#apache hadoop cluster
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Text

Wielding Big Data Using PySpark
Introduction to PySpark
PySpark is the Python API for Apache Spark, a distributed computing framework designed to process large-scale data efficiently. It enables parallel data processing across multiple nodes, making it a powerful tool for handling massive datasets.
Why Use PySpark for Big Data?
Scalability: Works across clusters to process petabytes of data.
Speed: Uses in-memory computation to enhance performance.
Flexibility: Supports various data formats and integrates with other big data tools.
Ease of Use: Provides SQL-like querying and DataFrame operations for intuitive data handling.
Setting Up PySpark
To use PySpark, you need to install it and set up a Spark session. Once initialized, Spark allows users to read, process, and analyze large datasets.
Processing Data with PySpark
PySpark can handle different types of data sources such as CSV, JSON, Parquet, and databases. Once data is loaded, users can explore it by checking the schema, summary statistics, and unique values.
Common Data Processing Tasks
Viewing and summarizing datasets.
Handling missing values by dropping or replacing them.
Removing duplicate records.
Filtering, grouping, and sorting data for meaningful insights.
Transforming Data with PySpark
Data can be transformed using SQL-like queries or DataFrame operations. Users can:
Select specific columns for analysis.
Apply conditions to filter out unwanted records.
Group data to find patterns and trends.
Add new calculated columns based on existing data.
Optimizing Performance in PySpark
When working with big data, optimizing performance is crucial. Some strategies include:
Partitioning: Distributing data across multiple partitions for parallel processing.
Caching: Storing intermediate results in memory to speed up repeated computations.
Broadcast Joins: Optimizing joins by broadcasting smaller datasets to all nodes.
Machine Learning with PySpark
PySpark includes MLlib, a machine learning library for big data. It allows users to prepare data, apply machine learning models, and generate predictions. This is useful for tasks such as regression, classification, clustering, and recommendation systems.
Running PySpark on a Cluster
PySpark can run on a single machine or be deployed on a cluster using a distributed computing system like Hadoop YARN. This enables large-scale data processing with improved efficiency.
Conclusion
PySpark provides a powerful platform for handling big data efficiently. With its distributed computing capabilities, it allows users to clean, transform, and analyze large datasets while optimizing performance for scalability.
For Free Tutorials for Programming Languages Visit-https://www.tpointtech.com/
2 notes
·
View notes
Text
From Curious Novice to Data Enthusiast: My Data Science Adventure
I've always been fascinated by data science, a field that seamlessly blends technology, mathematics, and curiosity. In this article, I want to take you on a journey—my journey—from being a curious novice to becoming a passionate data enthusiast. Together, let's explore the thrilling world of data science, and I'll share the steps I took to immerse myself in this captivating realm of knowledge.

The Spark: Discovering the Potential of Data Science
The moment I stumbled upon data science, I felt a spark of inspiration. Witnessing its impact across various industries, from healthcare and finance to marketing and entertainment, I couldn't help but be drawn to this innovative field. The ability to extract critical insights from vast amounts of data and uncover meaningful patterns fascinated me, prompting me to dive deeper into the world of data science.
Laying the Foundation: The Importance of Learning the Basics
To embark on this data science adventure, I quickly realized the importance of building a strong foundation. Learning the basics of statistics, programming, and mathematics became my priority. Understanding statistical concepts and techniques enabled me to make sense of data distributions, correlations, and significance levels. Programming languages like Python and R became essential tools for data manipulation, analysis, and visualization, while a solid grasp of mathematical principles empowered me to create and evaluate predictive models.
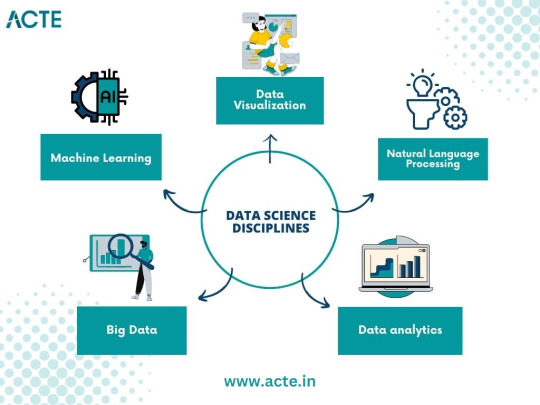
The Quest for Knowledge: Exploring Various Data Science Disciplines
A. Machine Learning: Unraveling the Power of Predictive Models
Machine learning, a prominent discipline within data science, captivated me with its ability to unlock the potential of predictive models. I delved into the fundamentals, understanding the underlying algorithms that power these models. Supervised learning, where data with labels is used to train prediction models, and unsupervised learning, which uncovers hidden patterns within unlabeled data, intrigued me. Exploring concepts like regression, classification, clustering, and dimensionality reduction deepened my understanding of this powerful field.
B. Data Visualization: Telling Stories with Data
In my data science journey, I discovered the importance of effectively visualizing data to convey meaningful stories. Navigating through various visualization tools and techniques, such as creating dynamic charts, interactive dashboards, and compelling infographics, allowed me to unlock the hidden narratives within datasets. Visualizations became a medium to communicate complex ideas succinctly, enabling stakeholders to understand insights effortlessly.
C. Big Data: Mastering the Analysis of Vast Amounts of Information
The advent of big data challenged traditional data analysis approaches. To conquer this challenge, I dived into the world of big data, understanding its nuances and exploring techniques for efficient analysis. Uncovering the intricacies of distributed systems, parallel processing, and data storage frameworks empowered me to handle massive volumes of information effectively. With tools like Apache Hadoop and Spark, I was able to mine valuable insights from colossal datasets.
D. Natural Language Processing: Extracting Insights from Textual Data
Textual data surrounds us in the digital age, and the realm of natural language processing fascinated me. I delved into techniques for processing and analyzing unstructured text data, uncovering insights from tweets, customer reviews, news articles, and more. Understanding concepts like sentiment analysis, topic modeling, and named entity recognition allowed me to extract valuable information from written text, revolutionizing industries like sentiment analysis, customer service, and content recommendation systems.
Building the Arsenal: Acquiring Data Science Skills and Tools
Acquiring essential skills and familiarizing myself with relevant tools played a crucial role in my data science journey. Programming languages like Python and R became my companions, enabling me to manipulate, analyze, and model data efficiently. Additionally, I explored popular data science libraries and frameworks such as TensorFlow, Scikit-learn, Pandas, and NumPy, which expedited the development and deployment of machine learning models. The arsenal of skills and tools I accumulated became my assets in the quest for data-driven insights.
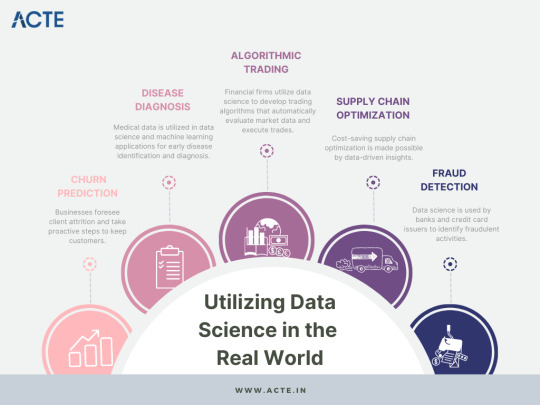
The Real-World Challenge: Applying Data Science in Practice
Data science is not just an academic pursuit but rather a practical discipline aimed at solving real-world problems. Throughout my journey, I sought to identify such problems and apply data science methodologies to provide practical solutions. From predicting customer churn to optimizing supply chain logistics, the application of data science proved transformative in various domains. Sharing success stories of leveraging data science in practice inspires others to realize the power of this field.
Cultivating Curiosity: Continuous Learning and Skill Enhancement
Embracing a growth mindset is paramount in the world of data science. The field is rapidly evolving, with new algorithms, techniques, and tools emerging frequently. To stay ahead, it is essential to cultivate curiosity and foster a continuous learning mindset. Keeping abreast of the latest research papers, attending data science conferences, and engaging in data science courses nurtures personal and professional growth. The journey to becoming a data enthusiast is a lifelong pursuit.
Joining the Community: Networking and Collaboration
Being part of the data science community is a catalyst for growth and inspiration. Engaging with like-minded individuals, sharing knowledge, and collaborating on projects enhances the learning experience. Joining online forums, participating in Kaggle competitions, and attending meetups provides opportunities to exchange ideas, solve challenges collectively, and foster invaluable connections within the data science community.
Overcoming Obstacles: Dealing with Common Data Science Challenges
Data science, like any discipline, presents its own set of challenges. From data cleaning and preprocessing to model selection and evaluation, obstacles arise at each stage of the data science pipeline. Strategies and tips to overcome these challenges, such as building reliable pipelines, conducting robust experiments, and leveraging cross-validation techniques, are indispensable in maintaining motivation and achieving success in the data science journey.
Balancing Act: Building a Career in Data Science alongside Other Commitments
For many aspiring data scientists, the pursuit of knowledge and skills must coexist with other commitments, such as full-time jobs and personal responsibilities. Effectively managing time and developing a structured learning plan is crucial in striking a balance. Tips such as identifying pockets of dedicated learning time, breaking down complex concepts into manageable chunks, and seeking mentorships or online communities can empower individuals to navigate the data science journey while juggling other responsibilities.
Ethical Considerations: Navigating the World of Data Responsibly
As data scientists, we must navigate the world of data responsibly, being mindful of the ethical considerations inherent in this field. Safeguarding privacy, addressing bias in algorithms, and ensuring transparency in data-driven decision-making are critical principles. Exploring topics such as algorithmic fairness, data anonymization techniques, and the societal impact of data science encourages responsible and ethical practices in a rapidly evolving digital landscape.
Embarking on a data science adventure from a curious novice to a passionate data enthusiast is an exhilarating and rewarding journey. By laying a foundation of knowledge, exploring various data science disciplines, acquiring essential skills and tools, and engaging in continuous learning, one can conquer challenges, build a successful career, and have a good influence on the data science community. It's a journey that never truly ends, as data continues to evolve and offer exciting opportunities for discovery and innovation. So, join me in your data science adventure, and let the exploration begin!
#data science#data analytics#data visualization#big data#machine learning#artificial intelligence#education#information
17 notes
·
View notes
Text
Big Data Technologies: Hadoop, Spark, and Beyond

In this era where every click, transaction, or sensor emits a massive flux of information, the term "Big Data" has gone past being a mere buzzword and has become an inherent challenge and an enormous opportunity. These are datasets so enormous, so complex, and fast-growing that traditional data-processing applications cannot handle them. The huge ocean of information needs special tools; at the forefront of this big revolution being Big Data Technologies- Hadoop, Spark, and beyond.
One has to be familiar with these technologies if they are to make some modern-day sense of the digital world, whether they be an aspiring data professional or a business intent on extracting actionable insights out of their massive data stores.
What is Big Data and Why Do We Need Special Technologies?
Volume: Enormous amounts of data (terabytes, petabytes, exabytes).
Velocity: Data generated and processed at incredibly high speeds (e.g., real-time stock trades, IoT sensor data).
Variety: Data coming in diverse formats (structured, semi-structured, unstructured – text, images, videos, logs).
Traditional relational databases and processing tools were not built to handle this scale, speed, or diversity. They would crash, take too long, or simply fail to process such immense volumes. This led to the emergence of distributed computing frameworks designed specifically for Big Data.
Hadoop: The Pioneer of Big Data Processing
Apache Hadoop was an advanced technological tool in its time. It had completely changed the facets of data storage and processing on a large scale. It provides a framework for distributed storage and processing of datasets too large to be processed on a single machine.
· Key Components:
HDFS (Hadoop Distributed File System): It is a distributed file system, where the data is stored across multiple machines and hence are fault-tolerant and highly scalable.
MapReduce: A programming model for processing large data sets with a parallel, distributed algorithm on a cluster. It subdivides a large problem into smaller ones that can be solved independently in parallel.
What made it revolutionary was the fact that Hadoop enabled organizations to store and process data they previously could not, hence democratizing access to massive datasets.
Spark: The Speed Demon of Big Data Analytics
While MapReduce on Hadoop is a formidable force, disk-based processing sucks up time when it comes to iterative algorithms and real-time analytics. And so came Apache Spark: an entire generation ahead in terms of speed and versatility.
· Key Advantages over Hadoop MapReduce:
In-Memory Processing: Spark processes data in memory, which is from 10 to 100 times faster than MapReduce-based operations, primarily in iterative algorithms (Machine Learning is an excellent example here).
Versatility: Several libraries exist on top of Spark's core engine:
Spark SQL: Structured data processing using SQL
Spark Streaming: Real-time data processing.
MLlib: Machine Learning library.
GraphX: Graph processing.
What makes it important, actually: Spark is the tool of choice when it comes to real-time analytics, complex data transformations, and machine learning on Big Data.
And Beyond: Evolving Big Data Technologies
The Big Data ecosystem is growing by each passing day. While Hadoop and Spark are at the heart of the Big Data paradigm, many other technologies help in complementing and extending their capabilities:
NoSQL Databases: (e.g., MongoDB, Cassandra, HBase) – The databases were designed to handle massive volumes of unstructured or semi-structured data with high scale and high flexibility as compared to traditional relational databases.
Stream Processing Frameworks: (e.g., Apache Kafka, Apache Flink) – These are important for processing data as soon as it arrives (real-time), crucial for fraud-detection, IoT Analytics, and real-time dashboards.
Data Warehouses & Data Lakes: Cloud-native solutions (example, Amazon Redshift, Snowflake, Google BigQuery, Azure Synapse Analytics) for scalable, managed environments to store and analyze big volumes of data often with seamless integration to Spark.
Cloud Big Data Services: Major cloud providers running fully managed services of Big Data processing (e.g., AWS EMR, Google Dataproc, Azure HDInsight) reduce much of deployment and management overhead.
Data Governance & Security Tools: As data grows, the need to manage its quality, privacy, and security becomes paramount.
Career Opportunities in Big Data
Mastering Big Data technologies opens doors to highly sought-after roles such as:
Big Data Engineer
Data Architect
Data Scientist (often uses Spark/Hadoop for data preparation)
Business Intelligence Developer
Cloud Data Engineer
Many institutes now offer specialized Big Data courses in Ahmedabad that provide hands-on training in Hadoop, Spark, and related ecosystems, preparing you for these exciting careers.
The journey into Big Data technologies is a deep dive into the engine room of the modern digital economy. By understanding and mastering tools like Hadoop, Spark, and the array of complementary technologies, you're not just learning to code; you're learning to unlock the immense power of information, shaping the future of industries worldwide.
Contact us
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Real Time Spark Project for Beginners: Hadoop, Spark, Docker
🚀 Building a Real-Time Data Pipeline for Server Monitoring Using Kafka, Spark, Hadoop, PostgreSQL & Django
In today’s data centers, various types of servers constantly generate vast volumes of real-time event data—each event representing the server’s status. To ensure stability and minimize downtime, monitoring teams need instant insights into this data to detect and resolve issues swiftly.
To meet this demand, a scalable and efficient real-time data pipeline architecture is essential. Here’s how we’re building it:
🧩 Tech Stack Overview: Apache Kafka acts as the real-time data ingestion layer, handling high-throughput event streams with minimal latency.
Apache Spark (Scala + PySpark), running on a Hadoop cluster (via Docker), performs large-scale, fault-tolerant data processing and analytics.
Hadoop enables distributed storage and computation, forming the backbone of our big data processing layer.
PostgreSQL stores the processed insights for long-term use and querying.
Django serves as the web framework, enabling dynamic dashboards and APIs.
Flexmonster powers data visualization, delivering real-time, interactive insights to monitoring teams.
🔍 Why This Stack? Scalability: Each tool is designed to handle massive data volumes.
Real-time processing: Kafka + Spark combo ensures minimal lag in generating insights.
Interactivity: Flexmonster with Django provides a user-friendly, interactive frontend.
Containerized: Docker simplifies deployment and management.
This architecture empowers data center teams to monitor server statuses live, quickly detect anomalies, and improve infrastructure reliability.
Stay tuned for detailed implementation guides and performance benchmarks!
0 notes
Text
Hadoop Meets NoSQL: How HBase Enables High-Speed Big Data Processing
In today's data-driven world, businesses and organisations are inundated with huge amounts of information that must be processed and analysed quickly to make informed decisions. Traditional relational databases often struggle to handle this scale and speed. That’s where modern data architectures like Hadoop and NoSQL databases come into play. Among the powerful tools within this ecosystem, HBase stands out for enabling high-speed big data processing. This blog explores how Hadoop and HBase work together to handle large-scale data efficiently and why this integration is essential in the modern data landscape.
Understanding Hadoop and the Rise of Big Data
Hadoop is a framework that is publicly available, developed by the Apache Software Foundation. It allows for the distributed storage and processing of huge datasets across clusters of computers using simple programming models. What makes Hadoop unique is its ability to scale from a single server to thousands of them, each offering local storage and computation.
As more industries—finance, healthcare, e-commerce, and education—generate massive volumes of data, the limitations of traditional databases become evident. The rigid structure and limited scalability of relational databases are often incompatible with the dynamic and unstructured nature of big data. This need for flexibility and performance led to the rise of NoSQL databases.
What is NoSQL and Why HBase Matters
NoSQL stands for "Not Only SQL," referring to a range of database technologies that can handle non-relational, semi-structured, or unstructured data. These databases offer high performance, scalability, and flexibility, making them ideal for big data applications.
HBase, modelled after Google's Bigtable, is a column-oriented NoSQL database that runs on top of Hadoop's Hadoop Distributed File System (HDFS). It is designed to provide quick read/write access to large volumes of sparse data. Unlike traditional databases, HBase supports real-time data access while still benefiting from Hadoop’s batch processing capabilities.
How HBase Enables High-Speed Big Data Processing
HBase’s architecture is designed for performance. Here’s how it enables high-speed big data processing:
Real-Time Read/Write Operations: Unlike Hadoop’s MapReduce, which is primarily batch-oriented, HBase allows real-time access to data. This is crucial for applications where speed is essential, like fraud detection or recommendation engines.
Horizontal Scalability: HBase scales easily by adding more nodes to the cluster, enabling it to handle petabytes of data without performance bottlenecks.
Automatic Sharding: It automatically distributes data across different nodes (regions) in the cluster, ensuring balanced load and faster access.
Integration with Hadoop Ecosystem: HBase integrates seamlessly with other tools like Apache Hive, Pig, and Spark, providing powerful analytics capabilities on top of real-time data storage.
Fault Tolerance: Thanks to HDFS, HBase benefits from robust fault tolerance, ensuring data is not lost even if individual nodes fail.
Real-World Applications of Hadoop and HBase
Organisations across various sectors are leveraging Hadoop and HBase for impactful use cases:
Telecommunications: Managing call detail records and customer data in real-time for billing and service improvements.
Social Media: Storing and retrieving user interactions at a massive scale to generate insights and targeted content.
Healthcare: Analysing patient records and sensor data to offer timely and personalised care.
E-commerce: Powering recommendation engines and customer profiling for better user experiences.
For those interested in diving deeper into these technologies, a data science course in Pune can offer hands-on experience with Hadoop and NoSQL databases like HBase. Courses often cover practical applications, enabling learners to tackle real-world data problems effectively.
HBase vs. Traditional Databases
While traditional databases like MySQL and Oracle are still widely used, they are not always suitable for big data scenarios. Here’s how HBase compares:
Schema Flexibility: HBase does not necessitate a rigid schema, which facilitates adaptation to evolving data needs.
Speed: HBase is optimised for high-throughput and low-latency access, which is crucial for modern data-intensive applications.
Data Volume: It can efficiently store and retrieve billions of rows and millions of columns, far beyond the capacity of most traditional databases.
These capabilities make HBase a go-to solution for big data projects, especially when integrated within the Hadoop ecosystem.
The Learning Path to Big Data Mastery
As data continues to grow in size and importance, understanding the synergy between Hadoop and HBase is becoming essential for aspiring data professionals. Enrolling in data science training can be a strategic step toward mastering these technologies. These programs are often designed to cover everything from foundational concepts to advanced tools, helping learners build career-ready skills.
Whether you're an IT professional looking to upgrade or a fresh graduate exploring career paths, a structured course can provide the guidance and practical experience needed to succeed in the big data domain.
Conclusion
The integration of Hadoop and HBase represents a powerful solution for processing and managing big data at speed and scale. While Hadoop handles distributed storage and batch processing, HBase adds real-time data access capabilities, making the duo ideal for a range of modern applications. As industries continue to embrace data-driven strategies, professionals equipped with these skills will be in huge demand. Exploring educational paths such as data science course can be your gateway to thriving in this evolving landscape.
By understanding how HBase enhances Hadoop's capabilities, you're better prepared to navigate the complexities of big data—and transform that data into meaningful insights.
Contact Us:
Name: Data Science, Data Analyst and Business Analyst Course in Pune
Address: Spacelance Office Solutions Pvt. Ltd. 204 Sapphire Chambers, First Floor, Baner Road, Baner, Pune, Maharashtra 411045
Phone: 095132 59011
0 notes
Text
Hadoop Training in Mumbai – Master Big Data for a Smarter Career Move

In the age of data-driven decision-making, Big Data professionals are in high demand. Among the most powerful tools in the Big Data ecosystem is Apache Hadoop, a framework that allows businesses to store, process, and analyze massive volumes of data efficiently. If you're aiming to break into data science, analytics, or big data engineering, Hadoop Training in Mumbai is your gateway to success.
Mumbai, being India’s financial and technology hub, offers a range of professional courses tailored to help you master Hadoop and related technologies—no matter your experience level.
Why Learn Hadoop?
Data is the new oil, and Hadoop is the refinery.
Apache Hadoop is an open-source platform that allows the distributed processing of large data sets across clusters of computers. It powers the backend of major tech giants, financial institutions, and healthcare systems across the world.
Key Benefits of Learning Hadoop:
Manage and analyze massive datasets
Open doors to Big Data, AI, and machine learning roles
High-paying career opportunities in leading firms
Work globally with a recognized skillset
Strong growth trajectory in data engineering and analytics fields
Why Choose Hadoop Training in Mumbai?
Mumbai isn’t just the financial capital of India—it’s also home to top IT parks, multinational corporations, and data-centric startups. From Andheri and Powai to Navi Mumbai and Thane, you’ll find world-class Hadoop training institutes.
What Makes Mumbai Ideal for Hadoop Training?
Hands-on training with real-world data sets
Expert instructors with industry experience
Updated curriculum with Hadoop 3.x, Hive, Pig, HDFS, Spark, etc.
Options for beginners, working professionals, and tech graduates
Job placement assistance with top MNCs and startups
Flexible learning modes – classroom, weekend, online, fast-track
What You’ll Learn in Hadoop Training
Most Hadoop Training in Mumbai is designed to be job-oriented and certification-ready.
A typical course covers:
Fundamentals of Big Data & Hadoop
HDFS (Hadoop Distributed File System)
MapReduce Programming
Hive, Pig, Sqoop, Flume, and HBase
Apache Spark Integration
YARN – Resource Management
Data Ingestion and Real-Time Processing
Hands-on Projects + Mock Interviews
Some courses also prepare you for Cloudera, Hortonworks, or Apache Certification exams.
Who Should Take Hadoop Training?
Students from Computer Science, BSc IT, BCA, MCA backgrounds
Software developers and IT professionals
Data analysts and business intelligence experts
Anyone searching for “Hadoop Training Near Me” to move into Big Data roles
Working professionals looking to upskill in a high-growth domain
Career Opportunities After Hadoop Training
With Hadoop skills, you can explore job titles like:
Big Data Engineer
Hadoop Developer
Data Analyst
Data Engineer
ETL Developer
Data Architect
Companies like TCS, Accenture, Capgemini, LTI, Wipro, and data-driven startups in Mumbai’s BKC, Vikhroli, and Andheri hire Hadoop-trained professionals actively.
Find the Best Hadoop Training Near You with Quick India
QuickIndia.in is your trusted platform to explore the best Hadoop Training in Mumbai. Use it to:
Discover top-rated institutes in your area
Connect directly for demo sessions and course details
Compare course content, fees, and timings
Read verified reviews and ratings from past learners
Choose training with certifications and placement support
Final Thoughts
The future belongs to those who can handle data intelligently. By choosing Hadoop Training in Mumbai, you're investing in a skill that’s in-demand across the globe.
Search “Hadoop Training Near Me” on QuickIndia.in today Enroll. Learn. Get Certified. Get Hired.
Quick India – Powering India’s Skill Economy Smart Search | Skill-Based Listings | Career Growth Starts Here
0 notes
Text
Big Data Analytics Training - Learn Hadoop, Spark

Big Data Analytics Training – Learn Hadoop, Spark & Boost Your Career
Meta Title: Big Data Analytics Training | Learn Hadoop & Spark Online Meta Description: Enroll in Big Data Analytics Training to master Hadoop and Spark. Get hands-on experience, industry certification, and job-ready skills. Start your big data career now!
Introduction: Why Big Data Analytics?
In today’s digital world, data is the new oil. Organizations across the globe are generating vast amounts of data every second. But without proper analysis, this data is meaningless. That’s where Big Data Analytics comes in. By leveraging tools like Hadoop and Apache Spark, businesses can extract powerful insights from large data sets to drive better decisions.
If you want to become a data expert, enrolling in a Big Data Analytics Training course is the first step toward a successful career.
What is Big Data Analytics?
Big Data Analytics refers to the complex process of examining large and varied data sets—known as big data—to uncover hidden patterns, correlations, market trends, and customer preferences. It helps businesses make informed decisions and gain a competitive edge.
Why Learn Hadoop and Spark?
Hadoop: The Backbone of Big Data
Hadoop is an open-source framework that allows distributed processing of large data sets across clusters of computers. It includes:
HDFS (Hadoop Distributed File System) for scalable storage
MapReduce for parallel data processing
Hive, Pig, and Sqoop for data manipulation
Apache Spark: Real-Time Data Engine
Apache Spark is a fast and general-purpose cluster computing system. It performs:
Real-time stream processing
In-memory data computing
Machine learning and graph processing
Together, Hadoop and Spark form the foundation of any robust big data architecture.
What You'll Learn in Big Data Analytics Training
Our expert-designed course covers everything you need to become a certified Big Data professional:
1. Big Data Basics
What is Big Data?
Importance and applications
Hadoop ecosystem overview
2. Hadoop Essentials
Installation and configuration
Working with HDFS and MapReduce
Hive, Pig, Sqoop, and Flume
3. Apache Spark Training
Spark Core and Spark SQL
Spark Streaming
MLlib for machine learning
Integrating Spark with Hadoop
4. Data Processing Tools
Kafka for data ingestion
NoSQL databases (HBase, Cassandra)
Data visualization using tools like Power BI
5. Live Projects & Case Studies
Real-time data analytics projects
End-to-end data pipeline implementation
Domain-specific use cases (finance, healthcare, e-commerce)
Who Should Enroll?
This course is ideal for:
IT professionals and software developers
Data analysts and database administrators
Engineering and computer science students
Anyone aspiring to become a Big Data Engineer
Benefits of Our Big Data Analytics Training
100% hands-on training
Industry-recognized certification
Access to real-time projects
Resume and job interview support
Learn from certified Hadoop and Spark experts
SEO Keywords Targeted
Big Data Analytics Training
Learn Hadoop and Spark
Big Data course online
Hadoop training and certification
Apache Spark training
Big Data online training with certification
Final Thoughts
The demand for Big Data professionals continues to rise as more businesses embrace data-driven strategies. By mastering Hadoop and Spark, you position yourself as a valuable asset in the tech industry. Whether you're looking to switch careers or upskill, Big Data Analytics Training is your pathway to success.
0 notes
Text
Creating a Scalable Amazon EMR Cluster on AWS in Minutes

Minutes to Scalable EMR Cluster on AWS
AWS EMR cluster
Spark helps you easily build up an Amazon EMR cluster to process and analyse data. This page covers Plan and Configure, Manage, and Clean Up.
This detailed guide to cluster setup:
Amazon EMR Cluster Configuration
Spark is used to launch an example cluster and run a PySpark script in the course. You must complete the “Before you set up Amazon EMR” exercises before starting.
While functioning live, the sample cluster will incur small per-second charges under Amazon EMR pricing, which varies per location. To avoid further expenses, complete the tutorial’s final cleaning steps.
The setup procedure has numerous steps:
Amazon EMR Cluster and Data Resources Configuration
This initial stage prepares your application and input data, creates your data storage location, and starts the cluster.
Setting Up Amazon EMR Storage:
Amazon EMR supports several file systems, but this article uses EMRFS to store data in an S3 bucket. EMRFS reads and writes to Amazon S3 in Hadoop.
This lesson requires a specific S3 bucket. Follow the Amazon Simple Storage Service Console User Guide to create a bucket.
You must create the bucket in the same AWS region as your Amazon EMR cluster launch. Consider US West (Oregon) us-west-2.
Amazon EMR bucket and folder names are limited. Lowercase letters, numerals, periods (.), and hyphens (-) can be used, but bucket names cannot end in numbers and must be unique across AWS accounts.
The bucket output folder must be empty.
Small Amazon S3 files may incur modest costs, but if you’re within the AWS Free Tier consumption limitations, they may be free.
Create an Amazon EMR app using input data:
Standard preparation involves uploading an application and its input data to Amazon S3. Submit work with S3 locations.
The PySpark script examines 2006–2020 King County, Washington food business inspection data to identify the top ten restaurants with the most “Red” infractions. Sample rows of the dataset are presented.
Create a new file called health_violations.py and copy the source code to prepare the PySpark script. Next, add this file to your new S3 bucket. Uploading instructions are in Amazon Simple Storage Service’s Getting Started Guide.
Download and unzip the food_establishment_data.zip file, save the CSV file to your computer as food_establishment_data.csv, then upload it to the same S3 bucket to create the example input data. Again, see the Amazon Simple Storage Service Getting Started Guide for uploading instructions.
“Prepare input data for processing with Amazon EMR” explains EMR data configuration.
Create an Amazon EMR Cluster:
Apache Spark and the latest Amazon EMR release allow you to launch the example cluster after setting up storage and your application. This may be done with the AWS Management Console or CLI.
Console Launch:
Launch Amazon EMR after login into AWS Management Console.
Start with “EMR on EC2” > “Clusters” > “Create cluster”. Note the default options for “Release,” “Instance type,” “Number of instances,” and “Permissions”.
Enter a unique “Cluster name” without <, >, $, |, or `. Install Spark from “Applications” by selecting “Spark”. Note: Applications must be chosen before launching the cluster. Check “Cluster logs” to publish cluster-specific logs to Amazon S3. The default destination is s3://amzn-s3-demo-bucket/logs. Replace with S3 bucket. A new ‘logs’ subfolder is created for log files.
Select your two EC2 keys under “Security configuration and permissions”. For the instance profile, choose “EMR_DefaultRole” for Service and “EMR_EC2_DefaultRole” for IAM.
Choose “Create cluster”.
The cluster information page appears. As the EMR fills the cluster, its “Status” changes from “Starting” to “Running” to “Waiting”. Console view may require refreshing. Status switches to “Waiting” when cluster is ready to work.
AWS CLI’s aws emr create-default-roles command generates IAM default roles.
Create a Spark cluster with aws emr create-cluster. Name your EC2 key pair –name, set –instance-type, –instance-count, and –use-default-roles. The sample command’s Linux line continuation characters () may need Windows modifications.
Output will include ClusterId and ClusterArn. Remember your ClusterId for later.
Check your cluster status using aws emr describe-cluster –cluster-id myClusterId>.
The result shows the Status object with State. As EMR deployed the cluster, the State changed from STARTING to RUNNING to WAITING. When ready, operational, and up, the cluster becomes WAITING.
Open SSH Connections
Before connecting to your operating cluster via SSH, update your cluster security groups to enable incoming connections. Amazon EC2 security groups are virtual firewalls. At cluster startup, EMR created default security groups: ElasticMapReduce-slave for core and task nodes and ElasticMapReduce-master for main.
Console-based SSH authorisation:
Authorisation is needed to manage cluster VPC security groups.
Launch Amazon EMR after login into AWS Management Console.
Select the updateable cluster under “Clusters”. The “Properties” tab must be selected.
Choose “Networking” and “EC2 security groups (firewall)” from the “Properties” tab. Select the security group link under “Primary node”.
EC2 console is open. Select “Edit inbound rules” after choosing “Inbound rules”.
Find and delete any public access inbound rule (Type: SSH, Port: 22, Source: Custom 0.0.0.0/0). Warning: The ElasticMapReduce-master group’s pre-configured rule that allowed public access and limited traffic to reputable sources should be removed.
Scroll down and click “Add Rule”.
Choose “SSH” for “Type” to set Port Range to 22 and Protocol to TCP.
Enter “My IP” for “Source” or a range of “Custom” trustworthy client IP addresses. Remember that dynamic IPs may need updating. Select “Save.”
When you return to the EMR console, choose “Core and task nodes” and repeat these steps to provide SSH access to those nodes.
Connecting with AWS CLI:
SSH connections may be made using the AWS CLI on any operating system.
Use the command: AWS emr ssh –cluster-id –key-pair-file <~/mykeypair.key>. Replace with your ClusterId and the full path to your key pair file.
After connecting, visit /mnt/var/log/spark to examine master node Spark logs.
The next critical stage following cluster setup and access configuration is phased work submission.
#AmazonEMRcluster#EMRcluster#DataResources#SSHConnections#AmazonEC2#AWSCLI#technology#technews#technologynews#news#govindhtech
0 notes
Text
Hadoop is the most used opensource big data platform. Over the last decade, it has become a very large ecosystem with dozens of tools and projects supporting it. Most information technology companies have invested in Hadoop based data analytics and this has created a huge job market for Hadoop engineers and analysts. Hadoop is a large-scale system that requires Map Reduce programmers, data scientists, and administrators to maintain it. Getting a Hadoop job may seem difficult but not impossible. There are hundreds of useful free resources available online that can help you learn it on your own. Many programmers have switched to data scientist role by simply self-learning Hadoop development. I am a Cloudera certified Hadoop developer since 2008 and I have hand-curated this list of resources for all Hadoop aspirants to learn faster. Hadoop Beginners Tutorials: Simple and Easy to Follow Hadoop requires a lot of prior knowledge of computer science. It may be overwhelming for a total beginner to start using it. I would recommend to take small steps and learn part of it at a time. Try to apply what you learn using a simple project. The pre-bundled distributions of Hadoop are, the best way to avoid complicated setup. You can use Cloudera or Hortonworks bundled packages to quick start your experiments. At first, you need no create a large Hadoop cluster. Even doing a one or two node cluster would be sufficient to verify your learnings. Apache Hadoop - Tutorial 24 Hadoop Interview Questions & Answers for MapReduce developers | FromDev Hadoop Tutorial - YDN Hadoop Tutorial for Beginners: Hadoop Basics Hadoop Tutorial – Learn Hadoop from experts – Intellipaat Free Hadoop Tutorial: Master BigData Hadoop Tutorial Apache Hadoop 2.9.2 – MapReduce Tutorial Learn Hadoop Tutorial - javatpoint Hadoop Tutorial | Getting Started With Big Data And Hadoop | Edureka Hadoop Tutorial for Beginners | Learn Hadoop from A to Z - DataFlair Map Reduce - A really simple introduction « Kaushik Sathupadi Running Hadoop On Ubuntu Linux (Single-Node Cluster) Learn Hadoop Online for Free with Big Data and Map Reduce Cloudera Essentials for Apache Hadoop | Cloudera OnDemand Hadoop Video Tutorials To Watch and Learn Video tutorials are also available for learning Hadoop. There are dozens of beginners video tutorials on Youtube and other websites. Some of the most popular ones are listed below. Hadoop Tutorials Beginners - YouTube Apache Hadoop Tutorial | Hadoop Tutorial For Beginners | Big Data Hadoop | Hadoop Training | Edureka - YouTube Big Data Hadoop Tutorial Videos - YouTube Demystifying Hadoop 2.0 - Playlist Full - YouTube Hadoop Architecture Tutorials Playlist - YouTube Hadoop Tutorials - YouTube Durga Hadoop - YouTube Big Data & Hadoop Tutorials - YouTube Hadoop Tutorials for Beginners - YouTube Big Data and Hadoop Tutorials - YouTube Big Data Hadoop Tutorial Videos | Simplilearn - YouTube Hadoop Training Tutorials - Big Data, Hadoop Big Data,Hadoop Tutorials for Beginners - YouTube Hadoop Training and Tutorials - YouTube Hadoop Tutorials - YouTube Best Hadoop eBooks and PDF to Learn Looking for a PDF downloadable for Hadoop learning? Below list has plenty of options for you from various sources on the internet. Apache Hadoop Tutorial Mapreduce Osdi04 Book Mapreduce Book Final Hadoop The Definitive Guide Hadoop Mapreduce Cookbook Bigdata Hadoop Tutorial Hadoop Books Hadoop In Practice Hadoop Illuminated Hdfs Design Hadoop Real World Solutions Cookbook Hadoop Explained Hadoop With Python Apache Hadoop Tutorial Best Free Mongodb Tutorials Pdf Hadoop Cheatsheets and Quick Reference Resources Hadoop has many commands, memorizing those may take time. You can use a simple cheat sheet that can be used as a quick reference. I recommend you to print one of your favorite cheat sheets and stick it on your desk pinboard. This way you can easily lookup for commands as you work.
Commands Manual Hadoop Hdfs Commands Cheatsheet Hadoop For Dummies Cheat Sheet - dummies Hadoop Deployment Cheat Sheet | Jethro Hdfs Cheatsheet HDFS Cheat Sheet - DZone Big Data Big Data Hadoop Cheat Sheet - Intellipaat Hadoop Websites and Blogs To Learn On Web This is a list of blogs and websites related to Hadoop. These can be handy to keep your knowledge on Hadoop up to date with the latest industry trends. Hadoop Eco System - Hadoop Online Tutorials Big Data Hadoop Tutorial for Beginners- Hadoop Installation,Free Hadoop Online Tutorial Hadoop Tutorial – Getting Started with HDP - Hortonworks Hortonworks Sandbox Tutorials for Apache Hadoop | Hortonworks Hadoop – An Apache Hadoop Tutorials for Beginners - TechVidvan Hadoop Tutorial -- with HDFS, HBase, MapReduce, Oozie, Hive, and Pig Free Online Video Tutorials, Online Hadoop Tutorials, HDFS Video Tutorials | hadooptutorials.co.in Free Hadoop Training Hadoop Fundamentals - Cognitive Class Hadoop Courses | Coursera hadoop Courses | edX MapR Training Options | MapR Hadoop Forums and Discussion Boards To Get Help Looking for help related to Hadoop, you may be lucky if you go online. Many people are willing to help with Hadoop related queries. Below forums are very active with high participation from hundreds of people. Official Apache Hadoop Mailing list Frequent 'Hadoop' Questions - Stack Overflow Forums - Hadoop Forum Hadoop Courses and Training (Including Paid Options) Hadoop courses may not be free but have been proven very useful for quickly learning from experts. The courses can exhaustive, however, it may give you a faster learning curve and greater confidence. There are many costly courses available, my recommendation will be to try out the free courses first and then invest wisely into areas where you need to learn more. Apache Hadoop training from Cloudera University - Following are the key things to notice about this training. Expert trainers Good place for networking for fellow Hadoop engineers. Usually in-person training. It may be costly as an individual, but if you get corporate sponsorship this is probably the best option. This is the Most popular choice for corporate training. Live Training - Hortonworks - Following are the key things to notice about this training. Another good option for corporate level training. Expert trainers. Usually in-person training. It may be costly. Big Data Training - Education Services - US and Canada | HPE™ Big Data Hadoop Training | Hadoop Certification Online Course - Simplilearn Hadoop Tutorial Training Certification - Paid but a cheaper option. Search for ProTech Courses - Hadoop courses are offered at a physical training. TecheTraining Learning Hadoop - Hadoop Training Course on LinkedIn that can be free with a one month trial. Please share your experience If you know about more training options or have any feedback about any training listed here. Summary I have created this huge list of Hadoop tutorials to help learn faster. At first, it may become overwhelming to jump onto any tutorial and start learning, however, I would encourage you to no give up on learning. My recommendation to beginners will be to start small and no give up. Based on the couple hour spent every day you may be able to learn Hadoop ecosystem in a matter of a few weeks. I hope you find this resource page useful. Please mention in comments, If you find something useful that is not listed on this page.
0 notes
Text
Apache Hadoop is a Java-based framework that uses clusters to store and process large amounts of data in parallel. Being a framework, Hadoop is formed from multiple modules which are supported by a vast ecosystem of technologies. Let’s take a closer look at the Apache Hadoop ecosystem and the components that make it up.
1 note
·
View note
Text
Big Data Analytics: Tools & Career Paths

In this digital era, data is being generated at an unimaginable speed. Social media interactions, online transactions, sensor readings, scientific inquiries-all contribute to an extremely high volume, velocity, and variety of information, synonymously referred to as Big Data. Impossible is a term that does not exist; then, how can we say that we have immense data that remains useless? It is where Big Data Analytics transforms huge volumes of unstructured and semi-structured data into actionable insights that spur decision-making processes, innovation, and growth.
It is roughly implied that Big Data Analytics should remain within the triangle of skills as a widely considered niche; in contrast, nowadays, it amounts to a must-have capability for any working professional across tech and business landscapes, leading to numerous career opportunities.
What Exactly Is Big Data Analytics?
This is the process of examining huge, varied data sets to uncover hidden patterns, customer preferences, market trends, and other useful information. The aim is to enable organizations to make better business decisions. It is different from regular data processing because it uses special tools and techniques that Big Data requires to confront the three Vs:
Volume: Masses of data.
Velocity: Data at high speed of generation and processing.
Variety: From diverse sources and in varying formats (!structured, semi-structured, unstructured).
Key Tools in Big Data Analytics
Having the skills to work with the right tools becomes imperative in mastering Big Data. Here are some of the most famous ones:
Hadoop Ecosystem: The core layer is an open-source framework for storing and processing large datasets across clusters of computers. Key components include:
HDFS (Hadoop Distributed File System): For storing data.
MapReduce: For processing data.
YARN: For resource-management purposes.
Hive, Pig, Sqoop: Higher-level data warehousing and transfer.
Apache Spark: Quite powerful and flexible open-source analytics engine for big data processing. It is much faster than MapReduce, especially for iterative algorithms, hence its popularity in real-time analytics, machine learning, and stream processing. Languages: Scala, Python (PySpark), Java, R.
NoSQL Databases: In contrast to traditional relational databases, NoSQL (Not only SQL) databases are structured to maintain unstructured and semic-structured data at scale. Examples include:
MongoDB: Document-oriented (e.g., for JSON-like data).
Cassandra: Column-oriented (e.g., for high-volume writes).
Neo4j: Graph DB (e.g., for data heavy with relationships).
Data Warehousing & ETL Tools: Tools for extracting, transforming, and loading (ETL) data from various sources into a data warehouse for analysis. Examples: Talend, Informatica. Cloud-based solutions such as AWS Redshift, Google BigQuery, and Azure Synapse Analytics are also greatly used.
Data Visualization Tools: Essential for presenting complex Big Data insights in an understandable and actionable format. Tools like Tableau, Power BI, and Qlik Sense are widely used for creating dashboards and reports.
Programming Languages: Python and R are the dominant languages for data manipulation, statistical analysis, and integrating with Big Data tools. Python's extensive libraries (Pandas, NumPy, Scikit-learn) make it particularly versatile.
Promising Career Paths in Big Data Analytics
As Big Data professionals in India was fast evolving, there were diverse professional roles that were offered with handsome perks:
Big Data Engineer: Designs, builds, and maintains the large-scale data processing systems and infrastructure.
Big Data Analyst: Work on big datasets, finding trends, patterns, and insights that big decisions can be made on.
Data Scientist: Utilize statistics, programming, and domain expertise to create predictive models and glean deep insights from data.
Machine Learning Engineer: Concentrates on the deployment and development of machine learning models on Big Data platforms.
Data Architect: Designs the entire data environment and strategy of an organization.
Launch Your Big Data Analytics Career
Some more Specialized Big Data Analytics course should be taken if you feel very much attracted to data and what it can do. Hence, many computer training institutes in Ahmedabad offer comprehensive courses covering these tools and concepts of Big Data Analytics, usually as a part of Data Science with Python or special training in AI and Machine Learning. Try to find those courses that offer real-time experience and projects along with industry mentoring, so as to help you compete for these much-demanded jobs.
When you are thoroughly trained in the Big Data Analytics tools and concepts, you can manipulate information for innovation and can be highly paid in the working future.
At TCCI, we don't just teach computers — we build careers. Join us and take the first step toward a brighter future.
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
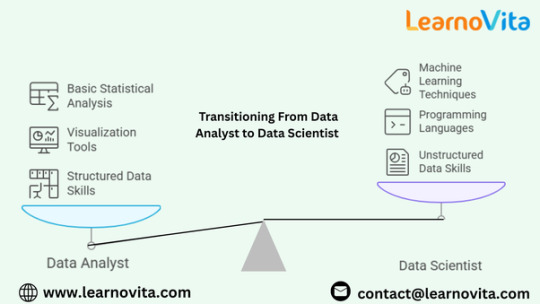
Key Skills You Need to Move from Data Analyst to Data Scientist
Transitioning from a data analyst to a data scientist requires expanding your skill set beyond basic data manipulation and visualization. While both roles revolve around extracting insights from data, data scientists rely heavily on machine learning, programming, and advanced statistical techniques to build predictive models. If you are a data analyst looking to move into data science, developing key technical and analytical skills is crucial. This blog outlines the essential skills you need to successfully transition into a data science role from the best Data Analytics Online Training.

Programming Proficiency: Python and R
A fundamental requirement for data science is strong programming skills. While data analysts often use SQL and Excel, data scientists must be proficient in Python or R. These languages are widely used in machine learning and statistical analysis. Python, in particular, is a preferred choice due to its vast ecosystem of libraries like Pandas, NumPy, Matplotlib, and Seaborn for data manipulation and visualization. Additionally, frameworks such as Scikit-learn, TensorFlow, and PyTorch enable machine learning model development. Mastering these tools is essential for handling large datasets and building predictive models.
Advanced Statistics and Probability
While data analysts use basic statistical techniques to summarize data and find patterns, data scientists require a deeper understanding of statistics and probability. Concepts such as hypothesis testing, Bayesian inference, A/B testing, regression analysis, and time series forecasting play a significant role in making data-driven decisions. Strong statistical knowledge helps in feature selection, model evaluation, and performance optimization. If you want to learn more about Data Analytics, consider enrolling in an Best Online Training & Placement programs . They often offer certifications, mentorship, and job placement opportunities to support your learning journey.
Machine Learning and Deep Learning
One of the biggest differences between data analysts and data scientists is the ability to build machine learning models. Data scientists use supervised learning techniques like classification and regression, as well as unsupervised methods like clustering and dimensionality reduction. Understanding model training, evaluation metrics, and hyperparameter tuning is crucial. Additionally, learning deep learning concepts such as neural networks, natural language processing (NLP), and computer vision can further expand career opportunities.
Data Wrangling and Preprocessing
Real-world data is often messy and unstructured, making data preprocessing a critical step in data science. Data scientists must be skilled in handling missing values, dealing with outliers, normalizing and transforming data, and feature engineering. Tools like Pandas, SQL, and OpenCV help in cleaning and structuring data for effective analysis. Efficient data preparation ensures that machine learning models perform accurately.
Big Data Technologies
As businesses generate vast amounts of data, working with big data technologies becomes essential. Data scientists often use distributed computing frameworks such as Hadoop, Spark, and Apache Kafka to process large datasets efficiently. Cloud computing platforms like AWS, Google Cloud, and Microsoft Azure also offer data science tools that facilitate large-scale analytics. Understanding these technologies allows data scientists to work with real-time and large-scale data environments.
Data Visualization and Storytelling
Even though data scientists build complex models, their findings must be communicated effectively. Data visualization is essential for interpreting and presenting insights. Proficiency in tools like Tableau, Power BI, and Python visualization libraries such as Matplotlib and Seaborn is necessary. Additionally, the ability to tell a compelling data-driven story helps stakeholders understand the impact of insights on business decisions.
SQL and Database Management
While programming and machine learning are important, SQL remains a fundamental skill for any data professional. Data scientists frequently work with structured databases, writing advanced queries to extract relevant data. Understanding indexing, joins, window functions, and stored procedures can enhance efficiency when dealing with relational databases like MySQL, PostgreSQL, or SQL Server.
Business Acumen and Problem-Solving
A successful data scientist must bridge the gap between technical expertise and business impact. Understanding industry-specific problems and applying data science techniques to solve them is key. Data scientists must be able to translate business problems into data-driven solutions, making business acumen an invaluable skill. Additionally, problem-solving skills help in selecting the right algorithms, optimizing models, and making data-driven recommendations.
Version Control and Deployment Skills
Data scientists not only build models but also deploy them into production. Learning version control systems like Git and GitHub helps in tracking code changes and collaborating with teams. Deploying machine learning models using tools like Flask, Docker, and Kubernetes ensures that models can be integrated into real-world applications. Understanding MLOps (Machine Learning Operations) can also enhance the ability to maintain and improve models post-deployment.
Continuous Learning and Experimentation
Data science is an evolving field, requiring continuous learning and adaptation to new technologies. Experimenting with new algorithms, participating in data science competitions like Kaggle, and keeping up with research papers can help stay ahead in the field. The ability to learn, experiment, and apply new techniques is crucial for long-term success.
Conclusion
The transition from data analyst to data scientist requires developing a robust skill set that includes programming, machine learning, statistical analysis, and business problem-solving. While data analysts already have experience working with data, advancing technical skills in Python, deep learning, and big data technologies is essential for stepping into data science. By continuously learning, working on real-world projects, and gaining hands-on experience, data analysts can successfully move into data science roles and contribute to solving complex business challenges with data-driven insights.
0 notes
Text
Decoding Hadoop’s Core: HDFS, YARN, and MapReduce Explained
In today's data-driven world, handling massive volumes of data efficiently is more critical than ever. As organisations continue to generate and analyse vast datasets, they rely on powerful frameworks like Apache Hadoop to manage big data workloads. At the heart of Hadoop are three core components—HDFS, YARN, and MapReduce. These technologies work in tandem to store, process, and manage data across distributed computing environments.
Whether you're a tech enthusiast or someone exploring a Data Scientist Course in Pune, understanding how Hadoop operates is essential for building a solid foundation in big data analytics.
What is Hadoop?
Apache Hadoop is a free, open-source framework intended for the storage and processing of large data sets across networks of computers. It provides a reliable, scalable, and cost-effective way to manage big data. Hadoop is widely used in industries such as finance, retail, healthcare, and telecommunications, where massive volumes of both form of data, structured and unstructured, are generated daily.
To understand how Hadoop works, we must dive into its three core components: HDFS, YARN, and MapReduce.
HDFS: Hadoop Distributed File System
HDFS is the storage backbone of Hadoop. It allows data to be stored across multiple machines while appearing as a unified file system to the user. Designed for high fault tolerance, HDFS replicates data blocks across different nodes to ensure reliability.
Key Features of HDFS:
Scalability: Easily scales by adding new nodes to the cluster.
Fault Tolerance: Automatically replicates data to handle hardware failures.
High Throughput: Optimised for high data transfer rates, making it ideal for large-scale data processing.
For someone pursuing a Data Scientist Course, learning how HDFS handles storage can provide valuable insight into managing large datasets efficiently.
YARN: Yet Another Resource Negotiator
YARN is the system resource management layer in Hadoop. It coordinates the resources required for running applications in a Hadoop cluster. Before YARN, resource management and job scheduling were tightly coupled within the MapReduce component. YARN decouples these functionalities, making the system more flexible and efficient.
Components of YARN:
Resource Manager (RM): Allocates resources across all applications.
Node Manager (NM): Manages resources and monitors tasks on individual nodes.
Application Master: Coordinates the execution of a specific application.
By separating resource management from the data processing component, YARN allows Hadoop to support multiple processing models beyond MapReduce, such as Apache Spark and Tez. This makes YARN a critical piece in modern big data ecosystems.
MapReduce: The Data Processing Engine
MapReduce is the original data processing engine in Hadoop. It processes data in two main stages: Map and Reduce.
Map Function: Breaks down large datasets into key-value pairs and processes them in parallel.
Reduce Function: Aggregates the outputs of the Map phase and summarises the results.
For example, if you want to count the frequency of words in a document, the Map function would tokenise the words and count occurrences, while the Reduce function would aggregate the total count for each word.
MapReduce is efficient for batch processing and is highly scalable. Although newer engines like Apache Spark are gaining popularity, MapReduce remains a fundamental concept in big data processing.
The Synergy of HDFS, YARN, and MapReduce
The true power of Hadoop lies in the integration of its three core components. Here’s how they work together:
Storage: HDFS stores massive volumes of data across multiple nodes.
Resource Management: YARN allocates and manages the resources needed for processing.
Processing: MapReduce processes the data in a distributed and parallel fashion.
This combination enables Hadoop to manage and analyse data at a scale unimaginable with traditional systems.
Why Should Aspiring Data Scientists Learn Hadoop?
As the volume of data continues to grow, professionals skilled in managing big data frameworks like Hadoop are in high demand. Understanding the architecture of Hadoop is a technical and strategic advantage for anyone pursuing a career in data science.
If you're considering a Data Scientist Course in Pune, ensure it includes modules on big data technologies like Hadoop. This hands-on knowledge is crucial for analysing and interpreting complex datasets in real-world scenarios.
Additionally, a comprehensive course will cover not only Hadoop but also related tools like Hive, Pig, Spark, and machine learning techniques—empowering you to become a well-rounded data professional.
Conclusion
Apache Hadoop remains a cornerstone technology in the big data landscape. Its core components—HDFS, YARN, and MapReduce—form a robust framework for storing and processing large-scale data efficiently. HDFS ensures reliable storage, YARN manages computational resources, and MapReduce enables scalable data processing.
For aspiring data scientists and IT professionals, mastering Hadoop is an important step toward becoming proficient in big data analytics. Whether through self-learning or enrolling in a structured Data Scientist Course, gaining knowledge of Hadoop's core functionalities will greatly enhance your ability to work with large and complex data systems.
By understanding the building blocks of Hadoop, you're not just learning a tool—you’re decoding the very foundation of modern data science.
Contact Us:
Name: Data Science, Data Analyst and Business Analyst Course in Pune
Address: Spacelance Office Solutions Pvt. Ltd. 204 Sapphire Chambers, First Floor, Baner Road, Baner, Pune, Maharashtra 411045
Phone: 095132 59011
0 notes
Text
What is PySpark? A Beginner’s Guide
Introduction
The digital era gives rise to continuous expansion in data production activities. Organizations and businesses need processing systems with enhanced capabilities to process large data amounts efficiently. Large datasets receive poor scalability together with slow processing speed and limited adaptability from conventional data processing tools. PySpark functions as the data processing solution that brings transformation to operations.
The Python Application Programming Interface called PySpark serves as the distributed computing framework of Apache Spark for fast processing of large data volumes. The platform offers a pleasant interface for users to operate analytics on big data together with real-time search and machine learning operations. Data engineering professionals along with analysts and scientists prefer PySpark because the platform combines Python's flexibility with Apache Spark's processing functions.
The guide introduces the essential aspects of PySpark while discussing its fundamental elements as well as explaining operational guidelines and hands-on usage. The article illustrates the operation of PySpark through concrete examples and predicted outputs to help viewers understand its functionality better.
What is PySpark?
PySpark is an interface that allows users to work with Apache Spark using Python. Apache Spark is a distributed computing framework that processes large datasets in parallel across multiple machines, making it extremely efficient for handling big data. PySpark enables users to leverage Spark’s capabilities while using Python’s simple and intuitive syntax.
There are several reasons why PySpark is widely used in the industry. First, it is highly scalable, meaning it can handle massive amounts of data efficiently by distributing the workload across multiple nodes in a cluster. Second, it is incredibly fast, as it performs in-memory computation, making it significantly faster than traditional Hadoop-based systems. Third, PySpark supports Python libraries such as Pandas, NumPy, and Scikit-learn, making it an excellent choice for machine learning and data analysis. Additionally, it is flexible, as it can run on Hadoop, Kubernetes, cloud platforms, or even as a standalone cluster.
Core Components of PySpark
PySpark consists of several core components that provide different functionalities for working with big data:
RDD (Resilient Distributed Dataset) – The fundamental unit of PySpark that enables distributed data processing. It is fault-tolerant and can be partitioned across multiple nodes for parallel execution.
DataFrame API – A more optimized and user-friendly way to work with structured data, similar to Pandas DataFrames.
Spark SQL – Allows users to query structured data using SQL syntax, making data analysis more intuitive.
Spark MLlib – A machine learning library that provides various ML algorithms for large-scale data processing.
Spark Streaming – Enables real-time data processing from sources like Kafka, Flume, and socket streams.
How PySpark Works
1. Creating a Spark Session
To interact with Spark, you need to start a Spark session.

Output:

2. Loading Data in PySpark
PySpark can read data from multiple formats, such as CSV, JSON, and Parquet.

Expected Output (Sample Data from CSV):

3. Performing Transformations
PySpark supports various transformations, such as filtering, grouping, and aggregating data. Here’s an example of filtering data based on a condition.

Output:

4. Running SQL Queries in PySpark
PySpark provides Spark SQL, which allows you to run SQL-like queries on DataFrames.

Output:
5. Creating a DataFrame Manually
You can also create a PySpark DataFrame manually using Python lists.

Output:

Use Cases of PySpark
PySpark is widely used in various domains due to its scalability and speed. Some of the most common applications include:
Big Data Analytics – Used in finance, healthcare, and e-commerce for analyzing massive datasets.
ETL Pipelines – Cleans and processes raw data before storing it in a data warehouse.
Machine Learning at Scale – Uses MLlib for training and deploying machine learning models on large datasets.
Real-Time Data Processing – Used in log monitoring, fraud detection, and predictive analytics.
Recommendation Systems – Helps platforms like Netflix and Amazon offer personalized recommendations to users.
Advantages of PySpark
There are several reasons why PySpark is a preferred tool for big data processing. First, it is easy to learn, as it uses Python’s simple and intuitive syntax. Second, it processes data faster due to its in-memory computation. Third, PySpark is fault-tolerant, meaning it can automatically recover from failures. Lastly, it is interoperable and can work with multiple big data platforms, cloud services, and databases.
Getting Started with PySpark
Installing PySpark
You can install PySpark using pip with the following command:

To use PySpark in a Jupyter Notebook, install Jupyter as well:

To start PySpark in a Jupyter Notebook, create a Spark session:

Conclusion
PySpark is an incredibly powerful tool for handling big data analytics, machine learning, and real-time processing. It offers scalability, speed, and flexibility, making it a top choice for data engineers and data scientists. Whether you're working with structured data, large-scale machine learning models, or real-time data streams, PySpark provides an efficient solution.
With its integration with Python libraries and support for distributed computing, PySpark is widely used in modern big data applications. If you’re looking to process massive datasets efficiently, learning PySpark is a great step forward.
youtube
#pyspark training#pyspark coutse#apache spark training#apahe spark certification#spark course#learn apache spark#apache spark course#pyspark certification#hadoop spark certification .#Youtube
0 notes
Text
What are the benefits of Amazon EMR? Drawbacks of AWS EMR

Benefits of Amazon EMR
Amazon EMR has many benefits. These include AWS's flexibility and cost savings over on-premises resource development.
Cost-saving
Amazon EMR costs depend on instance type, number of Amazon EC2 instances, and cluster launch area. On-demand pricing is low, but Reserved or Spot Instances save much more. Spot instances can save up to a tenth of on-demand costs.
Note
Using Amazon S3, Kinesis, or DynamoDB with your EMR cluster incurs expenses irrespective of Amazon EMR usage.
Note
Set up Amazon S3 VPC endpoints when creating an Amazon EMR cluster in a private subnet. If your EMR cluster is on a private subnet without Amazon S3 VPC endpoints, you will be charged extra for S3 traffic NAT gates.
AWS integration
Amazon EMR integrates with other AWS services for cluster networking, storage, security, and more. The following list shows many examples of this integration:
Use Amazon EC2 for cluster nodes.
Amazon VPC creates the virtual network where your instances start.
Amazon S3 input/output data storage
Set alarms and monitor cluster performance with Amazon CloudWatch.
AWS IAM permissions setting
Audit service requests with AWS CloudTrail.
Cluster scheduling and launch with AWS Data Pipeline
AWS Lake Formation searches, categorises, and secures Amazon S3 data lakes.
Its deployment
The EC2 instances in your EMR cluster do the tasks you designate. When you launch your cluster, Amazon EMR configures instances using Spark or Apache Hadoop. Choose the instance size and type that best suits your cluster's processing needs: streaming data, low-latency queries, batch processing, or big data storage.
Amazon EMR cluster software setup has many options. For example, an Amazon EMR version can be loaded with Hive, Pig, Spark, and flexible frameworks like Hadoop. Installing a MapR distribution is another alternative. Since Amazon EMR runs on Amazon Linux, you can manually install software on your cluster using yum or the source code.
Flexibility and scalability
Amazon EMR lets you scale your cluster as your computing needs vary. Resizing your cluster lets you add instances during peak workloads and remove them to cut costs.
Amazon EMR supports multiple instance groups. This lets you employ Spot Instances in one group to perform jobs faster and cheaper and On-Demand Instances in another for guaranteed processing power. Multiple Spot Instance types might be mixed to take advantage of a better price.
Amazon EMR lets you use several file systems for input, output, and intermediate data. HDFS on your cluster's primary and core nodes can handle data you don't need to store beyond its lifecycle.
Amazon S3 can be used as a data layer for EMR File System applications to decouple computation and storage and store data outside of your cluster's lifespan. EMRFS lets you scale up or down to meet storage and processing needs independently. Amazon S3 lets you adjust storage and cluster size to meet growing processing needs.
Reliability
Amazon EMR monitors cluster nodes and shuts down and replaces instances as needed.
Amazon EMR lets you configure automated or manual cluster termination. Automatic cluster termination occurs after all procedures are complete. Transitory cluster. After processing, you can set up the cluster to continue running so you can manually stop it. You can also construct a cluster, use the installed apps, and manually terminate it. These clusters are “long-running clusters.”
Termination prevention can prevent processing errors from terminating cluster instances. With termination protection, you can retrieve data from instances before termination. Whether you activate your cluster by console, CLI, or API changes these features' default settings.
Security
Amazon EMR uses Amazon EC2 key pairs, IAM, and VPC to safeguard data and clusters.
IAM
Amazon EMR uses IAM for permissions. Person or group permissions are set by IAM policies. Users and groups can access resources and activities through policies.
The Amazon EMR service uses IAM roles, while instances use the EC2 instance profile. These roles allow the service and instances to access other AWS services for you. Amazon EMR and EC2 instance profiles have default roles. By default, roles use AWS managed policies generated when you launch an EMR cluster from the console and select default permissions. Additionally, the AWS CLI may construct default IAM roles. Custom service and instance profile roles can be created to govern rights outside of AWS.
Security groups
Amazon EMR employs security groups to control EC2 instance traffic. Amazon EMR shares a security group for your primary instance and core/task instances when your cluster is deployed. Amazon EMR creates security group rules to ensure cluster instance communication. Extra security groups can be added to your primary and core/task instances for more advanced restrictions.
Encryption
Amazon EMR enables optional server-side and client-side encryption using EMRFS to protect Amazon S3 data. After submission, Amazon S3 encrypts data server-side.
The EMRFS client on your EMR cluster encrypts and decrypts client-side encryption. AWS KMS or your key management system can handle client-side encryption root keys.
Amazon VPC
Amazon EMR launches clusters in Amazon VPCs. VPCs in AWS allow you to manage sophisticated network settings and access functionalities.
AWS CloudTrail
Amazon EMR and CloudTrail record AWS account requests. This data shows who accesses your cluster, when, and from what IP.
Amazon EC2 key pairs
A secure link between the primary node and your remote computer lets you monitor and communicate with your cluster. SSH or Kerberos can authenticate this connection. SSH requires an Amazon EC2 key pair.
Monitoring
Debug cluster issues like faults or failures utilising log files and Amazon EMR management interfaces. Amazon EMR can archive log files on Amazon S3 to save records and solve problems after your cluster ends. The Amazon EMR UI also has a task, job, and step-specific debugging tool for log files.
Amazon EMR connects to CloudWatch for cluster and job performance monitoring. Alarms can be set based on cluster idle state and storage use %.
Management interfaces
There are numerous Amazon EMR access methods:
The console provides a graphical interface for cluster launch and management. You may examine, debug, terminate, and describe clusters to launch via online forms. Amazon EMR is easiest to use via the console, requiring no scripting.
Installing the AWS Command Line Interface (AWS CLI) on your computer lets you connect to Amazon EMR and manage clusters. The broad AWS CLI includes Amazon EMR-specific commands. You can automate cluster administration and initialisation with scripts. If you prefer command line operations, utilise the AWS CLI.
SDK allows cluster creation and management for Amazon EMR calls. They enable cluster formation and management automation systems. This SDK is best for customising Amazon EMR. Amazon EMR supports Go, Java,.NET (C# and VB.NET), Node.js, PHP, Python, and Ruby SDKs.
A Web Service API lets you call a web service using JSON. A custom SDK that calls Amazon EMR is best done utilising the API.
Complexity:
EMR cluster setup and maintenance are more involved than with AWS Glue and require framework knowledge.
Learning curve
Setting up and optimising EMR clusters may require adjusting settings and parameters.
Possible Performance Issues:
Incorrect instance types or under-provisioned clusters might slow task execution and other performance.
Depends on AWS:
Due to its deep interaction with AWS infrastructure, EMR is less portable than on-premise solutions despite cloud flexibility.
#AmazonEMR#AmazonEC2#AmazonS3#AmazonVirtualPrivateCloud#EMRFS#AmazonEMRservice#Technology#technews#NEWS#technologynews#govindhtech
0 notes