#benchmarks
Text







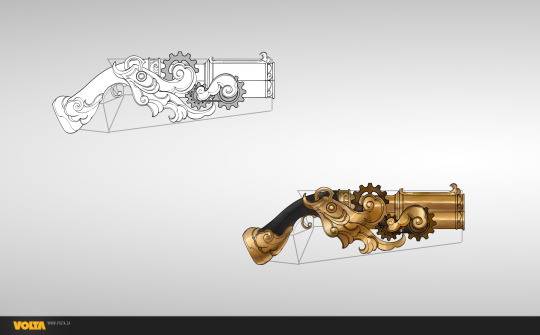
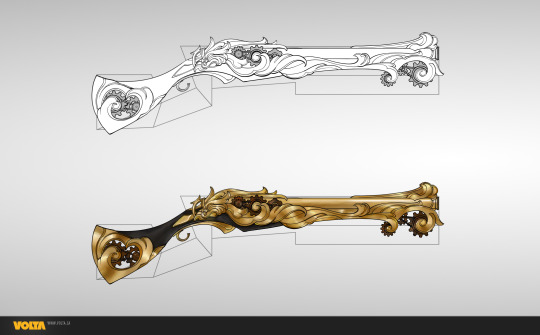








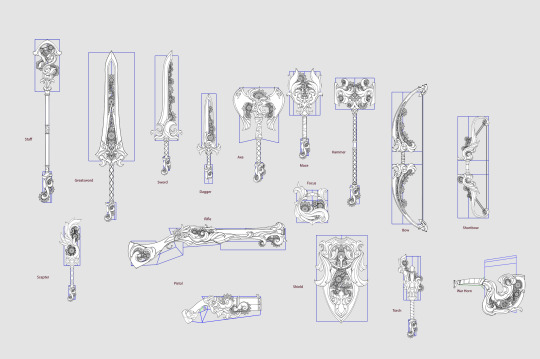
Sweet, I can post up to 30 images in one post now! (that is a lot)
BEHOLD: The clockwork weapons set, which I believe landed last year during the queens gambit events. As well as the Zephyrite Festival.
The prompt was centered around having fancy clockwork surrounded by craftsman like framing. The gears move on the weapons too!
Shown with permission. (c) ArenaNet, all rights reserved. Thank you for the opportunity with Volta to make such a fun set.
62 notes
·
View notes
Text






You guys I love her so much. I was so excited for the graphics update and when I spawned into character creator and saw her (her eyes!!!!! So pretty!!!) I literally cried, from joy! Then I continued to cry as I watched the benchmark and saw her with all the new environments and details and… Just *WOW.* She’s missing her hat (Matoya’s Hat) that she never takes off. But that can be a surprise for launch I suppose!!
I feel for the people who aren’t happy with their characters, I do, but these changes really brought Loran to life and I am *so* excited to see her in her proper attire, come 7.0!
It’s full speed ahead on *this* hype train! I am gonna be trying to make it through a full NG+ playthrough and enjoying the events as they come and go until June 28th!! (And probably popping back into the Benchmark to see my future girl on occasion!)
See you all in Dawntrail everyone!!! 💜✨
#ffxiv#final fantasy 14#ff14#ffxiv dawntrail#dawntrail#benchmarks#FFXIV benchmark#dawntrail benchmark
8 notes
·
View notes
Text

Greetings, everyone! I'd like to introduce the updated Athena! For a while, Athena's author has been treating her as half Miqo'te, half Hrothgar. They have done a lot of work to get the character to be a bit more in line with their mental image of Athena.
Now, that image is crystal clear.
Say hello again to Athena Natlho, daughter of a Hrothgar and Miqo'te, this time taking much more after her father.


Of note, we will not be changing any of the past screenshots, stories, or posts, but we will use this version of the character moving forward.
Stay tuned in Dawntrail for more cool screenshots of all the girls together again, and thanks for staying tuned this far.
<3
#ffxiv#ffxiv roleplay#ffxiv oc#ff14#final fantasy 14#ffxiv rp#gpose#gposers#ff14 gpose#ffxiv gpose#Athena Natlho#original character#final fantasy gpose#final fantasy xiv#final#dawntrail#ffxiv benchmark#benchmarks#hrothgar#hrothgal#hrothgirl#female hrothgar#fem hrothgar
13 notes
·
View notes
Text

Hellsguard women are one of the biggest losers of the graphical update. The nose spot was a charm point, and it looks like they tried to wipe it off with a washcloth
#ffxiv#ffxiv roegadyn#roegadame#roegadyn#final fantasy xiv#final fantasy 14#benchmarks#benchmark#ffxiv benchmark#dawntrail#ffxiv dawntrail
6 notes
·
View notes
Text
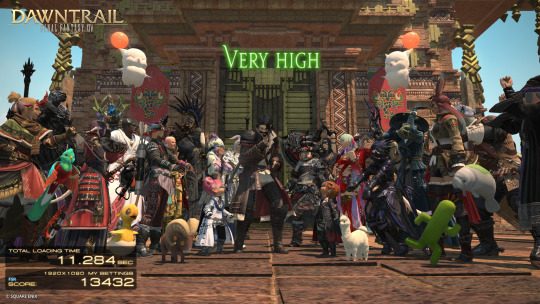
So uh
I think SE's min requirements for Dawntrail might have been a tiny bit overzealous
2 notes
·
View notes
Text
Google’s Multimodal AI Gemini – A Technical Deep Dive
New Post has been published on https://thedigitalinsider.com/googles-multimodal-ai-gemini-a-technical-deep-dive/
Google’s Multimodal AI Gemini – A Technical Deep Dive
Sundar Pichai, Google’s CEO, along with Demis Hassabis from Google DeepMind, have introduced Gemini in December 2023. This new large language model is integrated across Google’s vast array of products, offering improvements that ripple through services and tools used by millions.
Gemini, Google’s advanced multimodal AI, is birthed from the collaborative efforts of the unified DeepMind and Brain AI labs. Gemini stands on the shoulders of its predecessors, promising to deliver a more interconnected and intelligent suite of applications.
The announcement of Google Gemini, nestled closely after the debut of Bard, Duet AI, and the PaLM 2 LLM, marks a clear intention from Google to not only compete but lead in the AI revolution.
Contrary to any notions of an AI winter, the launch of Gemini suggests a thriving AI spring, teeming with potential and growth. As we reflect on a year since the emergence of ChatGPT, which itself was a groundbreaking moment for AI, Google’s move indicates that the industry’s expansion is far from over; in fact, it may just be picking up pace.
What is Gemini?
Google’s Gemini model is capable of processing diverse data types such as text, images, audio, and video. It comes in three versions—Ultra, Pro, and Nano—each tailored for specific applications, from complex reasoning to on-device use. Ultra excels in multifaceted tasks and will be available on Bard Advanced, while Pro offers a balance of performance and resource efficiency, already integrated into Bard for text prompts. Nano, optimized for on-device deployment, comes in two sizes and features hardware optimizations like 4-bit quantization for offline use in devices like the Pixel 8 Pro.
Gemini’s architecture is unique in its native multimodal output capability, using discrete image tokens for image generation and integrating audio features from the Universal Speech Model for nuanced audio understanding. Its ability to handle video data as sequential images, interweaved with text or audio inputs, exemplifies its multimodal prowess.
Gemini supports sequences of text, image, audio, and video as inputs
Accessing Gemini
Gemini 1.0 is rolling out across Google’s ecosystem, including Bard, which now benefits from the refined capabilities of Gemini Pro. Google has also integrated Gemini into its Search, Ads, and Duet services, enhancing user experience with faster, more accurate responses.
For those keen on harnessing the capabilities of Gemini, Google AI Studio and Google Cloud Vertex offer access to Gemini Pro, with the latter providing greater customization and security features.
To experience the enhanced capabilities of Bard powered by Gemini Pro, users can take the following straightforward steps:
Navigate to Bard: Open your preferred web browser and go to the Bard website.
Secure Login: Access the service by signing in with your Google account, assuring a seamless and secure experience.
Interactive Chat: You can now use Bard, where Gemini Pro’s advanced features can be opted.
Power of Multimodality:
At its core, Gemini utilizes a transformer-based architecture, similar to those employed in successful NLP models like GPT-3. However, Gemini’s uniqueness lies in its ability to process and integrate information from multiple modalities, including text, images, and code. This is achieved through a novel technique called cross-modal attention, which allows the model to learn relationships and dependencies between different types of data.
Here’s a breakdown of Gemini’s key components:
Multimodal Encoder: This module processes the input data from each modality (e.g., text, image) independently, extracting relevant features and generating individual representations.
Cross-modal Attention Network: This network is the heart of Gemini. It allows the model to learn relationships and dependencies between the different representations, enabling them to “talk” to each other and enrich their understanding.
Multimodal Decoder: This module utilizes the enriched representations generated by the cross-modal attention network to perform various tasks, such as image captioning, text-to-image generation, and code generation.
Gemini model isn’t just about understanding text or images—it’s about integrating different kinds of information in a way that’s much closer to how we, as humans, perceive the world. For instance, Gemini can look at a sequence of images and determine the logical or spatial order of objects within them. It can also analyze the design features of objects to make judgments, such as which of two cars has a more aerodynamic shape.
But Gemini’s talents go beyond just visual understanding. It can turn a set of instructions into code, creating practical tools like a countdown timer that not only functions as directed but also includes creative elements, such as motivational emojis, to enhance user interaction. This indicates an ability to handle tasks that require a blend of creativity and functionality—skills that are often considered distinctly human.
Gemini’s capabilities : Spatial Reasoning (Source)
Gemini’s capabilities extend to executing programming tasks(Source)
Gemini sophisticated design is based on a rich history of neural network research and leverages Google’s cutting-edge TPU technology for training. Gemini Ultra, in particular, has set new benchmarks in various AI domains, showcasing remarkable performance lifts in multimodal reasoning tasks.
With its ability to parse through and understand complex data, Gemini offers solutions for real-world applications, especially in education. It can analyze and correct solutions to problems, like in physics, by understanding handwritten notes and providing accurate mathematical typesetting. Such capabilities suggest a future where AI assists in educational settings, offering students and educators advanced tools for learning and problem-solving.
Gemini’s has been leveraged to create agents like AlphaCode 2, which excels at competitive programming problems. This showcases Gemini’s potential to act as a generalist AI, capable of handling complex, multi-step problems.
Gemini Nano brings the power of AI to everyday devices, maintaining impressive abilities in tasks like summarization and reading comprehension, as well as coding and STEM-related challenges. These smaller models are fine-tuned to offer high-quality AI functionalities on lower-memory devices, making advanced AI more accessible than ever.
The development of Gemini involved innovations in training algorithms and infrastructure, using Google’s latest TPUs. This allowed for efficient scaling and robust training processes, ensuring that even the smallest models deliver exceptional performance.
The training dataset for Gemini is as diverse as its capabilities, including web documents, books, code, images, audio, and videos. This multimodal and multilingual dataset ensures that Gemini models can understand and process a wide variety of content types effectively.
Gemini and GPT-4
Despite the emergence of other models, the question on everyone’s mind is how Google’s Gemini stacks up against OpenAI’s GPT-4, the industry’s benchmark for new LLMs. Google’s data suggest that while GPT-4 may excel in commonsense reasoning tasks, Gemini Ultra has the upper hand in almost every other area.
Gemini VS GPT-4
The above benchmarking table shows the impressive performance of Google’s Gemini AI across a variety of tasks. Notably, Gemini Ultra has achieved remarkable results in the MMLU benchmark with 90.04% accuracy, indicating its superior understanding in multiple-choice questions across 57 subjects.
In the GSM8K, which assesses grade-school math questions, Gemini Ultra scores 94.4%, showcasing its advanced arithmetic processing skills. In coding benchmarks, with Gemini Ultra attaining a score of 74.4% in the HumanEval for Python code generation, indicating its strong programming language comprehension.
The DROP benchmark, which tests reading comprehension, sees Gemini Ultra again leading with an 82.4% score. Meanwhile, in a common-sense reasoning test, HellaSwag, Gemini Ultra performs admirably, though it does not surpass the extremely high benchmark set by GPT-4.
Conclusion
Gemini’s unique architecture, powered by Google’s cutting-edge technology, positions it as a formidable player in the AI arena, challenging existing benchmarks set by models like GPT-4. Its versions—Ultra, Pro, and Nano—each cater to specific needs, from complex reasoning tasks to efficient on-device applications, showcasing Google’s commitment to making advanced AI accessible across various platforms and devices.
The integration of Gemini into Google’s ecosystem, from Bard to Google Cloud Vertex, highlights its potential to enhance user experiences across a spectrum of services. It promises not only to refine existing applications but also to open new avenues for AI-driven solutions, whether in personalized assistance, creative endeavors, or business analytics.
As we look ahead, the continuous advancements in AI models like Gemini underscore the importance of ongoing research and development. The challenges of training such sophisticated models and ensuring their ethical and responsible use remain at the forefront of discussion.
#2023#ai#Algorithms#Analytics#applications#architecture#Artificial Intelligence#audio#bard#benchmarks#Books#Brain#browser#Business#business analytics#Cars#CEO#chatGPT#Cloud#code#coding#collaborative#Competitive Programming#comprehension#continuous#creativity#cutting#data#december#DeepMind
2 notes
·
View notes
Photo
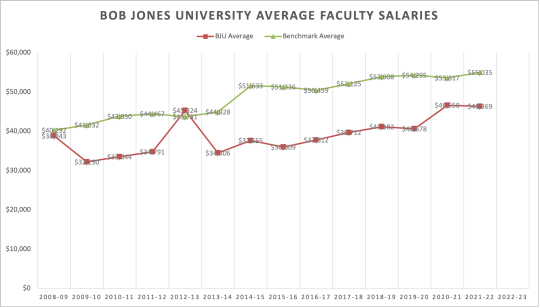
So taking the BJU faculty salary average and comparing it to their benchmarks, you can see that there was a bump for 2020-21, but then things leveled out.
#Bob Jones University#Financial Crisis#Charts and Graphs#Revenue#Expenses#990s#501c3#IPEDS#Salary#Benchmarks#Faculty
1 note
·
View note
Video
youtube
iPhone 14 Plus & The Problem with Benchmarks
The iPhone 14 Plus is here. But let's talk about something else...
2 notes
·
View notes
Text


Ģ̷̧̻̙̮̣̗̺̞̖̟̙͎̫̒ I̴̡̡̝͔̼̗̼̟̥̣͍̙̯͒̒̄̍̒̄͆̚͜͝ V̴̢̛̤̬͔̤͙̖͙͇͔̺̫̬͎͈̱̆̃̈́̐̌̔̐̈̽͜ Ê̷̳͍̗̩̪̯̘̯̣̮̥̤͙̱̟̜͗́̍̊͗̊́̉̈́̈́̓̇̀͘͝͝ ̸̧̜͚̱͔̺̗̠̤̼͍̼̳̽͛̏̀́̾̉̍͛̓̕͝M̵̧̨͇̝͔͔͍̟̫̗̦͒̂͋̇̾̌͐ Ȩ̷̪̯̼͐̈͋̏̈́̐̀͝ ̸̡͙͚̺̤̳́ Ḅ̵̘̲͇͙̳̀̃ À̴̡̨͈̲͔̤̝͚̻̬͕͕̘̪̳̺̽͂ͅ C̷̢̛̟̯̱̩̖̖̝̓̉͛̏̒̈́̉͑̽͂̌͝ Ķ̷̳̠͔̥̟̥͚̭͖͓̻̿̀̐̐̿̂̅͑̃͋͋́̀́͘͘͜͝ͅ ̴̢̨̛͉̪̲͇̮̺̝̼͕̩̬̱M̸̉͊̋͋̔̆̆̊͛̉̕͝��̧̥͔͍̘̦̞̻̯̮̼̗̻̫̊͆͜͜ Ỳ̶̢̨̝̭̼͕̹̭̻̮̥͚̳̳̳̑͑͜͠ ̶̢̮͙̬̭̥̫͈͉̥͖̖̰͋̈́̇̾̅̌͂̓̕͘͜Ę̵̰̈̽̇͗͐͐͝ Y̸̧̧̨̲̩̣̗̏͆̏ Ẽ̸̡̨̛̛̜̖͔̿̅̄͋͐̉͒̀͛͝͠͝ B̶̧̨̢̝͍̗̖̱̺͚̝̼̣̬̪͊̈́̋̾̀̀̎̏̊͑̈̋͆͑͋ͅ Ą̵̳͍̥͇̪̀͛̈́̃̍̂̀͗̄̑̀͝ L̷͓̙͖͇̪͇̤͔̓̆̾̾̿̎̌͋̉̾̐͂̕͜͝ L̶̲͇͚̇͑̈́̈́ S̴̨̮̪͔͉̦͖̹̞̯͍̭̎̏́͠ͅ
0 notes
Text
Benchmark Hydroponics: Your Premier Hydroponic Equipment Supplier
Benchmark Hydroponics take pride in being Australia's premier hydroponic equipment supplier. Shop online our store today.

Address: 676 Warrigal Rd, South Oakleigh VIC 3167, Australia.
Phone: 03 9570 8213
Website: https://benchmarkhydroponics.com.au/
Email: [email protected]
Don't miss out on the amazing information about hydroponics in Australia by following Benchmark Hydroponics.
https://folkd.com/profile/benchmarkhydroponics
1 note
·
View note
Text


Doubt I'll post many of these, but here's a side-by-side of current settings in current patch, vs current settings in the benchmark.
#ffxiv#ff14#final fantasy 14#gpose#carmen weaver#dawntrail#benchmarks#final fantasy xiv#FFXIV benchmark
7 notes
·
View notes
Text
DIY developer builds 3D printed cat TV with Raspberry Pi 5
New Post has been published on https://petn.ws/lJd59
DIY developer builds 3D printed cat TV with Raspberry Pi 5
Ever wanted to give your cat a dedicated TV for entertainment? Becky Stern has made it easier to make one by yourself. The DIY maker and developer created a feline-friendly television powered by the popular Raspberry Pi 5 SBC. At the core, the project is a tiny computer setup designed to loop cat-friendly YouTube videos […]
See full article at https://petn.ws/lJd59
#CatsNews #3DPrinted, #Benchmarks, #Cat, #CatTv, #Diy, #GraphicsCard, #Laptop, #Netbook, #Notebook, #Pi5, #Processor, #Project, #Raspberry, #RaspberryPi, #Reports, #Review, #Reviews, #Test, #Tests, #Tv
#3d-printed#benchmarks#cat#cat tv#diy#graphics card#laptop#netbook#notebook#Pi 5#processor#project#raspberry#Raspberry Pi#reports#review:#reviews#test#tests#tv#Cats News
0 notes
Text
Qualcomm Chip Closes in on Apple M3 Performance: Leaked Test

A leaked set of performance benchmarks for Qualcomm’s Snapdragon X Elite Arm chip reveals a narrowing of the performance gap with Apple’s top-of-the-line M3 silicon.
https://jpmellojr.blogspot.com/2024/02/qualcomm-chip-closes-in-on-apple-m3.html
0 notes
Text
AI leaderboards are no longer useful. It's time to switch to Pareto curves.
New Post has been published on https://thedigitalinsider.com/ai-leaderboards-are-no-longer-useful-its-time-to-switch-to-pareto-curves/
AI leaderboards are no longer useful. It's time to switch to Pareto curves.

By Sayash Kapoor, Benedikt Stroebl, Arvind Narayanan
Which is the most accurate AI system for generating code? Surprisingly, there isn’t currently a good way to answer questions like these.
Based on HumanEval, a widely used benchmark for code generation, the most accurate publicly available system is LDB (short for LLM debugger). But there’s a catch. The most accurate generative AI systems, including LDB, tend to be agents, which repeatedly invoke language models like GPT-4. That means they can be orders of magnitude more costly to run than the models themselves (which are already pretty costly). If we eke out a 2% accuracy improvement for 100x the cost, is that really better?
In this post, we argue that:
AI agent accuracy measurements that don’t control for cost aren’t useful.
Pareto curves can help visualize the accuracy-cost tradeoff.
Current state-of-the-art agent architectures are complex and costly but no more accurate than extremely simple baseline agents that cost 50x less in some cases.
Proxies for cost such as parameter count are misleading if the goal is to identify the best system for a given task. We should directly measure dollar costs instead.
Published agent evaluations are difficult to reproduce because of a lack of standardization and questionable, undocumented evaluation methods in some cases.
LLMs are stochastic. Simply calling a model many times and outputting the most common answer can increase accuracy.
On some tasks, there is seemingly no limit to the amount of inference compute that can improve accuracy. Google Deepmind’s AlphaCode, which improved accuracy on automated coding evaluations, showed that this trend holds even when calling LLMs millions of times.
The accuracy of AlphaCode on coding tasks continues to improve even after making a million calls to the underlying model (the different curves represent varying parameter counts). Accuracy is measured by how often one of the top 10 answers generated by the model is correct.
A useful evaluation of agents must therefore ask: What did it cost? If we don’t do cost-controlled comparisons, it will encourage researchers to develop extremely costly agents just to claim they topped the leaderboard.
In fact, when we evaluate agents that have been proposed in the last year for solving coding tasks, we find that visualizing the tradeoff between cost and accuracy yields surprising insights.
We re-evaluated the accuracy of three agents that have been claimed to occupy top spots on the HumanEval leaderboard: LDB, LATS, and Reflexion. We also evaluated the cost and time requirements of running these agents.
These agents rely on running the code generated by the model, and if it fails the test cases provided with the problem description, they try to debug the code, look at alternative paths in the code generation process, or “reflect” on why the model’s outputs were incorrect before generating another solution.
In addition, we calculated the accuracy, cost, and running time of a few simple baselines:
GPT-3.5 and GPT-4 models (zero shot; no agent architecture)
Retry: We repeatedly invoke a model with the temperature set to zero, up to five times, if it fails the test cases provided with the problem description. Retrying makes sense because LLMs aren’t deterministic even at temperature zero.
Warming: This is the same as the retry strategy, but we gradually increase the temperature of the underlying model with each run, from 0 to 0.5. This increases the stochasticity of the model and, we hope, increases the likelihood that at least one of the retries will succeed.
Escalation: We start with a cheap model (Llama-3 8B) and escalate to more expensive models (GPT-3.5, Llama-3 70B, GPT-4) if we encounter a test case failure.
Surprisingly, we are not aware of any papers that compare their proposed agent architectures with any of the latter three simple baselines.
Our most striking result is that agent architectures for HumanEval do not outperform our simpler baselines despite costing more. In fact, agents differ drastically in terms of cost: for substantially similar accuracy, the cost can differ by almost two orders of magnitude! Yet, the cost of running these agents isn’t a top-line metric reported in any of these papers.
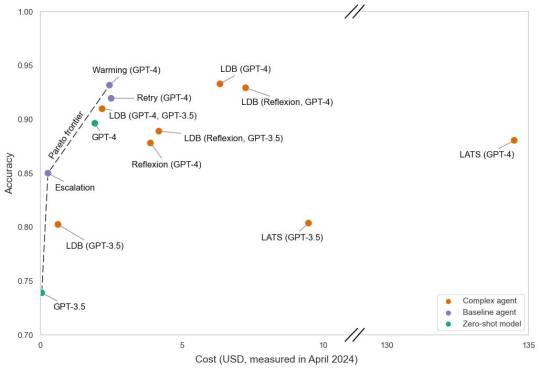
Our simple baselines offer Pareto improvements over existing agent architectures. We run each agent five times and report the mean accuracy and the mean total cost on the 164 HumanEval problems. Where results for LDB have two models/agents in parenthesis, they indicate the language model or agent used to generate the code, followed by the language model used to debug the code. Where they have just one, they indicate that the same model was used to both generate the code and debug it. Note that the y-axis is shown from 0.7 to 1; figures with the full axis (0 to 1) and error bars, robustness checks, and other details about our empirical results are included in the appendix.
There is no significant accuracy difference between the warming strategy and the best-performing agent architecture. Yet, Reflexion and LDB cost over 50% more than the warming strategy, and LATS over 50 times more (all these costs are entirely or predominantly from calls to GPT-4, so these ratios will be stable even if model costs change). Meanwhile, the escalation strategy strictly improves accuracy while costing less than half of LDB (GPT-3.5) at current inference prices.
Our results point to another underlying problem: papers making claims about the usefulness of agents have so far failed to test if simple agent baselines can lead to similar accuracy. This has led to widespread beliefs among AI researchers that complex ideas like planning, reflection, and debugging are responsible for accuracy gains. In fact, Lipton and Steinhardt noted a trend in the AI literature of failing to identify the sources of empirical gains back in 2018.
Based on our findings, the question of whether debugging, reflection, and other such “System 2” approaches are useful for code generation remains open. It is possible that they will be useful on harder programming tasks than those represented in HumanEval. For now, the over-optimism about System 2 approaches is exacerbated by a lack of reproducibility and standardization that we report below.
At first glance, reporting dollar costs is jarring. It breaks many properties of benchmarking that we take for granted: that measurements don’t change over time (whereas costs tend to come down) and that different models compete on a level playing field (whereas some developers may benefit from economies of scale, leading to lower inference costs). Because of this, researchers usually pick a different axis for the Pareto curve, such as parameter count.
The downsides of reporting costs are real, but we describe below how they can be mitigated. More importantly, we think using attributes like parameter count as a proxy for cost is a mistake and doesn’t solve the problem it’s intended to solve. To understand why, we need to introduce a conceptual distinction.
AI evaluations serve at least two distinct purposes. Model developers and AI researchers use them to identify which changes to the training data and architecture improve accuracy. We call this model evaluation. And downstream developers, such as programmers who use AI to build consumer-facing products, use evaluations to decide which AI systems to use in their products. We call this downstream evaluation.
The difference between model evaluation and downstream evaluation is underappreciated. This has led to much confusion about how to factor in the cost of running AI.
Model evaluation is a scientific question of interest to researchers. So it makes sense to stay away from dollar costs for the aforementioned reasons. Instead, controlling for compute is a reasonable approach: if we normalize the amount of compute used to train a model, we can then understand if factors like architectural changes or changes in the data composition are responsible for improvements, as opposed to more compute. Notably, Nathan Lambert argues that many of the accuracy gains in the last year (such as Meta’s Llama 2) are simply consequences of using more compute.
On the other hand, downstream evaluation is an engineering question that helps inform a procurement decision. Here, cost is the actual construct of interest. The downsides of cost measurement aren’t downsides at all; they are exactly what’s needed. Inference costs do come down over time, and that greatly matters to downstream developers. It is unnecessary and counterproductive for the evaluation to stay frozen in time.
In this context, proxies for cost (such as the number of active parameters or amount of compute used) are misleading. For example, Mistral released the figure below alongside their latest model, Mixtral 8x22B, to explain why developers should choose it over competitors.

Substituting active parameters as a proxy for cost is misleading. Source: Mistral.
In this figure, the number of active parameters is a poor proxy for cost. On Anyscale, Mixtral 8x7B costs twice as much as Llama 2 13B, yet Mistral’s figure shows it costs about the same, because they only consider the number of active parameters. Of course, downstream developers don’t care about the number of active parameters when they’re using an API. They simply care about the dollar cost relative to accuracy. Mistral chose “active parameters” as a proxy, presumably because it makes their models look better than dense models such as Meta’s Llama and Cohere’s Command R+. If we start using proxies for cost, every model developer can pick a proxy that makes their model look good.
Some hurdles to cost evaluation remain. Different providers can charge different amounts for the same model, the cost of an API call might change overnight, and cost might vary based on model developer decisions, such as whether bulk API calls are charged differently. These downsides can be partly addressed by making the evaluation results customizable using mechanisms to adjust the cost of running models, i.e., providing users the option to adjust the cost of input and output tokens for their provider of choice to recalculate the tradeoff between cost and accuracy. In turn, downstream evaluations of agents should include input/output token counts in addition to dollar costs, so that anyone looking at the evaluation in the future can instantly recalculate the cost using current prices.
But ultimately, despite the hurdles, good measurement requires modeling the underlying construct of interest. For downstream evaluations, that underlying construct is cost. All other proxies are lacking.
In the course of our evaluation, we found many shortcomings in the reproducibility and standardization of agent evaluations.
We were unable to reproduce the results of the LATS and LDB agents on HumanEval. In particular, across all 5 runs for LDB (Reflexion, GPT-3.5), the maximum accuracy was 91.5%, much lower than the 95.1% reported in the paper. The maximum accuracy of LATS across all five runs was similarly lower, at 91.5% instead of 94.4%.
Similarly, the accuracy for the baseline GPT-4 model reported in the LDB paper is drastically lower than our reproduction of the paper’s code (75.0% vs. a mean of 89.6% across five runs). In fact, according to the paper, the GPT-3.5 and GPT-4 models perform very similarly (73.9% vs. 75.0%). Weak baselines could give a false sense of the amount of improvement attributable to the agent architecture.
The LATS agent was evaluated on only a subset of the test cases provided in the HumanEval benchmark. This exaggerated their accuracy numbers, since the code for a particular HumanEval problem might be incorrect, but if it passes only a portion of the test cases for that problem, it could still be marked as correct. In our analysis, this was responsible for a 3% difference in accuracy (mean across five runs), which explains a substantial part of the difference between the accuracy we found and the one reported in the paper. In addition, many details about the implementation, such as hyperparameter values, were not reported in the paper or GitHub repository (see appendix for details).
To the best of our knowledge, this post is the first time the four agents with the highest accuracy—Retry, Warming, LDB (GPT-4), and LDB (GPT-4 + Reflexion)—have been tested on HumanEval.
Reflexion, LDB, and LATS all use different subsets of HumanEval. Three (out of 164) coding problems in the original version of HumanEval lack example tests. Since these agents require example tests to debug or rerun their solutions, Reflexion removes the three problems that don’t have example tests. LATS removes these three problems, plus another problem, for unreported reasons. LDB adds example tests for the three problems that are missing in the original benchmark. None of the three papers reports this. The paper introducing LATS claims (incorrectly): “We use all 164 problems for our experiments.” In our analysis, we conducted all evaluations on the version of the benchmark provided by LDB, since it contains example tests for all problems.
The LDB paper claims to use GPT-3.5 for code generation using Reflexion: “For Reflexion, we select the version based on GPT-3.5 and utilize the corresponding generated programs published in the official Github repository.” However, the generated program they used from the Reflexion repository relies on GPT-4 for code generation, not GPT-3.5.
These shortcomings in the empirical results have also led to errors of interpretation in broader discussions around the accuracy of AI agents. For example, a recent post by Andrew Ng claimed that agents that use GPT-3.5 can outperform GPT-4. In particular, he claimed:
[For HumanEval,] GPT-3.5 (zero shot) was 48.1% correct. GPT-4 (zero shot) does better at 67.0%. However, the improvement from GPT-3.5 to GPT-4 is dwarfed by incorporating an iterative agent workflow. Indeed, wrapped in an agent loop, GPT-3.5 achieves up to 95.1%.
While this claim received a lot of attention, it is incorrect. The claim (“GPT-3.5 wrapped in an agent workflow achieves 95.1% accuracy”) seems to be about the LDB agent. The Papers With Code leaderboard for HumanEval makes the same claim. However, as we discussed above, for LDB, GPT-3.5 is only used to find bugs. The code is generated using GPT-4 (or the Reflexion agent that uses GPT-4), not GPT-3.5. Unfortunately, the error in the paper has led to much overoptimism about agents in the broader AI community.
Ng’s post also makes the familiar error of repeating results from papers without verifying them or accounting for changes in prompts and model versions. For example, the zero-shot accuracy numbers of GPT-3.5 (48.1%) and GPT-4 (67.0%) seem to be copied from the GPT-4 technical report from March 2023. However, the models have been updated many times since release. Indeed, in our comparison, we find that the base models perform much better compared to the claimed figures in Ng’s post when we use them with the prompts provided with the LDB paper (GPT-3.5: 73.9%, GPT-4: 89.6%). As a result, the post drastically overestimates the improvement attributable to agent architectures.
Evaluation frameworks like Stanford’s HELM and EleutherAI’s LM Evaluation Harness attempt to fix similar shortcomings for model evaluations, by providing standardized evaluation results. We are working on solutions to make agent evaluations standardized and reproducible, especially from the perspective of downstream evaluation of agents.
Finally, downstream developers should keep in mind that HumanEval or any other standardized benchmark is nothing more than a rough proxy for the specific tasks that arise in a particular downstream application. To understand how agents will perform in practice, it is necessary to evaluate them on a custom dataset from the domain of interest — or even better, A/B test different agents in the production environment.
Zaharia et al. observe that state-of-the-art accuracy on AI benchmarks is often attained by composite systems. If the adoption of agents continues, visualizing cost and accuracy as a Pareto curve would become even more necessary.
Santhanam et al. point out the importance of evaluating cost alongside accuracy for information retrieval benchmarks.
Ozrmazabal et al. highlight the accuracy vs. cost per output token tradeoffs for various models (but not agents) on MMLU. While the cost of output tokens might not be a good indicator of the overall cost, given the varying input token costs as well as output lengths for different models, it is better than not reporting the tradeoffs at all.
The Berkeley Function Calling leaderboard includes various metrics for language model evaluations of function calling, including cost and latency.
Xie et al. develop OSWorld, a benchmark for evaluating agents in computer environments. In their GitHub repository (though not in the paper), they give a rough cost estimate for running various multimodal agents on their benchmark.
Unsurprisingly, the main impetus for cost vs. accuracy tradeoffs has come from the downstream developers who use AI.
In a previous talk, we discussed three major pitfalls in LLM evaluation: prompt sensitivity, construct validity, and contamination. The current research is largely orthogonal: prompt sensitivity isn’t a concern for agent evaluation (as agents are allowed to define their own prompts); downstream developers can address contamination and construct validity by evaluating on custom datasets.
The code for reproducing our analysis is available here. The appendix includes more details about our setup and results.
We thank Rishi Bommasani, Rumman Chowdhury, Percy Liang, Shayne Longpre, Yifan Mai, Nitya Nadgir, Matt Salganik, Hailey Schoelkopf, Zachary Siegel, and Venia Veselovsky for discussions and inputs that informed our analysis. We acknowledge Cunxiang Wang and Ruoxi Ning for their prompt responses to our questions about the NovelQA benchmark.
We are grateful to the authors of the papers we engage with in this post for their quick responses and for sharing their code, which makes such reproduction analysis possible in the first place. In particular, we are grateful to Zilong Wang (LDB), Andy Zhou (LATS), and Karthik Narasimhan (Reflexion), who gave us feedback in response to an earlier draft of this blog post.
#000#2023#8x22b#accounting#agent#agents#ai#ai agent#AI AGENTS#AI systems#Analysis#API#approach#architecture#Art#attention#benchmark#benchmarking#benchmarks#Best Of#Blog#bugs#change#code#code generation#coding#command#Community#comparison#Composition
0 notes
Text


my machine was mid when it was built on a budget in Q4 2018, but the venerable 580 is a trooper. I run it on mostly medium settings and it gets ~45fps average. Capped at 60, it tops out in much of the game, especially the act 1 dungeons. Lows are in the 30s in the city of Baldur's Gate itself.
see my full specs: Euripides at PCpartpicker
0 notes

Last Seen Blogs

geminiresearch
Abed Nadir

toshiibaa
Toshiiba@

gtfodaria2
Daria Rae Berenato

pharmmedexpert
www.pharmmedexpert.com

poefanatic97
Poefanatic97