#base64 encode a file
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Note
Why do achievements and upgrades not use run length encoding in the save file??? Why??? Why??? I needed those 512 bytes
the save system in cookie clicker was written 10 years ago back when i was still Getting Silly With It. it is my own little format full of goofy attempts to minimize save files size so they can be comfortably copypasted. at one point i was trying to shrink the upgrade/achiev bitmasks (long strings of 0 if locked, 1 if unlocked) by condensing multiple bits into fewer characters but something in there wasn't surviving the base64 conversion and saves started getting randomly corrupted if a specific pattern of things you unlocked happened to combine into some cursed symbol i yet have to identify. to answer your question: there is so much worse you should worry about. i am a self-taught programmer and should not be trusted around computers, yet here we are. these days all my new projects use JSON files for saving because i've learned to be humble
718 notes
·
View notes
Text

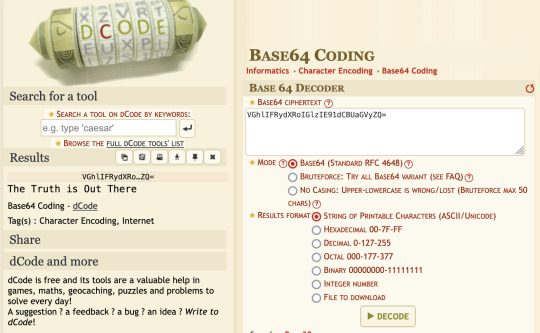
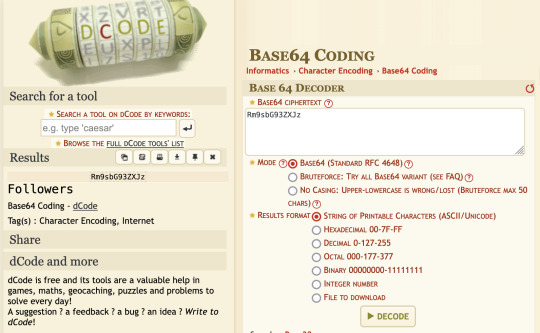
Ok so I'm finally watching Season 11 of The X-Files.
Episode 7 is called "Rm9sbG93ZXJz" which always bugged me cuz whenever anyone talked about it they called it the "sushi restaurant" episode. I avoided googling what the actual name meant cuz I didn't want spoilers.
But while watching the episode, right after the intro credits they flash this "VGhlIFRydXRoIGlzIE91dCBUaGVyZQ=" on the screen. And that's when I realized the episode title must be encrypted since this second encrypted text was obviously placed where "The Truth Is Out There" is typically placed.
So I ran both of them through this online tool called dcode and figured out they used base64 encoding to encrypt their messages.
You can play around with this tool here: https://www.dcode.fr/base-64-encoding
If you don't want to know what the results are...don't continue reading...
Maybe they reveal all this in the episode, idk I literally paused it at the credits screen to post this after figuring it out lol
So don't hate on me if this is obvious or well known. I just figured it out now and thought it was fun.
Rm9sbG93ZXJz -> "Followers"
VGhlIFRydXRoIGlzIE91dCBUaGVyZQ= -> "The Truth is Out There"
If one of you can figure out this text I encrypted using a different encoding, I'll send you a funny meme as a prize:
☌⟟⌰⌰⟟⏃⋏ ⏃⋏⎅⟒⍀⌇⍜⋏ ⟟⌇ ⏃ ☌⍜⎅⎅⟒⌇⌇ ⏃⋏⎅ ⍙⟒'⍀⟒ ⋏⍜⏁ ⍙⍜⍀⏁⊑⊬.
#the x files#txf#x files#thexfiles#dana scully#fox mulder#mulder and scully#scully x mulder#gillian anderson#encryption#ciphers#s11#episode 7#sushi restaurant
106 notes
·
View notes
Text
Project Special K progress report
Villagers and players: Shadow the Hedgehog is a bitch-ass motherfucker. He pissed on my wife. Details to follow in a separate post.
Items: When I first started drafting this, I was planning to do user-facing inventory management next. I did not, as could've been foreseen. Instead I worked on maps. And how!
Maps: I somewhat overhauled the way the exterior town map is saved. Instead of a straight JSON array with elevation/ground type pairs, it now saves a ton more information by first deflating the data and then Base64-encoding the result. For a single mostly-empty acre, this is a massive gain. But then it turned out weird differences between Debug and Release builds caused the former to not inflate the stuff correctly and only loading half an acre, so I ended up just blasting the whole tilemap to a binary file.
Maps again: I've started on having a Lua script generate the map. This ties into the planned feature where you get to pick a basic style based on the various Animal Crossing games.
Maps again again: at @lahnsette-maekohlira's suggestion, I tried generating a 100 by 100 acre map. That's 1600 by 1600 tiles, taking almost 15 megabytes just for that part, without any objects or houses or any of that other stuff yet to be implemented. And yet, saving a PNG of it took longer than the entire rest of the process.
Items again: this time, on the map. As seen before, dropped items can appear on the map. So that's a thing, and so are placed items.
I was actually gonna do another post before this but this was apparently supposed to go out on the 15th of... I guess March? And then Shadow whipped his quilly hedgehog dick out. Wow that meme does not want to leave my head now. Goddamn. So anyway I guess I'll just post this progress now and piss on the moon in a bit.
7 notes
·
View notes
Text
yarr harr, fiddle de dee [more on piracy networks]
being a pirate is all right to be...
I didn't really intend this post as an overview of all the major methods of piracy. But... since a couple of alternatives have been mentioned in the comments... let me infodump talk a little about 1. Usenet and 2. direct peer-to-peer systems like Gnutella and Soulseek. How they work, what their advantages are on a system level, how convenient they are for the user, that kind of thing.
(Also a bit at the end about decentralised hash table driven networks like IPFS and Freenet, and the torrent indexer BTDigg).
Usenet
First Usenet! Usenet actually predates the web, it's one of the oldest ways people communicated on the internet. Essentially it's somewhere between a mailing list and a forum (more accurately, a BBS - BBSes were like forums you had to phone, to put it very crudely, and predate the internet as such).
On Usenet, it worked like this. You would subscribe to a newsgroup, which would have a hierarchical name like rec.arts.sf.tv.babylon5.moderated (for talking about your favourite TV show, Babylon 5) or alt.transgendered (for talking about trans shit circa 1992). You could send messages to the newsgroup, which would then be copied between the various Usenet servers, where other people could download them using a 'news reader' program. If one of the Usenet servers went down, the others acted as a backup. Usenet was a set of protocols rather than a service as such; it was up to the server owners which other servers they would sync with.
Usenet is only designed to send text information. In theory. Back in the day, when the internet was slow, this was generally exactly what people sent. Which didn't stop people posting, say, porn... in ASCII form. (for the sake of rigour, that textfile's probably from some random BBS, idk if that one ever got posted to Usenet). The maximum size of a Usenet post ('article', in traditional language) depends on the server, but it's usually less than a megabyte, which does not allow for much.
As the internet took off, use of Usenet in the traditional way declined. Usenet got flooded with new users (an event named 'Eternal September'; September was traditionally when a cohort of students would start at university and thus gain access to Usenet, causing an influx of new users who didn't know the norms) and superseded by the web. But it didn't get shut down or anything - how could it? It's a protocol; as long as at least one person is running a Usenet server, Usenet exists.
But while Usenet may be nigh-unusable as a discussion forum now thanks to the overwhelming amount of spam, people found another use for the infrastructure. Suppose you have a binary file - an encoded movie, for example. You can encode that into ASCII strings using Base64 or similar methods, split it up into small chunks, and post the whole lot onto Usenet, where it will get synchronised across the network. Then, somewhere on the web, you publish a list of all the Usenet posts and their position in the file. This generally uses the NZB format. A suitable newsreader can then take that NZB file and request all the relevant pieces from a Usenet server and assemble them into a file.
NZB sites are similar to torrent trackers in that they don't directly host pirated content, but tell you where to get it. Similar to torrent trackers, some are closed and some are open. However, rather than downloading the file piecemeal from whoever has a copy as in a torrent, you are downloading it piecemeal from a big central server farm. Since these servers are expensive to run, access to Usenet is usually a paid service.
For this to work you need the Usenet servers to hold onto the data for long enough to people to get it. Generally speaking the way it works is that the server has a certain storage buffer; when it runs out of space, it starts overwriting old files. So there's an average length of time until the old file gets deleted, known as the 'retention time'. For archival purposes, that's how long you got; if you want to keep something on Usenet after that, upload it again.
As a system for file distribution... well, it's flawed, because it was never really designed as a file sharing system, but somehow it works. The operator of a Usenet server has to keep tens of petabytes of storage, to hold onto all the data on the Usenet network for a retention period of years, including the hundreds of terabytes uploaded daily, much of which is spam; it also needs to fetch it reliably and quickly for users, when the files are spread across the stream of data in random places. That's quite a system engineering challenge! Not surprisingly, data sometimes ends up corrupted. There is also a certain amount of overhead associated with encoding to ASCII and including parity checks to avoid corruption, but it's not terribly severe. In practice... if you have access to Usenet and know your way to a decent NZB site, I remember it generally working pretty well. Sometimes there's stuff on Usenet that's hard to find on other sources.
Like torrents, Usenet offers a degree of redundancy. Suppose there's a copyrighted file on Usenet server A, and it gets a DMCA notice and complies. But it's still on Usenet servers B, C and D, and so the (ostensible) copyright holder has to go and DMCA them as well. However, it's less redundant, since there are fewer Usenet servers, and operating one is so much more involved. I think if the authorities really wanted to crush Usenet as a functional file distribution system, they'd have an easier time of it than destroying torrents. Probably the major reason they don't is that Usenet is now a fairly niche system, so the cost/benefit ratio would be limited.
In terms of security for users, compared to direct peer to peer services, downloading from Usenet has the advantage of not broadcasting your IP on the network. Assuming the server implements TLS (any modern service should), if you don't use a VPN, your ISP will be able to see that you connected to a Usenet server, but not what you downloaded.
In practice?
for torrenting, if you use public trackers you definitely 100% want a VPN. Media companies operate sniffers which will connect to the torrent swarm and keep track of what IP addresses connect. Then, they will tell your ISP 'hey, someone is seeding our copyrighted movie on xyz IP, tell them to stop'. At this point, your ISP will usually send you a threatening email on a first offence and maybe cutoff your internet on a second. Usually this is a slap on the wrist sort of punishment, ISPs really don't care that much, and they will reconnect you if you say sorry... but you can sidestep that completely with a VPN. at that point the sniffer can only see the VPN's IP address, which is useless to them.
for Usenet, the threat model is more niche. There's no law against connecting to Usenet, and to my knowledge, Usenet servers don't really pay attention to anyone downloading copyrighted material from their servers (after all, there's no way they don't know the main reason people are uploading terabytes of binary data every day lmao). But if you want to be sure the Usenet server doesn't ever see your IP address, and your ISP doesn't know you connected to Usenet, you can use a VPN.
(In general I would recommend a VPN any time you're pirating or doing anything you don't want your IP to be associated with. Better safe than sorry.)
What about speed? This rather depends on your choice of Usenet provider, how close it is to you, and what rate limits they impose, but in practice it's really good since it's built on incredibly robust, pre-web infrastructure; this is one of the biggest advantages of Usenet. For torrents, by contrast... it really depends on the swarm. A well seeded torrent can let you use your whole bandwidth, but sometimes you get unlucky and the only seed is on the other side of the planet and you can only get about 10kB/s off them.
So, in short, what's better, Usenet or BitTorrent? The answer is really It Depends, but there's no reason not to use both, because some stuff is easier to find on torrents (most anime fansub groups tend to go for torrent releases) and some stuff is easier to find on Usenet (e.g. if it's so old that the torrents are all dead). In the great hierarchy of piracy exclusivity, Usenet sits somewhere between private and public torrent trackers.
For Usenet, you will need to figure out where to find those NZBs. Many NZB sites require registration/payment to access the NZB listing, and some require you to be invited. However, it's easier to get into an NZB site than getting on a private torrent tracker, and requires less work once you're in to stay in.
Honestly? It surprises me that Usenet hasn't been subject to heavier suppression, since it's relatively centralised. It's got some measure of resilience, since Usenet servers are distributed around the world, and if they started ordering ISPs to block noncomplying Usenet servers, people would start using VPNs, proxies would spring up; it would go back to the familiar whack-a-mole game.
I speculate the only reason it's not more popular is the barrier to entry is just very slightly higher than torrents. Like, free always beats paid, even though in practice torrents cost the price of a VPN sub. Idk.
(You might say it requires technical know-how... but is 'go on the NZB indexer to download an NZB and then download a file from Usenet' really so much more abstruse than 'go on the tracker to download a torrent and then download a file from the swarm'?)
direct peer to peer (gnutella, soulseek, xdcc, etc.)
In a torrent, the file is split into small chunks, and you download pieces of your file from everyone who has a copy. This is fantastic for propagation of the file across a network because as soon as you have just one piece, you can start passing it on to other users. And it's great for downloading, since you can connect to lots of different seeds at once.
However, there is another form of peer to peer which is a lot simpler. You provide some means to find another person who has your file, and they send you the file directly.
This is the basis that LimeWire worked on. LimeWire used two protocols under the hood, one of them BitTorrent, the other a protocol called Gnutella. When the US government ordered LimeWire shut down, the company sent out a patch to LimeWire users that made the program delete itself. But both these protocols are still functioning. (In fact there's even an 'unofficial' fork of the LimeWire code that you can use.)
After LimeWire was shut down, Gnutella declined, but it didn't disappear by any means. The network is designed to be searchable, so you can send out a query like 'does anyone have a file whose name contains the string "Akira"' and this will spread out across the network, and you will get a list of people with copies of Akira, or the Akira soundtrack, and so on. So there's no need for indexers or trackers, the whole system is distributed. That said, you are relying on the user to tell the truth about the contents of the file. Gnutella has some algorithmic tricks to make scanning the network more efficient, though not to the same degree as DHTs in torrents. (DHTs can be fast because they are looking for one computer, the appointed tracker, based on a hash of the file contents. Tell me if you wanna know about DHTs, they're a fascinating subject lol).
Gnutella is not the only direct file sharing protocol. Another way you can introduce 'person who wants a file' and 'person who has a file' is to have a central server which everyone connects to, often providing a chatroom function along with coordinating connections.
This can be as simple as an IRC server. Certain IRC clients (by no means all) support a protocol called XDCC, which let you send files to another user. This has been used by, for example, anime fansub groups - it's not really true anymore, but there was a time where the major anime fansub groups operated XDCC bots and if you wanted their subs, you had to go on their IRC and write a command to the bot to send it to you.
XDCC honestly sucked though. It was slow if you didn't live near the XDCC bot, and often the connection would often crap out mid download and you'd have to manually resume (thankfully it was smart enough not to have to start over from the beginning), and of course, it is fiddly to go on a server and type a bunch of IRC commands. It also put the onus of maintaining distribution entirely on the fansub group - your group ran out of money or went defunct and shut down its xdcc bot? Tough luck. That said, it was good for getting old stuff that didn't have a torrent available.
Then there's Soulseek! Soulseek is a network that can be accessed using a handful of clients. It is relatively centralised - there are two major soulseek servers - and they operate a variety of chat rooms, primarily for discussing music.
To get on Soulseek you simply register a username, and you mark at least one folder for sharing. There doesn't have to be anything in it, but a lot of users have it set so that they won't share anything unless you're sharing a certain amount of data yourself.
You can search the network and get a list of users who have matching files, or browse through a specific user's folder. Each user can set up their own policy about upload speed caps and so on. If you find something you want to download, you can queue it up. The files will be downloaded in order.
One interesting quirk of Soulseek is that the uploader will be notified (not like a push notification, but you see a list of who's downloading/downloaded your files). So occasionally someone will notice you downloading and send you a friendly message.
Soulseek is very oriented towards music. Officially, its purpose is to help promote unsigned artists, not to infringe copyright; in practice it's primarily a place for music nerds to hang out and share their collections. And although it's faced a bit of legal heat, it seems to be getting by just fine.
However, there's no rule that you can only share music. A lot of people share films etc. There's really no telling what will be on Soulseek.
Since Soulseek is 1-to-1 connections only, it's often pretty slow, but it's often a good bet if you can't find something anywhere else, especially if that something is music. In terms of resilience, the reliance on a single central server to connect people to peers is a huge problem - that's what killed Napster back in the day, if the Soulseek server was shut down that would be game over... unless someone else set up a replacement and told all the clients where to connect. And yet, somehow it's gotten away with it so far!
In terms of accessibility, it's very easy: just download a client, pick a name and password, and share a few gigs (for example: some movies you torrented) and you're good.
In terms of safety, your IP is not directly visible in the client, but any user who connects directly to you would be able to find it out with a small amount of effort. I'm not aware of any cases of IP sniffers being used on Soulseek, but I would recommend a VPN all the same to cover your bases - better safe than sorry.
Besides the public networks like Soulseek and Gnutella, there are smaller-scale, secret networks that also work on direct connection basis, e.g. on university LANs, using software such as DC++. I cannot give you any advice on getting access to these, you just have to know the right person.
Is that all the ways you can possibly pirate? Nah, but I think that's the main ones.
Now for some more niche shit that's more about the kind of 'future of piracy' type questions in the OP, like, can the points of failure be removed..?
IPFS
Since I talked a little above about DHTs for torrents, I should maybe spare a few words about this thing. Currently on the internet you specify the address of a certain computer connected to the network using an IP address. (Well, typically the first step is to use the DNS to get an IP address.) IPFS is based on the idea of 'content-based addressing' instead; like torrents, it specifies a file using a hash of the content.
This leads to a 'distributed file system'; the ins and outs are fairly complicated but it has several layers of querying. You can broadcast that you want a particular chunk of data to "nearby" nodes; if that fails to get a hit, you can query a DHT which directs you to someone who has a list of sources.
In part, the idea is to create a censorship-resistant network: if a node is removed, the data may still be available on other nodes. However, it makes no claim to outright permanence, and data that is not requested is gradually flushed from nodes by garbage collection. If you host a node, you can 'pin' data so it won't be deleted, or you can pay someone else to do that on their node. (There's also some cryptocurrency blockchain rubbish that is supposed to offer more genuine permanence.)
IPFS is supposed to act as a replacement for the web, according to its designers. This is questionable. Most of what we do on the web right now is impossible on IPFS. However, I happen to like static sites, and it's semi-good at that. It is, sympathetically, very immature; I remember reading one very frustrated author writing about how hard it was to deploy a site to IPFS, although that was some years ago and matters seem to have improved a bit since then.
I said 'semi-good'. Since the address of your site changes every time you update it, you will end up putting multiple redundant copies of your site onto the network at different hashes (though the old hashes will gradually disappear). You can set a DNS entry that points to the most recent IPFS address of your site, and rely on that propagating across the DNS servers. Or, there's a special mutable distributed name service on the IPFS network based around public/private key crypto; basically you use a hash of your public key as the address and that returns a link to the latest version of your site signed with your private key.
Goddamn that's a lot to try to summarise.
Does it really resist censorship? Sorta. If a file is popular enough to propagate enough the network, it's hard to censor it. If there's only one node with it, it's no stronger than any other website. If you wanted to use it as a long term distributed archive, it's arguably worse than torrents, because data that's not pinned is automatically flushed out of the network.
It's growing, if fairly slowly. You can announce and share stuff on it. It has been used to bypass various kinds of web censorship now and then. Cloudflare set a bunch of IPFS nodes on their network last year. But honestly? Right now it's one of those projects that is mostly used by tech nerds to talk to other tech nerds. And unfortunately, it seems to have caught a mild infection of cryptocurrency bullshit as well. Thankfully none of that is necessary.
What about piracy? Is this useful for our nefarious purposes? Well, sort of. Libgen has released all its books on IPFS; there is apparently an effort to upload the content of ZLib to IPFS as well, under the umbrella of 'Anna's Archive' which is a meta-search engine for LibGen, SciHub and a backup of ZLib. By nature of IPFS, you can't put the actual libgen index site on it (since it constantly changes as new books are uploaded, and dynamic serverside features like search are impossible on IPFS). But books are an ideal fit for IPFS since they're usually pretty small.
For larger files, they are apparently split into 256kiB chunks and hashed individually. The IPFS address links to a file containing a list of chunk hashes, or potentially a list of lists of chunk hashes in a tree structure. (Similar to using a magnet link to acquire a torrent file; the short hash finds you a longer list of hashes. Technically, it's all done with Merkle trees, the same data structure used in torrents).
One interesting consequence of this design is that the chunks don't necessarily 'belong' to a particular file. If you're very lucky, some of your chunks will already be established on the network. This also further muddies the waters of whether a particular user is holding onto copyrighted data or not, since a particular hash/block might belong to both the tree of some copyrighted file and the tree of some non-copyrighted file. Isn't that fun?
The other question I had was about hash collisions. Allegedly, these are almost impossible with the SHA-256 hash used by default on IPFS, which produces a 256-bit address. This is tantamount to saying that of all the possible 256KiB strings of data, only at most about 1 in 8000 will actually ever be distributed with the IPFS. Given the amount of 256-kibibyte strings is around 4.5 * 10^631305, this actually seems like a fairly reasonable assumption. Though, given that number, it seems a bit unlikely that two files will ever actually have shared chunks. But who knows, files aren't just random data so maybe now and then, there will be the same quarter-megabyte in two different places.
That said, for sharing large files, IPFS doesn't fundamentally offer a huge advantage over BitTorrent with DHT. If a lot of people are trying to download a file over IPFS, you will potentially see similar dynamics to a torrent swarm, where chunks spread out across the network. Instead of 'seeding' you have 'pinning'.
It's an interesting technology though, I'll be curious to see where it goes. And I strongly hope 'where it goes' is not 'increasingly taken over by cryptocurrency bullshit'.
In terms of security, an IPFS node is not anonymous. It's about as secure as torrents. Just like torrents, the DFT keeps a list of all the nodes that have a file. So if you run an IPFS node, it would be easy to sniff out if you are hosting a copyrighted file on IPFS. That said, you can relatively safely download from IPFS without running a node or sharing anything, since the IPFS.tech site can fetch data for you. Although - if you fetch a site via the IPFS.tech site (or any other site that provides IPFS access over http), IPFS.tech will gain a copy of the file and temporarily provide it. So it's not entirely tantamount to leeching - although given the level of traffic on IPFS.tech I can't imagine stuff lasts very long on there.
Freenet Hyphanet
Freenet (officially renamed to Hyphanet last month, but most widely known as Freenet) is another, somewhat older, content-based addressing distributed file store built around a DHT. The difference between IPFS and Freenet is that Freenet prioritises anonymity over speed. Like in IPFS, the data is split into chunks - but on Freenet, the file is spread out redundantly across multiple different nodes immediately, not when they download it, and is duplicated further whenever it's downloaded.
Unlike torrents and IPFS, looking up a file causes it to spread out across the network, instead of referring you to an IP address. Your request is routed around the network using hashes in the usual DHT way. If it runs into the file, it comes back, writing copies at each step along the way. If a node runs out of space it overwrites the chunks that haven't been touched in a while. So if you get a file back, you don't know where it came from. The only IP addresses you know are your neighbours in the network.
There's a lot of complicated and clever stuff about how the nodes swap roles and identities in the network to gradually converge towards an efficient structure while maintaining that degree of anonymity.
Much like IPFS, data on Freenet is not guaranteed to last forever. If there's a lot of demand, it will stick around - but if no nodes request the file for a while, it will gradually get flushed out.
As well as content-based hashing, the same algorithm can be used for routing to a cryptographic signature, which lets you define a semi-mutable 'subspace' (you can add new files later which will show up when the key is queried). In fact a whole lot of stuff seems to be built on this, including chat services and even a Usenet-like forum with a somewhat complex 'web of trust' anti-spam system.
If you use your computer as a Freenet node, you will necessarily be hosting whatever happens to route through it. Freenet is used for much shadier shit than piracy. As far as safety, the cops are trying to crack it, though probably copyrighted stuff is lower on their priority list than e.g. CSAM.
Is Freenet used for piracy? If it is, I can't find much about it on a cursory search. The major problem it has is latency. It's slow to look stuff up, and slow to download it since it has to be copied to every node between you and the source. The level of privacy it provides is just not necessary for everyday torrenting, where a VPN suffices.
BTDigg
Up above I lamented the lack of discoverability on BitTorrent. There is no way to really search the BitTorrent network if you don't know exactly the file you want. This comes with advantages (it's really fast; DHT queries can be directed to exactly the right node rather than spreading across the network as in Gnutella) but it means BitTorrent is dependent on external indices to know what's available on the network and where to look for it.
While I was checking I had everything right about IPFS, I learned there is a site called BTDigg (wikipedia) which maintains a database of torrents known from the Mainline DHT (the primary DHT used by BitTorrent). Essentially, when you use a magnet link to download a torrent file, you query the DHT to find a node that has the full .torrent file, which tells you what you need to download to get the actual content of the torrent. BTDigg has been running a scraper which notes magnet links coming through its part of the DHT and collects the corresponding .torrent files; it stores metadata and magnet links in a database that is text-searchable.
This database isn't hosted on the BitTorrent network, so it's as vulnerable to takedown as any other tracker, but it does function as a kind of backup record of what torrents exist if the original tracker has gone. So give that a try if the other sites fail.
Say something about TOR?
I've mentioned VPNs a bunch, but what about TOR? tl;dr: don't use TOR for most forms of piracy.
I'm not gonna talk about TOR in detail beyond to say I wouldn't recommend using TOR for piracy for a few reasons:
TOR doesn't protect you if you're using torrents. Due to the way the BitTorrent protocol works, your IP will leak to the tracker/DHT. So there's literally no point to using TOR.
If that's not enough to deter you, TOR is slow. It's not designed for massive file transfers and it's already under heavy use. Torrents would strain it much further.
If you want an anonymisation network designed with torrents in mind, instead consider I2P. Using a supported torrent client (right now p much just Vuze and its fork BiglyBT - I would recommend the latter), you can connect to a torrent swarm that exists purely inside the I2P network. That will protect you from IP sniffers, at the cost of reducing the pool of seeds you can reach. (It also might be slower in general thanks to the onion routing, not sure.)
What's the future of piracy?
So far the history of piracy has been defined by churn. Services and networks grow popular, then get shut down. But the demand continues to exist and sooner or later, they are replaced. Techniques are refined.
It would be nice to imagine that somewhere up here comes the final, unbeatable piracy technology. It should be... fast, accessible, easy to navigate, reliably anonymous, persistent, and too widespread and ~rhizomatic~ to effectively stamp out. At that point, when 'copies of art' can no longer function as a scarce commodity, what happens? Can it finally be decoupled from the ghoulish hand of capital? Well, if we ever find out, it will be in a very different world to this one.
Right now, BitTorrent seems the closest candidate. The persistent weaknesses: the need for indexers and trackers, the lack of IP anonymity, and the potential for torrents to die out. Also a lot of people see it as intimidating - there's a bunch of jargon (seeds, swarms, magnet links, trackers, peers, leeches, DHT) which is pretty simple in practice (click link, get thing) but presents a barrier to entry compared to googling 'watch x online free'.
Anyway, really the thing to do is, continue to pirate by any and all means available. Don't put it all in one basket, you know? Fortunately, humanity is waaaay ahead of me on that one.
do what you want 'cos a pirate is free you are a pirate
47 notes
·
View notes
Text
How to enjoy my electronic zines
Each of the issues are Base64 encoded, and once decoded with the default settings, become a main.py file to be used on a MicroPython enabled Raspberry Pi Pico W. Once up and running, you don’t need to worry about the password for the “Spring83” network which would eventually show up.
NB. I’ve tried to connect myself to the wifi through my iPad, but I kept getting errors; had better luck on a Chromebook.
4 notes
·
View notes
Text
Vogon Media Server v0.43a
So I decided I did want to deal with the PDF problem.
I didn't resolve the large memory footprint problem yet, but I think today's work puts me closer to a solution. I've written a new custom PDF reader on top of the PDF.js library from Mozilla. This reader is much more simple than the full one built into Firefox browsers, but it utilizes the same underlying rendering libraries so it should be relatively accurate (for desktop users). The big benefit this brings is that it's a match for the existing CBZ reader controls and behavior, unifying the application and bringing in additional convenience features like history tracking and auto link to next issue/book when you reach the end of the current one.
The history tracking on the PDFs is a big win, in my opinion, as I have a lot of comics in PDF form that I can now throw into series and read.
Word of warning. PDFs bigger than a few MB can completely overload mobile browsers, resulting in poor rendering with completely missing elements, or a full browser crash. I'm betting the limit has a lot to do with your device's RAM, but I don't have enough familiarity to know for sure. These limitations are almost the same as the limits for the Mozilla written reader, so I think it has more to do with storing that much binary data in a browser session than how I am navigating around their APIs.
As far as addressing that problem, I suspect that if I can get TCPDF to read the meta data (i.e. the number of pages), I can use the library to write single page PDF files to memory and serve those instead of the full file. I'm already serving the PDF as a base64 encoded binary glob rather than from the file system directly. It doesn't solve the problem of in-document links, but since I provide the full Mozilla reader as a backup (accessible by clicking the new "Switch Reader" button), you can always swap readers if you need that.
As noted earlier today, the install script is still not working correctly so unless you have a working install already you'll have to wait until I get my VMs set up to be able to test and fix that. Good news on that front, the new media server builds much much faster than the old PI, so fast iteration should be very doable.
But, if you want to look at the code: https://github.com/stephentkennedy/vogon_media_server
6 notes
·
View notes
Text
Matrix Breakout: 2 Morpheus
Hello everyone, it's been a while. :)

Haven't been posting much recently as I haven't really done anything noteworthy- I've just been working on methodologies for different types of penetration tests, nothing interesting enough to write about!
However, I have my methodologies largely covered now and so I'll have the time to do things again. There are a few things I want to look into, particularly binary exploit development and OS level security vulnerabilities, but as a bit of a breather I decided to root Morpheus from VulnHub.
It is rated as medium to hard, however I don't feel there's any real difficulty to it at all.
Initial Foothold
Run the standard nmap scans and 3 open ports will be discovered:
Port 22: SSH
Port 80: HTTP
Port 31337: Elite
I began with the web server listening at port 80.

The landing page is the only page offered- directory enumeration isn't possible as requests to pages just time out. However, there is the hint to "Follow the White Rabbit", along with an image of a rabbit on the page. Inspecting the image of the rabbit led to a hint in the image name- p0rt_31337.png. Would never have rooted this machine if I'd known how unrealistic and CTF-like it was. *sigh*
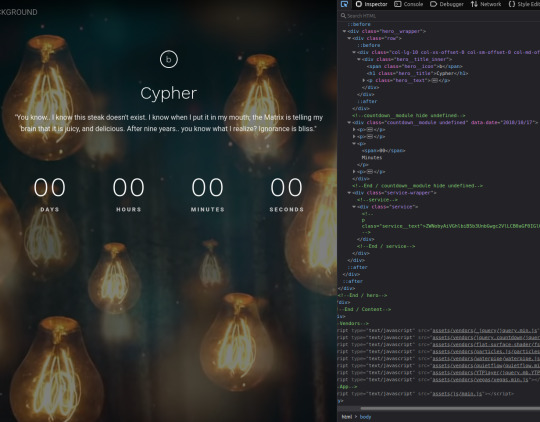
The above is the landing page of the web server listening at port 31337, along with the page's source code. There's a commented out paragraph with a base64 encoded string inside.
The string as it is cannot be decoded, however the part beyond the plus sign can be- it decodes to 'Cypher.matrix'.

This is a file on the web server at port 31337 and visiting it triggers a download. Open the file in a text editor and see this voodoo:
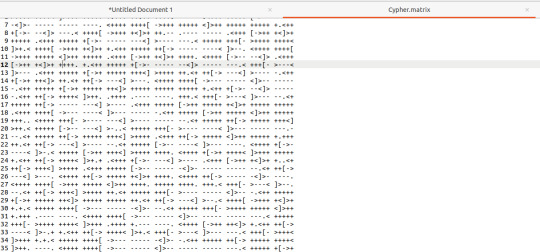
Upon seeing the ciphertext, I was immediately reminded of JSFuck. However, it seemed to include additional characters. It took me a little while of looking around before I came across this cipher identifier.

I'd never heard of Brainfuck, but I was confident this was going to be the in-use encryption cipher due to the similarity in name to JSFuck. So, I brainfucked the cipher and voila, plaintext. :P
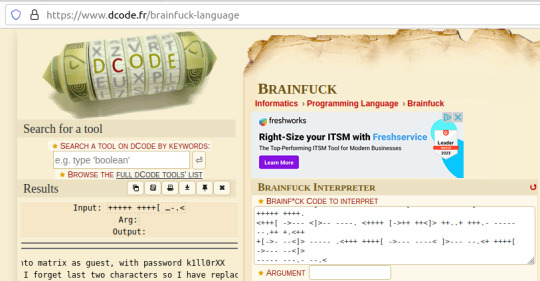
Here, we are given a username and a majority of the password for accessing SSH apart from the last two character that were 'forgotten'.
I used this as an excuse to use some Python- it's been a while and it was a simple script to create. I used the itertools and string modules.
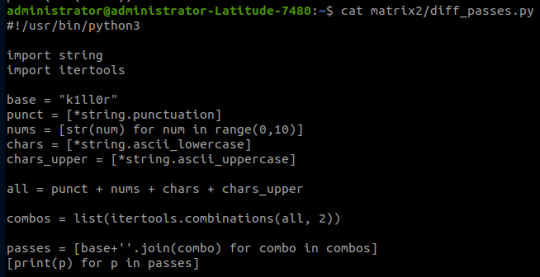
The script generates a password file with the base password 'k1ll0r' along with every possible 2-character combination appended. I simply piped the output into a text file and then ran hydra.
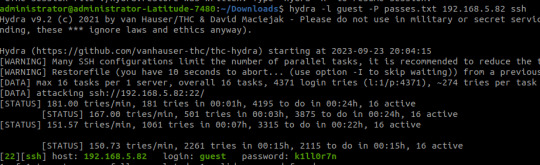
The password is eventually revealed to be 'k1ll0r7n'. Surely enough this grants access to SSH; we are put into an rbash shell with no other shells immediately available. It didn't take me long to discover how to bypass this- I searched 'rbash escape' and came across this helpful cheatsheet from PSJoshi. Surely enough, the first suggested command worked:

The t flag is used to force tty allocation, needed for programs that require user input. The "bash --noprofile" argument will cause bash to be run; it will be in the exec channel rather than the shell channel, thus the need to force tty allocation.
Privilege Escalation
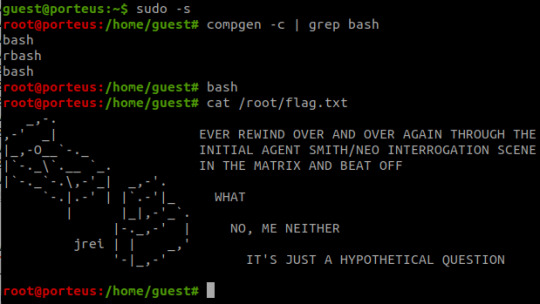
With access to Bash commands now, it is revealed that we have sudo access to everything, making privilege escalation trivial- the same rbash shell is created, but this time bash is directly available.
Thoughts
I did enjoy working on Morpheus- the CTF element of it was fun, and I've never came across rbash before so that was new.
However, it certainly did not live up to the given rating of medium to hard. I'm honestly not sure why it was given such a high rating as the decoding and decryption elements are trivial to overcome if you have a foundational knowledge of hacking and there is alot of information on bypassing rbash.
It also wasn't realistic in any way, really, and the skills required are not going to be quite as relevant in real-world penetration testing (except from the decoding element!)
#brainfuck#decryption#decoding#base64#CTF#vulnhub#cybersecurity#hacking#rbash#matrix#morpheus#cypher
9 notes
·
View notes
Text
- the api documentation states explicitly that tab-delineated text is an acceptable format for file upload
- for a week i am emailing back and forth with their team re: an odd exception error. i send a sample file on monday and in every email i say “i am calling the endpoint with a base64 encoded tab-delineated text file, as per the documentation”
- zero progress
- we finally have a call
- “can i see the file you’re encoding?”
- sure i say. here is the text body
- him: oh that’s tab-delineated text? That’s The Problem.
- me: …
- him: try it as a csv
- SIR.
- DID THAT REALLY HAVE TO TAKE A WEEK
- FIX YOUR API DOCUMENTATION
14 notes
·
View notes
Text
UNC4057 LOSTKEYS Malware Targets Western NGOs

UNC4057 LOSTKEYS
The Russian government-backed outfit COLDRIVER targets Western and non-governmental organisations with its latest spyware, LOSTKEYS.
The Russian government-backed threat organisation COLDRIVER (also known as UNC4057, Star Blizzard, and Callisto) has stolen data from NGOs and Western targets using LOSTKEYS, a new virus. The Google Threat Intelligence Group (GTIG) been tracking COLDRIVER for years, including its SPICA malware in 2024, and believes LOSTKEYS is a new tool.
COLDRIVER focusses on credential phishing targeting well-known targets. People at NGO or personal email addresses are generally targeted. They steal login passwords, emails, and contact lists after gaining access to a target's account. COLDRIVER may also access system files and infect devices with malware.
COLDRIVER has attacked journalists, think institutes, NGOs, and past and current Western government and military advisors. Plus, the gang has kept targeting Ukrainians. COLDRIVER's principal goal is to acquire intelligence for Russia's strategic goals. In several cases, the gang hacked and leaked NGO and UK official data.
January, March, and April 2025 saw the discovery of LOSTKEYS malware. The malicious application may take files from a hard-coded set of folders and extensions and transmit the attacker system details and active processes. COLDRIVER normally utilises credentials to access contacts and emails, although they have utilised SPICA to access target system documents. LOSTKEYS has a unique purpose and is utilised in certain scenarios.
The multi-step LOSTKEYS infection chain begins with a tempting website featuring a fake CAPTCHA. After the CAPTCHA is “verified,” the PowerShell code is transferred to the user's clipboard and the page invites them to execute it using Windows' “run” prompt. The “ClickFix” approach includes socially engineering targets to copy, paste, and run PowerShell scripts. Google Threat Intelligence Group said many APT and financially driven attackers use this method, which has been well documented.
PowerShell does the first stage's second step. In numerous instances, the IP address 165.227.148[.] provided this second step.68. The second step computes the display resolution MD5 hash and stops execution if it matches one of three specified values. This step may avoid virtual machine execution. The request must contain IDs unique to each observed instance of this chain to proceed. In every observation, the third stage comes from the same host as the previous phases.
Base64-encoded blobs decode into additional PowerShell in the third phase. This step requires retrieving and decoding the latest LOSTKEYS payload. It does this by downloading two additional files from the same host using different identities for each infection chain. The first-downloaded Visual Basic Script (VBS) file decodes the second file. Each infection chain is decoded with two keys. One unique key is in the decoder script, while stage 3 saves the second. Keys are used to replace cypher the encoded data.
The final payload is LOSTKEYS VBS. File theft and system data collection are its purposes.
Two more LOSTKEYS samples dated December 2023 were uncovered during this behaviour investigation. These previous PE files posing as Maltego files change greatly from the execution chain starting in 2025. It is unclear if these December 2023 samples are related to COLDRIVER or if the malware was reused from another operation into January 2025. Exchanged Indicators of Compromise (IOCs) include binary hashes and C2 addresses like njala[.]dev and 80.66.88[.]67.
Google Threat Intelligence Group uses threat actor research like COLDRIVER to improve product security and safety to safeguard consumers. Once detected, hazardous websites, domains, and files are added to Safe Browsing to protect users. Government-backed attacker warnings alerted Gmail and Workspace users. Potential targets should enrol in Google's Advanced Protection Program, enable Chrome's Enhanced Safe Browsing, and update all devices.
Google shares its findings with the security community to raise awareness and help targeted companies and people. Sharing methods and approaches improves threat hunting and sector user protections. The original post comprises YARA rules and compromise indicators and is available as a Google Threat Intelligence collection and rule bundle.
#UNC4057LOSTKEYS#UNC4057#COLDRIVER#GoogleThreatIntelligence#virtualmachines#VisualBasicScript#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
Unlocking Seamless Integrations: A Comprehensive Guide to the 'Contact Form to Any API' WordPress Plugin
In today's digital landscape, integrating your website's contact forms with various APIs is crucial for streamlined operations and enhanced user experiences. The Contact Form to Any API WordPress plugin stands out as a versatile tool, enabling seamless connections between your contact forms and a multitude of third-party services. This comprehensive guide delves into the features, benefits, and practical applications of this powerful plugin.

Understanding the Need for API Integration
Before exploring the plugin's capabilities, it's essential to grasp the significance of API integrations:
Enhanced Efficiency: Automating data transfer between your website and external platforms reduces manual tasks.
Improved Data Accuracy: Direct integrations minimize errors associated with manual data entry.
Real-Time Updates: Immediate data synchronization ensures up-to-date information across platforms.
Scalability: As your business grows, integrated systems can handle increased data flow without additional overhead.
Introducing 'Contact Form to Any API'
Developed by IT Path Solutions, 'Contact Form to Any API' is designed to bridge the gap between your WordPress contact forms and external APIs. Whether you're using Contact Form 7 or WPForms, this plugin facilitates the transmission of form data to various services, including CRMs, marketing platforms, and custom APIs.
Key Features
1. Broad API Compatibility
Supports Over 150 APIs: Seamlessly connect with platforms like Mailchimp, HubSpot, Zapier, Odoo CRM, and more.
Custom API Integration: Configure connections with virtually any REST API, providing unparalleled flexibility.
2. Flexible Data Transmission
Multiple HTTP Methods: Choose between POST and GET requests based on your API's requirements.
JSON Formatting: Send data in simple or nested JSON structures, accommodating complex API schemas.
Header Customization: Set custom headers, including Authorization tokens, to meet specific API authentication needs.
3. File Handling Capabilities
File Upload Support: Enable users to upload files through your forms.
Base64 Encoding: Automatically convert uploaded files to Base64 format for API compatibility.
4. Data Management and Export
Database Storage: Store form submissions within your WordPress database for easy access.
Export Options: Download submission data in CSV, Excel, or PDF formats for reporting and analysis.
5. Conditional Data Sending
Timing Control: Decide whether to send data to the API before or after the form's email notification is dispatched.
6. Authentication Support
Multiple Authentication Methods: Utilize Basic Auth, Bearer Tokens, or custom headers to authenticate API requests.
Pro Version Enhancements
Upgrading to the Pro version unlocks additional features:
Multi-API Support: Send form data to multiple APIs simultaneously.
Advanced JSON Structures: Handle multi-level JSON formats for complex integrations.
Priority Support: Receive expedited assistance from the development team.
OAuth 2.0 and JWT Integration: Facilitate secure connections with APIs requiring advanced authentication protocols.
Real-World Applications
The versatility of 'Contact Form to Any API' opens doors to numerous practical applications:
CRM Integration: Automatically add new leads to your CRM system upon form submission.
Email Marketing: Subscribe users to your mailing list in platforms like Mailchimp or Sendinblue.
Support Ticketing: Create support tickets in systems like Zendesk or Freshdesk directly from contact forms.
Project Management: Generate tasks in tools like Trello or Asana based on form inputs.
User Testimonials
The plugin has garnered positive feedback from the WordPress community:
"Does exactly what is needed – connects your contact form to API. Works great out of the box, and amazing support." — Olay
"I used the free plugin for a while already, recently stepped over to the pro and I must say the pro and agency version come with amazing new features and the support is quick and always there to help you with any questions!" — Samuellegrand
Getting Started: Installation and Configuration
Step 1: Installation
Navigate to your WordPress dashboard.
Go to Plugins > Add New.
Search for "Contact Form to Any API."
Click "Install Now" and then "Activate."
Step 2: Configuration
Access the plugin settings via the WordPress dashboard.
Choose the form (Contact Form 7 or WPForms) you wish to integrate.
Enter the API endpoint URL.
Configure the request method (POST or GET).
Set up headers and authentication details as required.
Map form fields to the corresponding API parameters.
Save your settings and test the integration.
Best Practices for Optimal Integration
Test Thoroughly: Use tools like Postman to test API endpoints before full integration.
Secure Sensitive Data: Ensure that authentication tokens and sensitive information are stored securely.
Monitor Logs: Regularly check logs for any errors or issues in data transmission.
Stay Updated: Keep the plugin and WordPress core updated to benefit from the latest features and security patches.
Conclusion
'Contact Form to Any API' stands as a robust solution for WordPress users seeking seamless integration between their contact forms and external services. Its flexibility, extensive feature set, and user-friendly interface make it an invaluable tool for enhancing website functionality and streamlining workflows.
Whether you're aiming to automate lead generation, enhance customer support, or synchronize data across platforms, this plugin offers the capabilities to achieve your goals efficiently.
0 notes
Text
All of a sudden, release builds of Project Special K started eating half the map data. Something in the inflation process went wrong. But only in release builds! If I restore the base64-encoded deflated map data from a helpful copy of the save and load it in a debug build, things are fine. It loads, it saves, no problem.
But if I run a release build? Miniz fails, ostensibly because it's out of space to decompress to or something like that.
I can't be arsed, so the obvious solution is to simplify the process — just blast the map data straight to/from a file without any further processing.
Kinda looks like this:

That's the correct data, yeah.
2 notes
·
View notes
Text
Kaltrinkeda — A ToolBox e suas Funcionalidades.
Olá leitores, eu sou o Kirey e hoje trago mais uma Inovação do Kaltrinkeda:
O ToolBox ou Caixa de Utilidades é uma ferramenta que vem nativa em nossa IDE, e seu propósito é facilitar a rotina do programador com uma seleção de ferramentas nativas, otimizadas para produtividade para tornar essa experiência inesquecível
Não é necessário baixar nenhum pacote adicional para usá-lo.
O ToolBox pode ser acessado diretamente do Editor do seu projeto, basta clicar no botão e ele abre diretamente, com funções como:
Gerador de Lorem Ipsum
Gerador de UUID / GUID
Slugify Tool (transforma texto em slug para URLs)
Base64 Encoder/Decoder
Minificador de JSON, HTML, CSS, JS e Python
Conversor de Texto: maiúsculas, minúsculas, capitalize etc.
Markdown Preview (nativo em arquivos .md)
Editor HEX (pegue cores, tenha prévias, altere opacidade, gere paletas)
Diff Viewer (comparar dois textos)
Criptografia Simples: SHA-1 / SHA-256 / MD5 / Bash / AES-256
Conversores Numéricos: Binário ↔ Decimal ↔ Hex ↔ Octal
Timestamp ↔ Data (Unix Timestamp converter)
IMG Pogger (transforme Imagens em Base64)
IMG Hoster (permite hostear imagens no PostImg direto do app, útil para projetos HTML, transforme imagens em links)
Atalhos de teclado
Essas são algumas das funções na qual estamos trabalhando, mas a idéia é de que a ferramenta tenha centenas ou até milhares de ferramentas úteis, na ToolBox você pode buscar por palavras-chave e assim encontrar a ferramenta perfeita com mais facilidade.
Estamos avaliando cuidadosamente a implementação do ToolBox apenas por questões de desempenho, nossa proposta é oferecer um app funcional, independente da condição do usuário
Seja ele pobre, rico, intermediário, seu dispositivo deve suportar rodar a IDE em pelo menos 40 FPS estável, embora tenhamos toda uma Engenharia pra tornar o app otimizado, e mesmo com otimizações, reconhecemos que a performance pode variar em dispositivos mais limitados, podendo falhar.
Estamos abertos a idéias do público, você, caro leitor da NMBAH, oque você gostaria que sua IDE tivesse? Qual função seria maravilhosa de experienciar;
Entrar no seu projeto, estar no editor, clicar em 1 botão, e a ferramenta já estar pronta para uso. Conte pra gente nos comentários.
Nosso maior medo é lançar um aplicativo infuncional, temos compromisso com nossos usuários, e estamos prometendo um app funcional, diferente de outras IDEs de navegador que lagam, travam e são lentas
Preferimos arriscar não fazer do que entregar um produto ruim, isso inclusive ocorreu nessa postagem, o plano era demonstrar uma prévia da ToolBox, mas devido dificuldades técnicas, o design não atendeu as expectativas, portanto foi criada uma capa gráfica ao invés de mostrar o projeto.
Se essa função compromete a proposta do app, infelizmente não podemos implementar se não for possível otimizar para Todos.
A proposta da ToolBox é facilitar a vida do programador, como dito, as funções são pensadas propriamente para serem práticas, ela vem com múltiplas ferramentas que abrangem todas as linguagens
Você não precisa estar em um file de CSS para usar o Hex Editor, e pode usá-lo do Python ao MarkDown à vontade, essa caixa é um item Global, e se possível, poderá ser usado até mesmo no Console Pancreon.
Agradecemos a atenção de todos.


0 notes
Text
Unlock Your Potential: The Ultimate Guide to HugeTools.net
In today’s fast-paced digital world, having access to the right tools can make all the difference in boosting productivity, saving time, and achieving success. Enter HugeTools.net , your ultimate toolkit designed to simplify even the most complex tasks. Whether you're a developer, marketer, student, or entrepreneur, this platform has everything you need to get things done efficiently.
Welcome to our comprehensive guide where we’ll explore what makes HugeTools.net so special, highlight its key features, and show you how it can transform the way you work. Let's dive in!
What Is HugeTools.net?
HugeTools.net is an innovative online platform offering a vast array of free tools tailored to meet the needs of modern professionals and hobbyists alike. From text manipulation and image optimization to data conversion and SEO utilities, HugeTools.net provides solutions for almost every task imaginable.
Our mission is simple: empower users by delivering powerful, user-friendly tools that save time, reduce effort, and deliver high-quality results. No matter your skill level, you'll find something here to help you achieve your goals.
Key Features of HugeTools.net
Let’s take a closer look at some of the standout features available on HugeTools.net:
1. Text Tools
Manipulating text has never been easier with our collection of text tools:
Convert case (uppercase, lowercase, sentence case).
Remove extra spaces or duplicate lines.
Generate Lorem Ipsum for testing purposes.
Perfect for writers, developers, and anyone working with large amounts of text.
2. Image Optimization Tools
Optimize your images effortlessly with these handy utilities:
Resize images for web or print.
Convert file formats (JPEG to PNG, etc.).
Add watermarks for branding purposes.
Ideal for designers, bloggers, and photographers who need optimized visuals without compromising quality.
3. Data Conversion Tools
Transform data into different formats quickly and easily:
CSV to JSON converter.
XML to HTML transformer.
Base64 encoder/decoder.
Great for developers and analysts handling complex datasets.
4. SEO & Marketing Tools
Enhance your online presence with our suite of SEO and marketing tools:
Meta tag generator.
URL shortener.
Keyword density checker.
Helps marketers and content creators improve website performance and visibility.
5. Developer Utilities
Streamline coding tasks with specialized developer tools:
Color picker and palette generator.
Regex tester.
QR code generator.
Saves time for developers and simplifies common coding challenges.
Why Choose HugeTools.net?
Here are just a few reasons why HugeTools.net stands out from the competition:
User-Friendly Interface: Our tools are intuitive and require no technical expertise to operate.
Free to Use: Access all our tools without any hidden fees or subscriptions.
Constant Updates: We regularly update our platform with new features based on user feedback.
Reliable Performance: Trust us to deliver accurate results every time.
At HugeTools.net, usability, reliability, and accessibility are our top priorities. That’s why thousands of users worldwide rely on us to simplify their workflows.
How to Get Started
Ready to try HugeTools.net? Follow these simple steps:
Visit https://hugetools.net and browse through the categories.
Select the tool that matches your needs.
Follow the on-screen prompts to input your data or upload files.
Download or copy the output as needed.
Explore additional options within each tool for advanced functionality.
It’s that easy! Within minutes, you’ll be up and running with one of our powerful tools.
Tips and Tricks
To get the most out of HugeTools.net, consider these pro tips:
Combine multiple tools for enhanced productivity (e.g., optimize an image and then add a watermark).
Bookmark frequently used tools for quick access.
Check the "Help" section for tutorials and FAQs if you encounter any issues.
Share your experience with others—your feedback helps us improve!
Success Stories
Don’t just take our word for it—here’s what real users have to say about HugeTools.net:
"As a freelance graphic designer, I rely heavily on HugeTools.net to compress my images before sending them to clients. It saves me hours of work every week!" – Sarah M., Graphic Designer
"The CSV-to-JSON converter saved my team during a tight deadline. We couldn’t have completed the project without it." – John D., Software Engineer
These testimonials speak volumes about the impact HugeTools.net can have on your workflow.
Conclusion
HugeTools.net isn’t just another collection of tools—it’s a powerhouse designed to revolutionize the way you work. With its diverse range of functionalities, commitment to user satisfaction, and constant innovation, there’s no reason not to give it a try.
Start exploring today and discover how HugeTools.net can transform your productivity. Who knows? You might just find your new favorite tool!
Call to Action
Ready to boost your productivity? Head over to HugeTools.net now and start using our free tools! Don’t forget to leave a comment below sharing your favorite tool or suggesting new ones we could add. Happy tooling!
#Secondary Tags (Specific Features)#Text Tools#Image Optimization#Data Conversion#SEO Tools#Marketing Tools#Developer Utilities#CSV to JSON Converter#QR Code Generator#Regex Tester#Meta Tag Generator#Tertiary Tags (Audience & Use Cases)#For Developers#For Marketers#For Students#For Entrepreneurs#For Designers#Work-from-Home Tools#Remote Work Tools#Digital Marketing Tools#Content Creation Tools#Graphic Design Tools#Long-Tail Tags (Specific Phrases)#Best Free Online Tools#Tools for Boosting Productivity#How to Optimize Images Online#Convert CSV to JSON Easily#Free SEO Tools for Beginners#Quick Text Manipulation Tools#Enhance Your Workflow with HugeTools.net
0 notes
Text
Haven't done a computer status update in a little bit. Raspberry Pi media server has been psuedo-retired. It's currently still functioning as a media server for a christmas display at my wife's work until the end of December.
It has been successfully replaced by the Dell Optiplex that I got from work. I was able to skip the process of building a migration script for the server (to allow files to be moved and refound via filename & hash), but only because I've been mapping storage outside the server's webroot via link files in the upload directory. So on the new HD the files are actually in the upload directory rather than linked to it. As far as the server knows they're in the same place.
I transferred the software between machines by making a new install of vogon on the optiplex and then importing a mysqldump of the existing install into it, bringing the user accounts, media data, and other configuration elements with it. I did end up changing the storage engine of the data and data_meta tables into innodb (from isam) and adding some additional indexing. There were some noticeable performance differences on the generated join queries between servers. We were looking at 7sec+ lookup times for searches in the audio module. I'm still not sure if it's a mariadb version difference between raspbian and ubuntu lts, if something got corrupted in the export/import process, or if it was some strange storage lookup difference between running the database off of a SETA Hard-Drive versus an SD card. I initially thought maybe it was a fragmentation issue, but the built in optimization processes didn't really impact it, but with the adjustments to the indexing we're regularly getting query times measured in microseconds versus seconds, so it's working pretty well now.
The x86 processor and the faster storage (without the power dropout issues) have really improved the experience. Especially with reading comic books.
If I haven't explained it before, the way the CBZ reader works is that it sends a file list from the archive to the browser, the browser requests an image, and the server extracts the image data into RAM, base64 encodes it, and sends it back to the browser. It's a process that is bottlenecked by both CPU and storage speeds, so it's noticeably snappier on the new machine, even if the CPU is over a decade old at this point.
I'm actually considering taking a crack at forking mozilla's pdf.js to work a similar way, sending a page of data at a time, to decrease transfer times and allow lower memory devices to open large PDFs without having to actually download the whole thing. I suspect that means I'm going to have to build smaller single page PDF files on the fly, which would mean coming up with some kind of solution for in document links. I'm still in the phase of deciding if it's enough of a problem to put effort into solving, so I haven't done enough research to know if it will be easy or difficult. It's always hard to tell in situations like this because just about every web reader project assumes downloading the whole file, and the question is do they do it this way because it's hard to sub-divide the format, or do they do it because full clientside logic can be demoed on github pages.
3 notes
·
View notes
Text
Odoo Data Files Tutorial: Add Records via XML
Odoo Data Files tutorial: Learn how to add record data through XML, incorporate Many2one relationships, and encode binary data with Base64. Follow our step-by-step guide. #Odoo #XML #Many2one
In this tutorial, we start with Odoo Data Files and Add records data through XML by exploring how to implement Many2one – base64 Data Types in your projects. We explain every step and show you how to use XML to create records efficiently with active instructions and clear examples. You will learn to implement the key concepts, and we use practical code snippets to walk you through the process…
0 notes
Text
Games Production (Feb 5th)
An Overview
This week was about consolidating everything I did last week, getting the assets I was waiting for, and improving Star In The Making (the game) and Workflow Toolkit (the Unity Plugin/Tool Project).
Star In The Making
The person I'm commissioning finally managed to get back to me - and gave me the songs; I had to ask a friend who knows a lot about mixing to touch up one or two of the songs to ensure all of the volumes matched, as one of them was louder than the rest. I now have 4 out of the 5 total songs for this project (and OST I will release on SoundCloud, Bandcamp and Spotify as a part of my Post-Production Module)
The tracklist is supposed to tell a story for this game.
Here are all of the songs! Feel free to listen to them (and give your feedback!)
Tracklist (could be changed):
Celestial Prelude
Star In The Making
Into The void
VOID (Cosmic Echoes?)
I am very proud of this so far. The final song hasn't been commissioned yet, but will be the star leaving the void, and entering a new world.
Balance Changes
I made some balance changes for Star In The Making as I felt the game took too long.
Normalisation Factor: 12,500 -> 10,000 (leading to faster games)
Difficulty Factor: 0.55 -> 0.65 (black holes grow more with less points)
Minimum Pull Radius: 0.5 -> 0.6 (black holes start with a little bit of power)
Here's a visual difference in growth - measuring from 0 points to 500.
Before

After

More features to come, like my planned pick-ups.
Workflow Toolkit
I managed to get all translations for English, Spanish and Dutch, and consolidated them all on my Localisation Sheet - a good way to express this data (and I will be able to script and auto-export in the future)

These have been added to the toolkit itself and are now fully compatible with these three languages.
I managed to talk to my cousin (who is Portuguese), and she thankfully agreed to translate these strings into Portuguese (EU); I will have to wait for week three to get all of them, though.
I also fixed one or two issues with the Workflow Toolkit (UI bugs regarding localisation).
Due to security concerns, I also reworked the previous "BUG REPORTING" and "FEEDBACK" pages for the Workflow Toolkit; I felt that having discord hard-coded webhooks in your project is unsafe and looks unprofessional. I opted to have a Google Sheets feedback page for both.
Before
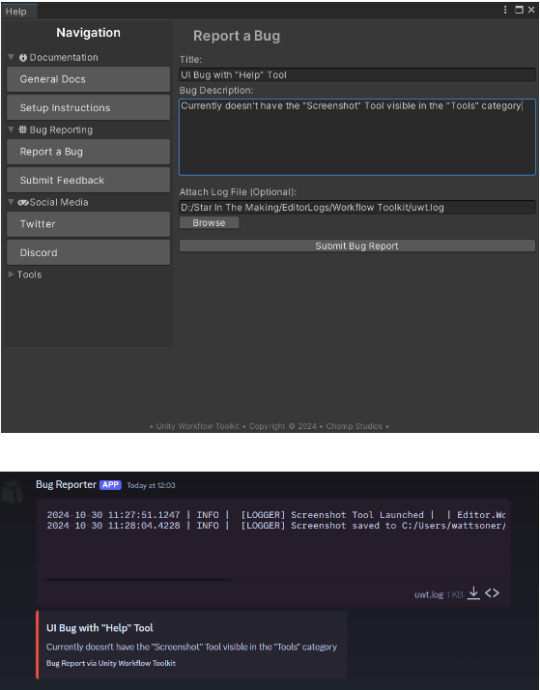

After



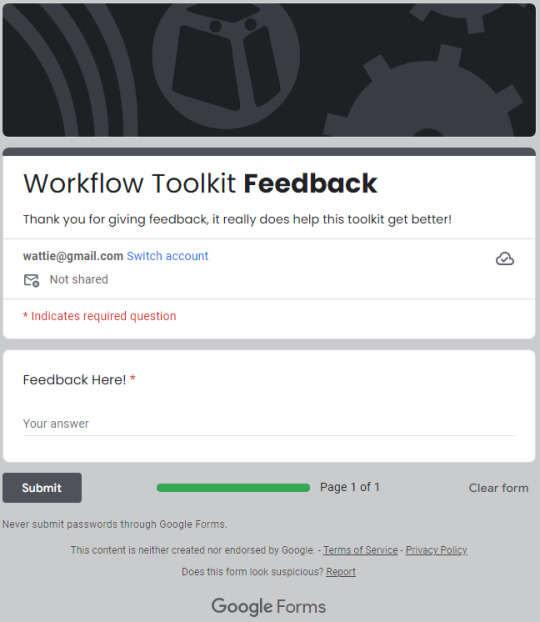
Unfortunately, I lost the ability to upload log files, but I feel like this is far more professional.
Note, This modification was started during the last week of last semester, but I have fully finished it here.
Website
I also fixed countless issues with the website for both mobile and PC viewing - here's a before (left) and after (right):


I also converted the base64 encoded SVG background and put it as an actual file, which greatly optimises the project.


I also removed some unused CSS.
Some other improvements were backend optimisation for both the website and the project.
QuickBlock
I used Rider's built-in tools to refactor and re-format the code; I did not do much else on this project this week due to focusing on wrapping up the other two projects.
================================================
Performance Evaluation
[ I consolidated last week's work very nicely, getting integral assets created and polished (mixing and mastering for songs). I am quite proud of this, as I have something to listen to and share with the world.
I am also proud with my improvements to the website, The changes I made won't bring new people, or be stunning for the user, but the optimised website allows it to just run faster, and more efficiently - making them more professional. ]
[ I can tell that I am struggling with project prioritisation, QuickBlock has been taking a backseat for a while, which does indicate that next week, I need to push the project further, even if it is just a tiny bit, as I don't want this project to be sidelined, and my focus diluted. ]
I am happy with this week's work overall though, I pushed Workflow Toolkit quite far with the improvements, and Star In The Making's soundtrack will open up some new doors (like potentially putting these songs on Spotify, Soundcloud and/or Bandcamp)
================================================
Action Plan
Next week, I need to focus on bringing up QuickBlock to a respectable place, even if I don't do much on the project, something needs to be done, and ideas that were discussed in the Game Design Document will need to be planned and researched as I don't want this project falling even further than it already is.
I need to also continue refining the website's UI to something I'm happy with, potentially adding a custom .404 error page to make sure users are able to navigate back to the website if they type something wrong.
GitHub Pages (the hoster I'm using) has it's own .404 error page, but it is quite "boring".

I will also ensure that if signs of burnout appear, I will sort them out first, by diverting attention from hard, important tasks, to less critical, but more "fun" tasks.
================================================
0 notes