#bitext
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has a low social media market share in South America.
Text
Text Analytics Market Size, Share, Analysis, Forecast, and Growth Trends to 2032: Regulatory Compliance and Risk Management Boost Market Relevance

The Text Analytics Market size was recorded at USD 9.55 billion in 2023 and is expected to reach USD 41.2 billion in 2032, growing at a CAGR of 17.65% Over the Forecast Period of 2024-2032.
The text analytics market is experiencing robust growth as organizations increasingly rely on data-driven insights for competitive advantage. Fueled by the explosion of unstructured data across digital platforms, businesses are rapidly adopting text analytics tools to decode consumer behavior, streamline operations, and enhance strategic planning. The demand for real-time sentiment analysis, customer feedback evaluation, and content classification is redefining decision-making processes across industries.
Text Analytics Market Enterprises are harnessing the power of artificial intelligence and natural language processing to extract value from textual content, fueling the expansion of the text analytics market. From social media listening to risk management, these solutions are enabling brands to uncover hidden trends and anticipate market shifts. The shift towards cloud-based analytics platforms is further propelling adoption, offering scalability and real-time access to insights.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/3868
Market Keyplayers:
Microsoft Corporation
Luminoso Technologies, Inc.
HP Enterprise
IBM Corporation
Knime.Com AG
RapidMiner, Inc.
SAS Institute, Inc.
OpenText Corporation
Indium Software
Bitext Innovations S.L.
Infegy, Inc.
Brandwatch
Lexalytics, Inc.
Netbase Solutions
Clarabridge
SAP SE
Megaputer Intelligence, Inc.
Market Analysis The global text analytics market is expanding rapidly, driven by the convergence of big data and machine learning. Organizations across sectors—such as retail, BFSI, healthcare, and telecom—are implementing text analytics to derive actionable intelligence from customer interactions, product reviews, and support tickets. The integration of text analytics with CRM and business intelligence tools is becoming a game changer for customer-centric strategies.
Vendors are focusing on innovation, offering domain-specific solutions and user-friendly dashboards, which enhance usability for non-technical users. As data privacy regulations tighten, demand for secure and compliant analytics platforms is also influencing purchasing decisions.
Market Trends
Integration of AI and NLP for contextual and semantic analysis
Surge in cloud-based analytics deployments
Rising demand for multilingual text processing
Growing focus on customer experience management
Expansion of predictive analytics in social media and e-commerce
Use of voice-of-customer analytics to drive personalization
Increasing adoption of text analytics in fraud detection and compliance
Market Scope
Versatile Applications: Text analytics is empowering industries from retail to healthcare by delivering insights across customer service, risk management, and competitive intelligence.
Multilingual Capability: Growing global business operations drive the need for language-agnostic analysis tools.
Scalability and Speed: Modern platforms offer real-time processing and flexible cloud deployment to accommodate diverse enterprise needs.
Regulatory Compliance: Enhanced features now support data governance and compliance with global privacy laws.
User Accessibility: Easy-to-use interfaces enable professionals across functions—not just data scientists—to leverage analytics.
The dynamic scope of the text analytics market reflects its pivotal role in modern business ecosystems. As digital communication expands, the ability to analyze and interpret text data is no longer a luxury but a strategic necessity.
Market Forecast The future of the text analytics market is marked by continuous innovation and widespread integration across enterprise workflows. With evolving AI capabilities and the growing emphasis on customer-centric strategies, organizations will continue to invest in smarter, faster, and more accurate analytics platforms. The proliferation of connected devices and digital channels will only increase the volume of unstructured data, necessitating advanced tools that can deliver real-time, actionable insights. As a result, text analytics is set to become an indispensable element in shaping responsive, data-informed organizations across the globe.
Access Complete Report: https://www.snsinsider.com/reports/text-analytics-market-3868
Conclusion As businesses strive to stay agile in a data-saturated world, the text analytics market stands at the forefront of digital transformation. Its ability to decode vast volumes of text into strategic intelligence is not just revolutionizing how companies operate but also how they engage with their customers.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#Text Analytics Market#Text Analytics Market Scope#Text Analytics Market Size#Text Analytics Market Trends
0 notes
Text
Text Analytics Market Size, Share, Scope, Analysis, Forecast, Growth Factors, and Industry Report 2032
The Text Analytics Market size was recorded at USD 9.55 billion in 2023 and is expected to reach USD 41.2 billion in 2032, growing at a CAGR of 17.65% Over the Forecast Period of 2024-2032.
The Text Analytics Market is experiencing significant growth, driven by the increasing volume of unstructured data and advancements in artificial intelligence (AI) and machine learning (ML). This growth is being fueled by the need for businesses to extract actionable insights from vast amounts of textual data across industries like healthcare, finance, and retail. The market’s ability to transform complex text into valuable information is revolutionizing how businesses operate.
Text Analytics Market is expanding rapidly as organizations seek to leverage data-driven insights to enhance decision-making processes. With more businesses adopting text analytics tools, the demand for such solutions has been steadily rising. These tools enable organizations to analyze customer feedback, social media posts, reviews, and more, offering a deeper understanding of market trends and consumer behavior.
Get Sample Copy of This Report: https://www.snsinsider.com/sample-request/3868
Market Keyplayers:
Bitext Innovations S.L.,
Infegy, Inc.
Brandwatch
Lexalytics, Inc.
Netbase Solutions
Clarabridge
SAP SE
Megaputer Intelligence, Inc.
Trends in the Text Analytics Market
Integration of AI and Machine Learning: The adoption of AI and ML is enhancing the accuracy and efficiency of text analytics platforms, enabling more precise sentiment analysis, topic extraction, and predictive analytics.
Cloud-Based Solutions: With the shift toward cloud computing, many text analytics tools are being deployed on cloud platforms, providing scalability, cost-effectiveness, and flexibility.
Growth in Social Media Analytics: As social media continues to be a major communication channel, businesses are increasingly turning to text analytics to monitor brand sentiment and manage customer engagement.
Real-Time Data Processing: The ability to process and analyze data in real-time is a significant trend, allowing businesses to make immediate, informed decisions based on customer interactions and feedback.
Enquiry of This Report: https://www.snsinsider.com/enquiry/3868
Market Segmentation:
By Component
software
Services
By Enterprise Size
SMEs
Large Enterprises
By Application
Competitive Intelligence
Customer Relationship management
Predictive Analytics
Fraud detection
Risk Management
Social Media Analysis
Workforce management
Document management
Market Analysis The Text Analytics Market is projected to grow substantially over the coming years, driven by technological advancements and the increased importance of data-driven strategies. Large-scale enterprises, as well as small and medium-sized businesses (SMBs), are investing in text analytics to improve customer experiences, gain insights into market trends, and optimize business operations. The rise of automated customer service and chatbots is also contributing to this demand. Additionally, as the world becomes more digitally connected, the volume of textual data being generated is increasing exponentially, providing ample opportunities for text analytics to be integrated across various sectors.
Future Prospects Looking ahead, the Text Analytics Market is expected to continue expanding, particularly with advancements in natural language processing (NLP) and deep learning. The growing importance of predictive analytics and sentiment analysis will also drive the demand for sophisticated text analytics tools. Moreover, industries like healthcare and finance, which deal with vast amounts of unstructured data, are likely to see significant benefits from these technologies. The future of text analytics lies in its ability to understand context, tone, and intent, providing businesses with more accurate and actionable insights.
Access Complete Report: https://www.snsinsider.com/reports/text-analytics-market-3868
Conclusion In conclusion, the Text Analytics Market is poised for substantial growth, supported by technological innovation and the increasing need for organizations to process and understand unstructured data. As businesses across industries continue to recognize the value of text analytics, the market is expected to thrive in the coming years. With the integration of AI, ML, and NLP technologies, the ability to extract meaningful insights from text data will only improve, enabling businesses to stay competitive and customer-centric in an increasingly data-driven world.
About Us:
SNS Insider is one of the leading market research and consulting agencies that dominates the market research industry globally. Our company's aim is to give clients the knowledge they require in order to function in changing circumstances. In order to give you current, accurate market data, consumer insights, and opinions so that you can make decisions with confidence, we employ a variety of techniques, including surveys, video talks, and focus groups around the world.
Contact Us:
Jagney Dave - Vice President of Client Engagement
Phone: +1-315 636 4242 (US) | +44- 20 3290 5010 (UK)
#Text Analytics Market#Text Analytics Market AnalysisText Analytics Market Scope#Text Analytics Market Growth
0 notes
Text
✨GIRLS ARE CUTE✨
💞and religion shouldn’t come between me and them.💞
#wlw#wlwpostivity#wlwpost#wlwtextpost#wlwpride#bipride#bitext#bitextpost#bi#lesbian#lesbianpride#lesbiantext#lesbiantextpost#lesbianpositivity#lgbtq
13 notes
·
View notes
Text
Neural Machine Translation

For centuries people have been dreaming of easier communication with foreigners. The idea to teach computers to translate human languages is probably as old as computers themselves. The first attempts to build such technology go back to the 1950s. However, the first decade of research failed to produce satisfactory results, and the idea of machine translation was forgotten until the late 1990s. At that time, the internet portal AltaVista launched a free online translation service called Babelfish — a system that became a forefather for a large family of similar services, including Google Translate. At present, modern machine translation system rely on Machine Learning and Deep Learning techniques to improve the output and probably tackle the issues of understanding context, tone, language registers and informal expressions.
The techniques that were used until recently, including by Google Translate, were mainly statistical. Although quite effective for related languages, they tended to perform worse for languages from different families. The problem lies in the fact that they break down sentences into individual words or phrases and can span across only several words at a time while generating translations. Therefore, if languages have different words orderings, this method results in an awkward sequence of chunks of text.
Turn to Neural Networks
Recent application of neural networks provides more accurate and fluent translations that would take into account the entire context of the source sentence and everything generated so far. Neural machine translation is typically a neural network with an encoder/decoder architecture. Generally speaking, the encoder infers a continuous space representation of the source sentence and the decoder is a neural language model conditioned on the encoder output. To maximize the likelihood of the source and the target sentences, the parameters of both models are learned jointly from a parallel corpus (Sutskever et al., 2014; Cho et al., 2014). At inference, a target sentence is generated by left-to-right decoding.
Neural Network Advantages
Dealing with Unknown Words
Due to natural differences between languages, a word from a source sentence often has no direct translation in the target vocabulary. In this case, a neural system generates a placeholder for the unknown word with the help of the soft alignment between the source and the target enabled by the attention mechanism. Afterwards the translation can be looked up in a bilingual lexicon built from the training data to allow for typos, abbreviations and slips of the tongue — a problem that was not fully resolved by traditional statistical approaches.

Tuning model parameters
Neural networks have tunable parameters to control things like the learning rate of the model. Finding the optimal set of hyperparameters can boost performance, but such parameters can be different for each model and each machine translation project. Therefore, in practice However, this presents a significant challenge for machine translation at scale, since each translation direction is represented by a unique model with its own set of hyperparameters. Since the optimal values may be different for each model, we had to tune them for each system in production separately.
Less data
Typically, neural machine translation models calculate a probability distribution over all the words in the target vocabulary, which increases the calculation time drastically. However, for low-resource languages, it is possible to develop bi- or multilingual systems on related languages for parameter transfer, using linguistic features of the surface word form, and achieving direct zero-shot translation
Types of Neural Networks for Machine Translation
There are a number of approaches that use different neural architectures, including recurrent networks (Sutskever et al., 2014; Bahdanau et al., 2015; Luong et al., 2015), convolutional networks (Kalchbrenner et al., 2016; Gehring et al., 2017; Kaiser et al., 2017) and transformer networks (Vaswani et al., 2017).
The state-of-the-art, though, is attention mechanisms where the encoder produces a sequence of vectors and the decoder attends to the most relevant part of the source through a context-dependent weighted-sum of the encoder vectors (Bahdanau et al., 2015; Luong et al., 2015).
Sequence-to-Sequence LSTM with Attention
One of the most promising algorithms in this sense is the recurrent neural network known as sequence-to-sequence LSTM (long short-term memory) with attention.
Sequence-to-Sequence (or Seq2Seq) models are very useful for translation tasks, as in their essence, they take a sequence of words from one language and transform it into a sequence of different words in another language. Sentences are intrinsically sequence-dependent since the order of the words is crucial for rendering the meaning. LSTM models, in their turn, can give meaning to the sequence by remembering (or forgetting) certain parts. Finally, the attention-mechanism looks at an input sequence and decides which parts of the sequence are important, quite similar to human text perception. When we are reading, we focus on the current word, but at the same time we old in our memory important keywords to build the context and make sense of the whole sentence.
Transformer
Another step forward was the introduction of the Transformer model in the paper ‘Attention Is All You Need’. Similar to LSTM, Transformer translates one sequence into another with the help of Encoder and Decoder, but without any Recurrent Network.
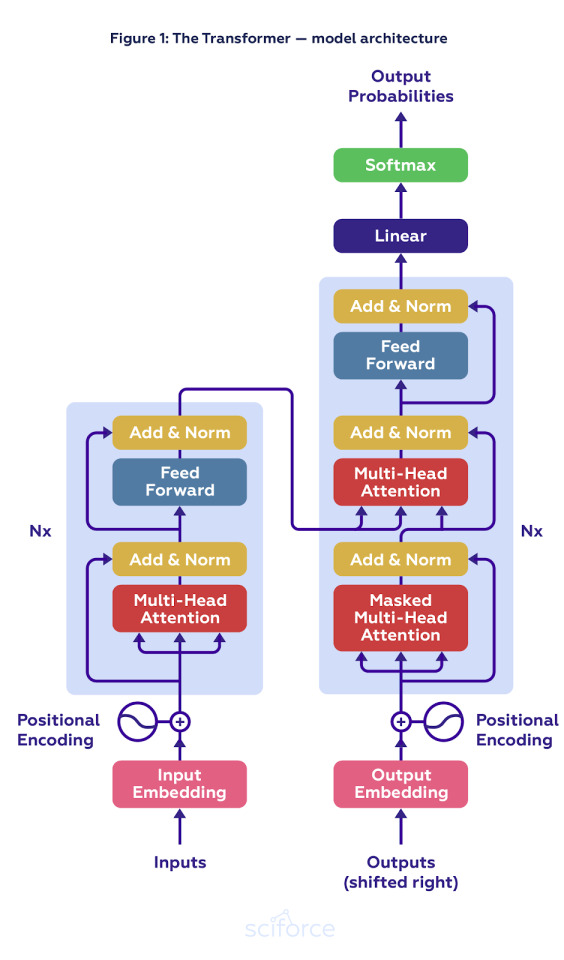
In this figure, the Encoder (on the left) and the Decoder (on the right) are composed of modules that can be stacked on top of each other multiple times and mainly consists of Multi-Head Attention and Feed Forward layers. The inputs and outputs are first embedded into an n-dimensional space.
An important part of the Transformer is the positional encoding of different words. Since it does not have recurrent networks to remember how sequences are fed into a model, it gives every word/part of a sequence a relative position since a sequence depends on the order of its elements. These positions are added to the embedded representation (n-dimensional vector) of each word.
Neural Machine Translation (NMT) achieved significant results in large-scale translation tasks such as from English to French (Luong et al., 2015) and English to German (Jean et al., 2015).
Sciforce Takes Action
Inspired by the results for En-De model by Edunov et al. (2018), we expanded it with back translation. Our final goal was to develop a machine translation system for an En/De news website.
For the task we created a De-En machine translation system based on the Transformer model (Edunov et al., 2018) that was a part of the fairseq toolkit.
As a first step, we tested the performance of the pre-trained EN-DE models on Google Colab. The p1-model is 12gb, split into 6 models of 2gb. We only managed to start 3 of those because of RAM limits, but it still showed excellent results. The second p2-model is 1.9gb and it performed reasonably well, though not as great as p1. At the same time, it is more lightweight and needs less resources to train.
Following the advice of the authors of the reference paper, we used the transformer_wmt_en_de_big architecture to train the back-translation model. The task fell into three modules: De-En translation, De-En translation with back translation, and En-De translation. The internal stages for each module were the same:
Data collection and cleaning
We used two types of corpora for the tasks:
De-En and En-De parallel corpora
English monolingual corpora for news
To collect and clean up the data we used the prepare-wmt14de2en.sh script — a modification of the original prepare-wmt14en2de.sh, using additional datasets and removing duplicates.
cd examples/translations BPE_TOKENS=32764 bash prepare-wmt14en2de.sh
For bilingual data generation, we assumed that all monolingual data was gathered and split into 104 shards and was available for downloading. To get backtranslation data from monolingual shards, we used the script named run_batches.sh. Then we distributed shards translation tasks between GPUs manually. With all shards translated, and all bilingual data gathered, we applied BPE to them, concatenated to the whole dataset, and ran a clean-up script. BPE code file obtained from the bilingual data was reused for all three subtasks.
Preprocessing
For the two De-En tasks, the shell commands and methods used were almost identical to those supplied with the model documentation.
For the En-De task, we reuseв dictionaries supplied with the baseline model with the following shell commands and methods:
$ TEXT=examples/translation/wmt17_de_en $ python preprocess.py --source-lang en --target-lang de \ --trainpref $TEXT/train --validpref $TEXT/valid --testpref $TEXT/test \ --destdir data-bin/wmt17_en_de_joined_dict \ --srcdict data-bin/wmt17_en_de_joined_dict/dict.en.txt \ --tgtdict data-bin/wmt17_en_de_joined_dict/dict.de.txt
Training
For monolingual and bilingual En-De translation tasks, we used shell commands and methods similar to those specified here. To reduce the training time, we tried to use bigger batches and a higher learning rate on 8 GPUs. For this we specified --update-freq 16 and learning rate --lr 0.001. However, training often failed with an error message offering to reduce learning rate or increase batch size. So, we had to reduce learning rate several times during training. Overall training for achieving the best BLEU score should take ~20 hours.
The logic behind training a reverse model was using only parallel data. The target side monolingual data was translated with the mode we trained at stage. Afterwards, we combined available bitext and generated data, preprocessed it with preprocess.py and trained the final model.
Shell commands and methods used:
python train.py data-bin/wmt17_en_de_joined_dict \ --arch transformer_vaswani_wmt_en_de_big --share-all-embeddings \ --optimizer adam --adam-betas ‘(0.9, 0.98)’ --clip-norm 0.0 \ --lr-scheduler inverse_sqrt --warmup-init-lr 1e-07 --warmup-updates 4000 \ --lr 0.0005 --min-lr 1e-09 \ --dropout 0.3 --weight-decay 0.0 --criterion label_smoothed_cross_entropy --label-smoothing 0.1 \ --max-tokens 3584 \ --fp16 --reset-lr-scheduler
The actual command for training may differ from one specified above, however, the key point is specifying --reset-lr-scheduler parameter, otherwise, Fairseq will report an error.
The resulting model scored as high in BLEU-score (~35) as the reference model or even higher. Empirically, it also performed as good as the pre-trained EN-DE model discussed in the reference paper by Edunov et al. (2018).
Besides from the practical side of the task, we proved that the Transformer model used in fairseq for machine translation yields good results and can be quickly expanded to cover other language pairs, which is a valuable feature for similar projects — and a step for neural machine translation to conquer the world.
17 notes
·
View notes
Text
grad school update: i just wanted to learn how to get a job working with The Pokemon Company...what the fuck is bitext? and TM stands for Translation Memory (no idea what that is) and not Technical Machine? bitch i’m going to kill you
30 notes
·
View notes
Text
Text Analytics Market is estimated to exhibit a CAGR of 17.7% with increasing economy and rising online business industry worldwide.
Text Analytics Market research report is a comprehensive examination of the current business environment, including highly useful reviews and strategic assessments, such as profiles and strategies of leading companies, as well as general market trends, emerging technologies, industry drivers, challenges, and regulatory policies that drive market growth.
The competitive landscape of the Text Analytics market is thoroughly examined, with an emphasis on the nature of the market’s competitiveness and anticipated changes in the market’s competitive environment. Raw material sources, distribution networks, techniques, manufacturing capacity, industry supply chain, and product specifications are all included in the report.
Click To get Sample PDF (Including Full TOC, Table & Figures): https://www.coherentmarketinsights.com/insight/request-pdf/833
The global text analytics market was valued at US$ 3,031.5 million in 2016 and is estimated to witness a CAGR of 17.7% over the forecast period. According to Coherent Market Insights, North America held the dominant position in the global text analytics market in 2016, valued US$ 1045 million and is projected to reach US$ 4,237.6 million by 2025, with a CAGR of 16.9% over the forecast period. The U.S. and Canada are the major countries driving growth of the text analytics market in North America region. This is owing to factors such as dominance of digitalization and high presence of leading companies, provides the dominant position to the market in the region. Moreover, Asia Pacific text analytic market is projected to exhibit largest CAGR of 19.1% over the forecast period. India, China, and Japan are some of the major countries which drives the growth of this market in Asia Pacific region. This is due to factors such as increasing economy and rising online business industry, which fuels the text analytics market in the region.
Competitive Scenario:-
SAP SE, International Business Machines Corporation, SAS Institute, Inc., Opentext Corporation, Clarabridge, Inc., Bitext Innovations S.L., Lexalytics, Inc., Megaputer Intelligence, Inc., Luminoso Technologies, Inc., and Knime com AG.
Get More Insightful Information: https://www.coherentmarketinsights.com/insight/request-sample/833
Reasons to Buy the Report:
Learn about the driving factors, affecting the market growth.
Understand where the market opportunities lie.
Compare and evaluate various options affecting the market.
Pick up on the leading market players within the market.
Envision the restrictions and restraints that are likely to hamper the market.
In-depth market segmentation by Type, Application, etc.
Historical, current and projected market size in terms of volume and value
Recent industry trends and developments
Strategies of key players and product offerings
Potential and niche segments/regions exhibiting promising
Breakup by Region:
· North America: (United States, Canada)
· Asia Pacific: (China, Japan, India, South Korea, Australia, Indonesia, Others)
· Europe: (Germany, France, United Kingdom, Italy, Spain, Russia, Others)
· Latin America: (Brazil, Mexico, Others)
· Middle East and Africa
Table of Contents:-
· Chapter 1. Methodology & Sources
· Chapter 2. Executive Summary
· Chapter 3. Key Insights
· Chapter 4. Text Analytics Market Segmentation & Impact Analysis
· Chapter 5. Text Analytics Market by Components Insights & Trends, Revenue (USD Million
· Chapter 6. Text Analytics Market by Application Insights & Trends, Revenue (USD Million)
· Chapter 7. Text Analytics Market by End-Use Insights & Trends, Revenue (USD Million)
· Chapter 8. Text Analytics Market Regional Outlook
· Chapter 9. Competitive Landscape
Go For Interesting Discount Here: https://www.coherentmarketinsights.com/insight/buy-now/833
COVID-19 scenario:-
The COVID-19 pandemic impacted the production of Text Analytics in the first and second quarters of 2020–21.The adoption of new technology in the automotive, food & beverage, and electronics sectors added to the demand for Text Analytics in the third and fourth quarters of 2020. The COVID-19 pandemic impacted many sectors such as transportation and supply chains on a global level. This caused a decline in the manufacturing of robots as well as their demand in the market. The re-initiation of Text Analytics manufacturing businesses is expected in the near future, which will boost the Text Analytics market.
𝐂𝐨𝐧𝐭𝐚𝐜𝐭 𝐮𝐬:- Mr Shah Coherent Market Insights 1001 4th Ave, #3200 Seattle, WA 98154 Phone: US +12067016702 / UK +4402081334027 𝑬𝒎𝒂𝒊𝒍: [email protected]
0 notes
Text
Natural Language Processing (NLP) Market Size, Share With Top Companies, Region Forecast 2021-2027
Natural Language Processing (NLP) Market 2021-2027
A New Market Study, Titled “Natural Language Processing (NLP) Market Upcoming Trends, Growth Drivers and Challenges” has been featured on fusionmarketresearch.
Description
This global study of the Natural Language Processing (NLP) market offers an overview of the existing market trends, drivers, restrictions, and metrics and also offers a viewpoint for important segments. The report also tracks product and services demand growth forecasts for the market. There is also to the study approach a detailed segmental review. A regional study of the global Natural Language Processing (NLP) industry is also carried out in North America, Latin America, Asia-Pacific, Europe, and the Near East & Africa. The report mentions growth parameters in the regional markets along with major players dominating the regional growth.
Request Free Sample Report @ https://www.fusionmarketresearch.com/sample_request/2020-2029-Report-on-Global-Natural-Language-Processing-(NLP)-Market/42249
This report analyses the impact of COVID-19 on this industry. COVID-19 can affect the global market in 3 ways: by directly affecting production and demand, by creating supply chain and market disruption, and by its financial impact on enterprises and financial markets.
This report provides detailed historical analysis of global market for Natural Language Processing (NLP) from 2014-2019, and provides extensive market forecasts from 2020-2029 by region/country and subsectors. It covers the sales volume, price, revenue, gross margin, historical growth and future perspectives in the Natural Language Processing (NLP) market.
Leading players of Natural Language Processing (NLP) including: 3M Linguamatics Amazon AWS Nuance Communications SAS IBM Microsoft Averbis Health Fidelity Dolbey Systems Google Intel Apple Facebook Inbenta Technologies Veritone Narrative Science Bitext Conversica SparkCognition Automated Insights Baidu
Market split by Type, can be divided into: Machine Translation Information Extraction Automatic Summarization Text and Voice Processing Others
Market split by Application, can be divided into: Healthcare and Life Sciences BFSI Retail and eCommerce Manufacturing Telecommunications and IT
Market split by Sales Channel, can be divided into: Direct Channel Distribution Channel
Market segment by Region/Country including: North America (United States, Canada and Mexico) Europe (Germany, UK, France, Italy, Russia and Spain etc.) Asia-Pacific (China, Japan, Korea, India, Australia and Southeast Asia etc.) South America (Brazil, Argentina and Colombia etc.) Middle East & Africa (South Africa, UAE and Saudi Arabia etc.)
Ask Queries @ https://www.fusionmarketresearch.com/enquiry.php/2020-2029-Report-on-Global-Natural-Language-Processing-(NLP)-Market/42249
Table of Contents
Chapter 1 Natural Language Processing (NLP) Market Overview 1.1 Natural Language Processing (NLP) Definition 1.2 Global Natural Language Processing (NLP) Market Size Status and Outlook (2014-2029) 1.3 Global Natural Language Processing (NLP) Market Size Comparison by Region (2014-2029) 1.4 Global Natural Language Processing (NLP) Market Size Comparison by Type (2014-2029) 1.5 Global Natural Language Processing (NLP) Market Size Comparison by Application (2014-2029) 1.6 Global Natural Language Processing (NLP) Market Size Comparison by Sales Channel (2014-2029) 1.7 Natural Language Processing (NLP) Market Dynamics (COVID-19 Impacts) 1.7.1 Market Drivers/Opportunities 1.7.2 Market Challenges/Risks 1.7.3 Market News (Mergers/Acquisitions/Expansion) 1.7.4 COVID-19 Impacts on Current Market 1.7.5 Post-Strategies of COVID-19 Outbreak
Chapter 2 Natural Language Processing (NLP) Market Segment Analysis by Player 2.1 Global Natural Language Processing (NLP) Sales and Market Share by Player (2017-2019) 2.2 Global Natural Language Processing (NLP) Revenue and Market Share by Player (2017-2019) 2.3 Global Natural Language Processing (NLP) Average Price by Player (2017-2019) 2.4 Players Competition Situation & Trends 2.5 Conclusion of Segment by Player
Chapter 3 Natural Language Processing (NLP) Market Segment Analysis by Type 3.1 Global Natural Language Processing (NLP) Market by Type 3.1.1 Machine Translation 3.1.2 Information Extraction 3.1.3 Automatic Summarization 3.1.4 Text and Voice Processing 3.1.5 Others 3.2 Global Natural Language Processing (NLP) Sales and Market Share by Type (2014-2019) 3.3 Global Natural Language Processing (NLP) Revenue and Market Share by Type (2014-2019) 3.4 Global Natural Language Processing (NLP) Average Price by Type (2014-2019) 3.5 Leading Players of Natural Language Processing (NLP) by Type in 2019 3.6 Conclusion of Segment by Type
Chapter 4 Natural Language Processing (NLP) Market Segment Analysis by Application 4.1 Global Natural Language Processing (NLP) Market by Application 4.1.1 Healthcare and Life Sciences 4.1.2 BFSI 4.1.3 Retail and eCommerce 4.1.4 Manufacturing 4.1.5 Telecommunications and IT 4.2 Global Natural Language Processing (NLP) Sales and Market Share by Application (2014-2019) 4.3 Leading Consumers of Natural Language Processing (NLP) by Application in 2019 4.4 Conclusion of Segment by Application
Chapter 5 Natural Language Processing (NLP) Market Segment Analysis by Sales Channel 5.1 Global Natural Language Processing (NLP) Market by Sales Channel 5.1.1 Direct Channel 5.1.2 Distribution Channel 5.2 Global Natural Language Processing (NLP) Sales and Market Share by Sales Channel (2014-2019) 5.3 Leading Distributors/Dealers of Natural Language Processing (NLP) by Sales Channel in 2019 5.4 Conclusion of Segment by Sales Channel
Continue…
ABOUT US :
Fusion Market Research is one of the largest collections of market research reports from numerous publishers. We have a team of industry specialists providing unbiased insights on reports to best meet the requirements of our clients. We offer a comprehensive collection of competitive market research reports from a number of global leaders across industry segments.
CONTACT US
Phone: + (210) 775-2636 (USA) + (91) 853 060 7487
0 notes
Text
Global Text Analytics Market Size 2021-2030 By Top Key Players
The global Text Analytics Market Size research is an intelligence report announced by Absolute Markets Insights. The erudite market study provides insightful data for readers to help them in making informed business decisions. Primary and secondary research methodologies have also been used to discover the correct and applicable data of Text Analytics Market Size. Effective business strategies of key market players and of new startup industries are also studied thoroughly to provide extensive market knowledge. The report makes use of an effective analysis technique such as SWOT and Porter’s five analysis to present its accurate results on the market.
The major key pillars for global Text Analytics Market Size are listed below: Crimson Hexagon, Averbis, Bitext Innovations, S.L., Clarabridge, IBM, Infegy, Inc., KNIME.com AG, Lexalytics, LUMINOSO, MeaningCloud LLC, Megaputer Intelligence, Inc., Microsoft Corporation, OpenText Corp, Oracle, SAP SE, SAS Institute, Inc., TABLEAU SOFTWARE, The Hewlett-Packard Company and TIBCO Software Inc.
The Text Analytics Market Size was valued at US$ 4043.4 Mn in 2020 is expected to reach US$ 8961.3 Mn by 2030.
For more information about this report visit: https://www.absolutemarketsinsights.com/reports/Text-Analytics-Market-2018-2026-107
Text Analytics is a new IT discipline with its foundations in linguistics and data mining. The discipline is used to convert unstructured text data into meaningful data to conduct analysis, provide search facility, assemble feedback, search for client perspectives, analyze opinions, track product audits and entity modeling to enhance and support decision making which depends on certainties. Different linguistic, statistical, and machine learning techniques are used to retrieve information from unstructured data, structure the data and accordingly derive patterns, trends, assess and interpret data. The analysis techniques similarly include lexical analysis, categorization, grouping, pattern recognition, labeling, annotation, data extraction, link, association analysis and visualization. Moreover, text analysts are collaborating with retail and e-commerce enterprises to establish themselves in the market. The development in cloud-based technologies has pushed the demand for adoption in deployment of text analytic solution.
The Text Analytics Market Size is primarily driven by the increase in volume of unstructured data. Text analysis is used to offer a rapid, automated response to the customer, reducing their reliance on call center operators to resolve problems. Adoption of hybrid cloud IT strategies in areas such as internet of things (IoT) is expected to fuel end-user spending on IT-based services. However, Big Data offers various lucrative opportunities for many industries and likewise represents a big risk for many users. This risk emerges from fact that these analytics tools comprise of storing, managing and efficiently analyzing data gathered from possible and available sources. Hence, individuals become widely vulnerable to exposure because of combining and exploring specific behavioral data. Hence, the need for efficient and reliable plaform solution is gaining importance. The industries such as BFSI, ecommerce and retail sectors operate on advanced technologies such as IoT, cloud system and Big Data. The rise in internet technologies among industries that require high data security drives the Text Analytics Market Size.
Global Text Analytics Market Size Segmentation:
By Component
Support and Maintenance
Consulting Services
System Integration and Deployment
By Deployment Model
Cloud
On-Premises
By Organization Size
Small and Medium-sized Enterprises (SMEs)
Large Enterprises
By Application
Customer Experience Management
Document Management
Governance, Risk and Compliance Management
Marketing Management
Workforce Management
Others
By Vertical
Banking, Financial Services, and Insurance (BFSI)
Energy and utilities •Government and defense
Healthcare and life sciences
Manufacturing
Media and entertainment
Retail and Ecommerce
Telecommunications and Information Technology (IT)
Travel and hospitality
By Region
North America
Europe
Asia Pacific
Middle East and Africa
Latin America
Contact Us:
Company: Absolute Markets Insights
Email id: [email protected]
Phone: +91-740-024-2424
Contact Name: Shreyas Tanna
Website: https://www.absolutemarketsinsights.com/
0 notes
Text
Text Analytics Market To Reach US$10.39 Bn By 2028

Global Text Analytics Market was valued US$ 2.95 Bn in 2017 and is estimated to reach US$ 10.39 Bn by 2026 at a CAGR of 17.04%.
Global text analytics market is segmented into component, application, deployment, end user, and region. Based on application, the text analytics market is classified into workforce management, customer experience management, marketing management, documentation management, and risk & compliance management. Customer experience management segment estimated to hold the largest share of the market in the forecast period. In terms of deployment, the text analytics market is divided into on-premise and cloud. Cloud is lead the market in forecast period due to less storage space and reduce maintenance cost.
Rising usage of social media such as Facebook, inclination towards cloud for data storage, ability to manage risk, plan effective marketing for companies, and club fraud will boost the market of text analytics at same time lack of awareness about software handling, high deployment cost, and insecurity act as restrains to the market.
North America is holding the largest share of the market text analytics followed by Europe, Asia Pacific, Latin America, and Middle East & Africa. In North America rising the numbers of text analytics vendors and adoptions of new technologies will boost the market.
Request for Sample with Complete TOC and Figures & Graphs @ https://www.trendsmarketresearch.com/report/sample/10315
Key player’s studies, analyzed, profiled and benchmarked in text analytics market are SAP SE, IBM Corporation, SAS Institute, Inc., OpenText Corporation, Clarabridge, Meghaputer Intelligence, Luminoso Technologies, MeaningCloud LLC, KNIME.com AG, Infegy, Bitext Innovations S.L., Averbis, HP, Jive, Kana, Lexalytics, Listenlogic, Lithium, Netbase solution, Networked insights, Sysomos, Unmetric, Conversation, Confirmit, Averbis, Microsoft, Hewlett-Packard Development Company, L.P., Attensity Inc., TIBCO Software Inc., Tableau Software, and Collective Intellect.
Scope of Global Text Analytics Market:
Global Text Analytics Market, by Component: Software Services
Global Text Analytics Market, by Application: Workforce management Customer experience management Marketing management Documentation management Risk & compliance management
Global Text Analytics Market, by Deployment: Cloud On-premise
Global Text Analytics Market, by End User: Retail & e-commerce Government IT & Telecommunication BFSI Manufacturing Energy & utilities Travel Hospitals Others
Global Text Analytics Market, by Region: North America Europe Asia Pacific Middle East & Africa Latin America
Direct Purchase this Market Research Report Now @ https://www.trendsmarketresearch.com/checkout/10315/Single
Key Players in Global Text Analytics Market: SAP SE IBM Corporation SAS Institute Inc. OpenText Corporation Clarabridge Meghaputer Intelligence Luminoso Technologies MeaningCloud LLC KNIME.com AG Infegy, Bitext Innovations S.L. Averbis, HP Jive Kana Lexalytics Listenlogic Lithium Netbase solution Networked insights Sysomos Unmetric Conversition Confirmit Averbis Microsoft Hewlett-Packard Development Company L.P. Attensity Inc. TIBCO Software Inc. Tableau Software Collective intellect.
Get Discount On The Purchase Of This Report @ https://www.trendsmarketresearch.com/report/discount/10315
0 notes
Text
Text Analytics Market with Growth Trends, Cost Structure, Driving Factors and Future Prospects 2027
Market Summary
Market Research Future (MRFR), in its research study, emphasizes that the Text Analytics Market 2020 is projected to rise exponentially over the review period, ensuring significant market valuation of USD 9 Billion by 2023, and a healthy 17% CAGR over the review period.
Drivers and Restraints
The need for a market for text analytics is increasingly rising on a global platform. The factors fueling the development of the market for text analytics are a growing need for social media analysis, effective brand building and a rapidly increasing big data market. Due to its multidisciplinary application including multiple domains such as e-commerce, IT, telecommunications, government , healthcare, BSFI, and others, the inclination to adopt text analytics drives the global text analytics market largely. Text analytics beneficial aspects such as market research, competitive intelligence, brand-reputation management, customer service and support and others are acting as demand creators for text analytics in the global market.
Get a Free Sample @ https://www.marketresearchfuture.com/sample_request/2989
The omnipresent availability of unstructured data in the form of online news, forums, tweets and others drives the market for text analytics that has competitive advantages for the companies. During the forecast period, the growing demand for actionable insights derived from real-time data analysis that are used in tactical approaches for business growth is projected to propel the expansion of the global text analysis market.
On the other hand, the increasing availability of data analytics software, high costs and lack of awareness among stakeholders as text analytics is an emerging technology that is likely to act as constraints on the global text analysis market.
Segmental Analysis
The text analytics market has been analyzed on the basis of components, deployment, application, and vertical.
Based on component, the text analytics market is bifurcated into software and services. The services segment comprises managed services and professional services.
On the basis of application, the text analytics market is segmented into marketing management, workforce management customer experience management, documentation management, along with risk and compliance management.
Based on deployment, the text analytics market is bifurcated into on-premise and cloud. Given the high-security risks of cloud-based deployment models, the on-premise deployment model is largely adopted by governmental organizations. Whereas the cloud-based deployment model is slated to account for the largest market share in the global text analytics market during the forecast period due to the increasing demand on the global market for cloud-based solutions.
Based on vertical, the global text analytics market is segmented into BSFI, IT and telecommunication, retail and e-commerce, government, manufacturing, travel and hospitality, energy and utilities, and others.
Browse Complete Report @ https://www.marketresearchfuture.com/reports/text-analytics-market-2989
Regional Analysis
The global market geographic overview was conducted in four major regions including Asia Pacific , North America, Europe and the rest of the world. North America is expected to account for the highest market share, it has been noted. Due to the technologically advanced industrial infrastructures and the rapid growth of digital channels such as social media and e-commerce in this area, the North America region dominates the global text analytics market. In comparison, Asia-Pacific is expected to expand at the fastest pace over the forecast period. Owing to the rapid growth of mobile technology and increasing population on social media platforms, North America will witness significant competition from the Europe region during the forecast time period. Owing to the easy adoption of advanced technologies and growing demand for cloud-based solutions in this region, the Europe region stands second in the global text analysis market.
Competitive Analysis
The major market players functioning in the global market as identified by MRFR are IBM Corporation (US), SAP SE (Germany), SAS Institute, Inc. (US), Clarabridge, Inc. (US), OpenText Corporation (Canada), Megaputer Intelligence, Inc. (US), MeaningCloud LLC (US), Luminoso Technologies, Inc. (US), KNIME.com AG (Switzerland), Infegy, Inc. (US), Averbis (Germany), Lexalytics, Inc. (US), Bitext Innovations S.L.(Spain), among others.
Also Read:
https://latestmarketresearchtrends.tumblr.com/post/648342305071398912/deception-technology-market-revenue-growth
https://latestmarketresearchtrends.tumblr.com/post/648343501080231936/zigbee-market-top-players-demands-overview
https://latestmarketresearchtrends.tumblr.com/post/648344333032030208/5g-market-segmentation-applications-dynamics
https://latestglobalresearchreport.wordpress.com/2021/04/14/hr-payroll-software-market-key-players-supply-consumption-demand-growth-application-analysis-and-forecast-to-2027/
https://latestglobalresearchreport.wordpress.com/2021/04/14/clickstream-analytics-market-segmentation-competitive-landscape-and-industry-poised-for-rapid-growth-2027/
About Market Research Future:
At Market Research Future (MRFR), we enable our customers to unravel the complexity of various industries through our Cooked Research Report (CRR), Half-Cooked Research Reports (HCRR), Raw Research Reports (3R), Continuous-Feed Research (CFR), and Market Research & Consulting Services.
MRFR team have supreme objective to provide the optimum quality market research and intelligence services to our clients. Our market research studies by products, services, technologies, applications, end users, and market players for global, regional, and country level market segments, enable our clients to see more, know more, and do more, which help to answer all their most important questions.
Contact:
Market Research Future
+1 646 845 9312
Email: [email protected]
0 notes
Text
Natural Language Processing Market by Component, Type (Statistical, Hybrid), Application (Automatic Summarization, Sentiment Analysis, Risk & Threat Detection), Deployment Mode, Organization Size, Vertical, and Region - Global Forecast to 2026 published on
https://www.sandlerresearch.org/natural-language-processing-market-by-component-type-statistical-hybrid-application-automatic-summarization-sentiment-analysis-risk-threat-detection-deployment-mode-organization-size-ver.html
Natural Language Processing Market by Component, Type (Statistical, Hybrid), Application (Automatic Summarization, Sentiment Analysis, Risk & Threat Detection), Deployment Mode, Organization Size, Vertical, and Region - Global Forecast to 2026
“The need to make sense of unstructured data and extract insights is expected to drive the adoption of NLP solutions and services, which will contribute to the growth of the NLP market.”
The global Natural Language Processing (NLP) market size to grow from USD 11.6 billion in 2020 to USD 35.1 billion by 2026, at a Compound Annual Growth Rate (CAGR) of 20.3% during the forecast period. Growing demand for cloud-based NLP solutions to reduce overall costs and better scalability and increasing usage of smart devices to facilitate smart enviroments are expected to drive the NLP market growth. The rise in the adoption of NLP-based applications across verticals to enhance customer experience and increase in investments in the healthcare vertical is expected to offer opportunities for NLP vendors.
The global spread of COVID-19 has generated numerous privacy, data protection, security, and compliance questions. These challenges have increased the need for companies and organizations to secure and analyze their sensitive data for strategic business decisions. New practices such as work from home and social distancing have increased the requirement of NLP solutions and services, and the development of digital infrastructures for large-scale technology deployments. Organizations are implementing NLP solutions and services to access the landscape of scientific papers relevant to the coronavirus pandemic. Moreover, scientists are developing COVID-19 therapeutics which uses NLP technology to track new papers, particularly around drug or vaccine safety.
The services segment is expected to grow at a higher CAGR during the forecast period
The NLP market is segmented on the basis of components into solutions and services. The services segment is expected to grow at a higher CAGR during the forecast period. NLP services play a vital role in the functionality of NLP platform and software tools. These services are an integral step in deploying tools and are taken care of by solution, platform, and service providers. The demand for NLP software tools and platform is increasing globally due to the rising demand to gain real-time insights from voice or speech data across BFSI, healthcare and life sciences, and retail and eCommerce vertical.
On-premises segment is expected to grow at a higher CAGR during the forecast period
The NLP market by deployment mode has been segmented into on-premises and cloud. Enterprises opt for the deployment mode based on their requirements regarding the scalability and level of data security required. The on-premises mode is the most preferable among the enterprises, which consider data as a valuable asset and need to maintain high-level security to comply with regulations. The cloud deployment mode is dominating the market due to its advantages, such as scalability, easy availability, and cost-savings. The cloud segment is expected to account for a larger market size during the forecast period.
Among verticals, the healthcare and life sciences segment to grow at the highest CAGR during the forecast period
The NLP market is segmented into the various verticals, particularly BFSI, IT and telecom, retail and ecommerce, healthcare and life sciences, transportation and logistics , government and public sector, energy and utilities, manufacturing, others (education, travel and hospitality, and media and entertainment). The healthcare and life sciences vertical is expected to grow at the highest CAGR during the forecast period. The vertical’s high growth rate can be attributed to the increasing healthcare complexities and growing need for advanced NLP-driven EHRs to extract meaningful insights from unstructured clinical data. To address the COVID-19 impact on the BFSI vertical, the adoption of digital technologies such as video banking facilities, AI-supported tools, and conversational platforms has become essential.
North America to hold the largest market size during the forecast period
The NLP market has been segmented into five regions: North America, Europe, APAC, MEA, and Latin America. Among these regions, North America is projected to hold the largest market size during the forecast period. Improvements in cloud computing platforms, which are now more efficient, affordable, and capable of processing complex information, have led to the growth of inexpensive software development tools and plentiful datasets, which play a vital role in the development of AI technology in the US market. APAC is expected to grow at the highest CAGR during the forecast period on account of the rising awareness and increasing AI investments.
Breakdown of primaries
In-depth interviews were conducted with Chief Executive Officers (CEOs), innovation and technology directors, system integrators, and executives from various key organizations operating in the NLP market.
By Company: Tier I: 34%, Tier II: 43%, and Tier III: 23%
By Designation: C-Level Executives: 50%, Directors: 30%, and Others: 20%
By Region: North America: 25%, APAC: 30%, Europe: 30%, MEA: 10%, and Latin America: 5%
The report includes the study of key players offering NLP solutions and services. It profiles major vendors in the global NLP market. The major vendors in the global NLP market are include IBM (US), Microsoft (US), Google (US), AWS (US), Facebook (US), Apple (US), 3M (US), Intel (US), SAS Institute (US), Baidu (China), Inbenta (US), Veritone (US), Dolbey (US), Narrative Science (US), Bitext (Spain), Health Fidelity (US), Linguamatics (UK), Conversica (US), SparkCognition (US), Automated Insights (US), Gnani.ai (India), Niki (India), Mihup (India), Observe.AI (US), Hyro (US), Just AI (England), RaGaVeRa (India).
Research Coverage
The market study covers the NLP market across segments. It aims at estimating the market size and the growth potential of this market across different segments, such as components, type, application, organization size, deployment mode, vertical, and regions. It includes an in-depth competitive analysis of the key players in the market, along with their company profiles, key observations related to product and business offerings, recent developments, and key market strategies.
Key Benefits of Buying the Report
The report would provide the market leaders/new entrants in this market with information on the closest approximations of the revenue numbers for the overall NLP market and its sub segments. It would help stakeholders understand the competitive landscape and gain more insights better to position their business and plan suitable go-to-market strategies. It also helps stakeholders understand the pulse of the market and provides them with information on key market drivers, restraints, challenges, and opportunities.
0 notes
Text
Text Analytics Industry 2020 - Developments and Trends, Potential of the Market from 2020-2023
Market Research Future published a research report on “Text Analytics Industry Research Report- Global Forecast 2023” – Market Analysis, Scope, Stake, Progress, Trends and Forecast to 2023.
Market Study
Market Research Future (MRFR), in its latest “Text Analytics Industry” report, states that the market is expected to achieve USD 9 Bn valuation at 17% CAGR by 2023. The rise in need for data mining delineate the growing utility of text analytics. This is identified as a chief driver for the global text analytics market. The rise in demand for relevant information for the optimum functioning of an enterprises is expected to prompt the expansion of the global Text Analytics Industry. Social medias are providing a strong ground for brand building. E-commerce business is largely influenced by social media dynamics. Text analytics play significant role in boosting the efficacy of social medias. Thus, can promote the expansion of the global Text Analytics Market. The report offers market dynamics, ongoing trends, and contribution of key players in making the market prosperous.
Get More Details of Report @ https://www.abnewswire.com/pressreleases/covid19-impact-on-text-analytics-market-2020-global-size-analytical-overview-company-profile-emerging-trends-opportunity-assessment-future-trends-and-forecast-2023_488389.html
Key Players
The prominent players in Text Analytics Industry are – SAP SE (Germany), IBM Corporation (US), SAS Institute, Inc. (US), OpenText Corporation (Canada), Clarabridge, Inc. (US), Megaputer Intelligence, Inc. (US), Luminoso Technologies, Inc. (US), MeaningCloud LLC (US), KNIME.com AG (Switzerland), Infegy, Inc. (US), Lexalytics, Inc. (US), Averbis (Germany), Bitext Innovations S.L.(Spain) among others.
Global Text Analytics Market - Segments
The global market of text analytics is studied by application, components, vertical, and deployment. The global text analytics market’s segmental study provides indispensable insights that empower investors to make rational decisions.
By component, software and services are the text analytics market segments. The services segment covers professional services and managed services. The growing utility of managed services can bolster the expansion of the text analytics market.
The text analytics market’s application-based segments are workforce management, documentation management, marketing management, customer experience management, and risk and compliance management. The high utility of documentation management can prompt the global text analytics market growth.
The text analytics market’s deployment-based segments are cloud and on-premise. The on-premise segment can earn large profit for the global text analytics market due to the high rate of adoption of on-premise deployment model by government organizations. On the other hand, the dynamics of cloud-based deployment model segment can dictate the growth of the text analytic market. The cost-saving advantage of cloud is surging its adoption across verticals. Thus, the cloud-based deployment model segment can earn decent revenue for the global text analytics market.
The vertical-based segments of the text analytics market are retail, BSFI, e-commerce, IT and telecommunication, government, energy and utilities, manufacturing, travel, hospitality, and others. The growing application of text analytics across e-commerce and IT sectors is expected to cause the global text analytics market growth.
Global Text Analytics Market - Regional Analysis
North America text analytics market, led by the US, is expected to achieve substantial valuation. Countries in North America boasting their technological advancements can lay ground work for the regional text analytics market to surge. The surge in workforce management solutions applications in North America companies can boost the expansion of the global text analytics market growth. Europe text analytics market expansion can be attributed to the high rate of deployment of cloud technology. In Asia Pacific, the booming e-commerce business and robustness of digital platforms to cast advertisements can provide boost the regional text analytics market impetus.
Get complete Report @ https://www.marketresearchfuture.com/reports/text-analytics-market-2989
TABLE OF CONTENTS
1 Market Introduction
1.1 Introduction
1.2 Scope Of Study
1.2.1 Research Objective
1.2.2 Assumptions
1.2.3 Limitations
1.3 Market Structure
2 Research Methodology
2.1 Research Type
2.2 Primary Research
2.3 Secondary Research
2.4 Forecast Model
2.4.1 Market Data Collection, Analysis & Forecast
2.4.2 Market Size Estimation
3 Market Dynamics
3.1 Introduction
3.2 Market Drivers
3.3 Market Challenges
Continued…
Get New Updates @ https://www.linkedin.com/company/ict-mrfr
About Us:
At Market Research Future (MRFR), we enable our customers to unravel the complexity of various industries through our Cooked Research Report (CRR), Half-Cooked Research Reports (HCRR), Raw Research Reports (3R), Continuous-Feed Research (CFR), and Market Research & Consulting Services.
Media Contact:
Market Research Future
Office No. 528, Amanora Chambers
Magarpatta Road, Hadapsar,
Pune - 411028
Maharashtra, India
+1 646 845 9312
Email: [email protected]
0 notes
Text
Text Analytics Market (2021-2030): Global Industry Analysis
Absolute Markets Insights has announced addition of an insightful analytical data to its massive repository titled Text Analytics market. The report highlights significant key players operating in the global regions such as North America, Latin America, Europe, Asia-Pacific, and India. The study uses several graphical presentation techniques such as charts, graphs, table, and pictures while curating the report. With regards to SWOT analysis and Porter’s Five analysis, the market data has been effectively measured. Various dynamic aspects of the businesses such as drivers, challenges, risks, opportunities, and restraints have also been evaluated to present a detailed knowledge to ease the process of making informed decisions in the businesses. The study further also draws attention to the statistics of the current market scenario, presents information on the past progress as well as on the futuristic progress.
Global competitors such as Crimson Hexagon, Averbis, Bitext Innovations, S.L., Clarabridge, IBM, Infegy, Inc., KNIME.com AG, Lexalytics, LUMINOSO, MeaningCloud LLC, Megaputer Intelligence, Inc., Microsoft Corporation, OpenText Corp, Oracle, SAP SE, SAS Institute, Inc., TABLEAU SOFTWARE, The Hewlett-Packard Company and TIBCO Software Inc. are also highlighted in the study in order to get a stronger and effective outlook of the competition at domestic as well as global regions. The report further also offers comprehensive information based on primary and secondary research techniques to examine the data accurately.
Additionally, the report also provides a detailed description of current market attributes such as manufacturing base, raw material, technical advancements, demanding trends, marketing channels, and business models. With the help of facts and figures of import and exports, local consumption, buyers, sellers and distributors better market insights into the businesses are provided, which is one of the many distinctive features of the report.
For more information about this report visit: https://www.absolutemarketsinsights.com/reports/Text-Analytics-Market-2018-2026-107
The text analytics market was valued at US$ 4043.4 Mn in 2020 is expected to reach US$ 8961.3+ Mn by 2030.
Text Analytics is a new IT discipline with its foundations in linguistics and data mining. The discipline is used to convert unstructured text data into meaningful data to conduct analysis, provide search facility, assemble feedback, search for client perspectives, analyze opinions, track product audits and entity modeling to enhance and support decision making which depends on certainties. Different linguistic, statistical, and machine learning techniques are used to retrieve information from unstructured data, structure the data and accordingly derive patterns, trends, assess and interpret data. The analysis techniques similarly include lexical analysis, categorization, grouping, pattern recognition, labeling, annotation, data extraction, link, association analysis and visualization. Moreover, text analysts are collaborating with retail and e-commerce enterprises to establish themselves in the market. The development in cloud-based technologies has pushed the demand for adoption in deployment of text analytic solution.
Global Text Analytics Market: Research Scope:
By Component:
Software
Service
Managed services
Professional services
Support and maintenance
Consulting services
System integration and deployment
By Application:
Customer experience management
Marketing management
Governance, risk, and compliance management
Document management
Workforce management
Others
By Deployment:
On-premises
Cloud
By Organization:
Large Enterprises
Small and Medium-sized Enterprises (SMEs)
By Industry Vertical:
Banking, Financial Services, and Insurance (BFSI)
Telecommunications and Information Technology (IT)
Retail and e-Commerce
Healthcare and life sciences
Manufacturing
Government and defense
Energy and utilities
Media and entertainment
Travel and hospitality
Others
By Region
North America
Europe
Asia Pacific
Middle East and Africa
Latin America
Contact Us:
Company: Absolute Markets Insights
Email id: [email protected]
Phone: +91-740-024-2424
Contact Name: Shreyas Tanna
Website: https://www.absolutemarketsinsights.com/
0 notes
Text
Machine Learning For ECommerce Fraud Detection
Contents
1 Machine Learning For ECommerce Fraud Detection
1.1 1. Konduto
1.2 2. Bitext
1.3 3. Seclytics
1.4 4. Emailage
1.5 5. Ravelin
2 Conclusion
Machine Learning For ECommerce Fraud Detection

(4 votes, average: 5.00 out of 5)

Loading...
Machine learning is now being used in an intriguing number of ways for ECommerce, including integrations with fraud detection software. There are an ever-increasing number of startup companies building businesses to target the intersection of these sectors.
Check out the following five machine learning startups to discover a variety of ways bleeding edge machine learning technology is applied to fraud detection in ECommerce.
1. Konduto
Based out of Brazil, Konduto uses machine learning to help ECommerce business owners understand customer patterns and detect fraud. Using tools like IP geo-tagging, proxy detecting, and device analysis, Konduto is able to monitor business transactions and warn clients of suspicious transactions. When customers shop, the system evaluates in real-time and provides a score stating the probability of the transaction being fraudulent, how confident the system is of their estimates and recommendations of what to do. This really helps the online merchant focus his attention on the really suspicious transactions.
2. Bitext
Madrid’s Bitext combines machine learning with text analytics to help business’ understand the details in their data. From sales organizations to market researchers, multiple businesses are able to put Bitext’s proprietary linguistic technology to work for their company. Bitext also offers an API for additional data discovery on everything from sentiment analysis to concept extraction. If you like the idea of big data + market research + machine learning + ECommerce, you will enjoy getting to know Bitext. They boast very high accuracy rates of over 90%.
3. Seclytics
Based out of Santa Clara, CA, Seclytics combines machine learning and predictive analytics for fraud detection. Targeted at enterprise customers, the Seclytics platform can be utilized to discover malvertizing (malicious code injected into online advertisements) and fraudulent or suspicious activities. Businesses are able to receive threat predictions and act fast to protect their corporate data.
4. Emailage
With offices spanning the planet (Brazil, United Kingdom, USA), Emailage provides fraud detection services on a global scale. Emailage combines machine learning and email analysis to help businesses detect and prevent fraudulent activities. The Emailage risk detection platform uses email reputation analytics to help businesses fight fraudulent accounts and transaction charge-backs. Features include query velocity tracking, syntax analytics, IP validation, customizable access restriction capabilities, and API alerts.
5. Ravelin
London’s Ravelin uses machine learning and transaction analytics for fraud detection and prevention. Businesses using Ravelin software are able to receive transaction alerts regarding suspected fraudulent patterns and can act to prevent transaction completion. Ravelin uses algorithms, historical transaction patterns, and real-time business analysis to offer companies a defense against suspicious activity. It scales to provide the same level of protection even when volume spikes.
Conclusion
These are just five of numerous startup companies using machine learning to power fraud protection logic that can be used in various sectors including ECommerce. Stay tuned; the market of Machine Learning For ECommerce Fraud Detection is only getting started.
Brought to you by RobustTechHouse. We provide E-Commerce Development services.
Machine Learning For ECommerce Fraud Detection was originally published on RobustTechHouse - Mobile App Development Singapore
0 notes
Text
Machine Learning и не только: как устроены чат-боты
Продолжая тему прикладного использования искусственного интеллекта в различных бизнес-кейсах, сегодня мы расскажем о том, как устроены чат-боты, при чем здесь большие данные (Big Data) и машинное обучение (Machine Learning), системы распознавания речи и понимания естественного языка.
Какие бывают чат-боты
Все многообразие чат-ботов можно разделить на 2 большие категории [1]: · работающие по заранее известным командам на основе ограниченного списка ключевых слов. Их гораздо проще создавать, однако практическое применение таких чат-ботов ограничено ключевыми словами, при отсутствии которых в запросе бот не сможет помочь пользователю. · самообучающиеся на базе алгоритмов Machine Learning и методов понимания естественного языка (NLU, Natural Language Understanding). Создавать такие боты намного сложнее, однако на практике они оказываются намного эффективнее за счет накопления знаний на основе предыдущих взаимодействий с пользователем. С учетом развития ИТ и повсеместной цифровизации с помощью Big Data и Machine Learning, не сложно предположить, что будущее – за самообучающимися чат-ботами. Не случайно аналитическое агентство Gartner считает их наиболее перспективными технологиями, которые сейчас на пике интереса, наряду с методами обработки естественного языка (NLP, Natural Language Processing), распознавания речи и голосовыми пользовательскими интерфейсами [2].
Как работают чат-боты
Вообще типовой цикл работы любого чат-бота можно представить цепочкой следующих действий [3]: получение запроса от клиента; разбор запроса – понимание высказывания и определение намерений клиента в контексте его бизнес-кейса; выполнение действий согласно заранее определенному сценарию (скрипту) по обработке клиентского кейса; генерация ответа на естественном языке; сохранение запроса, контекста и параметров диалога для обработки последующих обращений; отправка ответа клиенту. Наиболее сложным этапом работы является разбор клиентского запроса. Как мы уже отметили раньше, самообучающиеся чат-боты на базе Machine Learning используют для этого методы NLU и NLP. Например, для текстовых чат-ботов процесс разбора включает следующие этапы [3]: · предварительная обработка текста – токенизация (разбиение на слова), исправление опечаток, лемматизация и стемминг (определение нормальной формы слов и частей речи), отбрасывание стоп-слов (артикли, междометия, союзы и пр.), расширение запроса с помощью словарей синонимов, дополнение информацией о значимости отдельных слов, расширение запроса деревом синтаксического разбора и результатами разрешения местоимений, а также определение именованных сущностей. · классификация запроса на основе примеров фраз и ML-алгоритмов или формальных правил (шаблонов), ранжирование гипотез классификации в соответствии с текущим контекстом беседы; извлечение параметров запроса из фразы пользователя. Примечательно, что примерно до 2015 года при разработке чат-ботов, в основном, использовался подход на основе формальных правил (rule-based), суть которого состоит в выделении семантически значимых элементов фраз и их кодификации. Далее на основе этих результатов создавали сценарии диалогов с помощью скриптовых языков программирования [3], например, Javascript, PHP, Python [1]. Однако, после 2015 года развитие алгоритмов семантической близости текстов, технологий синтеза и распознавания речи, а также Big Data и Machine Learning привело к распространению новых подходов к классификации текстов и обучению NLU-систем [3]. В частности, здесь стоит отметить WikiMatrix и CCMatrix – огромные датасеты для NLP-задач и машинного перевода, основанном на определении семантической близости словосочетаний в разных языках [4]. Таким образом, большинство современных чат-ботов устроены на базе последних достижений в области Data Science: NLU и NLP-техники, методы распознавания речи и обработки текстов с помощью нейросетей и других инструментов искусственного интеллекта.
Как создать своего чат-бота: краткий обзор готовых решений
Как правило, чат-боты имеют следующую архитектуру [1]: · серверная часть (backend), где собственно и выполняются работы по распознаванию запроса и формированию ответа; · клиентская часть (front-end), обычно в виде мессенджера (Facebook Messenger, Slack, Telegram и пр.). Как правило, мессенджер предоставляет API и документацию по связи платформы backend’а с чат-интерфейсом бота через HTTP. Сегодня можно создать собственного чат-бота с нуля, взяв специальные библиотеки или использовать полностью готовый сервис. Например, для любителей разработки подойдут следующие решения [1]: · BotKit - open-source набор инструментов для создания ботов с подробной документацией; · Claudia - конструктор чат-ботов для работы в AWS Lambda; · Bottr – фреймво��к на Node.js с готовым приложением для тестирования; · wit.ai - сервис, который принимает текст или голосовые сообщения и использует NLP-методы для управления ответами на запросы; · Chatfuel - инструмент для настройки Facebook Messenger или Telegram-ботов без пограммирования; · motion.ai - сервис для создания чат-ботов; · api.ai - сервис, использующий NLP-методы для создания ботов и определения возможные сценариев их общения с клиентами; Отдельно перечислим веб-сервисы для самостоятельной настройки чат-ботов (конструкторы): SendPulse, Flow XO, ManyChat, Chatfuel, MobileMonkey, Chatbots BuilderBotmother, ChatBot.com [5]. В этом е ряду находится онлайн-сервис от Google – бесплатная платформа DialogFlow [6]. Также отметим уже готовые решения для различных отраслей деятельности [1]: · сервисы и инструменты - Poncho, FindoBot, Trim; · ритейл - Uber, Bly, TacoBot; · Развлечения и новости - Digg, CNN, 2048bot; · сервис обратной связи - Oratio, Troops, Helpbot. Еще больше готовых решений можно найти в Botlist или Telegram Bot Store [1]. В заключение подчеркнем, что, помимо автоматизации обработки клиентских запросов, сокращения времени и затрат на этот процесс, чат-боты помогут внедрить бизнес-аналитику клиентского сервиса. В частности, анализируя уже обработанные кейсы, можно выявить «узкие места» (бутылочные горлышки) текущих бизнес-процессов, улучшить взаимодействие с клиентами, найти идеи для создания новых продуктов/услуг и оптимизировать деятельность компании. Чат-бот - это не только автоматизация взаимодействия с клиентом, но и аналитика этого процесса Как успешно применять чат-ботов и другие технологии больших данных и машинного обучения для цифровизации своего бизнеса, вы узнаете на наших образовательных курсах в лицензированном учебном центре обучения и повышения квалификации руководителей и ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве: Аналитика больших данных для руководителей

Смотреть расписание занятий

Зарегистрироваться на курс Источники 1. https://proglib.io/p/chat-bots-intro/amp/ 2. https://www.gartner.com/smarterwithgartner/top-trends-on-the-gartner-hype-cycle-for-artificial-intelligence-2019 3. https://m.habr.com/ru/company/just_ai/blog/364149/ 4. https://ai.facebook.com/blog/ccmatrix-a-billion-scale-bitext-data-set-for-training-translation-models/ 5. https://sendpulse.com/ru/blog/chat-bot-services 6. https://habr.com/ru/post/412863/ Read the full article
#BigData#MachineLearning#Большиеданные#Искусственныйинтеллект#МашинноеОбучение#предиктивнаяаналитика
0 notes
Text
小數據條件下的語意分析
語意分析在近年的大數據與機器學習乃至深度學習的潮流下,已成為人工智慧在自然語言處理以及輿情分析的標準應用。但由於工具原理的限制,語意分析的結果往往會用一個詞頻分佈圖、關鍵字的文字雲…等方式呈現。要讀懂究竟這張圖表的意義,還需要一個「分析師」像解盤股市��現一樣地說明各個指數的意義,才能讓人一窺目標市場不經間透過文字或語言留下的思緒痕跡或是情緒傾向。
這幾乎讓「語意分析」一詞聽起來就像是某種星座算命用的神秘詞彙。
另一個和星座算命類似的性質是,幾乎所有的語言分析應用場景的先決條件就是「數據量要大,愈大愈準」。但如果某個專業領域裡面只有寥寥數篇相關文件,例如新產品的行銷文案、專業技能的訓練課程講稿內容乃至候選人的政見發表或是辯論文字稿…等。

這些文件少則只有一篇,多也不過是在幾十篇而已,如何在最短的時間裡利用語意分析來評估文本內容的品質好壞,或是計算它的關鍵詞彙以便做延伸的搜尋或領域研究呢?數量不夠的話,是沒辦法採用大數據的人工智慧方法的。
但是相較於需要大數據的人工智慧,幾乎任何一個心智正常的經理人,都能只憑少少的幾篇文字,就做出準確的商業判斷「這個人是否言過其實?」、「這個報告是否用心製作?」、「這個伙伴的計劃是否值得信任?」那麼,問題來了…
為什麼我們不能讓「人工智慧」來幫我們透過少量的數據,就做出像人的判斷呢?
這是因為,大數據條件下的人工智慧運作的方式,和人類做邏輯判斷的方式不太一樣。人類的語言能力,能讓我們透過極少的資料,就感知到一個句子是屬於「有料」或是「沒料」。
以前幾年流行的「語言癌」為例。聯經出版社邀集了國內的語言學家精英,從語法、功能、歷史、結構…等等角度做出了四平八穩的結論,但就是忽略解釋了「一般人聽到:『做了一個擁抱的動作』時,那股冗贅的不適感從何而來呢?」
同樣的道理,在近年來部份心靈導師的訓練課程中或是一年多以來的總統選舉活動中,也有許多發言內容常讓人覺得「你的確講了很多話,但我總覺得只接收到很少的資訊」。
這種「資訊」和「收訊」之間的落差感,是否有個科學的解釋呢?
這個問題,致力於將「語言學」領域的先驗知識帶進語意分析以及其它自然語言處理任務的卓騰語言科技有解決方案。卓騰語言科技並不是世界上第一家將語言學知識引入語言分析任務,因而大幅縮小數據量需求的公司。在國外,幾乎和我們同時成立的 Bitext 也是一家利用語言學背景打造各種能大符提升機器學習模型正確率表現的的跨國企業。差別只在 Bitext 專精於歐美語系,而卓騰語言科技則主攻亞洲的語系。
以往在數據量大的時候,我們就能基於統計方法,先將一篇中文文章進行中文斷詞處理以後,計算這篇文章和其它文章最具代表性的「關鍵字」,或是計算每個詞條的出現的次數,以「詞頻」做為語意分析時的素材。
用料理做為類比,可能更好理解。民以食為天,您一定曾經有過明明點了一道名稱很長,好像用了許多食材,似乎很厲害的料理以後,嚐了一口卻只是平平淡淡的沒什麼滋味。這種「名稱很長」和「淡淡的沒什麼味道」之間的落差,該怎麼計算呢?
如果要採用機器學習的話,它會需要「許多菜單的樣本」以及「食用後的客戶意見」來建立「餐點名稱的長度或內含��彙」以及「客戶意見」之間的關係以後,在您看到一個新的菜色時,系統再依這道菜色的「名稱長度或內含字彙」來給您「它是味道豐富」或是「它可能平淡���味」的預測。
但如果這個問題交給一個「具有專業領域知識的廚師」的話,他根本不需要吃過多少菜,就可以依據他對每一道食材以及料理方式的知識,看著菜名,就告訴你「這道菜名字很長,但大概沒什麼味道,因為食材都是些小白菜、豆芽菜、豆腐…等東西,而且料理的方式也不容易入味」。
樣本多時,您可以採用機器學習的 AI 方法,
樣本少的時候,不妨利用廚師的專業知識。
我們提供的,就是基於「對語言的專業知識」而打造的演算法。以語言癌的句子「做了一個擁抱的動作」為例,其實它的意思就是「擁抱」。那麼我們能否「讓電腦計算」這個語言癌句子的「空洞感」從何而來呢?我們將句子送入卓騰語言科技的「Articut 斷詞引擎」以 lv1 計算,並代入「名詞、動詞的詞彙數量除以整個句子的詞彙數量」這個公式來計算兩個句子:
公式:(Noun + Verb) / All
做了一個擁抱的動作 =>
做(verb) 了(ASPECT) 一個(classifier) 擁抱(verb) 的(FUNC) 動作(nouny)
斷詞處理後共有 6 個詞 (做/了/一個/擁抱/的/動作),其中動詞有 2 個 (做/擁抱),而名詞有 1 個 (動作),依公式計算得:(2+1)/6 = 0.5
也就是說,整句「做了一個擁抱的動作」裡,只帶了 50% 的資訊。這麼一來,當然會讓聽者覺得有一種「餐點名稱很長很厲害,結果嚐起來沒什麼味道」的空洞感了。
這個公式並不是我們發明的,而是在歐美語系的語意分析工作中已經有悠久應用歷史以及為了不同的場景,也有許多不同版本的變體。但以往幾乎不曾在「中文語意分析」中看到這種方法,主要的原因還是在 Articut 斷詞引擎出現以前,常見的中文斷詞方案有的是詞性標記錯誤過多以致無法使用 (例如 Jieba 結巴斷詞),再不然就是詞性標記分類過細以致於操作複雜。
同樣公式,我們在本屆總統大選的第一次政見發表會中也加以應用 [註]。這是一個教科書式的完美應用場景。三位候選人的發表時間是一致的,我們不用擔心是否像對話一樣,每個人的句子有長有短讓公式中的分母差異過大。三個人的發言主要都是在單方向的「說明」而不是雙向或是多向的「對話」,如此一來可以更確定發言時所用的詞彙是自己的意思,而不是在重覆對方問題時說的話。
把三位候選人的政見內容,送入 Articut 進行斷詞處理後,計算詞彙總數,並另外計算了名詞和動詞的數量,依前述公式計算後得到以下的圖表分佈:
這個圖表的數字分佈,剛好符合了閱讀逐字稿以後網友的主流意見:「其中一位候選人似乎都在講空話」。現在我們有了 Articut 斷詞引擎的 POS 標記以後,終於能跟上歐美行之有年的語意分析技術水準,將「網友主觀的感覺」以「客觀量化數據」呈現。
透過小數據條件的語意分析技術,我們可在演講稿完成的同時,就進行計算;而不需要等到演講稿發佈以後,再從網路蒐集網友意見,進行後續的分析操作。
我們可以用同樣的公式,現場進行一個實驗。以下有兩段健身房的文案,一段比較沒有吸引力,另一段則充滿節奏。我們將文字透過 Articut 斷詞引擎處理後,再來看看您的感受:
文案一:25歲以後肌肉就會慢慢流失,只有透過不斷的訓練才能讓肌肉流失的速度變慢,並且在老了以後保有堅硬的骨骼。
文案二:25歲以後肌肉開始流失,唯有訓練才能減緩肌肉流失速度,同時保有堅硬的骨骼。
您可先自行判定,哪一個文案的文筆較佳。再往下看看,您的感受是否和計算出來的「資訊密度」表現一致?
文案一:
25歲(Noun) 以後(TIME) 肌肉(Noun) 就(FUNC) 會(MODAL) 慢慢(MODIFIER) 流失(verb),只有(MODIFIER) 透過(verb) 不斷(MODIFIER) 的(FUNC_inner) 訓練(Noun) 才能(MODAL) 讓(verb) 肌肉(Noun) 流失(verb) 的(FUNC) 速度(Noun) 變(verb) 慢(MODIFIER),並且(FUNC) 在(ASPECT) 老了(verb) 以後(TIME) 保有(verb) 堅硬(MODIFIER) 的(FUNC) 骨骼(Noun)
共 28 個詞,其中的名詞及動詞共 13 個 (標為淡黃色)。資訊密度為:13/28 = 0.46
文案二:
25歲(Noun) 以後(TIME) 肌肉(Noun) 開始(verb) 流失(verb),唯(MODIFIER) 有(verb) 訓練(Noun) 才能(MODAL) 減緩(verb) 肌肉(Noun) 流失(verb) 速度(Noun) 同時(TIME) 保有(verb) 堅硬(MODIFIER) 的(FUNC) 骨骼(Noun)
共 18 個詞,其中的名詞及動詞共 12 個 (標為淡黃色)。資訊密度為:12/18 = 0.67
透過這個計算公式,我們也能發現資訊密度高的文案,通常也避免了「誇張賣弄」、「行話」、「囉嗦」、「討論自己」、「過度興奮」或「主觀強烈」…等行銷文案的地雷。因為誇張賣弄、過度興奮或是主觀強烈多半是透過形容詞來呈現。但在這個公式裡的形容詞不計分;行話和囉嗦的詞彙容易被斷詞引擎處理錯誤而失分;此外,談論自己時用的代名詞一樣是不計分的。
利用 Articut 斷詞引擎的詞性標記,計算資訊密度最少最少只需要「一個句子」。從此以後,我們便能利用這個公式掌握了「小數據」條件下的語意分析能力。
小數據的語意分析可強化大數據的機器學習效果
這兩種技術在本質上並不衝突,因此您可以輕易地將兩者融合成為新的產品或是決策輔助工具。在突發事件或是可掌握的資料不多時,採用小數據的語意分析方式,在累積了足夠呈現統計意義的資料量後,再採用大數據的機器學習方法挖掘更多潛在的趨勢。或是再次結合小數據方法,從不同的面向觀察長時間的語意分析變化,掌握市場伏流的動向。
註:我們略過了第二次政見發表會的原因是第二次政見發表會在形式上是單方的發表會,但實際上三個回合已經形成了類似辯論的對話模式。這應該要採用其它的變體加以計算。
0 notes