#AI for machine learning
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Celebrities use Tumblr as well.
Text

(Source)
73K notes
·
View notes
Text

#I'm serious stop doing it#theyre scraping fanfics and other authors writing#'oh but i wanna rp with my favs' then learn to write#studios wanna use ai to put writers AND artists out of business stop feeding the fucking machine!!!!
166K notes
·
View notes
Text
Challenges and Best Practices in Data Annotation
Data annotation is a crucial step in training machine learning models, but it comes with its own set of challenges. Addressing these challenges effectively through best practices can significantly enhance the quality of the resulting AI models.
Challenges in Data Annotation
Consistency and Accuracy: One of the major challenges is ensuring consistency and accuracy in annotations. Different annotators might interpret data differently, leading to inconsistencies. This can degrade the performance of the machine learning model.
Scalability: Annotating large datasets manually is time-consuming and labor-intensive. As datasets grow, maintaining quality while scaling up the annotation process becomes increasingly difficult.
Subjectivity: Certain data, such as sentiment in text or complex object recognition in images, can be highly subjective. Annotators’ personal biases and interpretations can affect the consistency of the annotations.
Domain Expertise: Some datasets require specific domain knowledge for accurate annotation. For instance, medical images need to be annotated by healthcare professionals to ensure correctness.
Bias: Bias in data annotation can stem from the annotators' cultural, demographic, or personal biases. This can result in biased AI models that do not generalize well across different populations.
Best Practices in Data Annotation
Clear Guidelines and Training: Providing annotators with clear, detailed guidelines and comprehensive training is essential. This ensures that all annotators understand the criteria uniformly and reduces inconsistencies.
Quality Control Mechanisms: Implementing quality control mechanisms, such as inter-annotator agreement metrics, regular spot-checks, and using a gold standard dataset, can help maintain high annotation quality. Continuous feedback loops are also critical for improving annotator performance over time.
Leverage Automation: Utilizing automated tools can enhance efficiency. Semi-automated approaches, where AI handles simpler tasks and humans review the results, can significantly speed up the process while maintaining quality.
Utilize Expert Annotators: For specialized datasets, employ domain experts who have the necessary knowledge and experience. This is particularly important for fields like healthcare or legal documentation where accuracy is critical.
Bias Mitigation: To mitigate bias, diversify the pool of annotators and implement bias detection mechanisms. Regular reviews and adjustments based on detected biases are necessary to ensure fair and unbiased data.
Iterative Annotation: Use an iterative process where initial annotations are reviewed and refined. Continuous cycles of annotation and feedback help in achieving more accurate and reliable data.
For organizations seeking professional assistance, companies like Data Annotation Services provide tailored solutions. They employ advanced tools and experienced annotators to ensure precise and reliable data annotation, driving the success of AI projects.
#datasets for machine learning#Data Annotation services#data collection#AI for machine learning#business
0 notes
Text
31% of employees are actively ‘sabotaging’ AI efforts. Here’s why
"In a new study, almost a third of respondents said they are refusing to use their company’s AI tools and apps. A few factors could be at play."

1K notes
·
View notes
Text
AI hasn't improved in 18 months. It's likely that this is it. There is currently no evidence the capabilities of ChatGPT will ever improve. It's time for AI companies to put up or shut up.
I'm just re-iterating this excellent post from Ed Zitron, but it's not left my head since I read it and I want to share it. I'm also taking some talking points from Ed's other posts. So basically:
We keep hearing AI is going to get better and better, but these promises seem to be coming from a mix of companies engaging in wild speculation and lying.
Chatgpt, the industry leading large language model, has not materially improved in 18 months. For something that claims to be getting exponentially better, it sure is the same shit.
Hallucinations appear to be an inherent aspect of the technology. Since it's based on statistics and ai doesn't know anything, it can never know what is true. How could I possibly trust it to get any real work done if I can't rely on it's output? If I have to fact check everything it says I might as well do the work myself.
For "real" ai that does know what is true to exist, it would require us to discover new concepts in psychology, math, and computing, which open ai is not working on, and seemingly no other ai companies are either.
Open ai has already seemingly slurped up all the data from the open web already. Chatgpt 5 would take 5x more training data than chatgpt 4 to train. Where is this data coming from, exactly?
Since improvement appears to have ground to a halt, what if this is it? What if Chatgpt 4 is as good as LLMs can ever be? What use is it?
As Jim Covello, a leading semiconductor analyst at Goldman Sachs said (on page 10, and that's big finance so you know they only care about money): if tech companies are spending a trillion dollars to build up the infrastructure to support ai, what trillion dollar problem is it meant to solve? AI companies have a unique talent for burning venture capital and it's unclear if Open AI will be able to survive more than a few years unless everyone suddenly adopts it all at once. (Hey, didn't crypto and the metaverse also require spontaneous mass adoption to make sense?)
There is no problem that current ai is a solution to. Consumer tech is basically solved, normal people don't need more tech than a laptop and a smartphone. Big tech have run out of innovations, and they are desperately looking for the next thing to sell. It happened with the metaverse and it's happening again.
In summary:
Ai hasn't materially improved since the launch of Chatgpt4, which wasn't that big of an upgrade to 3.
There is currently no technological roadmap for ai to become better than it is. (As Jim Covello said on the Goldman Sachs report, the evolution of smartphones was openly planned years ahead of time.) The current problems are inherent to the current technology and nobody has indicated there is any way to solve them in the pipeline. We have likely reached the limits of what LLMs can do, and they still can't do much.
Don't believe AI companies when they say things are going to improve from where they are now before they provide evidence. It's time for the AI shills to put up, or shut up.
5K notes
·
View notes
Text
shout out to machine learning tech (and all the human-input adjustment contributors) that's brought about the present developmental stage of machine translation, making the current global village 地球村 moment on rednote小红书 accessible in a way that would not have been possible years ago.
#translation#rednote#xhs#machine learning#linguistics#accessibility#unfinished thought pls read down the whole chain ty#when AI is accessibility tool for the masses :D
1K notes
·
View notes
Text
verdant garden
567 notes
·
View notes
Text
"The first satellite in a constellation designed specifically to locate wildfires early and precisely anywhere on the planet has now reached Earth's orbit, and it could forever change how we tackle unplanned infernos.
The FireSat constellation, which will consist of more than 50 satellites when it goes live, is the first of its kind that's purpose-built to detect and track fires. It's an initiative launched by nonprofit Earth Fire Alliance, which includes Google and Silicon Valley-based space services startup Muon Space as partners, among others.
According to Google, current satellite systems rely on low-resolution imagery and cover a particular area only once every 12 hours to spot significantly large wildfires spanning a couple of acres. FireSat, on the other hand, will be able to detect wildfires as small as 270 sq ft (25 sq m) – the size of a classroom – and deliver high-resolution visual updates every 20 minutes.
The FireSat project has only been in the works for less than a year and a half. The satellites are fitted with custom six-band multispectral infrared cameras, designed to capture imagery suitable for machine learning algorithms to accurately identify wildfires – differentiating them from misleading objects like smokestacks.
These algorithms look at an image from a particular location, and compare it with the last 1,000 times it was captured by the satellite's camera to determine if what it's seeing is indeed a wildfire. AI technology in the FireSat system also helps predict how a fire might spread; that can help firefighters make better decisions about how to control the flames safely and effectively.
This could go a long way towards preventing the immense destruction of forest habitats and urban areas, and the displacement of residents caused by wildfires each year. For reference, the deadly wildfires that raged across Los Angeles in January were estimated to have cuased more than $250 billion in damages.
Muon is currently developing three more satellites, which are set to launch next year. The entire constellation should be in orbit by 2030.
The FireSat effort isn't the only project to watch for wildfires from orbit. OroraTech launched its first wildfire-detection satellite – FOREST-1 – in 2022, followed by one more in 2023 and another earlier this year. The company tells us that another eight are due to go up toward the end of March."
-via March 18, 2025
#wildfire#wildfires#la wildfires#los angeles#ai#artificial intelligence#machine learning#satellite#natural disasters#good news#hope
722 notes
·
View notes
Text
why neuroscience is cool
space & the brain are like the two final frontiers
we know just enough to know we know nothing
there are radically new theories all. the. time. and even just in my research assistant work i've been able to meet with, talk to, and work with the people making them
it's such a philosophical science
potential to do a lot of good in fighting neurological diseases
things like BCI (brain computer interface) and OI (organoid intelligence) are soooooo new and anyone's game - motivation to study hard and be successful so i can take back my field from elon musk
machine learning is going to rapidly increase neuroscience progress i promise you. we get so caught up in AI stealing jobs but yes please steal my job of manually analyzing fMRI scans please i would much prefer to work on the science PLUS computational simulations will soon >>> animal testing to make all drug testing safer and more ethical !! we love ethical AI <3
collab with...everyone under the sun - psychologists, philosophers, ethicists, physicists, molecular biologists, chemists, drug development, machine learning, traditional computing, business, history, education, literally try to name a field we don't work with
it's the brain eeeeee
#my motivation to study so i can be a cool neuroscientist#science#women in stem#academia#stem#stemblr#studyblr#neuroscience#stem romanticism#brain#psychology#machine learning#AI#brain computer interface#organoid intelligence#motivation#positivity#science positivity#cogsci#cognitive science
2K notes
·
View notes
Text
We need to change the way we think about AI and remember that arms races don’t just exist between nations. The problem is once again capitalism, not the technology itself or some other boogeyman.
#leftblr#late stage capitalism#working class#left wing#class war#leftist#socialism#tech#technology#ai#machine learning
306 notes
·
View notes
Text

Frank Rosenblatt, often cited as the Father of Machine Learning, photographed in 1960 alongside his most-notable invention: the Mark I Perceptron machine — a hardware implementation for the perceptron algorithm, the earliest example of an artificial neural network, est. 1943.
#frank rosenblatt#tech history#machine learning#neural network#artificial intelligence#AI#perceptron#60s#black and white#monochrome#technology#u
820 notes
·
View notes
Text

Dragon…
||DO NOT FEED TO AI DO NOT USE FOR MACHINE LEARNING||
#my art#art#dragon#traditional art#drawing#sketch#tradtional drawing#sketchbook#dragon art#artists on tumblr#do not feed to ai#do not use for machine learning
336 notes
·
View notes
Text
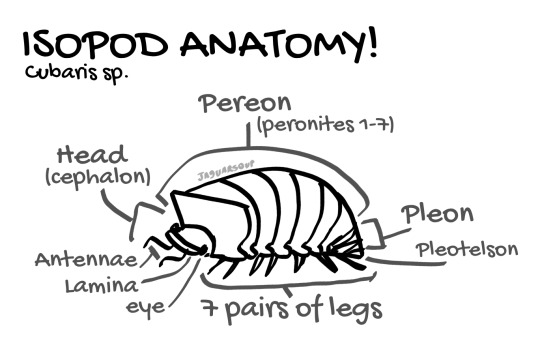
Dichotomous key is nowhere near functional yet so here’s a little anatomy diagram I made.
#real isopod hours#isopods#not an identification#isopod differentiation guide#the (iso)podcast#Cubaris sp#art#bug art#diagram#do not feed to ai#do not use for machine learning
172 notes
·
View notes
Note

Straight from the bull's mouth.
AI Art simply cannot make artistic choices or apply craft or storytelling, it just spits out an average.
467 notes
·
View notes
Text
There is no such thing as AI.
How to help the non technical and less online people in your life navigate the latest techbro grift.
I've seen other people say stuff to this effect but it's worth reiterating. Today in class, my professor was talking about a news article where a celebrity's likeness was used in an ai image without their permission. Then she mentioned a guest lecture about how AI is going to help finance professionals. Then I pointed out, those two things aren't really related.
The term AI is being used to obfuscate details about multiple semi-related technologies.
Traditionally in sci-fi, AI means artificial general intelligence like Data from star trek, or the terminator. This, I shouldn't need to say, doesn't exist. Techbros use the term AI to trick investors into funding their projects. It's largely a grift.
What is the term AI being used to obfuscate?
If you want to help the less online and less tech literate people in your life navigate the hype around AI, the best way to do it is to encourage them to change their language around AI topics.
By calling these technologies what they really are, and encouraging the people around us to know the real names, we can help lift the veil, kill the hype, and keep people safe from scams. Here are some starting points, which I am just pulling from Wikipedia. I'd highly encourage you to do your own research.
Machine learning (ML): is an umbrella term for solving problems for which development of algorithms by human programmers would be cost-prohibitive, and instead the problems are solved by helping machines "discover" their "own" algorithms, without needing to be explicitly told what to do by any human-developed algorithms. (This is the basis of most technologically people call AI)
Language model: (LM or LLM) is a probabilistic model of a natural language that can generate probabilities of a series of words, based on text corpora in one or multiple languages it was trained on. (This would be your ChatGPT.)
Generative adversarial network (GAN): is a class of machine learning framework and a prominent framework for approaching generative AI. In a GAN, two neural networks contest with each other in the form of a zero-sum game, where one agent's gain is another agent's loss. (This is the source of some AI images and deepfakes.)
Diffusion Models: Models that generate the probability distribution of a given dataset. In image generation, a neural network is trained to denoise images with added gaussian noise by learning to remove the noise. After the training is complete, it can then be used for image generation by starting with a random noise image and denoise that. (This is the more common technology behind AI images, including Dall-E and Stable Diffusion. I added this one to the post after as it was brought to my attention it is now more common than GANs.)
I know these terms are more technical, but they are also more accurate, and they can easily be explained in a way non-technical people can understand. The grifters are using language to give this technology its power, so we can use language to take it's power away and let people see it for what it really is.
12K notes
·
View notes