#Competitive Programming
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
25. 01. 2024.
man my acc j got recognised by a schoolmate of mine… oops
this morning i had a talk in school about how to communicate effectively to get what i want. it was rather interesting and especially entertaining when we got to watch our schoolmates roleplay some of the scenarios hehe
i attempted to revise the classic techniques of competitive programming which included greedy, binary search and sliding window. i’m still unsure on how to apply the sliding window algorithm on problems that don’t specify the window size but i’ll figure it out i hope… the hint provided was to binary search the window size but i’m lost as hell
4h of coding
finally set up my github acc and added a readme file to better document my progress
📖: what’s not to love, emily wibberly
☕️: iced coffee from the school canteen
#studyblr#study motivation#studying#study aesthetic#school#study#high school#study space#gcse#dark academia#light academia#wonyoungism#that girl#chaotic academia#coding#programming#women in tech#c++#competitive programming
23 notes
·
View notes
Text
youtube
I had watched this video in my 4th semester while studying Data Structures and Algorithms, and for some reason I hadn't been able to really appreciate the power of binary representation for this problem.
Coming back to this again in my 6th semester as a part of my Competitive Programming course, I was blown away this time. It is elegant solutions like these that increase my conviction that I love this side of Computer Science: algorithms and mathematics. Do watch if you want to have 14 minutes of cool and simple mathematics.
6 notes
·
View notes
Text
i am writing a competitive programming task in toki pona and there's an edge case if the submitted solution is more optimal than the official solution and i had to write the single greatest error message i've written in my life

#programming#competitive programming#toki pona#kalama musi#jan Usawi#o toki sin#O TOKI SINN MI WILE KUTEEEE JAN PI KULUPU MI LI KUTEEEe
2 notes
·
View notes
Text
Two stars my first time doing Advent of Code. Let us in fact go.
I'll try to edit it and post it for historical preservation, but idk. Nobody is going to read this but I am pretty proud of it. They were pretty easy problems, but at least I learned how to read from files in C++ and not just in python. Yippe Kay Yay
1 note
·
View note
Text
oh my god, i just found out leetcode is a legit and valid tag on tumblr. i am SHOOK. the cs girlie in me is slowly dying
0 notes
Text
Don't Always Follow the Algorithm | A criticism of the recent CS Trends in India
A very personal vent on the current situation.
[TW: It will go a little bit personal] As a programmer for 5 years, I have seen what language or questions people have been obssessing over for the past couple of years. It’s literal simping out there. Interview questions. DSA. And a lot of other stuff are included within this list. As someone who passed JEE, I knew the right path. But it was too. Damn. Hard. Let me give you the context. The…

View On WordPress
0 notes
Text

figure skating set right now please. thanks
#project sekai#pjsk#prsk#emu otori#proseka#tsukasa tenma#nene kusanagi#rui kamishiro#wxs#wonderlands x showtime#GUYS I AM PUTTING OFF WORKING ON MY COSPLAY SOMETHING STUPID. im tireddddd i like sleeepingggff i want to play and drawwwww#after work I literally ate a giant bowl of mac n cheese and climbed into bed. lifestyle choices of a 9 year old#anyways i want figure skaitng set. bad. PJSK HAS A WEIRDLY LOW NUMBER OF ACTUALLY WINTERY SETS... like 3. kind of.#i have some thumbnail sketches but im kind of stumped on composition for them. my idea was a nene focus set#(IF HER NEXT FOCUS ISNT PHANTOM OF THE OPERA THEMED INWILL DIE. BADLY. THEYRE GOING TO AN OPER AHOUSE. PLEADBR)#originally my idea was for nene to be biting a medal i was very sold on it bc i love nenes competitive side#however her outfit is so nice i want it to also be part of the art .. its heavily inspired by that one iconic eunsoo lim dress#from her somewhere in time program iirc. im really undatisfied with emus dress tbh my origimal idea was to give it a phoenix look#but a lot of the firebird/phoenix skating programs have very sleek dresses and i want emus to be fluffy. the balance is hard ..#and since i want her program song to be once upon a dream from sleeping beauty i swerved to make it look a bit like auroras ? but again#it definitely feels like the weakest of everybodys ... maybe i just love her too much and want her to look the best. sorry wxs.#tsukasas outfit is supposed to look like a shooting star. easy. program music moonlight sonata 3rd movement like from dazzling light. easy.#actually i like takahashi daisukes moonlight sonata program its a medley of the 1st and 3rd movement.. i think the calm at the beginning#is best. maybe smth like that.. for his card inhad him doing a haircutter spin but again. the outfits good i want the outfit visible. damn.#ruis the one im very set on even now. girl why are you so phantom of the opera.#it has a lot of beautiful programs to reference but the outfit i didnt really have any solid reference i kind of just balled#my main idea was to make it look a bit like both christine and the phantom.... gender Fluid.#my yapfest... i should be SEWING!!!!!!!!#despite my yapping im not that well versed in figure skating i cant really distinguish jumps i just like it . and medalist#i only do normal skating. bc i played hockey for like 7 years LOLLLL inlove skating though Heart.
2K notes
·
View notes
Text






Midori Ito: Aqua » 2024 ISU Adult Skating Competition
#midori ito#fskateedit#figure skating#isu adult competition 2024#program#her smile ;;;;;#this is love...
573 notes
·
View notes
Text

TRIED DRAWING SIFFRIN FOR THE FIRST TIME!!! FINDING MY STYLE FOR FUTURE ISAT FANART BLAH BLAH!!! NEED TO PRACTISE DRAWING SIF. SIF IS INEVITABLE
#isat#in stars and time#siffrin#artsy lynne things#BRUH this is a binary/pixel-y artwork but it just smoothes out when viewed from afar... Sad#i really wanted to include one where sif is crying... sorry sif...#70% of the time i was like “hmm this sif looks wrong” and the fix was to make their hat bigger unironically#i still dont think ive made the hats big enough tbh#it's so hard to fuse my artstyle with insertdisc5's artstyle... but i know i'm not the only one...#i'm glad ISAT is monochrome. i really struggle with color comprehension so this just means i can pump out more ISAT fanart theoretically...#...without it sticking out too much#or the opposite#without my hypothetical future fanart getting drowned out by mere color competition#i finally started ISAT after playing SASASA;AP 3 years ago... and promptly bingeplayed it within like a week#Not surprising. Just like it's not surprising that I can't stop thinking about ISAT... and Sif...#i wanna do an ISAT animation... ...big words for someone who has little animation experience and like. 0 proper programs for it either#WE BALL!!!!!!!!!!#congratulations ISAT for being the first fanart i draw and finish and post in. months? a year?#ISAT gives you 3 traumas and heals 5#PS: i have no idea why but i one-layer'd this whole thing? which seems unspectacular but#it was really bothersome when doing the shading bits or details#but at that point i was too committed to WE BALL so i just kept it this way throughout
126 notes
·
View notes
Text

some "new" designs for different crassus and pompey, specifically for a side project I've been playing with that's so removed from anything relevant (action/adventure/horror standalone story lmao) that they kind of needed their own thing. this story's pompey has a neck scar from an Incident™, crassus has shorter hair and wears (checks notes) jewelry sometimes.
#graves grime and gore tag#the default designs are still the ''''trikaranos''''' ones because it's nebulously like. eh. grounded enough in rome#this is the dmbj au but it's less dmbj and more like i put on every tomb robber movie on youku and went 'yeah okay'#while i was working. anyway. when i post from that story. i will make it clear that it is a separate contained story doing it's own thing#this version of crassus also more or less has black hair while my main crassus has brown hair#pompey is bottle blond no matter what universe he's in#god what else what else. it's set during their first joint consulship. crassus is more of an outright dick but it's because he's annoyed#that pompey is not getting with the program (you cannot become sulla during peace time!)#and this version of pompey is like a specific imposter syndrome anxiety has been cranked up to eleven and it's made him#overly competitive in stupid ways like the thing you think crassus is doing does not matter to him in the slightest#we gotta establish characterizations right off the bat and we're swinging big because i am NOT setting up anything prior to Events#like (snaps fingers) go explore the ruins consuls! get in the TOMB FELLAS. KEEP GOING GUYS
219 notes
·
View notes
Text




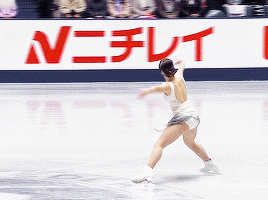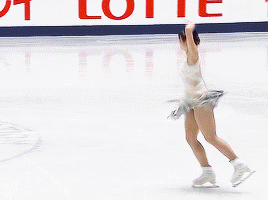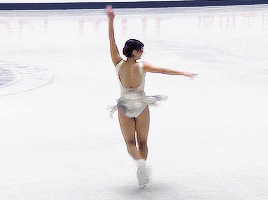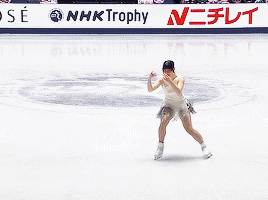



Alysa Liu, Promise • NHK Trophy 2024
#alysa liu#figure skating#fskateedit#nhk trophy 2024#nhk 2024#what a gorgeous program#i havent talked about it much but i did read some of her interviews about her return to competition#and they really resonated with me. just what it means to love something you've 'always' done#and what it means to rediscover things that defined you on your own terms. made me think about my own life a little#anyways i hope she's enjoying the season so far!! i know i'm really glad to see her back :)
154 notes
·
View notes
Text




Sara Conti / Niccolò Macii - Run the World (Girls) at 2025 World Team Trophy gala
#sara conti#niccolo macii#conti macii#competition#season: 2024 2025#wtt 2025#cm program: run the world girls#pairs#pics#figure skating#gala
59 notes
·
View notes
Text
The Sequence Radar #554 : The New DeepSeek R1-0528 is Very Impressive
New Post has been published on https://thedigitalinsider.com/the-sequence-radar-554-the-new-deepseek-r1-0528-is-very-impressive/
The Sequence Radar #554 : The New DeepSeek R1-0528 is Very Impressive
The new model excels at math and reasoning.
Created Using GPT-4o
Next Week in The Sequence:
In our series about evals, we discuss multiturn benchmarks. The engineering section dives into the amazing Anthropic Circuits for ML interpretability. In research, we discuss some of UC Berkeley’s recent work in LLM reasoning. Our opinion section dives into the state of AI interpretablity.
You can subscribe to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: The New DeepSeek R1-0528 is Very Impressive
This week, DeepSeek AI pushed the boundaries of open-source language modeling with the release of DeepSeek R1-0528. Building on the foundation of the original R1 release, this update delivers notable gains in mathematical reasoning, code generation, and long-context understanding. With improvements derived from enhanced optimization and post-training fine-tuning, R1-0528 marks a critical step toward closing the performance gap between open models and their proprietary counterparts like GPT-4 and Gemini 1.5.
At its core, DeepSeek R1-0528 preserves the powerful 672B Mixture-of-Experts (MoE) architecture, activating 37B parameters per forward pass. This architecture delivers high-capacity performance while optimizing for efficiency, especially in inference settings. One standout feature is its support for 64K-token context windows, enabling the model to engage with substantially larger inputs—ideal for technical documents, structured reasoning chains, and multi-step planning.
In terms of capability uplift, the model shows remarkable progress in competitive benchmarks. On AIME 2025, DeepSeek R1-0528 jumped from 70% to an impressive 87.5%, showcasing an increasingly sophisticated ability to tackle complex mathematical problems. This leap highlights not just better fine-tuning, but a fundamental improvement in reasoning depth—an essential metric for models serving scientific, technical, and educational use cases.
For software engineering and development workflows, R1-0528 brings meaningful updates. Accuracy on LiveCodeBench rose from 63.5% to 73.3%, confirming improvements in structured code synthesis. The inclusion of JSON-formatted outputs and native function calling support positions the model as a strong candidate for integration into automated pipelines, copilots, and tool-augmented environments where structured outputs are non-negotiable.
To ensure broad accessibility, DeepSeek also launched a distilled variant: R1-0528-Qwen3-8B. Despite its smaller footprint, this model surpasses Qwen3-8B on AIME 2024 by over 10%, while rivaling much larger competitors like Qwen3-235B-thinking. This reflects DeepSeek’s commitment to democratizing frontier performance, enabling developers and researchers with constrained compute resources to access state-of-the-art capabilities.
DeepSeek R1-0528 is more than just a model upgrade—it’s a statement. In an ecosystem increasingly dominated by closed systems, DeepSeek continues to advance the case for open, high-performance AI. By combining transparent research practices, scalable deployment options, and world-class performance, R1-0528 signals a future where cutting-edge AI remains accessible to the entire community—not just a privileged few.
Join Me for a Chat About AI Evals and Benchmarks:
🔎 AI Research
FLEX-Judge: THINK ONCE, JUDGE ANYWHERE
Lab: KAIST AI Summary: FLEX-Judge is a reasoning-first multimodal evaluator trained on just 1K text-only explanations, achieving zero-shot generalization across images, audio, video, and molecular tasks while outperforming larger commercial models. Leverages textual reasoning alone to train a judge model that generalizes across modalities without modality-specific supervision.
Learning to Reason without External Rewards
Lab: UC Berkeley & Yale University Summary: INTUITOR introduces a novel self-supervised reinforcement learning framework using self-certainty as intrinsic reward, matching supervised methods on math and outperforming them on code generation without any external feedback. The technique proposes self-certainty as an effective intrinsic reward signal for reinforcement learning, replacing gold labels.
Beyond Markovian: Reflective Exploration via Bayes-Adaptive RL for LLM Reasoning
AI Lab: Google DeepMind & Northwestern University Summary: This paper introduces BARL, a novel Bayes-Adaptive RL algorithm that enables large language models to perform test-time reflective reasoning by switching strategies based on posterior beliefs over MDPs. The authors show that BARL significantly outperforms Markovian RL approaches in math reasoning tasks by improving token efficiency and adaptive exploration.
rStar-Coder: Scaling Competitive Code Reasoning with a Large-Scale Verified Dataset
AI Lab: Microsoft Research Asia Summary: The authors present rStar-Coder, a dataset of 418K competitive programming problems and 580K verified long-reasoning code solutions, which drastically boosts the performance of Qwen models on code reasoning benchmarks. Their pipeline introduces a robust input-output test case synthesis method and mutual-verification mechanism, achieving state-of-the-art performance even with smaller models.
MME-Reasoning: A Comprehensive Benchmark for Logical Reasoning in MLLMs
AI Lab: Fudan University, CUHK MMLab, Shanghai AI Lab Summary: MME-Reasoning offers a benchmark of 1,188 multimodal reasoning tasks spanning inductive, deductive, and abductive logic, revealing significant limitations in current MLLMs’ logical reasoning. The benchmark includes multiple question types and rigorous metadata annotations, exposing reasoning gaps especially in abductive tasks.
DeepResearchGym: A Free, Transparent, and Reproducible Evaluation Sandbox for Deep Research
AI Lab: Carnegie Mellon University, NOVA LINCS, INESC-ID Summary: DeepResearchGym is an open-source sandbox providing reproducible search APIs and evaluation protocols over ClueWeb22 and FineWeb for benchmarking deep research agents. It supports scalable dense retrieval and long-form response evaluation using LLM-as-a-judge assessments across dimensions like relevance and factual grounding.
Fine-Tuning Large Language Models with User-Level Differential Privacy
AI Lab: Google Research Summary: This study compares two scalable user-level differential privacy methods (ELS and ULS) for LLM fine-tuning, with a novel privacy accountant that tightens DP guarantees for ELS. Experiments show that ULS generally offers better utility under large compute budgets or strong privacy settings, while maintaining scalability to hundreds of millions of parameters and users.
🤖 AI Tech Releases
DeepSeek-R1-0528
DeeSeek released a new version of its marquee R1 model.
Anthropic Circuits
Anthropic open sourced its circuit interpretability technology.
Perplexity Labs
Perplexity released a new tool that can generate charts, spreadsheets and dashboards.
Codestral Embed
Mistral released Codestral Embed, an embedding model specialized in coding.
🛠 AI in Production
Multi-Task Learning at Netflix
Netflix shared some details about its multi-task prediction strategy for user intent.
📡AI Radar
Salesforce agreed to buy Informatica for $8 billion.
xAI and Telegram partnered to enable Grok for its users.
Netflix’s Reed Hastings joined Anthropic’s board of directors.
Grammarly raised $1 billion to accelerate sales and acquisitions.
Spott raises $3.2 million for an AI-native recruiting firm.
Buildots $45 million for its AI for construction platform.
Context raised $11 million to power an AI-native office suite.
Rillet raised $25 million to enable AI for mid market accounting.
HuggingFace unveiled two new open source robots.
#2024#2025#Accessibility#accounting#acquisitions#agents#ai#algorithm#amazing#amp#anthropic#APIs#architecture#Art#audio#benchmark#benchmarking#benchmarks#billion#board#budgets#Building#Buildots#Carnegie Mellon University#charts#code#code generation#coding#Community#Competitive Programming
0 notes
Text
after getting rejected from 3 schools in a row due to lack of federal funding i got accepted to the masters program version of my top choice, but it’s fully unfunded and i don’t have 80k to pay for it… it’s soooo cool and exciting and i’m so sad i can’t go
#:(#i’m still happy though because at least this really awesome competitive program saw something in me#but also so sad i can’t actually go lol
79 notes
·
View notes
Text
Apparently I have been waitlisted for admission at one of the PhD programs I applied to?? Which isn't an acceptance yet, obviously, but it's not a rejection either, and also speaks to my application being pretty decent, actually.
It sounds like it's a matter of not being sure if there will be space in my specific area of focus, so we'll see what comes of it, but. Send good vibes, I guess!
#i am just glad that the vibe continues to be 'my application was fine actually; grad programs are just competitive'#because even if i don't get in this round knowing i have a decent application for resubmission is really good information to have#i am.... also not sure about the livability re: the stipend offered by this school vs cost of living in the area but. we'll see#if i get in i'll have numbers to crunch and if i don't i won't#but also. if i start asking a lot of questions about the vibes in a certain part of california..... give me a hand....
86 notes
·
View notes
Text








Sofia Samodelkina (KAZ): Libertango | 2025 Four Continents Championships, SP
now representing kazakhstan, sofia samodelkina makes a stunning 4CC debut! 💃🏻
#figure skating#sofia samodelkina#fskateedit#4cc 2025#my gifs#this is a big improvement from that first competition of the season!!#actually surprised by how much i like this program#the closeups by the cameraman are also rly great so thanks for that#look at those muscles she looks so strong#so glad she's doing well
52 notes
·
View notes