker of Matches. Born and raised in the South, she knows first-hand the challenges Muslims face in finding love. Sometimes it’s hard to gauge chemistry, when you can’t even be alone together. Free matching quiz maker & test generator by Wordsmyth. Type the words for your quiz in the space below. Separate each keyword with a space. To list two words together, contain them in quotation marks (example: 'test tube').

. Ad-free experience for children. Unlimited access to Interactive Stories with 'Read to me' feature. Informative assessment tools with detailed reports pointing out successes and weak spots. Audio Instructions for all games. The payment provider we use (Stripe) employ bank grade security and are fully PCI compliant. I have another question! Our support team is more than happy to help. Contact us at [email protected] or reach out to us on twitter. We are based in the UK and operate between 8am - 5pm GMT.
Using advanced search find the most suited profiles.
3. CONNECT NOW
Once you expressed interest you can start interacting.
MatchMaker.lk is the best matrimony portal in Sri Lanka which is to help you to find your life partner from anywhere in the world. Start your search for your life partner without even leaving your seat for 100% free.
Like and follow us on our Facebook Page: https://www.facebook.com/matchmakerlk/
Our Andriod mobile app is live: (Click on the below button to install)
Why MatchMaker.lk? for Sri Lanka Marriage Proposals
Supports basic & advanced search
The website supports all the devices
Support multiple photos upload
Advanced & interactive profiles
100% unlimited free usage
View phone number and WhatsApp number
Favorites and shortlist the profiles
Send virtual gifts to members
Live chat with live notifications
Send private messages to members
Srilankan Matrimony
MatchMaker.lk is a free Sri Lanka online marriage proposals website which is developed to help Sri Lankan on their matrimonial search. Our goal is to help you find lanka love and assist you in lanka matrimony search.
We offer wedding and matchmaking services for all the religions including Buddhism, Hinduism, Christianity and all the language including Sinhala, Tamil & English speaking person in Ceylon or Sri Lankan living outside the country.

Our member profiles will also enable you to view members with photos and with phone numbers (members will share when they are ready).
Mangala Yojana Sinhala
We provide perfect mangala yojana service to our Sinhalese brothers and sisters. We help manaliyo and manalayo in their search.
Thirumanam Matrimony
Free Online Matchmaker
We provide ideal thirumanam kalyanam service to our Tamil brothers and sisters. We help manamagal and manamagan in their search.

Advertisement
Overhead Wave Match Maker v.1Overhead Wave MatchMaker 1 is created to be a simple and effective program which can find similar sounding samples in a user selected source wave file (songs, compilation) and save the result to a wave file. Good for people trying to build samples ...
Cupid's Match-Up! v.1.00You get to be a matchmaker in this adorable new arcade game.
Love Calculator Pro v.1.5.0Test your love and find your perfect match. Love Calculator Pro is a love test and matchmaker tool that combines various relationship tests to perform compatibility test of two people. It also predicts baby's gender using three kinds of baby charts ...
Cupid's Match-Up! v.1.00You get to be a matchmaker in this adorable new arcade game. You play cupid and fly around the ice rink joining couple together by shooting your arrows. Sound easy? Well the catch is that not every gal is a compatible match for every guy.
PROF. YO'S YO VOCAB HOME MEGA PACK v.1.0.7Includes Vocabulary, Short Meanings, Long Meanings, Usage Examples, Synonyms, Antonyms, Homonyms, Homophones, Related Vocabulary, etc.Multiple Choice, Acrossword, Word Juggler, Memory Challenge, Hang-Over, MatchMaker, Fill in the blanksAge Groups ...
PROF.YO'S YO VOCAB CARDS MEGA PACK v.1.0.4Includes Vocabulary, Short Meanings, Long Meanings, Usage Examples, Synonyms, Antonyms, Homonyms, Homophones, Related Vocabulary, etc. Multiple Choice, Acrossword, Word Juggler, Memory Challenge, Hang-Over, MatchMaker, Fill in the blanksAge Groups ...
OSGMM v.0.9OSGMM, the Open Science Grid MatchMaker, is a matchmaker which sits on top of the OSG Client software stack. It gets site information from ReSS and uses a feedback system with Condor to publish the site information and keep job success history ...
Wedding v.1.0A matchmaker website. Provides a platform for brides and grooms to register online, browse profiles, access premium services by paying and registering. In short enables providing community matrimonial services.
Scripts For Profit v.1.0I Have Put Together Some Of The Most Profitable Money Making Membership Based Scripts Available Online Today. You Can Run The Scripts To Generate A Cash Flow, You Can Resell This Entire Package And Keep 100% Of The Profits ...

MB Free Astro Compatibility Test Software v.1.85MB Free Astro Compatibility Test Software is an unique relationship compatibility test software that helps one analyze his/ her relationships based on the planetary positions at the time of birth. The calculations are based on the astrodynes.
MB Astro Compatibility Test Software v.2.00MB Free Astro Compatibility Test Software is an unique relationship compatibility test software that helps one analyze his/ her relationships based on the planetary positions at the time of birth. The calculations are based on the astrodynes.
Head Numerologist v.3.2.1Head Numerologist is a standard Numerology software based on Chaldean and Pythagorean number theories. Its Predictions module generates numerology forecast report for a person that gives information on many interesting things viz. name number, birth ...
Mate Matcher v.2.0Mate Matcher - is a love calculator, which lets you calculate your love for your partner. Also the site lets you find your dream ...
24 Update Web Cam Portal ScriptThe web cam portal script is an web cam community, with web cam archives, where web cam images is being automatic stored, with multi user interface, and with a admin panel. Multi language files. With Community options like Internal e-mail, Instant ...
AdWords Maker v.1.00_beta_4Make more money from Google AdWords by generating more AdWord phrases. Use AdWords Maker to make hundreds of unique, relevant AdWords phrases for your AdWords campaigns. Substitute, rearrange, format for match type and filter phrases.
Web Page Calendar Maker v.1.2Web Page Calendar Maker for Macintosh gives you the freedom to create monthly web page calendars without the need to write lengthy web page code. Change the style of your calendars to match your site with color schemes and alignments. You can place ...
Sothink Logo Maker Professional v.4.4Sothink Logo Maker Pro creates awesome logos and vector artworks like professionals. Benefiting from smart drawing pens, color schemes, rich effects and build-in symbols, it becomes fairly easy and comfortable to design logos for Web and print.
Free Html5 Story Flip Book maker v.4.3Did you miss the story bed-time when you were a child? And now would you like to make a fabulous story e-book for your children? Then do you know how? Today we are going to share a wonderful story book maker to you.
Abee CHM Maker freeware v.1.3Abee Chm Maker is program for making chm-files. Program has a simple and comprehensible interface and allow to make CHM-files(with contents) easily and quickly.
Audio MP3 Maker Deluxe v.1.18Audio MP3 Maker - is the best cd ripper and wav to mp3 converter .It can ripper your Favorite CDs to MP3s in an extremely easy way. If you want to make your own MP3 from audio CD , this is exactly what you are looking for.
Match Maker software by TitlePopularityFreewareLinuxMac
Today's Top Ten Downloads for Match Maker
Free Matchmaker Relationship
Easy Icon Maker ICON Maker is a small and easy-to-use icon editing
MB Astro Compatibility Test Software MB Free Astro Compatibility Test Software is an unique
Photo Frame Maker Photo Frame Maker is easy to use photo frame software .
ID Flow ID Badge Maker Software ID Flow Photo ID Badge Maker Software is the industry
Love Calculator Pro Test your love and find your perfect match . Love
Abee CHM Maker freeware Abee Chm Maker is program for making chm-files.
PackPal MP3 Ringtone Maker With PackPal Mp3 Ringtone Maker , you can quickly make
Belltech Label Maker Pro Belltech Label Maker Pro is a label designer software to
Video DVD Maker FREE Video DVD Maker is a freeware authoring tool that allows
AlltoMP3 Maker Besides downloading MP3 from Internet, you can also DIY(Do
Free Match Maker Websites
Visit HotFiles@Winsite for more of the top downloads here at WinSite!
0 notes
Text
Version 447
youtube
windows
zip
exe
macOS
app
linux
tar.gz
I had a great week. The database should be a bit faster when doing file work, and I have fixed several annoying bugs. It will take your client a few seconds to update this week, maybe a minute or two if you have millions of files.
multi column lists
I gave the weird column widths another go. Some users had this fun but quite annoying situation where a dialog with a list could grow magically wider before their eyes, maybe 20 pixels four times a second, until it reached their monitor width. Other users (me included) had a handful of lists still growing or shrinking a few pixels on every reopen.
So I drilled down into the logic again and improved things. Some calculations are now more accurate, some are more precise, and I think I fixed the runaway growth situation. Let me know how you get on, and sorry for the trouble!
performance improvements
Thanks to profile feedback from users, I discovered some file routines that were working inefficiently, particularly on very large clients. Mostly unusual jobs like 'get all the trashed files that are due for deletion' or 'get the repository update files I still need to process'. It was mostly when you were looking at a small domain when a very large 'my files' domain was right next door, getting in the way of the query. Having done lots of similar improvement work for tags, I updated how files are stored this week. Several big tables are now split into many smaller pieces that do not interfere with each other. This was actually a long overdue job, so I am happy it is done.
There isn't much to say beyond 'your client should be a bit faster with files now', but let me know how you get on anyway. Mostly you should have fewer lag spikes as background jobs go about their work, but you may notice the duplicates system going a bit faster and general file searches working better too.
Some users with very large sessions have also reported CPU lag with the new session saving system. Thanks again to some user profiles, I was able to speed up session save, particularly for pages with tens or hundreds of thousands of thumbails. The next step will be optimising downloader page save, so if you have a lot of heavy downloaders, I would be interested in some profiles.
In that vein, I significantly improved the profile mode (help->debug->profile mode) this week. All the modes are now merged into one, and all the popup spam is gone. It now makes a new log file every time you turn it on, and only the most useful information is logged. I will keep working here to get more and more information profiled so we can nail down and eliminate slow code.
I have altered core components of the database this week, and it unfortunately caused some bit rot in older update routines. 447 cannot update databases older than 411, and it may have trouble updating before 436. If either of these apply to you, the client will error out or warn you before continuing. I'd like to know what happens to you if you are v411-435 so I can refine these messages.
And while I have tested this all back and forth, there may be a typo bug in some of the more unusual queries. I am sorry ahead of time if you run into any of these--send me the traceback and I'll fix them up.
full list
misc:
fixed drag and dropping multiple newline separated urls onto the client when those urls come from a generic text source
pages now cache their 'ordered' file id list. this speeds up several little jobs, but most importantly should reduce session save time for sessions with tens of thousands of files
common file resolutions such as 1920x1080 are now replaced in labels with '1080p' strings as already used in the duplicate system. also added 'vertical' variants of 720p, 1080p, and 4k
when a page preview viewer gets a call to clear its current media when it is not currently the page in view, it now recognises that properly. this was happening (a 'sticky' preview) on drag and drops that navigated and terminated on other pages
the various 'retry ignored' commands on downloaders now give an interstitial dialog where you can choose to retry 'all', '404s', or 'blacklisted' files only
manage tag siblings/parents now disables its import button until its data is loaded. imports that were clicked through before loading were being forgotten due to tangled logic, so for now I'll just disable the button!
reduced some more spiky database I/O overhead from the UI's perspective (now savepoints are performed after a result is returned, just like I recently did with transaction commit)
duplicate potentials search will now update the y in its x/y progress display if many files have been imported since the search was started and x becomes larger than y (due to y secretly growing)
fixed the default 'gelbooru md5' file lookup script. if you have a lookup script with this name, it will be updated to my new default automatically. I don't really like fixing this old system, but I am not sure when I will fit in my big rewrite that will merge it with the normal downloader system, so this is a quick fix for the meantime
if you are one of the users who had weird unfixable 404 update file problems with the PTR, please try unpausing and doing a metadata resync one more time this week. fingers crossed, this is fixed. please let me know how you get on too, fixed or not, and also if you have had 'malformed' database problems in the past
.
multi column lists:
improved the precision of longer text pixel_width->text and text->pixel_width calculations, which are particularly used in the multi-column list state saving system. another multi-column size calculation bug, where lists could grow by 1 character's width on >~60 character width columns on every dialog reopen, is now fixed
multi-column lists should now calculate last column width more precisely and accurately regardless of vertical scrollbar presence or recent show/hide
the snapping system that locks last column size to 5-character multiples can now snap up or down, increasing error tolerance
I added a hack to stop the bug some people had of multi-column lists suddenly growing wide, up to screen width, in a resize loop. I think it works, but as I cannot reproduce this error, please let me know how you get on. resizing the options->external programs panel seems to initiate it reliably for those users affected
.
profile mode:
all debug profile modes (callto, db, server, menu, pubsub, and ui) are now merged into one mode under help->debug
this new mode no longer spams popups, and it only prints 'slow' jobs to the profile log
it also makes a new profile log every time it is turned on, using mode start timestamp rather than client boot timestamp, and when profile mode is turned off, there is a popup summary of how many fast and slow jobs passed through during the log time
touched up profile code, timing thresholds, summary statements, and the help
.
special update rule this week:
due to the big file storage rework this week, there's some bit rot in older update routines. 447 cannot update databases older than 411, and it _may_ have trouble updating before 436. if this applies to you, the client will error out or warn you before continuing. I'd like to know what happens to you if you are v411-435 so I can refine these messages
.
boring database refactoring:
the primary current, deleted, pending, and petitioned files tables are now split according to service, much as I have done with mapping tables in the past. this saves a little space and accelerates many file calculations on large clients. if you have a client database script or patch that inspects 'current_files' or 'deleted_files', you'll now be looking at client_files_x etc.., where x is the service_id, and they obviously no longer have a service_id column
a new file storage database module manages these tables, and also some misc file deletion metadata
refactored all raw file storage updates, filters, and searches to the new module
the mappings and new file storage database modules are now responsible for various 'num files/mappings' metadata calculations
most file operations on smaller domains, typically trash or repository update files, will be significantly faster (since the much larger 'my files' table data isn't fattening the relevant indices, and worst case query planning is so much better)
cleaned up a ton of file domain filtering code as a result of all this
physical file deletion is now much faster when the client has many pending file uploads to a file repository or IPFS service
complicated duplicate file operations of many sorts should be a _little_ faster now, particularly on large clients
searching files with 'file import time' sort should be a little faster in many situations
tag repositories no longer bother going down to the database level to to see if they have any thumbnails to sync with
everyone also gets a local file id cache regen this week, it may take a few seconds on update
next week
Next week is a cleanup week. I would like to continue my long term database refactoring job, breaking the code into neater and saner pieces that will also support some neat future maintenance jobs. I also want to bring back the vacuum maintenance command with some new UI.
0 notes
Text
macOS Monterey: Here’s Every feature Apple Is Bringing To Mac
Apple has packed macOS Monterey with many new features, keyboard support, universal mouse, Quick Notes, a more functional and stylish Safari, and many more.
Apple has announced a massive number of improvements to Mac. All these new improvements to the device will come with the macOS Monterey, the next operating system update. Among these new features, the enhanced and streamlined Safari browser is the most exciting.
It combines the tab bar with the search bar and adds tab groups. You can share these added tab groups across the Apple devices. Plus, the integration across Apple devices continues with a new type of keyboard and cursor. It is nothing but quite revolutionary on its own.
Apple’s Device Integration Features
Continuity was first introduced in 2014, and since then, it became a powerful and essential part of the Mac. It makes the flow and integration between Mac, iPad, and iPhone easy and quick. In addition, however, Apple brings Universal Control with macOS Monterey. It is a unique feature that allows a single keyboard, mouse, and trackpad to control an iPad and a Mac.
User Experience with Universal Control is very much similar to Sidebar. However, there is an exception as you can’t iPad as a secondary display for the Mac. But, it will accept gestures, respond to the cursor, and keyboard input from any Mac device. Implementation of these things is very impressive that you may not see on any platform. The most incredible is that it does not need any setup.
Advanced Privacy Features For Safari With macOS Monterey
Safari is an efficient and powerful web browser. It has many advanced features to protect users’ privacy. But, Apple is bringing several enhancements with macOS Monterey to Safari. For example, the tech giant will slim down the tabs to combine the search bar with the tab bar. In addition, it will allow more space for content.
Users can access Reader view at the search field’s right side. Plus, you can access more options further in its drop-down menu. Moreover, the company will add more tab groups to Safari. It will provide extra organization and appear consistently on each Apple device that users have signed in with the same Apple ID.
It means you can use a tab group with a Mac, iPad, and iPhone. Plus, it can be removed or added as required, with each device automatically updating. So, it results in providing seamless browsing across various devices. Above all, Safari has in-built translation. Now, it has been extended to the Mac system entirely that includes even third-party apps. So, you only need to choose text, right-click on it and then select the translate option. Then, it will replace the selected text with the translation.
FaceTime, Live Text, & More
With the new macOS version, the Photos app will get Live Text capabilities. It will make text that becomes visible in an image that you can both select and translate. So, for example, you will be able to copy a text from the Photos app to use elsewhere and even begin composing a new email by tapping an email address that you found in a photograph.
Besides, Spotlight can also be used to find text in photos. It demonstrates the thorough integration of Live Text throughout macOS Monterey. Now, Mac and other Apple devices can be used as an AirPlay destination. Moreover, it will make the prominent display of iMac accessible for playing videos from any Apple device, including an iPad mini.
Similarly, a MacBook Pro’s Spatial Audio speakers can playback music and receive more clarity and volume when you send it from your iPhone through AirPlay. Plus, users can also use their Mac device for multiform audio as a speaker.
FaceTime: New Improvements With macOS Monterey
FaceTime is an integral part of the MacBook. The new advanced video and audio features that macOS Monterey will bring will make it better than ever before. For example, it includes Spatial Audio and Voice Isolation. Spatial Audio in FaceTime will place sound relative to the speaker’s position on the screen. Simultaneously, Voice Isolation makes the voice of the users clear and sharp by eliminating background noise virtually.
Apart from these improvements, FaceTime has also got the Portrait Mode. It gives a pleasing blur to the background clutter focusing on the person instead of surroundings. Also, a SharePlay feature allows a Mac device to share music, video, and screen with the entire group. Above all, you can access FaceTime video calls to both Android and Windows.
In the future, Apple will make notifications more manageable. For example, you will group them according to work, sleep, and personal categories. Additionally, you can use the ‘Do Not Disturb’ option for complete focus and silence. The Notes app will also get improvements. Moreover, the Quick Notes will be able to sync with a webpage. It will further allow the note to appear with the website in the Safari browser. Here, it will highlight the text snippets in context on the webpage.
So, it will improve the workflow significantly for referencing online material or people doing website design. Meanwhile, Apple has built some coding to keep all users happy. For example, Shortcuts coming to the Mac will be more familiar to iPad and iPhone users than the older Apple Script and Automator technologies.
So, you can import Automator workflows into Shortcuts. In addition, it will help to prevent existing codes from losing when users use the new system. Overall, the tech giant is set to bring many exciting and new features to macOS later this year.
Source: https://answersnorton.com/macos-monterey-heres-every-feature-apple-is-bringing-to-mac/
0 notes
Text
Page Level Query Analysis at Scale with Google Colab, Python, & the GSC API [Video Instructions Included]
The YouTube playlist referenced throughout this blog can be found here:6 Part YouTube Series [Setting Up & Using the Query Optimization Checker]
Anyone who does SEO as part of their job knows that there’s a lot of value in analyzing which queries are and are not sending traffic to specific pages on a site.
The most common uses for these datasets are to align on-page optimizations with existing rankings and traffic, and to identify gaps in ranking keywords.
However, working with this data is extremely tedious because it’s only available in the Google Search Console interface, and you have to look at only one page at a time.
On top of that, to get information on the text included in the ranking page, you either need to manually review it or extract it with a tool like Screaming Frog.
You need this kind of view:
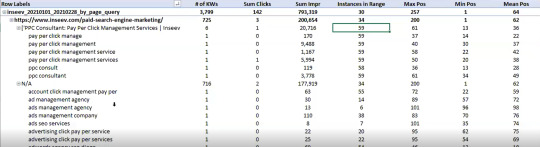
…but even the above view would only be viable one page at a time, and as mentioned, the actual text extraction would have had to be separate as well.
Given these apparent issues with the readily available data at the SEO community’s disposal, the data engineering team at Inseev Interactive has been spending a lot of time thinking about how we can improve these processes at scale.
One specific example that we’ll be reviewing in this post is a simple script that allows you to get the above data in a flexible format for many great analytical views.
Better yet, this will all be available with only a few single input variables.
A quick rundown of tool functionality
The tool automatically compares the text on-page to the Google Search Console top queries at the page-level to let you know which queries are on-page as well as how many times they appear on the page. An optional XPath variable also allows you to specify the part of the page you want to analyze text on.
This means you’ll know exactly what queries are driving clicks/impressions that are not in your <title>, <h1>, or even something as specific as the first paragraph within the main content (MC). The sky's the limit.
For those of you not familiar, we’ve also provided some quick XPath expressions you can use, as well as how to create site-specific XPath expressions within the "Input Variables" section of the post.
Post setup usage & datasets
Once the process is set up, all that’s required is filling out a short list of variables and the rest is automated for you.
The output dataset includes multiple automated CSV datasets, as well as a structured file format to keep things organized. A simple pivot of the core analysis automated CSV can provide you with the below dataset and many other useful layouts.
… Even some "new metrics"?
Okay, not technically "new," but if you exclusively use the Google Search Console user interface, then you haven’t likely had access to metrics like these before: "Max Position," "Min Position," and "Count Position" for the specified date range – all of which are explained in the "Running your first analysis" section of the post.

To really demonstrate the impact and usefulness of this dataset, in the video below we use the Colab tool to:
[3 Minutes] — Find non-brand <title> optimization opportunities for https://www.inseev.com/ (around 30 pages in video, but you could do any number of pages)
[3 Minutes] — Convert the CSV to a more useable format
[1 Minute] – Optimize the first title with the resulting dataset
youtube
Okay, you’re all set for the initial rundown. Hopefully we were able to get you excited before moving into the somewhat dull setup process.
Keep in mind that at the end of the post, there is also a section including a few helpful use cases and an example template! To jump directly to each section of this post, please use the following links:
One-time setup of the script in Google Colab
Running your first analysis
Practical use cases and templates
[Quick Consideration #1] — The web scraper built into the tool DOES NOT support JavaScript rendering. If your website uses client-side rendering, the full functionality of the tool unfortunately will not work.
[Quick Consideration #2] — This tool has been heavily tested by the members of the Inseev team. Most bugs [specifically with the web scraper] have been found and fixed, but like any other program, it is possible that other issues may come up.
If you encounter any errors, feel free to reach out to us directly at [email protected] or [email protected], and either myself or one of the other members of the data engineering team at Inseev would be happy to help you out.
If new errors are encountered and fixed, we will always upload the updated script to the code repository linked in the sections below so the most up-to-date code can be utilized by all!
One-time setup of the script in Google Colab (in less than 20 minutes)
Things you’ll need:
Google Drive
Google Cloud Platform account
Google Search Console access
Video walkthrough: tool setup process
Below you’ll find step-by-step editorial instructions in order to set up the entire process. However, if following editorial instructions isn’t your preferred method, we recorded a video of the setup process as well.
As you’ll see, we start with a brand new Gmail and set up the entire process in approximately 12 minutes, and the output is completely worth the time.
youtube
Keep in mind that the setup is one-off, and once set up, the tool should work on command from there on!
Editorial walkthrough: tool setup process
Four-part process:
Download the files from Github and set up in Google Drive
Set up a Google Cloud Platform (GCP) Project (skip if you already have an account)
Create the OAuth 2.0 client ID for the Google Search Console (GSC) API (skip if you already have an OAuth client ID with the Search Console API enabled)
Add the OAuth 2.0 credentials to the Config.py file
Part one: Download the files from Github and set up in Google Drive
Download source files (no code required)
1. Navigate here.
2. Select "Code" > "Download Zip"
*You can also use 'git clone https://github.com/jmelm93/query-optmization-checker.git' if you’re more comfortable using the command prompt.

Initiate Google Colab in Google Drive
If you already have a Google Colaboratory setup in your Google Drive, feel free to skip this step.
1. Navigate here.
2. Click "New" > "More" > "Connect more apps".
3. Search "Colaboratory" > Click into the application page.
4. Click "Install" > "Continue" > Sign in with OAuth.
5. Click "OK" with the prompt checked so Google Drive automatically sets appropriate files to open with Google Colab (optional).

Import the downloaded folder to Google Drive & open in Colab
1. Navigate to Google Drive and create a folder called "Colab Notebooks".
IMPORTANT: The folder needs to be called "Colab Notebooks" as the script is configured to look for the "api" folder from within "Colab Notebooks".
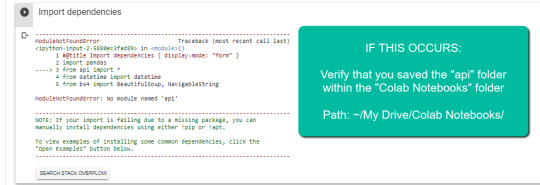
Error resulting in improper folder naming.
2. Import the folder downloaded from Github into Google Drive.
At the end of this step, you should have a folder in your Google Drive that contains the below items:

Part two: Set up a Google Cloud Platform (GCP) project
If you already have a Google Cloud Platform (GCP) account, feel free to skip this part.
1. Navigate to the Google Cloud page.
2. Click on the "Get started for free" CTA (CTA text may change over time).
3. Sign in with the OAuth credentials of your choice. Any Gmail email will work.
4. Follow the prompts to sign up for your GCP account.
You’ll be asked to supply a credit card to sign up, but there is currently a $300 free trial and Google notes that they won’t charge you until you upgrade your account.
Part three: Create a 0Auth 2.0 client ID for the Google Search Console (GSC) API
1. Navigate here.
2. After you log in to your desired Google Cloud account, click "ENABLE".

3. Configure the consent screen.
In the consent screen creation process, select "External," then continue onto the "App Information."
Example below of minimum requirements:

Skip "Scopes"
Add the email(s) you’ll use for the Search Console API authentication into the "Test Users". There could be other emails versus just the one that owns the Google Drive. An example may be a client’s email where you access the Google Search Console UI to view their KPIs.
4. In the left-rail navigation, click into "Credentials" > "CREATE CREDENTIALS" > "OAuth Client ID" (Not in image).
5. Within the "Create OAuth client ID" form, fill in:
Application Type = Desktop app
Name = Google Colab
Click "CREATE"
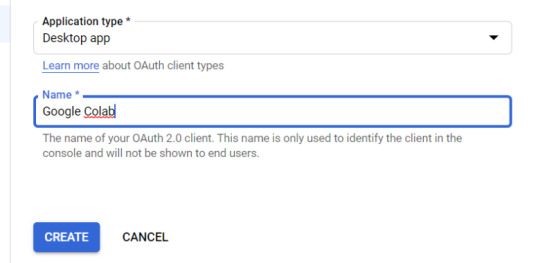
6. Save the "Client ID" and "Client Secret" — as these will be added into the "api" folder config.py file from the Github files we downloaded.
These should have appeared in a popup after hitting "CREATE"
The "Client Secret" is functionally the password to your Google Cloud (DO NOT post this to the public/share it online)
Part four: Add the OAuth 2.0 credentials to the Config.py file
1. Return to Google Drive and navigate into the "api" folder.
2. Click into config.py.

3. Choose to open with "Text Editor" (or another app of your choice) to modify the config.py file.

4. Update the three areas highlighted below with your:
CLIENT_ID: From the OAuth 2.0 client ID setup process
CLIENT_SECRET: From the OAuth 2.0 client ID setup process
GOOGLE_CREDENTIALS: Email that corresponds with your CLIENT_ID & CLIENT_SECRET

5. Save the file once updated!
Congratulations, the boring stuff is over. You are now ready to start using the Google Colab file!
Running your first analysis
Running your first analysis may be a little intimidating, but stick with it and it will get easy fast.
Below, we’ve provided details regarding the input variables required, as well as notes on things to keep in mind when running the script and analyzing the resulting dataset.
After we walk through these items, there are also a few example projects and video walkthroughs showcasing ways to utilize these datasets for client deliverables.
Setting up the input variables
XPath extraction with the "xpath_selector" variable
Have you ever wanted to know every query driving clicks and impressions to a webpage that aren’t in your <title> or <h1> tag? Well, this parameter will allow you to do just that.
While optional, using this is highly encouraged and we feel it "supercharges" the analysis. Simply define site sections with Xpaths and the script will do the rest.
youtube
In the above video, you’ll find examples on how to create site specific extractions. In addition, below are some universal extractions that should work on almost any site on the web:
'//title' # Identifies a <title> tag
'//h1' # Identifies a <h1> tag
'//h2' # Identifies a <h2> tag
Site Specific: How to scrape only the main content (MC)?
Chaining Xpaths – Add a "|" Between Xpaths
'//title | //h1' # Gets you both the <title> and <h1> tag in 1 run
'//h1 | //h2 | //h3' # Gets you both the <h1>, <h2> and <h3> tags in 1 run
Other variables
Here’s a video overview of the other variables with a short description of each.
youtube
'colab_path' [Required] – The path in which the Colab file lives. This should be "/content/drive/My Drive/Colab Notebooks/".
'domain_lookup' [Required] – Homepage of the website utilized for analysis.
'startdate' & 'enddate' [Required] – Date range for the analysis period.
'gsc_sorting_field' [Required] – The tool pulls the top N pages as defined by the user. The "top" is defined by either "clicks_sum" or "impressions_sum." Please review the video for a more detailed description.
'gsc_limit_pages_number' [Required] – Numeric value that represents the number of resulting pages you’d like within the dataset.
'brand_exclusions' [Optional] – The string sequence(s) that commonly result in branded queries (e.g., anything containing "inseev" will be branded queries for "Inseev Interactive").
'impressions_exclusion' [Optional] – Numeric value used to exclude queries that are potentially irrelevant due to the lack of pre-existing impressions. This is primarily relevant for domains with strong pre-existing rankings on a large scale number of pages.
'page_inclusions' [Optional] – The string sequence(s) that are found within the desired analysis page type. If you’d like to analyze the entire domain, leave this section blank.
Running the script
Keep in mind that once the script finishes running, you’re generally going to use the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file for analysis, but there are others with the raw datasets to browse as well.
Practical use cases for the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file can be found in the "Practical use cases and templates" section.
That said, there are a few important things to note while testing things out:
1. No JavaScript Crawling: As mentioned at the start of the post, this script is NOT set up for JavaScript crawling, so if your target website uses a JS frontend with client-side rendering to populate the main content (MC), the scrape will not be useful. However, the basic functionality of quickly getting the top XX (user-defined) queries and pages can still be useful by itself.
2. Google Drive / GSC API Auth: The first time you run the script in each new session it will prompt you to authenticate both the Google Drive and the Google Search Console credentials.
Google Drive authentication: Authenticate to whatever email is associated with the Google Drive with the script.
GSC authentication: Authenticate whichever email has permission to use the desired Google Search Console account.
If you attempt to authenticate and you get an error that looks like the one below, please revisit the "Add the email(s) you’ll use the Colab app with into the 'Test Users'" from Part 3, step 3 in the process above: setting up the consent screen.
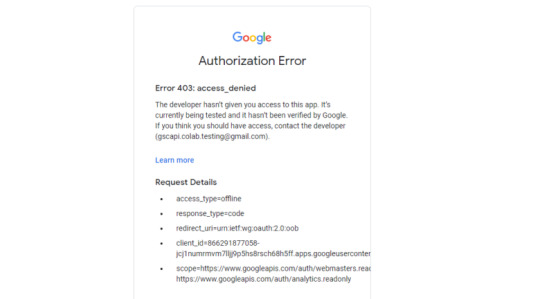
Quick tip: The Google Drive account and the GSC Authentication DO NOT have to be the same email, but they do require separate authentications with OAuth.
3. Running the script: Either navigate to "Runtime" > "Restart and Run All" or use the keyboard shortcut CTRL + fn9 to start running the script.
4. Populated datasets/folder structure: There are three CSVs populated by the script – all nested within a folder structure based on the "domain_lookup" input variable.
Automated Organization [Folders]: Each time you rerun the script on a new domain, it will create a new folder structure in order to keep things organized.
Automated Organization [File Naming]: The CSVs include the date of the export appended to the end, so you’ll always know when the process ran as well as the date range for the dataset.
5. Date range for dataset: Inside of the dataset there is a "gsc_datasetID" column generated, which includes the date range of the extraction.

6. Unfamiliar metrics: The resulting dataset has all the KPIs we know and love – e.g. clicks, impressions, average (mean) position — but there are also a few you cannot get directly from the GSC UI:
'count_instances_gsc' — the number of instances the query got at least 1 impression during the specified date range. Scenario example: GSC tells you that you were in an average position 6 for a large keyword like "flower delivery" and you only received 20 impressions in a 30-day date range. Doesn’t seem possible that you were really in position 6, right? Well, now you can see that was potentially because you only actually showed up on one day in that 30-day date range (e.g. count_instances_gsc = 1)
'max_position' & 'min_position' — the MAXIMUM and MINIMUM ranking position the identified page showed up for in Google Search within the specified date range.
Quick tip #1: Large variance in max/min may tell you that your keyword has been fluctuating heavily.
Quick tip #2: These KPIs, in conjunction with the "count_instances_gsc", can exponentially further your understanding of query performance and opportunity.
Practical use cases and templates
Access the recommended multi-use template.
Recommended use: Download file and use with Excel. Subjectively speaking, I believe Excel has a much more user friendly pivot table functionality in comparison to Google Sheets — which is critical for using this template.
Alternative use: If you do not have Microsoft Excel or you prefer a different tool, you can use most spreadsheet apps that contain pivot functionality.
For those who opt for an alternative spreadsheet software/app:
Below are the pivot fields to mimic upon setup.
You may have to adjust the Vlookup functions found on the "Step 3 _ Analysis Final Doc" tab, depending on whether your updated pivot columns align with the current pivot I’ve supplied.
Project example: Title & H1 re-optimizations (video walkthrough)
Project description: Locate keywords that are driving clicks and impressions to high value pages and that do not exist within the <title> and <h1> tags by reviewing GSC query KPIs vs. current page elements. Use the resulting findings to re-optimize both the <title> and <h1> tags for pre-existing pages.
Project assumptions: This process assumes that inserting keywords into both the <title> and <h1> tags is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Project example: On-page text refresh/re-optimization
Project description: Locate keywords that are driving clicks and impressions to editorial pieces of content that DO NOT exist within the first paragraph within the body of the main content (MC). Perform an on-page refresh of introductory content within editorial pages to include high value keyword opportunities.
Project assumptions: This process assumes that inserting keywords into the first several sentences of a piece of content is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Final thoughts
We hope this post has been helpful and opened you up to the idea of using Python and Google Colab to supercharge your relevancy optimization strategy.
As mentioned throughout the post, keep the following in mind:
Github repository will be updated with any changes we make in the future.
There is the possibility of undiscovered errors. If these occur, Inseev is happy to help! In fact, we would actually appreciate you reaching out to investigate and fix errors (if any do appear). This way others don’t run into the same problems.
Other than the above, if you have any ideas on ways to Colab (pun intended) on data analytics projects, feel free to reach out with ideas.
0 notes
Text
Page Level Query Analysis at Scale with Google Colab, Python, & the GSC API [Video Instructions Included]
The YouTube playlist referenced throughout this blog can be found here:6 Part YouTube Series [Setting Up & Using the Query Optimization Checker]
Anyone who does SEO as part of their job knows that there’s a lot of value in analyzing which queries are and are not sending traffic to specific pages on a site.
The most common uses for these datasets are to align on-page optimizations with existing rankings and traffic, and to identify gaps in ranking keywords.
However, working with this data is extremely tedious because it’s only available in the Google Search Console interface, and you have to look at only one page at a time.
On top of that, to get information on the text included in the ranking page, you either need to manually review it or extract it with a tool like Screaming Frog.
You need this kind of view:
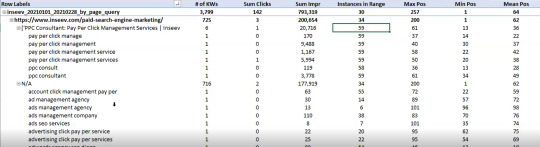
…but even the above view would only be viable one page at a time, and as mentioned, the actual text extraction would have had to be separate as well.
Given these apparent issues with the readily available data at the SEO community’s disposal, the data engineering team at Inseev Interactive has been spending a lot of time thinking about how we can improve these processes at scale.
One specific example that we’ll be reviewing in this post is a simple script that allows you to get the above data in a flexible format for many great analytical views.
Better yet, this will all be available with only a few single input variables.
A quick rundown of tool functionality
The tool automatically compares the text on-page to the Google Search Console top queries at the page-level to let you know which queries are on-page as well as how many times they appear on the page. An optional XPath variable also allows you to specify the part of the page you want to analyze text on.
This means you’ll know exactly what queries are driving clicks/impressions that are not in your <title>, <h1>, or even something as specific as the first paragraph within the main content (MC). The sky's the limit.
For those of you not familiar, we’ve also provided some quick XPath expressions you can use, as well as how to create site-specific XPath expressions within the "Input Variables" section of the post.
Post setup usage & datasets
Once the process is set up, all that’s required is filling out a short list of variables and the rest is automated for you.
The output dataset includes multiple automated CSV datasets, as well as a structured file format to keep things organized. A simple pivot of the core analysis automated CSV can provide you with the below dataset and many other useful layouts.
… Even some "new metrics"?
Okay, not technically "new," but if you exclusively use the Google Search Console user interface, then you haven’t likely had access to metrics like these before: "Max Position," "Min Position," and "Count Position" for the specified date range – all of which are explained in the "Running your first analysis" section of the post.

To really demonstrate the impact and usefulness of this dataset, in the video below we use the Colab tool to:
[3 Minutes] — Find non-brand <title> optimization opportunities for https://www.inseev.com/ (around 30 pages in video, but you could do any number of pages)
[3 Minutes] — Convert the CSV to a more useable format
[1 Minute] – Optimize the first title with the resulting dataset
youtube
Okay, you’re all set for the initial rundown. Hopefully we were able to get you excited before moving into the somewhat dull setup process.
Keep in mind that at the end of the post, there is also a section including a few helpful use cases and an example template! To jump directly to each section of this post, please use the following links:
One-time setup of the script in Google Colab
Running your first analysis
Practical use cases and templates
[Quick Consideration #1] — The web scraper built into the tool DOES NOT support JavaScript rendering. If your website uses client-side rendering, the full functionality of the tool unfortunately will not work.
[Quick Consideration #2] — This tool has been heavily tested by the members of the Inseev team. Most bugs [specifically with the web scraper] have been found and fixed, but like any other program, it is possible that other issues may come up.
If you encounter any errors, feel free to reach out to us directly at [email protected] or [email protected], and either myself or one of the other members of the data engineering team at Inseev would be happy to help you out.
If new errors are encountered and fixed, we will always upload the updated script to the code repository linked in the sections below so the most up-to-date code can be utilized by all!
One-time setup of the script in Google Colab (in less than 20 minutes)
Things you’ll need:
Google Drive
Google Cloud Platform account
Google Search Console access
Video walkthrough: tool setup process
Below you’ll find step-by-step editorial instructions in order to set up the entire process. However, if following editorial instructions isn’t your preferred method, we recorded a video of the setup process as well.
As you’ll see, we start with a brand new Gmail and set up the entire process in approximately 12 minutes, and the output is completely worth the time.
youtube
Keep in mind that the setup is one-off, and once set up, the tool should work on command from there on!
Editorial walkthrough: tool setup process
Four-part process:
Download the files from Github and set up in Google Drive
Set up a Google Cloud Platform (GCP) Project (skip if you already have an account)
Create the OAuth 2.0 client ID for the Google Search Console (GSC) API (skip if you already have an OAuth client ID with the Search Console API enabled)
Add the OAuth 2.0 credentials to the Config.py file
Part one: Download the files from Github and set up in Google Drive
Download source files (no code required)
1. Navigate here.
2. Select "Code" > "Download Zip"
*You can also use 'git clone https://github.com/jmelm93/query-optmization-checker.git' if you’re more comfortable using the command prompt.
Initiate Google Colab in Google Drive
If you already have a Google Colaboratory setup in your Google Drive, feel free to skip this step.
1. Navigate here.
2. Click "New" > "More" > "Connect more apps".
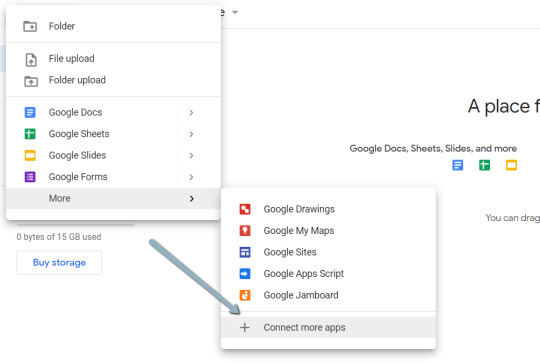
3. Search "Colaboratory" > Click into the application page.
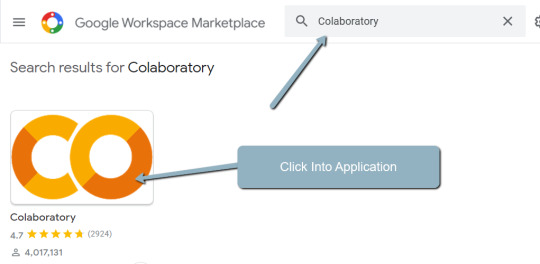
4. Click "Install" > "Continue" > Sign in with OAuth.
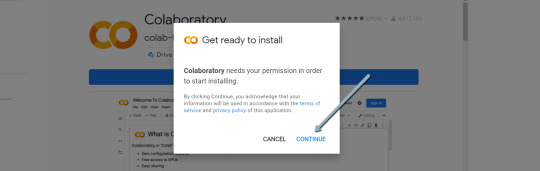
5. Click "OK" with the prompt checked so Google Drive automatically sets appropriate files to open with Google Colab (optional).

Import the downloaded folder to Google Drive & open in Colab
1. Navigate to Google Drive and create a folder called "Colab Notebooks".
IMPORTANT: The folder needs to be called "Colab Notebooks" as the script is configured to look for the "api" folder from within "Colab Notebooks".
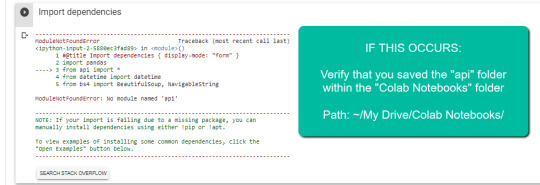
Error resulting in improper folder naming.
2. Import the folder downloaded from Github into Google Drive.
At the end of this step, you should have a folder in your Google Drive that contains the below items:

Part two: Set up a Google Cloud Platform (GCP) project
If you already have a Google Cloud Platform (GCP) account, feel free to skip this part.
1. Navigate to the Google Cloud page.
2. Click on the "Get started for free" CTA (CTA text may change over time).
3. Sign in with the OAuth credentials of your choice. Any Gmail email will work.
4. Follow the prompts to sign up for your GCP account.
You’ll be asked to supply a credit card to sign up, but there is currently a $300 free trial and Google notes that they won’t charge you until you upgrade your account.
Part three: Create a 0Auth 2.0 client ID for the Google Search Console (GSC) API
1. Navigate here.
2. After you log in to your desired Google Cloud account, click "ENABLE".
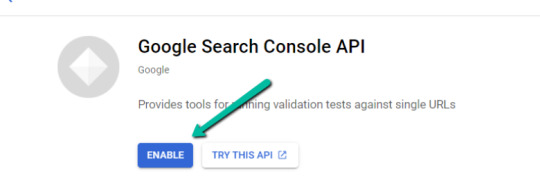
3. Configure the consent screen.
In the consent screen creation process, select "External," then continue onto the "App Information."
Example below of minimum requirements:
Skip "Scopes"
Add the email(s) you’ll use for the Search Console API authentication into the "Test Users". There could be other emails versus just the one that owns the Google Drive. An example may be a client’s email where you access the Google Search Console UI to view their KPIs.
4. In the left-rail navigation, click into "Credentials" > "CREATE CREDENTIALS" > "OAuth Client ID" (Not in image).
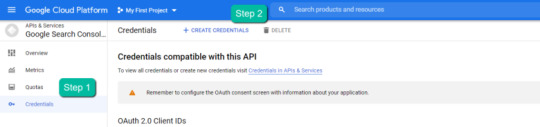
5. Within the "Create OAuth client ID" form, fill in:
Application Type = Desktop app
Name = Google Colab
Click "CREATE"
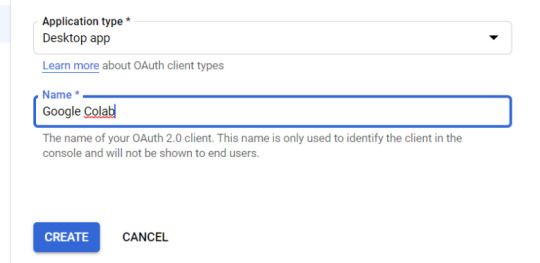
6. Save the "Client ID" and "Client Secret" — as these will be added into the "api" folder config.py file from the Github files we downloaded.
These should have appeared in a popup after hitting "CREATE"
The "Client Secret" is functionally the password to your Google Cloud (DO NOT post this to the public/share it online)
Part four: Add the OAuth 2.0 credentials to the Config.py file
1. Return to Google Drive and navigate into the "api" folder.
2. Click into config.py.

3. Choose to open with "Text Editor" (or another app of your choice) to modify the config.py file.
4. Update the three areas highlighted below with your:
CLIENT_ID: From the OAuth 2.0 client ID setup process
CLIENT_SECRET: From the OAuth 2.0 client ID setup process
GOOGLE_CREDENTIALS: Email that corresponds with your CLIENT_ID & CLIENT_SECRET

5. Save the file once updated!
Congratulations, the boring stuff is over. You are now ready to start using the Google Colab file!
Running your first analysis
Running your first analysis may be a little intimidating, but stick with it and it will get easy fast.
Below, we’ve provided details regarding the input variables required, as well as notes on things to keep in mind when running the script and analyzing the resulting dataset.
After we walk through these items, there are also a few example projects and video walkthroughs showcasing ways to utilize these datasets for client deliverables.
Setting up the input variables
XPath extraction with the "xpath_selector" variable
Have you ever wanted to know every query driving clicks and impressions to a webpage that aren’t in your <title> or <h1> tag? Well, this parameter will allow you to do just that.
While optional, using this is highly encouraged and we feel it "supercharges" the analysis. Simply define site sections with Xpaths and the script will do the rest.
youtube
In the above video, you’ll find examples on how to create site specific extractions. In addition, below are some universal extractions that should work on almost any site on the web:
'//title' # Identifies a <title> tag
'//h1' # Identifies a <h1> tag
'//h2' # Identifies a <h2> tag
Site Specific: How to scrape only the main content (MC)?
Chaining Xpaths – Add a "|" Between Xpaths
'//title | //h1' # Gets you both the <title> and <h1> tag in 1 run
'//h1 | //h2 | //h3' # Gets you both the <h1>, <h2> and <h3> tags in 1 run
Other variables
Here’s a video overview of the other variables with a short description of each.
youtube
'colab_path' [Required] – The path in which the Colab file lives. This should be "/content/drive/My Drive/Colab Notebooks/".
'domain_lookup' [Required] – Homepage of the website utilized for analysis.
'startdate' & 'enddate' [Required] – Date range for the analysis period.
'gsc_sorting_field' [Required] – The tool pulls the top N pages as defined by the user. The "top" is defined by either "clicks_sum" or "impressions_sum." Please review the video for a more detailed description.
'gsc_limit_pages_number' [Required] – Numeric value that represents the number of resulting pages you’d like within the dataset.
'brand_exclusions' [Optional] – The string sequence(s) that commonly result in branded queries (e.g., anything containing "inseev" will be branded queries for "Inseev Interactive").
'impressions_exclusion' [Optional] – Numeric value used to exclude queries that are potentially irrelevant due to the lack of pre-existing impressions. This is primarily relevant for domains with strong pre-existing rankings on a large scale number of pages.
'page_inclusions' [Optional] – The string sequence(s) that are found within the desired analysis page type. If you’d like to analyze the entire domain, leave this section blank.
Running the script
Keep in mind that once the script finishes running, you’re generally going to use the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file for analysis, but there are others with the raw datasets to browse as well.
Practical use cases for the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file can be found in the "Practical use cases and templates" section.
That said, there are a few important things to note while testing things out:
1. No JavaScript Crawling: As mentioned at the start of the post, this script is NOT set up for JavaScript crawling, so if your target website uses a JS frontend with client-side rendering to populate the main content (MC), the scrape will not be useful. However, the basic functionality of quickly getting the top XX (user-defined) queries and pages can still be useful by itself.
2. Google Drive / GSC API Auth: The first time you run the script in each new session it will prompt you to authenticate both the Google Drive and the Google Search Console credentials.
Google Drive authentication: Authenticate to whatever email is associated with the Google Drive with the script.
GSC authentication: Authenticate whichever email has permission to use the desired Google Search Console account.
If you attempt to authenticate and you get an error that looks like the one below, please revisit the "Add the email(s) you’ll use the Colab app with into the 'Test Users'" from Part 3, step 3 in the process above: setting up the consent screen.
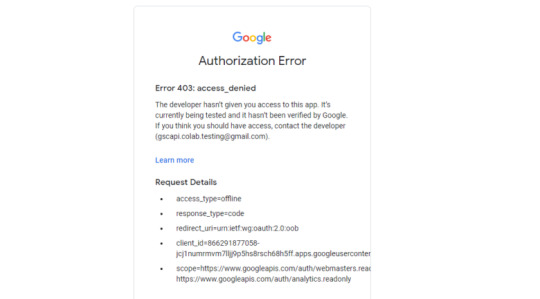
Quick tip: The Google Drive account and the GSC Authentication DO NOT have to be the same email, but they do require separate authentications with OAuth.
3. Running the script: Either navigate to "Runtime" > "Restart and Run All" or use the keyboard shortcut CTRL + fn9 to start running the script.
4. Populated datasets/folder structure: There are three CSVs populated by the script – all nested within a folder structure based on the "domain_lookup" input variable.
Automated Organization [Folders]: Each time you rerun the script on a new domain, it will create a new folder structure in order to keep things organized.
Automated Organization [File Naming]: The CSVs include the date of the export appended to the end, so you’ll always know when the process ran as well as the date range for the dataset.
5. Date range for dataset: Inside of the dataset there is a "gsc_datasetID" column generated, which includes the date range of the extraction.

6. Unfamiliar metrics: The resulting dataset has all the KPIs we know and love – e.g. clicks, impressions, average (mean) position — but there are also a few you cannot get directly from the GSC UI:
'count_instances_gsc' — the number of instances the query got at least 1 impression during the specified date range. Scenario example: GSC tells you that you were in an average position 6 for a large keyword like "flower delivery" and you only received 20 impressions in a 30-day date range. Doesn’t seem possible that you were really in position 6, right? Well, now you can see that was potentially because you only actually showed up on one day in that 30-day date range (e.g. count_instances_gsc = 1)
'max_position' & 'min_position' — the MAXIMUM and MINIMUM ranking position the identified page showed up for in Google Search within the specified date range.
Quick tip #1: Large variance in max/min may tell you that your keyword has been fluctuating heavily.
Quick tip #2: These KPIs, in conjunction with the "count_instances_gsc", can exponentially further your understanding of query performance and opportunity.
Practical use cases and templates
Access the recommended multi-use template.
Recommended use: Download file and use with Excel. Subjectively speaking, I believe Excel has a much more user friendly pivot table functionality in comparison to Google Sheets — which is critical for using this template.
Alternative use: If you do not have Microsoft Excel or you prefer a different tool, you can use most spreadsheet apps that contain pivot functionality.
For those who opt for an alternative spreadsheet software/app:
Below are the pivot fields to mimic upon setup.
You may have to adjust the Vlookup functions found on the "Step 3 _ Analysis Final Doc" tab, depending on whether your updated pivot columns align with the current pivot I’ve supplied.
Project example: Title & H1 re-optimizations (video walkthrough)
Project description: Locate keywords that are driving clicks and impressions to high value pages and that do not exist within the <title> and <h1> tags by reviewing GSC query KPIs vs. current page elements. Use the resulting findings to re-optimize both the <title> and <h1> tags for pre-existing pages.
Project assumptions: This process assumes that inserting keywords into both the <title> and <h1> tags is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Project example: On-page text refresh/re-optimization
Project description: Locate keywords that are driving clicks and impressions to editorial pieces of content that DO NOT exist within the first paragraph within the body of the main content (MC). Perform an on-page refresh of introductory content within editorial pages to include high value keyword opportunities.
Project assumptions: This process assumes that inserting keywords into the first several sentences of a piece of content is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Final thoughts
We hope this post has been helpful and opened you up to the idea of using Python and Google Colab to supercharge your relevancy optimization strategy.
As mentioned throughout the post, keep the following in mind:
Github repository will be updated with any changes we make in the future.
There is the possibility of undiscovered errors. If these occur, Inseev is happy to help! In fact, we would actually appreciate you reaching out to investigate and fix errors (if any do appear). This way others don’t run into the same problems.
Other than the above, if you have any ideas on ways to Colab (pun intended) on data analytics projects, feel free to reach out with ideas.
0 notes
Text
Page Level Query Analysis at Scale with Google Colab, Python, & the GSC API [Video Instructions Included]
The YouTube playlist referenced throughout this blog can be found here:6 Part YouTube Series [Setting Up & Using the Query Optimization Checker]
Anyone who does SEO as part of their job knows that there’s a lot of value in analyzing which queries are and are not sending traffic to specific pages on a site.
The most common uses for these datasets are to align on-page optimizations with existing rankings and traffic, and to identify gaps in ranking keywords.
However, working with this data is extremely tedious because it’s only available in the Google Search Console interface, and you have to look at only one page at a time.
On top of that, to get information on the text included in the ranking page, you either need to manually review it or extract it with a tool like Screaming Frog.
You need this kind of view:

…but even the above view would only be viable one page at a time, and as mentioned, the actual text extraction would have had to be separate as well.
Given these apparent issues with the readily available data at the SEO community’s disposal, the data engineering team at Inseev Interactive has been spending a lot of time thinking about how we can improve these processes at scale.
One specific example that we’ll be reviewing in this post is a simple script that allows you to get the above data in a flexible format for many great analytical views.
Better yet, this will all be available with only a few single input variables.
A quick rundown of tool functionality
The tool automatically compares the text on-page to the Google Search Console top queries at the page-level to let you know which queries are on-page as well as how many times they appear on the page. An optional XPath variable also allows you to specify the part of the page you want to analyze text on.
This means you’ll know exactly what queries are driving clicks/impressions that are not in your <title>, <h1>, or even something as specific as the first paragraph within the main content (MC). The sky's the limit.
For those of you not familiar, we’ve also provided some quick XPath expressions you can use, as well as how to create site-specific XPath expressions within the "Input Variables" section of the post.
Post setup usage & datasets
Once the process is set up, all that’s required is filling out a short list of variables and the rest is automated for you.
The output dataset includes multiple automated CSV datasets, as well as a structured file format to keep things organized. A simple pivot of the core analysis automated CSV can provide you with the below dataset and many other useful layouts.
… Even some "new metrics"?
Okay, not technically "new," but if you exclusively use the Google Search Console user interface, then you haven’t likely had access to metrics like these before: "Max Position," "Min Position," and "Count Position" for the specified date range – all of which are explained in the "Running your first analysis" section of the post.

To really demonstrate the impact and usefulness of this dataset, in the video below we use the Colab tool to:
[3 Minutes] — Find non-brand <title> optimization opportunities for https://www.inseev.com/ (around 30 pages in video, but you could do any number of pages)
[3 Minutes] — Convert the CSV to a more useable format
[1 Minute] – Optimize the first title with the resulting dataset
youtube
Okay, you’re all set for the initial rundown. Hopefully we were able to get you excited before moving into the somewhat dull setup process.
Keep in mind that at the end of the post, there is also a section including a few helpful use cases and an example template! To jump directly to each section of this post, please use the following links:
One-time setup of the script in Google Colab
Running your first analysis
Practical use cases and templates
[Quick Consideration #1] — The web scraper built into the tool DOES NOT support JavaScript rendering. If your website uses client-side rendering, the full functionality of the tool unfortunately will not work.
[Quick Consideration #2] — This tool has been heavily tested by the members of the Inseev team. Most bugs [specifically with the web scraper] have been found and fixed, but like any other program, it is possible that other issues may come up.
If you encounter any errors, feel free to reach out to us directly at [email protected] or [email protected], and either myself or one of the other members of the data engineering team at Inseev would be happy to help you out.
If new errors are encountered and fixed, we will always upload the updated script to the code repository linked in the sections below so the most up-to-date code can be utilized by all!
One-time setup of the script in Google Colab (in less than 20 minutes)
Things you’ll need:
Google Drive
Google Cloud Platform account
Google Search Console access
Video walkthrough: tool setup process
Below you’ll find step-by-step editorial instructions in order to set up the entire process. However, if following editorial instructions isn’t your preferred method, we recorded a video of the setup process as well.
As you’ll see, we start with a brand new Gmail and set up the entire process in approximately 12 minutes, and the output is completely worth the time.
youtube
Keep in mind that the setup is one-off, and once set up, the tool should work on command from there on!
Editorial walkthrough: tool setup process
Four-part process:
Download the files from Github and set up in Google Drive
Set up a Google Cloud Platform (GCP) Project (skip if you already have an account)
Create the OAuth 2.0 client ID for the Google Search Console (GSC) API (skip if you already have an OAuth client ID with the Search Console API enabled)
Add the OAuth 2.0 credentials to the Config.py file
Part one: Download the files from Github and set up in Google Drive
Download source files (no code required)
1. Navigate here.
2. Select "Code" > "Download Zip"
*You can also use 'git clone https://github.com/jmelm93/query-optmization-checker.git' if you’re more comfortable using the command prompt.
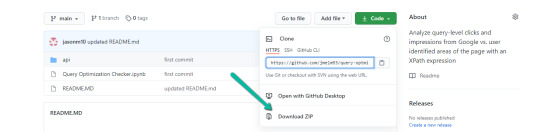
Initiate Google Colab in Google Drive
If you already have a Google Colaboratory setup in your Google Drive, feel free to skip this step.
1. Navigate here.
2. Click "New" > "More" > "Connect more apps".
3. Search "Colaboratory" > Click into the application page.

4. Click "Install" > "Continue" > Sign in with OAuth.
5. Click "OK" with the prompt checked so Google Drive automatically sets appropriate files to open with Google Colab (optional).

Import the downloaded folder to Google Drive & open in Colab
1. Navigate to Google Drive and create a folder called "Colab Notebooks".
IMPORTANT: The folder needs to be called "Colab Notebooks" as the script is configured to look for the "api" folder from within "Colab Notebooks".

Error resulting in improper folder naming.
2. Import the folder downloaded from Github into Google Drive.
At the end of this step, you should have a folder in your Google Drive that contains the below items:

Part two: Set up a Google Cloud Platform (GCP) project
If you already have a Google Cloud Platform (GCP) account, feel free to skip this part.
1. Navigate to the Google Cloud page.
2. Click on the "Get started for free" CTA (CTA text may change over time).
3. Sign in with the OAuth credentials of your choice. Any Gmail email will work.
4. Follow the prompts to sign up for your GCP account.
You’ll be asked to supply a credit card to sign up, but there is currently a $300 free trial and Google notes that they won’t charge you until you upgrade your account.
Part three: Create a 0Auth 2.0 client ID for the Google Search Console (GSC) API
1. Navigate here.
2. After you log in to your desired Google Cloud account, click "ENABLE".

3. Configure the consent screen.
In the consent screen creation process, select "External," then continue onto the "App Information."
Example below of minimum requirements:
Skip "Scopes"
Add the email(s) you’ll use for the Search Console API authentication into the "Test Users". There could be other emails versus just the one that owns the Google Drive. An example may be a client’s email where you access the Google Search Console UI to view their KPIs.

4. In the left-rail navigation, click into "Credentials" > "CREATE CREDENTIALS" > "OAuth Client ID" (Not in image).

5. Within the "Create OAuth client ID" form, fill in:
Application Type = Desktop app
Name = Google Colab
Click "CREATE"

6. Save the "Client ID" and "Client Secret" — as these will be added into the "api" folder config.py file from the Github files we downloaded.
These should have appeared in a popup after hitting "CREATE"
The "Client Secret" is functionally the password to your Google Cloud (DO NOT post this to the public/share it online)
Part four: Add the OAuth 2.0 credentials to the Config.py file
1. Return to Google Drive and navigate into the "api" folder.
2. Click into config.py.
3. Choose to open with "Text Editor" (or another app of your choice) to modify the config.py file.
4. Update the three areas highlighted below with your:
CLIENT_ID: From the OAuth 2.0 client ID setup process
CLIENT_SECRET: From the OAuth 2.0 client ID setup process
GOOGLE_CREDENTIALS: Email that corresponds with your CLIENT_ID & CLIENT_SECRET

5. Save the file once updated!
Congratulations, the boring stuff is over. You are now ready to start using the Google Colab file!
Running your first analysis
Running your first analysis may be a little intimidating, but stick with it and it will get easy fast.
Below, we’ve provided details regarding the input variables required, as well as notes on things to keep in mind when running the script and analyzing the resulting dataset.
After we walk through these items, there are also a few example projects and video walkthroughs showcasing ways to utilize these datasets for client deliverables.
Setting up the input variables
XPath extraction with the "xpath_selector" variable
Have you ever wanted to know every query driving clicks and impressions to a webpage that aren’t in your <title> or <h1> tag? Well, this parameter will allow you to do just that.
While optional, using this is highly encouraged and we feel it "supercharges" the analysis. Simply define site sections with Xpaths and the script will do the rest.
youtube
In the above video, you’ll find examples on how to create site specific extractions. In addition, below are some universal extractions that should work on almost any site on the web:
'//title' # Identifies a <title> tag
'//h1' # Identifies a <h1> tag
'//h2' # Identifies a <h2> tag
Site Specific: How to scrape only the main content (MC)?
Chaining Xpaths – Add a "|" Between Xpaths
'//title | //h1' # Gets you both the <title> and <h1> tag in 1 run
'//h1 | //h2 | //h3' # Gets you both the <h1>, <h2> and <h3> tags in 1 run
Other variables
Here’s a video overview of the other variables with a short description of each.
youtube
'colab_path' [Required] – The path in which the Colab file lives. This should be "/content/drive/My Drive/Colab Notebooks/".
'domain_lookup' [Required] – Homepage of the website utilized for analysis.
'startdate' & 'enddate' [Required] – Date range for the analysis period.
'gsc_sorting_field' [Required] – The tool pulls the top N pages as defined by the user. The "top" is defined by either "clicks_sum" or "impressions_sum." Please review the video for a more detailed description.
'gsc_limit_pages_number' [Required] – Numeric value that represents the number of resulting pages you’d like within the dataset.
'brand_exclusions' [Optional] – The string sequence(s) that commonly result in branded queries (e.g., anything containing "inseev" will be branded queries for "Inseev Interactive").
'impressions_exclusion' [Optional] – Numeric value used to exclude queries that are potentially irrelevant due to the lack of pre-existing impressions. This is primarily relevant for domains with strong pre-existing rankings on a large scale number of pages.
'page_inclusions' [Optional] – The string sequence(s) that are found within the desired analysis page type. If you’d like to analyze the entire domain, leave this section blank.
Running the script
Keep in mind that once the script finishes running, you’re generally going to use the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file for analysis, but there are others with the raw datasets to browse as well.
Practical use cases for the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file can be found in the "Practical use cases and templates" section.
That said, there are a few important things to note while testing things out:
1. No JavaScript Crawling: As mentioned at the start of the post, this script is NOT set up for JavaScript crawling, so if your target website uses a JS frontend with client-side rendering to populate the main content (MC), the scrape will not be useful. However, the basic functionality of quickly getting the top XX (user-defined) queries and pages can still be useful by itself.
2. Google Drive / GSC API Auth: The first time you run the script in each new session it will prompt you to authenticate both the Google Drive and the Google Search Console credentials.
Google Drive authentication: Authenticate to whatever email is associated with the Google Drive with the script.
GSC authentication: Authenticate whichever email has permission to use the desired Google Search Console account.
If you attempt to authenticate and you get an error that looks like the one below, please revisit the "Add the email(s) you’ll use the Colab app with into the 'Test Users'" from Part 3, step 3 in the process above: setting up the consent screen.

Quick tip: The Google Drive account and the GSC Authentication DO NOT have to be the same email, but they do require separate authentications with OAuth.
3. Running the script: Either navigate to "Runtime" > "Restart and Run All" or use the keyboard shortcut CTRL + fn9 to start running the script.
4. Populated datasets/folder structure: There are three CSVs populated by the script – all nested within a folder structure based on the "domain_lookup" input variable.
Automated Organization [Folders]: Each time you rerun the script on a new domain, it will create a new folder structure in order to keep things organized.
Automated Organization [File Naming]: The CSVs include the date of the export appended to the end, so you’ll always know when the process ran as well as the date range for the dataset.
5. Date range for dataset: Inside of the dataset there is a "gsc_datasetID" column generated, which includes the date range of the extraction.

6. Unfamiliar metrics: The resulting dataset has all the KPIs we know and love – e.g. clicks, impressions, average (mean) position — but there are also a few you cannot get directly from the GSC UI:
'count_instances_gsc' — the number of instances the query got at least 1 impression during the specified date range. Scenario example: GSC tells you that you were in an average position 6 for a large keyword like "flower delivery" and you only received 20 impressions in a 30-day date range. Doesn’t seem possible that you were really in position 6, right? Well, now you can see that was potentially because you only actually showed up on one day in that 30-day date range (e.g. count_instances_gsc = 1)
'max_position' & 'min_position' — the MAXIMUM and MINIMUM ranking position the identified page showed up for in Google Search within the specified date range.
Quick tip #1: Large variance in max/min may tell you that your keyword has been fluctuating heavily.
Quick tip #2: These KPIs, in conjunction with the "count_instances_gsc", can exponentially further your understanding of query performance and opportunity.
Practical use cases and templates
Access the recommended multi-use template.
Recommended use: Download file and use with Excel. Subjectively speaking, I believe Excel has a much more user friendly pivot table functionality in comparison to Google Sheets — which is critical for using this template.
Alternative use: If you do not have Microsoft Excel or you prefer a different tool, you can use most spreadsheet apps that contain pivot functionality.
For those who opt for an alternative spreadsheet software/app:
Below are the pivot fields to mimic upon setup.
You may have to adjust the Vlookup functions found on the "Step 3 _ Analysis Final Doc" tab, depending on whether your updated pivot columns align with the current pivot I’ve supplied.
Project example: Title & H1 re-optimizations (video walkthrough)
Project description: Locate keywords that are driving clicks and impressions to high value pages and that do not exist within the <title> and <h1> tags by reviewing GSC query KPIs vs. current page elements. Use the resulting findings to re-optimize both the <title> and <h1> tags for pre-existing pages.
Project assumptions: This process assumes that inserting keywords into both the <title> and <h1> tags is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Project example: On-page text refresh/re-optimization
Project description: Locate keywords that are driving clicks and impressions to editorial pieces of content that DO NOT exist within the first paragraph within the body of the main content (MC). Perform an on-page refresh of introductory content within editorial pages to include high value keyword opportunities.
Project assumptions: This process assumes that inserting keywords into the first several sentences of a piece of content is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Final thoughts
We hope this post has been helpful and opened you up to the idea of using Python and Google Colab to supercharge your relevancy optimization strategy.
As mentioned throughout the post, keep the following in mind:
Github repository will be updated with any changes we make in the future.
There is the possibility of undiscovered errors. If these occur, Inseev is happy to help! In fact, we would actually appreciate you reaching out to investigate and fix errors (if any do appear). This way others don’t run into the same problems.
Other than the above, if you have any ideas on ways to Colab (pun intended) on data analytics projects, feel free to reach out with ideas.
0 notes
Text
Page Level Query Analysis at Scale with Google Colab, Python, & the GSC API [Video Instructions Included]
The YouTube playlist referenced throughout this blog can be found here:6 Part YouTube Series [Setting Up & Using the Query Optimization Checker]
Anyone who does SEO as part of their job knows that there’s a lot of value in analyzing which queries are and are not sending traffic to specific pages on a site.
The most common uses for these datasets are to align on-page optimizations with existing rankings and traffic, and to identify gaps in ranking keywords.
However, working with this data is extremely tedious because it’s only available in the Google Search Console interface, and you have to look at only one page at a time.
On top of that, to get information on the text included in the ranking page, you either need to manually review it or extract it with a tool like Screaming Frog.
You need this kind of view:
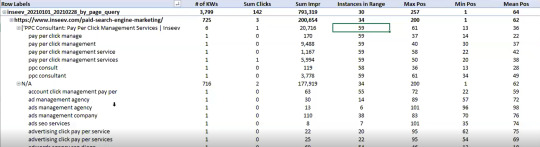
…but even the above view would only be viable one page at a time, and as mentioned, the actual text extraction would have had to be separate as well.
Given these apparent issues with the readily available data at the SEO community’s disposal, the data engineering team at Inseev Interactive has been spending a lot of time thinking about how we can improve these processes at scale.
One specific example that we’ll be reviewing in this post is a simple script that allows you to get the above data in a flexible format for many great analytical views.
Better yet, this will all be available with only a few single input variables.
A quick rundown of tool functionality
The tool automatically compares the text on-page to the Google Search Console top queries at the page-level to let you know which queries are on-page as well as how many times they appear on the page. An optional XPath variable also allows you to specify the part of the page you want to analyze text on.
This means you’ll know exactly what queries are driving clicks/impressions that are not in your <title>, <h1>, or even something as specific as the first paragraph within the main content (MC). The sky's the limit.
For those of you not familiar, we’ve also provided some quick XPath expressions you can use, as well as how to create site-specific XPath expressions within the "Input Variables" section of the post.
Post setup usage & datasets
Once the process is set up, all that’s required is filling out a short list of variables and the rest is automated for you.
The output dataset includes multiple automated CSV datasets, as well as a structured file format to keep things organized. A simple pivot of the core analysis automated CSV can provide you with the below dataset and many other useful layouts.
… Even some "new metrics"?
Okay, not technically "new," but if you exclusively use the Google Search Console user interface, then you haven’t likely had access to metrics like these before: "Max Position," "Min Position," and "Count Position" for the specified date range – all of which are explained in the "Running your first analysis" section of the post.

To really demonstrate the impact and usefulness of this dataset, in the video below we use the Colab tool to:
[3 Minutes] — Find non-brand <title> optimization opportunities for https://www.inseev.com/ (around 30 pages in video, but you could do any number of pages)
[3 Minutes] — Convert the CSV to a more useable format
[1 Minute] – Optimize the first title with the resulting dataset
youtube
Okay, you’re all set for the initial rundown. Hopefully we were able to get you excited before moving into the somewhat dull setup process.
Keep in mind that at the end of the post, there is also a section including a few helpful use cases and an example template! To jump directly to each section of this post, please use the following links:
One-time setup of the script in Google Colab
Running your first analysis
Practical use cases and templates
[Quick Consideration #1] — The web scraper built into the tool DOES NOT support JavaScript rendering. If your website uses client-side rendering, the full functionality of the tool unfortunately will not work.
[Quick Consideration #2] — This tool has been heavily tested by the members of the Inseev team. Most bugs [specifically with the web scraper] have been found and fixed, but like any other program, it is possible that other issues may come up.
If you encounter any errors, feel free to reach out to us directly at [email protected] or [email protected], and either myself or one of the other members of the data engineering team at Inseev would be happy to help you out.
If new errors are encountered and fixed, we will always upload the updated script to the code repository linked in the sections below so the most up-to-date code can be utilized by all!
One-time setup of the script in Google Colab (in less than 20 minutes)
Things you’ll need:
Google Drive
Google Cloud Platform account
Google Search Console access
Video walkthrough: tool setup process
Below you’ll find step-by-step editorial instructions in order to set up the entire process. However, if following editorial instructions isn’t your preferred method, we recorded a video of the setup process as well.
As you’ll see, we start with a brand new Gmail and set up the entire process in approximately 12 minutes, and the output is completely worth the time.
youtube
Keep in mind that the setup is one-off, and once set up, the tool should work on command from there on!
Editorial walkthrough: tool setup process
Four-part process:
Download the files from Github and set up in Google Drive
Set up a Google Cloud Platform (GCP) Project (skip if you already have an account)
Create the OAuth 2.0 client ID for the Google Search Console (GSC) API (skip if you already have an OAuth client ID with the Search Console API enabled)
Add the OAuth 2.0 credentials to the Config.py file
Part one: Download the files from Github and set up in Google Drive
Download source files (no code required)
1. Navigate here.
2. Select "Code" > "Download Zip"
*You can also use 'git clone https://github.com/jmelm93/query-optmization-checker.git' if you’re more comfortable using the command prompt.
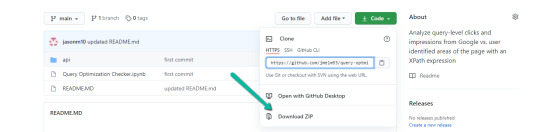
Initiate Google Colab in Google Drive
If you already have a Google Colaboratory setup in your Google Drive, feel free to skip this step.
1. Navigate here.
2. Click "New" > "More" > "Connect more apps".
3. Search "Colaboratory" > Click into the application page.
4. Click "Install" > "Continue" > Sign in with OAuth.
5. Click "OK" with the prompt checked so Google Drive automatically sets appropriate files to open with Google Colab (optional).

Import the downloaded folder to Google Drive & open in Colab
1. Navigate to Google Drive and create a folder called "Colab Notebooks".
IMPORTANT: The folder needs to be called "Colab Notebooks" as the script is configured to look for the "api" folder from within "Colab Notebooks".

Error resulting in improper folder naming.
2. Import the folder downloaded from Github into Google Drive.
At the end of this step, you should have a folder in your Google Drive that contains the below items:
Part two: Set up a Google Cloud Platform (GCP) project
If you already have a Google Cloud Platform (GCP) account, feel free to skip this part.
1. Navigate to the Google Cloud page.
2. Click on the "Get started for free" CTA (CTA text may change over time).
3. Sign in with the OAuth credentials of your choice. Any Gmail email will work.
4. Follow the prompts to sign up for your GCP account.
You’ll be asked to supply a credit card to sign up, but there is currently a $300 free trial and Google notes that they won’t charge you until you upgrade your account.
Part three: Create a 0Auth 2.0 client ID for the Google Search Console (GSC) API
1. Navigate here.
2. After you log in to your desired Google Cloud account, click "ENABLE".

3. Configure the consent screen.
In the consent screen creation process, select "External," then continue onto the "App Information."
Example below of minimum requirements:
Skip "Scopes"
Add the email(s) you’ll use for the Search Console API authentication into the "Test Users". There could be other emails versus just the one that owns the Google Drive. An example may be a client’s email where you access the Google Search Console UI to view their KPIs.

4. In the left-rail navigation, click into "Credentials" > "CREATE CREDENTIALS" > "OAuth Client ID" (Not in image).
5. Within the "Create OAuth client ID" form, fill in:
Application Type = Desktop app
Name = Google Colab
Click "CREATE"
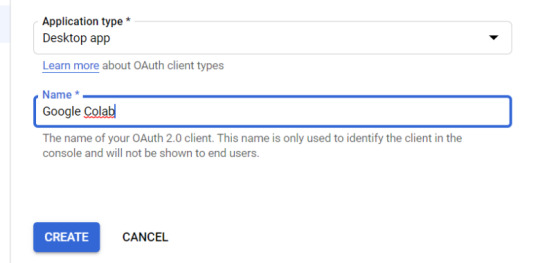
6. Save the "Client ID" and "Client Secret" — as these will be added into the "api" folder config.py file from the Github files we downloaded.
These should have appeared in a popup after hitting "CREATE"
The "Client Secret" is functionally the password to your Google Cloud (DO NOT post this to the public/share it online)
Part four: Add the OAuth 2.0 credentials to the Config.py file
1. Return to Google Drive and navigate into the "api" folder.
2. Click into config.py.
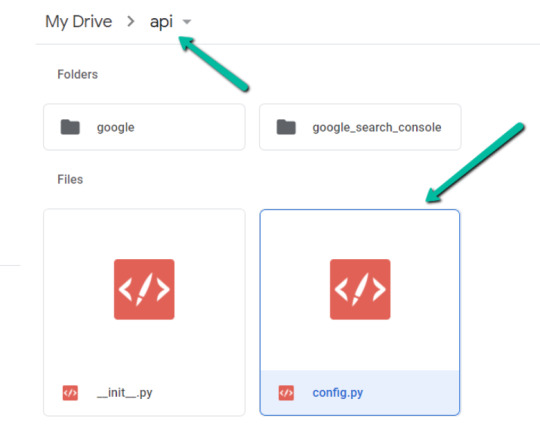
3. Choose to open with "Text Editor" (or another app of your choice) to modify the config.py file.

4. Update the three areas highlighted below with your:
CLIENT_ID: From the OAuth 2.0 client ID setup process
CLIENT_SECRET: From the OAuth 2.0 client ID setup process
GOOGLE_CREDENTIALS: Email that corresponds with your CLIENT_ID & CLIENT_SECRET
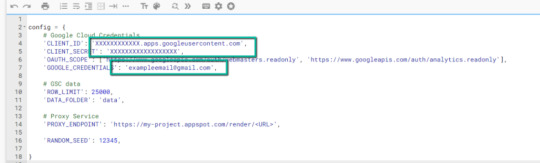
5. Save the file once updated!
Congratulations, the boring stuff is over. You are now ready to start using the Google Colab file!
Running your first analysis
Running your first analysis may be a little intimidating, but stick with it and it will get easy fast.
Below, we’ve provided details regarding the input variables required, as well as notes on things to keep in mind when running the script and analyzing the resulting dataset.
After we walk through these items, there are also a few example projects and video walkthroughs showcasing ways to utilize these datasets for client deliverables.
Setting up the input variables
XPath extraction with the "xpath_selector" variable
Have you ever wanted to know every query driving clicks and impressions to a webpage that aren’t in your <title> or <h1> tag? Well, this parameter will allow you to do just that.
While optional, using this is highly encouraged and we feel it "supercharges" the analysis. Simply define site sections with Xpaths and the script will do the rest.
youtube
In the above video, you’ll find examples on how to create site specific extractions. In addition, below are some universal extractions that should work on almost any site on the web:
'//title' # Identifies a <title> tag
'//h1' # Identifies a <h1> tag
'//h2' # Identifies a <h2> tag
Site Specific: How to scrape only the main content (MC)?
Chaining Xpaths – Add a "|" Between Xpaths
'//title | //h1' # Gets you both the <title> and <h1> tag in 1 run
'//h1 | //h2 | //h3' # Gets you both the <h1>, <h2> and <h3> tags in 1 run
Other variables
Here’s a video overview of the other variables with a short description of each.
youtube
'colab_path' [Required] – The path in which the Colab file lives. This should be "/content/drive/My Drive/Colab Notebooks/".
'domain_lookup' [Required] – Homepage of the website utilized for analysis.
'startdate' & 'enddate' [Required] – Date range for the analysis period.
'gsc_sorting_field' [Required] – The tool pulls the top N pages as defined by the user. The "top" is defined by either "clicks_sum" or "impressions_sum." Please review the video for a more detailed description.
'gsc_limit_pages_number' [Required] – Numeric value that represents the number of resulting pages you’d like within the dataset.
'brand_exclusions' [Optional] – The string sequence(s) that commonly result in branded queries (e.g., anything containing "inseev" will be branded queries for "Inseev Interactive").
'impressions_exclusion' [Optional] – Numeric value used to exclude queries that are potentially irrelevant due to the lack of pre-existing impressions. This is primarily relevant for domains with strong pre-existing rankings on a large scale number of pages.
'page_inclusions' [Optional] – The string sequence(s) that are found within the desired analysis page type. If you’d like to analyze the entire domain, leave this section blank.
Running the script
Keep in mind that once the script finishes running, you’re generally going to use the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file for analysis, but there are others with the raw datasets to browse as well.
Practical use cases for the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file can be found in the "Practical use cases and templates" section.
That said, there are a few important things to note while testing things out:
1. No JavaScript Crawling: As mentioned at the start of the post, this script is NOT set up for JavaScript crawling, so if your target website uses a JS frontend with client-side rendering to populate the main content (MC), the scrape will not be useful. However, the basic functionality of quickly getting the top XX (user-defined) queries and pages can still be useful by itself.
2. Google Drive / GSC API Auth: The first time you run the script in each new session it will prompt you to authenticate both the Google Drive and the Google Search Console credentials.
Google Drive authentication: Authenticate to whatever email is associated with the Google Drive with the script.
GSC authentication: Authenticate whichever email has permission to use the desired Google Search Console account.
If you attempt to authenticate and you get an error that looks like the one below, please revisit the "Add the email(s) you’ll use the Colab app with into the 'Test Users'" from Part 3, step 3 in the process above: setting up the consent screen.

Quick tip: The Google Drive account and the GSC Authentication DO NOT have to be the same email, but they do require separate authentications with OAuth.
3. Running the script: Either navigate to "Runtime" > "Restart and Run All" or use the keyboard shortcut CTRL + fn9 to start running the script.
4. Populated datasets/folder structure: There are three CSVs populated by the script – all nested within a folder structure based on the "domain_lookup" input variable.
Automated Organization [Folders]: Each time you rerun the script on a new domain, it will create a new folder structure in order to keep things organized.
Automated Organization [File Naming]: The CSVs include the date of the export appended to the end, so you’ll always know when the process ran as well as the date range for the dataset.
5. Date range for dataset: Inside of the dataset there is a "gsc_datasetID" column generated, which includes the date range of the extraction.

6. Unfamiliar metrics: The resulting dataset has all the KPIs we know and love – e.g. clicks, impressions, average (mean) position — but there are also a few you cannot get directly from the GSC UI:
'count_instances_gsc' — the number of instances the query got at least 1 impression during the specified date range. Scenario example: GSC tells you that you were in an average position 6 for a large keyword like "flower delivery" and you only received 20 impressions in a 30-day date range. Doesn’t seem possible that you were really in position 6, right? Well, now you can see that was potentially because you only actually showed up on one day in that 30-day date range (e.g. count_instances_gsc = 1)
'max_position' & 'min_position' — the MAXIMUM and MINIMUM ranking position the identified page showed up for in Google Search within the specified date range.
Quick tip #1: Large variance in max/min may tell you that your keyword has been fluctuating heavily.
Quick tip #2: These KPIs, in conjunction with the "count_instances_gsc", can exponentially further your understanding of query performance and opportunity.
Practical use cases and templates
Access the recommended multi-use template.
Recommended use: Download file and use with Excel. Subjectively speaking, I believe Excel has a much more user friendly pivot table functionality in comparison to Google Sheets — which is critical for using this template.
Alternative use: If you do not have Microsoft Excel or you prefer a different tool, you can use most spreadsheet apps that contain pivot functionality.
For those who opt for an alternative spreadsheet software/app:
Below are the pivot fields to mimic upon setup.
You may have to adjust the Vlookup functions found on the "Step 3 _ Analysis Final Doc" tab, depending on whether your updated pivot columns align with the current pivot I’ve supplied.
Project example: Title & H1 re-optimizations (video walkthrough)
Project description: Locate keywords that are driving clicks and impressions to high value pages and that do not exist within the <title> and <h1> tags by reviewing GSC query KPIs vs. current page elements. Use the resulting findings to re-optimize both the <title> and <h1> tags for pre-existing pages.
Project assumptions: This process assumes that inserting keywords into both the <title> and <h1> tags is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Project example: On-page text refresh/re-optimization
Project description: Locate keywords that are driving clicks and impressions to editorial pieces of content that DO NOT exist within the first paragraph within the body of the main content (MC). Perform an on-page refresh of introductory content within editorial pages to include high value keyword opportunities.
Project assumptions: This process assumes that inserting keywords into the first several sentences of a piece of content is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Final thoughts
We hope this post has been helpful and opened you up to the idea of using Python and Google Colab to supercharge your relevancy optimization strategy.
As mentioned throughout the post, keep the following in mind:
Github repository will be updated with any changes we make in the future.
There is the possibility of undiscovered errors. If these occur, Inseev is happy to help! In fact, we would actually appreciate you reaching out to investigate and fix errors (if any do appear). This way others don’t run into the same problems.
Other than the above, if you have any ideas on ways to Colab (pun intended) on data analytics projects, feel free to reach out with ideas.
0 notes
Text
Page Level Query Analysis at Scale with Google Colab, Python, & the GSC API [Video Instructions Included]
The YouTube playlist referenced throughout this blog can be found here:6 Part YouTube Series [Setting Up & Using the Query Optimization Checker]
Anyone who does SEO as part of their job knows that there’s a lot of value in analyzing which queries are and are not sending traffic to specific pages on a site.
The most common uses for these datasets are to align on-page optimizations with existing rankings and traffic, and to identify gaps in ranking keywords.
However, working with this data is extremely tedious because it’s only available in the Google Search Console interface, and you have to look at only one page at a time.
On top of that, to get information on the text included in the ranking page, you either need to manually review it or extract it with a tool like Screaming Frog.
You need this kind of view:

…but even the above view would only be viable one page at a time, and as mentioned, the actual text extraction would have had to be separate as well.
Given these apparent issues with the readily available data at the SEO community’s disposal, the data engineering team at Inseev Interactive has been spending a lot of time thinking about how we can improve these processes at scale.
One specific example that we’ll be reviewing in this post is a simple script that allows you to get the above data in a flexible format for many great analytical views.
Better yet, this will all be available with only a few single input variables.
A quick rundown of tool functionality
The tool automatically compares the text on-page to the Google Search Console top queries at the page-level to let you know which queries are on-page as well as how many times they appear on the page. An optional XPath variable also allows you to specify the part of the page you want to analyze text on.
This means you’ll know exactly what queries are driving clicks/impressions that are not in your <title>, <h1>, or even something as specific as the first paragraph within the main content (MC). The sky's the limit.
For those of you not familiar, we’ve also provided some quick XPath expressions you can use, as well as how to create site-specific XPath expressions within the "Input Variables" section of the post.
Post setup usage & datasets
Once the process is set up, all that’s required is filling out a short list of variables and the rest is automated for you.
The output dataset includes multiple automated CSV datasets, as well as a structured file format to keep things organized. A simple pivot of the core analysis automated CSV can provide you with the below dataset and many other useful layouts.
… Even some "new metrics"?
Okay, not technically "new," but if you exclusively use the Google Search Console user interface, then you haven’t likely had access to metrics like these before: "Max Position," "Min Position," and "Count Position" for the specified date range – all of which are explained in the "Running your first analysis" section of the post.

To really demonstrate the impact and usefulness of this dataset, in the video below we use the Colab tool to:
[3 Minutes] — Find non-brand <title> optimization opportunities for https://www.inseev.com/ (around 30 pages in video, but you could do any number of pages)
[3 Minutes] — Convert the CSV to a more useable format
[1 Minute] – Optimize the first title with the resulting dataset
youtube
Okay, you’re all set for the initial rundown. Hopefully we were able to get you excited before moving into the somewhat dull setup process.
Keep in mind that at the end of the post, there is also a section including a few helpful use cases and an example template! To jump directly to each section of this post, please use the following links:
One-time setup of the script in Google Colab
Running your first analysis
Practical use cases and templates
[Quick Consideration #1] — The web scraper built into the tool DOES NOT support JavaScript rendering. If your website uses client-side rendering, the full functionality of the tool unfortunately will not work.
[Quick Consideration #2] — This tool has been heavily tested by the members of the Inseev team. Most bugs [specifically with the web scraper] have been found and fixed, but like any other program, it is possible that other issues may come up.
If you encounter any errors, feel free to reach out to us directly at [email protected] or [email protected], and either myself or one of the other members of the data engineering team at Inseev would be happy to help you out.
If new errors are encountered and fixed, we will always upload the updated script to the code repository linked in the sections below so the most up-to-date code can be utilized by all!
One-time setup of the script in Google Colab (in less than 20 minutes)
Things you’ll need:
Google Drive
Google Cloud Platform account
Google Search Console access
Video walkthrough: tool setup process
Below you’ll find step-by-step editorial instructions in order to set up the entire process. However, if following editorial instructions isn’t your preferred method, we recorded a video of the setup process as well.
As you’ll see, we start with a brand new Gmail and set up the entire process in approximately 12 minutes, and the output is completely worth the time.
youtube
Keep in mind that the setup is one-off, and once set up, the tool should work on command from there on!
Editorial walkthrough: tool setup process
Four-part process:
Download the files from Github and set up in Google Drive
Set up a Google Cloud Platform (GCP) Project (skip if you already have an account)
Create the OAuth 2.0 client ID for the Google Search Console (GSC) API (skip if you already have an OAuth client ID with the Search Console API enabled)
Add the OAuth 2.0 credentials to the Config.py file
Part one: Download the files from Github and set up in Google Drive
Download source files (no code required)
1. Navigate here.
2. Select "Code" > "Download Zip"
*You can also use 'git clone https://github.com/jmelm93/query-optmization-checker.git' if you’re more comfortable using the command prompt.
Initiate Google Colab in Google Drive
If you already have a Google Colaboratory setup in your Google Drive, feel free to skip this step.
1. Navigate here.
2. Click "New" > "More" > "Connect more apps".
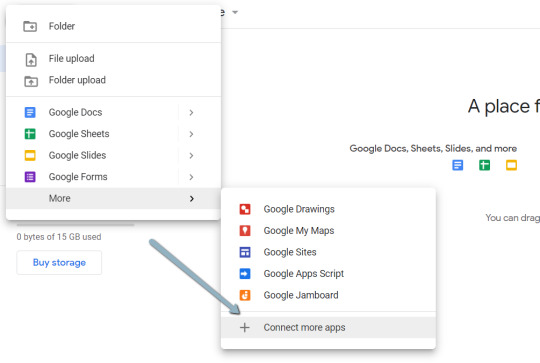
3. Search "Colaboratory" > Click into the application page.

4. Click "Install" > "Continue" > Sign in with OAuth.

5. Click "OK" with the prompt checked so Google Drive automatically sets appropriate files to open with Google Colab (optional).

Import the downloaded folder to Google Drive & open in Colab
1. Navigate to Google Drive and create a folder called "Colab Notebooks".
IMPORTANT: The folder needs to be called "Colab Notebooks" as the script is configured to look for the "api" folder from within "Colab Notebooks".
Error resulting in improper folder naming.
2. Import the folder downloaded from Github into Google Drive.
At the end of this step, you should have a folder in your Google Drive that contains the below items:
Part two: Set up a Google Cloud Platform (GCP) project
If you already have a Google Cloud Platform (GCP) account, feel free to skip this part.
1. Navigate to the Google Cloud page.
2. Click on the "Get started for free" CTA (CTA text may change over time).
3. Sign in with the OAuth credentials of your choice. Any Gmail email will work.
4. Follow the prompts to sign up for your GCP account.
You’ll be asked to supply a credit card to sign up, but there is currently a $300 free trial and Google notes that they won’t charge you until you upgrade your account.
Part three: Create a 0Auth 2.0 client ID for the Google Search Console (GSC) API
1. Navigate here.
2. After you log in to your desired Google Cloud account, click "ENABLE".
3. Configure the consent screen.
In the consent screen creation process, select "External," then continue onto the "App Information."
Example below of minimum requirements:

Skip "Scopes"
Add the email(s) you’ll use for the Search Console API authentication into the "Test Users". There could be other emails versus just the one that owns the Google Drive. An example may be a client’s email where you access the Google Search Console UI to view their KPIs.

4. In the left-rail navigation, click into "Credentials" > "CREATE CREDENTIALS" > "OAuth Client ID" (Not in image).

5. Within the "Create OAuth client ID" form, fill in:
Application Type = Desktop app
Name = Google Colab
Click "CREATE"
6. Save the "Client ID" and "Client Secret" — as these will be added into the "api" folder config.py file from the Github files we downloaded.
These should have appeared in a popup after hitting "CREATE"
The "Client Secret" is functionally the password to your Google Cloud (DO NOT post this to the public/share it online)
Part four: Add the OAuth 2.0 credentials to the Config.py file
1. Return to Google Drive and navigate into the "api" folder.
2. Click into config.py.

3. Choose to open with "Text Editor" (or another app of your choice) to modify the config.py file.
4. Update the three areas highlighted below with your:
CLIENT_ID: From the OAuth 2.0 client ID setup process
CLIENT_SECRET: From the OAuth 2.0 client ID setup process
GOOGLE_CREDENTIALS: Email that corresponds with your CLIENT_ID & CLIENT_SECRET

5. Save the file once updated!
Congratulations, the boring stuff is over. You are now ready to start using the Google Colab file!
Running your first analysis
Running your first analysis may be a little intimidating, but stick with it and it will get easy fast.
Below, we’ve provided details regarding the input variables required, as well as notes on things to keep in mind when running the script and analyzing the resulting dataset.
After we walk through these items, there are also a few example projects and video walkthroughs showcasing ways to utilize these datasets for client deliverables.
Setting up the input variables
XPath extraction with the "xpath_selector" variable
Have you ever wanted to know every query driving clicks and impressions to a webpage that aren’t in your <title> or <h1> tag? Well, this parameter will allow you to do just that.
While optional, using this is highly encouraged and we feel it "supercharges" the analysis. Simply define site sections with Xpaths and the script will do the rest.
youtube
In the above video, you’ll find examples on how to create site specific extractions. In addition, below are some universal extractions that should work on almost any site on the web:
'//title' # Identifies a <title> tag
'//h1' # Identifies a <h1> tag
'//h2' # Identifies a <h2> tag
Site Specific: How to scrape only the main content (MC)?
Chaining Xpaths – Add a "|" Between Xpaths
'//title | //h1' # Gets you both the <title> and <h1> tag in 1 run
'//h1 | //h2 | //h3' # Gets you both the <h1>, <h2> and <h3> tags in 1 run
Other variables
Here’s a video overview of the other variables with a short description of each.
youtube
'colab_path' [Required] – The path in which the Colab file lives. This should be "/content/drive/My Drive/Colab Notebooks/".
'domain_lookup' [Required] – Homepage of the website utilized for analysis.
'startdate' & 'enddate' [Required] – Date range for the analysis period.
'gsc_sorting_field' [Required] – The tool pulls the top N pages as defined by the user. The "top" is defined by either "clicks_sum" or "impressions_sum." Please review the video for a more detailed description.
'gsc_limit_pages_number' [Required] – Numeric value that represents the number of resulting pages you’d like within the dataset.
'brand_exclusions' [Optional] – The string sequence(s) that commonly result in branded queries (e.g., anything containing "inseev" will be branded queries for "Inseev Interactive").
'impressions_exclusion' [Optional] – Numeric value used to exclude queries that are potentially irrelevant due to the lack of pre-existing impressions. This is primarily relevant for domains with strong pre-existing rankings on a large scale number of pages.
'page_inclusions' [Optional] – The string sequence(s) that are found within the desired analysis page type. If you’d like to analyze the entire domain, leave this section blank.
Running the script
Keep in mind that once the script finishes running, you’re generally going to use the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file for analysis, but there are others with the raw datasets to browse as well.
Practical use cases for the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file can be found in the "Practical use cases and templates" section.
That said, there are a few important things to note while testing things out:
1. No JavaScript Crawling: As mentioned at the start of the post, this script is NOT set up for JavaScript crawling, so if your target website uses a JS frontend with client-side rendering to populate the main content (MC), the scrape will not be useful. However, the basic functionality of quickly getting the top XX (user-defined) queries and pages can still be useful by itself.
2. Google Drive / GSC API Auth: The first time you run the script in each new session it will prompt you to authenticate both the Google Drive and the Google Search Console credentials.
Google Drive authentication: Authenticate to whatever email is associated with the Google Drive with the script.
GSC authentication: Authenticate whichever email has permission to use the desired Google Search Console account.
If you attempt to authenticate and you get an error that looks like the one below, please revisit the "Add the email(s) you’ll use the Colab app with into the 'Test Users'" from Part 3, step 3 in the process above: setting up the consent screen.

Quick tip: The Google Drive account and the GSC Authentication DO NOT have to be the same email, but they do require separate authentications with OAuth.
3. Running the script: Either navigate to "Runtime" > "Restart and Run All" or use the keyboard shortcut CTRL + fn9 to start running the script.
4. Populated datasets/folder structure: There are three CSVs populated by the script – all nested within a folder structure based on the "domain_lookup" input variable.
Automated Organization [Folders]: Each time you rerun the script on a new domain, it will create a new folder structure in order to keep things organized.
Automated Organization [File Naming]: The CSVs include the date of the export appended to the end, so you’ll always know when the process ran as well as the date range for the dataset.
5. Date range for dataset: Inside of the dataset there is a "gsc_datasetID" column generated, which includes the date range of the extraction.

6. Unfamiliar metrics: The resulting dataset has all the KPIs we know and love – e.g. clicks, impressions, average (mean) position — but there are also a few you cannot get directly from the GSC UI:
'count_instances_gsc' — the number of instances the query got at least 1 impression during the specified date range. Scenario example: GSC tells you that you were in an average position 6 for a large keyword like "flower delivery" and you only received 20 impressions in a 30-day date range. Doesn’t seem possible that you were really in position 6, right? Well, now you can see that was potentially because you only actually showed up on one day in that 30-day date range (e.g. count_instances_gsc = 1)
'max_position' & 'min_position' — the MAXIMUM and MINIMUM ranking position the identified page showed up for in Google Search within the specified date range.
Quick tip #1: Large variance in max/min may tell you that your keyword has been fluctuating heavily.
Quick tip #2: These KPIs, in conjunction with the "count_instances_gsc", can exponentially further your understanding of query performance and opportunity.
Practical use cases and templates
Access the recommended multi-use template.
Recommended use: Download file and use with Excel. Subjectively speaking, I believe Excel has a much more user friendly pivot table functionality in comparison to Google Sheets — which is critical for using this template.
Alternative use: If you do not have Microsoft Excel or you prefer a different tool, you can use most spreadsheet apps that contain pivot functionality.
For those who opt for an alternative spreadsheet software/app:
Below are the pivot fields to mimic upon setup.
You may have to adjust the Vlookup functions found on the "Step 3 _ Analysis Final Doc" tab, depending on whether your updated pivot columns align with the current pivot I’ve supplied.
Project example: Title & H1 re-optimizations (video walkthrough)
Project description: Locate keywords that are driving clicks and impressions to high value pages and that do not exist within the <title> and <h1> tags by reviewing GSC query KPIs vs. current page elements. Use the resulting findings to re-optimize both the <title> and <h1> tags for pre-existing pages.
Project assumptions: This process assumes that inserting keywords into both the <title> and <h1> tags is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Project example: On-page text refresh/re-optimization
Project description: Locate keywords that are driving clicks and impressions to editorial pieces of content that DO NOT exist within the first paragraph within the body of the main content (MC). Perform an on-page refresh of introductory content within editorial pages to include high value keyword opportunities.
Project assumptions: This process assumes that inserting keywords into the first several sentences of a piece of content is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Final thoughts
We hope this post has been helpful and opened you up to the idea of using Python and Google Colab to supercharge your relevancy optimization strategy.
As mentioned throughout the post, keep the following in mind:
Github repository will be updated with any changes we make in the future.
There is the possibility of undiscovered errors. If these occur, Inseev is happy to help! In fact, we would actually appreciate you reaching out to investigate and fix errors (if any do appear). This way others don’t run into the same problems.
Other than the above, if you have any ideas on ways to Colab (pun intended) on data analytics projects, feel free to reach out with ideas.
0 notes
Text
Page Level Query Analysis at Scale with Google Colab, Python, & the GSC API [Video Instructions Included]
The YouTube playlist referenced throughout this blog can be found here:6 Part YouTube Series [Setting Up & Using the Query Optimization Checker]
Anyone who does SEO as part of their job knows that there’s a lot of value in analyzing which queries are and are not sending traffic to specific pages on a site.
The most common uses for these datasets are to align on-page optimizations with existing rankings and traffic, and to identify gaps in ranking keywords.
However, working with this data is extremely tedious because it’s only available in the Google Search Console interface, and you have to look at only one page at a time.
On top of that, to get information on the text included in the ranking page, you either need to manually review it or extract it with a tool like Screaming Frog.
You need this kind of view:

…but even the above view would only be viable one page at a time, and as mentioned, the actual text extraction would have had to be separate as well.
Given these apparent issues with the readily available data at the SEO community’s disposal, the data engineering team at Inseev Interactive has been spending a lot of time thinking about how we can improve these processes at scale.
One specific example that we’ll be reviewing in this post is a simple script that allows you to get the above data in a flexible format for many great analytical views.
Better yet, this will all be available with only a few single input variables.
A quick rundown of tool functionality
The tool automatically compares the text on-page to the Google Search Console top queries at the page-level to let you know which queries are on-page as well as how many times they appear on the page. An optional XPath variable also allows you to specify the part of the page you want to analyze text on.
This means you’ll know exactly what queries are driving clicks/impressions that are not in your <title>, <h1>, or even something as specific as the first paragraph within the main content (MC). The sky's the limit.
For those of you not familiar, we’ve also provided some quick XPath expressions you can use, as well as how to create site-specific XPath expressions within the "Input Variables" section of the post.
Post setup usage & datasets
Once the process is set up, all that’s required is filling out a short list of variables and the rest is automated for you.
The output dataset includes multiple automated CSV datasets, as well as a structured file format to keep things organized. A simple pivot of the core analysis automated CSV can provide you with the below dataset and many other useful layouts.
… Even some "new metrics"?
Okay, not technically "new," but if you exclusively use the Google Search Console user interface, then you haven’t likely had access to metrics like these before: "Max Position," "Min Position," and "Count Position" for the specified date range – all of which are explained in the "Running your first analysis" section of the post.

To really demonstrate the impact and usefulness of this dataset, in the video below we use the Colab tool to:
[3 Minutes] — Find non-brand <title> optimization opportunities for https://www.inseev.com/ (around 30 pages in video, but you could do any number of pages)
[3 Minutes] — Convert the CSV to a more useable format
[1 Minute] – Optimize the first title with the resulting dataset
youtube
Okay, you’re all set for the initial rundown. Hopefully we were able to get you excited before moving into the somewhat dull setup process.
Keep in mind that at the end of the post, there is also a section including a few helpful use cases and an example template! To jump directly to each section of this post, please use the following links:
One-time setup of the script in Google Colab
Running your first analysis
Practical use cases and templates
[Quick Consideration #1] — The web scraper built into the tool DOES NOT support JavaScript rendering. If your website uses client-side rendering, the full functionality of the tool unfortunately will not work.
[Quick Consideration #2] — This tool has been heavily tested by the members of the Inseev team. Most bugs [specifically with the web scraper] have been found and fixed, but like any other program, it is possible that other issues may come up.
If you encounter any errors, feel free to reach out to us directly at [email protected] or [email protected], and either myself or one of the other members of the data engineering team at Inseev would be happy to help you out.
If new errors are encountered and fixed, we will always upload the updated script to the code repository linked in the sections below so the most up-to-date code can be utilized by all!
One-time setup of the script in Google Colab (in less than 20 minutes)
Things you’ll need:
Google Drive
Google Cloud Platform account
Google Search Console access
Video walkthrough: tool setup process
Below you’ll find step-by-step editorial instructions in order to set up the entire process. However, if following editorial instructions isn’t your preferred method, we recorded a video of the setup process as well.
As you’ll see, we start with a brand new Gmail and set up the entire process in approximately 12 minutes, and the output is completely worth the time.
youtube
Keep in mind that the setup is one-off, and once set up, the tool should work on command from there on!
Editorial walkthrough: tool setup process
Four-part process:
Download the files from Github and set up in Google Drive
Set up a Google Cloud Platform (GCP) Project (skip if you already have an account)
Create the OAuth 2.0 client ID for the Google Search Console (GSC) API (skip if you already have an OAuth client ID with the Search Console API enabled)
Add the OAuth 2.0 credentials to the Config.py file
Part one: Download the files from Github and set up in Google Drive
Download source files (no code required)
1. Navigate here.
2. Select "Code" > "Download Zip"
*You can also use 'git clone https://github.com/jmelm93/query-optmization-checker.git' if you’re more comfortable using the command prompt.

Initiate Google Colab in Google Drive
If you already have a Google Colaboratory setup in your Google Drive, feel free to skip this step.
1. Navigate here.
2. Click "New" > "More" > "Connect more apps".

3. Search "Colaboratory" > Click into the application page.

4. Click "Install" > "Continue" > Sign in with OAuth.

5. Click "OK" with the prompt checked so Google Drive automatically sets appropriate files to open with Google Colab (optional).

Import the downloaded folder to Google Drive & open in Colab
1. Navigate to Google Drive and create a folder called "Colab Notebooks".
IMPORTANT: The folder needs to be called "Colab Notebooks" as the script is configured to look for the "api" folder from within "Colab Notebooks".
Error resulting in improper folder naming.
2. Import the folder downloaded from Github into Google Drive.
At the end of this step, you should have a folder in your Google Drive that contains the below items:
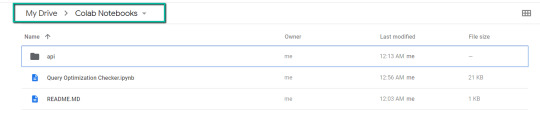
Part two: Set up a Google Cloud Platform (GCP) project
If you already have a Google Cloud Platform (GCP) account, feel free to skip this part.
1. Navigate to the Google Cloud page.
2. Click on the "Get started for free" CTA (CTA text may change over time).
3. Sign in with the OAuth credentials of your choice. Any Gmail email will work.
4. Follow the prompts to sign up for your GCP account.
You’ll be asked to supply a credit card to sign up, but there is currently a $300 free trial and Google notes that they won’t charge you until you upgrade your account.
Part three: Create a 0Auth 2.0 client ID for the Google Search Console (GSC) API
1. Navigate here.
2. After you log in to your desired Google Cloud account, click "ENABLE".
3. Configure the consent screen.
In the consent screen creation process, select "External," then continue onto the "App Information."
Example below of minimum requirements:
Skip "Scopes"
Add the email(s) you’ll use for the Search Console API authentication into the "Test Users". There could be other emails versus just the one that owns the Google Drive. An example may be a client’s email where you access the Google Search Console UI to view their KPIs.
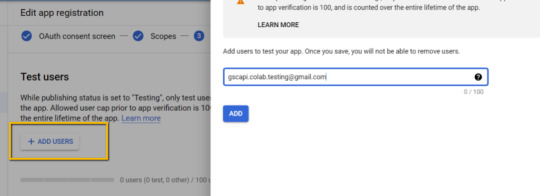
4. In the left-rail navigation, click into "Credentials" > "CREATE CREDENTIALS" > "OAuth Client ID" (Not in image).
5. Within the "Create OAuth client ID" form, fill in:
Application Type = Desktop app
Name = Google Colab
Click "CREATE"
6. Save the "Client ID" and "Client Secret" — as these will be added into the "api" folder config.py file from the Github files we downloaded.
These should have appeared in a popup after hitting "CREATE"
The "Client Secret" is functionally the password to your Google Cloud (DO NOT post this to the public/share it online)
Part four: Add the OAuth 2.0 credentials to the Config.py file
1. Return to Google Drive and navigate into the "api" folder.
2. Click into config.py.

3. Choose to open with "Text Editor" (or another app of your choice) to modify the config.py file.
4. Update the three areas highlighted below with your:
CLIENT_ID: From the OAuth 2.0 client ID setup process
CLIENT_SECRET: From the OAuth 2.0 client ID setup process
GOOGLE_CREDENTIALS: Email that corresponds with your CLIENT_ID & CLIENT_SECRET

5. Save the file once updated!
Congratulations, the boring stuff is over. You are now ready to start using the Google Colab file!
Running your first analysis
Running your first analysis may be a little intimidating, but stick with it and it will get easy fast.
Below, we’ve provided details regarding the input variables required, as well as notes on things to keep in mind when running the script and analyzing the resulting dataset.
After we walk through these items, there are also a few example projects and video walkthroughs showcasing ways to utilize these datasets for client deliverables.
Setting up the input variables
XPath extraction with the "xpath_selector" variable
Have you ever wanted to know every query driving clicks and impressions to a webpage that aren’t in your <title> or <h1> tag? Well, this parameter will allow you to do just that.
While optional, using this is highly encouraged and we feel it "supercharges" the analysis. Simply define site sections with Xpaths and the script will do the rest.
youtube
In the above video, you’ll find examples on how to create site specific extractions. In addition, below are some universal extractions that should work on almost any site on the web:
'//title' # Identifies a <title> tag
'//h1' # Identifies a <h1> tag
'//h2' # Identifies a <h2> tag
Site Specific: How to scrape only the main content (MC)?
Chaining Xpaths – Add a "|" Between Xpaths
'//title | //h1' # Gets you both the <title> and <h1> tag in 1 run
'//h1 | //h2 | //h3' # Gets you both the <h1>, <h2> and <h3> tags in 1 run
Other variables
Here’s a video overview of the other variables with a short description of each.
youtube
'colab_path' [Required] – The path in which the Colab file lives. This should be "/content/drive/My Drive/Colab Notebooks/".
'domain_lookup' [Required] – Homepage of the website utilized for analysis.
'startdate' & 'enddate' [Required] – Date range for the analysis period.
'gsc_sorting_field' [Required] – The tool pulls the top N pages as defined by the user. The "top" is defined by either "clicks_sum" or "impressions_sum." Please review the video for a more detailed description.
'gsc_limit_pages_number' [Required] – Numeric value that represents the number of resulting pages you’d like within the dataset.
'brand_exclusions' [Optional] – The string sequence(s) that commonly result in branded queries (e.g., anything containing "inseev" will be branded queries for "Inseev Interactive").
'impressions_exclusion' [Optional] – Numeric value used to exclude queries that are potentially irrelevant due to the lack of pre-existing impressions. This is primarily relevant for domains with strong pre-existing rankings on a large scale number of pages.
'page_inclusions' [Optional] – The string sequence(s) that are found within the desired analysis page type. If you’d like to analyze the entire domain, leave this section blank.
Running the script
Keep in mind that once the script finishes running, you’re generally going to use the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file for analysis, but there are others with the raw datasets to browse as well.
Practical use cases for the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file can be found in the "Practical use cases and templates" section.
That said, there are a few important things to note while testing things out:
1. No JavaScript Crawling: As mentioned at the start of the post, this script is NOT set up for JavaScript crawling, so if your target website uses a JS frontend with client-side rendering to populate the main content (MC), the scrape will not be useful. However, the basic functionality of quickly getting the top XX (user-defined) queries and pages can still be useful by itself.
2. Google Drive / GSC API Auth: The first time you run the script in each new session it will prompt you to authenticate both the Google Drive and the Google Search Console credentials.
Google Drive authentication: Authenticate to whatever email is associated with the Google Drive with the script.
GSC authentication: Authenticate whichever email has permission to use the desired Google Search Console account.
If you attempt to authenticate and you get an error that looks like the one below, please revisit the "Add the email(s) you’ll use the Colab app with into the 'Test Users'" from Part 3, step 3 in the process above: setting up the consent screen.
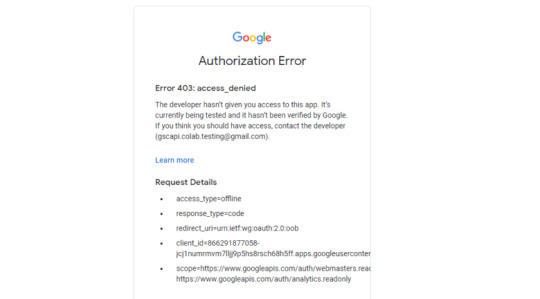
Quick tip: The Google Drive account and the GSC Authentication DO NOT have to be the same email, but they do require separate authentications with OAuth.
3. Running the script: Either navigate to "Runtime" > "Restart and Run All" or use the keyboard shortcut CTRL + fn9 to start running the script.
4. Populated datasets/folder structure: There are three CSVs populated by the script – all nested within a folder structure based on the "domain_lookup" input variable.
Automated Organization [Folders]: Each time you rerun the script on a new domain, it will create a new folder structure in order to keep things organized.
Automated Organization [File Naming]: The CSVs include the date of the export appended to the end, so you’ll always know when the process ran as well as the date range for the dataset.
5. Date range for dataset: Inside of the dataset there is a "gsc_datasetID" column generated, which includes the date range of the extraction.

6. Unfamiliar metrics: The resulting dataset has all the KPIs we know and love – e.g. clicks, impressions, average (mean) position — but there are also a few you cannot get directly from the GSC UI:
'count_instances_gsc' — the number of instances the query got at least 1 impression during the specified date range. Scenario example: GSC tells you that you were in an average position 6 for a large keyword like "flower delivery" and you only received 20 impressions in a 30-day date range. Doesn’t seem possible that you were really in position 6, right? Well, now you can see that was potentially because you only actually showed up on one day in that 30-day date range (e.g. count_instances_gsc = 1)
'max_position' & 'min_position' — the MAXIMUM and MINIMUM ranking position the identified page showed up for in Google Search within the specified date range.
Quick tip #1: Large variance in max/min may tell you that your keyword has been fluctuating heavily.
Quick tip #2: These KPIs, in conjunction with the "count_instances_gsc", can exponentially further your understanding of query performance and opportunity.
Practical use cases and templates
Access the recommended multi-use template.
Recommended use: Download file and use with Excel. Subjectively speaking, I believe Excel has a much more user friendly pivot table functionality in comparison to Google Sheets — which is critical for using this template.
Alternative use: If you do not have Microsoft Excel or you prefer a different tool, you can use most spreadsheet apps that contain pivot functionality.
For those who opt for an alternative spreadsheet software/app:
Below are the pivot fields to mimic upon setup.
You may have to adjust the Vlookup functions found on the "Step 3 _ Analysis Final Doc" tab, depending on whether your updated pivot columns align with the current pivot I’ve supplied.
Project example: Title & H1 re-optimizations (video walkthrough)
Project description: Locate keywords that are driving clicks and impressions to high value pages and that do not exist within the <title> and <h1> tags by reviewing GSC query KPIs vs. current page elements. Use the resulting findings to re-optimize both the <title> and <h1> tags for pre-existing pages.
Project assumptions: This process assumes that inserting keywords into both the <title> and <h1> tags is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Project example: On-page text refresh/re-optimization
Project description: Locate keywords that are driving clicks and impressions to editorial pieces of content that DO NOT exist within the first paragraph within the body of the main content (MC). Perform an on-page refresh of introductory content within editorial pages to include high value keyword opportunities.
Project assumptions: This process assumes that inserting keywords into the first several sentences of a piece of content is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Final thoughts
We hope this post has been helpful and opened you up to the idea of using Python and Google Colab to supercharge your relevancy optimization strategy.
As mentioned throughout the post, keep the following in mind:
Github repository will be updated with any changes we make in the future.
There is the possibility of undiscovered errors. If these occur, Inseev is happy to help! In fact, we would actually appreciate you reaching out to investigate and fix errors (if any do appear). This way others don’t run into the same problems.
Other than the above, if you have any ideas on ways to Colab (pun intended) on data analytics projects, feel free to reach out with ideas.
https://ift.tt/3uhS1Bo
0 notes
Text
Page Level Query Analysis at Scale with Google Colab, Python, & the GSC API [Video Instructions Included]
The YouTube playlist referenced throughout this blog can be found here:6 Part YouTube Series [Setting Up & Using the Query Optimization Checker]
Anyone who does SEO as part of their job knows that there’s a lot of value in analyzing which queries are and are not sending traffic to specific pages on a site.
The most common uses for these datasets are to align on-page optimizations with existing rankings and traffic, and to identify gaps in ranking keywords.
However, working with this data is extremely tedious because it’s only available in the Google Search Console interface, and you have to look at only one page at a time.
On top of that, to get information on the text included in the ranking page, you either need to manually review it or extract it with a tool like Screaming Frog.
You need this kind of view:
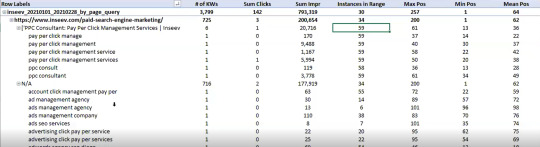
…but even the above view would only be viable one page at a time, and as mentioned, the actual text extraction would have had to be separate as well.
Given these apparent issues with the readily available data at the SEO community’s disposal, the data engineering team at Inseev Interactive has been spending a lot of time thinking about how we can improve these processes at scale.
One specific example that we’ll be reviewing in this post is a simple script that allows you to get the above data in a flexible format for many great analytical views.
Better yet, this will all be available with only a few single input variables.
A quick rundown of tool functionality
The tool automatically compares the text on-page to the Google Search Console top queries at the page-level to let you know which queries are on-page as well as how many times they appear on the page. An optional XPath variable also allows you to specify the part of the page you want to analyze text on.
This means you’ll know exactly what queries are driving clicks/impressions that are not in your <title>, <h1>, or even something as specific as the first paragraph within the main content (MC). The sky's the limit.
For those of you not familiar, we’ve also provided some quick XPath expressions you can use, as well as how to create site-specific XPath expressions within the "Input Variables" section of the post.
Post setup usage & datasets
Once the process is set up, all that’s required is filling out a short list of variables and the rest is automated for you.
The output dataset includes multiple automated CSV datasets, as well as a structured file format to keep things organized. A simple pivot of the core analysis automated CSV can provide you with the below dataset and many other useful layouts.
… Even some "new metrics"?
Okay, not technically "new," but if you exclusively use the Google Search Console user interface, then you haven’t likely had access to metrics like these before: "Max Position," "Min Position," and "Count Position" for the specified date range – all of which are explained in the "Running your first analysis" section of the post.

To really demonstrate the impact and usefulness of this dataset, in the video below we use the Colab tool to:
[3 Minutes] — Find non-brand <title> optimization opportunities for https://www.inseev.com/ (around 30 pages in video, but you could do any number of pages)
[3 Minutes] — Convert the CSV to a more useable format
[1 Minute] – Optimize the first title with the resulting dataset
youtube
Okay, you’re all set for the initial rundown. Hopefully we were able to get you excited before moving into the somewhat dull setup process.
Keep in mind that at the end of the post, there is also a section including a few helpful use cases and an example template! To jump directly to each section of this post, please use the following links:
One-time setup of the script in Google Colab
Running your first analysis
Practical use cases and templates
[Quick Consideration #1] — The web scraper built into the tool DOES NOT support JavaScript rendering. If your website uses client-side rendering, the full functionality of the tool unfortunately will not work.
[Quick Consideration #2] — This tool has been heavily tested by the members of the Inseev team. Most bugs [specifically with the web scraper] have been found and fixed, but like any other program, it is possible that other issues may come up.
If you encounter any errors, feel free to reach out to us directly at [email protected] or [email protected], and either myself or one of the other members of the data engineering team at Inseev would be happy to help you out.
If new errors are encountered and fixed, we will always upload the updated script to the code repository linked in the sections below so the most up-to-date code can be utilized by all!
One-time setup of the script in Google Colab (in less than 20 minutes)
Things you’ll need:
Google Drive
Google Cloud Platform account
Google Search Console access
Video walkthrough: tool setup process
Below you’ll find step-by-step editorial instructions in order to set up the entire process. However, if following editorial instructions isn’t your preferred method, we recorded a video of the setup process as well.
As you’ll see, we start with a brand new Gmail and set up the entire process in approximately 12 minutes, and the output is completely worth the time.
youtube
Keep in mind that the setup is one-off, and once set up, the tool should work on command from there on!
Editorial walkthrough: tool setup process
Four-part process:
Download the files from Github and set up in Google Drive
Set up a Google Cloud Platform (GCP) Project (skip if you already have an account)
Create the OAuth 2.0 client ID for the Google Search Console (GSC) API (skip if you already have an OAuth client ID with the Search Console API enabled)
Add the OAuth 2.0 credentials to the Config.py file
Part one: Download the files from Github and set up in Google Drive
Download source files (no code required)
1. Navigate here.
2. Select "Code" > "Download Zip"
*You can also use 'git clone https://github.com/jmelm93/query-optmization-checker.git' if you’re more comfortable using the command prompt.

Initiate Google Colab in Google Drive
If you already have a Google Colaboratory setup in your Google Drive, feel free to skip this step.
1. Navigate here.
2. Click "New" > "More" > "Connect more apps".
3. Search "Colaboratory" > Click into the application page.
4. Click "Install" > "Continue" > Sign in with OAuth.
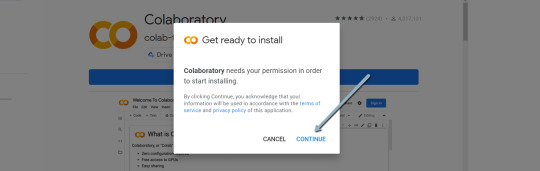
5. Click "OK" with the prompt checked so Google Drive automatically sets appropriate files to open with Google Colab (optional).

Import the downloaded folder to Google Drive & open in Colab
1. Navigate to Google Drive and create a folder called "Colab Notebooks".
IMPORTANT: The folder needs to be called "Colab Notebooks" as the script is configured to look for the "api" folder from within "Colab Notebooks".

Error resulting in improper folder naming.
2. Import the folder downloaded from Github into Google Drive.
At the end of this step, you should have a folder in your Google Drive that contains the below items:
Part two: Set up a Google Cloud Platform (GCP) project
If you already have a Google Cloud Platform (GCP) account, feel free to skip this part.
1. Navigate to the Google Cloud page.
2. Click on the "Get started for free" CTA (CTA text may change over time).
3. Sign in with the OAuth credentials of your choice. Any Gmail email will work.
4. Follow the prompts to sign up for your GCP account.
You’ll be asked to supply a credit card to sign up, but there is currently a $300 free trial and Google notes that they won’t charge you until you upgrade your account.
Part three: Create a 0Auth 2.0 client ID for the Google Search Console (GSC) API
1. Navigate here.
2. After you log in to your desired Google Cloud account, click "ENABLE".
3. Configure the consent screen.
In the consent screen creation process, select "External," then continue onto the "App Information."
Example below of minimum requirements:

Skip "Scopes"
Add the email(s) you’ll use for the Search Console API authentication into the "Test Users". There could be other emails versus just the one that owns the Google Drive. An example may be a client’s email where you access the Google Search Console UI to view their KPIs.
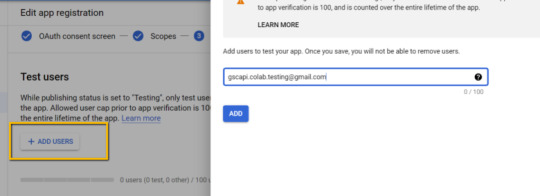
4. In the left-rail navigation, click into "Credentials" > "CREATE CREDENTIALS" > "OAuth Client ID" (Not in image).
5. Within the "Create OAuth client ID" form, fill in:
Application Type = Desktop app
Name = Google Colab
Click "CREATE"

6. Save the "Client ID" and "Client Secret" — as these will be added into the "api" folder config.py file from the Github files we downloaded.
These should have appeared in a popup after hitting "CREATE"
The "Client Secret" is functionally the password to your Google Cloud (DO NOT post this to the public/share it online)
Part four: Add the OAuth 2.0 credentials to the Config.py file
1. Return to Google Drive and navigate into the "api" folder.
2. Click into config.py.

3. Choose to open with "Text Editor" (or another app of your choice) to modify the config.py file.
4. Update the three areas highlighted below with your:
CLIENT_ID: From the OAuth 2.0 client ID setup process
CLIENT_SECRET: From the OAuth 2.0 client ID setup process
GOOGLE_CREDENTIALS: Email that corresponds with your CLIENT_ID & CLIENT_SECRET
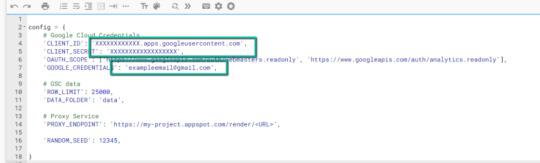
5. Save the file once updated!
Congratulations, the boring stuff is over. You are now ready to start using the Google Colab file!
Running your first analysis
Running your first analysis may be a little intimidating, but stick with it and it will get easy fast.
Below, we’ve provided details regarding the input variables required, as well as notes on things to keep in mind when running the script and analyzing the resulting dataset.
After we walk through these items, there are also a few example projects and video walkthroughs showcasing ways to utilize these datasets for client deliverables.
Setting up the input variables
XPath extraction with the "xpath_selector" variable
Have you ever wanted to know every query driving clicks and impressions to a webpage that aren’t in your <title> or <h1> tag? Well, this parameter will allow you to do just that.
While optional, using this is highly encouraged and we feel it "supercharges" the analysis. Simply define site sections with Xpaths and the script will do the rest.
youtube
In the above video, you’ll find examples on how to create site specific extractions. In addition, below are some universal extractions that should work on almost any site on the web:
'//title' # Identifies a <title> tag
'//h1' # Identifies a <h1> tag
'//h2' # Identifies a <h2> tag
Site Specific: How to scrape only the main content (MC)?
Chaining Xpaths – Add a "|" Between Xpaths
'//title | //h1' # Gets you both the <title> and <h1> tag in 1 run
'//h1 | //h2 | //h3' # Gets you both the <h1>, <h2> and <h3> tags in 1 run
Other variables
Here’s a video overview of the other variables with a short description of each.
youtube
'colab_path' [Required] – The path in which the Colab file lives. This should be "/content/drive/My Drive/Colab Notebooks/".
'domain_lookup' [Required] – Homepage of the website utilized for analysis.
'startdate' & 'enddate' [Required] – Date range for the analysis period.
'gsc_sorting_field' [Required] – The tool pulls the top N pages as defined by the user. The "top" is defined by either "clicks_sum" or "impressions_sum." Please review the video for a more detailed description.
'gsc_limit_pages_number' [Required] – Numeric value that represents the number of resulting pages you’d like within the dataset.
'brand_exclusions' [Optional] – The string sequence(s) that commonly result in branded queries (e.g., anything containing "inseev" will be branded queries for "Inseev Interactive").
'impressions_exclusion' [Optional] – Numeric value used to exclude queries that are potentially irrelevant due to the lack of pre-existing impressions. This is primarily relevant for domains with strong pre-existing rankings on a large scale number of pages.
'page_inclusions' [Optional] – The string sequence(s) that are found within the desired analysis page type. If you’d like to analyze the entire domain, leave this section blank.
Running the script
Keep in mind that once the script finishes running, you’re generally going to use the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file for analysis, but there are others with the raw datasets to browse as well.
Practical use cases for the "step3_query-optimizer_domain-YYYY-MM-DD.csv" file can be found in the "Practical use cases and templates" section.
That said, there are a few important things to note while testing things out:
1. No JavaScript Crawling: As mentioned at the start of the post, this script is NOT set up for JavaScript crawling, so if your target website uses a JS frontend with client-side rendering to populate the main content (MC), the scrape will not be useful. However, the basic functionality of quickly getting the top XX (user-defined) queries and pages can still be useful by itself.
2. Google Drive / GSC API Auth: The first time you run the script in each new session it will prompt you to authenticate both the Google Drive and the Google Search Console credentials.
Google Drive authentication: Authenticate to whatever email is associated with the Google Drive with the script.
GSC authentication: Authenticate whichever email has permission to use the desired Google Search Console account.
If you attempt to authenticate and you get an error that looks like the one below, please revisit the "Add the email(s) you’ll use the Colab app with into the 'Test Users'" from Part 3, step 3 in the process above: setting up the consent screen.

Quick tip: The Google Drive account and the GSC Authentication DO NOT have to be the same email, but they do require separate authentications with OAuth.
3. Running the script: Either navigate to "Runtime" > "Restart and Run All" or use the keyboard shortcut CTRL + fn9 to start running the script.
4. Populated datasets/folder structure: There are three CSVs populated by the script – all nested within a folder structure based on the "domain_lookup" input variable.
Automated Organization [Folders]: Each time you rerun the script on a new domain, it will create a new folder structure in order to keep things organized.
Automated Organization [File Naming]: The CSVs include the date of the export appended to the end, so you’ll always know when the process ran as well as the date range for the dataset.
5. Date range for dataset: Inside of the dataset there is a "gsc_datasetID" column generated, which includes the date range of the extraction.

6. Unfamiliar metrics: The resulting dataset has all the KPIs we know and love – e.g. clicks, impressions, average (mean) position — but there are also a few you cannot get directly from the GSC UI:
'count_instances_gsc' — the number of instances the query got at least 1 impression during the specified date range. Scenario example: GSC tells you that you were in an average position 6 for a large keyword like "flower delivery" and you only received 20 impressions in a 30-day date range. Doesn’t seem possible that you were really in position 6, right? Well, now you can see that was potentially because you only actually showed up on one day in that 30-day date range (e.g. count_instances_gsc = 1)
'max_position' & 'min_position' — the MAXIMUM and MINIMUM ranking position the identified page showed up for in Google Search within the specified date range.
Quick tip #1: Large variance in max/min may tell you that your keyword has been fluctuating heavily.
Quick tip #2: These KPIs, in conjunction with the "count_instances_gsc", can exponentially further your understanding of query performance and opportunity.
Practical use cases and templates
Access the recommended multi-use template.
Recommended use: Download file and use with Excel. Subjectively speaking, I believe Excel has a much more user friendly pivot table functionality in comparison to Google Sheets — which is critical for using this template.
Alternative use: If you do not have Microsoft Excel or you prefer a different tool, you can use most spreadsheet apps that contain pivot functionality.
For those who opt for an alternative spreadsheet software/app:
Below are the pivot fields to mimic upon setup.
You may have to adjust the Vlookup functions found on the "Step 3 _ Analysis Final Doc" tab, depending on whether your updated pivot columns align with the current pivot I’ve supplied.
Project example: Title & H1 re-optimizations (video walkthrough)
Project description: Locate keywords that are driving clicks and impressions to high value pages and that do not exist within the <title> and <h1> tags by reviewing GSC query KPIs vs. current page elements. Use the resulting findings to re-optimize both the <title> and <h1> tags for pre-existing pages.
Project assumptions: This process assumes that inserting keywords into both the <title> and <h1> tags is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Project example: On-page text refresh/re-optimization
Project description: Locate keywords that are driving clicks and impressions to editorial pieces of content that DO NOT exist within the first paragraph within the body of the main content (MC). Perform an on-page refresh of introductory content within editorial pages to include high value keyword opportunities.
Project assumptions: This process assumes that inserting keywords into the first several sentences of a piece of content is a strong SEO practice for relevancy optimization, and that it’s important to include related keyword variants into these areas (e.g. non-exact match keywords with matching SERP intent).
youtube
Final thoughts
We hope this post has been helpful and opened you up to the idea of using Python and Google Colab to supercharge your relevancy optimization strategy.
As mentioned throughout the post, keep the following in mind:
Github repository will be updated with any changes we make in the future.
There is the possibility of undiscovered errors. If these occur, Inseev is happy to help! In fact, we would actually appreciate you reaching out to investigate and fix errors (if any do appear). This way others don’t run into the same problems.
Other than the above, if you have any ideas on ways to Colab (pun intended) on data analytics projects, feel free to reach out with ideas.
0 notes
Last Seen Blogs

belgian-malinois
belgian-malinois

blog-surajit
Untitled

kabingo
☼

shitieattolowermycholesterol
Shit I Eat

memento-hazard
artukolatte