#annotation service
Text
Annotation and BPO Services
Reach out Infosearch BPO Services for Annotation & BPO Services in India
Annotation Service is a service that adds descriptive or metadata labels to images and text. This service is used for machine learning, natural-language processing and data classification.
BPO Services or Business Process Outsourcing Services are a wide range of services provided by service providers. These services include data entry and customer service, as well as IT support. BPO Services are a great way to reduce costs and improve efficiency for business.
1 note
·
View note
Link
Global Technology Solutions may assist other businesses with their artificial intelligence initiatives by providing services such as text collecting, image collection, speech collection, video, image annotation, audio transcription service, and many more.
0 notes
Text
Our IT Services

With more than 7 years of experience in the data annotation industry, LTS Global Digital Services has been honored to receive major domestic awards and trust from significant customers in the US, Germany, Korea, and Japan. Besides, having experienced hundreds of projects in different fields such as Automobile, Retail, Manufacturing, Construction, and Sports, our company confidently completes projects and ensures accuracy of up to 99.9%. This has also been confirmed by 97% of customers using the service.
If you are looking for an outsourcing company that meets the above criteria, contact LTS Global Digital Service for advice and trial!
2 notes
·
View notes
Text
What is a Data pipeline for Machine Learning?

As machine learning technologies continue to advance, the need for high-quality data has become increasingly important. Data is the lifeblood of computer vision applications, as it provides the foundation for machine learning algorithms to learn and recognize patterns within images or video. Without high-quality data, computer vision models will not be able to effectively identify objects, recognize faces, or accurately track movements.
Machine learning algorithms require large amounts of data to learn and identify patterns, and this is especially true for computer vision, which deals with visual data. By providing annotated data that identifies objects within images and provides context around them, machine learning algorithms can more accurately detect and identify similar objects within new images.
Moreover, data is also essential in validating computer vision models. Once a model has been trained, it is important to test its accuracy and performance on new data. This requires additional labeled data to evaluate the model's performance. Without this validation data, it is impossible to accurately determine the effectiveness of the model.
Data Requirement at multiple ML stage
Data is required at various stages in the development of computer vision systems.
Here are some key stages where data is required:
Training: In the training phase, a large amount of labeled data is required to teach the machine learning algorithm to recognize patterns and make accurate predictions. The labeled data is used to train the algorithm to identify objects, faces, gestures, and other features in images or videos.
Validation: Once the algorithm has been trained, it is essential to validate its performance on a separate set of labeled data. This helps to ensure that the algorithm has learned the appropriate features and can generalize well to new data.
Testing: Testing is typically done on real-world data to assess the performance of the model in the field. This helps to identify any limitations or areas for improvement in the model and the data it was trained on.
Re-training: After testing, the model may need to be re-trained with additional data or re-labeled data to address any issues or limitations discovered in the testing phase.
In addition to these key stages, data is also required for ongoing model maintenance and improvement. As new data becomes available, it can be used to refine and improve the performance of the model over time.
Types of Data used in ML model preparation
The team has to work on various types of data at each stage of model development.
Streamline, structured, and unstructured data are all important when creating computer vision models, as they can each provide valuable insights and information that can be used to train the model.
Streamline data refers to data that is captured in real-time or near real-time from a single source. This can include data from sensors, cameras, or other monitoring devices that capture information about a particular environment or process.
Structured data, on the other hand, refers to data that is organized in a specific format, such as a database or spreadsheet. This type of data can be easier to work with and analyze, as it is already formatted in a way that can be easily understood by the computer.
Unstructured data includes any type of data that is not organized in a specific way, such as text, images, or video. This type of data can be more difficult to work with, but it can also provide valuable insights that may not be captured by structured data alone.
When creating a computer vision model, it is important to consider all three types of data in order to get a complete picture of the environment or process being analyzed. This can involve using a combination of sensors and cameras to capture streamline data, organizing structured data in a database or spreadsheet, and using machine learning algorithms to analyze and make sense of unstructured data such as images or text. By leveraging all three types of data, it is possible to create a more robust and accurate computer vision model.
Data Pipeline for machine learning
The data pipeline for machine learning involves a series of steps, starting from collecting raw data to deploying the final model. Each step is critical in ensuring the model is trained on high-quality data and performs well on new inputs in the real world.
Below is the description of the steps involved in a typical data pipeline for machine learning and computer vision:
Data Collection: The first step is to collect raw data in the form of images or videos. This can be done through various sources such as publicly available datasets, web scraping, or data acquisition from hardware devices.
Data Cleaning: The collected data often contains noise, missing values, or inconsistencies that can negatively affect the performance of the model. Hence, data cleaning is performed to remove any such issues and ensure the data is ready for annotation.
Data Annotation: In this step, experts annotate the images with labels to make it easier for the model to learn from the data. Data annotation can be in the form of bounding boxes, polygons, or pixel-level segmentation masks.
Data Augmentation: To increase the diversity of the data and prevent overfitting, data augmentation techniques are applied to the annotated data. These techniques include random cropping, flipping, rotation, and color jittering.
Data Splitting: The annotated data is split into training, validation, and testing sets. The training set is used to train the model, the validation set is used to tune the hyperparameters and prevent overfitting, and the testing set is used to evaluate the final performance of the model.
Model Training: The next step is to train the computer vision model using the annotated and augmented data. This involves selecting an appropriate architecture, loss function, and optimization algorithm, and tuning the hyperparameters to achieve the best performance.
Model Evaluation: Once the model is trained, it is evaluated on the testing set to measure its performance. Metrics such as accuracy, precision, recall, and score are computed to assess the model's performance.
Model Deployment: The final step is to deploy the model in the production environment, where it can be used to solve real-world computer vision problems. This involves integrating the model into the target system and ensuring it can handle new inputs and operate in real time.
TagX Data as a Service
Data as a service (DaaS) refers to the provision of data by a company to other companies. TagX provides DaaS to AI companies by collecting, preparing, and annotating data that can be used to train and test AI models.
Here’s a more detailed explanation of how TagX provides DaaS to AI companies:
Data Collection: TagX collects a wide range of data from various sources such as public data sets, proprietary data, and third-party providers. This data includes image, video, text, and audio data that can be used to train AI models for various use cases.
Data Preparation: Once the data is collected, TagX prepares the data for use in AI models by cleaning, normalizing, and formatting the data. This ensures that the data is in a format that can be easily used by AI models.
Data Annotation: TagX uses a team of annotators to label and tag the data, identifying specific attributes and features that will be used by the AI models. This includes image annotation, video annotation, text annotation, and audio annotation. This step is crucial for the training of AI models, as the models learn from the labeled data.
Data Governance: TagX ensures that the data is properly managed and governed, including data privacy and security. We follow data governance best practices and regulations to ensure that the data provided is trustworthy and compliant with regulations.
Data Monitoring: TagX continuously monitors the data and updates it as needed to ensure that it is relevant and up-to-date. This helps to ensure that the AI models trained using our data are accurate and reliable.
By providing data as a service, TagX makes it easy for AI companies to access high-quality, relevant data that can be used to train and test AI models. This helps AI companies to improve the speed, quality, and reliability of their models, and reduce the time and cost of developing AI systems. Additionally, by providing data that is properly annotated and managed, the AI models developed can be exp
2 notes
·
View notes
Text
we gotta bring back pulps and mass market paperbacks STAT i cannot afford to spend 20 bucks on a tiny 200 page book i'm gonna finish in a day
#if i want to read a book like that i tend to get it through the library or a free book service like netgalley but even so#sometimes i just want!! a physical copy!! to hold and to annotate!!#also a LOT of books i want to read have become pretty inaccessible to me since the fall of z-lib may she rest in peace#cricket.chatterbox
13 notes
·
View notes
Text
The Importance of Video Annotation Services
In the realm of artificial intelligence and machine learning, Video Annotation Services play a pivotal role. These services are indispensable for training models that rely on visual data. As the digital world becomes increasingly video-centric, the demand for precise and efficient annotation services has surged. Understanding the critical importance of Video Annotation Services can illuminate their value in various industries, from autonomous vehicles to healthcare.
Enhancing Machine Learning Models
Machine learning models thrive on data. In the context of video, this data must be accurately labeled and annotated to train algorithms effectively. Video Annotation Services provide the necessary groundwork by meticulously tagging objects, actions, and events within video frames. This process ensures that machine learning models can learn from high-quality data, improving their ability to recognize patterns, make predictions, and perform tasks with high accuracy.
Object Detection and Recognition
One of the primary applications of Video Annotation Services is in object detection and recognition. By labeling objects within video frames, these services enable models to identify and categorize various entities, from vehicles and pedestrians in autonomous driving systems to medical instruments and anomalies in healthcare applications. The precision of these annotations directly impacts the model's performance, making the accuracy and thoroughness of annotation services paramount.
Accelerating Autonomous Technology
Autonomous vehicles, drones, and robots depend heavily on visual data to navigate and interact with their environment. Video Annotation Services are crucial for training these systems to understand and respond to real-world scenarios. Annotated videos help these machines learn to detect obstacles, interpret traffic signals, and recognize pedestrians, enhancing their operational safety and efficiency.
Training Autonomous Vehicles
In the automotive industry, the development of self-driving cars hinges on the quality of annotated video data. Video Annotation Services provide the detailed labeling required to train these vehicles to recognize road signs, lane markings, and other critical elements of the driving environment. High-quality annotations ensure that autonomous vehicles can make informed decisions, reducing the risk of accidents and improving overall safety.
Revolutionizing Healthcare
In healthcare, the application of Video Annotation Services is transformative. From surgical procedures to diagnostic imaging, annotated videos enable the development of advanced medical technologies. These technologies can assist in early diagnosis, improve surgical outcomes, and enhance patient care.
Medical Imaging and Diagnostics
Annotated medical videos are essential for training diagnostic algorithms to identify diseases and abnormalities. For instance, in radiology, annotated videos help train models to detect tumors, fractures, and other conditions with high accuracy. This not only accelerates the diagnostic process but also increases the likelihood of early detection, leading to better patient outcomes.
Improving Content Moderation
In the age of social media and user-generated content, Video Annotation Services are vital for content moderation. Platforms like YouTube, Facebook, and TikTok rely on annotated videos to filter inappropriate content, ensuring a safe and positive user experience. Annotating videos for offensive language, violence, and other harmful content allows these platforms to automate the moderation process, maintaining community standards and protecting users.
Ensuring Compliance and Safety
Beyond social media, other industries also benefit from video annotation for compliance and safety. In workplaces, annotated surveillance videos can help monitor compliance with safety protocols and detect hazardous behaviors, preventing accidents and promoting a safer work environment.
Conclusion
Video Annotation Services are the unsung heroes behind many of today’s technological advancements. Their role in enhancing machine learning models, accelerating autonomous technology, revolutionizing healthcare, and improving content moderation cannot be overstated. As the reliance on video data continues to grow, the importance of high-quality annotation services will only become more pronounced. By providing the foundational data that powers intelligent systems, Video Annotation Services are driving innovation and transforming industries across the globe. For more information, visit Video Annotation Services.
0 notes
Text
https://www.damcogroup.com/blogs/data-annotation-services-fueling-the-future-of-ai-ml-applications
Explore how Data Annotation Services are critical in enhancing AI and Machine Learning (AI/ML) Applications. Our detailed blog dives into the role of accurate data annotation and its impact on developing advanced AI/ML systems. Understand the intricacies and benefits of robust data annotation processes in driving future technological innovations. Visit our blog to learn more about how precise data annotation is shaping the future of AI/ML.
#Artificial Intelligence#machine learning#data annotation machine learning#data annotation companies#data annotation services#data annotation company
0 notes
Text

Discover the key factors to consider when outsourcing image annotation services to ensure quality, scalability, and cost-effectiveness. Boost your AI projects with expert insights!
0 notes
Text
ADVANTAGES OF DATA ANNOTATION
Data annotation is essential for training AI models effectively. Precise labeling ensures accurate predictions, while scalability handles large datasets efficiently. Contextual understanding enhances model comprehension, and adaptability caters to diverse needs. Quality assurance processes maintain data integrity, while collaboration fosters synergy among annotators, driving innovation in AI technologies.
#Data Annotation Company#Data Labeling Company#Computer Vision Companies in India#Data Labeling Companies in India#Image Annotation Services#Data labeling & annotation services#AI Data Solutions#Lidar Annotation
0 notes
Text
Challenges and Best Practices in Data Annotation
Data annotation is a crucial step in training machine learning models, but it comes with its own set of challenges. Addressing these challenges effectively through best practices can significantly enhance the quality of the resulting AI models.
Challenges in Data Annotation
Consistency and Accuracy: One of the major challenges is ensuring consistency and accuracy in annotations. Different annotators might interpret data differently, leading to inconsistencies. This can degrade the performance of the machine learning model.
Scalability: Annotating large datasets manually is time-consuming and labor-intensive. As datasets grow, maintaining quality while scaling up the annotation process becomes increasingly difficult.
Subjectivity: Certain data, such as sentiment in text or complex object recognition in images, can be highly subjective. Annotators’ personal biases and interpretations can affect the consistency of the annotations.
Domain Expertise: Some datasets require specific domain knowledge for accurate annotation. For instance, medical images need to be annotated by healthcare professionals to ensure correctness.
Bias: Bias in data annotation can stem from the annotators' cultural, demographic, or personal biases. This can result in biased AI models that do not generalize well across different populations.
Best Practices in Data Annotation
Clear Guidelines and Training: Providing annotators with clear, detailed guidelines and comprehensive training is essential. This ensures that all annotators understand the criteria uniformly and reduces inconsistencies.
Quality Control Mechanisms: Implementing quality control mechanisms, such as inter-annotator agreement metrics, regular spot-checks, and using a gold standard dataset, can help maintain high annotation quality. Continuous feedback loops are also critical for improving annotator performance over time.
Leverage Automation: Utilizing automated tools can enhance efficiency. Semi-automated approaches, where AI handles simpler tasks and humans review the results, can significantly speed up the process while maintaining quality.
Utilize Expert Annotators: For specialized datasets, employ domain experts who have the necessary knowledge and experience. This is particularly important for fields like healthcare or legal documentation where accuracy is critical.
Bias Mitigation: To mitigate bias, diversify the pool of annotators and implement bias detection mechanisms. Regular reviews and adjustments based on detected biases are necessary to ensure fair and unbiased data.
Iterative Annotation: Use an iterative process where initial annotations are reviewed and refined. Continuous cycles of annotation and feedback help in achieving more accurate and reliable data.
For organizations seeking professional assistance, companies like Data Annotation Services provide tailored solutions. They employ advanced tools and experienced annotators to ensure precise and reliable data annotation, driving the success of AI projects.
#datasets for machine learning#Data Annotation services#data collection#AI for machine learning#business
0 notes
Text
Buy Custom Critical Thinking Papers | Writing Sharks
Need custom critical thinking papers? Look no further than Writing Sharks. Our skilled writers craft thought-provoking analyses tailored to your requirements. With our expertise, you'll receive meticulously researched and carefully articulated papers that showcase your critical thinking prowess. Elevate your academic performance with our services today.

#Hire Creative Writing Service Online#Creative Writing Services Online#Buy Custom Critical Thinking Papers#Critical Thinking Essay Writing Service#Hire Annotated Bibliography Writing Services
0 notes
Photo

By providing their collection and annotation services, such as text collection, picture collection, speech collection, video, image annotation, audio transcription service, and many more, Global Technology Solutions may assist other businesses with their artificial intelligence initiatives.
0 notes
Text
Vee Technologies - One of the top Automatic Image Annotation companies

Whether you are from fashion, retail, e-commerce or the automobile industry, Vee Technologies, one of the top Automatic Image Annotation companies, ensures your product images are ready for computer vision so that your products attract your audience. We segment pictures based on pixels and so, the annotation is very precise.
Visit : www.veetechnologies.com/services/it-services/artificial-intelligence/image-processing/image-annotation.htm
0 notes
Text
MLOps and ML Data pipeline: Key Takeaways

If you have ever worked with a Machine Learning (ML) model in a production environment, you might have heard of MLOps. The term explains the concept of optimizing the ML lifecycle by bridging the gap between design, model development, and operation processes.
As more teams attempt to create AI solutions for actual use cases, MLOps is now more than just a theoretical idea; it is a hotly debated area of machine learning that is becoming increasingly important. If done correctly, it speeds up the development and deployment of ML solutions for teams all over the world.
MLOps is frequently referred to as DevOps for Machine Learning while reading about the word. Because of this, going back to its roots and drawing comparisons between it and DevOps is the best way to comprehend the MLOps concept.
MLOps vs DevOps
DevOps is an iterative approach to shipping software applications into production. MLOps borrows the same principles to take machine learning models to production. Either Devops or MLOps, the eventual objective is higher quality and control of software applications/ML models.
What is MLOps?
Machine Learning Operations is referred to as MLOps. Therefore, the function of MLOps is to act as a communication link between the operations team overseeing the project and the data scientists who deal with machine learning data.
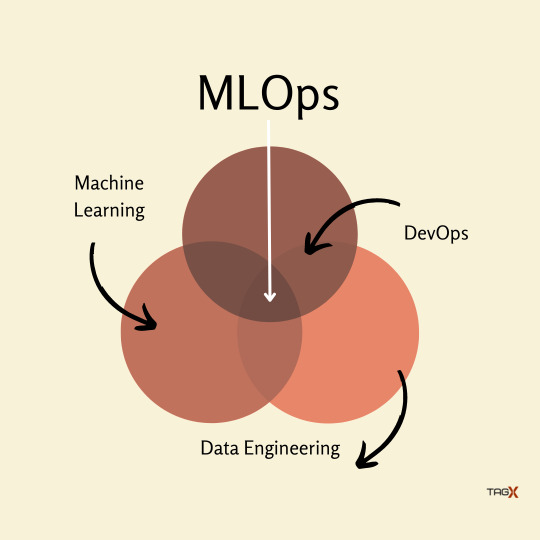
The key MLOps principles are:
Versioning – keeping track of the versions of data, ML model, code around it, etc.;
Testing – testing and validating an ML model to check whether it is working in the development environment;
Automation – trying to automate as many ML lifecycle processes as possible;
Reproducibility – we want to get identical results given the same input;
Deployment – deploying the model into production;
Monitoring – checking the model’s performance on real-world data.
What are the benefits of MLOps?
The primary benefits of MLOps are efficiency, scalability, and risk reduction.
Efficiency: MLOps allows data teams to achieve faster model development, deliver higher quality ML models, and faster deployment and production.
Scalability: Thousands of models may be supervised, controlled, managed, and monitored for continuous integration, continuous delivery, and continuous deployment thanks to MLOps’ extensive scalability and management capabilities. MLOps, in particular, makes ML pipelines reproducible, enables closer coordination between data teams, lessens friction between DevOps and IT, and speeds up release velocity.
Risk reduction: Machine learning models often need regulatory scrutiny and drift-check, and MLOps enables greater transparency and faster response to such requests and ensures greater compliance with an organization’s or industry’s policies.
Data pipeline for ML operations
One significant difference between DevOps and MLOps is that ML services require data–and lots of it. In order to be suitable for ML model training, most data has to be cleaned, verified, and tagged. Much of this can be done in a stepwise fashion, as a data pipeline, where unclean data enters the pipeline, and then the training, validating, and testing data exits the pipeline.
The data pipeline of a project involves several key steps:
Data collection:
Whether you source your data in-house, open-source, or from a third-party data provider, it’s important to set up a process where you can continuously collect data, as needed. You’ll not only need a lot of data at the start of the ML development lifecycle but also for retraining purposes at the end. Having a consistent, reliable source for new data is paramount to success.
Data cleansing:
This involves removing any unwanted or irrelevant data or cleaning up messy data. In some cases, it may be as simple as converting data into the format you need, such as a CSV file. Some steps of this may be automatable.
Data annotation:
Labeling your data is one of the most time-consuming, difficult, but crucial, phases of the ML lifecycle. Companies that try to take this step internally frequently struggle with resources and take too long. Other approaches give a wider range of annotators the chance to participate, such as hiring freelancers or crowdsourcing. Many businesses decide to collaborate with external data providers, who can give access to vast annotator communities, platforms, and tools for any annotating need. Depending on your use case and your need for quality, some steps in the annotation process may potentially be automated.
After the data has been cleaned, validated, and tagged, you can begin training the ML model to categorize, predict, or infer whatever it is that you want the model to do. Training, validation, and hold-out testing datasets are created out of the tagged data. The model architecture and hyperparameters are optimized many times using the training and validation data. Once that is finished, you test the algorithm on the hold-out test data one last time to check if it performs enough on the fresh data you need to release.
Setting up a continuous data pipeline is an important step in MLOps implementation. It’s helpful to think of it as a loop, because you’ll often realize you need additional data later in the build process, and you don’t want to have to start from scratch to find it and prepare it.
Conclusion
MLOps help ensure that deployed models are well maintained, performing as expected, and not having any adverse effects on the business. This role is crucial in protecting the business from risks due to models that drift over time, or that are deployed but unmaintained or unmonitored.
TagX is involved in delivering Data for each step of ML operations. At TagX, we provide high-quality annotated training data to power the world’s most innovative machine learning and business solutions. We can help your organization with data collection, Data cleaning, data annotation, and synthetic data to train your Machine learning models.
#annotation#data annotation for ml#it services#machine learning#viral topic#blog post#data annotation services#indore#india#instagram#tagx#service#ecommerce#digital marketing#seo service
5 notes
·
View notes
Text
How to Write an Outstanding Annotated Bibliography – A Step-by-Step Guide – 2024

Introduction
Are you struggling to create a well-structured and informative annotated bibliography? Don’t worry; you’re not alone. Many students and researchers find this task daunting, but it doesn’t have to be. An annotated bibliography is a powerful tool that helps you organize and evaluate your sources, making it easier to conduct research and write papers. This comprehensive guide will walk you through the entire process, from understanding what an annotated bibliography is to crafting clear and concise annotations that showcase the relevance and credibility of your sources.
Understanding Annotated Bibliography
Before diving into the process, let’s define what an annotated bibliography is. It’s a list of sources (books, articles, websites, etc.) that you’ve consulted or plan to use for your research project. Each source is followed by a brief descriptive and evaluative paragraph, known as the annotation. This annotation summarizes the source’s main ideas, assesses its credibility and relevance, and highlights its strengths and weaknesses.
Choosing Relevant Sources
The first step in creating an annotated bibliography is to gather a diverse range of sources relevant to your research topic. Start by exploring your university’s library databases, reputable academic journals, and authoritative websites. Look for sources that cover different perspectives, methodologies, and approaches to your subject matter.
Evaluating Sources
Not all sources are created equal, so it’s crucial to evaluate each one carefully. Consider the author’s credentials, the publication date, the intended audience, and the overall reliability of the source. Look for peer-reviewed articles, books published by reputable academic presses, and authoritative websites maintained by respected organizations or institutions.
Summarizing the Source
The first step in crafting an annotation is to provide a concise summary of the source’s main ideas, arguments, and findings. This summary should be objective and free of personal opinions or interpretations. Aim to capture the essence of the source in a few sentences, highlighting its purpose, scope, and key points.
Assessing the Source’s Credibility

After summarizing the source, it’s essential to evaluate its credibility. Consider the author’s expertise, the reliability of the publication, and the objectivity of the content. Look for any potential biases, conflicts of interest, or unsupported claims. Assessing credibility is crucial for determining the validity and trustworthiness of the information presented in the source.
Analyzing the Source’s Content
Go beyond the surface and delve into a deeper analysis of the source’s content. Examine the methodologies used, the evidence presented, and the overall quality of the arguments or findings. Identify any gaps, weaknesses, or limitations in the source’s approach or conclusions.
Identifying the Source’s Strengths and Weaknesses
Every source has its strengths and weaknesses. In your annotation, highlight the source’s unique contributions, innovative perspectives, or groundbreaking findings. At the same time, acknowledge any limitations, flaws, or areas that could be improved or expanded upon.
Organizing the Annotated Bibliography
Once you’ve gathered and evaluated your sources, it’s time to organize your annotated bibliography. Most citation styles (e.g., APA, MLA, Chicago) require sources to be listed in alphabetical order by the author’s last name or the title if no author is given.
Writing the Annotation
The annotation itself should be a concise yet informative paragraph that summarizes the source, evaluates its credibility, and highlights its strengths and weaknesses. Aim for a length of around 150-200 words per annotation, although this can vary depending on the specific requirements of your assignment or project.
Formatting and Styling
Consistency is key when it comes to formatting and styling your annotated bibliography. Follow the guidelines of the citation style required by your institution or publication. Pay attention to details such as indentation, line spacing, font size, and the use of hanging indents for each annotation.
Proofreading and Editing

Before submitting your annotated bibliography, take the time to proofread and edit your work carefully. Check for spelling and grammar errors, inconsistencies in formatting, and any typos or missing information. Consider having a peer or a writing center review your annotated bibliography to catch any potential mistakes or areas for improvement.
Adding Citations and References
Proper citation and referencing are essential components of an annotated bibliography. Make sure to include complete and accurate bibliographic information for each source, following the appropriate citation style (e.g., APA, MLA, Chicago). Double-check that all in-text citations and references are correctly formatted and correspond to the sources listed in your annotated bibliography.
Providing Clear and Concise Annotations
While annotations should be informative, they should also be clear and concise. Avoid using overly complex language or convoluted sentences. Aim for a straightforward and accessible writing style that effectively communicates the key points and evaluations of each source.
Ensuring Proper Grammar and Language Usage
Proper grammar and language usage are crucial for creating a professional and polished annotated bibliography. Pay attention to sentence structure, verb tenses, subject-verb agreement, and word choice. Proofread carefully to ensure that your annotations are free of grammatical errors and awkward phrasing.
Avoiding Plagiarism
Plagiarism is a serious offense in academic and professional settings. When summarizing or quoting from sources, be sure to properly attribute the information to the original author(s). Use quotation marks for direct quotes and provide appropriate citations. Never present someone else’s ideas or words as your own.
Including Relevant Keywords and Phrases
To help readers quickly grasp the main focus and content of each source, consider including relevant keywords and phrases in your annotations. These can include specific terms, concepts, or methodologies discussed in the source material.
Incorporating Different Perspectives
An annotated bibliography should reflect a diverse range of perspectives and approaches related to your research topic. Seek out sources that offer contrasting viewpoints, alternative methodologies, or unique interpretations. Incorporating these different perspectives will enrich your understanding of the subject matter and strengthen the overall quality of your annotated bibliography.
Highlighting Key Findings and Arguments

While summarizing the source’s main ideas, be sure to highlight any particularly significant findings, groundbreaking arguments, or innovative approaches. These key elements can help readers quickly identify the most valuable and impactful contributions of each source.
Addressing Gaps in Research
In some cases, your annotations may reveal gaps or limitations in the existing research on your topic. If applicable, note these gaps and suggest areas where further research or exploration could be beneficial. This demonstrates your critical thinking skills and ability to identify opportunities for advancing knowledge in your field.
Comparing and Contrasting Different Sources
In addition to evaluating each source individually, consider comparing and contrasting sources that address similar topics or take different approaches. Identify areas of agreement or disagreement, and analyze how these sources relate to or build upon one another.
Reflecting on the Significance of the Sources
As you craft your annotations, reflect on the overall significance and impact of each source within the larger context of your research topic or field of study. Consider how the source contributes to the ongoing scholarly conversation or advances understanding in a particular area.
Connecting the Sources to the Research Question
An effective annotated bibliography should demonstrate how each source relates to and informs your specific research question or thesis statement. Explicitly discuss how the source’s content, findings, or methodologies help address or shed light on the central issue or problem you are investigating.
Considering the Audience’s Needs
When writing your annotations, keep your intended audience in mind. Tailor the level of detail, use of technical language, and overall tone to suit the needs and background knowledge of your readers. For example, annotations intended for a general audience may require more explanation and context than those written for experts in the field.
Tailoring Annotations for Different Purposes

Annotated bibliographies can serve various purposes, such as supporting a research paper, providing an overview of literature in a particular field, or documenting sources for a specific project. Depending on the purpose, you may need to adjust the focus and depth of your annotations. For instance, annotations for a literature review may require a more comprehensive analysis and synthesis of sources.
Using Appropriate Tone and Language
The tone and language you use in your annotations should be formal, objective, and academic. Avoid using overly casual or colloquial language, and strive for a scholarly and professional writing style. Additionally, be mindful of maintaining an impartial and unbiased tone when evaluating and critiquing sources.
Reviewing and Revising the Annotated Bibliography
After completing a first draft of your annotated bibliography, take the time to review and revise your work. Look for areas that need clarification, additional details, or more concise phrasing. Ensure that your annotations are well-organized, logically structured, and provide a clear and comprehensive assessment of each source.
Seeking Feedback and Peer Review
Sharing your annotated bibliography with peers, instructors, or writing center consultants can be incredibly valuable. Fresh eyes can identify areas that need improvement, offer suggestions for strengthening your annotations, and help you catch any errors or inconsistencies you may have missed.
Understanding Citation Styles
Different academic disciplines and publications have their own preferred citation styles, such as APA, MLA, Chicago, or Harvard. Before you begin your annotated bibliography, make sure you understand the specific citation style required and adhere to its guidelines for formatting citations and references.
Examples of Well-Written Annotations
To get a better understanding of what a well-crafted annotation looks like, it can be helpful to examine examples from various disciplines and sources. Look for annotations that effectively summarize the source’s content, critically evaluate its credibility and relevance, and highlight both strengths and limitations.
Common Mistakes to Avoid
As with any academic writing task, there are common pitfalls to be aware of when creating an annotated bibliography. Some mistakes to avoid include:
Providing excessive details or plot summaries instead of focused annotations
Failing to assess the source’s credibility or relevance
Neglecting to highlight the source’s strengths and weaknesses
Copying verbatim from the source without proper attribution
Using an inconsistent citation style throughout the bibliography
Making unsupported claims or personal opinions in the annotations
Presenting annotations that are too brief or lacking in substance
Conclusion

Crafting an outstanding annotated bibliography is a valuable skill that can enhance your research projects, literature reviews, and academic writing. By following this step-by-step guide, you’ll learn how to choose relevant sources, evaluate their credibility and relevance, summarize key points, identify strengths and weaknesses, and provide clear and concise annotations.
Remember, an annotated bibliography is more than just a list of sources; it’s a powerful tool that demonstrates your ability to critically analyze and synthesize information from various sources. By taking the time to create a well-organized and thoughtful annotated bibliography, you’ll not only strengthen your research skills but also impress your instructors, peers, and potential readers with your attention to detail and commitment to scholarly excellence.
So, don’t let the task of creating an annotated bibliography intimidate you. Embrace the challenge, follow these guidelines, and produce a polished, informative, and insightful annotated bibliography that showcases your subject matter expertise and academic rigor.
0 notes
Text
Image annotation Services are the process by which images are labeled, tagged, or annotated to make it easy to train machine learning models. The image annotation process involves identifying data of interest in the annotation picture and then applying different image annotation techniques to mark it to make it easily recognizable by the AI model.
The purpose of annotating images is to make it possible for the ML model to identify the information of interest in an annotated picture without human input. Depending on project needs, image annotation could be simple or complex.
0 notes
Last Seen Blogs

nelly-shcherbina
Вперёд, и с песней!
nelly-shcherbina
Вперёд, и с песней!

jackroysenders
Unbetitelt

ggo229596
제목 없음
jackroysenders
Unbetitelt